DO_Diversity_Report
Hao He
2020-11-08
Last updated: 2020-11-08
Checks: 7 0
Knit directory: csna_workflow/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190922) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 04001f6. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: analysis/.Rhistory
Untracked files:
Untracked: analysis/.nfs0000000135a08b9b00002448
Untracked: analysis/.nfs0000000135a08ba50000244a
Untracked: analysis/csna_image.sif
Untracked: analysis/scripts/
Untracked: analysis/temp/
Untracked: analysis/temp2/
Untracked: analysis/workflow_proc.R
Untracked: analysis/workflow_proc.sh
Untracked: analysis/workflow_proc.stderr
Untracked: analysis/workflow_proc.stdout
Untracked: code/reconst_utils.R
Untracked: data/69k_grid_pgmap.RData
Untracked: data/FinalReport/
Untracked: data/GCTA/
Untracked: data/GM/
Untracked: data/Jackson_Lab_11_batches/
Untracked: data/Jackson_Lab_12_batches/
Untracked: data/Jackson_Lab_Bubier_MURGIGV01/
Untracked: data/Jackson_Lab_Gagnon/
Untracked: data/RTG/
Untracked: data/cc_variants.sqlite
Untracked: data/marker_grid_0.02cM_plus.txt
Untracked: data/mouse_genes_mgi.sqlite
Untracked: data/pheno/
Untracked: output/AfterQC_Percent_missing_genotype_data.pdf
Untracked: output/AfterQC_Proportion_matching_genotypes_after_removal_of_bad_samples.pdf
Untracked: output/AfterQC_Proportion_matching_genotypes_before_removal_of_bad_samples.pdf
Untracked: output/AfterQC_number_crossover.pdf
Untracked: output/DO_Gigamuga_chr2_WSB_G21.png
Untracked: output/DO_Gigamuga_chr2_WSB_G22.png
Untracked: output/DO_Gigamuga_chr2_WSB_G23.png
Untracked: output/DO_Gigamuga_chr2_WSB_G25.png
Untracked: output/DO_Gigamuga_chr2_WSB_G29.png
Untracked: output/DO_Gigamuga_chr2_WSB_G30.png
Untracked: output/DO_Gigamuga_chr2_WSB_G31.png
Untracked: output/DO_Gigamuga_chr2_WSB_G32.png
Untracked: output/DO_Gigamuga_chr2_WSB_G33.png
Untracked: output/DO_Gigamuga_founder_proportions_G21.png
Untracked: output/DO_Gigamuga_founder_proportions_G22.png
Untracked: output/DO_Gigamuga_founder_proportions_G23.png
Untracked: output/DO_Gigamuga_founder_proportions_G25.png
Untracked: output/DO_Gigamuga_founder_proportions_G29.png
Untracked: output/DO_Gigamuga_founder_proportions_G30.png
Untracked: output/DO_Gigamuga_founder_proportions_G31.png
Untracked: output/DO_Gigamuga_founder_proportions_G32.png
Untracked: output/DO_Gigamuga_founder_proportions_G33.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G21.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G22.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G23.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G25.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G29.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G30.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G31.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G32.png
Untracked: output/DO_Gigamuga_founder_proportions_chr2_G33.png
Untracked: output/DO_recom_block_size_G21.png
Untracked: output/DO_recom_block_size_G22.png
Untracked: output/DO_recom_block_size_G23.png
