Differentiable Programming and Neural Differential Equations
Chris Rackauckas
November 20th, 2020
Our last discussion focused on how, at a high mathematical level, one could in theory build programs which compute gradients in a fast manner by looking at the computational graph and performing reverse-mode automatic differentiation. Within the context of parameter identification, we saw many advantages to this approach because it did not scale multiplicatively in the number of parameters, and thus it is an efficient way to calculate Jacobians of objects where there are less rows than columns (think of the gradient as 1 row).
More precisely, this is seen to be more about sparsity patterns, with reverse-mode as being more efficient if there are "enough" less row seeds required than column partials (with mixed mode approaches sometimes being much better). However, to make reverse-mode AD realistically usable inside of a programming language instead of a compute graph, we need to do three things:
We need to have a way of implementing reverse-mode AD on a language.
We need a systematic way to derive "adjoint" relationships (pullbacks).
We need to see if there are better ways to fit parameters to data, rather than performing reverse-mode AD through entire programs!
Implementation of Reverse-Mode AD
Forward-mode AD was implementable through operator overloading and dual number arithmetic. However, reverse-mode AD requires reversing a program through its computational structure, which is a much more difficult operation. This begs the question, how does one actually build a reverse-mode AD implementation?
Static Graph AD
The most obvious solution is to use a static compute graph, since how we defined our differentiation structure was on a compute graph. Tensorflow is a modern example of this approach, where a user must define variables and operations in a graph language (that's embedded into Python, R, Julia, etc.), and then execution on the graph is easy to differentiate. This has the advantage of being a simplified and controlled form, which means that not only differentiation transformations are possible, but also things like automatic parallelization. However, many see directly writing a (static) computation graph as a barrier for practical use since it requires completely rewriting all existing programs to this structure.
Tracing-Based AD and Wengert Lists
Recall that an alternative formulation of reverse-mode AD for composed functions
\[ f = f^L \circ f^{L-1} \circ \ldots \circ f^1 \]
is through pullbacks on the Jacobians:
\[ v^T J = (\ldots ((v^T J_L) J_{L-1}) \ldots ) J_1 \]
Therefore, if one can transform the program structure into a list of composed functions, then reverse-mode AD is the successive application of pullbacks going in the reverse direction:
\[ \mathcal{B}_{f}^{x}(A)=\mathcal{B}_{f^{1}}^{x}\left(\ldots\left(\mathcal{\mathcal{B}}_{f^{L-1}}^{f^{L-2}(f^{L-3}(\ldots f^{1}(x)\ldots))}\left(\mathcal{B}_{f^{L}}^{f^{L-1}(f^{L-2}(\ldots f^{1}(x)\ldots))}(A)\right)\right)\ldots\right) \]
Recall that the pullback $\mathcal{B}_f^x(\overline{y})$ requires knowing:
The operation being performed
The value $x$ of the forward pass
The idea is to then build a Wengert list that is from exactly the forward pass of a specific $x$, also known as a trace, and thus giving rise to tracing-based reverse-mode AD. This is the basis of many reverse-mode implementations, such as Julia's Tracker.jl (Flux.jl's old AD), ReverseDiff.jl, PyTorch, Tensorflow Eager, Autograd, and Autograd.jl. It is widely adopted due to its simplicity in implementation.
