Data transformation with dplyr
John Blischak
2019-09-26
Last updated: 2019-09-26
Checks: 7 0
Knit directory: wflow-r4ds/
This reproducible R Markdown analysis was created with workflowr (version 1.4.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190925) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | b559641 | John Blischak | 2019-09-26 | Some more chp 3 dplyr exercises |
| html | 203788b | John Blischak | 2019-09-26 | Build site. |
| Rmd | 3b94f62 | John Blischak | 2019-09-26 | R is not C! ^ is exponentiation, not ‘exclusive or’ |
| html | 332efa0 | John Blischak | 2019-09-26 | Build site. |
| Rmd | ace5f59 | John Blischak | 2019-09-26 | more dplyr exercises |
| html | 2eac6e6 | John Blischak | 2019-09-26 | Build site. |
| Rmd | 5f7de6b | John Blischak | 2019-09-26 | Start chp 3 exercises on dplyr |
Setup
library(nycflights13)
library(tidyverse)── Attaching packages ──────────────────────────────────────────────────────────────────────────────────── tidyverse 1.2.1 ──✔ ggplot2 3.2.1 ✔ purrr 0.3.2
✔ tibble 2.1.3 ✔ dplyr 0.8.3
✔ tidyr 1.0.0 ✔ stringr 1.4.0
✔ readr 1.3.1 ✔ forcats 0.4.0── Conflicts ─────────────────────────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()Filter rows with filter()
p. 49
Find all flights that
Had an arrival delay of two or more hours
filter(flights, arr_delay > 2 * 60)# A tibble: 10,034 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 811 630 101 1047
2 2013 1 1 848 1835 853 1001
3 2013 1 1 957 733 144 1056
4 2013 1 1 1114 900 134 1447
5 2013 1 1 1505 1310 115 1638
6 2013 1 1 1525 1340 105 1831
7 2013 1 1 1549 1445 64 1912
8 2013 1 1 1558 1359 119 1718
9 2013 1 1 1732 1630 62 2028
10 2013 1 1 1803 1620 103 2008
# … with 10,024 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Flew to Houston (
IAHorHOU)
filter(flights, dest == "IAH" | dest == "HOU")# A tibble: 9,313 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 623 627 -4 933
4 2013 1 1 728 732 -4 1041
5 2013 1 1 739 739 0 1104
6 2013 1 1 908 908 0 1228
7 2013 1 1 1028 1026 2 1350
8 2013 1 1 1044 1045 -1 1352
9 2013 1 1 1114 900 134 1447
10 2013 1 1 1205 1200 5 1503
# … with 9,303 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Were operated by United, American, or Delta
filter(flights, carrier %in% c("UA", "AA", "DL"))# A tibble: 139,504 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 542 540 2 923
4 2013 1 1 554 600 -6 812
5 2013 1 1 554 558 -4 740
6 2013 1 1 558 600 -2 753
7 2013 1 1 558 600 -2 924
8 2013 1 1 558 600 -2 923
9 2013 1 1 559 600 -1 941
10 2013 1 1 559 600 -1 854
# … with 139,494 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Departed in summer (July, August, and September)
filter(flights, month %in% 7:9)# A tibble: 86,326 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 7 1 1 2029 212 236
2 2013 7 1 2 2359 3 344
3 2013 7 1 29 2245 104 151
4 2013 7 1 43 2130 193 322
5 2013 7 1 44 2150 174 300
6 2013 7 1 46 2051 235 304
7 2013 7 1 48 2001 287 308
8 2013 7 1 58 2155 183 335
9 2013 7 1 100 2146 194 327
10 2013 7 1 100 2245 135 337
# … with 86,316 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Arrived more than two hours late, but didn’t leave late
filter(flights, arr_delay > 2 * 60, dep_delay <=0)# A tibble: 29 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 27 1419 1420 -1 1754
2 2013 10 7 1350 1350 0 1736
3 2013 10 7 1357 1359 -2 1858
4 2013 10 16 657 700 -3 1258
5 2013 11 1 658 700 -2 1329
6 2013 3 18 1844 1847 -3 39
7 2013 4 17 1635 1640 -5 2049
8 2013 4 18 558 600 -2 1149
9 2013 4 18 655 700 -5 1213
10 2013 5 22 1827 1830 -3 2217
# … with 19 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Were delayed by at least an hour, but made up over 30 minutes in flight
filter(flights, dep_delay >= 60, arr_delay < 30)# A tibble: 206 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 3 1850 1745 65 2148
2 2013 1 3 1950 1845 65 2228
3 2013 1 3 2015 1915 60 2135
4 2013 1 6 1019 900 79 1558
5 2013 1 7 1543 1430 73 1758
6 2013 1 11 1020 920 60 1311
7 2013 1 12 1706 1600 66 1949
8 2013 1 12 1953 1845 68 2154
9 2013 1 19 1456 1355 61 1636
10 2013 1 21 1531 1430 61 1843
# … with 196 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Departed between midnight and 6am (inclusive)
filter(flights, hour <= 6)# A tibble: 27,905 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 542 540 2 923
4 2013 1 1 544 545 -1 1004
5 2013 1 1 554 600 -6 812
6 2013 1 1 554 558 -4 740
7 2013 1 1 555 600 -5 913
8 2013 1 1 557 600 -3 709
9 2013 1 1 557 600 -3 838
10 2013 1 1 558 600 -2 753
# … with 27,895 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Another useful dplyr filtering helper is
between(). What does it do? Can you use it to simplify the code needed to answer the previous challenges?
between() selects numeric values between a minimum and maximum value (inclusive).
While I think between() is useful, I don’t find these examples very compelling.
filter(flights, between(month, 7, 9))# A tibble: 86,326 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 7 1 1 2029 212 236
2 2013 7 1 2 2359 3 344
3 2013 7 1 29 2245 104 151
4 2013 7 1 43 2130 193 322
5 2013 7 1 44 2150 174 300
6 2013 7 1 46 2051 235 304
7 2013 7 1 48 2001 287 308
8 2013 7 1 58 2155 183 335
9 2013 7 1 100 2146 194 327
10 2013 7 1 100 2245 135 337
# … with 86,316 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>filter(flights, between(hour, 0, 6))# A tibble: 27,905 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 542 540 2 923
4 2013 1 1 544 545 -1 1004
5 2013 1 1 554 600 -6 812
6 2013 1 1 554 558 -4 740
7 2013 1 1 555 600 -5 913
8 2013 1 1 557 600 -3 709
9 2013 1 1 557 600 -3 838
10 2013 1 1 558 600 -2 753
# … with 27,895 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>How many flights have a missing
dep_time? What other variables are missing? What might these rows represent?
filter(flights, is.na(dep_time))# A tibble: 8,255 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 NA 1630 NA NA
2 2013 1 1 NA 1935 NA NA
3 2013 1 1 NA 1500 NA NA
4 2013 1 1 NA 600 NA NA
5 2013 1 2 NA 1540 NA NA
6 2013 1 2 NA 1620 NA NA
7 2013 1 2 NA 1355 NA NA
8 2013 1 2 NA 1420 NA NA
9 2013 1 2 NA 1321 NA NA
10 2013 1 2 NA 1545 NA NA
# … with 8,245 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>I assume these are cancelled flights since all columns relating to departure and arrival times are missing.
