Lactate dehydrogenase, troponin I, and calcium analysis
ERM
2023-09-26
Last updated: 2023-09-26
Checks: 7 0
Knit directory: Cardiotoxicity/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230109) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 36663b3. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/41588_2018_171_MOESM3_ESMeQTL_ST2_for paper.csv
Ignored: data/Arr_GWAS.txt
Ignored: data/Arr_geneset.RDS
Ignored: data/BC_cell_lines.csv
Ignored: data/BurridgeDOXTOX.RDS
Ignored: data/CADGWASgene_table.csv
Ignored: data/CAD_geneset.RDS
Ignored: data/CALIMA_Data/
Ignored: data/Clamp_Summary.csv
Ignored: data/Cormotif_24_k1-5_raw.RDS
Ignored: data/Counts_RNA_ERMatthews.txt
Ignored: data/DAgostres24.RDS
Ignored: data/DAtable1.csv
Ignored: data/DDEMresp_list.csv
Ignored: data/DDE_reQTL.txt
Ignored: data/DDEresp_list.csv
Ignored: data/DEG-GO/
Ignored: data/DEG_cormotif.RDS
Ignored: data/DF_Plate_Peak.csv
Ignored: data/DRC48hoursdata.csv
Ignored: data/Da24counts.txt
Ignored: data/Dx24counts.txt
Ignored: data/Dx_reQTL_specific.txt
Ignored: data/EPIstorelist24.RDS
Ignored: data/Ep24counts.txt
Ignored: data/Full_LD_rep.csv
Ignored: data/GOIsig.csv
Ignored: data/GOplots.R
Ignored: data/GTEX_setsimple.csv
Ignored: data/GTEX_sig24.RDS
Ignored: data/GTEx_gene_list.csv
Ignored: data/HFGWASgene_table.csv
Ignored: data/HF_geneset.RDS
Ignored: data/Heart_Left_Ventricle.v8.egenes.txt
Ignored: data/Heatmap_mat.RDS
Ignored: data/Heatmap_sig.RDS
Ignored: data/Hf_GWAS.txt
Ignored: data/K_cluster
Ignored: data/K_cluster_kisthree.csv
Ignored: data/K_cluster_kistwo.csv
Ignored: data/LD50_05via.csv
Ignored: data/LDH48hoursdata.csv
Ignored: data/Mt24counts.txt
Ignored: data/NoRespDEG_final.csv
Ignored: data/RINsamplelist.txt
Ignored: data/Seonane2019supp1.txt
Ignored: data/TMMnormed_x.RDS
Ignored: data/TOP2Bi-24hoursGO_analysis.csv
Ignored: data/TR24counts.txt
Ignored: data/TableS10.csv
Ignored: data/TableS11.csv
Ignored: data/TableS9.csv
Ignored: data/Top2biresp_cluster24h.csv
Ignored: data/Var_test_list.RDS
Ignored: data/Var_test_list24.RDS
Ignored: data/Var_test_list24alt.RDS
Ignored: data/Var_test_list3.RDS
Ignored: data/Vargenes.RDS
Ignored: data/Viabilitylistfull.csv
Ignored: data/allexpressedgenes.txt
Ignored: data/allfinal3hour.RDS
Ignored: data/allgenes.txt
Ignored: data/allmatrix.RDS
Ignored: data/allmymatrix.RDS
Ignored: data/annotation_data_frame.RDS
Ignored: data/averageviabilitytable.RDS
Ignored: data/avgLD50.RDS
Ignored: data/avg_LD50.RDS
Ignored: data/backGL.txt
Ignored: data/burr_genes.RDS
Ignored: data/calcium_data.RDS
Ignored: data/clamp_summary.RDS
Ignored: data/cormotif_3hk1-8.RDS
Ignored: data/cormotif_initalK5.RDS
Ignored: data/cormotif_initialK5.RDS
Ignored: data/cormotif_initialall.RDS
Ignored: data/cormotifprobs.csv
Ignored: data/counts24hours.RDS
Ignored: data/cpmcount.RDS
Ignored: data/cpmnorm_counts.csv
Ignored: data/crispr_genes.csv
Ignored: data/ctnnt_results.txt
Ignored: data/cvd_GWAS.txt
Ignored: data/dat_cpm.RDS
Ignored: data/data_outline.txt
Ignored: data/drug_noveh1.csv
Ignored: data/efit2.RDS
Ignored: data/efit2_final.RDS
Ignored: data/efit2results.RDS
Ignored: data/ensembl_backup.RDS
Ignored: data/ensgtotal.txt
Ignored: data/filcpm_counts.RDS
Ignored: data/filenameonly.txt
Ignored: data/filtered_cpm_counts.csv
Ignored: data/filtered_raw_counts.csv
Ignored: data/filtermatrix_x.RDS
Ignored: data/folder_05top/
Ignored: data/geneDoxonlyQTL.csv
Ignored: data/gene_corr_df.RDS
Ignored: data/gene_corr_frame.RDS
Ignored: data/gene_prob_tran3h.RDS
Ignored: data/gene_probabilityk5.RDS
Ignored: data/geneset_24.RDS
Ignored: data/gostresTop2bi_ER.RDS
Ignored: data/gostresTop2bi_LR
Ignored: data/gostresTop2bi_LR.RDS
Ignored: data/gostresTop2bi_TI.RDS
Ignored: data/gostrescoNR
Ignored: data/gtex/
Ignored: data/heartgenes.csv
Ignored: data/hsa_kegg_anno.RDS
Ignored: data/individualDRCfile.RDS
Ignored: data/individual_DRC48.RDS
Ignored: data/individual_LDH48.RDS
Ignored: data/indv_noveh1.csv
Ignored: data/kegglistDEG.RDS
Ignored: data/kegglistDEG24.RDS
Ignored: data/kegglistDEG3.RDS
Ignored: data/knowfig4.csv
Ignored: data/knowfig5.csv
Ignored: data/label_list.RDS
Ignored: data/ld50_table.csv
Ignored: data/mean_vardrug1.csv
Ignored: data/mean_varframe.csv
Ignored: data/mymatrix.RDS
Ignored: data/new_ld50avg.RDS
Ignored: data/nonresponse_cluster24h.csv
Ignored: data/norm_LDH.csv
Ignored: data/norm_counts.csv
Ignored: data/old_sets/
Ignored: data/organized_drugframe.csv
Ignored: data/plan2plot.png
Ignored: data/plot_intv_list.RDS
Ignored: data/plot_list_DRC.RDS
Ignored: data/qval24hr.RDS
Ignored: data/qval3hr.RDS
Ignored: data/qvalueEPItemp.RDS
Ignored: data/raw_counts.csv
Ignored: data/response_cluster24h.csv
Ignored: data/sigVDA24.txt
Ignored: data/sigVDA3.txt
Ignored: data/sigVDX24.txt
Ignored: data/sigVDX3.txt
Ignored: data/sigVEP24.txt
Ignored: data/sigVEP3.txt
Ignored: data/sigVMT24.txt
Ignored: data/sigVMT3.txt
Ignored: data/sigVTR24.txt
Ignored: data/sigVTR3.txt
Ignored: data/siglist.RDS
Ignored: data/siglist_final.RDS
Ignored: data/siglist_old.RDS
Ignored: data/slope_table.csv
Ignored: data/supp10_24hlist.RDS
Ignored: data/supp10_3hlist.RDS
Ignored: data/supp_normLDH48.RDS
Ignored: data/supp_pca_all_anno.RDS
Ignored: data/table3a.omar
Ignored: data/testlist.txt
Ignored: data/toplistall.RDS
Ignored: data/trtonly_24h_genes.RDS
Ignored: data/trtonly_3h_genes.RDS
Ignored: data/tvl24hour.txt
Ignored: data/tvl24hourw.txt
Ignored: data/venn_code.R
Ignored: data/viability.RDS
Untracked files:
Untracked: .RDataTmp
Untracked: .RDataTmp1
Untracked: .RDataTmp2
Untracked: .RDataTmp3
Untracked: 3hr all.pdf
Untracked: Code_files_list.csv
Untracked: Data_files_list.csv
Untracked: Doxorubicin_vehicle_3_24.csv
Untracked: Doxtoplist.csv
Untracked: EPIqvalue_analysis.Rmd
Untracked: GWAS_list_of_interest.xlsx
Untracked: KEGGpathwaylist.R
Untracked: OmicNavigator_learn.R
Untracked: SigDoxtoplist.csv
Untracked: analysis/ciFIT.R
Untracked: analysis/export_to_excel.R
Untracked: cleanupfiles_script.R
Untracked: code/biomart_gene_names.R
