Test retest for pilot in SICNU
Liang Zhang
2022-03-15
Last updated: 2022-03-16
Checks: 7 0
Knit directory: cogstruct/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20220104) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version cb367ff. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: _targets.yaml
Ignored: analysis/_targets.yaml
Ignored: bnu/_targets/
Ignored: bnu/archived/
Ignored: bnu/diagnose.Rmd
Ignored: bnu/images/
Ignored: figure/
Ignored: sicnu_pilot/_targets/
Untracked files:
Untracked: bnu/TOL.Rmd
Untracked: bnu/TOL.html
Untracked: bnu/TOL_files/
Untracked: bnu/config/CharFreq.txt
Untracked: bnu/config/characters.xlsx
Untracked: bnu/config/outlier_criterion.csv
Untracked: bnu/difficulty.xlsx
Untracked: bnu/difficulty_digit_reasoning.xlsx
Untracked: bnu/items.xlsx
Untracked: bnu/items_new_score.xlsx
Untracked: code/explore_structure.Rmd
Untracked: code/extract_reliability.R
Untracked: code/extract_reliability_sicnu_pilot.R
Untracked: code/reliability.xlsx
Untracked: code/reliability_simple.xlsx
Untracked: config/selected_indices.xlsx
Untracked: output/prob_rl.tsv
Untracked: output/reliability.xlsx
Untracked: output/reliability_simple.xlsx
Untracked: sicnu/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/test_checking_sicnu_pilot.Rmd) and HTML
