Step 1: Sample QC [4.batches]
Belinda Cornes
2022-02-10
Last updated: 2022-02-10
Checks: 6 1
Knit directory: Serreze-T1D_Workflow/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20220210) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Using absolute paths to the files within your workflowr project makes it difficult for you and others to run your code on a different machine. Change the absolute path(s) below to the suggested relative path(s) to make your code more reproducible.
| absolute | relative |
|---|---|
| /Users/corneb/Documents/MyJax/CS/Projects/Serreze/qc/workflowr/Serreze-T1D_Workflow | . |
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version d199bd4. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Untracked files:
Untracked: analysis/0.1.1_preparing.data_bqc_4batches.Rmd
Untracked: analysis/2.1_sample_bqc_3.batches.Rmd
Untracked: analysis/2.4_preparing.data_aqc_4batches.Rmd
Untracked: analysis/4.1.1_qtl.analysis_binary_ici.vs.eoi.Rmd
Untracked: analysis/4.1.1_qtl.analysis_binary_ici.vs.pbs.Rmd
Untracked: analysis/4.1.2_qtl.analysis_cont_age_ici.vs.eoi.Rmd
Untracked: analysis/4.1.2_qtl.analysis_cont_age_ici.vs.pbs.Rmd
Untracked: analysis/4.1.2_qtl.analysis_cont_rzage_ici.vs.eoi.Rmd
Untracked: analysis/4.1.2_qtl.analysis_cont_rzage_ici.vs.pbs.Rmd
Untracked: data/GM_covar.csv
Untracked: data/bad_markers_all_4.batches.RData
Untracked: data/covar_cleaned_ici.vs.eoi.csv
Untracked: data/covar_cleaned_ici.vs.pbs.csv
Untracked: data/e.RData
Untracked: data/e_snpg_samqc_4.batches.RData
Untracked: data/e_snpg_samqc_4.batches_bc.RData
Untracked: data/errors_ind_4.batches.RData
Untracked: data/errors_ind_4.batches_bc.RData
Untracked: data/genetic_map.csv
Untracked: data/genotype_errors_marker_4.batches.RData
Untracked: data/genotype_freq_marker_4.batches.RData
Untracked: data/gm_allqc_4.batches.RData
Untracked: data/gm_samqc_3.batches.RData
Untracked: data/gm_samqc_4.batches.RData
Untracked: data/gm_samqc_4.batches_bc.RData
Untracked: data/gm_serreze.192.RData
Untracked: data/percent_missing_id_3.batches.RData
Untracked: data/percent_missing_id_4.batches.RData
Untracked: data/percent_missing_id_4.batches_bc.RData
Untracked: data/percent_missing_marker_4.batches.RData
Untracked: data/pheno.csv
Untracked: data/physical_map.csv
Untracked: data/qc_info_bad_sample_3.batches.RData
Untracked: data/qc_info_bad_sample_4.batches.RData
Untracked: data/qc_info_bad_sample_4.batches_bc.RData
Untracked: data/sample_geno.csv
Untracked: data/sample_geno_bc.csv
Untracked: data/serreze_probs.rds
Untracked: data/serreze_probs_allqc.rds
Untracked: data/summary.cg_3.batches.RData
Untracked: data/summary.cg_4.batches.RData
Untracked: data/summary.cg_4.batches_bc.RData
Unstaged changes:
Modified: analysis/_site.yml
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/2.1_sample_bqc_4.batches.Rmd) and HTML (docs/2.1_sample_bqc_4.batches.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | d199bd4 | Belinda Cornes | 2022-02-10 | QC analysis |
This script is running genotype QC on raw data (with some outcomes already seen in the project at a glace). Here, we first load the R/qtl2 package and the data. We’ll also load the R/broman package for some utilities and plotting functions, and R/qtlcharts for interactive graphs.
