Test Performance Checking
Liang Zhang
2022-01-18
Last updated: 2022-01-19
Checks: 6 1
Knit directory: cogstruct/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20220104) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
- load-data
- pairwise-AntiSac
- pairwise-AscLanMd
- pairwise-AscMem
- pairwise-AttSrc
- pairwise-BirdsPro
- pairwise-BPS
- pairwise-CalcMed
- pairwise-CalcSpdMed
- pairwise-CardSortPro
- pairwise-ColStrpPro
- pairwise-ConRec
- pairwise-CRTPro
- pairwise-DD
- pairwise-Digit3back
- pairwise-DirectSrc
- pairwise-DR
- pairwise-DRM
- pairwise-Dual2back
- pairwise-DualTaskPro
- pairwise-FacesPro
- pairwise-FDSPro
- pairwise-FlkrPro
- pairwise-FPTPro
- pairwise-FR
- pairwise-FWSPro
- pairwise-Grid2back
- pairwise-HOP
- pairwise-JLO
- pairwise-KeepTrack
- pairwise-LdnTwr
- pairwise-LocMemStd
- pairwise-MOTPro
- pairwise-MR3D
- pairwise-MSynWin
- pairwise-Nback3
- pairwise-NLEMed
- pairwise-NsymNCmp
- pairwise-NVR
- pairwise-OCSpan
- pairwise-Paint2back
- pairwise-ProbRL
- pairwise-RAT
- pairwise-RP
- pairwise-RSpan
- pairwise-SchulteMed
- pairwise-SCSpan
- pairwise-Seman
- pairwise-SRTPro
- pairwise-SSTMPro
- pairwise-StopSigPro
- pairwise-TOJ
- pairwise-Tone
- pairwise-TOVAS
- pairwise-Verbal3back
- pairwise-VR
- pairwise-WxPred
- test-retest-AntiSac
- test-retest-AscLanMd
- test-retest-AscMem
- test-retest-AttSrc
- test-retest-BirdsPro
- test-retest-BPS
- test-retest-CalcMed
- test-retest-CalcSpdMed
- test-retest-CardSortPro
- test-retest-ColStrpPro
- test-retest-ConRec
- test-retest-CRTPro
- test-retest-DD
- test-retest-Digit3back
- test-retest-DirectSrc
- test-retest-DR
- test-retest-DRM
- test-retest-Dual2back
- test-retest-DualTaskPro
- test-retest-FacesPro
- test-retest-FDSPro
- test-retest-FlkrPro
- test-retest-FPTPro
- test-retest-FR
- test-retest-FWSPro
- test-retest-Grid2back
- test-retest-HOP
- test-retest-JLO
- test-retest-KeepTrack
- test-retest-LdnTwr
- test-retest-LocMemStd
- test-retest-MOTPro
- test-retest-MR3D
- test-retest-MSynWin
- test-retest-Nback3
- test-retest-NLEMed
- test-retest-NsymNCmp
- test-retest-NVR
- test-retest-OCSpan
- test-retest-Paint2back
- test-retest-ProbRL
- test-retest-RAT
- test-retest-RP
- test-retest-RSpan
- test-retest-SchulteMed
- test-retest-SCSpan
- test-retest-Seman
