Enrichment Analysis: Mutant Vs Wild-Type
Steve Pederson
28 January, 2020
Last updated: 2020-01-28
Checks: 7 0
Knit directory: 20170327_Psen2S4Ter_RNASeq/
This reproducible R Markdown analysis was created with workflowr (version 1.6.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200119) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 3a9933c | Steve Ped | 2020-01-28 | Finished Enrichment analysis on MutVsWt |
| html | 3a9933c | Steve Ped | 2020-01-28 | Finished Enrichment analysis on MutVsWt |
Setup
library(tidyverse)
library(magrittr)
library(edgeR)
library(scales)
library(pander)
library(goseq)
library(msigdbr)
library(AnnotationDbi)
library(RColorBrewer)
library(ngsReports)
library(fgsea)
library(metap)theme_set(theme_bw())
panderOptions("table.split.table", Inf)
panderOptions("table.style", "rmarkdown")
panderOptions("big.mark", ",")samples <- read_csv("data/samples.csv") %>%
distinct(sampleName, .keep_all = TRUE) %>%
dplyr::select(sample = sampleName, sampleID, genotype) %>%
mutate(
genotype = factor(genotype, levels = c("WT", "Het", "Hom")),
mutant = genotype %in% c("Het", "Hom"),
homozygous = genotype == "Hom"
)
genoCols <- samples$genotype %>%
levels() %>%
length() %>%
brewer.pal("Set1") %>%
setNames(levels(samples$genotype))dgeList <- read_rds("data/dgeList.rds")
fit <- read_rds("data/fit.rds")
entrezGenes <- dgeList$genes %>%
dplyr::filter(!is.na(entrezid)) %>%
unnest(entrezid) %>%
dplyr::rename(entrez_gene = entrezid)formatP <- function(p, m = 0.0001){
out <- rep("", length(p))
out[p < m] <- sprintf("%.2e", p[p<m])
out[p >= m] <- sprintf("%.4f", p[p>=m])
out
}Introduction
Enrichment analysis for this dataset present some challenges. Despite normalisation to account for gene length and GC bias, some appeared to still be present in the final results. In addition, the confounding of incomplete rRNA removal with genotype may lead to other distortions in both DE genes and ranking statistics.
Two steps for enrichment analysis will be undertaken.
- Testing for enrichment within discrete sets of DE genes as defined in the previous steps
- Testing for enrichment within ranked lists, regardless of DE status or statistical significance, before integration of all enrichment analyses using Fisher’s method for combining p-values.
Testing for enrichment within discrete gene sets will be performed using goseq as this allows for the incorporation of a single covariate as a predictor of differential expression. GC content, gene length and correlation with rRNA removal can all be supplied as separate covariates.
Testing for enrichment with ranked lists will be performed using:
fryas this can take into account inter-gene correlations. Values supplied will be fitted values for each gene/sample as these have been corrected for GC and length biases.camera, which also accommodates inter-gene correlations. Values supplied will be fitted values for each gene/sample as these have been corrected for GC and length biases.fgseawhich is an R implementation of GSEA. This approach simply takes a ranked list and doesn’t directly account for correlations. However, the ranked list will be derived from analysis using CQN-normalisation so will be robust to these technical artefacts.
In the case of camera, inter-gene correlations will be calculated for each gene-set prior to analysis to ensure more conservative p-values are obtained.
Databases used for testing
Data was sourced using the msigdbr package. The initial database used for testing was the Hallmark Gene Sets, with mappings from gene-set to EntrezGene IDs performed by the package authors.
Hallmark Gene Sets
hm <- msigdbr("Danio rerio", category = "H") %>%
left_join(entrezGenes) %>%
dplyr::filter(!is.na(gene_id))
hmByGene <- hm %>%
split(f = .$gene_id) %>%
lapply(extract2, "gs_name")
hmByID <- hm %>%
split(f = .$gs_name) %>%
lapply(extract2, "gene_id")Mappings are required from gene to pathway, and Ensembl identifiers were used to map from gene to pathway, based on the mappings in the previously used annotations (Ensembl Release 96). A total of 3459 Ensembl IDs were mapped to pathways from the hallmark gene sets.
KEGG Gene Sets
kg <- msigdbr("Danio rerio", category = "C2", subcategory = "CP:KEGG") %>%
left_join(entrezGenes) %>%
dplyr::filter(!is.na(gene_id))
kgByGene <- kg %>%
split(f = .$gene_id) %>%
lapply(extract2, "gs_name")
kgByID <- kg %>%
split(f = .$gs_name) %>%
lapply(extract2, "gene_id")The same mapping process was applied to KEGG gene sets. A total of 3614 Ensembl IDs were mapped to pathways from the KEGG gene sets.
Gene Ontology Gene Sets
goSummaries <- url("https://uofabioinformaticshub.github.io/summaries2GO/data/goSummaries.RDS") %>%
readRDS() %>%
mutate(
Term = Term(id),
gs_name = Term %>% str_to_upper() %>% str_replace_all("[ -]", "_"),
gs_name = paste0("GO_", gs_name)
)
minPath <- 3go <- msigdbr("Danio rerio", category = "C5") %>%
left_join(entrezGenes) %>%
dplyr::filter(!is.na(gene_id)) %>%
left_join(goSummaries) %>%
dplyr::filter(shortest_path >= minPath)
goByGene <- go %>%
split(f = .$gene_id) %>%
lapply(extract2, "gs_name")
goByID <- go %>%
split(f = .$gs_name) %>%
lapply(extract2, "gene_id")For analysis of gene-sets from the GO database, gene-sets were restricted to those with 3 or more steps back to the ontology root terms. A total of 11245 Ensembl IDs were mapped to pathways from restricted database of 8834 GO gene sets.