We will follow the steps by Karl Broman found here
Loading Project
gm <- get(load("/Users/corneb/Documents/MyJax/CS/Projects/Serreze/haplotype.reconstruction/output_hh/gm_serreze.192.RData"))
gmObject of class cross2 (crosstype "bc")
Total individuals 192
No. genotyped individuals 192
No. phenotyped individuals 192
No. with both geno & pheno 192
No. phenotypes 1
No. covariates 6
No. phenotype covariates 0
No. chromosomes 20
Total markers 133716
No. markers by chr:
1 2 3 4 5 6 7 8 9 10 11 12 13
10159 10172 7987 7736 7778 7911 7548 6561 6823 6472 7276 6226 6177
14 15 16 17 18 19 X
6082 5421 5075 5161 4682 3612 4857 sample_file <- dir(path = filepaths, pattern = "^DODB_*", full.names = TRUE)
samples <- read.csv(sample_file)
all.equal(as.character(ind_ids(gm)), as.character(samples$Original.Mouse.ID))[1] TRUEMissing Data
percent_missing <- n_missing(gm, "ind", "prop")*100
#labels <- paste0(as.character(do.call(rbind.data.frame, strsplit(names(percent_missing), "_"))[,7]), " (", round(percent_missing,2), "%)")
labels <- paste0(names(percent_missing), " (", round(percent_missing,2), "%)")
iplot(seq_along(percent_missing), percent_missing, indID=labels,
chartOpts=list(xlab="Mouse", ylab="Percent missing genotype data",
ylim=c(0, 70)))Set screen size to height=700 x width=1000#save into pdf
pdf(file = "output/Percent_missing_genotype_data_4.batches.pdf", width = 20, height = 20)
#labels <- as.character(do.call(rbind.data.frame, strsplit(names(totxo), "V01_"))[,2])
#labels <- as.character(do.call(rbind.data.frame, strsplit(ind_ids(gm), "_"))[,7])
#labels <- paste0(names(percent_missing), " (", round(percent_missing,2), "%)")
labels <- ind_ids(gm)
labels[percent_missing < 10] = ""
# Change point shapes and colors
p <- ggplot(data = data.frame(Mouse=seq_along(percent_missing),
Percent_missing_genotype_data = percent_missing,
batch = factor(as.character(do.call(rbind.data.frame, strsplit(as.character(samples$Unique.Sample.ID), "_"))[,6]))
#batch = factor(as.character(do.call(rbind.data.frame, strsplit(as.character(samples$Directory), "_"))[,5]))
),
aes(x=Mouse, y=Percent_missing_genotype_data, color = batch)) +
geom_point() +
geom_hline(yintercept=10, linetype="solid", color = "red") +
geom_text_repel(aes(label=labels), vjust = 0, nudge_y = 0.01, show.legend = FALSE, size=3) +
theme(text = element_text(size = 10))
p
dev.off()quartz_off_screen
2 p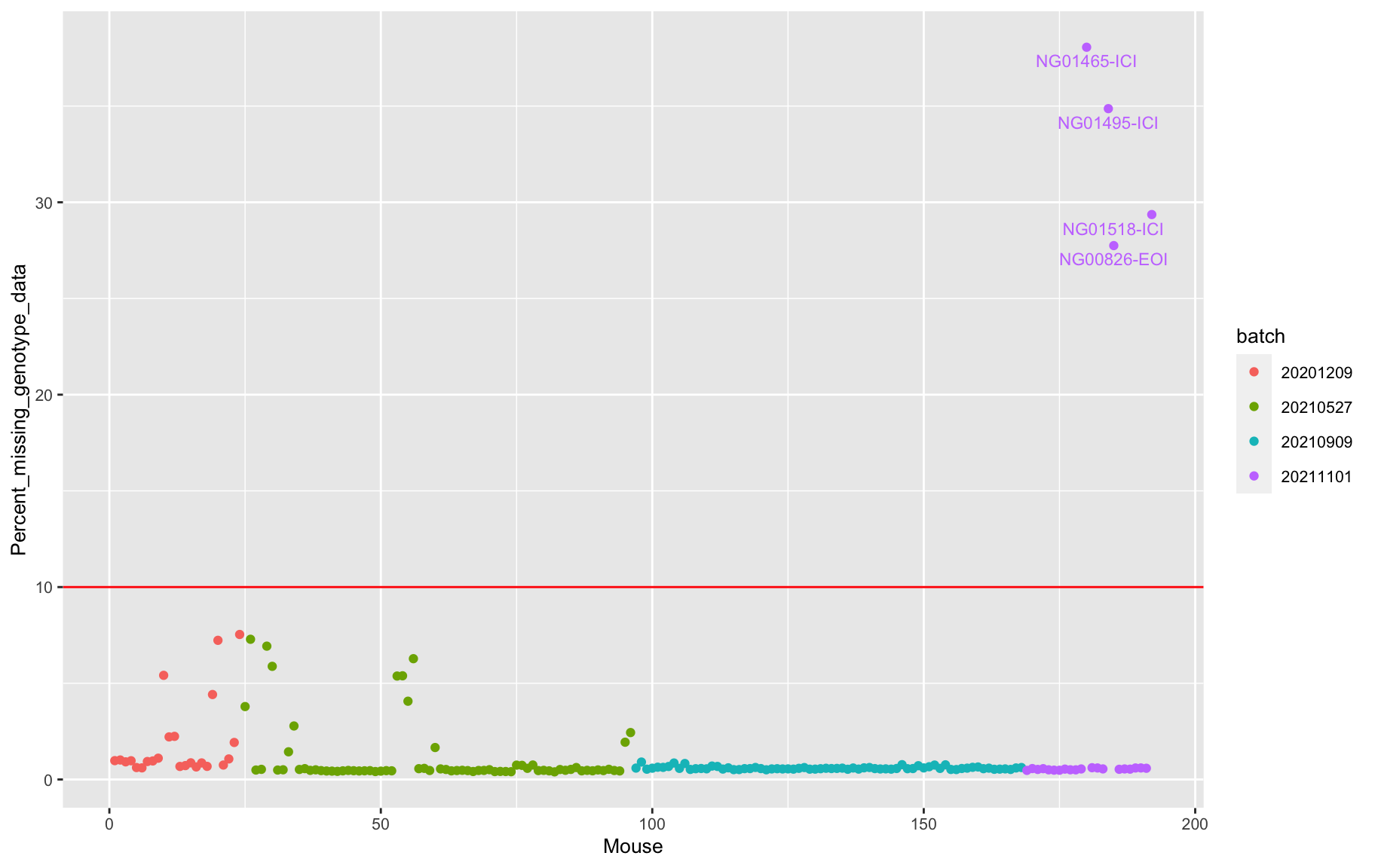
save(percent_missing,file = "data/percent_missing_id_4.batches.RData")
gm.covar = data.frame(id=rownames(gm$covar),gm$covar)
qc_info_cr <- merge(gm.covar,
