SCEPTRE analysis on LUHMES CROP-seq data
Kaixuan Luo
2022-05-25
Last updated: 2022-05-26
Checks: 7 0
Knit directory: GSFA_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it's best to always run the code in an empty environment.
The command set.seed(20220524) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version c21a39f. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: analysis/sceptre_TCells_data.Rmd
Untracked: analysis/test_sceptre.Rmd
Untracked: code/run_sceptre_LUHMES_data.sbatch
Untracked: code/run_sceptre_Tcells_stimulated_data.sbatch
Untracked: code/run_sceptre_Tcells_unstimulated_data.sbatch
Untracked: code/sceptre_LUHMES_data.R
Untracked: code/sceptre_Tcells_stimulated_data.R
Untracked: code/sceptre_Tcells_unstimulated_data.R
Untracked: sceptre_real_data.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/sceptre_LUHMES_data.Rmd) and HTML (docs/sceptre_LUHMES_data.html) files. If you've configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | c21a39f | kevinlkx | 2022-05-26 | SCEPTRE analysis on LUHMES data |
About the data sets
CROP-seq datasets: /project2/xinhe/yifan/Factor_analysis/shared_data/ The data are Seurat objects, with raw gene counts stored in obj@assays$RNA@counts, and cell meta data stored in obj@meta.data. Normalized and scaled data used for GSFA are stored in obj@assays$RNA@scale.data , the rownames of which are the 6k genes used for GSFA.
Analysis
Scripts for running the analysis:
cd /project2/xinhe/kevinluo/GSFA/log
sbatch --mem=50G --cpus-per-task=10 ~/projects/GSFA_analysis/code/run_sceptre_cropseq_data.sbatch /project2/xinhe/kevinluo/GSFA/sceptre_analysis/LUHMES_cropseq_dataLoad packages
suppressPackageStartupMessages(library(tidyverse))
library(cowplot)
library(Matrix)
library(sceptre)
library(Seurat)Load the LUHMES data
LUHMES_data <- readRDS('/project2/xinhe/yifan/Factor_analysis/shared_data/LUHMES_cropseq_data_seurat.rds')
datadir <- '/project2/xinhe/kevinluo/GSFA/sceptre_analysis/LUHMES_cropseq_data'
outdir <- '/project2/xinhe/kevinluo/GSFA/sceptre_analysis/LUHMES_cropseq_data/sceptre_output'
if(!dir.exists(outdir)) dir.create(outdir, recursive = TRUE)Prepare input data
We first prepare three separate data objects required to run SCEPTRE: the gene expression matrix, the perturbation matrix, and the covariate matrix.
- Gene expression matrices Gene expression (gene-by-cell) raw count matrix
gene_matrix <- LUHMES_data@assays$RNA@counts
# gene-by-cell expression matrix
gene_matrix[1:10, 1:3]10 x 3 sparse Matrix of class "dgCMatrix"
Run1_AAACCTGAGATCGATA Run1_AAACCTGCAGCTCGAC
ENSG00000243485 . .
ENSG00000237613 . .
ENSG00000186092 . .
ENSG00000238009 . .
ENSG00000239945 . .
ENSG00000239906 . .
ENSG00000241599 . .
ENSG00000279928 . .
ENSG00000279457 1 .
ENSG00000228463 1 .
Run1_AAACCTGCATTAGCCA
ENSG00000243485 .
ENSG00000237613 .
ENSG00000186092 .
ENSG00000238009 .
ENSG00000239945 .
ENSG00000239906 .
ENSG00000241599 .
ENSG00000279928 .
