Evaluate multi-mapping
Briana Mittleman
11/21/2019
Last updated: 2019-11-23
Checks: 7 0
Knit directory: Comparative_APA/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.5.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190902) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: code/chimp_log/
Ignored: code/human_log/
Ignored: data/.DS_Store
Ignored: data/RNASEQ_metadata.txt.sb-4426323c-TE4ns3/
Ignored: data/RNASEQ_metadata.txt.sb-51f67ae1-HXp7Gq/
Ignored: data/RNASEQ_metadata_2Removed.txt.sb-4426323c-a4lBwx/
Ignored: data/metadata_HCpanel.txt.sb-a3d92a2d-b9cYoF/
Ignored: data/metadata_HCpanel.txt.sb-f4823d1e-qihGek/
Untracked files:
Untracked: ._.DS_Store
Untracked: Chimp/
Untracked: Human/
Untracked: analysis/assessReadQual.Rmd
Untracked: code/._Config_chimp.yaml
Untracked: code/._Config_human.yaml
Untracked: code/._DiffSplice.sh
Untracked: code/._DiffSplicePlots.sh
Untracked: code/._DiffSplicePlots_gencode.sh
Untracked: code/._DiffSplice_gencode.sh
Untracked: code/._DiffSplice_removebad.sh
Untracked: code/._GetMAPQscore.py
Untracked: code/._GetSecondaryMap.py
Untracked: code/._LiftOrthoPAS2chimp.sh
Untracked: code/._MapBadSamples.sh
Untracked: code/._Snakefile
Untracked: code/._SnakefilePAS
Untracked: code/._SnakefilePASfilt
Untracked: code/._SortIndexBadSamples.sh
Untracked: code/._bed215upbed.py
Untracked: code/._bed2SAF_gen.py
Untracked: code/._buildIndecpantro5
Untracked: code/._buildIndecpantro5.sh
Untracked: code/._buildStarIndex.sh
Untracked: code/._cleanbed2saf.py
Untracked: code/._cluster.json
Untracked: code/._cluster2bed.py
Untracked: code/._clusterLiftReverse.sh
Untracked: code/._clusterLiftReverse_removebad.sh
Untracked: code/._clusterLiftprimary.sh
Untracked: code/._clusterLiftprimary_removebad.sh
Untracked: code/._converBam2Junc.sh
Untracked: code/._converBam2Junc_removeBad.sh
Untracked: code/._extraSnakefiltpas
Untracked: code/._filter5percPAS.py
Untracked: code/._filterPASforMP.py
Untracked: code/._filterPostLift.py
Untracked: code/._fixExonFC.py
Untracked: code/._fixUTRexonanno.py
Untracked: code/._formathg38Anno.py
Untracked: code/._formatpantro6Anno.py
Untracked: code/._getRNAseqMapStats.sh
Untracked: code/._intersectLiftedPAS.sh
Untracked: code/._liftPAS19to38.sh
Untracked: code/._makeSamplyGroupsHuman_TvN.py
Untracked: code/._mapRNAseqhg19.sh
Untracked: code/._maphg19.sh
Untracked: code/._maphg19_subjunc.sh
Untracked: code/._mergedBam2BW.sh
Untracked: code/._nameClusters.py
Untracked: code/._numMultimap.py
Untracked: code/._overlapapaQTLPAS.sh
Untracked: code/._prepareCleanLiftedFC_5perc4LC.py
Untracked: code/._preparePAS4lift.py
Untracked: code/._primaryLift.sh
Untracked: code/._processhg38exons.py
Untracked: code/._quantJunc.sh
Untracked: code/._quantJunc_removeBad.sh
Untracked: code/._recLiftchim2human.sh
Untracked: code/._revLiftPAShg38to19.sh
Untracked: code/._reverseLift.sh
Untracked: code/._runChimpDiffIso.sh
Untracked: code/._runHumanDiffIso.sh
Untracked: code/._runNuclearDifffIso.sh
Untracked: code/._run_chimpverifybam.sh
Untracked: code/._run_verifyBam.sh
Untracked: code/._snakemake.batch
Untracked: code/._snakemakePAS.batch
Untracked: code/._snakemakePASchimp.batch
Untracked: code/._snakemakePAShuman.batch