data.frame(id = names(percent_missing),percent_missing = percent_missing,stringsAsFactors = F),by = "id")
bad.sample.cr <- qc_info_cr[qc_info_cr$percent_missing >= 10,]| Sample_ID | percent_missing |
|---|---|
| NG00826-EOI | 27.7483622004846 |
| NG01465-ICI | 38.0582727571869 |
| NG01495-ICI | 34.8671811899847 |
| NG01518-ICI | 29.3622303987556 |
Sex
hdf5_filename <- dir(path = filepaths, pattern = "^hdf5_*", full.names = TRUE)
snps_file <- "/Users/corneb/Documents/MyJax/CS/Projects/support.files/MUGAarrays/UWisc/gm_uwisc_v1.csv"
snps <- read.csv(snps_file)
snps <- snps[snps$unique == TRUE, ]
#snps <- snps[snps$chr %in% c(1:19, "X"), ]
snps$chr <- sub("^chr", "", snps$chr) ###remove prefix "chr"
colnames(snps)[colnames(snps)=="bp_mm10"] <- "pos"
colnames(snps)[colnames(snps)=="cM_cox"] <- "cM"
snps <- snps %>% drop_na(chr, marker)
snps$pos <- snps$pos * 1e-6
rownames(snps) <- snps$marker
colnames(snps)[1:4] <- c("marker", "chr", "pos", "pos")
# g <- h5read(hdf5_filename, "G")
# g <- do.call(cbind, g)
x <- h5read(hdf5_filename, "X") # X channel intensities
x <- do.call(cbind, x)
y <- h5read(hdf5_filename, "Y") # Y channel intensities
y <- do.call(cbind, y)
rn <- h5read(hdf5_filename, "rownames")[[1]] # markers
cn <- h5read(hdf5_filename, "colnames") # samples
cn <- do.call(c, cn)
# dimnames(g) <- list(rn, cn)
dimnames(x) <- list(rn, cn)
dimnames(y) <- list(rn, cn)
#cr <- colMeans(g != "--") # Call rate for each sample avg 0.95
# sex <- determine_sex(x = x, y = y, markers = snps)$se
markers <- snps
chrx <- markers$marker[which(markers$chr == "X")]
chry <- markers$marker[which(markers$chr == "Y")]
#x[chrx,ind_ids(gm)]
chrx_int <- colMeans(x[chrx,as.character(ind_ids(gm))] + y[chrx,as.character(ind_ids(gm))], na.rm = T)
chry_int <- colMeans(x[chry,as.character(ind_ids(gm))] + y[chry,as.character(ind_ids(gm))], na.rm = T)
all.equal(as.character(ind_ids(gm)), as.character(samples$Original.Mouse.ID))[1] TRUE#sex order
samples$Sex <- 'F'
sex <- samples$Sex
point_colors <- as.character( brocolors("web")[c("green", "purple")] )
percent_missing <- n_missing(gm, summary="proportion")*100
labels <- paste0(names(chrx_int), " (", round(percent_missing), "%)")
iplot( chrx_int, chry_int, group=sex, indID=labels,
chartOpts=list(pointcolor=point_colors, pointsize=4,
xlab="Average X chr intensity", ylab="Average Y chr intensity"))For figures above and below, those labelled as female in metadata given, are coloured green, with those labelled as male are coloured as purple. The above is an interactive scatterplot of the average SNP intensity on the Y chromosome versus the average SNP intensity on the X chromosome.