ENSG00000279457 1
ENSG00000228463 .dim(gene_matrix)[1] 33694 8708- Cell meta data and covariate matrix
metadata <- LUHMES_data@meta.data
metadata[1:5, ] orig.ident nCount_RNA nFeature_RNA ADNP ARID1B ASH1L
Run1_AAACCTGAGATCGATA LUHMES_Run1 10655 3287 0 0 0
Run1_AAACCTGCAGCTCGAC LUHMES_Run1 8648 2791 0 0 0
Run1_AAACCTGCATTAGCCA LUHMES_Run1 9015 2922 0 0 0
Run1_AAACCTGGTAAGGGCT LUHMES_Run1 9090 2925 0 0 0
Run1_AAACCTGGTTCCGTCT LUHMES_Run1 10182 3052 0 0 0
CHD2 CHD8 CTNND2 DYRK1A HDAC5 MECP2 MYT1L Nontargeting
Run1_AAACCTGAGATCGATA 0 1 0 0 0 0 0 0
Run1_AAACCTGCAGCTCGAC 0 0 0 0 0 0 0 0
Run1_AAACCTGCATTAGCCA 1 0 0 0 0 0 0 0
Run1_AAACCTGGTAAGGGCT 0 0 0 1 0 0 0 0
Run1_AAACCTGGTTCCGTCT 0 0 0 0 1 0 0 0
POGZ PTEN RELN SETD5 percent_mt
Run1_AAACCTGAGATCGATA 0 0 0 0 3.594557
Run1_AAACCTGCAGCTCGAC 0 0 1 0 2.717391
Run1_AAACCTGCATTAGCCA 0 0 0 0 2.995008
Run1_AAACCTGGTAAGGGCT 0 0 0 0 3.080308
Run1_AAACCTGGTTCCGTCT 0 0 0 0 3.142801covariate_matrix <- metadata[,c('orig.ident', 'nCount_RNA', 'nFeature_RNA', 'percent_mt')]
covariate_matrix[1:5,] orig.ident nCount_RNA nFeature_RNA percent_mt
Run1_AAACCTGAGATCGATA LUHMES_Run1 10655 3287 3.594557
Run1_AAACCTGCAGCTCGAC LUHMES_Run1 8648 2791 2.717391
Run1_AAACCTGCATTAGCCA LUHMES_Run1 9015 2922 2.995008
Run1_AAACCTGGTAAGGGCT LUHMES_Run1 9090 2925 3.080308
Run1_AAACCTGGTTCCGTCT LUHMES_Run1 10182 3052 3.142801dim(covariate_matrix)[1] 8708 4- Perturbation matrix (a binary matrix of perturbations, rows are gRNA groups and columns are cell barcodes)
combined_perturbation_matrix <- t(metadata[,4:18])
dim(combined_perturbation_matrix)[1] 15 8708combined_perturbation_matrix[1:10,1:3] Run1_AAACCTGAGATCGATA Run1_AAACCTGCAGCTCGAC Run1_AAACCTGCATTAGCCA
ADNP 0 0 0
ARID1B 0 0 0
ASH1L 0 0 0
CHD2 0 0 1
CHD8 1 0 0
CTNND2 0 0 0
DYRK1A 0 0 0
HDAC5 0 0 0
MECP2 0 0 0
MYT1L 0 0 0range(combined_perturbation_matrix)[1] 0 1Specify the gene-gRNA group pairs to test for association
We include the genes used for GSFA in this analysis
