Consider Other metrics for PSI
Last updated: 2022-10-18
Checks: 6 1
Knit directory: ChromatinSplicingQTLs/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown is untracked by Git. To know which version of the R Markdown file created these results, you’ll want to first commit it to the Git repo. If you’re still working on the analysis, you can ignore this warning. When you’re finished, you can run wflow_publish to commit the R Markdown file and build the HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20191126) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version ef85e53. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.Rhistory
Ignored: code/.DS_Store
Ignored: code/.RData
Ignored: code/._.DS_Store
Ignored: code/._README.md
Ignored: code/._report.html
Ignored: code/.ipynb_checkpoints/
Ignored: code/.snakemake/
Ignored: code/APA_Processing/
Ignored: code/Alignments/
Ignored: code/ChromHMM/
Ignored: code/ENCODE/
Ignored: code/ExpressionAnalysis/
Ignored: code/FastqFastp/
Ignored: code/FastqFastpSE/
Ignored: code/Genotypes/
Ignored: code/IntronSlopes/
Ignored: code/Metaplots/
Ignored: code/Misc/
Ignored: code/MiscCountTables/
Ignored: code/Multiqc/
Ignored: code/Multiqc_chRNA/
Ignored: code/NonCodingRNA_annotation/
Ignored: code/PeakCalling/
Ignored: code/Phenotypes/
Ignored: code/PlotGruberQTLs/
Ignored: code/PlotQTLs/
Ignored: code/ProCapAnalysis/
Ignored: code/QC/
Ignored: code/QTL_SNP_Enrichment/
Ignored: code/QTLs/
Ignored: code/ReferenceGenome/
Ignored: code/Rplots.pdf
Ignored: code/Session.vim
Ignored: code/SplicingAnalysis/
Ignored: code/TODO
Ignored: code/Tehranchi/
Ignored: code/bigwigs/
Ignored: code/bigwigs_FromNonWASPFilteredReads/
Ignored: code/config/.DS_Store
Ignored: code/config/._.DS_Store
Ignored: code/config/.ipynb_checkpoints/
Ignored: code/debug.ipynb
Ignored: code/debug_python.ipynb
Ignored: code/deepTools/
Ignored: code/featureCounts/
Ignored: code/gwas_summary_stats/
Ignored: code/hyprcoloc/
Ignored: code/igv_session.xml
Ignored: code/log
Ignored: code/logs/
Ignored: code/notebooks/.ipynb_checkpoints/
Ignored: code/pi1/
Ignored: code/rules/.CreateUnstandardizedPhenotypeMatrices.smk.swp
Ignored: code/rules/.ipynb_checkpoints/
Ignored: code/rules/OldRules/
Ignored: code/rules/notebooks/
Ignored: code/scratch/
Ignored: code/scripts/.ipynb_checkpoints/
Ignored: code/scripts/GTFtools_0.8.0/
Ignored: code/scripts/__pycache__/
Ignored: code/scripts/liftOverBedpe/liftOverBedpe.py
Ignored: code/snakemake.log
Ignored: code/snakemake.sbatch.log
Ignored: code/test.introns.bed
Ignored: code/test.introns2.bed
Ignored: data/.DS_Store
Ignored: data/._.DS_Store
Ignored: data/._20220414203249_JASPAR2022_combined_matrices_25818_jaspar.txt
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-10.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-11.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-2.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-3.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-4.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-5.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-6.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-7.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022-8.csv
Ignored: data/GWAS_catalog_summary_stats_sources/._list_gwas_summary_statistics_6_Apr_2022.csv
Untracked files:
Untracked: analysis/20221016_ExplorePSI_alternatives.Rmd
Untracked: code/rules/CreateUnstandardizedPhenotypeMatrices.smk
Untracked: code/scripts/PrepareLogCPM_PhenotypeTables.R
Untracked: code/scripts/PrepareLogRPKM_H3K36ME3_PhenotypeTables.R
Untracked: code/scripts/PrepareLogRPKM_PhenotypeTables.R
Untracked: code/scripts/PrepareUnstandardizedPSIPhenotypeTables.R
Untracked: code/snakemake_profiles/slurm/__pycache__/
Unstaged changes:
Modified: analysis/20220928_ExploreIntronSum.Rmd
Modified: analysis/20221011_PlotHeatmapManyWays_ncRNA_Updated.Rmd
Modified: analysis/20221012_IntronRetentionAndExpressionConcordance.Rmd
Modified: code/Snakefile
Modified: code/envs/bedparse.yml
Modified: code/rules/ExpressionAnalysis.smk
Modified: code/rules/Metaplots.smk
Modified: code/rules/QTLTools.smk
Modified: code/rules/SplicingAnalysis.smk
Modified: code/scripts/CalculatePi1_GetAscertainmentP_AllPairs.py
Modified: code/scripts/CalculatePi1_GetTraitPairs_AllTraits.R
Modified: code/scripts/GenometracksByGenotype
Modified: code/scripts/MakeBigwigList.R
Modified: code/scripts/MakeNormalizedPSI.Tables.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
There are no past versions. Publish this analysis with wflow_publish() to start tracking its development.