Untracked: output/DO_recom_block_size_G25.png
Untracked: output/DO_recom_block_size_G29.png
Untracked: output/DO_recom_block_size_G30.png
Untracked: output/DO_recom_block_size_G31.png
Untracked: output/DO_recom_block_size_G32.png
Untracked: output/DO_recom_block_size_G33.png
Untracked: output/Histgram_Prj01_RL-Acquisition_preqc_02142020.pdf
Untracked: output/Histgram_Prj01_RL-Reversal_preqc_02142020.pdf
Untracked: output/Histgram_Prj02_Sensitization_preqc_02142020.pdf
Untracked: output/Histgram_Prj04_IVSA_preqc_02142020.pdf
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-69k-genelist.csv
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-69k-variantlist.csv
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-genelist.csv
Untracked: output/Novelty_residuals_RankNormal_datarelease_12182019-variantlist.csv
Untracked: output/Percent_genotype_errors_obs_vs_predicted.pdf
Untracked: output/Percent_missing_genotype_data.pdf
Untracked: output/Percent_missing_genotype_data_per_marker.pdf
Untracked: output/Proportion_matching_genotypes_after_removal_of_bad_samples.pdf
Untracked: output/Proportion_matching_genotypes_after_removal_samples_percent_missing_5.pdf
Untracked: output/Proportion_matching_genotypes_before_removal_of_bad_samples.pdf
Untracked: output/Proportion_matching_genotypes_before_removal_samples.pdf
Untracked: output/RTG/
Untracked: output/blup/
Untracked: output/condi.m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/condi.m2.qtl.blup_Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/condi.m2.qtl.out.RData
Untracked: output/conditional.69k.Novelty_residuals_RankNormal_datarelease_12182019-genelist.csv
Untracked: output/conditional.69k.Novelty_residuals_RankNormal_datarelease_12182019-variantlist.csv
Untracked: output/conditional.Novelty_residuals_RankNormal_datarelease_12182019-genelist.csv
Untracked: output/conditional.Novelty_residuals_RankNormal_datarelease_12182019-variantlist.csv
Untracked: output/conditional.m2.69k.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/conditional.m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/conditional.m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/conditional.m2.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/conditional.m2.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/conditional.m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/conditional.m2.qtl.out.RData
Untracked: output/conditional_m2.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/conditional_m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/genotype_error_marker.pdf
Untracked: output/genotype_frequency_marker.pdf
Untracked: output/m1.Novelty_resids_datarelease_07302918.RData
Untracked: output/m1.Novelty_resids_datarelease_07302918_coeffgeneplot.pdf
Untracked: output/m1.Novelty_resids_datarelease_07302918_genomescan.pdf
Untracked: output/m1.Novelty_resids_datarelease_12182019.RData
Untracked: output/m1.Novelty_resids_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m1.Novelty_resids_datarelease_12182019_genomescan.pdf