(docs/test_checking_sicnu_pilot.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | c640c6e | Liang Zhang | 2022-03-15 | Build site. |
| Rmd | 9b6ae7e | Liang Zhang | 2022-03-15 | wflow_publish("analysis/*.Rmd") |
tar_load(indices_clean)
tests_included <- deframe(distinct(indices_clean, game_name_abbr, game_name))render_content <- function(file, ...) {
knitr::knit(
text = knitr::knit_expand(file, ...),
quiet = TRUE
)
}
purrr::imap_chr(
tests_included,
~ render_content(
file = here::here("archetypes/child_check_index.Rmd"),
game_name_abbr = .x,
game_name = .y
)
) |>
str_c(collapse = "\n\n") |>
cat()舒尔特方格(中级)
data <- indices_clean |>
filter(
game_name_abbr == "SchulteMed",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: SchulteMed
- Sample Size: 46
- Index Names:
- nc_cor
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()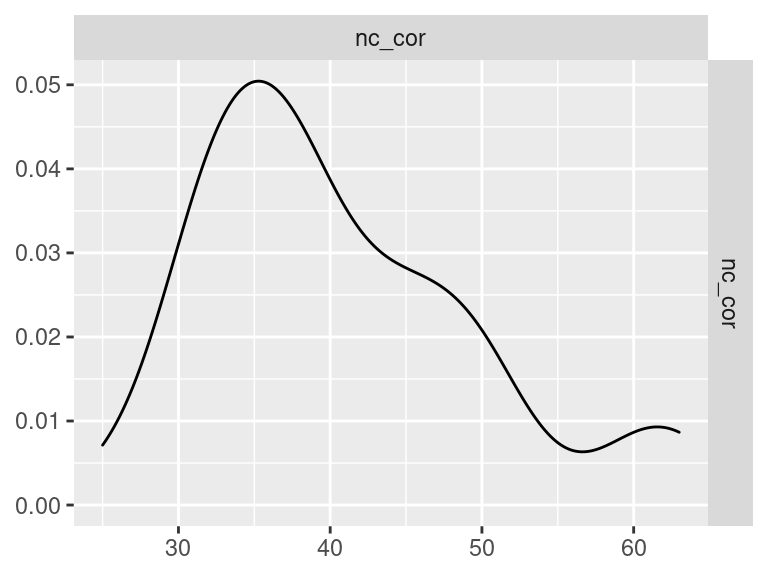
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
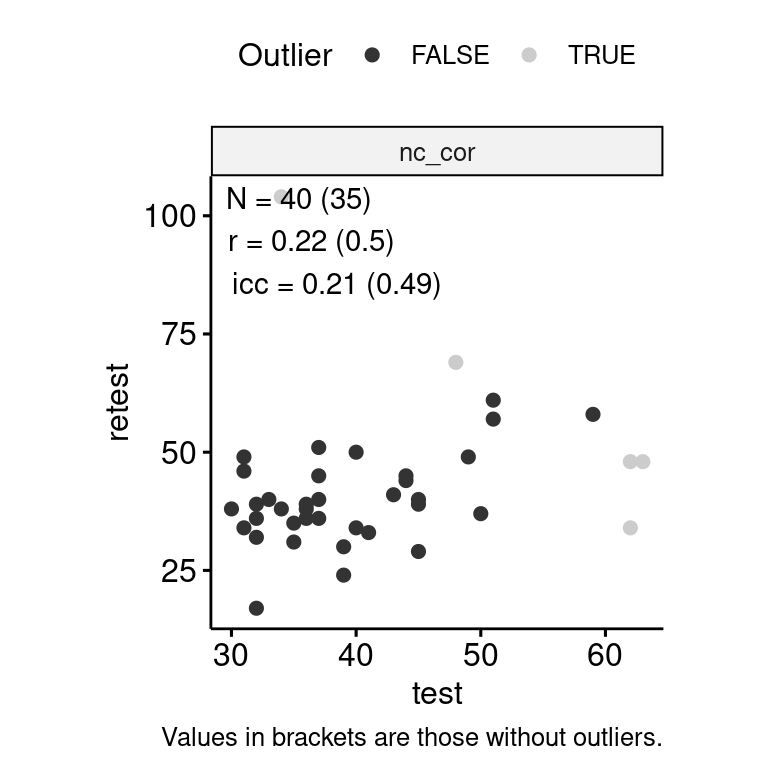
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
我是大厨
data <- indices_clean |>
filter(
game_name_abbr == "MSynWin",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: MSynWin
- Sample Size: 46
- Index Names:
- score_total
- score_aud
- score_mem
- score_vis
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()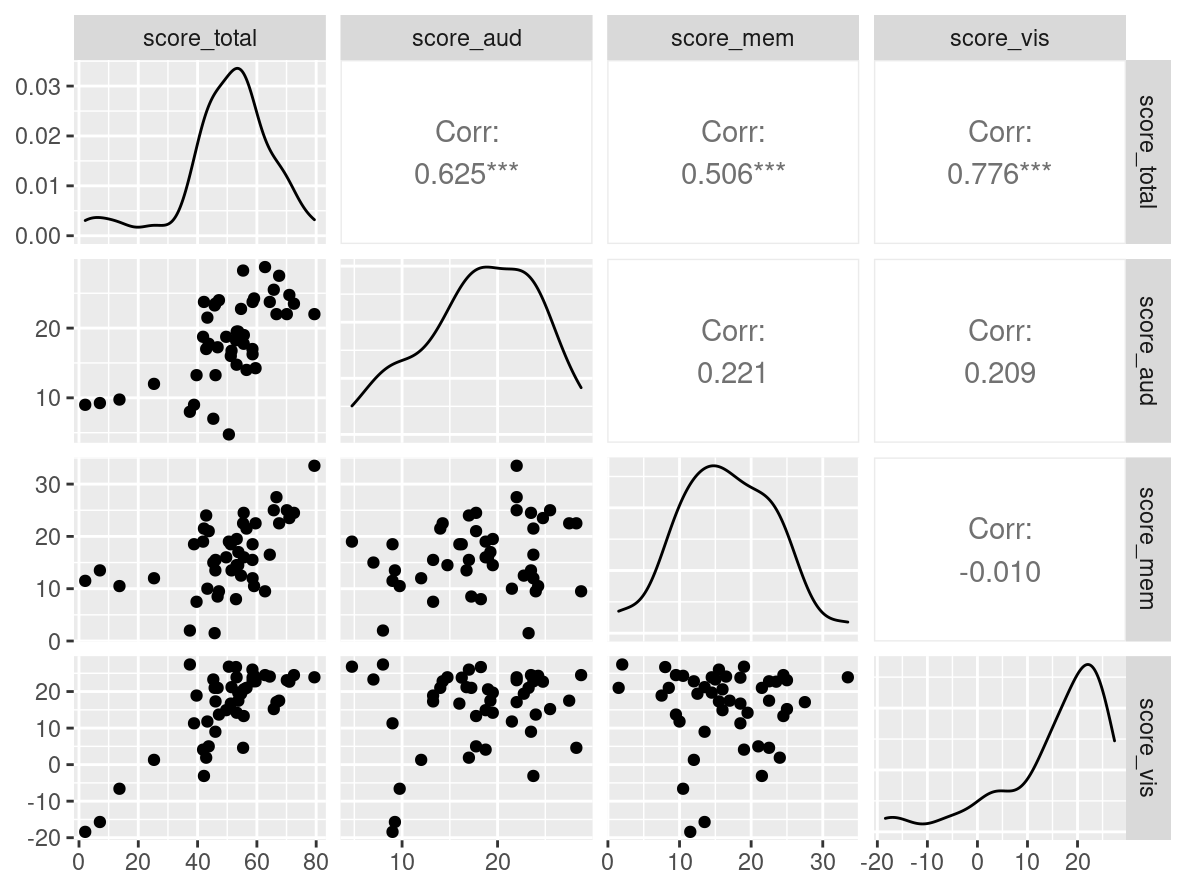