Untracked: code/._snakemake_chimp.batch
Untracked: code/._snakemake_human.batch
Untracked: code/._snakemakefiltPAS.batch
Untracked: code/._snakemakefiltPAS_chimp
Untracked: code/._snakemakefiltPAS_chimp.sh
Untracked: code/._snakemakefiltPAS_human.sh
Untracked: code/._submit-snakemake-chimp.sh
Untracked: code/._submit-snakemake-human.sh
Untracked: code/._submit-snakemakePAS-chimp.sh
Untracked: code/._submit-snakemakePAS-human.sh
Untracked: code/._submit-snakemakefiltPAS-chimp.sh
Untracked: code/._submit-snakemakefiltPAS-human.sh
Untracked: code/._subset_diffisopheno_Nuclear_HvC.py
Untracked: code/._transcriptDTplotsNuclear.sh
Untracked: code/._verifyBam4973.sh
Untracked: code/._verifyBam4973inHuman.sh
Untracked: code/._wrap_chimpverifybam.sh
Untracked: code/._wrap_verifyBam.sh
Untracked: code/.snakemake/
Untracked: code/Config_chimp.yaml
Untracked: code/Config_human.yaml
Untracked: code/DiffSplice.err
Untracked: code/DiffSplice.out
Untracked: code/DiffSplice.sh
Untracked: code/DiffSplicePlots.err
Untracked: code/DiffSplicePlots.out
Untracked: code/DiffSplicePlots.sh
Untracked: code/DiffSplicePlots_gencode.sh
Untracked: code/DiffSplice_gencode.sh
Untracked: code/DiffSplice_removebad.err
Untracked: code/DiffSplice_removebad.out
Untracked: code/DiffSplice_removebad.sh
Untracked: code/GencodeDiffSplice.err
Untracked: code/GencodeDiffSplice.out
Untracked: code/GetMAPQscore.py
Untracked: code/GetSecondaryMap.py
Untracked: code/LiftClustersFirst.err
Untracked: code/LiftClustersFirst.out
Untracked: code/LiftClustersFirst_remove.err
Untracked: code/LiftClustersFirst_remove.out
Untracked: code/LiftClustersSecond.err
Untracked: code/LiftClustersSecond.out
Untracked: code/LiftClustersSecond_remove.err
Untracked: code/LiftClustersSecond_remove.out
Untracked: code/LiftOrthoPAS2chimp.sh
Untracked: code/LiftorthoPAS.err
Untracked: code/LiftorthoPASt.out
Untracked: code/Log.out
Untracked: code/MapBadSamples.err
Untracked: code/MapBadSamples.out
Untracked: code/MapBadSamples.sh
Untracked: code/MapStats.err
Untracked: code/MapStats.out
Untracked: code/Rev_liftoverPAShg19to38.err
Untracked: code/Rev_liftoverPAShg19to38.out
Untracked: code/SAF215upbed_gen.py
Untracked: code/Snakefile
Untracked: code/SnakefilePAS
Untracked: code/SnakefilePASfilt
Untracked: code/SortIndexBadSamples.err
Untracked: code/SortIndexBadSamples.out
Untracked: code/SortIndexBadSamples.sh
Untracked: code/TotalTranscriptDTplot.err
Untracked: code/TotalTranscriptDTplot.out
Untracked: code/Upstream10Bases_general.py
Untracked: code/apaQTLsnake.err
Untracked: code/apaQTLsnake.out
Untracked: code/apaQTLsnakePAS.err
Untracked: code/apaQTLsnakePAS.out
Untracked: code/apaQTLsnakePAShuman.err
Untracked: code/bam2junc.err
Untracked: code/bam2junc.out
Untracked: code/bam2junc_remove.err
Untracked: code/bam2junc_remove.out
Untracked: code/bed215upbed.py
Untracked: code/bed2SAF_gen.py
Untracked: code/bed2saf.py
Untracked: code/bg_to_cov.py
Untracked: code/buildIndecpantro5
Untracked: code/buildIndecpantro5.sh
Untracked: code/buildStarIndex.sh
Untracked: code/callPeaksYL.py
Untracked: code/chooseAnno2Bed.py
Untracked: code/chooseAnno2SAF.py
Untracked: code/cleanbed2saf.py
Untracked: code/cluster.json
