Making a heatmap in R with the pheatmap package
2024-07-29
Last updated: 2024-07-29
Checks: 7 0
Knit directory: muse/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200712) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 548a54d. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: r_packages_4.3.3/
Ignored: r_packages_4.4.0/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/pheatmap.Rmd) and HTML
(docs/pheatmap.html) files. If you’ve configured a remote
Git repository (see ?wflow_git_remote), click on the
hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 548a54d | Dave Tang | 2024-07-29 | Use a table of contents |
| html | 7197009 | Dave Tang | 2021-07-13 | Build site. |
| Rmd | 88ec168 | Dave Tang | 2021-07-13 | Add title |
| html | 45e2b81 | Dave Tang | 2021-06-15 | Build site. |
| Rmd | 83190de | Dave Tang | 2021-06-15 | Own column order |
| html | d8e64e3 | Dave Tang | 2021-04-14 | Build site. |
| Rmd | 500529b | Dave Tang | 2021-04-14 | https://davetang.org/muse/2018/05/15/making-a-heatmap-in-r-with-the-pheatmap-package/#comment-8339 |
| html | c54efbf | Dave Tang | 2020-11-27 | Build site. |
| Rmd | 4da96c0 | Dave Tang | 2020-11-27 | More clusters |
| html | 2db13ea | davetang | 2020-11-10 | Build site. |
| Rmd | 268312f | davetang | 2020-11-10 | wflow_publish(files = c("analysis/index.Rmd", "analysis/google_trends.Rmd", |
| html | 586b91f | Dave Tang | 2020-07-12 | Build site. |
| Rmd | b1d6edd | Dave Tang | 2020-07-12 | pheatmap |
Example data
Load data and subset for demonstration purposes.
example_file <- "https://davetang.org/file/TagSeqExample.tab"
data <- read.delim(example_file, header = TRUE, row.names = "gene")
data_subset <- as.matrix(data[rowSums(data)>50000,])
dim(data_subset)[1] 49 6Default heatmap
Default heatmap using pheatmap.
pheatmap(data_subset)
Manually scale the rows of the dataset.
