Himalayan Climbers
Jim Gruman
September 22, 2020
Last updated: 2021-09-13
Checks: 7 0
Knit directory: myTidyTuesday/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210907) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version a7d52ca. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: catboost_info/
Ignored: data/2021-09-08/
Ignored: data/acs_poverty.rds
Ignored: data/fmhpi.rds
Ignored: data/grainstocks.rds
Ignored: data/hike_data.rds
Ignored: data/us_states.rds
Ignored: data/us_states_hexgrid.geojson
Ignored: data/weatherstats_toronto_daily.csv
Untracked files:
Untracked: code/work list batch targets.R
Untracked: figure/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/HimalayanClimbers.Rmd) and HTML (docs/HimalayanClimbers.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | a7d52ca | opus1993 | 2021-09-13 | update to new autoplot vis for confusion matrices |
This week’s data comes from the Himalayan Database, a compilation of records for all expeditions that have climbed in the Nepal Himalaya mountain chain. The data covers all expeditions from 1905 thru the spring of 2019 for more than 465 significant peaks in Nepal.
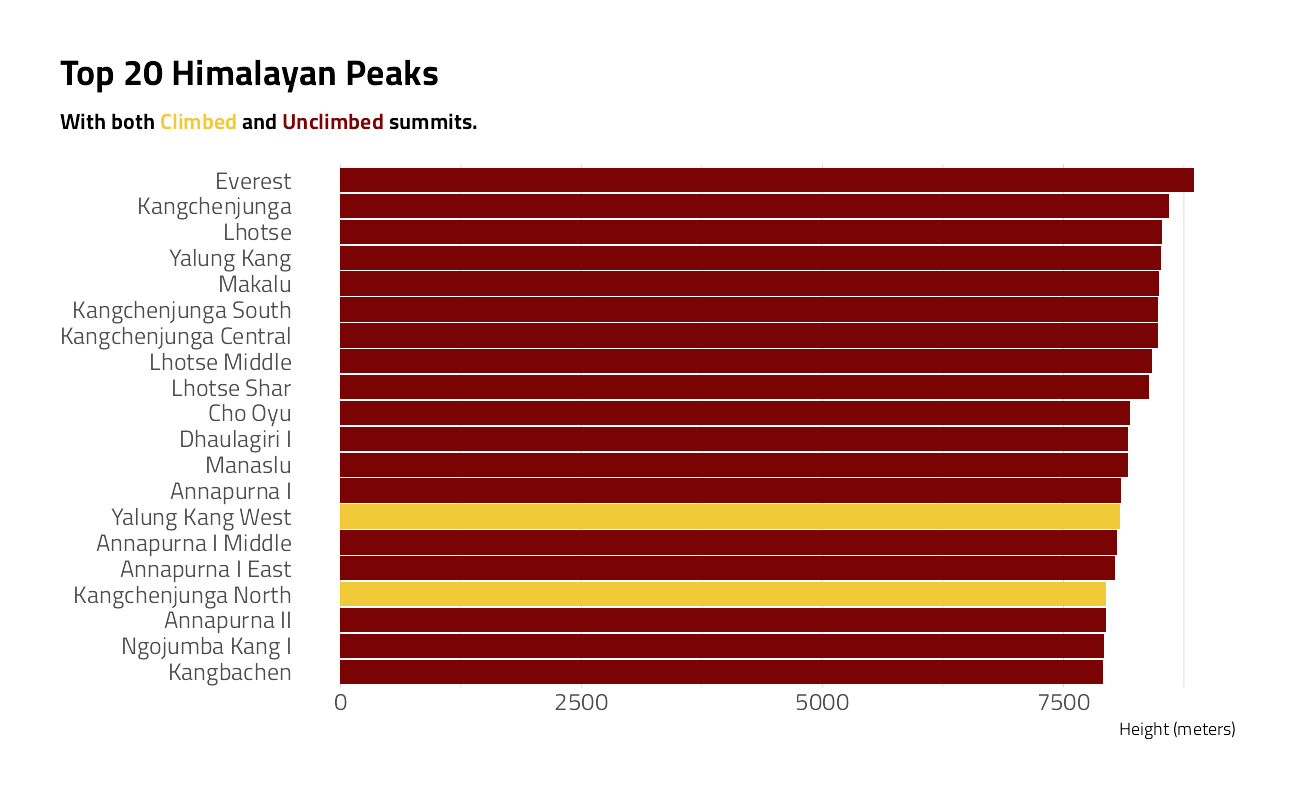
Let’s first explore the details of the mountain peaks
peaks %>%
arrange(desc(height_meters)) %>%
head(20) %>%
mutate(peak_name = fct_reorder(peak_name, height_meters)) %>%
ggplot(aes(height_meters, peak_name, fill = climbing_status)) +
geom_col(show.legend = FALSE) +
labs(
x = "Height (meters)",
y = NULL,
title = "Top 20 Himalayan Peaks",
subtitle = "With both <span style = 'color:#F1CA3AFF;'>Climbed</span>
and <span style = 'color:#7A0403FF;'>Unclimbed</span> summits.",
fill = ""
) +
theme(
plot.subtitle = ggtext::element_markdown(
size = 11, lineheight = 1.2,
face = "bold"
),
panel.grid.major.y = element_blank()
)
Let’s tidy some of the expeditions dataset
na_reasons <- c(
"Unknown",
"Attempt rumoured",
"Did not attempt climb",
"Did not reach base camp"
)
expeditions <- tt$expeditions %>%
mutate(
time_to_highpoint = highpoint_date -
basecamp_date,
success = case_when(
str_detect(termination_reason, "Success") ~ "Success",
termination_reason %in% na_reasons ~ "Other",
TRUE ~ "Failure"
),
days_to_highpoint = as.integer(highpoint_date - basecamp_date)
)Other questions that could be posed and possible answered with this dataset:
Fraction of successful climbs per year
Rate of death over time, deadliest peaks, by mountain
Death causes and rate of injury
Distribution of duration of climbs versus the height or time
Correlation between frequency of expeditions and death rate
Which are the most dangerous peaks that have been climbed?
summarize_expeditions <- function(tbl) {
tbl %>%
summarize(
first_climb = min(year),
success_rate = mean(success == "Success"),
n_climbs = n(),
across(members:hired_staff_deaths, sum),
.groups = "drop"
) %>%
mutate(
pct_death = member_deaths / members,
pct_hired_staff_deaths = hired_staff_deaths / hired_staff
)
}
peak_summarized <- expeditions %>%
group_by(peak_id, peak_name) %>%
summarize_expeditions() %>%
ungroup() %>%
arrange(desc(n_climbs)) %>%
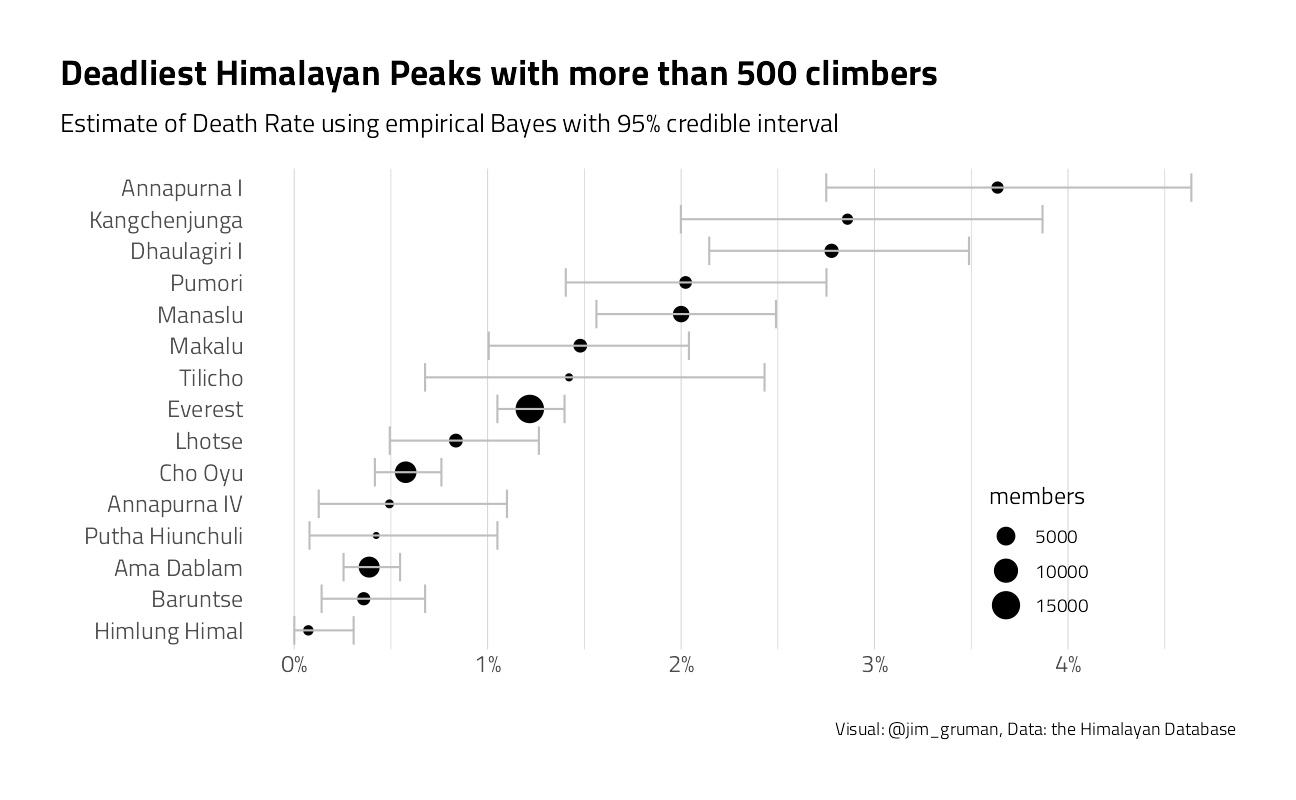
inner_join(peaks %>% select(peak_id, height_meters), by = "peak_id")What are the deadliest mountains?
Answering the question directly from the proportions may be misleading because some mountains have so few climbers.
Given the limited amount of data available on some mountains, the death rate is adjusted by adding the available priors from all climbing. The model could be further refined by regressing on information about oxygen use or other features.