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
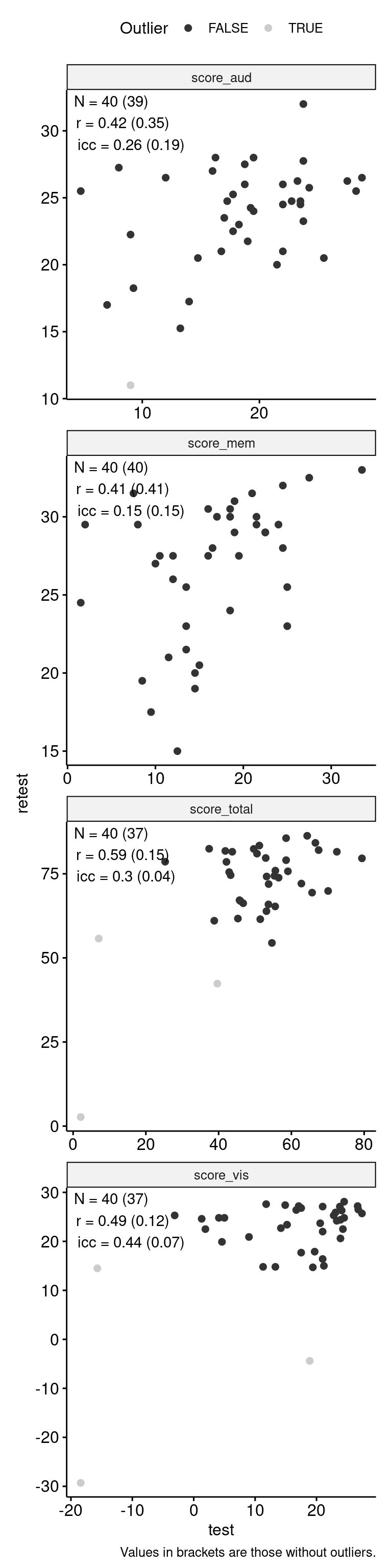
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
宇宙黑洞
data <- indices_clean |>
filter(
game_name_abbr == "LocMemStd",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
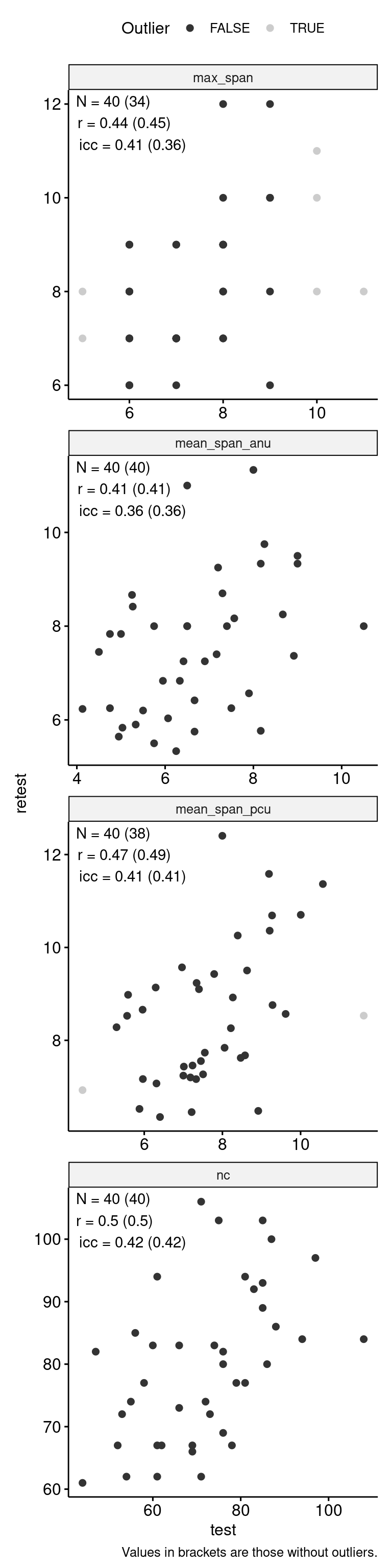
- Abbreviation: LocMemStd
- Sample Size: 46
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()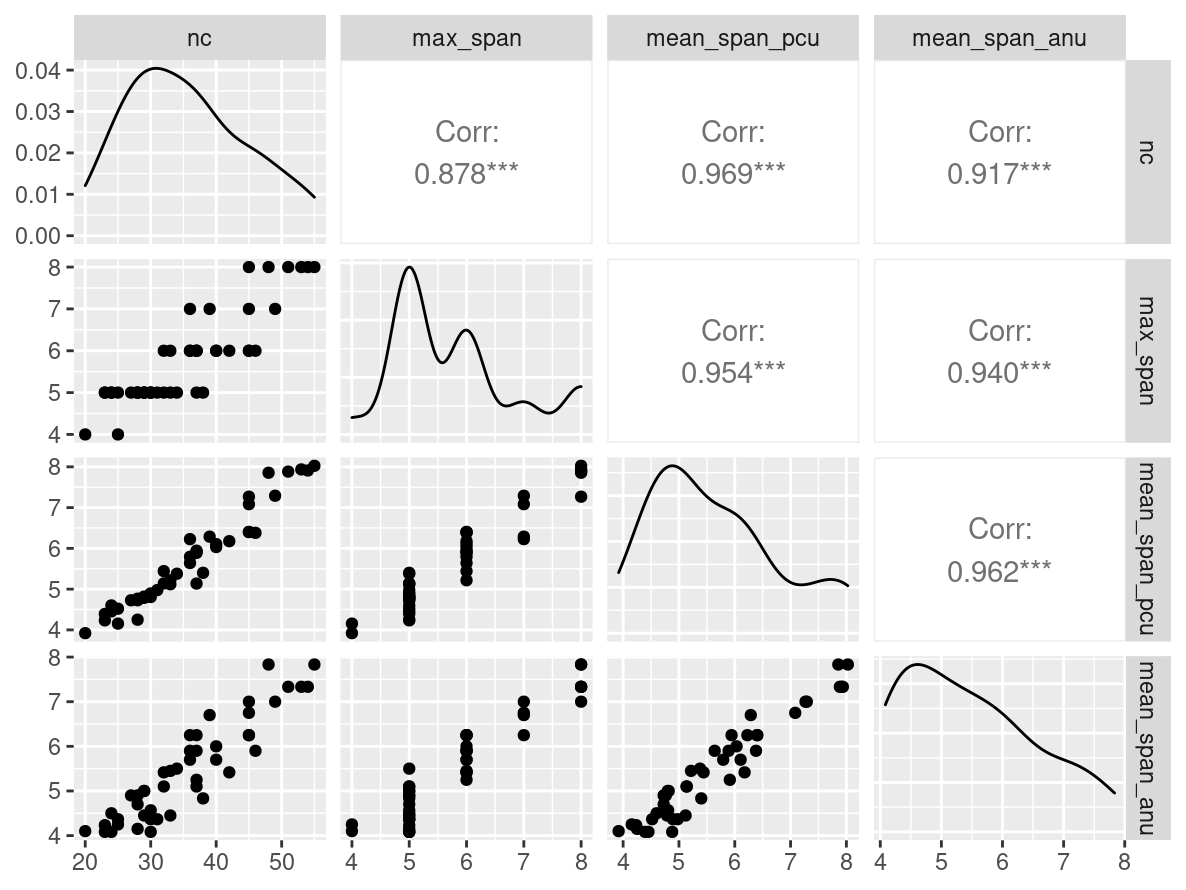
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
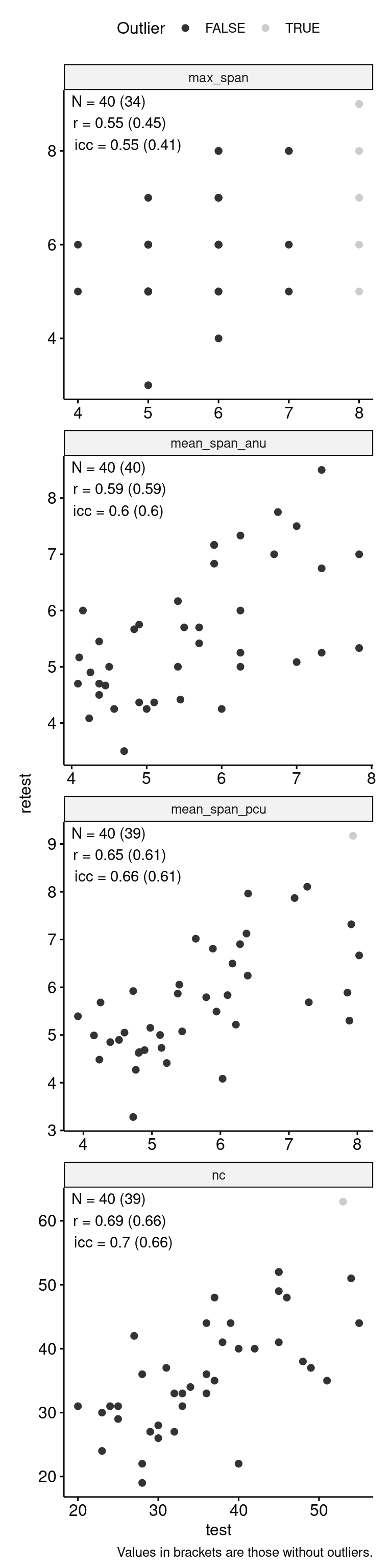
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
过目不忘PRO
data <- indices_clean |>
filter(
game_name_abbr == "FWSPro",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: FWSPro
- Sample Size: 46
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()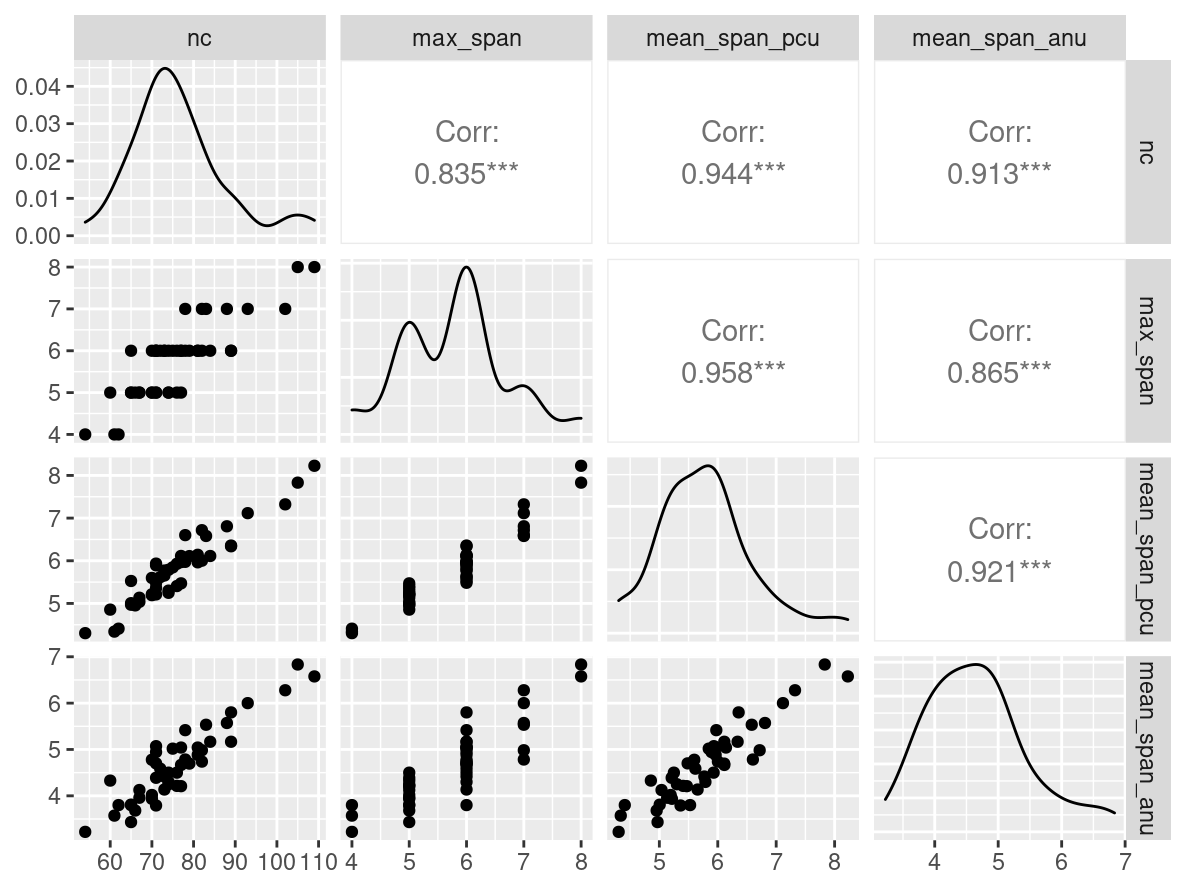
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
登陆月球(中级)
data <- indices_clean |>
filter(
game_name_abbr == "NLEMed",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
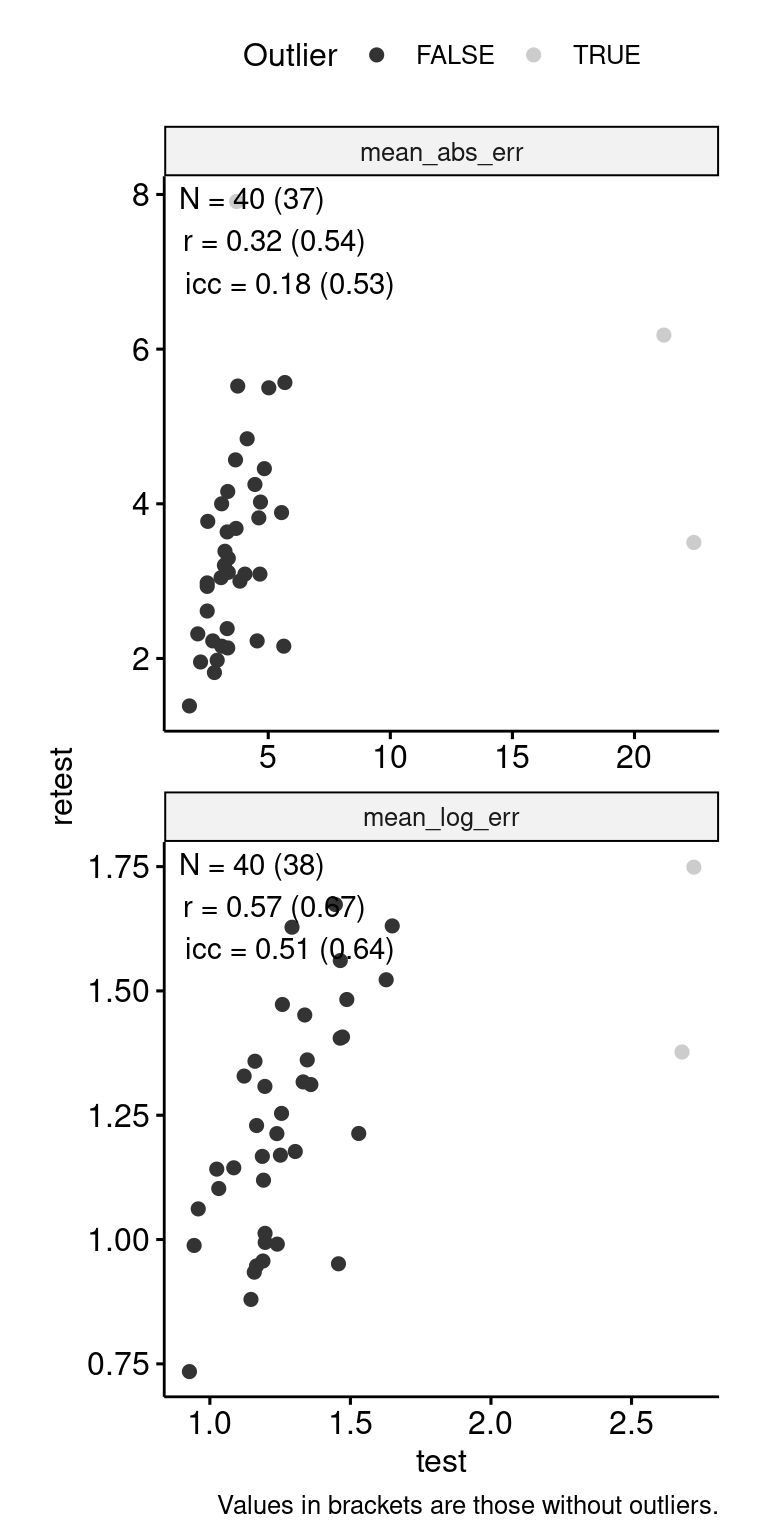
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: NLEMed
- Sample Size: 46
- Index Names:
- mean_abs_err
- mean_log_err
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()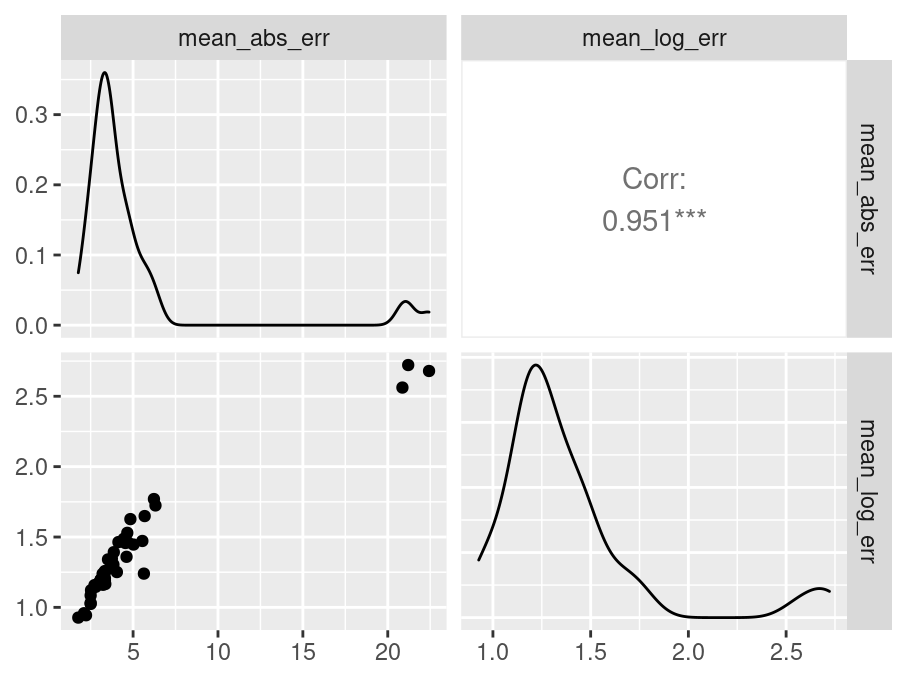
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