cal_z_score <- function(x){
(x - mean(x)) / sd(x)
}
data_subset_norm <- t(apply(data_subset, 1, cal_z_score))
pheatmap(data_subset_norm)
Using scale = "row" produces the same heatmap when we
manually scaled the data.
pheatmap(data_subset, scale = "row")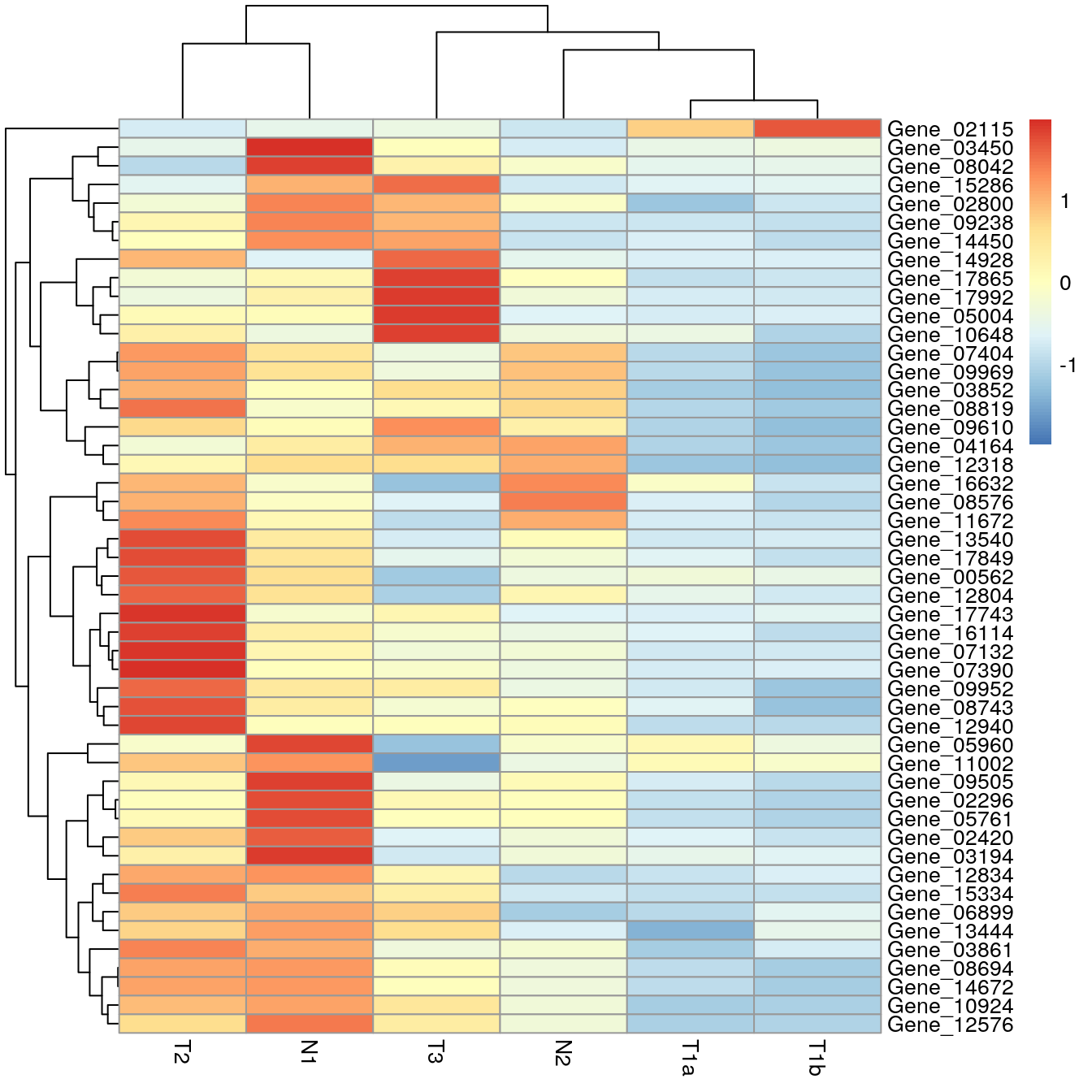
Adding a title
Add a title using main.
pheatmap(data_subset, main = "My title")
| Version | Author | Date |
|---|---|---|
| 7197009 | Dave Tang | 2021-07-13 |
Add a title using textGrob; you will need the
grid and gridExtra packages.
my_title <- textGrob("My title", gp = gpar(fontsize = 21, fontface = "bold"))
one <- pheatmap(data_subset, silent = TRUE)
grid.arrange(grobs = list(my_title, one[[4]]), heights = c(0.1, 1))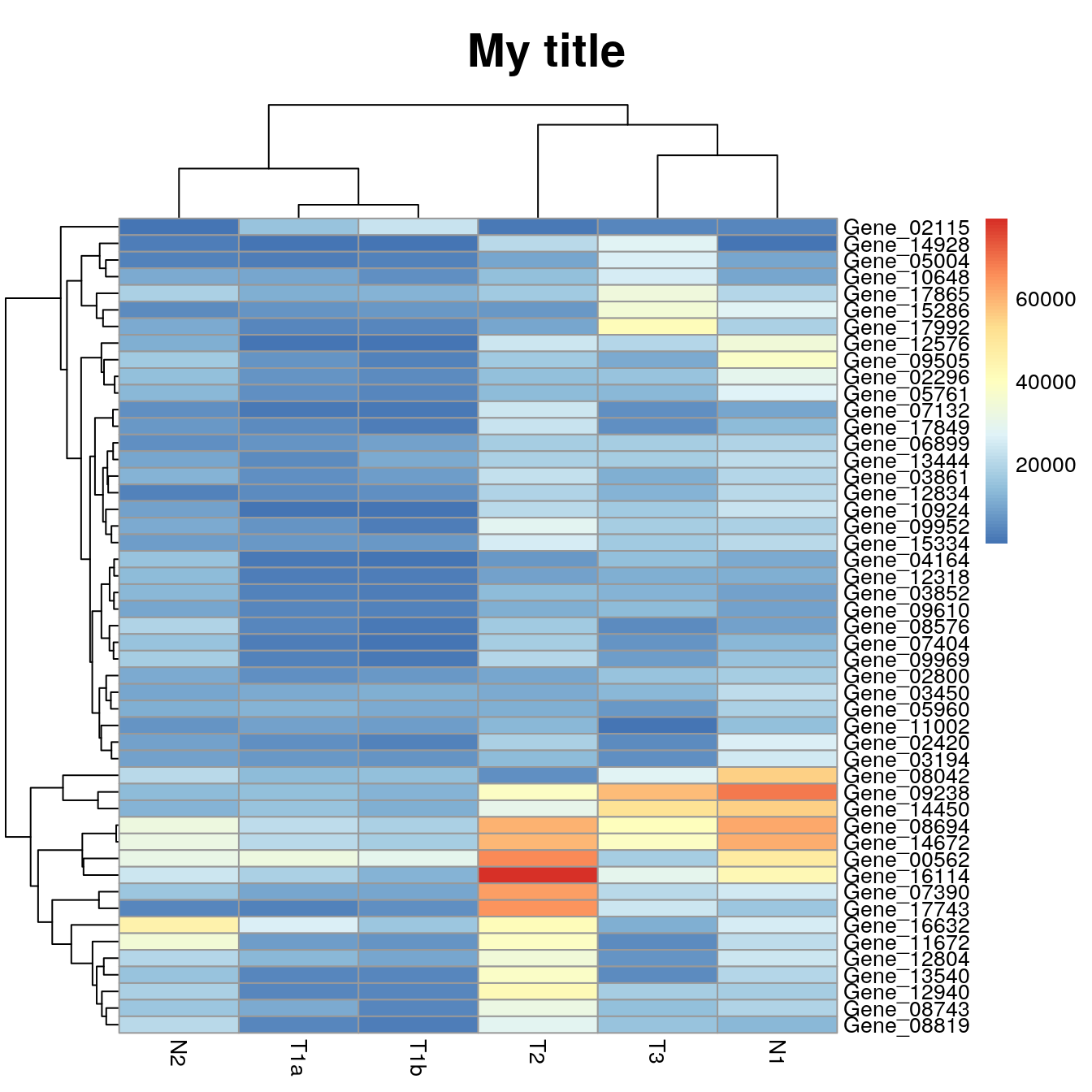
| Version | Author | Date |
|---|---|---|
| 7197009 | Dave Tang | 2021-07-13 |
Two heatmaps
Use grid.arrange to arrange multiple heatmaps.
one <- pheatmap(data_subset, silent = TRUE)