For further reading: Introduction to Empirical Bayes: Examples from Baseball Statistics
peaks_eb <- peak_summarized %>%
filter(members >= 20) %>%
arrange(desc(pct_death)) %>%
add_ebb_estimate(member_deaths, members)
peaks_eb %>%
ggplot(aes(pct_death, .fitted)) +
geom_point(aes(size = members)) +
geom_abline(color = "red") +
scale_x_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_color_viridis_c(trans = "log10") +
labs(
x = "Death Rate (raw)",
y = "Adjusted Estimate of Death Rate using empirical Bayes",
title = "How much adjustment compression using priors?"
) +
theme(legend.position = c(0.8, 0.2))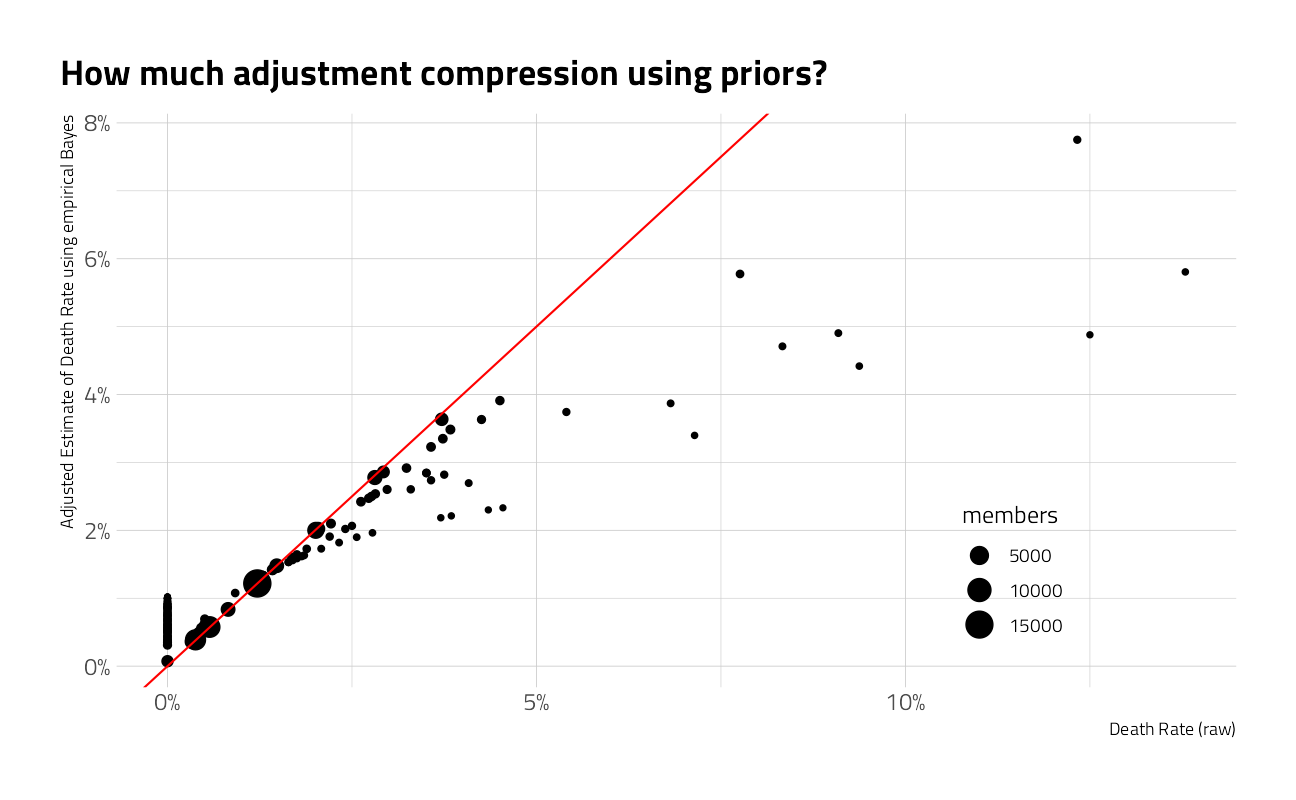
peaks_eb %>%
filter(members >= 500) %>%
arrange(desc(.fitted)) %>%
mutate(peak_name = fct_reorder(peak_name, .fitted)) %>%
ggplot(aes(.fitted, peak_name)) +
geom_point(aes(size = members)) +
geom_errorbarh(aes(xmin = .low, xmax = .high), color = "gray") +
expand_limits(x = 0) +
scale_x_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(
subtitle = "Estimate of Death Rate using empirical Bayes with 95% credible interval",
y = "", x = "",
title = "Deadliest Himalayan Peaks with more than 500 climbers",
caption = "Visual: @jim_gruman, Data: the Himalayan Database"
) +
theme(
panel.grid.major.y = element_blank(),
legend.position = c(0.8, 0.2)
)
How does death rate relate to elevation?
peaks_eb %>%
filter(members >= 500) %>%
ggplot(aes(height_meters, .fitted)) +
geom_point(aes(size = members)) +
labs(title = "There does not appear to be a relationship between death rate and height")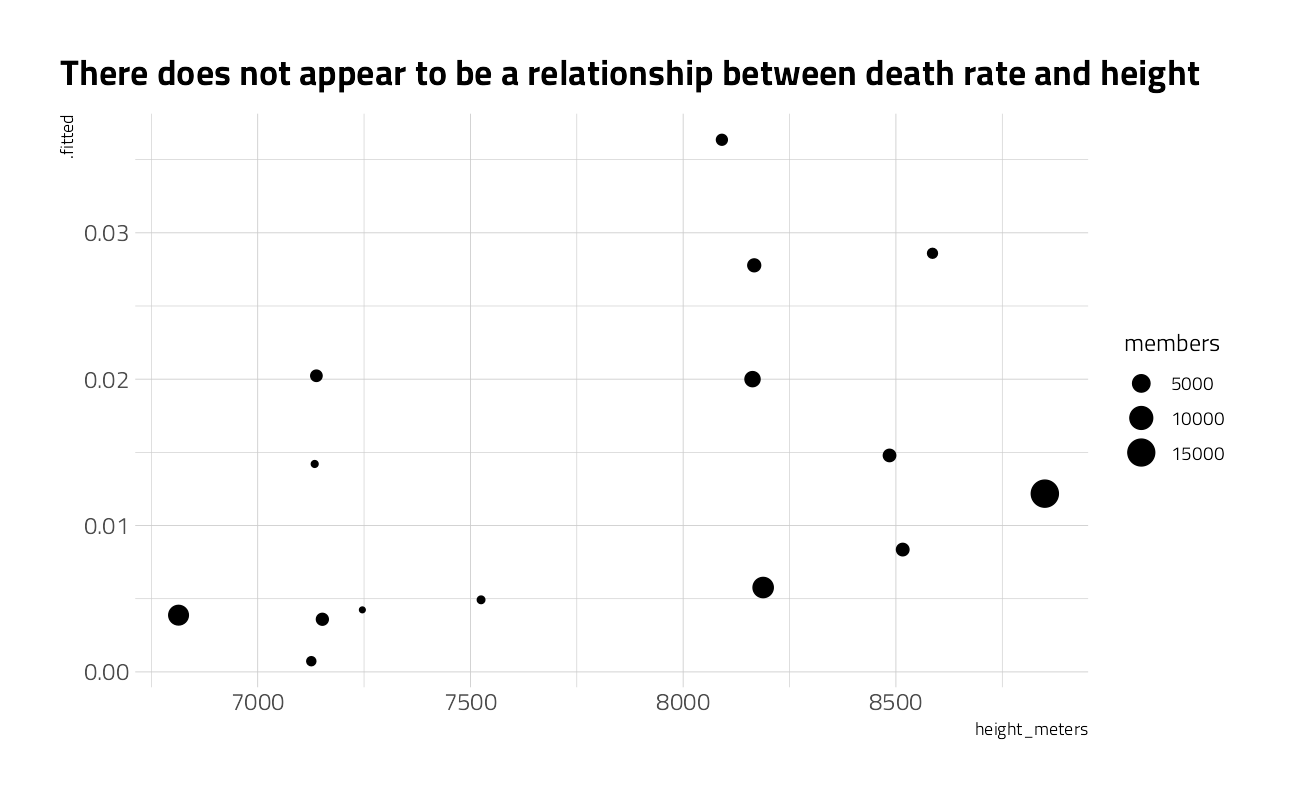
What is the distance between the base camp and the summit?