Inspecting Tracker.jl
Tracker.jl is a very simple implementation to inspect. The definition of its number and array types are as follows:
struct Call{F,As<:Tuple} func::F args::As end mutable struct Tracked{T} ref::UInt32 f::Call isleaf::Bool grad::T Tracked{T}(f::Call) where T = new(0, f, false) Tracked{T}(f::Call, grad::T) where T = new(0, f, false, grad) Tracked{T}(f::Call{Nothing}, grad::T) where T = new(0, f, true, grad) end mutable struct TrackedReal{T<:Real} <: Real data::T tracker::Tracked{T} end struct TrackedArray{T,N,A<:AbstractArray{T,N}} <: AbstractArray{T,N} tracker::Tracked{A} data::A grad::A TrackedArray{T,N,A}(t::Tracked{A}, data::A) where {T,N,A} = new(t, data) TrackedArray{T,N,A}(t::Tracked{A}, data::A, grad::A) where {T,N,A} = new(t, data, grad) end
As expected, it replaces every single number and array with a value that will store not just perform the operation, but also build up a list of operations along with the values at every stage. Then pullback rules are implemented for primitives via the @grad macro. For example, the pullback for the dot product is implemented as:
@grad dot(xs, ys) = dot(data(xs), data(ys)), Δ -> (Δ .* ys, Δ .* xs)
This is read as: the value going forward is computed by using the Julia dot function on the arrays, and the pullback embeds the backs of the forward pass and uses Δ .* ys as the derivative with respect to x, and Δ .* xs as the derivative with respect to y. This element-wise nature makes sense given the diagonal-ness of the Jacobian.
Note that this also allows utilizing intermediates of the forward pass within the reverse pass. This is seen in the definition of the pullback of meanpool:
@grad function meanpool(x, pdims::PoolDims; kw...) y = meanpool(data(x), pdims; kw...) y, Δ -> (nobacksies(:meanpool, NNlib.∇meanpool(data.((Δ, y, x))..., pdims; kw...)), nothing) end
where the derivative makes use of not only x, but also y so that the meanpool does not need to be re-calculated.
Using this style, Tracker.jl moves forward, building up the value and closures for the backpass and then recursively pulls back the input Δ to receive the derivatve.
Source-to-Source AD
Given our previous discussions on performance, you should be horrified with how this approach handles scalar values. Each TrackedReal holds as Tracked{T} which holds a Call, not a Call{F,As<:Tuple}, and thus it's not strictly typed. Because it's not strictly typed, this implies that every single operation is going to cause heap allocations. If you measure this in PyTorch, TensorFlow Eager, Tracker, etc. you get around 500ns-2ms of overhead. This means that a 2ns + operation becomes... >500ns! Oh my!
This is not the only issue with tracing. Another issue is that the trace is value-dependent, meaning that every new value can build a new trace. Thus one cannot easily JIT compile a trace because it'll be different for every gradient calculation (you can compile it, but you better make sure the compile times are short!). Lastly, the Wengert list can be much larger than the code itself. For example, if you trace through a loop that is for i in 1:100000, then the trace will be huge, even if the function is relatively simple. This is directly demonstrated in the JAX "how it works" slide:

To avoid these issues, another version of reverse-mode automatic differentiation is source-to-source transformations. In order to do source code transformations, you need to know how to transform all language constructs via the reverse pass. This can be quite difficult (what is the "adjoint" of lock?), but when worked out this has a few benefits. First of all, you do not have to track values, meaning stack-allocated values can stay on the stack. Additionally, you can JIT compile one backpass because you have a single function used for all backpasses. Lastly, you don't need to unroll your loops! Instead, which each branch you'd need to insert some data structure to recall the values used from the forward pass (in order to invert in the right directions). However, that can be much more lightweight than a tracking pass.
This can be a difficult problem to do on a general programming language. In general it needs a strong programmatic representation to use as a compute graph. Google's engineers did an analysis when choosing Swift for TensorFlow and narrowed it down to either Swift or Julia due to their internal graph structures. Thus, it should be no surprise that the modern source-to-source AD systems are Zygote.jl for Julia, and Swift for TensorFlow in Swift. Additionally, older AD systems, like Tampenade, ADIFOR, and TAF, all for Fortran, were source-to-source AD systems.
Derivation of Reverse Mode Rules: Adjoints and Implicit Function Theorem
In order to require the least amount of work from our AD system, we need to be able to derive the adjoint rules at the highest level possible. Here are a few well-known cases to start understanding. These next examples are from Steven Johnson's resource.