文字推理
data <- indices_clean |>
filter(
game_name_abbr == "VR",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
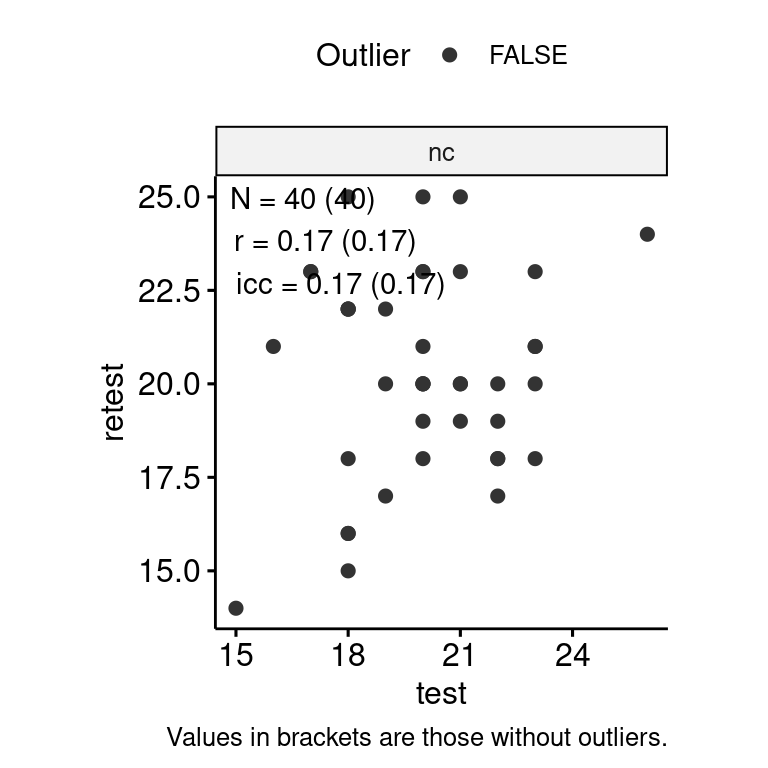
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: VR
- Sample Size: 46
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
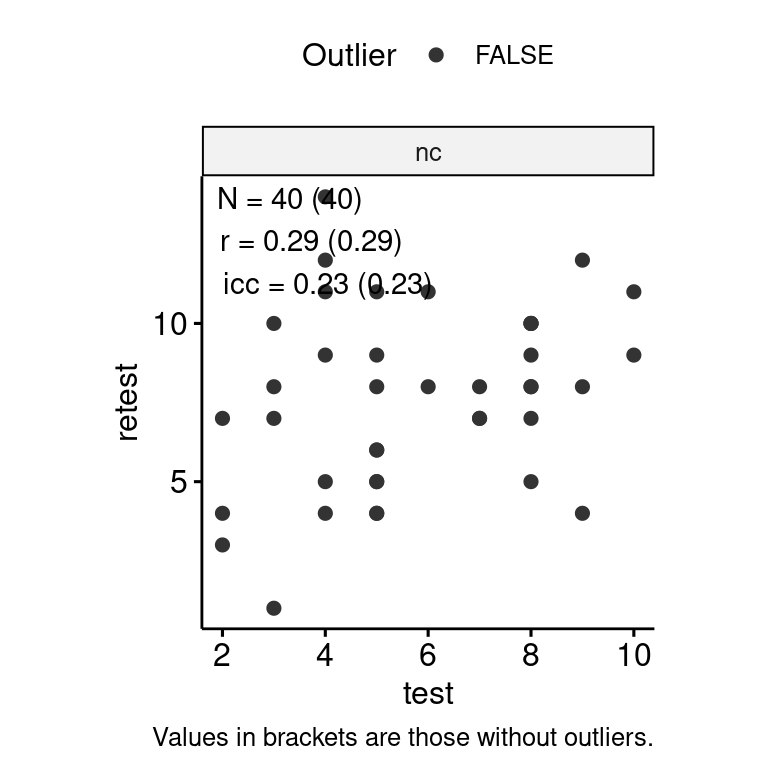
数字推理
data <- indices_clean |>
filter(
game_name_abbr == "DR",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: DR
- Sample Size: 46
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
各得其所
data <- indices_clean |>
filter(
game_name_abbr == "LdnTwr",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: LdnTwr
- Sample Size: 46
- Index Names:
- prop_perfect
- mrt_init
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()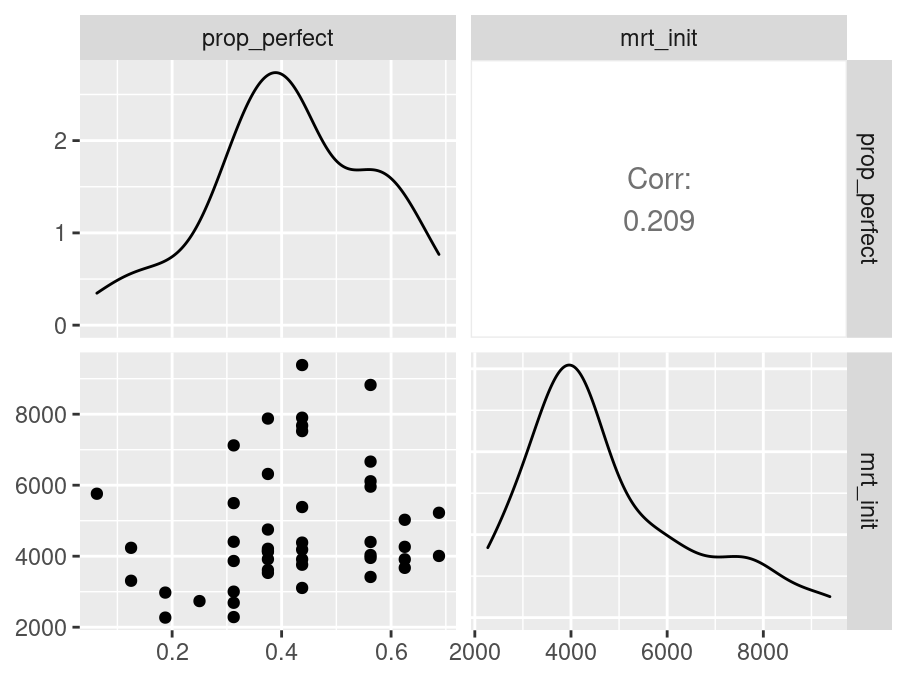
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
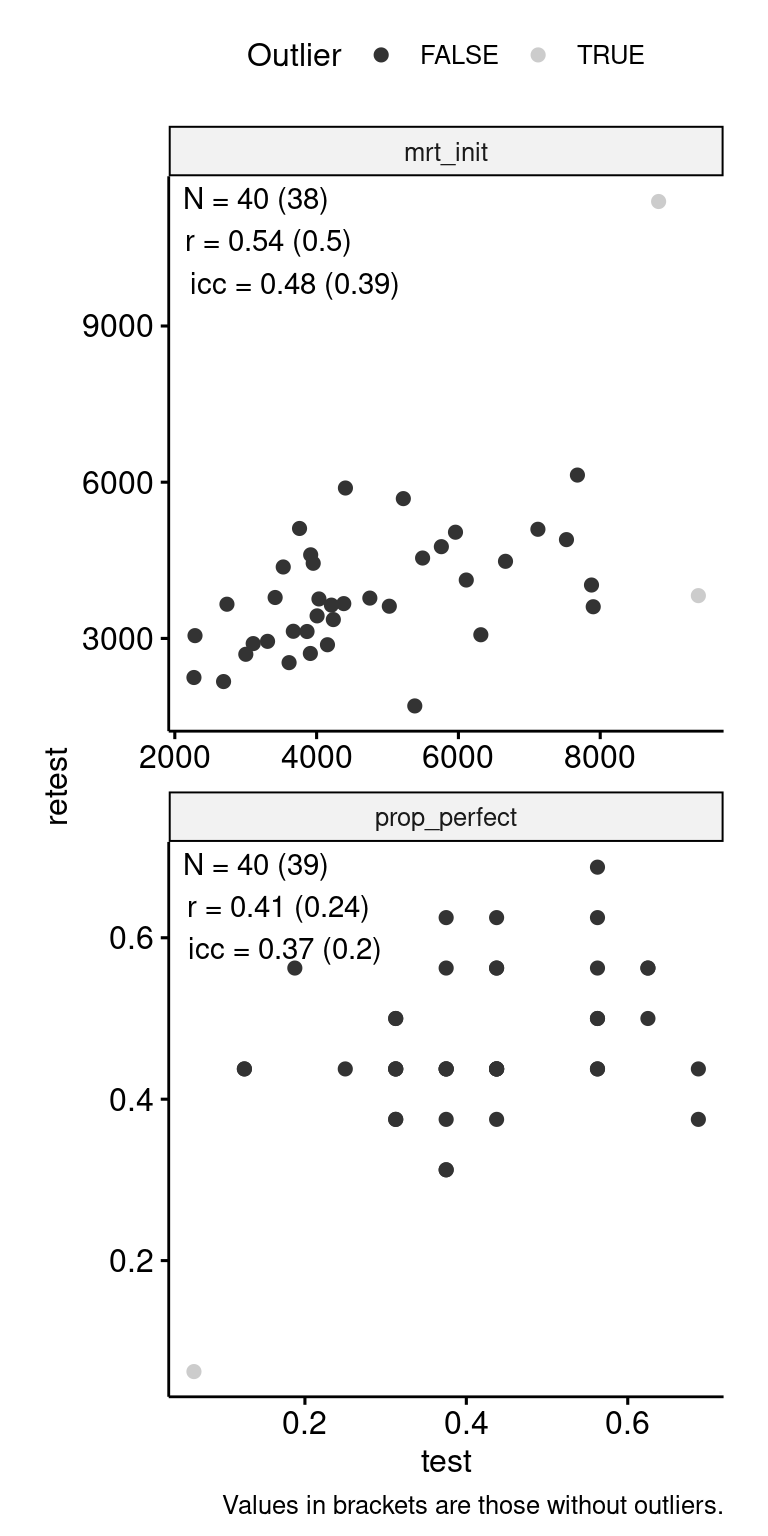
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
幸运小球
data <- indices_clean |>
filter(
game_name_abbr == "OCSpan",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
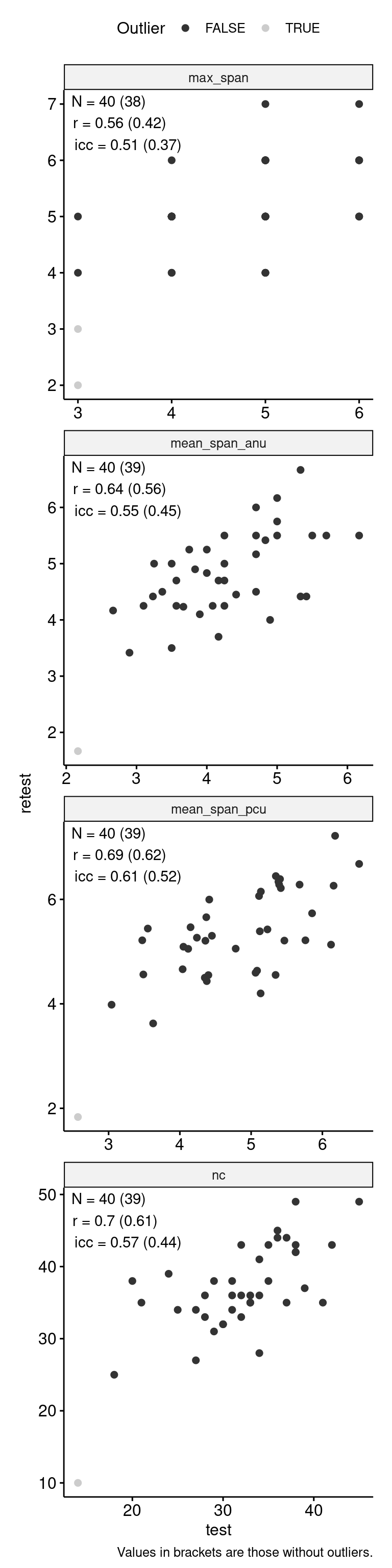
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: OCSpan
- Sample Size: 46
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()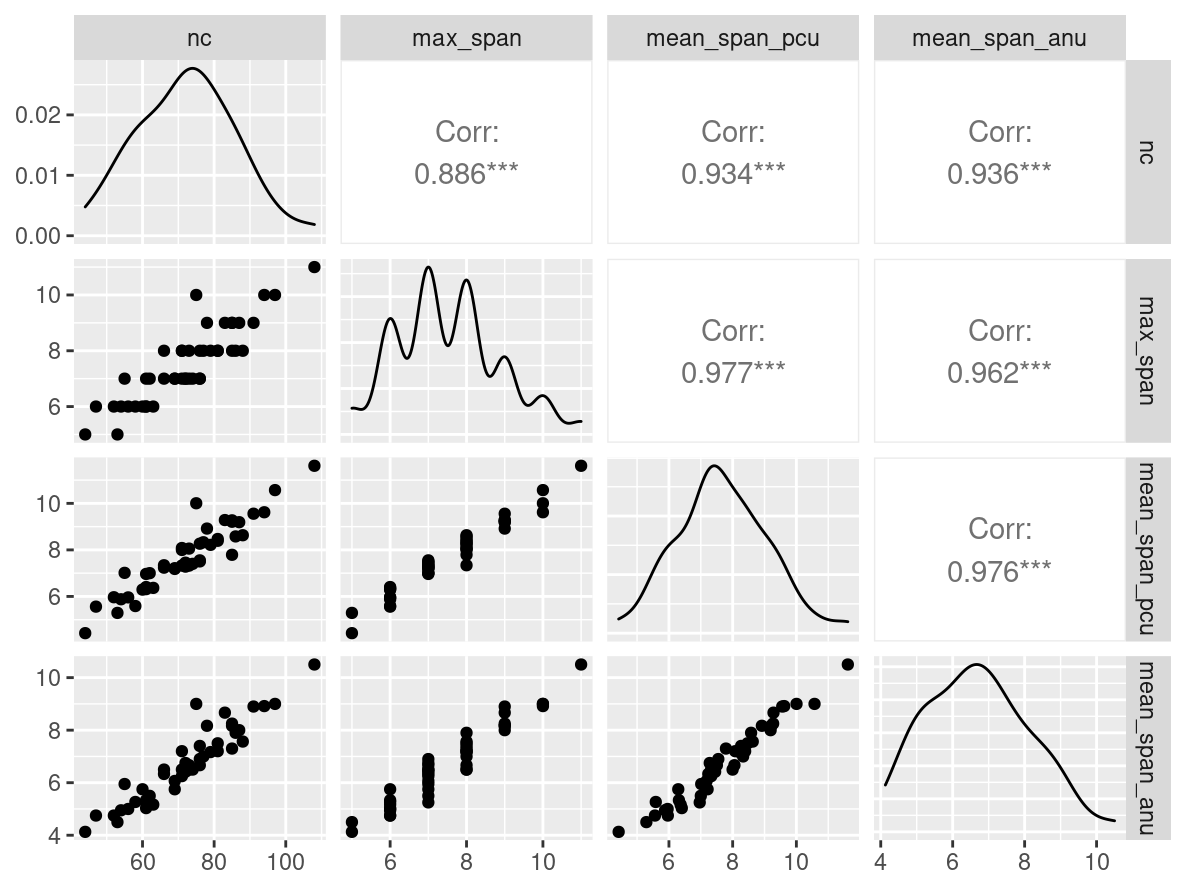