expeditions %>%
filter(
success == "Success",
!is.na(days_to_highpoint),
!is.na(peak_name)
) %>%
mutate(
peak_name = fct_lump(peak_name, 10),
peak_name = fct_reorder(peak_name, days_to_highpoint, mean)
) %>%
ggplot(aes(days_to_highpoint, peak_name)) +
geom_boxplot() +
labs(
title = "Duration to successfully summit the most popular Himalayan peaks",
caption = "Visual: @jim_gruman, Data: the Himalayan Database",
x = "Days from basecamp to summit",
y = ""
) +
theme(panel.grid.major.y = element_blank())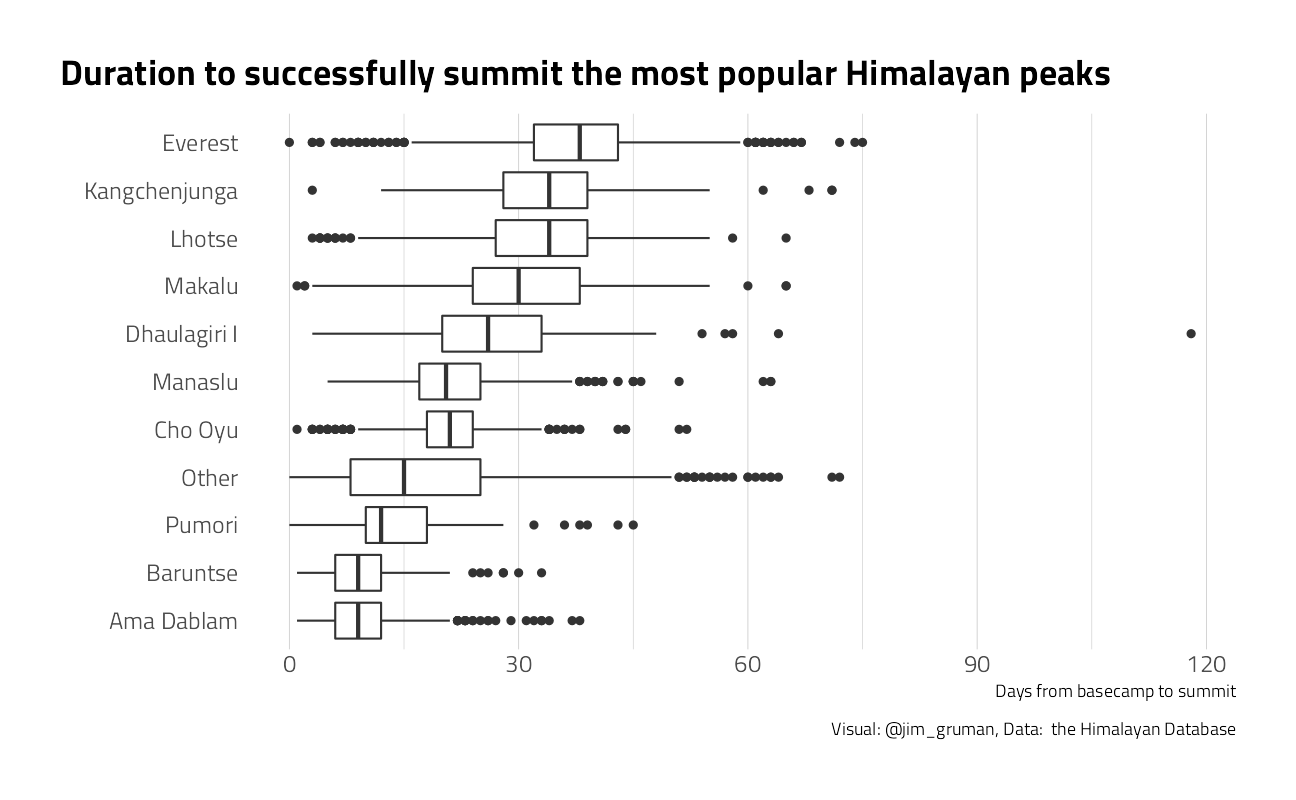
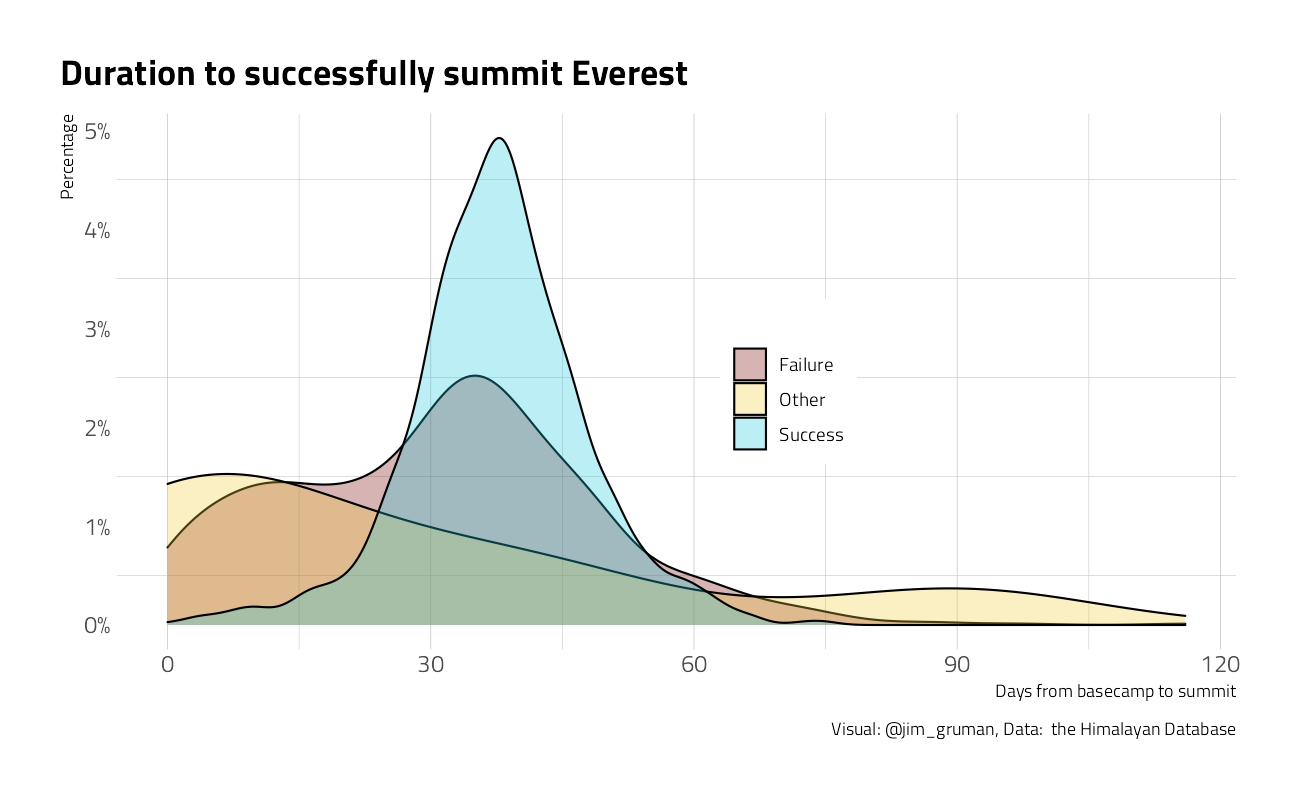
Explore Mount Everest more closely
expeditions %>%
filter(peak_name == "Everest") %>%
ggplot(aes(days_to_highpoint, fill = success)) +
geom_density(alpha = 0.3) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
labs(
title = "Duration to successfully summit Everest",
caption = "Visual: @jim_gruman, Data: the Himalayan Database",
x = "Days from basecamp to summit",
y = "Percentage",
fill = ""
) +
theme(
panel.grid.major.y = element_blank(),
legend.position = c(0.6, 0.5),
legend.background = element_rect(color = "white")
)
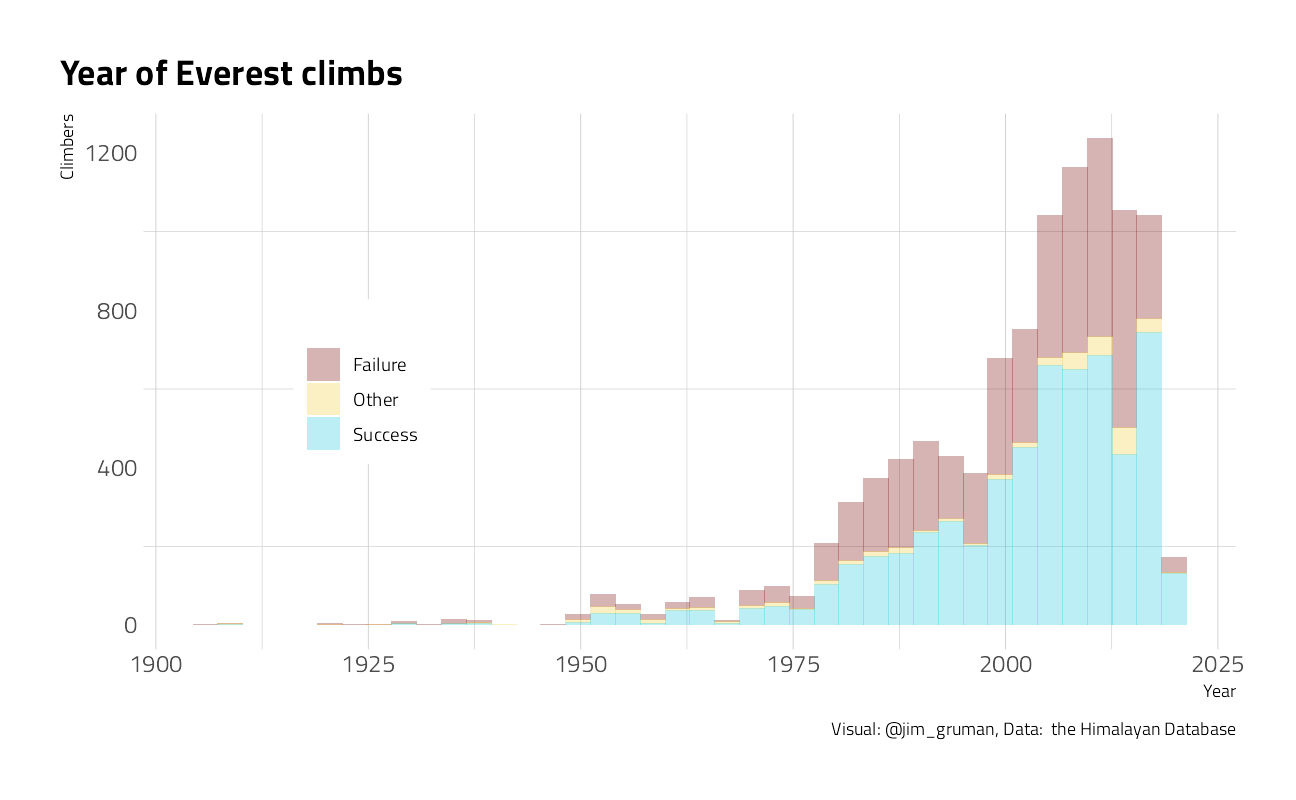
When have the Everest expeditions been successful?