Untracked: code/constantcode.R
Untracked: code/corMotifcustom.R
Untracked: code/cpm_boxplot.R
Untracked: code/extracting_ggplot_data.R
Untracked: code/movingfilesto_ppl.R
Untracked: code/pearson_extract_func.R
Untracked: code/pearson_tox_extract.R
Untracked: code/plot1C.fun.R
Untracked: code/spearman_extract_func.R
Untracked: code/venndiagramcolor_control.R
Untracked: cormotif_p.post.list_4.csv
Untracked: figS1024h.pdf
Untracked: individual-legenddark2.png
Untracked: installed_old.rda
Untracked: motif_ER.txt
Untracked: motif_LR.txt
Untracked: motif_NR.txt
Untracked: motif_TI.txt
Untracked: output/DNR_DEGlist.csv
Untracked: output/DNRvenn.RDS
Untracked: output/DOX_DEGlist.csv
Untracked: output/DOXvenn.RDS
Untracked: output/EPI_DEGlist.csv
Untracked: output/EPIvenn.RDS
Untracked: output/Figures/
Untracked: output/MTX_DEGlist.csv
Untracked: output/MTXvenn.RDS
Untracked: output/TRZ_DEGlist.csv
Untracked: output/TableS8.csv
Untracked: output/Volcanoplot_10
Untracked: output/Volcanoplot_10.RDS
Untracked: output/allfinal_sup10.RDS
Untracked: output/cormotif_probability_genelist.csv
Untracked: output/endocytosisgenes.csv
Untracked: output/gene_corr_fig9.RDS
Untracked: output/legend_b.RDS
Untracked: output/motif_ERrep.RDS
Untracked: output/motif_LRrep.RDS
Untracked: output/motif_NRrep.RDS
Untracked: output/motif_TI_rep.RDS
Untracked: output/output-old/
Untracked: output/rank24genes.csv
Untracked: output/rank3genes.csv
Untracked: output/reneem@ls6.tacc.utexas.edu
Untracked: output/sequencinginformationforsupp.csv
Untracked: output/sequencinginformationforsupp.prn
Untracked: output/sigVDA24.txt
Untracked: output/sigVDA3.txt
Untracked: output/sigVDX24.txt
Untracked: output/sigVDX3.txt
Untracked: output/sigVEP24.txt
Untracked: output/sigVEP3.txt
Untracked: output/sigVMT24.txt
Untracked: output/sigVMT3.txt
Untracked: output/sigVTR24.txt
Untracked: output/sigVTR3.txt
Untracked: output/supplementary_motif_list_GO.RDS
Untracked: output/toptablebydrug.RDS
Untracked: output/tvl24hour.txt
Untracked: output/x_counts.RDS
Untracked: reneebasecode.R
Unstaged changes:
Deleted: analysis/Cardiotoxicity.Rproj
Modified: analysis/Cormotifcluster_analysis.Rmd
Modified: analysis/Figure5.Rmd
Modified: analysis/GOI_plots.Rmd
Modified: analysis/Knowles2019.Rmd
Modified: analysis/Supplementary_figures.Rmd
Modified: analysis/index.Rmd
Modified: analysis/run_all_analysis.Rmd
Modified: analysis/variance_scrip.Rmd
Deleted: corMotifcustom.R
Modified: output/TNNI_LDH_RNAnormlist.txt
Modified: output/daplot.RDS
Modified: output/dxplot.RDS
Modified: output/epplot.RDS
Modified: output/mtplot.RDS
Modified: output/plan2plot.png
Modified: output/sequencing_info.txt
Modified: output/toplistall.csv
Modified: output/trplot.RDS
Modified: output/veplot.RDS
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/LDH_analysis.Rmd) and HTML
(docs/LDH_analysis.html) files. If you’ve configured a
remote Git repository (see ?wflow_git_remote), click on the
hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 36663b3 | reneeisnowhere | 2023-09-26 | updates to code for publishing |
| html | 90253fc | reneeisnowhere | 2023-07-07 | Build site. |
| Rmd | 090c643 | reneeisnowhere | 2023-07-07 | reformatting data to TLA order |
| html | 045545d | reneeisnowhere | 2023-07-03 | Build site. |
| Rmd | 86f80fa | reneeisnowhere | 2023-07-03 | adding in lineplots, Drug formats and ordering |
| Rmd | f4bd5e1 | reneeisnowhere | 2023-06-27 | checking code changes overtime |
| html | 87453aa | reneeisnowhere | 2023-06-23 | Build site. |
| Rmd | c1d667f | reneeisnowhere | 2023-06-23 | updating the codes at Friday start. |
| html | 1e97f64 | reneeisnowhere | 2023-06-21 | Build site. |
| Rmd | a04a4b6 | reneeisnowhere | 2023-06-21 | take out PCa clustering |
| html | 2c0b9c1 | reneeisnowhere | 2023-06-21 | Build site. |
| Rmd | 3cc0a11 | reneeisnowhere | 2023-06-21 | simplify code, add rho |
| html | e56d7a3 | reneeisnowhere | 2023-06-16 | Build site. |
| Rmd | 3d4ca64 | reneeisnowhere | 2023-06-16 | updates on Friday |
| html | c18ee15 | reneeisnowhere | 2023-06-02 | Build site. |
| Rmd | 89bce74 | reneeisnowhere | 2023-06-02 | axis label update |
| html | 01a3781 | reneeisnowhere | 2023-05-19 | Build site. |
| Rmd | 69b989f | reneeisnowhere | 2023-05-19 | update FWHM again |
| html | 2f5d21d | reneeisnowhere | 2023-05-17 | Build site. |
| Rmd | 2c5e87d | reneeisnowhere | 2023-05-17 | adding p value to correlation |
| html | 870c13f | reneeisnowhere | 2023-05-17 | Build site. |
| Rmd | 30686c3 | reneeisnowhere | 2023-05-17 | FWHM update |
| html | d0eaef8 | reneeisnowhere | 2023-04-20 | Build site. |
| Rmd | 5e61428 | reneeisnowhere | 2023-04-20 | updating calcium graphs and index |
| Rmd | 4e52216 | reneeisnowhere | 2023-03-31 | End of week updates |
| Rmd | 3a26d52 | reneeisnowhere | 2023-03-22 | Wed poster analysis changes |
| Rmd | 9cbe858 | reneeisnowhere | 2023-03-10 | Codescramble update |
| Rmd | 49191f8 | reneeisnowhere | 2023-03-03 | more tracking and updates |
| Rmd | 90a0227 | reneeisnowhere | 2023-02-27 | monday2-27 |
| Rmd | 28fb31f | reneeisnowhere | 2023-02-24 | Friday-updates |
| Rmd | accc241 | reneeisnowhere | 2023-02-10 | updates for the week |
##package loading
library(readxl)
library(ggpubr)
library(rstatix)
library(tidyverse)
library(zoo)
library(ggsignif)
library(RColorBrewer)
library(stats)
library(readr)
library(ggalt)48 hour Lactate Dehydrogenase analysis
level_order2 <- c('75','87','77','79','78','71')
drug_pal_fact <- c("#8B006D","#DF707E","#F1B72B", "#3386DD","#707031","#41B333")
RINsamplelist <-read_csv("data/RINsamplelist.txt",col_names = TRUE)
norm_LDH <- read.csv("data/norm_LDH.csv",row.names = 1)
clamp_summary <- read.csv("data/Clamp_Summary.csv", row.names=1)
full_list <- read.csv("data/DRC48hoursdata.csv", row.names = 1)
calcium_data <- read_csv("data/DF_Plate_Peak.csv", col_types = cols(...1 = col_skip()))
k_means <- read.csv("data/K_cluster_kisthree.csv")
