QC filtered sequencing reads
Evangelyn Sim
2/15/2021
Last updated: 2021-02-15
Checks: 6 1
Knit directory: Mouse_AAV_PGR_RNAseq_bulk/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210215) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Using absolute paths to the files within your workflowr project makes it difficult for you and others to run your code on a different machine. Change the absolute path(s) below to the suggested relative path(s) to make your code more reproducible.
| absolute | relative |
|---|---|
| /group/card2/Evangelyn_Sim/Transcriptome_chromatin_human/Sequencing_ATAC_RNA/GITHUB/Mouse_AAV_PGR_RNAseq_bulk/output/mrna_fulllen_pe_strrev_q30.mx.AAV_PR.fix_filt | output/mrna_fulllen_pe_strrev_q30.mx.AAV_PR.fix_filt |
| /group/card2/Evangelyn_Sim/Transcriptome_chromatin_human/Sequencing_ATAC_RNA/GITHUB/Mouse_AAV_PGR_RNAseq_bulk/output/2020021_AAV_PR_RNA_samplesheet.txt | output/2020021_AAV_PR_RNA_samplesheet.txt |
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 3bbb818. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/05.EdgeR_and_ScatterPlot.Rmd) and HTML (docs/05.EdgeR_and_ScatterPlot.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | e1cb83f | evangelynsim | 2021-02-15 | Build site. |
| Rmd | 2725f5e | evangelynsim | 2021-02-15 | wflow_publish(c(“analysis/01.Generate_reference_genome.Rmd”, |
Introduction
In the GEO submission 2 processed files were uploaded.
- mrna_fulllen_pe_strrev_q30.mx.AAV_PR.unfiltered
- mrna_fulllen_pe_strrev_q30.mx.AAV_PR.fix_filt
They have been uploaded in the /output folder and will be used below to generate different figures.
Used libraries and functions
library(edgeR)Loading required package: limmalibrary(limma)
library(dplyr)
Attaching package: 'dplyr'The following objects are masked from 'package:stats':
filter, lagThe following objects are masked from 'package:base':
intersect, setdiff, setequal, unionRead files
