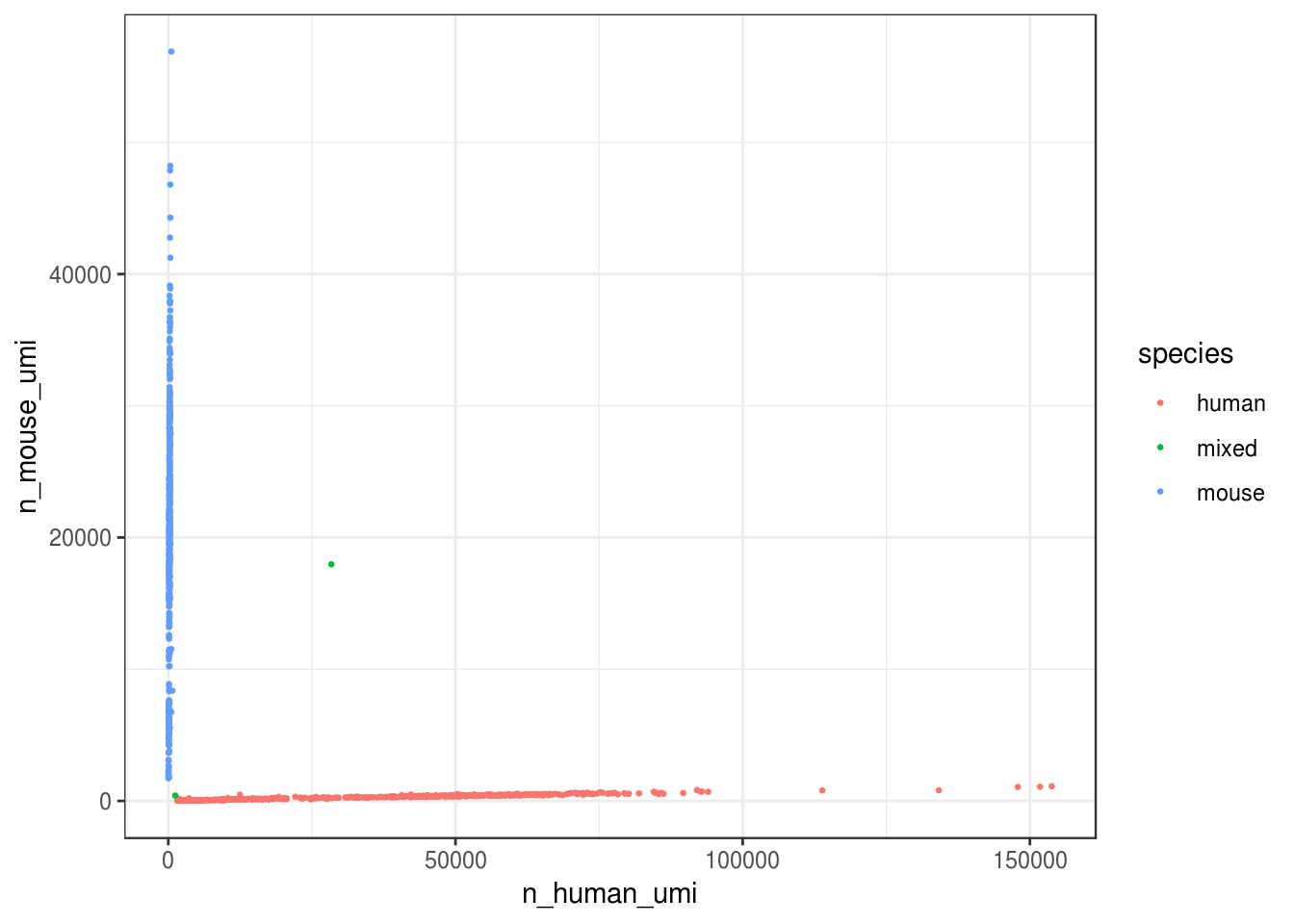
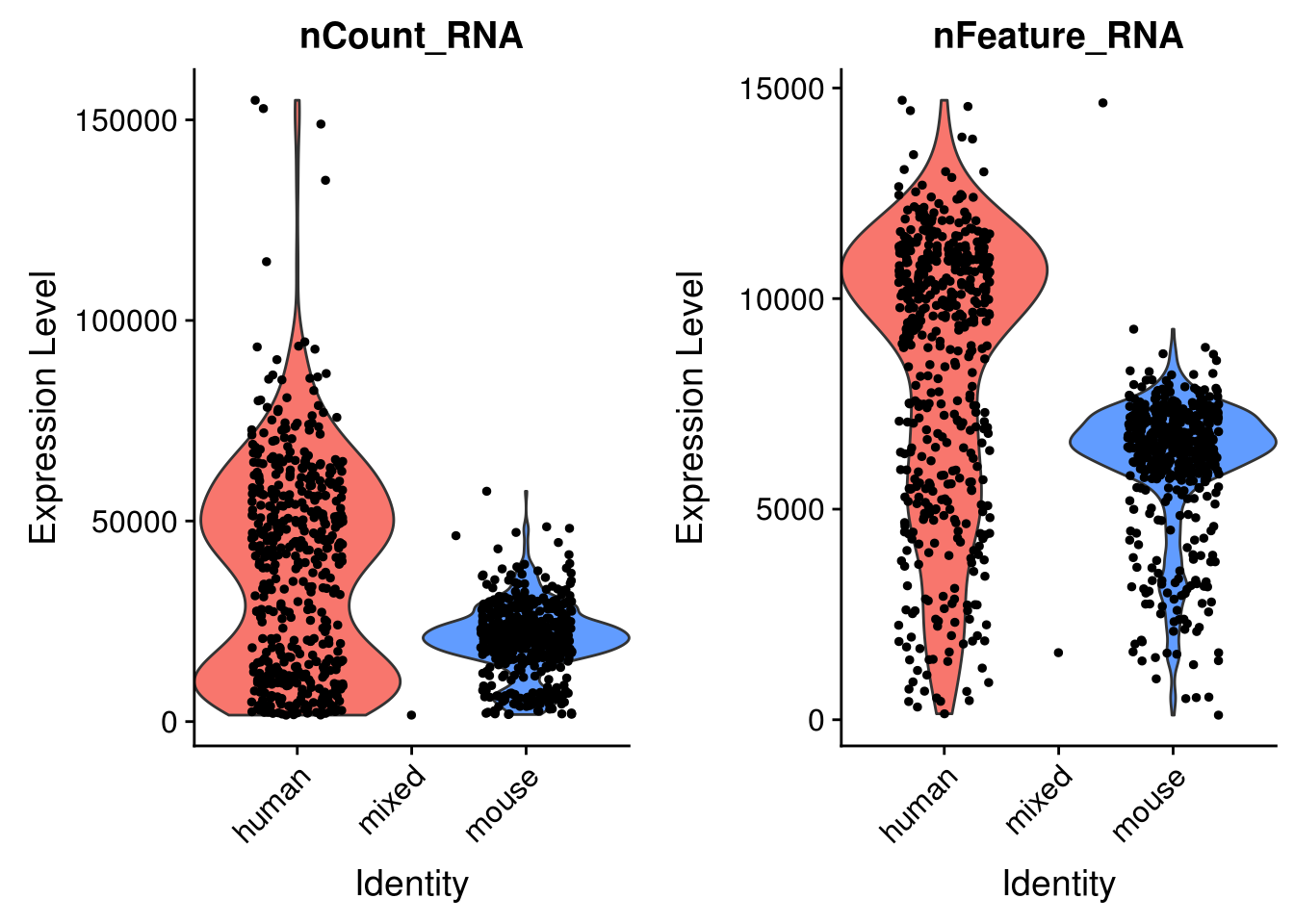
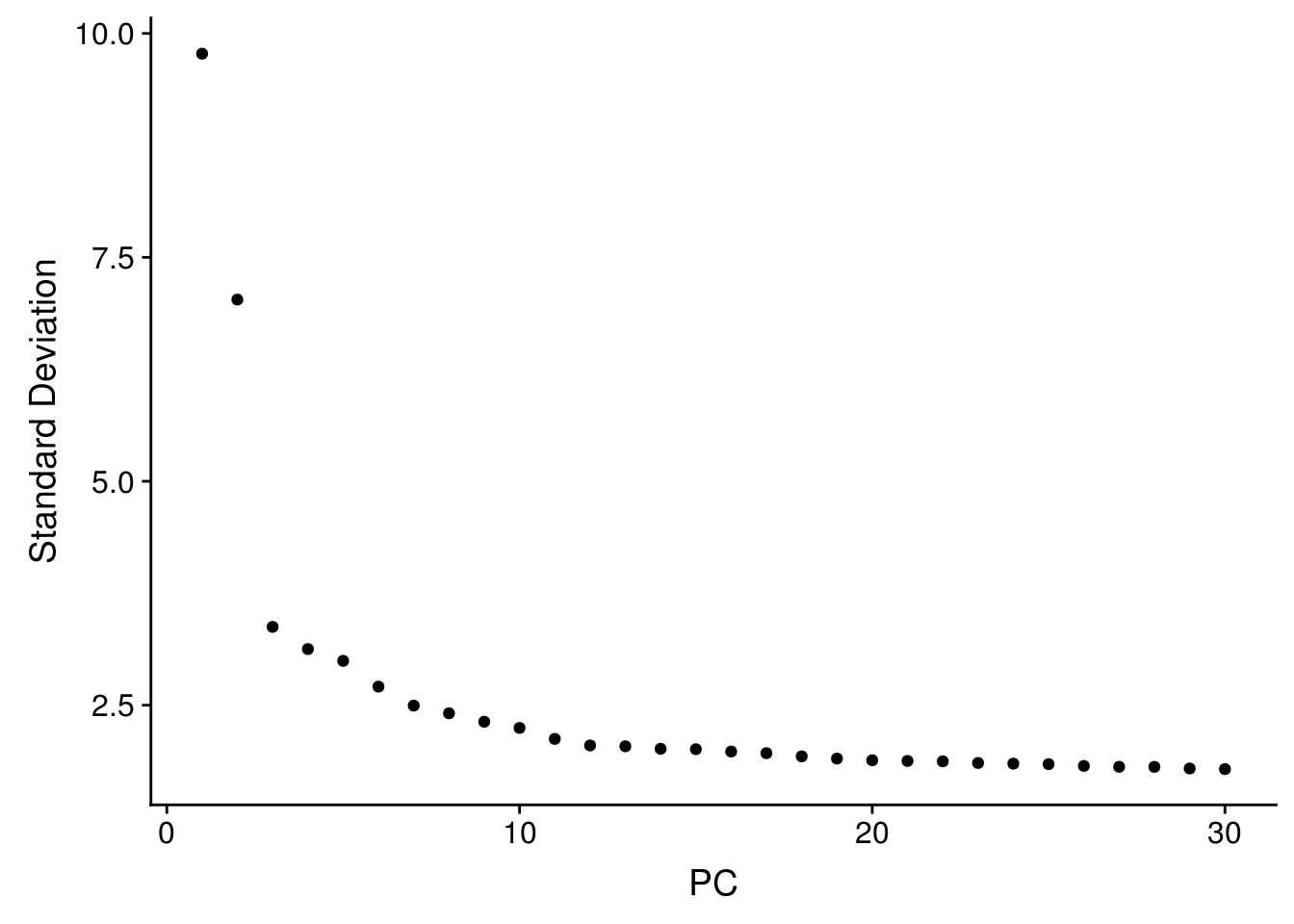
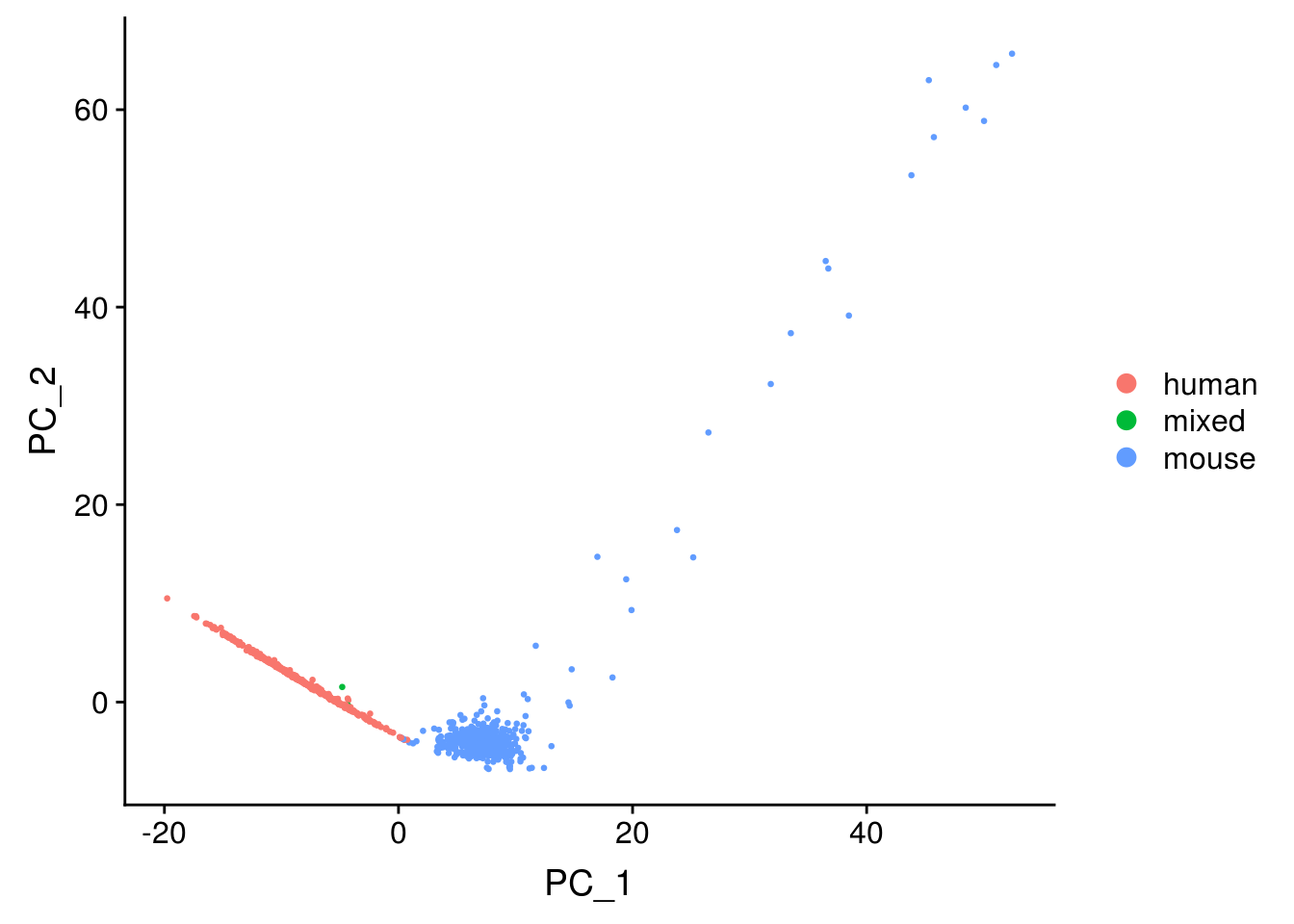
Primary analysis
Build the kallisto index
Here we use kallisto to pseudoalign the reads to the transcriptome and then to create the bus file to be converted to a sparse matrix. The first step is to build an index of the transcriptome. This