# drug_palexpand <- c("#41B333","#8B006D","#DF707E","#F1B72B", "#3386DD","#707031","purple3","darkgreen", "darkblue")
#named colors: dark pink,Red,yellow,blue, dark grey, green(green is always control, may need to move pal around)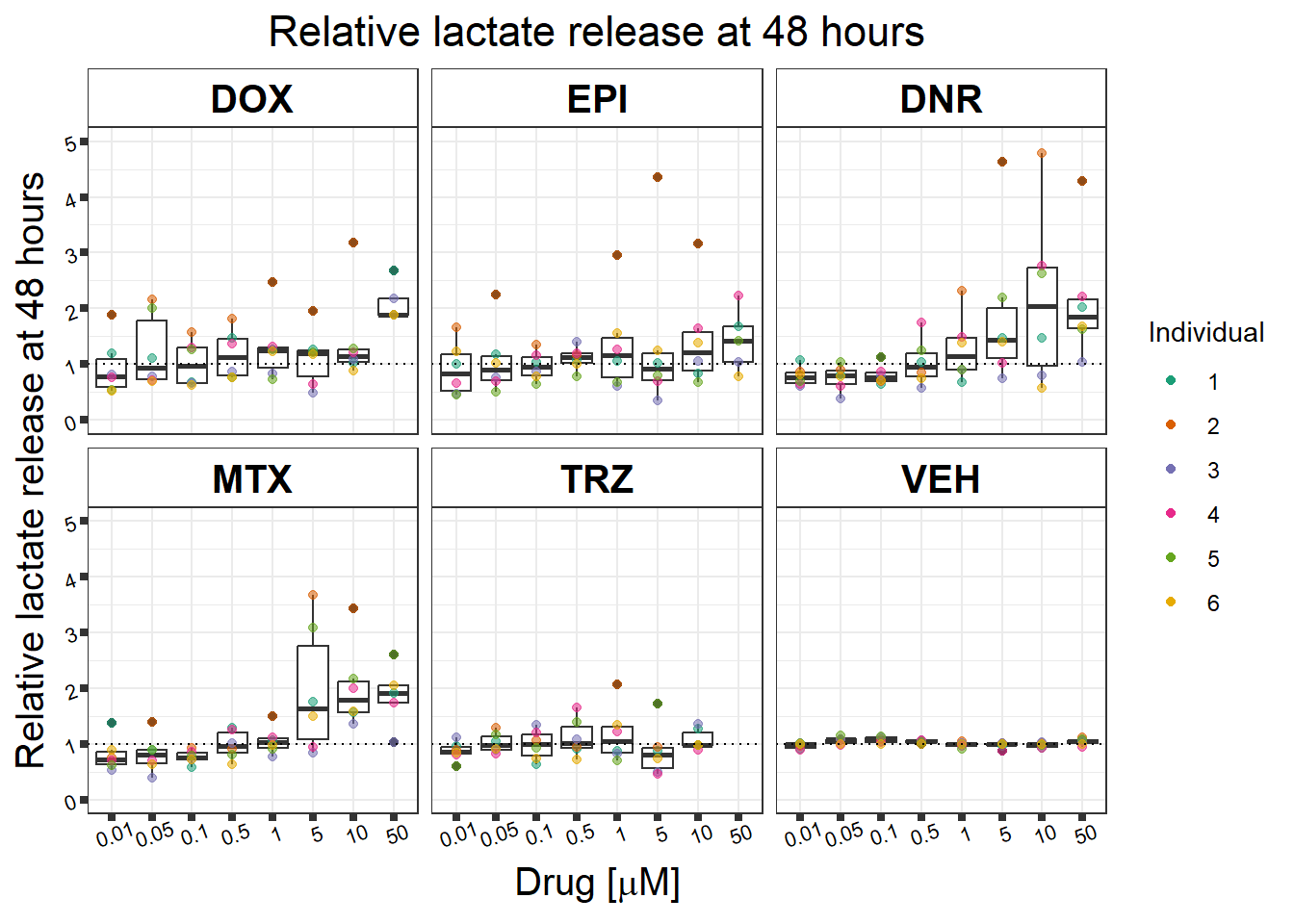
48 hour viability to LDH activity correlation
Pearson correlation of 48 hour 0.5 \(\mu\)M viability with LDH 48 hours 0.5 \(\mu\)M (supplemental data S4 Fig)
viability %>%
full_join(., norm_LDH48, by = c("indv","Drug","Conc")) %>%
ggplot(., aes(x=per.live, y=ldh))+
geom_point(aes(col=indv))+
geom_smooth(method="lm")+
facet_wrap("Drug")+
theme_bw()+
xlab("Average viability of cardiomyocytes/100") +
ylab("Average LDH") +
ggtitle("Relative viability and relative LDH release at 48 hours")+
scale_color_brewer(palette = "Dark2",
name = "Individual",
label = c("1","2","3","4","5","6"))+
ggpubr::stat_cor(method="pearson",
aes(label = paste(..r.label.., ..p.label.., sep = "~`,`~")),
color = "red")+
theme(plot.title = element_text(size = rel(1.5),
hjust = 0.5,
face = "bold"),
axis.title = element_text(size = 15,
color = "black"),
axis.ticks = element_line(size = 1.5),
axis.text = element_text(size = 8,
color = "black",
angle = 20),
strip.text.x = element_text(size = 15,
color = "black",
face = "bold")) 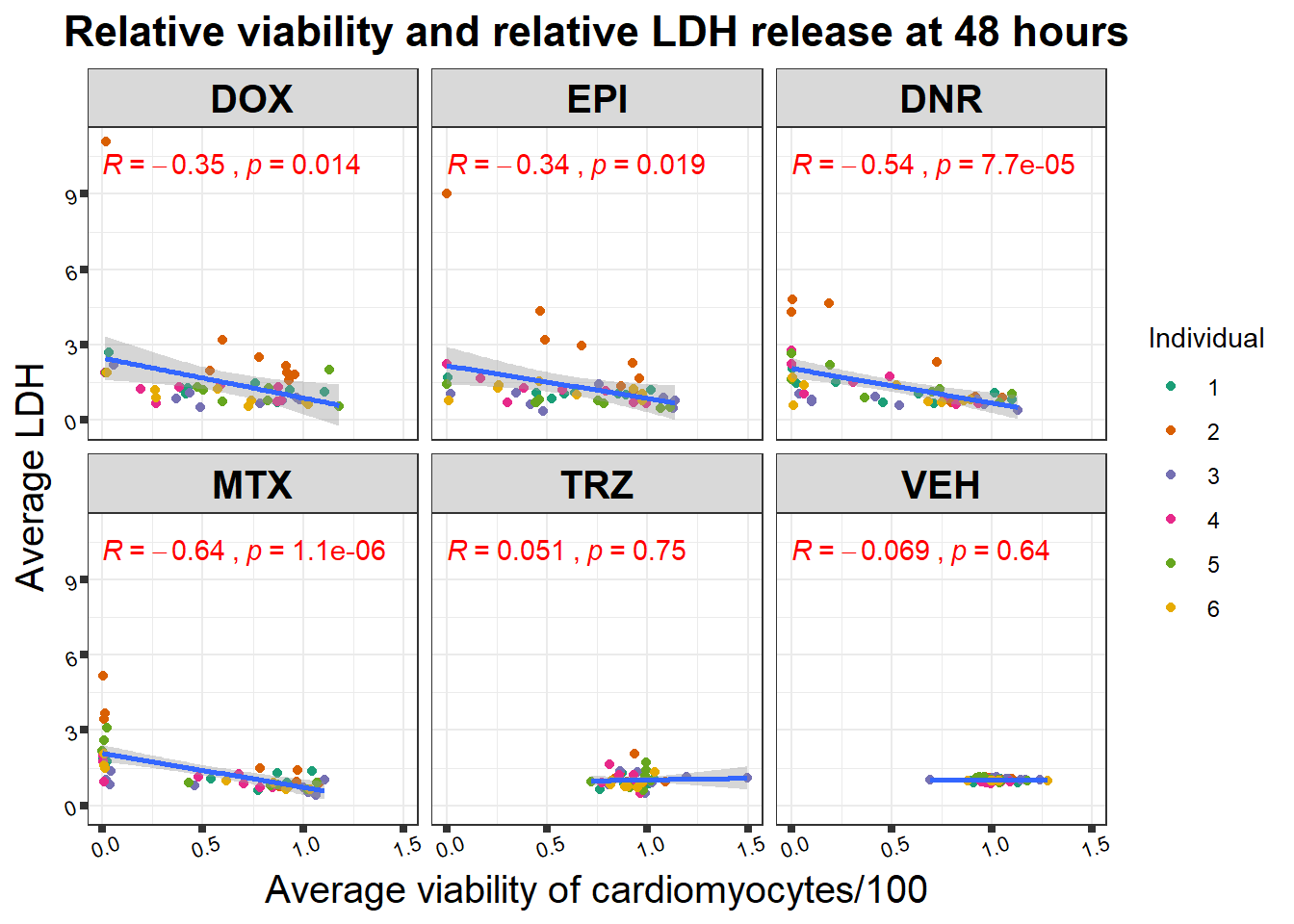
#24 hour LDH analysis
Data input
DA_24_ldh <- matrix(c(1.188,1.222,1.195,1.030,1.074,1.064,1.298,1.282,1.262,
1.901,1.975,1.970,3.131,3.246,3.080,1.339,1.438,1.367),
ncol =3, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','79_0.5','75_0.5','77_0.5','78_0.5','71_0.5')))
DX_24_ldh <-matrix(c(0.981,0.974,0.978,1.253,1.233,1.292,2.098,2.153,
2.114,2.214,2.244,2.239,3.808,3.825,3.735,1.037,1.030,1.030),
ncol =3, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','79_0.5','75_0.5','77_0.5','78_0.5','71_0.5')))
EP_24_ldh <- matrix(c(1.504,1.320,1.469,1.536,1.301,1.531,1.562,1.541,1.558,
3.414,3.103,3.236,3.588,3.398,3.611,1.013,0.958,0.991),
ncol =3, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','79_0.5','75_0.5','77_0.5','78_0.5','71_0.5')))
MT_24_ldh <- matrix(c(1.508,1.467,1.391,1.493,1.468,1.483,2.010,1.820,1.911,
3.089,2.936,2.921,3.623,3.377,3.560,1.222,1.211,1.215),
ncol =3, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','79_0.5','75_0.5','77_0.5','78_0.5','71_0.5')))
TR_24_ldh<- matrix(c(0.941,0.891,0.953,0.743,0.774,0.812,1.514,1.225,1.252,
2.391,1.989,2.172,3.040,2.622,2.613,0.970,0.917,0.895),
ncol =3, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','79_0.5','75_0.5','77_0.5','78_0.5','71_0.5')))
VE_24_ldh<- matrix(c(1.000,1.000,0.977,1.000,1.100,1.096,1.000,0.938,0.951,
1.000,1.027,1.038,1.000,1.058,1.062,1.000,1.011,0.975),
ncol =3, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','79_0.5','75_0.5','77_0.5','78_0.5','71_0.5')))
LDH24hstat <- list('VDA'=t.test(VE_24_ldh,DA_24_ldh),
'VDX'=t.test(VE_24_ldh,DX_24_ldh),
'VEP'=t.test(VE_24_ldh,EP_24_ldh),
'VMT'=t.test(VE_24_ldh,MT_24_ldh),
'VTR'=t.test(VE_24_ldh,TR_24_ldh),
'VVEH'=t.test(VE_24_ldh,VE_24_ldh))
LDH24hstat$VDA
Welch Two Sample t-test
data: VE_24_ldh and DA_24_ldh
t = -3.7541, df = 17.12, p-value = 0.001564
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.0263033 -0.2880301
sample estimates:
mean of x mean of y
1.012944 1.670111
$VDX
Welch Two Sample t-test
data: VE_24_ldh and DX_24_ldh
t = -3.7427, df = 17.065, p-value = 0.001611
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.3902576 -0.3880757
sample estimates:
mean of x mean of y
1.012944 1.902111
$VEP
Welch Two Sample t-test
data: VE_24_ldh and EP_24_ldh
t = -4.285, df = 17.065, p-value = 0.0004969
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.5254695 -0.5190861
sample estimates:
mean of x mean of y
1.012944 2.035222
$VMT
Welch Two Sample t-test
data: VE_24_ldh and MT_24_ldh
t = -5.1821, df = 17.085, p-value = 7.383e-05
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.5220379 -0.6415176
sample estimates:
mean of x mean of y
1.012944 2.094722
$VTR
Welch Two Sample t-test
data: VE_24_ldh and TR_24_ldh
t = -2.5982, df = 17.112, p-value = 0.01868
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.85356981 -0.08876353
sample estimates:
mean of x mean of y
1.012944 1.484111
$VVEH
Welch Two Sample t-test
data: VE_24_ldh and VE_24_ldh
t = 0, df = 34, p-value = 1
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.02989169 0.02989169
sample estimates:
mean of x mean of y
1.012944 1.012944 #24 hour Troponin I analysis
DA_24_TNNI <- matrix(c(0.790,0.783,1.855,1.693,1.009,1.071,0.736,0.771,
1.035,1.202,1.228,1.151),
ncol =2, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','71_0.5','75_0.5','77_0.5','78_0.5','79_0.5')))
DX_24_TNNI <-matrix(c(1.006,1.006,1.295,1.179,1.464,1.493,1.319,1.236,
1.231,1.221,1.342,1.296),
ncol =2, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','71_0.5','75_0.5','77_0.5','78_0.5','79_0.5')))
EP_24_TNNI <- matrix(c(0.955,0.822,1.220,1.092,1.459,1.425,1.076,1.222,
1.018,1.269,1.262,1.331),
ncol =2, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','71_0.5','75_0.5','77_0.5','78_0.5','79_0.5')))
MT_24_TNNI <- matrix(c(1.529,1.682,1.205,1.138,1.436,1.521,1.694,
1.778,1.115,1.231,1.006,0.957),
ncol =2, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','71_0.5','75_0.5','77_0.5','78_0.5','79_0.5')))
TR_24_TNNI<- matrix(c(2.089,1.911,1.245,0.968,1.180,1.168,1.118,
1.014,1.496,1.433,1.388,1.235),
ncol =2, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','71_0.5','75_0.5','77_0.5','78_0.5','79_0.5')))
VE_24_TNNI<- matrix(c(1.000,0.783,1.000,1.000,0.917,1.031,1.000,
0.958,1.000,1.000,1.087,1.106),
ncol =3, nrow =6, byrow =TRUE,
dimnames=list(c('87_0.5','71_0.5','75_0.5','77_0.5','78_0.5','79_0.5')))
tnni24hstat <- list('VDAT'=t.test(VE_24_TNNI,DA_24_TNNI),
'VDXT'=t.test(VE_24_TNNI,DX_24_TNNI),
'VEPT'=t.test(VE_24_TNNI,EP_24_TNNI),
'VMTT'=t.test(VE_24_TNNI,MT_24_TNNI),
'VTRT'=t.test(VE_24_TNNI,TR_24_TNNI),
'VVEHT'=t.test(VE_24_TNNI,VE_24_TNNI))
tnni24hstat$VDAT
Welch Two Sample t-test
data: VE_24_TNNI and DA_24_TNNI
t = -1.2565, df = 11.832, p-value = 0.2332
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.36079840 0.09713173