Intro
The leafcutter intron excision ratio (IER) is roughly analogous to a intron-centered version of the “Percent spliced in, PSI” metric used widely in the splicing field. However, it leaves a bit to be desired in terms of interpretability in a way analogous to PSI. For example, clusters with many introns will naturally have lower IER because the have to share with more introns, even though that aspect doesn’t reflect the percentage of transcripts with the particular intron spliced out. Here I will explore some other ideas to use the splice junction count (from which leafcutter IER is based) to consider alternative measures of splicing…
library(tidyverse)
library(data.table)
library(GGally)
library(edgeR)
intron.annotations <- fread("../code/SplicingAnalysis/regtools_annotate_combined/basic.bed.gz", sep='\t')
Normalized.IER.table.YRI <- fread("../code/QTLs/QTLTools/polyA.Splicing.Subset_YRI/OnlyFirstReps.sorted.qqnorm.bed.gz", sep='\t') %>%
dplyr::rename("#Chrom"="#Chr", "junc"="pid") %>%
mutate(junc = paste0("chr", junc)) %>%
dplyr::select(1:6, NA18486, NA18487)
leafcutter.IER <- fread("../code/SplicingAnalysis/leafcutter/NormalizedPsiTables/PSI.Expression.Splicing.bed.gz",sep = "\t") %>%
dplyr::select(colnames(Normalized.IER.table.YRI)) %>%
filter(junc %in% Normalized.IER.table.YRI$junc)
leafcutter.junctioncounts <- read_tsv("../code/SplicingAnalysis/leafcutter/NormalizedPsiTables/PSI.JunctionCounts.Expression.Splicing.bed.gz") %>%
dplyr::select(colnames(Normalized.IER.table.YRI)) %>%
filter(junc %in% Normalized.IER.table.YRI$junc)
rpkm <- read_tsv("../code/QTLs/QTLTools/Expression.Splicing.Subset_YRI/OnlyFirstRepsUnstandardized.qqnorm.bed.gz") %>%
dplyr::select(pid, NA18486, NA18487)Tangent for Pheonix/Yang about PLCL1:
rpkm.polyA <-read_tsv("../code/QTLs/QTLTools/Expression.Splicing.Subset_YRI/OnlyFirstRepsUnstandardized.qqnorm.bed.gz")
rpkm.chRNA <- read_tsv("../code/QTLs/QTLTools/chRNA.Expression.Splicing/OnlyFirstRepsUnstandardized.qqnorm.bed.gz")
Median.rpkm.chRNA <- rpkm.chRNA %>%
column_to_rownames("pid") %>%
dplyr::select(-c(1:6)) %>%
apply(1, median) %>%
as.data.frame() %>%
rownames_to_column("Geneid") %>%
dplyr::select(Geneid, Log2RPKM.chRNA = ".")
