3-mediation_late
bernard-liew
2020-06-10
Last updated: 2020-07-06
Checks: 6 1
Knit directory: 2020_LBPcausal/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of the R Markdown file created these results, you’ll want to first commit it to the Git repo. If you’re still working on the analysis, you can ignore this warning. When you’re finished, you can run wflow_publish to commit the R Markdown file and build the HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200422) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version c6431d0. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/figure/
Ignored: output/data_clean.xlsx
Untracked files:
Untracked: analysis/5-mediation_early2laterr.Rmd
Unstaged changes:
Modified: analysis/2-mediation_early.Rmd
Modified: analysis/3-mediation_late.Rmd
Modified: analysis/index.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/3-mediation_late.Rmd) and HTML (docs/3-mediation_late.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | c6431d0 | bernard-liew | 2020-07-03 | changed early2late mediation |
| html | c6431d0 | bernard-liew | 2020-07-03 | changed early2late mediation |
| Rmd | 024005a | bernard-liew | 2020-07-03 | changed figures and plot size |
| html | 024005a | bernard-liew | 2020-07-03 | changed figures and plot size |
| html | e41cc86 | bernard-liew | 2020-07-03 | Build site. |
| Rmd | ed632b0 | bernard-liew | 2020-07-03 | Initial bayesian network analysis |
| Rmd | f5b55d7 | bernard-liew | 2020-07-02 | removed function variable |
| Rmd | 807f52c | bernard-liew | 2020-07-02 | added all possible change values |
| Rmd | 127e9d3 | bernard-liew | 2020-06-11 | Original analysis |
Load library
# Helper packages
library (tidyverse)
library (tidyselect)
library (arsenal)
library (janitor)
library (magrittr)
library (Rgraphviz)
library (corrr)
# Import
library(readxl)
library (xlsx)
# Missing data
library (mice)
library (VIM)
# Modelling
library (bnlearn)
library (caret)