sample estimates:
mean of x mean of y
0.978500 1.110333
$VDXT
Welch Two Sample t-test
data: VE_24_TNNI and DX_24_TNNI
t = -5.8512, df = 15.728, p-value = 2.633e-05
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.3799972 -0.1776694
sample estimates:
mean of x mean of y
0.978500 1.257333
$VEPT
Welch Two Sample t-test
data: VE_24_TNNI and EP_24_TNNI
t = -3.4195, df = 13.915, p-value = 0.004181
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.32673646 -0.07476354
sample estimates:
mean of x mean of y
0.97850 1.17925
$VMTT
Welch Two Sample t-test
data: VE_24_TNNI and MT_24_TNNI
t = -4.4919, df = 12.316, p-value = 0.0006915
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.5625613 -0.1957720
sample estimates:
mean of x mean of y
0.978500 1.357667
$VTRT
Welch Two Sample t-test
data: VE_24_TNNI and TR_24_TNNI
t = -3.7217, df = 11.904, p-value = 0.002956
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.5951287 -0.1553713
sample estimates:
mean of x mean of y
0.97850 1.35375
$VVEHT
Welch Two Sample t-test
data: VE_24_TNNI and VE_24_TNNI
t = 0, df = 34, p-value = 1
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.0574163 0.0574163
sample estimates:
mean of x mean of y
0.9785 0.9785 24 hour TNNI and LDH
mean24ldh <- as.data.frame(rbind(colMeans(t(DA_24_ldh)),
colMeans(t(DX_24_ldh)),
colMeans(t(EP_24_ldh)),
colMeans(t(MT_24_ldh)),
colMeans(t(TR_24_ldh)),
colMeans(t(VE_24_ldh))))
mean24ldh$Drug <- c( "DNR", "DOX", "EPI", "MTX", "TRZ","VEH") ###add drug name then take out the 0.5 thing
colnames(mean24ldh) <- gsub("_0.5","",colnames(mean24ldh))
##now use pivot longer and join the frames
mean24ldh <- mean24ldh %>% pivot_longer(.,col=-Drug, names_to = 'indv', values_to = "ldh")
mean24tnni <- as.data.frame(rbind(colMeans(t(DA_24_TNNI)),
colMeans(t(DX_24_TNNI)),
colMeans(t(EP_24_TNNI)),
colMeans(t(MT_24_TNNI)),
colMeans(t(TR_24_TNNI)),
colMeans(t(VE_24_TNNI))))
mean24tnni$Drug <- c( "DNR", "DOX", "EPI", "MTX", "TRZ","VEH")
colnames(mean24tnni) <- gsub("_0.5","",colnames(mean24tnni))
mean24tnni <- pivot_longer(mean24tnni,
col=-Drug,
names_to = 'indv',
values_to = "tnni")
tvl24hour <- full_join(mean24ldh,mean24tnni, by=c("Drug","indv"))
# write.csv(tvl24hour,"output/tvl24hour.txt")Normalization of TNNI and LDH to RNA concentration
RNAnormlist <- RINsamplelist %>%
mutate(Drug=case_match(Drug,"daunorubicin"~"DNR",
"doxorubicin"~"DOX",
"epirubicin"~"EPI",
"mitoxantrone"~"MTX",
"trastuzumab"~"TRZ",
"vehicle"~"VEH", .default= Drug)) %>%
filter(time =="24h") %>%
ungroup() %>%
dplyr::select(indv,Drug,Conc_ng.ul) %>%
mutate(indv= factor(indv,levels= level_order2))
RNAnormlist <- RNAnormlist %>%
full_join(.,tvl24hour,by= c("Drug", "indv")) %>%
mutate(Drug = factor(Drug, levels = c( "DOX",
"DNR",
"EPI",
"MTX",
"TRZ",
"VEH"))) %>%
mutate(rldh= ldh/Conc_ng.ul) %>%
mutate(rtnni=tnni/Conc_ng.ul)
# write.csv(RNAnormlist,"output/TNNI_LDH_RNAnormlist.txt")
ggplot(RNAnormlist, aes(x=rldh, y=rtnni))+
geom_point(aes(col=indv))+
geom_smooth(method="lm")+
ggpubr::stat_cor(label.y.npc=1,
label.x.npc = 0,
method="pearson",
aes(label = paste(..r.label.., ..p.label..,
sep = "~`,`~")), color = "darkred")+
facet_wrap("Drug", scales="free")+
scale_color_brewer(palette = "Dark2")+
scale_color_brewer(palette = "Dark2",
name = "Individual",
label = c("1","2","3","4","5","6"))+
ylab("Troponin I release at 24 hours")+
xlab("Lactate DH release at 24 hours")+
theme_classic()+
theme(strip.background = element_rect(fill = "transparent")) +
theme(plot.title = element_text(size = rel(1.5), hjust = 0.5),
legend.position = "none",
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(size = 12, color = "black", angle = 0),
strip.text.x = element_text(size = 15, color = "black", face = "bold"))+
ggtitle("Correlation between Troponin I release and LDH activity")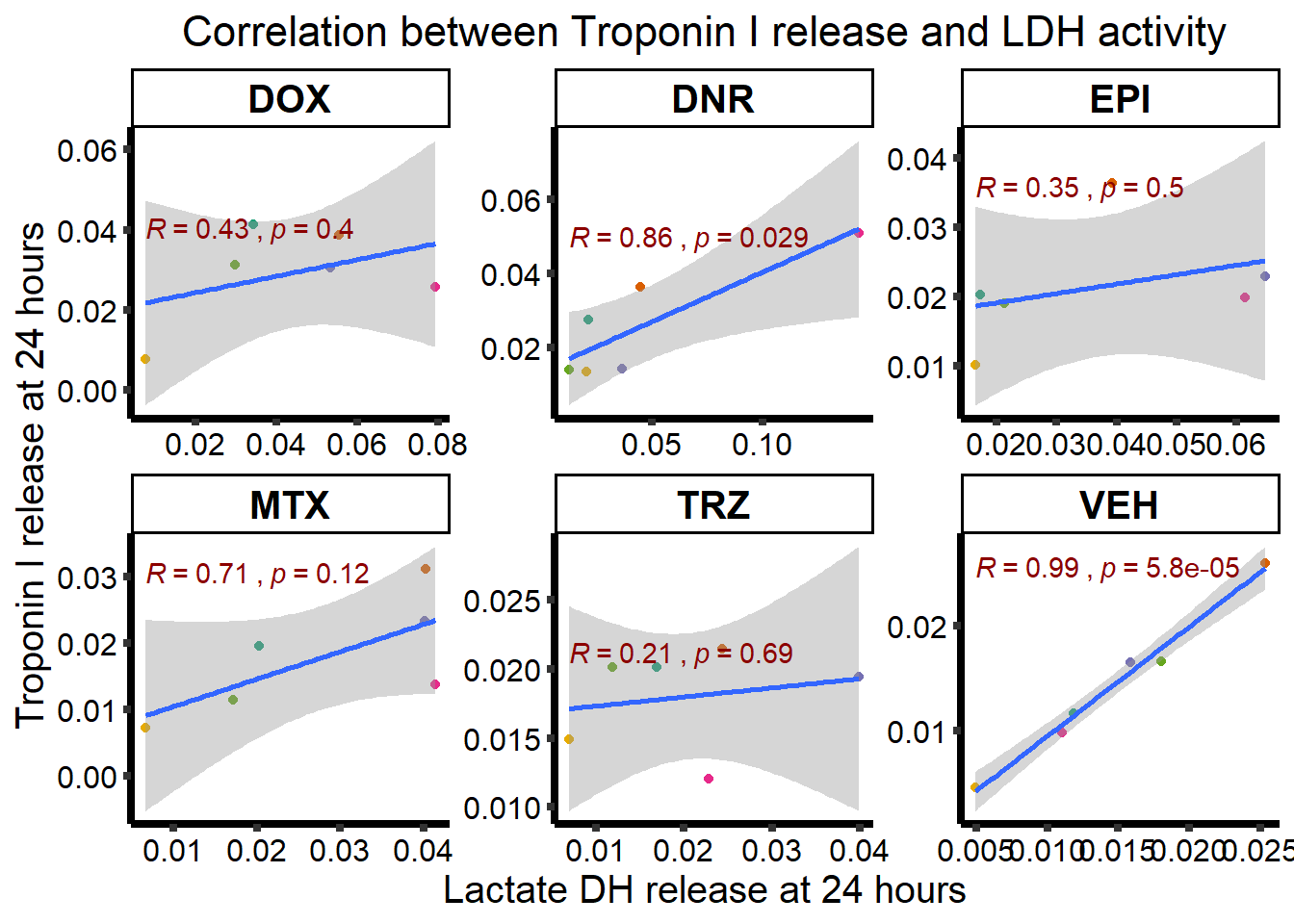
RNAnormlist %>%
mutate(Drug = factor(Drug, levels = c( "DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH"))) %>%
ggplot(., aes(x=Drug, y=rldh))+
geom_boxplot(position = "identity", fill = drug_pal_fact)+
geom_point(aes(col=indv, size =3,alpha=0.5))+
geom_signif(comparisons =list(c("VEH","DOX"),
c("VEH","EPI"),
c("VEH","DNR"),
c("VEH","MTX"),
c("VEH","TRZ")),
test="t.test",
map_signif_level=TRUE,
textsize =4,
step_increase = 0.1)+
theme_classic()+
guides(size = "none",alpha="none")+
scale_color_brewer(palette = "Dark2", name = "Individual")+
xlab("")+
ylab("Relative LDH activity ")+
ggtitle("Lactate dehydrogenase release at 24 hours")+
theme_classic()+
theme(strip.background = element_rect(fill = "transparent")) +
theme(plot.title = element_text(size = rel(1.5), hjust = 0.5),
legend.position = "none",
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(size = 12, color = "black", angle = 0),
strip.text.x = element_text(size = 15, color = "black", face = "bold"))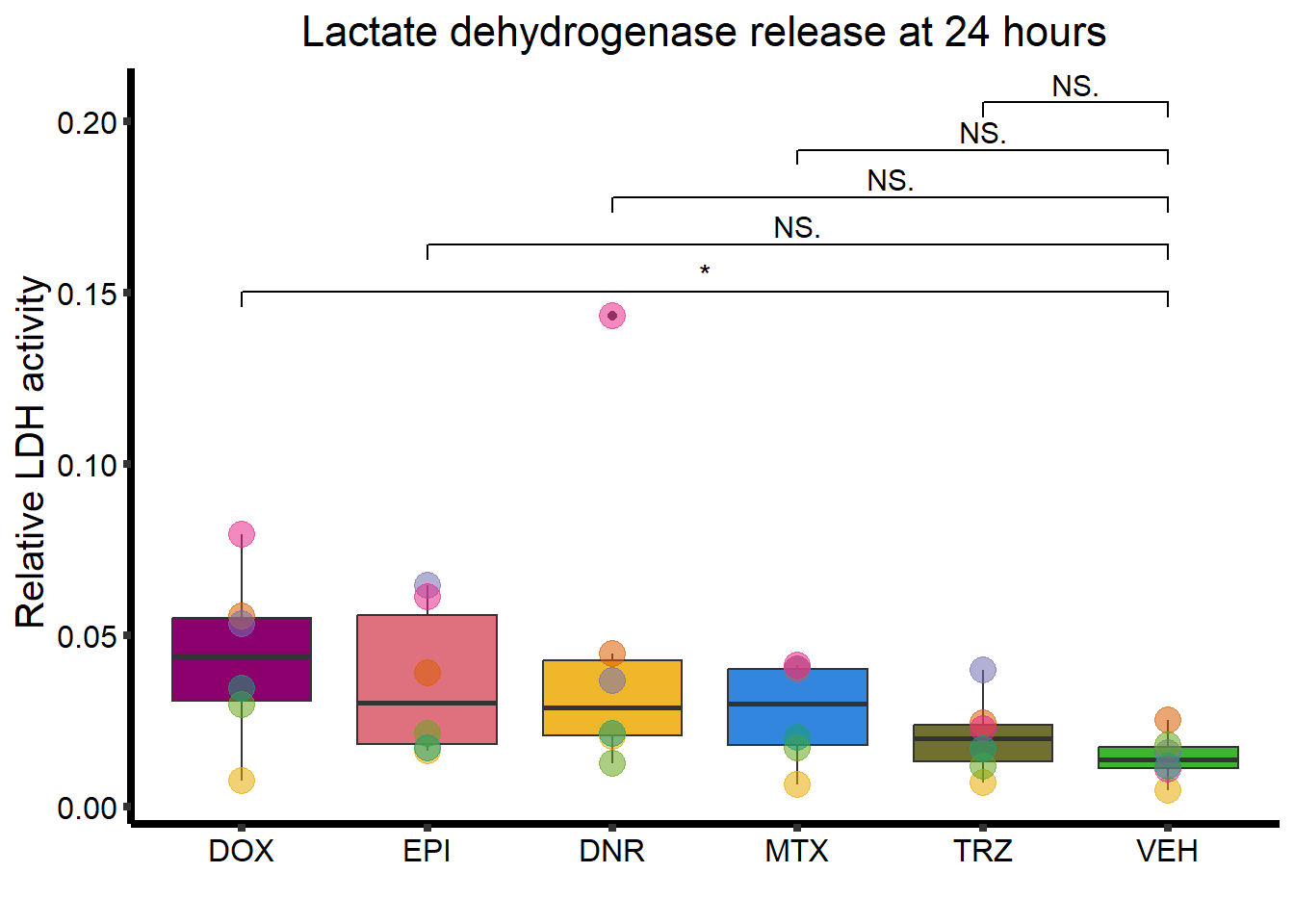
RNAnormlist %>%
mutate(Drug = factor(Drug, levels = c( "DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH"))) %>%
ggplot(., aes(x=Drug, y=rtnni))+
geom_boxplot(position = "identity", fill = drug_pal_fact)+
geom_point(aes(col=indv, size =3,alpha=0.5))+
geom_signif(comparisons =list(c("VEH","DOX"),
c("VEH","EPI"),
c("VEH","DNR"),
c("VEH","MTX"),
c("VEH","TRZ")),
test="t.test",
map_signif_level=TRUE,
textsize =4,
step_increase = 0.1)+
theme_classic()+
guides(size = "none",alpha="none")+
scale_color_brewer(palette = "Dark2", name = "Individual")+
xlab("")+
ylab("Relative Troponin I levels ")+
ggtitle("Troponin I release at 24 hours")+
theme_classic()+
theme(strip.background = element_rect(fill = "transparent")) +
theme(plot.title = element_text(size = rel(1.5), hjust = 0.5),
legend.position = "none",
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(size = 12, color = "black", angle = 0),
strip.text.x = element_text(size = 15, color = "black", face = "bold"))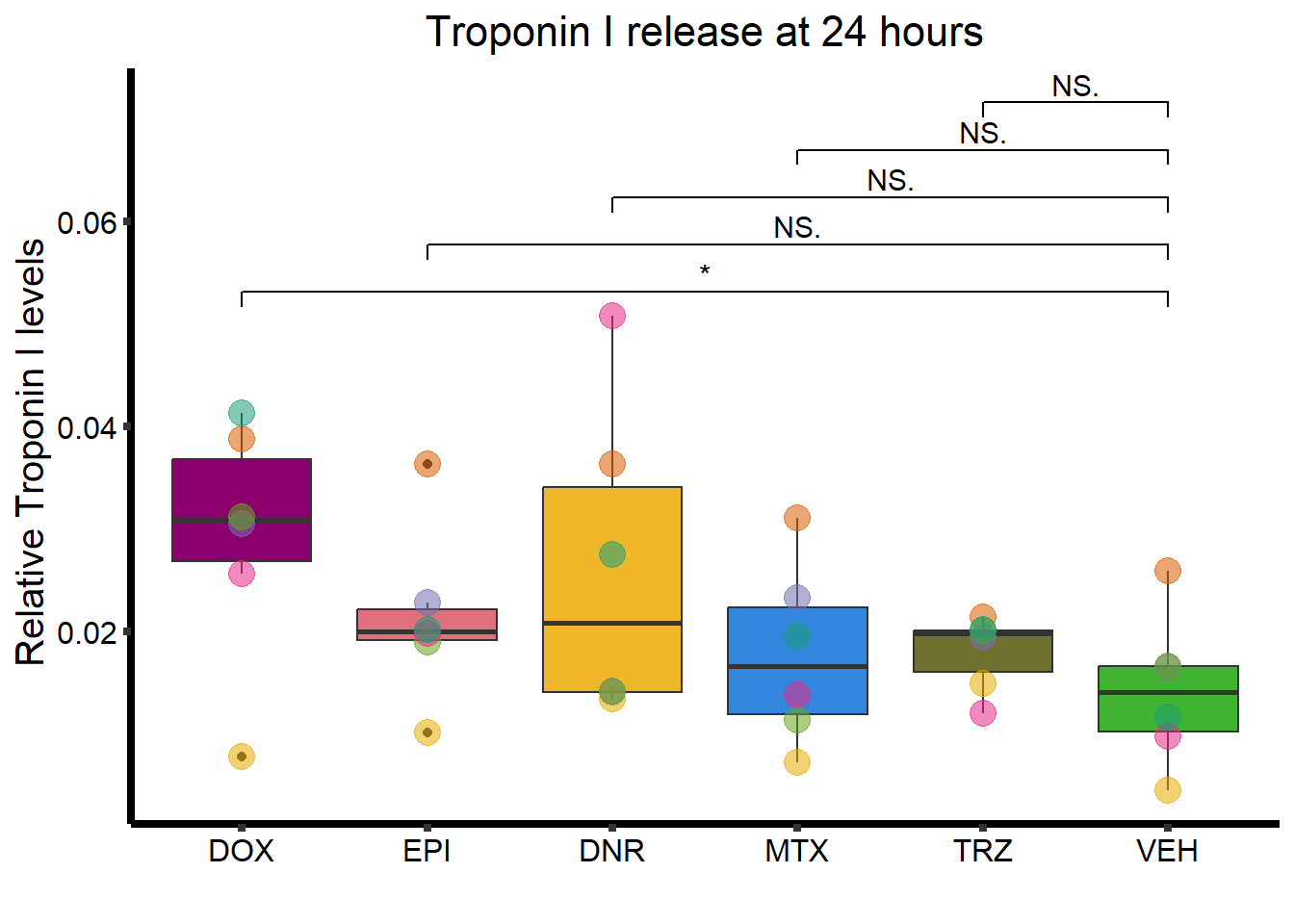
Calcium data at 24 hours
The data and code were given from Omar Johnson (except for the renaming of everything, that is me!) THANK YOU SIMON, FOR YOUR INPUT.