- test-retest-SRTPro
- test-retest-SSTMPro
- test-retest-StopSigPro
- test-retest-TOJ
- test-retest-Tone
- test-retest-TOVAS
- test-retest-Verbal3back
- test-retest-VR
- test-retest-WxPred
To ensure reproducibility of the results, delete the cache directory test_checking_cache and re-run the analysis. To have workflowr automatically delete the cache directory prior to building the file, set delete_cache = TRUE when running wflow_build() or wflow_publish().
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 76a75d1. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: _targets.yaml
Ignored: analysis/_targets.yaml
Ignored: analysis/test_checking_cache/
Ignored: bnu/_targets/meta/process
Ignored: bnu/_targets/meta/progress
Ignored: bnu/_targets/objects/
Ignored: bnu/_targets/user/
Ignored: bnu/archived/
Ignored: bnu/config/
Ignored: bnu/diagnose.Rmd
Ignored: bnu/images/
Ignored: figure/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/test_checking.Rmd) and HTML (docs/test_checking.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 76a75d1 | Liang Zhang | 2022-01-19 | wflow_publish("analysis/*.Rmd") |
| html | 94f7d3d | Liang Zhang | 2022-01-19 | Build site. |
| html | 011d01c | Liang Zhang | 2022-01-19 | Build site. |
| Rmd | 4e6f38d | Liang Zhang | 2022-01-19 | wflow_publish("analysis/*.Rmd") |
| html | 9690cf9 | Liang Zhang | 2022-01-19 | Build site. |
| Rmd | 433c01b | Liang Zhang | 2022-01-19 | wflow_publish("analysis/*.Rmd") |
| html | 655f04c | Liang Zhang | 2022-01-19 | Build site. |
| Rmd | 5afb062 | Liang Zhang | 2022-01-19 | wflow_publish("analysis/*.Rmd") |
| html | ddaae03 | Liang Zhang | 2022-01-19 | Build site. |
| Rmd | ce3f503 | Liang Zhang | 2022-01-19 | wflow_publish("analysis/test_checking.Rmd") |
| html | 22b9029 | Liang Zhang | 2022-01-19 | Build site. |
| Rmd | 02fac49 | Liang Zhang | 2022-01-19 | wflow_publish("analysis/test_checking.Rmd") |
tests_keyboard <- read_lines(here::here("config/require_keybord.txt"))
validation <- tar_read(device_info) |>
mutate(valid_device = !(game_name %in% tests_keyboard & used_mouse)) |>
inner_join(tar_read(data_validation)) |>
filter(valid_device & valid_version) |>
group_by(user_id, game_name) |>
filter(
if_else(
str_detect(game_name_abbr, "[A|B]$"),
