Simulations with UK Biobank genotypes and different effect structure across traits
Fabio Morgante & Deborah Kunkel
June 12, 2023
Last updated: 2023-06-12
Checks: 7 0
Knit directory: mr_mash_rss/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230612) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version e56eb43. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .snakemake/
Ignored: data/
Ignored: output/
Ignored: run/
Ignored: tmp/
Untracked files:
Untracked: .test.sbatch.swp
Untracked: Snakefile_old
Untracked: code/merge_sumstats_all_chr_ukb.R
Untracked: scripts/OLD/run_merge_sumstats_all_chr_ukb.sbatch
Untracked: scripts/compute_LD_test_data_for_vijay_by_chr_plink.sbatch
Untracked: scripts/create_test_data_for_vijay.sbatch
Untracked: scripts/readme.txt
Untracked: scripts/run_extract_list_inds_to_remove_from_LD_test_data_for_vijay_plink.sbatch
Untracked: test.sbatch
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/ukb_sim_results.Rmd) and
HTML (docs/ukb_sim_results.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | e56eb43 | fmorgante | 2023-06-12 | workflowr::wflow_publish("analysis/ukb_sim_results.Rmd") |
| html | 886b637 | fmorgante | 2023-06-12 | Build site. |
| Rmd | 2df5821 | fmorgante | 2023-06-12 | wflow_publish("analysis/ukb_sim_results.Rmd") |
Introduction
The goal of this analysis is to benchmark the newly developed mr.mash.rss (aka mr.mash with summary statistics) against already existing methods in the task of predicting phenotypes from genotypes using only summary data. To do so, we used real genotypes from the array data of the UK Biobank. We randomly sampled 105,000 nominally unrelated (\(r_A\) < 0.025 between any pair) individuals of European ancestry (i.e., Caucasian and white British fields). After retaining variants with minor allele frequency (MAF) > 0.01, minor allele count (MAC) > 5 genotype missing rate < 0.1 and Hardy-Weinberg Equilibrium (HWE) test p-value > \(1 *10^{-10}\), our data consisted of 595,071 genetic variants (i.e., our predictors). Missing genotypes were imputed with the mean genotype for the respective genetic variant.
The linkage disequilibrium (LD) matrices were computed using 146,288 nominally unrelated (\(r_A\) < 0.025 between any pair) individuals of European ancestry (i.e., Caucasian and white British fields), that did not overlap with the 105,000 individuals used for the rest of the analyses.
For each simulation replicate, we randomly sampled 5,000 (out of the 105,000) individuals to be the test set. The test set was only used to evaluate prediction accuracy. All the other steps were carried out on the training set of 100,000 individuals.
We simulated 5 traits (i.e., our responses) by randomly sampling 5,000 variants (out of the total of 595,071) to be causal, with different effect sharing structures across traits (see below). The genetic effects explain 50% of the total per-trait variance. The residuals are uncorrelated across traits.
Summary statistics (i.e., effect size and its standard error) were obtained by univariate simple linear regression of each trait on each variant, one at a time. Traits and variants were not standardized.
Three different methods were fitted:
- LDpred2 per-chromosome with the auto option, 500 iterations (after 500 burn-in iterations), \(h^2\) initialized as 0.5/22 and \(p\) initialized using the same grid as in the original paper.