data set has both human and mouse cells, so we need both human and mouse transcriptomes. The transcriptomes downloaded here are from Ensembl version 95, released in January 2019. As of the writing of this notebook, this is the most recent Ensembl release.
# Human transcriptome
download.file("ftp://ftp.ensembl.org/pub/release-95/fasta/homo_sapiens/cdna/Homo_sapiens.GRCh38.cdna.all.fa.gz", "./data/hs_cdna.fa.gz", quiet = TRUE)
# Mouse transcriptome
download.file("ftp://ftp.ensembl.org/pub/release-95/fasta/mus_musculus/cdna/Mus_musculus.GRCm38.cdna.all.fa.gz", "./data/mm_cdna.fa.gz", quiet = TRUE)~/mylibs/bin/kallisto version#> kallisto, version 0.45.0Actually, we don’t need to unzip the fasta files
~/mylibs/bin/kallisto index -i ./output/hs_mm_tr_index.idx ./data/hs_cdna.fa.gz ./data/mm_cdna.fa.gz#>
#> [build] loading fasta file ./data/hs_cdna.fa.gz
#> [build] loading fasta file ./data/mm_cdna.fa.gz
#> [build] k-mer length: 31
#> [build] warning: clipped off poly-A tail (longer than 10)
#> from 2083 target sequences
#> [build] warning: replaced 8 non-ACGUT characters in the input sequence
#> with pseudorandom nucleotides
#> [build] counting k-mers ... done.
