Transcript level analysis of mouse mammary gland RNA-seq data
Pedro Baldoni
06 January, 2023
Last updated: 2023-01-06
Checks: 5 2
Knit directory: wf-TranscriptDE/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of
the R Markdown file created these results, you’ll want to first commit
it to the Git repo. If you’re still working on the analysis, you can
ignore this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20221115) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
- dte_sleuth-lrt
- dte_sleuth-wald
- dte_swish
To ensure reproducibility of the results, delete the cache directory
mouse_cache and re-run the analysis. To have workflowr
automatically delete the cache directory prior to building the file, set
delete_cache = TRUE when running wflow_build()
or wflow_publish().
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 79576da. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/figure/
Ignored: analysis/mouse_cache/
Ignored: analysis/simulation-complete_cache/
Ignored: analysis/simulation-paper_cache/
Ignored: code/pkg/.Rhistory
Ignored: code/pkg/.Rproj.user/
Ignored: code/pkg/src/RcppExports.o
Ignored: code/pkg/src/pkg.so
Ignored: code/pkg/src/rcpparma_hello_world.o
Ignored: data/annotation/mm39/
Ignored: output/mouse/paired-end/
Ignored: output/mouse/single-end/
Ignored: output/simulation/
Ignored: renv/
Untracked files:
Untracked: code/mouse/single-end/
Untracked: data/mouse/paired-end/
Untracked: data/mouse/single-end/
Untracked: misc/
Unstaged changes:
Modified: .gitignore
Modified: analysis/mouse.Rmd
Modified: analysis/simulation-complete.Rmd
Modified: analysis/simulation-paper.Rmd
Deleted: data/mouse/misc/targets.txt
Modified: data/mouse/readme.txt
Modified: output/mouse/readme.txt
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/mouse.Rmd) and HTML
(docs/mouse.html) files. If you’ve configured a remote Git
repository (see ?wflow_git_remote), click on the hyperlinks
in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 481735c | Pedro Baldoni | 2022-11-24 | Build update from workflowr |
| Rmd | 3e9c510 | Pedro Baldoni | 2022-11-22 | Adding mouse report |
| html | 5ee1116 | Pedro Baldoni | 2022-11-22 | Updating docs |
Introduction
Setup
knitr::opts_chunk$set(
dev = "png",
dpi = 300,
dev.args = list(type = "cairo-png"),
root.dir = '.'
)library(edgeR)Loading required package: limmalibrary(data.table)
library(ggplot2)
library(readr)
library(Rsubread)
library(rtracklayer)Loading required package: GenomicRangesLoading required package: stats4Loading required package: BiocGenerics
Attaching package: 'BiocGenerics'The following object is masked from 'package:limma':
plotMAThe following objects are masked from 'package:stats':
IQR, mad, sd, var, xtabsThe following objects are masked from 'package:base':
anyDuplicated, aperm, append, as.data.frame, basename, cbind,
colnames, dirname, do.call, duplicated, eval, evalq, Filter, Find,
get, grep, grepl, intersect, is.unsorted, lapply, Map, mapply,
match, mget, order, paste, pmax, pmax.int, pmin, pmin.int,
Position, rank, rbind, Reduce, rownames, sapply, setdiff, sort,
table, tapply, union, unique, unsplit, which.max, which.minLoading required package: S4Vectors
Attaching package: 'S4Vectors'The following objects are masked from 'package:data.table':
first, secondThe following objects are masked from 'package:base':
expand.grid, I, unnameLoading required package: IRanges
Attaching package: 'IRanges'The following object is masked from 'package:data.table':
shiftLoading required package: GenomeInfoDblibrary(magrittr)
Attaching package: 'magrittr'The following object is masked from 'package:GenomicRanges':
subtractlibrary(ggpubr)
library(plyr)
Attaching package: 'plyr'The following object is masked from 'package:ggpubr':
mutateThe following object is masked from 'package:IRanges':
descThe following object is masked from 'package:S4Vectors':
renamelibrary(gplots)
Attaching package: 'gplots'The following object is masked from 'package:rtracklayer':
spaceThe following object is masked from 'package:IRanges':
spaceThe following object is masked from 'package:S4Vectors':
spaceThe following object is masked from 'package:stats':
lowesslibrary(grid)
library(ComplexHeatmap)========================================
ComplexHeatmap version 2.14.0
Bioconductor page: http://bioconductor.org/packages/ComplexHeatmap/
Github page: https://github.com/jokergoo/ComplexHeatmap
Documentation: http://jokergoo.github.io/ComplexHeatmap-reference
If you use it in published research, please cite either one:
- Gu, Z. Complex Heatmap Visualization. iMeta 2022.
- Gu, Z. Complex heatmaps reveal patterns and correlations in multidimensional
genomic data. Bioinformatics 2016.
The new InteractiveComplexHeatmap package can directly export static
complex heatmaps into an interactive Shiny app with zero effort. Have a try!
This message can be suppressed by:
suppressPackageStartupMessages(library(ComplexHeatmap))
========================================library(patchwork)
library(tibble)
library(tidyHeatmap)========================================
tidyHeatmap version 1.7.0
If you use tidyHeatmap in published research, please cite:
1) Mangiola et al. tidyHeatmap: an R package for modular heatmap production
based on tidy principles. JOSS 2020.
2) Gu, Z. Complex heatmaps reveal patterns and correlations in multidimensional
genomic data. Bioinformatics 2016.
This message can be suppressed by:
suppressPackageStartupMessages(library(tidyHeatmap))
========================================
Attaching package: 'tidyHeatmap'The following object is masked from 'package:stats':
heatmaplibrary(AnnotationHub)Loading required package: BiocFileCacheLoading required package: dbplyr
Attaching package: 'AnnotationHub'The following object is masked from 'package:rtracklayer':
hubUrllibrary(sleuth)
library(fishpond)
library(tximeta)
library(tidyverse)── Attaching packages
───────────────────────────────────────
tidyverse 1.3.2 ──✔ tidyr 1.2.1 ✔ stringr 1.4.1
✔ purrr 0.3.5 ✔ forcats 0.5.2
✔ dplyr 1.0.10
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::arrange() masks plyr::arrange()
✖ dplyr::between() masks data.table::between()
✖ dplyr::collapse() masks IRanges::collapse()
✖ dplyr::combine() masks BiocGenerics::combine()
✖ purrr::compact() masks plyr::compact()
✖ dplyr::count() masks plyr::count()
✖ dplyr::desc() masks plyr::desc(), IRanges::desc()
✖ tidyr::expand() masks S4Vectors::expand()
✖ tidyr::extract() masks magrittr::extract()
✖ dplyr::failwith() masks plyr::failwith()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::first() masks S4Vectors::first(), data.table::first()
✖ dplyr::id() masks plyr::id()
✖ dplyr::ident() masks dbplyr::ident()
✖ dplyr::lag() masks stats::lag()
✖ dplyr::last() masks data.table::last()
✖ dplyr::mutate() masks plyr::mutate(), ggpubr::mutate()
✖ BiocGenerics::Position() masks ggplot2::Position(), base::Position()
✖ purrr::reduce() masks GenomicRanges::reduce(), IRanges::reduce()
✖ dplyr::rename() masks plyr::rename(), S4Vectors::rename()
✖ purrr::set_names() masks magrittr::set_names()
✖ dplyr::slice() masks IRanges::slice()
✖ dplyr::sql() masks dbplyr::sql()
✖ magrittr::subtract() masks GenomicRanges::subtract()
✖ dplyr::summarise() masks plyr::summarise()
✖ dplyr::summarize() masks plyr::summarize()
✖ purrr::transpose() masks data.table::transpose()library(SummarizedExperiment)Loading required package: MatrixGenerics
Loading required package: matrixStats
Attaching package: 'matrixStats'
The following object is masked from 'package:dplyr':
count
The following object is masked from 'package:plyr':
count
Attaching package: 'MatrixGenerics'
The following objects are masked from 'package:matrixStats':
colAlls, colAnyNAs, colAnys, colAvgsPerRowSet, colCollapse,
colCounts, colCummaxs, colCummins, colCumprods, colCumsums,
colDiffs, colIQRDiffs, colIQRs, colLogSumExps, colMadDiffs,
colMads, colMaxs, colMeans2, colMedians, colMins, colOrderStats,
colProds, colQuantiles, colRanges, colRanks, colSdDiffs, colSds,
colSums2, colTabulates, colVarDiffs, colVars, colWeightedMads,
colWeightedMeans, colWeightedMedians, colWeightedSds,
colWeightedVars, rowAlls, rowAnyNAs, rowAnys, rowAvgsPerColSet,
rowCollapse, rowCounts, rowCummaxs, rowCummins, rowCumprods,
rowCumsums, rowDiffs, rowIQRDiffs, rowIQRs, rowLogSumExps,
rowMadDiffs, rowMads, rowMaxs, rowMeans2, rowMedians, rowMins,
rowOrderStats, rowProds, rowQuantiles, rowRanges, rowRanks,
rowSdDiffs, rowSds, rowSums2, rowTabulates, rowVarDiffs, rowVars,
rowWeightedMads, rowWeightedMeans, rowWeightedMedians,
rowWeightedSds, rowWeightedVars
Loading required package: Biobase
Welcome to Bioconductor
Vignettes contain introductory material; view with
'browseVignettes()'. To cite Bioconductor, see
'citation("Biobase")', and for packages 'citation("pkgname")'.