Untracked: code/cluster2bed.py
Untracked: code/clusterLiftReverse.sh
Untracked: code/clusterLiftReverse_removebad.sh
Untracked: code/clusterLiftprimary.sh
Untracked: code/clusterLiftprimary_removebad.sh
Untracked: code/clusterPAS.json
Untracked: code/clusterfiltPAS.json
Untracked: code/converBam2Junc.sh
Untracked: code/converBam2Junc_removeBad.sh
Untracked: code/convertNumeric.py
Untracked: code/environment.yaml
Untracked: code/extraSnakefiltpas
Untracked: code/filter5perc.R
Untracked: code/filter5percPAS.py
Untracked: code/filter5percPheno.py
Untracked: code/filterBamforMP.pysam2_gen.py
Untracked: code/filterMissprimingInNuc10_gen.py
Untracked: code/filterPASforMP.py
Untracked: code/filterPostLift.py
Untracked: code/filterSAFforMP_gen.py
Untracked: code/filterSortBedbyCleanedBed_gen.R
Untracked: code/filterpeaks.py
Untracked: code/fixExonFC.py
Untracked: code/fixFChead.py
Untracked: code/fixFChead_bothfrac.py
Untracked: code/fixUTRexonanno.py
Untracked: code/formathg38Anno.py
Untracked: code/generateStarIndex.err
Untracked: code/generateStarIndex.out
Untracked: code/generateStarIndexHuman.err
Untracked: code/generateStarIndexHuman.out
Untracked: code/getRNAseqMapStats.sh
Untracked: code/humanFiles
Untracked: code/intersectAnno.err
Untracked: code/intersectAnno.out
Untracked: code/intersectLiftedPAS.sh
Untracked: code/liftPAS19to38.sh
Untracked: code/liftoverPAShg19to38.err
Untracked: code/liftoverPAShg19to38.out
Untracked: code/log/
Untracked: code/make5percPeakbed.py
Untracked: code/makeFileID.py
Untracked: code/makePheno.py
Untracked: code/makeSamplyGroupsChimp_TvN.py
Untracked: code/makeSamplyGroupsHuman_TvN.py
Untracked: code/mapRNAseqhg19.sh
Untracked: code/maphg19.err
Untracked: code/maphg19.out
Untracked: code/maphg19.sh
Untracked: code/maphg19_sub.err
Untracked: code/maphg19_sub.out
Untracked: code/maphg19_subjunc.sh
Untracked: code/mergedBam2BW.sh
Untracked: code/mergedbam2bw.err
Untracked: code/mergedbam2bw.out
Untracked: code/nameClusters.py
Untracked: code/namePeaks.py
Untracked: code/nuclearTranscriptDTplot.err
Untracked: code/nuclearTranscriptDTplot.out
Untracked: code/numMultimap.py
Untracked: code/overlapPAS.err
Untracked: code/overlapPAS.out
Untracked: code/overlapapaQTLPAS.sh
Untracked: code/peak2PAS.py
Untracked: code/pheno2countonly.R
Untracked: code/prepareCleanLiftedFC_5perc4LC.py
Untracked: code/preparePAS4lift.py
Untracked: code/prepare_phenotype_table.py
Untracked: code/primaryLift.err
Untracked: code/primaryLift.out
Untracked: code/primaryLift.sh
Untracked: code/processhg38exons.py
Untracked: code/quantJunc.sh
Untracked: code/quantJunc_removeBad.sh
Untracked: code/quantLiftedPAS.err
Untracked: code/quantLiftedPAS.out
Untracked: code/quantLiftedPAS.sh
Untracked: code/quatJunc.err
Untracked: code/quatJunc.out
Untracked: code/recChimpback2Human.err
Untracked: code/recChimpback2Human.out
Untracked: code/recLiftchim2human.sh
Untracked: code/revLift.err
Untracked: code/revLift.out
Untracked: code/revLiftPAShg38to19.sh
Untracked: code/reverseLift.sh
Untracked: code/runChimpDiffIso.sh
Untracked: code/runHumanDiffIso.sh
Untracked: code/runNuclearDifffIso.sh
Untracked: code/run_Chimpleafcutter_ds.err
