Gene set testing for Illumina HumanMethylation Arrays
Generating "truth" gene sets from RNA-seq data
Jovana Maksimovic, Alicia Oshlack and Belinda Phipson
July 21, 2020
Last updated: 2020-07-21
Checks: 7 0
Knit directory: methyl-geneset-testing/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it's best to always run the code in an empty environment.
The command set.seed(20200302) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 7fd8e1c. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/figures.nb.html
Ignored: code/.job/
Ignored: code/old/
Ignored: data/
Ignored: output/.DS_Store
Ignored: output/450K.rds
Ignored: output/CD4vCD8.GO.csv
Ignored: output/CD4vCD8.KEGG.csv
Ignored: output/EPIC.rds
Ignored: output/FDR-analysis/
Ignored: output/compare-methods/
Ignored: output/figures/
Ignored: output/random-cpg-sims/
Unstaged changes:
Modified: .gitignore
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/expressionGenesets.Rmd) and HTML (docs/expressionGenesets.html) files. If you've configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 976b2b5 | JovMaksimovic | 2020-07-17 | Build site. |
| Rmd | c687383 | JovMaksimovic | 2020-07-17 | wflow_publish(c("analysis/exploreArrayBias450.Rmd", "analysis/exploreArrayBiasEPIC.Rmd", |
| Rmd | 2be6153 | JovMaksimovic | 2020-07-14 | Updated code for generating manuscript figures. |
| html | 9cb4fea | Jovana Maksimovic | 2020-05-22 | Build site. |
| Rmd | 95e0882 | Jovana Maksimovic | 2020-05-22 | wflow_publish(c("analysis/runTimeComparison.Rmd", "analysis/exploreData.Rmd", |
| html | 22f00e9 | Jovana Maksimovic | 2020-05-19 | Build site. |
| Rmd | 63b0011 | Jovana Maksimovic | 2020-05-19 | wflow_publish(c("analysis/exploreArrayBias450.Rmd", "analysis/exploreArrayBiasEPIC.Rmd", |
| html | afc650b | JovMaksimovic | 2020-05-11 | Build site. |
| Rmd | 25e58bc | JovMaksimovic | 2020-05-11 | Added BH to pdjust calls, added methylation vs expression plot. |
| html | da4f010 | JovMaksimovic | 2020-05-08 | Build site. |
| Rmd | c70ec78 | JovMaksimovic | 2020-05-08 | wflow_publish(c("analysis/expressionGenesets.Rmd", "analysis/exploreData.Rmd")) |
| html | 23cb749 | JovMaksimovic | 2020-04-28 | Build site. |
| Rmd | 81c97a7 | JovMaksimovic | 2020-04-28 | wflow_publish(c("analysis/expressionGenesets.Rmd", "analysis/exploreData.Rmd")) |
| html | 06648a4 | JovMaksimovic | 2020-04-27 | Build site. |
| Rmd | 89af323 | JovMaksimovic | 2020-04-27 | wflow_publish(c("analysis/index.Rmd", "analysis/exploreData.Rmd", |
| Rmd | 1fd15c3 | JovMaksimovic | 2020-04-24 | Added broad sets to RNAseq analysis. |
| Rmd | 36c5803 | JovMaksimovic | 2020-04-24 | Added broad sets to RNAseq analysis. |
| Rmd | 33d1652 | JovMaksimovic | 2020-04-24 | Updated RNAseq analysis with more samples |
| Rmd | 537c935 | JovMaksimovic | 2020-04-24 | Started RNAseq analysis for evaluating gene set testing performance |
library(tximport)
library(here)
library(tidyverse)
library(EnsDb.Hsapiens.v75)
library(readr)
library(limma)
library(edgeR)
library(EGSEA)
library(EGSEAdata)
library(glue)
library(patchwork)
library(biobroom)
library(ChAMP)
source(here("code/utility.R"))Data import
The dataset used to generate the RNAseq "truth" gene sets is avoilable from GEO at GSE107011 or SRA at SRP125125.
The data was quasi-mapped and quantified using Salmon (v1.2.1) with the hg19_cdna Ensembl human transcriptome.
Load sample information and file names.
targets <- read_csv(here("data/SRP125125/SraRunTableFull.txt"))Parsed with column specification:
cols(
.default = col_character()
)See spec(...) for full column specifications.targets$Cell_type <- gsub(" ", "_", targets$Cell_type)
targets$Cell_type <- gsub("-", "_", targets$Cell_type)
targets# A tibble: 24 x 27
Run `Assay Type` AvgSpotLen Bases BioProject BioSample Bytes `Center Name`
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 SRR6… RNA-Seq 100 1342… PRJNA4187… SAMN0803… 6876… GEO
2 SRR6… RNA-Seq 100 1427… PRJNA4187… SAMN0803… 7340… GEO
3 SRR6… RNA-Seq 100 1570… PRJNA4187… SAMN0803… 8071… GEO
4 SRR6… RNA-Seq 100 1904… PRJNA4187… SAMN0803… 9742… GEO
5 SRR6… RNA-Seq 100 1470… PRJNA4187… SAMN0803… 7564… GEO
6 SRR6… RNA-Seq 100 1248… PRJNA4187… SAMN0803… 6610… GEO
7 SRR6… RNA-Seq 100 2184… PRJNA4187… SAMN0803… 1114… GEO
8 SRR6… RNA-Seq 100 2065… PRJNA4187… SAMN0803… 1056… GEO
9 SRR6… RNA-Seq 100 1984… PRJNA4187… SAMN0803… 1014… GEO
10 SRR6… RNA-Seq 100 2082… PRJNA4187… SAMN0803… 1064… GEO
# … with 14 more rows, and 19 more variables: Consent <chr>, `DATASTORE
# filetype` <chr>, `DATASTORE provider` <chr>, `DATASTORE region` <chr>,
# Experiment <chr>, `GEO_Accession (exp)` <chr>, Instrument <chr>,
# LibraryLayout <chr>, LibrarySelection <chr>, LibrarySource <chr>,
# Organism <chr>, Platform <chr>, ReleaseDate <chr>, `Sample Name` <chr>,
# `SRA Study` <chr>, Cell_type <chr>, disease_status <chr>, gender <chr>,
# source_name <chr>files <- list.files(here("data/SRP125125/quants"),
recursive = TRUE, pattern = "quant.sf", full.names = TRUE)
pos <- regexpr("SRR6298[0-9][0-9][0-9]", files, perl = TRUE)
names(files) <- unname(substr(files, pos,
pos[1] + attr(pos, "match.length") - 1))Associate transcripts with gene IDs for gene-level summarization.
edb <- EnsDb.Hsapiens.v75
tx2gene <- transcripts(edb, columns = c("tx_id", "gene_id"),
return.type = "DataFrame")
tx2geneDataFrame with 215647 rows and 2 columns
tx_id gene_id
<character> <character>
1 ENST00000000233 ENSG00000004059
2 ENST00000000412 ENSG00000003056
3 ENST00000000442 ENSG00000173153
4 ENST00000001008 ENSG00000004478
5 ENST00000001146 ENSG00000003137
... ... ...