# Parallel
library (doParallel)Introduction
This is a bayesian network analysis where the variables are the change scores between week 52 and baseline.
Import data
rm (list = ls())
df_list <- readRDS("output/df_change.RDS")Subset data
df <- df_list[["wk52_base"]]
names(df)[1:8] <- paste0(str_remove(names(df)[1:8] , "wk52_"), "_late")Exploratory analysis
Between group comparisons
tableby (subgrp ~., data = df, digits = 2, digits.p = 2) %>%
summary () | dhr (N=54) | nrdp (N=8) | rdp (N=63) | mfp (N=91) | mtg (N=74) | Total (N=290) | p value | |
|---|---|---|---|---|---|---|---|
| osw_late | 0.10 | ||||||
| N-Miss | 1 | 0 | 6 | 4 | 2 | 13 | |
| Mean (SD) | -18.81 (16.70) | -14.50 (7.15) | -11.42 (11.50) | -13.85 (12.69) | -14.21 (15.68) | -14.41 (14.13) | |
| Range | -48.00 - 24.00 | -22.00 - 0.00 | -40.00 - 20.00 | -35.00 - 27.56 | -58.00 - 30.00 | -58.00 - 30.00 | |
| lbp_late | 0.06 | ||||||
| N-Miss | 1 | 0 | 6 | 4 | 1 | 12 | |
| Mean (SD) | -2.07 (2.78) | -2.44 (3.62) | -2.40 (2.24) | -2.72 (2.44) | -3.33 (2.21) | -2.68 (2.47) | |
| Range | -6.50 - 4.00 | -9.00 - 2.00 | -7.00 - 2.00 | -7.00 - 4.00 | -8.00 - 2.00 | -9.00 - 4.00 | |
| lp_late | 0.24 | ||||||
| N-Miss | 1 | 1 | 19 | 18 | 10 | 49 | |
| Mean (SD) | -3.41 (2.99) | -2.86 (2.12) | -2.14 (2.67) | -2.71 (2.60) | -2.48 (3.05) | -2.70 (2.82) | |
| Range | -8.00 - 1.50 | -5.00 - 0.00 | -7.00 - 2.50 | -9.00 - 6.00 | -8.00 - 7.00 | -9.00 - 7.00 | |
| pain_cope_success_late | 0.63 | ||||||
| N-Miss | 2 | 1 | 11 | 18 | 12 | 44 | |
| Mean (SD) | -1.30 (3.09) | -1.27 (3.36) | -2.13 (2.88) | -1.36 (3.38) | -1.82 (3.55) | -1.62 (3.26) | |
| Range | -6.00 - 7.00 | -5.00 - 5.00 | -9.00 - 4.00 | -9.00 - 7.00 | -8.00 - 7.00 | -9.00 - 7.00 | |
| anx_late | 0.05 | ||||||
| N-Miss | 2 | 1 | 11 | 17 | 12 | 43 | |
| Mean (SD) | -2.15 (2.87) | -4.71 (3.35) | -1.45 (2.47) | -1.69 (2.96) | -2.22 (2.88) | -1.96 (2.87) | |
| Range | -9.00 - 3.00 | -10.00 - -2.00 | -8.00 - 3.00 | -9.00 - 6.00 | -7.00 - 6.00 | -10.00 - 6.00 | |
