pity
Lijia Wang
2020-12-17
Last updated: 2020-12-18
Checks: 7 0
Knit directory: gacha/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20201216) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 5f646a0. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .RData
Ignored: .Rhistory
Ignored: gacha/.RData
Ignored: gacha/.Rhistory
Unstaged changes:
Modified: analysis/cite.bib
Modified: code/wflow_init.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/pity.Rmd) and HTML (docs/pity.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 5f646a0 | Lijia Wang | 2020-12-18 | case studies AFTER thesis |
| html | 9f25d18 | Lijia Wang | 2020-12-18 | Build site. |
| Rmd | 4f264ca | Lijia Wang | 2020-12-18 | updated pity |
| html | 27552b6 | Lijia Wang | 2020-12-17 | Build site. |
| Rmd | 1317343 | Lijia Wang | 2020-12-17 | started pity file |
Introduction
The “pity mechanism” is introduced rather recently as a method to encourage players by guaranteeing them that if they perform enough pulls, they are guaranteed to obtain a card of top rarity. The mechanism is employed in the following way: in the first \(N\) pulls, each pull is an i.i.d. Bernoulli trial with the default probabilities (we shall refer to them as base probabilities). After the N-th pull, in each subsequent pull, the probability of pulling a card of top rarity (SSR) will receive a small increment (\(\delta\)) until you pull a card of top rarity, after which the probability returns to base probabilities and the pull counter resets.
This mechanism is intended to guarantee the players that they can receive an SSR card as long as they make enough pulls. Typically, the player pulls an SSR card before the “pity probability” increases to 100%. We would like to investigate at what point we can actually reach a 95% chance of obtaining an SSR item.
Model:
The tricky part about pity mechanism is that pulls (trials, \(X_i\)) are i.i.d. Bernoulli up to a certain point (\(X_N\)), after which the SSR probability increases linearly with the number of trials attempted. Let’s assume the threshold number of pulls before pity mechanism take effect is \(N\). We will divide the probability up into two segments:
A: No SSR cards are pulled on the \(i = 1, 2, \dots, N\) trials before the pity mechanism takes effect. For these \(N\) trials, the probability of pulling an SSR card is \(p\), and the probability of pulling any other card is \(1-p\).
B: For all the subsequent pulls, \(i = N+1, N+2, \dots, k\), with each pull the probability of pulling an SSR increases with increment \(\delta\). This increase in probability is similar the idea of sampling without replacement, and the idea of “probability distribution for draws until first success without replacement” have also been explored before[@ahlgren2014probability]. However, in this case the probability of drawing the next success, termed as \(\frac{K}{N-n+1}\) at the \(n\)-th trial increases in a non-linear fashion. We would like to construct a model such that the probability of success increases linearly.
In the following analysis, we will use the probabilities of SSR cards from Arknights as an example, instead of F/GO or Genshin Impact. The benefit of using Arknights as our example is that 1) they have clear documentation of rate of increase for their pity mechanism, instead of observations and deductions made by players on reddit, and 2) they only have characters in their gacha, and not equipments. Arknights non-event gacha (on banners after the first 10 pulls) is constructed as follows:
The probability of pulling any SSR (6-star Operator): 2%
pity mechanism: If a 6-star Operator was not obtained after 50 pulls, the probability of pulling any 6-star Operator will increase to 4% in the 51st pull. If the 51st pull is still not a 6-star Operator, then the probability of pulling a 6-star Operator will increase to 6% in the 52nd pull, and the probability will keep increasing by 2% until it reaches 100%. This indicates that if the first 98 pulls (after the last 6-star Operator was pulled) did not yield a 6-star Operator, then a 6-star Operator is guaranteed to be drawn on the 99th pull (probability increases to 100%)
Part A
Probability in part A depicts the scenario before the pity mechanism has taken effect, so when trial number \(i \leq N\). In this scenario, the probabilty of first successful SSR draw after \(k\) trials is the same as that in single pulls.