expeditions %>%
ggplot(aes(year, fill = success)) +
geom_histogram(alpha = 0.3, bins = 40) +
labs(
title = "Year of Everest climbs",
caption = "Visual: @jim_gruman, Data: the Himalayan Database",
x = "Year",
y = "Climbers",
fill = ""
) +
theme(
panel.grid.major.y = element_blank(),
legend.position = c(0.2, 0.5),
legend.background = element_rect(color = "white")
)
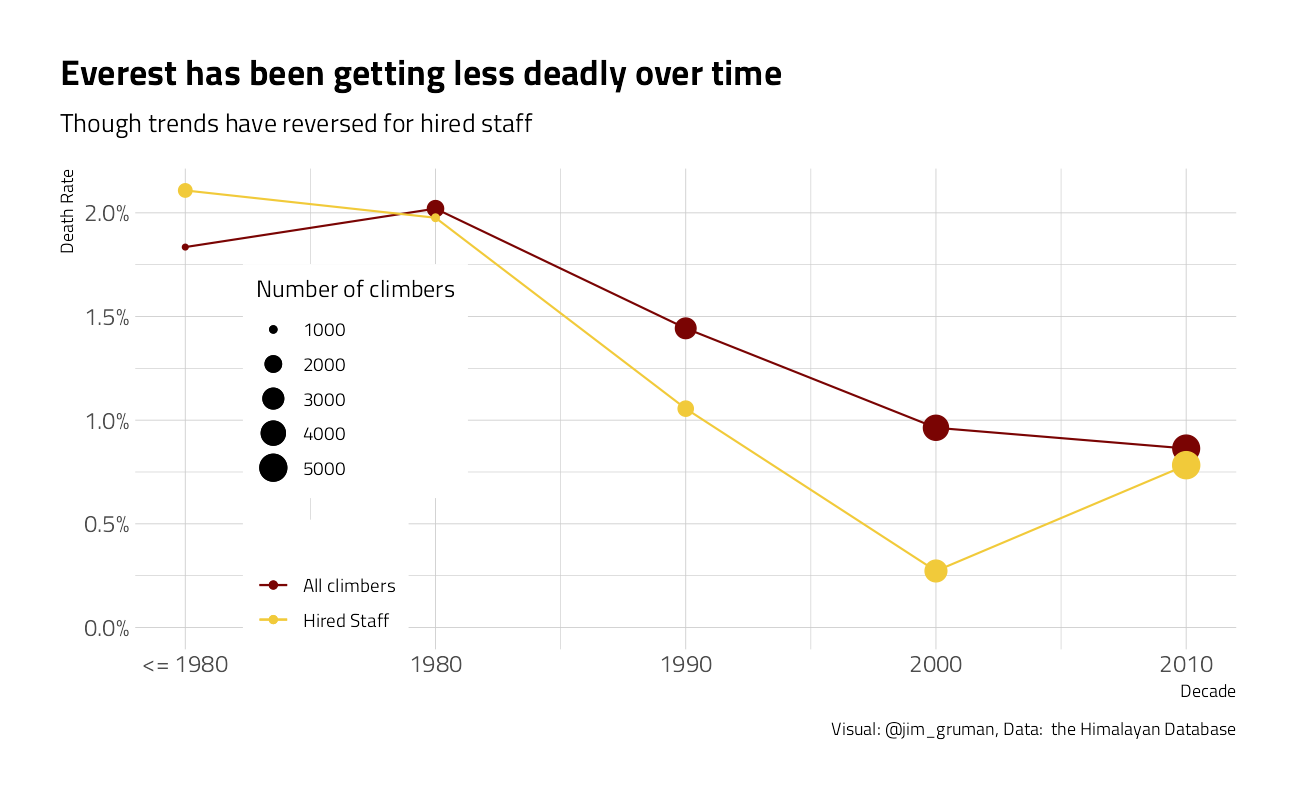
What is the median amount of time to climb?
everest_by_decade <- expeditions %>%
filter(peak_name == "Everest") %>%
mutate(decade = pmax(10 * (year %/% 10), 1970)) %>%
# limp prior to 1970
group_by(decade, peak_name) %>%
summarize_expeditions()
everest_by_decade %>%
ggplot(aes(decade, pct_death)) +
geom_line(aes(color = "All climbers")) +
geom_line(aes(y = pct_hired_staff_deaths, color = "Hired Staff")) +
geom_point(aes(color = "All climbers", size = members)) +
geom_point(aes(y = pct_hired_staff_deaths, color = "Hired Staff", size = hired_staff)) +
scale_y_continuous(labels = scales::percent_format(accuracy = .1)) +
scale_x_continuous(
breaks = seq(1970, 2010, 10),
labels = c("<= 1980", seq(1980, 2010, 10))
) +
expand_limits(y = 0) +
labs(
x = "Decade", color = "",
y = "Death Rate",
title = "Everest has been getting less deadly over time",
subtitle = "Though trends have reversed for hired staff",
size = "Number of climbers", caption = "Visual: @jim_gruman, Data: the Himalayan Database"
) +
theme(
legend.position = c(0.2, 0.4),
legend.background = element_rect(color = "white")
)
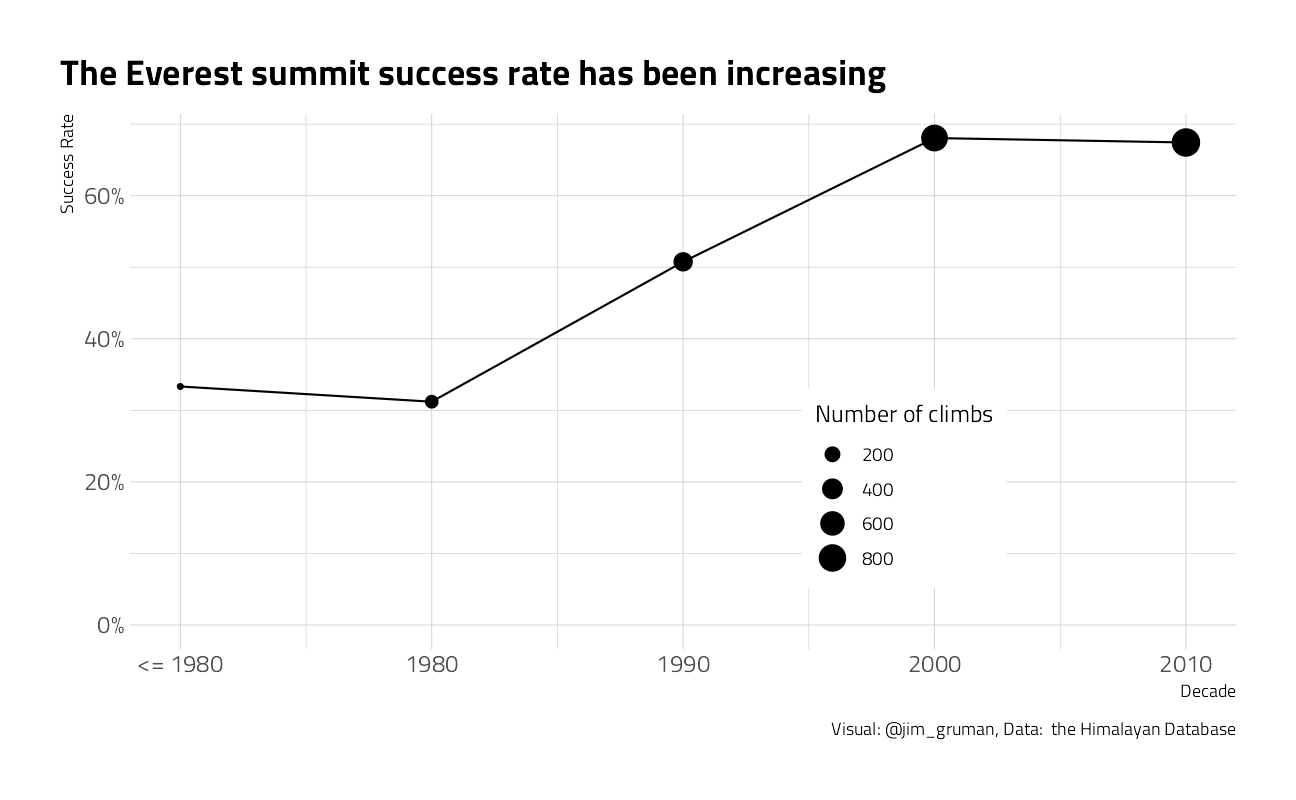
everest_by_decade %>%
ggplot(aes(decade, success_rate)) +
geom_line() +
geom_point(aes(size = n_climbs)) +
scale_y_continuous(labels = scales::percent_format(accuracy = 1)) +
scale_x_continuous(
breaks = seq(1970, 2010, 10),
labels = c("<= 1980", seq(1980, 2010, 10))
) +
expand_limits(y = 0) +
labs(
x = "Decade",
y = "Success Rate",
title = "The Everest summit success rate has been increasing",
size = "Number of climbs", caption = "Visual: @jim_gruman, Data: the Himalayan Database"
) +
theme(
legend.position = c(0.7, 0.3),
legend.background = element_rect(color = "white")
)
Examine the death probability per expedition member. What causes climber fatalities?
members <- tt$members
members %>%
count(died, death_cause) %>%
knitr::kable()| died | death_cause | n |
|---|---|---|
| FALSE | NA | 75413 |
| TRUE | AMS | 102 |
| TRUE | Avalanche | 369 |
| TRUE | Crevasse | 27 |
| TRUE | Disappearance (unexplained) | 49 |
| TRUE | Exhaustion | 41 |
| TRUE | Exposure / frostbite | 42 |
| TRUE | Fall | 331 |
| TRUE | Falling rock / ice | 26 |
| TRUE | Icefall collapse | 16 |
| TRUE | Illness (non-AMS) | 60 |
| TRUE | Other | 33 |
| TRUE | Unknown | 10 |
members %>%
count(sex) %>%
knitr::kable()| sex | n |
|---|---|
| F | 7044 |
| M | 69473 |
| NA | 2 |
For Everest, what are the significant features in predicting death?
members %>%
filter(peak_name == "Everest") %>%
mutate(expedition_role = fct_lump(expedition_role, 5)) %>%
glm(died ~ year + age + sex + expedition_role,
data = .,
family = "binomial"
) %>%
tidy() %>%
mutate(p.value = format.pval(p.value)) %>%
knitr::kable()| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 49.8368629 | 7.0523777 | 7.0666752 | 1.5869e-12 |
| year | -0.0276627 | 0.0035435 | -7.8066459 | 5.8730e-15 |
| age | 0.0182624 | 0.0066097 | 2.7629740 | 0.0057277 |
| sexM | 0.3353777 | 0.2907061 | 1.1536656 | 0.2486373 |
| expedition_roleDeputy Leader | -0.0639574 | 0.5124297 | -0.1248120 | 0.9006724 |
| expedition_roleExp Doctor | -0.1399287 | 0.4634403 | -0.3019346 | 0.7627019 |
| expedition_roleH-A Worker | 0.3469201 | 0.1625223 | 2.1346007 | 0.0327936 |
| expedition_roleLeader | 0.6033960 | 0.1852958 | 3.2563929 | 0.0011284 |
| expedition_roleOther | 0.0700387 | 0.2232777 | 0.3136842 | 0.7537609 |
The significant features include the year (lowers likelihood), the leader role (more likely to die), age (more likely to die), and the H-Aworker (much more likely to die)
members %>%
filter(peak_name == "Everest", !is.na(age)) %>%
group_by(age = 10 * (age %/% 10)) %>%
summarize(
n_climbers = n(),
pct_death = mean(died)
) %>%
knitr::kable()| age | n_climbers | pct_death |
|---|---|---|
| 10 | 263 | 0.0076046 |
| 20 | 5258 | 0.0125523 |
| 30 | 8079 | 0.0120064 |
| 40 | 5001 | 0.0115977 |
| 50 | 1897 | 0.0147601 |
| 60 | 446 | 0.0269058 |
| 70 | 48 | 0.0000000 |
| 80 | 5 | 0.4000000 |
members %>%
filter(peak_name == "Everest", !is.na(age)) %>%
group_by(hired) %>%
summarize(
n_climbers = n(),
pct_death = mean(died)
) %>%
knitr::kable()| hired | n_climbers | pct_death |
|---|---|---|
| FALSE | 14624 | 0.0121718 |
| TRUE | 6373 | 0.0136513 |
It seems that expedition role H-A worker may be confounded with hired in some funky way
What happens when oxygen is included?