215643 LRG_94t1 LRG_94
215644 LRG_96t1 LRG_96
215645 LRG_97t1 LRG_97
215646 LRG_98t1 LRG_98
215647 LRG_99t1 LRG_99Import gene-level counts and abundances.
txiG <- tximport(files, type = "salmon", tx2gene = tx2gene,
countsFromAbundance = "lengthScaledTPM",
ignoreTxVersion = TRUE)reading in files with read_tsv1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
summarizing abundance
summarizing counts
summarizing lengthcolnames(txiG$counts) <- names(files)
head(txiG$counts) SRR6298258 SRR6298271 SRR6298273 SRR6298278 SRR6298281
ENSG00000000003 61.8092088 64.34252 2.108605 7.108053 6.854211
ENSG00000000005 0.0000000 0.00000 0.000000 0.000000 0.000000
ENSG00000000419 308.0357168 453.78408 300.756056 184.887042 183.859446
ENSG00000000457 566.1655509 668.13279 536.765170 409.182211 554.068761
ENSG00000000460 88.1087011 149.58245 207.133830 96.734048 195.018761
ENSG00000000938 0.9993118 199.98401 6106.191865 17055.657470 15321.804086
SRR6298284 SRR6298286 SRR6298299 SRR6298302 SRR6298307
ENSG00000000003 12.16932 22.37741 207.2632 17.27445 4.634087
ENSG00000000005 0.00000 0.00000 0.0000 0.00000 0.000000
ENSG00000000419 137.81081 94.11433 324.2569 153.66560 285.821284
ENSG00000000457 506.88286 724.10043 831.8078 819.55366 287.623292
ENSG00000000460 36.97186 88.45333 305.1499 380.72895 250.642210
ENSG00000000938 6591.27698 64.65507 231.8483 5019.86572 17168.696404
SRR6298310 SRR6298313 SRR6298315 SRR6298328 SRR6298331
ENSG00000000003 5.597539 0.00000 191.5922 193.9760 12.63314
ENSG00000000005 0.000000 0.00000 0.0000 0.0000 0.00000
ENSG00000000419 157.483545 169.61751 411.3714 354.7413 245.31879
ENSG00000000457 577.570811 427.52646 528.0102 886.7599 639.44243
ENSG00000000460 245.554096 10.19566 121.0524 166.5221 259.31743
ENSG00000000938 12360.377205 9068.06785 49.0607 128.5385 5460.09143
SRR6298336 SRR6298339 SRR6298342 SRR6298344 SRR6298365
ENSG00000000003 7.548887 13.24455 9.167896 150.442321 6.321174
ENSG00000000005 0.000000 0.00000 0.000000 0.000000 0.000000
ENSG00000000419 414.301512 295.38687 299.028565 303.925491 389.002470
ENSG00000000457 251.307082 387.21898 289.416840 1037.669788 423.635676
ENSG00000000460 213.774478 186.27445 77.771446 230.877293 230.062502
ENSG00000000938 19652.208550 11370.32565 9706.096203 7.556217 3718.765758
SRR6298370 SRR6298373 SRR6298376
ENSG00000000003 2.440773 34.5469 23.76297
ENSG00000000005 0.000000 0.0000 0.00000
ENSG00000000419 287.085979 326.0884 254.49838
ENSG00000000457 279.957458 597.5548 292.36927
ENSG00000000460 113.801983 131.8787 84.14768
ENSG00000000938 21057.678193 16233.1932 12282.18942Set up DGElist object for downstream analysis.
z <- DGEList(txiG$counts)
z$genes <- ensembldb::genes(edb, filter = GeneIdFilter(rownames(z)),
columns = c("gene_id", "symbol", "entrezid"),
return.type = "DataFrame")
z$genes$entrezid <- sapply(z$genes$entrezid, function(x) x[1])
z$genes$length <- rowMedians(txiG$length)
targets <- targets[match(colnames(z), targets$Run), ]
z$samples$group <- targets$Cell_type
zAn object of class "DGEList"
$counts
SRR6298258 SRR6298271 SRR6298273 SRR6298278 SRR6298281
ENSG00000000003 61.80921 64.34252 2.108605 7.108053 6.854211
ENSG00000000005 0.00000 0.00000 0.000000 0.000000 0.000000
ENSG00000000419 308.03572 453.78408 300.756056 184.887042 183.859446
ENSG00000000457 566.16555 668.13279 536.765170 409.182211 554.068761
ENSG00000000460 88.10870 149.58245 207.133830 96.734048 195.018761
SRR6298284 SRR6298286 SRR6298299 SRR6298302 SRR6298307
ENSG00000000003 12.16932 22.37741 207.2632 17.27445 4.634087
ENSG00000000005 0.00000 0.00000 0.0000 0.00000 0.000000
ENSG00000000419 137.81081 94.11433 324.2569 153.66560 285.821284
ENSG00000000457 506.88286 724.10043 831.8078 819.55366 287.623292
ENSG00000000460 36.97186 88.45333 305.1499 380.72895 250.642210
SRR6298310 SRR6298313 SRR6298315 SRR6298328 SRR6298331
ENSG00000000003 5.597539 0.00000 191.5922 193.9760 12.63314
ENSG00000000005 0.000000 0.00000 0.0000 0.0000 0.00000
ENSG00000000419 157.483545 169.61751 411.3714 354.7413 245.31879
ENSG00000000457 577.570811 427.52646 528.0102 886.7599 639.44243
ENSG00000000460 245.554096 10.19566 121.0524 166.5221 259.31743
SRR6298336 SRR6298339 SRR6298342 SRR6298344 SRR6298365
ENSG00000000003 7.548887 13.24455 9.167896 150.4423 6.321174
ENSG00000000005 0.000000 0.00000 0.000000 0.0000 0.000000
ENSG00000000419 414.301512 295.38687 299.028565 303.9255 389.002470
ENSG00000000457 251.307082 387.21898 289.416840 1037.6698 423.635676
ENSG00000000460 213.774478 186.27445 77.771446 230.8773 230.062502
SRR6298370 SRR6298373 SRR6298376
ENSG00000000003 2.440773 34.5469 23.76297
ENSG00000000005 0.000000 0.0000 0.00000
ENSG00000000419 287.085979 326.0884 254.49838
ENSG00000000457 279.957458 597.5548 292.36927
ENSG00000000460 113.801983 131.8787 84.14768
36675 more rows ...
$samples
group lib.size norm.factors
SRR6298258 Naive_CD8_T_cells 8546013 1
SRR6298271 Naive_CD4_T_cells 9992761 1
SRR6298273 Naive_B_cells 11476629 1
SRR6298278 Classical_monocytes 14825624 1
SRR6298281 Natural_killer_cells 10978058 1
18 more rows ...
$genes
DataFrame with 36680 rows and 4 columns
gene_id symbol entrezid length
<character> <character> <integer> <numeric>
1 ENSG00000000003 TSPAN6 7105 1966.238
2 ENSG00000000005 TNMD 64102 704.094369565217
3 ENSG00000000419 DPM1 8813 838.86780308003
4 ENSG00000000457 SCYL3 57147 3715.56340085905
5 ENSG00000000460 C1orf112 55732 2687.24419290878
... ... ... ... ...
