Session 03 - Exercises Key
Last updated: 2022-07-25
Checks: 6 1
Knit directory:
SISG2022_Association_Mapping/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20220530) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Using absolute paths to the files within your workflowr project makes it difficult for you and others to run your code on a different machine. Change the absolute path(s) below to the suggested relative path(s) to make your code more reproducible.
| absolute | relative |
|---|---|
| /Users/joelle.mbatchou/software/github/SISG2022_Association_Mapping/ | . |
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version cb3e604. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: analysis/.Rhistory
Ignored: code/.Rhistory
Ignored: data/.DS_Store
Ignored: lectures/.DS_Store
Untracked files:
Untracked: analysis/Session07_practical_Key.Rmd
Untracked: analysis/Session08_practical_Key.Rmd
Untracked: data/sim_rels_geno.bed
Untracked: data/sim_rels_geno.bed?dl=0
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/Session03_practical_Key.Rmd) and HTML
(docs/Session03_practical_Key.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | cb3e604 | Joelle Mbatchou | 2022-07-25 | add key |
Before you begin:
- Make sure that R is installed on your computer
- For this lab, we will use the following R libraries:
require(data.table)
require(dplyr)
require(tidyr)
require(GWASTools)
require(ggplot2)GWAS in Samples with Structure
Introduction
We will be analyzing a simulated data set which contains sample structure to better understand the impact it can have in GWAS analyses if not accounted for. We will perform GWAS on a quantitative phenotype which was simulated to have high heritability and be highly polygenic.
The file “sim_rels_pheno.txt””
contains the phenotype measurements for a set of individuals and the
file “sim_rels_geno.bed” is a binary file in PLINK BED format with
accompanying BIM and FAM files which contains the genotype data
at null variants (i.e. simulated as not associated with
the phenotype).
How should we expect the QQ/Manhatthan plots to look like under this
scenario?
Exercises
Here are some things to try:
- Examine the dataset:
- How many samples are present?
famfile <- fread("data/sim_rels_geno.fam", header = FALSE)
famfile %>% strClasses 'data.table' and 'data.frame': 2400 obs. of 6 variables:
$ V1: int 2307 379 478 1545 990 1907 369 1694 2137 2314 ...
$ V2: int 2307 379 478 1545 990 1907 369 1694 2137 2314 ...
$ V3: int 0 0 0 0 0 0 0 0 0 0 ...
$ V4: int 0 0 0 0 0 0 0 0 0 0 ...
$ V5: int 1 2 1 1 1 2 2 1 2 1 ...
$ V6: int -9 -9 -9 -9 -9 -9 -9 -9 -9 -9 ...
- attr(*, ".internal.selfref")=<externalptr> - How many SNPs? In how many chromosomes?
bimfile <- fread("data/sim_rels_geno.bim", header = FALSE)
bimfile %>% strClasses 'data.table' and 'data.frame': 106134 obs. of 6 variables:
$ V1: int 1 1 1 1 1 1 1 1 1 1 ...
$ V2: chr "1:12000011:A:C" "1:12000012:A:C" "1:12000019:T:C" "1:12000027:C:T" ...
$ V3: int 0 0 0 0 0 0 0 0 0 0 ...
$ V4: int 12000011 12000012 12000019 12000027 12000036 12000061 12000073 12000074 12000117 12000136 ...
$ V5: chr "A" "A" "T" "C" ...
$ V6: chr "C" "C" "C" "T" ...
- attr(*, ".internal.selfref")=<externalptr> bimfile %>% select(V1) %>% table.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
4918 4857 4813 4772 4810 4914 4840 4696 4790 4906 4782 4756 4803 4671 4814 4869
17 18 19 20 21 22
4632 4834 4908 4942 4947 4860 - Examine the phenotype data:
- How many individuals in the study have measurements?
yfile <- fread("data/sim_rels_pheno.txt", header = TRUE)
yfile %>% strClasses 'data.table' and 'data.frame': 2400 obs. of 3 variables:
$ FID : int 2307 379 478 1545 990 1907 369 1694 2137 2314 ...
$ IID : int 2307 379 478 1545 990 1907 369 1694 2137 2314 ...
$ Pheno: num 0.00999 -1.45253 0.11097 1.11363 -0.20993 ...
- attr(*, ".internal.selfref")=<externalptr> yfile %>% pull(Pheno) %>% is.na %>% table.