Enrichment in the DE Gene Set
deTable <- file.path("output", "psen2VsWT.csv") %>%
read_csv() %>%
mutate(
entrezid = dgeList$genes$entrezid[gene_id]
)The first step of analysis using goseq, regardless of the gene-set, is estimation of the probability weight function (PWF) which quantifies the probability of a gene being considered as DE based on a single covariate. As GC content and length should have been accounted for during conditional-quantile normalisation, these were not required for any bias. However, the gene-level correlations with rRNA contamination were instead used a predictor of bias in selection of a gene as being DE.
rawFqc <- list.files(
path = "data/0_rawData/FastQC/",
pattern = "zip",
full.names = TRUE
) %>%
FastqcDataList()
gc <- getModule(rawFqc, "Per_sequence_GC") %>%
group_by(Filename) %>%
mutate(Freq = Count / sum(Count)) %>%
ungroup()
gcDev <- gc %>%
left_join(getGC(gcTheoretical, "Drerio", "Trans")) %>%
mutate(
sample = str_remove(Filename, "_R[12].fastq.gz"),
resid = Freq - Drerio
) %>%
left_join(samples) %>%
group_by(sample) %>%
summarise(
ss = sum(resid^2),
n = n(),
sd = sqrt(ss / (n - 1))
)riboVec <- structure(gcDev$sd, names = gcDev$sample)
riboCors <- cpm(dgeList, log = TRUE) %>%
apply(1, function(x){
cor(x, riboVec[names(x)])
})Values were calculated as per the previous steps, using the logCPM values for each gene, with the sample-level standard deviations from the theoretical GC distribution being used as a measure of rRNA contamination. For estimation of the probability weight function, squared correlations were used to place negative and positive correlations on the same scale. This accounts for genes which are both negatively & positively biased by the presence of excessive rRNA. Clearly, the confounding of genotype with rRNA means that some genes driven by the genuine biology may be down-weighted under this approach.
riboPwf <- deTable %>%
mutate(riboCors = riboCors[gene_id]^2) %>%
dplyr::select(gene_id, DE, riboCors) %>%
distinct(gene_id, .keep_all = TRUE) %>%
with(
nullp(
DEgenes = structure(
as.integer(DE), names = gene_id
),
genome = "danRer10",
id = "ensGene",
bias.data = riboCors,
plot.fit = FALSE
)
)
plotPWF(riboPwf, main = "Bias from rRNA proportions")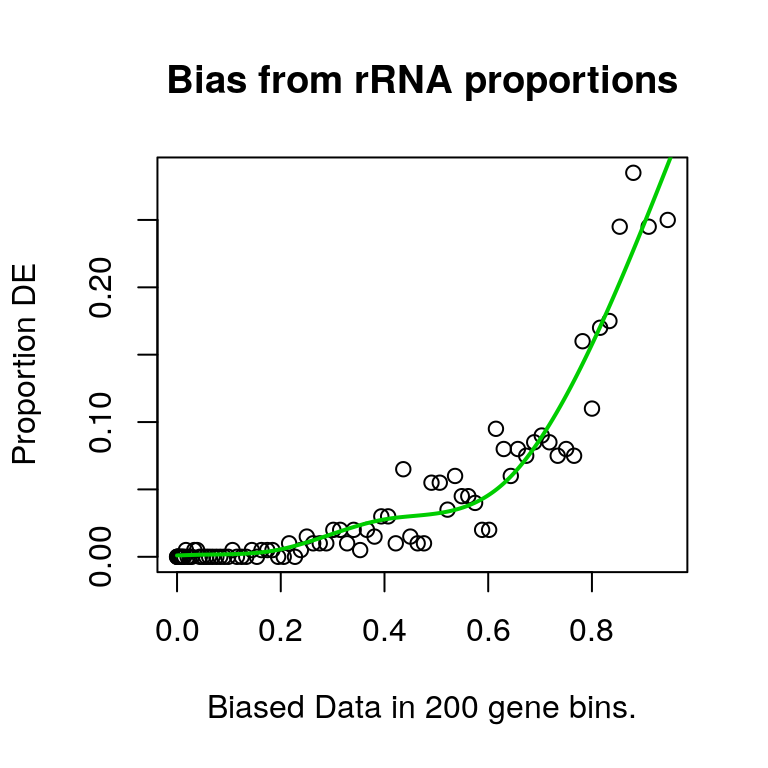
Using this approach, it was clear that correlation with rRNA proportions significantly biased the probability of a gene being considered as DE.
All gene-sets were then tested using this PWF.
Hallmark Gene Sets
hmRiboGoseq <- goseq(riboPwf, gene2cat = hmByGene) %>%
as_tibble %>%
dplyr::filter(numDEInCat > 0) %>%
mutate(
adjP = p.adjust(over_represented_pvalue, method = "bonf"),
FDR = p.adjust(over_represented_pvalue, method = "fdr")
) %>%
dplyr::select(-contains("under")) %>%
dplyr::rename(
gs_name = category,
PValue = over_represented_pvalue
)Once again, no gene-sets achieved significance with the lowest FDR being 41%
KEGG Gene Sets
kgRiboGoseq <- goseq(riboPwf, gene2cat = kgByGene) %>%
as_tibble %>%
dplyr::filter(numDEInCat > 0) %>%
mutate(
adjP = p.adjust(over_represented_pvalue, method = "bonf"),
FDR = p.adjust(over_represented_pvalue, method = "fdr")
) %>%
dplyr::select(-contains("under")) %>%
dplyr::rename(
gs_name = category,
PValue = over_represented_pvalue
)kgRiboGoseq %>%
dplyr::slice(1:5) %>%
mutate(
p = formatP(PValue),
adjP = formatP(adjP),
FDR = formatP(FDR)
) %>%
dplyr::select(
`Gene Set` = gs_name,
DE = numDEInCat,
`Set Size` = numInCat,
PValue,
`p~bonf~` = adjP,
`p~FDR~` = FDR
) %>%
pander(
justify = "lrrrrr",
caption = paste(
"The", nrow(.), "most highly-ranked KEGG pathways.",
"Bonferroni-adjusted p-values are the most stringent and give high",
"confidence when below 0.05."