phetX <- rowSums(gm$geno$X == 2)/rowSums(gm$geno$X != 0)
phetX <- phetX[as.character(ind_ids(gm)) %in% names(chrx_int)]
names(phetX) <- as.character(ind_ids(gm))
iplot(chrx_int, phetX, group=sex, indID=labels,
chartOpts=list(pointcolor=point_colors, pointsize=4,
xlab="Average X chr intensity", ylab="Proportion het on X chr"))In the above scatterplot, we show the proportion of hets vs the average intensity for the X chromosome SNPs. In calculating the proportion of heterozygous genotypes for the individuals, we look at X chromosome genotypes equal to 2 which corresponds to the heterozygote) relative to not being 0 (which is used to encode missing genotypes). The genotypes are arranged with rows being individuals and columns being markers.
The following are the mice that have had sex incorrectly assigned:
Sample Duplicates
cg <- compare_geno(gm, cores=10)
summary.cg <- summary(cg)Here is a histogram of the proportion of matching genotypes. The tick marks below the histogram indicate individual pairs.
save(summary.cg,file = "data/summary.cg_4.batches.RData")
pdf(file = "output/Proportion_matching_genotypes_before_removal_of_bad_samples_4.batches.pdf", width = 20, height = 20)
par(mar=c(5.1,0.6,0.6, 0.6))
hist(cg[upper.tri(cg)], breaks=seq(0, 1, length=201),
main="", yaxt="n", ylab="", xlab="Proportion matching genotypes")
rug(cg[upper.tri(cg)])
dev.off()quartz_off_screen
2 par(mar=c(5.1,0.6,0.6, 0.6))
hist(cg[upper.tri(cg)], breaks=seq(0, 1, length=201),
main="", yaxt="n", ylab="", xlab="Proportion matching genotypes")
rug(cg[upper.tri(cg)])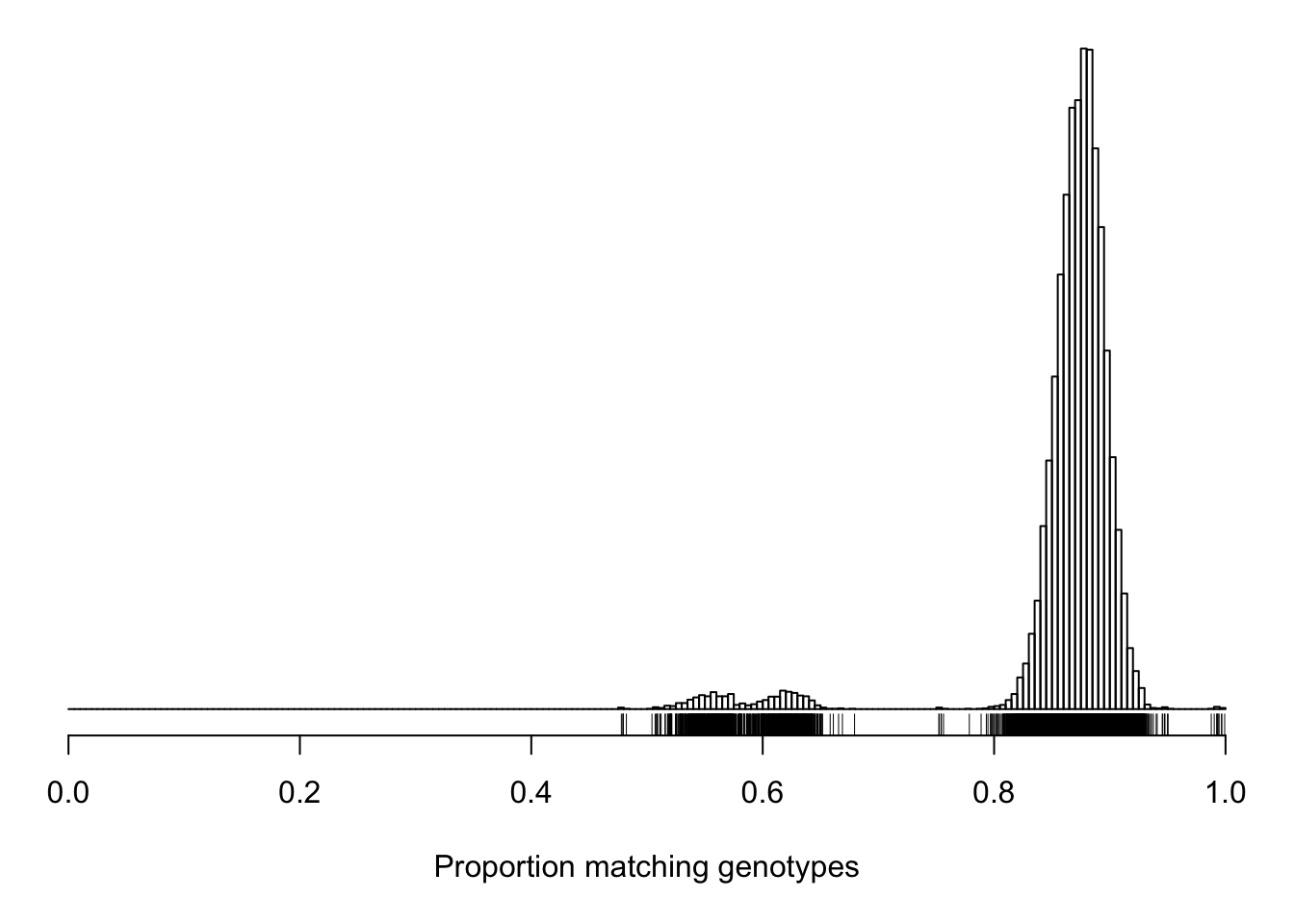
cgsub <- cg[percent_missing < 10, percent_missing < 10]