FALSE
2400 - Make a visual of the distribution of the phenotype?
yfile %>%
ggplot(aes(x = Pheno)) +
geom_histogram(colour="black", fill="white")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.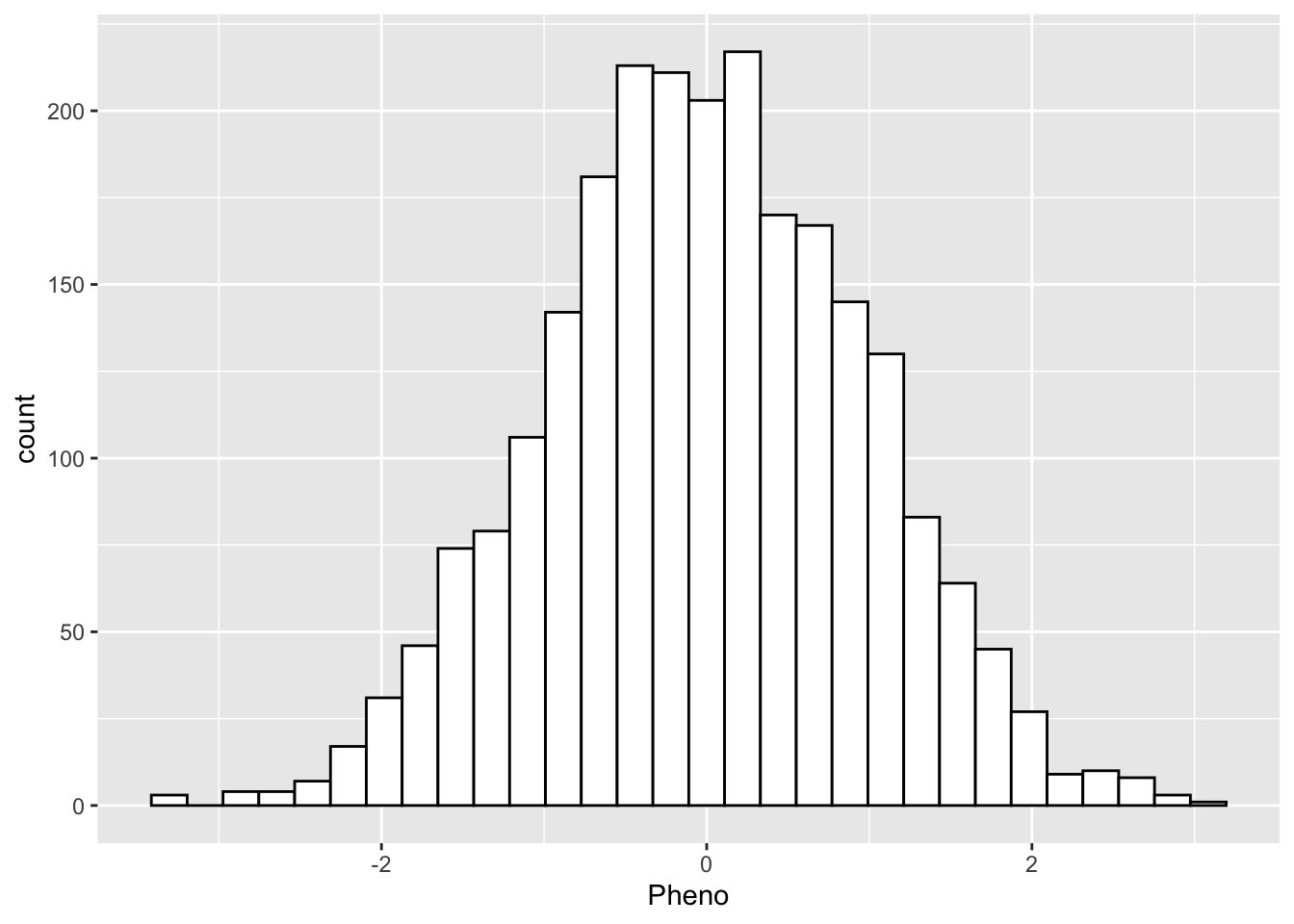
- Using PLINK, perform a GWAS using the phenotype file
sim_rels_pheno.txtand thesim_rels_geno.{bed,bim,fam}genotype files. Only perform association test on SNPs that pass the following quality control threshold filters:
- minor allele frequency (MAF) > 0.01
- at least a 99% genotyping call rate (less than 1% missing)
- HWE p-values greater than 0.001
~/software/bins/plink2 --bfile data/sim_rels_geno --pheno data/sim_rels_pheno.txt --pheno-name Pheno --maf 0.01 --geno 0.01 --hwe 0.001 --autosome --glm allow-no-covars --out /tmp/gwas_plinkPLINK v2.00a3 AVX2 (12 Dec 2020) www.cog-genomics.org/plink/2.0/
(C) 2005-2020 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to /tmp/gwas_plink.log.