two <- pheatmap(data_subset, silent = TRUE)
grid.arrange(grobs = list(one[[4]], two[[4]]))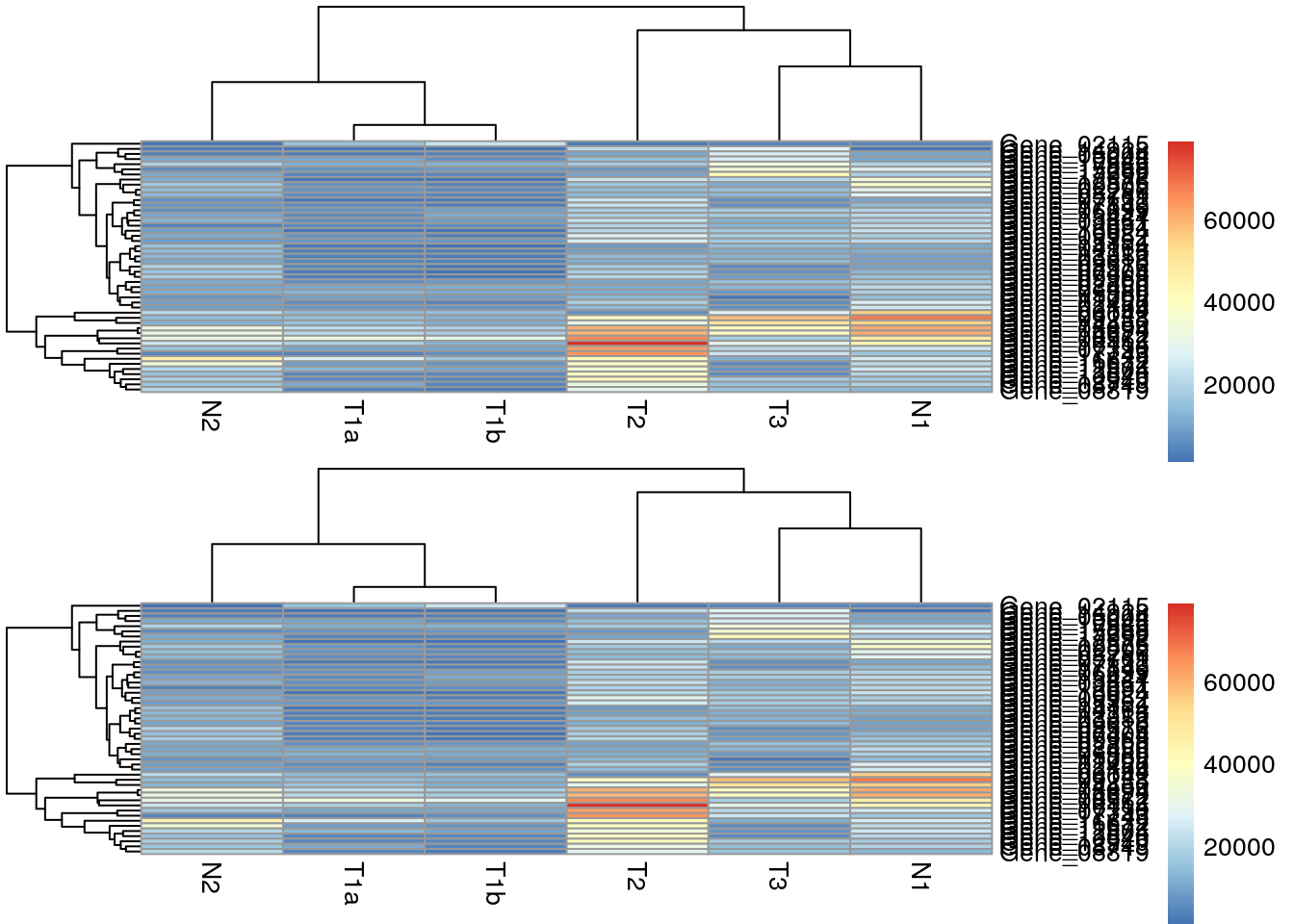
Dendrogram
Dendrogram results from pheatmap().
par(mar = c(3.1, 2.1, 1.1, 5.1))
my_heatmap <- pheatmap(data_subset, silent = TRUE)
names(my_heatmap)[1] "tree_row" "tree_col" "kmeans" "gtable" my_heatmap$tree_row %>%
as.dendrogram() %>%
plot(horiz = TRUE)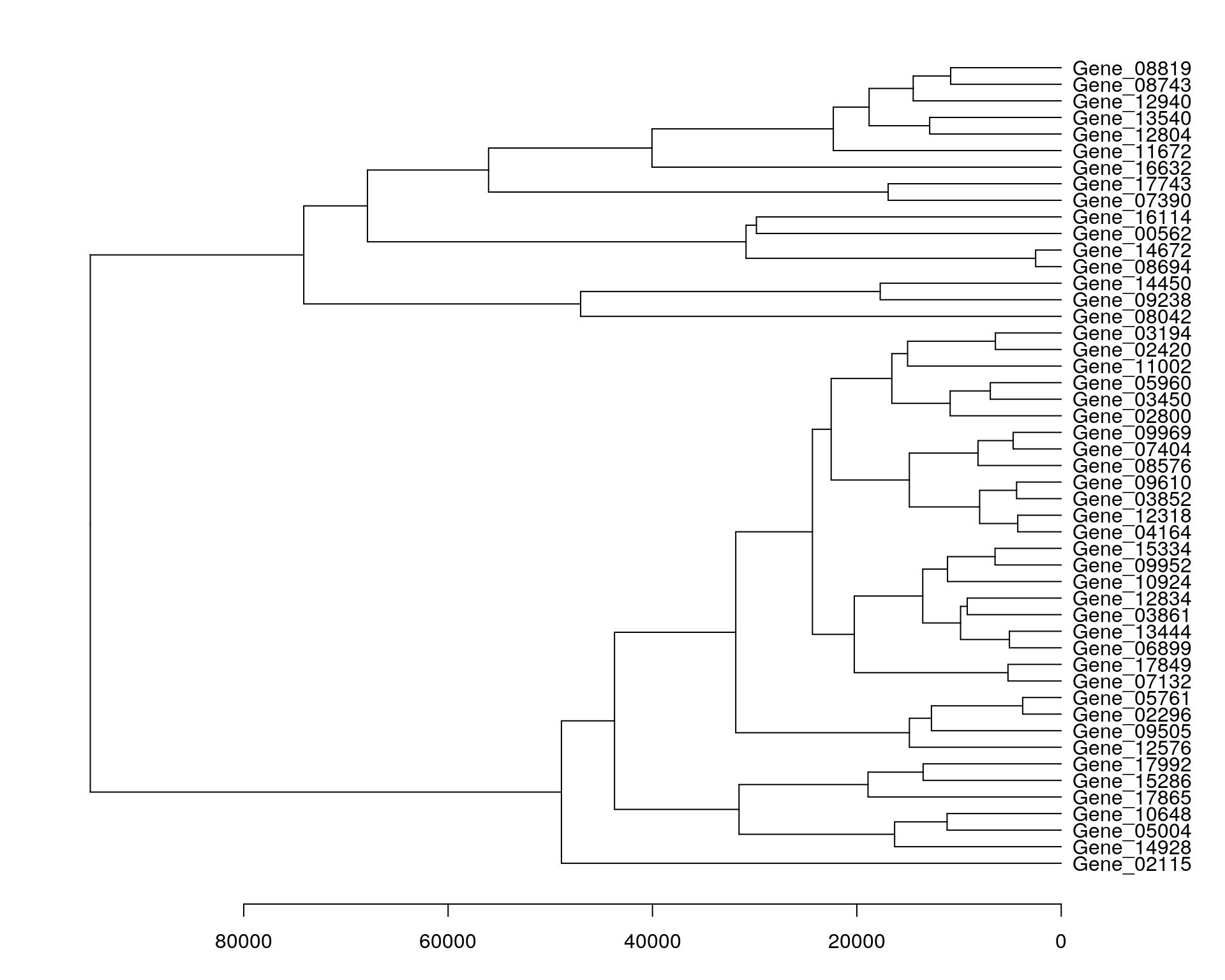
Reproduce the gene dendrogram.
par(mar = c(3.1, 2.1, 1.1, 5.1))
my_hclust_gene <- hclust(dist(data_subset), method = "complete")
my_hclust_gene$height [1] 2502.208 3771.244 4252.402 4366.211 4700.444 5069.851 5208.367
[8] 6439.545 6474.863 6938.482 7983.369 8141.632 9198.185 9849.175
[15] 10818.256 10868.066 11127.621 11168.654 12699.557 12871.187 13511.763
[22] 13549.622 14483.876 14856.478 14860.904 15033.046 16304.877 16574.315
[29] 16935.384 17713.534 18798.131 18904.899 20250.185 22302.634 22512.593