Median.rpkm.polyA <- rpkm.polyA %>%
column_to_rownames("pid") %>%
dplyr::select(-c(1:6)) %>%
apply(1, median) %>%
as.data.frame() %>%
rownames_to_column("Geneid") %>%
dplyr::select(Geneid, Log2RPKM.polyA = ".")
inner_join(Median.rpkm.polyA, Median.rpkm.chRNA) %>%
ggplot(aes(x=Log2RPKM.polyA, y=Log2RPKM.chRNA)) +
geom_point(alpha=0.1) +
theme_bw()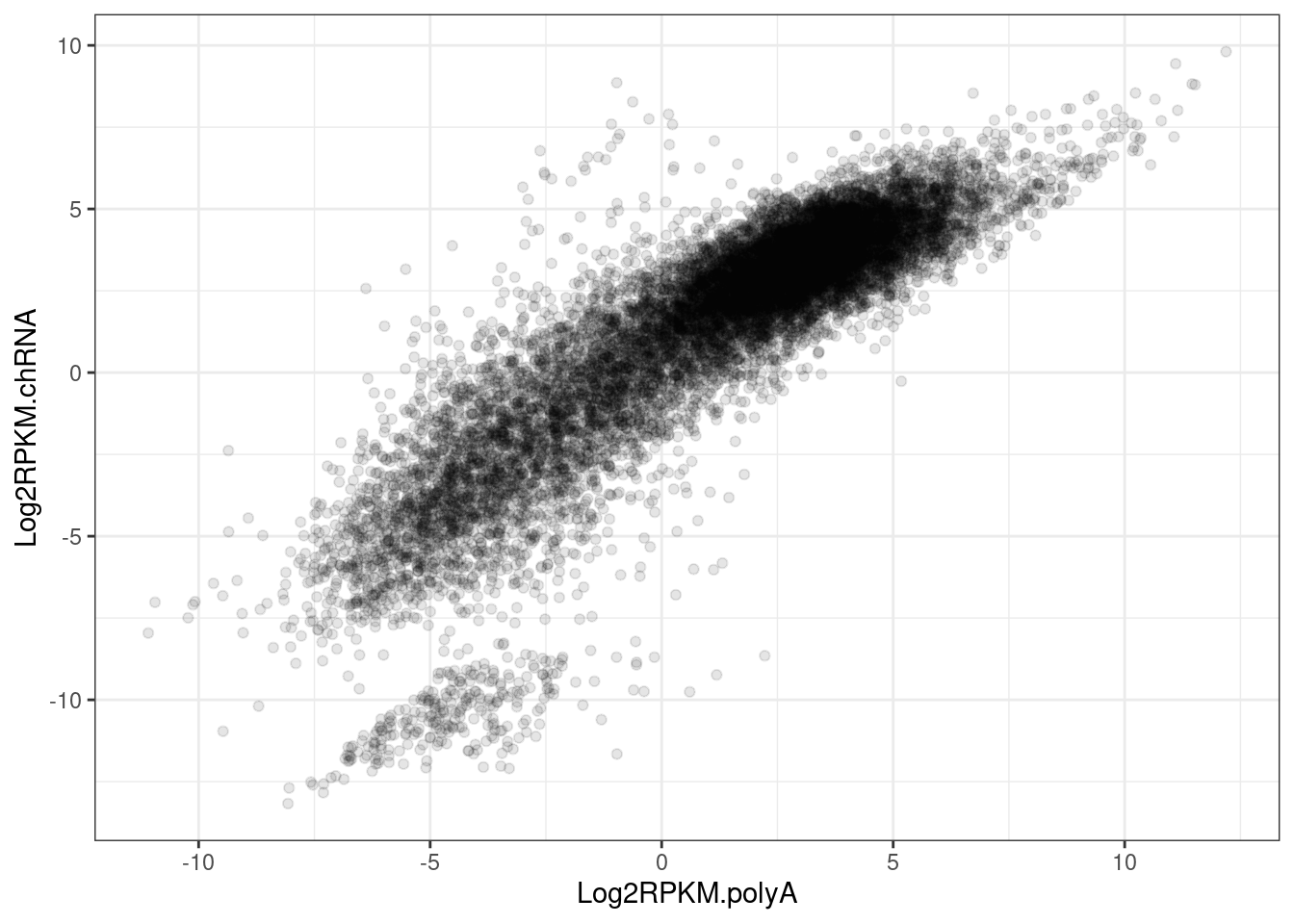
PLCL1.juncs <- Sys.glob("../code/scratch/PLCL1/*.juncs.bed") %>%
setNames(str_replace(., "../code/scratch/PLCL1/(.+?).juncs.bed", "\\1")) %>%
lapply(read_tsv) %>% bind_rows(.id="source")
PLCL1.juncs %>%
filter(end == 198083758) %>%
mutate(known_donor = factor(known_donor, levels=c(0, 1))) %>%
ggplot(aes(x=source, color=known_donor, fill=as.factor(start), y=score)) +
