Inflammation of Paediatric Pulmonary Diseases
DGE analysis of monocyte derived macrophages: CF versus Non-CF controls
Jovana Maksimovic
September 03, 2024
Last updated: 2024-09-03
Checks: 7 0
Knit directory: paed-inflammation-CITEseq/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20240216) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version fa156fc. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/C133_Neeland_batch1/
Ignored: data/C133_Neeland_merged/
Ignored: renv/library/
Ignored: renv/staging/
Untracked files:
Untracked: analysis/13.0_DGE_analysis_macro-alveolar_cells_CF-only-samples_OLD.Rmd
Untracked: analysis/13.1_DGE_analysis_macro-alveolar_cells_CF-vs-control-samples_OLD.Rmd
Untracked: analysis/13.3_DGE_analysis_macro-monocyte-derived_CF-only-samples_OLD.Rmd
Untracked: analysis/13.4_DGE_analysis_macro-monocyte-derived_CF-vs-control-samples_OLD.Rmd
Untracked: analysis/15.0_integrate_all_cells.Rmd
Untracked: data/c2.all.v2024.1.Hs.entrez.gmt
Untracked: data/c5.all.v2024.1.Hs.entrez.gmt
Untracked: data/h.all.v2024.1.Hs.entrez.gmt
Untracked: output/dge_analysis/macro-CCL/
Untracked: output/dge_analysis/macro-IFI27/
Untracked: output/dge_analysis/macro-alveolar/CAM.GO.CF.IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.GO.CF.NO_MODvCF.LUMA_IVA.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.GO.NA.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.HALLMARK.CF.NO_MOD.MvCF.NO_MOD.S.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.HALLMARK.CF.NO_MODvCF.IVA.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.HALLMARK.CF.NO_MODvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.REACTOME.CF.LUMA_IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.REACTOME.NA.csv
Untracked: output/dge_analysis/macro-alveolar/CAM.WP.NA.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.GO.CF.IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.GO.CF.NO_MODvCF.LUMA_IVA.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.GO.NA.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.HALLMARK.CF.NO_MOD.MvCF.NO_MOD.S.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.HALLMARK.CF.NO_MODvCF.IVA.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.HALLMARK.CF.NO_MODvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.REACTOME.CF.LUMA_IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.REACTOME.NA.csv
Untracked: output/dge_analysis/macro-alveolar/ORA.WP.NA.csv
Untracked: output/dge_analysis/macro-lipid/
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.GO.CF.IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.GO.CF.NO_MODvCF.LUMA_IVA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.GO.NA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.HALLMARK.CF.NO_MOD.MvCF.NO_MOD.S.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.HALLMARK.CF.NO_MODvCF.IVA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.HALLMARK.CF.NO_MODvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.REACTOME.CF.LUMA_IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.REACTOME.NA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/CAM.WP.NA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.GO.CF.IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.GO.CF.NO_MODvCF.LUMA_IVA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.GO.NA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.HALLMARK.CF.NO_MOD.MvCF.NO_MOD.S.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.HALLMARK.CF.NO_MODvCF.IVA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.HALLMARK.CF.NO_MODvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.REACTOME.CF.LUMA_IVAvNON_CF.CTRL.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.REACTOME.NA.csv
Untracked: output/dge_analysis/macro-monocyte-derived/ORA.WP.NA.csv
Unstaged changes:
Modified: analysis/09.0_integrate_cluster_macro_cells.Rmd
Deleted: analysis/13.3_DGE_analysis_macro-monocyte-derived_CF-only-samples.Rmd
Deleted: analysis/13.4_DGE_analysis_macro-monocyte-derived_CF-vs-control-samples.Rmd
Modified: output/dge_analysis/macro-alveolar/CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macro-alveolar/CF.NO_MOD.MvCF.NO_MOD.S.csv
Modified: output/dge_analysis/macro-alveolar/CF.NO_MODvCF.IVA.csv
Modified: output/dge_analysis/macro-alveolar/CF.NO_MODvNON_CF.CTRL.csv
Modified: output/dge_analysis/macro-monocyte-derived/CF.IVAvNON_CF.CTRL.csv
Modified: output/dge_analysis/macro-monocyte-derived/CF.NO_MOD.MvCF.NO_MOD.S.csv
Modified: output/dge_analysis/macro-monocyte-derived/CF.NO_MODvCF.IVA.csv
Modified: output/dge_analysis/macro-monocyte-derived/CF.NO_MODvNON_CF.CTRL.csv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/13.3_DGE_analysis_macro-monocyte-derived_CF-vs-control-samples.Rmd)
and HTML
(docs/13.3_DGE_analysis_macro-monocyte-derived_CF-vs-control-samples.html)
files. If you’ve configured a remote Git repository (see
?wflow_git_remote), click on the hyperlinks in the table
below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | fa156fc | Jovana Maksimovic | 2024-09-03 | wflow_publish("analysis/13.3_DGE_analysis_macro-monocyte-derived_CF-vs-control-samples.Rmd") |
| Rmd | 0d98ed2 | Jovana Maksimovic | 2024-08-06 | Delete mis-named files |
| html | 155ff98 | Jovana Maksimovic | 2024-08-06 | Build site. |
| Rmd | a496087 | Jovana Maksimovic | 2024-08-06 | wflow_publish(c("analysis/13.3_DGE_analysis_macro-monocyte-derived_CF-vs-control-samples.Rmd", |
Load libraries
suppressPackageStartupMessages({
library(BiocStyle)
library(tidyverse)
library(here)
library(glue)
library(Seurat)
library(patchwork)
library(paletteer)
library(limma)
library(edgeR)
library(RUVSeq)
library(scMerge)
library(SingleCellExperiment)
library(scater)
library(tidyHeatmap)
library(org.Hs.eg.db)
library(TxDb.Hsapiens.UCSC.hg38.knownGene)
library(missMethyl)
})
source(here("code/utility.R"))Load Data
ambient <- ""
file <- here("data",
"C133_Neeland_merged",
glue("C133_Neeland_full_clean{ambient}_macrophages_annotated_diet.SEU.rds"))
seu <- readRDS(file)
seuAn object of class Seurat
21568 features across 165209 samples within 1 assay
Active assay: RNA (21568 features, 0 variable features)Create pseudobulk samples by cell type (ann_level_2)
Use cell type and sample as our two factors; each column of the output corresponds to one unique combination of these two factors.
out <- here("data",
"C133_Neeland_merged",
glue("C133_Neeland_full_clean{ambient}_macrophages_pseudobulk.rds"))
sce <- SingleCellExperiment(list(counts = seu[["RNA"]]@counts),
colData = seu@meta.data)
if(!file.exists(out)){
pseudoBulk <- aggregateAcrossCells(sce,
id = colData(sce)[, c("ann_level_2", "sample.id")])
saveRDS(pseudoBulk, file = out)
} else {
pseudoBulk <- readRDS(file = out)
}
pseudoBulkclass: SingleCellExperiment
dim: 21568 533
metadata(0):
assays(1): counts
rownames(21568): A1BG A1BG-AS1 ... ZNRD2 ZRANB2-AS2
rowData names(0):
colnames: NULL
colData names(72): nCount_RNA nFeature_RNA ... sample.id ncells
reducedDimNames(0):
mainExpName: NULL
altExpNames(0):Code micro information
Create a factor that identifies individuals that were infected with the top 4 clinically important pathogens at time of sample collection i.e. Pseudomonas aeruginosa, Staphylococcus aureus, Haemophilus influenzae, and Aspergillus.
important_micro <- c("Pseudomonas aeruginosa", "Staphylococcus aureus",
"Haemophilus influenzae", "Aspergillus", "S. aureus",
"Staph Aureus (Methicillin Resistant)", "MRSA")
pseudoBulk$Micro_code <- sapply(strsplit(pseudoBulk$Bacteria_type, ","), function(bacteria){
any(tolower(str_trim(bacteria)) %in% tolower(important_micro))
})
table(pseudoBulk$Micro_code)
FALSE TRUE
312 221 No. cells per cell type
colData(pseudoBulk) %>%
data.frame %>%
group_by(ann_level_2) %>%
summarise(total = sum(ncells)) %>%
ggplot(aes(x = fct_reorder(ann_level_2, total),
y = total, fill = ann_level_2)) +
geom_col() +
geom_text(aes(label = total), vjust = -0.5, colour = "black", size = 2.5) +
scale_y_log10() +
labs(x = "Cell label",
y = "Log 10 No. cells") +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5),
legend.position = "bottom") +
geom_hline(yintercept = 1000, linetype = "dashed") +
NoLegend()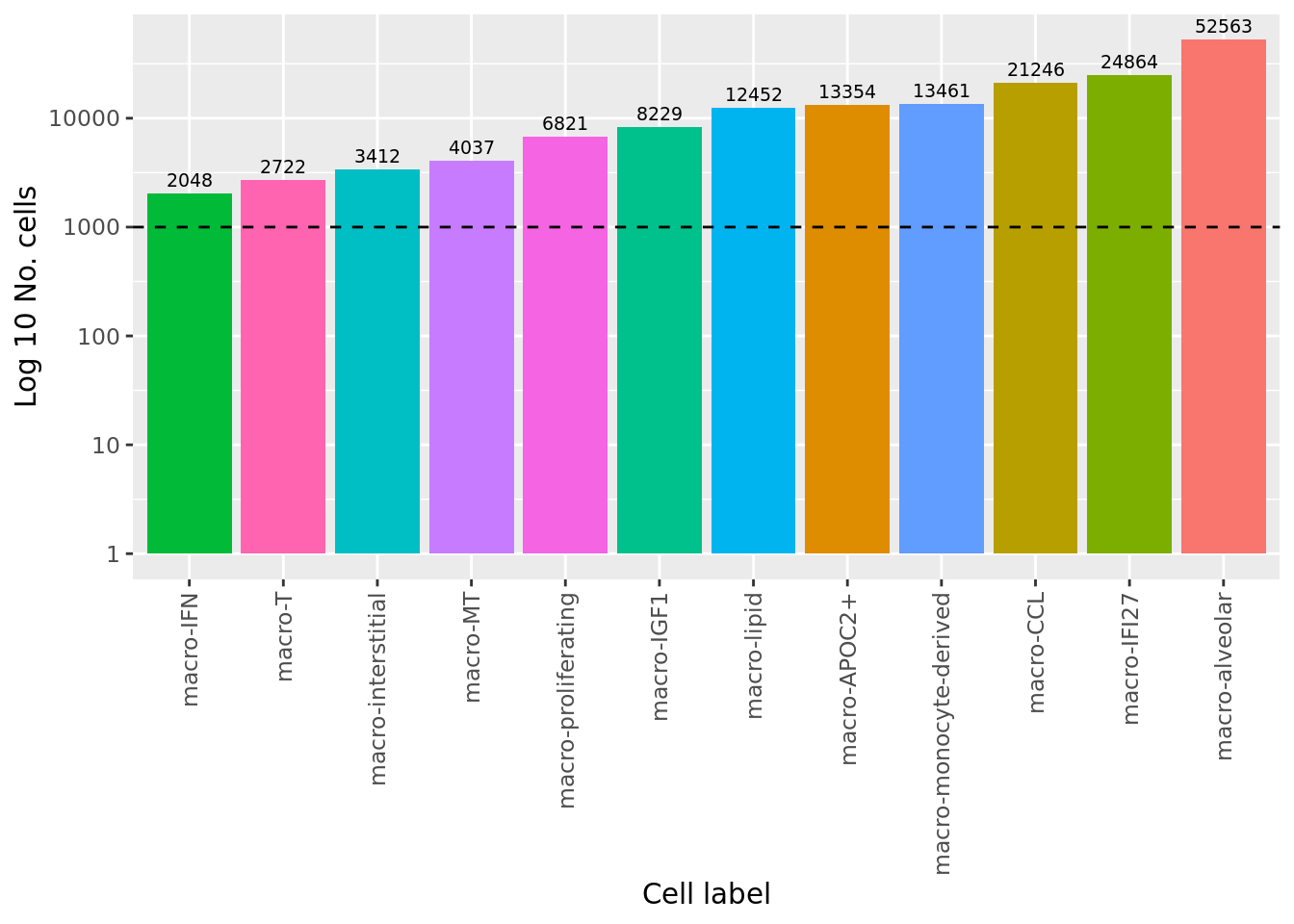
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
No. cells per cell type per sample
How many pseudobulk samples are comprised of >50 cells?
colData(pseudoBulk) %>%
data.frame %>%
arrange(Group) %>%
ggplot(aes(x = fct_inorder(sample.id),
y = ncells, fill = Group)) +
geom_col() +
scale_fill_brewer(palette = "Set2") +
scale_y_log10() +
facet_wrap(~ann_level_2, ncol = 2) +
labs(x = "Sample",
y = "Log10 No. cells") +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5,
size = 8),
legend.position = "bottom") +
geom_hline(yintercept = 50, linetype = "dashed") +
geom_hline(yintercept = 25, linetype = "dotted")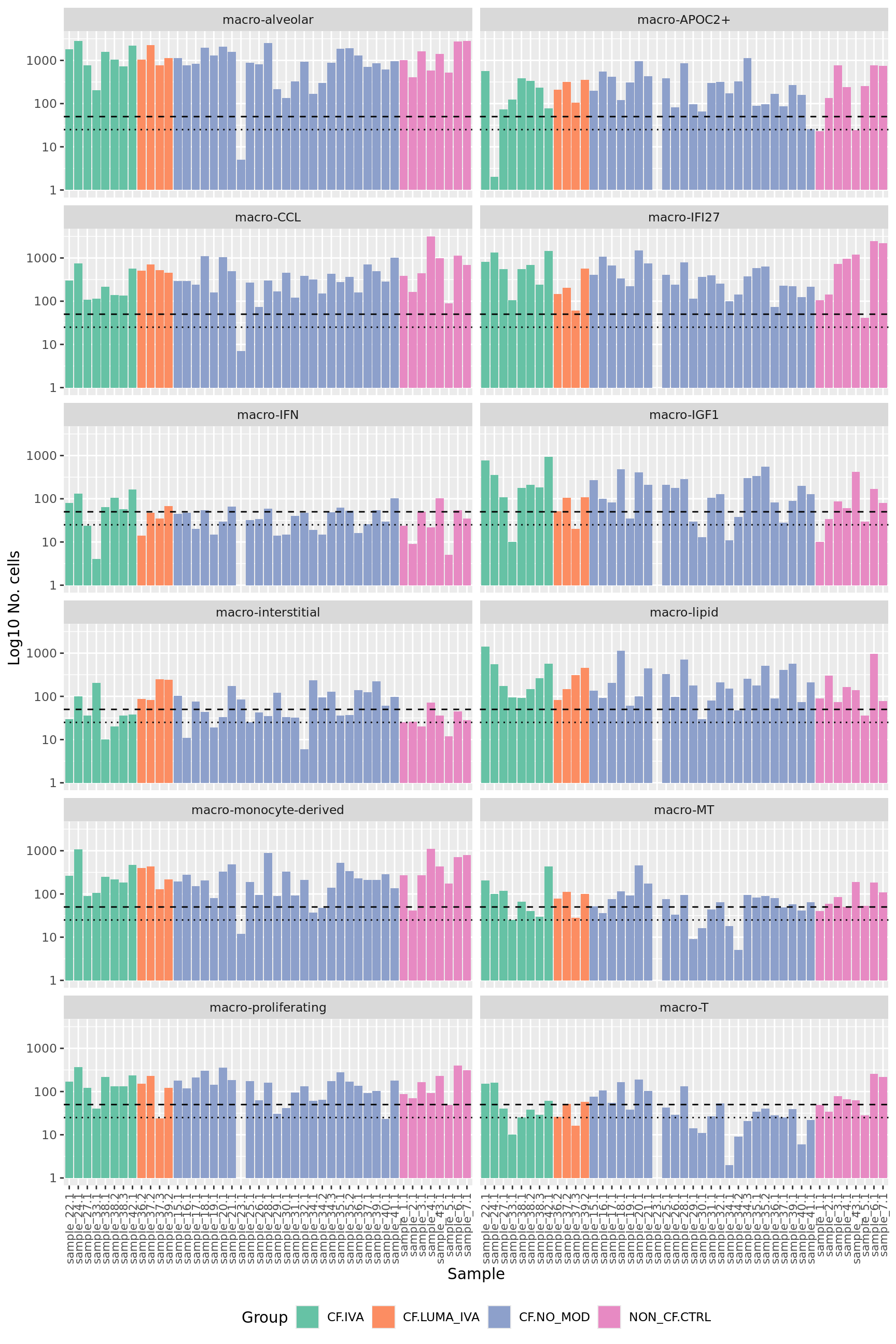
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Data preparation
Extract cell type
Make a DGElist object.
yPB <- DGEList(counts = counts(pseudoBulk),
samples = colData(pseudoBulk) %>% data.frame)
dim(yPB)[1] 21568 533Remove genes with zero counts in all samples.
keep <- rowSums(yPB$counts) > 0
yFlt <- yPB[keep, ]
dim(yFlt)[1] 21559 533Extract only the macro-monocyte-derived cells.
cell <- "macro-monocyte-derived"
ySub <- yFlt[, yFlt$samples$ann_level_2 == cell]
dim(ySub)[1] 21559 45Filter samples & genes
Examine MDS plot for outlier samples.