#> [build] building target de Bruijn graph ... done
#> [build] creating equivalence classes ... done
#> [build] target de Bruijn graph has 2145397 contigs and contains 206575877 k-mersRun kallisto bus
Here we will generate the bus file. Here bus stands for Barbode, UMI, Set (i.e. equivalent class). In text form, it is a table whose first column is the barcode. The second column is the UMI that are associated with the barcode. The third column is the index of the equivalence class reads with the UMI maps to (equivalence class will be explained later). The fourth column is count of reads with this barcode, UMI, and equivalence class combination, which is ignored as one UMI should stand for one molecule. See this paper for more detail.
These are the technologies supported by kallisto bus:
system("~/mylibs/bin/kallisto bus --list", intern = TRUE)#> Warning in system("~/mylibs/bin/kallisto bus --list", intern = TRUE):
#> running command '~/mylibs/bin/kallisto bus --list' had status 1#> [1] "List of supported single-cell technologies"
#> [2] ""
#> [3] "short name description"
#> [4] "---------- -----------"
#> [5] "10xv1 10x version 1 chemistry"
#> [6] "10xv2 10x version 2 chemistry"
#> [7] "10xv3 10x version 3 chemistry"
#> [8] "CELSeq CEL-Seq"
#> [9] "CELSeq2 CEL-Seq version 2"
#> [10] "DropSeq DropSeq"
#> [11] "inDrops inDrops"
#> [12] "SCRBSeq SCRB-Seq"
#> [13] "SureCell SureCell for ddSEQ"
#> [14] ""
#> attr(,"status")
#> [1] 1Here we see 10xv3 support. Here we have 2 samples. Each sample has 3 files: I1 means sample index, R1 means barcode and UMI, and R2 means the piece of cDNA. The -i argument specifies the index file we just built. The -o argument specifies the output directory. The -x argument specifies the sequencing technology used to generate this data set. The -t argument specifies the number of threads used, and 8 threads have been used in this example.
cd ./data
~/mylibs/bin/kallisto bus -i ../output/hs_mm_tr_index.idx \
-o ../output/out_hgmm1k_v3 -x 10xv3 -t8 \
./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L001_R1_001.fastq.gz \
./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L001_R2_001.fastq.gz \
./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L002_R1_001.fastq.gz \
./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L002_R2_001.fastq.gz#>
#> [index] k-mer length: 31
#> [index] number of targets: 303,693
#> [index] number of k-mers: 206,575,877
#> [index] number of equivalence classes: 1,256,267
#> [quant] will process sample 1: ./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L001_R1_001.fastq.gz
#> ./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L001_R2_001.fastq.gz
#> [quant] will process sample 2: ./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L002_R1_001.fastq.gz
#> ./hgmm_1k_v3_fastqs/hgmm_1k_v3_S1_L002_R2_001.fastq.gz
#> [quant] finding pseudoalignments for the reads ... done
#> [quant] processed 63,105,786 reads, 46,343,056 reads pseudoalignedSee what the outputs are
list.files("./output/out_hgmm1k_v3/")#> [1] "matrix.ec" "output.bus" "output.sorted"
#> [4] "output.sorted.txt" "run_info.json" "transcripts.txt"This is what the bus file looks like:
First column is barcode, second column is UMI, 3rd column is equivalence class index, and 4th column is count, which is ignored. This has already been sorted according to barcode.
head ./output/out_hgmm1k_v3/output.sorted.txt#> AAAAAAAAAAAAAAAA AAAAAAAAAAAA 319248 1
#> AAAAAAAAAAAAAAAA AAAAAAAAAAAA 322114 1
#> AAAAAAAAAAAAAAAA AAAAAAAAAAAA 553631 1
#> AAAAAAAAAAAAAAAA AAAAAAAAAAAA 572943 1
#> AAAAAAAAAAAAAAAA AAAAAAAAAAAA 981967 1
#> AAAAAAAAAAAAAAAA AAAAAAAAAAAA 1079758 1
#> AAAAAAAAAAAAAAAA AAAACAAAAAAA 1200393 1
#> AAAAAAAAAAAAAAAA AAAAGGACAACC 327044 1
#> AAAAAAAAAAAAAAAC CATAAAAAATAT 543283 1
#> AAAAAAAAAAAAAAAG ACACCTCTTGGC 106416 1Run BUStools
The output.bus file is a binary. In order to make R parse it, we need to convert it into a sorted text file. There’s a command line tool bustools for this. The reason why kallisto bus outputs this binary rather than the sorted text file directly is that the binary can be very compressed to save disk space. The such compression is achieved, a future version of R package BUSpaRse may support directly reading the binary to convert to sparse matrix. At present, as bustools is still under development, such compression has not been achieved, and as a result, the binary is slightly larger than the text file.