Attaching package: 'Biobase'
The following object is masked from 'package:MatrixGenerics':
rowMedians
The following objects are masked from 'package:matrixStats':
anyMissing, rowMedians
The following object is masked from 'package:AnnotationHub':
cachelibrary(stringr)
library(kableExtra)
Attaching package: 'kableExtra'
The following object is masked from 'package:dplyr':
group_rowsah <- AnnotationHub()snapshotDate(): 2022-10-31edb <- ah[['AH95775']] # This annotation corresponds to Ensembl 104 (release M27)loading from cacherequire("ensembldb")ensid <- keys(edb)
cols <- c("TXIDVERSION","TXEXTERNALNAME","TXBIOTYPE","GENEIDVERSION",
"GENENAME","GENEBIOTYPE","ENTREZID")
dt.anno <- select(edb,ensid,cols)
dt.anno <- as.data.table(dt.anno)
dt.anno.gene <- dt.anno[,.(NTranscriptPerGene = .N),by = c('GENEIDVERSION','GENEBIOTYPE','ENTREZID','GENENAME')]
dt.anno.gene[,GeneOfInterest := GENEBIOTYPE %in% c('protein_coding','lncRNA')]
dt.anno <- merge(dt.anno,dt.anno.gene[,-c(2,3,4)],by = 'GENEIDVERSION',all.x = TRUE)Analysis of paired-end data
Transcript-level analysis
Data wrangling
path.data <- '../data/mouse/paired-end'
path.anno <- '../data/annotation/mm39'
path.quant <- '../output/mouse/paired-end'dt.targets <- fread(file.path(path.data,'misc/targets.txt'))
dt.targets[,Sample := paste(Group,Replicate,sep = '.')]
dt.targets[,Color := mapvalues(Group,
from = c('Basal','LP','ML'),
to = c('blue','darkgreen','red'))]
setnames(dt.targets,old = 'Group',new = 'group')
dt.targets[,path := file.path(path.quant,'salmon',gsub('_R1.fastq.gz','',File1))]catch <- catchSalmon(dt.targets$path,verbose = FALSE)
key.catch.anno <- match(rownames(catch$annotation),dt.anno$TXIDVERSION)
catch$annotation$TranscriptName <- dt.anno$TXEXTERNALNAME[key.catch.anno]
catch$annotation$GeneID <- dt.anno$GENEIDVERSION[key.catch.anno]
catch$annotation$GeneName <- dt.anno$GENENAME[key.catch.anno]
catch$annotation$GeneEntrezID <- dt.anno$ENTREZID[key.catch.anno]
catch$annotation$GeneOfInterest <- dt.anno$GeneOfInterest[key.catch.anno]
catch$annotation$NTranscriptPerGene <- dt.anno$NTranscriptPerGene[key.catch.anno]
catch$annotation$Type <- dt.anno$TXBIOTYPE[key.catch.anno]Differential transcript expression between basal and LP populations
edgeR with count scaling
dte.scaled <- DGEList(counts = catch$counts/catch$annotation$Overdispersion,
genes = catch$annotation,
samples = dt.targets)
colnames(dte.scaled) <- dte.scaled$samples$Samplekeep.scaled <-
filterByExpr(dte.scaled) & dte.scaled$genes$GeneOfInterest
dte.scaled.filtr <- dte.scaled[keep.scaled,, keep.lib.sizes = FALSE]design <- model.matrix(~0+group,data = dte.scaled.filtr$samples)
dte.scaled.filtr <- calcNormFactors(dte.scaled.filtr)
dte.scaled.filtr <- estimateDisp(dte.scaled.filtr,design,robust = TRUE)fit.scaled <- glmQLFit(dte.scaled.filtr,design,robust = TRUE)
con.LPvsB <- makeContrasts(LPvsB = groupLP - groupBasal,levels = design)
con.MLvsLP <- makeContrasts(MLvsLP = groupML - groupLP,levels = design)
qlf.LPvsB.scaled <- glmQLFTest(fit.scaled,contrast = con.LPvsB)
qlf.MLvsLP.scaled <- glmQLFTest(fit.scaled,contrast = con.MLvsLP)
out.LPvsB.scaled <- topTags(qlf.LPvsB.scaled,n = Inf)
out.MLvsLP.scaled <- topTags(qlf.MLvsLP.scaled,n = Inf)
summary(decideTests(qlf.LPvsB.scaled)) -1*groupBasal 1*groupLP
Down 9002
NotSig 26192
Up 8382summary(decideTests(qlf.MLvsLP.scaled)) -1*groupLP 1*groupML
Down 2422
NotSig 38639
Up 2515edgeR with raw counts
dte.raw <- DGEList(counts = catch$counts,
genes = catch$annotation,
samples = dt.targets)
colnames(dte.raw) <- dte.raw$samples$Samplekeep.raw <-
filterByExpr(dte.raw) & dte.raw$genes$GeneOfInterest
dte.raw.filtr <- dte.raw[keep.raw,, keep.lib.sizes = FALSE]dte.raw.filtr <- calcNormFactors(dte.raw.filtr)
dte.raw.filtr <- estimateDisp(dte.raw.filtr,design,robust = TRUE)fit.raw <- glmQLFit(dte.raw.filtr,design,robust = TRUE)
con.LPvsB <- makeContrasts(LPvsB = groupLP - groupBasal,levels = design)
qlf.LPvsB.raw <- glmQLFTest(fit.raw,contrast = con.LPvsB)
out.LPvsB.raw <- topTags(qlf.LPvsB.raw,n = Inf)
summary(decideTests(qlf.LPvsB.raw)) -1*groupBasal 1*groupLP
Down 8216
NotSig 40699
Up 7322sleuth-LRT
dt.targets.sleuth <- dt.targets[group %in% c('Basal','LP'),]
setnames(dt.targets.sleuth,old = 'Sample',new = 'sample')
se.sleuth.lrt <-
sleuth_prep(sample_to_covariates = dt.targets.sleuth,full_model = ~ group)Warning in check_num_cores(num_cores): It appears that you are running Sleuth from within Rstudio.
Because of concerns with forking processes from a GUI, 'num_cores' is being set to 1.