Options in effect:
--autosome
--bfile data/sim_rels_geno
--geno 0.01
--glm allow-no-covars
--hwe 0.001
--maf 0.01
--out /tmp/gwas_plink
--pheno data/sim_rels_pheno.txt
--pheno-name Pheno
Start time: Mon Jul 25 16:18:13 2022
16384 MiB RAM detected; reserving 8192 MiB for main workspace.
Using up to 12 threads (change this with --threads).
2400 samples (1179 females, 1221 males; 2400 founders) loaded from
data/sim_rels_geno.fam.
106134 variants loaded from data/sim_rels_geno.bim.
1 quantitative phenotype loaded (2400 values).
Calculating allele frequencies... 0%61%done.
--geno: 0 variants removed due to missing genotype data.
--hwe: 123 variants removed due to Hardy-Weinberg exact test (founders only).
125 variants removed due to allele frequency threshold(s)
(--maf/--max-maf/--mac/--max-mac).
105886 variants remaining after main filters.
--glm linear regression on phenotype 'Pheno': 0%61%done.
Results written to /tmp/gwas_plink.Pheno.glm.linear .
End time: Mon Jul 25 16:18:13 2022- Make a Manhattan plot of the association results using the
manhattanPlot()R function.
plink.gwas <- fread("/tmp/gwas_plink.Pheno.glm.linear", header = TRUE)
plink.gwas %>% strClasses 'data.table' and 'data.frame': 105886 obs. of 13 variables:
$ #CHROM : int 1 1 1 1 1 1 1 1 1 1 ...
$ POS : int 12000011 12000012 12000019 12000027 12000036 12000061 12000073 12000074 12000117 12000136 ...