36676 ENSG00000273439 ZNF8 7554 1972.282
36677 ENSG00000273444 RP5-1147A1.2 NA 39.8542002006236
36678 ENSG00000273452 AC005358.1 NA 1817.5722173913
36679 ENSG00000273463 AL138834.1 NA 426.597217391304
36680 ENSG00000273484 OR6R2P NA 92.8252333966205Quality control
Genes that do not have an adequate number of reads in any sample should be filtered out prior to downstream analyses. From a biological perspective, genes that are not expressed at a biologically meaningful level in any condition are not of interest. Statistically, we get a better estimate of the mean-variance relationship in the data and reduce the number of statistical tests that are performes during differential expression analyses.
Filter out lowly expressed genes and calculate TMM normalisation factors.
keep <- filterByExpr(z, group = z$samples$group)
x <- z[keep, ]
y <- calcNormFactors(x)
yAn object of class "DGEList"
$counts
SRR6298258 SRR6298271 SRR6298273 SRR6298278 SRR6298281
ENSG00000000003 61.8092088 64.34252 2.108605 7.108053 6.854211
ENSG00000000419 308.0357168 453.78408 300.756056 184.887042 183.859446
ENSG00000000457 566.1655509 668.13279 536.765170 409.182211 554.068761
ENSG00000000460 88.1087011 149.58245 207.133830 96.734048 195.018761
ENSG00000000938 0.9993118 199.98401 6106.191865 17055.657470 15321.804086
SRR6298284 SRR6298286 SRR6298299 SRR6298302 SRR6298307
ENSG00000000003 12.16932 22.37741 207.2632 17.27445 4.634087
ENSG00000000419 137.81081 94.11433 324.2569 153.66560 285.821284
ENSG00000000457 506.88286 724.10043 831.8078 819.55366 287.623292
ENSG00000000460 36.97186 88.45333 305.1499 380.72895 250.642210
ENSG00000000938 6591.27698 64.65507 231.8483 5019.86572 17168.696404
SRR6298310 SRR6298313 SRR6298315 SRR6298328 SRR6298331
ENSG00000000003 5.597539 0.00000 191.5922 193.9760 12.63314
ENSG00000000419 157.483545 169.61751 411.3714 354.7413 245.31879
ENSG00000000457 577.570811 427.52646 528.0102 886.7599 639.44243
ENSG00000000460 245.554096 10.19566 121.0524 166.5221 259.31743
ENSG00000000938 12360.377205 9068.06785 49.0607 128.5385 5460.09143
SRR6298336 SRR6298339 SRR6298342 SRR6298344 SRR6298365
ENSG00000000003 7.548887 13.24455 9.167896 150.442321 6.321174
ENSG00000000419 414.301512 295.38687 299.028565 303.925491 389.002470
ENSG00000000457 251.307082 387.21898 289.416840 1037.669788 423.635676
ENSG00000000460 213.774478 186.27445 77.771446 230.877293 230.062502
ENSG00000000938 19652.208550 11370.32565 9706.096203 7.556217 3718.765758
SRR6298370 SRR6298373 SRR6298376
ENSG00000000003 2.440773 34.5469 23.76297
ENSG00000000419 287.085979 326.0884 254.49838
ENSG00000000457 279.957458 597.5548 292.36927
ENSG00000000460 113.801983 131.8787 84.14768
ENSG00000000938 21057.678193 16233.1932 12282.18942
18116 more rows ...
$samples
group lib.size norm.factors
SRR6298258 Naive_CD8_T_cells 8546013 1.2429013
SRR6298271 Naive_CD4_T_cells 9992761 1.2126078
SRR6298273 Naive_B_cells 11476629 0.9964633
SRR6298278 Classical_monocytes 14825624 0.7306961
SRR6298281 Natural_killer_cells 10978058 1.0729896
18 more rows ...