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
密码箱
data <- indices_clean |>
filter(
game_name_abbr == "KeepTrack",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: KeepTrack
- Sample Size: 46
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()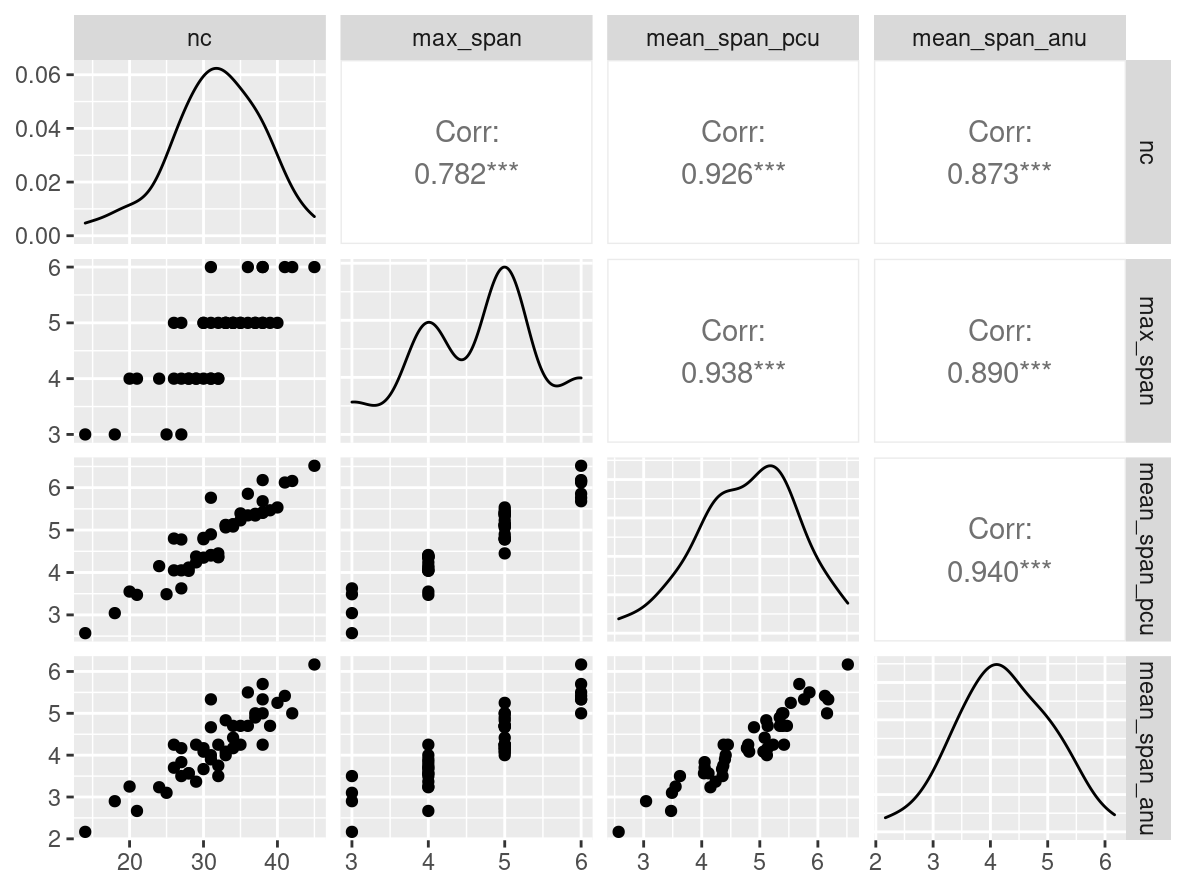
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
数感
data <- indices_clean |>
filter(
game_name_abbr == "NsymNCmp",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: NsymNCmp
- Sample Size: 46
- Index Names:
- pc
- mrt
- w
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()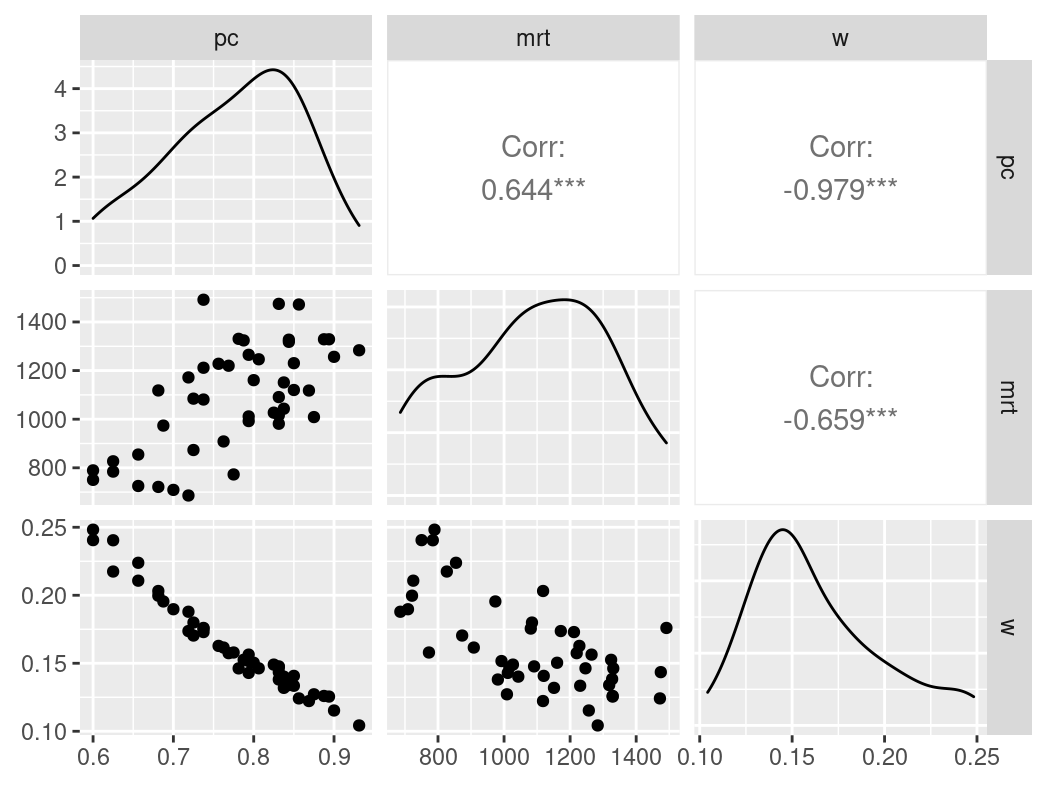
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
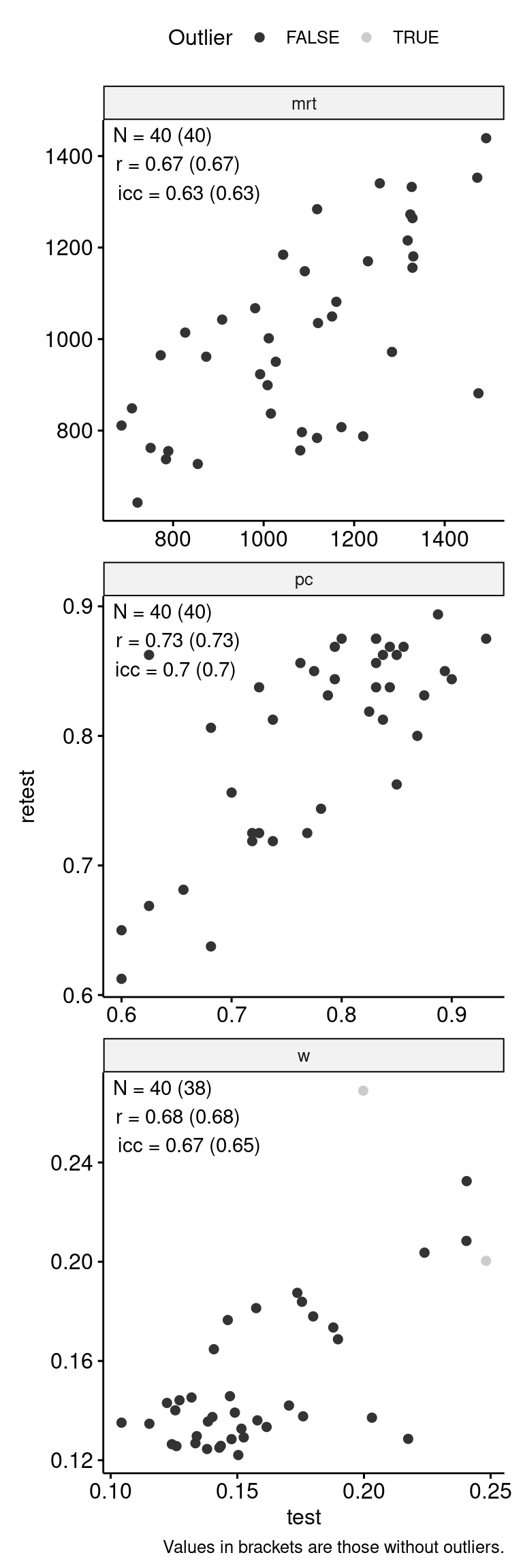
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
变色魔块PRO
data <- indices_clean |>
filter(
game_name_abbr == "StopSigPro",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: StopSigPro
- Sample Size: 46
- Index Names:
- rt_nth
- ssrt
- pc_all
- pc_go
- pc_stop
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()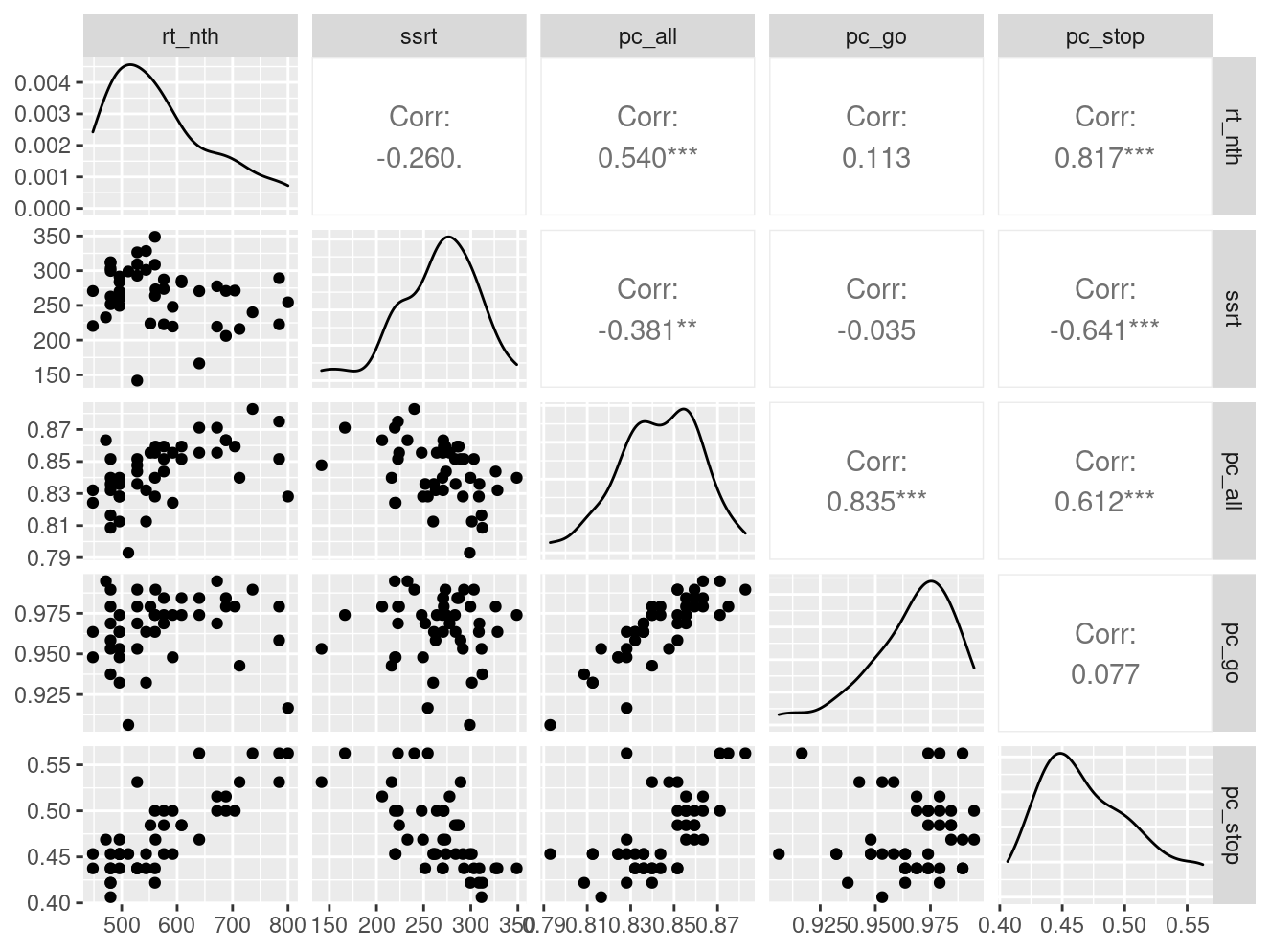
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
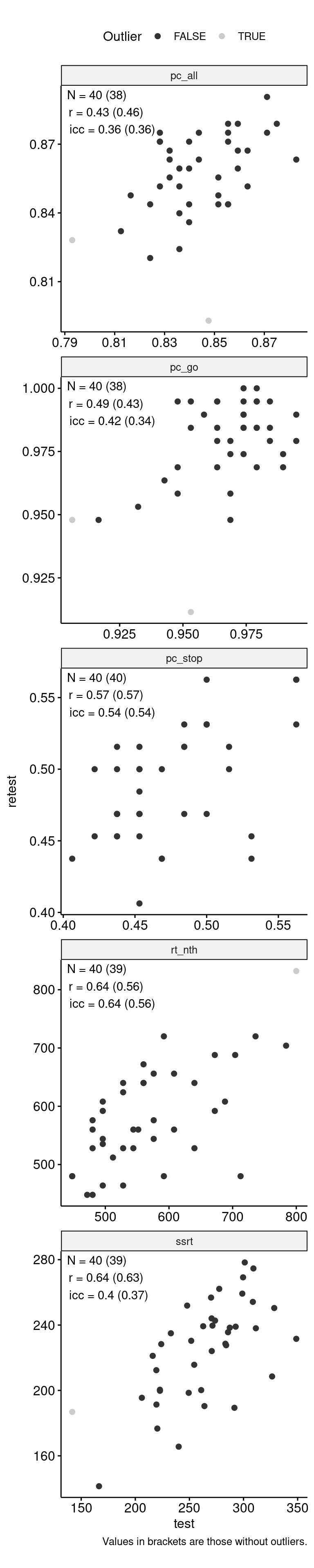
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
卡片分类PRO
data <- indices_clean |>
filter(
game_name_abbr == "CardSortPro",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: CardSortPro