mds_by_factor <- function(data, factor, lab){
dims <- list(c(1,2), c(2:3), c(3,4), c(4,5))
p <- vector("list", length(dims))
for(i in 1:length(dims)){
mds <- limma::plotMDS(edgeR::cpm(data,
log = TRUE),
gene.selection = "common",
plot = FALSE, dim.plot = dims[[i]])
data.frame(x = mds$x,
y = mds$y,
sample = rownames(mds$distance.matrix.squared)) %>%
left_join(rownames_to_column(data$samples, var = "sample")) -> dat
p[[i]] <- ggplot(dat, aes(x = x, y = y,
colour = eval(parse(text=(factor))))) +
geom_point(size = 3) +
ggrepel::geom_text_repel(aes(label = sample.id),
size = 2) +
labs(x = glue("Principal Component {dims[[i]][1]}"),
y = glue("Principal Component {dims[[i]][2]}"),
colour = lab) +
theme(legend.direction = "horizontal",
legend.text = element_text(size = 8),
legend.title = element_text(size = 9),
axis.text = element_text(size = 8),
axis.title = element_text(size = 9)) -> p[[i]]
}
wrap_plots(p, ncol = 2) +
plot_layout(guides = "collect") &
theme(legend.position = "bottom")
}
mds_by_factor(ySub, "as.factor(Batch)", "Batch") & scale_color_brewer(palette = "Set1")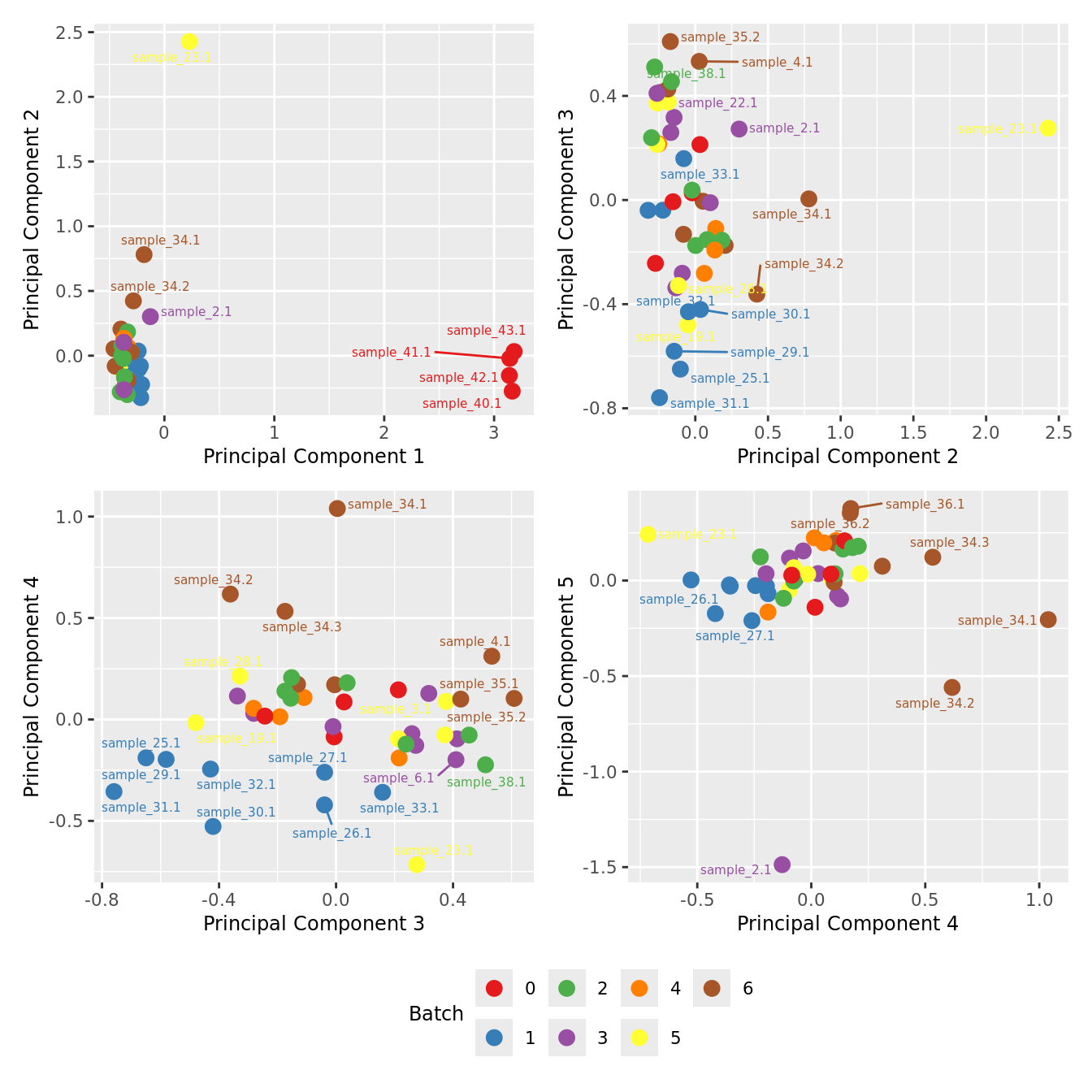
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Sex)", "Sex") & scale_color_brewer(palette = "Set2")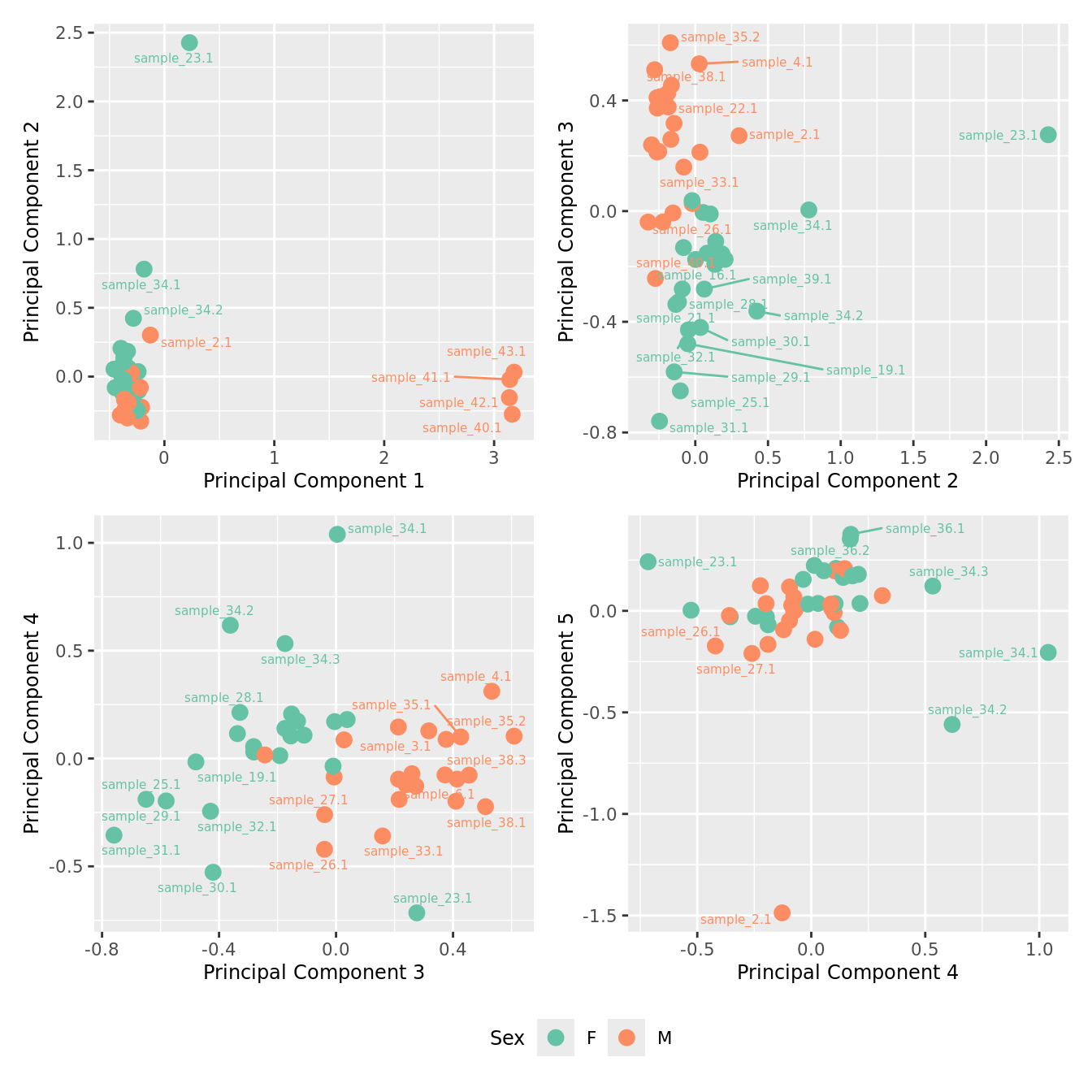
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "log2(Age)", "Log2 Age") & scale_colour_viridis_c(option = "magma") 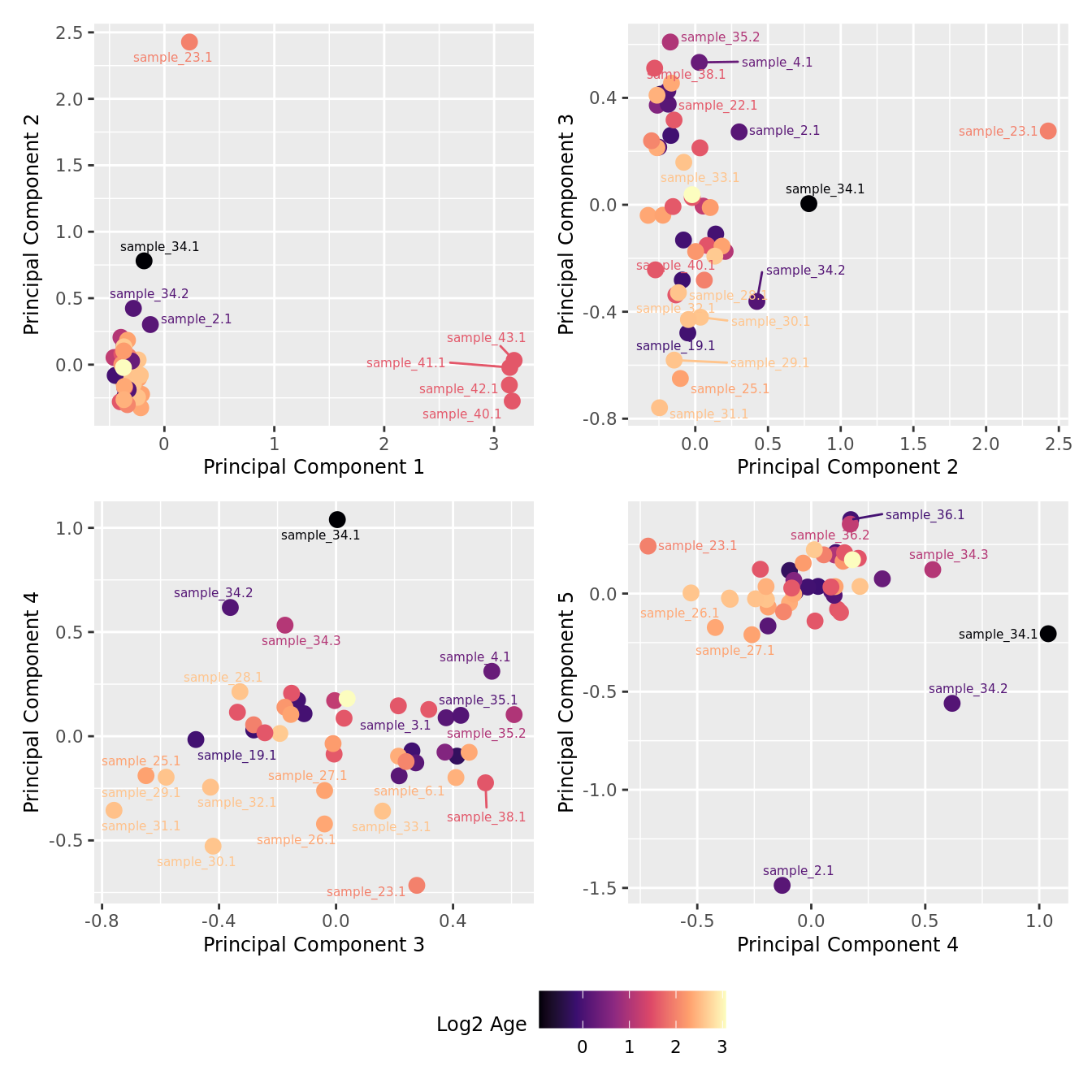
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Group)", "Group") & scale_color_brewer(palette = "Dark2")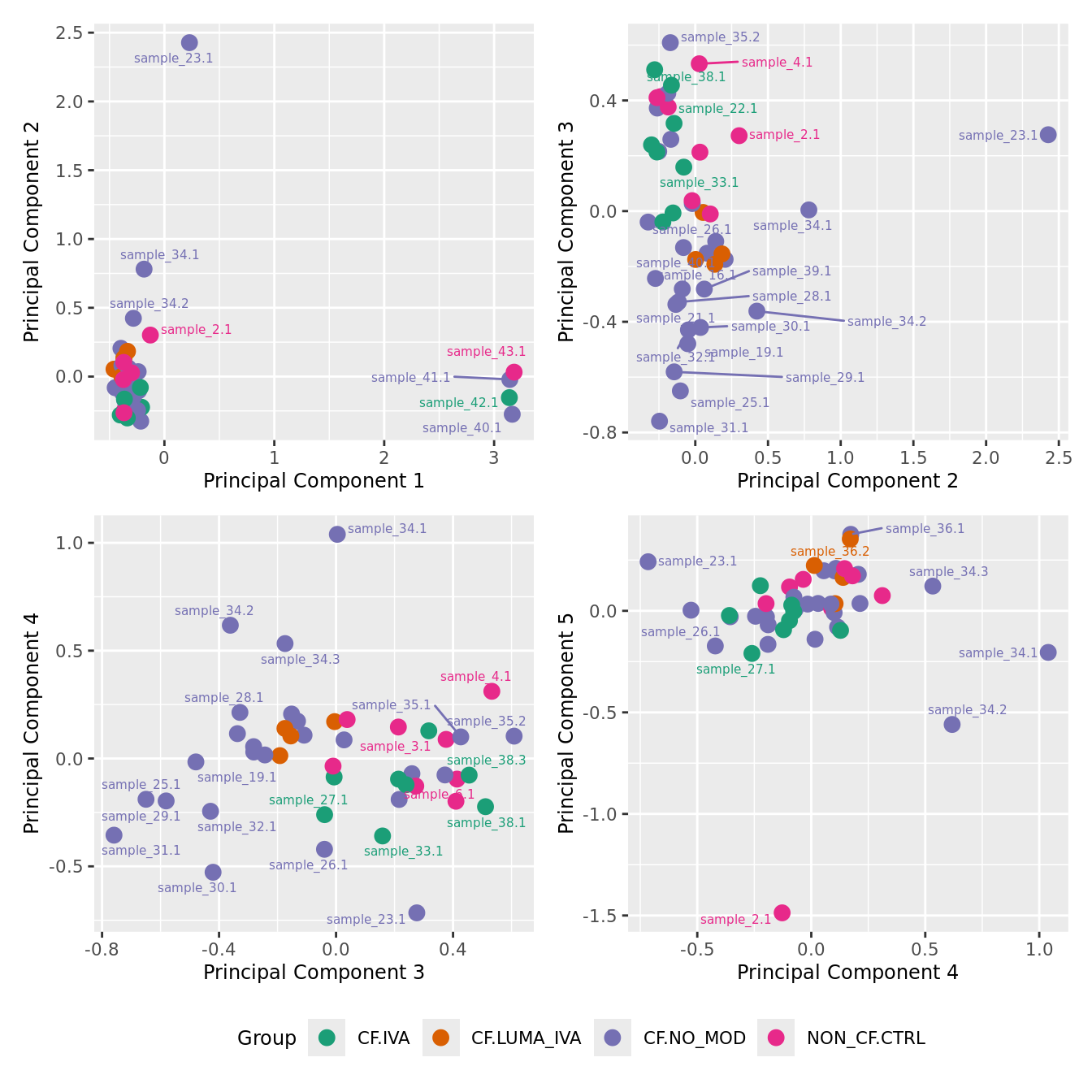
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Severity)", "Severity") & scale_color_brewer(palette = "Accent")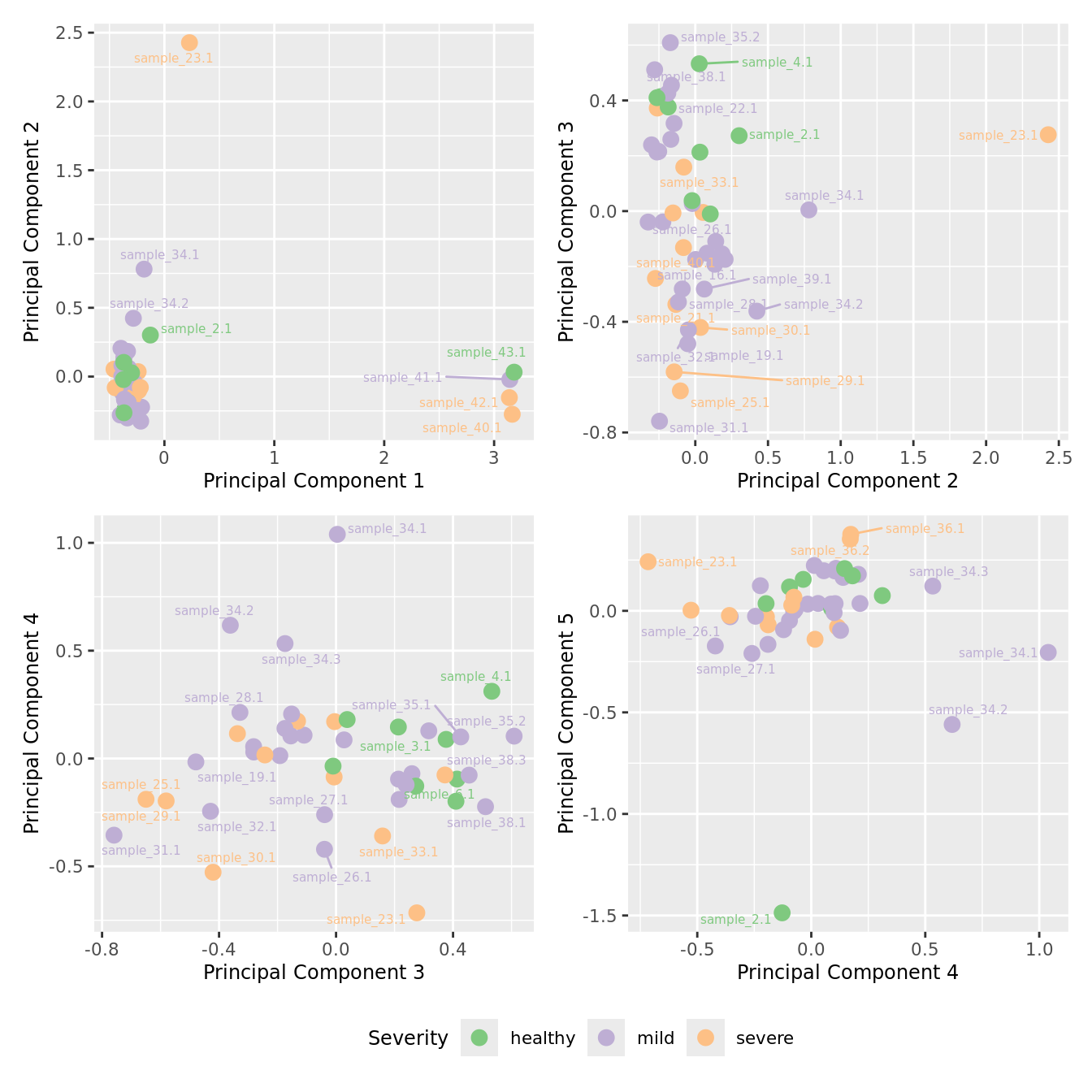
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Micro_code)", "Infection") & scale_color_brewer(palette = "Pastel1")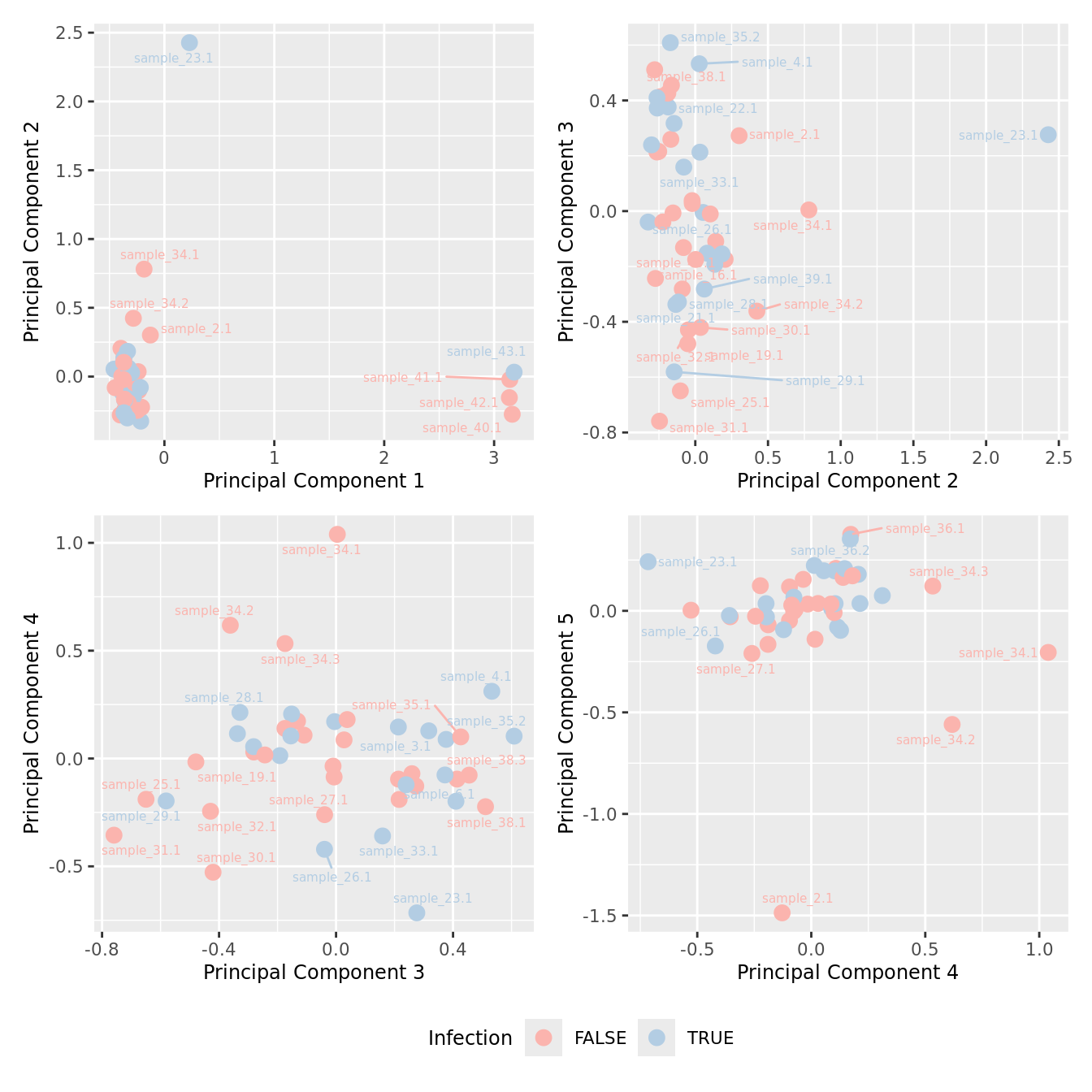
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Examine number of cells per sample. Identify outliers and cross-reference with MDS plot. Determine a threshold for minimum number of cells per sample.
minCells <- 50
ySub$samples %>%
ggplot(aes(x = sample.id, y = ncells, fill = Micro_code)) +
geom_col() +
labs(fill = "Infection") +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
geom_hline(yintercept = minCells, linetype = "dashed") +
facet_grid(~Group, space = "free_x", scales = "free_x") +
scale_fill_brewer(palette = "Pastel1")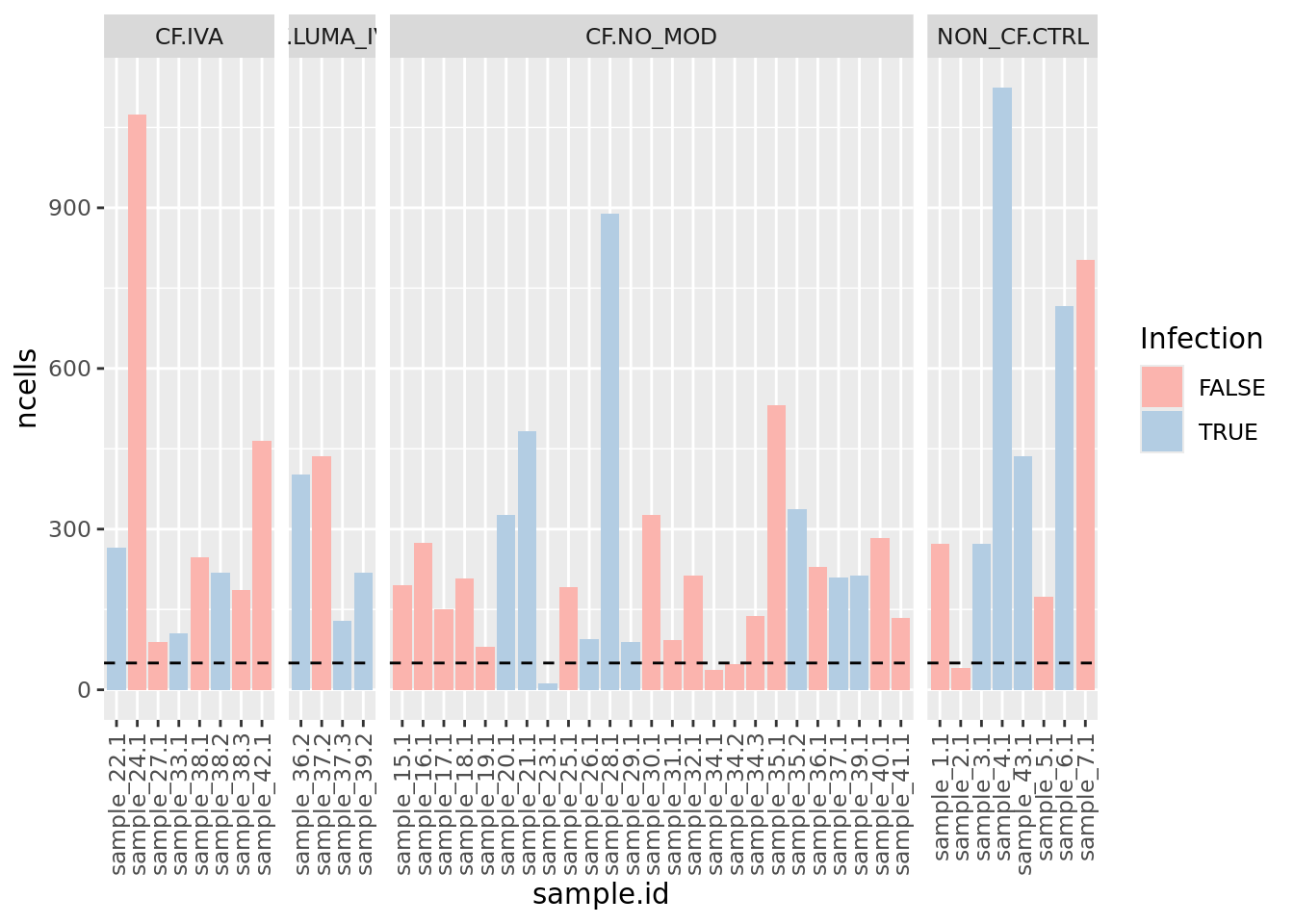
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
ySub$samples %>%
ggplot(aes(x = sample.id, y = ncells, fill = Severity)) +
geom_col() +
labs(fill = "Severity") +
theme(axis.text.x = element_text(angle = 90, vjust = 0.5, hjust = 1)) +
geom_hline(yintercept = minCells, linetype = "dashed") +
facet_grid(~Group, space = "free_x", scales = "free_x") +
scale_fill_brewer(palette = "Accent")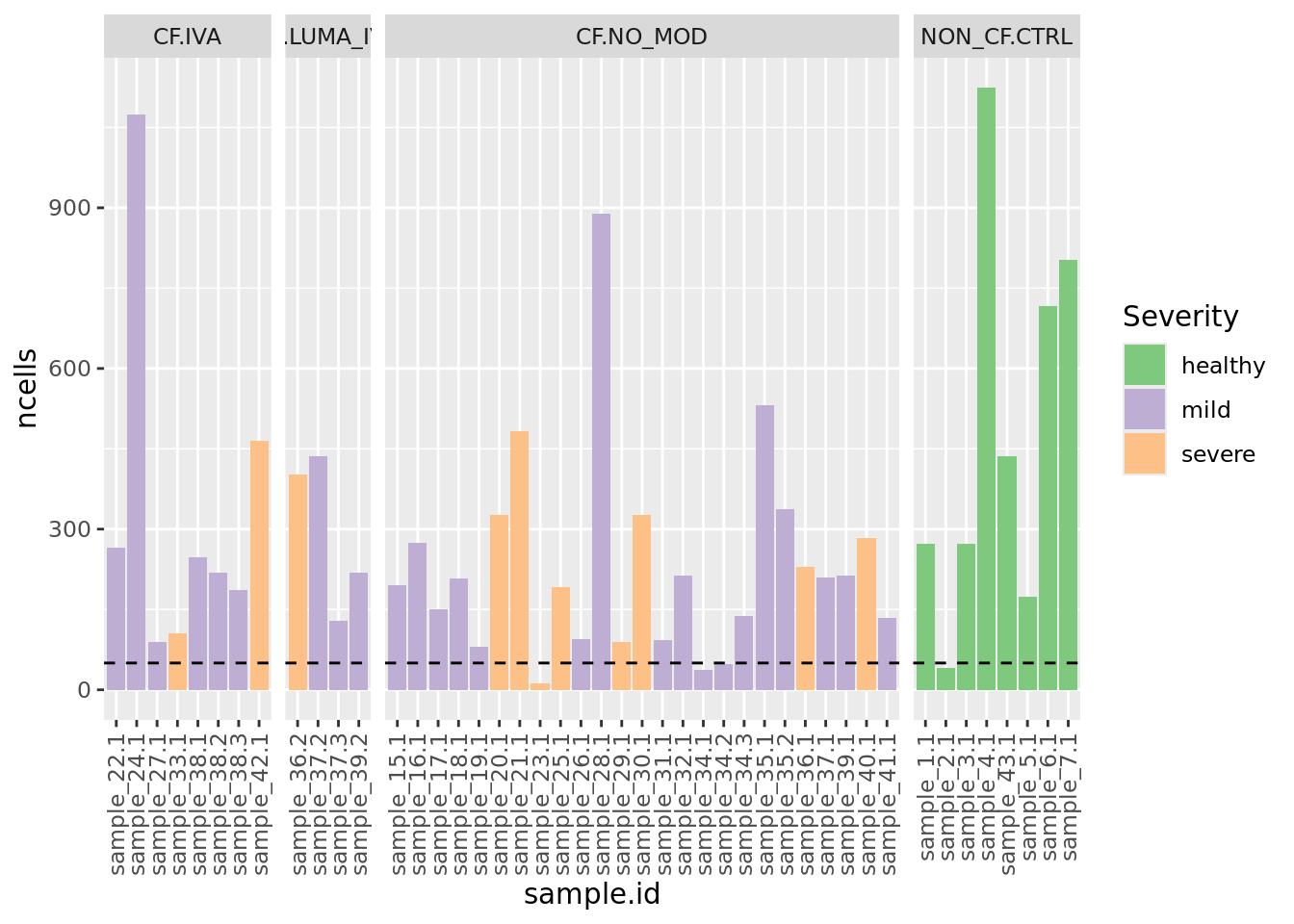
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Filter out samples with less than previously determined minimum number of cells.