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_07302918.RData
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m1.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/m2.69k.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m2.69k.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/m2.69k.Prj01_RL-Acquisition_preqc_02142020.RData
Untracked: output/m2.69k.Prj01_RL-Reversal_preqc_02142020.RData
Untracked: output/m2.69k.Prj02_Sensitization_preqc_02142020.RData
Untracked: output/m2.69k.Prj04_IVSA_preqc_02142020.RData
Untracked: output/m2.Novelty_resids_datarelease_07302918.RData
Untracked: output/m2.Novelty_resids_datarelease_07302918_genomescan.pdf
Untracked: output/m2.Novelty_resids_datarelease_12182019.RData
Untracked: output/m2.Novelty_resids_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m2.Novelty_resids_datarelease_12182019_genomescan.pdf
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_07302918.RData
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m2.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/m2.Prj01_RL-Acquisition_preqc_02142020.RData
Untracked: output/m2.Prj01_RL-Acquisition_preqc_02142020_qtl2scan.pdf
Untracked: output/m2.Prj01_RL-Reversal_preqc_02142020.RData
Untracked: output/m2.Prj01_RL-Reversal_preqc_02142020_qtl2scan.pdf
Untracked: output/m2.Prj02_Sensitization_preqc_02142020.RData
Untracked: output/m2.Prj02_Sensitization_preqc_02142020_qtl2scan.pdf
Untracked: output/m2.Prj04_IVSA_preqc_02142020.RData
Untracked: output/m2.Prj04_IVSA_preqc_02142020_qtl2scan.pdf
Untracked: output/m3.Novelty_resids_datarelease_07302918.RData
Untracked: output/m3.Novelty_resids_datarelease_07302918_genomescan.pdf
Untracked: output/m3.Novelty_resids_datarelease_12182019.RData
Untracked: output/m3.Novelty_resids_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m3.Novelty_resids_datarelease_12182019_genomescan.pdf
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_07302918.RData
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_07302918_genomescan.pdf
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_12182019.RData
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_12182019_coeffgeneplot.pdf
Untracked: output/m3.Novelty_residuals_RankNormal_datarelease_12182019_genomescan.pdf
Untracked: output/num.geno.pheno.in.Novelty_resids_datarelease_07302918.csv
Untracked: output/num.geno.pheno.in.Novelty_resids_datarelease_12182019.csv
Untracked: output/num.geno.pheno.in.Novelty_residuals_RankNormal_datarelease_07302918.csv
Untracked: output/num.geno.pheno.in.Novelty_residuals_RankNormal_datarelease_12182019.csv
Untracked: output/number_crossover.pdf
Untracked: output/permu/
Untracked: output/prop_across_generation_chr_p.RData
Unstaged changes:
Deleted: analysis/01_geneseek2qtl2.R
Deleted: analysis/02_geneseek2intensity.R
Deleted: analysis/03_firstgm2genoprobs.R
Deleted: analysis/04_diagnosis_qc_gigamuga_11_batches.Rmd
Deleted: analysis/04_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/04_diagnosis_qc_gigamuga_nine_batches.Rmd