# Normalized and scaled data used for GSFA, the rownames of which are the 6k genes used for GSFA
scaled_gene_matrix <- LUHMES_data@assays$RNA@scale.data
dim(scaled_gene_matrix)[1] 6000 8708selected_gene_id <- rownames(scaled_gene_matrix)
all(selected_gene_id %in% rownames(gene_matrix))[1] TRUEgRNA_group <- rownames(combined_perturbation_matrix)
pairs <- expand.grid(selected_gene_id, gRNA_group)
gene_gRNA_group_pairs <- data.frame(gene_id = pairs$Var1, gRNA_group = pairs$Var2, pair_type = "candidate")
gene_gRNA_group_pairs[gene_gRNA_group_pairs$gRNA_group == "Nontargeting", "pair_type"] <- "negative_control"
table(gene_gRNA_group_pairs$pair_type)
table(gene_gRNA_group_pairs$gRNA_group)
dim(gene_gRNA_group_pairs)save(list = c("gene_matrix", "combined_perturbation_matrix", "covariate_matrix"),
file = file.path(datadir, 'data.matrices.RData'))
saveRDS(gene_gRNA_group_pairs, file.path(datadir, "gene.gRNA.group.pairs.rds"))Run SCEPTRE
load(file.path(datadir, "data.matrices.RData"))
gene_gRNA_group_pairs <- readRDS(file.path(datadir, "gene.gRNA.group.pairs.rds"))
cat(sprintf('Dimenstion of gene expression matrix: %d rows %d columns.\n', nrow(gene_matrix), ncol(gene_matrix)))
cat(sprintf('Dimenstion of combined perturbation matrix: %d rows %d columns.\n', nrow(combined_perturbation_matrix), ncol(combined_perturbation_matrix)))
cat(sprintf('Dimenstion of covariate matrix: %d rows %d columns.\n', nrow(covariate_matrix), ncol(covariate_matrix)))
cat(sprintf('Dimenstion of gene gRNA-group pairs: %d rows %d columns.\n', nrow(gene_gRNA_group_pairs), ncol(gene_gRNA_group_pairs)))
table(gene_gRNA_group_pairs$pair_type)result <- run_sceptre_high_moi(gene_matrix = gene_matrix,
combined_perturbation_matrix = combined_perturbation_matrix,
covariate_matrix = covariate_matrix,
gene_gRNA_group_pairs = gene_gRNA_group_pairs,
side = "both",
storage_dir = outdir,
full_output = TRUE)