par(mar=c(5.1,0.6,0.6, 0.6))
hist(cgsub[upper.tri(cgsub)], breaks=seq(0, 1, length=201),
main="", yaxt="n", ylab="", xlab="Proportion matching genotypes [percent missing < 10%]")
rug(cgsub[upper.tri(cgsub)])
Array Intensities
#load the intensities.fst_4.batches.RData
#load("data/intensities.fst_4.batches.RData")
xn <- x[,as.character(ind_ids(gm))]
xn <- xn[snps$marker,]
xnm <- rownames(xn)
yn <- y[,as.character(ind_ids(gm))]
yn <- yn[snps$marker,]
# bring together in one matrix
result <- cbind(snp=rep(snps$marker, 2),
channel=rep(c("x", "y"), each=length(snps$marker)),
as.data.frame(rbind(xn, yn)))
rownames(result) <- 1:nrow(result)
# bring SNP rows together
result <- result[as.numeric(t(cbind(seq_along(snps$marker), seq_along(snps$marker)+length(snps$marker)))),]
rownames(result) <- 1:nrow(result)
#load the intensities.fst_4.batches.RData
#load("data/heh/intensities.fst_4.batches.RData")
#X and Y channel
X <- result[result$channel == "x",]
rownames(X) <- X$snp
X <- X[,c(-1,-2)]
Y <- result[result$channel == "y",]
rownames(Y) <- Y$snp
Y <- Y[,c(-1,-2)]
int <- result
#int <- result
#rm(result)
int <- int[seq(1, nrow(int), by=2),-(1:2)] + int[-seq(1, nrow(int), by=2),-(1:2)]
int <- int[,intersect(as.character(ind_ids(gm)), colnames(int))]
names(percent_missing) <- as.character(names(percent_missing))
n <- names(sort(percent_missing[intersect(as.character(ind_ids(gm)), colnames(int))], decreasing=TRUE))
iboxplot(log10(t(int[,n])+1), orderByMedian=FALSE, chartOpts=list(ylab="log10(SNP intensity + 1)"))The arrays are sorted by the proportion of missing genotype data for the sample, and the curves connect various quantiles of the intensities.