Deleted: analysis/05_after_diagnosis_qc_gigamuga_11_batches.Rmd
Deleted: analysis/05_after_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/05_after_diagnosis_qc_gigamuga_nine_batches.Rmd
Deleted: analysis/06_final_pr_apr_69K.R
Deleted: analysis/07.1_html_founder_prop.R
Deleted: analysis/07_recomb_size_founder_prop.R
Deleted: analysis/07_recomb_size_founder_prop.Rmd
Deleted: analysis/08_gcta_herit.R
Deleted: analysis/09_qtlmapping.R
Deleted: analysis/10_qtl_permu.R
Deleted: analysis/11_qtl_blup.R
Deleted: analysis/12_plot_69k_qtl_mapping_2.Rmd
Deleted: analysis/12_plot_qtl_mapping_1.Rmd
Deleted: analysis/12_plot_qtl_mapping_2.Rmd
Deleted: analysis/13_plot_69k_conditional_m2_qtlmapping.Rmd
Deleted: analysis/13_plot_conditional_m2_qtlmapping.Rmd
Deleted: analysis/16_diagnosis_qc_gigamuga_gagnon.Rmd
Deleted: analysis/16_diagnosis_qc_gigamuga_gagnon2.Rmd
Deleted: analysis/17_plot_qtl_mapping.Rmd
Deleted: analysis/run_01_geneseek2qtl2.R
Deleted: analysis/run_02_geneseek2intensity.R
Deleted: analysis/run_03_firstgm2genoprobs.R
Deleted: analysis/run_04_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/run_05_after_diagnosis_qc_gigamuga_nine_batches.R
Deleted: analysis/run_06_final_pr_apr_69K.R
Deleted: analysis/run_07.1_html_founder_prop.R
Deleted: analysis/run_07_recomb_size_founder_prop.R
Deleted: analysis/run_08_gcta_herit.R
Deleted: analysis/run_09_qtlmapping.R
Deleted: analysis/run_10_qtl_permu.R
Deleted: analysis/run_11_qtl_blup.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/07_do_diversity_report.Rmd) and HTML (docs/07_do_diversity_report.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 04001f6 | xhyuo | 2020-11-08 | do_diversity_report |
Diversity report for diversity outbred mice
After finishing 06_final_pr_apr_69K.R, 07_do_diversity_report.R, all the output will be used plot DO Diversity Report for 12 batches of DO mice
library
# Load packages
library(qtl2)
library(table1)
library(tidyr)
library(dplyr)
library(data.table)
library(foreach)
library(doParallel)
library(parallel)
library(abind)
library(gap)
library(regress)
library(lme4)
library(abind)
library(ggplot2)
library(vcd)
library(MASS)
library(plotly)
options(stringsAsFactors = FALSE)
source("code/reconst_utils.R")#Summary
load("data/Jackson_Lab_12_batches/gm_DO3173_qc.RData")#gm_after_qc
# make dataset with a few variables to summarize
table1 <- gm_after_qc$covar %>%
select(Name = name,
Sex = sex,
Generation = ngen) %>%
mutate(Sex = case_when(
Sex == "F" ~ "Female",
Sex == "M" ~ "Male"
))
# summarize the data
table1(~ Generation | Sex, data=table1)| Female (N=1661) |
Male (N=1512) |
Overall (N=3173) |
|
|---|---|---|---|
| Generation | |||
| 21 | 73 (4.4%) | 75 (5.0%) | 148 (4.7%) |
| 22 | 85 (5.1%) | 71 (4.7%) | 156 (4.9%) |
| 23 | 99 (6.0%) | 94 (6.2%) | 193 (6.1%) |
| 25 | 11 (0.7%) | 13 (0.9%) | 24 (0.8%) |
| 29 | 169 (10.2%) | 161 (10.6%) | 330 (10.4%) |
| 30 | 222 (13.4%) | 215 (14.2%) | 437 (13.8%) |
| 31 | 210 (12.6%) | 207 (13.7%) | 417 (13.1%) |