Untracked: code/run_Chimpleafcutter_ds.out
Untracked: code/run_Chimpverifybam.err
Untracked: code/run_Chimpverifybam.out
Untracked: code/run_Humanleafcutter_ds.err
Untracked: code/run_Humanleafcutter_ds.out
Untracked: code/run_Nuclearleafcutter_ds.err
Untracked: code/run_Nuclearleafcutter_ds.out
Untracked: code/run_chimpverifybam.sh
Untracked: code/run_verifyBam.sh
Untracked: code/run_verifybam.err
Untracked: code/run_verifybam.out
Untracked: code/slurm-62824013.out
Untracked: code/slurm-62825841.out
Untracked: code/slurm-62826116.out
Untracked: code/snakePASChimp.err
Untracked: code/snakePASChimp.out
Untracked: code/snakePAShuman.out
Untracked: code/snakemake.batch
Untracked: code/snakemakeChimp.err
Untracked: code/snakemakeChimp.out
Untracked: code/snakemakeHuman.err
Untracked: code/snakemakeHuman.out
Untracked: code/snakemakePAS.batch
Untracked: code/snakemakePASFiltChimp.err
Untracked: code/snakemakePASFiltChimp.out
Untracked: code/snakemakePASFiltHuman.err
Untracked: code/snakemakePASFiltHuman.out
Untracked: code/snakemakePASchimp.batch
Untracked: code/snakemakePAShuman.batch
Untracked: code/snakemake_chimp.batch
Untracked: code/snakemake_human.batch
Untracked: code/snakemakefiltPAS.batch
Untracked: code/snakemakefiltPAS_chimp.sh
Untracked: code/snakemakefiltPAS_human.sh
Untracked: code/submit-snakemake-chimp.sh
Untracked: code/submit-snakemake-human.sh
Untracked: code/submit-snakemakePAS-chimp.sh
Untracked: code/submit-snakemakePAS-human.sh
Untracked: code/submit-snakemakefiltPAS-chimp.sh
Untracked: code/submit-snakemakefiltPAS-human.sh
Untracked: code/subset_diffisopheno.py
Untracked: code/subset_diffisopheno_Chimp_tvN.py
Untracked: code/subset_diffisopheno_Huma_tvN.py
Untracked: code/subset_diffisopheno_Nuclear_HvC.py
Untracked: code/transcriptDTplotsNuclear.sh
Untracked: code/transcriptDTplotsTotal.sh
Untracked: code/verifyBam4973.sh
Untracked: code/verifyBam4973inHuman.sh
Untracked: code/verifybam4973.err
Untracked: code/verifybam4973.out
Untracked: code/verifybam4973HumanMap.err
Untracked: code/verifybam4973HumanMap.out
Untracked: code/wrap_Chimpverifybam.err
Untracked: code/wrap_Chimpverifybam.out
Untracked: code/wrap_chimpverifybam.sh
Untracked: code/wrap_verifyBam.sh
Untracked: code/wrap_verifybam.err
Untracked: code/wrap_verifybam.out
Untracked: data/._.DS_Store
Untracked: data/._RNASEQ_metadata.txt
Untracked: data/._RNASEQ_metadata.txt.sb-4426323c-TE4ns3
Untracked: data/._RNASEQ_metadata.txt.sb-51f67ae1-HXp7Gq
Untracked: data/._RNASEQ_metadata.xlsx
Untracked: data/._RNASEQ_metadata_2Removed.txt
Untracked: data/._RNASEQ_metadata_2Removed.txt.sb-4426323c-a4lBwx
Untracked: data/._RNASEQ_metadata_2Removed.xlsx
Untracked: data/._metadata_HCpanel.txt
Untracked: data/._metadata_HCpanel.txt.sb-a3d92a2d-b9cYoF
Untracked: data/._metadata_HCpanel.txt.sb-f4823d1e-qihGek
Untracked: data/._metadata_HCpanel.xlsx
Untracked: data/._~$RNASEQ_metadata.xlsx
Untracked: data/._~$metadata_HCpanel.xlsx
Untracked: data/CompapaQTLpas/
Untracked: data/DTmatrix/
Untracked: data/DiffIso_Nuclear/
Untracked: data/DiffSplice/
Untracked: data/DiffSplice_cluster_significance.txt
Untracked: data/DiffSplice_effect_sizes.txt
Untracked: data/DiffSplice_removeBad/