model <- members %>%
filter(peak_name == "Everest", !is.na(age)) %>%
mutate(leader = expedition_role == "Leader") %>%
glm(died ~ year + age + sex + leader + hired + oxygen_used,
data = .,
family = "binomial"
)
model %>%
tidy(conf.int = TRUE, exponentiate = TRUE) %>%
filter(term != "(Intercept)") %>%
mutate(term = fct_reorder(term, estimate)) %>%
ggplot(aes(estimate, term)) +
geom_point() +
geom_errorbarh(aes(xmin = conf.low, xmax = conf.high), color = "gray") +
geom_vline(xintercept = 1, color = "red") +
labs(
title = "Relative risk factors for death on Everest summits",
caption = "Visual: @jim_gruman, Data: the Himalayan Database",
x = "Exponentiated estimate for log odds"
)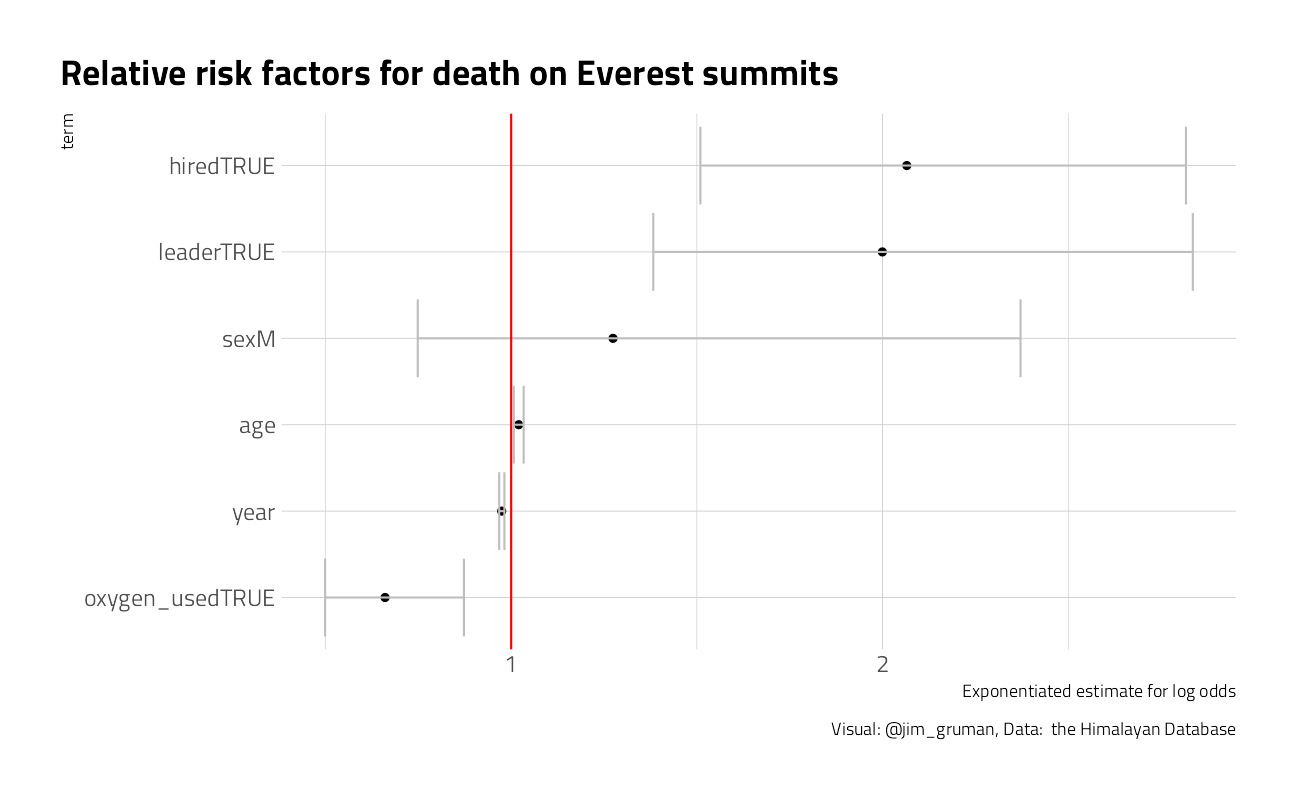 There may be an interaction, where added risk to hired workers is associated with climbing expeditions that use oxygen (maybe due to carrying the tanks). Maybe explore it further next time.
There may be an interaction, where added risk to hired workers is associated with climbing expeditions that use oxygen (maybe due to carrying the tanks). Maybe explore it further next time.
Women on Himalayan climbing expeditions @dm_ferrero
Calculate proportion of female climbers per peak per year
top_peaks <- members %>%
count(peak_name, sort = TRUE) %>%
slice(1:20) %>%
pull(peak_name)
prop_women <- members %>%
filter(peak_name %in% top_peaks) %>%
count(peak_name, year, sex) %>%
pivot_wider(names_from = sex, values_from = n, names_prefix = "num_") %>%
replace_na(list(num_F = 0)) %>%
mutate(
prop_F = num_F / (num_M + num_F),
total_peeps = num_M + num_F
) %>%
arrange(year)Calculate proportion of female climbers per peak per year
prop_women <- members %>%
filter(peak_name %in% top_peaks) %>%
count(peak_name, year, sex) %>%
pivot_wider(names_from = sex, values_from = n, names_prefix = "num_") %>%
replace_na(list(num_F = 0)) %>%
mutate(
prop_F = num_F / (num_M + num_F),
total_peeps = num_M + num_F
) %>%
arrange(year)Inspired by Danielle Ferraro @dm_ferraro
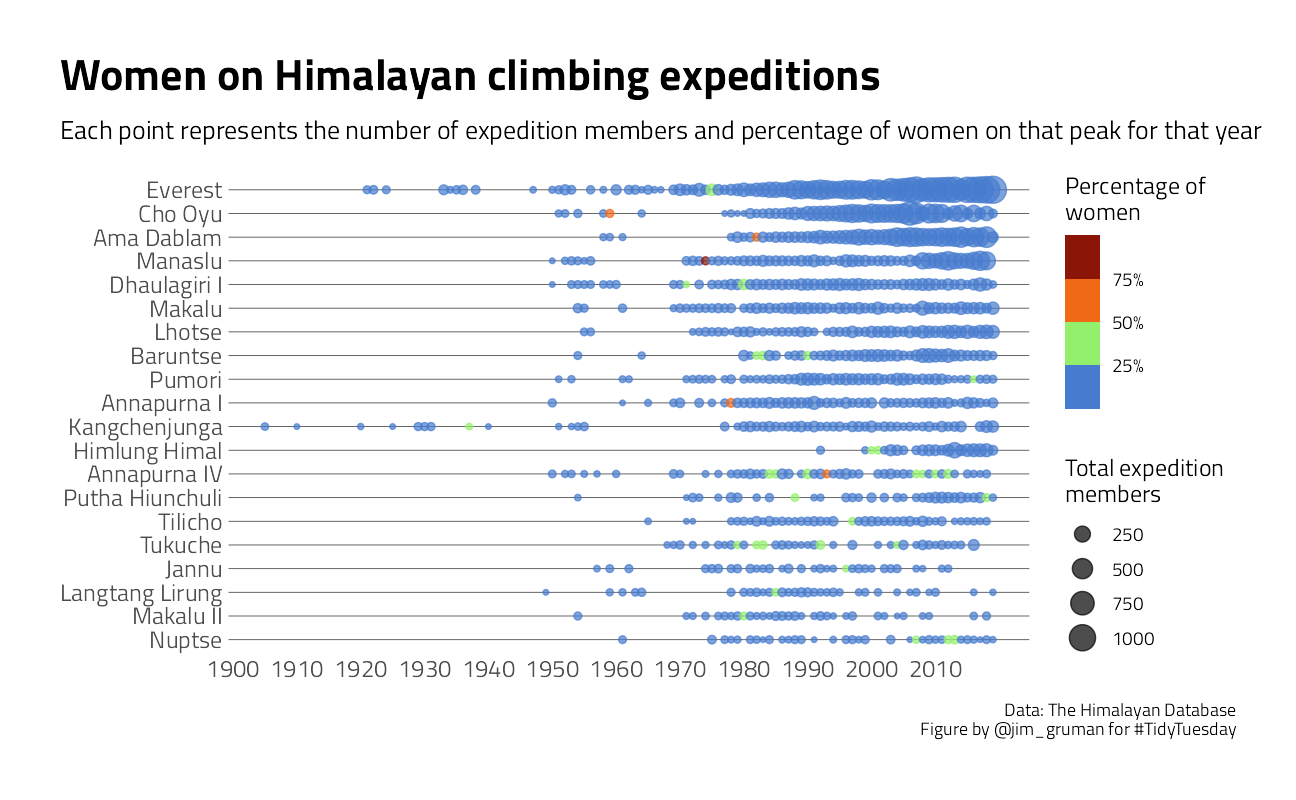
# Plot
ggplot(prop_women, aes(
x = year,
y = factor(peak_name, levels = rev(top_peaks))
)) +
geom_point(aes(size = total_peeps, color = prop_F), alpha = 0.7) +
scale_color_viridis_b(
n.breaks = 4,
labels = scales::percent_format(accuracy = 1),
option = "H"
) +
scale_x_continuous(breaks = seq(1900, 2010, by = 10)) +
labs(
x = NULL,
y = NULL,
size = "Total expedition\nmembers",
color = "Percentage of\nwomen",
title = "Women on Himalayan climbing expeditions",
subtitle = "Each point represents the number of expedition members and percentage of women on that peak for that year",
caption = "Data: The Himalayan Database\nFigure by @jim_gruman for #TidyTuesday"
) +
theme(
panel.background = element_blank(),
panel.grid.major = element_line(color = "grey30", size = 0.2),
panel.grid.minor = element_line(color = "grey30", size = 0.2),
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
legend.background = element_blank(),
axis.ticks = element_blank(),
legend.key = element_blank(),
plot.title = element_text(size = 22)
)
More Machine Learning Modeling
Strategies for handling class imbalances
Let’s make one last exploratory plot and look at seasons. How much difference is there in survival across the four seasons?