| 32 | 164 (9.9%) | 153 (10.1%) | 317 (10.0%) |
| 33 | 227 (13.7%) | 223 (14.7%) | 450 (14.2%) |
| 34 | 250 (15.1%) | 157 (10.4%) | 407 (12.8%) |
| 35 | 87 (5.2%) | 77 (5.1%) | 164 (5.2%) |
| 36 | 64 (3.9%) | 66 (4.4%) | 130 (4.1%) |
#Founder contributions
load("data/Jackson_Lab_12_batches/fp_DO3173.RData") #fp and fp_summary object
#change order of level in gen
fp$gen <- factor(fp$gen,levels = c(21,22,23,25,29,30,31,32,33,34,35,36))
#summarize per generation per chromosome
fp_summary = fp %>% group_by(chr, founder, gen) %>%
summarize(mean = round(100*mean(prop), 2),
sd = round(100*sd(prop), 2))`summarise()` regrouping output by 'chr', 'founder' (override with `.groups` argument)#Stackbar plot
#summarize per chromosome across generation
pdf(file = "data/Jackson_Lab_12_batches/stackbar_mean_prop_across_all_gen.pdf",width = 16)
p01 <- fp %>% group_by(chr, founder) %>%
summarise(grand_mean = round(100*mean(prop), 2)) %>%
ggplot(aes(x = chr, y = grand_mean, fill = founder)) +
geom_bar(stat="identity",
width=1) +
geom_text(aes(label = paste0(grand_mean)), position = position_stack(vjust = 0.5)) +
scale_fill_manual(values = CCcolors) +
ylab("Mean percentage across generations") +
xlab("Chromosome") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0.5),
text = element_text(size=16),
axis.title=element_text(size=16),
legend.title=element_blank())`summarise()` regrouping output by 'chr' (override with `.groups` argument)p01
dev.off()png
2 p01
#Stackbar plot
#summarize per chromosome across generation
pdf(file = "data/Jackson_Lab_12_batches/stackbar_mean_prop_across_all_chr.pdf",width = 16)
p02 <- fp %>% group_by(gen, founder) %>%
summarise(grand_mean = round(100*mean(prop), 2),
grand_sd = round(100*sd(prop), 2)) %>%
ggplot(aes(x = gen, y = grand_mean, fill = founder)) +
geom_bar(stat="identity",
width=0.99) +
geom_text(aes(label = paste0(grand_mean, " ± ", grand_sd)), position = position_stack(vjust = 0.5)) +
scale_fill_manual(values = CCcolors) +
ylab("Mean percentage across all chromosomes") +
xlab("Generation") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0.5),
text = element_text(size=16),
axis.title=element_text(size=16),
legend.title=element_blank())`summarise()` regrouping output by 'gen' (override with `.groups` argument)p02
dev.off()png
2 p02
#stackbar_prop_across_gen
for(c in c(1:19, "X")){
#print(c)
p <- ggplot(data = fp_summary[fp_summary$chr == c,], aes(x = gen, y = mean, fill = founder)) +
geom_bar(stat="identity",
width=1) +
geom_text(aes(label = paste0(mean," ± ", sd)), position = position_stack(vjust = 0.5)) +
scale_fill_manual(values = CCcolors) +
labs(title = paste0("Chr ", c)) +
ylab("Percentage") +
xlab("Generation") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0.5),
text = element_text(size=16),
axis.title=element_text(size=16),
legend.title=element_blank())
print(p)
}



















pdf(file = "data/Jackson_Lab_12_batches/stackbar_prop_across_gen.pdf",width = 16)
for(c in c(1:19, "X")){
#print(c)
p <- ggplot(data = fp_summary[fp_summary$chr == c,], aes(x = gen, y = mean, fill = founder)) +