qu <- apply(int, 2, quantile, c(0.01, 0.99), na.rm=TRUE)
group <- (percent_missing >= 19.97) + (percent_missing > 5) + (percent_missing > 2) + 1
labels <- paste0(colnames(qu), " (", round(percent_missing), "%)")
iplot(qu[1,], qu[2,], indID=labels, group=group,
chartOpts=list(xlab="1 %ile of array intensities",
ylab="99 %ile of array intensities",
pointcolor=c("#ccc", "slateblue", "Orchid", "#ff851b")))Genotyping Error LOD Scores
load("/Users/corneb/Documents/MyJax/CS/Projects/Serreze/haplotype.reconstruction/output_hh/e.RData")
errors_ind <- rowSums(e>2)[rownames(gm$covar)]/n_typed(gm)*100
lab <- paste0(as.character(names(errors_ind)), " (", myround(percent_missing[as.character(rownames(gm$covar))],1), "%)")
iplot(seq_along(errors_ind), errors_ind, indID=lab,
chartOpts=list(xlab="Mouse", ylab="Percent genotyping errors", ylim=c(0, 15),
axispos=list(xtitle=25, ytitle=50, xlabel=5, ylabel=5)))save(errors_ind, file = "data/errors_ind_4.batches.RData")Removing Samples
##percent missing
gm.covar = data.frame(id=as.character(rownames(gm$covar)),gm$covar)
qc_info <- merge(gm.covar,
data.frame(id = names(percent_missing),percent_missing = percent_missing,stringsAsFactors = F),by = "id")
#missing sex
#qc_info$sex.match <- ifelse(qc_info$sexp == qc_info$sex, TRUE, FALSE)
rownames(samples) <- as.character(samples$Original.Mouse.ID)
samples <- samples[as.character(qc_info$id),]
#samples$Unique.Sample.ID <- as.character(samples$Unique.Sample.ID)
all.equal(as.character(qc_info$id), as.character(samples$Original.Mouse.ID))[1] TRUEqc_info$sex.match <- ifelse(samples$Inferred.Sex == substring(samples$Sex, 1, 1), TRUE, FALSE)
#genotype errors
qc_info <- merge(qc_info,
data.frame(id = as.character(names(errors_ind)),
genotype_erros = errors_ind,stringsAsFactors = F),by = "id")
##duplicated id to be remove
qc_info$duplicate.id <- ifelse(qc_info$id %in% as.character(summary.cg$remove.id), TRUE,FALSE)
#bad.sample <- qc_info[qc_info$generation ==1 | qc_info$Number_crossovers <= 200 | qc_info$Number_crossovers >=1000 | qc_info$percent_missing >= 10 | qc_info$genotype_erros >= 1 | qc_info$remove.id.duplicated == TRUE,]
bad.sample <- qc_info[qc_info$percent_missing >= 10 | qc_info$genotype_erros >= 8,]
save(qc_info, bad.sample, file = "data/qc_info_bad_sample_4.batches.RData")
gm_samqc <- gm[paste0("-",as.character(bad.sample$id.1)),]
gm_samqcObject of class cross2 (crosstype "bc")
Total individuals 188
No. genotyped individuals 188
No. phenotyped individuals 188
No. with both geno & pheno 188
No. phenotypes 1
No. covariates 6
No. phenotype covariates 0
No. chromosomes 20
Total markers 133716
No. markers by chr:
1 2 3 4 5 6 7 8 9 10 11 12 13
10159 10172 7987 7736 7778 7911 7548 6561 6823 6472 7276 6226 6177
14 15 16 17 18 19 X
6082 5421 5075 5161 4682 3612 4857 save(gm_samqc, file = "data/gm_samqc_4.batches.RData")
# update other stuff
e <- e[ind_ids(gm_samqc),]
#g <- g[ind_ids(gm_samqc),]
#snpg <- snpg[ind_ids(gm_samqc),]
#save(e,g,snpg, file = "data/e_g_snpg_samqc_4.batches.RData")
save(e, file = "data/e_snpg_samqc_4.batches.RData")Here is the list of samples that were removed:
| Sample_ID |
|---|
| NG00826-EOI |
| NG01465-ICI |
| NG01495-ICI |
| NG01518-ICI |
Below is a table summarising the problematic samples found throughout QC. These include the following:
- no_pheno == sample does not have a phenotype (if applicable)