| depress_late | 0.02 | ||||||
| N-Miss | 2 | 1 | 13 | 17 | 13 | 46 | |
| Mean (SD) | -1.75 (3.03) | -4.43 (3.60) | -0.99 (2.80) | -0.76 (3.13) | -1.40 (2.70) | -1.28 (3.00) | |
| Range | -9.00 - 7.00 | -10.00 - -1.00 | -7.00 - 7.00 | -8.00 - 8.00 | -7.00 - 6.00 | -10.00 - 8.00 | |
| pain_persist_late | 0.03 | ||||||
| N-Miss | 2 | 1 | 12 | 18 | 12 | 45 | |
| Mean (SD) | -2.25 (3.35) | -6.29 (2.69) | -1.66 (3.50) | -2.40 (3.60) | -2.19 (3.64) | -2.27 (3.56) | |
| Range | -9.00 - 8.00 | -9.00 - -1.00 | -9.00 - 8.00 | -10.00 - 6.00 | -8.00 - 8.00 | -10.00 - 8.00 | |
| fear_late | 0.90 | ||||||
| N-Miss | 5 | 2 | 12 | 18 | 13 | 50 | |
| Mean (SD) | -4.57 (6.65) | -2.33 (10.41) | -3.63 (6.34) | -4.35 (7.00) | -4.50 (7.05) | -4.23 (6.86) | |
| Range | -20.00 - 10.00 | -19.00 - 8.00 | -25.00 - 10.00 | -21.00 - 18.00 | -24.00 - 9.00 | -25.00 - 18.00 | |
| grp | 0.99 | ||||||
| advice | 26 (48.1%) | 3 (37.5%) | 30 (47.6%) | 43 (47.3%) | 35 (47.3%) | 137 (47.2%) | |
| individualisedphysio | 28 (51.9%) | 5 (62.5%) | 33 (52.4%) | 48 (52.7%) | 39 (52.7%) | 153 (52.8%) | |
| id | < 0.01 | ||||||
| Mean (SD) | 1526.96 (209.06) | 4571.12 (52.77) | 5529.14 (211.09) | 2514.09 (228.03) | 3515.42 (234.58) | 3297.53 (1403.37) | |
| Range | 1101.00 - 1806.00 | 4501.00 - 4652.00 | 5101.00 - 5903.00 | 2101.00 - 2951.00 | 3101.00 - 3905.00 | 1101.00 - 5903.00 |
Correlation plots
df %>%
select_if (is.numeric) %>%
select(-id) %>%
correlate() %>%
rearrange() %>%
network_plot(colors = c("red", "green"))
Correlation method: 'pearson'
Missing treated using: 'pairwise.complete.obs'Registered S3 method overwritten by 'seriation':
method from
reorder.hclust gclus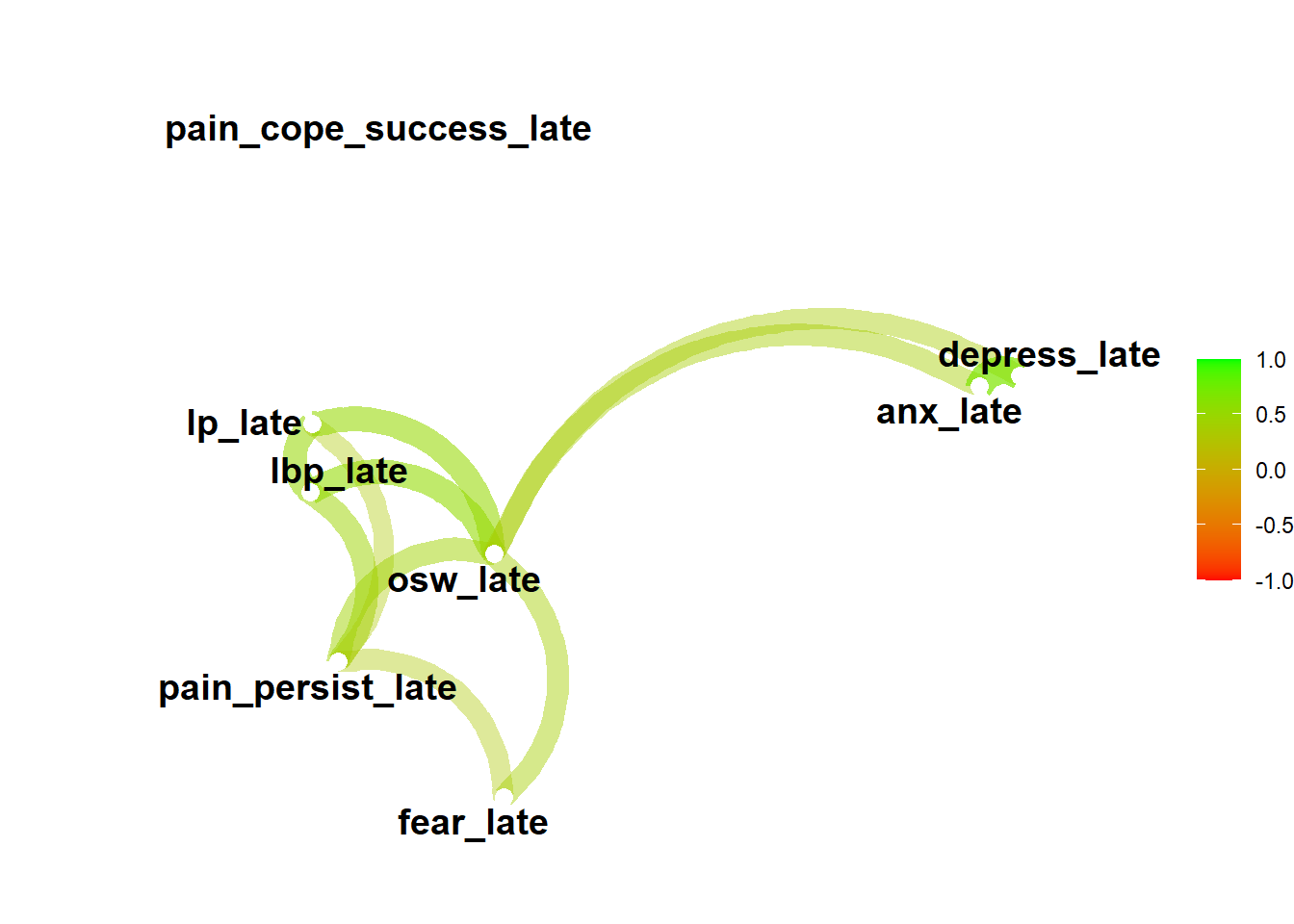
BN analysis
Early change
Create blacklist
df.bn = as.data.frame (df)
df.bn$id <- NULL
df.bn$subgrp <- NULL # since the earlier descriptives show no difference using ANOVA
tiers_bl = list (colnames (df.bn)[colnames(df.bn) %in% grep ("grp",colnames(df.bn), value = TRUE)],