geom_col()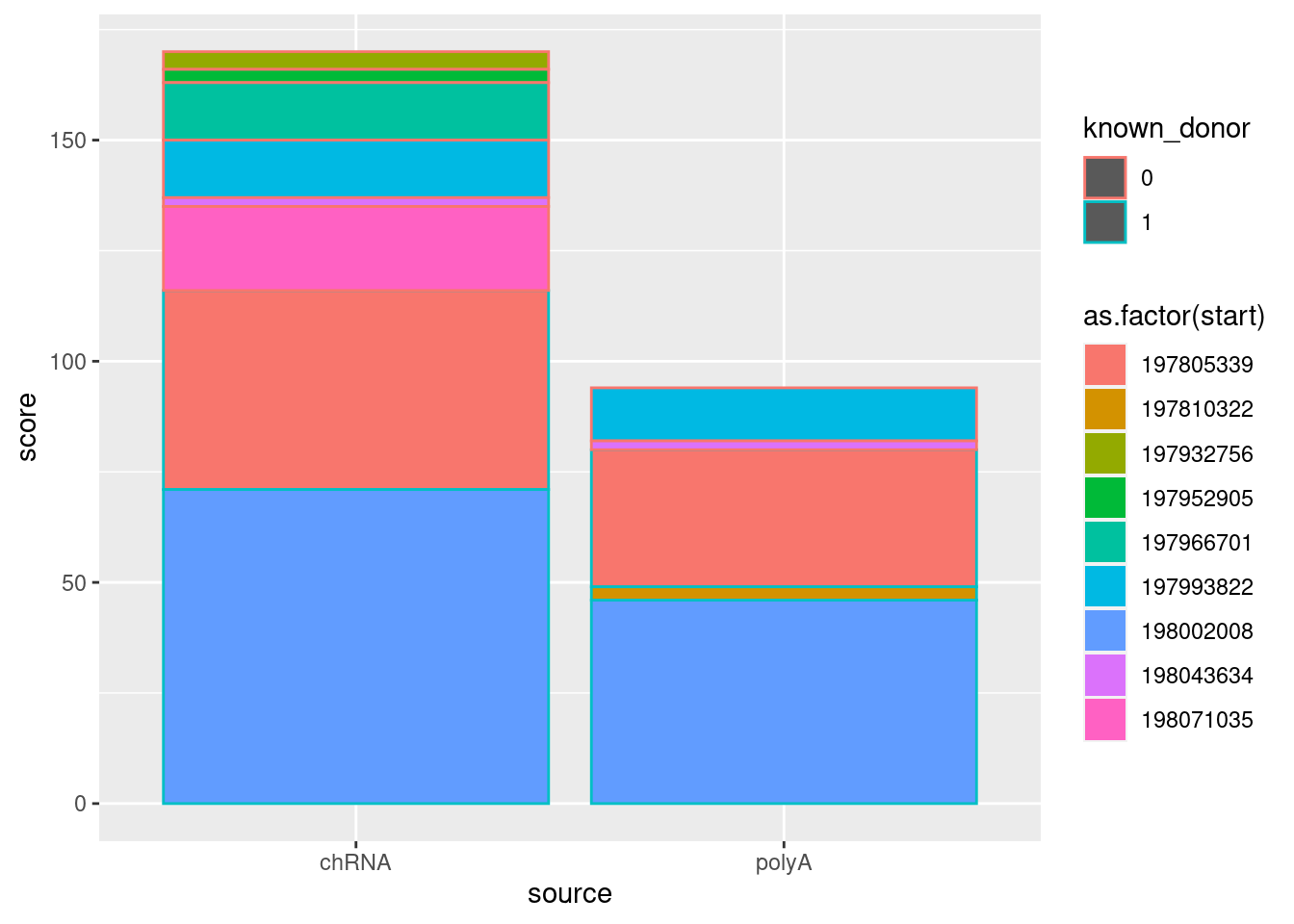
Let’s just subset a single sample to play with for simplicity
MetricsToCompare <- bind_rows(list(IER=leafcutter.IER, juncCounts=leafcutter.junctioncounts), .id="Metric") %>%
inner_join(intron.annotations, by=c("#Chrom"="chrom", "start", "end", "strand")) %>%
mutate(gene = str_replace(gene_id, "(^.+?)\\..+$", "\\1")) %>%
gather("Sample", "value", matches("^NA.+$")) %>%
inner_join(
rpkm %>%
mutate(gene = str_replace(pid, "(^.+?)\\..+$", "\\1")) %>%
gather("Sample", "log2rpkm", contains("NA"))) %>%
pivot_wider(names_from=c("Metric"), values_from=c("value")) %>%
group_by(Sample) %>%
mutate(TotalJuncCounts = sum(juncCounts)) %>%
ungroup() %>%
mutate(log2juncCountsPerTotal = log2((juncCounts+0.1)/TotalJuncCounts)) %>%