geom_bar(stat="identity",
width=1) +
geom_text(aes(label = paste0(mean," ± ", sd)), position = position_stack(vjust = 0.5)) +
scale_fill_manual(values = CCcolors) +
labs(title = paste0("Chr ", c)) +
ylab("Percentage") +
xlab("Generation") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0.5),
text = element_text(size=16),
axis.title=element_text(size=16),
legend.title=element_blank())
print(p)
}
dev.off()png
2 #stackbar_prop_across_chr
for(g in levels(fp_summary$gen)){
#print(g)
p <- ggplot(data = fp_summary[fp_summary$gen == g,], aes(x = chr, y = mean, fill = founder)) +
geom_bar(stat="identity",
width=1) +
geom_text(aes(label = paste0(mean)), position = position_stack(vjust = 0.5)) +
scale_fill_manual(values = CCcolors) +
labs(title = paste0("Generation ", g)) +
ylab("Percentage") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.title.x = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0.5),
text = element_text(size=16),
axis.title=element_text(size=16),
legend.title=element_blank())
#print(p)
}
pdf(file = "data/Jackson_Lab_12_batches/stackbar_prop_across_chr.pdf", width = 12)
for(g in levels(fp_summary$gen)){
#print(g)
p <- ggplot(data = fp_summary[fp_summary$gen == g,], aes(x = chr, y = mean, fill = founder)) +
geom_bar(stat="identity",
width=1) +
geom_text(aes(label = paste0(mean)), position = position_stack(vjust = 0.5)) +
scale_fill_manual(values = CCcolors) +
labs(title = paste0("Generation ", g)) +
ylab("Percentage") +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.title.x = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0.5),
text = element_text(size=16),
axis.title=element_text(size=16),
legend.title=element_blank())
print(p)
}
dev.off()png
2 #line plot
#plt <- htmltools::tagList()
for(c in unique(names(gm_after_qc$geno))){
print(c)
fp_subdata <- fp[fp$chr == c,]
pp <- ggplot(data = fp_subdata,aes(pos, prop, group = gen, color = founder)) +
geom_line(aes(linetype=gen)) +
scale_linetype_manual(values=rep("solid",12)) +
geom_hline(yintercept=0.125, linetype="dashed", color = "black", size = 0.25) +
scale_color_manual(values = CCcolors) +
facet_grid(founder~.) +
labs(title = paste0("Chr ", c)) +
theme(legend.position='none')
print(pp)
# Print an interactive plot
# Add to list
#plt[[c]] <- as_widget(ggplotly(pp, width = 1000, height = 1000))
}[1] "1"
[1] "2"
[1] "3"
[1] "4"
[1] "5"
[1] "6"
[1] "7"
[1] "8"
[1] "9"
[1] "10"
[1] "11"
[1] "12"
[1] "13"
[1] "14"
[1] "15"
[1] "16"
[1] "17"
[1] "18"
[1] "19"
[1] "X"
#plt#Average haplotype block size
load("data/Jackson_Lab_12_batches/recom_block_size.RData")
#Create an appropriately sized vector of names
nameVector <- unlist(mapply(function(x,y){ rep(y, length(x)) }, pos_ind_gen, names(pos_ind_gen)))
#Create the result
recom_block <- cbind.data.frame(unlist(pos_ind_gen), nameVector)
colnames(recom_block) <- c("sizeblock",
"ngen")
#remove 0
recom_block <- recom_block[recom_block$sizeblock != 0,]
recom_block$ngen <- factor(recom_block$ngen, levels = as.character(c(21:36)))