)
)| Gene Set | DE | Set Size | PValue | pbonf | pFDR |
|---|---|---|---|---|---|
| KEGG_RIBOSOME | 26 | 80 | 4.754e-09 | 5.32e-07 | 5.32e-07 |
| KEGG_PRIMARY_IMMUNODEFICIENCY | 2 | 15 | 0.01642 | 1.0000 | 0.7173 |
| KEGG_CYSTEINE_AND_METHIONINE_METABOLISM | 4 | 26 | 0.02959 | 1.0000 | 0.7173 |
| KEGG_ASTHMA | 1 | 3 | 0.04088 | 1.0000 | 0.7173 |
| KEGG_RETINOL_METABOLISM | 3 | 25 | 0.0512 | 1.0000 | 0.7173 |
Notably, the KEGG gene-set for Ribosomal genes was detected as enriched with no other KEGG gene-sets being considered significant.
GO Gene Sets
goRiboGoseq <- goseq(riboPwf, gene2cat = goByGene) %>%
as_tibble %>%
dplyr::filter(numDEInCat > 0) %>%
mutate(
adjP = p.adjust(over_represented_pvalue, method = "bonf"),
FDR = p.adjust(over_represented_pvalue, method = "fdr")
) %>%
dplyr::select(-contains("under")) %>%
dplyr::rename(
gs_name = category,
PValue = over_represented_pvalue
)goRiboGoseq %>%
dplyr::filter(adjP < 0.05) %>%
mutate(
p = formatP(PValue),
adjP = formatP(adjP),
FDR = formatP(FDR)
) %>%
dplyr::select(
`Gene Set` = gs_name,
DE = numDEInCat,
`Set Size` = numInCat,
PValue,
`p~bonf~` = adjP,
`p~FDR~` = FDR
) %>%
pander(
justify = "lrrrrr",
caption = paste(
"*The", nrow(.), "most highly-ranked GO terms.",
"Bonferroni-adjusted p-values are the most stringent and give high",
"confidence when below 0.05, with all terms here reaching this threshold.",
"However, most terms once again indicate the presence of rRNA.*"
)
)| Gene Set | DE | Set Size | PValue | pbonf | pFDR |
|---|---|---|---|---|---|
| GO_COTRANSLATIONAL_PROTEIN_TARGETING_TO_MEMBRANE | 28 | 93 | 7.36e-10 | 2.83e-06 | 2.03e-06 |
| GO_CYTOSOLIC_RIBOSOME | 27 | 97 | 1.056e-09 | 4.06e-06 | 2.03e-06 |
| GO_ESTABLISHMENT_OF_PROTEIN_LOCALIZATION_TO_ENDOPLASMIC_RETICULUM | 27 | 105 | 1.6e-08 | 6.16e-05 | 2.05e-05 |
| GO_TRANSLATIONAL_INITIATION | 29 | 177 | 2.178e-07 | 0.0008 | 0.0002 |
| GO_PROTEIN_TARGETING_TO_MEMBRANE | 30 | 171 | 2.533e-07 | 0.0010 | 0.0002 |
| GO_PROTEIN_LOCALIZATION_TO_ENDOPLASMIC_RETICULUM | 27 | 128 | 3.849e-07 | 0.0015 | 0.0002 |
| GO_CYTOSOLIC_PART | 30 | 206 | 4.424e-07 | 0.0017 | 0.0002 |
| GO_VIRAL_GENE_EXPRESSION | 29 | 172 | 6.939e-07 | 0.0027 | 0.0003 |
| GO_NUCLEAR_TRANSCRIBED_MRNA_CATABOLIC_PROCESS | 30 | 183 | 7.911e-07 | 0.0030 | 0.0003 |
| GO_RIBOSOMAL_SUBUNIT | 28 | 175 | 1.99e-06 | 0.0077 | 0.0008 |
| GO_RIBOSOME | 30 | 210 | 2.659e-06 | 0.0102 | 0.0009 |
| GO_CYTOSOLIC_LARGE_RIBOSOMAL_SUBUNIT | 15 | 51 | 2.826e-06 | 0.0109 | 0.0009 |
| GO_SYMPORTER_ACTIVITY | 10 | 94 | 7.571e-06 | 0.0291 | 0.0022 |
| GO_ANION_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 17 | 228 | 1.23e-05 | 0.0473 | 0.0034 |
Enrichment Testing on Ranked Lists
rnk <- structure(
-sign(deTable$logFC)*log10(deTable$PValue),
names = deTable$gene_id
) %>% sort()
np <- 5e5Genes were ranked by p-value alone for approaches which required a ranked list. Multiple approaches were first calculated individually, before being combined for the final integrated set of results.
Hallmark Gene Sets
hmFry <- fit$fitted.values %>%
cpm(log = TRUE) %>%
fry(
index = hmByID,
design = fit$design,
contrast = "mutant",
sort = "directional"
) %>%
rownames_to_column("gs_name") %>%
as_tibble()For analysis under camera when inter-gene correlations were calculated for a more conservative result.
hmCamera <- fit$fitted.values %>%
cpm(log = TRUE) %>%
camera(
index = hmByID,
design = fit$design,
contrast = "mutant",
inter.gene.cor = NULL
) %>%
rownames_to_column("gs_name") %>%
as_tibble()For generation of the GSEA ranked list, 510^{5} permutations were conducted.
hmGsea <- fgsea(
pathways = hmByID,
stats = rnk,
nperm = np
) %>%
as_tibble() %>%
dplyr::rename(gs_name = pathway, PValue = pval) %>%
arrange(PValue)Results for all analyses, including goseq were then combined using Wilkinson’s method to combine p-values. For a conservative approach, under \(m\) tests, the \(m - 1\)th smallest p-value was chosen.