Why is
NA ^ 0not missing? Why isNA | TRUEnot missing? Why isFALSE & NAnot missing? Can you figure out the general rule? (NA * 0is a tricky counterexample!)
NA ^ 0 # same as NA ^ FALSE[1] 1NA | TRUE[1] TRUEFALSE & NA[1] FALSENA * 0[1] NAI think the NA | TRUE and FALSE & NA make sense. They are short-circuitng the logic. For an “or” statement, a TRUE on one of the sides is sufficient to render the entire statement true, regardless if the other data is missing. Vice verse for the “and”: a FALSE on either side is sufficient to make the entire statement false.
# have to be TRUE
NA | TRUE[1] TRUETRUE | NA[1] TRUE# ambiguous
NA | FALSE[1] NAFALSE | NA[1] NA# have to be TRUE
NA & FALSE[1] FALSEFALSE & NA[1] FALSE# ambiguous
NA & TRUE[1] NATRUE & NA[1] NAThe exponentiation logic also makes less sense to me. Any number raised to the 0th power is equal to 1. Furthermore, 1 raised to any power is also 1. From the docs for ?Arithmetic:
1 ^ y and y ^ 0 are 1, always.
NA ^ 0[1] 11 ^ NA[1] 1Thus the general rule seems to be to allow NA if the missing value would not affect the outcome of the logic or arithmetic operation.
Thus I’m not sure why NA * 0 returns NA when it should be 0 no matter the value. My only guess is that it may be related to the potential risk of division by zero.
NA * 0[1] NA0 / NA[1] NANA / NA * 0[1] NAArrange rows with arrange()
p. 51
How could you use
arrange()to sort all missing values to the start? (Hint: useis.na()).
arrange(flights, desc(is.na(dep_time)))# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 NA 1630 NA NA
2 2013 1 1 NA 1935 NA NA
3 2013 1 1 NA 1500 NA NA
4 2013 1 1 NA 600 NA NA
5 2013 1 2 NA 1540 NA NA
6 2013 1 2 NA 1620 NA NA
7 2013 1 2 NA 1355 NA NA
8 2013 1 2 NA 1420 NA NA
9 2013 1 2 NA 1321 NA NA
10 2013 1 2 NA 1545 NA NA
# … with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Sort
flightsto find the most delayed flights. Find the flights that left earliest.
arrange(flights, desc(dep_delay))# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 9 641 900 1301 1242
2 2013 6 15 1432 1935 1137 1607
3 2013 1 10 1121 1635 1126 1239
4 2013 9 20 1139 1845 1014 1457
5 2013 7 22 845 1600 1005 1044
6 2013 4 10 1100 1900 960 1342
7 2013 3 17 2321 810 911 135
8 2013 6 27 959 1900 899 1236
9 2013 7 22 2257 759 898 121
10 2013 12 5 756 1700 896 1058
# … with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>arrange(flights, hour, minute) # left earliest in the AM# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 7 27 NA 106 NA NA
2 2013 1 2 458 500 -2 703
3 2013 1 3 458 500 -2 650
4 2013 1 4 456 500 -4 631
5 2013 1 5 458 500 -2 640
6 2013 1 6 458 500 -2 718
7 2013 1 7 454 500 -6 637
8 2013 1 8 454 500 -6 625
9 2013 1 9 457 500 -3 647
10 2013 1 10 450 500 -10 634
# … with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>arrange(flights, dep_delay) # left earliest in relation to scheduled dep time# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 12 7 2040 2123 -43 40
2 2013 2 3 2022 2055 -33 2240
3 2013 11 10 1408 1440 -32 1549
4 2013 1 11 1900 1930 -30 2233
5 2013 1 29 1703 1730 -27 1947
6 2013 8 9 729 755 -26 1002
7 2013 10 23 1907 1932 -25 2143
8 2013 3 30 2030 2055 -25 2213
9 2013 3 2 1431 1455 -24 1601
10 2013 5 5 934 958 -24 1225
# … with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Sort
flightsto find the fastest flights.
arrange(flights, air_time)# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 16 1355 1315 40 1442
2 2013 4 13 537 527 10 622
3 2013 12 6 922 851 31 1021
4 2013 2 3 2153 2129 24 2247
5 2013 2 5 1303 1315 -12 1342
6 2013 2 12 2123 2130 -7 2211
7 2013 3 2 1450 1500 -10 1547
8 2013 3 8 2026 1935 51 2131
9 2013 3 18 1456 1329 87 1533
10 2013 3 19 2226 2145 41 2305
# … with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Which flights travelled the longest? Which travelled the shortest?
arrange(flights, desc(distance))# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 857 900 -3 1516
2 2013 1 2 909 900 9 1525
3 2013 1 3 914 900 14 1504
4 2013 1 4 900 900 0 1516
5 2013 1 5 858 900 -2 1519
6 2013 1 6 1019 900 79 1558
7 2013 1 7 1042 900 102 1620
8 2013 1 8 901 900 1 1504
9 2013 1 9 641 900 1301 1242
10 2013 1 10 859 900 -1 1449
# … with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>arrange(flights, distance)# A tibble: 336,776 x 19
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 7 27 NA 106 NA NA
2 2013 1 3 2127 2129 -2 2222
3 2013 1 4 1240 1200 40 1333
4 2013 1 4 1829 1615 134 1937
5 2013 1 4 2128 2129 -1 2218
6 2013 1 5 1155 1200 -5 1241
7 2013 1 6 2125 2129 -4 2224
8 2013 1 7 2124 2129 -5 2212
9 2013 1 8 2127 2130 -3 2304
10 2013 1 9 2126 2129 -3 2217
# … with 336,766 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>Select columns with select()
p. 54
Brainstorm as many ways as possible to select
dep_time,dep_delay,arr_time, andarr_delayfromflights.
select(flights, dep_time, dep_delay, arr_time, arr_delay)# A tibble: 336,776 x 4
dep_time dep_delay arr_time arr_delay
<int> <dbl> <int> <dbl>
1 517 2 830 11
2 533 4 850 20
3 542 2 923 33
4 544 -1 1004 -18
5 554 -6 812 -25
6 554 -4 740 12
7 555 -5 913 19
8 557 -3 709 -14
9 557 -3 838 -8
10 558 -2 753 8
# … with 336,766 more rowsselect(flights, dep_time, dep_delay:arr_time, arr_delay)# A tibble: 336,776 x 4
dep_time dep_delay arr_time arr_delay
<int> <dbl> <int> <dbl>
1 517 2 830 11
2 533 4 850 20
3 542 2 923 33
4 544 -1 1004 -18
5 554 -6 812 -25
6 554 -4 740 12
7 555 -5 913 19
8 557 -3 709 -14
9 557 -3 838 -8
10 558 -2 753 8
# … with 336,766 more rowsselect(flights, starts_with("dep"), starts_with("arr"))# A tibble: 336,776 x 4
dep_time dep_delay arr_time arr_delay
<int> <dbl> <int> <dbl>
1 517 2 830 11
2 533 4 850 20
3 542 2 923 33
4 544 -1 1004 -18
5 554 -6 812 -25
6 554 -4 740 12
7 555 -5 913 19
8 557 -3 709 -14
9 557 -3 838 -8
10 558 -2 753 8
# … with 336,766 more rowsselect(flights, dep_time, arr_time, ends_with("delay"))# A tibble: 336,776 x 4
dep_time arr_time dep_delay arr_delay
<int> <int> <dbl> <dbl>
1 517 830 2 11
2 533 850 4 20
3 542 923 2 33
4 544 1004 -1 -18
5 554 812 -6 -25
6 554 740 -4 12
7 555 913 -5 19
8 557 709 -3 -14
9 557 838 -3 -8
10 558 753 -2 8
# … with 336,766 more rowsWhat happens if you include the name of a variable multiple times in a
select()call?