Adjoint of Linear Solve
Let's say we have the function $A(p)x=b(p)$, i.e. this is the function that is given by the linear solving process, and we want to calculate the gradients of a cost function $g(x,p)$. To evaluate the gradient directly, we'd calculate:
\[ \frac{dg}{dp} = g_p + g_x x_p \]
where $x_p$ is the derivative of each value of $x$ with respect to each parameter $p$, and thus it's an $M \times P$ matrix (a Jacobian). Since $g$ is a small cost function, $g_p$ and $g_x$ are easy to compute, but $x_p$ is given by:
\[ x_{p_i} = A^{-1}(b_{p_i}-A_{p_i}x) \]
and so this is $P$ $M \times M$ linear solves, which is expensive! However, if we multiply by
\[ \lambda^{T} = g_x A^{-1} \]
then we obtain
\[ \frac{dg}{dp}\vert_{f=0} = g_p - \lambda^T f_p = g_p - \lambda^T (A_p x - b_p) \]
which is an alternative formulation of the derivative at the solution value. However, in this case there is no computational benefit to this reformulation.
Adjoint of Nonlinear Solve
Now let's look at some $f(x,p)=0$ nonlinear solving. Differentiating by $p$ gives us:
\[ f_x x_p + f_p = 0 \]
and thus $x_p = -f_x^{-1}f_p$. Therefore, using our cost function we write:
\[ \frac{dg}{dp} = g_p + g_x x_p = g_p - g_x \left(f_x^{-1} f_p \right) \]
or
\[ \frac{dg}{dp} = g_p - \left(g_x f_x^{-1} \right) f_p \]
Since $g_x$ is $1 \times M$, $f_x^{-1}$ is $M \times M$, and $f_p$ is $M \times P$, this grouping changes the problem gets rid of the size $MP$ term.
As is normal with backpasses, we solve for $x$ through the forward pass however we like, and then for the backpass solve for
\[ f_x^T \lambda = g_x^T \]
to obtain
\[ \frac{dg}{dp}\vert_{f=0} = g_p - \lambda^T f_p \]
which does the calculation without ever building the size $M \times MP$ term.
Adjoint of Ordinary Differential Equations
We with to solve for some cost function $G(u,p)$ evaluated throughout the differential equation, i.e.:
\[ G(u,p) = G(u(p)) = \int_{t_0}^T g(u(t,p))dt \]
To derive this adjoint, introduce the Lagrange multiplier $\lambda$ to form:
\[ I(p) = G(p) - \int_{t_0}^T \lambda^\ast (u^\prime - f(u,p,t))dt \]
Since $u^\prime = f(u,p,t)$, this is the mathematician's trick of adding zero, so then we have that
\[ \frac{dG}{dp} = \frac{dI}{dp} = \int_{t_0}^T (g_p + g_u s)dt - \int_{t_0}^T \lambda^\ast (s^\prime - f_u s - f_p)dt \]
for $s$ being the sensitivity, $s = \frac{du}{dp}$. After applying integration by parts to $\lambda^\ast s^\prime$, we get that:
\[ \int_{t_{0}}^{T}\lambda^{\ast}\left(s^{\prime}-f_{u}s-f_{p}\right)dt =\int_{t_{0}}^{T}\lambda^{\ast}s^{\prime}dt-\int_{t_{0}}^{T}\lambda^{\ast}\left(f_{u}s-f_{p}\right)dt \]
\[ =|\lambda^{\ast}(t)s(t)|_{t_{0}}^{T}-\int_{t_{0}}^{T}\lambda^{\ast\prime}sdt-\int_{t_{0}}^{T}\lambda^{\ast}\left(f_{u}s-f_{p}\right)dt \]
To see where we ended up, let's re-arrange the full expression now:
\[ \frac{dG}{dp} =\int_{t_{0}}^{T}(g_{p}+g_{u}s)dt+|\lambda^{\ast}(t)s(t)|_{t_{0}}^{T}-\int_{t_{0}}^{T}\lambda^{\ast\prime}sdt-\int_{t_{0}}^{T}\lambda^{\ast}\left(f_{u}s-f_{p}\right)dt \]
\[ =\int_{t_{0}}^{T}(g_{p}+\lambda^{\ast}f_{p})dt+|\lambda^{\ast}(t)s(t)|_{t_{0}}^{T}-\int_{t_{0}}^{T}\left(\lambda^{\ast\prime}+\lambda^\ast f_{u}-g_{u}\right)sdt \]
That was just a re-arrangement. Now, let's require that
\[ \lambda^\prime = -\frac{df}{du}^\ast \lambda - \left(\frac{dg}{du} \right)^\ast \]
\[ \lambda(T) = 0 \]
This means that the boundary term of the integration by parts is zero, and also one of those integral terms are perfectly zero. Thus, if $\lambda$ satisfies that equation, then we get:
\[ \frac{dG}{dp} = \lambda^\ast(t_0)\frac{dG}{du}(t_0) + \int_{t_0}^T \left(g_p + \lambda^\ast f_p \right)dt \]
which gives us our adjoint derivative relation.