Untracked: data/DiffSplice_removeBad_cluster_significance.txt
Untracked: data/DiffSplice_removeBad_effect_sizes.txt
Untracked: data/MapStats/
Untracked: data/NuclearHvC/
Untracked: data/Peaks_5perc/
Untracked: data/Pheno_5perc/
Untracked: data/Pheno_5perc_nuclear/
Untracked: data/Pheno_5perc_total/
Untracked: data/RNASEQ_metadata.txt
Untracked: data/RNASEQ_metadata.xlsx
Untracked: data/RNASEQ_metadata_2Removed.txt
Untracked: data/RNASEQ_metadata_2Removed.xlsx
Untracked: data/TwoBadSampleAnalysis/
Untracked: data/chainFiles/
Untracked: data/cleanPeaks_anno/
Untracked: data/cleanPeaks_byspecies/
Untracked: data/cleanPeaks_lifted/
Untracked: data/liftover_files/
Untracked: data/metadata_HCpanel.txt
Untracked: data/metadata_HCpanel.xlsx
Untracked: data/primaryLift/
Untracked: data/reverseLift/
Untracked: data/~$RNASEQ_metadata.xlsx
Untracked: data/~$metadata_HCpanel.xlsx
Untracked: output/dtPlots/
Untracked: projectNotes.Rmd
Unstaged changes:
Modified: analysis/CorrbetweenInd.Rmd
Modified: analysis/MapRNAhg19.Rmd
Modified: analysis/PASnumperSpecies.Rmd
Modified: analysis/annotationInfo.Rmd
Modified: analysis/diffSplicing.Rmd
Modified: analysis/verifyBAM.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | c48aedc | brimittleman | 2019-11-24 | add multimap stat graphs |
In this analysis I will evaluate how many reads map to multiple places and see if I need to put a quality filter on multimapped reads. To do this I will look at the cigar strings and pull out the multimap numbers and quality scores. I should be able to do this with pysam.
library(tidyverse)── Attaching packages ─────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse 1.2.1 ──✔ ggplot2 3.1.1 ✔ purrr 0.3.2
✔ tibble 2.1.1 ✔ dplyr 0.8.0.1
✔ tidyr 0.8.3 ✔ stringr 1.3.1
✔ readr 1.3.1 ✔ forcats 0.3.0 ── Conflicts ────────────────────────────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()From Star documentation:
MAPQ Scores: 255 = Uniquely mapping 3 = Maps to 2 locations in the target 2 = Maps to 3 locations in the target 1 = Maps to 4-9 locations in the target 0 = Maps to 10 or more locations in the target
For multi-mappers, all alignments except one are marked with 0x100 (secondary alignment) in the FLAG (column 2 of the SAM). The unmarked alignment is selected from the best ones (i.e. highest scoring). This default behavior can be changed with –outSAMprimaryFlag AllBestScore option, that will output all alignments with the best score as primary alignments (i.e. 0x100 bit in the FLAG unset).
Get the secondry score, MAPQ, and number of hits for each read.
sbatch getRNAseqMapStats.sh
#I need to use python to evaluate this because its a huge number of lines. First I will just make a dictionary with the number of reads mapping to the location from 1-10. (NH:i:6). This is column 3 of the output.
python numMultimap.py /project2/gilad/briana/Comparative_APA/data/MapStats/Human_RNAseq_mapstats.txt /project2/gilad/briana/Comparative_APA/data/MapStats/Human_groupedMultstat.txt
python numMultimap.py /project2/gilad/briana/Comparative_APA/data/MapStats/Chimp_RNAseq_mapstats.txt /project2/gilad/briana/Comparative_APA/data/MapStats/Chimp_groupedMultstat.txtResults for number of reads mapping to N locations.