PRIOR = 20
FDR = 0.05
rm1 <- read.delim("/group/card2/Evangelyn_Sim/Transcriptome_chromatin_human/Sequencing_ATAC_RNA/GITHUB/Mouse_AAV_PGR_RNAseq_bulk/output/mrna_fulllen_pe_strrev_q30.mx.AAV_PR.fix_filt", row.names = 1)
colnames(rm1) = gsub("AAV.","",colnames(rm1))
info = read.delim("/group/card2/Evangelyn_Sim/Transcriptome_chromatin_human/Sequencing_ATAC_RNA/GITHUB/Mouse_AAV_PGR_RNAseq_bulk/output/2020021_AAV_PR_RNA_samplesheet.txt", header = TRUE, sep = "\t", stringsAsFactors = F)
info$ID = gsub("_",".",info$ID)
names(rm1) = info$ID[match(names(rm1),info$ID)]
m = match(info$ID,names(rm1))
rm2 = rm1[,m]
rm1 = rm2
sampleinfo = info
levels(factor(sampleinfo$Group))[1] "MCS" "PR" levels(factor(sampleinfo$BinSex))[1] "MCS_F" "MCS_M" "PR_F" "PR_M" table(colnames(rm2)==sampleinfo$ID)
TRUE
13 matrix = rm2
pheno = info
#write.table(pheno, file="../output/pheno.matrix_allsample.txt", sep="\t", quote = F, row.names = F)
#pheno = read.delim(file="../output/pheno.matrix_allsample.txt")Differential Gene Expresison Analysis Between Control and AAV-PGR
attach(pheno)
design = model.matrix(as.formula("~ 0 + Group + Sex "))
detach(pheno)
design GroupMCS GroupPR SexM
1 1 0 0
2 1 0 0
3 1 0 0
4 1 0 0
5 1 0 1
6 1 0 1
7 1 0 1
8 0 1 0
9 0 1 0
10 0 1 0
11 0 1 1
12 0 1 1
13 0 1 1
attr(,"assign")
[1] 1 1 2
attr(,"contrasts")
attr(,"contrasts")$Group
[1] "contr.treatment"
attr(,"contrasts")$Sex
[1] "contr.treatment"D = DGEList(counts=matrix)
D = calcNormFactors(D)
D = estimateGLMCommonDisp(D, design)
D = estimateGLMTagwiseDisp(D, design, prior.df = PRIOR)
fit = glmFit(D, design, prior.count = PRIOR)
Contrast = makeContrasts(MCSvsPR = GroupPR - GroupMCS,
levels=design)
res = list()
contrast.name = colnames(Contrast)
for(i in 1:length(contrast.name)){
lrt = glmLRT(fit, contrast = Contrast[,i])
results = lrt$table
disp = lrt$dispersion
fitted.vals = lrt$fitted.values
coefficients = lrt$coefficients