- LDpred2 genome-wide with the auto option, 500 iterations (after 500 burn-in iterations), \(h^2\) initialized as 0.5/22 (WRONG) and \(p\) initialized using the same grid as in the original paper.
- mr.mash.rss per-chromosome, with only data-driven covariance matrices computed as described in the mr.mash paper, updating the (full rank) residual covariance and the mixture weights, without standardizing the variables.
Equal effects scenario
###Load libraries
library(ggplot2)
library(cowplot)
repz <- 1:20
prefix <- "output/prediction_accuracy/ukb_caucasian_white_british_unrel_100000"
scenarioz <- "equal_effects_indep_resid"
methodz <- c("mr_mash_rss", "ldpred2_auto", "ldpred2_auto_gwide")
metric <- "r2"
traitz <- 1:5
i <- 0
n_col <- 6
n_row <- length(repz) * length(scenarioz) * length(methodz) * length(traitz)
res <- as.data.frame(matrix(NA, ncol=n_col, nrow=n_row))
colnames(res) <- c("rep", "scenario", "method", "trait", "metric", "score")
for(sce in scenarioz){
for(met in methodz){
for(repp in repz){
dat <- readRDS(paste0(prefix, "_", sce, "_", met, "_pred_acc_", repp, ".rds"))
for(trait in traitz){
i <- i + 1
res[i, 1] <- repp
res[i, 2] <- sce
res[i, 3] <- met
res[i, 4] <- trait
res[i, 5] <- metric
res[i, 6] <- dat$r2[trait]
}
}
}
}
res <- transform(res, scenario=as.factor(scenario),
method=as.factor(method),
trait=as.factor(trait))
p_methods_shared <- ggplot(res, aes(x = trait, y = score, fill = method)) +
geom_boxplot(color = "black", outlier.size = 1, width = 0.85) +
stat_summary(fun=mean, geom="point", shape=23,
position = position_dodge2(width = 0.87,
preserve = "single")) +
ylim(0.3, 0.51) +
scale_fill_manual(values = c("pink", "red", "green"))+ #, labels = c("g-lasso", "smt-lasso", "e-net")) +
labs(x = "Trait", y = expression(italic(R)^2), title = "Equal effects", fill="Method") +
geom_hline(yintercept=0.5, linetype="dotted", linewidth=1, color = "black") +
theme_cowplot(font_size = 16) +
theme(plot.title = element_text(hjust = 0.5, size=14))
print(p_methods_shared)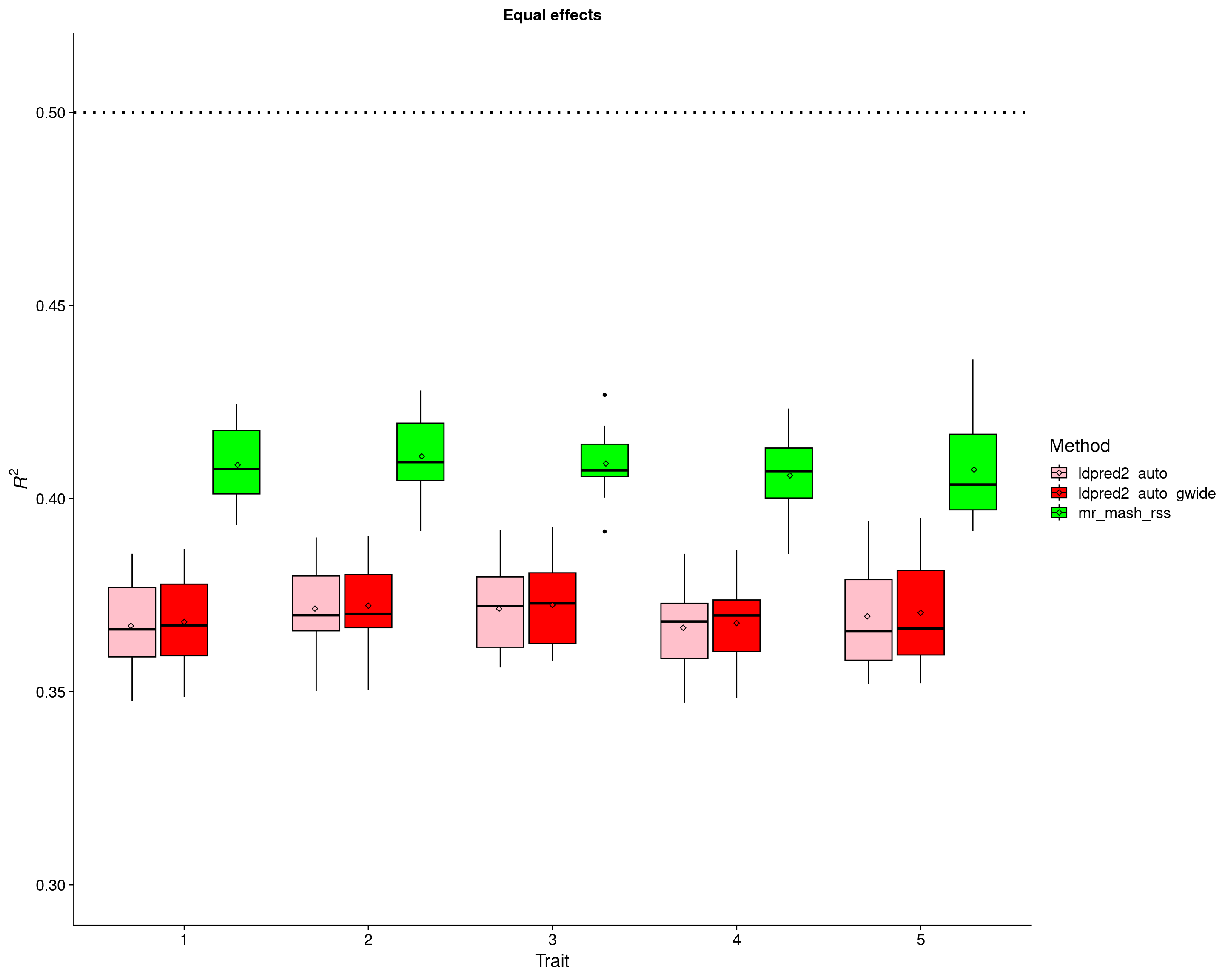
| Version | Author | Date |
|---|---|---|
| 886b637 | fmorgante | 2023-06-12 |
sessionInfo()R version 4.1.2 (2021-11-01)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Rocky Linux 8.5 (Green Obsidian)
Matrix products: default
BLAS/LAPACK: /opt/ohpc/pub/libs/gnu9/openblas/0.3.7/lib/libopenblasp-r0.3.7.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] cowplot_1.1.1 ggplot2_3.4.1
loaded via a namespace (and not attached):
[1] Rcpp_1.0.10 highr_0.10 pillar_1.9.0 compiler_4.1.2
[5] bslib_0.4.2 later_1.3.0 jquerylib_0.1.4 git2r_0.31.0
[9] workflowr_1.7.0 tools_4.1.2 digest_0.6.31 gtable_0.3.3
[13] jsonlite_1.8.4 evaluate_0.20 lifecycle_1.0.3 tibble_3.2.1
[17] pkgconfig_2.0.3 rlang_1.1.0 cli_3.6.1 rstudioapi_0.14
[21] yaml_2.3.7 xfun_0.37 fastmap_1.1.1 withr_2.5.0
[25] dplyr_1.1.1 stringr_1.5.0 knitr_1.42 generics_0.1.3
[29] fs_1.6.1 vctrs_0.6.1 sass_0.4.5 tidyselect_1.2.0
[33] rprojroot_2.0.3 grid_4.1.2 glue_1.6.2 R6_2.5.1
[37] fansi_1.0.4 rmarkdown_2.20 farver_2.1.1 magrittr_2.0.3
[41] whisker_0.4.1 scales_1.2.1 promises_1.2.0.1 htmltools_0.5.4
[45] colorspace_2.1-0 httpuv_1.6.9 labeling_0.4.2 utf8_1.2.3
[49] stringi_1.7.12 munsell_0.5.0 cachem_1.0.7