row_number(desc(game_time)) == 1,
row_number(desc(game_time)) <= 2
)
) |>
ungroup()
indices <- tar_read(indices) |>
semi_join(validation) |>
mutate(across(starts_with("game_name"), ~ str_remove(.x, "[A|B]$"))) |>
group_by(user_id, game_name_abbr, game_name, index_name) |>
mutate(occasion = recode(row_number(game_time), `1` = "test", `2` = "retest")) |>
ungroup() |>
pivot_wider(
id_cols = c(user_id, game_name, game_name_abbr, index_name),
names_from = occasion,
values_from = score
)
tests_included <- deframe(distinct(indices, game_name_abbr, game_name))render_content <- function(file, ...) {
knitr::knit(
text = knitr::knit_expand(file, ...),
quiet = TRUE
)
}
purrr::imap_chr(
tests_included,
~ render_content(
file = here::here("archetypes/child_check_index.Rmd"),
game_name_abbr = .x,
game_name = .y
)
) |>
str_c(collapse = "\n\n") |>
cat()快速归类PRO
data <- indices |>
filter(
game_name_abbr == "CRTPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: CRTPro
- Sample Size: 88
- Index Names:
- nc
- mrt
- rtsd
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()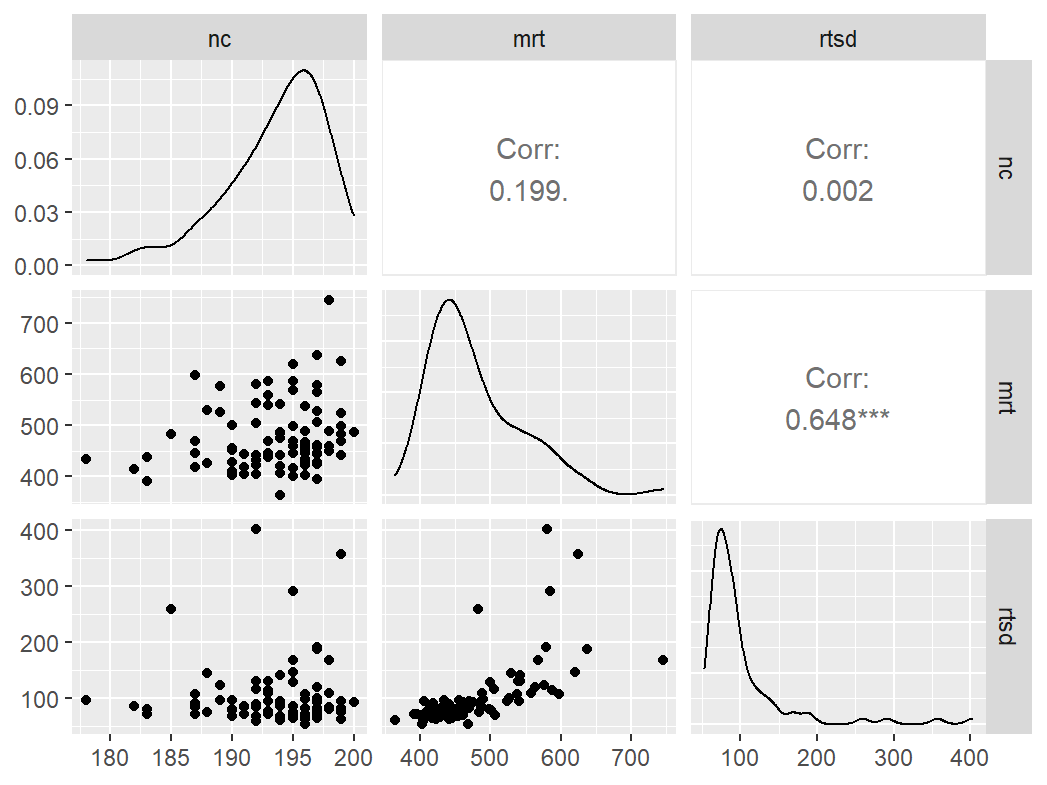
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)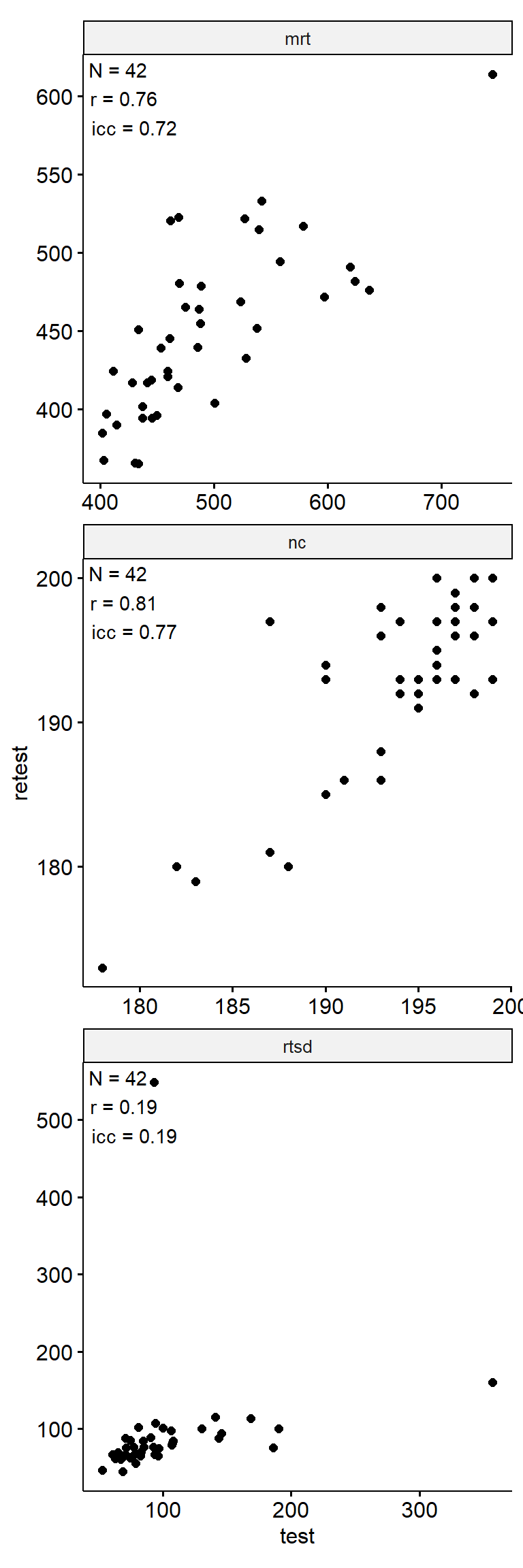
捉虫高级简版
data <- indices |>
filter(
game_name_abbr == "TOVAS",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: TOVAS
- Sample Size: 89
- Index Names:
- nc
- mrt
- rtsd
- dprime
- c
- commissions
- omissions
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()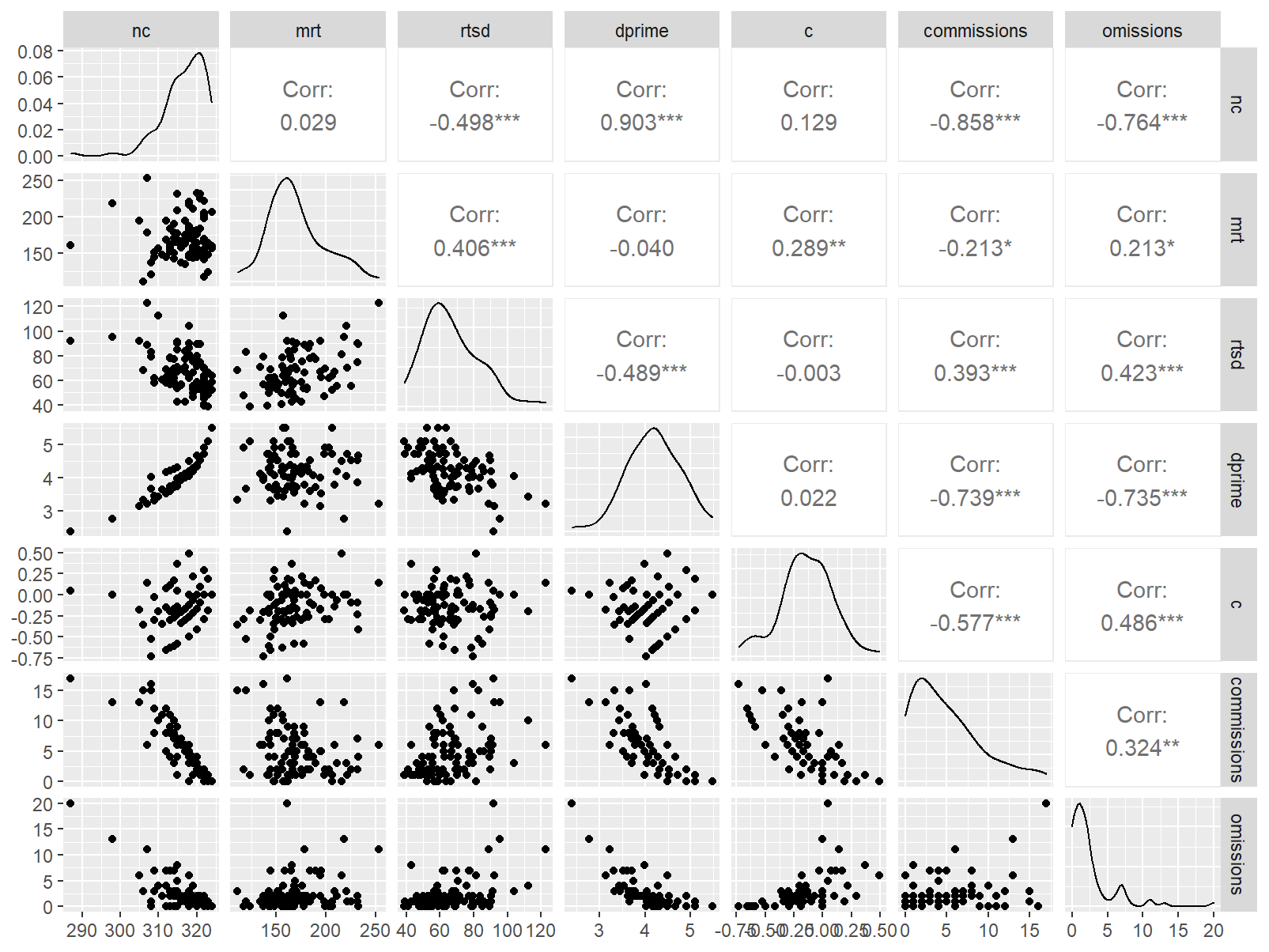
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
塔罗牌
data <- indices |>
filter(
game_name_abbr == "WxPred",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: WxPred
- Sample Size: 89
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()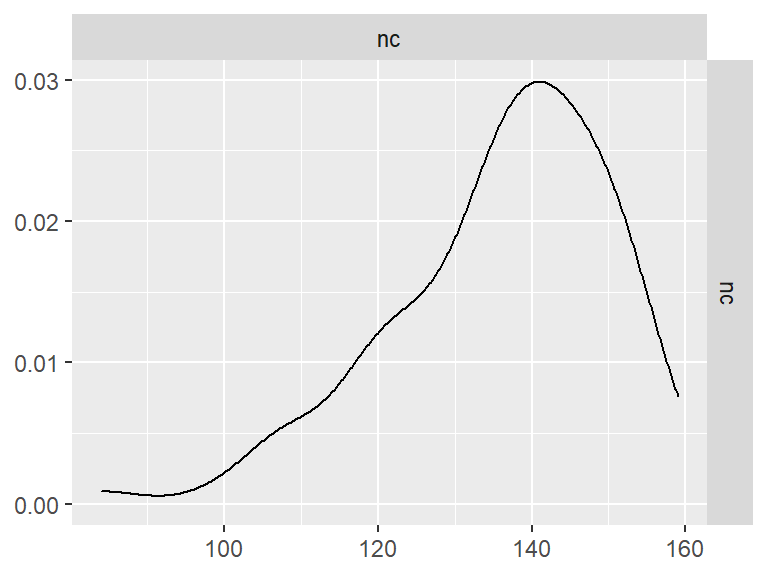
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)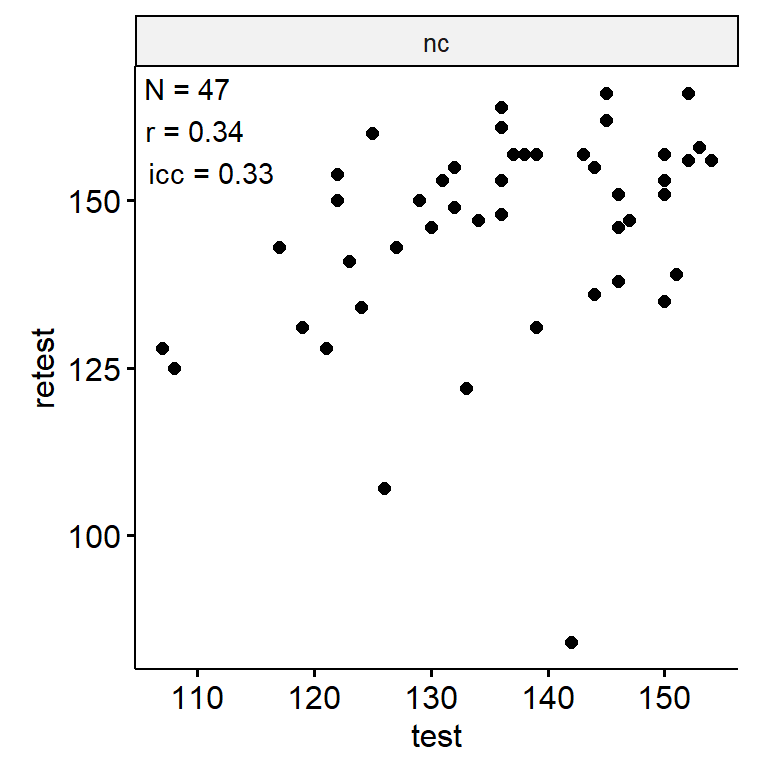
数感
data <- indices |>
filter(
game_name_abbr == "NsymNCmp",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: NsymNCmp
- Sample Size: 90
- Index Names:
- pc
- mrt
- w
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()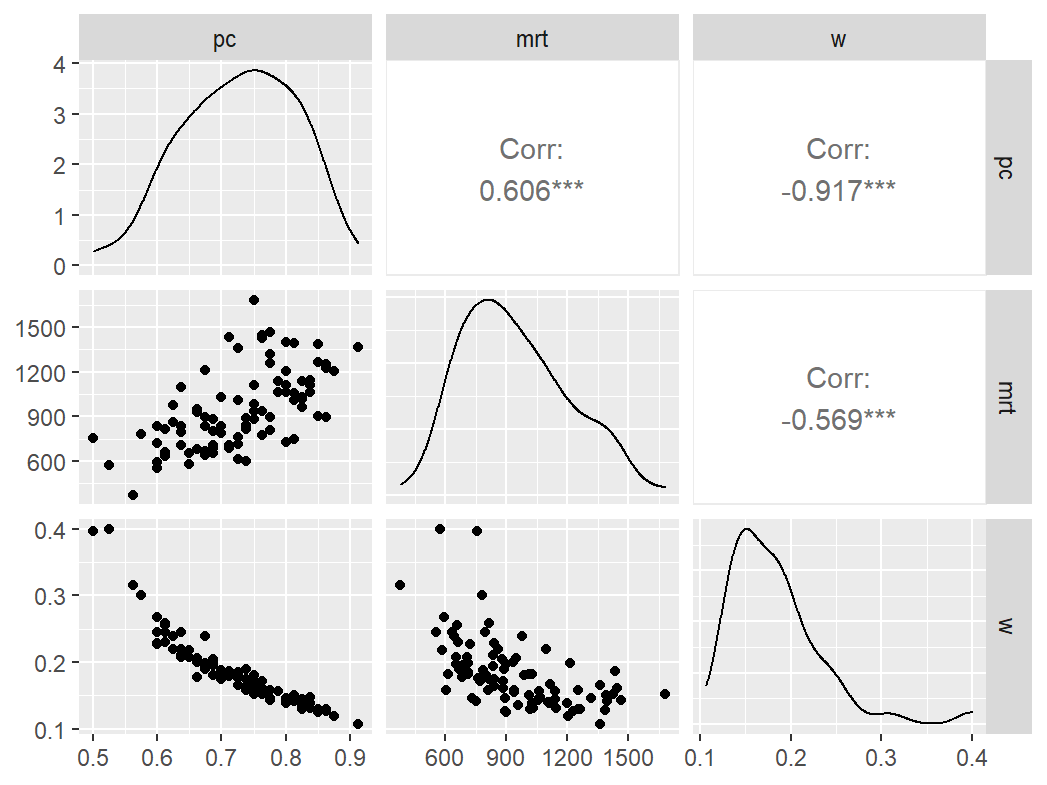
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
数字卡片
data <- indices |>
filter(