hmMeta <- hmFry %>%
dplyr::select(gs_name, fry = PValue) %>%
left_join(
dplyr::select(hmCamera, gs_name, camera = PValue)
) %>%
left_join(
dplyr::select(hmGsea, gs_name, gsea = PValue)
) %>%
left_join(
dplyr::select(hmRiboGoseq, gs_name, goseq = PValue)
) %>%
pivot_longer(
cols = one_of(c("fry", "camera", "gsea", "goseq")),
names_to = "method",
values_to = "p"
) %>%
dplyr::filter(!is.na(p)) %>%
group_by(gs_name) %>%
summarise(
n = n(),
p = wilkinsonp(p, r = n - 1)$p
) %>%
arrange(p) %>%
mutate(
FDR = p.adjust(p, "fdr"),
adjP = p.adjust(p, "bonf")
) hmMeta %>%
dplyr::filter(FDR < 0.05) %>%
mutate_at(vars(one_of(c("p", "FDR", "adjP"))), formatP) %>%
pander(
caption = "Results from combining all above approaches for the Hallmark Gene Sets. All terms are significant to an FDR of 0.05.",
justify = "lrrrr"
)| gs_name | n | p | FDR | adjP |
|---|---|---|---|---|
| HALLMARK_XENOBIOTIC_METABOLISM | 4 | 0.0001 | 0.0057 | 0.0057 |
| HALLMARK_MYC_TARGETS_V1 | 4 | 0.0003 | 0.0069 | 0.0138 |
| HALLMARK_REACTIVE_OXYGEN_SPECIES_PATHWAY | 4 | 0.0009 | 0.0143 | 0.0428 |
| HALLMARK_ADIPOGENESIS | 4 | 0.0019 | 0.0243 | 0.0971 |
| HALLMARK_OXIDATIVE_PHOSPHORYLATION | 4 | 0.0024 | 0.0243 | 0.1217 |
KEGG Gene Sets
kgFry <- fit$fitted.values %>%
cpm(log = TRUE) %>%
fry(
index = kgByID,
design = fit$design,
contrast = "mutant",
sort = "directional"
) %>%
rownames_to_column("gs_name") %>%
as_tibble()For analysis under camera when inter-gene correlations were calculated for a more conservative result.
kgCamera <- fit$fitted.values %>%
cpm(log = TRUE) %>%
camera(
index = kgByID,
design = fit$design,
contrast = "mutant",
inter.gene.cor = NULL
) %>%
rownames_to_column("gs_name") %>%
as_tibble()For generation of the GSEA ranked list, 510^{5} permutations were conducted.
kgGsea <- fgsea(
pathways = kgByID,
stats = rnk,
nperm = np
) %>%
as_tibble() %>%
dplyr::rename(gs_name = pathway, PValue = pval) %>%
arrange(PValue)Results for all analyses, including goseq were then combined using Wilkinson’s method to combine p-values. For a conservative approach, under \(m\) tests, the \(m - 1\)th smallest p-value was chosen.
kgMeta <- kgFry %>%
dplyr::select(gs_name, fry = PValue) %>%
left_join(
dplyr::select(kgCamera, gs_name, camera = PValue)
) %>%
left_join(
dplyr::select(kgGsea, gs_name, gsea = PValue)
) %>%
left_join(
dplyr::select(kgRiboGoseq, gs_name, goseq = PValue)
) %>%
pivot_longer(
cols = one_of(c("fry", "camera", "gsea", "goseq")),
names_to = "method",
values_to = "p"
) %>%
dplyr::filter(!is.na(p)) %>%
group_by(gs_name) %>%
summarise(
n = n(),
p = wilkinsonp(p, r = n - 1)$p
) %>%
arrange(p) %>%
mutate(
FDR = p.adjust(p, "fdr"),
adjP = p.adjust(p, "bonf")
) kgMeta %>%
dplyr::filter(FDR < 0.01) %>%
mutate_at(vars(one_of(c("p", "FDR", "adjP"))), formatP) %>%
pander(
caption = "Results from combining all above approaches for the Hallmark Gene Sets. All terms are significant to an FDR of 0.01.",
justify = "lrrrr"
)| gs_name | n | p | FDR | adjP |
|---|---|---|---|---|
| KEGG_RIBOSOME | 4 | 4.22e-16 | 7.85e-14 | 7.85e-14 |
| KEGG_BUTANOATE_METABOLISM | 3 | 9.17e-09 | 8.53e-07 | 1.71e-06 |
| KEGG_PORPHYRIN_AND_CHLOROPHYLL_METABOLISM | 3 | 1.80e-07 | 1.11e-05 | 3.34e-05 |
| KEGG_VALINE_LEUCINE_AND_ISOLEUCINE_DEGRADATION | 3 | 2.87e-07 | 1.33e-05 | 5.33e-05 |
| KEGG_LIMONENE_AND_PINENE_DEGRADATION | 3 | 1.77e-06 | 5.52e-05 | 0.0003 |
| KEGG_ASCORBATE_AND_ALDARATE_METABOLISM | 3 | 1.78e-06 | 5.52e-05 | 0.0003 |
| KEGG_BIOSYNTHESIS_OF_UNSATURATED_FATTY_ACIDS | 3 | 4.26e-06 | 0.0001 | 0.0008 |
| KEGG_PRIMARY_IMMUNODEFICIENCY | 4 | 1.75e-05 | 0.0004 | 0.0033 |
| KEGG_PROXIMAL_TUBULE_BICARBONATE_RECLAMATION | 3 | 1.78e-05 | 0.0004 | 0.0033 |
| KEGG_OXIDATIVE_PHOSPHORYLATION | 4 | 3.59e-05 | 0.0007 | 0.0067 |
| KEGG_CYSTEINE_AND_METHIONINE_METABOLISM | 4 | 0.0001 | 0.0017 | 0.0189 |
| KEGG_TERPENOID_BACKBONE_BIOSYNTHESIS | 3 | 0.0001 | 0.0023 | 0.0274 |
| KEGG_PEROXISOME | 3 | 0.0002 | 0.0033 | 0.0427 |
| KEGG_ASTHMA | 4 | 0.0003 | 0.0035 | 0.0493 |
| KEGG_PARKINSONS_DISEASE | 4 | 0.0003 | 0.0035 | 0.0534 |
| KEGG_VALINE_LEUCINE_AND_ISOLEUCINE_BIOSYNTHESIS | 3 | 0.0003 | 0.0035 | 0.0566 |
| KEGG_RETINOL_METABOLISM | 4 | 0.0005 | 0.0056 | 0.0960 |
GO Gene Sets
goFry <- fit$fitted.values %>%
cpm(log = TRUE) %>%
fry(
index = goByID,
design = fit$design,
contrast = "mutant",
sort = "directional"
) %>%
rownames_to_column("gs_name") %>%
as_tibble()For analysis under camera when inter-gene correlations were calculated for a more conservative result.