ySub <- ySub[, ySub$samples$ncells > minCells]
dim(ySub)[1] 21559 41Re-examine MDS plots.
mds_by_factor(ySub, "as.factor(Batch)", "Batch") & scale_color_brewer(palette = "Set1")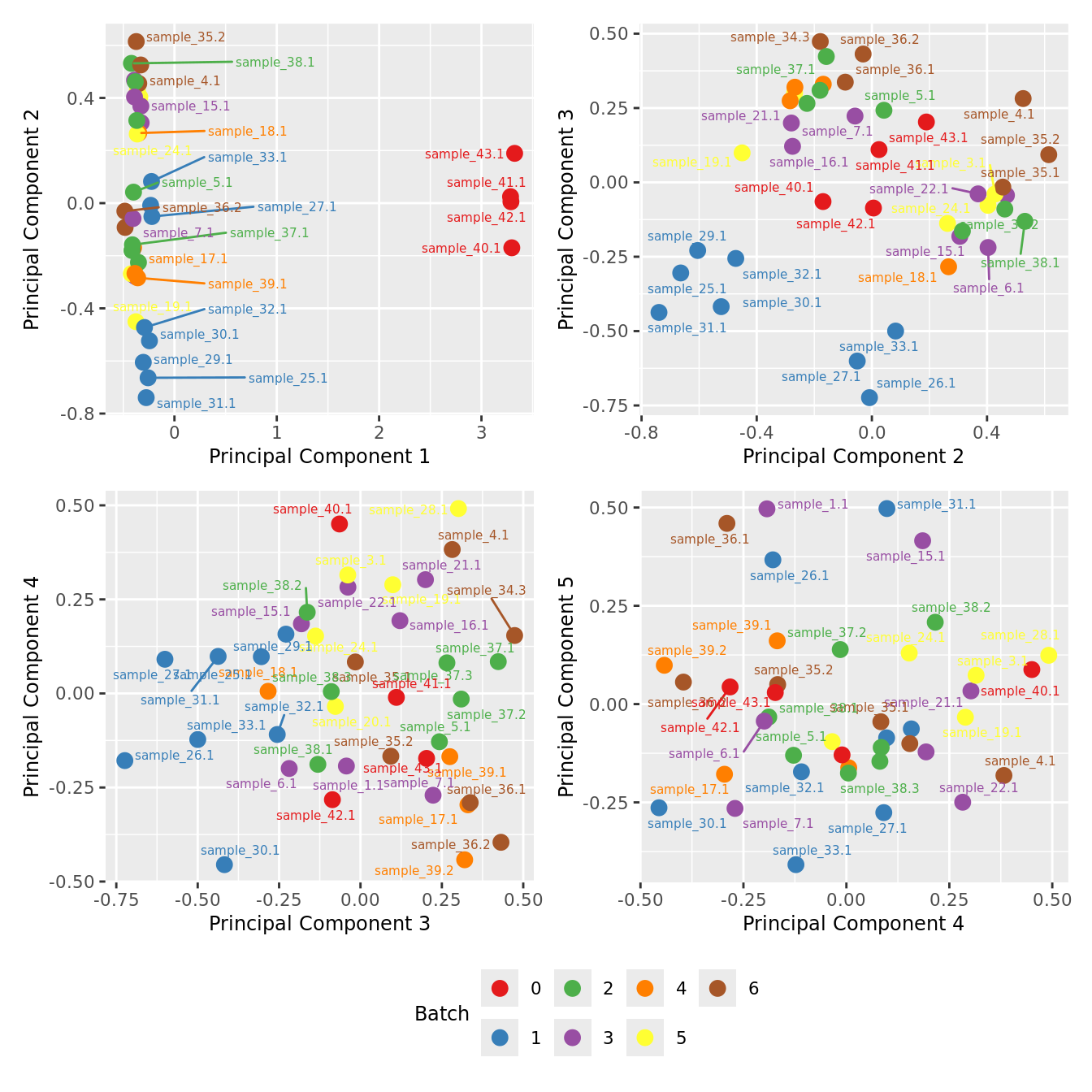
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Sex)", "Sex") & scale_color_brewer(palette = "Set2")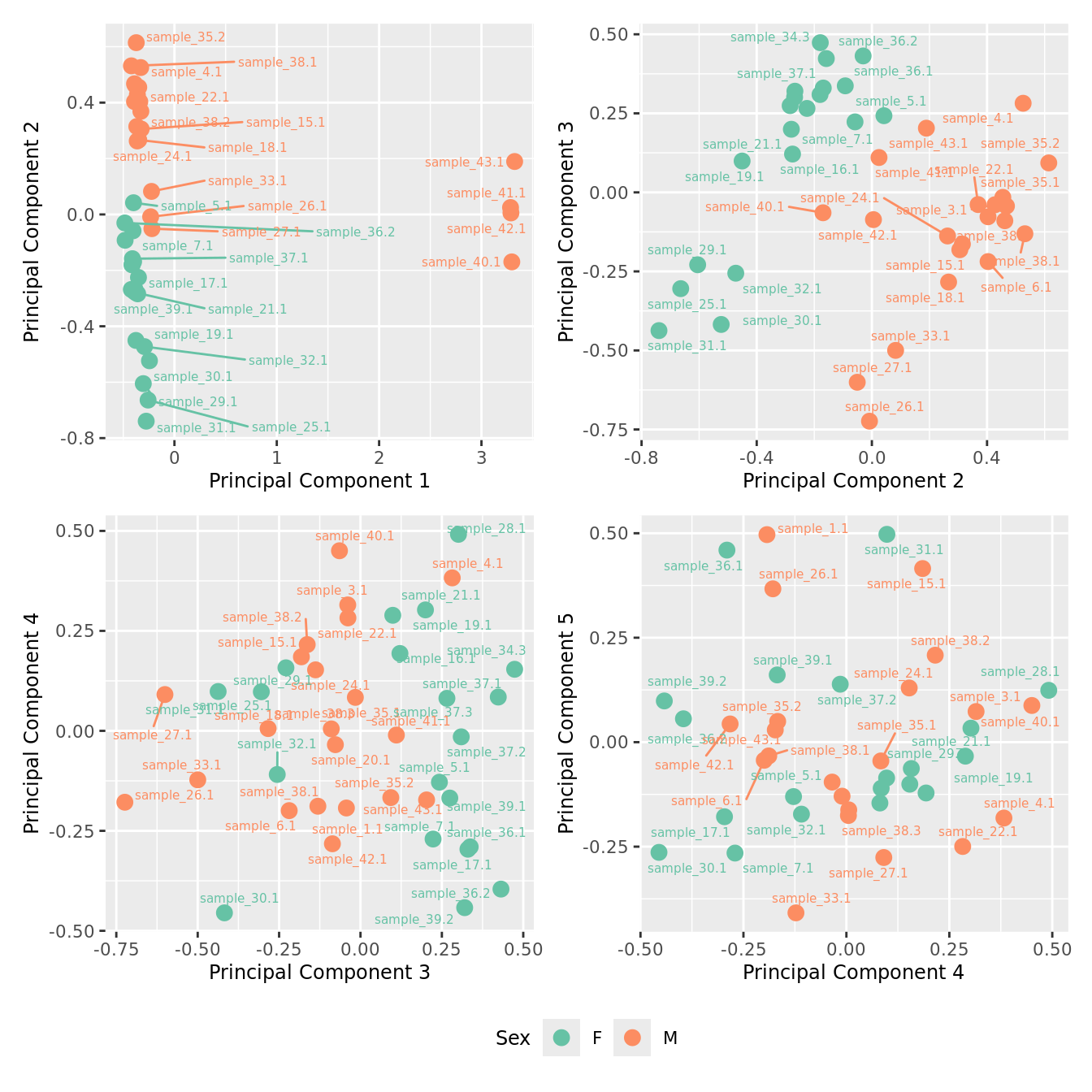
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "log2(Age)", "Log2 Age") & scale_colour_viridis_c(option = "magma") 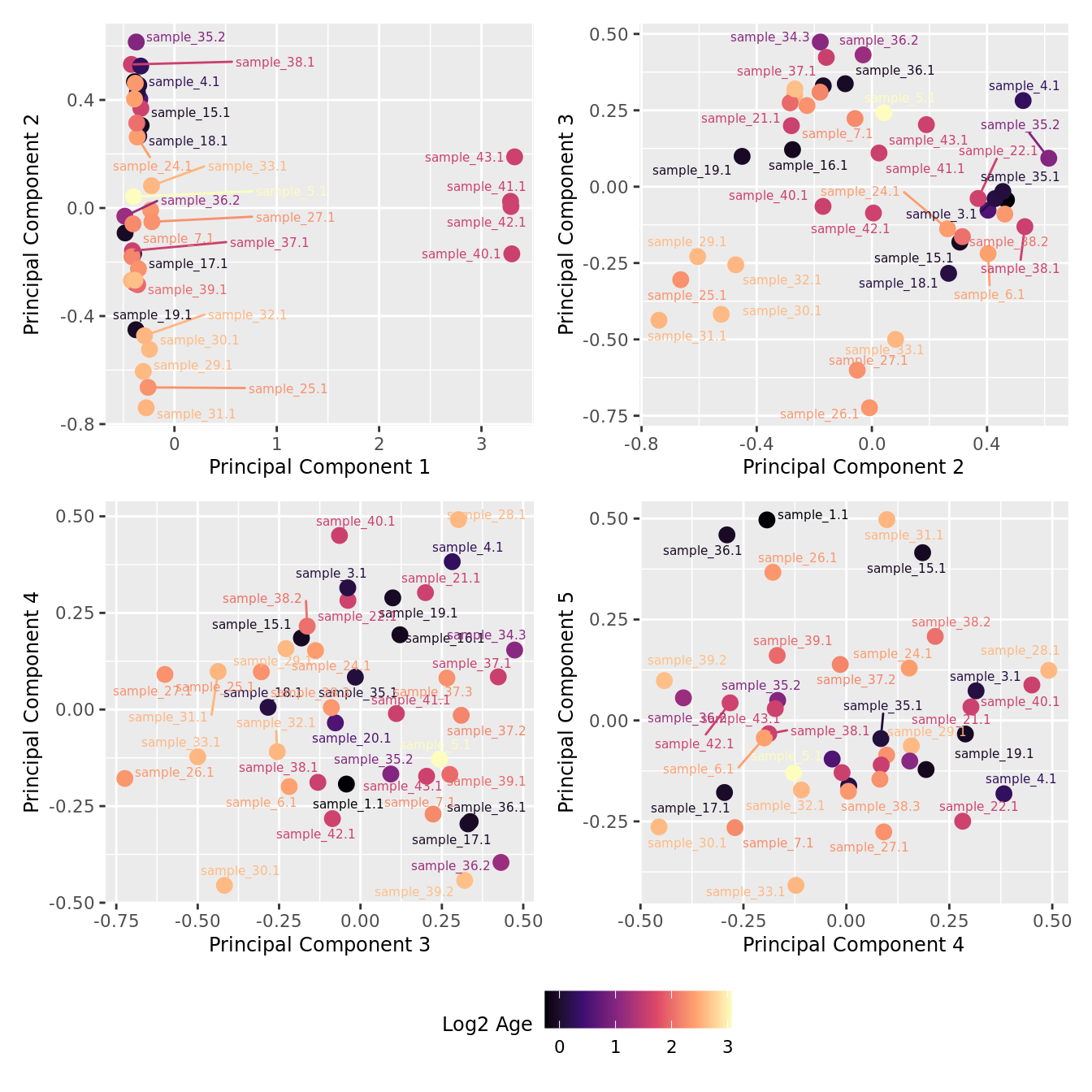
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Group)", "Group") & scale_color_brewer(palette = "Dark2")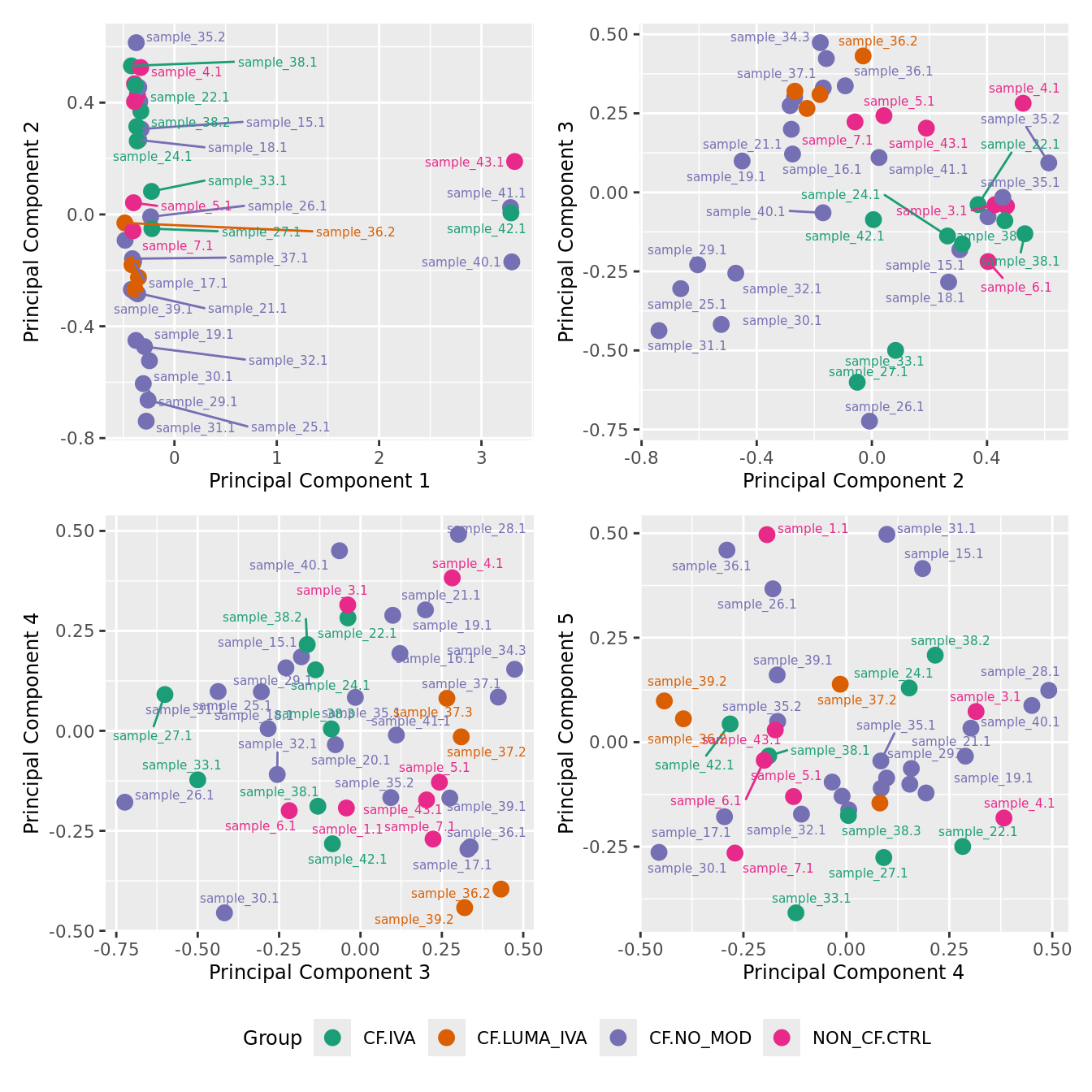
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Severity)", "Severity") & scale_color_brewer(palette = "Accent")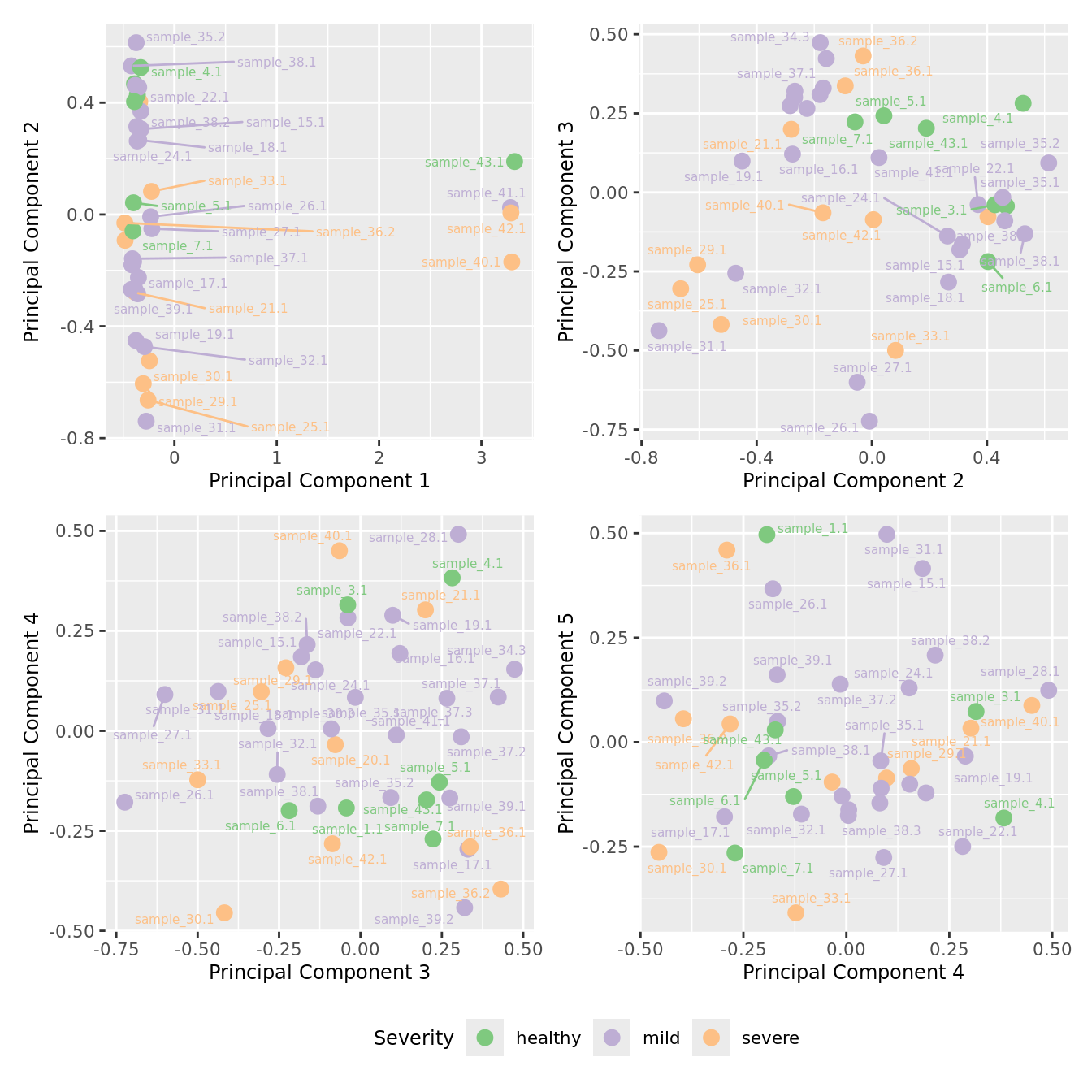
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub, "as.factor(Micro_code)", "Infection") & scale_color_brewer(palette = "Pastel1")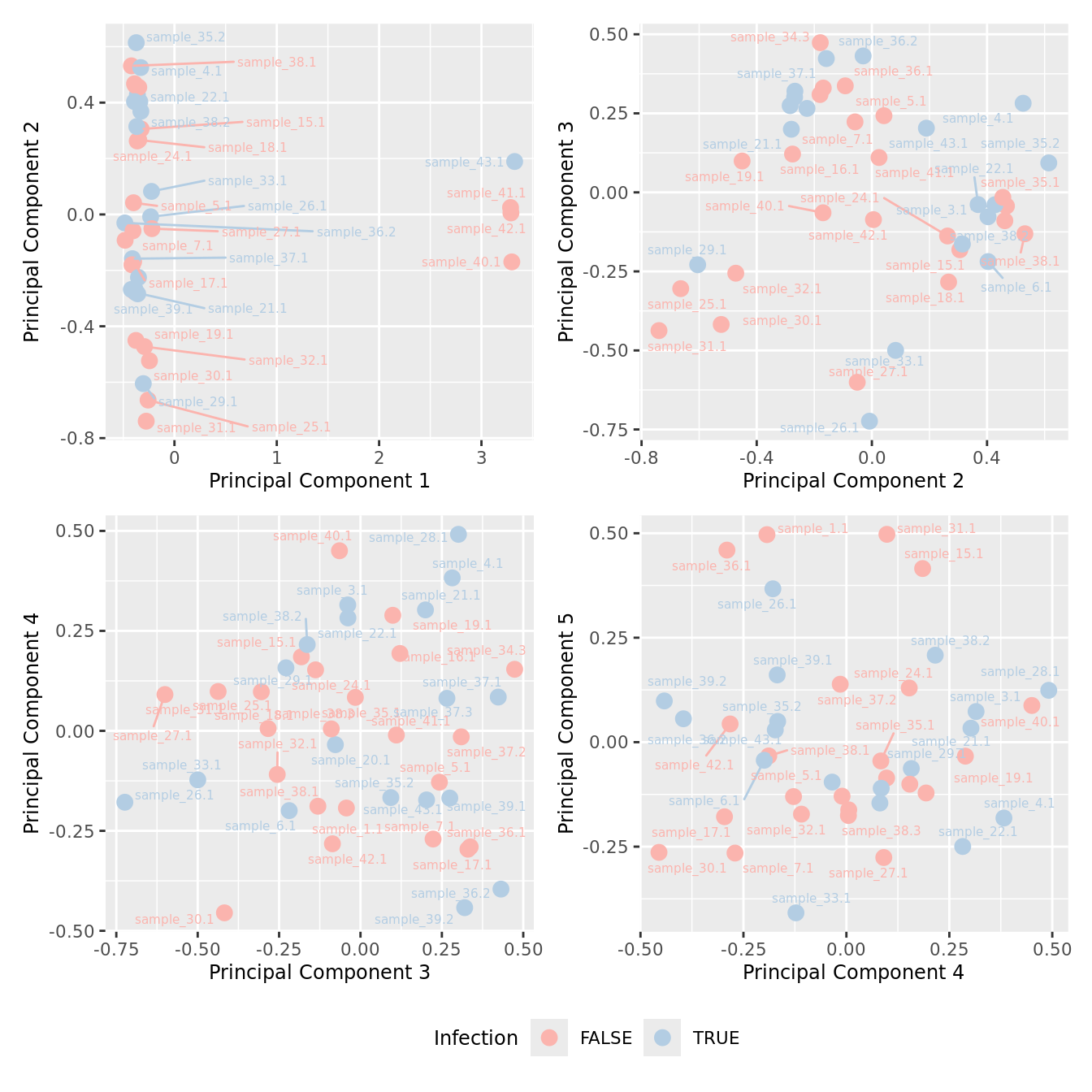
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Filter out genes with no ENTREZ IDs and very low expression.