# saveRDS(result, file.path(outdir, 'sceptre.result.rds'))Analyze the results
result <- readRDS(file.path(outdir, 'sceptre.result.rds'))
head(result, 10) gene_id gRNA_id pair_type p_value z_value
1 ENSG00000251562 ADNP candidate 8.276198e-04 -2.7128544
2 ENSG00000167552 ADNP candidate 5.699734e-05 5.6529476
3 ENSG00000205542 ADNP candidate 1.175300e-03 -3.2572089
4 ENSG00000104722 ADNP candidate 5.498633e-07 -11.9722455
5 ENSG00000156508 ADNP candidate 6.863815e-01 -0.4263849
6 ENSG00000034510 ADNP candidate 5.594500e-02 2.2087809
7 ENSG00000198712 ADNP candidate 8.261282e-01 0.1660938
8 ENSG00000213190 ADNP candidate 1.769592e-01 1.4053725
9 ENSG00000184009 ADNP candidate 5.329976e-01 0.7832493
10 ENSG00000198668 ADNP candidate 7.860573e-03 4.6174578Negative control pairs
neg_control_p_vals <- result %>% filter(pair_type == "negative_control") %>% pull(p_value)
qq_plot <- make_qq_plot(neg_control_p_vals)
plot(qq_plot)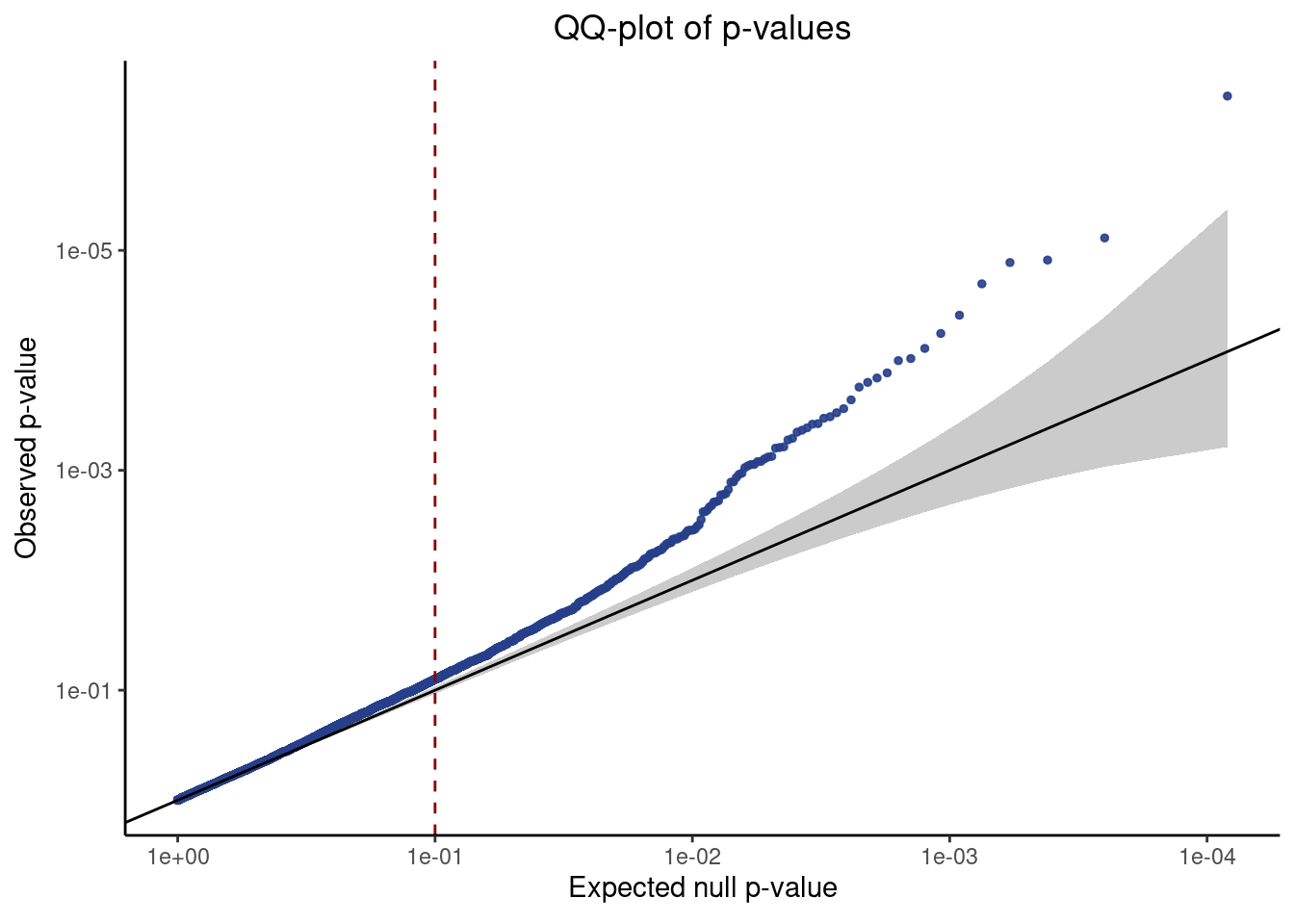
Candidate pairs We extract the p-values corresponding to the candidate pairs and apply a Benjamini-Hochberg (BH) correction to adjust for multiple testing.
candidate_pair_results <- result %>% filter(pair_type == "candidate")
candidate_pair_results_p_adj <- candidate_pair_results %>%
mutate(p_val_adj = p.adjust(p_value, method = "BH"))
head(candidate_pair_results_p_adj) gene_id gRNA_id pair_type p_value z_value p_val_adj
1 ENSG00000251562 ADNP candidate 8.276198e-04 -2.7128544 0.1020852591
2 ENSG00000167552 ADNP candidate 5.699734e-05 5.6529476 0.0134866957
3 ENSG00000205542 ADNP candidate 1.175300e-03 -3.2572089 0.1254449612
4 ENSG00000104722 ADNP candidate 5.498633e-07 -11.9722455 0.0002851143
5 ENSG00000156508 ADNP candidate 6.863815e-01 -0.4263849 0.9624904235
6 ENSG00000034510 ADNP candidate 5.594500e-02 2.2087809 0.6100669357We call pairs with an adjusted p-value of less or equal than 0.1 significant; the discovery set (i.e., the set of significant pairs) has a false discovery rate (FDR) of 10%.