goCamera <- fit$fitted.values %>%
cpm(log = TRUE) %>%
camera(
index = goByID,
design = fit$design,
contrast = "mutant",
inter.gene.cor = NULL
) %>%
rownames_to_column("gs_name") %>%
as_tibble()For generation of the GSEA ranked list, 510^{5} permutations were conducted.
goGsea <- fgsea(
pathways = goByID,
stats = rnk,
nperm = np
) %>%
as_tibble() %>%
dplyr::rename(gs_name = pathway, PValue = pval) %>%
arrange(PValue)Results for all analyses, including goseq were then combined using Wilkinson’s method to combine p-values. For a conservative approach, under \(m\) tests, the \(m - 1\)th smallest p-value was chosen.
goMeta <- goFry %>%
dplyr::select(gs_name, fry = PValue) %>%
left_join(
dplyr::select(goCamera, gs_name, camera = PValue)
) %>%
left_join(
dplyr::select(goGsea, gs_name, gsea = PValue)
) %>%
left_join(
dplyr::select(goRiboGoseq, gs_name, goseq = PValue)
) %>%
pivot_longer(
cols = one_of(c("fry", "camera", "gsea", "goseq")),
names_to = "method",
values_to = "p"
) %>%
dplyr::filter(!is.na(p)) %>%
group_by(gs_name) %>%
summarise(
n = n(),
p = wilkinsonp(p, r = n - 1)$p
) %>%
arrange(p) %>%
mutate(
FDR = p.adjust(p, "fdr"),
adjP = p.adjust(p, "bonf")
) goMeta %>%
dplyr::filter(adjP < 0.01) %>%
mutate_at(vars(one_of(c("p", "FDR", "adjP"))), formatP) %>%
pander(
caption = "Results from combining all above approaches for the Hallmark Gene Sets. All terms are significant using a Bonferroni-adjusted p-value < 0.01.",
justify = "lrrrr"
)| gs_name | n | p | FDR | adjP |
|---|---|---|---|---|
| GO_CYTOSOLIC_LARGE_RIBOSOMAL_SUBUNIT | 4 | 3.87e-16 | 4.30e-13 | 3.42e-12 |
| GO_COTRANSLATIONAL_PROTEIN_TARGETING_TO_MEMBRANE | 4 | 4.34e-16 | 4.30e-13 | 3.83e-12 |
| GO_CYTOSOLIC_RIBOSOME | 4 | 4.49e-16 | 4.30e-13 | 3.96e-12 |
| GO_ESTABLISHMENT_OF_PROTEIN_LOCALIZATION_TO_ENDOPLASMIC_RETICULUM | 4 | 4.50e-16 | 4.30e-13 | 3.97e-12 |
| GO_PROTEIN_LOCALIZATION_TO_ENDOPLASMIC_RETICULUM | 4 | 4.77e-16 | 4.30e-13 | 4.22e-12 |
| GO_VIRAL_GENE_EXPRESSION | 4 | 5.31e-16 | 4.30e-13 | 4.69e-12 |
| GO_PROTEIN_TARGETING_TO_MEMBRANE | 4 | 5.31e-16 | 4.30e-13 | 4.69e-12 |
| GO_TRANSLATIONAL_INITIATION | 4 | 5.38e-16 | 4.30e-13 | 4.76e-12 |
| GO_RIBOSOMAL_SUBUNIT | 4 | 5.43e-16 | 4.30e-13 | 4.80e-12 |
| GO_NUCLEAR_TRANSCRIBED_MRNA_CATABOLIC_PROCESS | 4 | 5.43e-16 | 4.30e-13 | 4.80e-12 |
| GO_CYTOSOLIC_PART | 4 | 5.84e-16 | 4.30e-13 | 5.16e-12 |
| GO_RIBOSOME | 4 | 5.84e-16 | 4.30e-13 | 5.16e-12 |
| GO_LARGE_RIBOSOMAL_SUBUNIT | 4 | 8.71e-12 | 5.92e-09 | 7.70e-08 |
| GO_RNA_CATABOLIC_PROCESS | 4 | 3.70e-11 | 2.33e-08 | 3.27e-07 |
| GO_ESTABLISHMENT_OF_PROTEIN_LOCALIZATION_TO_MEMBRANE | 4 | 4.55e-11 | 2.68e-08 | 4.02e-07 |
| GO_CYTOSOLIC_SMALL_RIBOSOMAL_SUBUNIT | 4 | 6.56e-11 | 3.62e-08 | 5.80e-07 |
| GO_PROTEIN_TARGETING | 4 | 2.20e-10 | 1.14e-07 | 1.94e-06 |
| GO_RRNA_BINDING | 4 | 3.48e-10 | 1.71e-07 | 3.07e-06 |
| GO_PROTON_EXPORTING_ATPASE_ACTIVITY | 3 | 4.98e-09 | 2.27e-06 | 4.40e-05 |
| GO_SYMPORTER_ACTIVITY | 4 | 5.13e-09 | 2.27e-06 | 4.53e-05 |
| GO_DRUG_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 4 | 1.08e-08 | 4.53e-06 | 9.52e-05 |
| GO_PHAGOSOME_ACIDIFICATION | 3 | 1.52e-08 | 6.10e-06 | 0.0001 |
| GO_ORGANIC_ACID_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 4 | 1.81e-08 | 6.96e-06 | 0.0002 |