$genes
DataFrame with 18121 rows and 4 columns
gene_id symbol entrezid length
<character> <character> <integer> <numeric>
1 ENSG00000000003 TSPAN6 7105 1966.238
2 ENSG00000000419 DPM1 8813 838.86780308003
3 ENSG00000000457 SCYL3 57147 3715.56340085905
4 ENSG00000000460 C1orf112 55732 2687.24419290878
5 ENSG00000000938 FGR 2268 1818.20676818474
... ... ... ... ...
18117 ENSG00000273398 RP11-474G23.1 NA 2069.21667875588
18118 ENSG00000273423 OR13I1P NA 1026.282
18119 ENSG00000273425 AC073107.1 NA 1492.075
18120 ENSG00000273429 AC253572.2 NA 1540.075
18121 ENSG00000273439 ZNF8 7554 1972.282Plotting the distribution log-CPM values shows that a majority of genes within each sample are either not expressed or lowly-expressed with log-CPM values that are small or negative.
L <- mean(z$samples$lib.size) * 1e-6
M <- median(z$samples$lib.size) * 1e-6
dat <- tidy(z, addSamples = TRUE)Warning: `tbl_df()` is deprecated as of dplyr 1.0.0.
Please use `tibble::as_tibble()` instead.
This warning is displayed once every 8 hours.
Call `lifecycle::last_warnings()` to see where this warning was generated.dat$cpm <- reshape2::melt(cpm(z, log = TRUE), value.name = "cpm")$cpm
p1 <- ggplot(dat, aes(x = cpm, colour = group)) +
geom_density() +
labs(colour = "Cell Type", x = "Log CPM", y = "Density",
title = "Unfiltered") +
geom_vline(xintercept = log2(10/M + 2/L), linetype = "dashed")
dat <- tidy(y, addSamples = TRUE)
dat$cpm <- reshape2::melt(cpm(y, log = TRUE), value.name = "cpm")$cpm
p2 <- ggplot(dat, aes(x = cpm, colour = group)) +
geom_density() +
labs(colour = "Cell Type", x = "Log CPM", y = "Density",
title = "Filtered") +
geom_vline(xintercept = log2(10/M + 2/L), linetype = "dashed")
p1 + p2 + plot_layout(guides = "collect")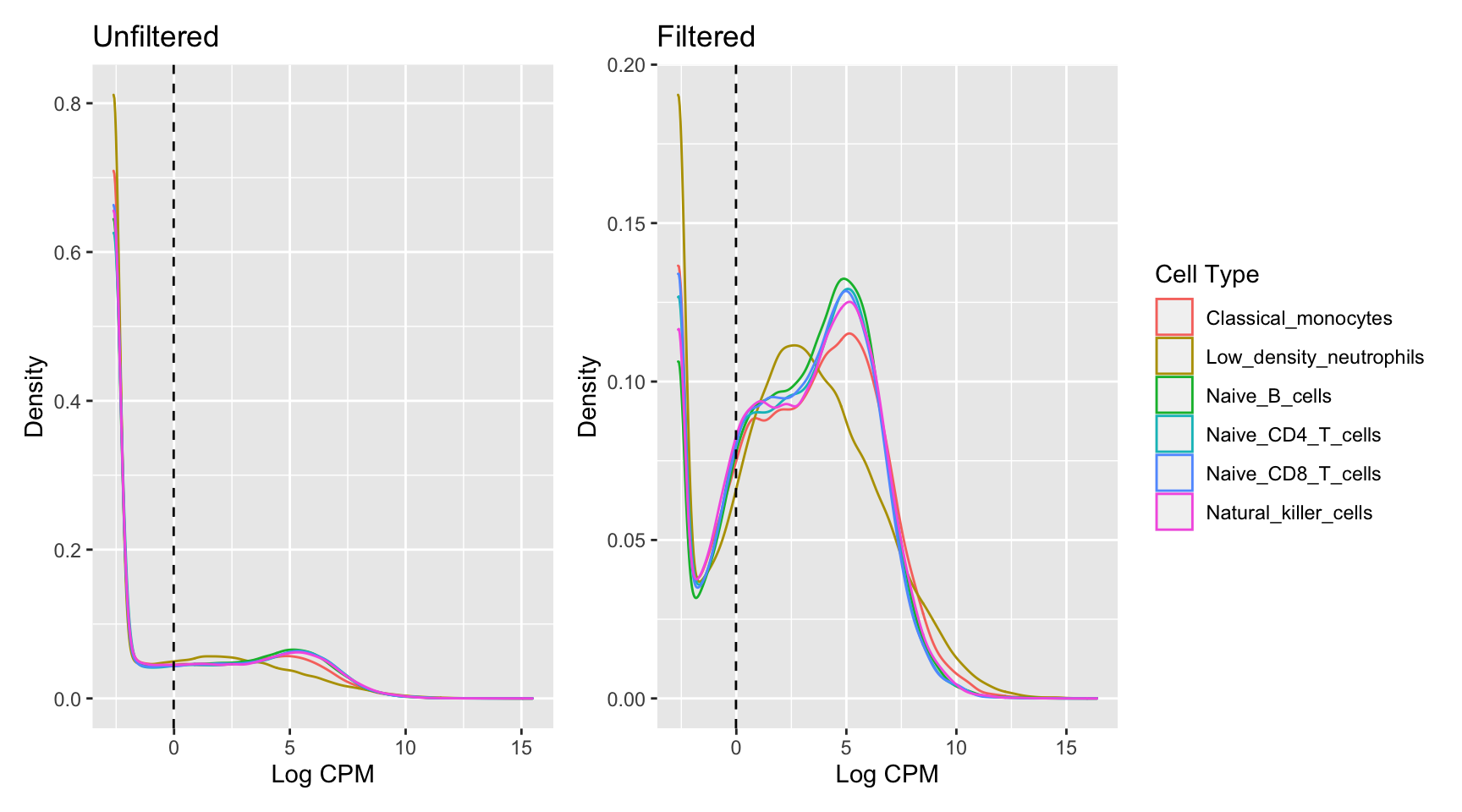
cellPal <- RColorBrewer::brewer.pal(6, "Dark2")[c(4, 5, 1, 2, 3, 6)]
dat <- tidy(y, addSamples = TRUE)
p1 <- ggplot(dat, aes(x = sample, y = lib.size, fill = group)) +
geom_bar(stat = "identity") +
labs(fill = "Cell Type", x = "Sample", y = "Library Size") +
scale_fill_manual(values = cellPal) +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 7),
legend.position = "bottom")
dat$cpm <- reshape2::melt(cpm(y, log = TRUE), value.name = "cpm")$cpm
p2 <- ggplot(dat, aes(x = sample, y = cpm, fill = group)) +
geom_boxplot(show.legend = FALSE) +
labs(x = "Sample", y = "CPM") +
theme(axis.text.x = element_text(angle = 45, hjust = 1, size = 7),
legend.position = "bottom") +
scale_fill_manual(values = cellPal)
p <- p1 + p2 + plot_layout(guides = "collect") & theme(legend.position = "bottom")
p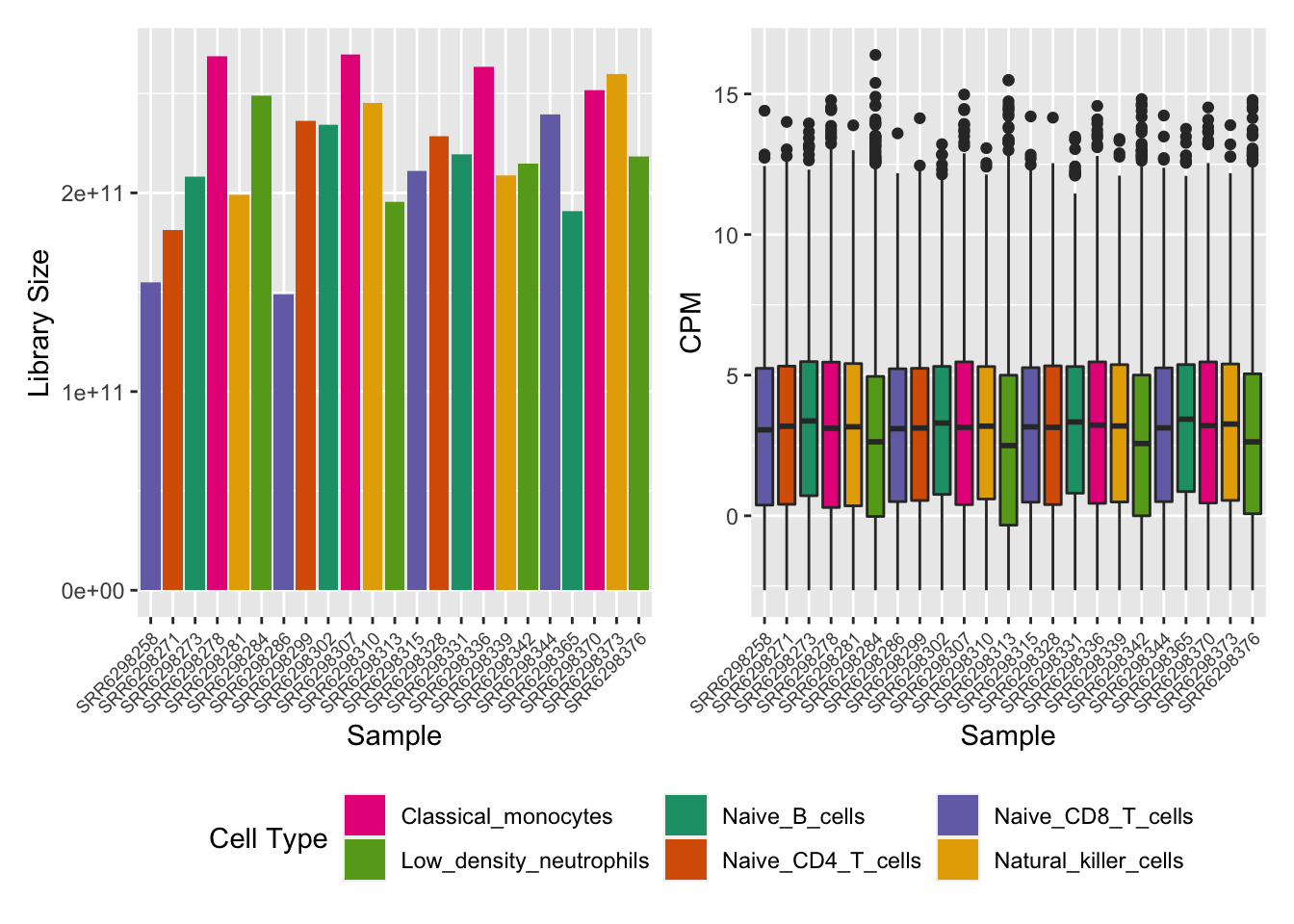
fig <- here("output/figures/SFig-4A.rds")
saveRDS(p1, fig, compress = FALSE)
fig <- here("output/figures/SFig-4B.rds")
saveRDS(p2, fig, compress = FALSE)Multi-dimensional scaling (MDS) plots show the largest sources of variation in the data. They are a good way of exploring the relationships between the samples and identifying structure in the data. The following series of MDS plots examines the first four principal components.