calcium_data <- calcium_data %>%
rename('Treatment' = 'Condition', 'indv' = 'Experiment') %>%
mutate(
Drug = case_match(
Treatment,
"Dau_0.5" ~ "DNR",
"Dau_1" ~ "DNR",
"Dox_0.5" ~ "DOX",
"Dox_1" ~ "DOX",
"Epi_0.5" ~ "EPI",
"Epi_1" ~ "EPI",
"Mito_0.5" ~ "MTX",
"Mito_1" ~ "MTX",
"Tras_0.5" ~ "TRZ",
"Tras_1" ~ "TRZ",
"Control" ~ "VEH",
.default = Treatment
)
) %>%
mutate(Drug = factor(Drug,
levels = c("DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH"))) %>%
mutate(
Conc = case_match(
Treatment,
"Dau_0.5" ~ "0.5",
"Dau_1" ~ "1.0",
"Dox_0.5" ~ "0.5",
"Dox_1" ~ "1.0",
"Epi_0.5" ~ "0.5",
"Epi_1" ~ "1.0",
"Mito_0.5" ~ "0.5",
"Mito_1" ~ "1.0",
"Tras_0.5" ~ "0.5",
"Tras_1" ~ "1.0",
'Control' ~ '0',
.default = Treatment
)
)
clamp_summary <- clamp_summary %>%
rename('Treatment' = 'Cond', 'indv' = 'Exp') %>%
mutate(
Drug = case_match(
Treatment,
"Dau_0.5" ~ "DNR",
"Dau_1" ~ "DNR",
"Dox_0.5" ~ "DOX",
"Dox_1" ~ "DOX",
"Epi_0.5" ~ "EPI",
"Epi_1" ~ "EPI",
"Mito_0.5" ~ "MTX",
"Mito_1" ~ "MTX",
"Tras_0.5" ~ "TRZ",
"Tras_1" ~ "TRZ",
"Control" ~ "VEH" ,
.default = Treatment
)
) %>%
mutate(Drug = factor(Drug,
levels = c("DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH"))) %>%
mutate(
Conc = case_match(
Treatment,
"Dau_0.5" ~ "0.5",
"Dau_1" ~ "1.0",
"Dox_0.5" ~ "0.5",
"Dox_1" ~ "1.0",
"Epi_0.5" ~ "0.5",
"Epi_1" ~ "1.0",
"Mito_0.5" ~ "0.5",
"Mito_1" ~ "1.0",
"Tras_0.5" ~ "0.5",
"Tras_1" ~ "1.0",
'Control' ~ '0',
.default = Treatment
)
) %>%
rename(
c(
'Mean_Amplitude' = 'R1S1_Mean..a.u..',
'Rise_Slope' = 'R1S1_Rise_Slope..a.u..ms.',
'FWHM' = 'R1S1_Half_Width..ms.',
'Decay_Slope' = 'R1S1_Decay_Slope..a.u..ms.',
'Decay_Time' = 'Decay_Time..ms.',
'Rise_Time' = 'R1S1_Rise_Time'
)
) %>%
mutate(indv = substr(indv, 1, 2)) %>%
mutate(indv = factor(indv, levels = level_order2)) %>%
filter(Conc == 0 | Conc == 0.5)
saveRDS(calcium_data,"data/calcium_data.RDS")
saveRDS(clamp_summary ,"data/clamp_summary.RDS")Mean amplitude
MA_plot <- clamp_summary %>%
dplyr::select(Drug, Conc, indv, Mean_Amplitude) %>%
ggplot(., aes(Drug, Mean_Amplitude)) +
geom_boxplot(position = "identity", fill = drug_pal_fact) +
geom_point(aes(col = indv, size = 2, alpha = 0.5)) +
guides(size = "none",
alpha = "none",
colour = "none") +
scale_color_brewer(palette = "Dark2",
name = "Individual",
label = c("2", "3", "5")) +
geom_signif(
comparisons = list(
c("VEH", "TRZ"),
c("VEH", "MTX"),
c("VEH", "DNR"),
c("VEH", "EPI"),
c("VEH", "DOX")
),
test = "t.test",
map_signif_level = TRUE,
step_increase = 0.1,
textsize = 4
) +
ggtitle("Mean amplitude") +
ylab("a.u.") +
xlab(" ") +
theme_classic() +
theme(
plot.title = element_text(size = 18, hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(
size = 12,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 15,
color = "black",
face = "bold"
)
)
MA_plot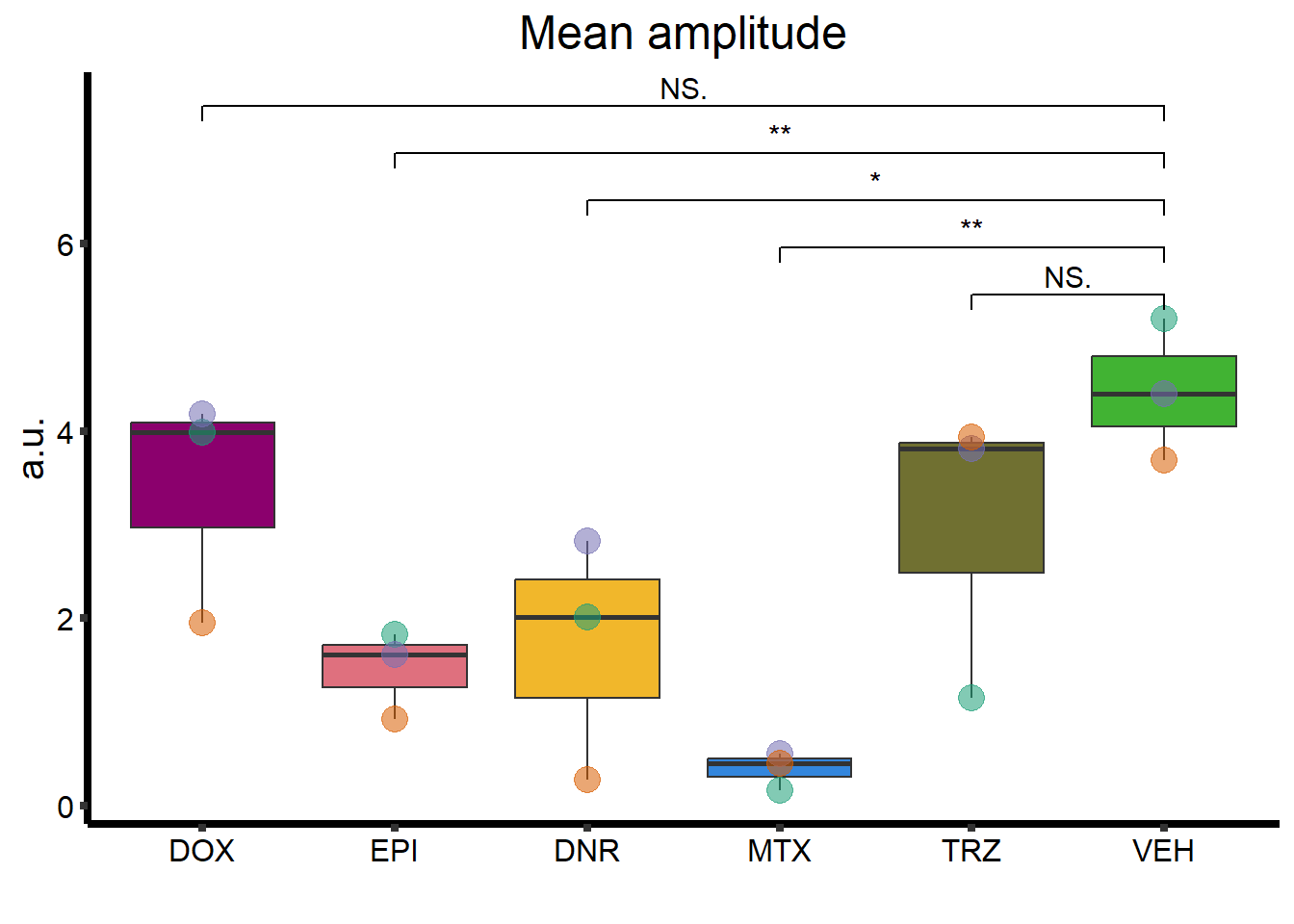
Rising Slope
RS_plot <- clamp_summary %>%
dplyr::select(Drug, Conc, indv, Rise_Slope) %>%
ggplot(., aes(Drug, Rise_Slope)) +
geom_boxplot(position = "identity", fill = drug_pal_fact) +
geom_point(aes(col = indv, size = 2, alpha = 0.5)) +
guides(size = "none",
alpha = "none",
colour = "none") +
scale_color_brewer(palette = "Dark2",
name = "Individual",
label = c("2", "3", "5")) +
geom_signif(
comparisons = list(
c("VEH", "TRZ"),
c("VEH", "MTX"),
c("VEH", "DNR"),
c("VEH", "EPI"),
c("VEH", "DOX")
),
test = "t.test",
map_signif_level = TRUE,
step_increase = 0.1,
textsize = 4
) +
ggtitle(expression(paste("Rising slope"))) +
labs(y = "a.u./sec") +
theme_classic() +
theme(
