Terrain Ruggedness Index
Johannes Schielein, Om Prakash Bhandari
5/12/2021
Last updated: 2021-07-01
Checks: 7 0
Knit directory: mapme.protectedareas/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210305) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 364ae4b. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data-raw/addons/docs/rest/
Ignored: data-raw/addons/etc/
Ignored: data-raw/addons/scripts/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/terrain_ruggedness_index.rmd) and HTML (public/terrain_ruggedness_index.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | dd5c325 | Johannes Schielein | 2021-06-30 | Build site. |
| html | 8bd1321 | Johannes Schielein | 2021-06-30 | Host with GitLab. |
| html | 3a39ee3 | Johannes Schielein | 2021-06-30 | Host with GitHub. |
| html | ae67dca | Johannes Schielein | 2021-06-30 | Host with GitLab. |
| Rmd | 1a4c934 | Om Bandhari | 2021-06-30 | minor updates tri rmd analysis |
| Rmd | 6e62dc4 | Ohm-Np | 2021-05-14 | create terrain ruggedness index rmd |
# load required libraries
library("raster")
library("elevatr")
library("wdpar")
library("rgdal")
library("tidyverse")
starttime<-Sys.time() # mark the start time of this routine to calculate processing time at the endIntroduction
Terrain Ruggedness Index is a measurement developed by Riley, et al. (1999). The elevation difference between the center pixel and its eight immediate pixels are squared and then averaged and its square root is taken to get the TRI value. The resulting value is then breakdown into seven different possible classes[1]:
- 0 - 80 m :- level surface
- 81-116 m :- nearly level surface
- 117-161 m :- slightly rugged surface
- 162-239 m :- intermediately rugged surface