[36] 24345.199 29826.722 30846.374 31530.137 31849.145 40048.202 43714.148
[43] 47029.264 48908.962 56038.953 67891.667 74124.247 95015.400as.dendrogram(my_hclust_gene) %>%
plot(horiz = TRUE)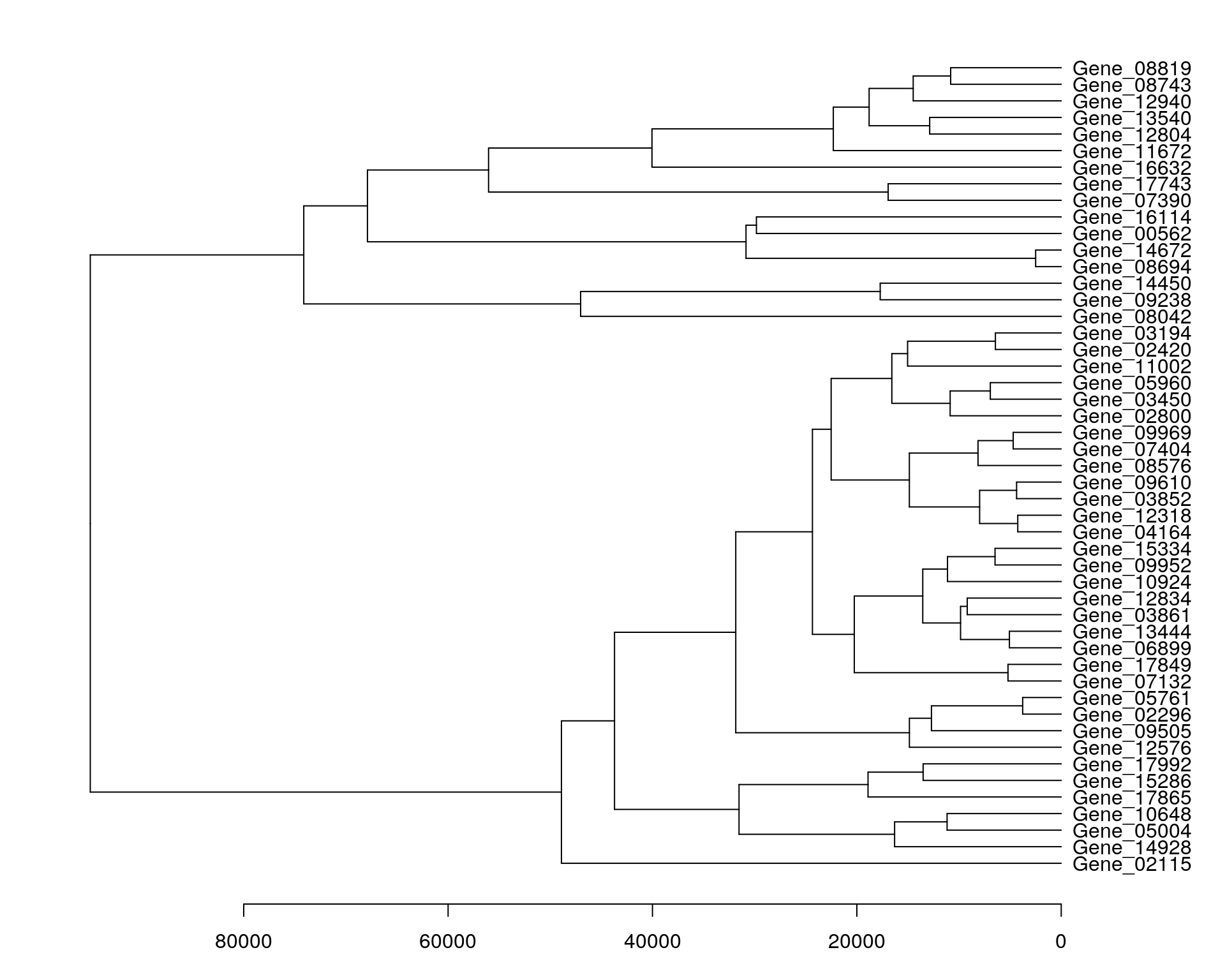
Obtaining the gene IDs as per the order of the dendrogram (from top to bottom).
rev(row.names(data_subset)[my_hclust_gene$order]) [1] "Gene_08819" "Gene_08743" "Gene_12940" "Gene_13540" "Gene_12804"
[6] "Gene_11672" "Gene_16632" "Gene_17743" "Gene_07390" "Gene_16114"
[11] "Gene_00562" "Gene_14672" "Gene_08694" "Gene_14450" "Gene_09238"
[16] "Gene_08042" "Gene_03194" "Gene_02420" "Gene_11002" "Gene_05960"
[21] "Gene_03450" "Gene_02800" "Gene_09969" "Gene_07404" "Gene_08576"
[26] "Gene_09610" "Gene_03852" "Gene_12318" "Gene_04164" "Gene_15334"
[31] "Gene_09952" "Gene_10924" "Gene_12834" "Gene_03861" "Gene_13444"
[36] "Gene_06899" "Gene_17849" "Gene_07132" "Gene_05761" "Gene_02296"
[41] "Gene_09505" "Gene_12576" "Gene_17992" "Gene_15286" "Gene_17865"
[46] "Gene_10648" "Gene_05004" "Gene_14928" "Gene_02115"Reproduce the sample dendrogram.
my_hclust_sample <- hclust(dist(t(data_subset)), method = "complete")
as.dendrogram(my_hclust_sample) %>%
plot()
Heatmap annotations
Add row and column annotations.
my_gene_col <- cutree(tree = as.dendrogram(my_hclust_gene), k = 2)
my_gene_col <- data.frame(cluster = ifelse(test = my_gene_col == 1, yes = "cluster 1", no = "cluster 2"))
my_sample_col <- data.frame(sample = rep(c("tumour", "normal"), c(4,2)))
row.names(my_sample_col) <- colnames(data_subset)
set.seed(1984)
my_random <- as.factor(sample(x = 1:2, size = nrow(my_gene_col), replace = TRUE))
my_gene_col$random <- my_random
pheatmap(data_subset, annotation_row = my_gene_col, annotation_col = my_sample_col)
Define your own column order by modifying data_subset
and setting cluster_cols to FALSE.