gns <- AnnotationDbi::mapIds(org.Hs.eg.db,
keys = rownames(ySub),
column = c("ENTREZID"),
keytype = "SYMBOL",
multiVals = "first")
keep <- !is.na(gns)
ySub <- ySub[keep,]
thresh <- 1.5
m <- rowMedians(edgeR::cpm(ySub$counts, log = TRUE))
plot(density(m))
abline(v = thresh, lty = 2)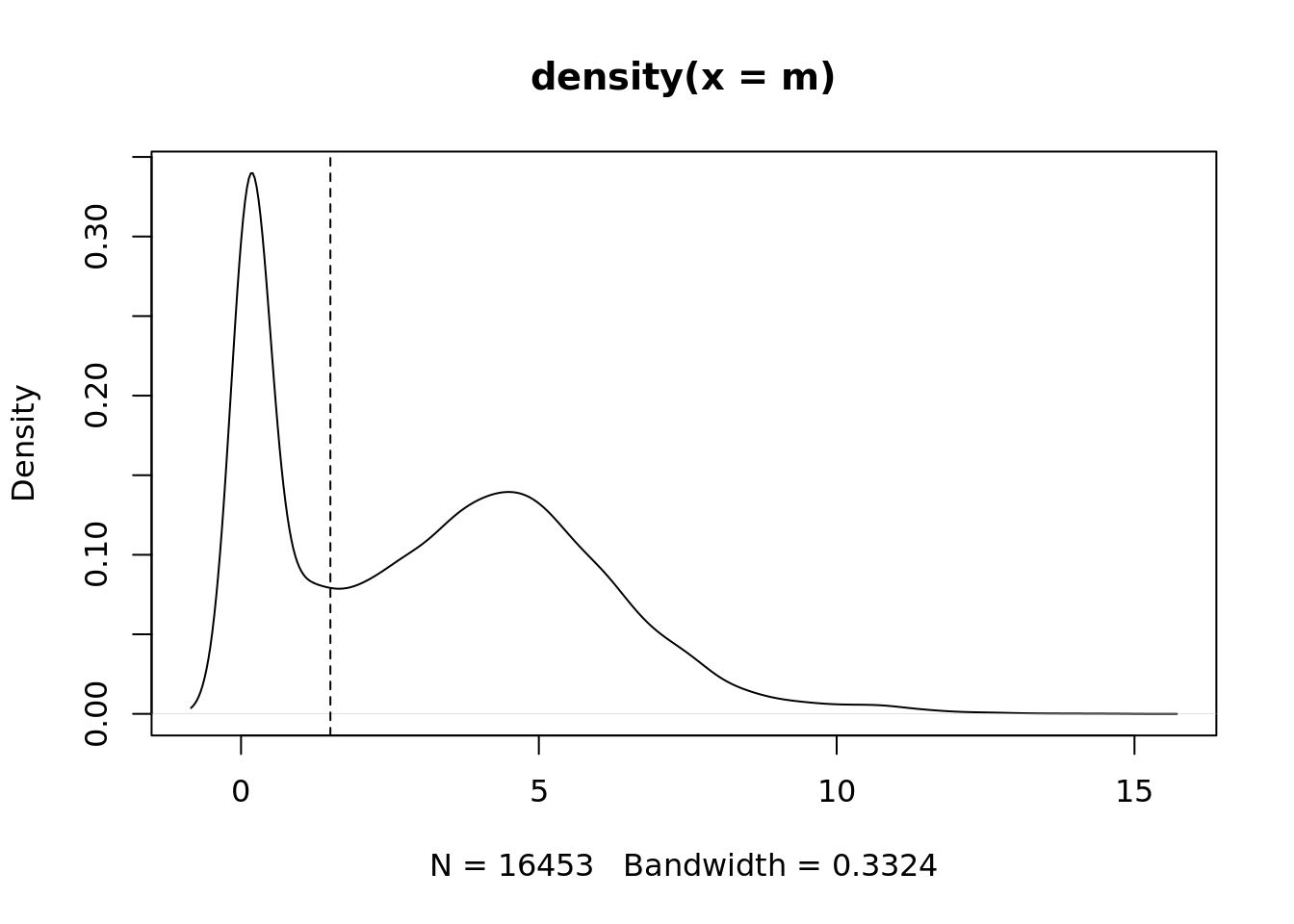
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
# filter out genes with low median expression
keep <- m > thresh
table(keep)keep
FALSE TRUE
5836 10617 ySub <- ySub[keep, ]
dim(ySub)[1] 10617 41Examine covariates
Principal components analysis (PCA) allows us to mathematically determine the sources of variation in the data. We can then investigate whether these correlate with any of the specifed covariates.
Prepare the data.
PCs <- prcomp(t(edgeR::cpm(ySub$counts, log = TRUE)),
center = TRUE, retx = TRUE)
loadings = PCs$x # pc loadings
nGenes = nrow(ySub)
nSamples = ncol(ySub)
datTraits <- ySub$samples %>% dplyr::select(Batch, Disease, Micro_code,
Severity, Age, Sex, ncells) %>%
mutate(Batch = factor(Batch),
Disease = factor(Disease,
labels = 1:length(unique(Disease))),
Sex = factor(Sex, labels = length(unique(Sex))),
Severity = factor(Severity, labels = length(unique(Severity)))) %>%
mutate(across(everything(), as.numeric))
moduleTraitCor <- suppressWarnings(cor(loadings[, 1:min(10, nSamples)],
datTraits, use = "p"))
moduleTraitPvalue <- WGCNA::corPvalueStudent(moduleTraitCor, (nSamples-2))
textMatrix <- paste(signif(moduleTraitCor, 2), "\n(",
signif(moduleTraitPvalue, 1), ")", sep = "")
dim(textMatrix) <- dim(moduleTraitCor)Output results.
par(mfrow = c(2, 1))
plot(PCs, type="lines", main = cell) # scree plot
## Display the correlation values within a heatmap plot
par(cex=0.75, mar = c(3, 5, 2, 1))
WGCNA::labeledHeatmap(Matrix = t(moduleTraitCor),
xLabels = colnames(loadings)[1:min(10, nSamples)],
yLabels = names(datTraits),
colorLabels = FALSE,
colors = WGCNA::blueWhiteRed(6),
textMatrix = t(textMatrix),
setStdMargins = FALSE,
cex.text = 1,
zlim = c(-1,1),
main = paste0("PCA-trait relationships: Top ",
min(10, nSamples),
" PCs"))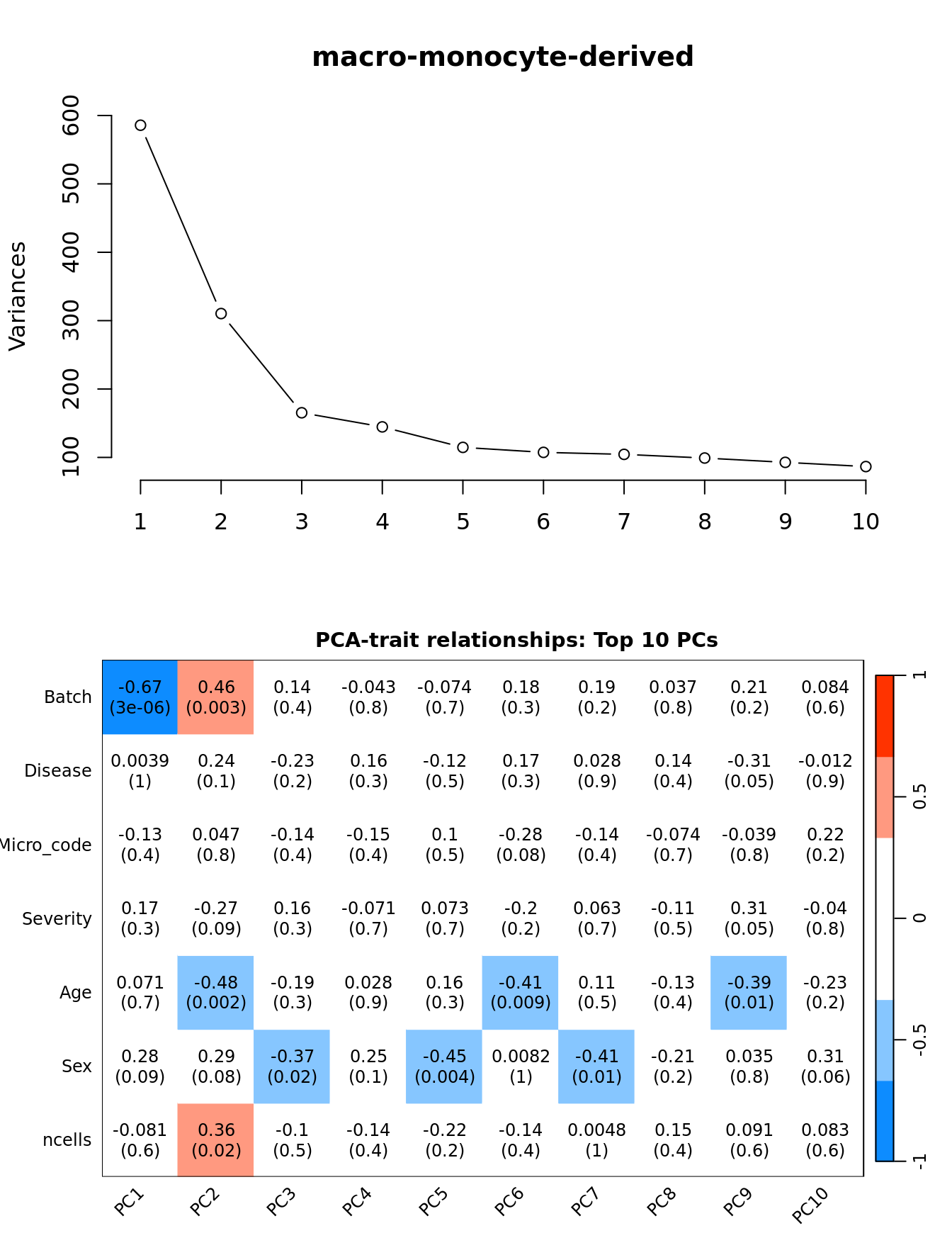
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Statistical analysis with RUVseq
Use RUVseq and edgeR for differential
expression analysis between sample groups.
Negative control genes
Use house-keeping genes (HKG) identified from human single-cell RNAseq experiments.
data("segList", package = "scMerge")
HKGs <- segList$human$bulkRNAseqHK
ctl <- rownames(ySub) %in% HKGs
table(ctl)ctl
FALSE TRUE
7168 3449 Plot HKG expression profiles across all the samples.
edgeR::cpm(ySub$counts, log = TRUE) %>%
data.frame %>%
rownames_to_column(var = "gene") %>%
pivot_longer(-gene, names_to = "sample") %>%
left_join(rownames_to_column(ySub$samples,
var = "sample")) %>%
dplyr::filter(gene %in% HKGs) %>%
dplyr::filter(ann_level_2 == cell) %>%
mutate(Batch = as.factor(Batch)) -> dat
dat %>%
heatmap(gene, sample, value,
scale = "row",
show_row_names = FALSE,
show_column_names = FALSE) %>%