If $G$ is discrete, then it can be represented via the Dirac delta:
\[ G(u,p) = \int_{t_0}^T \sum_{i=1}^N \Vert d_i - u(t_i,p)\Vert^2 \delta(t_i - t)dt \]
in which case
\[ g_u(t_i) = 2(d_i - u(t_i,p)) \]
at the data points $(t_i,d_i)$. Therefore, the derivative of an ODE solution with respect to a cost function is given by solving for $\lambda^\ast$ using an ODE for $\lambda^T$ in reverse time, and then using that to calculate $\frac{dG}{dp}$. Note that $\frac{dG}{dp}$ can be calculated simultaniously by appending a single value to the reverse ODE, since we can simply define the new ODE term as $g_p + \lambda^\ast f_p$, which would then calculate the integral on the fly (ODE integration is just... integration!).
Complexities of Implementing ODE Adjoints
The image below explains the dilemma:
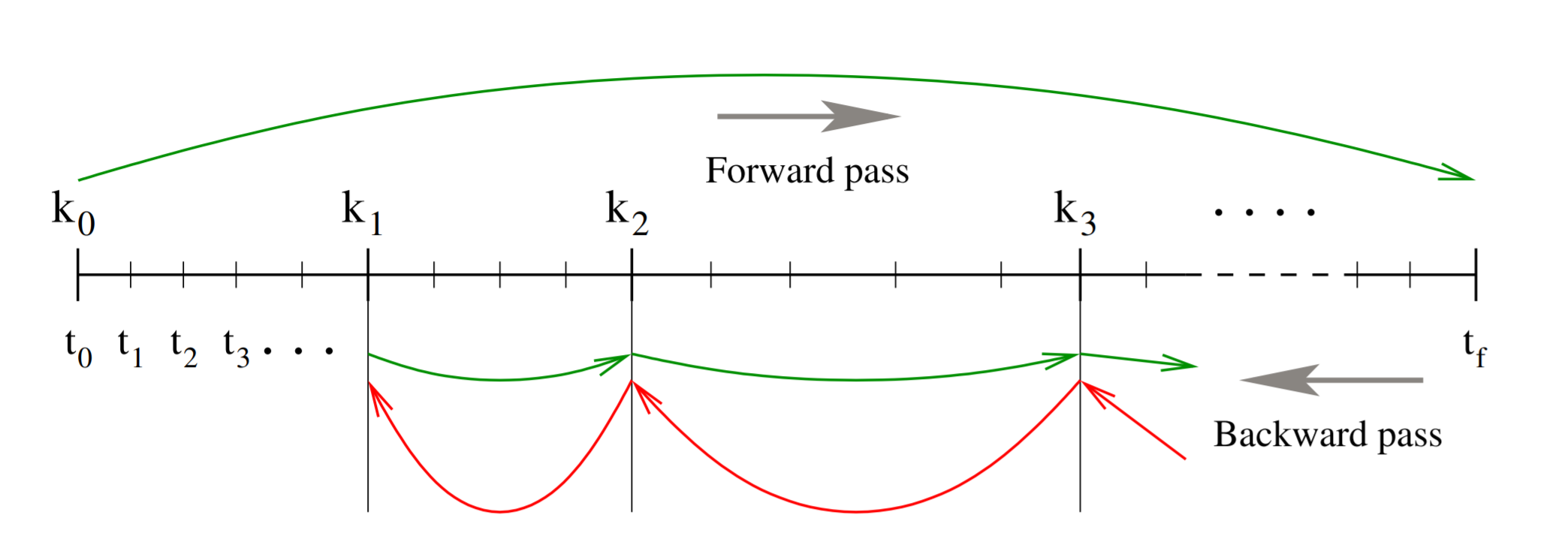
Essentially, the whole problem is that we need to solve the ODE
\[ \lambda^\prime = -\frac{df}{du}^\ast \lambda - \left(\frac{dg}{du} \right)^\ast \]
\[ \lambda(T) = 0 \]
in reverse, but $\frac{df}{du}$ is defined by $u(t)$ which is a value only computed in the forward pass (the forward pass is embedded within the backpass!). Thus we need to be able to retrieve the value of $u(t)$ to get the Jacobian on-demand. There are three ways which this can be done:
If you solve the reverse ODE $u^\prime = f(u,p,t)$ backwards in time, mathematically it'll give equivalent values. Computation-wise, this means that you can append $u(t)$ to $\lambda(t)$ (to $\frac{dG}{dp}$) to calculate all terms at the same time with a single reverse pass ODE. However, numerically this is unstable and thus not always recommended (ODEs are reversible, but ODE solver methods are not necessarily going to generate the same exact values or trajectories in reverse!)