members %>%
filter(season != "Unknown") %>%
count(season, died) %>%
group_by(season) %>%
mutate(
percent = n / sum(n),
died = case_when(
died ~ "Died",
TRUE ~ "Did not die"
)
) %>%
ggplot(aes(season, percent, fill = season)) +
geom_col(position = "dodge", show.legend = FALSE) +
scale_fill_viridis_d(option = "H") +
scale_y_continuous(labels = scales::percent_format()) +
facet_wrap(~died, scales = "free") +
labs(x = NULL, y = "% of expedition members")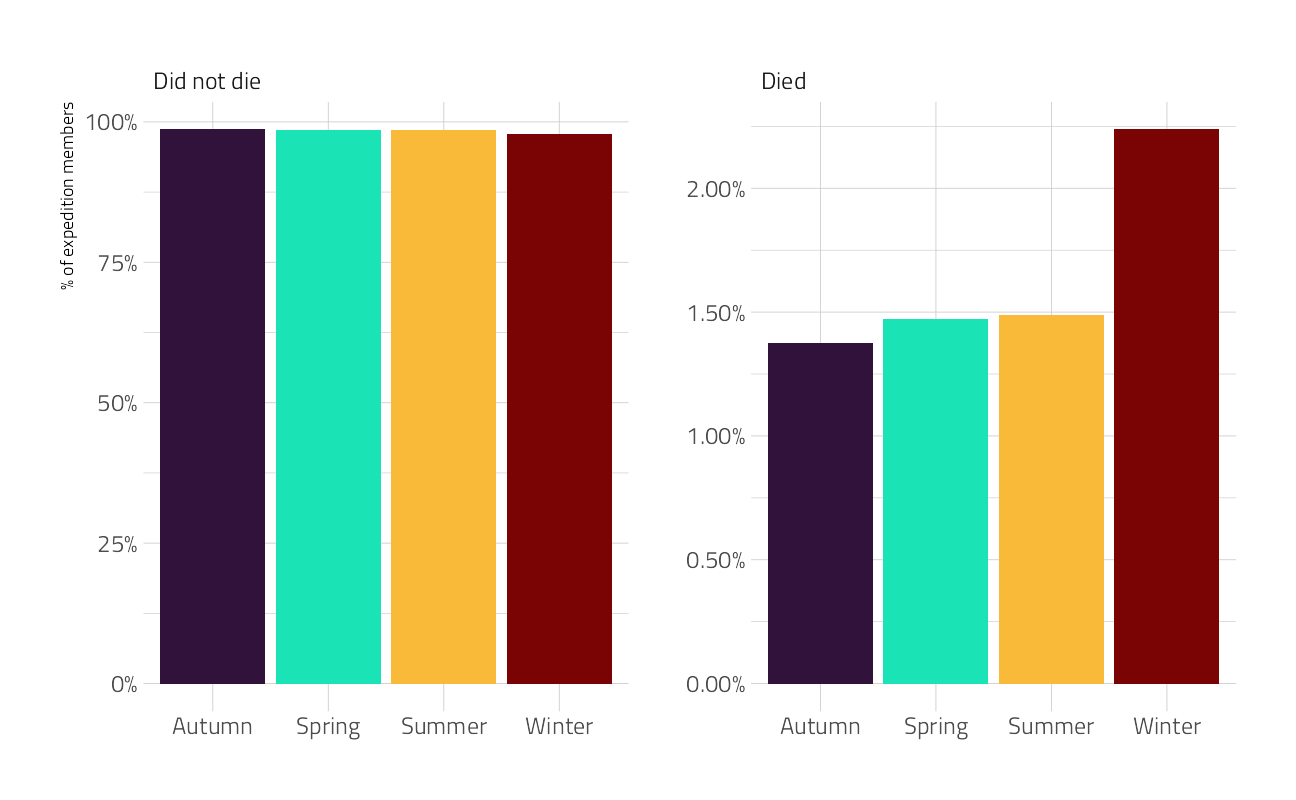
Let’s now create the dataset that we’ll use for modeling by filtering on some of the variables and transforming some variables to a be factors. There are still lots of NA values for age but we are going to impute those.
members_df <- members %>%
filter(season != "Unknown", !is.na(sex), !is.na(citizenship)) %>%
select(peak_id, year, season, sex, age, citizenship, hired, success, died) %>%
mutate(died = case_when(
died ~ "died",
TRUE ~ "survived"
)) %>%
mutate_if(is.character, factor) %>%
mutate_if(is.logical, as.integer)Build a Model
We can start by loading the tidymodels metapackage, and splitting our data into training and testing sets.
members_split <- initial_split(members_df, strata = died)
members_train <- training(members_split)
members_test <- testing(members_split)We are going to use resampling to evaluate model performance.
members_folds <- vfold_cv(members_train, strata = died)Next we build a recipe for data preprocessing.
First, we must tell the
recipe()what our model is going to be (using a formula here) and what our training data is.Next, we impute the missing values for age using the median age in the training data set. There are more complex steps available for imputation, but we’ll stick with a straightforward option here.
Next, we use
step_other()to collapse categorical levels for peak and citizenship. Before this step, there were hundreds of values in each variable.After this, we can create indicator variables for the non-numeric, categorical values, except for the outcome died which we need to keep as a factor.
Finally, there are many more people who survived their expedition than who died (thankfully) so we will use
step_smote()to balance the classes.
members_rec <- recipe(died ~ ., data = members_train) %>%
step_impute_median(age) %>%
step_other(peak_id, citizenship, threshold = 0.01) %>%
step_dummy(all_nominal_predictors()) %>%
step_smote(died)
members_recData Recipe
Inputs:
role #variables
outcome 1
predictor 8
Operations:
Median Imputation for age
Collapsing factor levels for peak_id, citizenship
Dummy variables from all_nominal_predictors()
SMOTE based on diedWe’re going to use this recipe in a workflow() so we don’t need to stress a lot about whether to prep() or not. If you want to explore the what the recipe is doing to your data, you can first prep() the recipe to estimate the parameters needed for each step and then bake(new_data = NULL) to pull out the training data with those steps applied.
Let’s compare two different models, a logistic regression model and a random forest model. We start by creating the model specifications.
glm_spec <- logistic_reg() %>%
set_engine("glm")
glm_specLogistic Regression Model Specification (classification)
Computational engine: glm rf_spec <- rand_forest(trees = 1000) %>%
set_mode("classification") %>%
set_engine("ranger")
rf_specRandom Forest Model Specification (classification)
Main Arguments:
trees = 1000
Computational engine: ranger Next let’s start putting together a tidymodelsworkflow(), a helper object to help manage modeling pipelines with pieces that fit together like Lego blocks. Notice that there is no model yet: Model: None.
members_wf <- workflow() %>%
add_recipe(members_rec)
members_wf== Workflow ====================================================================
Preprocessor: Recipe
Model: None
-- Preprocessor ----------------------------------------------------------------
4 Recipe Steps
* step_impute_median()
* step_other()
* step_dummy()
* step_smote()Now we can add a model, and the fit to each of the resamples. First, we can fit the logistic regression model. Let’s set a non-default metric set so we can add sensitivity and specificity.
all_cores <- parallelly::availableCores(omit = 1)
all_coressystem
11 future::plan("multisession", workers = all_cores) # on Windows
members_metrics <- metric_set(roc_auc, accuracy, sensitivity, specificity)
# doParallel::registerDoParallel()
glm_rs <- members_wf %>%
add_model(glm_spec) %>%
fit_resamples(
resamples = members_folds,
metrics = members_metrics,
control = control_resamples(save_pred = TRUE)
)Second, we can fit the random forest model.
rf_rs <- members_wf %>%
add_model(rf_spec) %>%
fit_resamples(
resamples = members_folds,
metrics = members_metrics,
control = control_resamples(save_pred = TRUE)
)We have fit each of our candidate models to our resampled training set!
Evaluate Models
Let’s check out how we did
collect_metrics(glm_rs) %>% knitr::kable()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| accuracy | binary | 0.6676891 | 10 | 0.0015514 | Preprocessor1_Model1 |
| roc_auc | binary | 0.7202278 | 10 | 0.0085022 | Preprocessor1_Model1 |
| sens | binary | 0.6798315 | 10 | 0.0148981 | Preprocessor1_Model1 |
| spec | binary | 0.6674792 | 10 | 0.0016366 | Preprocessor1_Model1 |
Well, this is middling but at least mostly consistent for the positive and negative classes.
collect_metrics(rf_rs) %>% knitr::kable()| .metric | .estimator | mean | n | std_err | .config |
|---|---|---|---|---|---|
| accuracy | binary | 0.9780237 | 10 | 0.0003557 | Preprocessor1_Model1 |
| roc_auc | binary | 0.7594277 | 10 | 0.0104190 | Preprocessor1_Model1 |
| sens | binary | 0.1355960 | 10 | 0.0075674 | Preprocessor1_Model1 |
| spec | binary | 0.9903824 | 10 | 0.0004311 | Preprocessor1_Model1 |
The accuracy is great but that sensitivity is not what we’d like to see. The random forest model has not done a great job of learning how to recognize both classes, even with our oversampling strategy. Let’s dig deeper into how these models are doing to see this more. For example, how are they predicting the two classes?
glm_rs %>%
conf_mat_resampled(tidy = FALSE) %>%
autoplot() +
labs(title = "GLM Confidence Matrix across resamples")
rf_rs %>%
conf_mat_resampled(tidy = FALSE) %>%
autoplot() +
labs(title = "Random Forest Confidence Matrix across resamples")
The random forest model is quite bad at identifying which expedition members died, while the logistic regression model does about the same for both classes.