$ ID : chr "1:12000011:A:C" "1:12000012:A:C" "1:12000019:T:C" "1:12000027:C:T" ...
$ REF : chr "C" "C" "C" "T" ...
$ ALT : chr "A" "A" "T" "C" ...
$ A1 : chr "A" "A" "T" "C" ...
$ TEST : chr "ADD" "ADD" "ADD" "ADD" ...
$ OBS_CT : int 2400 2400 2400 2400 2400 2400 2400 2400 2400 2400 ...
$ BETA : num 0.0122 -0.018 -0.0849 0.0125 0.0111 ...
$ SE : num 0.0438 0.0362 0.0284 0.0435 0.0288 ...
$ T_STAT : num 0.279 -0.497 -2.992 0.288 0.387 ...
$ P : num 0.78 0.6192 0.0028 0.7731 0.6991 ...
$ ERRCODE: chr "." "." "." "." ...
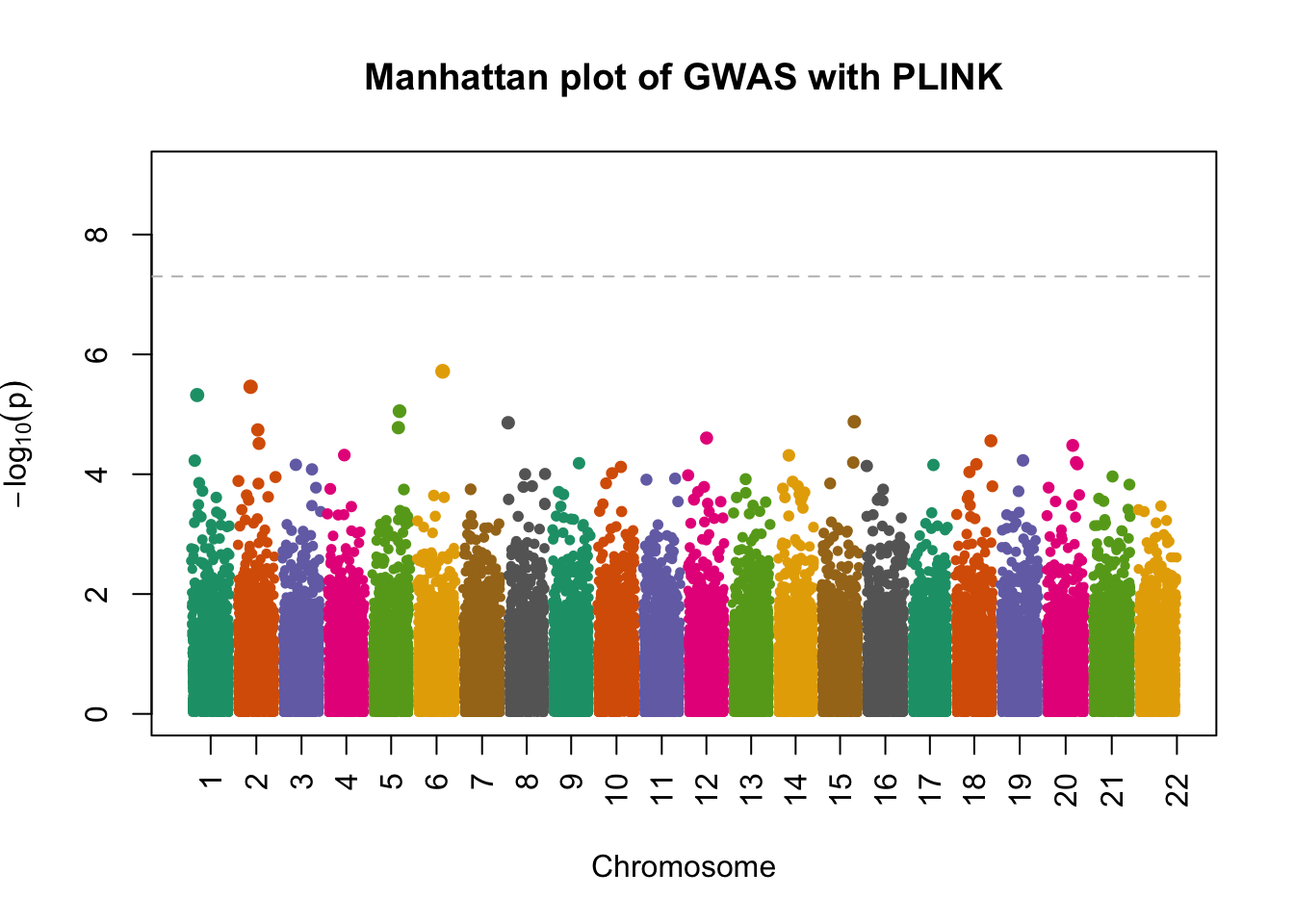
- attr(*, ".internal.selfref")=<externalptr> manhattanPlot(
p = plink.gwas$P,
chromosome = plink.gwas$`#CHROM`,
thinThreshold = 1e-4,
main= "Manhattan plot of GWAS with PLINK"
)
- Make a Q-Q plot of the association results using the
qqPlot()R function.
qqPlot(
pval = plink.gwas$P,
thinThreshold = 1e-4,
main= "Q-Q plot of GWAS with PLINK"
)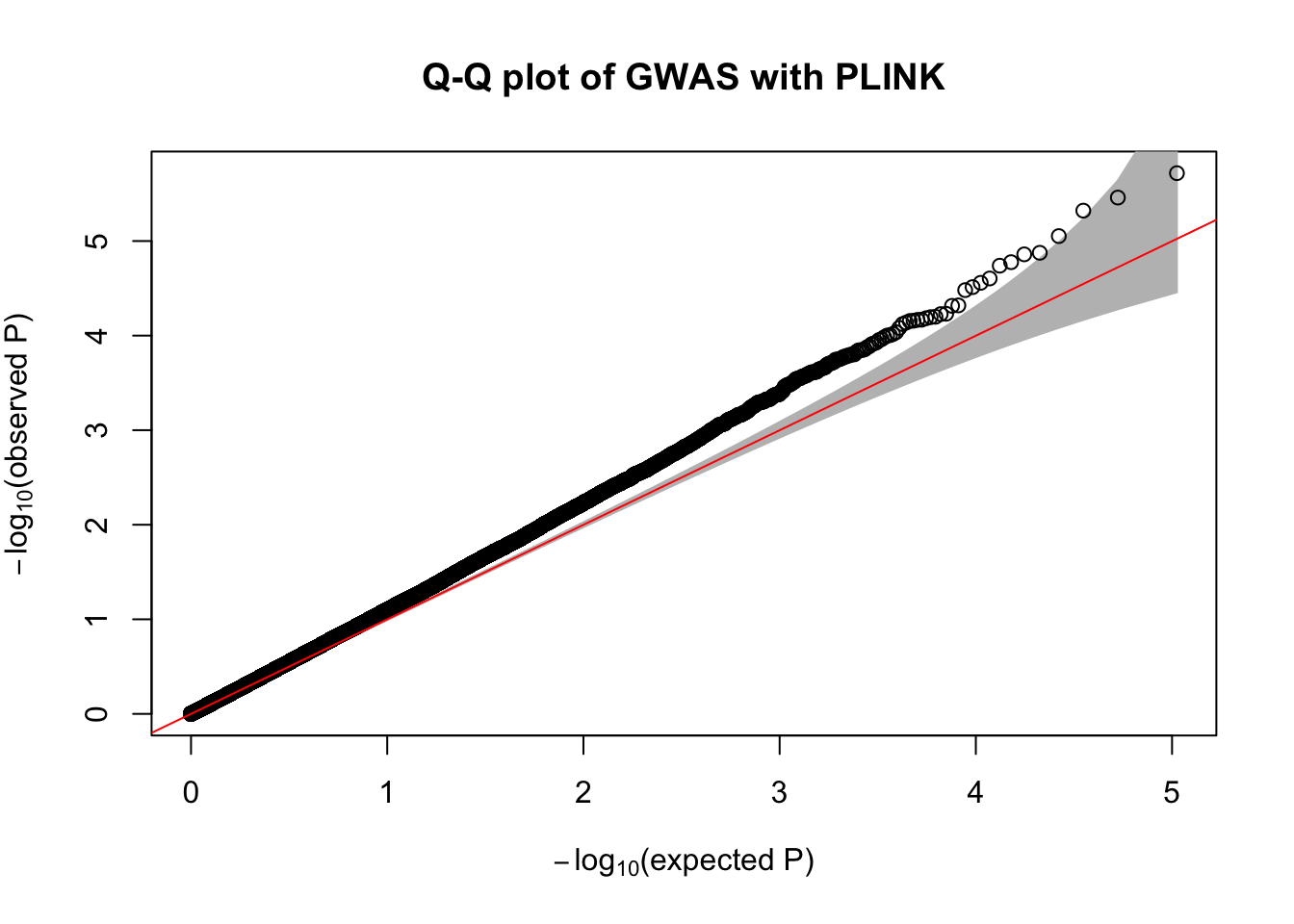
- Compute the genomic control inflation factor \(\lambda_{GC}\) based on the p-values. Is there evidence of possible inflation due to confounding?
chisq.stats <- qchisq(plink.gwas$P, df = 1, lower.tail = FALSE)
median(chisq.stats) / qchisq(0.5,1)[1] 1.148451- Now use REGENIE to perform a GWAS of the phenotype using a whole genome regression model.