mutate(log2juncCountsPerRPKM = log2juncCountsPerTotal-log2rpkm) %>%
dplyr::select(known_junction, junc, gid, gene, Sample, log2rpkm, IER, log2juncCountsPerTotal, log2juncCountsPerRPKM) %>%
pivot_wider(names_from = "Sample", values_from = log2rpkm:log2juncCountsPerRPKM) %>%
mutate(known_junction = if_else(known_junction==1, "annotated", "unannotated"))
MetricsToCompare %>%
pivot_longer(names_to=c("Metric", "Sample"), names_sep="_", -c(1:4)) %>%
ggplot(aes(x=value, fill=known_junction)) +
geom_histogram() +
facet_grid(cols=vars(Metric), rows=vars(Sample), scales = "free")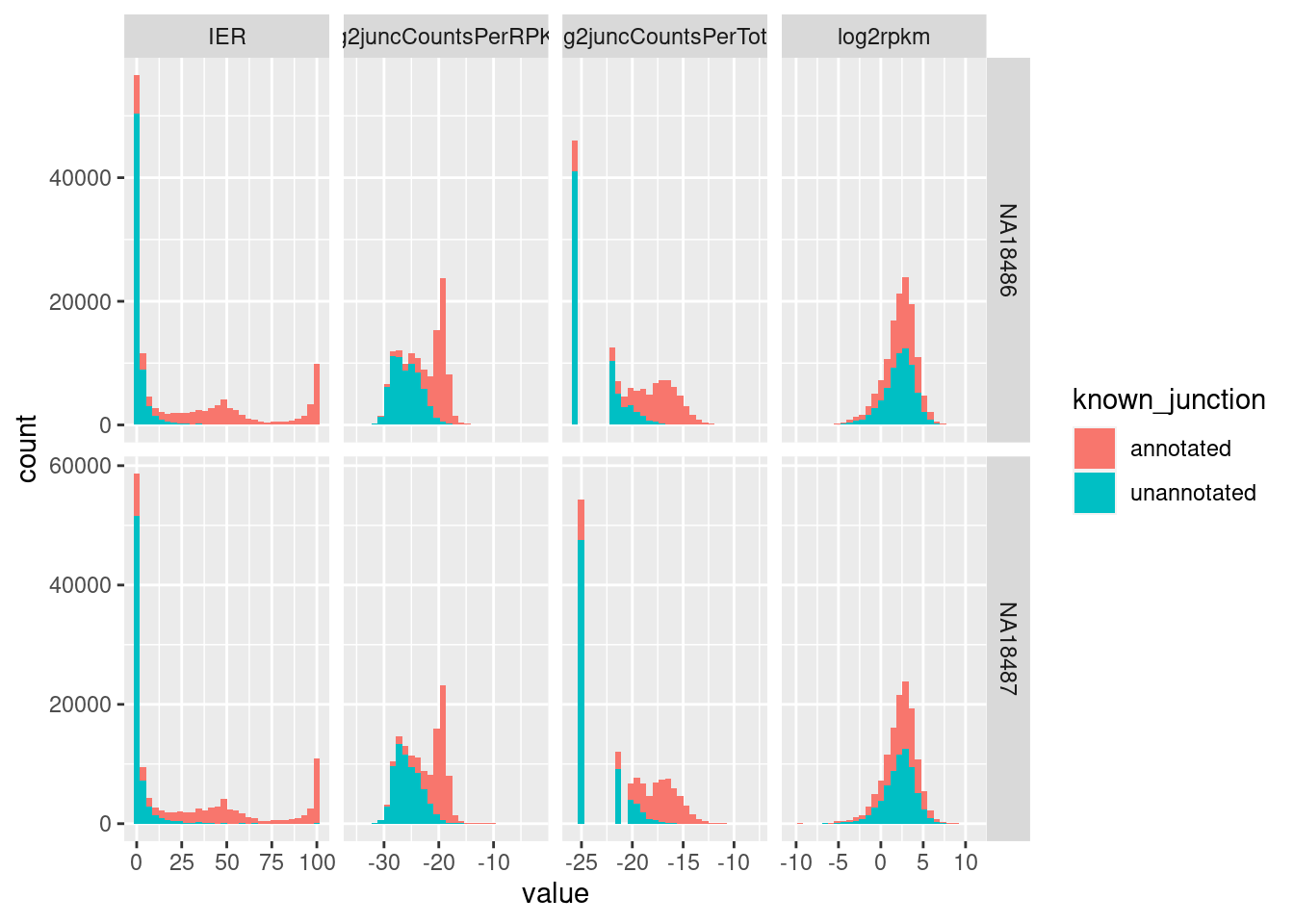
upper_point <- function(data, mapping, ...) {
ggplot(data = data, mapping = mapping, ...) +
geom_hex(bins=100) +
scale_fill_viridis_c() +