game_name_abbr == "Digit3back",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Digit3back
- Sample Size: 83
- Index Names:
- pc
- mrt
- dprime
- c
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()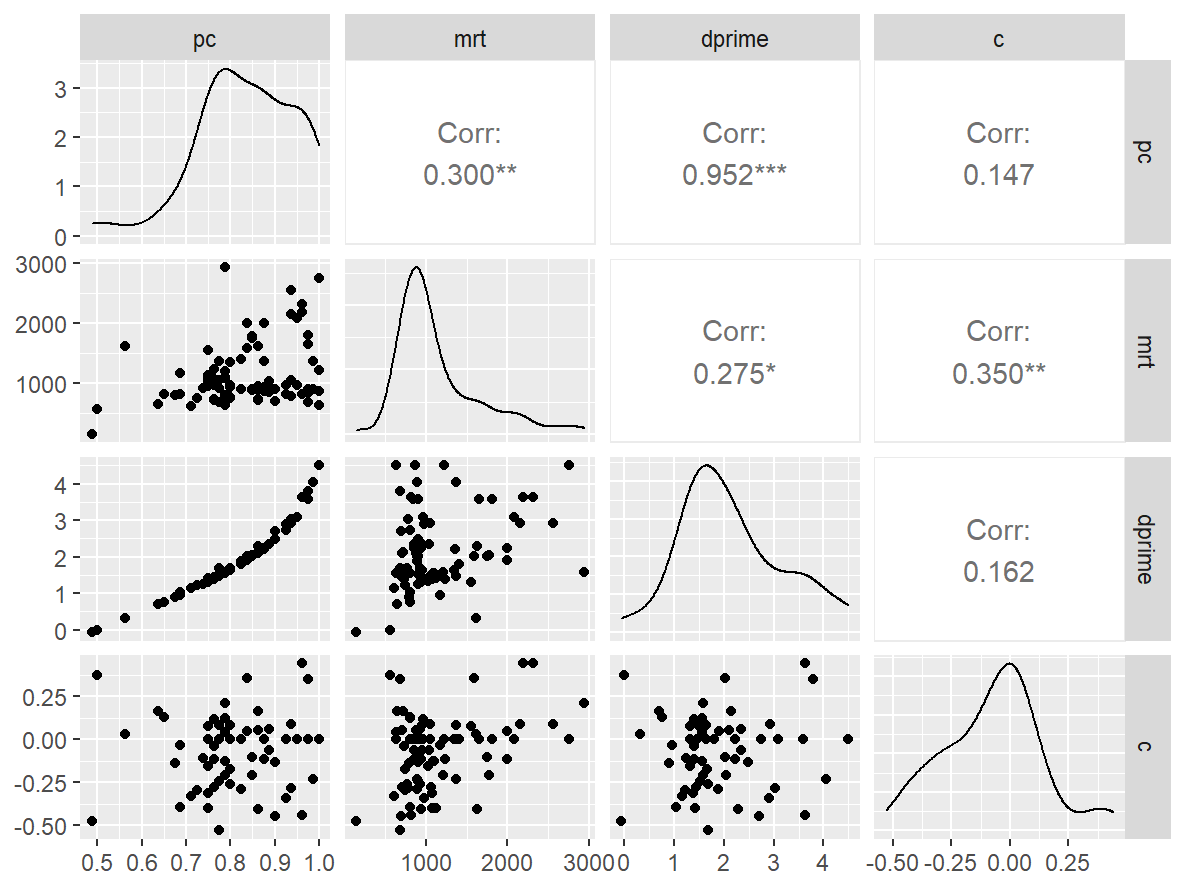
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)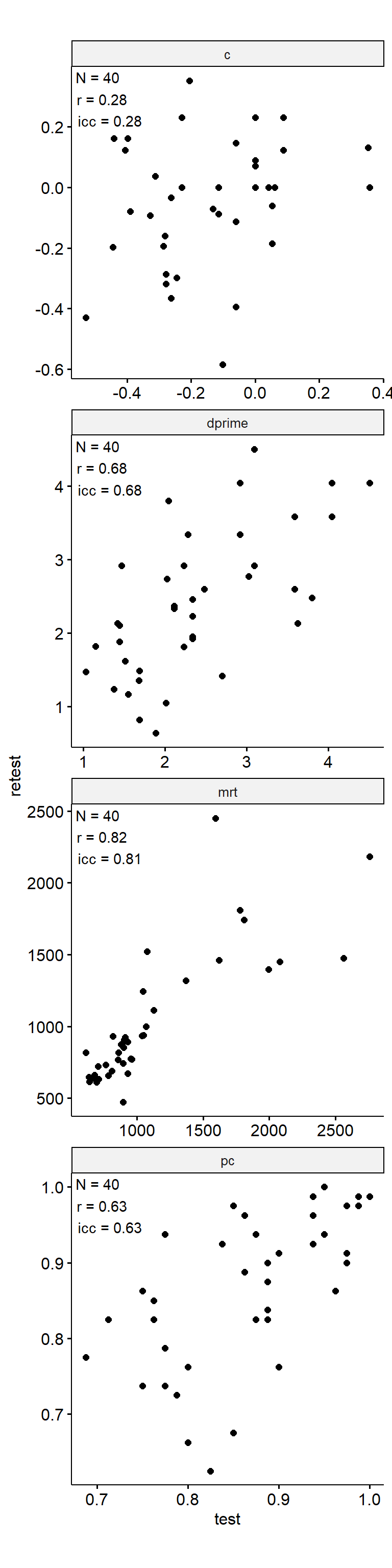
格子卡片
data <- indices |>
filter(
game_name_abbr == "Grid2back",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Grid2back
- Sample Size: 83
- Index Names:
- pc
- mrt
- dprime
- c
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()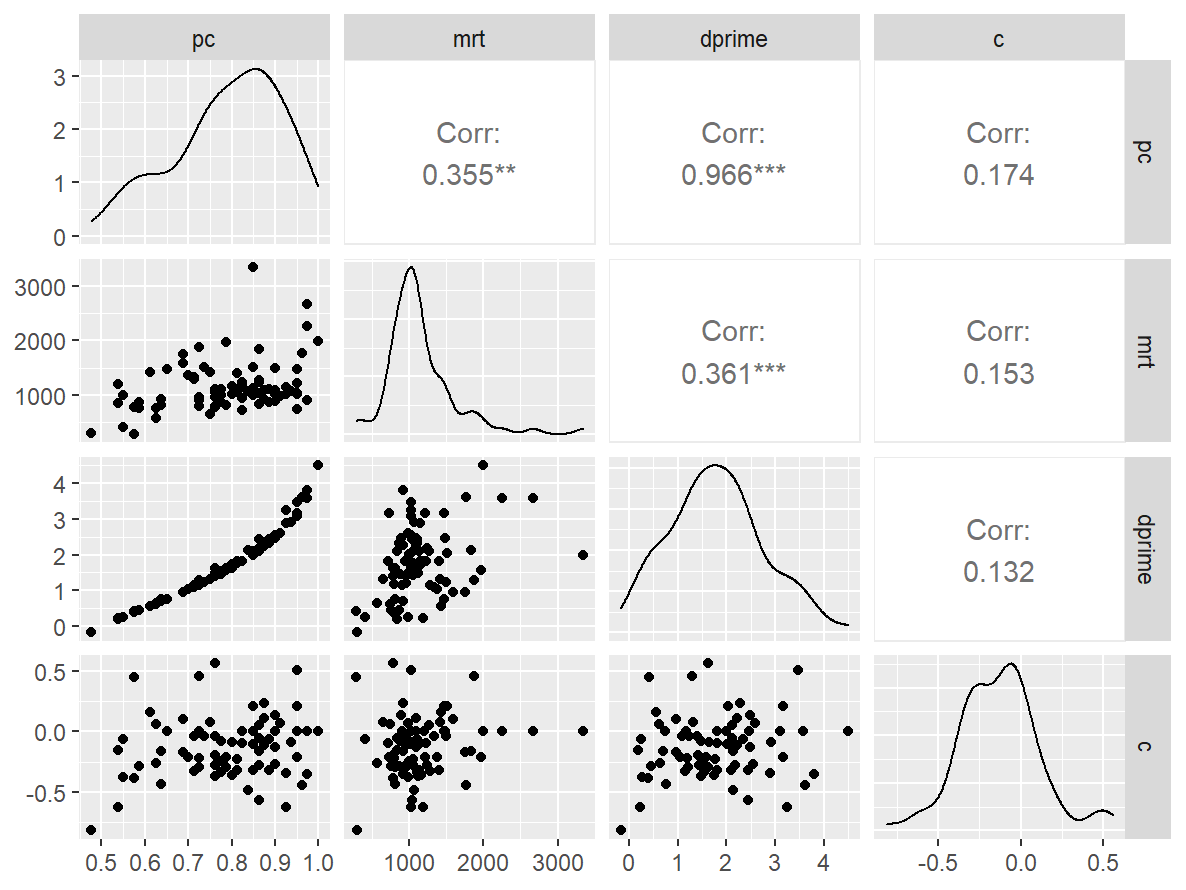
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)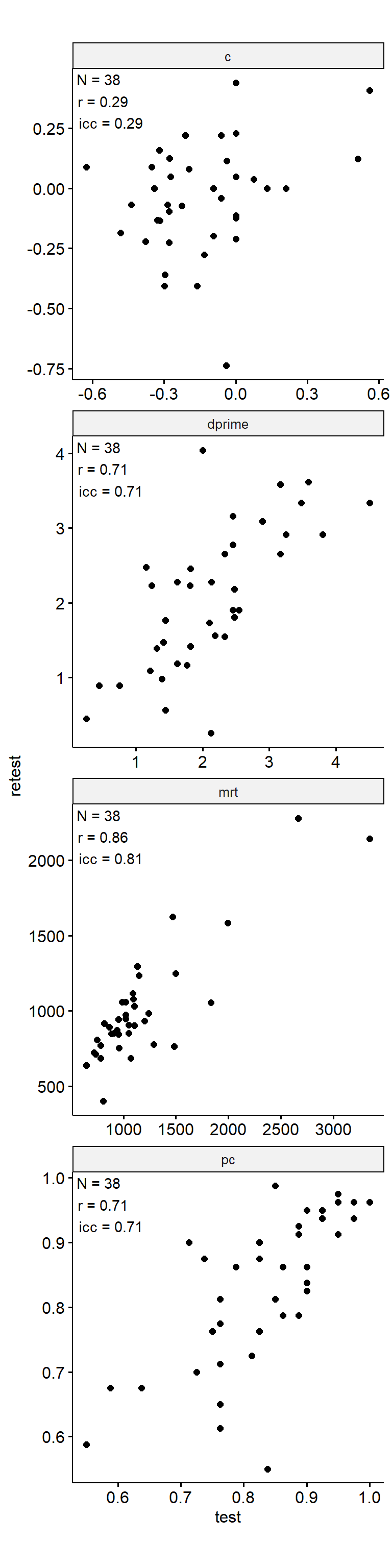
美术卡片
data <- indices |>
filter(
game_name_abbr == "Paint2back",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Paint2back
- Sample Size: 85
- Index Names:
- pc
- mrt
- dprime
- c
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()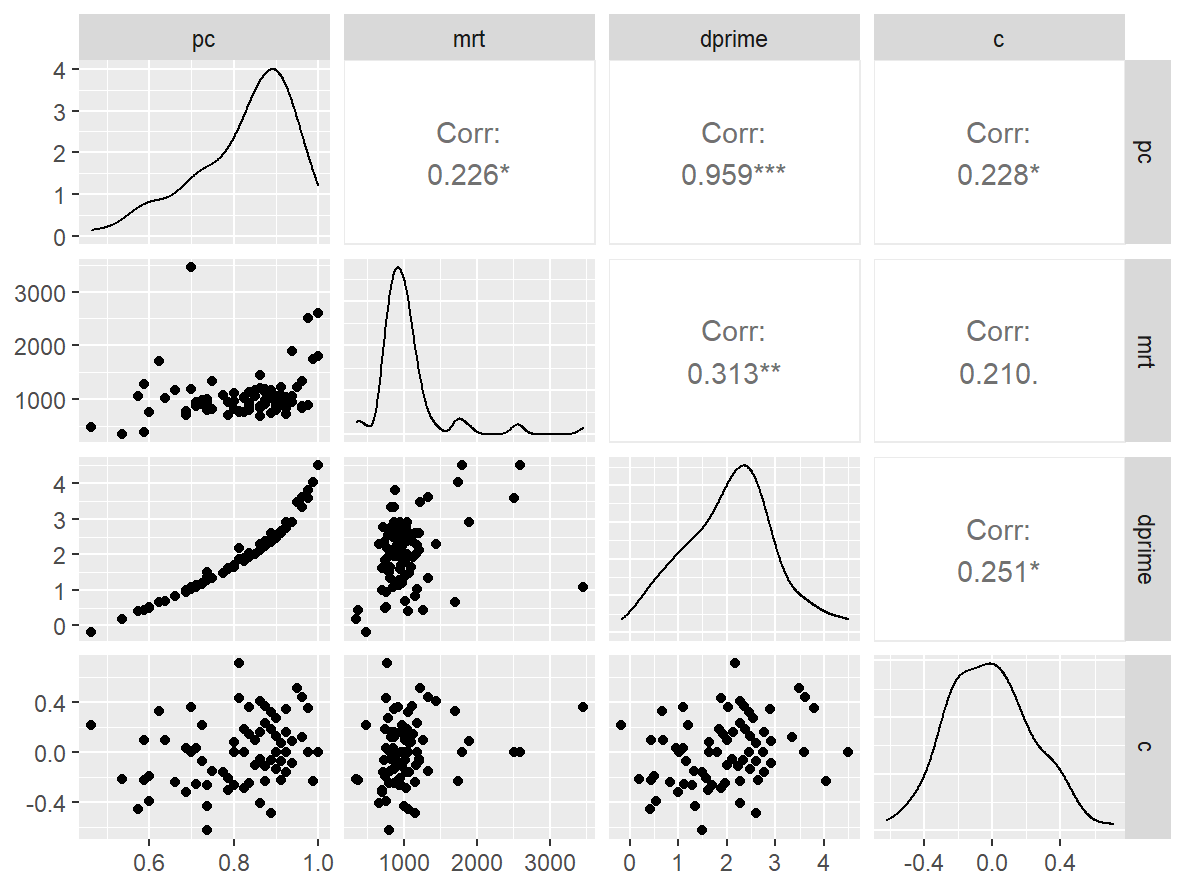
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)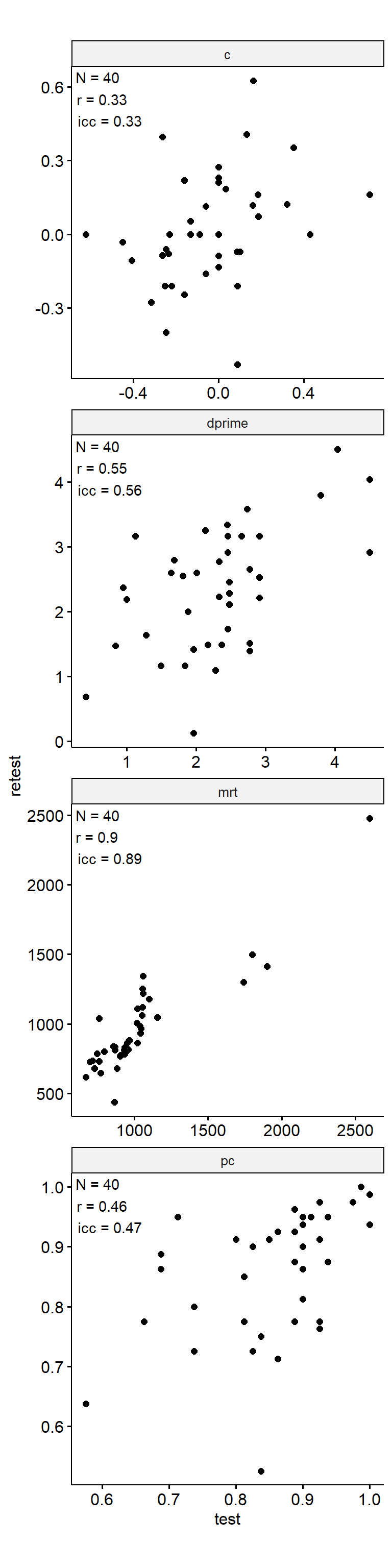
文字卡片
data <- indices |>
filter(
game_name_abbr == "Verbal3back",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Verbal3back
- Sample Size: 84
- Index Names:
- pc
- mrt
- dprime
- c
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()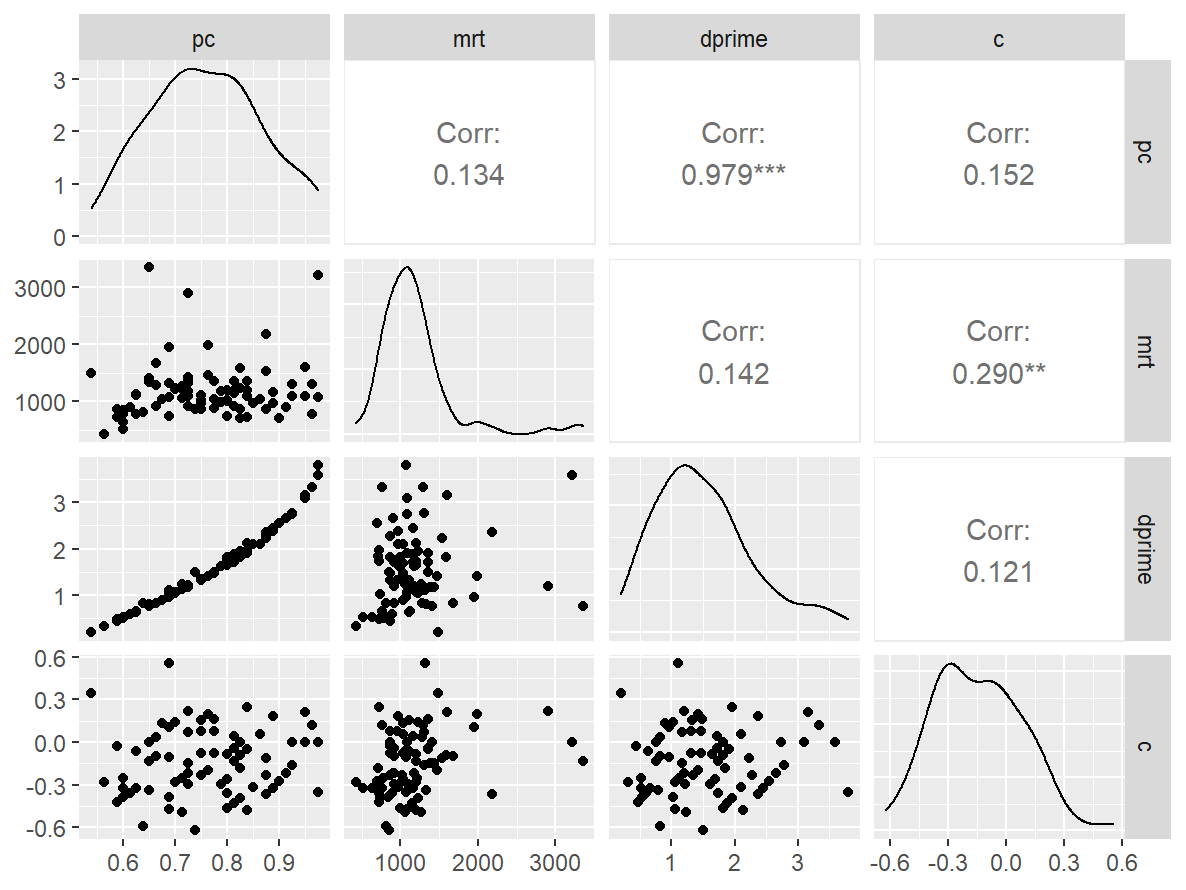
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)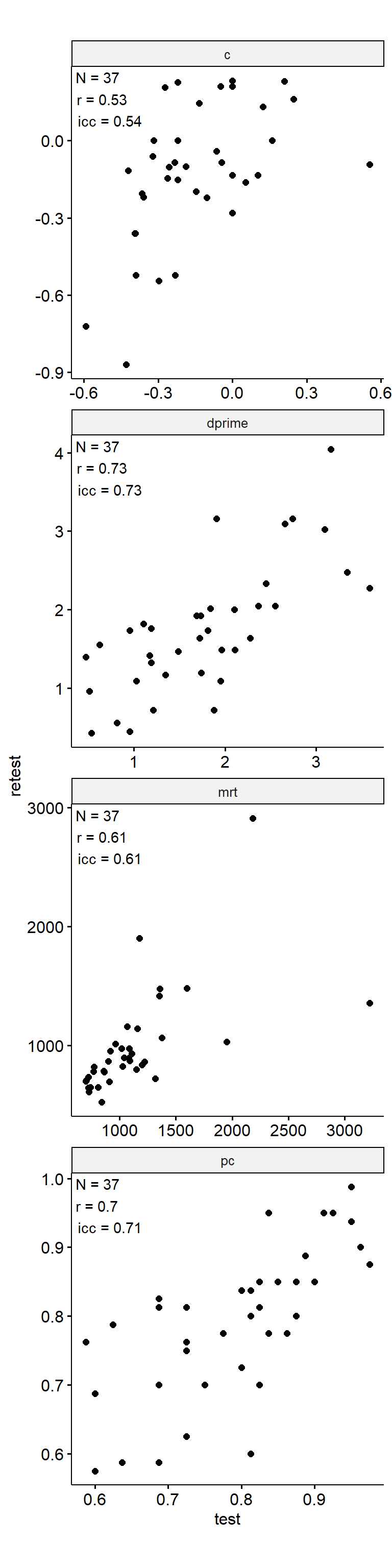
魔术师高级
data <- indices |>
filter(
game_name_abbr == "Nback3",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Nback3
- Sample Size: 89
- Index Names:
- pc
- mrt
- dprime
- c
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()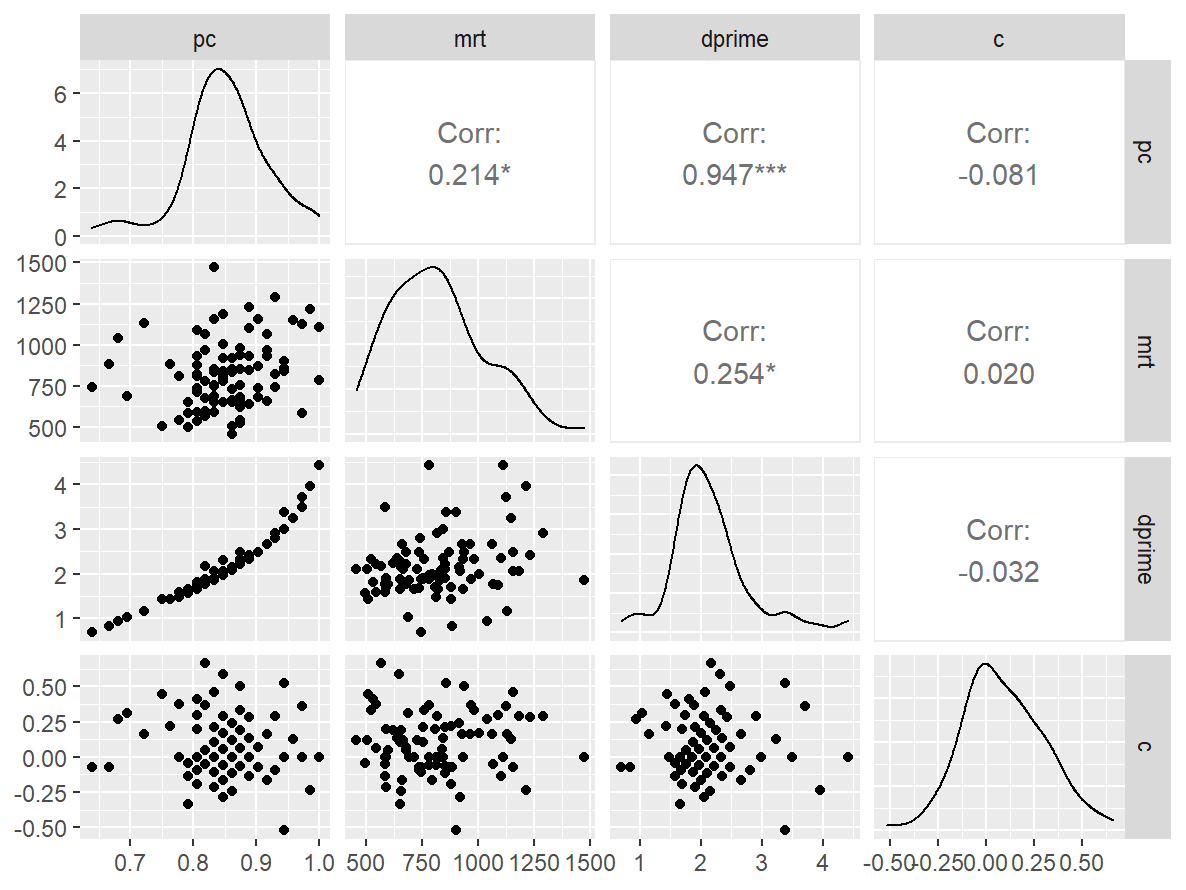
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)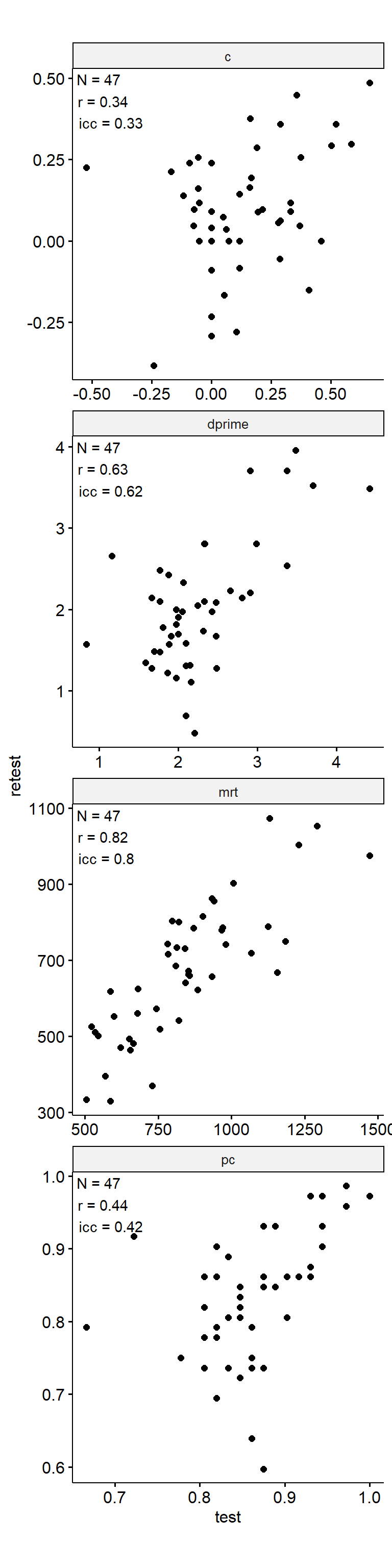
变色魔块PRO
data <- indices |>
filter(
game_name_abbr == "StopSigPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: StopSigPro
- Sample Size: 88
- Index Names:
- rt_nth
- ssrt
- pc_all
- pc_go
- pc_stop
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()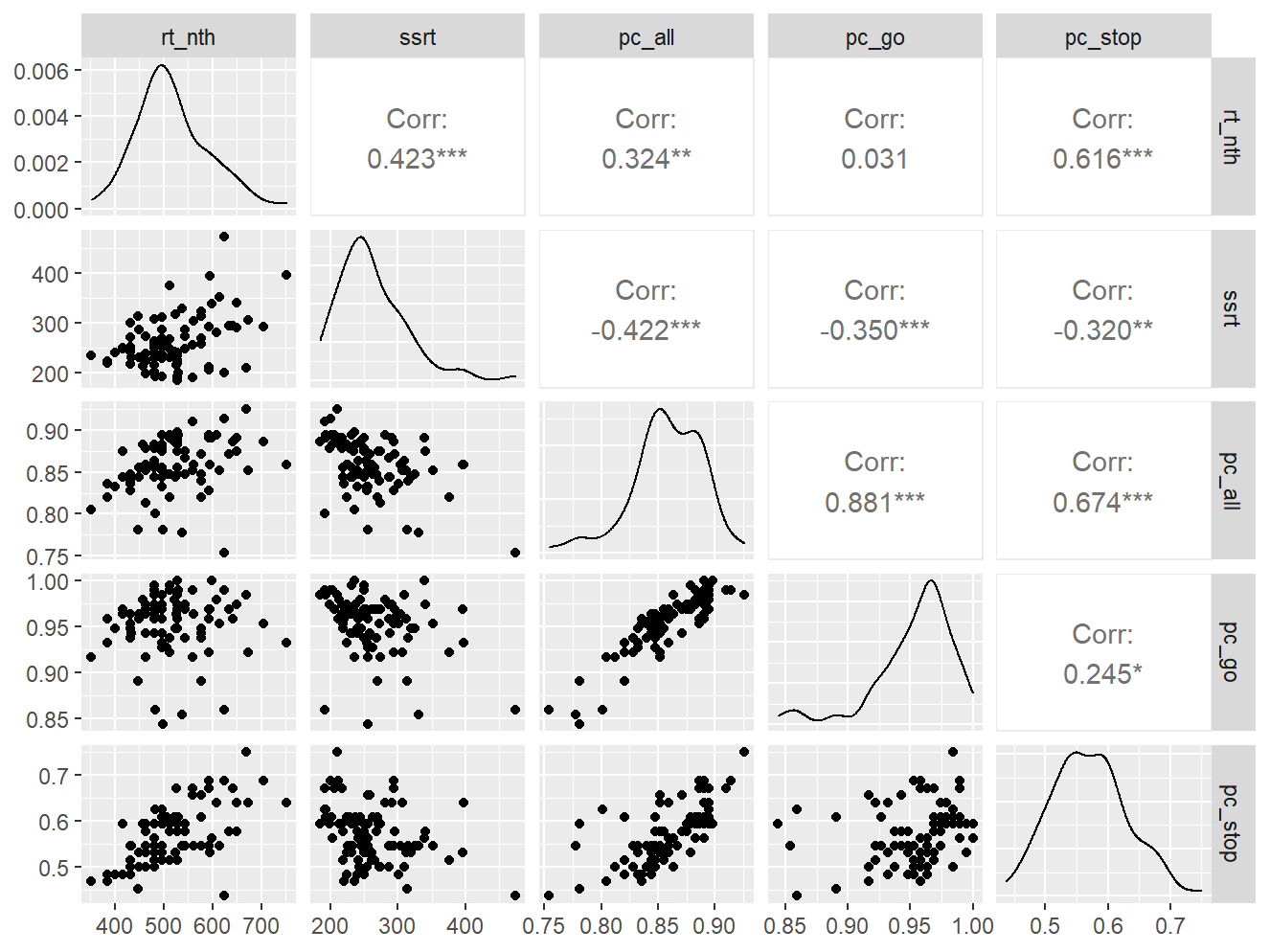
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)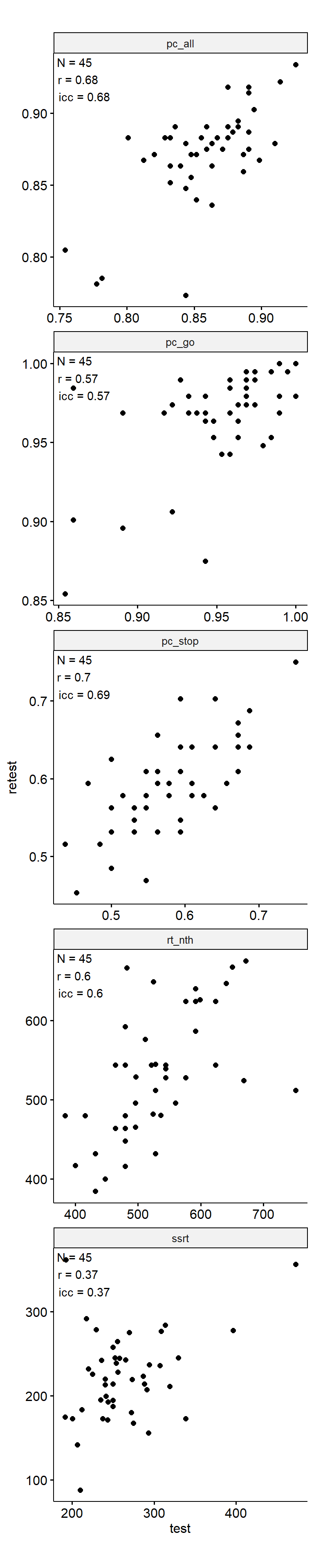
多彩文字PRO
data <- indices |>
filter(