If you wish to take advantage of multiple cores, please consider running sleuth from the command line.reading in kallisto resultsdropping unused factor levels......
normalizing est_counts
58890 targets passed the filter
normalizing tpm
merging in metadata
summarizing bootstraps
......se.sleuth.lrt <- sleuth_fit(obj = se.sleuth.lrt, fit_name = 'full')fitting measurement error models
shrinkage estimation
1 NA values were found during variance shrinkage estimation due to mean observation values outside of the range used for the LOESS fit.
The LOESS fit will be repeated using exact computation of the fitted surface to extrapolate the missing values.
These are the target ids with NA values: ENSMUST00000042235.15
computing variance of betasse.sleuth.lrt <-
sleuth_fit(obj = se.sleuth.lrt,formula = ~ 1,fit_name = 'reduced')fitting measurement error models
shrinkage estimation
1 NA values were found during variance shrinkage estimation due to mean observation values outside of the range used for the LOESS fit.
The LOESS fit will be repeated using exact computation of the fitted surface to extrapolate the missing values.
These are the target ids with NA values: ENSMUST00000230860.2
computing variance of betasse.sleuth.lrt <-
sleuth_lrt(obj = se.sleuth.lrt,null_model = 'reduced',alt_model = 'full')
out.sleuth.lrt <-
sleuth_results(obj = se.sleuth.lrt, test = 'reduced:full', test_type = 'lrt',
show_all = FALSE)
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
sleuth-Wald
se.sleuth.wald <-
sleuth_prep(sample_to_covariates = dt.targets.sleuth,full_model = ~ group)Warning in check_num_cores(num_cores): It appears that you are running Sleuth from within Rstudio.
Because of concerns with forking processes from a GUI, 'num_cores' is being set to 1.
If you wish to take advantage of multiple cores, please consider running sleuth from the command line.reading in kallisto resultsdropping unused factor levels......
normalizing est_counts
58890 targets passed the filter
normalizing tpm
merging in metadata
summarizing bootstraps
......se.sleuth.wald <- sleuth_fit(obj = se.sleuth.wald, fit_name = 'full')fitting measurement error models
shrinkage estimation
1 NA values were found during variance shrinkage estimation due to mean observation values outside of the range used for the LOESS fit.
The LOESS fit will be repeated using exact computation of the fitted surface to extrapolate the missing values.
These are the target ids with NA values: ENSMUST00000042235.15
computing variance of betasse.sleuth.wald <-
sleuth_wt(obj = se.sleuth.wald,which_beta = 'groupLP',which_model = 'full')
out.sleuth.wald <-
sleuth_results(obj = se.sleuth.wald, test = 'groupLP', test_type = 'wald',
show_all = FALSE)
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Swish
dt.targets.swish <- dt.targets[group %in% c('Basal','LP'),]
dt.targets.swish[,files := file.path(path,'quant.sf')]
dt.targets.swish$group %<>% factor(levels = c('Basal','LP'))
setnames(dt.targets.swish,old = 'Sample',new = 'names')
se.swish <- tximeta(coldata = dt.targets.swish,type = 'salmon')importing quantificationsreading in files with read_tsv1 2 3 4 5 6
found matching transcriptome:
[ GENCODE - Mus musculus - release M27 ]
loading existing TxDb created: 2022-04-05 23:03:51
loading existing transcript ranges created: 2022-04-05 23:03:52
fetching genome info for GENCODEWarning in valid.GenomicRanges.seqinfo(x, suggest.trim = TRUE): GRanges object contains 87 out-of-bound ranges located on sequences
chr4, chr8, chr13, chr14, and chr17. Note that ranges located on a
sequence whose length is unknown (NA) or on a circular sequence are not
considered out-of-bound (use seqlengths() and isCircular() to get the
lengths and circularity flags of the underlying sequences). You can use
trim() to trim these ranges. See ?`trim,GenomicRanges-method` for more
information.se.swish <- scaleInfReps(se.swish)
se.swish <- labelKeep(se.swish)
se.swish <- se.swish[mcols(se.swish)$keep,]
se.swish <- swish(y = se.swish, x = "group")
out.swish <- as.data.frame(mcols(se.swish))
Warning: The above code chunk cached its results, but
it won’t be re-run if previous chunks it depends on are updated. If you
need to use caching, it is highly recommended to also set