discovery_set <- candidate_pair_results_p_adj %>% filter(p_val_adj <= 0.1)
head(discovery_set) gene_id gRNA_id pair_type p_value z_value p_val_adj
1 ENSG00000167552 ADNP candidate 5.699734e-05 5.652948 1.348670e-02
2 ENSG00000104722 ADNP candidate 5.498633e-07 -11.972246 2.851143e-04
3 ENSG00000124766 ADNP candidate 2.428708e-06 -5.419528 1.004982e-03
4 ENSG00000173267 ADNP candidate 2.220446e-16 12.720042 1.243450e-12
5 ENSG00000131711 ADNP candidate 1.852806e-05 4.984110 5.441809e-03
6 ENSG00000277586 ADNP candidate 6.380460e-05 -6.488863 1.480549e-02saveRDS(candidate_pair_results_p_adj, file.path(outdir, 'sceptre.candidate.pair.results.rds'))
saveRDS(discovery_set, file.path(outdir, 'sceptre.discovery.set.results.rds'))
sessionInfo()R version 4.0.4 (2021-02-15)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.4 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.3.13-el7-x86_64/lib/libopenblas_haswellp-r0.3.13.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] SeuratObject_4.0.4 Seurat_4.1.0 sceptre_0.1.0 Matrix_1.4-1
[5] cowplot_1.1.1 forcats_0.5.1 stringr_1.4.0 dplyr_1.0.8
[9] purrr_0.3.4 readr_2.1.2 tidyr_1.2.0 tibble_3.1.6
[13] ggplot2_3.3.5 tidyverse_1.3.1 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] readxl_1.4.0 backports_1.4.1 plyr_1.8.6
[4] igraph_1.2.11 lazyeval_0.2.2 splines_4.0.4
[7] listenv_0.8.0 scattermore_0.7 digest_0.6.29
[10] htmltools_0.5.2 fansi_1.0.3 magrittr_2.0.3
[13] tensor_1.5 cluster_2.1.2 ROCR_1.0-11
[16] tzdb_0.3.0 globals_0.14.0 modelr_0.1.8
[19] matrixStats_0.61.0 spatstat.sparse_2.1-0 colorspace_2.0-3
[22] rvest_1.0.2 ggrepel_0.9.1 haven_2.5.0
[25] xfun_0.30 callr_3.7.0 crayon_1.5.1
[28] jsonlite_1.8.0 spatstat.data_2.1-2 survival_3.3-1
[31] zoo_1.8-9 glue_1.6.2 polyclip_1.10-0
[34] gtable_0.3.0 leiden_0.3.9 future.apply_1.8.1
[37] abind_1.4-5 scales_1.2.0 DBI_1.1.2
[40] spatstat.random_2.1-0 miniUI_0.1.1.1 Rcpp_1.0.8.3
[43] viridisLite_0.4.0 xtable_1.8-4 reticulate_1.24
[46] spatstat.core_2.4-0 htmlwidgets_1.5.4 httr_1.4.2
[49] RColorBrewer_1.1-3 ellipsis_0.3.2 ica_1.0-2
[52] farver_2.1.0 pkgconfig_2.0.3 sass_0.4.1
[55] uwot_0.1.11 dbplyr_2.1.1 deldir_1.0-6
[58] utf8_1.2.2 tidyselect_1.1.2 rlang_1.0.2
[61] reshape2_1.4.4 later_1.3.0 munsell_0.5.0
[64] cellranger_1.1.0 tools_4.0.4 cli_3.2.0
[67] generics_0.1.2 broom_0.8.0 ggridges_0.5.3
[70] evaluate_0.15 fastmap_1.1.0 yaml_2.3.5
[73] goftest_1.2-3 processx_3.5.3 knitr_1.38
[76] fs_1.5.2 fitdistrplus_1.1-8 RANN_2.6.1
[79] pbapply_1.5-0 future_1.24.0 nlme_3.1-155
[82] whisker_0.4 mime_0.12 xml2_1.3.3
[85] compiler_4.0.4 rstudioapi_0.13 plotly_4.10.0
[88] png_0.1-7 spatstat.utils_2.3-0 reprex_2.0.1
[91] bslib_0.3.1 stringi_1.7.6 highr_0.9
[94] ps_1.6.0 lattice_0.20-45 vctrs_0.4.1
[97] pillar_1.7.0 lifecycle_1.0.1 spatstat.geom_2.3-2
[100] lmtest_0.9-40 jquerylib_0.1.4 RcppAnnoy_0.0.19
[103] data.table_1.14.2 irlba_2.3.5 httpuv_1.6.5
[106] patchwork_1.1.1 R6_2.5.1 promises_1.2.0.1
[109] KernSmooth_2.23-20 gridExtra_2.3 parallelly_1.31.0
[112] codetools_0.2-18 MASS_7.3-56 assertthat_0.2.1
[115] rprojroot_2.0.2 withr_2.5.0 sctransform_0.3.3
[118] mgcv_1.8-39 parallel_4.0.4 hms_1.1.1
[121] grid_4.0.4 rpart_4.1-15 rmarkdown_2.13
[124] Rtsne_0.15 git2r_0.30.1 getPass_0.2-2
[127] shiny_1.7.1 lubridate_1.8.0