- We want to use high quality variants in the Step 1 null model fitting. Using PLINK, apply QC filters to remove variants with MAF below 5%, missingness above 1%, HWE p-value below 0.001, minor allele count (MAC) below 20.
~/software/bins/plink2 --bfile data/sim_rels_geno --maf 0.05 --geno 0.01 --hwe 0.001 --mac 20 --write-snplist --out /tmp/qc_passPLINK v2.00a3 AVX2 (12 Dec 2020) www.cog-genomics.org/plink/2.0/
(C) 2005-2020 Shaun Purcell, Christopher Chang GNU General Public License v3
Logging to /tmp/qc_pass.log.
Options in effect:
--bfile data/sim_rels_geno
--geno 0.01
--hwe 0.001
--mac 20
--maf 0.05
--out /tmp/qc_pass
--write-snplist
Start time: Mon Jul 25 16:18:28 2022
16384 MiB RAM detected; reserving 8192 MiB for main workspace.
Using up to 12 threads (change this with --threads).
2400 samples (1179 females, 1221 males; 2400 founders) loaded from
data/sim_rels_geno.fam.
106134 variants loaded from data/sim_rels_geno.bim.
Note: No phenotype data present.
Calculating allele frequencies... 0%61%done.
--geno: 0 variants removed due to missing genotype data.
--hwe: 123 variants removed due to Hardy-Weinberg exact test (founders only).
8624 variants removed due to allele frequency threshold(s)
(--maf/--max-maf/--mac/--max-mac).
97387 variants remaining after main filters.
--write-snplist: Variant IDs written to /tmp/qc_pass.snplist .