HumanMM= read.table("../data/MapStats/Human_groupedMultstat.txt", header = F, col.names = c("HI", "HumanCount"), stringsAsFactors = F)
ChimpMM=read.table("../data/MapStats/Chimp_groupedMultstat.txt",header = F, col.names = c("HI", "ChimpCount"),stringsAsFactors = F)
bothMM=HumanMM %>% inner_join(ChimpMM ,by="HI") %>% gather("species", "Count", HumanCount:ChimpCount) %>% separate(HI, into=c("N", "i", "num"),sep=":")
bothMM$num=as.integer(as.character(bothMM$num))
ggplot(bothMM, aes(x=num, y=Count, fill=species,by=species)) + geom_bar(position = "dodge",stat="identity") + labs(x="Number of loacations read maps to", y="Reads", title="Multimapping statistics for RNA seq") + scale_fill_brewer(palette = "Dark2")
Remap for only reads with more than 1 location
bothMM_minus1= bothMM %>% filter(num>1)
ggplot(bothMM_minus1, aes(x=num, y=Count, fill=species,by=species)) + geom_bar(position = "dodge",stat="identity") + labs(x="Number of loacations read maps to", y="Reads", title="Multimapping statistics for RNA seq") + scale_fill_brewer(palette = "Dark2")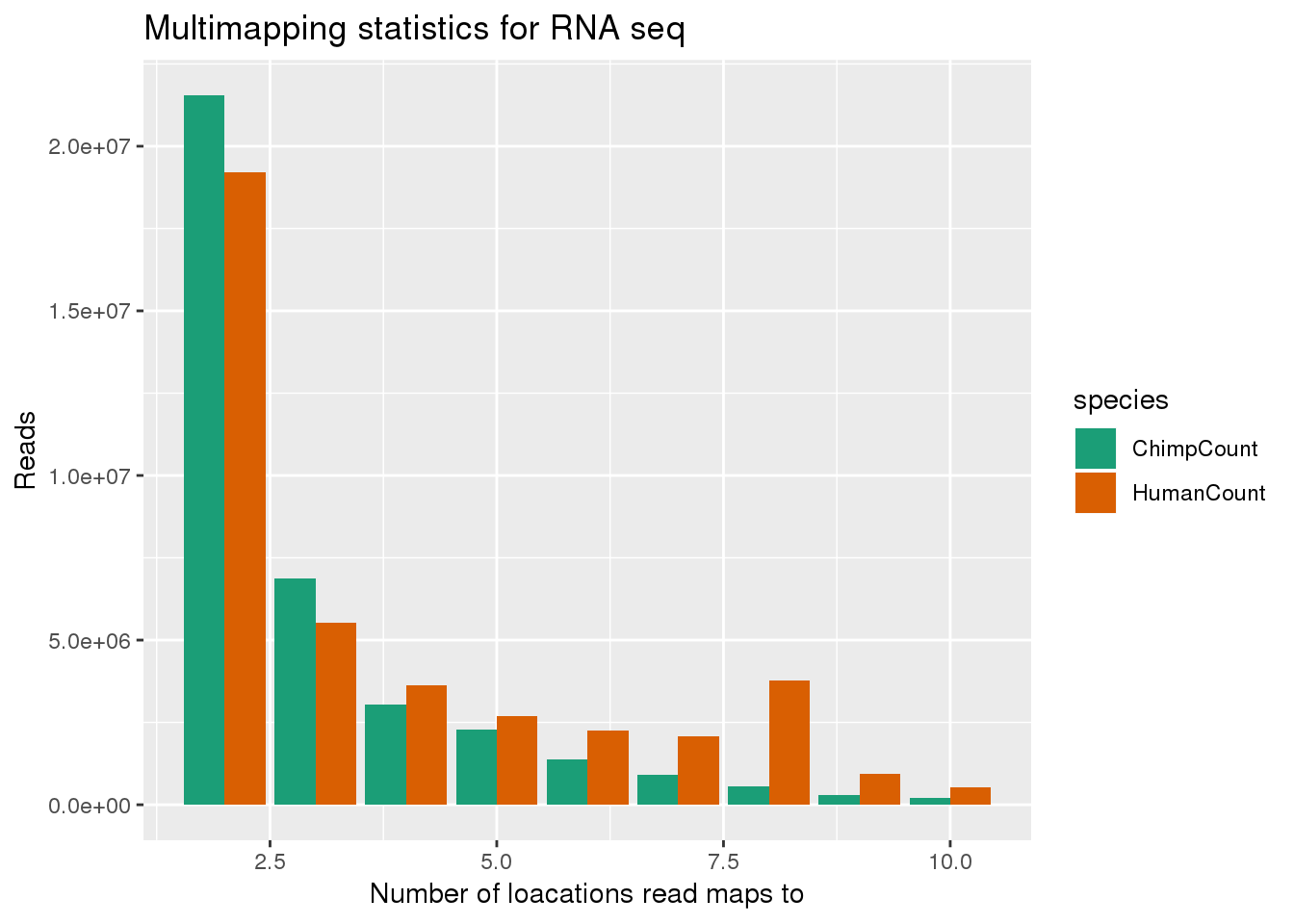
This shows that reads that map to more than one location usually map to 2 locations. I next want to look at the scores for the best hits. This is the MAPQ score. this is the second column of the stats files.