add_tile(Group) %>%
add_tile(Severity) %>%
add_tile(Batch) %>%
add_tile(Participant) %>%
add_tile(Age) %>%
add_tile(Sex)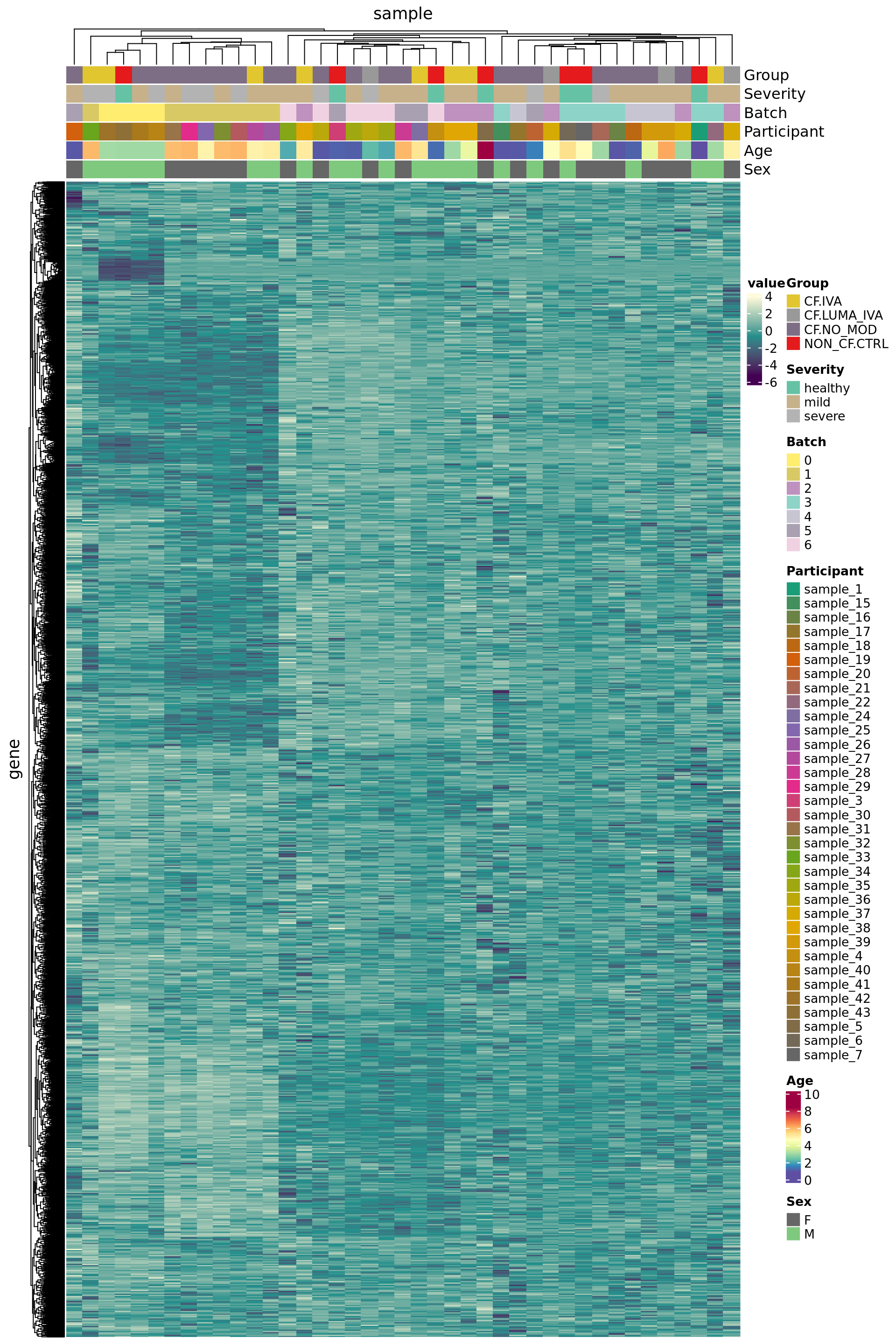
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub[rownames(ySub) %in% HKGs,], "as.factor(Batch)", "Batch") & scale_color_brewer(palette = "Set1")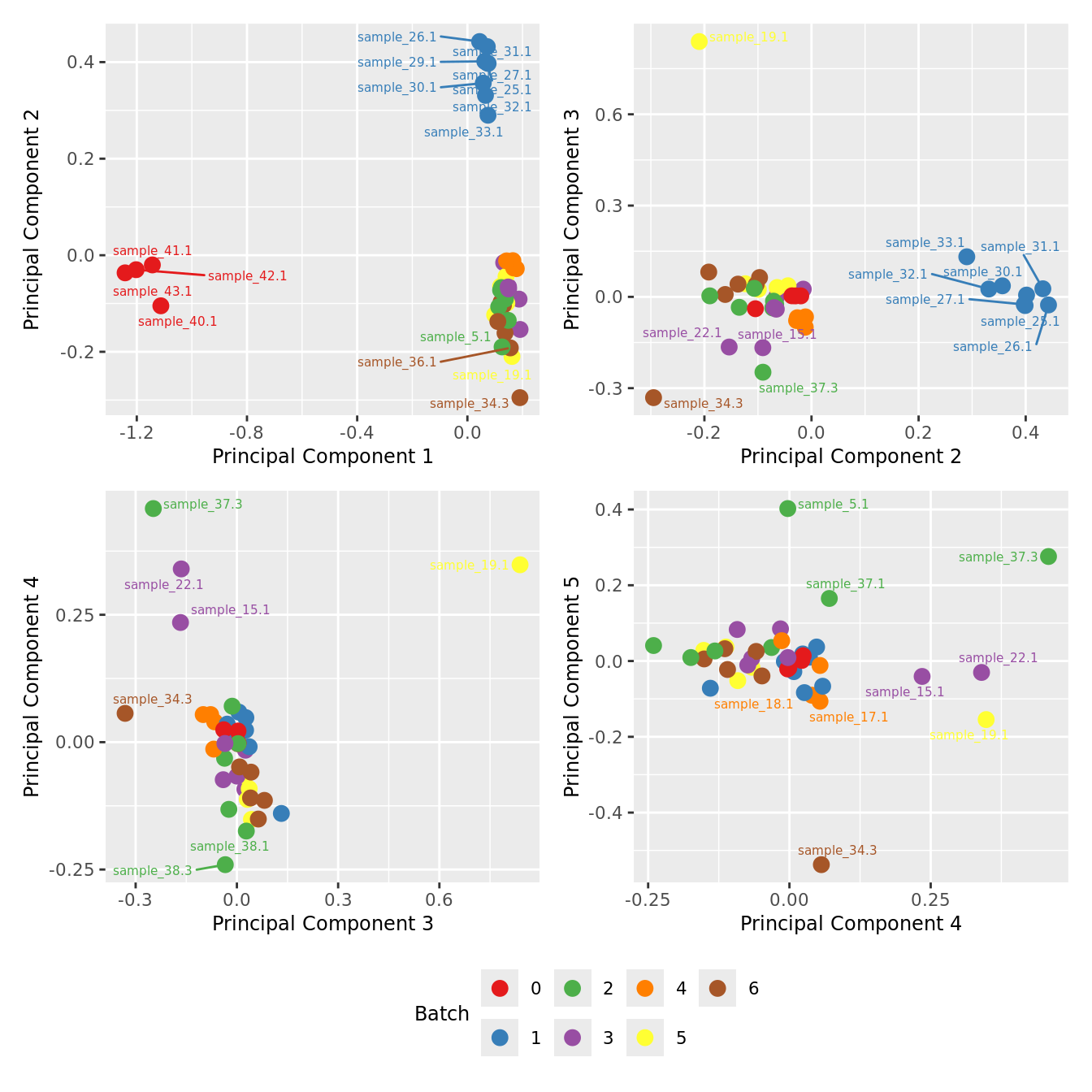
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub[rownames(ySub) %in% HKGs,], "as.factor(Sex)", "Sex") & scale_color_brewer(palette = "Set2")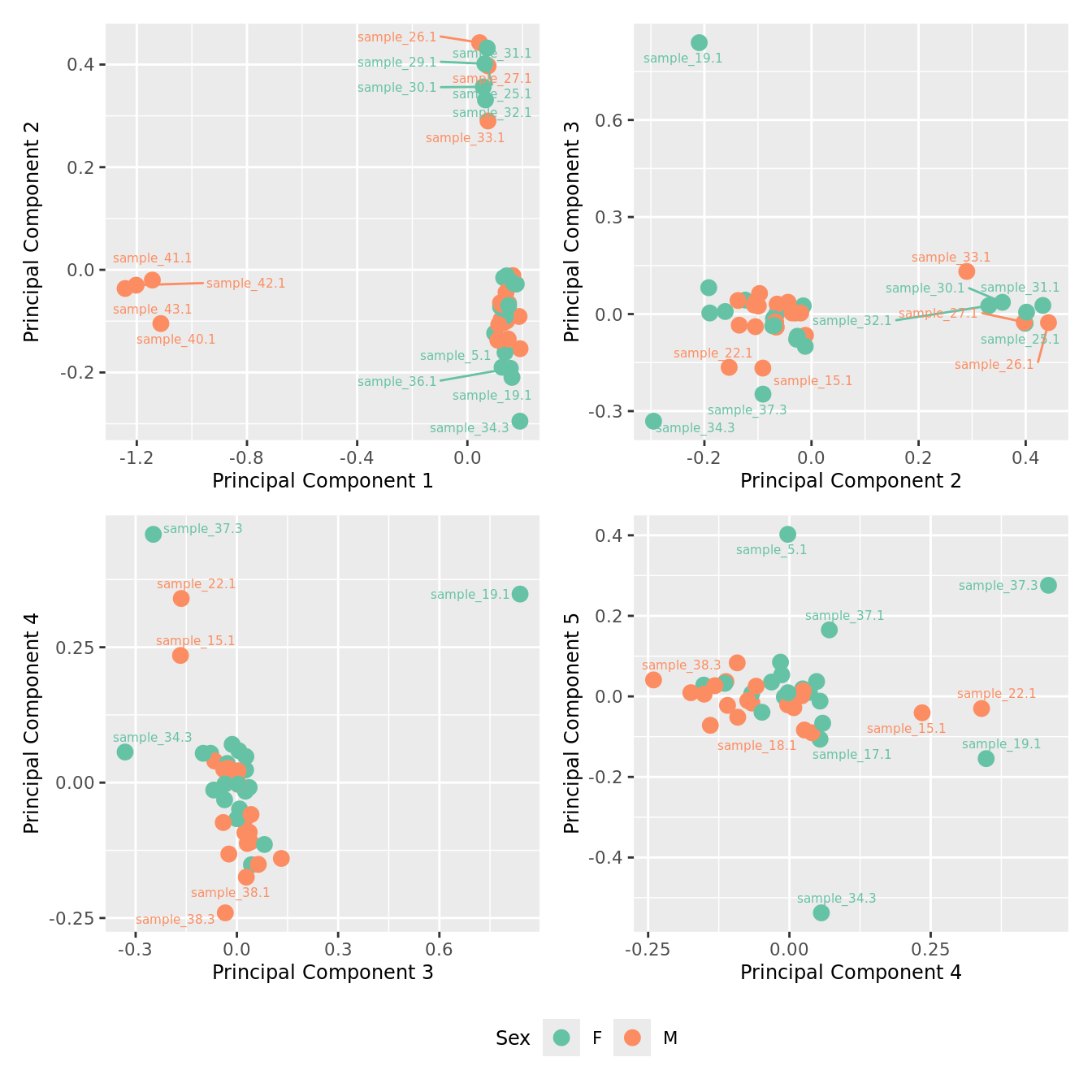
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub[rownames(ySub) %in% HKGs,], "log2(Age)", "Log2 Age") & scale_colour_viridis_c(option = "magma") 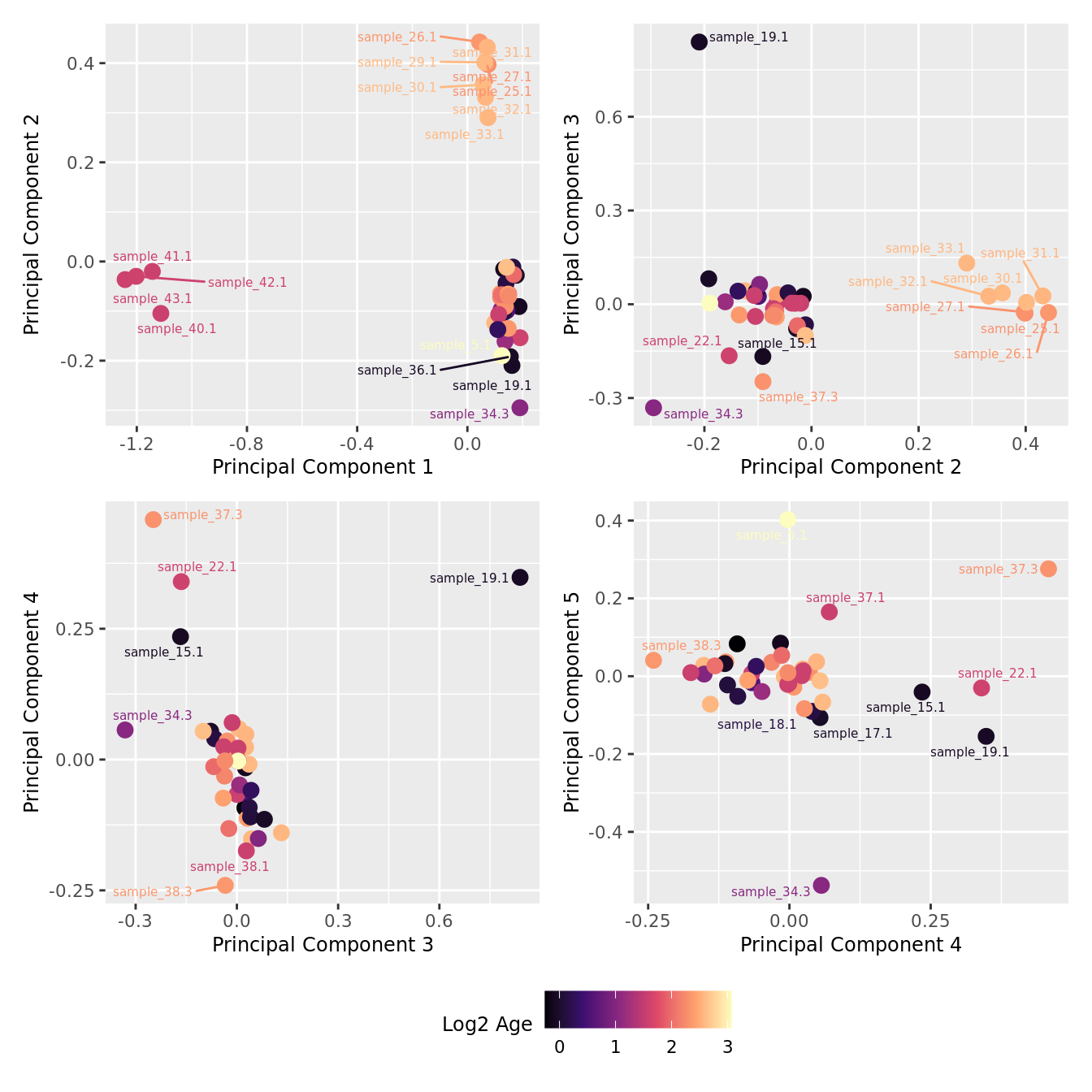
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub[rownames(ySub) %in% HKGs,], "as.factor(Group)", "Group") & scale_color_brewer(palette = "Dark2")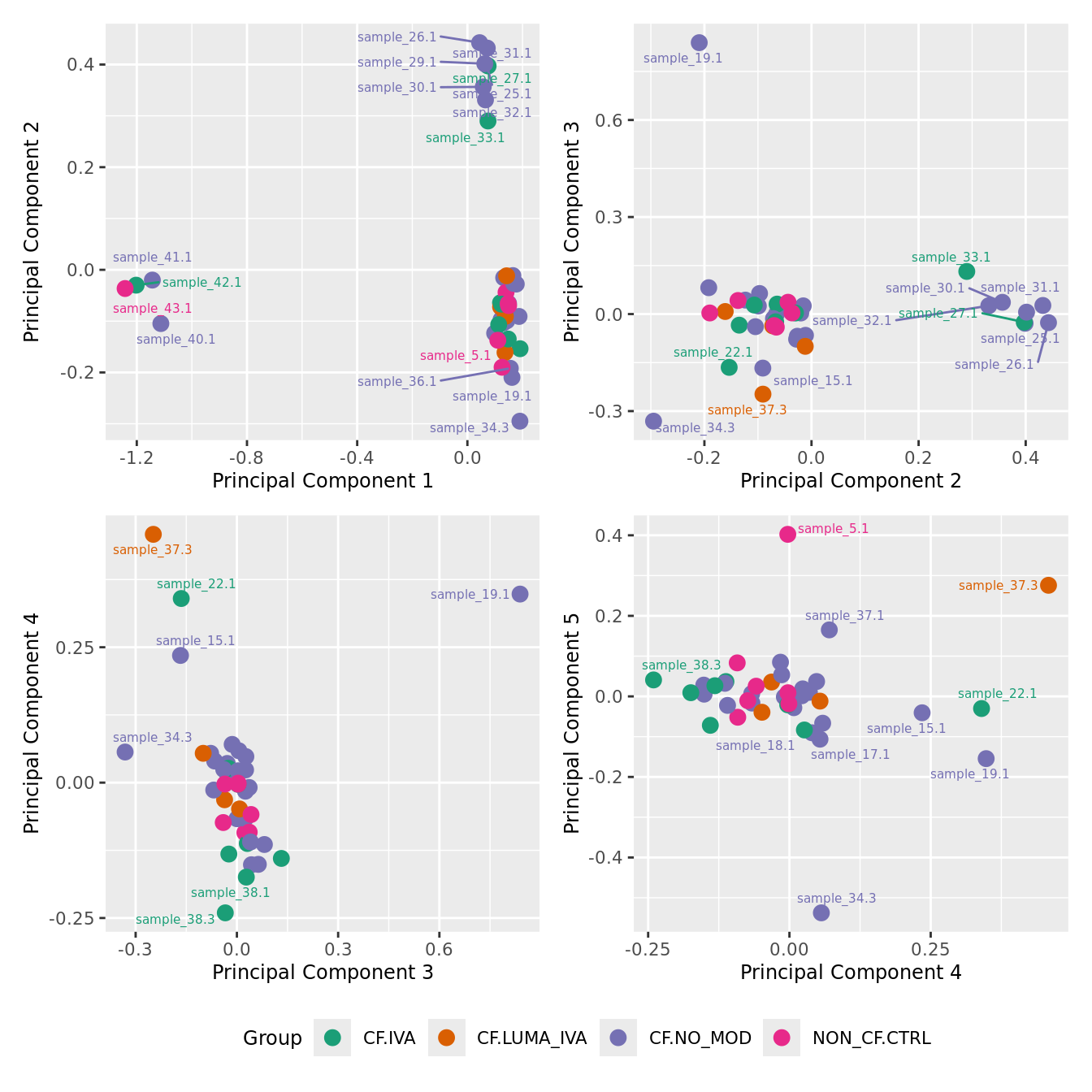
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub[rownames(ySub) %in% HKGs,], "as.factor(Severity)", "Severity") &
scale_color_brewer(palette = "Accent")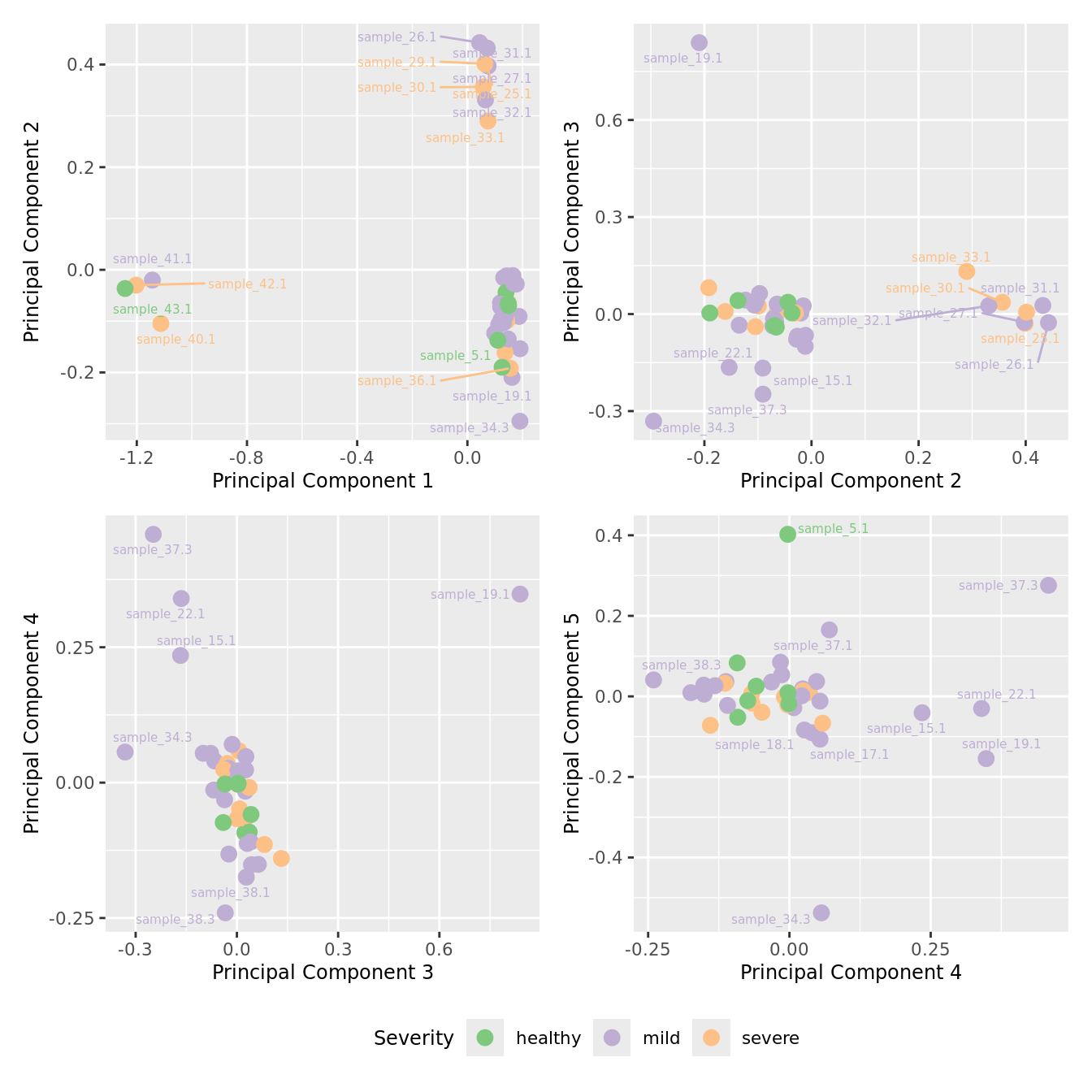
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
mds_by_factor(ySub[rownames(ySub) %in% HKGs,], "as.factor(Micro_code)", "Infection") & scale_color_brewer(palette = "Pastel1")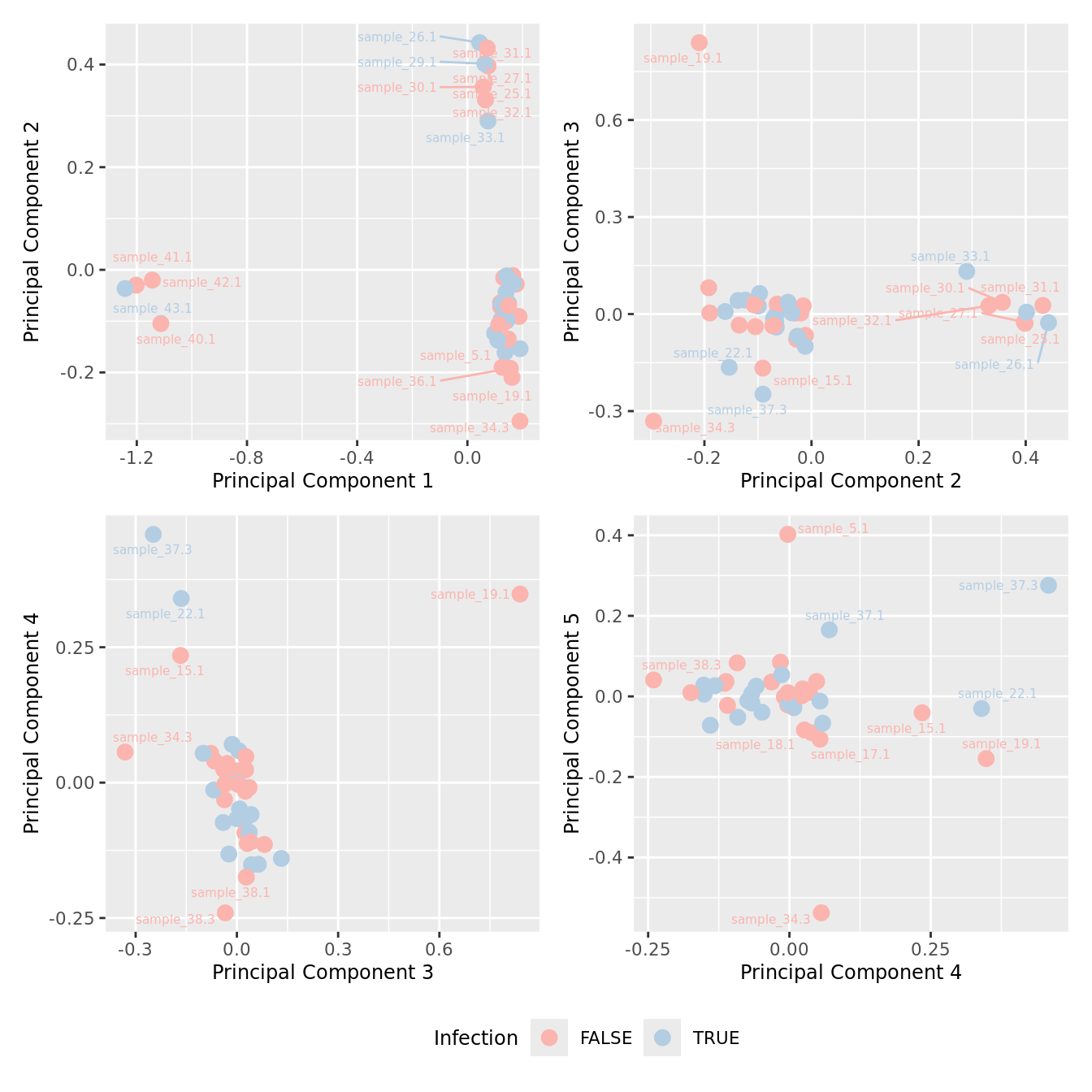
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Investigate whether HKG PCAs correlate with any known covariates. Prepare the data.
PCs <- prcomp(t(edgeR::cpm(ySub$counts[ctl, ], log = TRUE)),
center = TRUE, retx = TRUE)
loadings = PCs$x # pc loadings
nGenes = nrow(ySub)
nSamples = ncol(ySub)
datTraits <- ySub$samples %>% dplyr::select(Batch, Disease,
Severity, Age, Sex, ncells, Micro_code) %>%
mutate(Batch = factor(Batch),
Disease = factor(Disease,
labels = 1:length(unique(Disease))),
Sex = factor(Sex, labels = length(unique(Sex))),
Severity = factor(Severity, labels = length(unique(Severity)))) %>%
mutate(across(everything(), as.numeric))
moduleTraitCor <- suppressWarnings(cor(loadings[, 1:min(10, nSamples)],
datTraits, use = "p"))
moduleTraitPvalue <- WGCNA::corPvalueStudent(moduleTraitCor, (nSamples-2))
textMatrix <- paste(signif(moduleTraitCor, 2), "\n(",
signif(moduleTraitPvalue, 1), ")", sep = "")
dim(textMatrix) <- dim(moduleTraitCor)Output results.
par(mfrow = c(2, 1))
plot(PCs, type="lines", main = cell) # scree plot
## Display the correlation values within a heatmap plot
par(cex=0.75, mar = c(3, 5, 2, 1))
WGCNA::labeledHeatmap(Matrix = t(moduleTraitCor),
xLabels = colnames(loadings)[1:min(10, nSamples)],
yLabels = names(datTraits),
colorLabels = FALSE,
colors = WGCNA::blueWhiteRed(6),
textMatrix = t(textMatrix),
setStdMargins = FALSE,
cex.text = 1,
zlim = c(-1,1),
main = paste0("PCA-trait relationships: Top ",
min(10, nSamples),
" PCs"))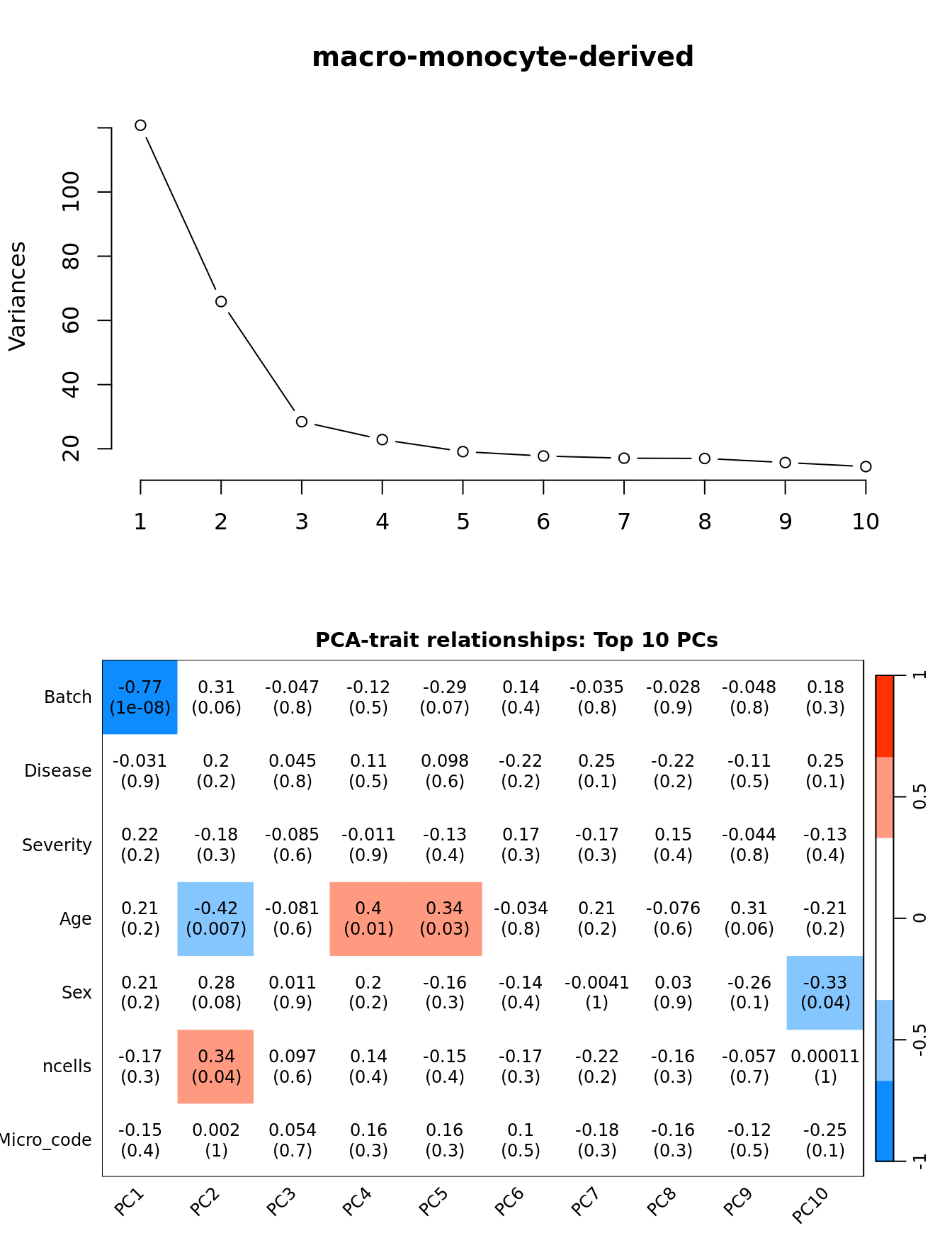
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Select k value
First, we need to select k for use with
RUVseq. Examine the structure of the raw pseudobulk
data.