End time: Mon Jul 25 16:18:28 2022- Run REGENIE Step 1 to fit the null model and obtain polygenic predictions using a leave-one-chromosome-out (LOCO) scheme
regenie --bed data/sim_rels_geno --phenoFile data/sim_rels_pheno.txt --step 1 --loocv --bsize 1000 --qt --extract /tmp/qc_pass.snplist --out /tmp/regenie_step1The prediction list file output from Step 1 contains the path to the LOCO polygenic predictions:
cat /tmp/regenie_step1_pred.listPheno /tmp/regenie_step1_1.loco- Run REGENIE Step 2 to perform association testing at the same set of SNPs tested in PLINK.
plink.gwas %>%
select(ID) %>%
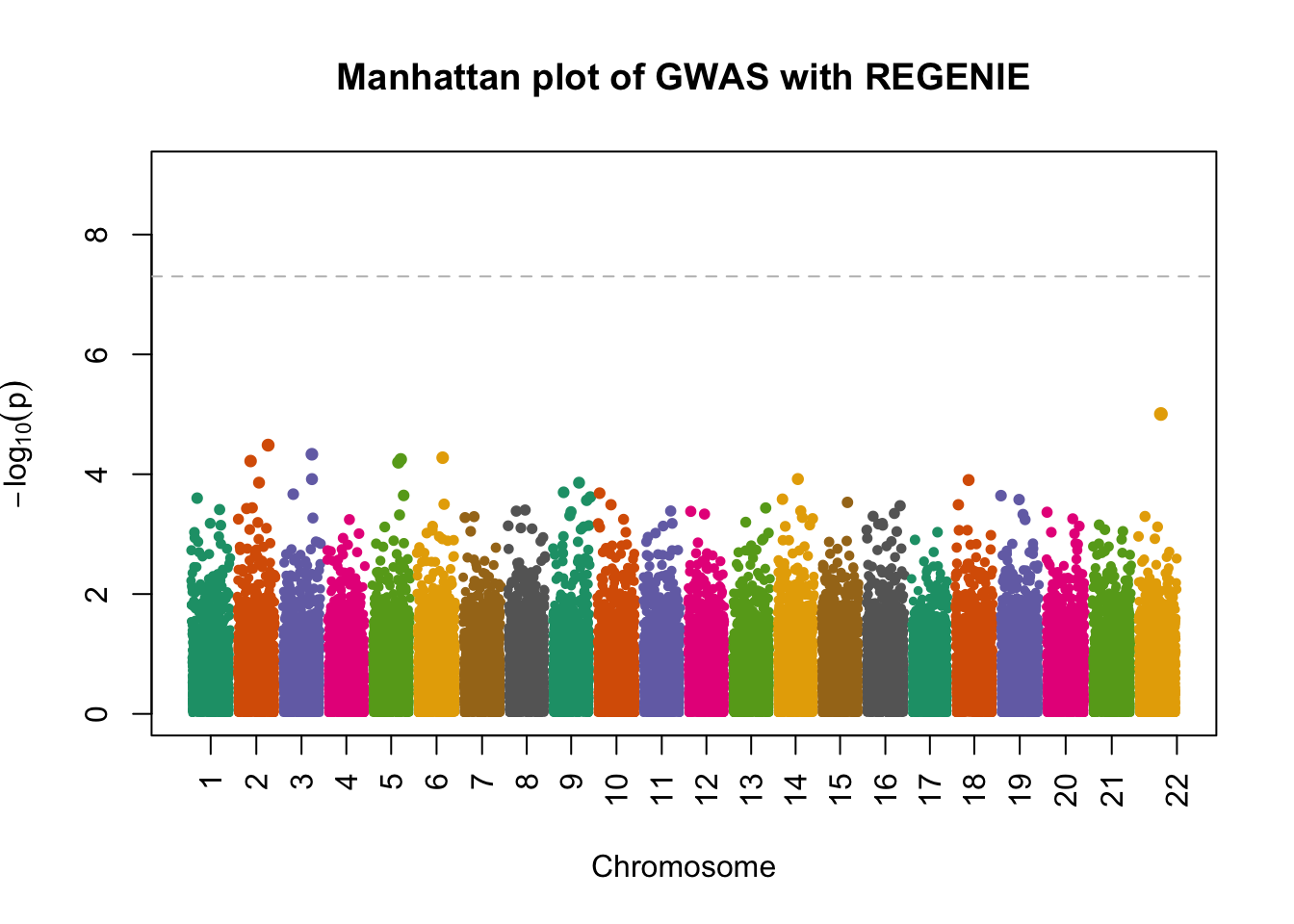
fwrite("/tmp/plink_gwas.snplist", col.names = FALSE, quote = FALSE)regenie --bed data/sim_rels_geno --phenoFile data/sim_rels_pheno.txt --step 2 --bsize 400 --qt --pred /tmp/regenie_step1_pred.list --extract /tmp/plink_gwas.snplist --out /tmp/regenie_step2- Generate Manhatthan and Q-Q plots based on the association results and compute \(\lambda_{GC}\). Compare with output from Questions 4-6.
regenie.gwas <- fread("/tmp/regenie_step2_Pheno.regenie", header = TRUE)
regenie.gwas %>% strClasses 'data.table' and 'data.frame': 105886 obs. of 13 variables:
$ CHROM : int 1 1 1 1 1 1 1 1 1 1 ...