If you solve the forward ODE and receive a continuous solution $u(t)$, you can interpolate it to retrieve the values at any given the time reverse pass needs the $\frac{df}{du}$ Jacobian. This is fast but memory-intensive.
Every time you need a value $u(t)$ during the backpass, you re-solve the forward ODE to $u(t)$. This is expensive! Thus one can instead use checkpoints, i.e. save at finitely many time points during the forward pass, and use those as starting points for the $u(t)$ calculation.
Alternative strategies can be investigated, such as an interpolation which stores values in a compressed form.
The vjp and Neural Ordinary Differential Equations
It is here that we can note that, if $f$ is a function defined by a neural network, we arrive at the neural ordinary differential equation. This adjoint method is thus the backpropogation method for the neural ODE. However, the backpass
\[ \lambda^\prime = -\frac{df}{du}^\ast \lambda - \left(\frac{dg}{du} \right)^\ast \]
\[ \lambda(T) = 0 \]
can be improved by noticing $\frac{df}{du}^\ast \lambda$ is a vjp, and thus it can be calculated using $\mathcal{B}_f^{u(t)}(\lambda^\ast)$, i.e. reverse-mode AD on the function $f$. If $f$ is a neural network, this means that the reverse ODE is defined through successive backpropogation passes of that neural network. The result is a derivative with respect to the cost function of the parameters defining $f$ (either a model or a neural network), which can then be used to fit the data ("train").
Alternative "Training" Strategies
Those are the "brute force" training methods which simply use $u(t,p)$ evaluations to calculate the cost. However, it is worth noting that there are a few better strategies that one can employ in the case of dynamical models.