We can also make an ROC curve.
glm_rs %>%
collect_predictions() %>%
group_by(id) %>%
roc_curve(died, .pred_died) %>%
ggplot(aes(1 - specificity, sensitivity, color = id)) +
geom_abline(lty = 2, color = "gray80", size = 1.5) +
geom_path(show.legend = FALSE, alpha = 0.6, size = 1.2) +
coord_equal()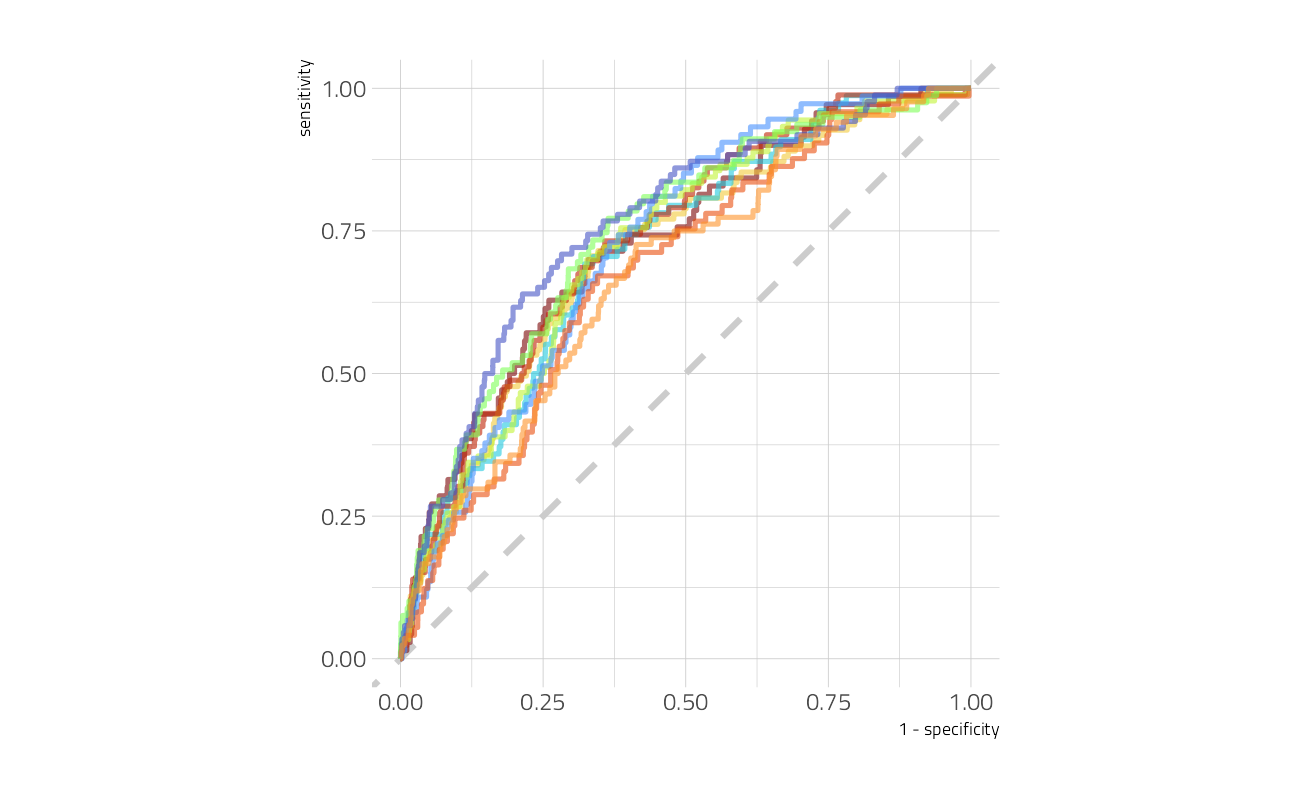
It is finally time for us to return to the testing set. Notice that we have not used the testing set yet during this whole analysis; to compare and assess models we used resamples of the training set. Let’s fit one more time to the training data and evaluate on the testing data using the function last_fit().
members_final <- members_wf %>%
add_model(glm_spec) %>%
last_fit(members_split)
members_final# Resampling results
# Manual resampling
# A tibble: 1 x 6
splits id .metrics .notes .predictions .workflow
<list> <chr> <list> <list> <list> <list>
1 <split [57380/19127]> train/test split <tibble ~ <tibb~ <tibble [19~ <workflo~The metrics and predictions here are on the testing data.
collect_metrics(members_final) %>% knitr::kable()| .metric | .estimator | .estimate | .config |
|---|---|---|---|
| accuracy | binary | 0.6715115 | Preprocessor1_Model1 |
| roc_auc | binary | 0.7243124 | Preprocessor1_Model1 |
collect_predictions(members_final) %>%
conf_mat(died, .pred_class) %>%
autoplot() +
labs(title = "GLM Model Performance on Testing Data")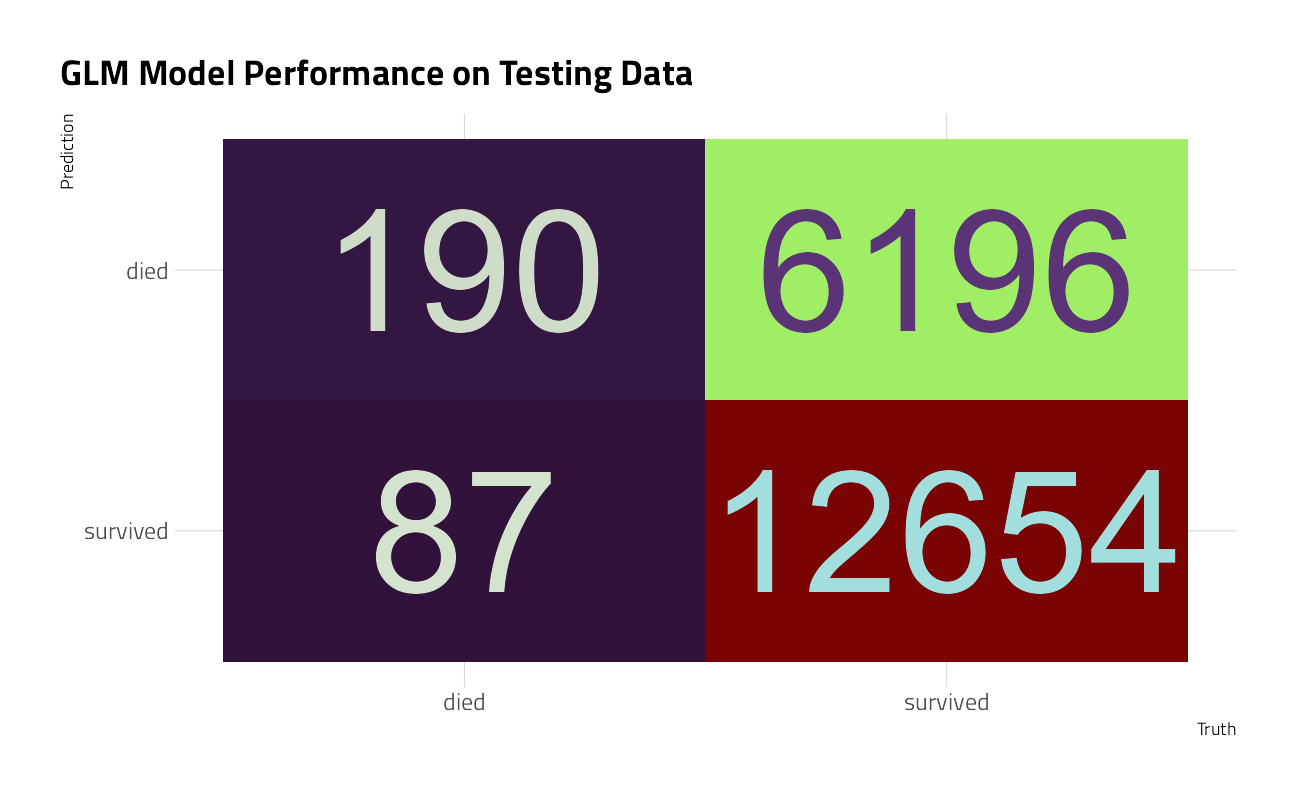
The coefficients (which we can get out using tidy()) have been estimated using the training data. If we use exponentiate = TRUE, we have odds ratios.
members_final %>%
extract_workflow() %>%
tidy(exponentiate = TRUE) %>%
arrange(estimate) %>%
knitr::kable(digits = 4)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 0.0000 | 1.0071 | -50.7877 | 0.0000 |
| peak_id_ANN1 | 0.0814 | 0.0529 | -47.4281 | 0.0000 |
| peak_id_DHA1 | 0.0983 | 0.0480 | -48.3149 | 0.0000 |
| peak_id_KANG | 0.1000 | 0.0570 | -40.3997 | 0.0000 |
| peak_id_PUMO | 0.1652 | 0.0537 | -33.5158 | 0.0000 |
| peak_id_MAKA | 0.1952 | 0.0504 | -32.4175 | 0.0000 |
| peak_id_MANA | 0.1973 | 0.0433 | -37.5068 | 0.0000 |
| peak_id_EVER | 0.2294 | 0.0377 | -39.0889 | 0.0000 |
| peak_id_other | 0.2550 | 0.0375 | -36.4663 | 0.0000 |
| hired | 0.4030 | 0.0575 | -15.8060 | 0.0000 |
| sex_M | 0.4672 | 0.0317 | -24.0209 | 0.0000 |
| peak_id_LHOT | 0.5757 | 0.0587 | -9.4069 | 0.0000 |
| peak_id_CHOY | 0.6400 | 0.0427 | -10.4613 | 0.0000 |
| citizenship_Russia | 0.8491 | 0.0698 | -2.3435 | 0.0191 |
| peak_id_HIML | 0.8916 | 0.0832 | -1.3781 | 0.1682 |
| peak_id_BARU | 0.9108 | 0.0656 | -1.4230 | 0.1547 |
| peak_id_ANN4 | 0.9647 | 0.0917 | -0.3919 | 0.6952 |
| age | 0.9904 | 0.0008 | -12.7651 | 0.0000 |
| year | 1.0267 | 0.0005 | 52.1618 | 0.0000 |
| citizenship_India | 1.0906 | 0.0635 | 1.3655 | 0.1721 |
| season_Spring | 1.1001 | 0.0168 | 5.6950 | 0.0000 |
| season_Winter | 1.1219 | 0.0444 | 2.5881 | 0.0096 |
| citizenship_Germany | 1.3270 | 0.0623 | 4.5435 | 0.0000 |
| citizenship_S.Korea | 1.4019 | 0.0591 | 5.7147 | 0.0000 |
| citizenship_Poland | 1.7852 | 0.0686 | 8.4455 | 0.0000 |
| citizenship_other | 1.8164 | 0.0521 | 11.4518 | 0.0000 |
| success | 2.3182 | 0.0166 | 50.7364 | 0.0000 |
| citizenship_Japan | 2.4260 | 0.0542 | 16.3549 | 0.0000 |
| citizenship_Spain | 2.8580 | 0.0603 | 17.4191 | 0.0000 |
| citizenship_Switzerland | 2.9370 | 0.0660 | 16.3193 | 0.0000 |
| citizenship_France | 2.9518 | 0.0578 | 18.7304 | 0.0000 |
| citizenship_Nepal | 2.9763 | 0.0747 | 14.5924 | 0.0000 |
| citizenship_Austria | 3.4269 | 0.0680 | 18.1080 | 0.0000 |
| citizenship_China | 4.0187 | 0.0714 | 19.4695 | 0.0000 |
| citizenship_New.Zealand | 4.4991 | 0.0960 | 15.6614 | 0.0000 |
| citizenship_Canada | 4.9039 | 0.0905 | 17.5721 | 0.0000 |
| citizenship_UK | 5.0950 | 0.0587 | 27.7364 | 0.0000 |
| citizenship_Italy | 5.3972 | 0.0662 | 25.4856 | 0.0000 |
| citizenship_USA | 5.6072 | 0.0581 | 29.6837 | 0.0000 |
| season_Summer | 6.4447 | 0.0974 | 19.1391 | 0.0000 |
we can also visualize the results.