knitr::opts_chunk$set(autodep = TRUE) at the top of the
file (in a chunk that is not cached). Alternatively, you can customize
the option dependson for each individual chunk that is
cached. Using either autodep or dependson will
remove this warning. See the
knitr cache options for more details.
Gene-level analysis
# Function computing catchSalmon's formula for gene-level counts
# To be used only for exploratory purposes
geneLevelCatchSalmon <- function(x) {
NSamples <- ncol(x)
NBoot <- sum(grepl('infRep', assayNames(x)))
NTx <- nrow(x)
DF <- rep_len(0L, NTx)
OverDisp <- rep_len(0, NTx)
for (i.samples in 1:NSamples) {
Boot <- lapply(1:NBoot, function(i.boot) {
assay(x, paste0('infRep', i.boot))[, i.samples]
})
Boot <- do.call(cbind, Boot)
M <- rowMeans(Boot)
i <- (M > 0)
OverDisp[i] <- OverDisp[i] + rowSums((Boot[i,] - M[i]) ^ 2) / M[i]
DF[i] <- DF[i] + NBoot - 1L
}
i <- (DF > 0L)
OverDisp[i] <- OverDisp[i] / DF[i]
DFMedian <- median(DF[i])
DFPrior <- 3
OverDispPrior <-
median(OverDisp[i]) / qf(0.5, df1 = DFMedian, df2 = DFPrior)
if (OverDispPrior < 1) {
OverDispPrior <- 1
}
OverDisp[i] <-
(DFPrior * OverDispPrior + DF[i] * OverDisp[i]) / (DFPrior + DF[i])
OverDisp <- pmax(OverDisp, 1)
OverDisp[!i] <- OverDispPrior
rowData(x)$Overdispersion <- OverDisp
return(x)
}dt.targets.tximeta <- dt.targets
dt.targets.tximeta[,files := file.path(path,'quant.sf')]
dt.targets.tximeta$group %<>% factor(levels = c('Basal','LP','ML'))
setnames(dt.targets.tximeta,old = 'Sample',new = 'names')
txm <- tximeta(coldata = dt.targets.tximeta[,c('files','names')])importing quantificationsreading in files with read_tsv1 2 3 4 5 6 7 8 9
found matching transcriptome:
[ GENCODE - Mus musculus - release M27 ]
loading existing TxDb created: 2022-04-05 23:03:51
loading existing transcript ranges created: 2022-04-05 23:03:52
fetching genome info for GENCODEWarning in valid.GenomicRanges.seqinfo(x, suggest.trim = TRUE): GRanges object contains 87 out-of-bound ranges located on sequences
chr4, chr8, chr13, chr14, and chr17. Note that ranges located on a
sequence whose length is unknown (NA) or on a circular sequence are not
considered out-of-bound (use seqlengths() and isCircular() to get the
lengths and circularity flags of the underlying sequences). You can use
trim() to trim these ranges. See ?`trim,GenomicRanges-method` for more
information.se.gene <- summarizeToGene(txm)loading existing TxDb created: 2022-04-05 23:03:51
obtaining transcript-to-gene mapping from database
loading existing gene ranges created: 2022-06-02 01:59:12Warning in valid.GenomicRanges.seqinfo(x, suggest.trim = TRUE): GRanges object contains 46 out-of-bound ranges located on sequences
chr14, chr8, chr17, chr4, and chr13. Note that ranges located on a
sequence whose length is unknown (NA) or on a circular sequence are not
considered out-of-bound (use seqlengths() and isCircular() to get the
lengths and circularity flags of the underlying sequences). You can use
trim() to trim these ranges. See ?`trim,GenomicRanges-method` for more
information.summarizing abundance
summarizing counts
summarizing length
summarizing inferential replicatesse.gene <- geneLevelCatchSalmon(se.gene)
dge <- DGEList(counts = assay(se.gene,'counts'),
samples = dt.targets.tximeta,
genes = as.data.frame(rowData(se.gene)))
key.dge.anno.gene <- match(rownames(dge),dt.anno.gene$GENEIDVERSION)
dge$genes$GeneOfInterest <- dt.anno.gene$GeneOfInterest[key.dge.anno.gene]
dge$genes$NTranscriptPerGene <- dt.anno.gene$NTranscriptPerGene[key.dge.anno.gene]
dge$genes$GeneEntrezID <- dt.anno.gene$ENTREZID[key.dge.anno.gene]
dge$genes$GeneName <- dt.anno.gene$GENENAME[key.dge.anno.gene]
dge$genes$GeneType <- dt.anno.gene$GENEBIOTYPE[key.dge.anno.gene]
keep <- filterByExpr(dge) & dge$genes$GeneOfInterest
dge.filtr <- dge[keep, , keep.lib.sizes = FALSE]
dge.filtr <- calcNormFactors(dge.filtr)
design.dge <- model.matrix(~0+group,data = dge.filtr$samples)
dge.filtr <-
estimateDisp(dge.filtr, design = design.dge, robust = TRUE)
con.LPvsB.dge <-
makeContrasts(LPvsBasal = groupLP - groupBasal,levels = design.dge)
con.MLvsLP.dge <-
makeContrasts(MLvsLP = groupML - groupLP,levels = design.dge)
fit.filtr <- glmQLFit(dge.filtr,design.dge, robust = TRUE)
qlf.LPvsBasal.filtr <- glmQLFTest(fit.filtr,contrast = con.LPvsB.dge)