#mean
means <- aggregate(sizeblock~ngen, data= recom_block,mean)
means$sizeblock <- round(means$sizeblock, 2)
pdf(file = "data/Jackson_Lab_12_batches/boxplot_mean_recomb_block_size.pdf", height = 8, width = 10)
p1 <- ggplot(recom_block, aes(x=ngen, y=sizeblock, group = ngen, fill = ngen)) +
geom_boxplot(show.legend = F , outlier.size = 0.5, notchwidth = 3) +
scale_x_discrete(drop=FALSE, breaks = c(21:23,NA,25,rep(NA,3),29:36)) +
scale_fill_brewer(palette="RdBu") +
geom_text(data = means, alpha = 0.85, aes(label = sizeblock, y = sizeblock + 0.15 )) +
ylab("Recombination Block Size (Mb)") +
xlab("Generation") +
labs(fill = "") +
#ylim(c(0, 60)) +
scale_y_continuous(breaks=c(0,5,10, 20, 40, 60), limits=c(0, 60)) +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
text = element_text(size=16),
axis.title=element_text(size=16)) +
guides(shape = guide_legend(override.aes = list(size = 12)))
p1Warning in RColorBrewer::brewer.pal(n, pal): n too large, allowed maximum for palette RdBu is 11
Returning the palette you asked for with that many colorsdev.off()png
2 p1Warning in RColorBrewer::brewer.pal(n, pal): n too large, allowed maximum for palette RdBu is 11
Returning the palette you asked for with that many colors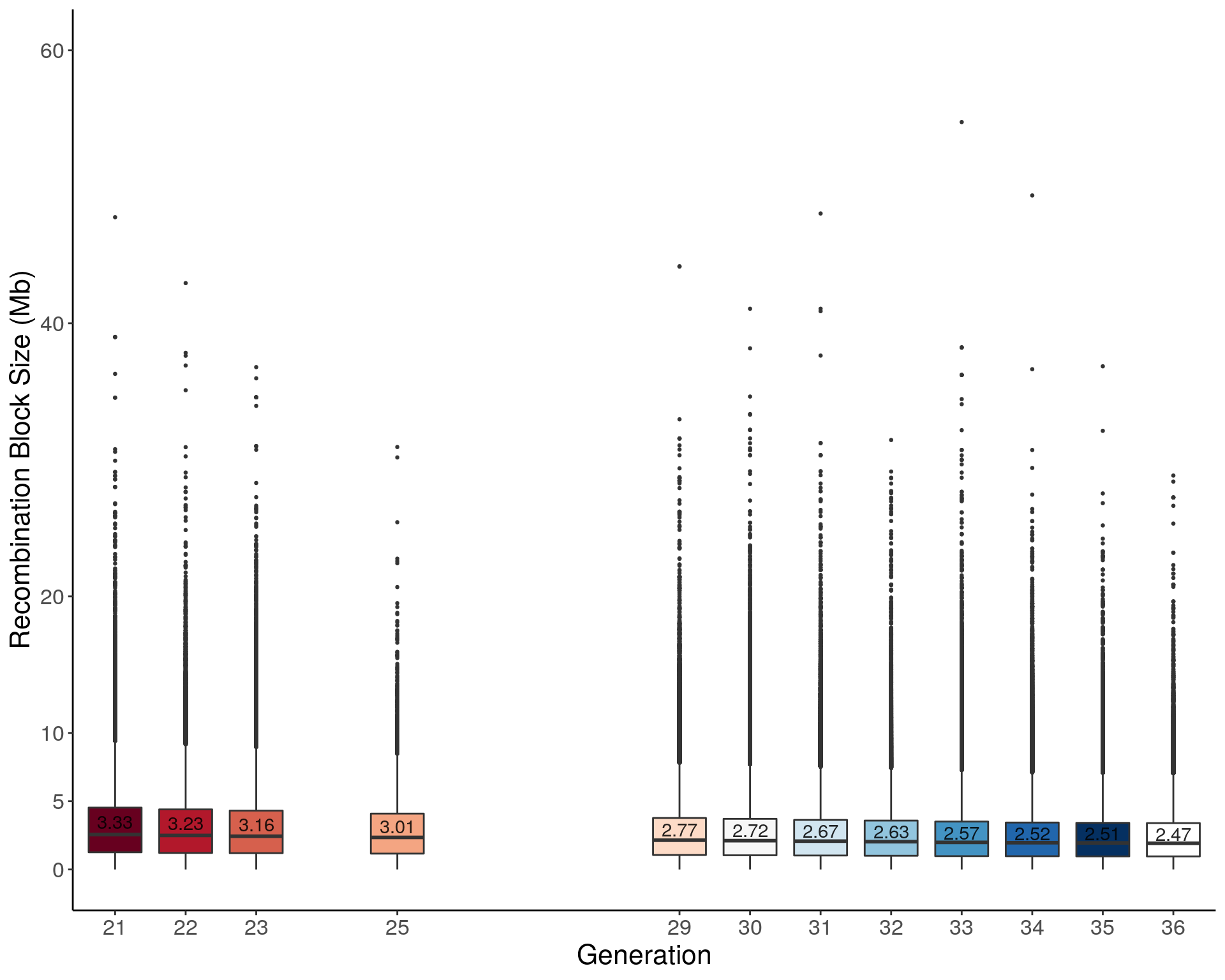
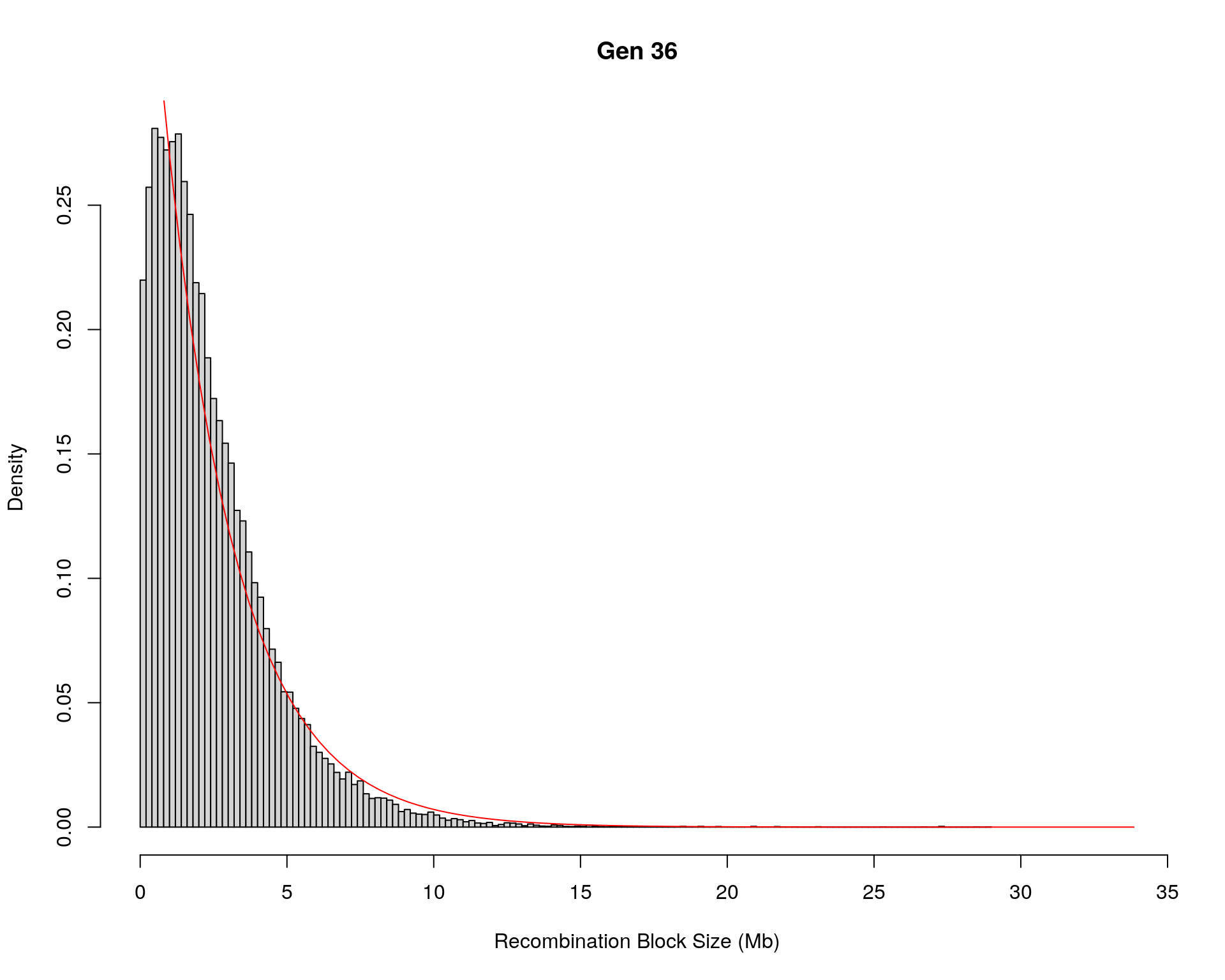
#block size distribution
for(g in unique(gm_after_qc$covar$ngen)){
#plot for recom block size
#png(paste0("data/Jackson_Lab_12_batches/DO_recom_block_size_G", g, ".png"))
x <- pos_ind_gen[[g]][pos_ind_gen[[g]] != 0]
# estimate the parameters
fit1 <- fitdistr(x, "exponential")
# goodness of fit test
ks.test(x, "pexp", fit1$estimate) # p-value > 0.05 -> distribution not refused
# plot a graph
hist(x,
freq = FALSE,
breaks = 200,
xlim = c(0, 5+quantile(x, 1)),
#ylim = c(0,0.3),
xlab = "Recombination Block Size (Mb)",
main = paste0("Gen ", g))
curve(dexp(x, rate = fit1$estimate),
from = 0,
to = 5+quantile(x, 1),
col = "red",
add = TRUE)
#dev.off()
}Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov testWarning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test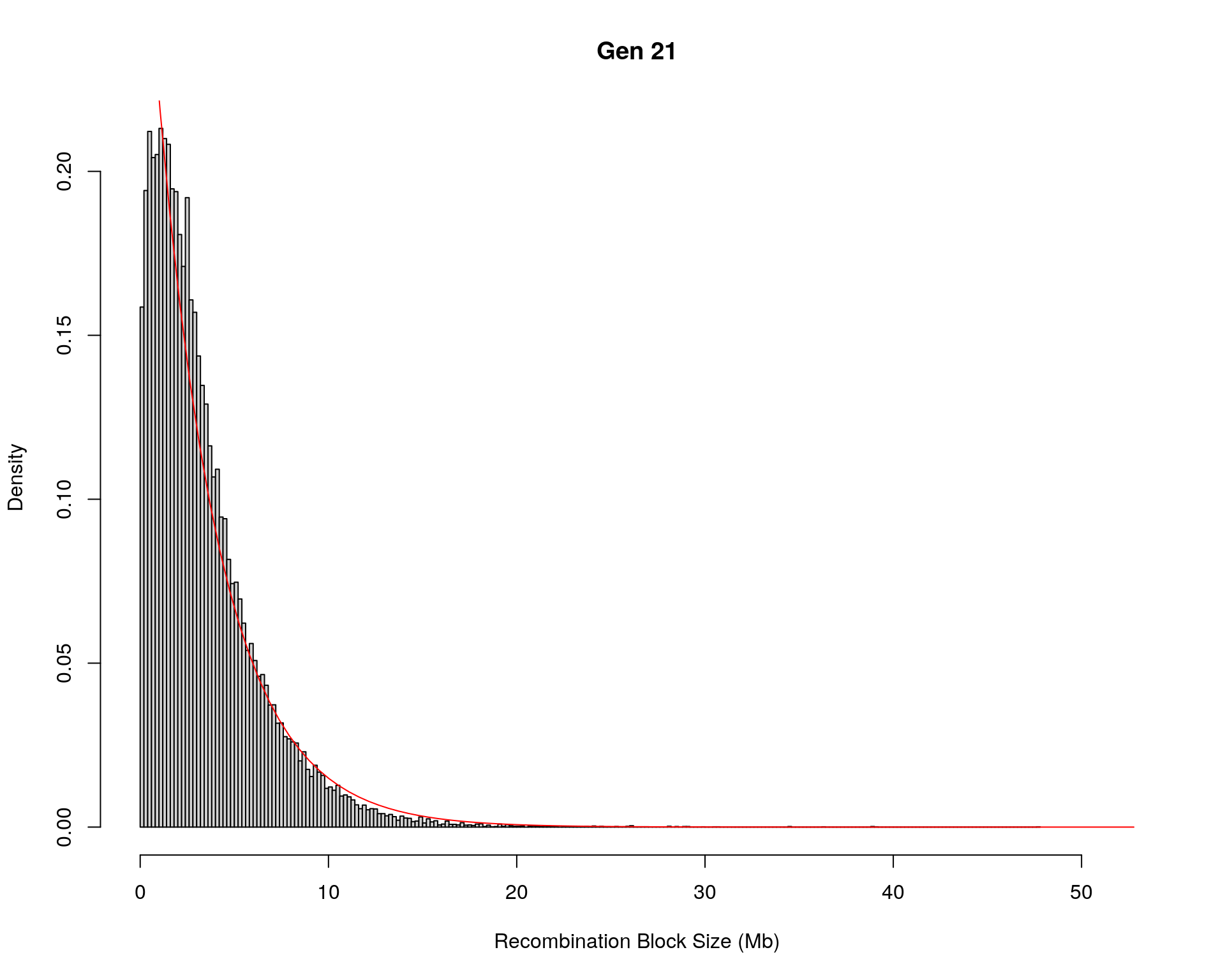
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test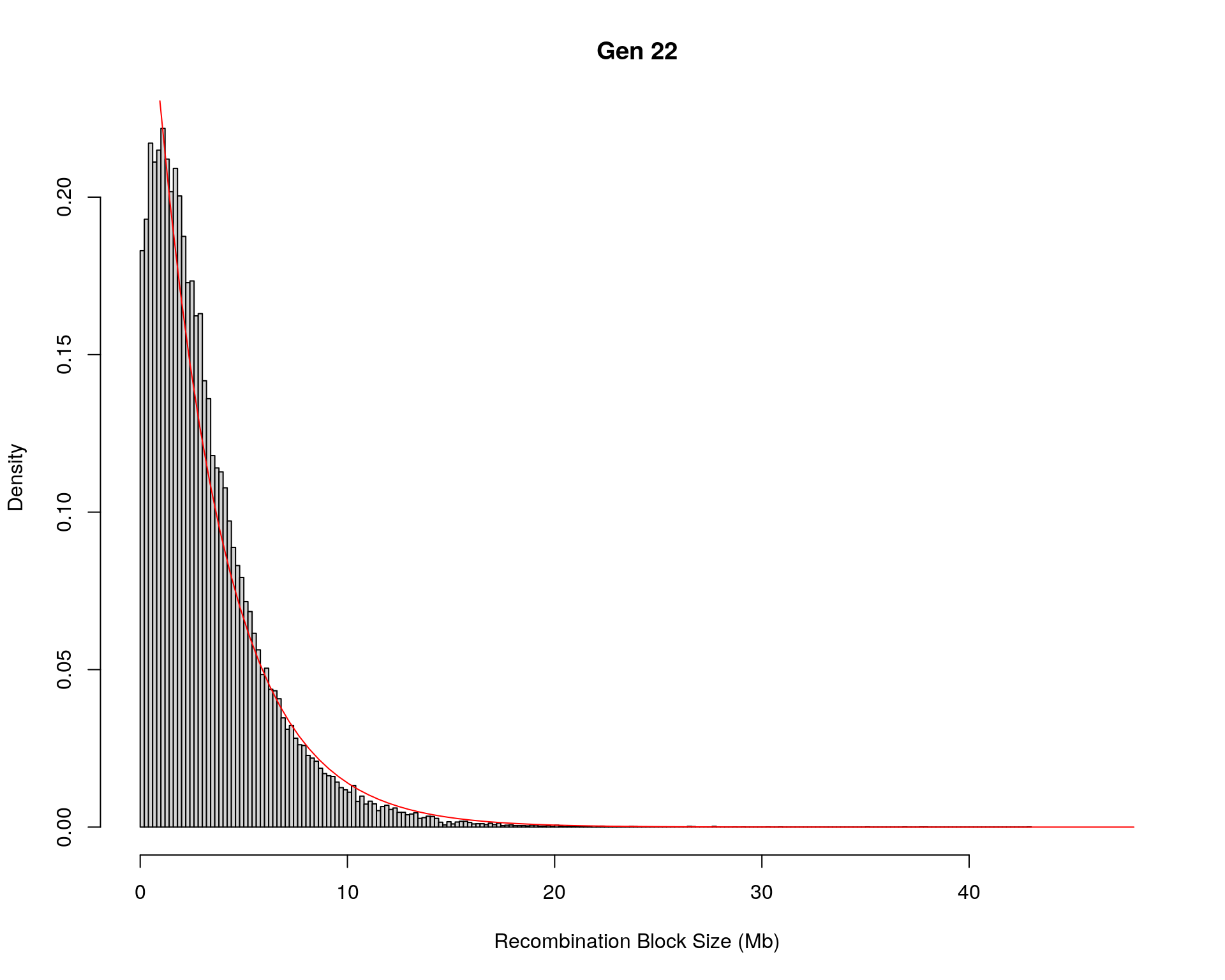
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test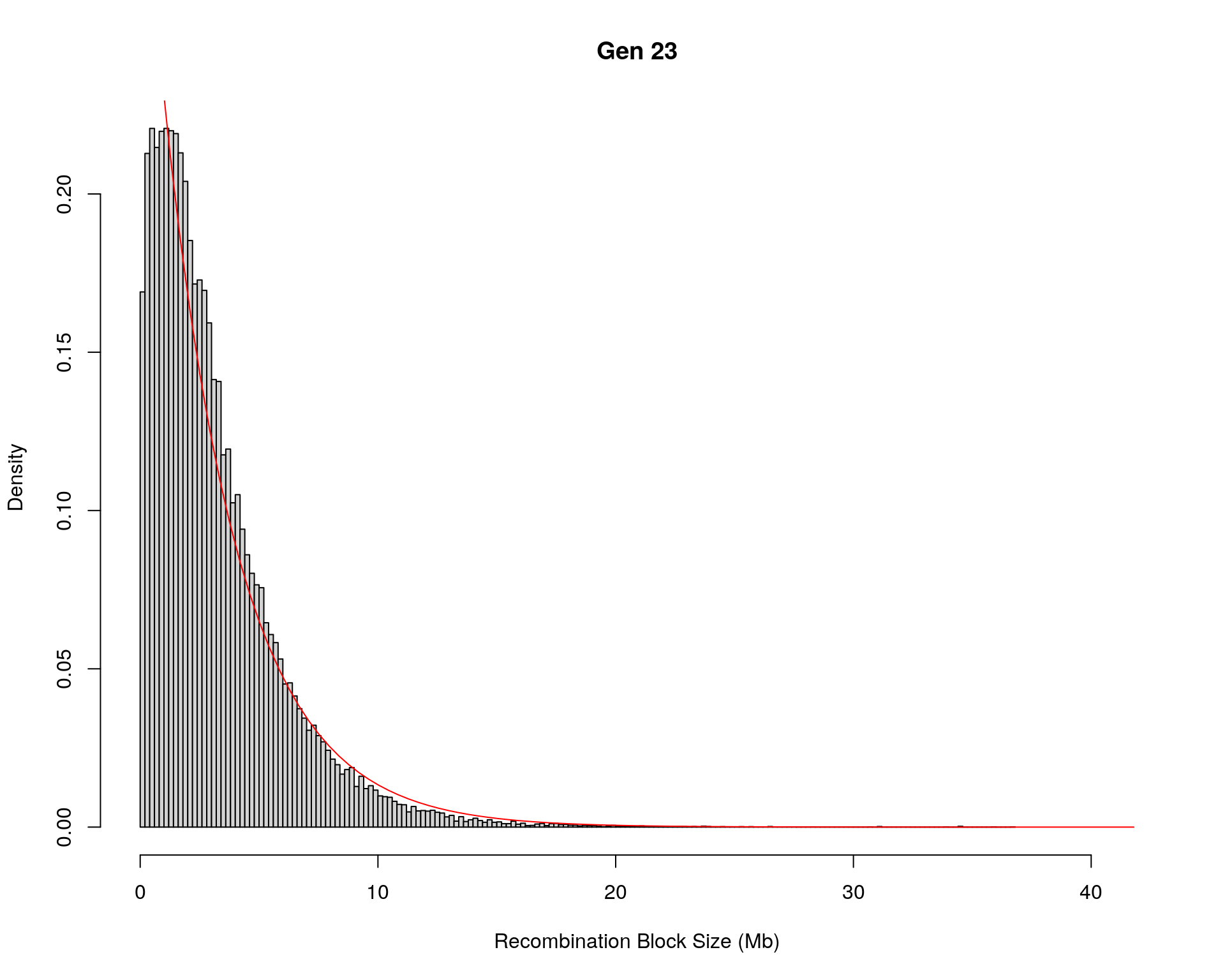
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test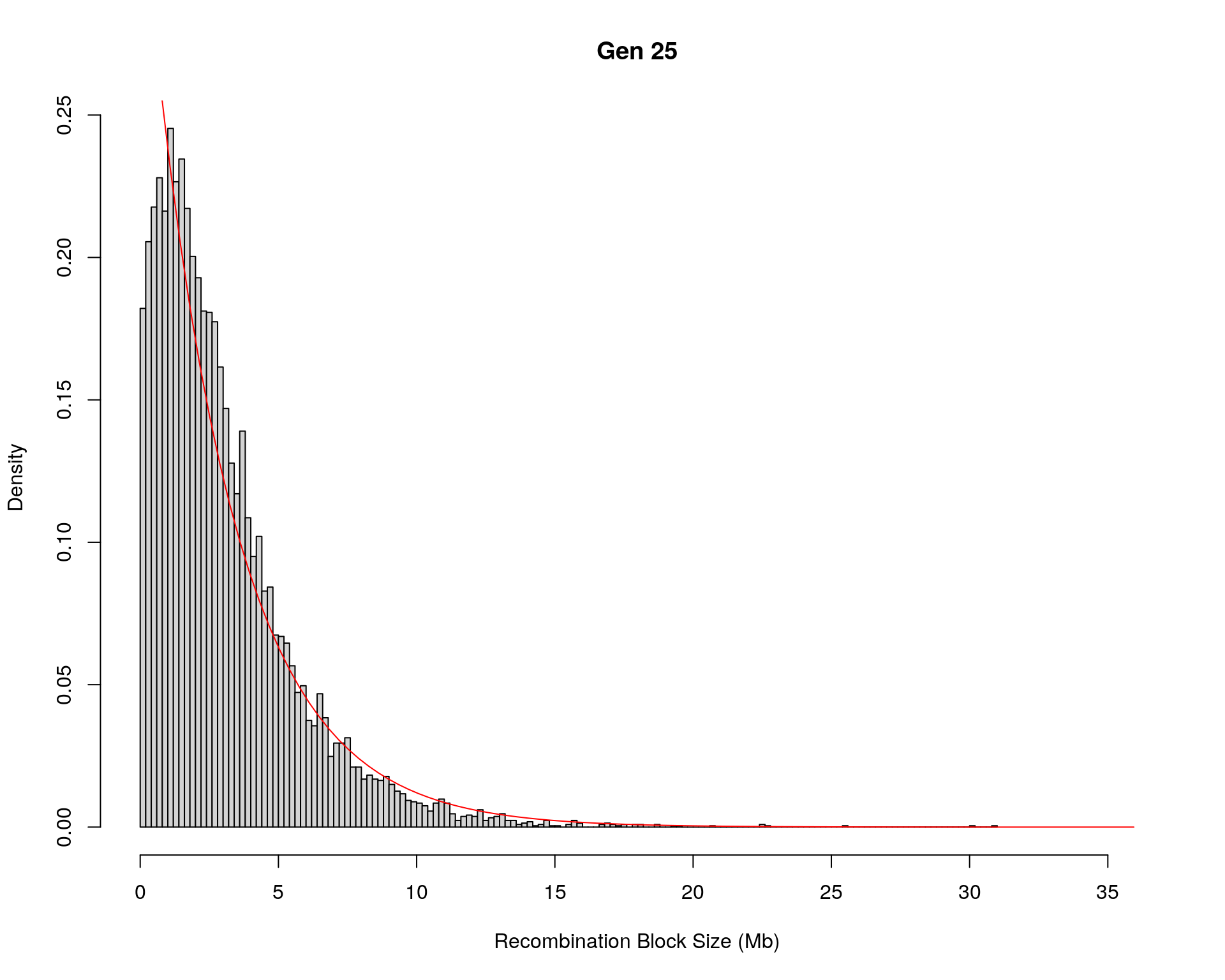
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test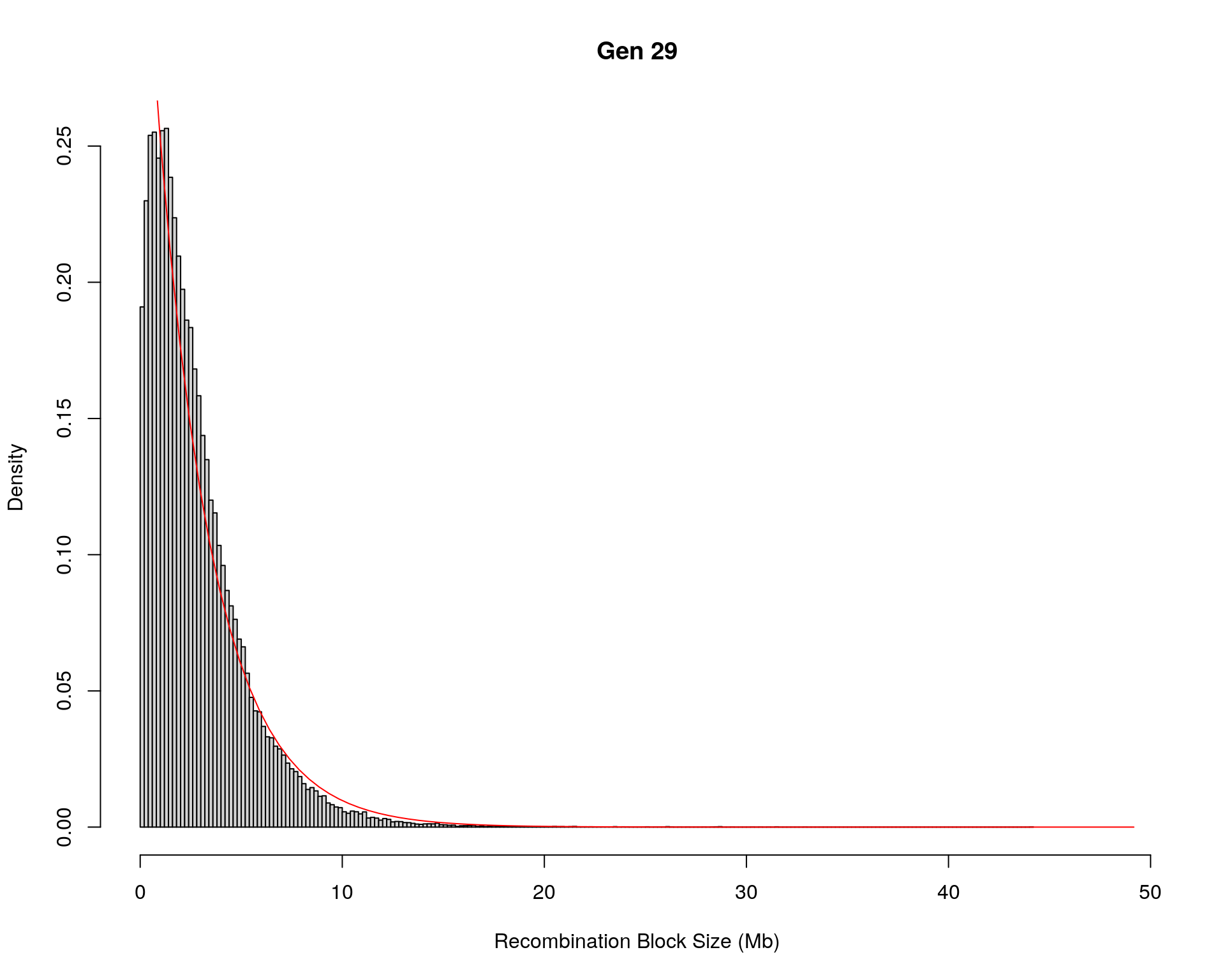
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test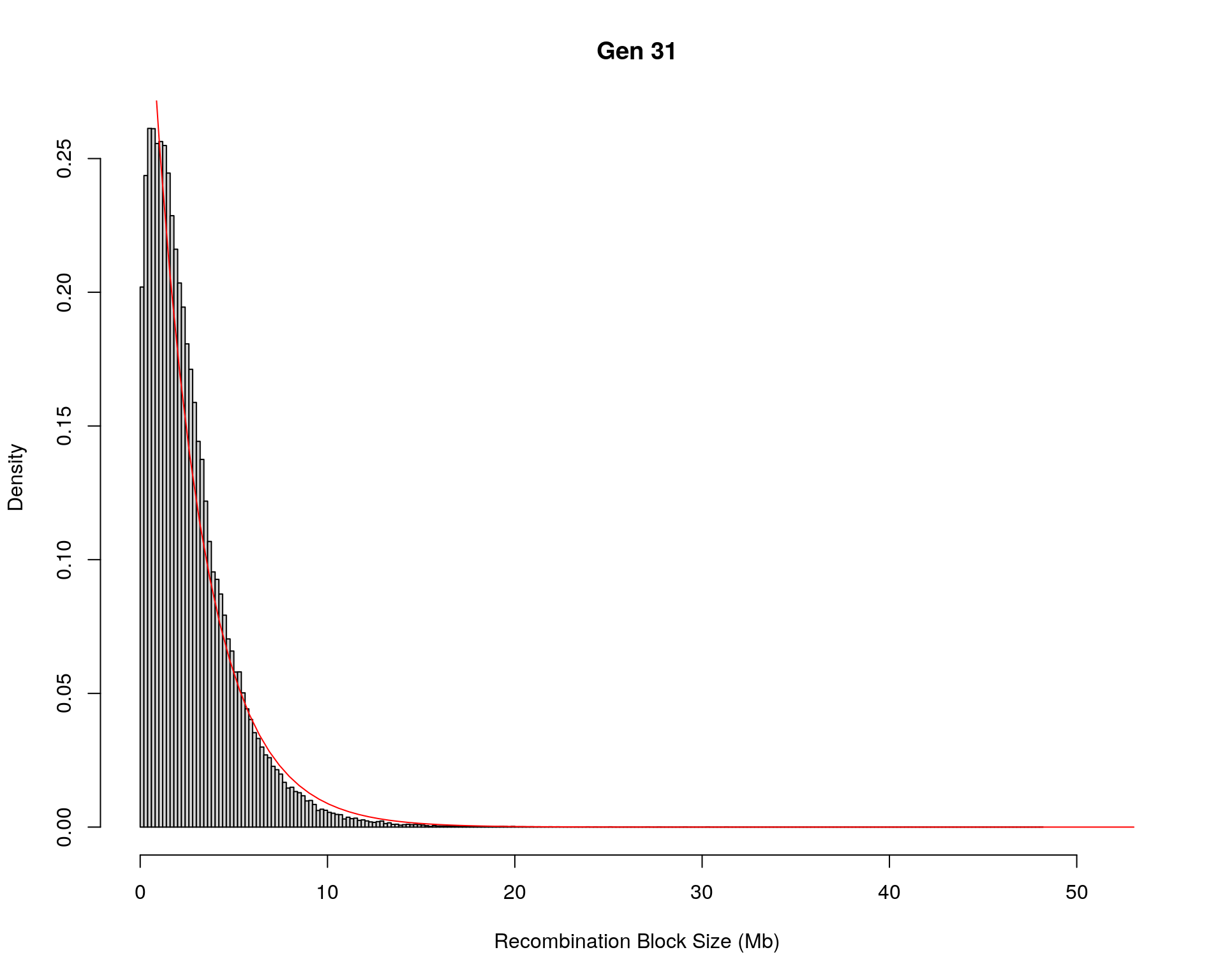
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test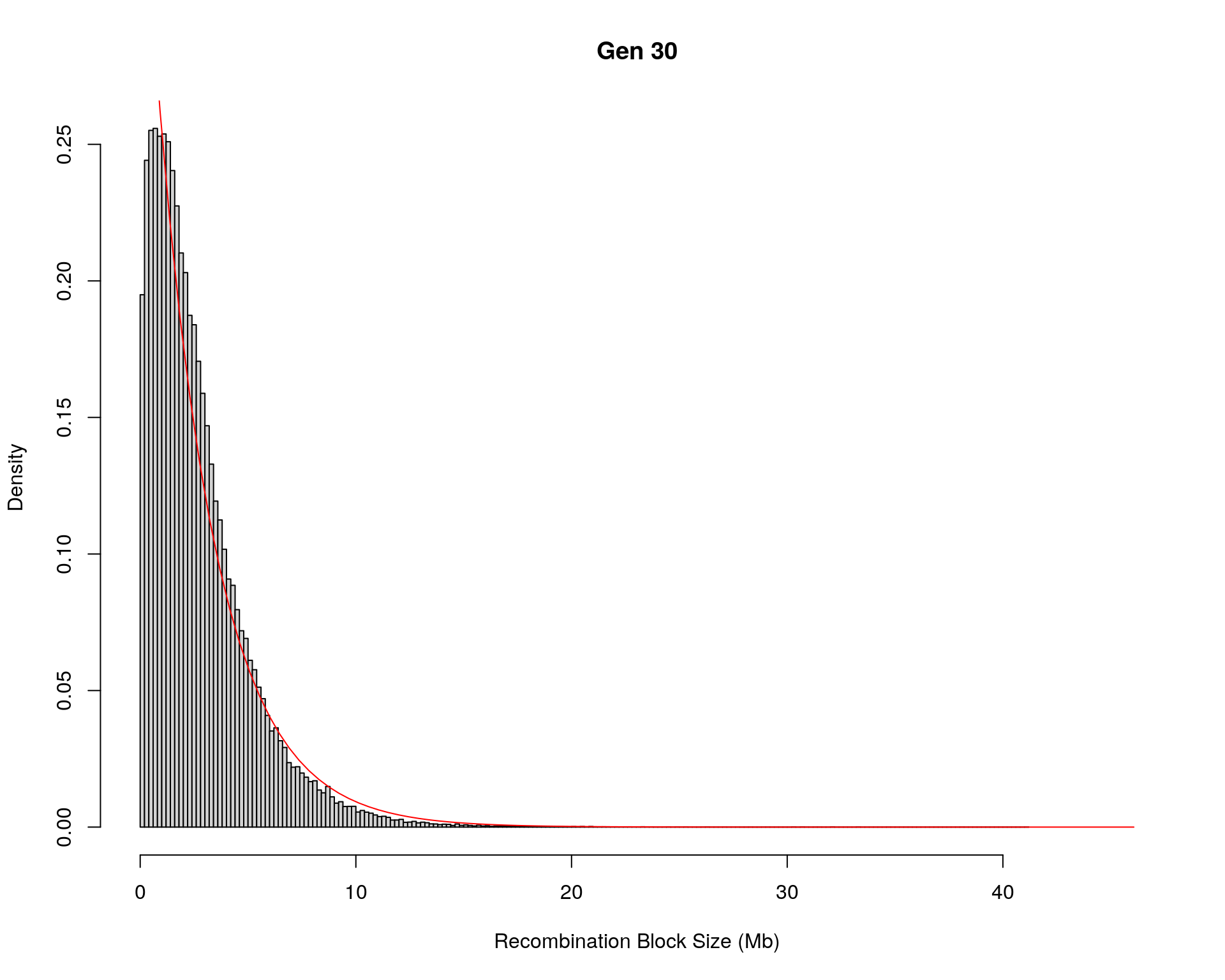
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test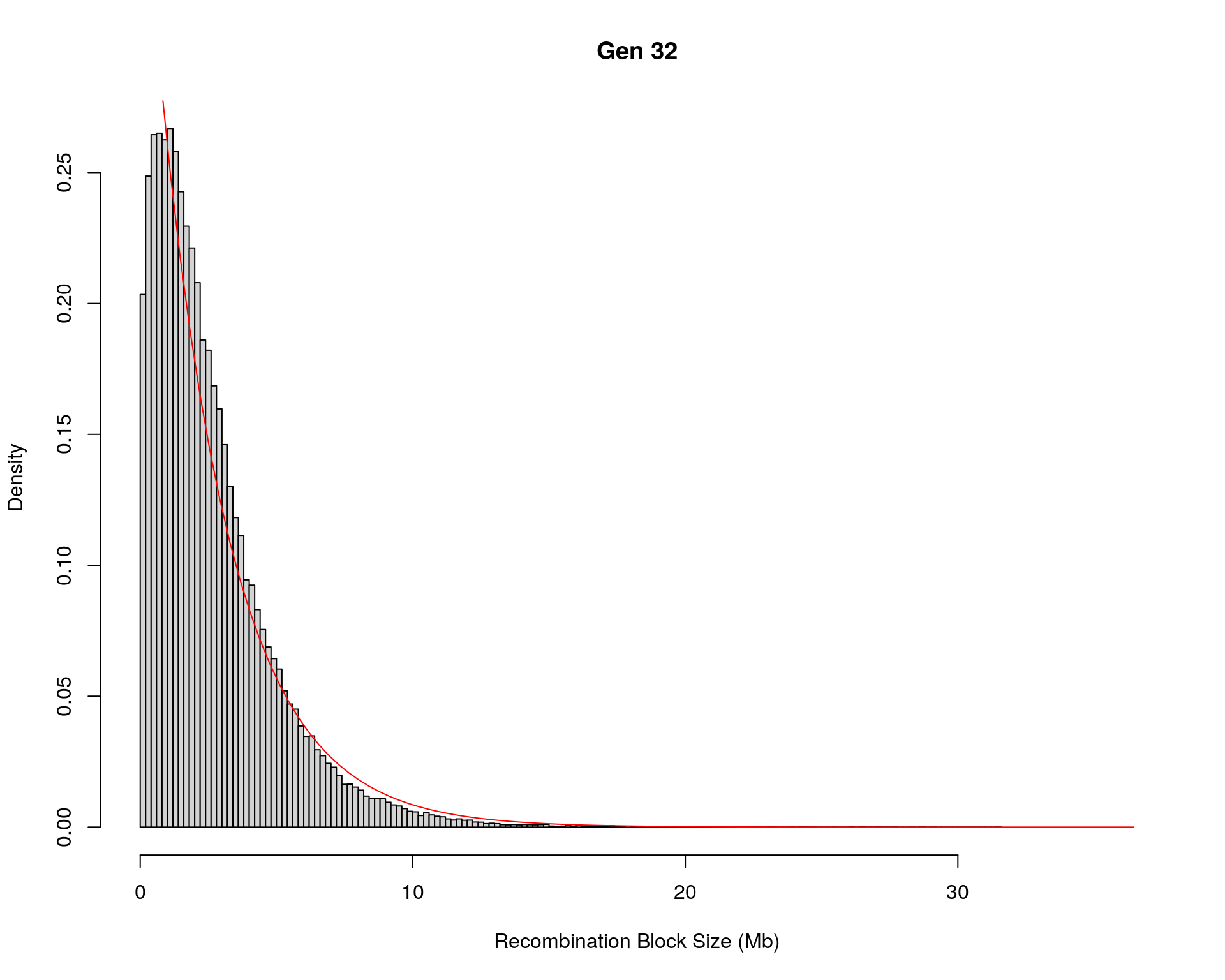
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test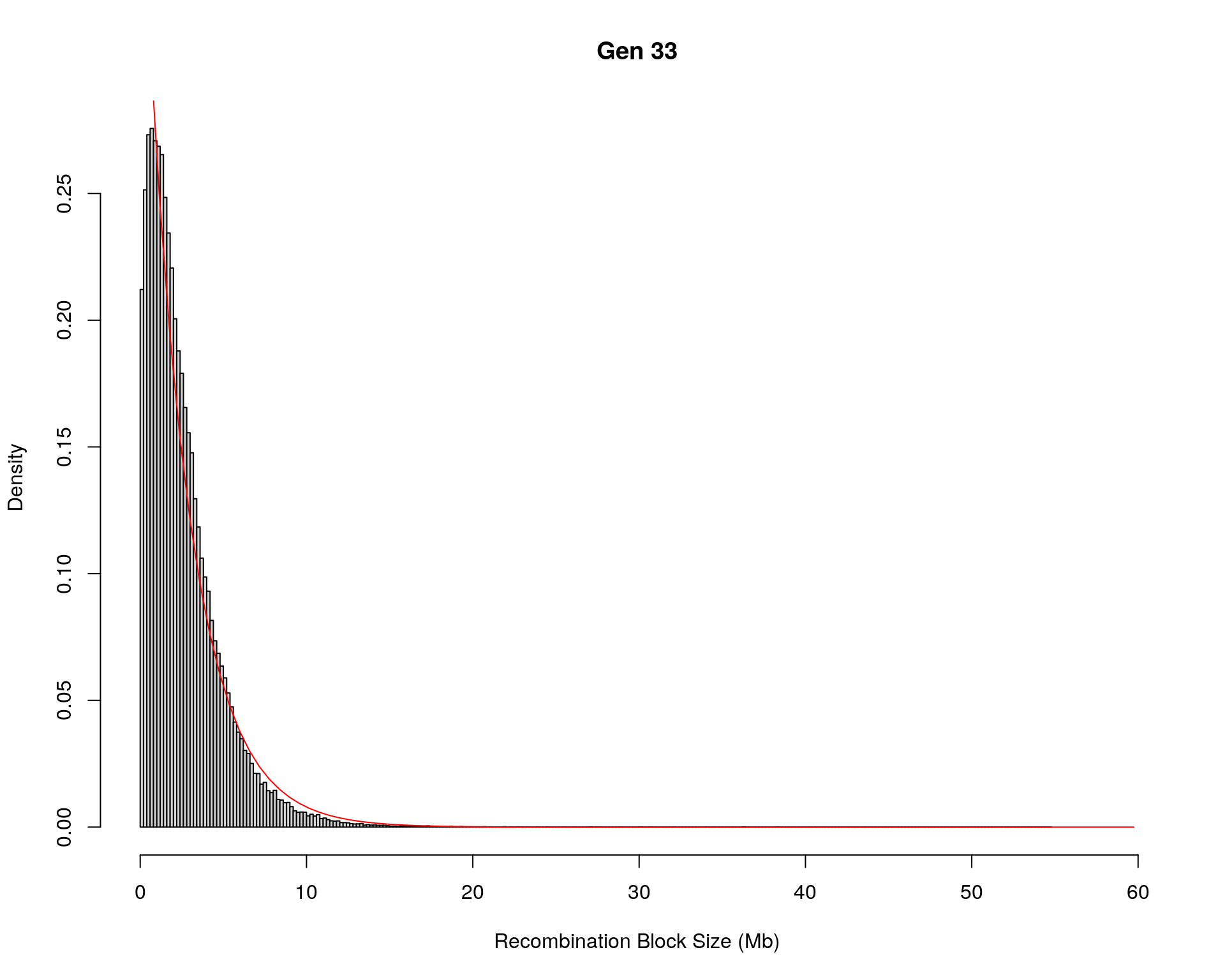
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test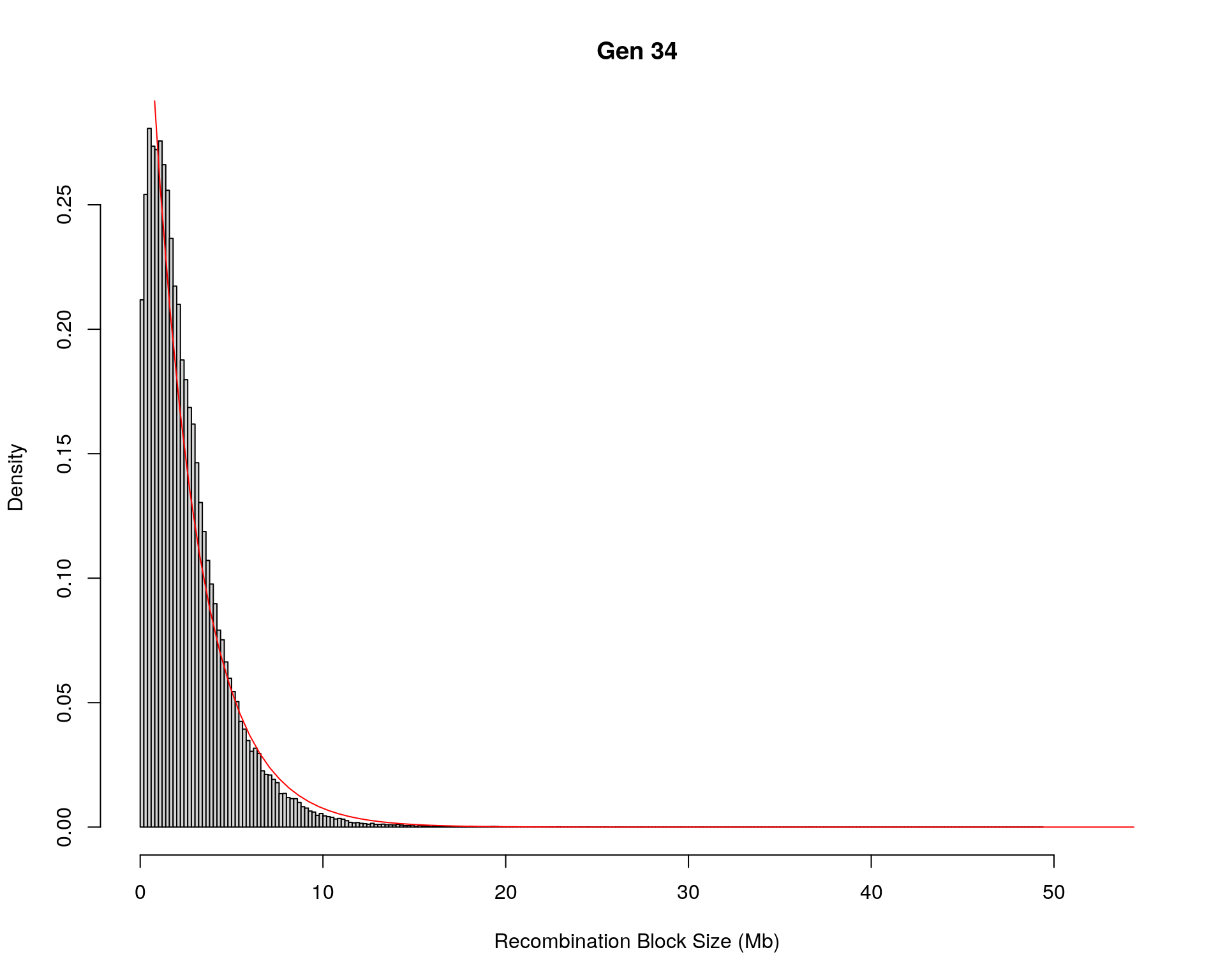