results$adj.p.value = p.adjust(p = results$PValue, method = "fdr" )
table(row.names(results) == row.names(fitted.vals))
Name = row.names(results)
res0 = cbind(Name, results, disp, fitted.vals, coefficients)
res[[i]] = res0[order(res0$adj.p.value),]
#write.table(res[[i]], file= paste0("edgeR_RNA_all_", contrast.name[i] ,".xls"), quote=F, sep="\t", col.names = T, row.names = F)
res[[i]]= mutate(res[[i]], cs= ifelse(res[[i]]$adj.p.value <= 0.05 & res[[i]]$logFC <= 0, "purple",
ifelse(res[[i]]$adj.p.value <= 0.05 & res[[i]]$logFC >= 0, "springgreen3", "grey")))
mxFDR = res[[i]][res[[i]]$adj.p.value <= FDR,]
mxFDR_Up = mxFDR[mxFDR$logFC>0,]
mxFDR_Dn = mxFDR[mxFDR$logFC<0,]
res[[i]]= mutate(res[[i]], FDR= nrow(mxFDR))
res[[i]]= mutate(res[[i]], FDRup= nrow(mxFDR_Up))
res[[i]]= mutate(res[[i]], FDRdn= nrow(mxFDR_Dn))
}
for(i in 1:length(contrast.name)){
print(contrast.name[i])
print(table(res[[i]]$adj.p.value < 0.05))
#write.table(res[[i]][res[[i]]$PValue < 0.01,], file= paste0("edgeR_RNA_all_", contrast.name[i] ,"_p001.xls"), quote=F, sep="\t", col.names = T, row.names = F)
}[1] "MCSvsPR"
FALSE TRUE
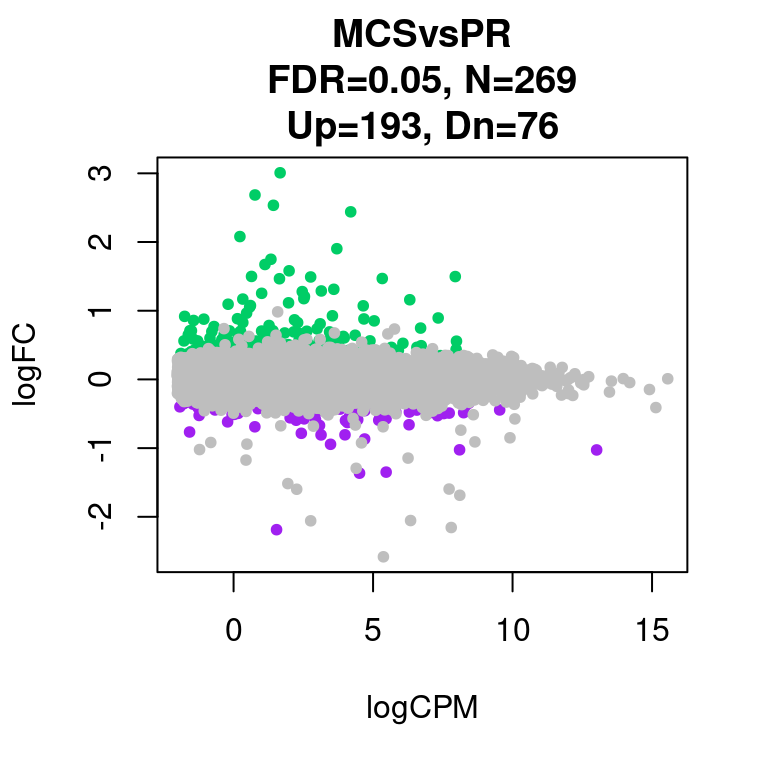
15376 269 Plot Scatter Plot
par(mfrow=c(1,1))
for(i in 1:length(contrast.name)){
plot(res[[i]]$logCPM, res[[i]]$logFC, pch=20, cex=1, col=res[[i]]$cs,
xlab = "logCPM", ylab = "logFC",
main = paste0(contrast.name[i],
"\nFDR=0.05, N=", res[[i]][1,ncol(res[[i]])-2],
"\nUp=",res[[i]][1,ncol(res[[i]])-1],", Dn=",res[[i]][1,ncol(res[[i]])]))
}
| Version | Author | Date |
|---|---|---|
| e1cb83f | evangelynsim | 2021-02-15 |
Differential Sex-specific Gene Expresison Analysis Between Control and AAV-PGR
########################################################################################################Dev
attach(pheno)
#design = model.matrix(as.formula("~ 0 + condition + lane + replicate + time"))
design_dev = model.matrix(as.formula("~ 0 + BinSex"))
detach(pheno)