- 240-497 m :- moderately rugged surface
- 498-958 m :- highly rugged surface
- 959-4367 m:- extremely rugged surface
To obtain this variable, first we need elevation data for our polygons of interest. For this, we are going to use the package elevatr developed by Hollister, et al. We will use the function get_elev_raster from this package which expects two arguments (i) sp-object (polygon of interest) and (ii) zoom level. The zoom level ranges from 0 to 15 in increasing order of spatial resolution, 0 being the least available resolution while 15 being the highest. For this analysis, we would chose zoom level 12 as we get the spatial resolution of approx. 38.2 meters at 0° latitude. After getting the raster, we will compute TRI using terrain function offered by raster package.
Datasource and Metadata Information
- Dataset: - Zoom level 12 Elevation raster - SRTM [elevatr]
- Geographical Coverage: Global
- Spatial resolution: ~38.2 m
- Temporal resolution: Latest Update [2021-01-21]
- Unit: meters
- Data accessed: 14th May, 2021
- Metadata Link
Processing Workflow
The purpose of this analysis is to determine whether the terrain surface of a particular protected area’s polygon is leveled or rugged, if rugged then how much, by analyzing its numerical value. In order to obtain the result, we need to go through several steps of processing as shown in the routine workflow:
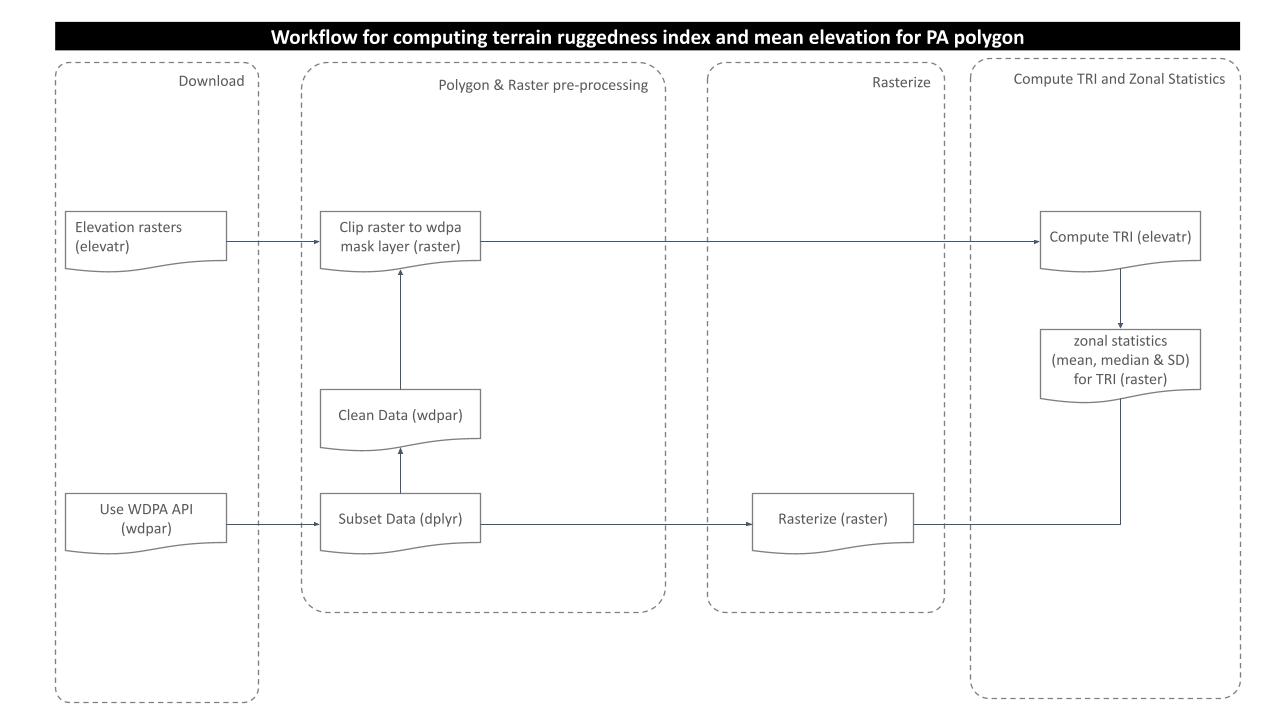
Download and Prepare WDPA Polygons
We will try to get the country level polygon data from wdpar package. wdpar is a library to interface to the World Database on Protected Areas (WDPA). The library is used to monitor the performance of existing PAs and determine priority areas for the establishment of new PAs. We will use Venezuela - for other countries of your choice, simply provide the country name or the ISO name e.g. Gy for Guyana, COL for Colombia, BRA for Brazil.