out.LPvsBasal <- topTags(qlf.LPvsBasal.filtr,n = Inf)
qlf.MLvsLP.filtr <- glmQLFTest(fit.filtr,contrast = con.MLvsLP.dge)
out.MLvsLP <- topTags(qlf.MLvsLP.filtr,n = Inf) Plots and other exploratory analyses
# Foxp1-216
out.LPvsB.scaled$table['ENSMUST00000175838.2',] Length EffectiveLength Overdispersion TranscriptName
ENSMUST00000175838.2 420 163.755 1.111807 Foxp1-216
GeneID GeneName GeneEntrezID GeneOfInterest
ENSMUST00000175838.2 ENSMUSG00000030067.18 Foxp1 108655 TRUE
NTranscriptPerGene Type logFC
ENSMUST00000175838.2 31 processed_transcript 1.806999
logCPM F PValue FDR
ENSMUST00000175838.2 -0.5914241 14.03927 0.002188547 0.008318195dt.mao.plot <- as.data.table(dte.scaled.filtr$genes)
dt.mao.plot[,NTranscriptPerGeneTrunc := ifelse(NTranscriptPerGene<10,NTranscriptPerGene,paste0('>=10'))]
dt.mao.plot$NTranscriptPerGeneTrunc %<>% factor(levels = paste0(c(1:10,'>=10')))
dt.mao.plot[,.(sum(NTranscriptPerGene == 1),
sum(NTranscriptPerGene == 1 & Overdispersion>2)/sum(NTranscriptPerGene == 1))] V1 V2
1: 2967 0.03943377dt.mao.plot[,.(sum(NTranscriptPerGene > 1),
sum(NTranscriptPerGene > 1 & Overdispersion>2)/sum(NTranscriptPerGene > 1))] V1 V2
1: 40609 0.4484966dt.mao.plot[NTranscriptPerGene >=10,.(.N,mean(Overdispersion))] N V2
1: 12558 5.315015plot.mao.2 <-
ggplot(data = dt.mao.plot,aes(x = NTranscriptPerGeneTrunc,y = log10(Overdispersion))) +
geom_boxplot(fill = 'gray',outlier.alpha = 0.2) +
geom_smooth(aes(group = 1),color = 'red',se = FALSE,span = 0.8,method = 'loess') +
labs(x = 'Number of expressed transcripts per gene', y = 'Overdispersion (log10 scale)') +
scale_y_continuous(limits = c(0,3),breaks = seq(0,3,0.5)) +
theme_bw() +
theme(panel.grid = element_blank())
plot.mao.2`geom_smooth()` using formula = 'y ~ x'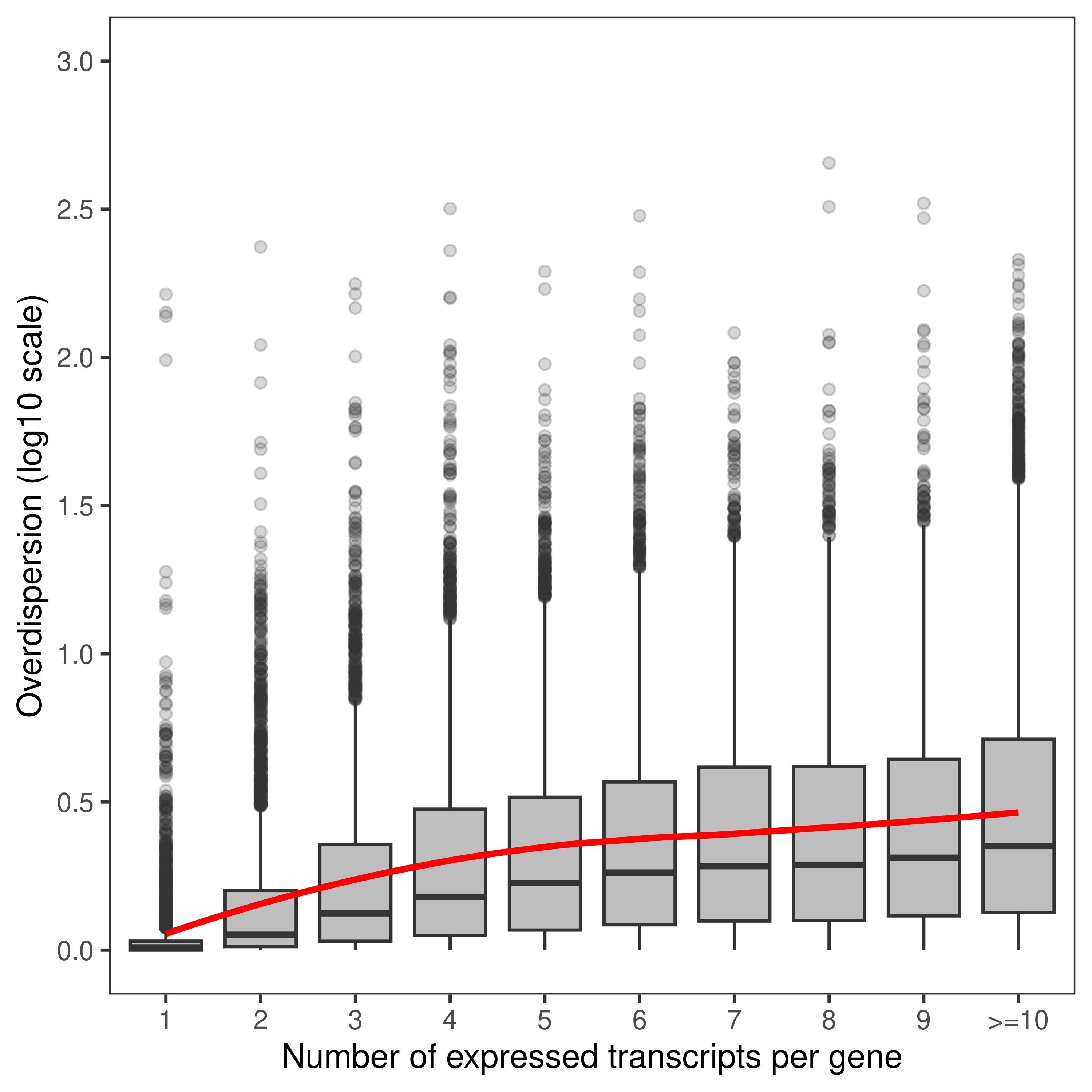
| Version | Author | Date |
|---|---|---|
| 5dcd60b | Pedro Baldoni | 2023-01-04 |
# Heatmap of Foxp1 transcripts
cpm.scaled.filtr <- cpm(dte.scaled.filtr,log = TRUE)
rownames(cpm.scaled.filtr) <- dte.scaled.filtr$genes$TranscriptName
cpm.scaled.filtr.LPvsBasal <-
cpm.scaled.filtr[,grepl('Basal|LP',colnames(cpm.scaled.filtr))]
cpm.scaled.filtr.LPvsBasal <- t(scale(t(cpm.scaled.filtr.LPvsBasal)))
cpm.scaled.filtr.LPvsBasal.foxp1 <-
cpm.scaled.filtr.LPvsBasal[grepl('foxp1',rownames(cpm.scaled.filtr.LPvsBasal),ignore.case = TRUE),]
foo.heat <- function(x,cluster_rows = TRUE,fontsize = 10){
tb <- data.table(TranscriptName = rownames(x),x)
tb <- melt(tb,id.vars = 'TranscriptName',value.name = 'Expression')
tb <- as_tibble(tb)
tb %>%
heatmap(.row = TranscriptName,.column = variable,.value = Expression,
scale = 'none',palette_value = c("blue", "white", "red"),
column_title = NULL,row_title = NULL,
cluster_rows = cluster_rows,
row_names_gp = gpar(fontsize = fontsize),
column_names_gp = gpar(fontsize = fontsize),
clustering_method_rows = "complete",
clustering_method_columns = "complete",
heatmap_legend_param = list(at = seq(-3,3,1),
direction = "horizontal")) %>%
as_ComplexHeatmap() %>%
draw(heatmap_legend_side = "top")
}
plot.heat <-
wrap_elements(grid.grabExpr(draw(foo.heat(cpm.scaled.filtr.LPvsBasal.foxp1))))tidyHeatmap says: (once per session) from release 1.7.0 the scaling is set to "none" by default. Please use scale = "row", "column" or "both" to apply scaling# Heatmap of significant transcripts of non-significant breast cancer genes
tb.LPvsB.scaled <- as.data.table(out.LPvsB.scaled$table)
tb.LPvsBasal <- as.data.table(out.LPvsBasal$table)
tb.LPvsB.scaled$FDR.Gene <-
tb.LPvsBasal$FDR[match(tb.LPvsB.scaled$GeneID,tb.LPvsBasal$gene_id)]
tb.LPvsB.scaled$logFC.Gene <-
tb.LPvsBasal$logFC[match(tb.LPvsB.scaled$GeneID,tb.LPvsBasal$gene_id)]
interestGenes <-
tb.LPvsB.scaled[FDR.Gene > 0.05 &
FDR < 0.05 &
!is.na(GeneEntrezID),unique(GeneEntrezID)]
length(interestGenes)[1] 1818tb.kegga <- kegga(interestGenes,species = 'Mm')
tb.kegga['path:mmu05224',] Pathway N DE P.DE
path:mmu05224 Breast cancer 147 15 0.2535296GK <- getGeneKEGGLinks(species.KEGG = "mmu")
interestGenes.breast <-
interestGenes[interestGenes %in% GK$GeneID[GK$PathwayID == 'path:mmu05224']]
tb.LPvsB.scaled.breast <-
tb.LPvsB.scaled[tb.LPvsB.scaled$GeneEntrezID %in% interestGenes.breast,]
tb.LPvsB.scaled.breast <-
tb.LPvsB.scaled.breast[tb.LPvsB.scaled.breast$FDR<0.05,]