design_dev BinSexMCS_F BinSexMCS_M BinSexPR_F BinSexPR_M
1 1 0 0 0
2 1 0 0 0
3 1 0 0 0
4 1 0 0 0
5 0 1 0 0
6 0 1 0 0
7 0 1 0 0
8 0 0 1 0
9 0 0 1 0
10 0 0 1 0
11 0 0 0 1
12 0 0 0 1
13 0 0 0 1
attr(,"assign")
[1] 1 1 1 1
attr(,"contrasts")
attr(,"contrasts")$BinSex
[1] "contr.treatment"D_dev = DGEList(counts=matrix)
D_dev = calcNormFactors(D_dev)
D_dev = estimateGLMCommonDisp(D_dev, design_dev)
D_dev = estimateGLMTagwiseDisp(D_dev, design_dev, prior.df = PRIOR)
fit_dev = glmFit(D_dev, design_dev, prior.count = PRIOR)
Contrast_dev = makeContrasts(MCS_FvsMCS_M = BinSexMCS_M - BinSexMCS_F,
MCS_FvsPR_F = BinSexPR_F - BinSexMCS_F,
MCS_MvsPR_M = BinSexPR_M - BinSexMCS_M,
PR_FvsPR_M = BinSexPR_M - BinSexPR_F,
levels=design_dev)
res_dev = list()
contrast.name_dev = colnames(Contrast_dev)
for(i in 1:length(contrast.name_dev)){
lrt_dev = glmLRT(fit_dev, contrast = Contrast_dev[,i])
results_dev = lrt_dev$table
disp_dev = lrt_dev$dispersion
fitted.vals_dev = lrt_dev$fitted.values
coefficients_dev = lrt_dev$coefficients
results_dev$adj.p.value = p.adjust(p = results_dev$PValue, method = "fdr" )
table(row.names(results_dev) == row.names(fitted.vals_dev))
Name = row.names(results_dev)
res0_dev = cbind(Name, results_dev, disp_dev, fitted.vals_dev, coefficients_dev)
res_dev[[i]] = res0_dev[order(res0_dev$adj.p.value),]
#write.table(res_dev[[i]], file= paste0("edgeR_RNA_all_sex_", contrast.name_dev[i] ,".xls"), quote=F, sep="\t", col.names = T, row.names = F)
res_dev[[i]]= mutate(res_dev[[i]], cs= ifelse(res_dev[[i]]$adj.p.value <= 0.05 & res_dev[[i]]$logFC <= 0, "purple",
ifelse(res_dev[[i]]$adj.p.value <= 0.05 & res_dev[[i]]$logFC >= 0, "springgreen3", "grey")))
mxFDR = res_dev[[i]][res_dev[[i]]$adj.p.value <= FDR,]
mxFDR_Up = mxFDR[mxFDR$logFC>0,]
mxFDR_Dn = mxFDR[mxFDR$logFC<0,]
res_dev[[i]]= mutate(res_dev[[i]], FDR= nrow(mxFDR))
res_dev[[i]]= mutate(res_dev[[i]], FDRup= nrow(mxFDR_Up))