colnames (df.bn)[colnames(df.bn) %in% grep ("late",colnames(df.bn), value = TRUE)])
bl1 = tiers2blacklist(tiers_bl)
bl = rbind(bl1)Create whitelist
wl = matrix(c("grp", "lbp_late"), nrow = 1, ncol = 2, byrow = TRUE,
dimnames = list(NULL,c("from", "to")))
wl = rbind(wl,
c("grp", "lp_late"),
c("grp", "osw_late")) Build BN model
Just with blacklist
doParallel::registerDoParallel(7)
n_boot = 200
############
boot_bl <- foreach (B = 1: n_boot) %dopar%{
boot.sample = df.bn[sample(nrow(df.bn),
nrow(df.bn), replace = TRUE), ]
bnlearn::structural.em(boot.sample, impute = "bayes-lw", max.iter = 3,
maximize.args = list(blacklist = bl))
}
#############See results
bootstr = custom.strength(boot_bl, nodes = names(df.bn))
avg = averaged.network(bootstr, threshold = 0.5)Warning in averaged.network.backend(strength = strength, nodes = nodes, : arc
anx_late -> depress_late would introduce cycles in the graph, ignoring.fit = bn.fit (avg, df.bn, method = "mle")
g = strength.plot(avg,
bootstr,
shape = "rectangle",
main = "Figure")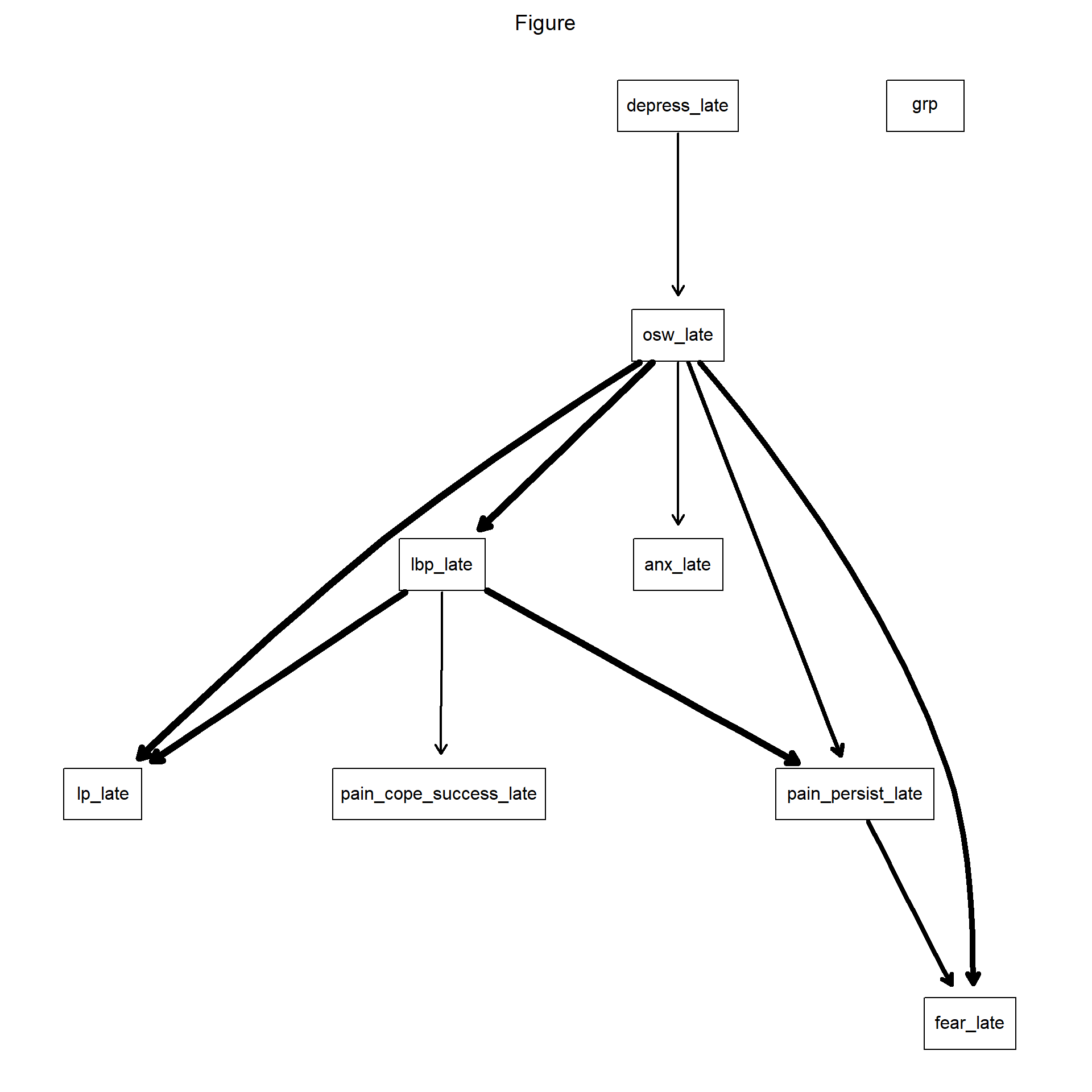
graph::nodeRenderInfo(g) = list(fontsize=18)With blacklist and whitelist
doParallel::registerDoParallel(7)
n_boot = 200
############
boot_wl = foreach (B = 1: n_boot) %dopar%{
boot.sample = df.bn[sample(nrow(df.bn),
nrow(df.bn), replace = TRUE), ]
bnlearn::structural.em(boot.sample, impute = "bayes-lw", max.iter = 3,
maximize.args = list(blacklist = bl))
}
#############See results
bootstr = custom.strength(boot_wl, nodes = names(df.bn))
avg = averaged.network(bootstr, threshold = 0.5)
fit = bn.fit (avg, df.bn, method = "mle")
g = strength.plot(avg,
bootstr,
shape = "rectangle",
highlight = list (arcs = wl),
main = "Figure")
graph::nodeRenderInfo(g) = list(fontsize=18)Performance evaluation
On model with just blacklist
Nested Cross validation. Inner is bootstrap resampling for model averaging. Outer is 10 fold CV for performance evaluation.