The column is added in the first place it is mentioned:
select(flights, dep_time, dep_time)# A tibble: 336,776 x 1
dep_time
<int>
1 517
2 533
3 542
4 544
5 554
6 554
7 555
8 557
9 557
10 558
# … with 336,766 more rowsselect(flights, dep_time, arr_time, dep_time)# A tibble: 336,776 x 2
dep_time arr_time
<int> <int>
1 517 830
2 533 850
3 542 923
4 544 1004
5 554 812
6 554 740
7 555 913
8 557 709
9 557 838
10 558 753
# … with 336,766 more rowsWhat does the
one_of()function do? Why might it be helpful in conjunction with this vector?
From docs:
one_of(): Matches variable names in a character vector.
Thus it serves a similar purpose as %in%. But %in% returns a logical vector (which could be used in filter()), whereas, select() accepts the integer position of the columns:
vars <- c("year", "month", "day", "dep_delay", "arr_delay")
select(flights, one_of(vars))# A tibble: 336,776 x 5
year month day dep_delay arr_delay
<int> <int> <int> <dbl> <dbl>
1 2013 1 1 2 11
2 2013 1 1 4 20
3 2013 1 1 2 33
4 2013 1 1 -1 -18
5 2013 1 1 -6 -25
6 2013 1 1 -4 12
7 2013 1 1 -5 19
8 2013 1 1 -3 -14
9 2013 1 1 -3 -8
10 2013 1 1 -2 8
# … with 336,766 more rows# This would be how to replace one_of()
select(flights, which(colnames(flights) %in% vars))# A tibble: 336,776 x 5
year month day dep_delay arr_delay
<int> <int> <int> <dbl> <dbl>
1 2013 1 1 2 11
2 2013 1 1 4 20
3 2013 1 1 2 33
4 2013 1 1 -1 -18
5 2013 1 1 -6 -25
6 2013 1 1 -4 12
7 2013 1 1 -5 19
8 2013 1 1 -3 -14
9 2013 1 1 -3 -8
10 2013 1 1 -2 8
# … with 336,766 more rowsDoes the result of running the following code surprise you? How do the select helpers deal with case by default? How can you change that default?
select(flights, contains("TIME"))# A tibble: 336,776 x 6
dep_time sched_dep_time arr_time sched_arr_time air_time
<int> <int> <int> <int> <dbl>
1 517 515 830 819 227
2 533 529 850 830 227
3 542 540 923 850 160
4 544 545 1004 1022 183
5 554 600 812 837 116
6 554 558 740 728 150
7 555 600 913 854 158
8 557 600 709 723 53
9 557 600 838 846 140
10 558 600 753 745 138
# … with 336,766 more rows, and 1 more variable: time_hour <dttm>The tidyselect helpers ignore case by default (ignore.case = TRUE):
formals(contains)$ignore.case[1] TRUEselect(flights, contains("TIME", ignore.case = FALSE))# A tibble: 336,776 x 0Add new variables with mutate()
p. 58
Currently
dep_timeandsched_dep_timeare convenient to look at, but hard to compute with because they’re not really continuous numbers. Convert them to a more convenient representation of number of minutes since midnight.
select(flights, dep_time, sched_dep_time)# A tibble: 336,776 x 2
dep_time sched_dep_time
<int> <int>
1 517 515
2 533 529
3 542 540
4 544 545
5 554 600
6 554 558
7 555 600
8 557 600
9 557 600
10 558 600
# … with 336,766 more rowstransmute(flights, dep_time, sched_dep_time,
dep_time_min = dep_time %/% 100 * 60 + dep_time %% 100,
sched_dep_time_min = sched_dep_time %/% 100 * 60 + sched_dep_time %% 100)# A tibble: 336,776 x 4
dep_time sched_dep_time dep_time_min sched_dep_time_min
<int> <int> <dbl> <dbl>
1 517 515 317 315
2 533 529 333 329
3 542 540 342 340
4 544 545 344 345
5 554 600 354 360
6 554 558 354 358
7 555 600 355 360
8 557 600 357 360
9 557 600 357 360
10 558 600 358 360
# … with 336,766 more rowsCompare
air_timewitharr_time - dep_time. What do you expect to see? What do you see? What do you need to do to fix it?
I expect them to be the same.
transmute(flights, air_time, arr_time - dep_time)# A tibble: 336,776 x 2
air_time `arr_time - dep_time`
<dbl> <int>
1 227 313
2 227 317
3 160 381
4 183 460
5 116 258
6 150 186
7 158 358
8 53 152
9 140 281
10 138 195
# … with 336,766 more rowsarr_time - dep_time is greater than air_time
transmute(flights, air_time, total = arr_time - dep_time, total - air_time)# A tibble: 336,776 x 3
air_time total `total - air_time`
<dbl> <int> <dbl>
1 227 313 86
2 227 317 90
3 160 381 221
4 183 460 277
5 116 258 142
6 150 186 36
7 158 358 200
8 53 152 99
9 140 281 141
10 138 195 57
# … with 336,766 more rowsair_time is in minutes, but the delays are in HHMM format. I first need to convert the delays to minutes from midnight, as above. I am pretty sure the departure and arrival times are reported using the same timezone.
minutes <- transmute(flights,
dep_time,
dep_time_min = dep_time %/% 100 * 60 + dep_time %% 100,
arr_time,
arr_time_min = arr_time %/% 100 * 60 + arr_time %% 100,
air_time,
total = arr_time_min - dep_time_min,
concord = air_time == total)
minutes# A tibble: 336,776 x 7
dep_time dep_time_min arr_time arr_time_min air_time total concord
<int> <dbl> <int> <dbl> <dbl> <dbl> <lgl>
1 517 317 830 510 227 193 FALSE
2 533 333 850 530 227 197 FALSE
3 542 342 923 563 160 221 FALSE
4 544 344 1004 604 183 260 FALSE
5 554 354 812 492 116 138 FALSE
6 554 354 740 460 150 106 FALSE
7 555 355 913 553 158 198 FALSE
8 557 357 709 429 53 72 FALSE
9 557 357 838 518 140 161 FALSE
10 558 358 753 473 138 115 FALSE
# … with 336,766 more rowsI checked to see if air_time was computed from the scheduled departure and arrival times, but these didn’t match either.
minutes <- transmute(flights,
sched_dep_time,
sched_dep_time_min = sched_dep_time %/% 100 * 60 + sched_dep_time %% 100,
sched_arr_time,
sched_arr_time_min = sched_arr_time %/% 100 * 60 + sched_arr_time %% 100,
air_time,
total = sched_arr_time_min - sched_dep_time_min,
concord = air_time == total)
minutes# A tibble: 336,776 x 7
sched_dep_time sched_dep_time_… sched_arr_time sched_arr_time_… air_time
<int> <dbl> <int> <dbl> <dbl>
1 515 315 819 499 227
2 529 329 830 510 227
3 540 340 850 530 160
4 545 345 1022 622 183
5 600 360 837 517 116
6 558 358 728 448 150
7 600 360 854 534 158
8 600 360 723 443 53
9 600 360 846 526 140
10 600 360 745 465 138
# … with 336,766 more rows, and 2 more variables: total <dbl>,
# concord <lgl>Doing some research online (source), it appears that these won’t match up since air_time does not include taxi-ing.