plot.title = element_text(size = 18, hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(
size = 12,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 15,
color = "black",
face = "bold"
)
)
RS_plot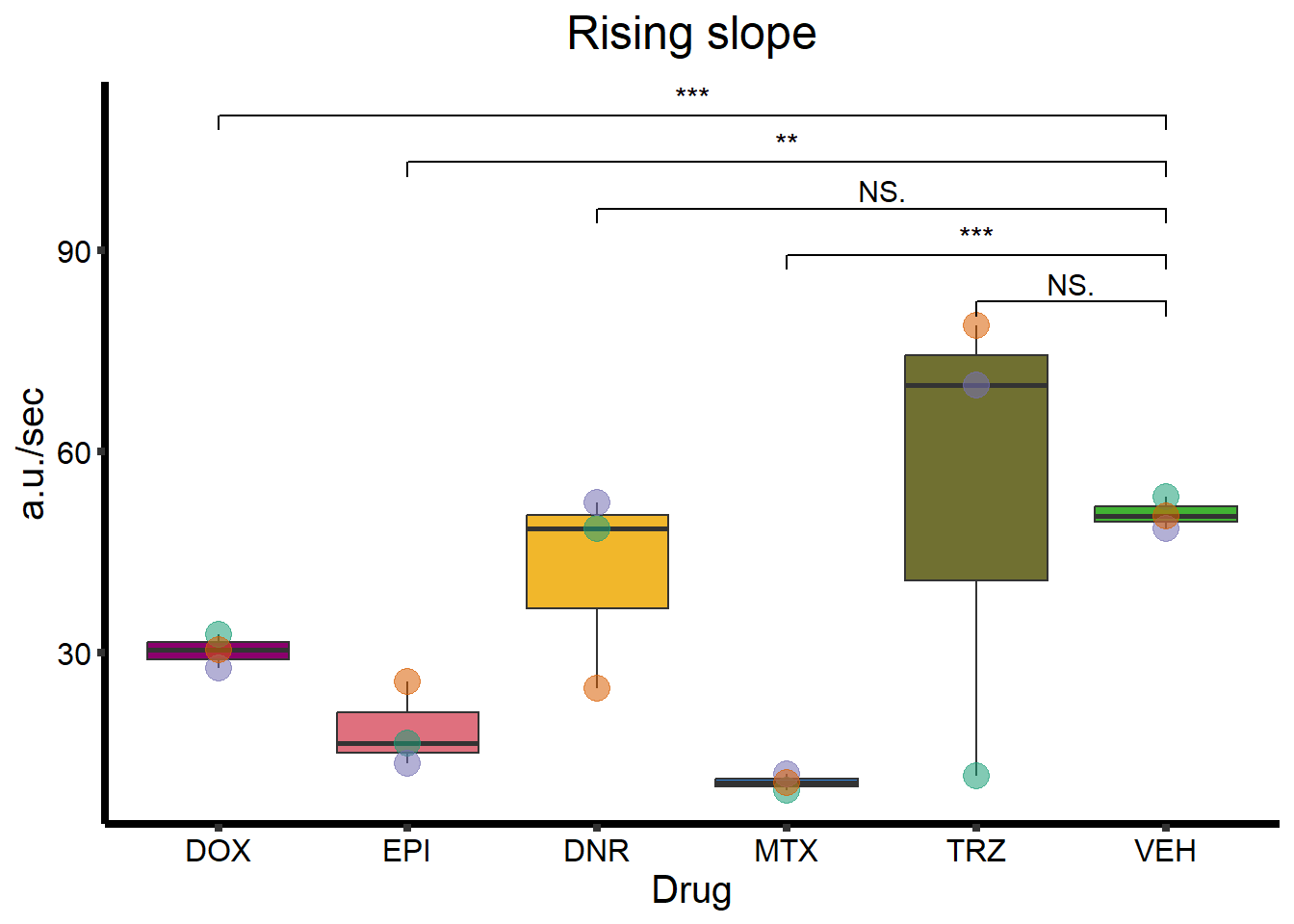
Decay slope
Decay_plot <- clamp_summary %>%
dplyr::select(Drug, Conc, indv, Decay_Slope) %>%
ggplot(., aes(Drug, Decay_Slope)) +
geom_boxplot(position = "identity", fill = drug_pal_fact) +
geom_point(aes(col = indv, size = 2, alpha = 0.5)) +
guides(size = "none",
alpha = "none",
colour = "none") +
scale_color_brewer(palette = "Dark2",
name = "Individual",
label = c("2", "3", "5")) +
geom_signif(
comparisons = list(
c("VEH", "TRZ"),
c("VEH", "MTX"),
c("VEH", "DNR"),
c("VEH", "EPI"),
c("VEH", "DOX")
),
test = "t.test",
map_signif_level = TRUE,
step_increase = 0.1,
textsize = 4
) +
ggtitle(expression(paste("Decay slope "))) +
labs(y = "a.u./sec") +
theme_classic() +
theme(
plot.title = element_text(size = 18, hjust = 0.5),
axis.title = element_text(size = 15, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(
size = 12,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 15,
color = "black",
face = "bold"
)
)
Decay_plot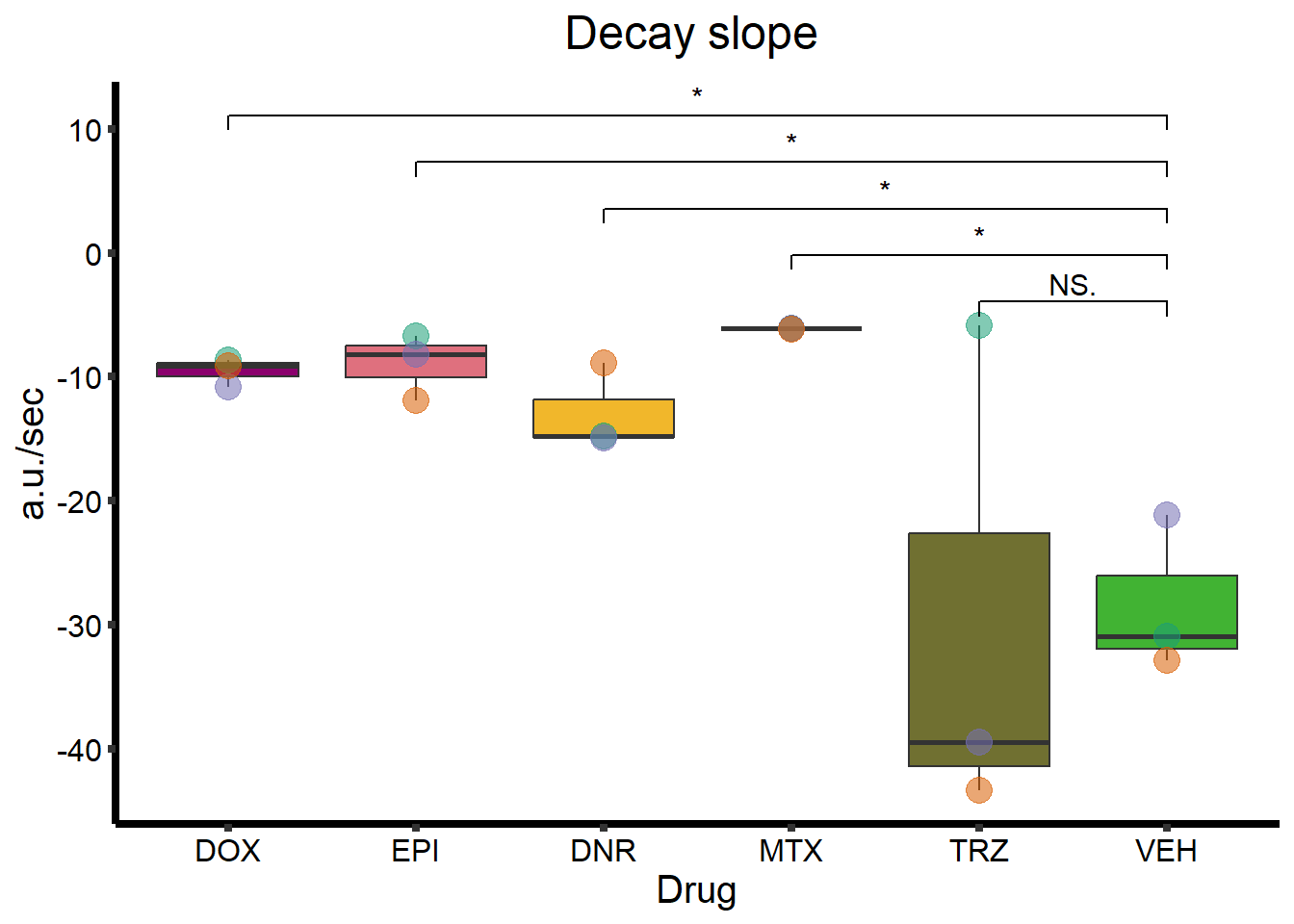
Full-Width-half max
FWHM_plot <- clamp_summary %>%
dplyr::select(Drug, Conc, indv, FWHM) %>%
ggplot(., aes(Drug, FWHM)) +
geom_boxplot(position = "identity", fill = drug_pal_fact) +
geom_point(aes(col = indv, size = 2, alpha = 0.5)) +
guides(size = "none",
alpha = "none",
colour = "none") +
scale_color_brewer(palette = "Dark2",
name = "Individual",
label = c("2", "3", "5")) +
geom_signif(
comparisons = list(
c("VEH", "TRZ"),
c("VEH", "MTX"),
c("VEH", "DNR"),
c("VEH", "EPI"),
c("VEH", "DOX")
),
test = "t.test",
map_signif_level = TRUE,
step_increase = 0.1,
textsize = 4
) +
ylab("sec") +
xlab(" ") +
theme_classic() +
ggtitle("Full-width at half-max") +
theme(
plot.title = element_text(size = 14, hjust = 0.5),
axis.title = element_text(size = 10, color = "black"),
axis.ticks = element_line(linewidth = 1),
axis.line = element_line(linewidth = 1),
axis.text = element_text(
size = 10,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 12,
color = "black",
face = "bold"
)
)
FWHM_plot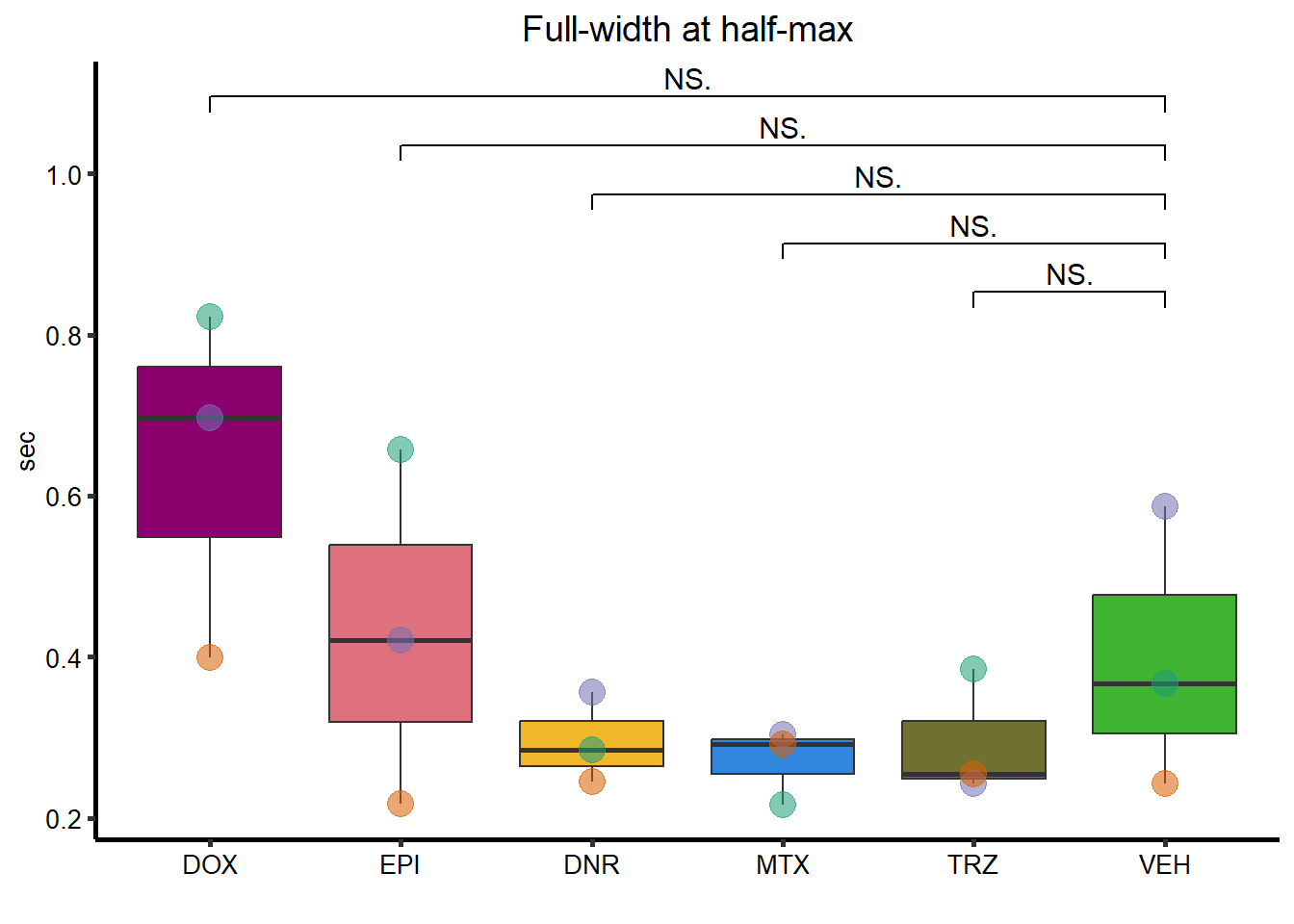
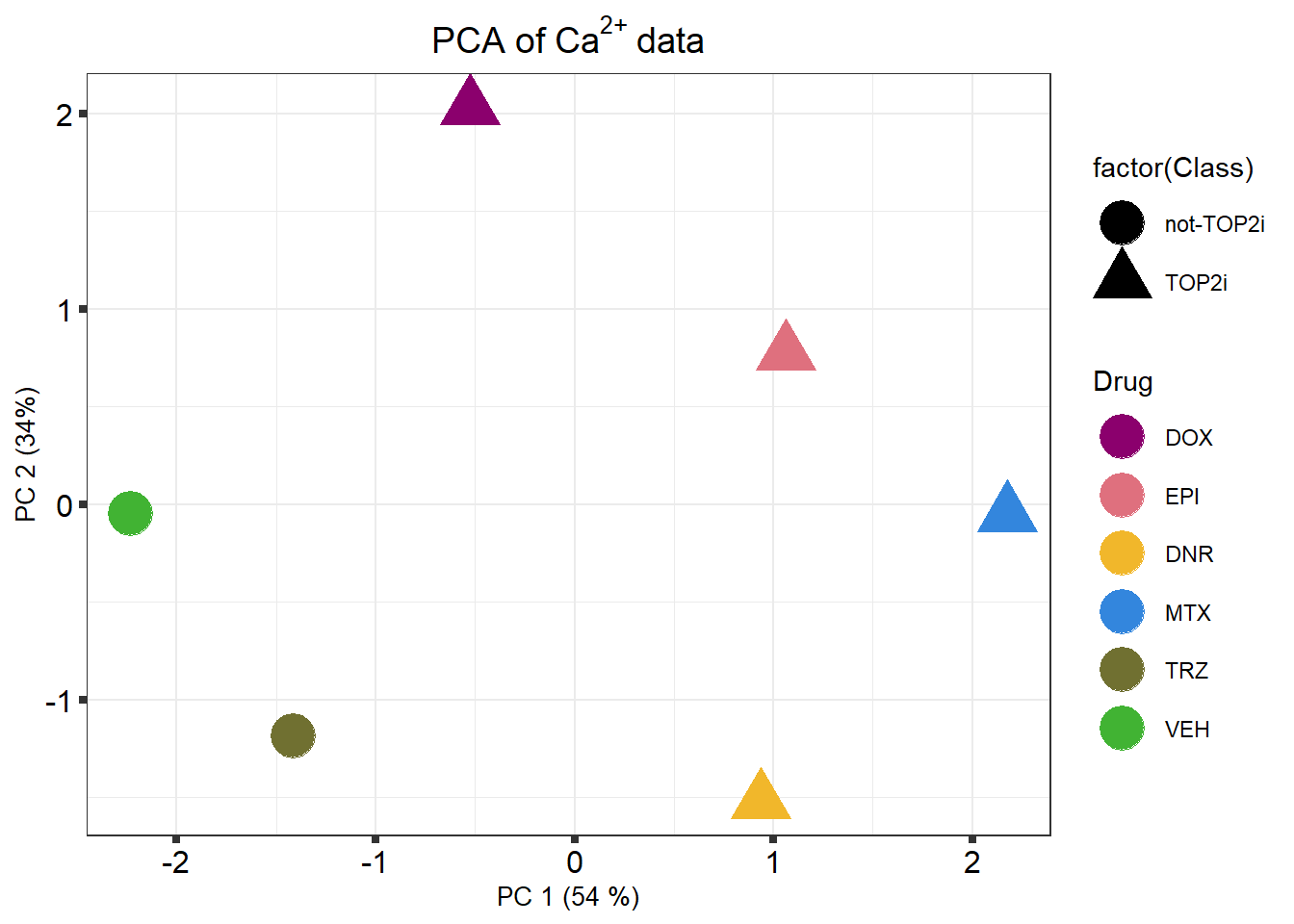
k means plot
k_means %>% mutate(
Drug = case_match(
Drug_Name,
"Dau_0.5" ~ "DNR",
"Dau_0.5.1" ~ "DNR",
"Dau_0.5.2" ~ "DNR",
"Dox_0.5" ~ "DOX",
"Dox_0.5.1" ~ "DOX",
"Dox_0.5.2" ~ "DOX",
"Epi_0.5" ~ "EPI",
"Epi_0.5.1" ~ "EPI",
"Epi_0.5.2" ~ "EPI",
"Mito_0.5" ~ "MTX",
"Mito_0.5.1" ~ "MTX",
"Mito_0.5.2" ~ "MTX",
"Tras_0.5" ~ "TRZ",
"Tras_0.5.1" ~ "TRZ",
"Tras_0.5.2" ~ "TRZ",
"Control.1" ~ "VEH",
"Control.2" ~ "VEH",
"Control" ~ "VEH",
.default = Drug_Name
)
) %>%
mutate(
Class = case_match(
Drug,
"DOX" ~ "TOP2i",
"DNR" ~ "TOP2i",
"EPI" ~ "TOP2i",
"MTX" ~ "TOP2i",
"TRZ" ~ "not-TOP2i",
"VEH" ~ "not-TOP2i",
.default = Drug
)
) %>%
mutate(Drug = factor(Drug, levels = c("DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH"))) %>%
ggplot(., aes(
x = PC1,
y = PC2,
col = Drug,
shape = factor(Class)
)) +
geom_point(size = 8) +
scale_shape_manual(values = c(19, 17, 15)) +
scale_color_manual(values = drug_pal_fact) +
# geom_encircle(aes(group=Cluster))+
# annotate("text", label = c("Cluster 1","Cluster 2", "Cluster 3"), x = c(-2,0,1.5),y=c(-0.5,0,0.5))+
ggtitle(expression("PCA of Ca" ^ "2+" ~ "data")) +
theme_bw() +
labs(x = "PC 1 (54 %)", y = "PC 2 (34%)") +
theme(
plot.title = element_text(size = 14, hjust = 0.5),
axis.title = element_text(size = 10, color = "black"),