flds <- flds <- createFolds(1:nrow(df.bn),
k = 10, list = TRUE, returnTrain = TRUE)
n_boot = 200
doParallel::registerDoParallel(7)
corr.df.list <- list()
for (k in seq_along(flds)) {
train <- df.bn [flds[[k]], ] %>% as.data.frame()
test <- df.bn [-flds[[k]], ] %>% as.data.frame()
############
boot = foreach (B = 1: n_boot) %dopar%{
boot.sample = train[sample(nrow(train),
nrow(train), replace = TRUE), ]
bnlearn::structural.em(boot.sample, impute = "bayes-lw", max.iter = 3,
maximize.args = list(blacklist = bl,
#whitelist = wl.list[[n]],
k = log(nrow(boot.sample))))
}
#############
bootstr <- custom.strength(boot, nodes = names(train))
avg <- averaged.network(bootstr, threshold = 0.5)
fit <- bn.fit (avg, train, method = "mle")
imp.list = impute (fit, data = test, method = "bayes-lw")
inames = names (imp.list) [!names (imp.list) %in% c("grp", "subgrp")]
corr.df = structure(numeric(length (inames)), names = inames)
for (var in inames) {
corr.df[var] = cor(predict(fit, data = imp.list, var, method = "bayes-lw"),
imp.list[, var])
}
corr.df.list[[k]] <- corr.df
}
corr.df <- bind_cols (corr.df.list) %>%
apply (1, mean)
names (corr.df) <- inames
corr.df
cat ("The mean correlation is:", mean (corr.df))On model with blacklist and whitelist
Nested Cross validation. Inner is bootstrap resampling for model averaging. Outer is 10 fold CV for performance evaluation.
flds <- flds <- createFolds(1:nrow(df.bn),
k = 10, list = TRUE, returnTrain = TRUE)
n_boot = 200
doParallel::registerDoParallel(7)
corr.df.list <- list()
for (k in seq_along(flds)) {
train <- df.bn [flds[[k]], ] %>% as.data.frame()
test <- df.bn [-flds[[k]], ] %>% as.data.frame()
############
boot = foreach (B = 1: n_boot) %dopar%{
boot.sample = train[sample(nrow(train),
nrow(train), replace = TRUE), ]
bnlearn::structural.em(boot.sample, impute = "bayes-lw", max.iter = 3,
maximize.args = list(blacklist = bl,
whitelist = wl,
k = log(nrow(boot.sample))))
}
#############
bootstr <- custom.strength(boot, nodes = names(train))
avg <- averaged.network(bootstr, threshold = 0.5)
fit <- bn.fit (avg, train, method = "mle")
imp.list = impute (fit, data = test, method = "bayes-lw")
inames = names (imp.list) [!names (imp.list) %in% c("grp", "subgrp")]
corr.df = structure(numeric(length (inames)), names = inames)
for (var in inames) {
corr.df[var] = cor(predict(fit, data = imp.list, var, method = "bayes-lw"),
imp.list[, var])
}
corr.df.list[[k]] <- corr.df
}
corr.df <- bind_cols (corr.df.list) %>%
apply (1, mean)
names (corr.df) <- inames
corr.df
cat ("The mean correlation is:", mean (corr.df))