Compare
dep_time,sched_dep_time, anddep_delay. How would you expect those three numbers to be related?
transmute(flights, dep_time, sched_dep_time, dep_delay)# A tibble: 336,776 x 3
dep_time sched_dep_time dep_delay
<int> <int> <dbl>
1 517 515 2
2 533 529 4
3 542 540 2
4 544 545 -1
5 554 600 -6
6 554 558 -4
7 555 600 -5
8 557 600 -3
9 557 600 -3
10 558 600 -2
# … with 336,766 more rowsI expect dep_delay to be the number of minutes between dep_time and sched_dep_time.
transmute(flights, dep_time, sched_dep_time, dep_delay,
dep_time_min = dep_time %/% 100 * 60 + dep_time %% 100,
sched_dep_time_min = sched_dep_time %/% 100 * 60 + sched_dep_time %% 100,
expected_delay = dep_time_min - sched_dep_time_min,
concond = expected_delay == dep_delay)# A tibble: 336,776 x 7
dep_time sched_dep_time dep_delay dep_time_min sched_dep_time_…
<int> <int> <dbl> <dbl> <dbl>
1 517 515 2 317 315
2 533 529 4 333 329
3 542 540 2 342 340
4 544 545 -1 344 345
5 554 600 -6 354 360
6 554 558 -4 354 358
7 555 600 -5 355 360
8 557 600 -3 357 360
9 557 600 -3 357 360
10 558 600 -2 358 360
# … with 336,766 more rows, and 2 more variables: expected_delay <dbl>,
# concond <lgl>Find the 10 most delayed flights using a ranking function. How do you want to handle ties? Carefully read the documentation for
min_rank().
Use desc() with min_rank() so that the most delayed flight is ranked first.
delayed <- transmute(flights, carrier, flight, dep_delay, rank = min_rank(desc(dep_delay)))
arrange(delayed, rank)# A tibble: 336,776 x 4
carrier flight dep_delay rank
<chr> <int> <dbl> <int>
1 HA 51 1301 1
2 MQ 3535 1137 2
3 MQ 3695 1126 3
4 AA 177 1014 4
5 MQ 3075 1005 5
6 DL 2391 960 6
7 DL 2119 911 7
8 DL 2007 899 8
9 DL 2047 898 9
10 AA 172 896 10
# … with 336,766 more rowsThe NA’s are left as is:
sum(is.na(delayed$dep_delay))[1] 8255sum(is.na(delayed$rank))[1] 8255What does
1:3 + 1:10return? Why?
1:3 + 1:10Warning in 1:3 + 1:10: longer object length is not a multiple of shorter
object length [1] 2 4 6 5 7 9 8 10 12 11The 1:3 is recycled. Thus it gets used 3 times, and then just the final 1. Thus it is equivalent to the following:
c(1:3 + 1:3, 1:3 + 4:6, 1:3 + 7:9, 1 + 10) [1] 2 4 6 5 7 9 8 10 12 11What trigonometric functions does R provide?
?Trigcos(x)
sin(x)
tan(x)
acos(x)
asin(x)
atan(x)
atan2(y, x)
cospi(x)
sinpi(x)
tanpi(x)Group summaries with summarize()
p. 72
Brainstorm at least 5 different ways to assess the typical delay characteristics of a group of flights. Consider the following scenarios:
* A flight is 15 minutes early 50% of the time, and 15 minutes late 50% of
the time.
* A flight is always 10 minutes late.
* A flight is 30 minutes early 50% of the time, and 30 minutes late 50% of
the time.
* 99% of the time a flight is on time. 1% of the time it's 2 hours late.
Which is more important: arrival delay or departure delay?Come up with another approach that will give you the same output as
not_cancelled %>% count(dest)andnot_cancelled %>% count(tailnum, wt = distance)(without usingcount()).
not_cancelled <- flights %>%
filter(!is.na(dep_delay), !is.na(arr_delay))
not_cancelled %>% count(dest)# A tibble: 104 x 2
dest n
<chr> <int>
1 ABQ 254
2 ACK 264
3 ALB 418
4 ANC 8
5 ATL 16837
6 AUS 2411
7 AVL 261
8 BDL 412
9 BGR 358
10 BHM 269
# … with 94 more rowsnot_cancelled %>%
group_by(dest) %>%
summarize(n = n())# A tibble: 104 x 2
dest n
<chr> <int>
1 ABQ 254
2 ACK 264
3 ALB 418
4 ANC 8
5 ATL 16837
6 AUS 2411
7 AVL 261
8 BDL 412
9 BGR 358
10 BHM 269
# … with 94 more rowsnot_cancelled %>% count(tailnum, wt = distance)# A tibble: 4,037 x 2
tailnum n
<chr> <dbl>
1 D942DN 3418
2 N0EGMQ 239143
3 N10156 109664
4 N102UW 25722
5 N103US 24619
6 N104UW 24616
7 N10575 139903
8 N105UW 23618
9 N107US 21677
10 N108UW 32070
# … with 4,027 more rowsnot_cancelled %>%
group_by(tailnum) %>%
summarize(n = sum(distance))# A tibble: 4,037 x 2
tailnum n
<chr> <dbl>
1 D942DN 3418
2 N0EGMQ 239143
3 N10156 109664
4 N102UW 25722
5 N103US 24619
6 N104UW 24616
7 N10575 139903
8 N105UW 23618
9 N107US 21677
10 N108UW 32070
# … with 4,027 more rowsOur definition of cancelled flights (
is.na(dep_delay) | is.na(arr_delay)) is slightly suboptimal. Why? Which is the most important column?
I think arr_delay is more important. If a flight takes off on time, but lands at a different airport, that’s a big issue.
There are 1,175 flights that have a dep_delay but not a arr_delay.
sum(is.na(flights$dep_delay) | is.na(flights$arr_delay))[1] 9430sum(is.na(flights$dep_delay))[1] 8255sum(is.na(flights$arr_delay))[1] 9430sum(xor(is.na(flights$dep_delay), is.na(flights$arr_delay)))[1] 1175sum(is.na(flights$dep_delay) & !is.na(flights$arr_delay))[1] 0sum(!is.na(flights$dep_delay) & is.na(flights$arr_delay))[1] 1175Thus I guess a more strict definintion of “cancelled” would be is.na(dep_delay) and the few cases where the plane departs but doesn’t arrive could be classified as “no arrivals” (presumably this includes redirections and crashes).