lcpm <- cpm(y, log = TRUE)
dims <- list(c(1,2), c(1,3), c(2,3), c(3,4))
p <- vector("list", length(dims))
for(i in 1:length(dims)){
tmp <- plotMDS(lcpm, top=1000, gene.selection="common", plot = FALSE,
dim.plot = dims[[i]])
dat <-data.frame(x = tmp$x, y = tmp$y, cellType = targets$Cell_type)
p[[i]] <- ggplot(dat, aes(x = x, y = y, colour = cellType)) +
geom_point() +
scale_colour_manual(values = cellPal) +
labs(colour = "Cell Type", x = glue("PC {tmp$dim.plot[1]}"),
y = glue("PC {tmp$dim.plot[2]}"))
}
(p[[1]] | p[[2]]) / (p[[3]] | p[[4]]) + plot_layout(guides = "collect")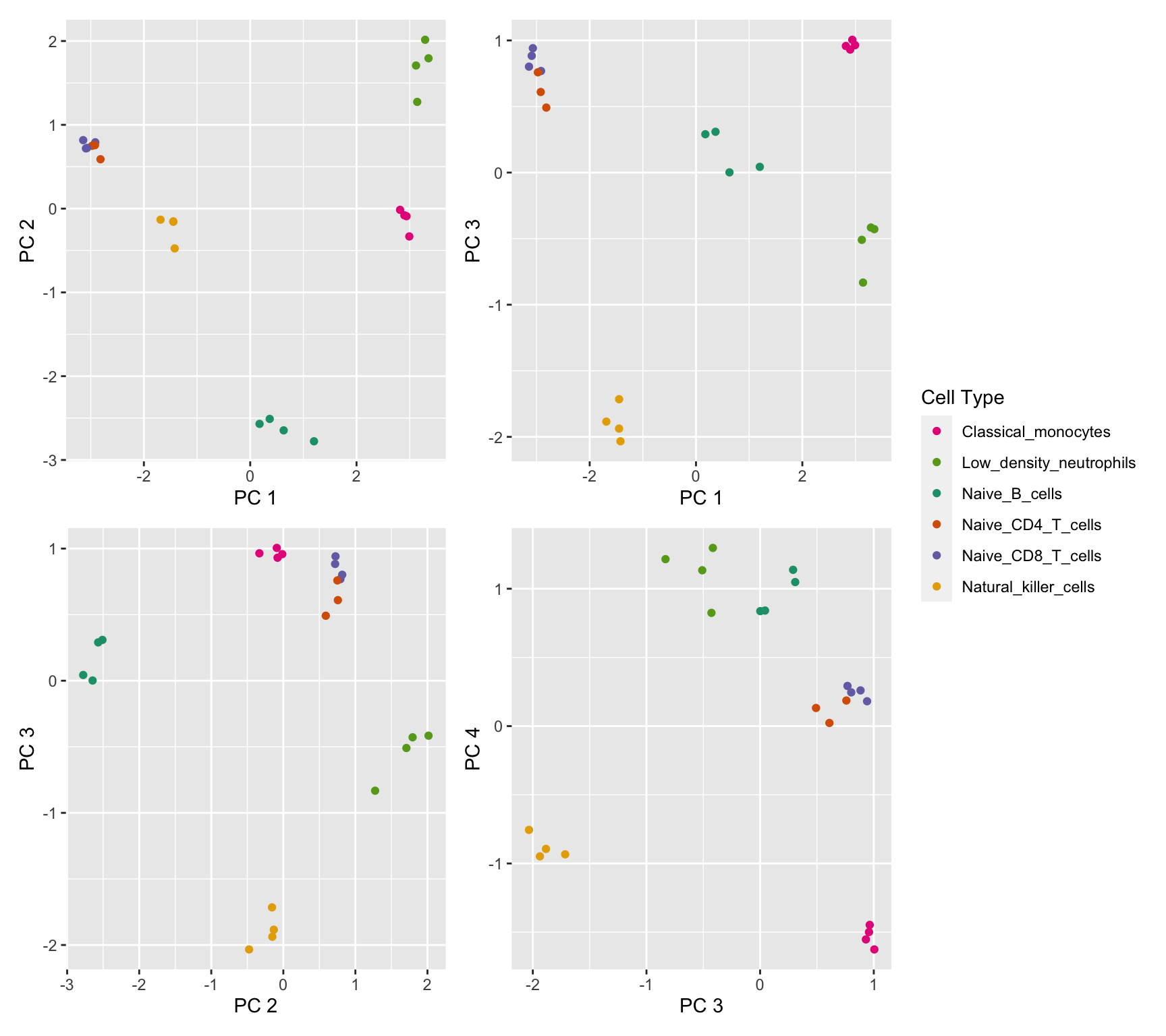
fig <- here("output/figures/SFig-4C.rds")
saveRDS(p[[1]], fig, compress = FALSE)Differential expression analysis
The TMM normalised data was transformed using voomWithQualityWeights. This takes into account the differing library sizes and the mean variance relationship in the data as well as calculating sample-specific quality weights. Linear models were fit in limma, taking into account the voom weights.