Therefore, we can continue to use the Geometric distribution model with \(p=0.02\):
\[ Pr(X=k) = (1-p)^{k-1}p\]
and we have the cumulative distribution function:
\[ Pr(X\leq k) = 1-(1-p)^k \]
And we can easily get the probability of obtaining at least 1 SSR within 50 pulls:
\[ Pr(X\leq 50) = 1-(1-0.02)^{50} = 0.636 \]
This shows that we have more than 60% chance of pulling our first SSR card within 50 pulls, without the aid of the pity mechanism. And the probability of not pulling any SSR cards in those 50 pulls is
\[ Pr(X > 50) = (1-0.02)^{50} = 0.364 \]
If there is no pity mechanism in this gacha, the number of trials to achieve a 95% probability of getting one SSR is about 148 pulls.
\[ Pr(X\leq k) = 1-(1-p)^k = 1-(1-0.02)^k = 0.95\]
\[ k = \frac{log(0.05)}{log(1-0.02)} = 148.28\]
Part B
In part B, we focus only on the trials that took place AFTER the pity mechanisms is starting to take an effect. We will write the probability of obtaining the first SSR at each pull as \(S_i\), the probability of obtaining only failure up to this pull as \(F_i\), and the probability of SSR at that specific pull as \(p_i\), and the pity increment as \(\delta\).
Pull #1:
Probablity of first success: \(S_1 = p_1 = p + \delta\)
Probablity of failure: \(F_1 = 1-S_1 = 1-p_1 = 1-(p+\delta)\)
Pull #2:
Probablity of first success: \(S_2 = F_1p_2 = (1-(p+\delta))(p+2\delta)\)
Probablity of failure: \(F_2 = 1-S_2 = 1- F_1p_2 = 1-(1-(p+\delta))(p+2\delta)\)
Pull #3:
Probablity of first success: \(S_3 = F_1F_2p_3 = [1-(p+\delta)][1-(1-(p+\delta))(p+2\delta)](p+3\delta)\)
Probablity of failure: \(F_3 = 1-S_3 = 1-F_1F_2p_3 = 1-[1-(p+\delta)][1-(1-(p+\delta))(p+2\delta)](p+3\delta)\)
\[\dots\]
Pull #n:
Probability of first succcess: \(S_t = F_1F_2F_3 \dots F_{n-1}p_n = F_1F_2F_3 \dots F_{n-1}(p+n\delta)\)
The cumulative probability can be calculated as:
\[Pr(n\leq k) = 1-F_1\cdot F_2 \cdot F_3 \cdot \dots \cdot F_n\]
From a first glance an analytical solution seems difficult to find for this problem, but we can still visualize the results and find out the numerical values at cumulative probability at 50%, 95%, and 99%. Note that at the 99th pull, the probability of pulling an SSR card increases to 100%, after which the gacha resets to base probabilities.