Look at the number of cancelled flights per day. Is there a pattern? Is the proportion of cancelled flights related to the average delay?
flights %>%
mutate(cancelled = is.na(dep_delay)) %>%
group_by(year, month, day) %>%
summarize(n = n(),
prop_canc = sum(cancelled) / n,
avg_delay = mean(dep_delay, na.rm = TRUE)) %>%
ggplot(aes(x = avg_delay, y = prop_canc)) +
geom_point(alpha = 0.25) +
geom_smooth()`geom_smooth()` using method = 'loess' and formula 'y ~ x'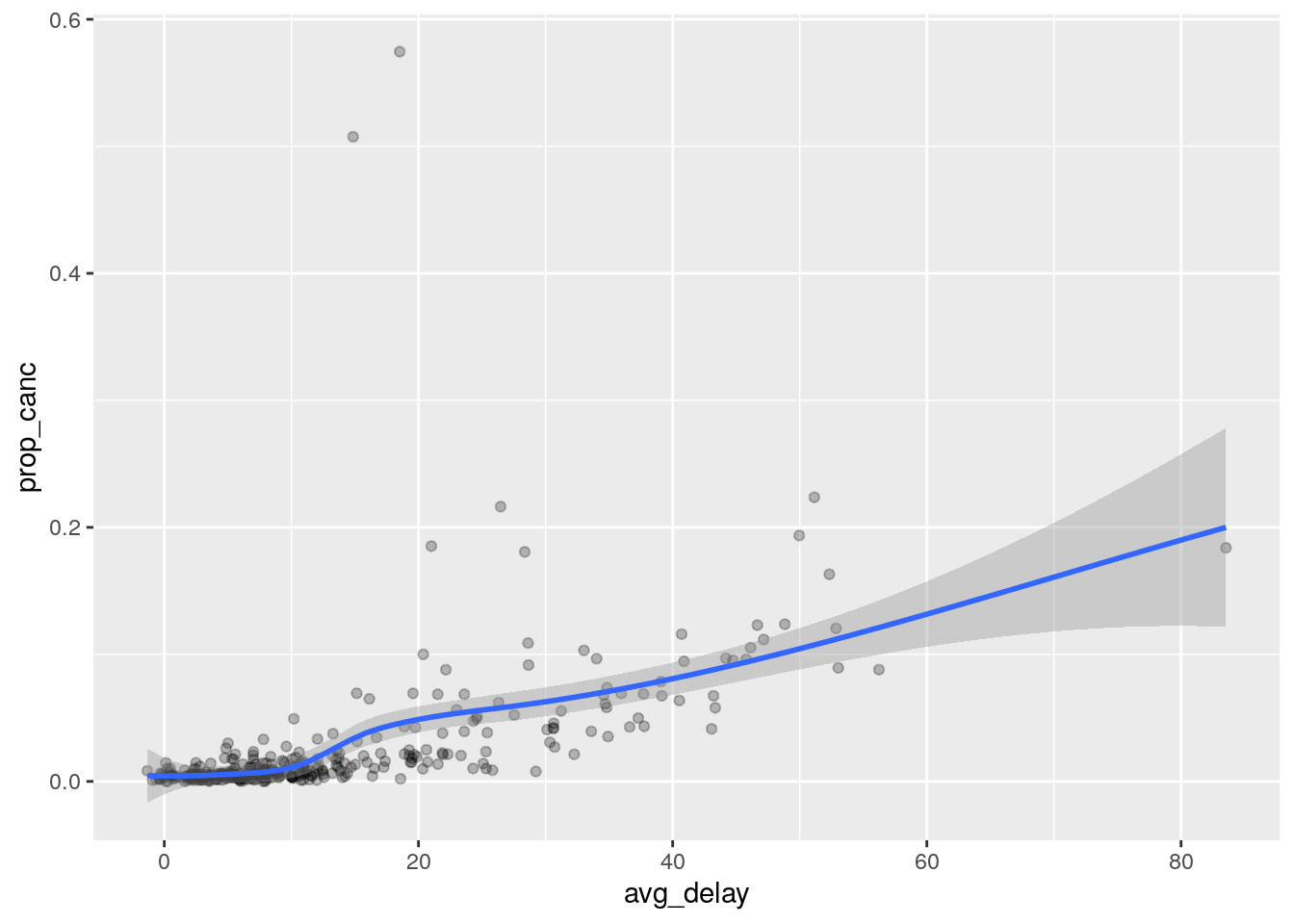
| Version | Author | Date |
|---|---|---|
| 332efa0 | John Blischak | 2019-09-26 |
There is a slight pattern, but it’s mostly driven by the days where the average delay is greater than 10 minutes.
Which carrier has the worst delays? Challenge: can you disentangle the effects of bad airports vs. bad carriers? Why/why not? (Hint: think about
flights %>% group_by(carrier, dest) %>% summarise(n()))
flights %>%
group_by(carrier) %>%
summarize(mean_delay = mean(arr_delay, na.rm = TRUE)) %>%
arrange(desc(mean_delay))# A tibble: 16 x 2
carrier mean_delay
<chr> <dbl>
1 F9 21.9
2 FL 20.1
3 EV 15.8
4 YV 15.6
5 OO 11.9
6 MQ 10.8
7 WN 9.65
8 B6 9.46
9 9E 7.38
10 UA 3.56
11 US 2.13
12 VX 1.76
13 DL 1.64
14 AA 0.364
15 HA -6.92
16 AS -9.93 flights %>% group_by(carrier, dest) %>% summarise(n())# A tibble: 314 x 3
# Groups: carrier [16]
carrier dest `n()`
<chr> <chr> <int>
1 9E ATL 59
2 9E AUS 2
3 9E AVL 10
4 9E BGR 1
5 9E BNA 474
6 9E BOS 914
7 9E BTV 2
8 9E BUF 833
9 9E BWI 856
10 9E CAE 3
# … with 304 more rowsWhat does the
sortargument tocount()do. When might you use it?
Sorts by value of n. Can be used instead of piping to arrange().
Group mutates (and filters)
A grouped filter is a grouped mutate followed by an ungrouped filter.
This is miserable to try and reason about. I can’t imagine ever wanting to do this. I find it much more natural to use summarize().