axis.ticks = element_line(size = 1.5),
axis.text = element_text(
size = 12,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 15,
color = "black",
face = "bold"
)
)
Beat Rate
BR_plot <- calcium_data %>%
dplyr::select(Drug, Conc, indv, Rate) %>% #Peak_variance,Ave_FF0,
mutate(indv = substr(indv, 1, 2)) %>%
mutate(indv = factor(indv, levels = level_order2)) %>%
mutate(contrl = 0.383) %>%
mutate(norm_rate = Rate / contrl) %>%
filter(Conc == 0 | Conc == 0.5) %>%
ggplot(., aes(x = Drug, y = Rate)) +
geom_boxplot(position = "identity", fill = drug_pal_fact) +
geom_point(aes(col = indv, size = 2, alpha = 0.5)) +
guides(alpha = "none") +
geom_signif(
comparisons = list(
c("VEH", "TRZ"),
c("VEH", "MTX"),
c("VEH", "DNR"),
c("VEH", "EPI"),
c("VEH", "DOX")
),
test = "t.test",
map_signif_level = TRUE,
step_increase = 0.1,
textsize = 4
) +
guides(alpha = "none", size = "none") +
scale_color_brewer(palette = "Dark2",
name = "Individual",
label = c("2", "3", "5")) +
ggtitle("Contraction rate") +
theme_classic() +
guides(size = "none",
colour = guide_legend(override.aes = list(size = 4, alpha = 0.5))) +
labs(y = "avg. beats/sec") +
theme(
plot.title = element_text(size = 18, hjust = 0.5),
axis.title = element_text(size = 14, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(
size = 10,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 12,
color = "black",
face = "bold"
)
)
BR_plot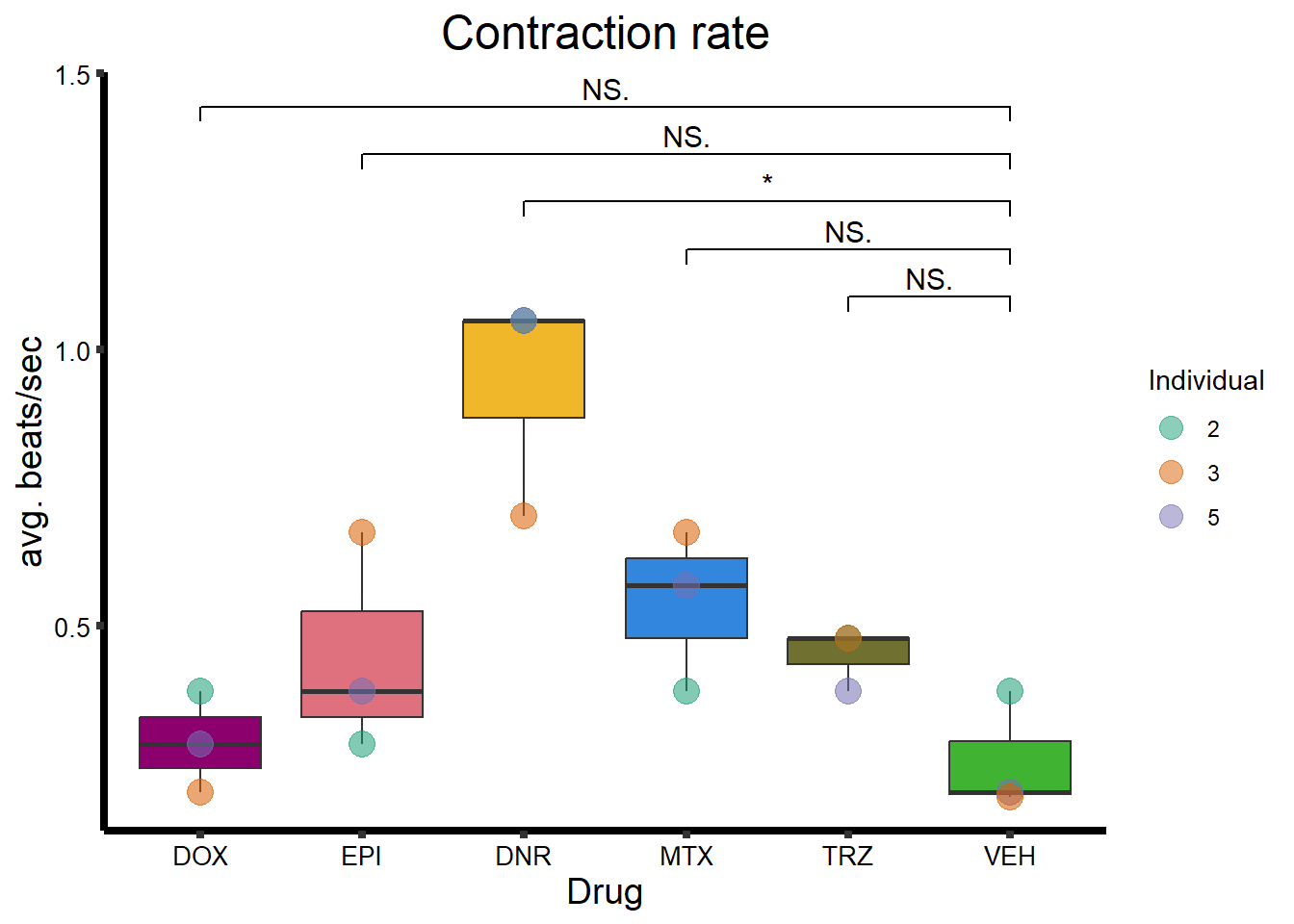
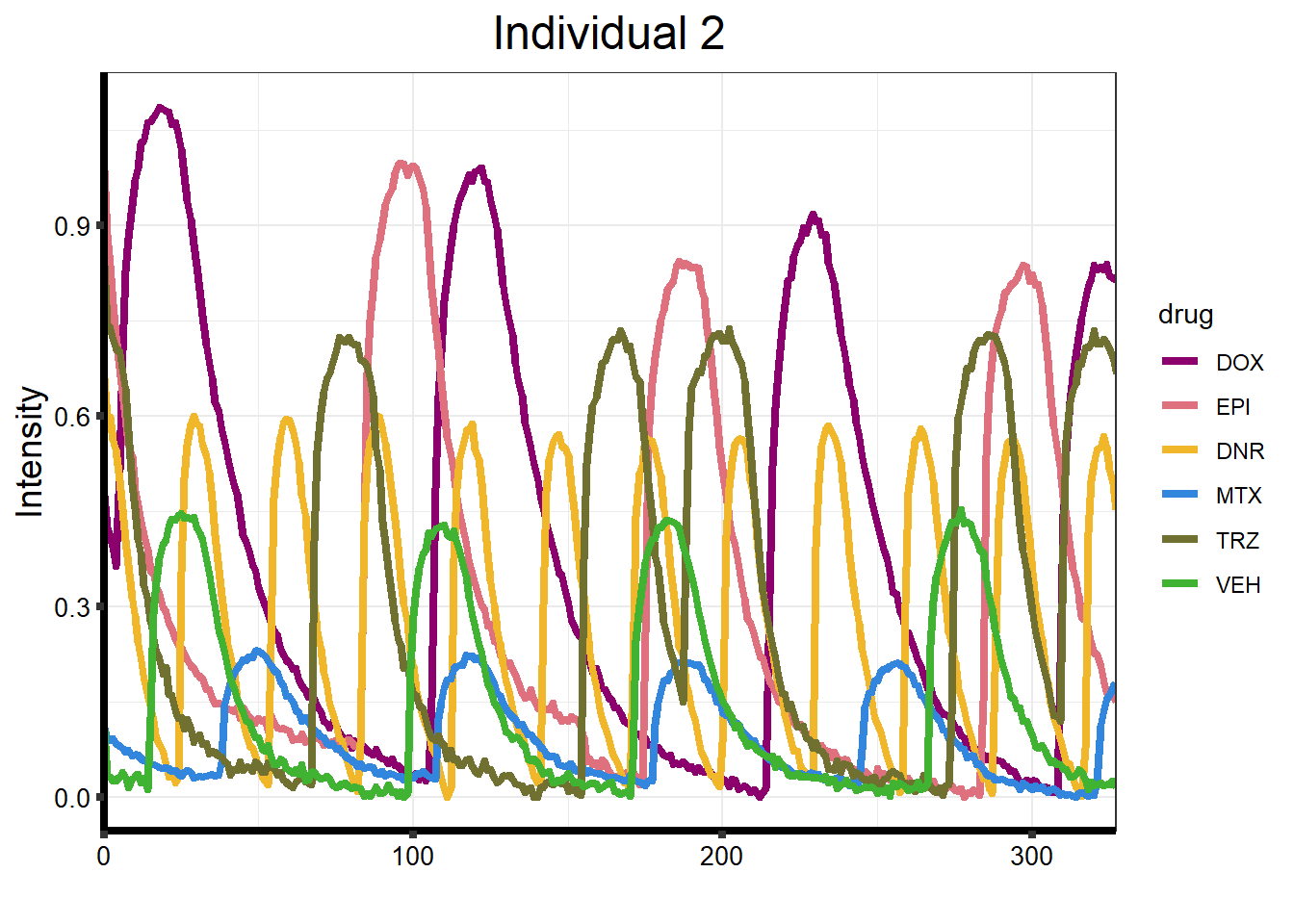
Line Plots of Calcium data
myfiles <-
list.files(path = "data/CALIMA_Data/78-1/",
pattern = "*.csv",
full.names = TRUE)
myfiles <- myfiles %>% as.tibble() %>%
mutate(filenames = value) %>%
separate(filenames, c(NA, NA, NA, "file"), sep = "/") %>%
separate(file, c("Drug", "indv"))
Normalization_And_Set_File <- function(file_path) {
# Read in the data from the file
CALIMA_obj <- read.csv(file_path)
# Normalize the data
ROI_cut <- CALIMA_obj[, 2:ncol(CALIMA_obj)]
ROI_cut_rowmeans <- rowMeans(ROI_cut)
Intensity <- (ROI_cut_rowmeans / min(ROI_cut_rowmeans))
Final_ROI <-
tibble::as_tibble(cbind(CALIMA_obj[, 1], Intensity, ROI_cut))
Final_ROI$Intensity <- Final_ROI$Intensity - 1
return(Final_ROI)
}
Plot_Line_df <- function(directory) {
holder <- list()
# List CSV files in the folder that is output from CALIMA
file_list <-
list.files(directory, pattern = "*.csv", full.names = TRUE)
file_list <- file_list %>% as.tibble() %>%
mutate(filenames = value) %>%
separate(filenames, c(NA, NA, NA, "file"), sep = "/") %>%
separate(file, c("Drug", "indv"))
# Loop over all files in directory
for (i in 1:length(file_list$value)) {
normalized_data <-
data.frame("indv" = file_list$indv[i], "drug" = file_list$Drug[i])
# Normalize the data from the file
norm_out <- Normalization_And_Set_File(file_list$value[i])
holder[[file_list$Drug[i]]] <-
cbind(normalized_data, norm_out[, 1:2])
# Return the plot
}
return(holder)
}plot_87 <- Plot_Line_df("data/CALIMA_Data/87-1/")
df_87forplot <- plot_87 %>%
bind_rows() %>%
rename("Xaxis" = `CALIMA_obj[, 1]`) %>%
mutate(drug = factor(drug, levels = c("DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH")))
ggplot(df_87forplot, aes(x = Xaxis, y = Intensity, group = drug)) +
geom_line(size = 1.5, aes(color = drug)) +
xlab("") +
theme_bw() +
ggtitle("Individual 2") +
scale_x_continuous(expand = c(0, 0)) +
scale_color_manual(values = drug_pal_fact) +
theme(
plot.title = element_text(size = 18, hjust = 0.5),
axis.title = element_text(size = 14, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(
size = 10,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 12,