| GO_ORGANIC_ANION_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 4 | 2.33e-08 | 8.58e-06 | 0.0002 |
| GO_TRABECULA_FORMATION | 4 | 2.79e-08 | 9.86e-06 | 0.0002 |
| GO_ORGANIC_CYCLIC_COMPOUND_CATABOLIC_PROCESS | 4 | 3.73e-08 | 1.27e-05 | 0.0003 |
| GO_ESTABLISHMENT_OF_PROTEIN_LOCALIZATION_TO_ORGANELLE | 4 | 7.96e-08 | 2.60e-05 | 0.0007 |
| GO_ORGANIC_ACID_TRANSMEMBRANE_TRANSPORT | 4 | 8.97e-08 | 2.83e-05 | 0.0008 |
| GO_NEGATIVE_REGULATION_OF_INSULIN_SECRETION_INVOLVED_IN_CELLULAR_RESPONSE_TO_GLUCOSE_STIMULUS | 4 | 1.06e-07 | 3.22e-05 | 0.0009 |
| GO_PROTON_TRANSPORTING_V_TYPE_ATPASE_COMPLEX | 3 | 1.36e-07 | 3.99e-05 | 0.0012 |
| GO_SECONDARY_ACTIVE_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 4 | 1.87e-07 | 5.32e-05 | 0.0016 |
| GO_RIBOSOME_ASSEMBLY | 4 | 1.97e-07 | 5.40e-05 | 0.0017 |
| GO_DRUG_TRANSMEMBRANE_TRANSPORT | 4 | 2.02e-07 | 5.40e-05 | 0.0018 |
| GO_POLYSOMAL_RIBOSOME | 4 | 2.58e-07 | 6.60e-05 | 0.0023 |
| GO_L_AMINO_ACID_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 4 | 2.62e-07 | 6.60e-05 | 0.0023 |
| GO_AEROBIC_ELECTRON_TRANSPORT_CHAIN | 4 | 2.99e-07 | 7.34e-05 | 0.0026 |
| GO_CYTOPLASMIC_TRANSLATION | 4 | 3.11e-07 | 7.44e-05 | 0.0028 |
| GO_INNER_MITOCHONDRIAL_MEMBRANE_PROTEIN_COMPLEX | 4 | 3.77e-07 | 8.77e-05 | 0.0033 |
| GO_SMALL_RIBOSOMAL_SUBUNIT | 4 | 3.93e-07 | 8.90e-05 | 0.0035 |
| GO_ACTIVE_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 4 | 4.19e-07 | 9.25e-05 | 0.0037 |
| GO_PYRUVATE_DEHYDROGENASE_COMPLEX | 3 | 4.59e-07 | 9.89e-05 | 0.0041 |
| GO_UBIQUITIN_LIGASE_INHIBITOR_ACTIVITY | 4 | 6.91e-07 | 0.0001 | 0.0061 |
| GO_AMINO_ACID_TRANSMEMBRANE_TRANSPORTER_ACTIVITY | 4 | 7.80e-07 | 0.0002 | 0.0069 |
| GO_GONADAL_MESODERM_DEVELOPMENT | 3 | 7.82e-07 | 0.0002 | 0.0069 |
| GO_PEPTIDE_BIOSYNTHETIC_PROCESS | 4 | 9.11e-07 | 0.0002 | 0.0081 |
devtools::session_info()─ Session info ───────────────────────────────────────────────────────────────
setting value
version R version 3.6.2 (2019-12-12)
os Ubuntu 18.04.3 LTS
system x86_64, linux-gnu
ui X11
language en_AU:en
collate en_AU.UTF-8
ctype en_AU.UTF-8
tz Australia/Adelaide
date 2020-01-28
─ Packages ───────────────────────────────────────────────────────────────────
package * version date lib source
AnnotationDbi * 1.48.0 2019-10-29 [2] Bioconductor
askpass 1.1 2019-01-13 [2] CRAN (R 3.6.0)
assertthat 0.2.1 2019-03-21 [2] CRAN (R 3.6.0)
backports 1.1.5 2019-10-02 [2] CRAN (R 3.6.1)
BiasedUrn * 1.07 2015-12-28 [2] CRAN (R 3.6.1)
bibtex 0.4.2.2 2020-01-02 [2] CRAN (R 3.6.2)
Biobase * 2.46.0 2019-10-29 [2] Bioconductor
BiocFileCache 1.10.2 2019-11-08 [2] Bioconductor
BiocGenerics * 0.32.0 2019-10-29 [2] Bioconductor
BiocParallel 1.20.1 2019-12-21 [2] Bioconductor
biomaRt 2.42.0 2019-10-29 [2] Bioconductor
Biostrings 2.54.0 2019-10-29 [2] Bioconductor
bit 1.1-15.1 2020-01-14 [2] CRAN (R 3.6.2)
bit64 0.9-7 2017-05-08 [2] CRAN (R 3.6.0)
bitops 1.0-6 2013-08-17 [2] CRAN (R 3.6.0)
blob 1.2.1 2020-01-20 [2] CRAN (R 3.6.2)
broom 0.5.3 2019-12-14 [2] CRAN (R 3.6.2)
callr 3.4.1 2020-01-24 [2] CRAN (R 3.6.2)
cellranger 1.1.0 2016-07-27 [2] CRAN (R 3.6.0)
cli 2.0.1 2020-01-08 [2] CRAN (R 3.6.2)
cluster 2.1.0 2019-06-19 [2] CRAN (R 3.6.1)
codetools 0.2-16 2018-12-24 [4] CRAN (R 3.6.0)
colorspace 1.4-1 2019-03-18 [2] CRAN (R 3.6.0)
crayon 1.3.4 2017-09-16 [2] CRAN (R 3.6.0)