cpm.scaled.filtr.LPvsBasal.breast <-
cpm.scaled.filtr.LPvsBasal[tb.LPvsB.scaled.breast$TranscriptName,]
plot.heat.breast <-
wrap_elements(grid.grabExpr(draw(foo.heat(cpm.scaled.filtr.LPvsBasal.breast))))
# plotMD does not return invisible(), so we just use wrap_elements
foo.md <- function(){
par(mar = c(5, 4, 2, 2))
plotMD(qlf.LPvsB.scaled,xlim = c(-2.5,17.5),
main = NULL,cex = 0.5,legend = FALSE)
legend('topright',
legend = c('NotSig','Up','Down'),
pch = rep(16,3),
col = c('black','red','blue'),
cex = 0.75,
pt.cex = c(0.3,0.5,0.5))
}
plot.md <-
wrap_elements(full = ~foo.md())
# plotMDS returns invisible(), we need to manually export the plot (code from limma::plotMDS.MDS)
obj.mds <- plotMDS(dte.scaled.filtr,col = dte.scaled.filtr$samples$Color,main = NULL)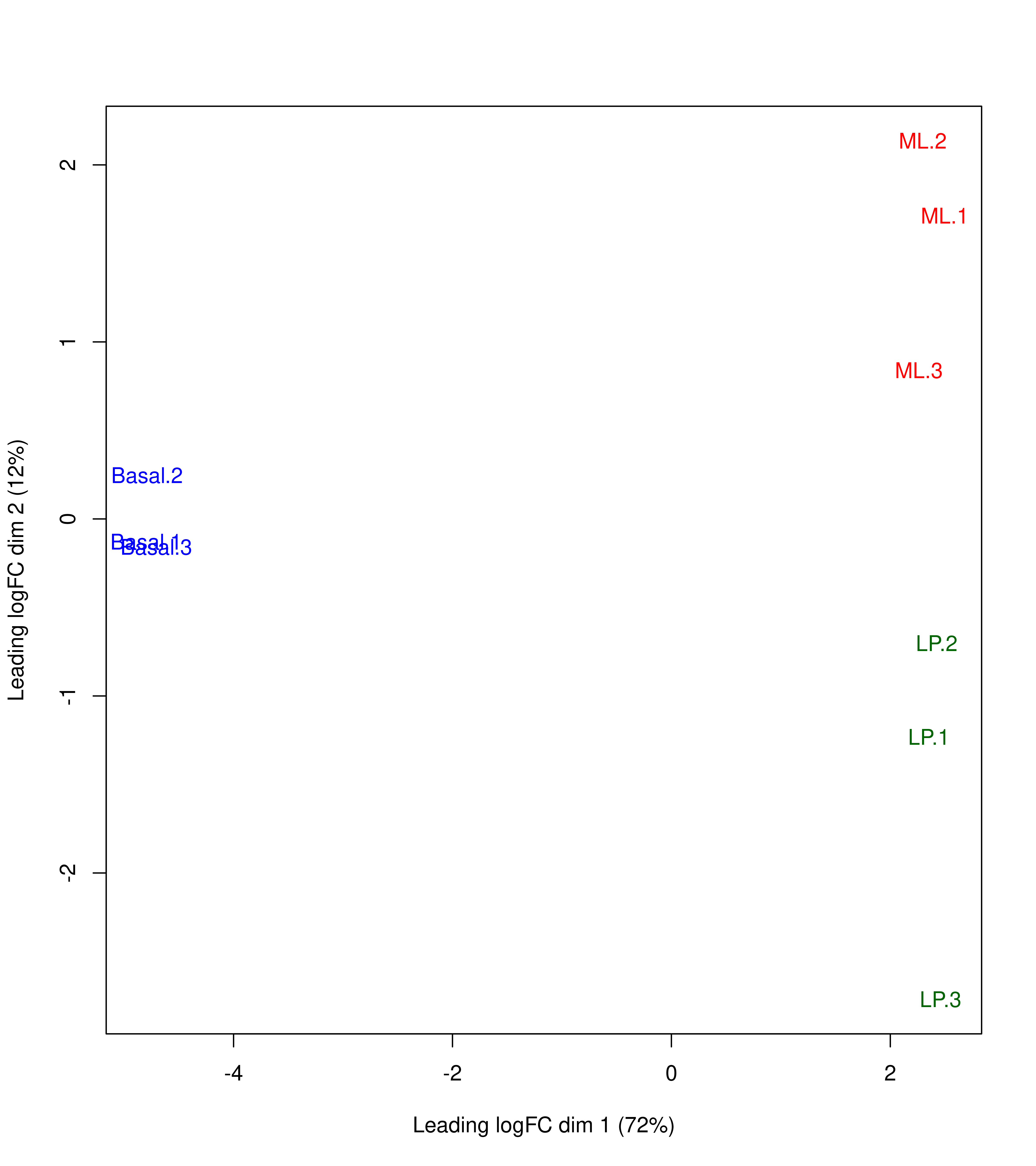
| Version | Author | Date |
|---|---|---|
| 5dcd60b | Pedro Baldoni | 2023-01-04 |
foo.mds <- function(){
par(mar = c(5, 4, 2, 2))
labels <- colnames(obj.mds$distance.matrix.squared)
StringRadius <- 0.15 * 1 * nchar(labels)
left.x <- obj.mds$x - StringRadius
right.x <- obj.mds$x + StringRadius
Perc <- round(obj.mds$var.explained * 100)
xlab <- paste(obj.mds$axislabel, 1)
ylab <- paste(obj.mds$axislabel, 2)
xlab <- paste0(xlab, " (", Perc[1], "%)")
ylab <- paste0(ylab, " (", Perc[2], "%)")
plot(c(-6, 3), c(-3, 3),
#c(left.x, right.x), c(obj.mds$y, obj.mds$y),
type = "n",xlab = xlab,ylab = ylab)
text(obj.mds$x, obj.mds$y, labels = labels, cex = 1,col = dte.scaled.filtr$samples$Color)
}
plot.mds <- wrap_elements(full = ~foo.mds())
plot.design <- c(area(1, 1),area(1,2),area(2, 1),area(2,2))
wrap_plots(A = plot.mds,
B = plot.md,
C = plot.heat,
D = plot.heat.breast,
design = plot.design,
heights = c(0.35,0.65)) +
plot_annotation(tag_levels = 'a',tag_prefix = '(',tag_suffix = ')') 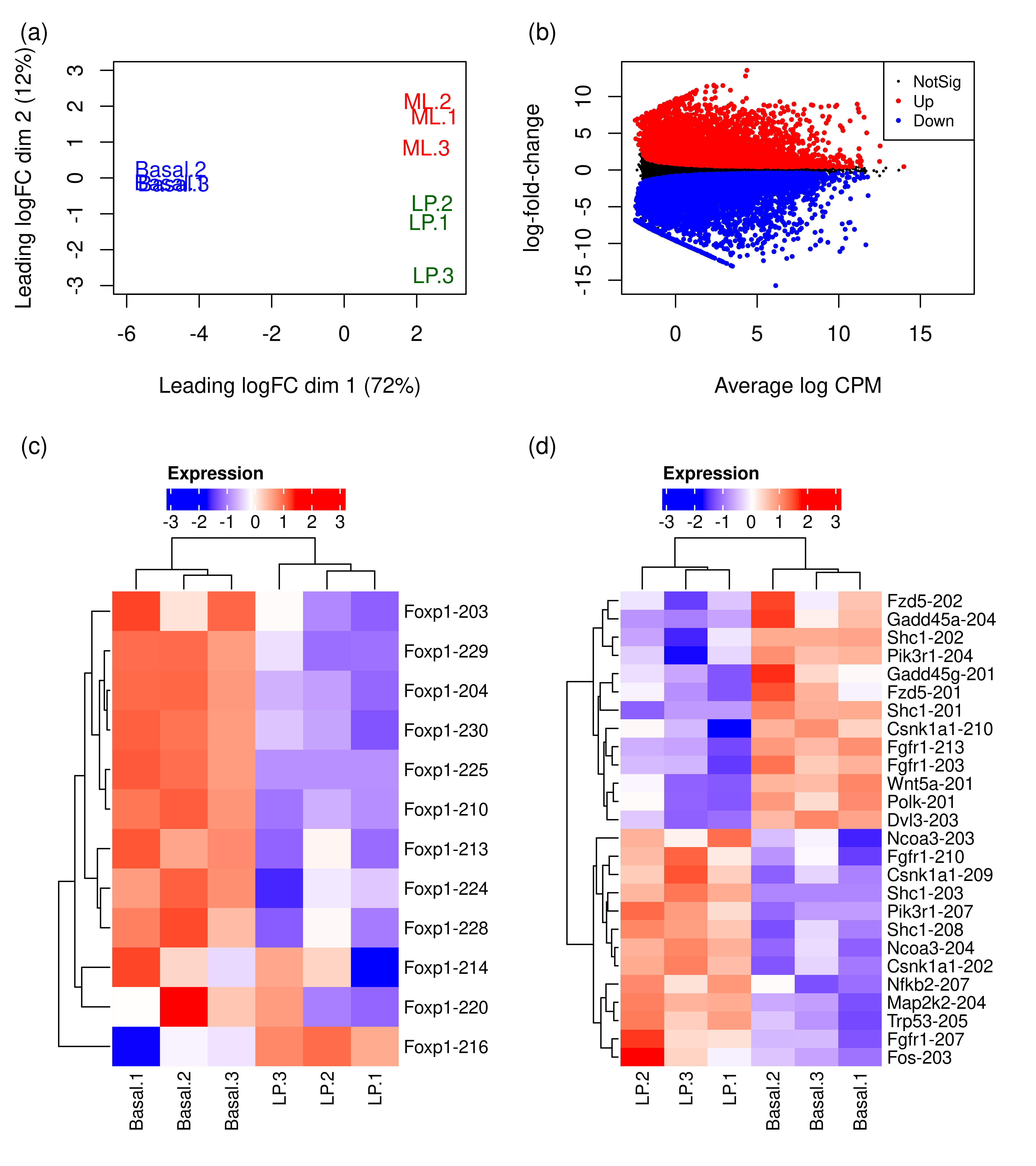
| Version | Author | Date |
|---|---|---|
| 5dcd60b | Pedro Baldoni | 2023-01-04 |
kb <- out.LPvsBasal[grepl('ENSMUSG00000030067',out.LPvsBasal$table$gene_id),]$table
kb <- data.frame(kb[,-c(2,3,4,5)],row.names = NULL)
setnames(kb,
old = c('gene_id','GeneEntrezID'),
new = c('Ensembl ID','Entrez ID'))
kb$GeneType <- gsub("_"," ",kb$GeneType)
kb <- kbl(kb,
escape = FALSE,
format = 'latex',
booktabs = TRUE,
caption = 'Results from gene-level DE analysis for the Foxp1 gene with edgeR via count scaling comparing basal and LP cells (NCBI Gene Expression Omnibus accession number GSEXXXXX)',
align = c('l',rep('r',6))) %>%
kable_styling(latex_options = "scale_down")
save_kable(kb,file = "../misc/mouse_foxp1_gene.tex")## Gene-level
df.output.gene <- as.data.table(dge$genes[,c('GeneName','GeneEntrezID','GeneType','Overdispersion')])
setnames(df.output.gene,
old = c('GeneName','GeneEntrezID','GeneType','Overdispersion'),
new = c('Symbol','EntrezID','Type','Overdispersion'))
df.output.gene[,Level := 'Gene']
## Transcript-level
df.output.tx <- data.table(Symbol = catch$annotation$TranscriptName,
EntrezID = catch$annotation$GeneEntrezID,
Type = catch$annotation$Type,
Overdispersion = catch$annotation$Overdispersion,
Level = 'Transcript')
df.output <- rbindlist(list(df.output.gene,
df.output.tx))
fig.dge.mao <- ggplot(df.output,aes(x = log10(Overdispersion),y = Level,fill = Level)) +
geom_boxplot(outlier.alpha = 0.5) +
scale_fill_brewer(palette = 'Set1') +
labs(y = NULL,x = 'Mapping ambiguity overdispersion (log10 scale)') +
theme_bw() +
theme(legend.position = 'none')
fig.dge.mao
df.output.gene.top <- df.output.gene[order(-Overdispersion),][1:20,]
df.output.gene.top[,Level := NULL]
df.output.gene.top$Type <-
gsub("_"," ",df.output.gene.top$Type)
df.output.gene.top$EntrezID[is.na(df.output.gene.top$EntrezID)] <-
"-"
cap <- paste("Top 20 genes with largest mapping ambiguity overdispersion.",
"Here, mapping ambiguity overdispersion at the gene-level was",
"estimated with bootstrap counts summarized to the gene-wise",
"counts computed with the function summarizeToGene from the",
"tximport package. The majority of such genes are classified as",
"gene models or pseudo-genes, and exhibit high levels of overlap",
"with other annotated genes. Data from the mouse mammary gland",
"epithelial cell population experiment generated with paired-end",
"reads (NCBI Gene Expression Omnibus accession number GSEXXXXX).")