- Sample Size: 46
- Index Names:
- mrt_repeat
- mrt_switch
- pc_repeat
- pc_switch
- switch_cost_rt_spe
- switch_cost_pc_spe
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()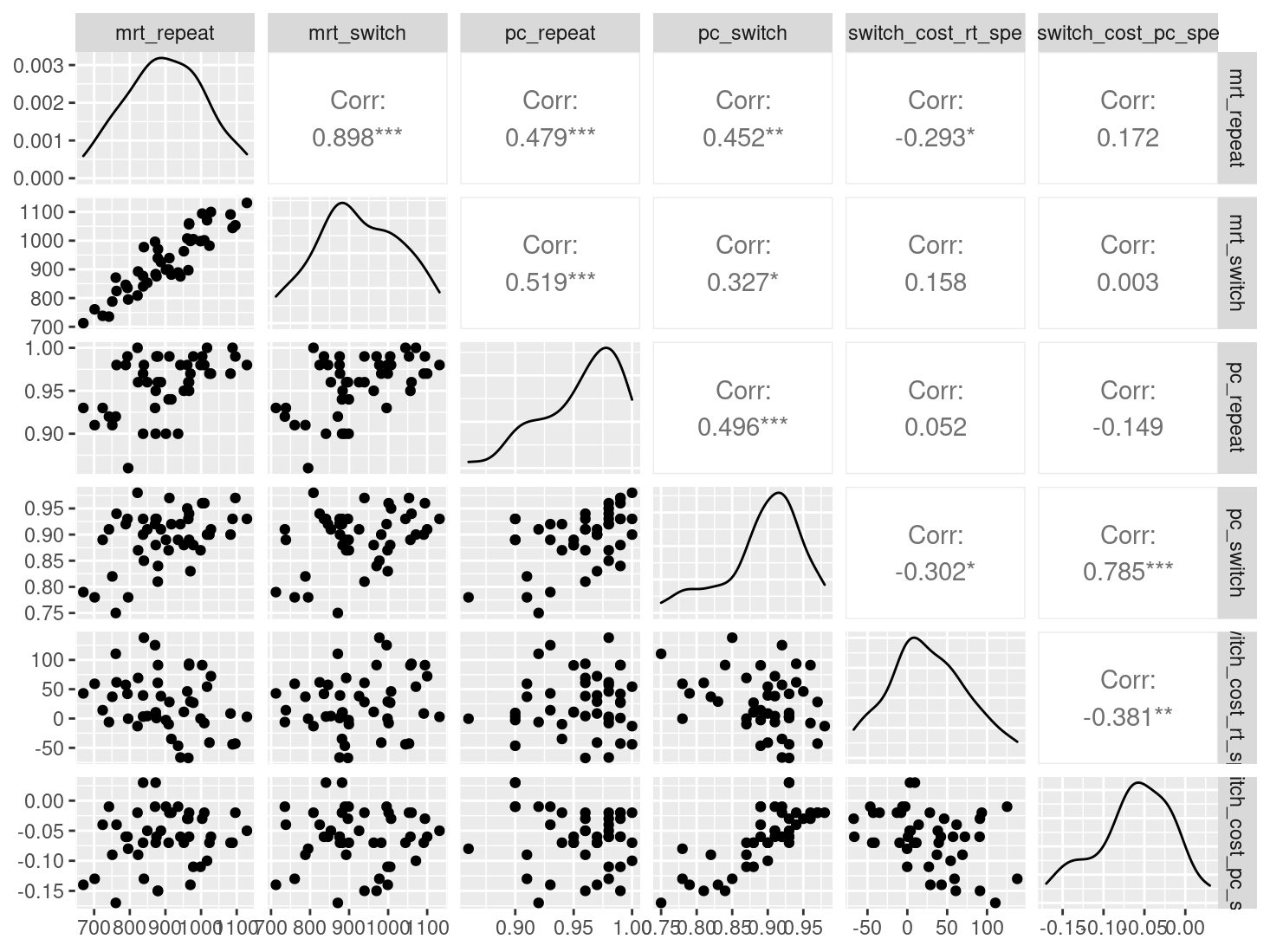
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
节奏感知
data <- indices_clean |>
filter(
game_name_abbr == "RP",
if_all(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
) |>
group_by(index_name) |>
mutate(
across(
contains("test"),
list(
is_outlier = ~ .x %in% boxplot.stats(.x)$out
)
)
) |>
ungroup() |>
mutate(
is_outlier = test_is_outlier | retest_is_outlier,
.keep = "unused"
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: RP
- Sample Size: 46
- Index Names:
- thresh_peak_valley
- thresh_last_block
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()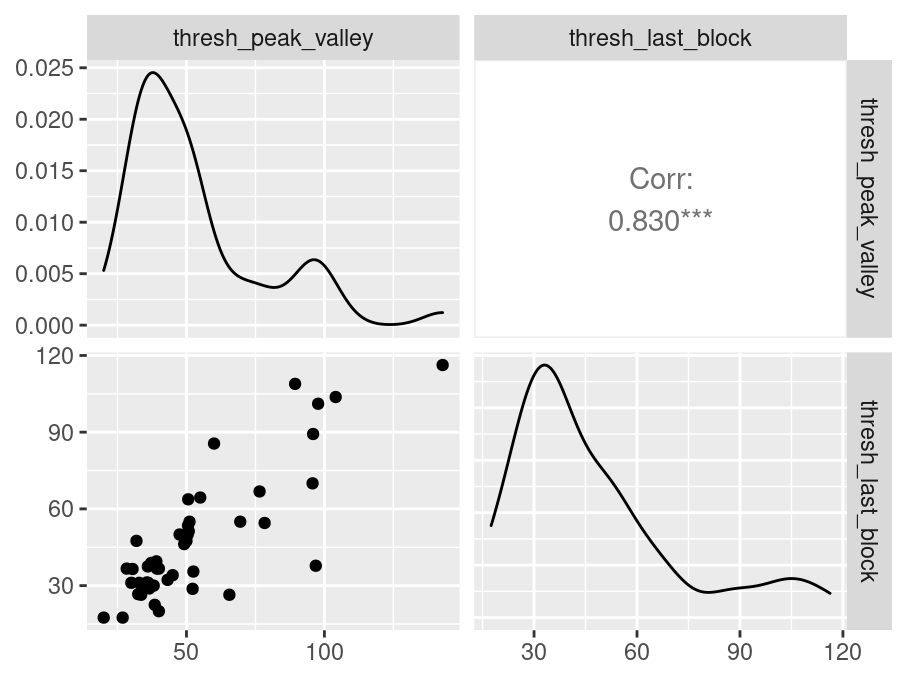
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
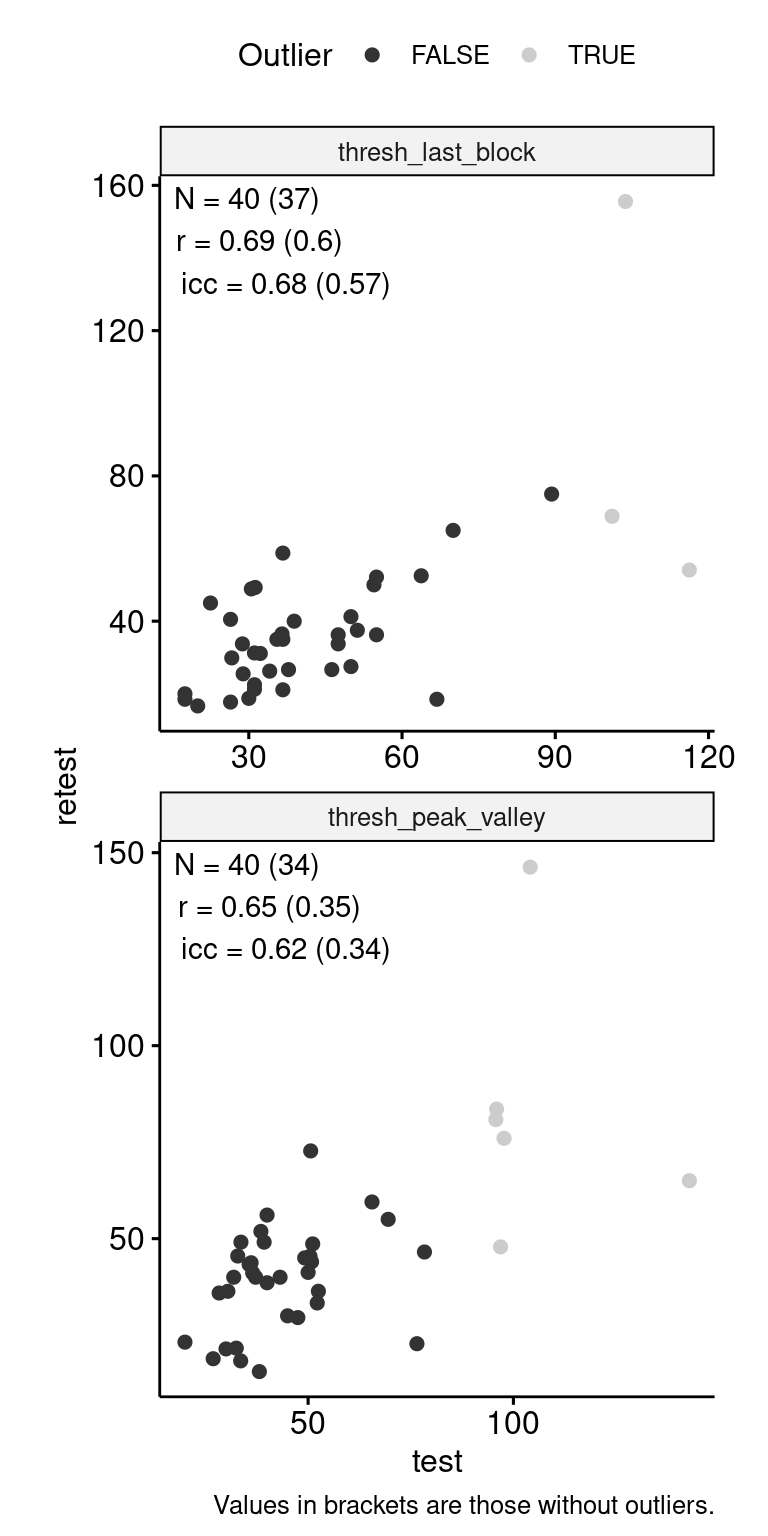
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
n_no_outlier = .x |>
filter(!is_outlier) |>
nrow(),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
icc_no_outlier = .x |>
filter(!is_outlier) |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 2),
r = cor(.x$test, .x$retest),
r_no_outlier = .x |>
filter(!is_outlier) |>
summarise(r = cor(test, retest)) |>