flights_sml <- select(flights,
year:day,
ends_with("delay"),
distance,
air_time
)
flights_sml %>%
group_by(year, month, day) %>%
filter(rank(desc(arr_delay)) < 10)# A tibble: 3,306 x 7
# Groups: year, month, day [365]
year month day dep_delay arr_delay distance air_time
<int> <int> <int> <dbl> <dbl> <dbl> <dbl>
1 2013 1 1 853 851 184 41
2 2013 1 1 290 338 1134 213
3 2013 1 1 260 263 266 46
4 2013 1 1 157 174 213 60
5 2013 1 1 216 222 708 121
6 2013 1 1 255 250 589 115
7 2013 1 1 285 246 1085 146
8 2013 1 1 192 191 199 44
9 2013 1 1 379 456 1092 222
10 2013 1 2 224 207 550 94
# … with 3,296 more rowsjan_1 <- flights_sml %>%
filter(year == 2013, month == 1, day == 1)
dim(jan_1)[1] 842 7desc(jan_1$arr_delay) [1] -11 -20 -33 18 25 -12 -19 14 8 -8 2 3 -7 14
[15] -31 4 8 7 -12 6 8 -16 12 8 17 -32 -14 -4
[29] 21 9 -3 -5 -1 -29 -10 0 3 -29 -14 19 9 -12
[43] -48 5 10 18 11 9 -5 6 7 6 -11 33 9 8
[57] 18 -4 10 -27 23 14 -5 -2 7 -1 6 9 31 -44
[71] -20 15 12 -21 -10 -5 4 -31 10 -12 -7 -3 26 1
[85] -2 -30 -4 26 12 -26 -2 -7 11 -3 -10 10 -49 18
[99] 4 4 14 2 -33 1 30 -8 6 19 22 12 13 -10
[113] -12 4 0 7 -11 28 26 -137 -10 -23 -7 -17 -17 16
[127] 14 40 -24 13 2 5 -16 -2 7 -51 13 -15 -7 8
[141] 23 -3 13 18 24 -32 -20 8 39 9 27 -851 -19 4
[155] 3 -9 -26 -2 2 -6 10 23 14 13 9 25 8 24
[169] 2 -8 -3 -50 19 -40 -9 7 29 -9 -16 -21 7 30
[183] -4 -15 -28 5 16 -14 -27 -10 4 17 -2 -13 26 14
[197] -30 -9 1 -13 6 5 -42 -15 16 12 -3 -7 11 -6
[211] -2 16 17 -13 -12 -39 -11 0 -123 6 15 25 -39 -5
[225] -7 10 6 -11 -5 21 -2 10 11 -26 4 -11 -11 -32
[239] 17 22 11 -15 6 -11 -21 1 -19 -1 11 6 9 -12
[253] -4 13 6 6 6 14 5 9 -13 11 -23 5 23 4
[267] -2 -3 -145 -78 -5 -34 -4 0 7 6 -16 4 15 4
[281] -3 6 -3 2 16 6 -5 -11 -8 12 -9 -29 39 13
[295] -22 -7 12 -1 3 5 3 4 -10 4 -7 -12 -4 8
[309] -24 26 -12 2 3 -38 -10 -24 4 0 9 -23 -43 6
[323] -27 -2 -3 6 10 -5 -23 6 0 13 -1 38 -36 0
[337] -16 -34 -48 -4 -5 -81 1 8 9 -4 5 -19 -53 -93
[351] -26 2 8 -56 -12 -3 -27 -12 -5 -2 10 3 11 18
[365] 3 11 -43 -1 17 5 -37 0 -8 -78 23 -23 -4 -73
[379] -18 -21 -26 -11 14 13 -24 4 22 -46 4 -22 -27 -60
[393] -11 -19 -27 -103 2 -84 -6 -66 -14 6 -7 18 -26 28
[407] -18 11 15 -65 -15 -83 -26 9 -5 -11 8 -20 15 -15
[421] 27 2 10 -19 22 -4 -11 2 2 18 -22 19 21 1
[435] 22 -1 -10 17 -17 -17 17 4 -3 0 1 -3 4 -127
[449] 1 -18 18 5 -3 -26 0 -11 3 18 -11 -5 -52 -5
[463] -60 12 -1 -7 -6 -3 -3 -27 -125 NA -24 14 -27 21
[477] -44 NA -6 -46 4 5 -34 -47 -19 -20 -19 24 6 17
[491] -35 -115 21 -8 2 -5 -8 -91 -136 8 -13 -12 -6 8
[505] -18 33 -16 -10 2 29 -4 -65 -123 -7 28 17 -15 4
[519] -12 -12 -9 -28 -6 -67 -4 -20 -78 -72 -28 23 35 3
[533] -18 -29 -20 -17 -23 -34 -3 -4 -15 -2 -80 40 -59 16
[547] -67 30 -13 4 15 -23 -14 -21 -20 8 -39 -96 -9 34
[561] -25 -16 -26 -56 4 -35 13 1 14 -40 -3 22 5 14
[575] -41 -22 32 -11 -16 -16 -44 -9 12 -6 -32 -14 -33 -68
[589] 19 -6 8 0 6 -61 -16 -10 7 -3 -16 -3 -24 -4
[603] 18 -3 -107 3 -14 -16 19 -123 -46 12 -3 21 -68 NA
[617] 24 -66 2 -27 4 -10 -34 6 -4 -65 -21 -17 -51 15
[631] 12 5 -37 -8 6 3 14 12 -37 -138 -20 2 -17 NA
[645] 19 15 -14 -116 29 -338 -8 -18 -11 -3 -26 19 2 -3
[659] -14 -2 13 -9 -32 -6 -8 4 0 -7 -32 -94 -12 -25
[673] 3 -263 -8 -2 29 7 -52 19 -78 -2 9 -1 -9 14
[687] -40 5 -3 -127 22 0 1 9 47 15 48 11 -10 33
[701] -2 12 -40 -19 -15 5 19 15 19 4 7 -18 4 -54
[715] -5 13 -21 -43 18 4 -81 -151 -40 -25 -166 NA 2 -12
[729] 10 -174 -16 -14 -44 NA 11 -6 6 26 22 -11 -25 -3
[743] -75 16 4 9 -222 -2 -83 4 -123 4 10 -5 NA -50
[757] -47 3 10 7 -10 -34 -91 14 -7 -24 -50 -45 7 35
[771] -12 -10 -9 17 28 -34 -3 29 28 -45 1 2 -4 5
[785] -44 -61 6 -5 -17 -25 -5 -9 -17 6 12 32 5 14
[799] 6 -55 -17 -250 10 -142 2 -43 -22 24 -3 9 -28 14
[813] 14 -2 13 -246 -21 -23 -28 26 -73 -127 -8 -49 16 7
[827] -49 -23 -35 -9 -191 -69 -73 -33 -456 20 24 12 NA NA
[841] NA NArank(desc(jan_1$arr_delay)) [1] 296.5 202.0 123.5 746.5 792.0 279.0 211.0 703.5 616.5 339.5 495.5
[12] 512.5 352.5 703.5 132.5 534.5 616.5 601.5 279.0 580.5 616.5 239.0
[23] 674.0 616.5 735.5 128.5 259.5 398.0 767.5 632.5 420.5 380.0 457.0
[34] 137.5 313.0 468.0 512.5 137.5 259.5 758.0 632.5 279.0 79.5 558.0
[45] 647.5 746.5 660.5 632.5 380.0 580.5 601.5 580.5 296.5 820.0 632.5
[56] 616.5 746.5 398.0 647.5 149.0 781.5 703.5 380.0 443.5 601.5 457.0
[67] 580.5 632.5 816.0 90.0 202.0 717.5 674.0 193.5 313.0 380.0 534.5
[78] 132.5 647.5 279.0 352.5 420.5 797.0 480.0 443.5 134.5 398.0 797.0
[89] 674.0 158.5 443.5 352.5 660.5 420.5 313.0 647.5 77.0 746.5 534.5
[100] 534.5 703.5 495.5 123.5 480.0 814.0 339.5 580.5 758.0 774.5 674.0
[111] 688.0 313.0 279.0 534.5 468.0 601.5 296.5 805.0 797.0 15.0 313.0
[122] 180.0 352.5 227.5 227.5 726.5 703.5 828.5 172.0 688.0 495.5 558.0
[133] 239.0 443.5 601.5 71.5 688.0 250.0 352.5 616.5 781.5 420.5 688.0
[144] 746.5 787.5 128.5 202.0 616.5 826.5 632.5 801.5 1.0 211.0 534.5
[155] 512.5 327.0 158.5 443.5 495.5 365.0 647.5 781.5 703.5 688.0 632.5
[166] 792.0 616.5 787.5 495.5 339.5 420.5 74.0 758.0 101.0 327.0 601.5
[177] 810.0 327.0 239.0 193.5 601.5 814.0 398.0 250.0 142.0 558.0 726.5
[188] 259.5 149.0 313.0 534.5 735.5 443.5 267.5 797.0 703.5 134.5 327.0
[199] 480.0 267.5 580.5 558.0 97.0 250.0 726.5 674.0 420.5 352.5 660.5
[210] 365.0 443.5 726.5 735.5 267.5 279.0 105.0 296.5 468.0 22.5 580.5
[221] 717.5 792.0 105.0 380.0 352.5 647.5 580.5 296.5 380.0 767.5 443.5
[232] 647.5 660.5 158.5 534.5 296.5 296.5 128.5 735.5 774.5 660.5 250.0
[243] 580.5 296.5 193.5 480.0 211.0 457.0 660.5 580.5 632.5 279.0 398.0
[254] 688.0 580.5 580.5 580.5 703.5 558.0 632.5 267.5 660.5 180.0 558.0
[265] 781.5 534.5 443.5 420.5 12.0 41.5 380.0 118.0 398.0 468.0 601.5
[276] 580.5 239.0 534.5 717.5 534.5 420.5 580.5 420.5 495.5 726.5 580.5
[287] 380.0 296.5 339.5 674.0 327.0 137.5 826.5 688.0 187.0 352.5 674.0
[298] 457.0 512.5 558.0 512.5 534.5 313.0 534.5 352.5 279.0 398.0 616.5
[309] 172.0 797.0 279.0 495.5 512.5 107.0 313.0 172.0 534.5 468.0 632.5
[320] 180.0 94.5 580.5 149.0 443.5 420.5 580.5 647.5 380.0 180.0 580.5
[331] 468.0 688.0 457.0 825.0 111.0 468.0 239.0 118.0 79.5 398.0 380.0
[342] 37.5 480.0 616.5 632.5 398.0 558.0 211.0 68.0 31.0 158.5 495.5
[353] 616.5 64.5 279.0 420.5 149.0 279.0 380.0 443.5 647.5 512.5 660.5
[364] 746.5 512.5 660.5 94.5 457.0 735.5 558.0 109.0 468.0 339.5 41.5
[375] 781.5 180.0 398.0 46.0 219.0 193.5 158.5 296.5 703.5 688.0 172.0
[386] 534.5 774.5 84.0 534.5 187.0 149.0 61.5 296.5 211.0 149.0 28.0
[397] 495.5 34.0 365.0 54.5 259.5 580.5 352.5 746.5 158.5 805.0 219.0
[408] 660.5 717.5 57.0 250.0 35.5 158.5 632.5 380.0 296.5 616.5 202.0
[419] 717.5 250.0 801.5 495.5 647.5 211.0 774.5 398.0 296.5 495.5 495.5
[430] 746.5 187.0 758.0 767.5 480.0 774.5 457.0 313.0 735.5 227.5 227.5
[441] 735.5 534.5 420.5 468.0 480.0 420.5 534.5 18.0 480.0 219.0 746.5
[452] 558.0 420.5 158.5 468.0 296.5 512.5 746.5 296.5 380.0 69.5 380.0
[463] 61.5 674.0 457.0 352.5 365.0 420.5 420.5 149.0 20.0 832.0 172.0
[474] 703.5 149.0 767.5 90.0 833.0 365.0 84.0 534.5 558.0 118.0 81.5
[485] 211.0 202.0 211.0 787.5 580.5 735.5 113.0 26.0 767.5 339.5 495.5
[496] 380.0 339.5 32.5 16.0 616.5 267.5 279.0 365.0 616.5 219.0 820.0
[507] 239.0 313.0 495.5 810.0 398.0 57.0 22.5 352.5 805.0 735.5 250.0
[518] 534.5 279.0 279.0 327.0 142.0 365.0 52.5 398.0 202.0 41.5 48.0
[529] 142.0 781.5 823.5 512.5 219.0 137.5 202.0 227.5 180.0 118.0 420.5
[540] 398.0 250.0 443.5 39.0 828.5 63.0 726.5 52.5 814.0 267.5 534.5