game_name_abbr == "ColStrpPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: ColStrpPro
- Sample Size: 90
- Index Names:
- mrt_inc
- mrt_con
- pc_inc
- pc_con
- cong_eff_rt
- cong_eff_pc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()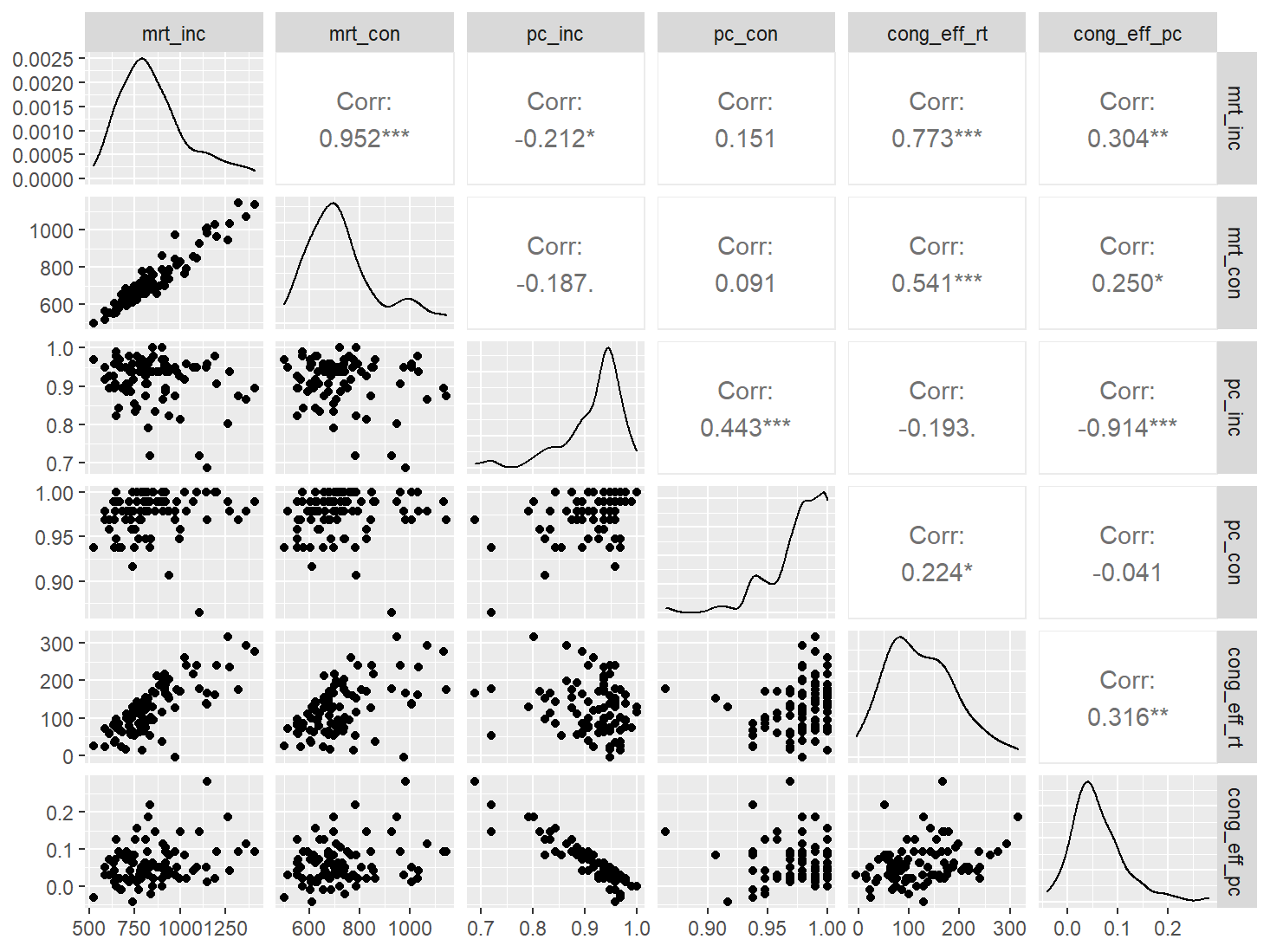
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
卡片分类PRO
data <- indices |>
filter(
game_name_abbr == "CardSortPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: CardSortPro
- Sample Size: 86
- Index Names:
- mrt_repeat
- mrt_switch
- pc_repeat
- pc_switch
- switch_cost_rt_spe
- switch_cost_pc_spe
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()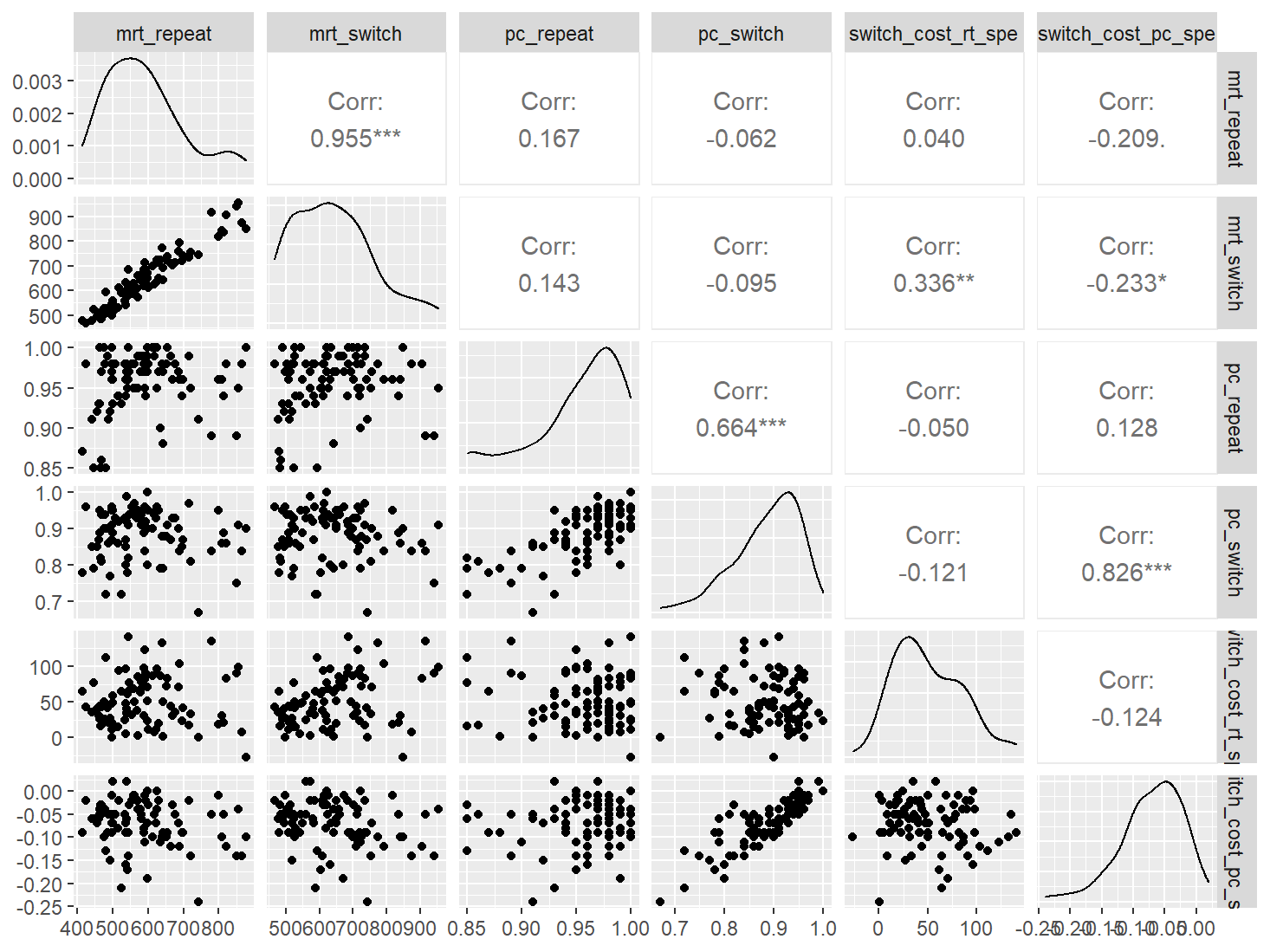
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
候鸟迁徙PRO
data <- indices |>
filter(
game_name_abbr == "BirdsPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: BirdsPro
- Sample Size: 90
- Index Names:
- mrt_inc
- mrt_con
- pc_inc
- pc_con
- cong_eff_rt
- cong_eff_pc
- mrt_repeat
- mrt_switch
- pc_repeat
- pc_switch
- switch_cost_rt_spe
- switch_cost_pc_spe
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()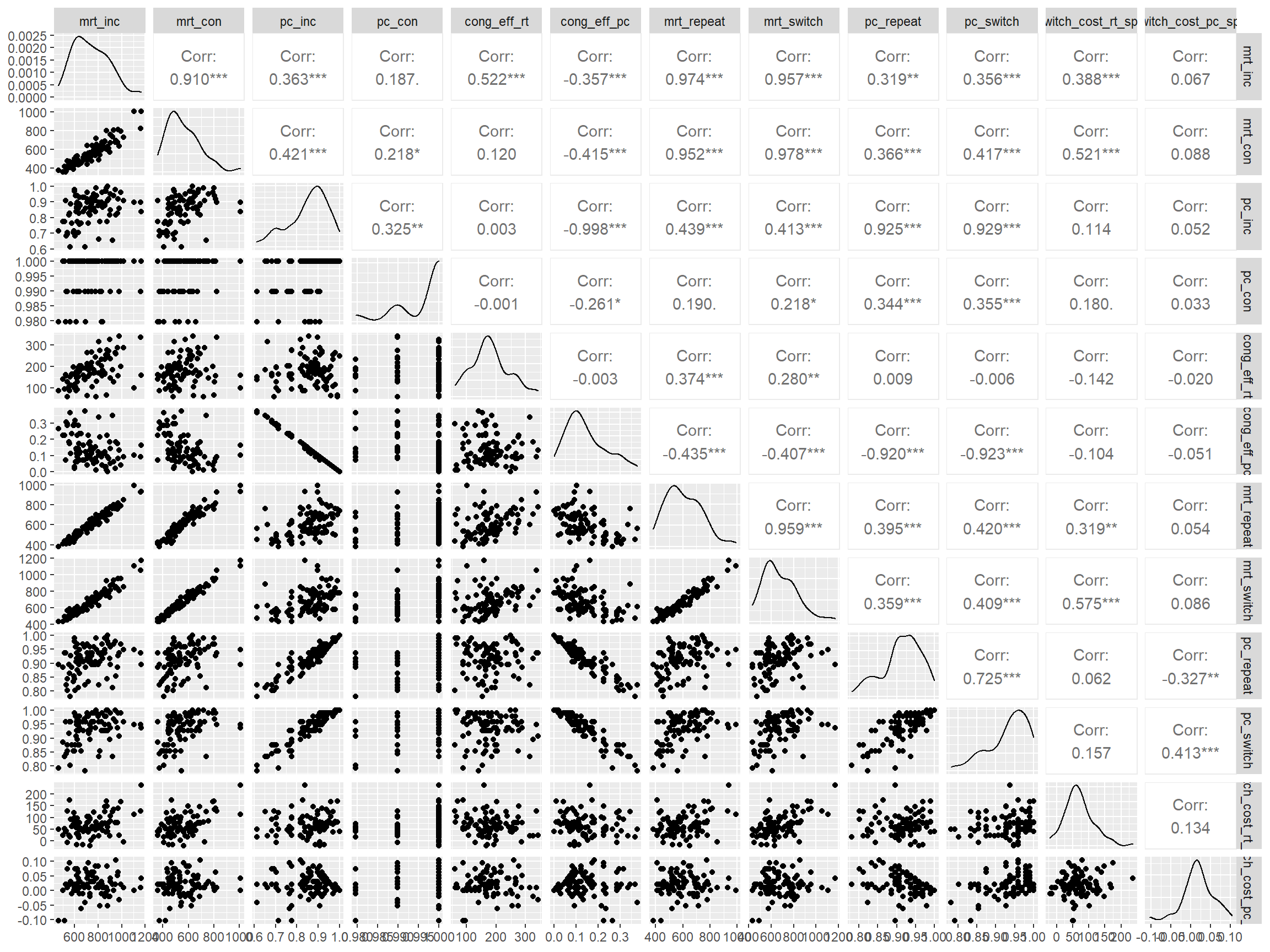
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
方向临摹
data <- indices |>
filter(
game_name_abbr == "JLO",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: JLO
- Sample Size: 102
- Index Names:
- nc
- mean_ang_err
- mean_log_err
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()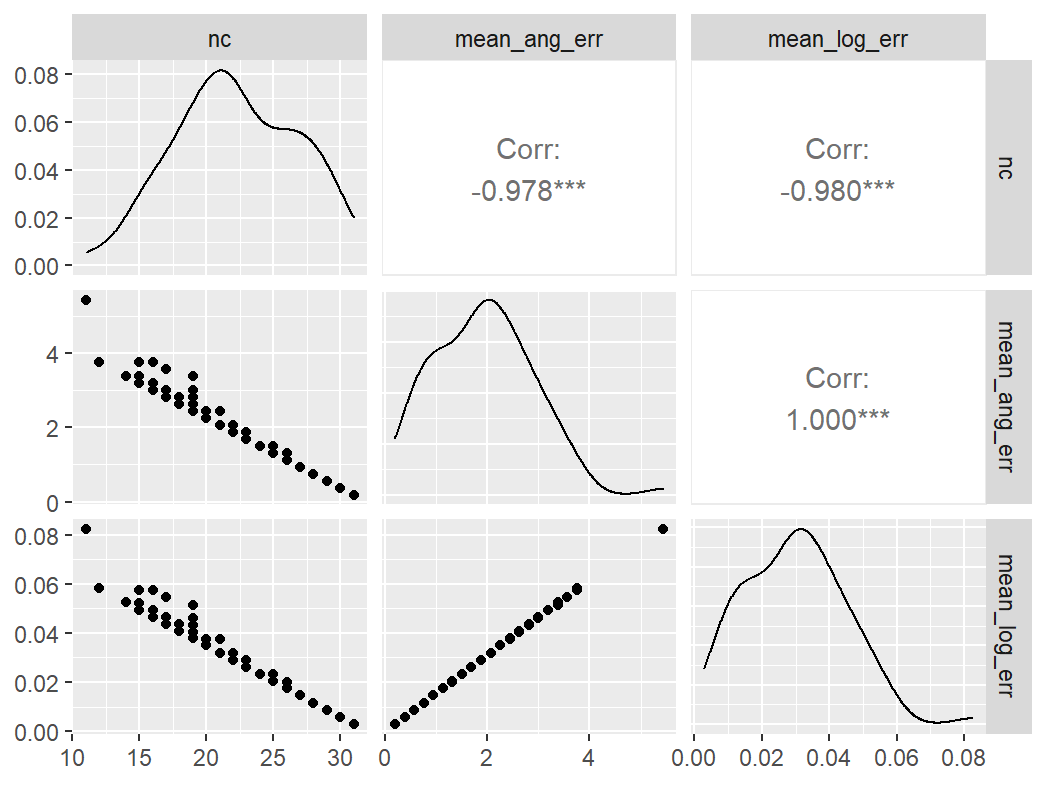
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)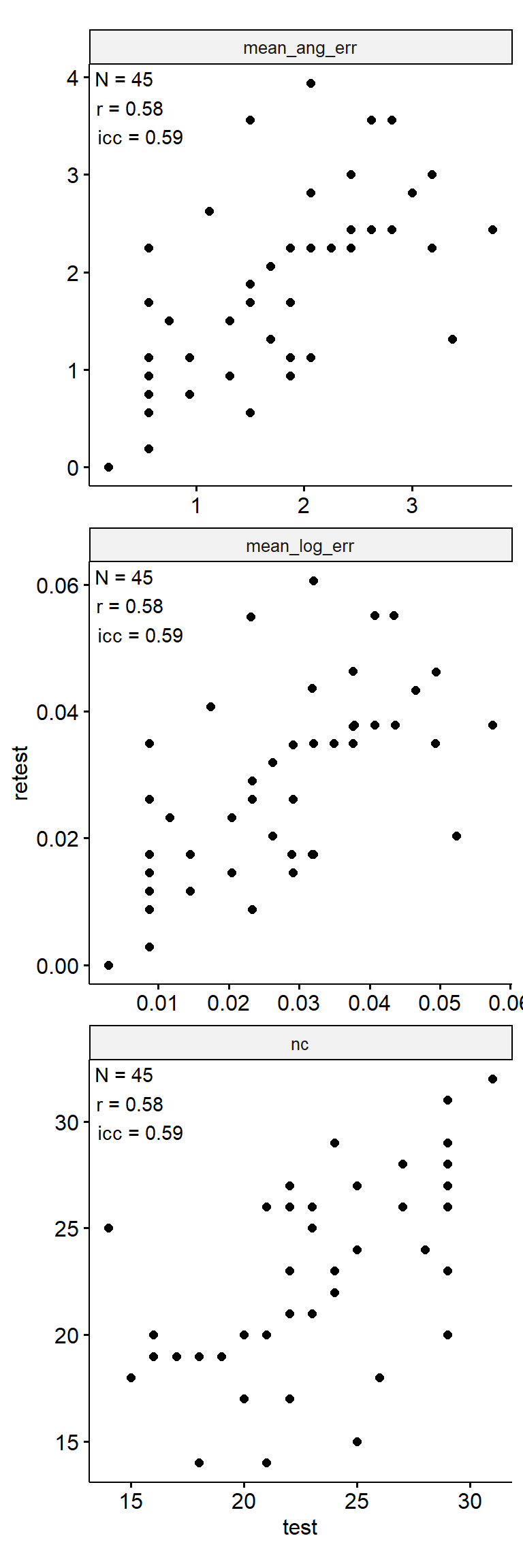
按图索骥
data <- indices |>
filter(
game_name_abbr == "HOP",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: HOP
- Sample Size: 102
- Index Names:
- mean_dist_err_allo
- mean_dist_err_both
- mean_dist_err_ego
- mean_log_err_allo
- mean_log_err_both
- mean_log_err_ego
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()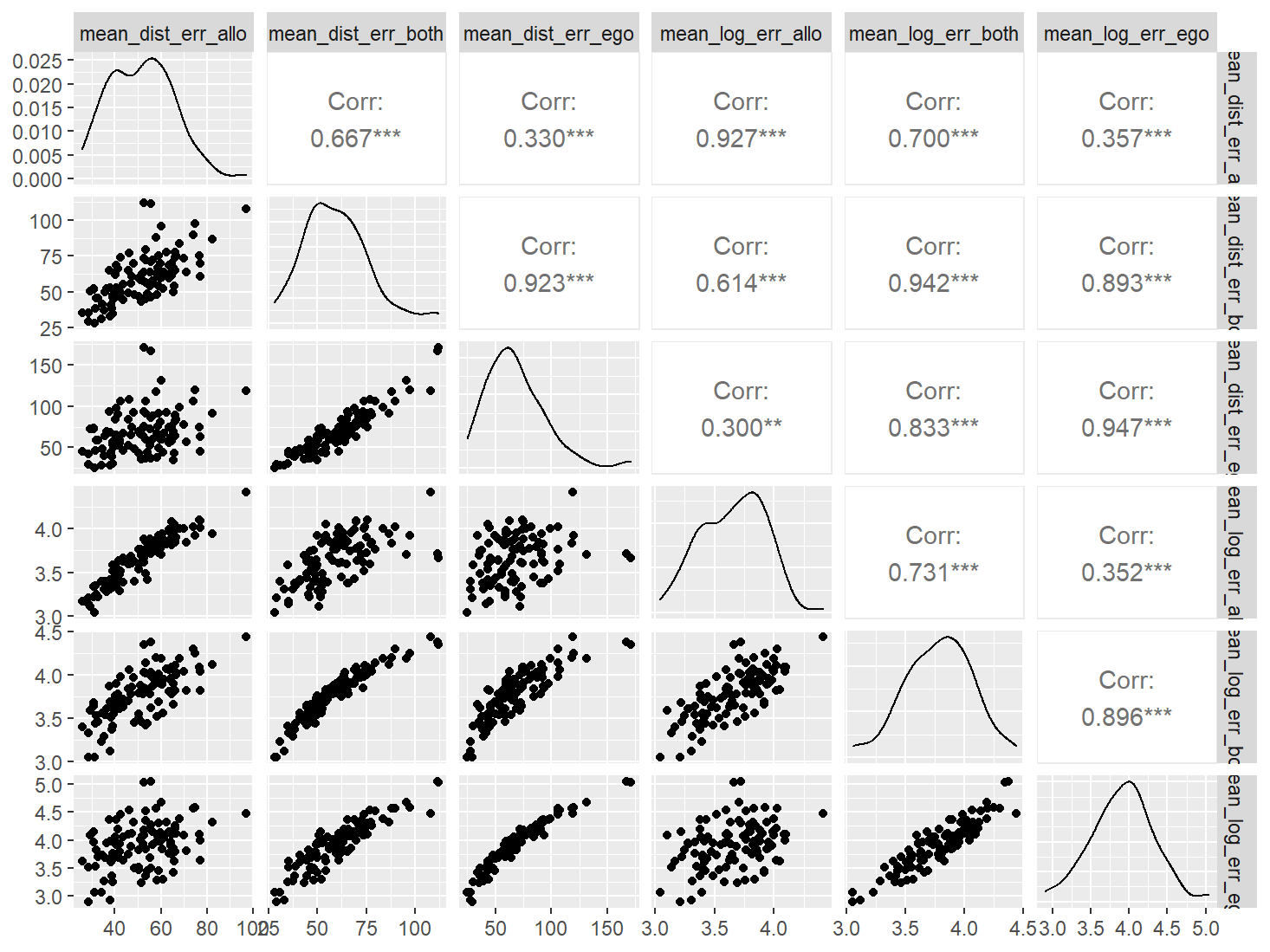
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
萤火虫PRO
data <- indices |>
filter(
game_name_abbr == "MOTPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: MOTPro
- Sample Size: 102
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()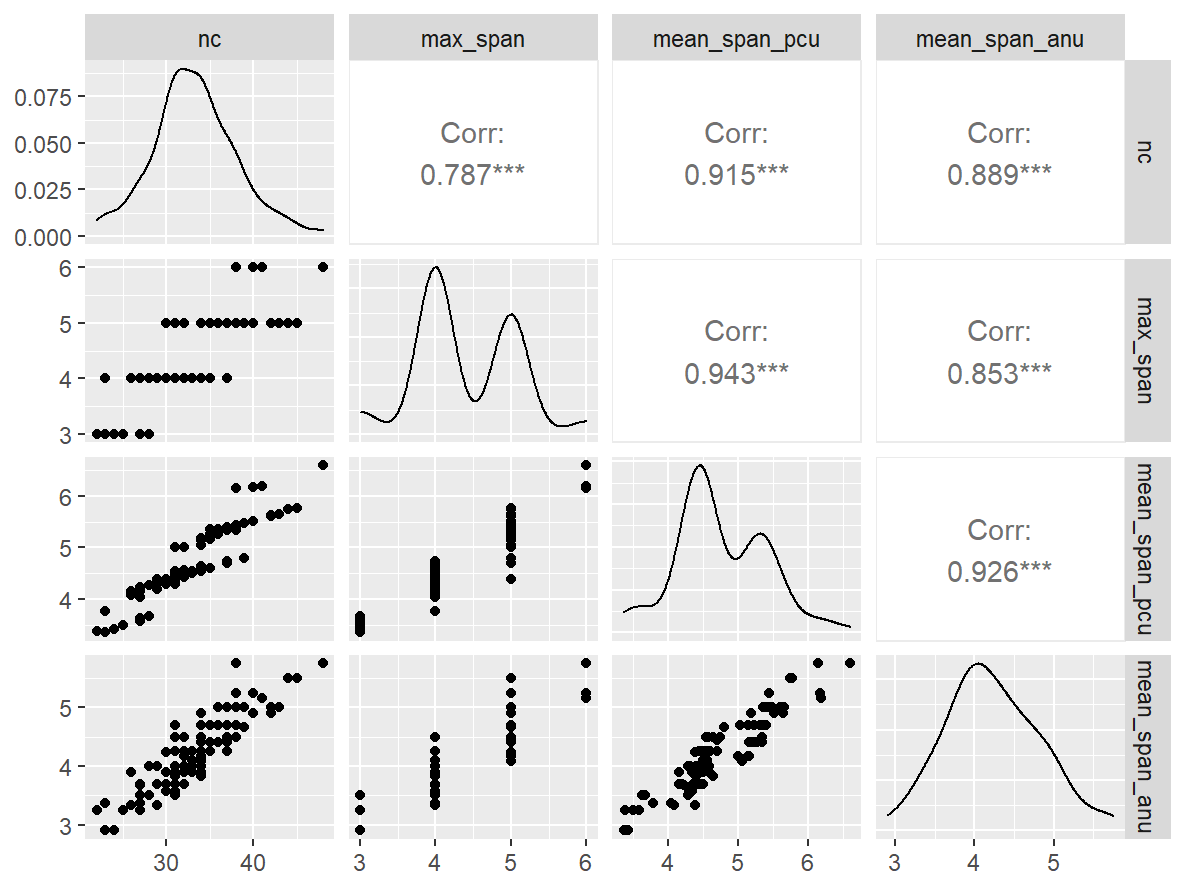
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)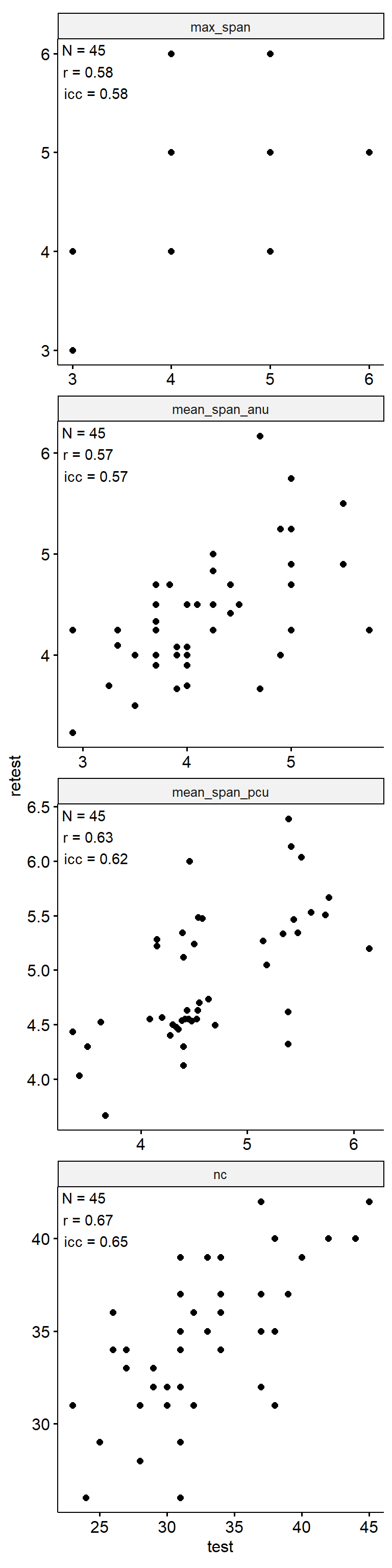