pull(r)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest", color = "is_outlier") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue(
"N = {n} ({n_no_outlier})\n",
"r = {round(r, 2)} ({round(r_no_outlier, 2)})\n",
"icc = {round(icc, 2)} ({round(icc_no_outlier, 2)})"
)
),
hjust = -0.1, vjust = 1.1
) +
scale_color_grey() +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1) +
labs(
color = "Outlier",
caption = "Values in brackets are those without outliers."
)
| Version | Author | Date |
|---|---|---|
| c640c6e | Liang Zhang | 2022-03-15 |
sessionInfo()R version 4.1.2 (2021-11-01)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.04.4 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C LC_TIME=C.UTF-8
[4] LC_COLLATE=C.UTF-8 LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
[7] LC_PAPER=C.UTF-8 LC_NAME=C LC_ADDRESS=C
[10] LC_TELEPHONE=C LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] targets_0.10.0 forcats_0.5.1 stringr_1.4.0 dplyr_1.0.8
[5] purrr_0.3.4 readr_2.1.2 tidyr_1.2.0 tibble_3.1.6
[9] ggplot2_3.3.5 tidyverse_1.3.1 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] minqa_1.2.4 colorspace_2.0-3 ggsignif_0.6.3
[4] ellipsis_0.3.2 rprojroot_2.0.2 fs_1.5.2
[7] rstudioapi_0.13 ggpubr_0.4.0 farver_2.1.0
[10] fansi_1.0.2 lubridate_1.8.0 xml2_1.3.3