# geom_point(..., alpha=0.05) +
theme_bw()
}
MetricsToCompare %>%
ggpairs(columns=5:ncol(MetricsToCompare),
upper=list(continuous = wrap("cor", method = "spearman", hjust=0.7)),
lower=list(continuous = upper_point)) +
theme(strip.text = element_text(size = 5))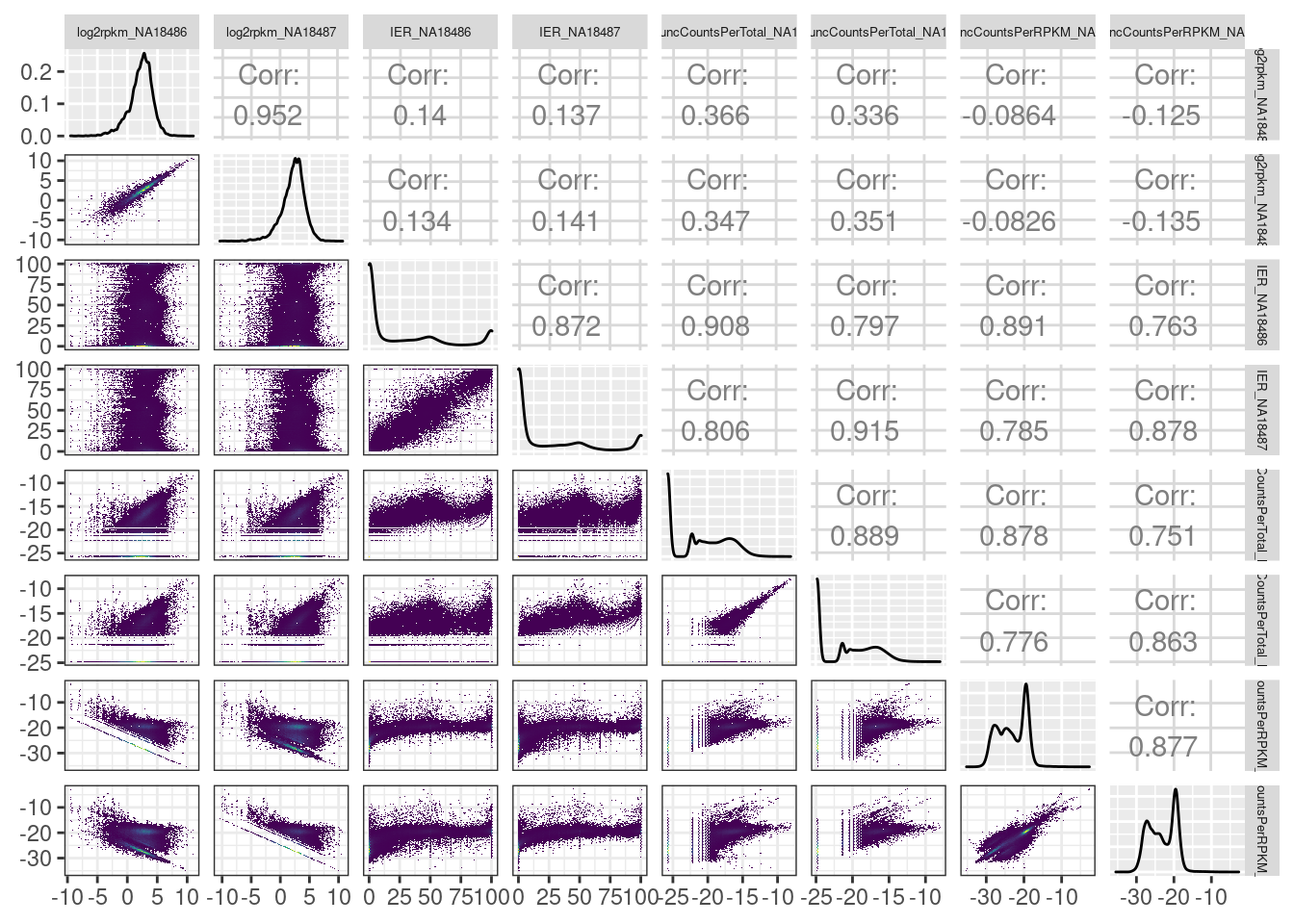
MetricsToCompare %>%
filter(known_junction=="annotated") %>%
ggpairs(columns=5:ncol(MetricsToCompare),
upper=list(continuous = wrap("cor", method = "spearman", hjust=0.7)),
lower=list(continuous = upper_point)) +
theme(strip.text = element_text(size = 5))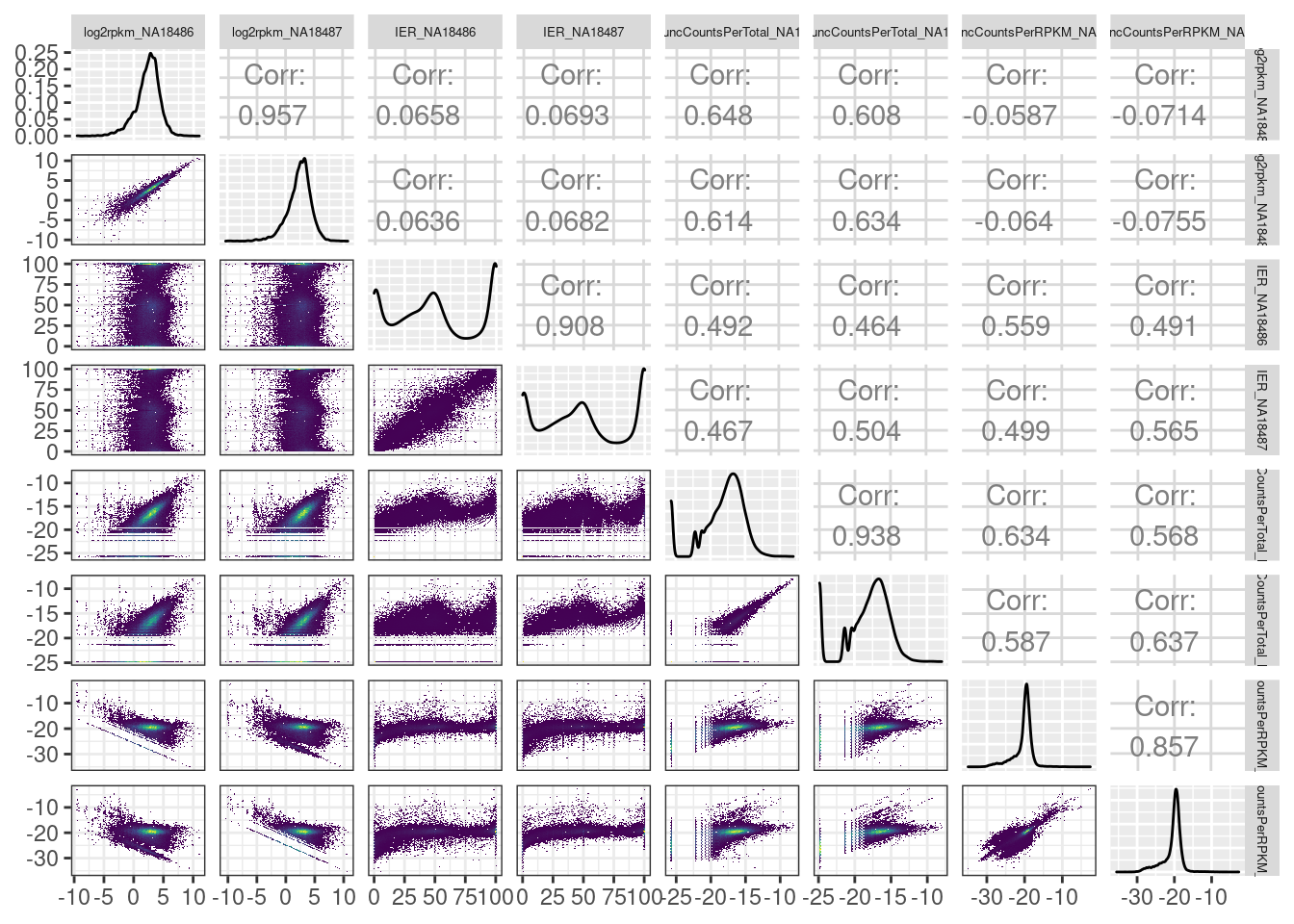
I think I will just stick with the leafcutter intron excision ratio.