design <- model.matrix(~0+y$samples$group, data = targets)
colnames(design) <- c(levels(factor(y$samples$group)))
v <- voomWithQualityWeights(y, design, plot = TRUE)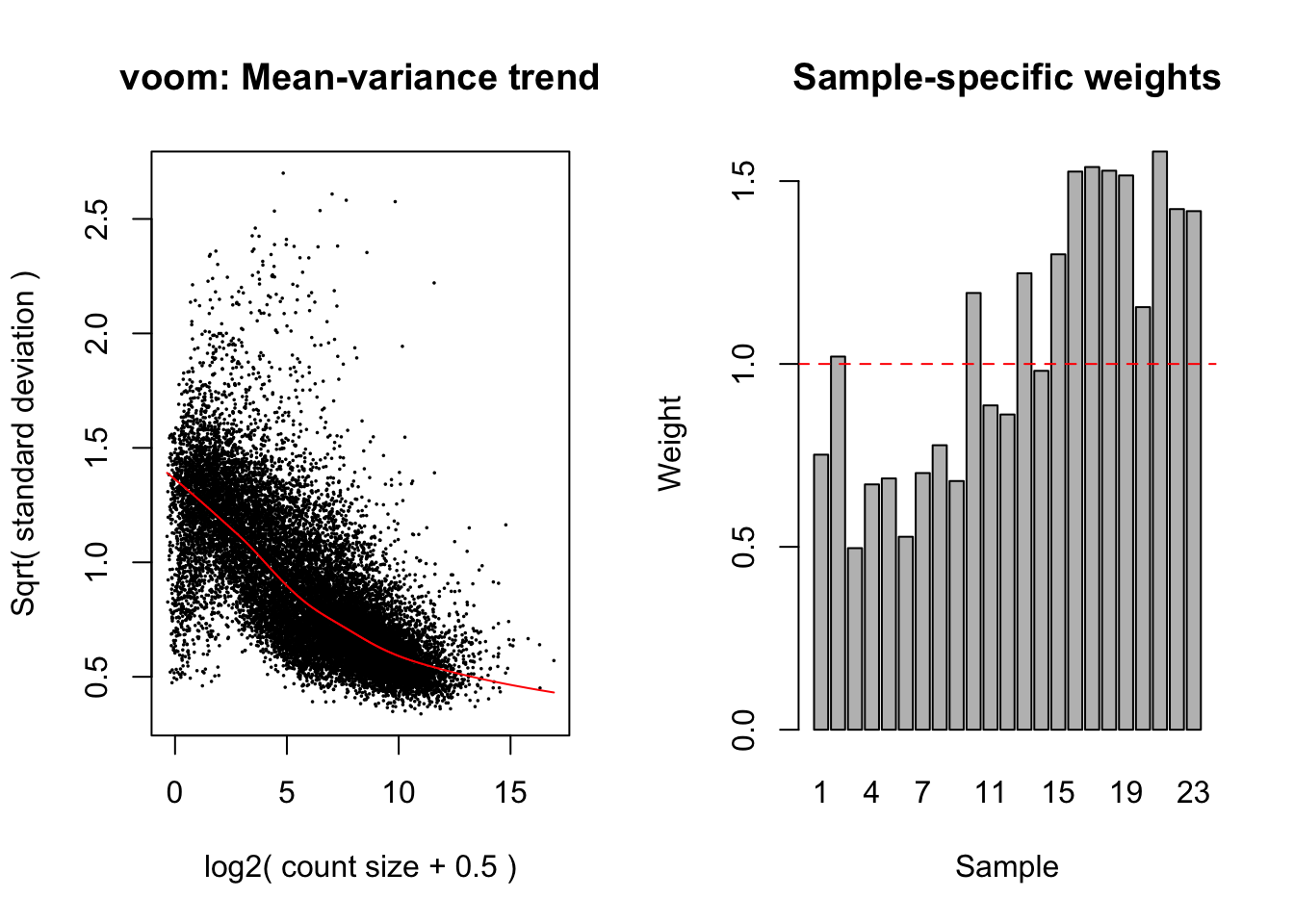
| Version | Author | Date |
|---|---|---|
| 976b2b5 | JovMaksimovic | 2020-07-17 |
cont <- makeContrasts(CD4vCD8=Naive_CD4_T_cells-Naive_CD8_T_cells,
MonovNeu=Classical_monocytes-Low_density_neutrophils,
BcellvNK=Naive_B_cells-Natural_killer_cells,
levels=design)
fit <- lmFit(v, design)
cfit <- contrasts.fit(fit, cont)
fit2 <- eBayes(cfit, robust = TRUE)
summary(decideTests(fit2, p.value = 0.05)) CD4vCD8 MonovNeu BcellvNK
Down 89 4295 2293
NotSig 17917 8703 13282
Up 115 5123 2546fitSum <- summary(decideTests(fit2, p.value = 0.05))
dat <- reshape2::melt(fitSum[rownames(fitSum) != "NotSig", ])
colnames(dat) <- c("dir","comp","num")
p <- ggplot(dat, aes(x = comp, y = num, fill = dir)) +
geom_bar(stat = "identity", position = "dodge") +
labs(x = "Comparison", y = "No. DM CpGs (FDR < 0.05)", fill = "Direction") +
scale_fill_brewer(palette = "Set1", direction = -1)
p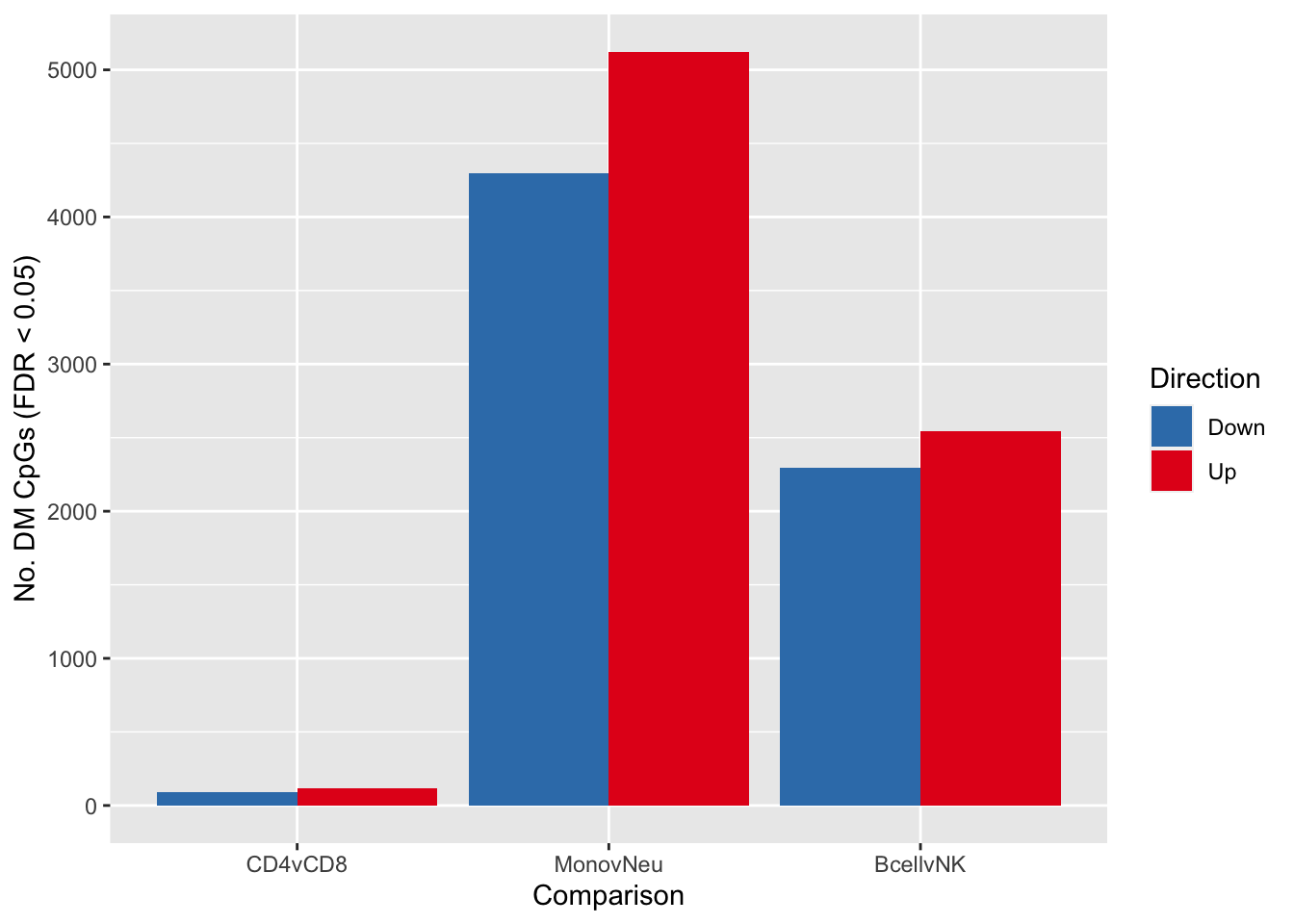
| Version | Author | Date |
|---|---|---|
| 976b2b5 | JovMaksimovic | 2020-07-17 |
fig <- here("output/figures/SFig-4D.rds")
saveRDS(p, fig, compress = FALSE)Gene set testing
Testing for enrichment of GO categories and KEGG pathways amongst statistically significant differentially expressed genes.