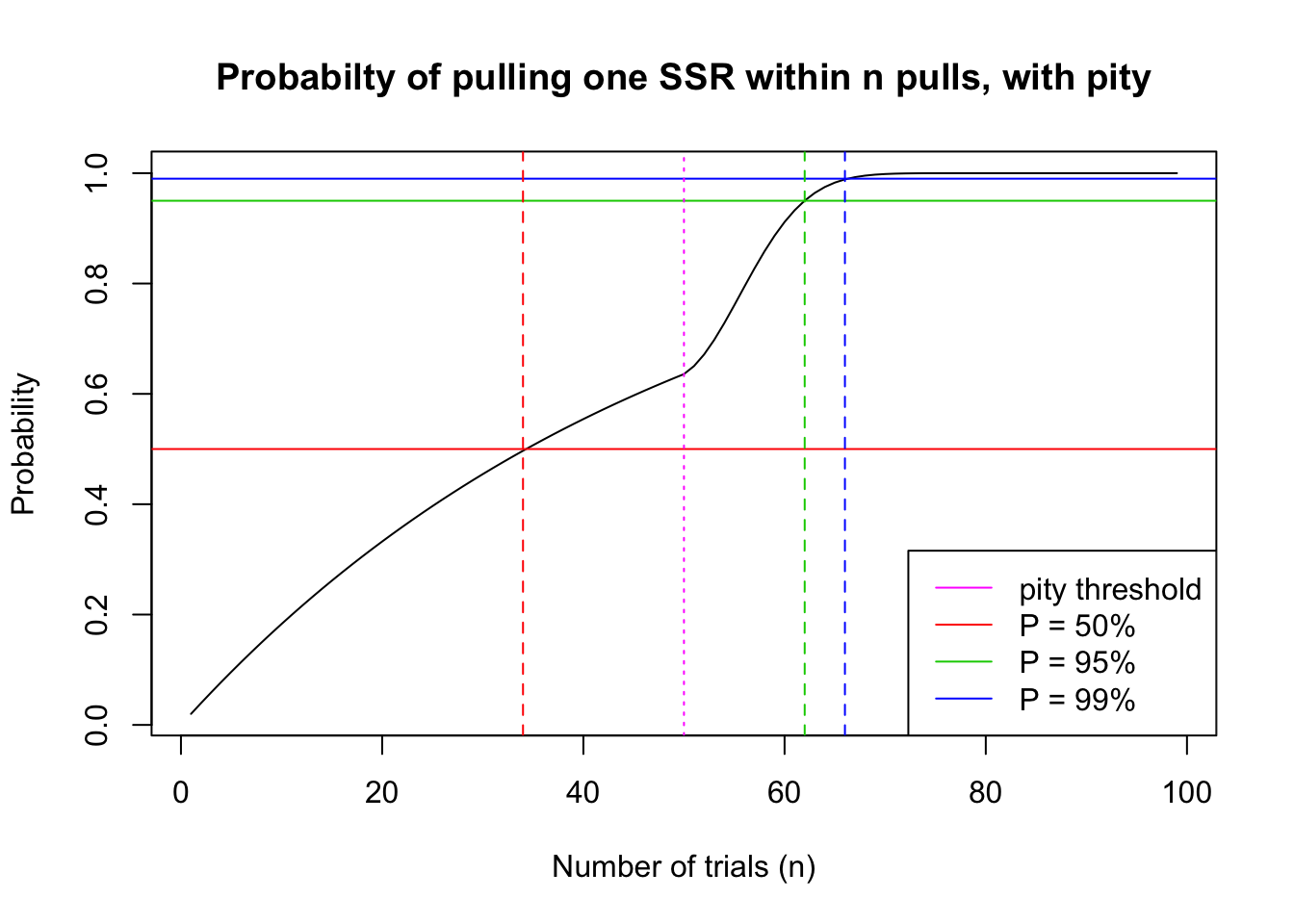
[1] "Player has 50% probability to pull their first SSR within 34 pulls."[1] "Player has 95% probability to pull their first SSR within 62 pulls."[1] "Player has 99% probability to pull their first SSR within 66 pulls."We can see that a 95% probability of one SSR at 62 pulls is a significant improvement from the 148 pulls we estimated if there is no pity mechanism in this gacha.