curl 4.3 2019-12-02 [2] CRAN (R 3.6.2)
data.table 1.12.8 2019-12-09 [2] CRAN (R 3.6.2)
DBI 1.1.0 2019-12-15 [2] CRAN (R 3.6.2)
dbplyr 1.4.2 2019-06-17 [2] CRAN (R 3.6.0)
DelayedArray 0.12.2 2020-01-06 [2] Bioconductor
desc 1.2.0 2018-05-01 [2] CRAN (R 3.6.0)
devtools 2.2.1 2019-09-24 [2] CRAN (R 3.6.1)
digest 0.6.23 2019-11-23 [2] CRAN (R 3.6.1)
dplyr * 0.8.3 2019-07-04 [2] CRAN (R 3.6.1)
edgeR * 3.28.0 2019-10-29 [2] Bioconductor
ellipsis 0.3.0 2019-09-20 [2] CRAN (R 3.6.1)
evaluate 0.14 2019-05-28 [2] CRAN (R 3.6.0)
FactoMineR 2.1 2020-01-17 [2] CRAN (R 3.6.2)
fansi 0.4.1 2020-01-08 [2] CRAN (R 3.6.2)
fastmatch 1.1-0 2017-01-28 [2] CRAN (R 3.6.0)
fgsea * 1.12.0 2019-10-29 [2] Bioconductor
flashClust 1.01-2 2012-08-21 [2] CRAN (R 3.6.1)
forcats * 0.4.0 2019-02-17 [2] CRAN (R 3.6.0)
fs 1.3.1 2019-05-06 [2] CRAN (R 3.6.0)
gbRd 0.4-11 2012-10-01 [2] CRAN (R 3.6.0)
geneLenDataBase * 1.22.0 2019-11-05 [2] Bioconductor
generics 0.0.2 2018-11-29 [2] CRAN (R 3.6.0)
GenomeInfoDb 1.22.0 2019-10-29 [2] Bioconductor
GenomeInfoDbData 1.2.2 2019-11-21 [2] Bioconductor
GenomicAlignments 1.22.1 2019-11-12 [2] Bioconductor
GenomicFeatures 1.38.1 2020-01-22 [2] Bioconductor
GenomicRanges 1.38.0 2019-10-29 [2] Bioconductor
ggdendro 0.1-20 2016-04-27 [2] CRAN (R 3.6.0)
ggplot2 * 3.2.1 2019-08-10 [2] CRAN (R 3.6.1)
ggrepel 0.8.1 2019-05-07 [2] CRAN (R 3.6.0)
git2r 0.26.1 2019-06-29 [2] CRAN (R 3.6.1)
glue 1.3.1 2019-03-12 [2] CRAN (R 3.6.0)
GO.db 3.10.0 2019-11-21 [2] Bioconductor
goseq * 1.38.0 2019-10-29 [2] Bioconductor
gridExtra 2.3 2017-09-09 [2] CRAN (R 3.6.0)
gtable 0.3.0 2019-03-25 [2] CRAN (R 3.6.0)
haven 2.2.0 2019-11-08 [2] CRAN (R 3.6.1)
highr 0.8 2019-03-20 [2] CRAN (R 3.6.0)
hms 0.5.3 2020-01-08 [2] CRAN (R 3.6.2)
htmltools 0.4.0 2019-10-04 [2] CRAN (R 3.6.1)
htmlwidgets 1.5.1 2019-10-08 [2] CRAN (R 3.6.1)
httpuv 1.5.2 2019-09-11 [2] CRAN (R 3.6.1)
httr 1.4.1 2019-08-05 [2] CRAN (R 3.6.1)
hwriter 1.3.2 2014-09-10 [2] CRAN (R 3.6.0)
IRanges * 2.20.2 2020-01-13 [2] Bioconductor
jpeg 0.1-8.1 2019-10-24 [2] CRAN (R 3.6.1)
jsonlite 1.6 2018-12-07 [2] CRAN (R 3.6.0)
kableExtra 1.1.0 2019-03-16 [2] CRAN (R 3.6.1)
knitr 1.27 2020-01-16 [2] CRAN (R 3.6.2)
later 1.0.0 2019-10-04 [2] CRAN (R 3.6.1)
lattice 0.20-38 2018-11-04 [4] CRAN (R 3.6.0)
latticeExtra 0.6-29 2019-12-19 [2] CRAN (R 3.6.2)
lazyeval 0.2.2 2019-03-15 [2] CRAN (R 3.6.0)
leaps 3.1 2020-01-16 [2] CRAN (R 3.6.2)
lifecycle 0.1.0 2019-08-01 [2] CRAN (R 3.6.1)
limma * 3.42.0 2019-10-29 [2] Bioconductor
locfit 1.5-9.1 2013-04-20 [2] CRAN (R 3.6.0)
lubridate 1.7.4 2018-04-11 [2] CRAN (R 3.6.0)
magrittr * 1.5 2014-11-22 [2] CRAN (R 3.6.0)
MASS 7.3-51.5 2019-12-20 [4] CRAN (R 3.6.2)
Matrix 1.2-18 2019-11-27 [2] CRAN (R 3.6.1)
matrixStats 0.55.0 2019-09-07 [2] CRAN (R 3.6.1)
memoise 1.1.0 2017-04-21 [2] CRAN (R 3.6.0)
metap * 1.3 2020-01-23 [2] CRAN (R 3.6.2)
mgcv 1.8-31 2019-11-09 [4] CRAN (R 3.6.1)
mnormt 1.5-5 2016-10-15 [2] CRAN (R 3.6.1)
modelr 0.1.5 2019-08-08 [2] CRAN (R 3.6.1)
msigdbr * 7.0.1 2019-09-04 [2] CRAN (R 3.6.2)
multcomp 1.4-12 2020-01-10 [2] CRAN (R 3.6.2)
multtest 2.42.0 2019-10-29 [2] Bioconductor
munsell 0.5.0 2018-06-12 [2] CRAN (R 3.6.0)
mutoss 0.1-12 2017-12-04 [2] CRAN (R 3.6.2)
mvtnorm 1.0-12 2020-01-09 [2] CRAN (R 3.6.2)
ngsReports * 1.1.2 2019-10-16 [1] Bioconductor