go <- NULL
kegg <- NULL
for(i in 1:ncol(cont)){
top <- topTable(fit2, coef = i, p.value = 0.05, number = Inf)
tmp <- goana(top$entrezid, universe = v$genes$entrezid,
covariate = v$genes$length)
tmp <- topGO(tmp, number = Inf)
tmp$FDR <- p.adjust(tmp$P.DE, method = "BH")
tmp <- rownames_to_column(tmp, var = "ID")
tmp$contrast <- colnames(cont)[i]
go <- bind_rows(go, tmp)
tmp <- kegga(top$entrezid, universe = v$genes$entrezid, species = "Hs",
covariate = v$genes$length, species.KEGG = "hsa")
tmp <- topKEGG(tmp, number = Inf)
tmp$FDR <- p.adjust(tmp$P.DE, method = "BH")
tmp <- rownames_to_column(tmp, var = "PID")
tmp$contrast <- colnames(cont)[i]
kegg <- bind_rows(kegg, tmp)
}Warning in rowsum.default(covariate, group = universe, reorder = FALSE): missing
values for 'group'Warning in rowsum.default(rep_len(1L, length(universe)), group = universe, :
missing values for 'group'Warning in rowsum.default(covariate, group = universe, reorder = FALSE): missing
values for 'group'Warning in rowsum.default(rep_len(1L, length(universe)), group = universe, :
missing values for 'group'Warning in rowsum.default(covariate, group = universe, reorder = FALSE): missing
values for 'group'Warning in rowsum.default(rep_len(1L, length(universe)), group = universe, :
missing values for 'group'saveRDS(go, here(glue("data/RNAseq-GO.rds")))
saveRDS(kegg, here(glue("data/RNAseq-KEGG.rds")))Test whether any of the genes in the BROAD sets are differentially expressed.
data(PathwayList)
keep <- sapply(PathwayList, function(x) any(x %in% v$genes$symbol))
ensembl <- suppressMessages(lapply(PathwayList[keep], function(x){
tmp <- v$genes$gene_id[v$genes$symbol %in% x]
tmp[!is.na(tmp)]
}))
idx <- ids2indices(ensembl, v$genes$gene_id)
broad <- NULL
for(i in 1:ncol(cont)){
tmp <- camera(v, index = idx, design = design, contrast = cont[,i],
trend.var = TRUE)
tmp <- rownames_to_column(tmp, var = "ID")
tmp$contrast <- colnames(cont)[i]
broad <- bind_rows(broad, tmp)
}
saveRDS(broad, here("data/RNAseq-BROAD.rds"))Test whether the BROAD sets are enriched for the differentially expressed genes using Belinda's gsaseq function.
entrez <- suppressMessages(lapply(ensembl, function(x){
tmp <- unname(v$genes$entrezid[v$genes$gene_id %in% x])
tmp[!is.na(tmp)]
}))
gsa <- NULL
for(i in 1:ncol(cont)){
top <- topTable(fit2, coef = i, p.value = 0.05, number = Inf)
tmp <- gsaseq(top$entrezid, universe = v$genes$entrezid,
collection = entrez, gene.length = v$genes$length)
tmp <- rownames_to_column(data.frame(tmp), var = "ID")
tmp$contrast <- colnames(cont)[i]
gsa <- bind_rows(gsa, tmp)
}
saveRDS(gsa, here("data/RNAseq-BROAD-GSA.rds"))
sessionInfo()R version 3.6.3 (2020-02-29)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS Mojave 10.14.6
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
locale:
[1] en_AU.UTF-8/en_AU.UTF-8/en_AU.UTF-8/C/en_AU.UTF-8/en_AU.UTF-8
attached base packages:
[1] stats4 parallel stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] ChAMP_2.16.2
[2] DT_0.14
[3] IlluminaHumanMethylationEPICmanifest_0.3.0
[4] Illumina450ProbeVariants.db_1.22.0
[5] DMRcate_2.0.7
[6] FEM_3.14.0
[7] impute_1.60.0
[8] igraph_1.2.5
[9] corrplot_0.84
[10] marray_1.64.0
[11] Matrix_1.2-18
[12] ChAMPdata_2.18.0
[13] minfi_1.32.0
[14] bumphunter_1.28.0
[15] locfit_1.5-9.4
[16] iterators_1.0.12
[17] foreach_1.5.0
[18] Biostrings_2.54.0
[19] XVector_0.26.0
[20] SummarizedExperiment_1.16.1
[21] DelayedArray_0.12.3
[22] BiocParallel_1.20.1
[23] matrixStats_0.56.0
[24] biobroom_1.18.0
[25] broom_0.7.0
[26] patchwork_1.0.1
[27] glue_1.4.1
[28] EGSEAdata_1.14.0
[29] EGSEA_1.14.0
[30] pathview_1.26.0
[31] org.Hs.eg.db_3.10.0
[32] topGO_2.38.1
[33] SparseM_1.78
[34] GO.db_3.10.0
[35] graph_1.64.0
[36] gage_2.36.0
[37] edgeR_3.28.1
[38] limma_3.42.2
[39] EnsDb.Hsapiens.v75_2.99.0
[40] ensembldb_2.10.2
[41] AnnotationFilter_1.10.0
[42] GenomicFeatures_1.38.2
[43] AnnotationDbi_1.48.0
[44] Biobase_2.46.0
[45] GenomicRanges_1.38.0
[46] GenomeInfoDb_1.22.1
[47] IRanges_2.20.2
[48] S4Vectors_0.24.4
[49] BiocGenerics_0.32.0
[50] forcats_0.5.0
[51] stringr_1.4.0
[52] dplyr_1.0.0
[53] purrr_0.3.4
[54] readr_1.3.1
[55] tidyr_1.1.0
[56] tibble_3.0.3
[57] ggplot2_3.3.2
[58] tidyverse_1.3.0
[59] here_0.1
[60] tximport_1.14.2
[61] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Hmisc_4.4-0
[2] Rsamtools_2.2.3
[3] rprojroot_1.3-2
[4] crayon_1.3.4
[5] MASS_7.3-51.6
[6] nlme_3.1-148
[7] backports_1.1.8