Comparison with no-pity:
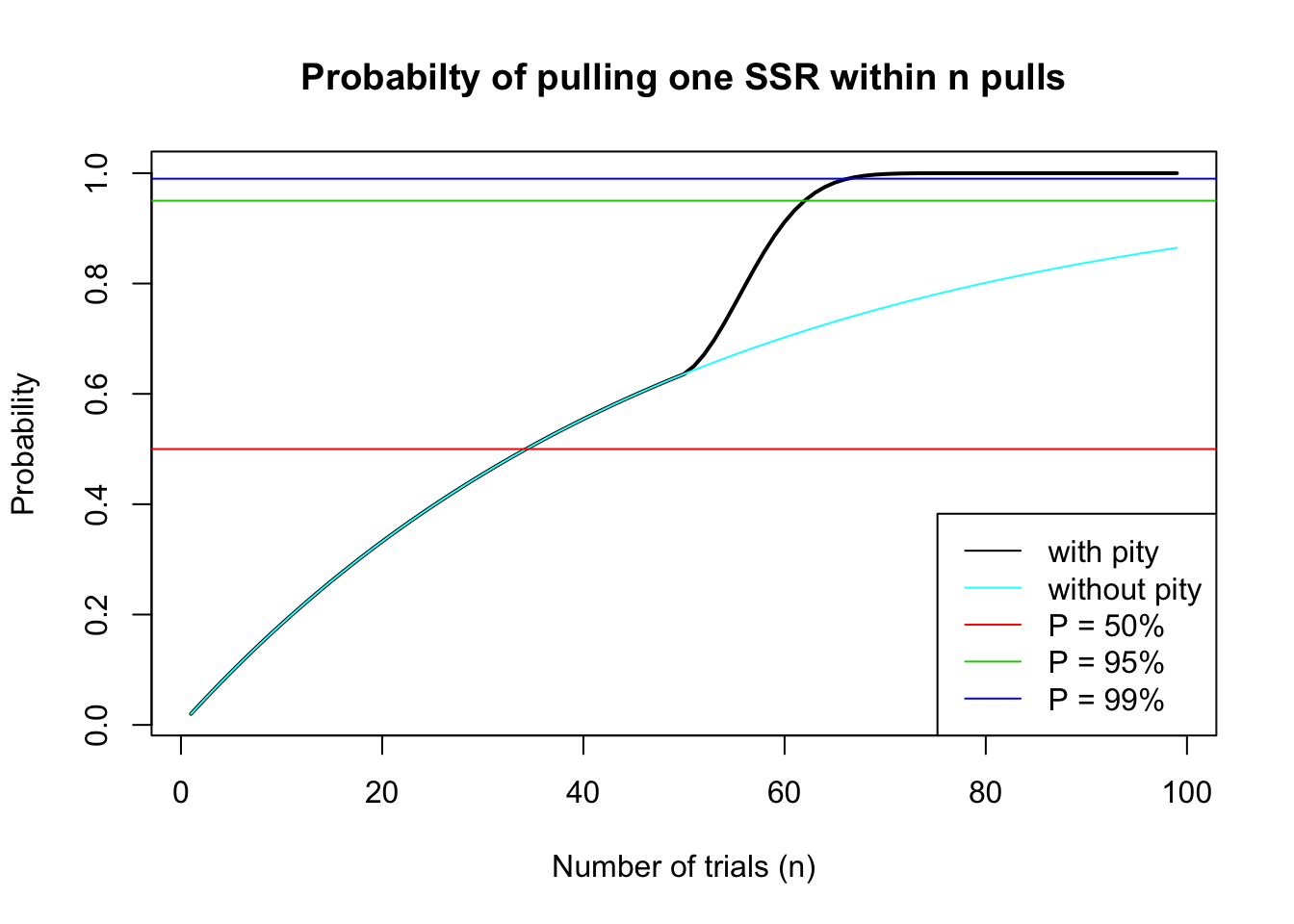
We can easily observe that without the pity mechanism, players will not be able to reach 95% probability of pulling an SSR card within 99 pulls.
R version 3.6.2 (2019-12-12)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.3 rprojroot_1.3-2 digest_0.6.25 later_1.0.0
[5] R6_2.4.1 backports_1.1.5 git2r_0.26.1 magrittr_1.5
[9] evaluate_0.14 stringi_1.4.6 rlang_0.4.5 fs_1.3.2
[13] promises_1.1.0 whisker_0.4 rmarkdown_2.1 tools_3.6.2
[17] stringr_1.4.0 glue_1.3.2 httpuv_1.5.2 xfun_0.12
[21] yaml_2.2.1 compiler_3.6.2 htmltools_0.4.0 knitr_1.28