火眼金睛
data <- indices |>
filter(
game_name_abbr == "AttSrc",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: AttSrc
- Sample Size: 102
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()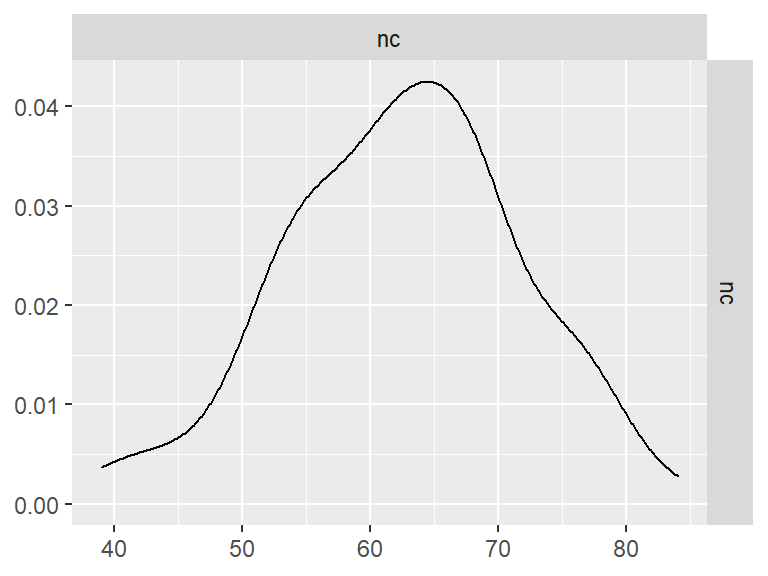
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)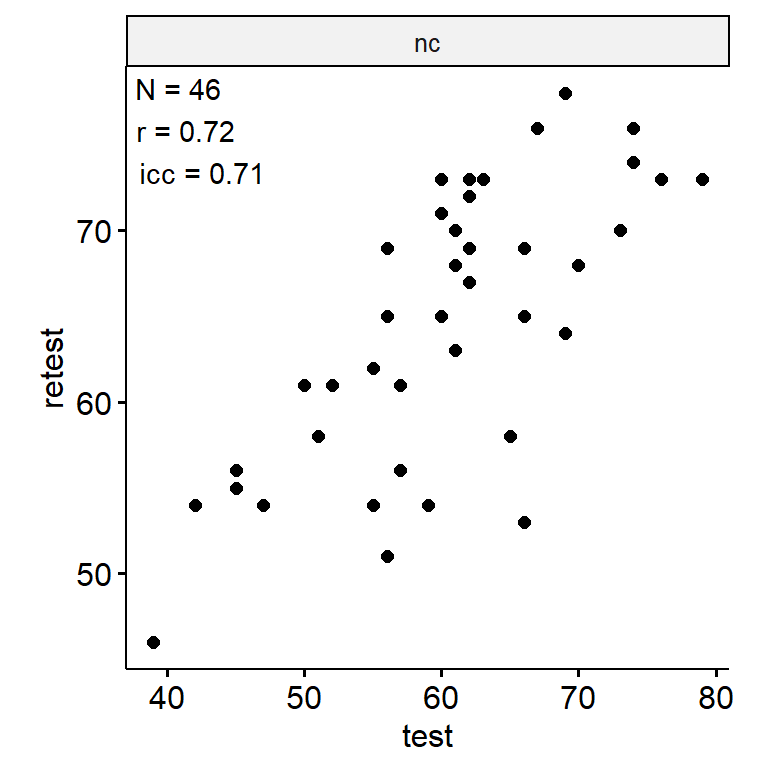
位置记忆PRO
data <- indices |>
filter(
game_name_abbr == "SSTMPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: SSTMPro
- Sample Size: 102
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()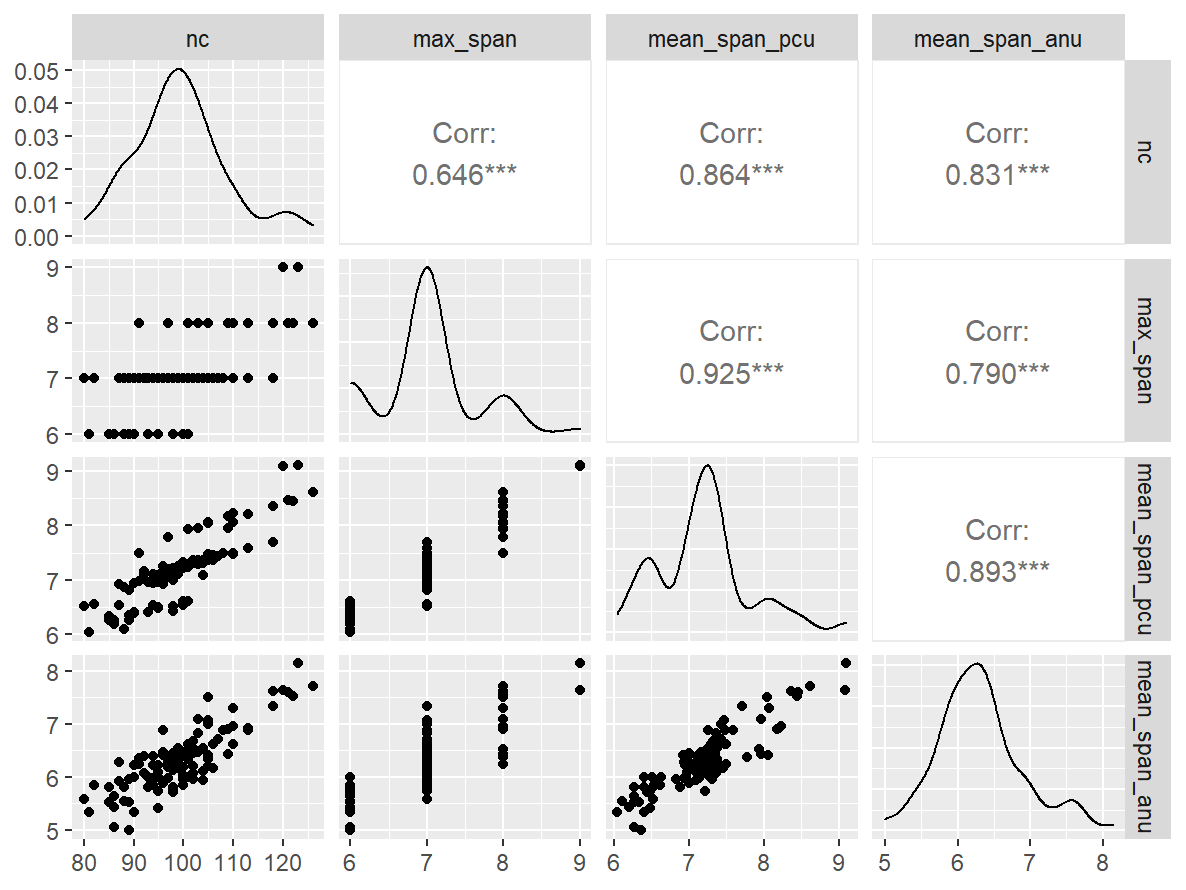
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)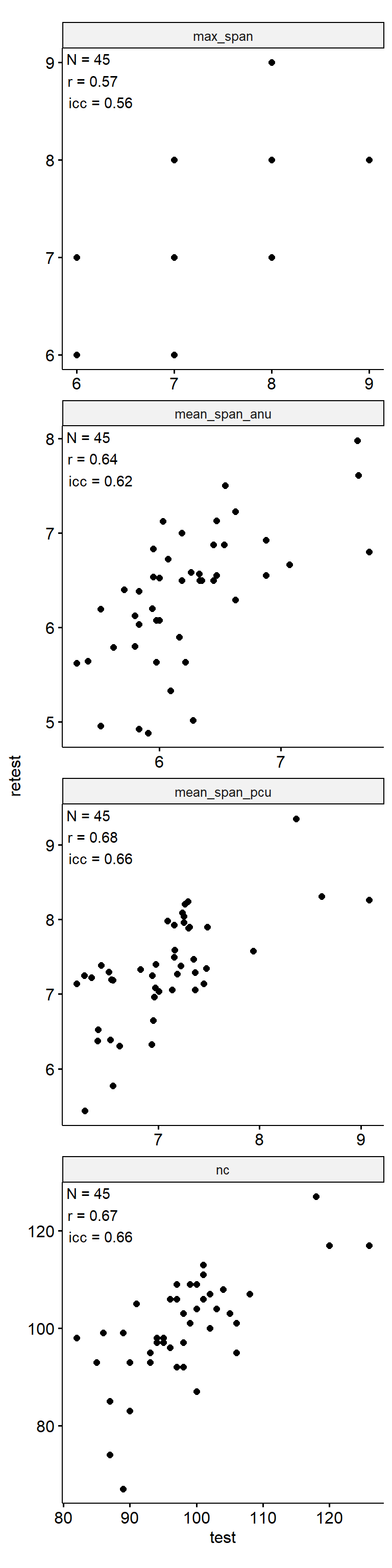
宇宙黑洞
data <- indices |>
filter(
game_name_abbr == "LocMemStd",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: LocMemStd
- Sample Size: 102
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()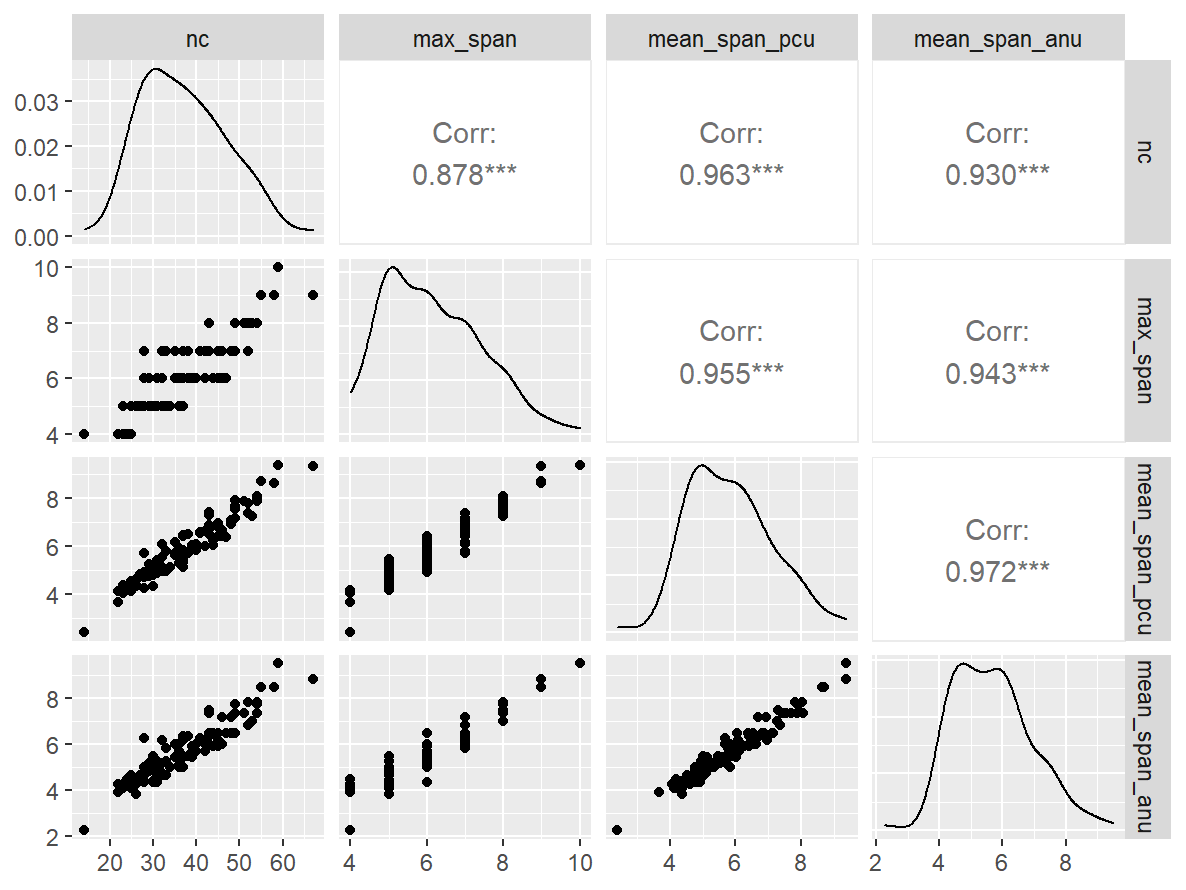
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)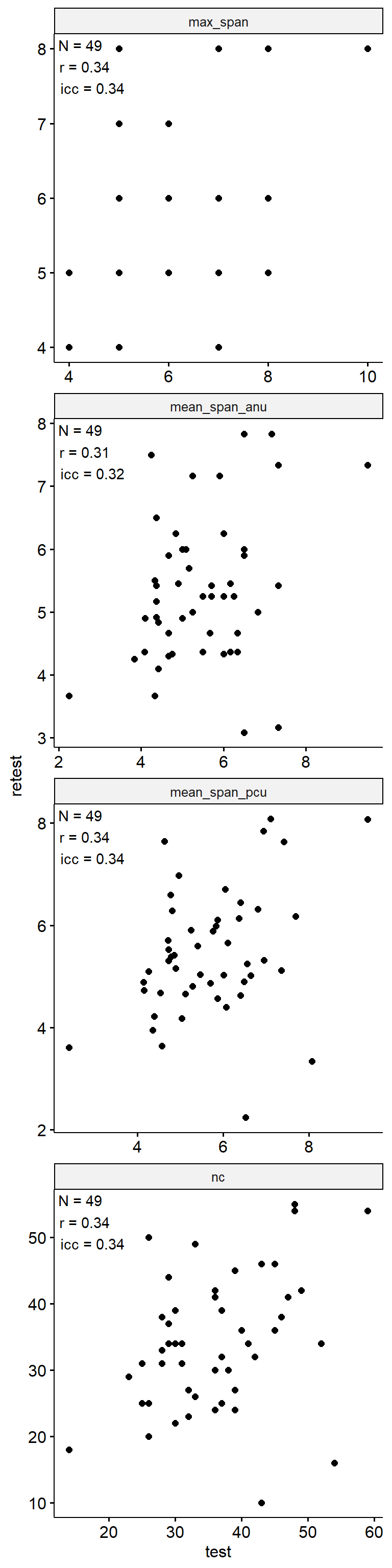
过目不忘PRO
data <- indices |>
filter(
game_name_abbr == "FWSPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: FWSPro
- Sample Size: 102
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()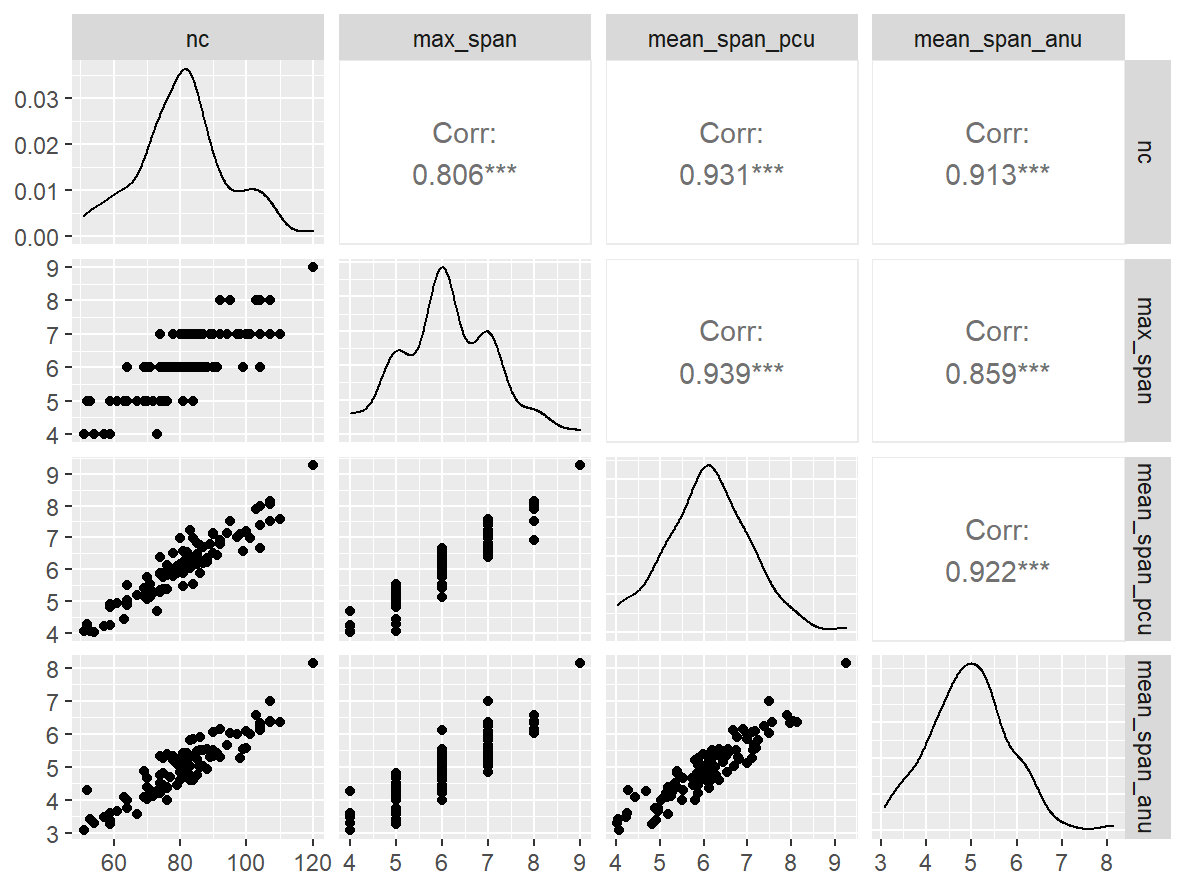
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)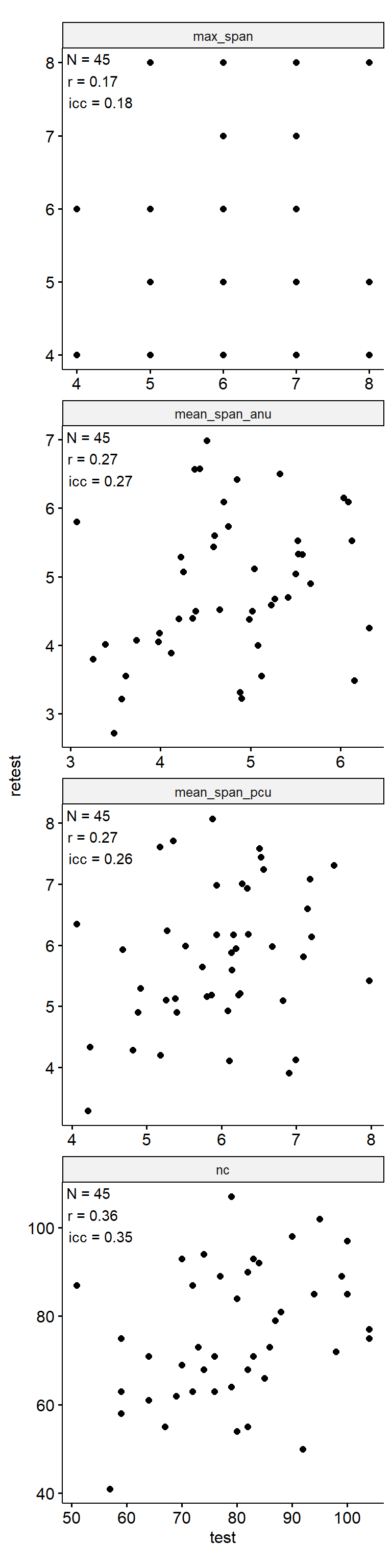
人工语言-中级
data <- indices |>
filter(
game_name_abbr == "AscLanMd",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: AscLanMd
- Sample Size: 102
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()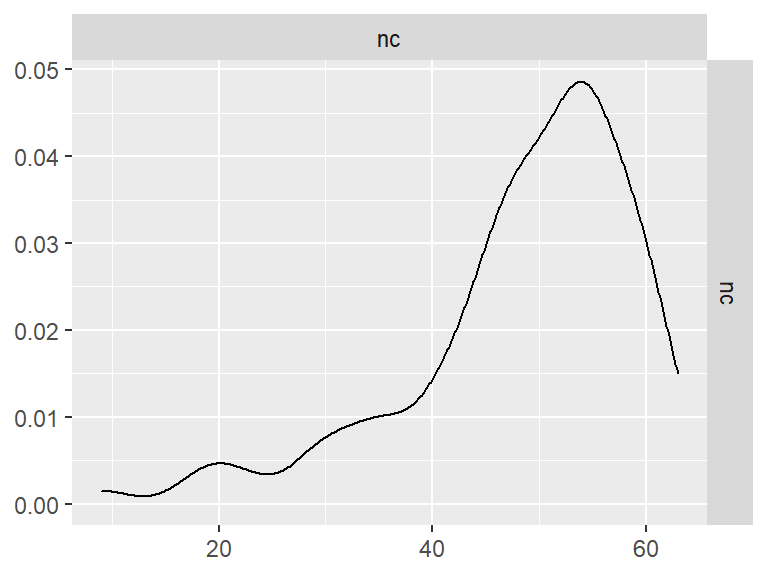
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)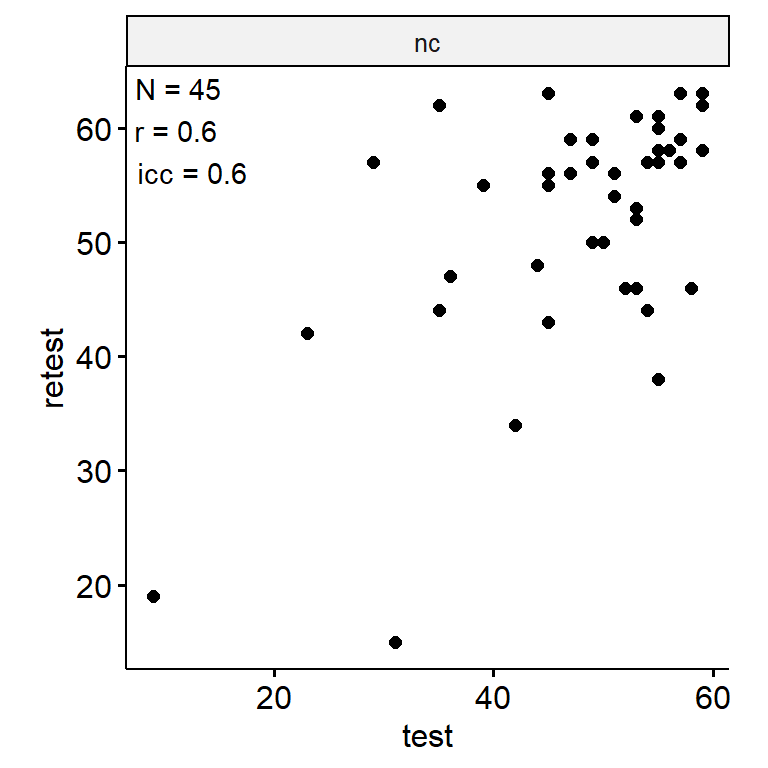
各得其所
data <- indices |>
filter(
game_name_abbr == "LdnTwr",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: LdnTwr
- Sample Size: 98
- Index Names:
- prop_perfect
- mrt_init
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()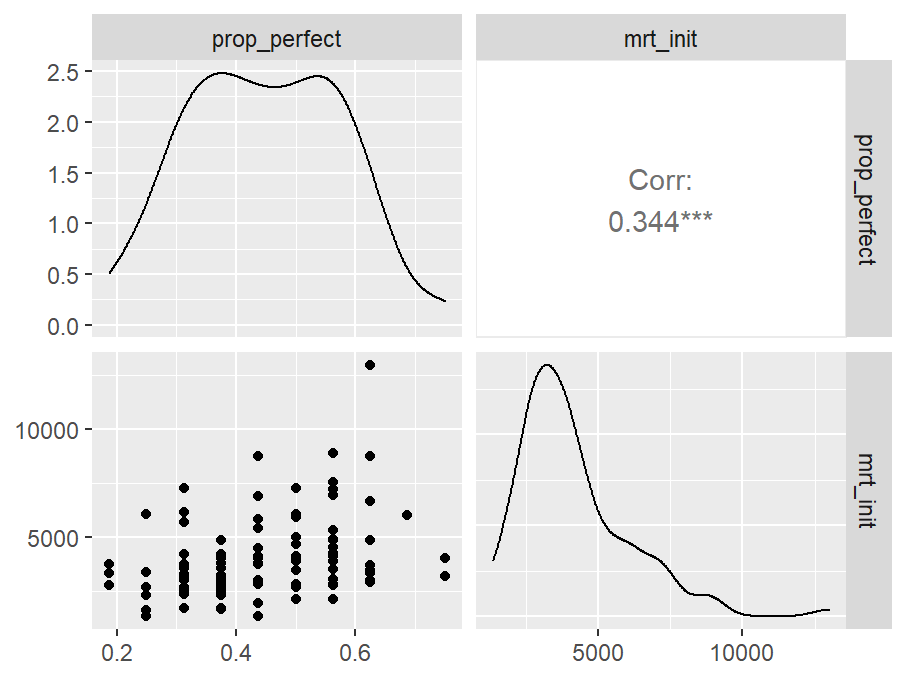
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)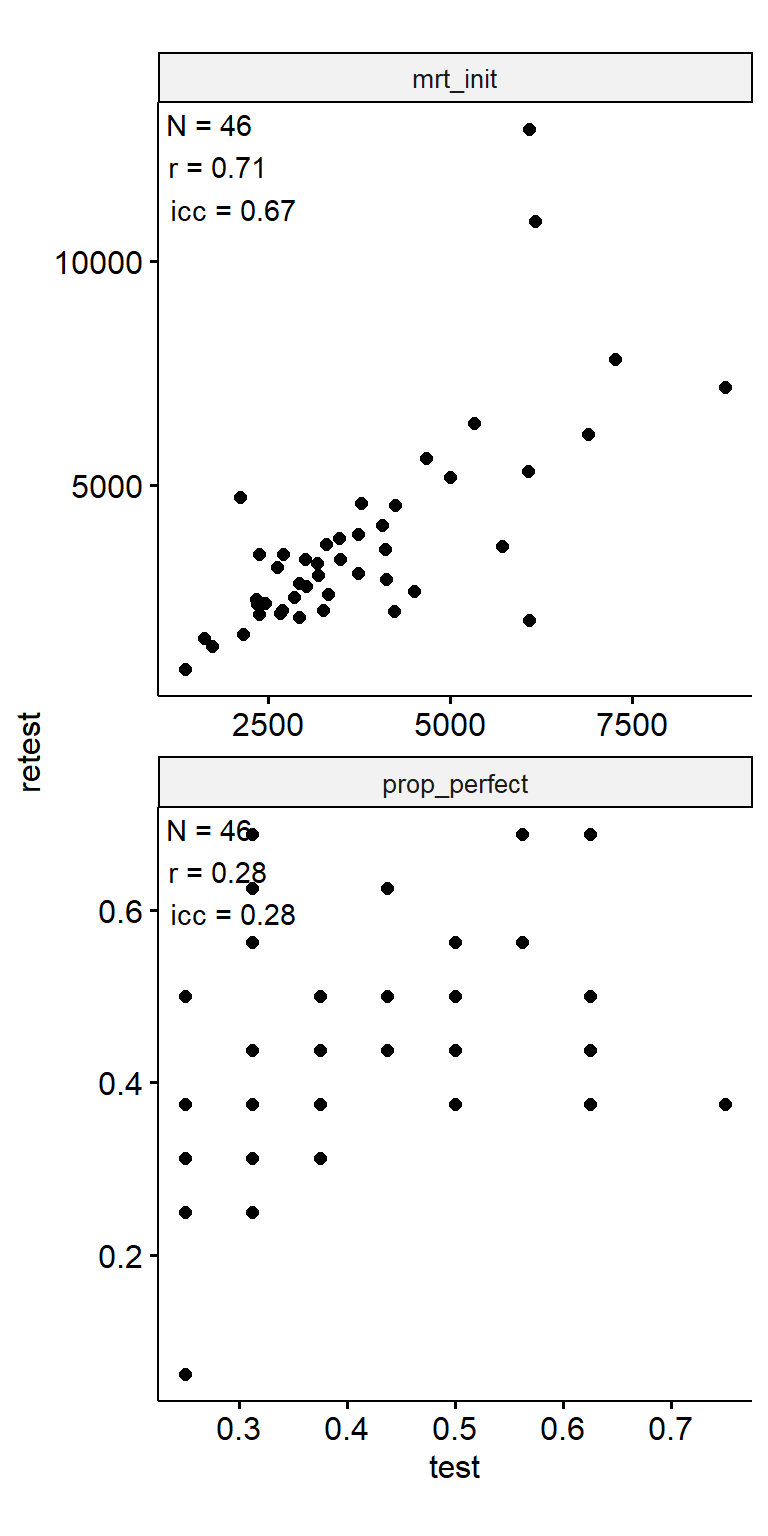
连点成画PRO
data <- indices |>
filter(
game_name_abbr == "FPTPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: FPTPro
- Sample Size: 102
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()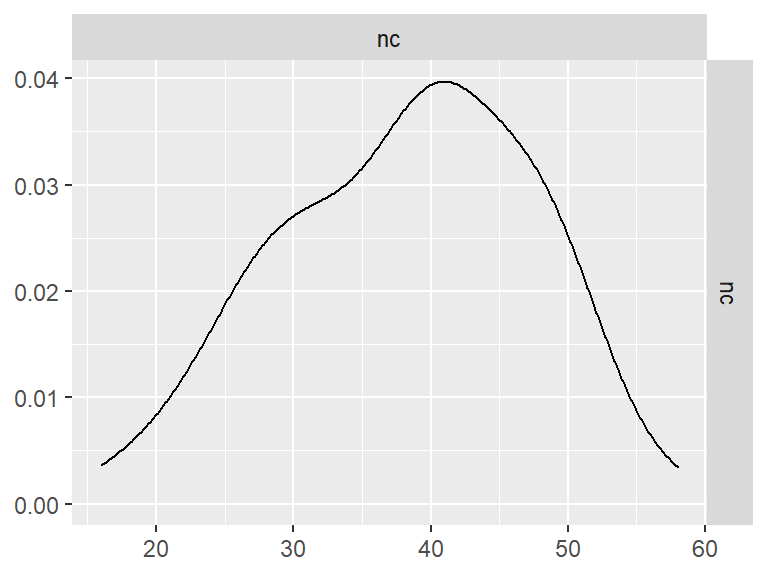