# fetch the raw data from wdpar of country
vn_raw_pa_data <-
wdpa_fetch("VEN")Since there are multiple enlisted protected areas in Brazil, we want to compute zonal statistics only for the polygon data of: - Cerro de María Lionza - wdpaid 307
For this, we have to subset the country level polygon data to the PA level.
# subset three wdpa polygons by their wdpa ids
ven<-
vn_raw_pa_data%>%
filter(WDPAID %in% 307)
# plot the sample polygon
plot(ven[1])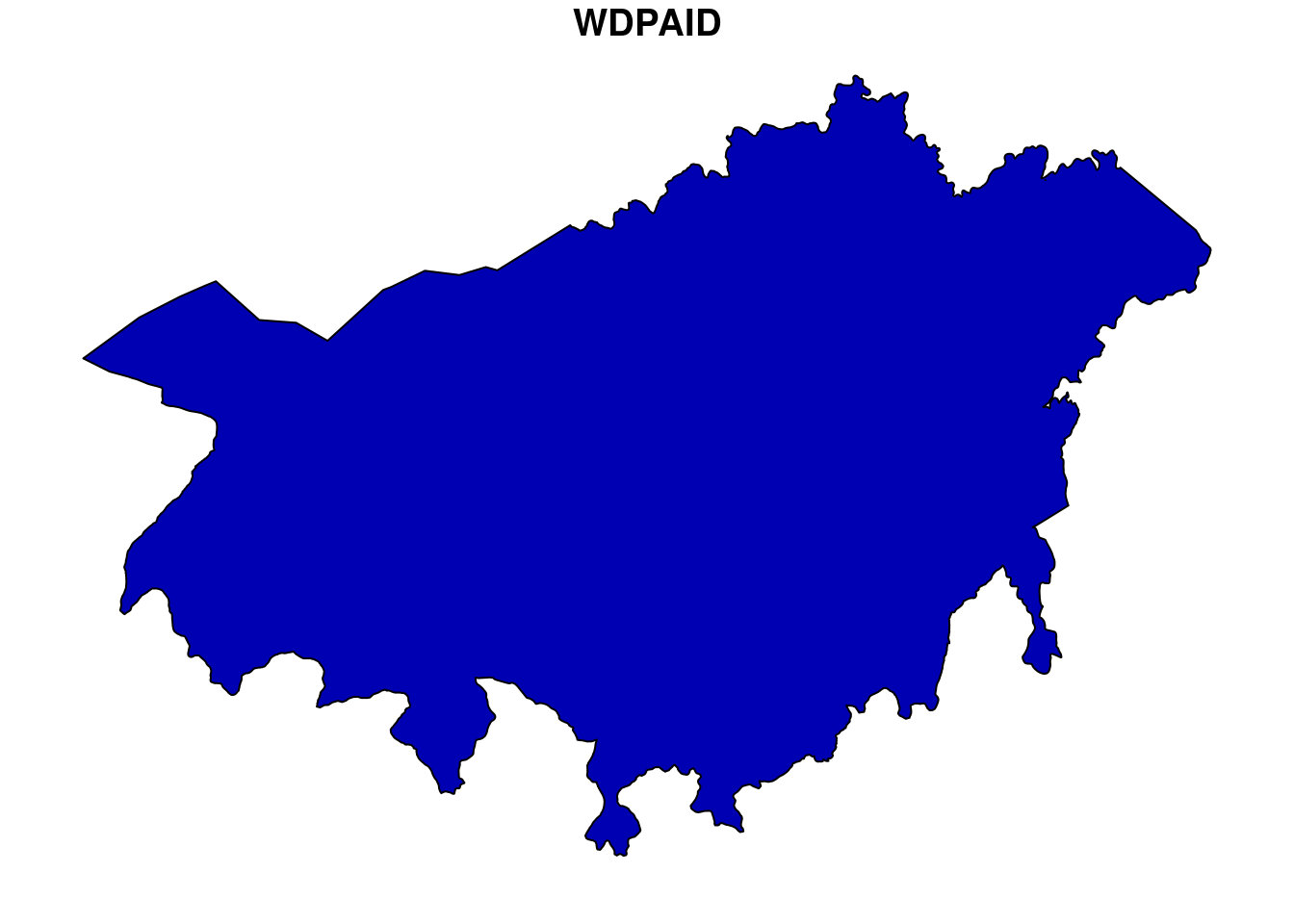
Download and Prepare elevation raster data
Since we already prepared polygon data for our analysis, now will download and prepare elevation raster for selected polygons using elevatr.
# get elevation raster from package `elevatr` at zoom level 12
elevation <- get_elev_raster(ven,
z = 12)dist is assumed to be in decimal degrees (arc_degrees).Mosaicing & ProjectingNote: Elevation units are in meters.
Note: The coordinate reference system is:
GEOGCRS["WGS 84 (with axis order normalized for visualization)",
DATUM["World Geodetic System 1984",
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
CS[ellipsoidal,2],
AXIS["geodetic longitude (Lon)",east,
ORDER[1],
ANGLEUNIT["degree",0.0174532925199433,
ID["EPSG",9122]]],
AXIS["geodetic latitude (Lat)",north,
ORDER[2],
ANGLEUNIT["degree",0.0174532925199433,
ID["EPSG",9122]]]]Crop the elevation raster
As we completed raster and vector data preparation, the next step would be to clip the raster layer by the selected PA polygon both by its extent and mask layer.