color = "black",
face = "bold"
)
)
| Version | Author | Date |
|---|---|---|
| 90253fc | reneeisnowhere | 2023-07-07 |
plot_78 <- Plot_Line_df("data/CALIMA_Data/78-1/")
df_78forplot <- plot_78 %>%
bind_rows() %>%
rename("Xaxis" = `CALIMA_obj[, 1]`) %>%
mutate(drug = factor(drug, levels = c("DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH")))
ggplot(df_78forplot, aes(x = Xaxis, y = Intensity, group = as.factor(drug))) +
geom_line(size = 1.5, aes(color = drug)) +
xlab("") +
theme_bw() +
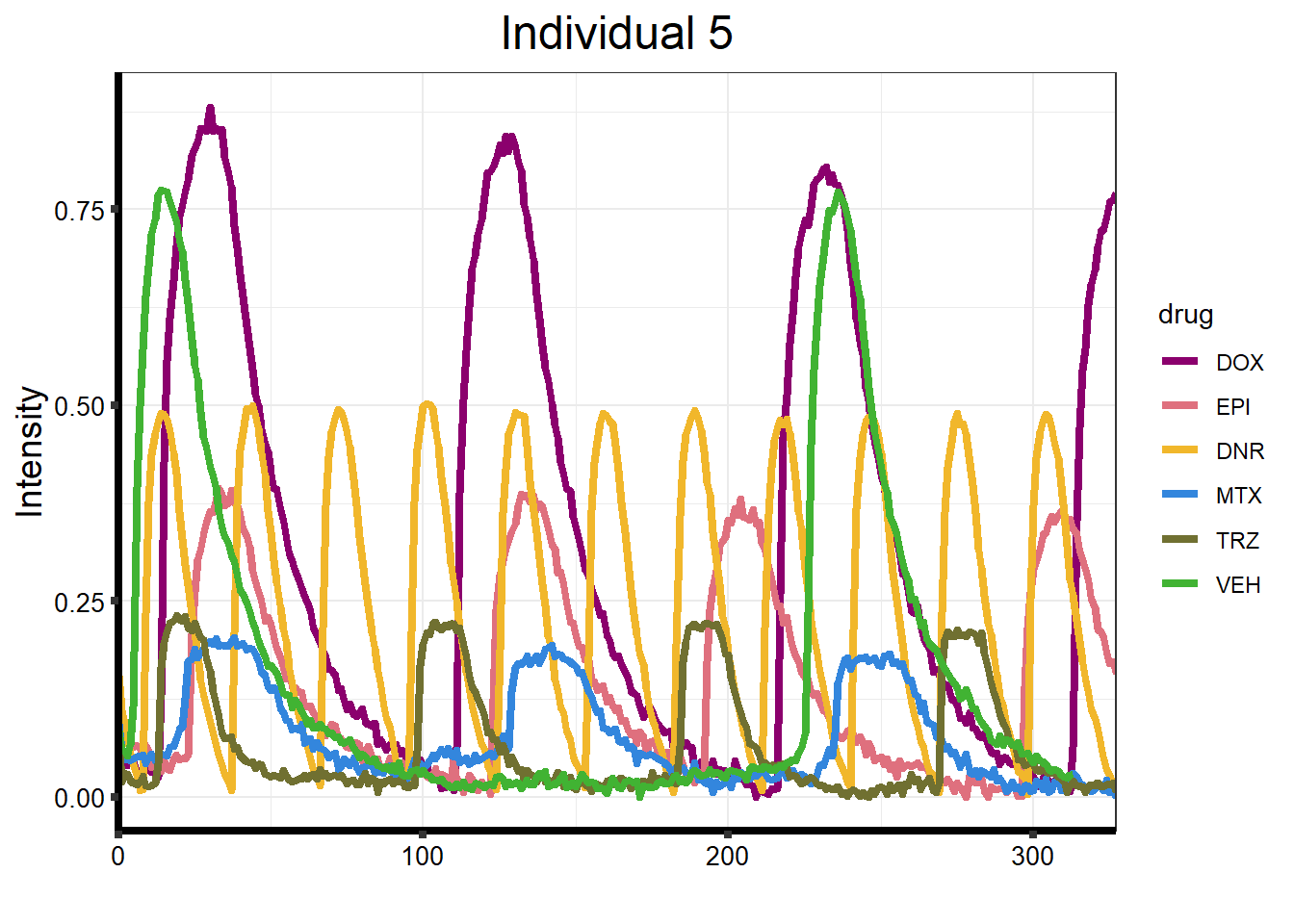
ggtitle("Individual 5") +
scale_x_continuous(expand = c(0, 0)) +
scale_color_manual(values = drug_pal_fact) +
theme(
plot.title = element_text(size = 18, hjust = 0.5),
axis.title = element_text(size = 14, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(
size = 10,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 12,
color = "black",
face = "bold"
)
)
| Version | Author | Date |
|---|---|---|
| 90253fc | reneeisnowhere | 2023-07-07 |
plot_77 <- Plot_Line_df("data/CALIMA_Data/77-1/")
df_77forplot <- plot_77 %>%
bind_rows() %>%
rename("Xaxis" = `CALIMA_obj[, 1]`) %>%
mutate(drug = factor(drug, levels = c("DOX",
"EPI",
"DNR",
"MTX",
"TRZ",
"VEH")))
ggplot(df_77forplot, aes(x = Xaxis, y = Intensity, group = as.factor(drug))) +
geom_line(size = 1.5, aes(color = drug)) +
xlab("") +
theme_bw() +
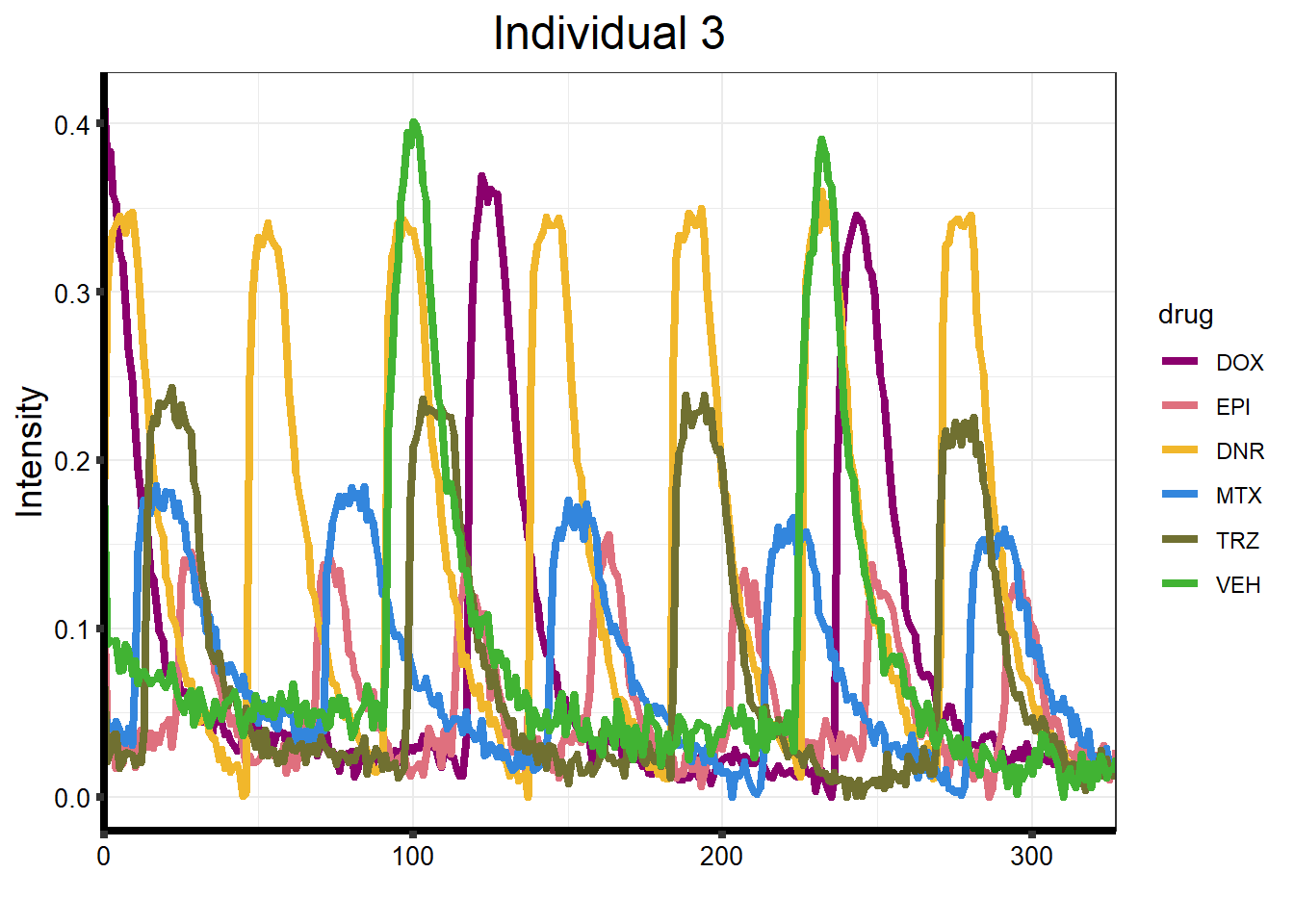
ggtitle("Individual 3") +
scale_x_continuous(expand = c(0, 0)) +
scale_color_manual(values = drug_pal_fact) +
theme(
plot.title = element_text(size = 18, hjust = 0.5),
axis.title = element_text(size = 14, color = "black"),
axis.ticks = element_line(linewidth = 1.5),
axis.line = element_line(linewidth = 1.5),
axis.text = element_text(
size = 10,
color = "black",
angle = 0
),
strip.text.x = element_text(
size = 12,
color = "black",
face = "bold"
)
)
| Version | Author | Date |
|---|---|---|
| 90253fc | reneeisnowhere | 2023-07-07 |
sessionInfo()R version 4.3.1 (2023-06-16 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19045)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggalt_0.4.0 RColorBrewer_1.1-3 ggsignif_0.6.4 zoo_1.8-12
[5] lubridate_1.9.2 forcats_1.0.0 stringr_1.5.0 dplyr_1.1.3
[9] purrr_1.0.2 readr_2.1.4 tidyr_1.3.0 tibble_3.2.1
[13] tidyverse_2.0.0 rstatix_0.7.2 ggpubr_0.6.0 ggplot2_3.4.3
[17] readxl_1.4.3 workflowr_1.7.1
loaded via a namespace (and not attached):
[1] tidyselect_1.2.0 farver_2.1.1 fastmap_1.1.1 ash_1.0-15
[5] promises_1.2.1 digest_0.6.33 timechange_0.2.0 lifecycle_1.0.3
[9] processx_3.8.2 magrittr_2.0.3 compiler_4.3.1 rlang_1.1.1
[13] sass_0.4.7 tools_4.3.1 utf8_1.2.3 yaml_2.3.7
[17] knitr_1.44 labeling_0.4.3 bit_4.0.5 abind_1.4-5
[21] KernSmooth_2.23-22 withr_2.5.0 grid_4.3.1 proj4_1.0-13
[25] fansi_1.0.4 git2r_0.32.0 colorspace_2.1-0 extrafontdb_1.0
[29] scales_1.2.1 MASS_7.3-60 cli_3.6.1 rmarkdown_2.24
[33] crayon_1.5.2 generics_0.1.3 rstudioapi_0.15.0 httr_1.4.7
[37] tzdb_0.4.0 cachem_1.0.8 splines_4.3.1 maps_3.4.1
[41] parallel_4.3.1 cellranger_1.1.0 vctrs_0.6.3 Matrix_1.6-1
[45] jsonlite_1.8.7 carData_3.0-5 car_3.1-2 callr_3.7.3
[49] hms_1.1.3 bit64_4.0.5 jquerylib_0.1.4 glue_1.6.2
[53] ps_1.7.5 stringi_1.7.12 gtable_0.3.4 later_1.3.1
[57] extrafont_0.19 munsell_0.5.0 pillar_1.9.0 htmltools_0.5.6
[61] R6_2.5.1 rprojroot_2.0.3 vroom_1.6.3 evaluate_0.21
[65] lattice_0.21-8 backports_1.4.1 broom_1.0.5 httpuv_1.6.11
[69] bslib_0.5.1 Rcpp_1.0.11 nlme_3.1-163 Rttf2pt1_1.3.12
[73] mgcv_1.9-0 whisker_0.4.1 xfun_0.40 fs_1.6.3
[77] getPass_0.2-2 pkgconfig_2.0.3