[551] 717.5 180.0 259.5 193.5 202.0 616.5 105.0 29.0 327.0 822.0 166.0
[562] 239.0 158.5 64.5 534.5 113.0 688.0 480.0 703.5 101.0 420.5 774.5
[573] 558.0 703.5 98.0 187.0 817.5 296.5 239.0 239.0 90.0 327.0 674.0
[584] 365.0 128.5 259.5 123.5 50.5 758.0 365.0 616.5 468.0 580.5 59.5
[595] 239.0 313.0 601.5 420.5 239.0 420.5 172.0 398.0 746.5 420.5 27.0
[606] 512.5 259.5 239.0 758.0 22.5 84.0 674.0 420.5 767.5 50.5 834.0
[617] 787.5 54.5 495.5 149.0 534.5 313.0 118.0 580.5 398.0 57.0 193.5
[628] 227.5 71.5 717.5 674.0 558.0 109.0 339.5 580.5 512.5 703.5 674.0
[639] 109.0 14.0 202.0 495.5 227.5 835.0 758.0 717.5 259.5 25.0 810.0
[650] 3.0 339.5 219.0 296.5 420.5 158.5 758.0 495.5 420.5 259.5 443.5
[661] 688.0 327.0 128.5 365.0 339.5 534.5 468.0 352.5 128.5 30.0 279.0
[672] 166.0 512.5 4.0 339.5 443.5 810.0 601.5 69.5 758.0 41.5 443.5
[683] 632.5 457.0 327.0 703.5 101.0 558.0 420.5 18.0 774.5 468.0 480.0
[694] 632.5 830.0 717.5 831.0 660.5 313.0 820.0 443.5 674.0 101.0 211.0
[705] 250.0 558.0 758.0 717.5 758.0 534.5 601.5 219.0 534.5 67.0 380.0
[716] 688.0 193.5 94.5 746.5 534.5 37.5 11.0 101.0 166.0 10.0 836.0
[727] 495.5 279.0 647.5 9.0 239.0 259.5 90.0 837.0 660.5 365.0 580.5
[738] 797.0 774.5 296.5 166.0 420.5 44.0 726.5 534.5 632.5 7.0 443.5
[749] 35.5 534.5 22.5 534.5 647.5 380.0 838.0 74.0 81.5 512.5 647.5
[760] 601.5 313.0 118.0 32.5 703.5 352.5 172.0 74.0 86.5 601.5 823.5
[771] 279.0 313.0 327.0 735.5 805.0 118.0 420.5 810.0 805.0 86.5 480.0
[782] 495.5 398.0 558.0 90.0 59.5 580.5 380.0 227.5 166.0 380.0 327.0
[793] 227.5 580.5 674.0 817.5 558.0 703.5 580.5 66.0 227.5 5.0 647.5
[804] 13.0 495.5 94.5 187.0 787.5 420.5 632.5 142.0 703.5 703.5 443.5
[815] 688.0 6.0 193.5 180.0 142.0 797.0 46.0 18.0 339.5 77.0 726.5
[826] 601.5 77.0 180.0 113.0 327.0 8.0 49.0 46.0 123.5 2.0 764.0
[837] 787.5 674.0 839.0 840.0 841.0 842.0rank(desc(jan_1$arr_delay)) < 10 [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[12] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[23] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[34] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[45] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[56] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[67] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[78] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[89] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[100] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[111] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[122] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[133] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[144] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE
[155] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[166] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[177] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[188] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[199] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[210] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[221] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[232] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[243] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[254] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[265] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[276] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[287] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[298] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[309] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[320] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[331] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[342] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[353] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[364] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[375] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[386] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[397] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[408] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[419] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[430] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[441] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[452] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[463] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[474] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[485] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[496] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[507] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[518] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[529] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[540] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[551] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[562] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[573] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[584] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[595] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[606] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[617] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[628] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[639] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[650] TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[661] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[672] FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[683] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[694] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[705] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[716] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[727] FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[738] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
[749] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[760] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[771] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[782] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[793] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE FALSE
[804] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[815] FALSE TRUE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE
[826] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE TRUE FALSE
[837] FALSE FALSE FALSE FALSE FALSE FALSE# OK. Starting to make sense. For each day, it keeps the 9 worst flightspopular_dests <- flights %>%
group_by(dest) %>%
filter(n() > 365)
popular_dests# A tibble: 332,577 x 19
# Groups: dest [77]
year month day dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <int> <int> <dbl> <int>
1 2013 1 1 517 515 2 830
2 2013 1 1 533 529 4 850
3 2013 1 1 542 540 2 923
4 2013 1 1 544 545 -1 1004
5 2013 1 1 554 600 -6 812
6 2013 1 1 554 558 -4 740
7 2013 1 1 555 600 -5 913
8 2013 1 1 557 600 -3 709
9 2013 1 1 557 600 -3 838
10 2013 1 1 558 600 -2 753
# … with 332,567 more rows, and 12 more variables: sched_arr_time <int>,
# arr_delay <dbl>, carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>length(unique(flights$dest))[1] 105length(unique(popular_dests$dest))[1] 77p. 75
Refer back to the lists of useful mutate and filtering functions. Describe how each operation changes when you combine it with grouping.