my_col_order <- c("N2", "T1a", "N1", "T1b", "T2", "T3")
pheatmap(
data_subset[, my_col_order],
annotation_col = my_sample_col,
cluster_cols = FALSE
)
| Version | Author | Date |
|---|---|---|
| 45e2b81 | Dave Tang | 2021-06-15 |
Gene clusters
Adding more clusters.
my_gene_col <- cutree(tree = as.dendrogram(my_hclust_gene), k = 6)
my_gene_col <- data.frame(cluster = paste0("cluster ", my_gene_col), row.names = names(my_gene_col))
my_sample_col <- data.frame(sample = rep(c("tumour", "normal"), c(4,2)))
row.names(my_sample_col) <- colnames(data_subset)
set.seed(1984)
my_random <- as.factor(sample(x = 1:2, size = nrow(my_gene_col), replace = TRUE))
my_gene_col$random <- my_random
pheatmap(data_subset, annotation_row = my_gene_col, annotation_col = my_sample_col)
Change annotation colours and ordering.
my_gene_col <- cutree(tree = as.dendrogram(my_hclust_gene), k = 2)
my_gene_col <- data.frame(cluster = ifelse(test = my_gene_col == 1, yes = "cluster1", no = "cluster2"))
my_sample_col <- data.frame(sample = rep(c("tumour", "normal"), c(4,2)))
row.names(my_sample_col) <- colnames(data_subset)
# change order
my_sample_col$sample <- factor(my_sample_col$sample, levels = c("normal", "tumour"))
set.seed(1984)
my_random <- as.factor(sample(x = c("random1", "random2"), size = nrow(my_gene_col), replace = TRUE))
my_gene_col$random <- my_random
my_colour = list(
sample = c(normal = "#5977ff", tumour = "#f74747"),
random = c(random1 = "#82ed82", random2 = "#9e82ed"),
cluster = c(cluster1 = "#e89829", cluster2 = "#cc4ee0")
)
p <- pheatmap(data_subset,
annotation_colors = my_colour,
annotation_row = my_gene_col,
annotation_col = my_sample_col,
cellheight = 7,
cellwidth = 18)