$ GENPOS : int 12000011 12000012 12000019 12000027 12000036 12000061 12000073 12000074 12000117 12000136 ...
$ ID : chr "1:12000011:A:C" "1:12000012:A:C" "1:12000019:T:C" "1:12000027:C:T" ...
$ ALLELE0: chr "C" "C" "C" "T" ...
$ ALLELE1: chr "A" "A" "T" "C" ...
$ A1FREQ : num 0.12 0.187 0.402 0.12 0.415 ...
$ N : int 2400 2400 2400 2400 2400 2400 2400 2400 2400 2400 ...
$ TEST : chr "ADD" "ADD" "ADD" "ADD" ...
$ BETA : num 0.00851 -0.01943 -0.0747 -0.023 0.01463 ...
$ SE : num 0.0419 0.0346 0.0272 0.0416 0.0275 ...
$ CHISQ : num 0.0413 0.3153 7.5548 0.3058 0.2823 ...
$ LOG10P : num 0.0762 0.2407 2.2229 0.2364 0.2254 ...
$ EXTRA : logi NA NA NA NA NA NA ...
- attr(*, ".internal.selfref")=<externalptr> manhattanPlot(
p = 10^-regenie.gwas$LOG10P,
chromosome = regenie.gwas$CHROM,
thinThreshold = 1e-4,
main= "Manhattan plot of GWAS with REGENIE"
)
qqPlot(
pval = 10^-regenie.gwas$LOG10P,
thinThreshold = 1e-4,
main= "Q-Q plot of GWAS with REGENIE"
)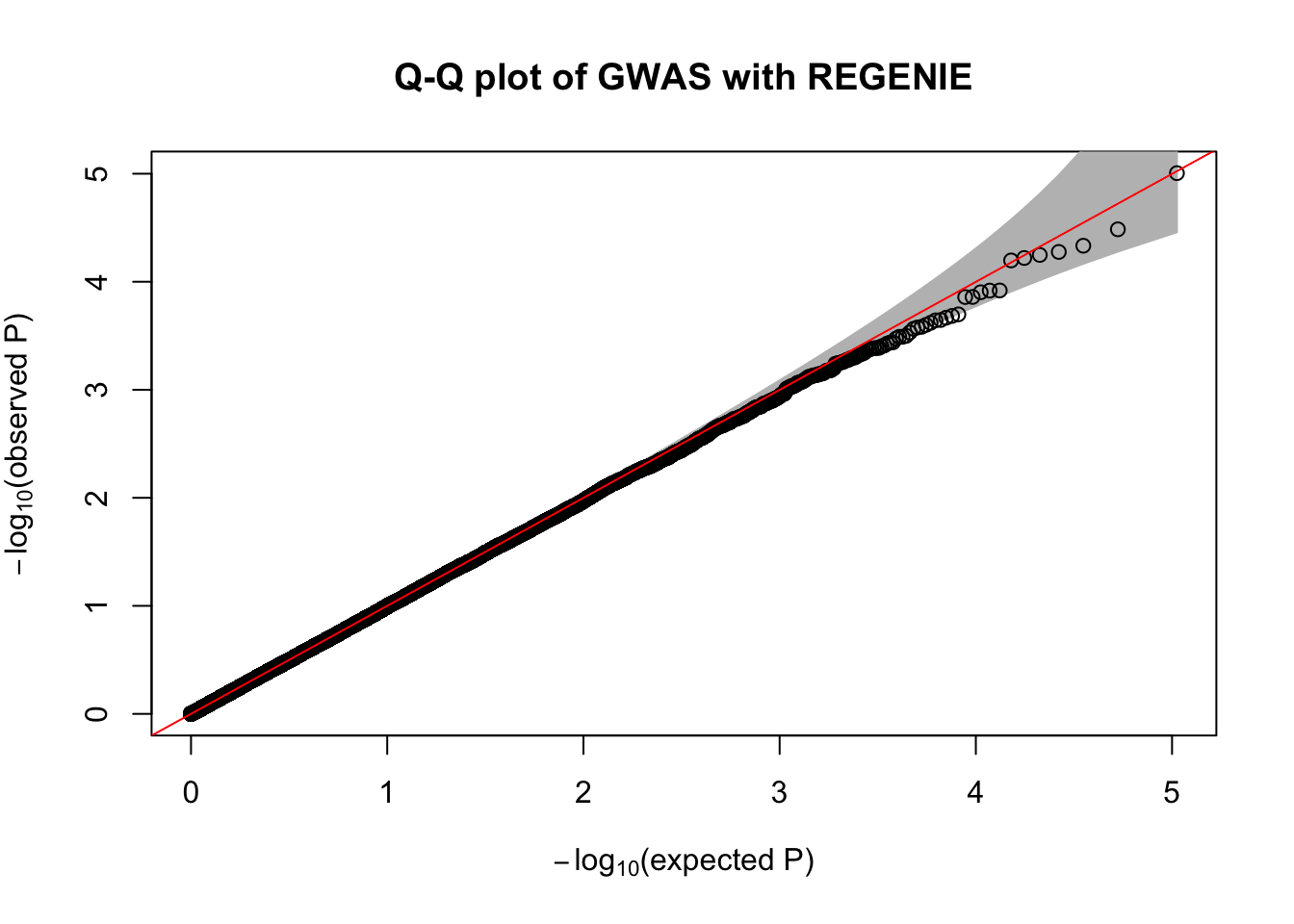
chisq.stats <- qchisq(10^-regenie.gwas$LOG10P, df = 1, lower.tail = FALSE)
median(chisq.stats) / qchisq(0.5,1)[1] 0.9962878
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] parallel stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] ggplot2_3.3.3 GWASTools_1.32.0 Biobase_2.46.0
[4] BiocGenerics_0.32.0 tidyr_1.0.2 dplyr_1.0.8