x1 <- as.factor(ySub$samples$Batch)
cols1 <- RColorBrewer::brewer.pal(7, "Set2")
par(mfrow = c(1,3))
EDASeq::plotRLE(edgeR::cpm(ySub$counts),
col = cols1[x1], ylim = c(-0.5, 0.5),
main = "Raw RLE by batch", las = 2)
EDASeq::plotPCA(edgeR::cpm(ySub$counts),
col = cols1[x1], labels = FALSE,
pch = 19, main = "Raw PCA by batch")
x2 <- as.factor(ySub$samples$Group)
cols2 <- RColorBrewer::brewer.pal(4, "Set1")
EDASeq::plotPCA(edgeR::cpm(ySub$counts),
col = cols2[x2], labels = FALSE,
pch = 19, main = "Raw PCA by disease")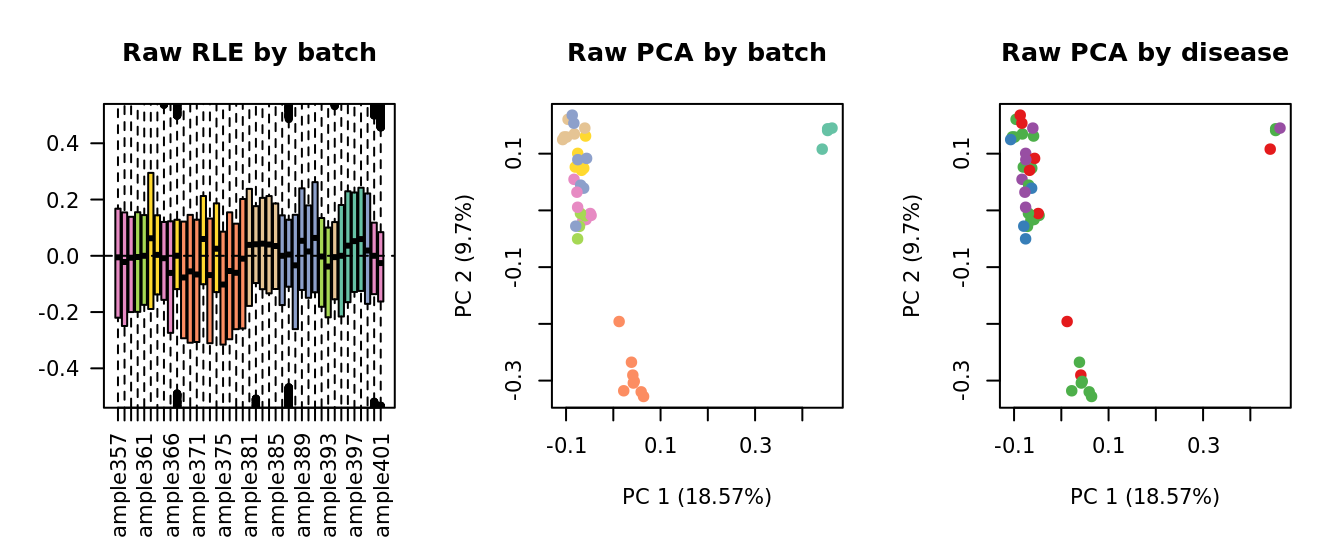
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
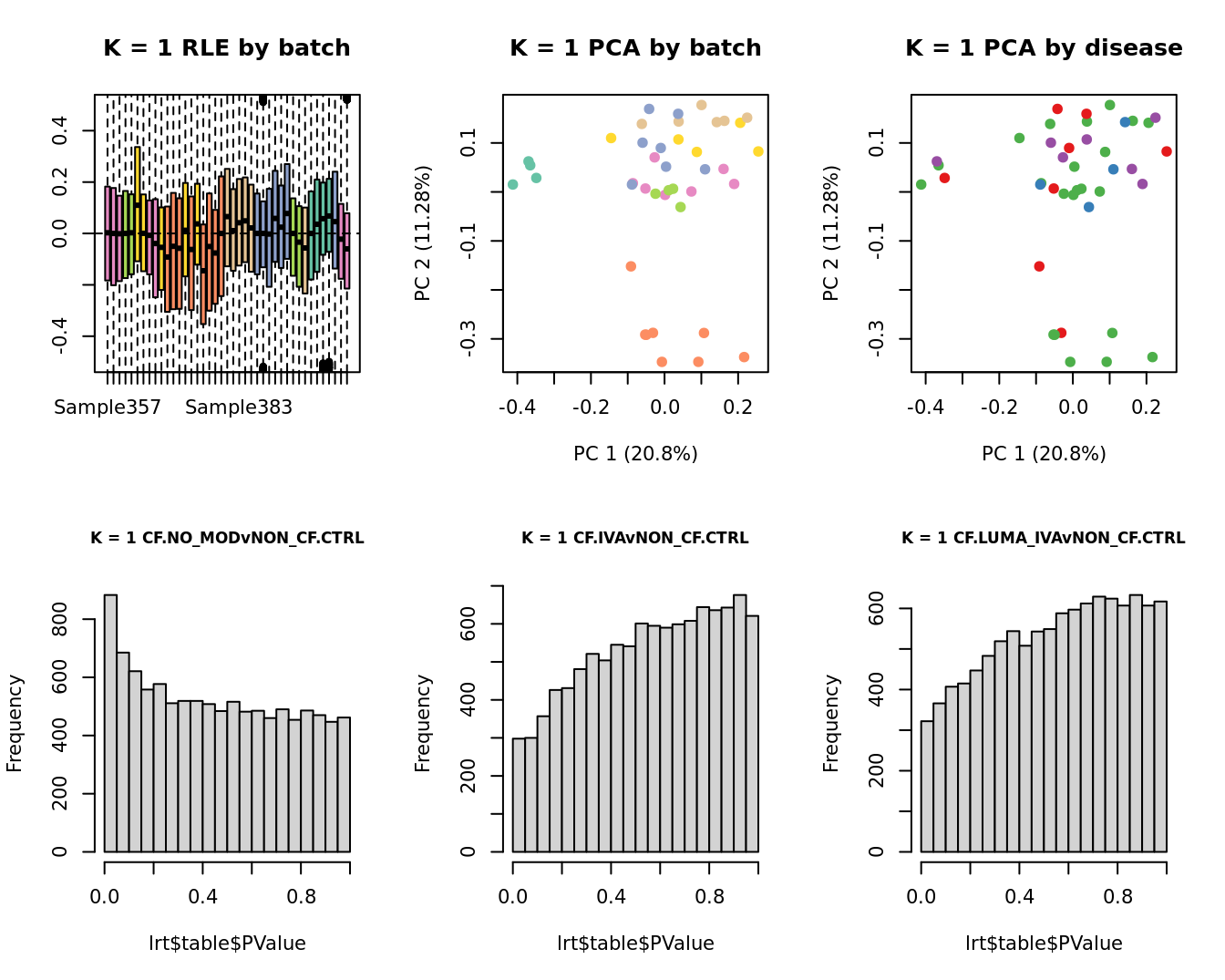
Select the value for the k parameter i.e. the number of
columns of the W matrix that will be included in the
modelling.
# define the sample groups
group <- factor(ySub$samples$Group)
#micro <- factor(ySub$samples$Micro_code)
sex <- factor(ySub$samples$Sex)
age <- log2(ySub$samples$Age)
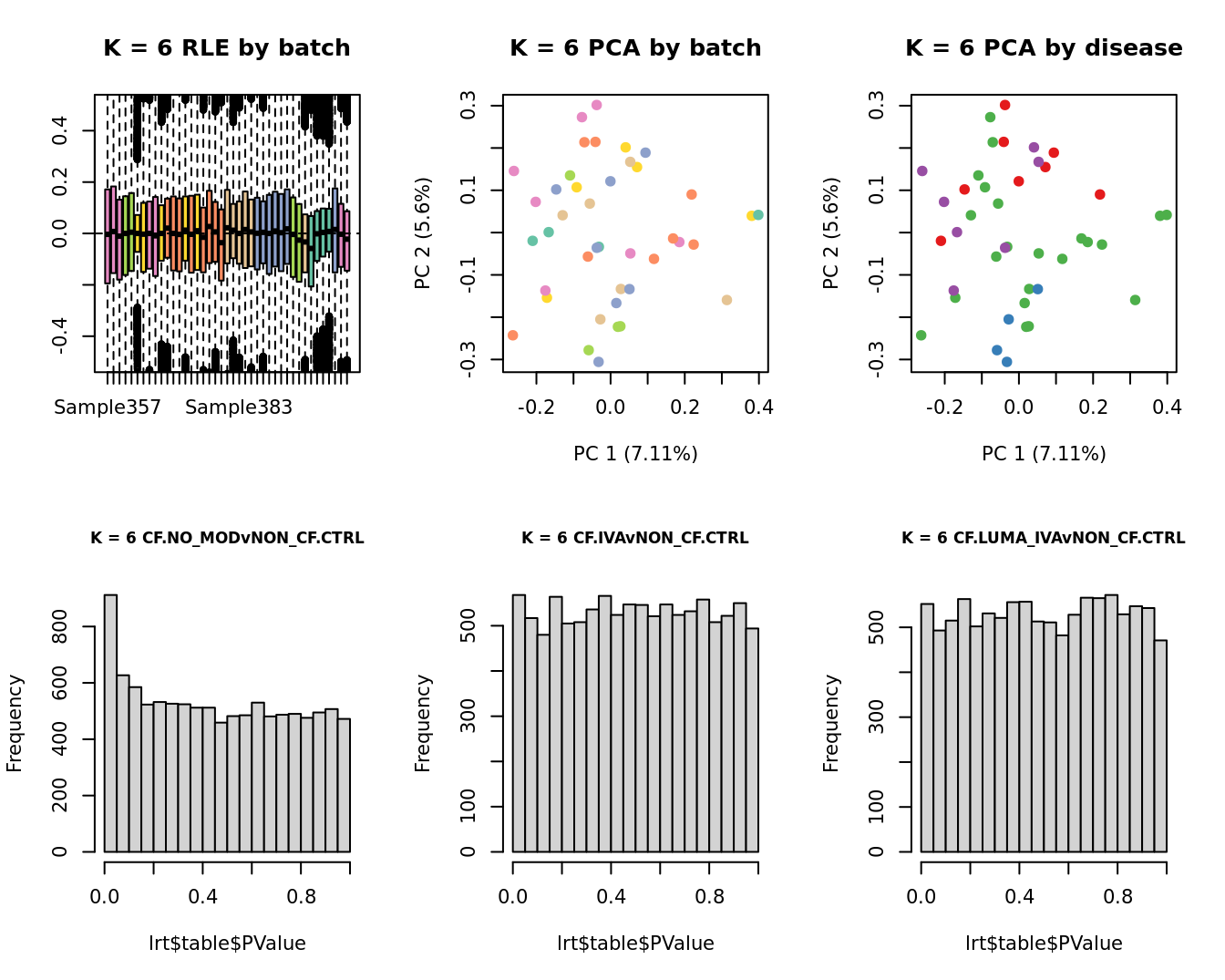
for(k in 1:6){
adj <- RUVg(ySub$counts, ctl, k = k)
W <- adj$W
# create the design matrix
design <- model.matrix(~0 + group + W + sex + age)
colnames(design)[1:length(levels(group))] <- levels(group)
# add the factors for the replicate samples
dups <- unique(ySub$samples$Participant[duplicated(ySub$samples$Participant)])
dups <- sapply(dups, function(d){
ifelse(ySub$samples$Participant == d, 1, 0)
}, USE.NAMES = TRUE)
contr <- makeContrasts(CF.NO_MODvNON_CF.CTRL = CF.NO_MOD - NON_CF.CTRL,
CF.IVAvNON_CF.CTRL = CF.IVA - NON_CF.CTRL,
CF.LUMA_IVAvNON_CF.CTRL = CF.LUMA_IVA - NON_CF.CTRL,
levels = design)
y <- DGEList(counts = ySub$counts)
y <- calcNormFactors(y)
y <- estimateGLMCommonDisp(y, design)
y <- estimateGLMTagwiseDisp(y, design)
fit <- glmFit(y, design)
x1 <- as.factor(ySub$samples$Batch)
cols1 <- RColorBrewer::brewer.pal(7, "Set2")
par(mfrow = c(2,3))
EDASeq::plotRLE(edgeR::cpm(adj$normalizedCounts),
col = cols1[x1], ylim = c(-0.5, 0.5),
main = paste0("K = ", k, " RLE by batch"))
EDASeq::plotPCA(edgeR::cpm(adj$normalizedCounts),
col = cols1[x1], labels = FALSE,
pch = 19,
main = paste0("K = ", k, " PCA by batch"))
x2 <- as.factor(ySub$samples$Group)
cols2 <- RColorBrewer::brewer.pal(5, "Set1")
EDASeq::plotPCA(edgeR::cpm(adj$normalizedCounts),
col = cols2[x2], labels = FALSE,
pch = 19,
main = paste0("K = ", k, " PCA by disease"))
lrt <- glmLRT(fit, contrast = contr[, 1])
hist(lrt$table$PValue, main = paste0("K = ", k, " ", colnames(contr)[1]),
cex.main = 0.8)
lrt <- glmLRT(fit, contrast = contr[, 2])
hist(lrt$table$PValue, main = paste0("K = ", k, " ", colnames(contr)[2]),
cex.main = 0.8)
lrt <- glmLRT(fit, contrast = contr[, 3])
hist(lrt$table$PValue, main = paste0("K = ", k, " ", colnames(contr)[3]),
cex.main = 0.8)
}
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
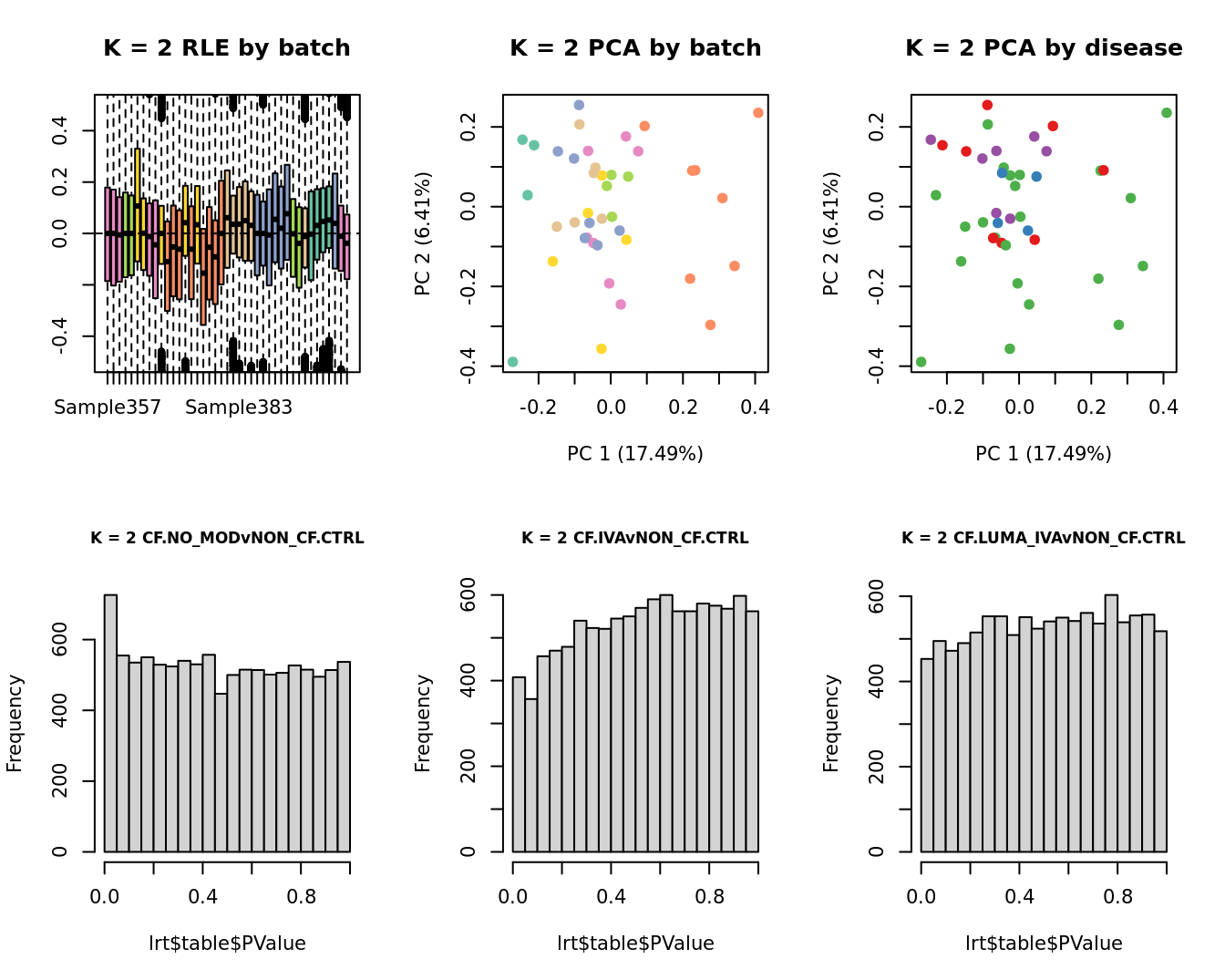
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
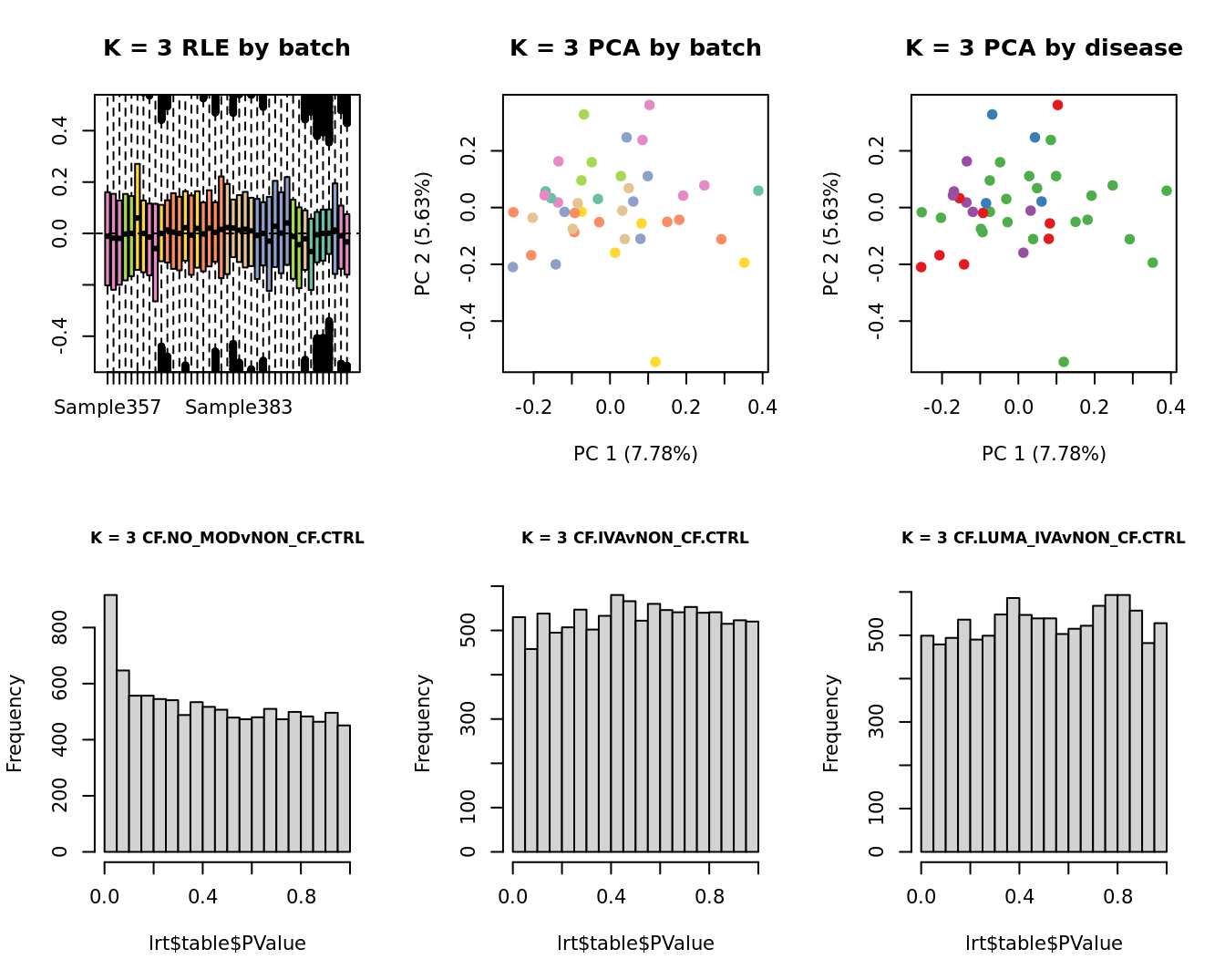
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
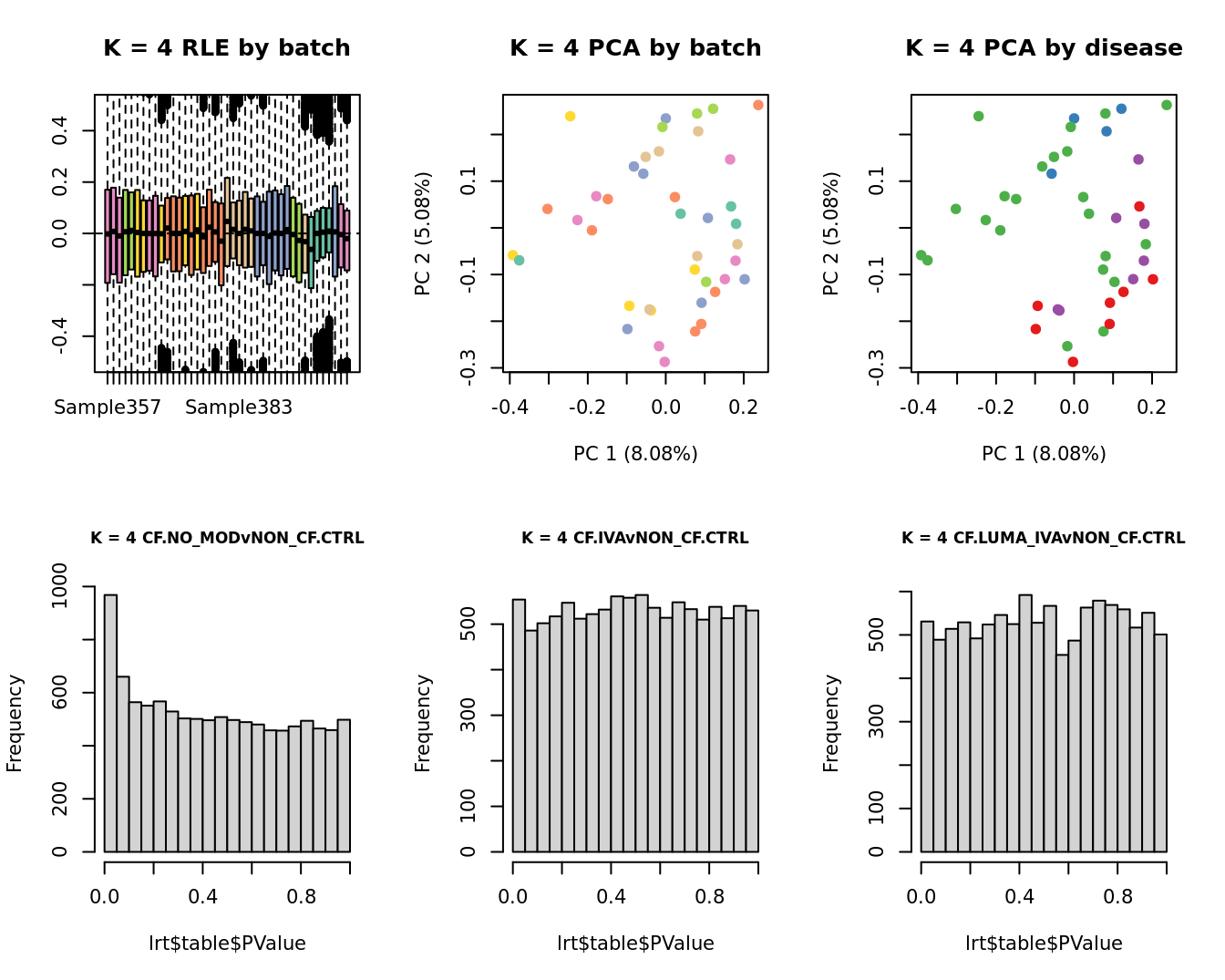
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
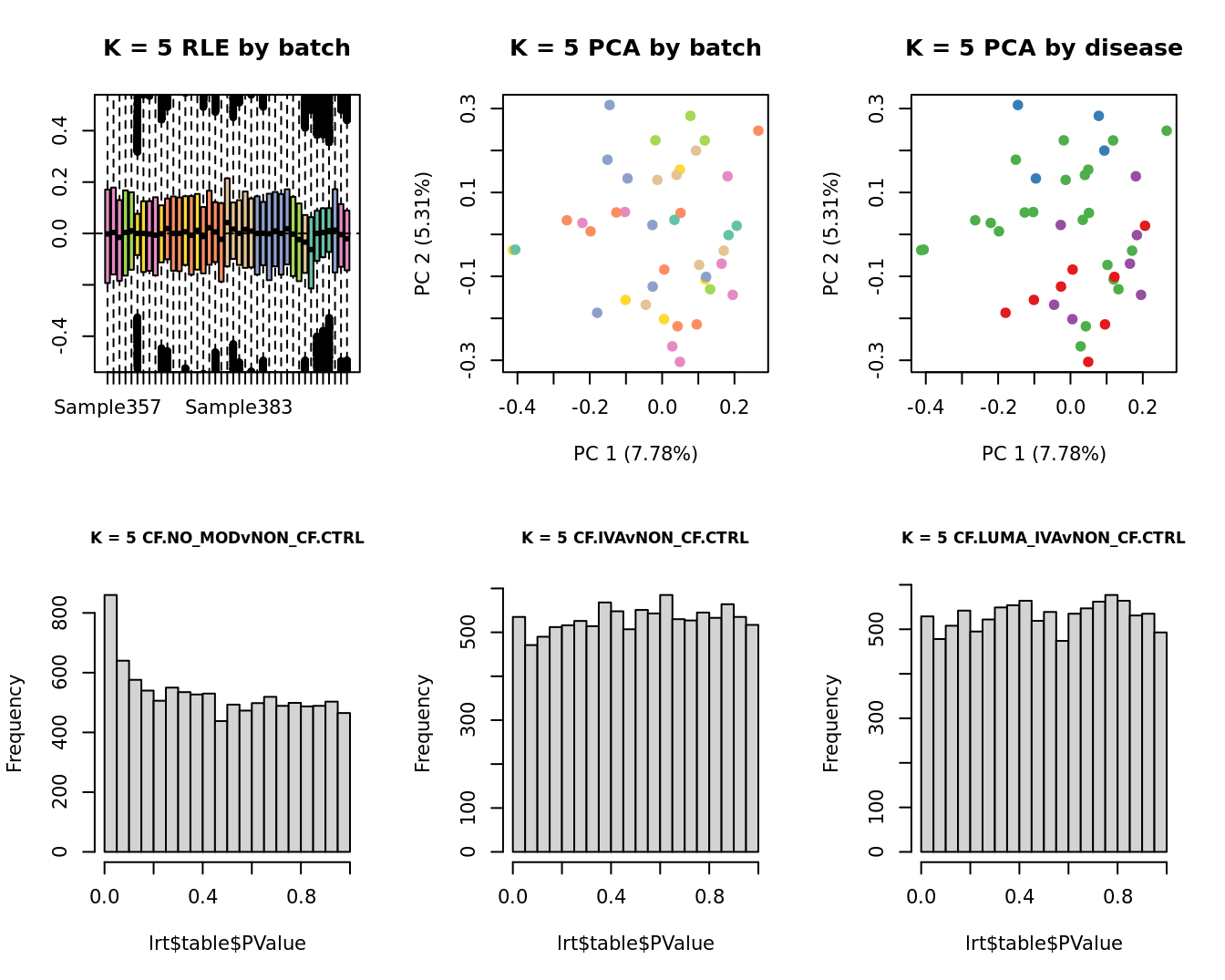
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Test for DGE using RUVSeq and edgeR. First,
create design matrix to model the sample groups and take into account
the unwanted variation, age, sex, severity and replicate samples from
the same individual.