# crop raster using polygon extent
elevation_cropped <- crop(elevation,
ven)
# plot the data - shows the raster after getting cropped by the extent of polygon
plot(elevation_cropped)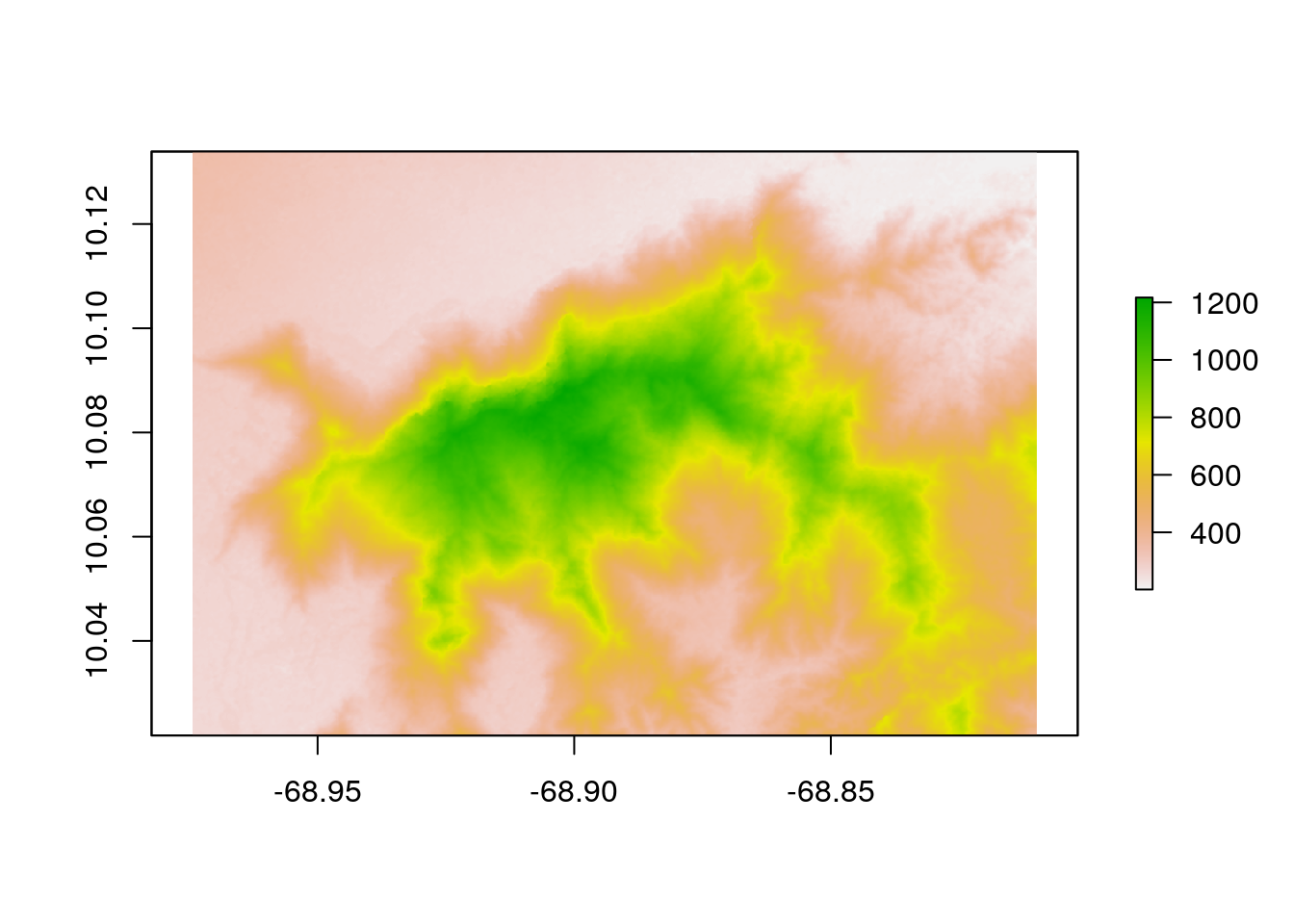
# crop raster using polygon mask
elevation_masked <- mask(elevation_cropped,
ven)
# plot the data - shows the raster after getting cropped by the polygon mask
plot(elevation_masked)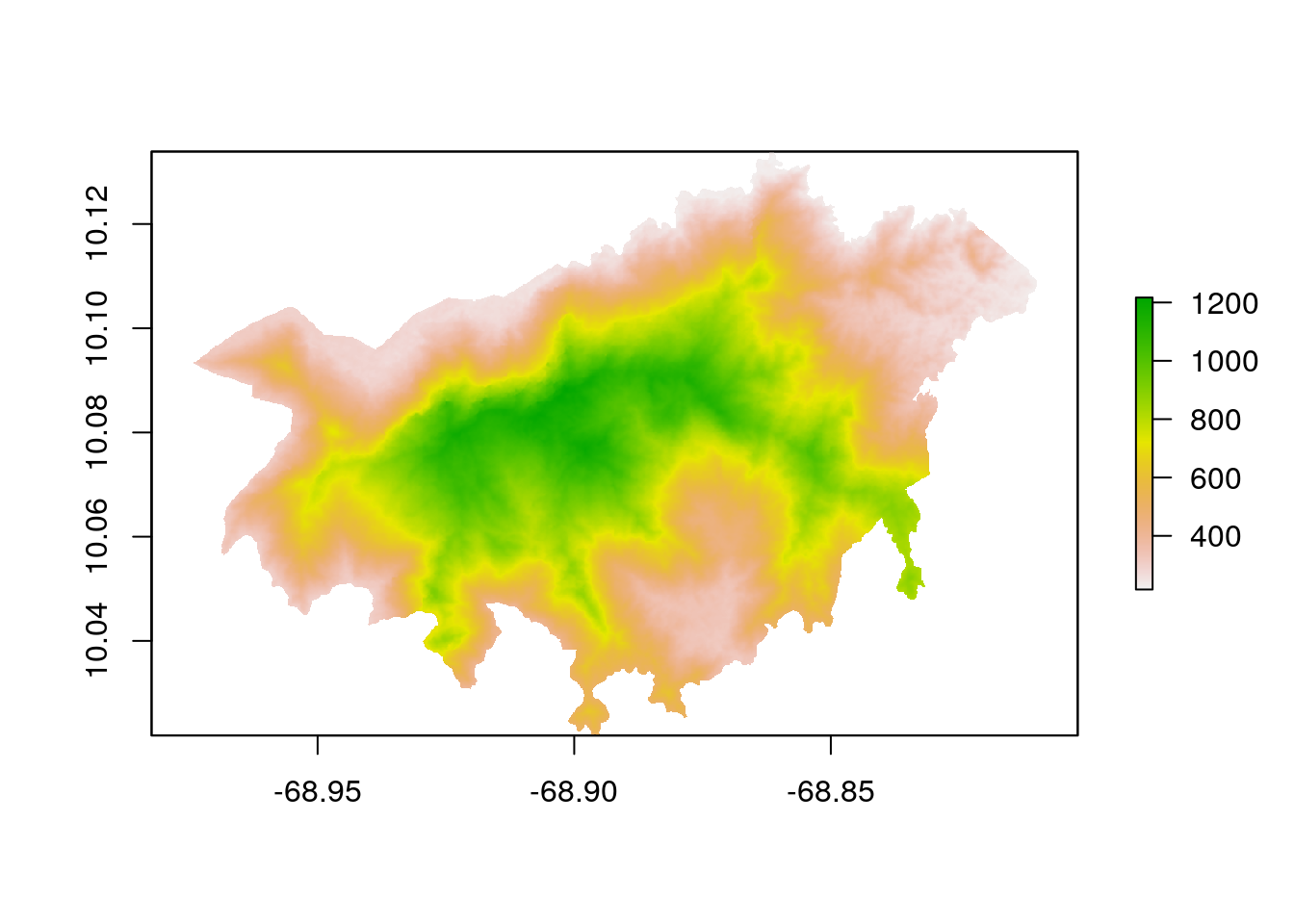
Compute Terrain Ruggedness Index (TRI)
The function terrain from raster package provides functionality to compute terrain ruggedness index for the desired polygons. We use neighbors=8, to specify the function to take immediate 8 neighbor cells for TRI computation.
# compute terrain ruggedness index
tri <- terrain(elevation_masked,
opt="TRI",
neighbors=8,
unit="degrees")Rasterize the polygon layer
To compute the zonal statistics, it is necessary to rasterize the polygon layer. Doing so, values are transferred from the spatial objects to raster cells. We need to pass the extent layer and the mask layer to the rasterize function.
# rasterize
r <- rasterize(ven,
elevation_masked,
ven$WDPAID)Compute Zonal Statistics
A zonal statistics operation is one that calculates statistics on cell values of a raster (a value raster) within the zones defined by another dataset [ArcGIS definition]. For TRI, we will compute mean, median and standard deviation while for the elevation values, we will only compute its average value within the polygon.
# zonal stats - mean value of TRI
tri_mean <- zonal(tri, r, 'mean', na.rm=T)
# zonal stats - median value of TRI
tri_median <- zonal(tri, r, 'median', na.rm=T)
# zonal stats - standard deviation of TRI values
tri_sd <- zonal(tri, r, 'sd', na.rm=T)
# zonal stats - mean elevation values
elevation_mean <- zonal(elevation_masked, r, 'mean', na.rm=T)Finally, we can create the data frame.