kb <- kbl(df.output.gene.top,
escape = FALSE,
format = 'latex',
booktabs = TRUE,
caption = cap,
digits = 2,
align = c('l',rep('r',3)),
col.names = c('Gene Symbol','Entrez ID','Biotype','Overdispersion')) %>%
kable_styling(latex_options = "scale_down")
save_kable(kb,file = "../misc/mouse_top_genes.tex")Analysis of single-end data
Transcript-level analysis
Data wrangling
path.data.se <- '../data/mouse/single-end'
path.quant.se <- '../output/mouse/single-end'dt.targets.se <- fread(file.path(path.data.se,'misc/targets.txt'))
dt.targets.se[,Sample := paste(Group,Replicate,sep = '.')]
dt.targets.se[,Population := mapvalues(Population,'Luminal','LP')]
dt.targets.se$Stage <- strsplit2(dt.targets.se$Group,"\\.")[,2]
dt.targets.se$Group <- NULL
dt.targets.se[,Color := mapvalues(Population,
from = c('Basal','LP'),
to = c('blue','darkgreen'))]
dt.targets.se[,path := file.path(path.quant.se,'salmon',gsub('.fastq.gz','',File))]catch.se <- catchSalmon(dt.targets.se$path,verbose = FALSE)
key.catch.se.anno <- match(rownames(catch.se$annotation),dt.anno$TXIDVERSION)
catch.se$annotation$TranscriptName <- dt.anno$TXEXTERNALNAME[key.catch.se.anno]
catch.se$annotation$GeneID <- dt.anno$GENEIDVERSION[key.catch.se.anno]
catch.se$annotation$GeneName <- dt.anno$GENENAME[key.catch.se.anno]
catch.se$annotation$GeneEntrezID <- dt.anno$ENTREZID[key.catch.se.anno]
catch.se$annotation$GeneOfInterest <- dt.anno$GeneOfInterest[key.catch.se.anno]
catch.se$annotation$NTranscriptPerGene <- dt.anno$NTranscriptPerGene[key.catch.se.anno]Differential transcript expression between basal and LP populations
edgeR with count scaling
dte.se.scaled <- DGEList(counts = catch.se$counts/catch.se$annotation$Overdispersion,
genes = catch.se$annotation,
samples = dt.targets.se)
colnames(dte.se.scaled) <- dte.se.scaled$samples$Samplekeep.se.scaled <-
filterByExpr(dte.se.scaled,group = dte.se.scaled$samples$Population) &
dte.se.scaled$genes$GeneOfInterest
dte.se.scaled.filtr <- dte.se.scaled[keep.se.scaled,, keep.lib.sizes = FALSE]design.se <- model.matrix(~Stage + Population,data = dte.se.scaled.filtr$samples)
dte.se.scaled.filtr <- calcNormFactors(dte.se.scaled.filtr)
dte.se.scaled.filtr <- estimateDisp(dte.se.scaled.filtr,design.se,robust = TRUE)fit.se.scaled <- glmQLFit(dte.se.scaled.filtr,design.se,robust = TRUE)
qlf.se.LPvsB.scaled <- glmQLFTest(fit.se.scaled)
out.se.LPvsB.scaled <- topTags(qlf.se.LPvsB.scaled,n = Inf)
summary(decideTests(qlf.se.LPvsB.scaled)) PopulationLP
Down 7895
NotSig 9895
Up 6921edgeR with raw counts
dte.se.raw <-
DGEList(counts = catch.se$counts,
genes = catch.se$annotation,
samples = dt.targets.se)
colnames(dte.se.raw) <- dte.se.raw$samples$Samplekeep.se.raw <-
filterByExpr(dte.se.raw,group = dte.se.raw$samples$Population) &
dte.se.raw$genes$GeneOfInterest
dte.se.raw.filtr <- dte.se.raw[keep.se.raw,,keep.lib.sizes = FALSE]dte.se.raw.filtr <- calcNormFactors(dte.se.raw.filtr)
dte.se.raw.filtr <- estimateDisp(dte.se.raw.filtr,design.se,robust = TRUE)fit.se.raw <- glmQLFit(dte.se.raw.filtr,design.se,robust = TRUE)
qlf.se.LPvsB.raw <- glmQLFTest(fit.se.raw)
out.se.LPvsB.raw <- topTags(qlf.se.LPvsB.raw,n = Inf)
summary(decideTests(qlf.se.LPvsB.raw)) PopulationLP
Down 8659
NotSig 21789
Up 6929Plots and other exploratory analyses
plotMD(qlf.se.LPvsB.scaled,main = NULL)
# Foxp1 transcripts (EntrezID 108655)
out.se.LPvsB.scaled$table[out.se.LPvsB.scaled$table$GeneEntrezID %in% '108655',] Length EffectiveLength Overdispersion TranscriptName
ENSMUST00000177227.8 967 717 1.871821 Foxp1-224
ENSMUST00000177437.8 2468 2218 5.880765 Foxp1-230
ENSMUST00000113322.9 7177 6927 14.765060 Foxp1-204
ENSMUST00000177229.8 1848 1598 30.837225 Foxp1-225
ENSMUST00000177307.8 2121 1871 12.186063 Foxp1-228
GeneID GeneName GeneEntrezID GeneOfInterest
ENSMUST00000177227.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000177437.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000113322.9 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000177229.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000177307.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
NTranscriptPerGene logFC logCPM F
ENSMUST00000177227.8 31 -3.014221 0.6298492 136.33621
ENSMUST00000177437.8 31 -2.475768 2.5825100 92.30263
ENSMUST00000113322.9 31 -2.703752 2.5325759 79.71248
ENSMUST00000177229.8 31 -4.554117 -0.7874704 68.27378
ENSMUST00000177307.8 31 -1.756318 -0.1121722 13.86188
PValue FDR
ENSMUST00000177227.8 8.014176e-08 1.412541e-06
ENSMUST00000177437.8 6.483437e-07 6.896062e-06
ENSMUST00000113322.9 1.394285e-06 1.269498e-05
ENSMUST00000177229.8 3.085925e-06 2.385992e-05
ENSMUST00000177307.8 3.008508e-03 6.963119e-03out.se.LPvsB.raw$table[out.se.LPvsB.raw$table$GeneEntrezID %in% '108655',] Length EffectiveLength Overdispersion TranscriptName
ENSMUST00000177227.8 967 717 1.871821 Foxp1-224
ENSMUST00000124058.8 1213 963 4.075548 Foxp1-210
ENSMUST00000177437.8 2468 2218 5.880765 Foxp1-230
ENSMUST00000113322.9 7177 6927 14.765060 Foxp1-204
ENSMUST00000177229.8 1848 1598 30.837225 Foxp1-225
ENSMUST00000113326.9 7029 6779 153.195592 Foxp1-206
ENSMUST00000176565.8 3727 3477 23.742224 Foxp1-220
ENSMUST00000177307.8 2121 1871 12.186063 Foxp1-228