res_dev[[i]]= mutate(res_dev[[i]], FDRdn= nrow(mxFDR_Dn))
}
for(i in 1:length(contrast.name_dev)){
print(contrast.name_dev[i])
print(table(res_dev[[i]]$adj.p.value < 0.05))
#write.table(res_dev[[i]][res_dev[[i]]$PValue< 0.01,], file= paste0("edgeR_RNA_all_sex_", contrast.name_dev[i] ,"_p001.xls"), quote=F, sep="\t", col.names = T, row.names = F)
}[1] "MCS_FvsMCS_M"
FALSE TRUE
15168 477
[1] "MCS_FvsPR_F"
FALSE TRUE
15545 100
[1] "MCS_MvsPR_M"
FALSE TRUE
15553 92
[1] "PR_FvsPR_M"
FALSE TRUE
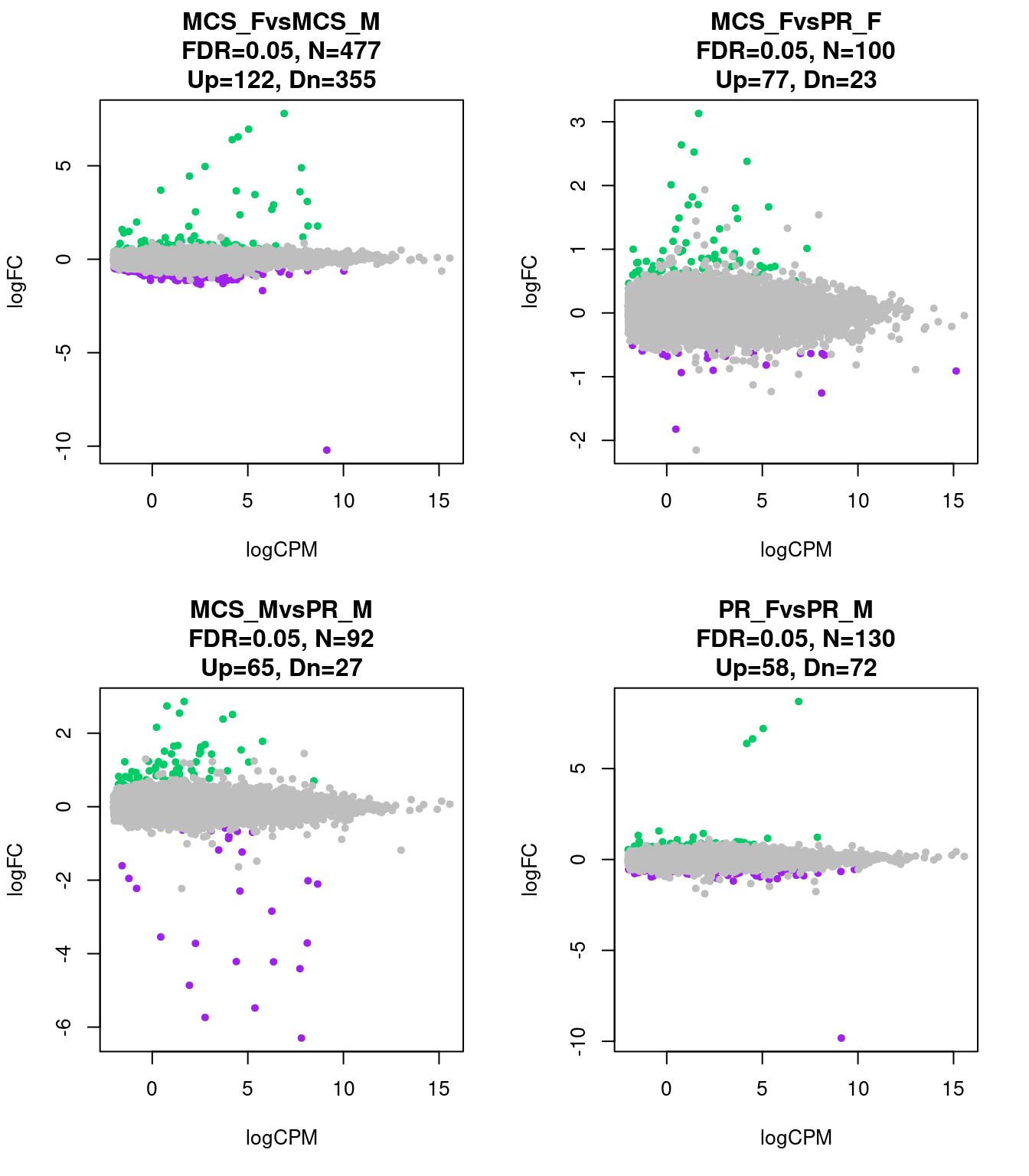
15515 130 Plot Scatter Plot
par(mfrow=c(2,2))
for(i in 1:length(contrast.name_dev)){
plot(res_dev[[i]]$logCPM, res_dev[[i]]$logFC, pch=20, cex=1, col=res_dev[[i]]$cs,
xlab = "logCPM", ylab = "logFC",
main = paste0(contrast.name_dev[i],
"\nFDR=0.05, N=", res_dev[[i]][1,ncol(res_dev[[i]])-2],
"\nUp=",res_dev[[i]][1,ncol(res_dev[[i]])-1],", Dn=",res_dev[[i]][1,ncol(res_dev[[i]])]))
}
| Version | Author | Date |
|---|---|---|
| e1cb83f | evangelynsim | 2021-02-15 |
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: CentOS Linux 7 (Core)
Matrix products: default
BLAS: /hpc/software/installed/R/3.6.1/lib64/R/lib/libRblas.so
LAPACK: /hpc/software/installed/R/3.6.1/lib64/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] dplyr_1.0.2 edgeR_3.26.8 limma_3.40.6 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.5 pillar_1.4.6 compiler_3.6.1 later_1.1.0.1
[5] git2r_0.27.1 highr_0.8 tools_3.6.1 digest_0.6.27
[9] evaluate_0.14 lifecycle_0.2.0 tibble_3.0.3 lattice_0.20-41
[13] pkgconfig_2.0.3 rlang_0.4.7 rstudioapi_0.11 yaml_2.2.1
[17] xfun_0.18 stringr_1.4.0 knitr_1.30 generics_0.1.0
[21] fs_1.5.0 vctrs_0.3.2 tidyselect_1.1.0 locfit_1.5-9.4
[25] rprojroot_1.3-2 grid_3.6.1 glue_1.4.2 R6_2.5.0
[29] rmarkdown_2.5 purrr_0.3.4 magrittr_1.5 whisker_0.4
[33] backports_1.1.10 promises_1.1.1 ellipsis_0.3.1 htmltools_0.5.0
[37] httpuv_1.5.4 stringi_1.5.3 crayon_1.3.4