[7] data.table_1.13.2 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] nlme_3.1-140 fs_1.5.2 bit64_4.0.5
[4] httr_1.4.3 rprojroot_2.0.3 tools_3.6.1
[7] backports_1.1.5 bslib_0.3.1 utf8_1.1.4
[10] R6_2.4.1 colorspace_2.0-0 DBI_1.1.3
[13] mgcv_1.8-28 withr_2.5.0 DNAcopy_1.60.0
[16] tidyselect_1.1.1 processx_3.5.3 bit_4.0.4
[19] compiler_3.6.1 git2r_0.30.1 cli_3.1.1
[22] quantreg_5.54 mice_3.8.0 SparseM_1.78
[25] sandwich_3.0-1 labeling_0.4.2 sass_0.4.0
[28] scales_1.1.1 lmtest_0.9-40 quantsmooth_1.52.0
[31] callr_3.7.0 stringr_1.4.0 digest_0.6.25
[34] minqa_1.2.4 GWASExactHW_1.01 rmarkdown_2.14
[37] pkgconfig_2.0.3 htmltools_0.5.2 lme4_1.1-21
[40] fastmap_1.1.0 highr_0.8 rlang_1.0.4
[43] rstudioapi_0.13 RSQLite_2.2.15 farver_2.0.3
[46] jquerylib_0.1.4 generics_0.0.2 zoo_1.8-9
[49] jsonlite_1.7.2 magrittr_1.5 Matrix_1.2-17
[52] Rcpp_1.0.8.3 munsell_0.5.0 fansi_0.4.1
[55] lifecycle_1.0.1 stringi_1.4.6 whisker_0.4
[58] yaml_2.2.1 MASS_7.3-51.4 grid_3.6.1
[61] formula.tools_1.7.1 blob_1.2.3 promises_1.2.0.1
[64] crayon_1.3.4 lattice_0.20-38 splines_3.6.1
[67] knitr_1.39 ps_1.7.0 pillar_1.7.0
[70] boot_1.3-22 logistf_1.24.1 gdsfmt_1.22.0
[73] glue_1.6.1 evaluate_0.15 getPass_0.2-2
[76] operator.tools_1.6.3 vctrs_0.3.8 nloptr_1.2.2.1
[79] httpuv_1.6.5 MatrixModels_0.4-1 gtable_0.3.0
[82] purrr_0.3.3 cachem_1.0.6 xfun_0.31
[85] broom_0.5.5 later_1.3.0 survival_3.2-10
[88] tibble_3.1.6 memoise_2.0.1 ellipsis_0.3.2