# Sort, with 8 threads
bustools sort -o ./output/out_hgmm1k_v3/output.sorted -t8 ./output/out_hgmm1k_v3/output.bus
# Convert sorted file to text
bustools text -o ./output/out_hgmm1k_v3/output.sorted.txt ./output/out_hgmm1k_v3/output.sorted#> Read in 46343056 number of busrecords
#> All sorted
#> Read in 37843256 number of busrecordsMap transcripts to genes
For the sparse matrix, most people are interested in how many UMIs per gene per cell, we here we will quantify this from the bus output, and to do so, we need to find which gene corresponds to each transcript. Remember in the output of kallisto bus, there’s the file transcripts.txt. Those are the transcripts in the transcriptome index. Now we’ll only keep the transcripts present there and make sure that the transcripts in tr2g are in the same order as those in the index. You will soon see why the order is important.
Remember that we downloaded transcriptome FASTA files from Ensembl just now. In FASTA files, each entry is a sequence with a name. In Ensembl FASTA files, the sequence name has genome annotation of the corresponding sequence, so we can extract transcript IDs and corresponding gene IDs and gene names from there.
tr2g <- transcript2gene(fasta_file = c("./data/hs_cdna.fa.gz", "./data/mm_cdna.fa.gz"),
kallisto_out_path = "./output/out_hgmm1k_v3")#> Reading FASTA file.
#> Reading FASTA file.#> Sorting transcriptshead(tr2g) %>% knitr::kable()| transcript | gene | gene_name |
|---|---|---|
| ENST00000632684.1 | ENSG00000282431.1 | TRBD1 |
| ENST00000434970.2 | ENSG00000237235.2 | TRDD2 |
| ENST00000448914.1 | ENSG00000228985.1 | TRDD3 |
| ENST00000415118.1 | ENSG00000223997.1 | TRDD1 |
| ENST00000631435.1 | ENSG00000282253.1 | TRBD1 |
| ENST00000390583.1 | ENSG00000211923.1 | IGHD3-10 |
Alternative ways of getting tr2g have been implemented in the BUSpaRse package. You may use tr2g_ensembl to query Ensembl with biomart to get transcript and gene IDs. If you use this method, then please make sure that the Ensembl version used in the query matches that of the transcriptome. This method is convenient for the user since you only need to input species names, but it can be slow since biomart database query can be slow. You may also use tr2g_gtf for GTF files and tr2g_gff3 for GFF3 files, which are more useful for non-model organisms absent from Ensemble. After calling the tr2g_* family of functions, you should sort the transcripts from those functions with sort_tr2g so the transcripts are in the same order as those in the kallisto index. The FASTA way is the fastest, as reading FASTA files is faster than reading GTF and GFF files. Whichever way you choose, this shouldn’t take much more than half a minute per species.
The function transcript2gene not only gets the transcript and gene IDs but also sorts the transcripts. This function only supports Ensembl biomart query and Ensembl fasta files as the source of transcript and gene IDs, as the attribute field of GTF and GFF3 files can differ between sources and further cleanup may be needed.
Map ECs to genes
The 3rd column in the output.sorted.txt is the equivalence class (EC) index of each UMI for each cell barcode. Equivalence class (EC) means the set of transcripts in the transcriptome that the read is compatible to. While in most cases, an EC only has transcripts for the same gene, there are some ECs that have transcripts for different genes. The file in the kallisto bus output, matrix.ec, maps the EC index in output.sorted.txt to sets of line numbers in the transcriptome assembly. That’s why we ensured that the tr2g data frame has the same order as the transcripts in the index.