Multiple Shooting Techniques
Instead of shooting just from the beginning, one can instead shoot from multiple points in time:
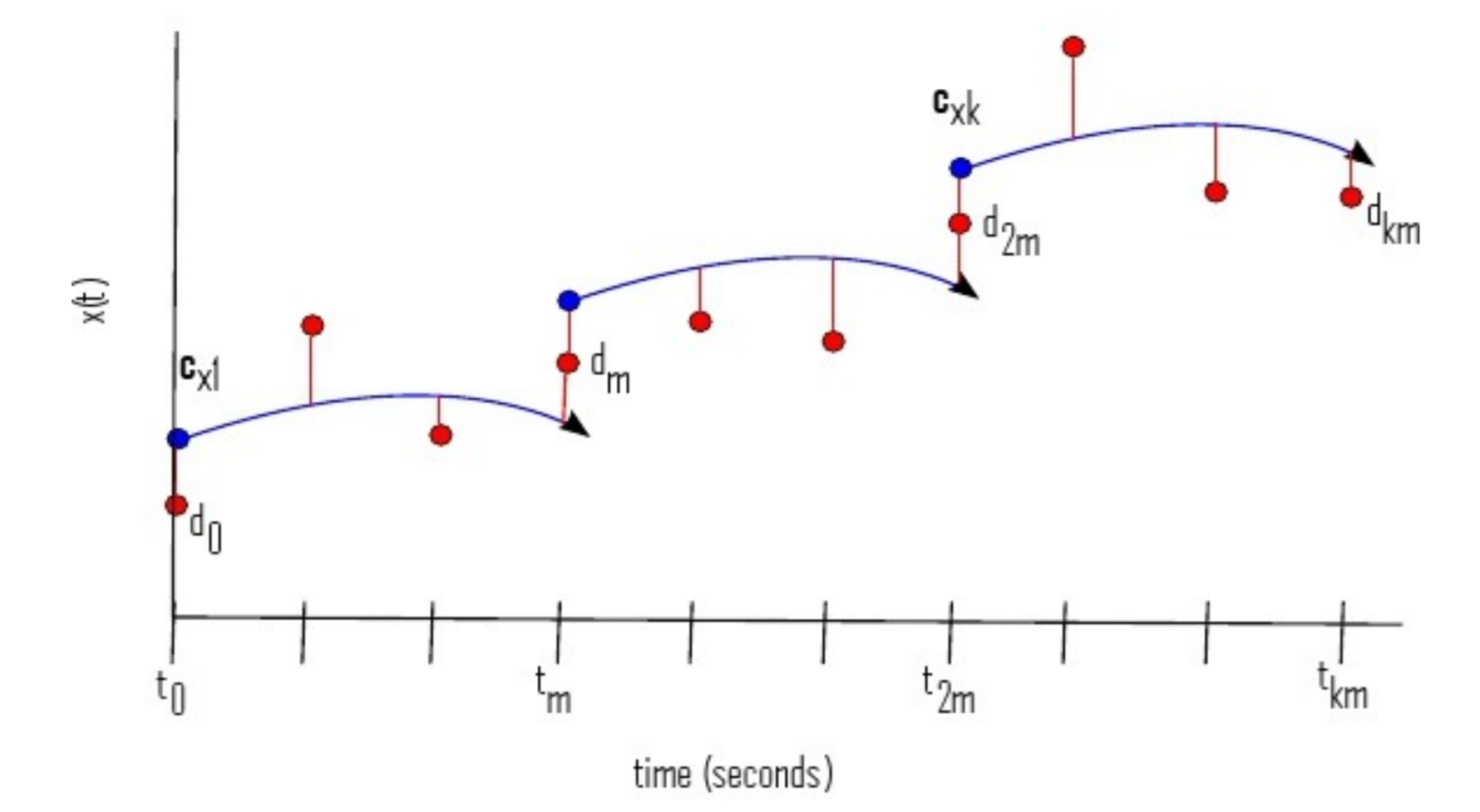
Of course, one won't know what the "initial condition in the future" is, but one can instead make that a parameter. By doing so, each interval can be solved independently, and one can then add to the cost function that the end of one interval must match up with the beginning of the other. This can make the integration more robust, since shooting with incorrect parameters over long time spans can give massive gradients which makes it hard to hone in on the correct values.