nlme 3.1-143 2019-12-10 [4] CRAN (R 3.6.2)
numDeriv 2016.8-1.1 2019-06-06 [2] CRAN (R 3.6.2)
openssl 1.4.1 2019-07-18 [2] CRAN (R 3.6.1)
pander * 0.6.3 2018-11-06 [2] CRAN (R 3.6.0)
pillar 1.4.3 2019-12-20 [2] CRAN (R 3.6.2)
pkgbuild 1.0.6 2019-10-09 [2] CRAN (R 3.6.1)
pkgconfig 2.0.3 2019-09-22 [2] CRAN (R 3.6.1)
pkgload 1.0.2 2018-10-29 [2] CRAN (R 3.6.0)
plotly 4.9.1 2019-11-07 [2] CRAN (R 3.6.1)
plotrix 3.7-7 2019-12-05 [2] CRAN (R 3.6.2)
plyr 1.8.5 2019-12-10 [2] CRAN (R 3.6.2)
png 0.1-7 2013-12-03 [2] CRAN (R 3.6.0)
prettyunits 1.1.1 2020-01-24 [2] CRAN (R 3.6.2)
processx 3.4.1 2019-07-18 [2] CRAN (R 3.6.1)
progress 1.2.2 2019-05-16 [2] CRAN (R 3.6.0)
promises 1.1.0 2019-10-04 [2] CRAN (R 3.6.1)
ps 1.3.0 2018-12-21 [2] CRAN (R 3.6.0)
purrr * 0.3.3 2019-10-18 [2] CRAN (R 3.6.1)
R6 2.4.1 2019-11-12 [2] CRAN (R 3.6.1)
rappdirs 0.3.1 2016-03-28 [2] CRAN (R 3.6.0)
RColorBrewer * 1.1-2 2014-12-07 [2] CRAN (R 3.6.0)
Rcpp * 1.0.3 2019-11-08 [2] CRAN (R 3.6.1)
RCurl 1.98-1.1 2020-01-19 [2] CRAN (R 3.6.2)
Rdpack 0.11-1 2019-12-14 [2] CRAN (R 3.6.2)
readr * 1.3.1 2018-12-21 [2] CRAN (R 3.6.0)
readxl 1.3.1 2019-03-13 [2] CRAN (R 3.6.0)
remotes 2.1.0 2019-06-24 [2] CRAN (R 3.6.0)
reprex 0.3.0 2019-05-16 [2] CRAN (R 3.6.0)
reshape2 1.4.3 2017-12-11 [2] CRAN (R 3.6.0)
rlang 0.4.3 2020-01-24 [2] CRAN (R 3.6.2)
rmarkdown 2.1 2020-01-20 [2] CRAN (R 3.6.2)
rprojroot 1.3-2 2018-01-03 [2] CRAN (R 3.6.0)
Rsamtools 2.2.1 2019-11-06 [2] Bioconductor
RSQLite 2.2.0 2020-01-07 [2] CRAN (R 3.6.2)
rstudioapi 0.10 2019-03-19 [2] CRAN (R 3.6.0)
rtracklayer 1.46.0 2019-10-29 [2] Bioconductor
rvest 0.3.5 2019-11-08 [2] CRAN (R 3.6.1)
S4Vectors * 0.24.3 2020-01-18 [2] Bioconductor
sandwich 2.5-1 2019-04-06 [2] CRAN (R 3.6.1)
scales * 1.1.0 2019-11-18 [2] CRAN (R 3.6.1)
scatterplot3d 0.3-41 2018-03-14 [2] CRAN (R 3.6.1)
sessioninfo 1.1.1 2018-11-05 [2] CRAN (R 3.6.0)
ShortRead 1.44.1 2019-12-19 [2] Bioconductor
sn 1.5-4 2019-05-14 [2] CRAN (R 3.6.2)
statmod 1.4.33 2020-01-10 [2] CRAN (R 3.6.2)
stringi 1.4.5 2020-01-11 [2] CRAN (R 3.6.2)
stringr * 1.4.0 2019-02-10 [2] CRAN (R 3.6.0)
SummarizedExperiment 1.16.1 2019-12-19 [2] Bioconductor
survival 3.1-8 2019-12-03 [2] CRAN (R 3.6.2)
testthat 2.3.1 2019-12-01 [2] CRAN (R 3.6.1)
TFisher 0.2.0 2018-03-21 [2] CRAN (R 3.6.2)
TH.data 1.0-10 2019-01-21 [2] CRAN (R 3.6.1)
tibble * 2.1.3 2019-06-06 [2] CRAN (R 3.6.0)
tidyr * 1.0.2 2020-01-24 [2] CRAN (R 3.6.2)
tidyselect 0.2.5 2018-10-11 [2] CRAN (R 3.6.0)
tidyverse * 1.3.0 2019-11-21 [2] CRAN (R 3.6.1)
truncnorm 1.0-8 2018-02-27 [2] CRAN (R 3.6.0)
usethis 1.5.1 2019-07-04 [2] CRAN (R 3.6.1)
vctrs 0.2.2 2020-01-24 [2] CRAN (R 3.6.2)
viridisLite 0.3.0 2018-02-01 [2] CRAN (R 3.6.0)
webshot 0.5.2 2019-11-22 [2] CRAN (R 3.6.1)
whisker 0.4 2019-08-28 [2] CRAN (R 3.6.1)
withr 2.1.2 2018-03-15 [2] CRAN (R 3.6.0)
workflowr * 1.6.0 2019-12-19 [2] CRAN (R 3.6.2)
xfun 0.12 2020-01-13 [2] CRAN (R 3.6.2)
XML 3.99-0.3 2020-01-20 [2] CRAN (R 3.6.2)
xml2 1.2.2 2019-08-09 [2] CRAN (R 3.6.1)
XVector 0.26.0 2019-10-29 [2] Bioconductor
yaml 2.2.0 2018-07-25 [2] CRAN (R 3.6.0)
zlibbioc 1.32.0 2019-10-29 [2] Bioconductor
zoo 1.8-7 2020-01-10 [2] CRAN (R 3.6.2)
[1] /home/steveped/R/x86_64-pc-linux-gnu-library/3.6
[2] /usr/local/lib/R/site-library
[3] /usr/lib/R/site-library
[4] /usr/lib/R/library