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: CentOS Linux 7 (Core)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.2.19-el7-x86_64/lib/libopenblas_haswellp-r0.2.19.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C LC_TIME=C
[4] LC_COLLATE=C LC_MONETARY=C LC_MESSAGES=C
[7] LC_PAPER=C LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] edgeR_3.26.5 limma_3.40.6 GGally_1.4.0 data.table_1.14.2
[5] forcats_0.4.0 stringr_1.4.0 dplyr_1.0.9 purrr_0.3.4
[9] readr_1.3.1 tidyr_1.2.0 tibble_3.1.7 ggplot2_3.3.6
[13] tidyverse_1.3.0
loaded via a namespace (and not attached):
[1] httr_1.4.4 jsonlite_1.6 viridisLite_0.3.0 R.utils_2.9.0
[5] modelr_0.1.8 assertthat_0.2.1 highr_0.9 cellranger_1.1.0
[9] yaml_2.2.0 pillar_1.7.0 backports_1.4.1 lattice_0.20-38
[13] glue_1.6.2 digest_0.6.20 RColorBrewer_1.1-2 promises_1.0.1
[17] rvest_0.3.5 colorspace_1.4-1 htmltools_0.5.3 httpuv_1.5.1
[21] R.oo_1.22.0 plyr_1.8.4 pkgconfig_2.0.2 broom_1.0.0
[25] haven_2.3.1 scales_1.1.0 later_0.8.0 git2r_0.26.1
[29] generics_0.1.3 farver_2.1.0 ellipsis_0.3.2 withr_2.5.0
[33] hexbin_1.27.3 cli_3.3.0 magrittr_1.5 crayon_1.3.4
[37] readxl_1.3.1 evaluate_0.15 R.methodsS3_1.7.1 fs_1.5.2
[41] fansi_0.4.0 xml2_1.3.2 tools_3.6.1 hms_0.5.3
[45] lifecycle_1.0.1 munsell_0.5.0 reprex_0.3.0 locfit_1.5-9.1
[49] compiler_3.6.1 rlang_1.0.5 grid_3.6.1 rstudioapi_0.14
[53] labeling_0.3 rmarkdown_1.13 gtable_0.3.0 DBI_1.1.0
[57] reshape_0.8.8 R6_2.4.0 lubridate_1.7.4 knitr_1.39
[61] fastmap_1.1.0 utf8_1.1.4 workflowr_1.6.2 rprojroot_2.0.2
[65] stringi_1.4.3 Rcpp_1.0.5 vctrs_0.4.1 dbplyr_1.4.2
[69] tidyselect_1.1.2 xfun_0.31