Collocation Methods
If the data is dense enough, one can fit a curve through the points, such as a spline:
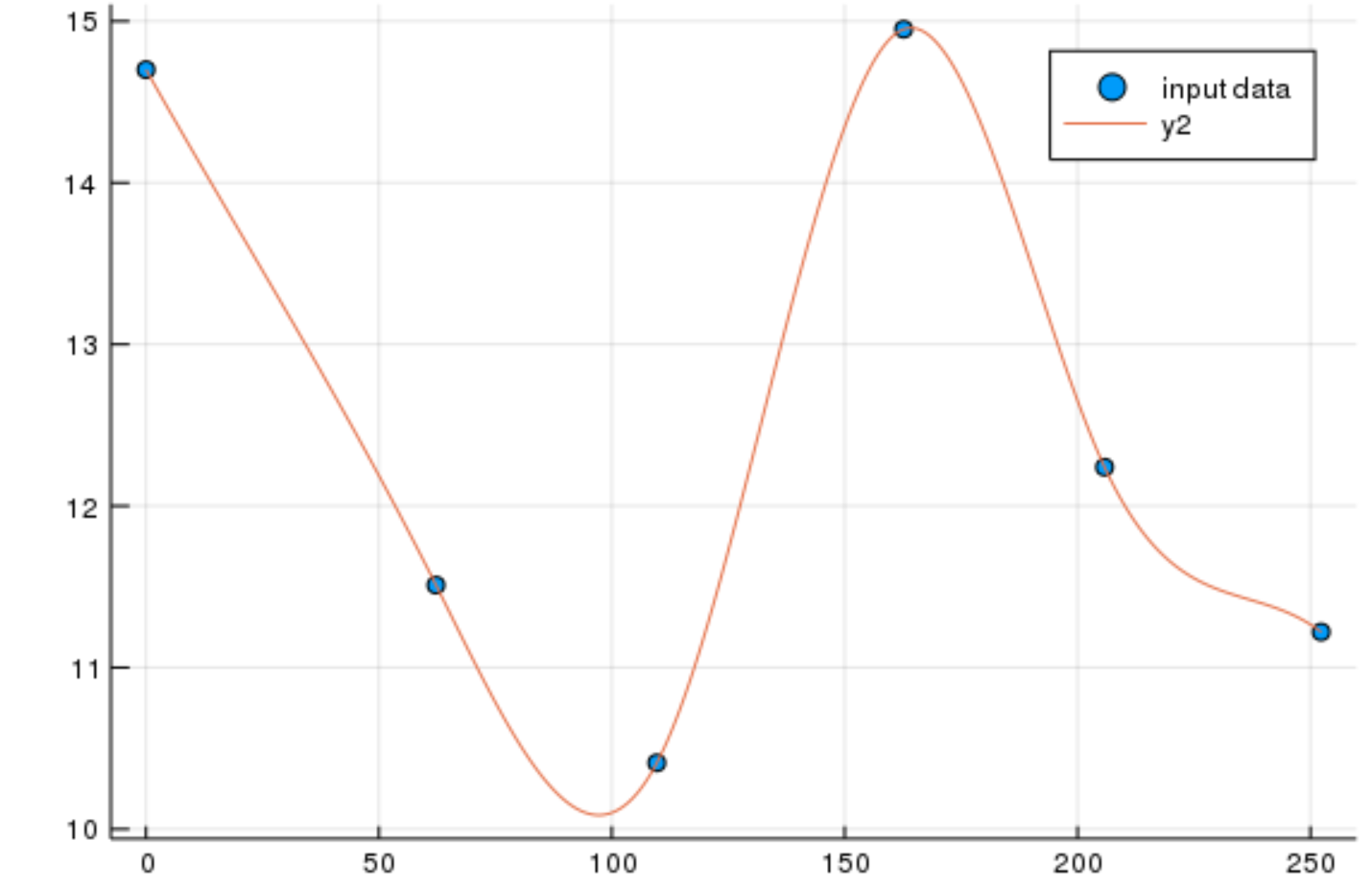
If that's the case, one can use the fit spline in order to estimate the derivative at each point. Since the ODE is defined as $u^\prime = f(u,p,t)$, one then then use the cost function
\[ C(p) = \sum_{i=1}^N \Vert\tilde{u}^{\prime}(t_i) - f(u(t_i),p,t)\Vert \]
where $\tilde{u}^{\prime}(t_i)$ is the estimated derivative at the time point $t_i$. Then one can fit the parameters to ensure this holds. This method can be extremely fast since the ODE doesn't ever have to be solved! However, note that this is not able to compensate for error accumulation, and thus early errors are not accounted for in the later parts of the data. This means that the integration won't necessarily match the data even if this fit is "good" if the data points are too far apart, a property that is not true with fitting. Thus, this is usually done as part of a two-stage method, where the starting stage uses collocation to get initial parameters which is then completed with a shooting method.