python GetMAPQscore.py /project2/gilad/briana/Comparative_APA/data/MapStats/Human_RNAseq_mapstats.txt /project2/gilad/briana/Comparative_APA/data/MapStats/Human_MAPQscore.txt
python GetMAPQscore.py /project2/gilad/briana/Comparative_APA/data/MapStats/Chimp_RNAseq_mapstats.txt /project2/gilad/briana/Comparative_APA/data/MapStats/Chimp_MAPQscore.txtResults for scores:
Humanmapq= read.table("../data/MapStats/Human_MAPQscore.txt", header = F, col.names = c("mapq", "HumanCount"), stringsAsFactors = F)
Chimpmapq=read.table("../data/MapStats/Chimp_MAPQscore.txt",header = F, col.names = c("mapq", "ChimpCount"),stringsAsFactors = F)
bothmapq=Humanmapq %>% inner_join(Chimpmapq ,by="mapq") %>% gather("species", "Count", HumanCount:ChimpCount)
ggplot(bothmapq, aes(x=mapq, y=Count, fill=species,by=species)) + geom_bar(position = "dodge",stat="identity") + labs(x="Mapq score", y="Reads", title="MapQ for RNA seq") + scale_fill_brewer(palette = "Dark2")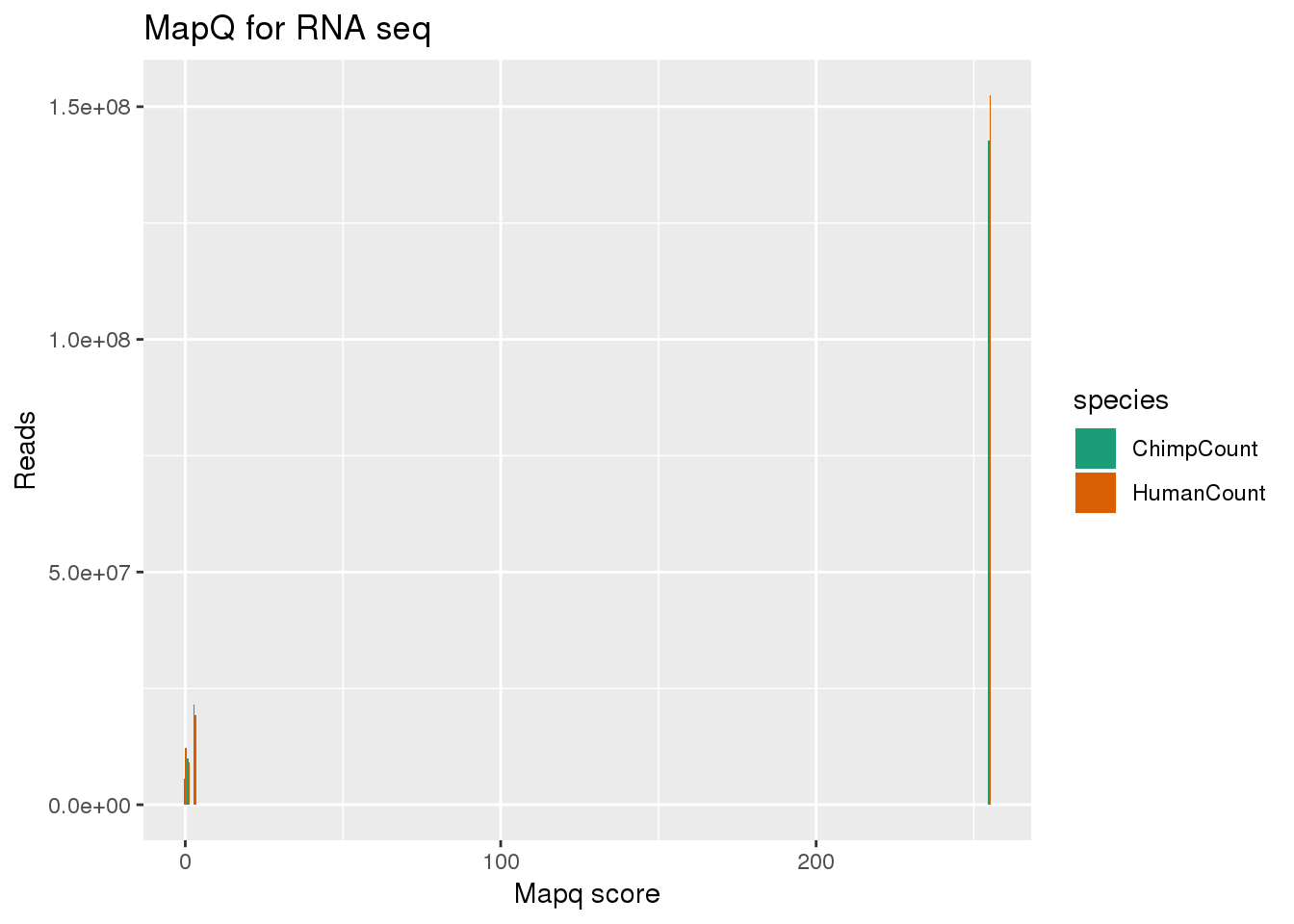 filter out 255:
filter out 255:
bothmapq_lower=bothmapq %>% filter(mapq <10)
ggplot(bothmapq_lower, aes(x=mapq, y=Count, fill=species,by=species)) + geom_bar(position = "dodge",stat="identity") + labs(x="Mapq score", y="Reads", title="MapQ for RNA seq") + scale_fill_brewer(palette = "Dark2")
Do for secondary the score are 0, 16, and 1616. I should look into this more.