- high_miss == sample has higher than 10% missing genotypes
- diff_sex == sample has sex mismatch
- high_geno_errors == Sample has geno errors above 10%
- dublicate_ID == sample was duplicated (or highly concordant)
NB: For duplcate pairs, the one that was chosen to be removed was the one that had a higher missing rate
| Sample_ID | high_miss | diff_sex | high_geno.errors | highly_concordant |
|---|---|---|---|---|
| DF06129 | XX | |||
| LQ01806 | XX | |||
| LQ01807 | XX | |||
| ML00983 | XX | |||
| ML00984 | XX | |||
| NG00158 | XX | |||
| NG00160 | XX | |||
| NG00161 | XX | |||
| NG00165 | XX | |||
| NG00183 | XX | |||
| NG00186 | XX | |||
| NG00192 | XX | |||
| NG00197 | XX | |||
| NG00198-ICI-LATE | XX | |||
| NG00203 | XX | |||
| NG00205-PBS | XX | |||
| NG00218-EOI | XX | |||
| NG00239 | XX | |||
| NG00241-ICI | XX | |||
| NG00242-EOI | XX | |||
| NG00246-PBS | XX | |||
| NG00249-ICI | XX | |||
| NG00261 | XX | |||
| NG00269-EOI | XX | |||
| NG00290-PBS | XX | |||
| NG00292 | XX | |||
| NG00293-EOI | XX | |||
| NG00294-EOI | XX | |||
| NG00295 | XX | |||
| NG00296-EOI | XX | |||
| NG00298-PBS | XX | |||
| NG00302-EOI | XX | |||
| NG00303 | XX | |||
| NG00305-EOI | XX | |||
| NG00309-EOI | XX | |||
| NG00310-EOI | XX | |||
| NG00316-EOI | XX | |||
| NG00324-EOI | XX | |||
| NG00327-EOI | XX | |||
| NG00329-ICI-LATE | XX | |||
| NG00334 | XX | |||
| NG00343-ICI-LATE | XX | |||
| NG00345 | XX | |||
| NG00351-EOI | XX | |||
| NG00386-ICI-LATE | XX | |||
| NG00388-EOI | XX | |||
| NG00389-EOI | XX | |||
| NG00395 | XX | |||
| NG00396-EOI | XX | |||
| NG00432-PBS | XX | |||
| NG00440-EOI | XX | |||
| NG00442-ICI-LATE | XX | |||
| NG00443-ICI-LATE | XX | |||
| NG00446-EOI | XX | |||
| NG00450-EOI | XX | |||
| NG00451-EOI | XX | |||
| NG00452-EOI | XX | |||
| NG00453 | XX | |||
| NG00485 | XX | |||
| NG00494-ICI | XX | |||
| NG00497-EOI | XX | |||
| NG00498-ICI | XX | |||
| NG00499-EOI | XX | |||
| NG00507-PBS | XX | |||
| NG00522-ICI-LATE | XX | |||
| NG00524-ICI | XX | |||
| NG00526-ICI-LATE | XX | |||
| NG00527-EOI | XX | |||
| NG00530-EOI | XX | |||
| NG00532-EOI | XX | |||
| NG00534-EOI | XX | |||
| NG00538-PBS | XX | |||
| NG00548-PBS | XX | |||
| NG00551-ICI | XX | |||
| NG00561-PBS | XX | |||
| NG00565-EOI | XX | |||
| NG00566-EOI | XX | |||
| NG00567-EOI | XX | |||
| NG00577-ICI | XX | |||
| NG00578-EOI | XX | |||
| NG00579-EOI | XX | |||
| NG00586-PBS | XX | |||
| NG00606-PBS | XX | |||
| NG00617-EOI | XX | |||
| NG00626-EOI | XX | |||
| NG00628-EOI | XX | |||
| NG00629-EOI | XX | |||
| NG00630-ICI | XX | |||
| NG00638-PBS | XX | |||
| NG00647-PBS | XX | |||
| NG00654-EOI | XX | |||
| NG00657-EOI | XX | |||
| NG00659-EOI | XX | |||
| NG00662-ICI | XX | |||
| NG00664-EOI | XX | |||
| NG00665-EOI | XX | |||
| NG00673-PBS | XX | |||
| NG00674-PBS | XX | |||
| NG00686-PBS | XX | |||
| NG00695-EOI | XX | |||
| NG00696-EOI | XX | |||
| NG00698-ICI | XX | |||
| NG00699-EOI | XX | |||
| NG00736-EOI | XX | |||
| NG00738-EOI | XX | |||
| NG00777-ICI | XX | |||
| NG00779-ICI | XX | |||
| NG00781-EOI | XX | |||
| NG00783-EOI | XX | |||
| NG00790-ICI-LATE | XX | |||
| NG00791-EOI | XX | |||
| NG00792-EOI | XX | |||
| NG00793-EOI | XX | |||
| NG00794-EOI | XX | |||
| NG00795-EOI | XX | |||
| NG00796-ICI | XX | |||
| NG00797-ICI | XX | |||
| NG00798-EOI | XX | |||