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)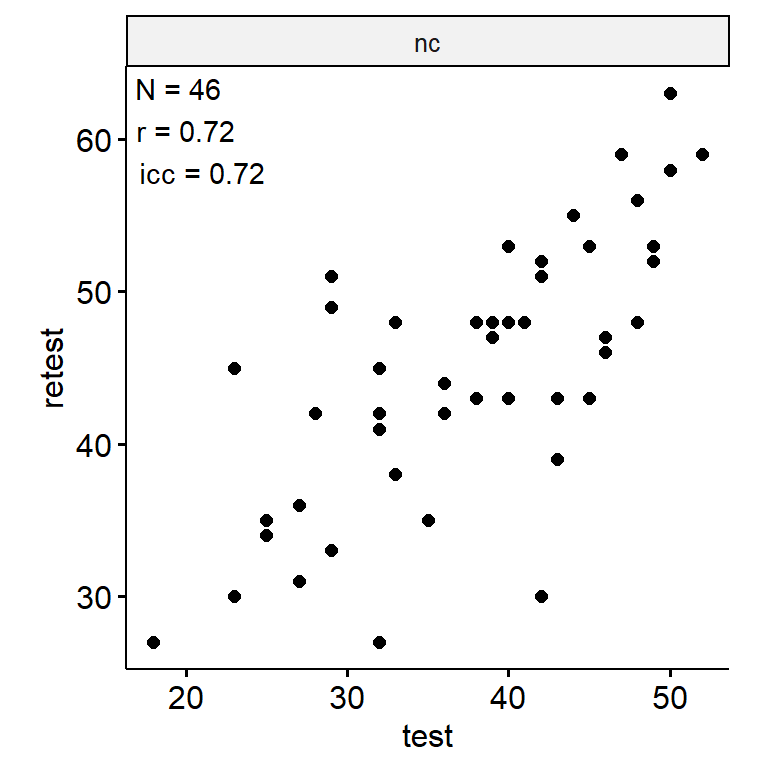
蝴蝶照相机
data <- indices |>
filter(
game_name_abbr == "SCSpan",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: SCSpan
- Sample Size: 102
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()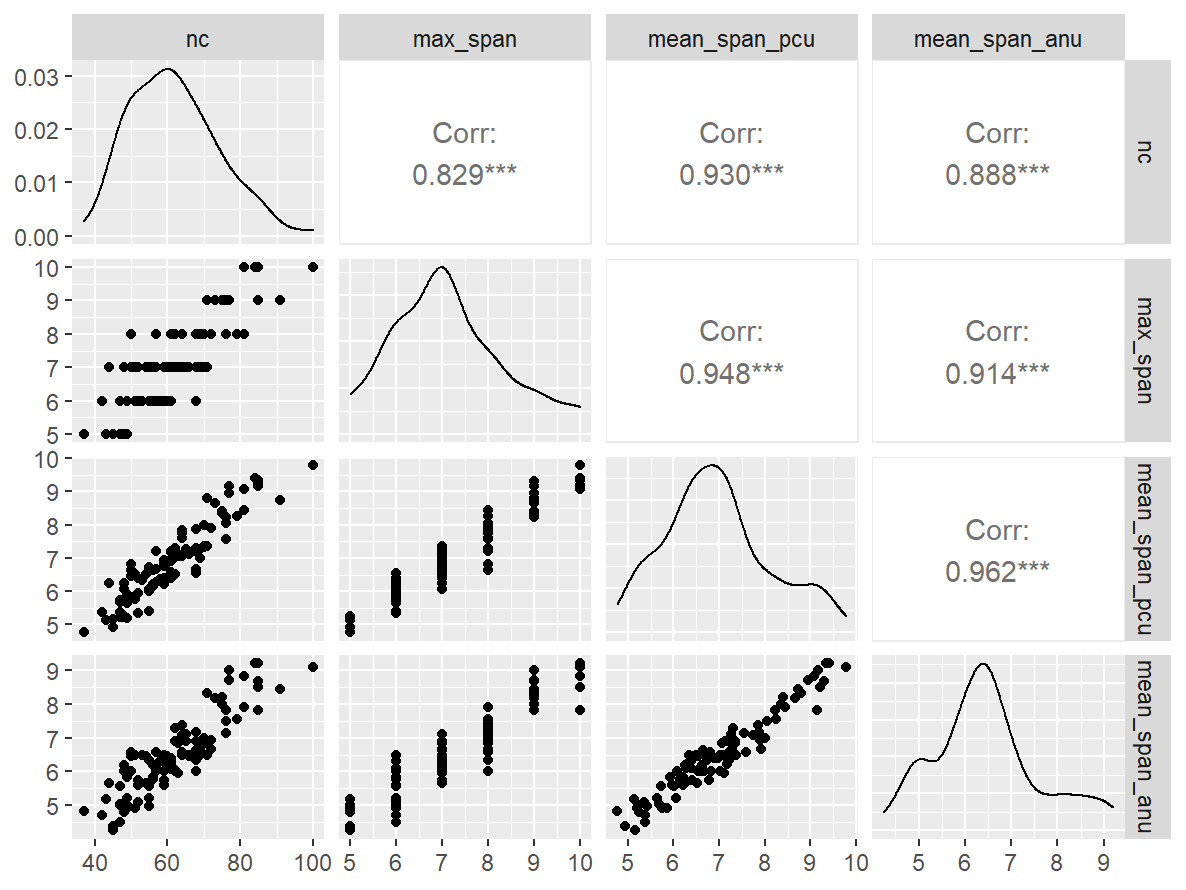
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)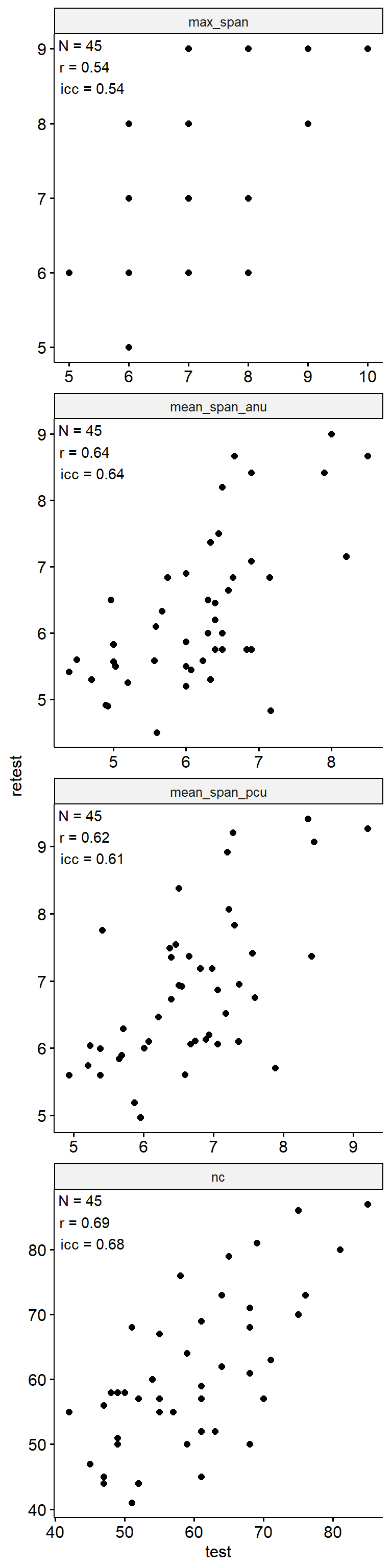
密码箱
data <- indices |>
filter(
game_name_abbr == "KeepTrack",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: KeepTrack
- Sample Size: 102
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()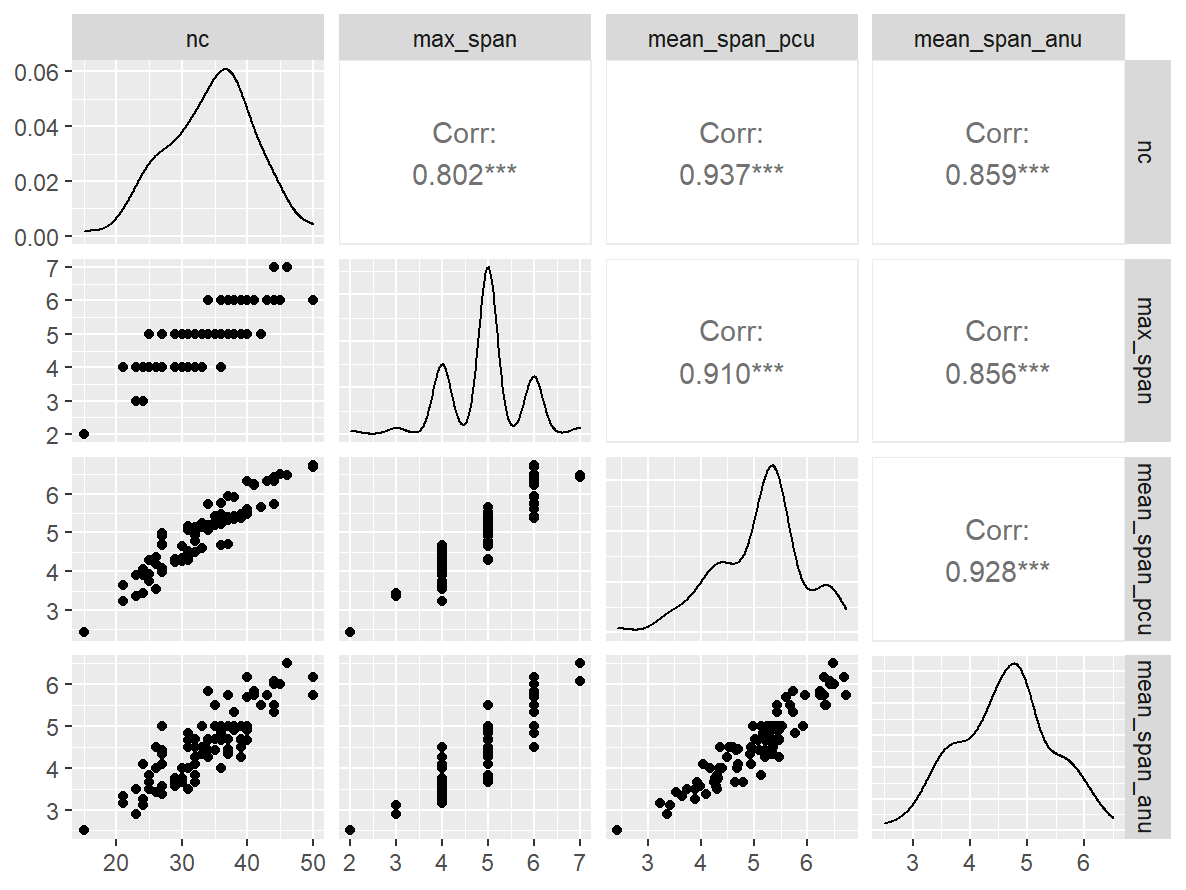
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)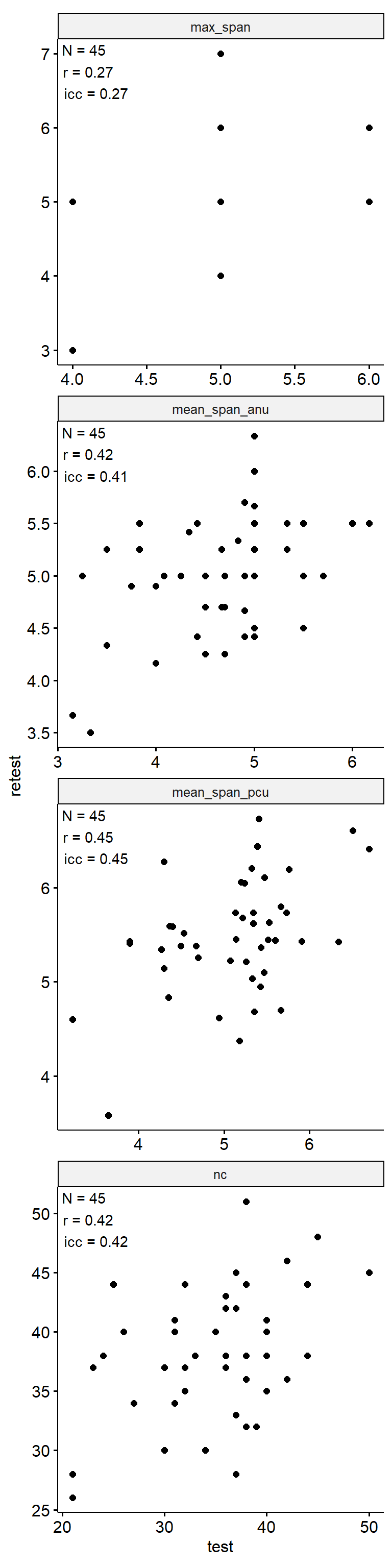
超级秒表PRO
data <- indices |>
filter(
game_name_abbr == "SRTPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: SRTPro
- Sample Size: 99
- Index Names:
- mrt
- rtsd
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()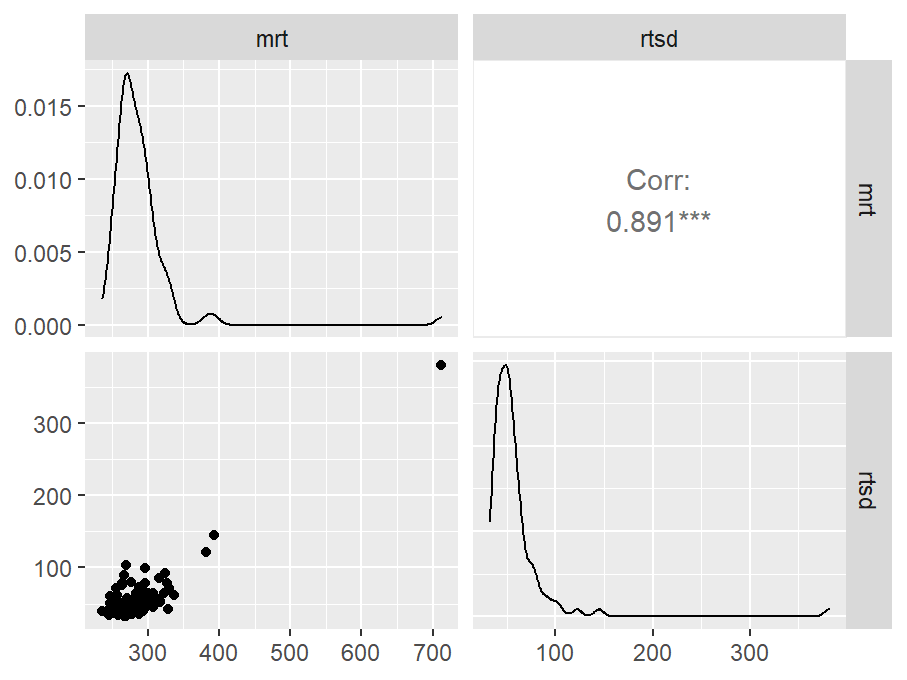
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)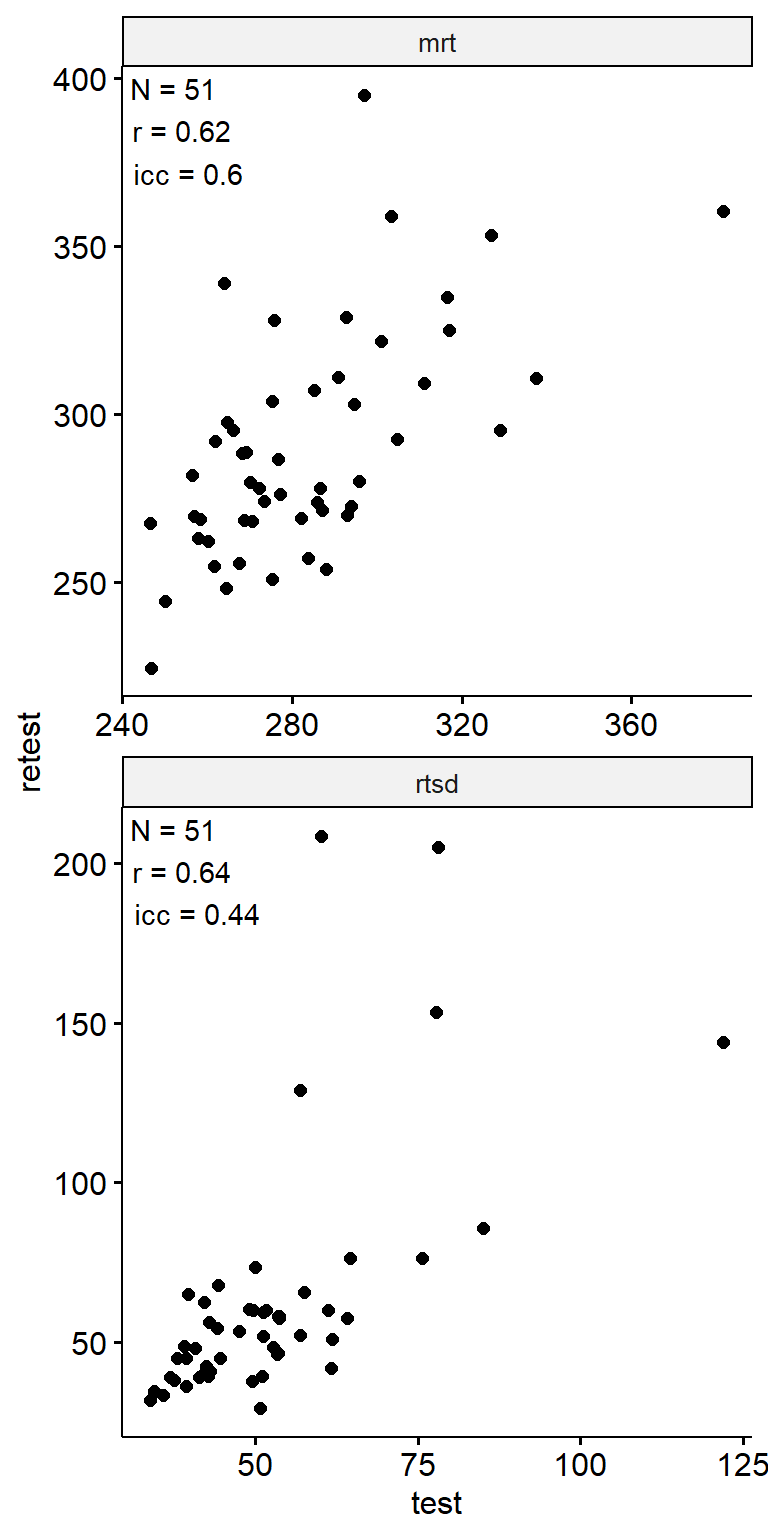
一心二用PRO
data <- indices |>
filter(
game_name_abbr == "DualTaskPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: DualTaskPro
- Sample Size: 99
- Index Names:
- nc
- mrt
- rtsd
- dprime
- c
- commissions
- omissions
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()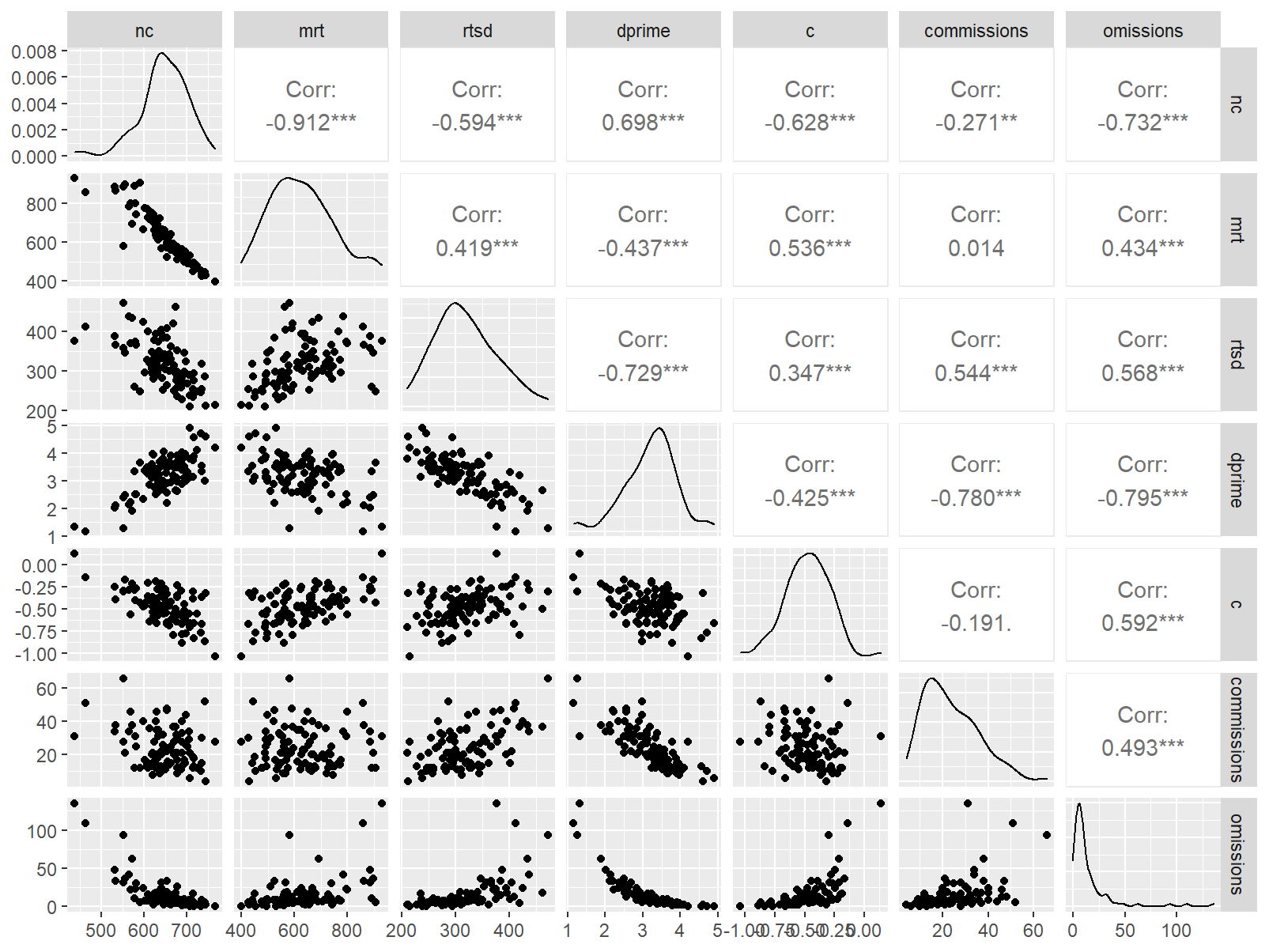
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
连续再认
data <- indices |>
filter(
game_name_abbr == "ConRec",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: ConRec
- Sample Size: 99
- Index Names:
- nc
- mrt
- rtsd
- dprime
- c
- commissions
- omissions
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()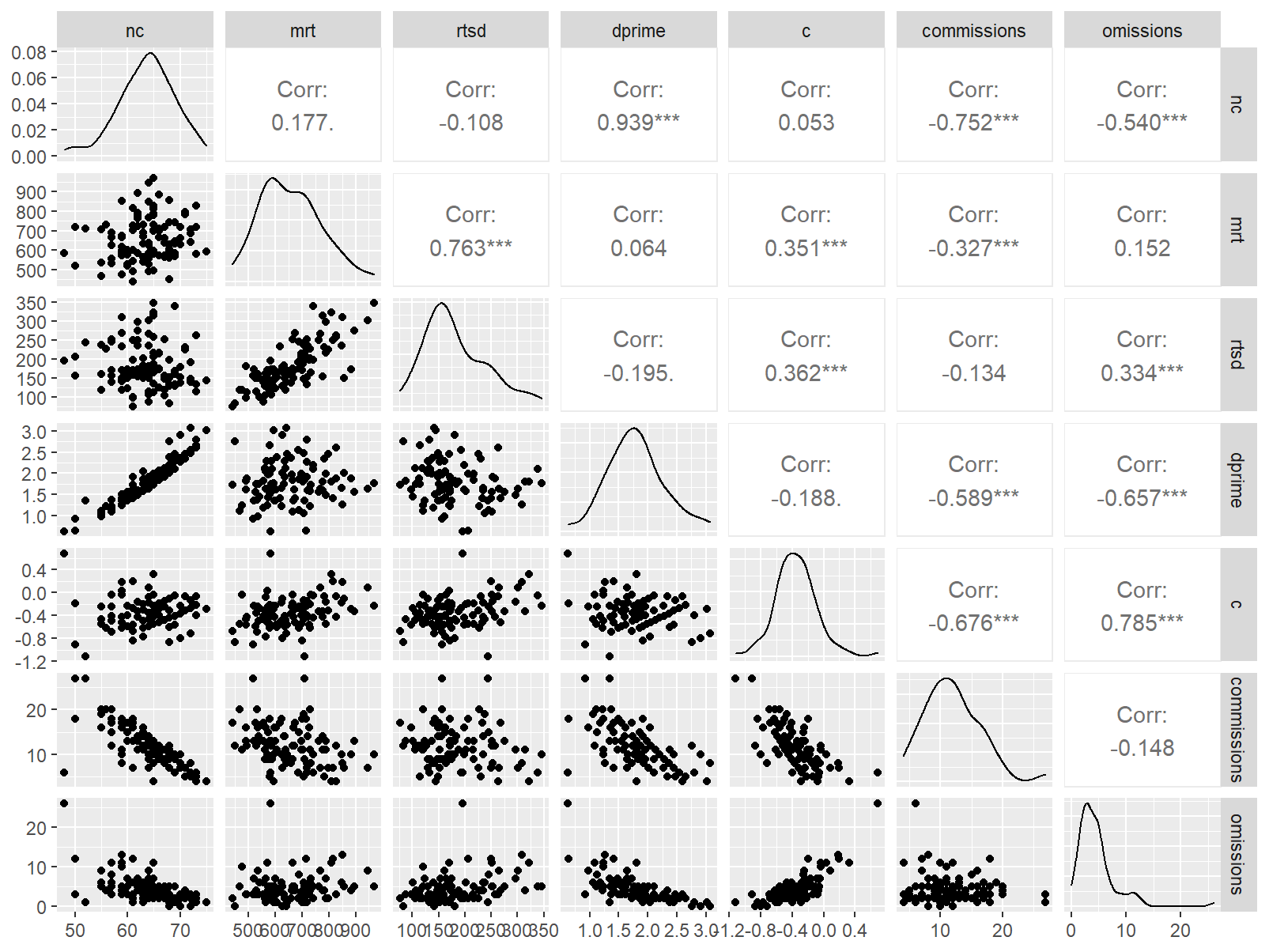
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
图片记忆
data <- indices |>
filter(
game_name_abbr == "BPS",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: BPS
- Sample Size: 99
- Index Names:
- pc
- p_sim_foil
- p_sim_lure
- p_sim_target
- bps_score
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()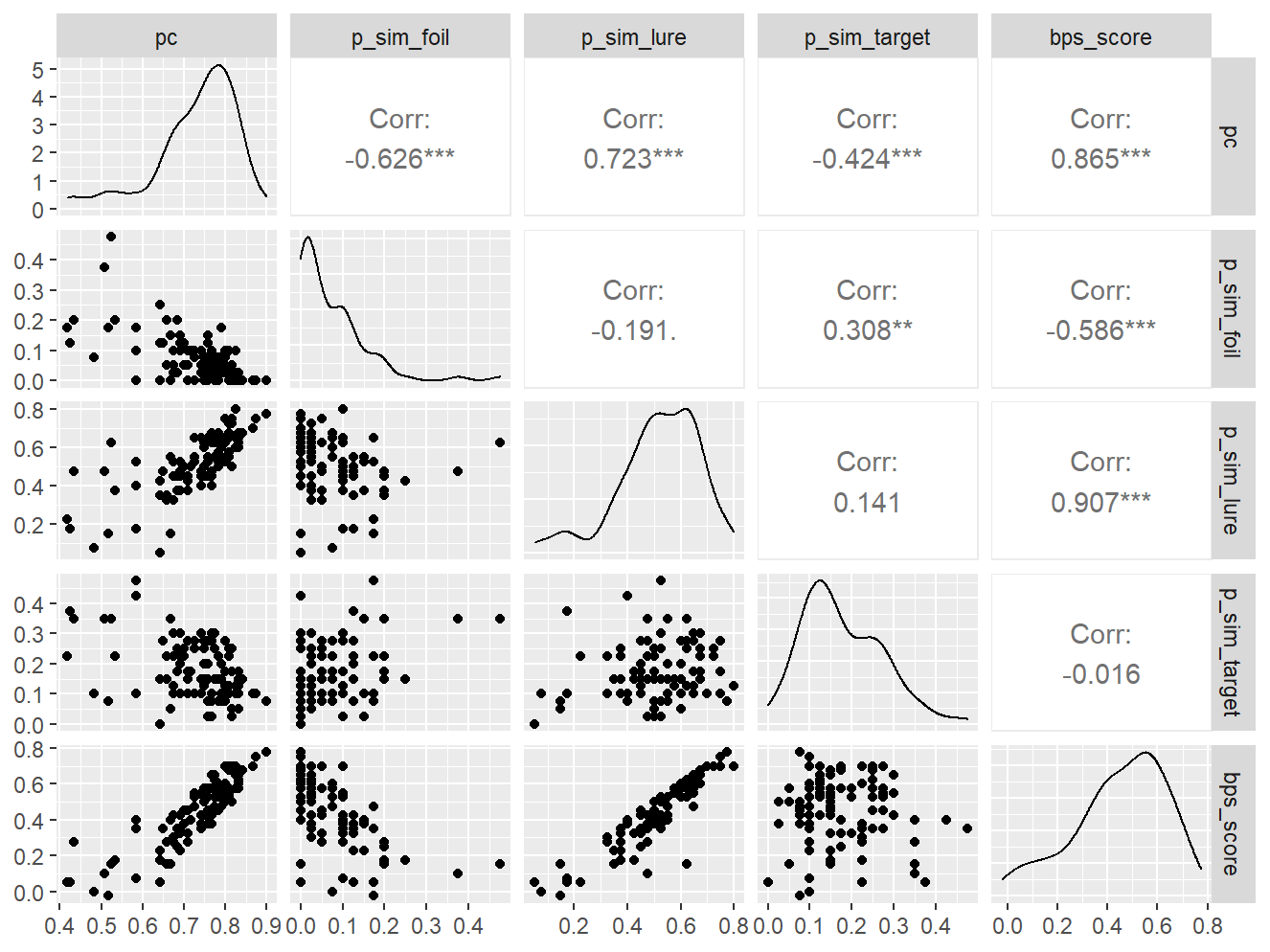
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)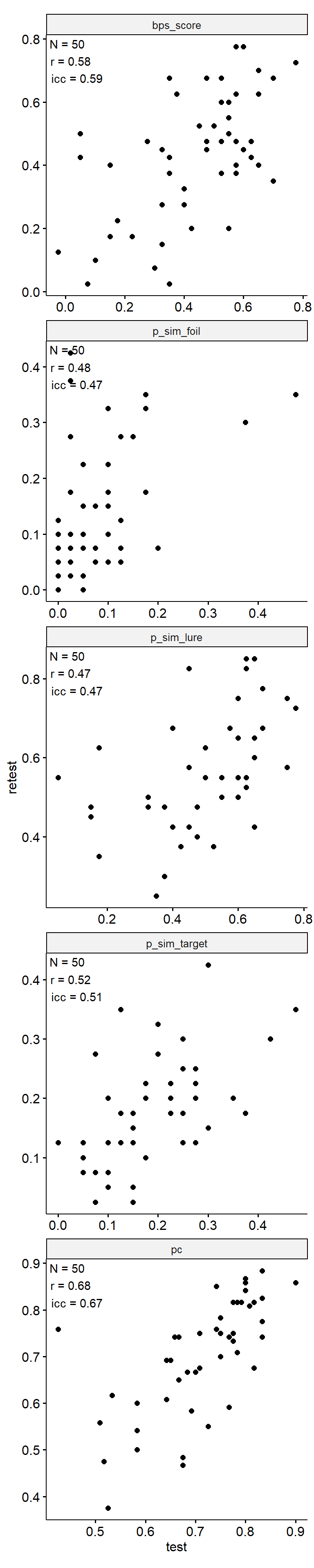