Also note that while this function supports multithreading, unless the matrix.ec file is really large, setting ncores > 1 will not improve performance since only 1 core will be used anyway. It may even compromise performance since creating multiple processes has overhead. For this dataset, where matrix.ec is 68.8MB, it is not large enough to warrant the use of more than 1 core.
genes <- EC2gene(tr2g, "./output/out_hgmm1k_v3", ncores = 1)#> Reading matrix.ec#> Processing genesNow for each EC, we have a set of genes the EC is compatible to.
head(genes)#> [[1]]
#> [1] "ENSG00000282431.1"
#>
#> [[2]]
#> [1] "ENSG00000237235.2"
#>
#> [[3]]
#> [1] "ENSG00000228985.1"
#>
#> [[4]]
#> [1] "ENSG00000223997.1"
#>
#> [[5]]
#> [1] "ENSG00000282253.1"
#>
#> [[6]]
#> [1] "ENSG00000211923.1"tail(genes)#> [[1]]
#> [1] "ENSG00000196418.12" "ENSG00000178199.13" "ENSG00000011523.13"
#>
#> [[2]]
#> [1] "ENSMUSG00000044026.2" "ENSMUSG00000026470.14" "ENSMUSG00000048424.17"
#> [4] "ENSMUSG00000110746.3"
#>
#> [[3]]
#> [1] "ENSG00000121413.12" "ENSG00000117115.12" "ENSG00000117475.13"
#> [4] "ENSG00000197380.10" "ENSG00000158220.13" "ENSG00000163378.13"
#> [7] "ENSG00000196417.12" "ENSG00000149311.18" "ENSG00000167984.17"
#> [10] "ENSG00000274897.2" "ENSG00000265863.1"
#>
#> [[4]]
#> [1] "ENSG00000070814.19" "ENSG00000166847.9"
#>
#> [[5]]
#> [1] "ENSG00000135930.13" "ENSG00000204842.15" "ENSG00000141665.12"
#> [4] "ENSG00000163877.10" "ENSG00000197580.11" "ENSG00000131686.14"
#> [7] "ENSG00000159023.21" "ENSG00000183323.12" "ENSG00000113558.18"
#> [10] "ENSG00000277868.4"
#>
#> [[6]]
#> [1] "ENSG00000148734.7" "ENSG00000187715.13"Apparently some ECs map to many genes.
Make the sparse matrix
For 10x, we do have a file with all valid cell barcodes that comes with CellRanger.
# Copy v3 chemistry whitelist to working directory
cp ~/cellranger-3.0.1/cellranger-cs/3.0.1/lib/python/cellranger/barcodes/3M-february-2018.txt.gz \
./data/whitelist_v3.txt.gz# Read in the whitelist
whitelist_v3 <- fread("./data/whitelist_v3.txt.gz", header = FALSE)$V1
length(whitelist_v3)#> [1] 6794880That’s an order of magnitude more than the 737K in v2 chemistry.
Now we have everything we need to make the sparse matrix. This function reads in output.sorted.txt line by line and processes them. It does not do barcode correction for now, so the barcode must exactly match those in the whitelist if one is provided. It took 5 to 6 minutes to construct the sparse matrix in the hgmm6k dataset, which has over 280 million lines in output.sorted.txt, which is over 9GB. Here the data set is smaller, and it takes less than a minute. A future version of BUSpaRse will parallelize this process to make it more scalable for huge datasets. For now, it’s single threaded.
Note that the arguments est_ncells (estimated number of cells) and est_ngenes (estimated number of genes) are important. With the estimate, this function reserves memory for the data to be added into, reducing the need of reallocation, which will slow the function down. Since the vast majority of “cells” you get in this sparse matrix are empty droplets rather than cells, please put at least 200 times more “cells” than you actually expect in est_ncells.
If you do not have a whitelist of barcodes, then it’s fine; the whitelist argument is optional.
res_mat <- make_sparse_matrix("./output/out_hgmm1k_v3/output.sorted.txt",
genes = genes, est_ncells = 3e5,
est_ngenes = nrow(tr2g),
whitelist = whitelist_v3)#> Reading data
#> Read 5 million lines
#> Read 10 million lines
#> Read 15 million lines
#> Read 20 million lines
#> Read 25 million lines
#> Read 30 million lines
#> Read 35 million lines
#> Constructing sparse matrixThe matrix we get has genes in rows and barcode in columns. The row names are the gene IDs (not using human readable gene names since they’re not guaranteed to be unique), and the column names are cell barcodes.
For Ensembl transcriptomes, all the 3 steps in BUSpaRse we have just done can be condensed into one step, with the busparse_gene_count function.