# create dataframe to receive results
df.tri <- data.frame(WDPA_PID=ven$WDPAID,
terrain_ruggedness_index_mean=tri_mean[ ,2],
terrain_ruggedness_index_median=tri_median[ ,2],
terrain_ruggedness_index_standard_deviation=tri_sd[ ,2],
elevation_mean=elevation_mean[ ,2])
# change the data frame to long table format
df.tri_long <- pivot_longer(df.tri,
cols=c(terrain_ruggedness_index_mean,
terrain_ruggedness_index_median,
terrain_ruggedness_index_standard_deviation,
elevation_mean))The results looking like this:
# view the result
df.tri_long# A tibble: 4 x 3
WDPA_PID name value
<dbl> <chr> <dbl>
1 307 terrain_ruggedness_index_mean 5.02
2 307 terrain_ruggedness_index_median 4.62
3 307 terrain_ruggedness_index_standard_deviation 2.64
4 307 elevation_mean 628. From the above result, we can say that the polygon which we used for our analysis have leveled surface since the mean value of TRI is around 5 meters and having average elevation of approx. 628 meters. In similar way, we can compute elevation for the desired region of interest and see whether it has leveled or rugged surface.
In the end we are going to have a look how long the rendering of this file took so that we could get an idea about the processing speed of this routine.
stoptime<-Sys.time()
print(starttime-stoptime)Time difference of -11.96523 secsReferences
[1] Riley, S. J., DeGloria, S. D., & Elliot, R. (1999). Index that quantifies topographic heterogeneity. intermountain Journal of sciences, 5(1-4), 23-27.
sessionInfo()R version 3.6.3 (2020-02-29)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 18.04.5 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.7.1
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.7.1
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] forcats_0.5.1 stringr_1.4.0 dplyr_1.0.6 purrr_0.3.4
[5] readr_1.4.0 tidyr_1.1.3 tibble_3.1.1 ggplot2_3.3.4
[9] tidyverse_1.3.1 rgdal_1.5-23 wdpar_1.0.6 sf_0.9-8
[13] elevatr_0.3.4 raster_3.4-10 sp_1.4-5
loaded via a namespace (and not attached):
[1] httr_1.4.2 jsonlite_1.7.2 modelr_0.1.8 assertthat_0.2.1
[5] countrycode_1.2.0 cellranger_1.1.0 progress_1.2.2 yaml_2.2.1
[9] pillar_1.6.0 backports_1.2.1 lattice_0.20-44 glue_1.4.2
[13] digest_0.6.27 promises_1.2.0.1 rvest_1.0.0 colorspace_2.0-1
[17] htmltools_0.5.1.1 httpuv_1.6.1 pkgconfig_2.0.3 broom_0.7.6
[21] haven_2.3.1 scales_1.1.1 whisker_0.4 later_1.2.0
[25] git2r_0.28.0 proxy_0.4-26 generics_0.1.0 ellipsis_0.3.2
[29] withr_2.4.2 cli_2.5.0 magrittr_2.0.1 crayon_1.4.1
[33] readxl_1.3.1 evaluate_0.14 fs_1.5.0 fansi_0.5.0
[37] xml2_1.3.2 class_7.3-19 prettyunits_1.1.1 tools_3.6.3
[41] hms_1.0.0 lifecycle_1.0.0 munsell_0.5.0 reprex_2.0.0
[45] compiler_3.6.3 e1071_1.7-7 rlang_0.4.11 classInt_0.4-3
[49] units_0.7-1 grid_3.6.3 rstudioapi_0.13 rappdirs_0.3.3
[53] rmarkdown_2.6 gtable_0.3.0 codetools_0.2-18 curl_4.3.1
[57] DBI_1.1.1 R6_2.5.0 lubridate_1.7.10 knitr_1.30
[61] utf8_1.2.1 workflowr_1.6.2 rprojroot_2.0.2 KernSmooth_2.23-20
[65] stringi_1.6.2 Rcpp_1.0.6 vctrs_0.3.8 dbplyr_2.1.1
[69] tidyselect_1.1.1 xfun_0.20