members_final %>%
extract_workflow() %>%
tidy() %>%
filter(term != "(Intercept)") %>%
ggplot(aes(estimate, fct_reorder(term, estimate))) +
geom_vline(xintercept = 0, color = "gray50", lty = 2, size = 1.2) +
geom_errorbar(aes(
xmin = estimate - std.error,
xmax = estimate + std.error
),
width = .2, color = "gray50", alpha = 0.7
) +
geom_point(size = 2) +
labs(y = NULL, x = "Coefficent from logistic regression")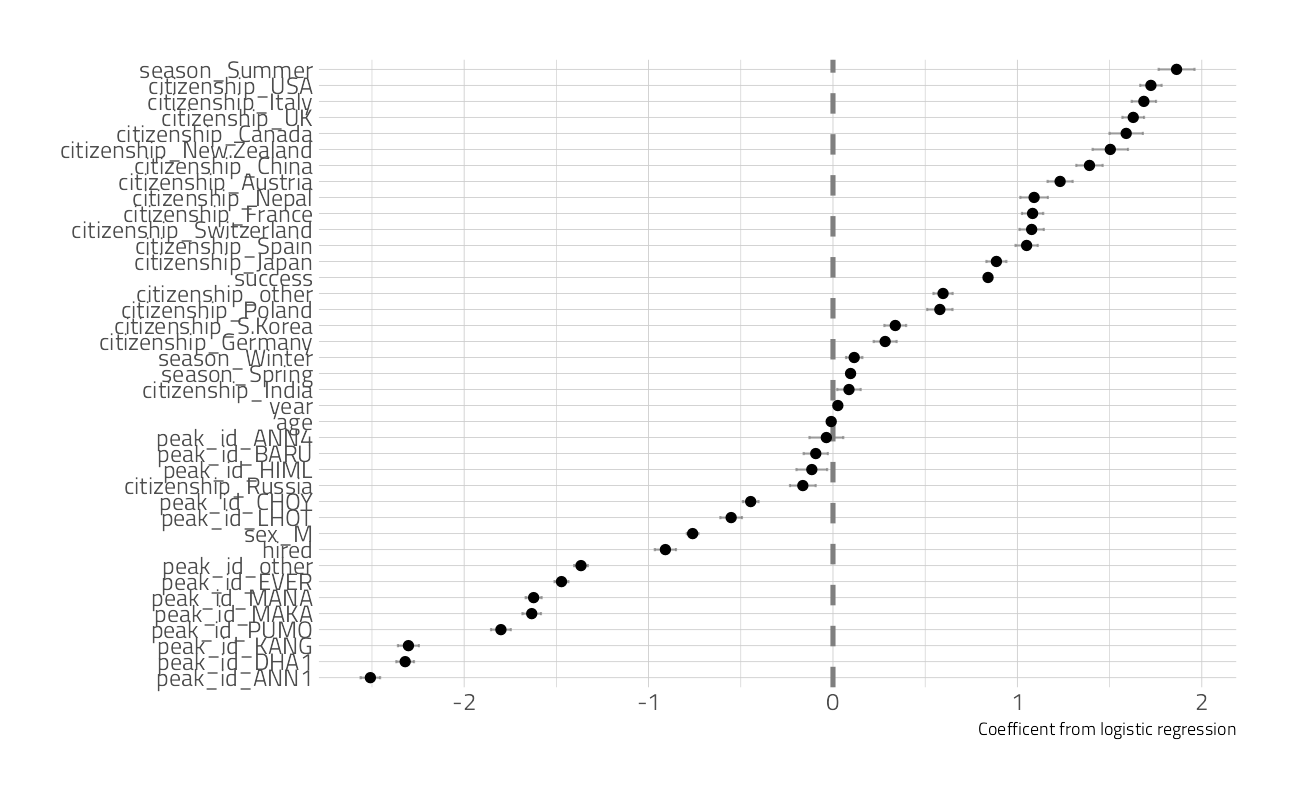
The features with coefficients on the positive side (like climbing in summer, being on a successful expedition, or being from the UK or US) are associated with surviving.
The features with coefficients on the negative side (like climbing specific peaks including Everest, being one of the hired members of a expedition, or being a man) are associated with dying.
Remember that we have to interpret model coefficients like this in light of the predictive accuracy of our model, which was somewhat middling; there are more factors at play in who survives these expeditions than what we have accounted for in the model directly. Also note that we see evidence in this model for how dangerous it is to be a native Sherpa climber in Nepal, hired as an expedition member.
sessionInfo()R version 4.1.1 (2021-08-10)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19043)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252
[2] LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ranger_0.13.1 vctrs_0.3.8 rlang_0.4.11 themis_0.1.4
[5] yardstick_0.0.8 workflowsets_0.1.0 workflows_0.2.3 tune_0.1.6
[9] rsample_0.1.0 recipes_0.1.16 parsnip_0.1.7.900 modeldata_0.1.1
[13] infer_1.0.0 dials_0.0.9.9000 scales_1.1.1 broom_0.7.9
[17] tidymodels_0.1.3 gt_0.3.1 ebbr_0.1 forcats_0.5.1
[21] stringr_1.4.0 dplyr_1.0.7 purrr_0.3.4 readr_2.0.1
[25] tidyr_1.1.3 tibble_3.1.4 ggplot2_3.3.5 tidyverse_1.3.1
[29] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] utf8_1.2.2 R.utils_2.10.1 tidyselect_1.1.1
[4] grid_4.1.1 pROC_1.18.0 munsell_0.5.0
[7] codetools_0.2-18 ragg_1.1.3 future_1.22.1
[10] withr_2.4.2 colorspace_2.0-2 highr_0.9
[13] knitr_1.34 rstudioapi_0.13 stats4_4.1.1
[16] Rttf2pt1_1.3.9 listenv_0.8.0 labeling_0.4.2
[19] git2r_0.28.0 bit64_4.0.5 DiceDesign_1.9
[22] farver_2.1.0 rprojroot_2.0.2 mlr_2.19.0
[25] parallelly_1.28.1 generics_0.1.0 ipred_0.9-11
[28] xfun_0.25 R6_2.5.1 markdown_1.1
[31] doParallel_1.0.16 VGAM_1.1-5 lhs_1.1.3
[34] cachem_1.0.6 assertthat_0.2.1 promises_1.2.0.1
[37] vroom_1.5.4 nnet_7.3-16 gtable_0.3.0
[40] globals_0.14.0 timeDate_3043.102 BBmisc_1.11
[43] systemfonts_1.0.2 splines_4.1.1 extrafontdb_1.0
[46] lazyeval_0.2.2 selectr_0.4-2 prismatic_1.0.0
[49] checkmate_2.0.0 yaml_2.2.1 modelr_0.1.8
[52] backports_1.2.1 httpuv_1.6.2 gridtext_0.1.4
[55] extrafont_0.17 tools_4.1.1 lava_1.6.10
[58] usethis_2.0.1 ellipsis_0.3.2 jquerylib_0.1.4
[61] Rcpp_1.0.7 plyr_1.8.6 parallelMap_1.5.1
[64] rpart_4.1-15 ParamHelpers_1.14 viridis_0.6.1
[67] haven_2.4.3 hrbrthemes_0.8.0 fs_1.5.0
[70] here_1.0.1 furrr_0.2.3 unbalanced_2.0
[73] magrittr_2.0.1 data.table_1.14.0 reprex_2.0.1
[76] RANN_2.6.1 GPfit_1.0-8 whisker_0.4
[79] ROSE_0.0-4 R.cache_0.15.0 hms_1.1.0
[82] evaluate_0.14 readxl_1.3.1 gridExtra_2.3
[85] compiler_4.1.1 crayon_1.4.1 R.oo_1.24.0
[88] htmltools_0.5.2 later_1.3.0 tzdb_0.1.2
[91] ggtext_0.1.1 lubridate_1.7.10 DBI_1.1.1
[94] dbplyr_2.1.1 MASS_7.3-54 Matrix_1.3-4
[97] cli_3.0.1 R.methodsS3_1.8.1 parallel_4.1.1
[100] gower_0.2.2 pkgconfig_2.0.3 xml2_1.3.2
[103] foreach_1.5.1 bslib_0.3.0 hardhat_0.1.6
[106] tidytuesdayR_1.0.1 prodlim_2019.11.13 rvest_1.0.1
[109] digest_0.6.27 rmarkdown_2.10 cellranger_1.1.0
[112] fastmatch_1.1-3 gdtools_0.2.3 curl_4.3.2
[115] lifecycle_1.0.0 jsonlite_1.7.2 viridisLite_0.4.0
[118] fansi_0.5.0 pillar_1.6.2 lattice_0.20-44
[121] fastmap_1.1.0 httr_1.4.2 survival_3.2-11
[124] glue_1.4.2 conflicted_1.0.4 FNN_1.1.3
[127] iterators_1.0.13 bit_4.0.4 class_7.3-19
[130] stringi_1.7.4 sass_0.4.0 rematch2_2.1.2
[133] textshaping_0.3.5 styler_1.5.1 future.apply_1.8.1