[13] codetools_0.2-18 splines_4.1.2 mnormt_2.0.2
[16] knitr_1.37 jsonlite_1.8.0 nloptr_2.0.0
[19] broom_0.7.12 dbplyr_2.1.1 compiler_4.1.2
[22] httr_1.4.2 backports_1.4.1 assertthat_0.2.1
[25] Matrix_1.4-0 fastmap_1.1.0 cli_3.2.0
[28] later_1.3.0 htmltools_0.5.2 tools_4.1.2
[31] igraph_1.2.11 gtable_0.3.0 glue_1.6.2
[34] Rcpp_1.0.8 carData_3.0-5 cellranger_1.1.0
[37] jquerylib_0.1.4 vctrs_0.3.8 nlme_3.1-155
[40] psych_2.1.9 xfun_0.30 ps_1.6.0
[43] lme4_1.1-28 rvest_1.0.2 lifecycle_1.0.1
[46] rstatix_0.7.0 getPass_0.2-2 MASS_7.3-55
[49] scales_1.1.1 hms_1.1.1 promises_1.2.0.1
[52] parallel_4.1.2 RColorBrewer_1.1-2 qs_0.25.3
[55] yaml_2.3.5 sass_0.4.0 reshape_0.8.8
[58] stringi_1.7.6 highr_0.9 boot_1.3-28
[61] rlang_1.0.2 pkgconfig_2.0.3 evaluate_0.15
[64] lattice_0.20-45 labeling_0.4.2 processx_3.5.2
[67] tidyselect_1.1.2 here_1.0.1 GGally_2.1.2
[70] plyr_1.8.6 magrittr_2.0.2 R6_2.5.1
[73] generics_0.1.2 base64url_1.4 DBI_1.1.2
[76] pillar_1.7.0 haven_2.4.3 whisker_0.4
[79] withr_2.5.0 abind_1.4-5 modelr_0.1.8
[82] crayon_1.5.0 car_3.0-12 utf8_1.2.2
[85] tmvnsim_1.0-2 RApiSerialize_0.1.0 tzdb_0.2.0
[88] rmarkdown_2.12 grid_4.1.2 readxl_1.3.1
[91] data.table_1.14.2 callr_3.7.0 git2r_0.29.0
[94] reprex_2.0.1 digest_0.6.29 httpuv_1.6.5
[97] RcppParallel_5.1.5 munsell_0.5.0 stringfish_0.15.5
[100] bslib_0.3.1