# use RUVSeq to identify the factors of unwanted variation
adj <- RUVg(ySub$counts, ctl, k = 3)
W <- adj$W
# create the design matrix
design <- model.matrix(~ 0 + group + W + sex + age)
colnames(design)[1:length(levels(group))] <- levels(group)
# add the factors for the replicate samples
dups <- unique(ySub$samples$Participant[duplicated(ySub$samples$Participant)])
dups <- sapply(dups, function(d){
ifelse(ySub$samples$Participant == d, 1, 0)
}, USE.NAMES = TRUE)
design <- cbind(design, dups)
design %>% knitr::kable()| CF.IVA | CF.LUMA_IVA | CF.NO_MOD | NON_CF.CTRL | WW_1 | WW_2 | WW_3 | sexM | age | sample_35 | sample_36 | sample_37 | sample_38 | sample_39 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | -0.1437662 | 0.0011697 | 0.0525579 | 1 | -0.2590872 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.2028730 | -0.0384871 | 0.0495647 | 1 | -0.0939001 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.1002027 | 0.0304465 | 0.0184327 | 0 | -0.1151479 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.1325417 | -0.0128797 | -0.0044466 | 0 | -0.0441471 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.0800182 | 0.0272859 | -0.0190892 | 1 | 0.1428834 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.2562208 | -0.0732738 | 0.1863840 | 0 | -0.0729608 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.0236507 | 0.1265742 | 0.0033188 | 1 | 0.5597097 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.0064411 | 0.0918162 | -0.0386636 | 0 | 1.5743836 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | -0.1532371 | 0.0089063 | 0.0263988 | 1 | 1.5993830 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0.2404498 | 0.2645831 | -0.0541630 | 1 | 2.3883594 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.1182804 | -0.1061536 | -0.3476675 | 0 | 2.2957230 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.0905017 | -0.2186001 | -0.2381350 | 1 | 2.3360877 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | -0.0658536 | -0.1924206 | -0.2496399 | 1 | 2.2980155 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.1899541 | 0.2513092 | 0.0421990 | 0 | 2.5790214 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.0917928 | -0.2029666 | -0.2291939 | 0 | 2.5823250 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | -0.0493768 | 0.0792807 | 0.0458111 | 1 | 0.1321035 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.2325692 | -0.0144086 | -0.3557418 | 0 | 2.5889097 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.0180552 | -0.1706817 | -0.2797811 | 0 | 2.5583683 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.1188785 | -0.0776992 | -0.2963634 | 0 | 2.5670653 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | -0.1528687 | -0.1833380 | -0.0846122 | 1 | 2.5730557 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.1850749 | 0.0319117 | 0.1540092 | 0 | 1.0409164 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.1108105 | 0.2112524 | 0.0285714 | 1 | 0.0807044 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.0117612 | 0.1615952 | 0.0791381 | 1 | 0.9940589 | 1 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.0735353 | 0.1092558 | 0.1175878 | 0 | -0.0564254 | 0 | 1 | 0 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0.0573915 | 0.1873858 | 0.0589150 | 0 | 1.1764977 | 0 | 1 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | -0.0966222 | 0.0295238 | 0.0349720 | 0 | 1.5597097 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | 0.0555960 | 0.0990469 | -0.0245262 | 0 | 2.1930156 | 0 | 0 | 1 | 0 | 0 |
| 0 | 1 | 0 | 0 | -0.2165304 | -0.0584157 | 0.0790783 | 0 | 2.2980155 | 0 | 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 0 | -0.0549707 | 0.0653553 | 0.0895342 | 1 | 1.5703964 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | -0.0908964 | 0.0284230 | 0.0616099 | 1 | 2.0206033 | 0 | 0 | 0 | 1 | 0 |
| 1 | 0 | 0 | 0 | -0.1442825 | 0.0265833 | 0.1415853 | 1 | 2.3485584 | 0 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | -0.0798300 | 0.0415446 | -0.0067097 | 0 | 1.9730702 | 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 0 | -0.0651105 | 0.0349164 | -0.0356553 | 0 | 2.6297159 | 0 | 0 | 0 | 0 | 1 |
| 0 | 0 | 0 | 1 | 0.2115593 | 0.2703489 | 0.0053372 | 1 | 0.2923784 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.2995962 | -0.2172400 | 0.2679462 | 1 | 1.5801455 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 0 | 0.1350133 | -0.3586142 | 0.2580759 | 1 | 1.5801455 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0.3327185 | -0.2792548 | 0.2289091 | 1 | 1.5993178 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0.3430994 | -0.3031316 | 0.2341782 | 1 | 1.5849625 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | -0.1656759 | -0.0178843 | 0.1235556 | 0 | 3.0699187 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0.0941395 | 0.1641167 | -0.0523744 | 1 | 2.4204621 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 1 | 0.1279280 | 0.1828176 | -0.0709075 | 0 | 2.2356012 | 0 | 0 | 0 | 0 | 0 |
edgeR::cpm(ySub$counts, log = TRUE) %>%
data.frame %>%
rownames_to_column(var = "gene") %>%
pivot_longer(-gene,
names_to = "sample",
values_to = "raw") %>%
inner_join(edgeR::cpm(adj$normalizedCounts, log = TRUE) %>%
data.frame %>%
rownames_to_column(var = "gene") %>%
pivot_longer(-gene,
names_to = "sample",
values_to = "norm")) %>%
left_join(rownames_to_column(ySub$samples,
var = "sample")) %>%
mutate(Batch = as.factor(Batch)) %>%
dplyr::filter(gene %in% c("ZFY", "EIF1AY", "XIST")) %>%
ggplot(aes(x = Sex,
y = norm,
colour = Sex)) +
geom_boxplot(outlier.shape = NA, colour = "grey") +
geom_jitter(stat = "identity",
width = 0.15,
size = 1.25) +
geom_jitter(aes(x = Sex,
y = raw), stat = "identity",
width = 0.15,
size = 2,
alpha = 0.2,
stroke = 0) +
ggrepel::geom_text_repel(aes(label = sample.id),
size = 2) +
theme_classic() +
theme(axis.text.x = element_text(angle = 90,
hjust = 1,
vjust = 0.5),
legend.position = "bottom",
legend.direction = "horizontal",
strip.text = element_text(size = 7),
axis.text.y = element_text(size = 6)) +
labs(x = "Group", y = "log2 CPM") +
facet_wrap(~gene, scales = "free_y") +
scale_color_brewer(palette = "Set2") +
ggtitle("Sex gene expression check") -> p2
p2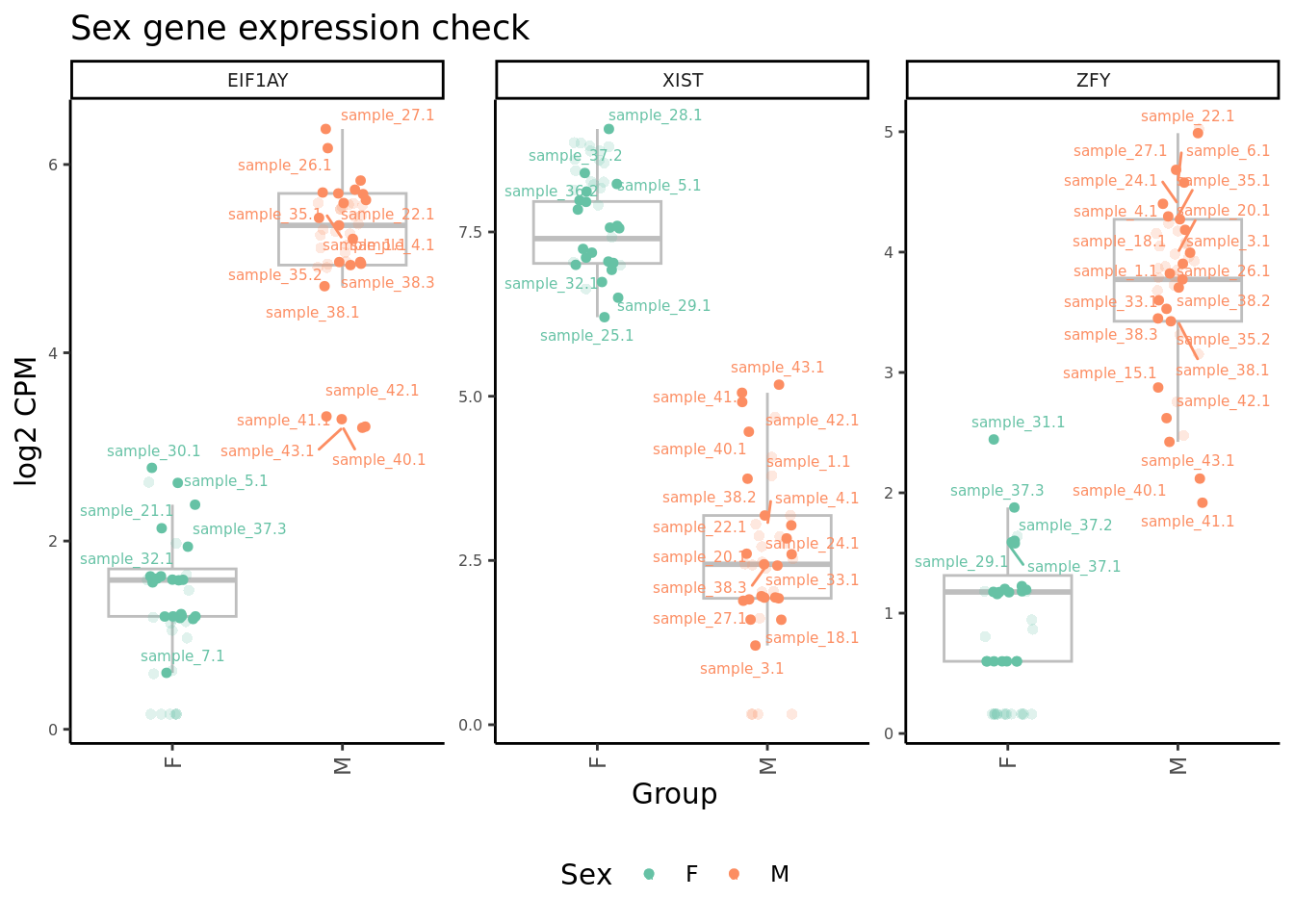
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Create the contrast matrix for the sample group comparisons.
contr <- makeContrasts(CF.NO_MODvNON_CF.CTRL = CF.NO_MOD - NON_CF.CTRL,
CF.IVAvNON_CF.CTRL = CF.IVA - NON_CF.CTRL,
CF.LUMA_IVAvNON_CF.CTRL = CF.LUMA_IVA - NON_CF.CTRL,
levels = design)
contr %>% knitr::kable()| CF.NO_MODvNON_CF.CTRL | CF.IVAvNON_CF.CTRL | CF.LUMA_IVAvNON_CF.CTRL | |
|---|---|---|---|
| CF.IVA | 0 | 1 | 0 |
| CF.LUMA_IVA | 0 | 0 | 1 |
| CF.NO_MOD | 1 | 0 | 0 |
| NON_CF.CTRL | -1 | -1 | -1 |
| WW_1 | 0 | 0 | 0 |
| WW_2 | 0 | 0 | 0 |
| WW_3 | 0 | 0 | 0 |
| sexM | 0 | 0 | 0 |
| age | 0 | 0 | 0 |
| sample_35 | 0 | 0 | 0 |
| sample_36 | 0 | 0 | 0 |
| sample_37 | 0 | 0 | 0 |
| sample_38 | 0 | 0 | 0 |
| sample_39 | 0 | 0 | 0 |
Fit the model.
y <- DGEList(counts = ySub$counts)
y <- calcNormFactors(y)
y <- estimateGLMCommonDisp(y, design)
y <- estimateGLMTagwiseDisp(y, design)
fit <- glmFit(y, design)Results summary
cutoff <- 0.05
dt <- lapply(1:ncol(contr), function(i){
decideTests(glmLRT(fit, contrast = contr[,i]),
p.value = cutoff)
})
s <- sapply(dt, function(d){
summary(d)
})
colnames(s) <- colnames(contr)
rownames(s) <- c("Down", "NotSig", "Up")
pal <- c(paletteer::paletteer_d("RColorBrewer::Set1")[2:1], "grey")
s[-2,] %>%
data.frame %>%
rownames_to_column(var = "Direction") %>%
pivot_longer(-Direction) %>%
ggplot(aes(x = name, y = value, fill = Direction)) +
geom_col(position = "dodge") +
geom_text(aes(label = value),
position = position_dodge(width = 0.9),
vjust = -0.5,
size = 3) +
labs(y = glue("No. DGE (FDR < {cutoff})"),
x = "Contrast") +
scale_fill_manual(values = pal) +
theme(axis.text.x = element_text(angle = 45,
hjust = 1,
vjust = 1)) +
scale_fill_manual(values = pal)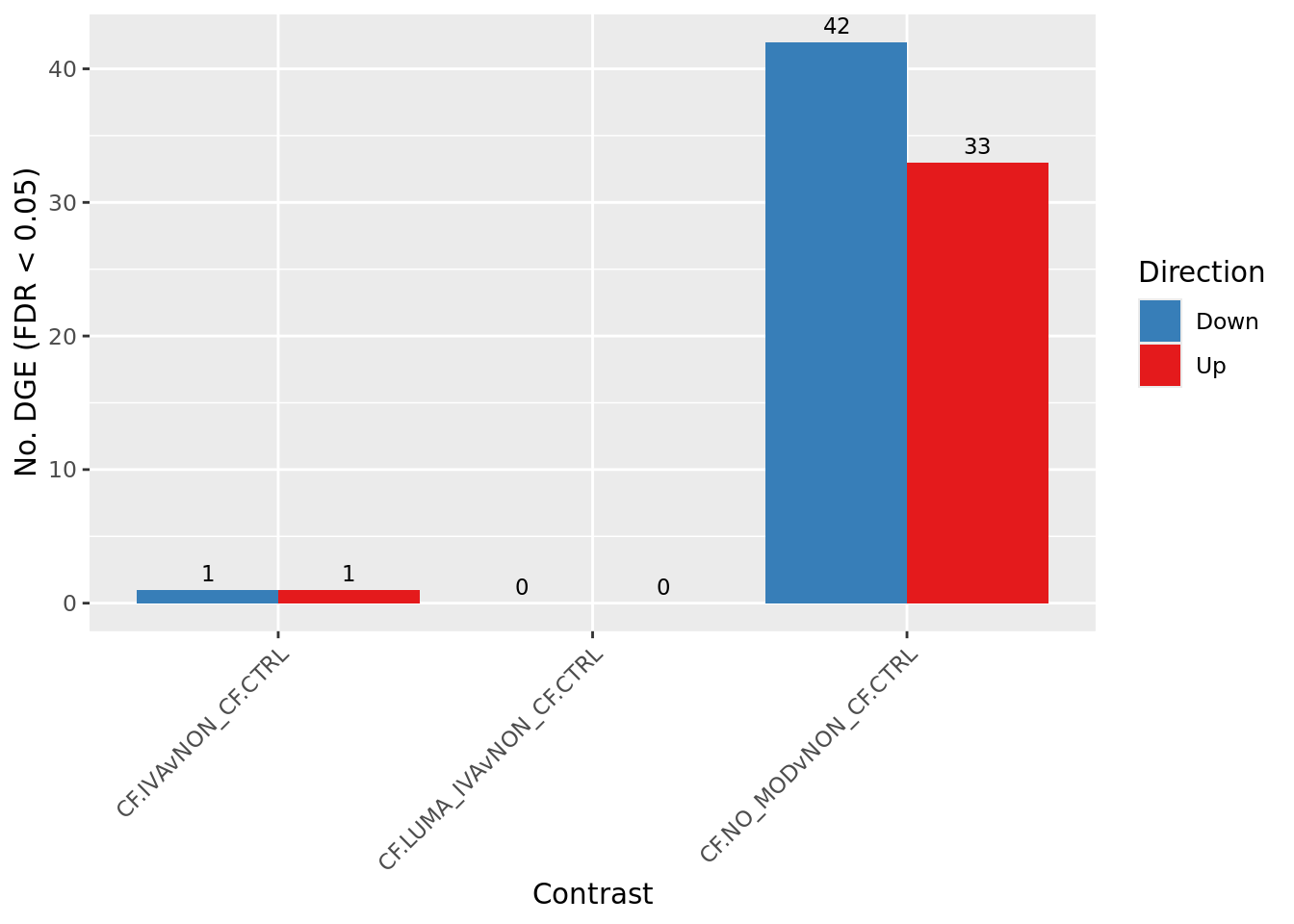
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Explore results of statistical analysis for each contrast with significant DGEs. First, setup the output directories.
outDir <- here("output","dge_analysis")
if(!dir.exists(outDir)) dir.create(outDir)
cellDir <- file.path(outDir, cell)
if(!dir.exists(cellDir)) dir.create(cellDir)Also, perform gene set enrichment analysis (GSEA) using the
cameraPR method. cameraPR tests whether a set
of genes is highly ranked relative to other genes in terms of
differential expression, accounting for inter-gene correlation. Prepare
the Broad MSigDB Gene Ontology, Hallmark gene sets and Reactome
pathways.