Warning in ks.test(x, "pexp", fit1$estimate): ties should not be present for the
Kolmogorov-Smirnov test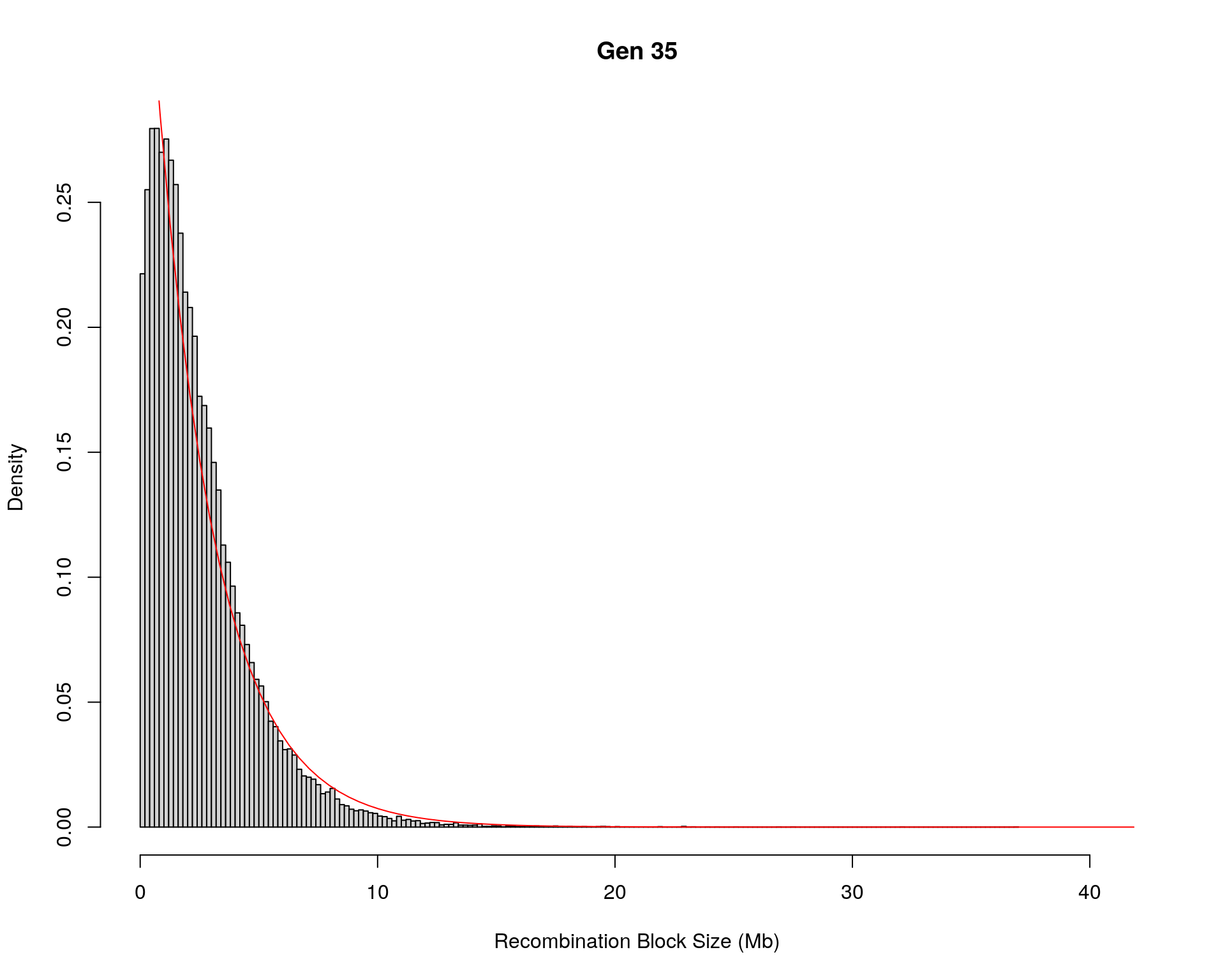
#Average heterozygosity value
load("data/Jackson_Lab_12_batches/dat_het_ind_pr.RData")
dat_het_ind_pr$ngen <- factor(dat_het_ind_pr$ngen, levels = as.character(c(21:36)))
pdf(paste("data/Jackson_Lab_12_batches/DO_Heterozygosity_value_violin_genoprops.pdf"), width = 10, height =8)
p2 <- ggplot(dat_het_ind_pr, aes(x=ngen, y=het, group=ngen, fill=ngen)) +
geom_violin(show.legend = FALSE) +
geom_boxplot(show.legend = FALSE, width=0.35, color="black", alpha=0.6) +
scale_x_discrete(drop=FALSE, breaks = c(21:23,NA,25,rep(NA,3),29:36)) +
scale_fill_brewer(palette="RdBu") +
ylab("Heterozygosity from genotype props") +
xlab("Generation") +
ylim(c(0.65, 1)) +
geom_hline(yintercept=0.875, linetype="dashed", color = "red") +
#scale_y_continuous(breaks=c(0.55, 0.65, 0.75, 0.85, 0.95, 1), limits=c(0.55, 1)) +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
text = element_text(size=16),
axis.title=element_text(size=16),
legend.title=element_blank())
p2Warning in RColorBrewer::brewer.pal(n, pal): n too large, allowed maximum for palette RdBu is 11
Returning the palette you asked for with that many colorsdev.off()png
2 p2Warning in RColorBrewer::brewer.pal(n, pal): n too large, allowed maximum for palette RdBu is 11
Returning the palette you asked for with that many colors
sessionInfo()R version 4.0.0 (2020-04-24)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 18.04.4 LTS
Matrix products: default
BLAS/LAPACK: /usr/lib/x86_64-linux-gnu/libopenblasp-r0.2.20.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=C
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] grid parallel stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] plotly_4.9.2.1 MASS_7.3-51.6 vcd_1.4-8 ggplot2_3.3.2
[5] lme4_1.1-23 Matrix_1.2-18 regress_1.3-21 gap_1.2.2
[9] abind_1.4-5 doParallel_1.0.15 iterators_1.0.12 foreach_1.5.0
[13] data.table_1.12.8 dplyr_1.0.0 tidyr_1.1.0 table1_1.2
[17] qtl2_0.22-8 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.4.6 lattice_0.20-41 zoo_1.8-8 rprojroot_1.3-2
[5] digest_0.6.25 lmtest_0.9-38 R6_2.4.1 backports_1.1.6
[9] RSQLite_2.2.0 evaluate_0.14 httr_1.4.1 pillar_1.4.4
[13] rlang_0.4.6 lazyeval_0.2.2 minqa_1.2.4 whisker_0.4
[17] nloptr_1.2.2.2 blob_1.2.1 rmarkdown_2.5 labeling_0.4.2
[21] splines_4.0.0 statmod_1.4.34 stringr_1.4.0 htmlwidgets_1.5.1
[25] bit_1.1-15.2 munsell_0.5.0 compiler_4.0.0 httpuv_1.5.4
[29] xfun_0.13 pkgconfig_2.0.3 htmltools_0.4.0 tidyselect_1.1.0
[33] tibble_3.0.1 codetools_0.2-16 viridisLite_0.3.0 crayon_1.3.4
[37] withr_2.2.0 later_1.0.0 jsonlite_1.6.1 nlme_3.1-147
[41] gtable_0.3.0 lifecycle_0.2.0 DBI_1.1.0 git2r_0.27.1
[45] magrittr_1.5 scales_1.1.1 stringi_1.4.6 farver_2.0.3
[49] fs_1.4.1 promises_1.1.0 ellipsis_0.3.0 generics_0.0.2
[53] vctrs_0.3.1 boot_1.3-25 Formula_1.2-4 RColorBrewer_1.1-2
[57] tools_4.0.0 bit64_0.9-7 glue_1.4.0 purrr_0.3.4
[61] yaml_2.2.1 colorspace_1.4-1 memoise_1.1.0 knitr_1.28