GeneID GeneName GeneEntrezID GeneOfInterest
ENSMUST00000177227.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000124058.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000177437.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000113322.9 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000177229.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000113326.9 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000176565.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
ENSMUST00000177307.8 ENSMUSG00000030067.18 Foxp1 108655 TRUE
NTranscriptPerGene logFC logCPM F
ENSMUST00000177227.8 31 -3.213702 0.6403438 81.362703
ENSMUST00000124058.8 31 -6.522550 -0.1418186 74.459703
ENSMUST00000177437.8 31 -2.596572 4.2931573 73.376381
ENSMUST00000113322.9 31 -2.920534 5.5645277 63.534522
ENSMUST00000177229.8 31 -6.697337 2.9158442 21.558158
ENSMUST00000113326.9 31 -7.212378 2.1561872 20.217520
ENSMUST00000176565.8 31 -3.195532 1.2426544 10.122064
ENSMUST00000177307.8 31 -2.596993 2.4348401 5.705185
PValue FDR
ENSMUST00000177227.8 4.037266e-06 8.099887e-05
ENSMUST00000124058.8 6.043586e-06 1.064018e-04
ENSMUST00000177437.8 7.343061e-06 1.213914e-04
ENSMUST00000113322.9 1.371310e-05 1.853723e-04
ENSMUST00000177229.8 9.674814e-04 4.391203e-03
ENSMUST00000113326.9 1.208199e-03 5.221279e-03
ENSMUST00000176565.8 1.003522e-02 2.790614e-02
ENSMUST00000177307.8 3.852069e-02 8.181077e-02
sessionInfo()R version 4.2.1 (2022-06-23)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: CentOS Linux 7 (Core)
Matrix products: default
BLAS: /stornext/System/data/apps/R/R-4.2.1/lib64/R/lib/libRblas.so
LAPACK: /stornext/System/data/apps/R/R-4.2.1/lib64/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] ensembldb_2.22.0 AnnotationFilter_1.22.0
[3] GenomicFeatures_1.50.2 AnnotationDbi_1.60.0
[5] kableExtra_1.3.4 SummarizedExperiment_1.28.0
[7] Biobase_2.58.0 MatrixGenerics_1.10.0
[9] matrixStats_0.63.0 forcats_0.5.2
[11] stringr_1.4.1 dplyr_1.0.10
[13] purrr_0.3.5 tidyr_1.2.1
[15] tidyverse_1.3.2 tximeta_1.16.0
[17] fishpond_2.4.0 sleuth_0.30.0
[19] AnnotationHub_3.6.0 BiocFileCache_2.6.0
[21] dbplyr_2.2.1 tidyHeatmap_1.7.0
[23] tibble_3.1.8 patchwork_1.1.2
[25] ComplexHeatmap_2.14.0 gplots_3.1.3
[27] plyr_1.8.8 ggpubr_0.5.0
[29] magrittr_2.0.3 rtracklayer_1.58.0
[31] GenomicRanges_1.50.1 GenomeInfoDb_1.34.3
[33] IRanges_2.32.0 S4Vectors_0.36.0
[35] BiocGenerics_0.44.0 Rsubread_2.12.0
[37] readr_2.1.3 ggplot2_3.4.0
[39] data.table_1.14.6 edgeR_3.40.0
[41] limma_3.54.0 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] utf8_1.2.2 tidyselect_1.2.0
[3] RSQLite_2.2.19 BiocParallel_1.32.3
[5] munsell_0.5.0 ragg_1.2.4
[7] codetools_0.2-18 statmod_1.4.37
[9] withr_2.5.0 colorspace_2.0-3
[11] filelock_1.0.2 highr_0.9
[13] knitr_1.41 rstudioapi_0.14
[15] SingleCellExperiment_1.20.0 ggsignif_0.6.4
[17] labeling_0.4.2 git2r_0.30.1
[19] tximport_1.26.0 GenomeInfoDbData_1.2.9
[21] farver_2.1.1 bit64_4.0.5
[23] rhdf5_2.42.0 rprojroot_2.0.3
[25] vctrs_0.5.1 generics_0.1.3
[27] xfun_0.35 timechange_0.1.1
[29] R6_2.5.1 doParallel_1.0.17
[31] clue_0.3-63 locfit_1.5-9.6
[33] gridGraphics_0.5-1 bitops_1.0-7
[35] rhdf5filters_1.10.0 cachem_1.0.6
[37] DelayedArray_0.24.0 assertthat_0.2.1
[39] vroom_1.6.0 promises_1.2.0.1
[41] BiocIO_1.8.0 scales_1.2.1
[43] googlesheets4_1.0.1 gtable_0.3.1
[45] Cairo_1.6-0 processx_3.8.0
[47] rlang_1.0.6 systemfonts_1.0.4
[49] splines_4.2.1 GlobalOptions_0.1.2
[51] rstatix_0.7.1 lazyeval_0.2.2
[53] gargle_1.2.1 broom_1.0.1
[55] modelr_0.1.10 BiocManager_1.30.19
[57] yaml_2.3.6 abind_1.4-5
[59] backports_1.4.1 httpuv_1.6.6
[61] tools_4.2.1 ellipsis_0.3.2
[63] jquerylib_0.1.4 RColorBrewer_1.1-3
[65] Rcpp_1.0.9 progress_1.2.2
[67] zlibbioc_1.44.0 RCurl_1.98-1.9
[69] ps_1.7.2 prettyunits_1.1.1
[71] GetoptLong_1.0.5 viridis_0.6.2
[73] haven_2.5.1 cluster_2.1.4
[75] fs_1.5.2 svMisc_1.2.3
[77] circlize_0.4.15 reprex_2.0.2
[79] googledrive_2.0.0 whisker_0.4
[81] ProtGenerics_1.30.0 hms_1.1.2
[83] mime_0.12 evaluate_0.18
[85] xtable_1.8-4 XML_3.99-0.12
[87] readxl_1.4.1 gridExtra_2.3
[89] shape_1.4.6 compiler_4.2.1
[91] biomaRt_2.54.0 KernSmooth_2.23-20
[93] crayon_1.5.2 htmltools_0.5.3
[95] mgcv_1.8-41 later_1.3.0
[97] tzdb_0.3.0 lubridate_1.9.0
[99] DBI_1.1.3 rappdirs_0.3.3
[101] Matrix_1.5-3 car_3.1-1
[103] cli_3.4.1 parallel_4.2.1
[105] pkgconfig_2.0.3 getPass_0.2-2
[107] GenomicAlignments_1.34.0 xml2_1.3.3
[109] foreach_1.5.2 svglite_2.1.0
[111] bslib_0.4.1 webshot_0.5.4
[113] XVector_0.38.0 rvest_1.0.3
[115] callr_3.7.3 digest_0.6.30
[117] Biostrings_2.66.0 cellranger_1.1.0
[119] rmarkdown_2.18 dendextend_1.16.0
[121] restfulr_0.0.15 curl_4.3.3
[123] shiny_1.7.3 Rsamtools_2.14.0
[125] gtools_3.9.3 rjson_0.2.21
[127] nlme_3.1-160 lifecycle_1.0.3
[129] jsonlite_1.8.3 Rhdf5lib_1.20.0
[131] carData_3.0-5 viridisLite_0.4.1
[133] fansi_1.0.3 pillar_1.8.1
[135] lattice_0.20-45 KEGGREST_1.38.0
[137] fastmap_1.1.0 httr_1.4.4
[139] interactiveDisplayBase_1.36.0 glue_1.6.2
[141] png_0.1-7 iterators_1.0.14
[143] BiocVersion_3.16.0 bit_4.0.5
[145] stringi_1.7.8 sass_0.4.4
[147] blob_1.2.3 textshaping_0.3.6
[149] caTools_1.18.2 memoise_2.0.1