Which plane (
tailnum) has the worst on-time record?
# interpretation: worst arrival delay for flights that arrived at their destination
flights %>%
filter(!is.na(tailnum), !is.na(arr_delay)) %>%
group_by(tailnum) %>%
summarize(mean_delay = mean(arr_delay)) %>%
filter(rank(desc(mean_delay)) < 10)# A tibble: 9 x 2
tailnum mean_delay
<chr> <dbl>
1 N587NW 264
2 N654UA 185
3 N665MQ 175.
4 N7715E 188
5 N844MH 320
6 N851NW 219
7 N911DA 294
8 N922EV 276
9 N928DN 201 What time of day should you fly if you want to avoid delays as much as possible?
You would want to leave before 9 AM. Solution below using summarize() + arrange(). I assume you can also do this with only filter(), but I don’t see the advantage.
not_cancelled %>%
group_by(hour) %>%
summarize(mean_delay = mean(arr_delay)) %>%
arrange(mean_delay)# A tibble: 19 x 2
hour mean_delay
<dbl> <dbl>
1 7 -5.30
2 5 -4.80
3 6 -3.38
4 9 -1.45
5 8 -1.11
6 10 0.954
7 11 1.48
8 12 3.49
9 13 6.54
10 14 9.20
11 23 11.8
12 15 12.3
13 16 12.6
14 18 14.8
15 22 16.0
16 17 16.0
17 19 16.7
18 20 16.7
19 21 18.4 For each destination, compute the total minutes of delay. For each flight, compute the proportion of the total delay for its destination.
Total minutes of delay per destination
not_cancelled %>%
filter(arr_delay > 0) %>%
group_by(dest) %>%
summarize(total_delay = sum(arr_delay))# A tibble: 103 x 2
dest total_delay
<chr> <dbl>
1 ABQ 4487
2 ACK 2974
3 ALB 9580
4 ANC 62
5 ATL 300299
6 AUS 39940
7 AVL 3671
8 BDL 6953
9 BGR 6940
10 BHM 7267
# … with 93 more rowsPer flight proportion of delay per destination
props <- not_cancelled %>%
filter(arr_delay > 0) %>%
group_by(dest) %>%
mutate(prop_delay = arr_delay / sum(arr_delay)) %>%
select(flight, dest, arr_delay, prop_delay)
props# A tibble: 133,004 x 4
# Groups: dest [103]
flight dest arr_delay prop_delay
<int> <chr> <dbl> <dbl>
1 1545 IAH 11 0.000111
2 1714 IAH 20 0.000201
3 1141 MIA 33 0.000235
4 1696 ORD 12 0.0000424
5 507 FLL 19 0.0000938
6 301 ORD 8 0.0000283
7 194 LAX 7 0.0000344
8 707 DFW 31 0.000282
9 4650 ATL 12 0.0000400
10 4401 DTW 16 0.000116
# … with 132,994 more rowssum(props$prop_delay[props$dest == "IAH"])[1] 1Delays are typically temporally correlated: even once the problem that caused the initial delay has been resolved, later flights are delayed to allow earlier flights to leave. Using
lag(), explore how the delay of a flight is related to the delay of the immediately preceding flight.
Look at each destination. Can you find flights that are suspiciously fast? (i.e. flights that represent a potential data entry error). Compute the air time a flight relative to the shortest flight to that destination. Which flights were most delayed in the air?
Find all destinations that are flown by at least two carriers. Use that information to rank the carriers.
For each plane, count the number of flights before the first delay of greater than 1 hour.
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 18.04.3 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/atlas/libblas.so.3.10.3
LAPACK: /usr/lib/x86_64-linux-gnu/atlas/liblapack.so.3.10.3
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] forcats_0.4.0 stringr_1.4.0 dplyr_0.8.3
[4] purrr_0.3.2 readr_1.3.1 tidyr_1.0.0
[7] tibble_2.1.3 ggplot2_3.2.1 tidyverse_1.2.1
[10] nycflights13_1.0.1
loaded via a namespace (and not attached):
[1] tidyselect_0.2.5 xfun_0.9 haven_2.1.1 lattice_0.20-38
[5] colorspace_1.4-1 vctrs_0.2.0 generics_0.0.2 htmltools_0.3.6
[9] yaml_2.2.0 utf8_1.1.4 rlang_0.4.0 pillar_1.4.2
[13] glue_1.3.1 withr_2.1.2 modelr_0.1.5 readxl_1.3.1
[17] lifecycle_0.1.0 munsell_0.5.0 gtable_0.3.0 workflowr_1.4.0
[21] cellranger_1.1.0 rvest_0.3.4 evaluate_0.14 labeling_0.3
[25] knitr_1.25 fansi_0.4.0 broom_0.5.2 Rcpp_1.0.2
[29] backports_1.1.4 scales_1.0.0 jsonlite_1.6 fs_1.3.1
[33] hms_0.5.1 digest_0.6.21 stringi_1.4.3 grid_3.6.1
[37] rprojroot_1.2 cli_1.1.0 tools_3.6.1 magrittr_1.5
[41] lazyeval_0.2.2 crayon_1.3.4 whisker_0.4 pkgconfig_2.0.2
[45] zeallot_0.1.0 xml2_1.2.2 lubridate_1.7.4 assertthat_0.2.1
[49] rmarkdown_1.15 httr_1.4.1 rstudioapi_0.10 R6_2.4.0
[53] nlme_3.1-141 git2r_0.26.1 compiler_3.6.1