[8] reprex_0.3.0
[9] sva_3.34.0
[10] rlang_0.4.7
[11] readxl_1.3.1
[12] DSS_2.34.0
[13] globaltest_5.40.0
[14] bit64_0.9-7.1
[15] isva_1.9
[16] rngtools_1.5
[17] methylumi_2.32.0
[18] R2HTML_2.3.2
[19] haven_2.3.1
[20] tidyselect_1.1.0
[21] nleqslv_3.3.2
[22] XML_3.99-0.3
[23] zoo_1.8-8
[24] GenomicAlignments_1.22.1
[25] org.Mm.eg.db_3.10.0
[26] xtable_1.8-4
[27] magrittr_1.5
[28] evaluate_0.14
[29] bibtex_0.4.2.2
[30] Rdpack_1.0.0
[31] cli_2.0.2
[32] zlibbioc_1.32.0
[33] sn_1.6-2
[34] hwriter_1.3.2
[35] rstudioapi_0.11
[36] doRNG_1.8.2
[37] whisker_0.4
[38] rpart_4.1-15
[39] mathjaxr_1.0-1
[40] KEGGdzPathwaysGEO_1.24.0
[41] GSA_1.03.1
[42] IlluminaHumanMethylationEPICanno.ilm10b4.hg19_0.6.0
[43] shiny_1.5.0
[44] GSVA_1.34.0
[45] xfun_0.15
[46] clue_0.3-57
[47] askpass_1.1
[48] org.Rn.eg.db_3.10.0
[49] multtest_2.42.0
[50] cluster_2.1.0
[51] caTools_1.18.0
[52] KEGGREST_1.26.1
[53] interactiveDisplayBase_1.24.0
[54] base64_2.0
[55] biovizBase_1.34.1
[56] scrime_1.3.5
[57] dendextend_1.13.4
[58] png_0.1-7
[59] permute_0.9-5
[60] reshape_0.8.8
[61] withr_2.2.0
[62] lumi_2.38.0
[63] bitops_1.0-6
[64] plyr_1.8.6
[65] cellranger_1.1.0
[66] GSEABase_1.48.0
[67] PADOG_1.28.0
[68] JADE_2.0-3
[69] pillar_1.4.6
[70] gplots_3.0.4
[71] multcomp_1.4-13
[72] fs_1.4.2
[73] DelayedMatrixStats_1.8.0
[74] vctrs_0.3.2
[75] ellipsis_0.3.1
[76] generics_0.0.2
[77] metap_1.4
[78] tools_3.6.3
[79] foreign_0.8-76
[80] munsell_0.5.0
[81] fastmap_1.0.1
[82] compiler_3.6.3
[83] httpuv_1.5.4
[84] rtracklayer_1.46.0
[85] geneLenDataBase_1.22.0
[86] ExperimentHub_1.12.0
[87] beanplot_1.2
[88] Gviz_1.30.3
[89] plotly_4.9.2.1
[90] DNAcopy_1.60.0
[91] GenomeInfoDbData_1.2.2
[92] gridExtra_2.3
[93] lattice_0.20-41
[94] mutoss_0.1-12
[95] utf8_1.1.4
[96] later_1.1.0.1
[97] BiocFileCache_1.10.2
[98] affy_1.64.0
[99] jsonlite_1.7.0
[100] scales_1.1.1
[101] genefilter_1.68.0
[102] lazyeval_0.2.2
[103] promises_1.1.1
[104] doParallel_1.0.15
[105] latticeExtra_0.6-29
[106] R.utils_2.9.2
[107] goseq_1.38.0
[108] checkmate_2.0.0
[109] rmarkdown_2.3
[110] nor1mix_1.3-0
[111] sandwich_2.5-1
[112] statmod_1.4.34
[113] siggenes_1.60.0
[114] dichromat_2.0-0
[115] BSgenome_1.54.0
[116] HDF5Array_1.14.4
[117] bsseq_1.22.0
[118] survival_3.2-3
[119] numDeriv_2016.8-1.1
[120] yaml_2.2.1
[121] plotrix_3.7-8
[122] Glimma_1.14.0
[123] htmltools_0.5.0
[124] memoise_1.1.0
[125] VariantAnnotation_1.32.0
[126] quadprog_1.5-8
[127] viridisLite_0.3.0
[128] digest_0.6.25
[129] assertthat_0.2.1
[130] mime_0.9
[131] rappdirs_0.3.1
[132] BiasedUrn_1.07
[133] RSQLite_2.2.0
[134] data.table_1.12.8
[135] blob_1.2.1
[136] R.oo_1.23.0
[137] preprocessCore_1.48.0
[138] labeling_0.3
[139] fastICA_1.2-2
[140] shinythemes_1.1.2
[141] splines_3.6.3
[142] Formula_1.2-3
[143] Rhdf5lib_1.8.0
[144] illuminaio_0.28.0
[145] AnnotationHub_2.18.0
[146] ProtGenerics_1.18.0
[147] RCurl_1.98-1.2
[148] hms_0.5.3
[149] modelr_0.1.8
[150] rhdf5_2.30.1
[151] colorspace_1.4-1
[152] base64enc_0.1-3
[153] BiocManager_1.30.10
[154] mnormt_1.5-7
[155] nnet_7.3-14
[156] GEOquery_2.54.1
[157] Rcpp_1.0.5
[158] mclust_5.4.6
[159] mvtnorm_1.1-1
[160] fansi_0.4.1
[161] R6_2.4.1
[162] grid_3.6.3
[163] lifecycle_0.2.0
[164] acepack_1.4.1
[165] TFisher_0.2.0
[166] kpmt_0.1.0
[167] curl_4.3
[168] affyio_1.56.0
[169] gdata_2.18.0
[170] RPMM_1.25
[171] safe_3.26.0
[172] qvalue_2.18.0
[173] ROC_1.62.0
[174] TH.data_1.0-10
[175] RColorBrewer_1.1-2
[176] IlluminaHumanMethylationEPICanno.ilm10b2.hg19_0.6.0
[177] IlluminaHumanMethylation450kmanifest_0.4.0
[178] htmlwidgets_1.5.1
[179] biomaRt_2.42.1
[180] missMethyl_1.20.4
[181] mgcv_1.8-31
[182] rvest_0.3.5
[183] openssl_1.4.2
[184] hgu133plus2.db_3.2.3
[185] htmlTable_2.0.1
[186] KEGGgraph_1.46.0
[187] IlluminaHumanMethylation450kanno.ilmn12.hg19_0.6.0
[188] codetools_0.2-16
[189] lubridate_1.7.9
[190] gtools_3.8.2
[191] prettyunits_1.1.1
[192] dbplyr_1.4.4
[193] R.methodsS3_1.8.0
[194] gtable_0.3.0
[195] DBI_1.1.0
[196] wateRmelon_1.30.0
[197] git2r_0.27.1
[198] httr_1.4.2
[199] KernSmooth_2.23-17
[200] stringi_1.4.6
[201] progress_1.2.2
[202] farver_2.0.3
[203] reshape2_1.4.4
[204] viridis_0.5.1
[205] annotate_1.64.0
[206] Rgraphviz_2.30.0
[207] combinat_0.0-8
[208] xml2_1.3.2
[209] KEGG.db_3.2.3
[210] geneplotter_1.64.0
[211] BiocVersion_3.10.1
[212] bit_1.1-15.2
[213] jpeg_0.1-8.1
[214] hgu133a.db_3.2.3
[215] pkgconfig_2.0.3
[216] HTMLUtils_0.1.7
[217] ruv_0.9.7.1
[218] gbRd_0.4-11
[219] knitr_1.29