| NG00815-PBS | XX | |||
| NG00826-EOI | XX | XX | ||
| NG00833-EOI | XX | |||
| NG00835-EOI | XX | |||
| NG00836-EOI | XX | |||
| NG00852-ICI | XX | |||
| NG00864-PBS | XX | |||
| NG00872-ICI | XX | |||
| NG00874-ICI-LATE | XX | |||
| NG00877-ICI | XX | |||
| NG00878-EOI | XX | |||
| NG00920-ICI | XX | |||
| NG00922-ICI | XX | |||
| NG00923-ICI | XX | |||
| NG00927-ICI | XX | |||
| NG00929-ICI-LATE | XX | |||
| NG00959-ICI | XX | |||
| NG00971-ICI | XX | |||
| NG00974-ICI | XX | |||
| NG00985-ICI | XX | |||
| NG00993-ICI | XX | |||
| NG01018-ICI | XX | |||
| NG01021-ICI | XX | |||
| NG01022-ICI | XX | |||
| NG01024-ICI | XX | |||
| NG01026-ICI | XX | |||
| NG01034-ICI | XX | |||
| NG01036-ICI | XX | |||
| NG01050-ICI | XX | |||
| NG01105-ICI | XX | |||
| NG01129-ICI | XX | |||
| NG01131-ICI | XX | |||
| NG01154-PBS | XX | |||
| NG01182-PBS | XX | |||
| NG01190-ICI | XX | |||
| NG01204-PBS | XX | |||
| NG01213-ICI | XX | |||
| NG01225-ICI-LATE | XX | |||
| NG01228-ICI | XX | |||
| NG01229-ICI | XX | |||
| NG01245-ICI | XX | |||
| NG01287-ICI | XX | |||
| NG01290-ICI | XX | |||
| NG01294-ICI | XX | |||
| NG01299-ICI | XX | |||
| NG01303-ICI-LATE | XX | |||
| NG01310-ICI | XX | |||
| NG01311-ICI | XX | |||
| NG01332-ICI | XX | |||
| NG01343-ICI | XX | |||
| NG01358-ICI | XX | |||
| NG01369-ICI | XX | |||
| NG01370-ICI | XX | |||
| NG01374-ICI | XX | |||
| NG01377-ICI | XX | |||
| NG01383-ICI | XX | |||
| NG01386-ICI | XX | |||
| NG01391-ICI | XX | |||
| NG01398-ICI | XX | |||
| NG01422-ICI | XX | |||
| NG01435-ICI | XX | |||
| NG01439-ICI | XX | |||
| NG01444-ICI | XX | |||
| NG01455-ICI | XX | |||
| NG01464-ICI | XX | |||
| NG01465-ICI | XX | XX | ||
| NG01483-ICI | XX | |||
| NG01493-ICI | XX | |||
| NG01495-ICI | XX | XX | ||
| NG01506-ICI | XX | |||
| NG01507-ICI | XX | |||
| NG01513-ICI | XX | |||
| NG01518-ICI | XX | XX |
sessionInfo()R version 3.6.2 (2019-12-12)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
locale:
[1] en_AU.UTF-8/en_AU.UTF-8/en_AU.UTF-8/C/en_AU.UTF-8/en_AU.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] readxl_1.3.1 cluster_2.1.0 dplyr_0.8.5 optparse_1.6.6
[5] rhdf5_2.28.1 tidyr_1.0.2 data.table_1.14.0 fst_0.9.2
[9] knitr_1.33 kableExtra_1.1.0 mclust_5.4.6 ggrepel_0.8.2
[13] ggplot2_3.3.5 qtlcharts_0.11-6 qtl2_0.22 broman_0.70-4
[17] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.7 assertthat_0.2.1 rprojroot_1.3-2 digest_0.6.27
[5] utf8_1.2.1 cellranger_1.1.0 R6_2.5.0 backports_1.2.1
[9] RSQLite_2.2.7 evaluate_0.14 httr_1.4.1 highr_0.9
[13] pillar_1.6.1 rlang_0.4.11 rstudioapi_0.13 whisker_0.4
[17] blob_1.2.1 rmarkdown_2.1 labeling_0.4.2 qtl_1.46-2
[21] webshot_0.5.2 readr_1.3.1 stringr_1.4.0 htmlwidgets_1.5.3
[25] bit_4.0.4 munsell_0.5.0 compiler_3.6.2 httpuv_1.5.2
[29] xfun_0.24 pkgconfig_2.0.3 htmltools_0.5.1.1 tidyselect_1.0.0
[33] tibble_3.1.2 fansi_0.5.0 viridisLite_0.4.0 crayon_1.4.1
[37] withr_2.4.2 later_1.0.0 grid_3.6.2 jsonlite_1.7.2
[41] gtable_0.3.0 lifecycle_1.0.0 DBI_1.1.1 git2r_0.26.1
[45] magrittr_2.0.1 scales_1.1.1 stringi_1.7.2 cachem_1.0.5
[49] farver_2.1.0 fs_1.4.1 promises_1.1.0 getopt_1.20.3
[53] xml2_1.3.1 ellipsis_0.3.2 vctrs_0.3.8 Rhdf5lib_1.6.3
[57] tools_3.6.2 bit64_4.0.5 glue_1.4.2 purrr_0.3.4
[61] hms_0.5.3 parallel_3.6.2 fastmap_1.1.0 yaml_2.2.1
[65] colorspace_2.0-2 rvest_0.3.5 memoise_2.0.0