sessionInfo()R version 3.6.2 (2019-12-12)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 18363)
Matrix products: default
locale:
[1] LC_COLLATE=English_United Kingdom.1252
[2] LC_CTYPE=English_United Kingdom.1252
[3] LC_MONETARY=English_United Kingdom.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United Kingdom.1252
attached base packages:
[1] grid parallel stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] doParallel_1.0.15 iterators_1.0.12 foreach_1.5.0
[4] caret_6.0-86 lattice_0.20-38 bnlearn_4.5
[7] VIM_5.1.1 data.table_1.12.8 colorspace_1.4-1
[10] mice_3.9.0 xlsx_0.6.3 readxl_1.3.1
[13] corrr_0.4.2 Rgraphviz_2.30.0 graph_1.64.0
[16] BiocGenerics_0.32.0 magrittr_1.5 janitor_2.0.1
[19] arsenal_3.4.0 tidyselect_1.1.0 forcats_0.5.0
[22] stringr_1.4.0 dplyr_0.8.4 purrr_0.3.3
[25] readr_1.3.1 tidyr_1.0.0 tibble_3.0.1
[28] ggplot2_3.3.2 tidyverse_1.3.0 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] backports_1.1.5 plyr_1.8.6 sp_1.4-2
[4] splines_3.6.2 digest_0.6.23 htmltools_0.5.0
[7] viridis_0.5.1 gdata_2.18.0 fansi_0.4.0
[10] cluster_2.1.0 gclus_1.3.2 openxlsx_4.1.5
[13] recipes_0.1.13 modelr_0.1.8 gower_0.2.2
[16] ggrepel_0.8.2 blob_1.2.1 rvest_0.3.5
[19] haven_2.2.0 xfun_0.15 crayon_1.3.4
[22] jsonlite_1.6 survival_3.2-3 zoo_1.8-8
[25] glue_1.3.1 registry_0.5-1 gtable_0.3.0
[28] ipred_0.9-9 car_3.0-8 DEoptimR_1.0-8
[31] abind_1.4-5 scales_1.1.1 DBI_1.1.0
[34] Rcpp_1.0.3 viridisLite_0.3.0 laeken_0.5.1
[37] foreign_0.8-72 stats4_3.6.2 lava_1.6.7
[40] prodlim_2019.11.13 vcd_1.4-7 httr_1.4.1
[43] gplots_3.0.3 ellipsis_0.3.1 farver_2.0.3
[46] pkgconfig_2.0.3 rJava_0.9-12 nnet_7.3-14
[49] dbplyr_1.4.4 labeling_0.3 rlang_0.4.6
[52] reshape2_1.4.4 later_1.0.0 munsell_0.5.0
[55] cellranger_1.1.0 tools_3.6.2 cli_2.0.2
[58] generics_0.0.2 ranger_0.12.1 broom_0.5.6
[61] evaluate_0.14 yaml_2.2.1 ModelMetrics_1.2.2.2
[64] knitr_1.29 fs_1.3.1 zip_2.0.4
[67] robustbase_0.93-6 caTools_1.18.0 dendextend_1.13.4
[70] nlme_3.1-142 whisker_0.4 xml2_1.2.2
[73] compiler_3.6.2 rstudioapi_0.11 curl_4.3
[76] e1071_1.7-3 reprex_0.3.0 stringi_1.4.3
[79] highr_0.8 Matrix_1.2-18 vctrs_0.3.1
[82] pillar_1.4.4 lifecycle_0.2.0 lmtest_0.9-37
[85] bitops_1.0-6 seriation_1.2-8 httpuv_1.5.2
[88] R6_2.4.1 promises_1.1.0 TSP_1.1-10
[91] gridExtra_2.3 KernSmooth_2.23-17 rio_0.5.16
[94] codetools_0.2-16 boot_1.3-25 MASS_7.3-51.6
[97] gtools_3.8.2 assertthat_0.2.1 xlsxjars_0.6.1
[100] rprojroot_1.3-2 withr_2.2.0 hms_0.5.3
[103] rpart_4.1-15 timeDate_3043.102 class_7.3-17
[106] rmarkdown_2.3 snakecase_0.11.0 carData_3.0-4
[109] git2r_0.27.1 pROC_1.16.2 lubridate_1.7.4