Hs.c2.all <- convert_gmt_to_list(here("data/c2.all.v2024.1.Hs.entrez.gmt"))
Hs.h.all <- convert_gmt_to_list(here("data/h.all.v2024.1.Hs.entrez.gmt"))
Hs.c5.all <- convert_gmt_to_list(here("data/c5.all.v2024.1.Hs.entrez.gmt"))
gene_sets_list <- list(HALLMARK = Hs.h.all,
GO = Hs.c5.all,
REACTOME = Hs.c2.all[str_detect(names(Hs.c2.all), "REACTOME")],
WP = Hs.c2.all[str_detect(names(Hs.c2.all), "^WP")]) Plot a detailed summary of the results.
layout <- "
AAAA
AAAA
AAAA
BBBB
BBBB
BBBB
BBBB
EEEE
EEEE
EEEE
EEEE"
plot_ruv_results_summary(contr, cutoff, cellDir, gene_sets_list, gns,
raw_counts = ySub$counts,
norm_counts = adj$normalizedCounts,
group_info = data.frame(Group = ySub$samples$Group,
sample = rownames(ySub$samples)),
layout,
pal) -> p
p[[1]]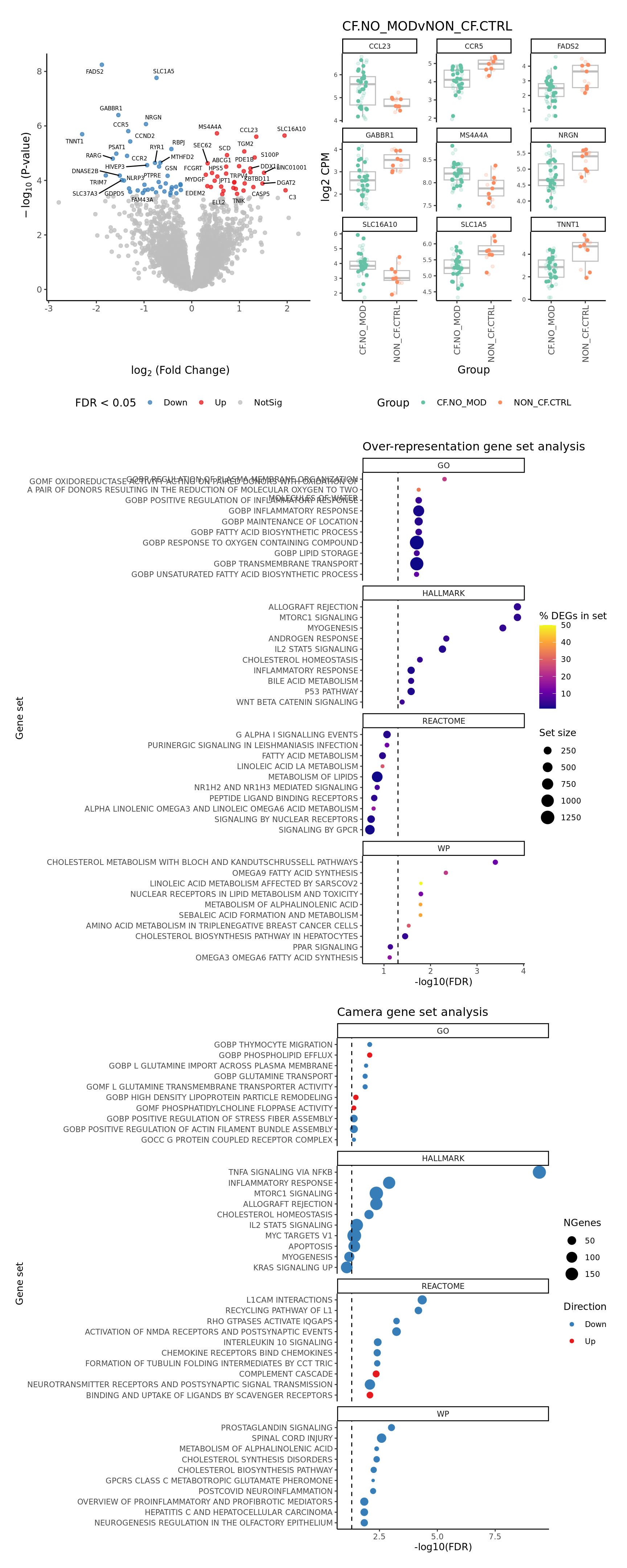
[[2]]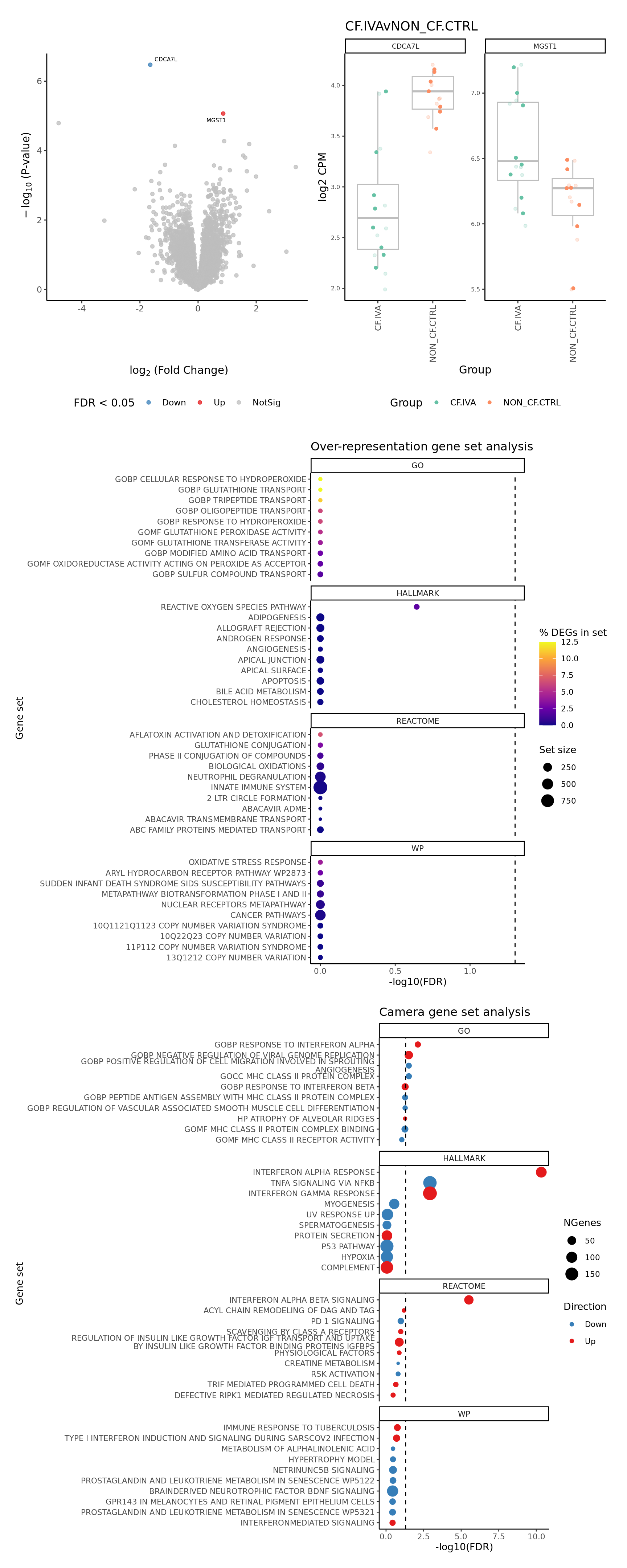
[[3]]
NULLCompare contrasts
Compare log fold changes and statistical significance between various contrasts.
lapply(1:ncol(contr), function(i) {
lrt <- glmLRT(fit, contrast = contr[,i])
topTags(lrt, n = Inf) %>%
data.frame %>%
rownames_to_column(var = "Symbol") %>%
dplyr::arrange(Symbol) %>%
dplyr::rename_with(~ paste0(.x, ".", i))
}) %>% bind_cols -> all_lrt
all_lrt %>%
mutate(IVA = ifelse(FDR.1 < 0.05 & FDR.2 < 0.05, "red",
ifelse(FDR.1 < 0.05 & FDR.2 >= 0.05, "orange",
ifelse(FDR.1 >= 0.05 & FDR.2 < 0.05, "green",
"grey")))) -> all_lrt
ggplot(all_lrt, aes(x = logFC.1,
y = logFC.2)) +
geom_point(data = subset(all_lrt, IVA %in% "grey"), aes(colour = "grey")) +
geom_point(data = subset(all_lrt, IVA %in% "green"), aes(colour = "green")) +
geom_point(data = subset(all_lrt, IVA %in% "orange"), aes(colour = "orange")) +
geom_point(data = subset(all_lrt, IVA %in% "red"), aes(colour = "red")) +
ggrepel::geom_text_repel(data = subset(all_lrt, (!IVA %in% "grey")),
aes(x = logFC.1, y = logFC.2,
label = Symbol.1),
size = 2, colour = "black", max.overlaps = 10) +
labs(x = "log2FC CF.NO_MODvNON_CF.CTRL",
y = "log2FC CF.IVAvNON_CF.CTRL") +
scale_colour_identity(guide = "legend",
breaks = c("red", "green", "orange","grey"),
labels = c("Sig. in both",
"Sig. CF.IVAvNON_CF.CTRL & N.S. CF.NO_MODvNON_CF.CTRL",
"Sig. CF.NO_MODvNON_CF.CTRL & N.S. CF.IVAvNON_CF.CTRL",
"N.S. in both"),
name = "Statistical significance") +
theme(legend.position = "bottom",
legend.direction = "vertical")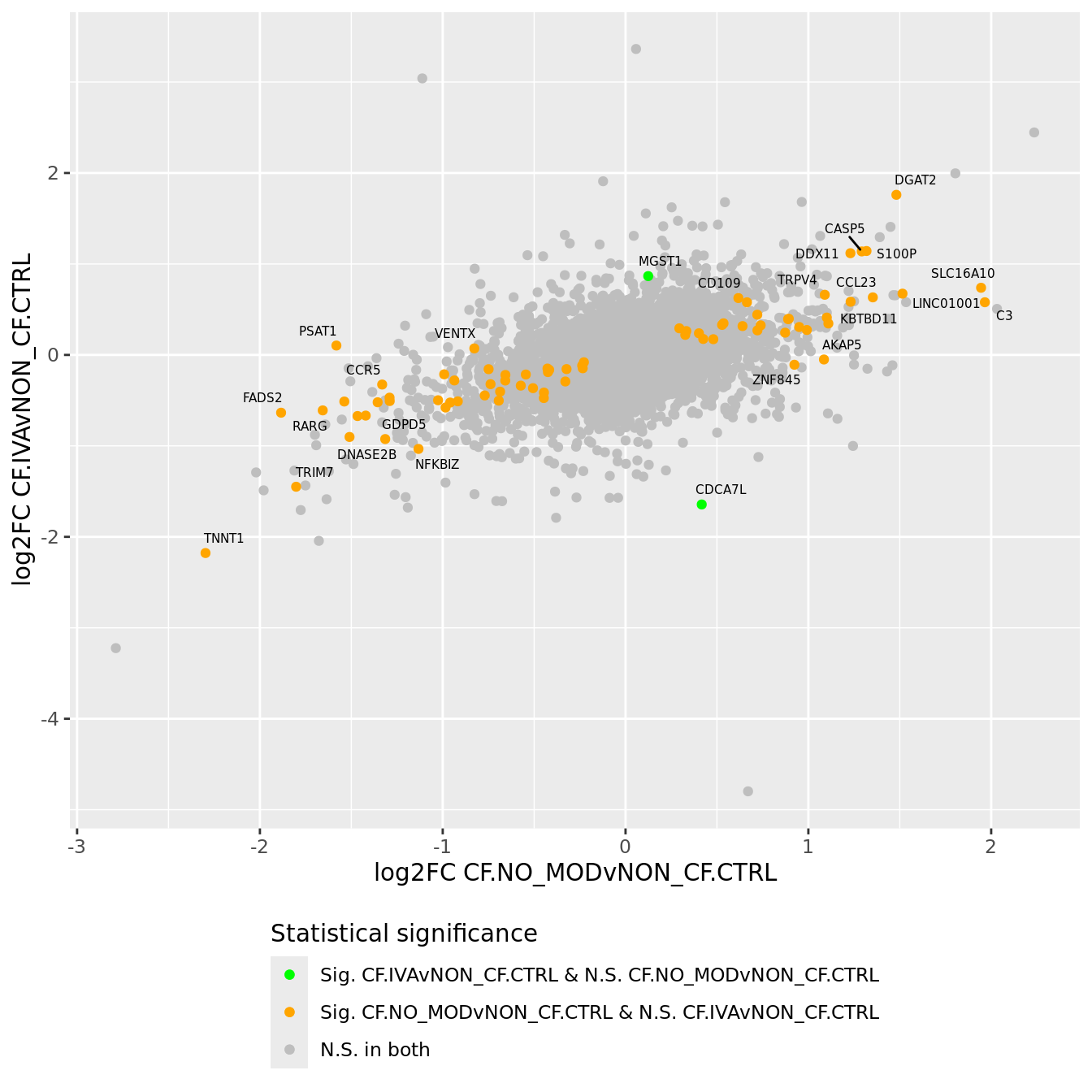
| Version | Author | Date |
|---|---|---|
| 155ff98 | Jovana Maksimovic | 2024-08-06 |
Session info
sessionInfo()R version 4.3.3 (2024-02-29)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 22.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
locale:
[1] LC_CTYPE=en_AU.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_AU.UTF-8 LC_COLLATE=en_AU.UTF-8
[5] LC_MONETARY=en_AU.UTF-8 LC_MESSAGES=en_AU.UTF-8
[7] LC_PAPER=en_AU.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_AU.UTF-8 LC_IDENTIFICATION=C
time zone: Etc/UTC
tzcode source: system (glibc)
attached base packages:
[1] parallel stats4 stats graphics grDevices datasets utils
[8] methods base
other attached packages:
[1] missMethyl_1.36.0
[2] IlluminaHumanMethylationEPICanno.ilm10b4.hg19_0.6.0
[3] IlluminaHumanMethylation450kanno.ilmn12.hg19_0.6.1
[4] minfi_1.48.0
[5] bumphunter_1.44.0
[6] locfit_1.5-9.8
[7] iterators_1.0.14
[8] foreach_1.5.2
[9] TxDb.Hsapiens.UCSC.hg38.knownGene_3.18.0
[10] GenomicFeatures_1.54.3
[11] org.Hs.eg.db_3.18.0
[12] AnnotationDbi_1.64.1
[13] tidyHeatmap_1.8.1
[14] scater_1.30.1
[15] scuttle_1.12.0
[16] SingleCellExperiment_1.24.0
[17] scMerge_1.18.0
[18] RUVSeq_1.36.0
[19] EDASeq_2.36.0
[20] ShortRead_1.60.0
[21] GenomicAlignments_1.38.2
[22] SummarizedExperiment_1.32.0
[23] MatrixGenerics_1.14.0
[24] matrixStats_1.2.0
[25] Rsamtools_2.18.0
[26] GenomicRanges_1.54.1
[27] Biostrings_2.70.2
[28] GenomeInfoDb_1.38.6
[29] XVector_0.42.0
[30] IRanges_2.36.0
[31] S4Vectors_0.40.2
[32] BiocParallel_1.36.0
[33] Biobase_2.62.0
[34] BiocGenerics_0.48.1
[35] edgeR_4.0.15
[36] limma_3.58.1
[37] paletteer_1.6.0
[38] patchwork_1.2.0
[39] SeuratObject_4.1.4
[40] Seurat_4.4.0
[41] glue_1.7.0
[42] here_1.0.1
[43] lubridate_1.9.3
[44] forcats_1.0.0
[45] stringr_1.5.1
[46] dplyr_1.1.4
[47] purrr_1.0.2
[48] readr_2.1.5
[49] tidyr_1.3.1
[50] tibble_3.2.1
[51] ggplot2_3.5.0
[52] tidyverse_2.0.0
[53] BiocStyle_2.30.0
[54] workflowr_1.7.1
loaded via a namespace (and not attached):
[1] igraph_2.0.1.1 ica_1.0-3
[3] plotly_4.10.4 Formula_1.2-5
[5] rematch2_2.1.2 zlibbioc_1.48.0
[7] tidyselect_1.2.0 bit_4.0.5
[9] doParallel_1.0.17 clue_0.3-65
[11] lattice_0.22-5 rjson_0.2.21
[13] nor1mix_1.3-3 M3Drop_1.28.0
[15] blob_1.2.4 rngtools_1.5.2
[17] S4Arrays_1.2.0 base64_2.0.1
[19] scrime_1.3.5 png_0.1-8
[21] ResidualMatrix_1.12.0 cli_3.6.2
[23] askpass_1.2.0 openssl_2.1.1
[25] multtest_2.58.0 goftest_1.2-3
[27] BiocIO_1.12.0 bluster_1.12.0
[29] BiocNeighbors_1.20.2 densEstBayes_1.0-2.2
[31] uwot_0.1.16 dendextend_1.17.1
[33] curl_5.2.0 mime_0.12
[35] evaluate_0.23 leiden_0.4.3.1
[37] ComplexHeatmap_2.18.0 stringi_1.8.3
[39] backports_1.4.1 XML_3.99-0.16.1
[41] httpuv_1.6.14 magrittr_2.0.3
[43] rappdirs_0.3.3 splines_4.3.3
[45] mclust_6.1 jpeg_0.1-10
[47] doRNG_1.8.6 sctransform_0.4.1
[49] ggbeeswarm_0.7.2 DBI_1.2.1
[51] HDF5Array_1.30.0 genefilter_1.84.0
[53] jquerylib_0.1.4 withr_3.0.0
[55] git2r_0.33.0 rprojroot_2.0.4
[57] lmtest_0.9-40 bdsmatrix_1.3-6
[59] rtracklayer_1.62.0 BiocManager_1.30.22
[61] htmlwidgets_1.6.4 fs_1.6.3
[63] biomaRt_2.58.2 ggrepel_0.9.5
[65] labeling_0.4.3 SparseArray_1.2.4
[67] DEoptimR_1.1-3 annotate_1.80.0
[69] reticulate_1.35.0 zoo_1.8-12
[71] knitr_1.45 beanplot_1.3.1
[73] timechange_0.3.0 fansi_1.0.6
[75] caTools_1.18.2 grid_4.3.3
[77] data.table_1.15.0 rhdf5_2.46.1
[79] ruv_0.9.7.1 R.oo_1.26.0
[81] irlba_2.3.5.1 ellipsis_0.3.2
[83] aroma.light_3.32.0 lazyeval_0.2.2
[85] yaml_2.3.8 survival_3.7-0
[87] scattermore_1.2 crayon_1.5.2
[89] RcppAnnoy_0.0.22 RColorBrewer_1.1-3
[91] progressr_0.14.0 later_1.3.2
[93] ggridges_0.5.6 codetools_0.2-19
[95] base64enc_0.1-3 GlobalOptions_0.1.2
[97] KEGGREST_1.42.0 bbmle_1.0.25.1
[99] Rtsne_0.17 shape_1.4.6
[101] startupmsg_0.9.6.1 filelock_1.0.3
[103] foreign_0.8-86 pkgconfig_2.0.3
[105] xml2_1.3.6 getPass_0.2-4
[107] sfsmisc_1.1-17 spatstat.sparse_3.0-3
[109] viridisLite_0.4.2 xtable_1.8-4
[111] interp_1.1-6 fastcluster_1.2.6
[113] highr_0.10 hwriter_1.3.2.1
[115] plyr_1.8.9 httr_1.4.7
[117] tools_4.3.3 globals_0.16.2
[119] pkgbuild_1.4.3 beeswarm_0.4.0
[121] htmlTable_2.4.2 checkmate_2.3.1
[123] nlme_3.1-164 loo_2.6.0
[125] dbplyr_2.4.0 digest_0.6.34
[127] numDeriv_2016.8-1.1 Matrix_1.6-5
[129] farver_2.1.1 tzdb_0.4.0
[131] reshape2_1.4.4 viridis_0.6.5
[133] cvTools_0.3.2 rpart_4.1.23
[135] cachem_1.0.8 BiocFileCache_2.10.1
[137] polyclip_1.10-6 WGCNA_1.72-5
[139] Hmisc_5.1-1 generics_0.1.3
[141] proxyC_0.3.4 dynamicTreeCut_1.63-1
[143] mvtnorm_1.2-4 parallelly_1.37.0
[145] statmod_1.5.0 impute_1.76.0
[147] ScaledMatrix_1.10.0 GEOquery_2.70.0
[149] pbapply_1.7-2 dqrng_0.3.2
[151] utf8_1.2.4 siggenes_1.76.0
[153] StanHeaders_2.32.5 gtools_3.9.5
[155] preprocessCore_1.64.0 gridExtra_2.3
[157] shiny_1.8.0 GenomeInfoDbData_1.2.11
[159] R.utils_2.12.3 rhdf5filters_1.14.1
[161] RCurl_1.98-1.14 memoise_2.0.1
[163] rmarkdown_2.25 scales_1.3.0
[165] R.methodsS3_1.8.2 future_1.33.1
[167] reshape_0.8.9 RANN_2.6.1
[169] renv_1.0.3 Cairo_1.6-2
[171] illuminaio_0.44.0 spatstat.data_3.0-4
[173] rstudioapi_0.15.0 cluster_2.1.6
[175] QuickJSR_1.1.3 whisker_0.4.1
[177] rstantools_2.4.0 spatstat.utils_3.0-4
[179] hms_1.1.3 fitdistrplus_1.1-11
[181] munsell_0.5.0 cowplot_1.1.3
[183] colorspace_2.1-0 quadprog_1.5-8
[185] rlang_1.1.3 DelayedMatrixStats_1.24.0
[187] sparseMatrixStats_1.14.0 circlize_0.4.15
[189] mgcv_1.9-1 xfun_0.42
[191] reldist_1.7-2 abind_1.4-5
[193] rstan_2.32.5 Rhdf5lib_1.24.2
[195] bitops_1.0-7 ps_1.7.6
[197] promises_1.2.1 inline_0.3.19
[199] RSQLite_2.3.5 DelayedArray_0.28.0
[201] GO.db_3.18.0 compiler_4.3.3
[203] prettyunits_1.2.0 beachmat_2.18.1
[205] listenv_0.9.1 Rcpp_1.0.12
[207] BiocSingular_1.18.0 tensor_1.5
[209] MASS_7.3-60.0.1 progress_1.2.3
[211] spatstat.random_3.2-2 R6_2.5.1
[213] fastmap_1.1.1 vipor_0.4.7
[215] distr_2.9.3 ROCR_1.0-11
[217] rsvd_1.0.5 nnet_7.3-19
[219] gtable_0.3.4 KernSmooth_2.23-24
[221] latticeExtra_0.6-30 miniUI_0.1.1.1
[223] deldir_2.0-2 htmltools_0.5.7
[225] RcppParallel_5.1.7 bit64_4.0.5
[227] spatstat.explore_3.2-6 lifecycle_1.0.4
[229] processx_3.8.3 callr_3.7.3
[231] restfulr_0.0.15 sass_0.4.8
[233] vctrs_0.6.5 spatstat.geom_3.2-8
[235] robustbase_0.99-2 scran_1.30.2
[237] sp_2.1-3 future.apply_1.11.1
[239] bslib_0.6.1 pillar_1.9.0
[241] batchelor_1.18.1 prismatic_1.1.1
[243] gplots_3.1.3.1 metapod_1.10.1
[245] jsonlite_1.8.8 GetoptLong_1.0.5