save_pheatmap_png <- function(x, filename, width=1200, height=1000, res = 150) {
png(filename, width = width, height = height, res = res)
grid::grid.newpage()
grid::grid.draw(x$gtable)
dev.off()
}
# not run
# save_pheatmap_png(p, "heatmap_colour.png")Breaks
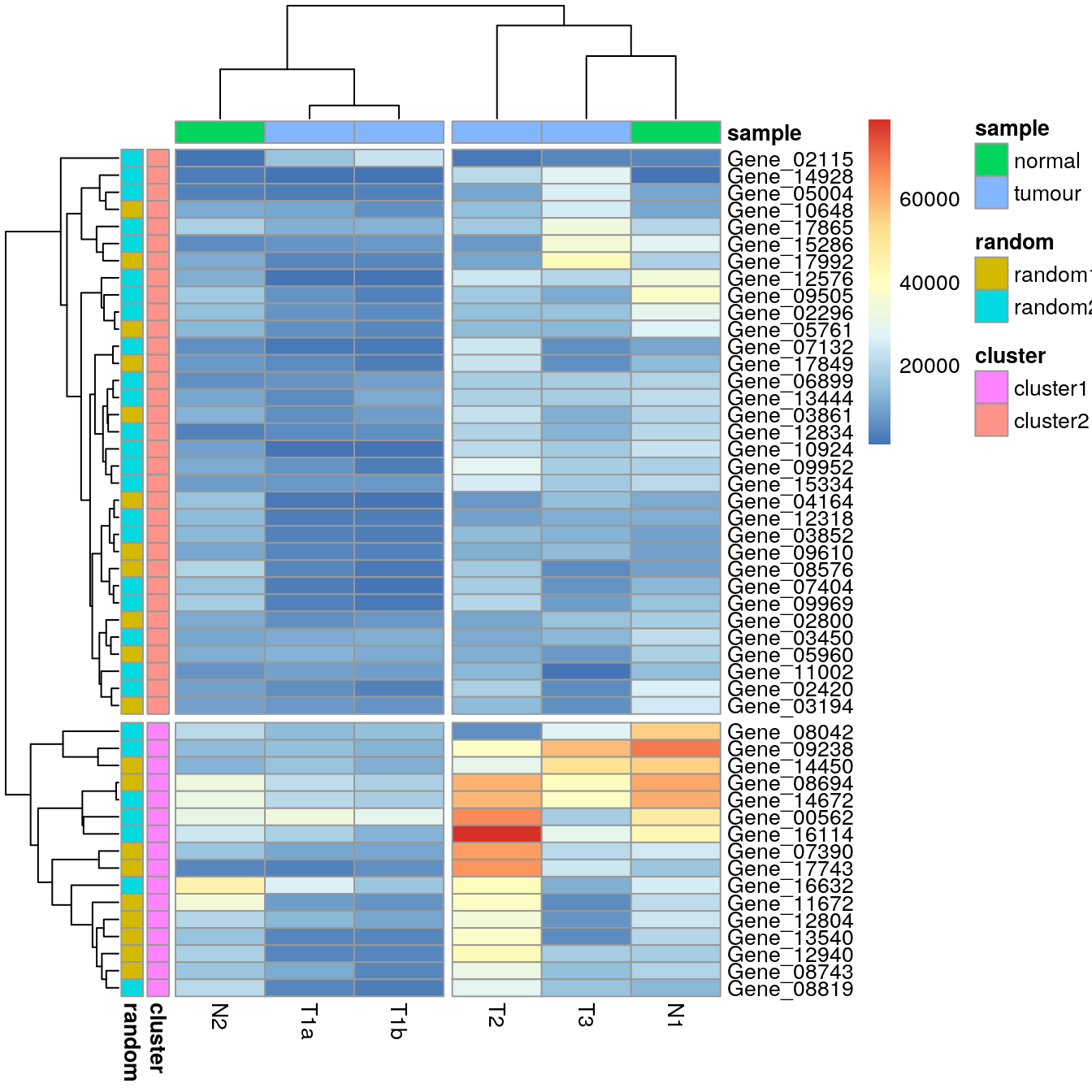
Introduce breaks by cutting the dendrogram.
pheatmap(
data_subset,
annotation_row = my_gene_col,
annotation_col = my_sample_col,
cutree_rows = 2,
cutree_cols = 2
)
sessionInfo()R version 4.4.0 (2024-04-24)
Platform: x86_64-pc-linux-gnu
Running under: Ubuntu 22.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: Etc/UTC
tzcode source: system (glibc)
attached base packages:
[1] grid stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] gridExtra_2.3 dendextend_1.17.1 pheatmap_1.0.12 workflowr_1.7.1
loaded via a namespace (and not attached):
[1] viridis_0.6.5 sass_0.4.9 utf8_1.2.4 generics_0.1.3
[5] stringi_1.8.4 digest_0.6.35 magrittr_2.0.3 evaluate_0.24.0
[9] RColorBrewer_1.1-3 fastmap_1.2.0 rprojroot_2.0.4 jsonlite_1.8.8
[13] processx_3.8.4 whisker_0.4.1 ps_1.7.6 promises_1.3.0
[17] httr_1.4.7 fansi_1.0.6 viridisLite_0.4.2 scales_1.3.0
[21] jquerylib_0.1.4 cli_3.6.2 rlang_1.1.4 munsell_0.5.1
[25] cachem_1.1.0 yaml_2.3.8 tools_4.4.0 dplyr_1.1.4
[29] colorspace_2.1-0 ggplot2_3.5.1 httpuv_1.6.15 vctrs_0.6.5
[33] R6_2.5.1 lifecycle_1.0.4 git2r_0.33.0 stringr_1.5.1
[37] fs_1.6.4 pkgconfig_2.0.3 callr_3.7.6 pillar_1.9.0
[41] bslib_0.7.0 later_1.3.2 gtable_0.3.5 glue_1.7.0
[45] Rcpp_1.0.12 highr_0.11 xfun_0.44 tibble_3.2.1
[49] tidyselect_1.2.1 rstudioapi_0.16.0 knitr_1.47 farver_2.1.2
[53] htmltools_0.5.8.1 rmarkdown_2.27 compiler_4.4.0 getPass_0.2-4