python GetSecondaryMap.py /project2/gilad/briana/Comparative_APA/data/MapStats/Human_RNAseq_mapstats.txt /project2/gilad/briana/Comparative_APA/data/MapStats/Human_Secondaryscore.txt
python GetSecondaryMap.py /project2/gilad/briana/Comparative_APA/data/MapStats/Chimp_RNAseq_mapstats.txt /project2/gilad/briana/Comparative_APA/data/MapStats/Chimp_Secondaryscore.txtResults:
Humansec= read.table("../data/MapStats/Human_Secondaryscore.txt", header = F, col.names = c("secondary", "HumanCount"), stringsAsFactors = F)
Chimpsec=read.table("../data/MapStats/Chimp_Secondaryscore.txt",header = F, col.names = c("secondary", "ChimpCount"),stringsAsFactors = F)
bothsec=Humansec %>% inner_join(Chimpsec ,by="secondary") %>% gather("species", "Count", HumanCount:ChimpCount)
ggplot(bothsec, aes(x=secondary, y=Count, fill=species,by=species)) + geom_bar(position = "dodge",stat="identity") + labs(x="Secondary score", y="Reads", title="Seqcondary for RNA seq") + scale_fill_brewer(palette = "Dark2")
Look at just 0 and 16
bothsec_small= bothsec %>% filter(secondary<100)
ggplot(bothsec_small, aes(x=secondary, y=Count, fill=species,by=species)) + geom_bar(position = "dodge",stat="identity") + labs(x="Secondary score", y="Reads", title="Secondary for RNA seq") + scale_fill_brewer(palette = "Dark2")
sessionInfo()R version 3.5.1 (2018-07-02)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.4 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.2.19-el7-x86_64/lib/libopenblas_haswellp-r0.2.19.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] forcats_0.3.0 stringr_1.3.1 dplyr_0.8.0.1 purrr_0.3.2
[5] readr_1.3.1 tidyr_0.8.3 tibble_2.1.1 ggplot2_3.1.1
[9] tidyverse_1.2.1
loaded via a namespace (and not attached):
[1] tidyselect_0.2.5 haven_1.1.2 lattice_0.20-38
[4] colorspace_1.3-2 generics_0.0.2 htmltools_0.3.6
[7] yaml_2.2.0 rlang_0.4.0 later_0.7.5
[10] pillar_1.3.1 glue_1.3.0 withr_2.1.2
[13] RColorBrewer_1.1-2 modelr_0.1.2 readxl_1.1.0
[16] plyr_1.8.4 munsell_0.5.0 gtable_0.2.0
[19] workflowr_1.5.0 cellranger_1.1.0 rvest_0.3.2
[22] evaluate_0.12 labeling_0.3 knitr_1.20
[25] httpuv_1.4.5 broom_0.5.1 Rcpp_1.0.2
[28] promises_1.0.1 scales_1.0.0 backports_1.1.2
[31] jsonlite_1.6 fs_1.3.1 hms_0.4.2
[34] digest_0.6.18 stringi_1.2.4 grid_3.5.1
[37] rprojroot_1.3-2 cli_1.1.0 tools_3.5.1
[40] magrittr_1.5 lazyeval_0.2.1 crayon_1.3.4
[43] whisker_0.3-2 pkgconfig_2.0.2 xml2_1.2.0
[46] lubridate_1.7.4 assertthat_0.2.0 rmarkdown_1.10
[49] httr_1.3.1 rstudioapi_0.10 R6_2.3.0
[52] nlme_3.1-137 git2r_0.26.1 compiler_3.5.1