言语记忆
data <- indices |>
filter(
game_name_abbr == "DRM",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: DRM
- Sample Size: 100
- Index Names:
- tm_dprime
- tm_bias
- fm_dprime
- fm_bias
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()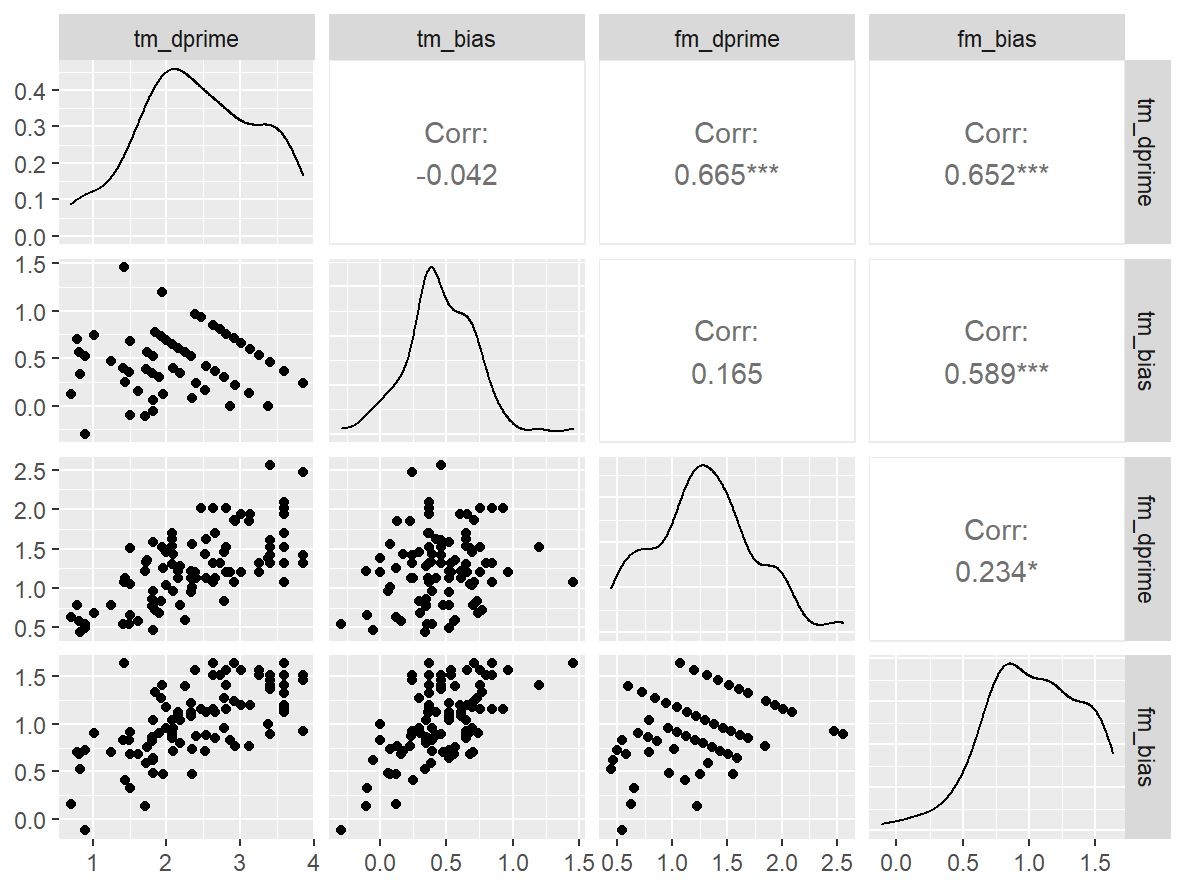
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)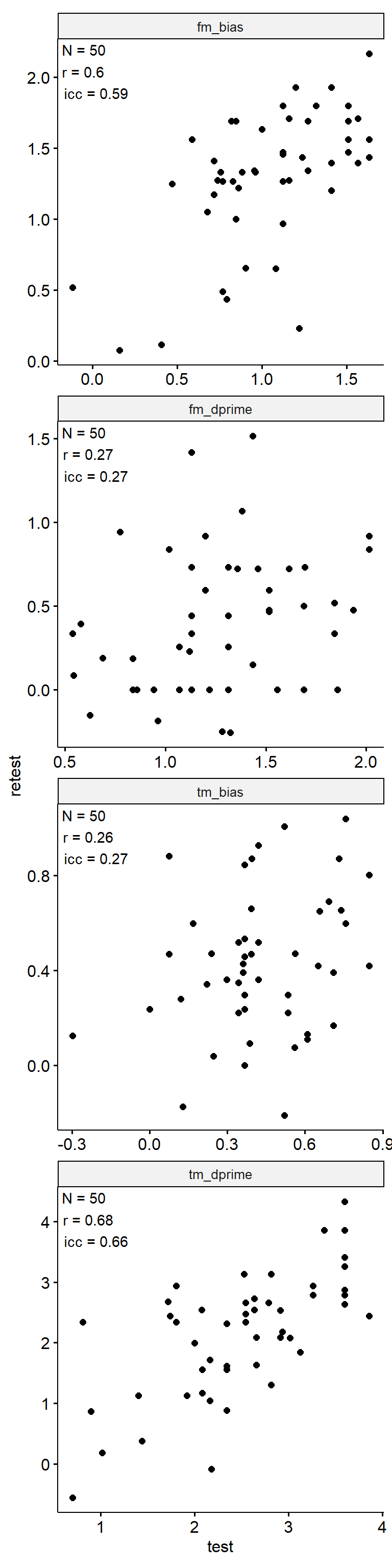
强化学习
data <- indices |>
filter(
game_name_abbr == "ProbRL",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: ProbRL
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()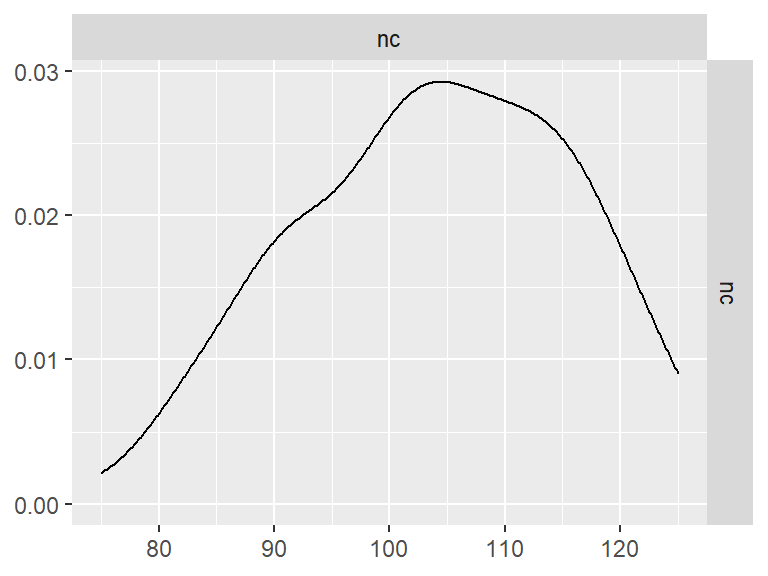
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)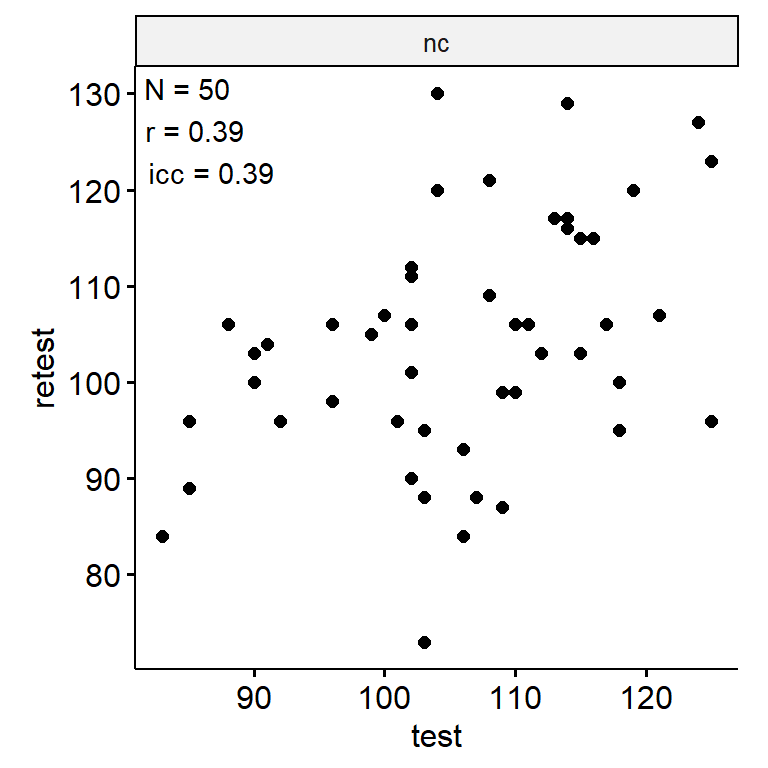
语义判断
data <- indices |>
filter(
game_name_abbr == "Seman",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Seman
- Sample Size: 99
- Index Names:
- nc
- mrt
- rtsd
- dprime
- c
- commissions
- omissions
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()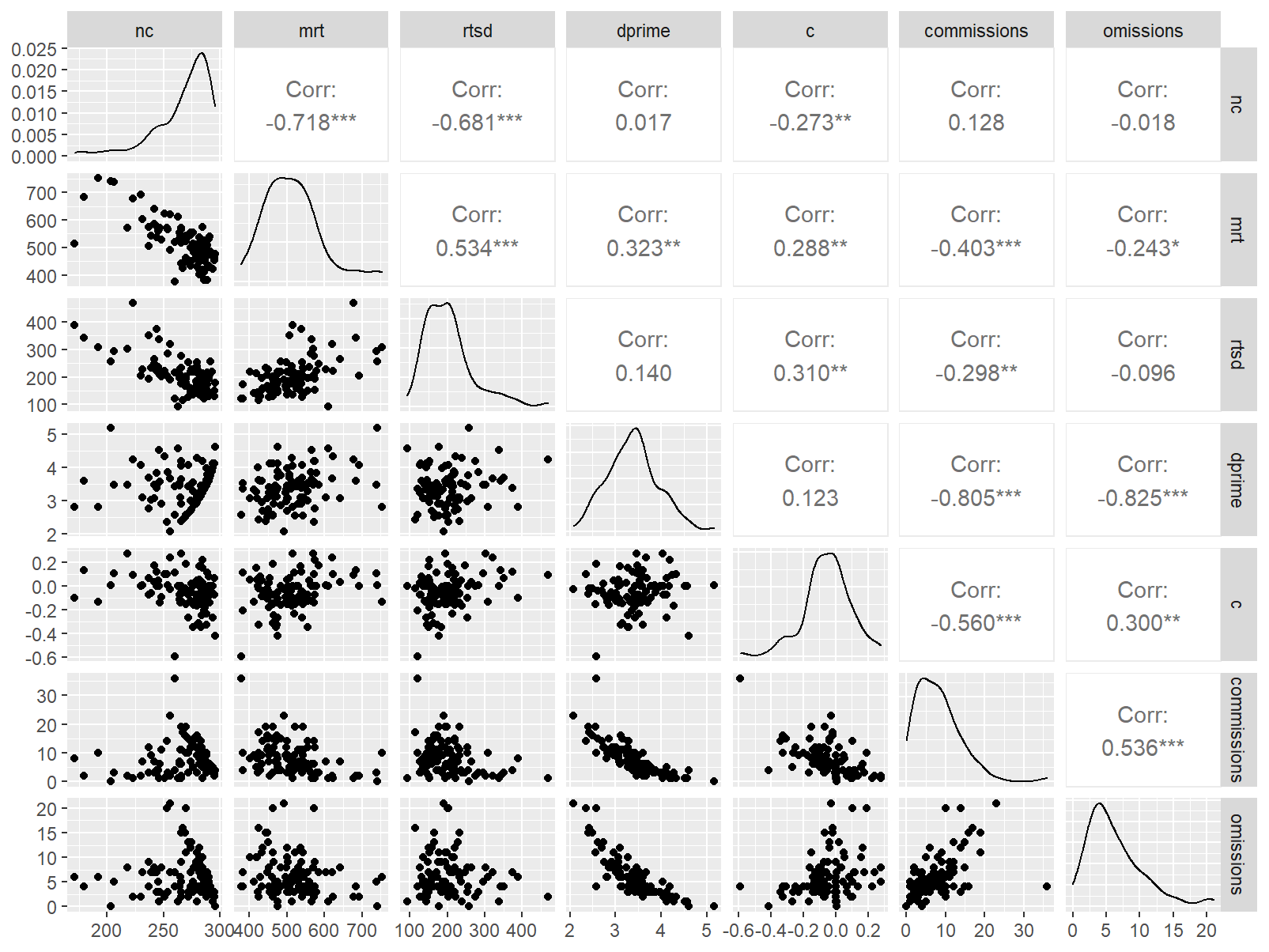
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
声调判断
data <- indices |>
filter(
game_name_abbr == "Tone",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Tone
- Sample Size: 98
- Index Names:
- nc
- mrt
- rtsd
- dprime
- c
- commissions
- omissions
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()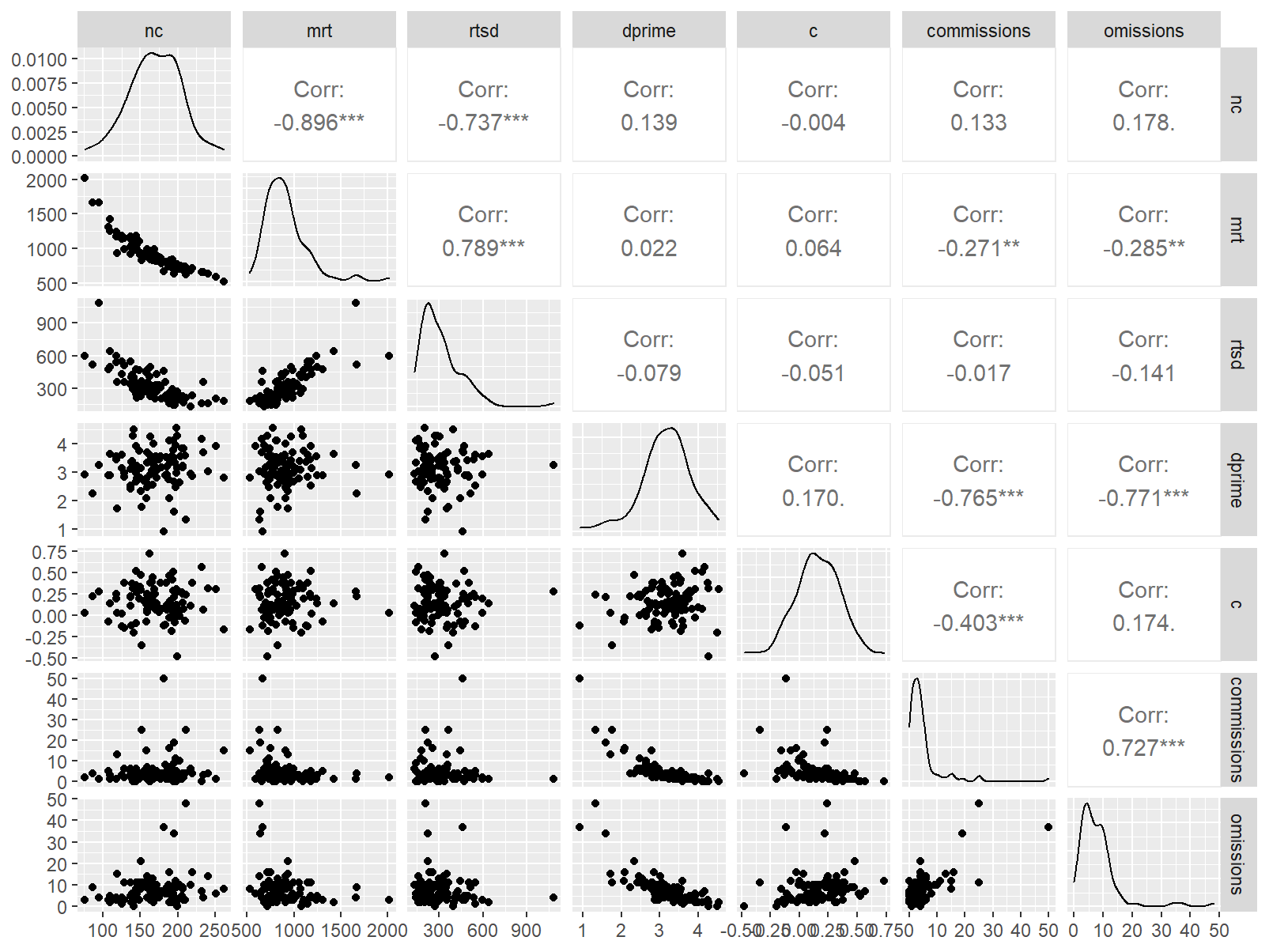
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
太空飞船PRO
data <- indices |>
filter(
game_name_abbr == "FlkrPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: FlkrPro
- Sample Size: 99
- Index Names:
- mrt_inc
- mrt_con
- pc_inc
- pc_con
- cong_eff_rt
- cong_eff_pc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
察颜观色PRO
data <- indices |>
filter(
game_name_abbr == "FacesPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: FacesPro
- Sample Size: 99
- Index Names:
- mrt_inc
- mrt_con
- pc_inc
- pc_con
- cong_eff_rt
- cong_eff_pc
- mrt_repeat
- mrt_switch
- pc_repeat
- pc_switch
- switch_cost_rt_spe
- switch_cost_pc_spe
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
顺背数PRO
data <- indices |>
filter(
game_name_abbr == "FDSPro",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: FDSPro
- Sample Size: 99
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()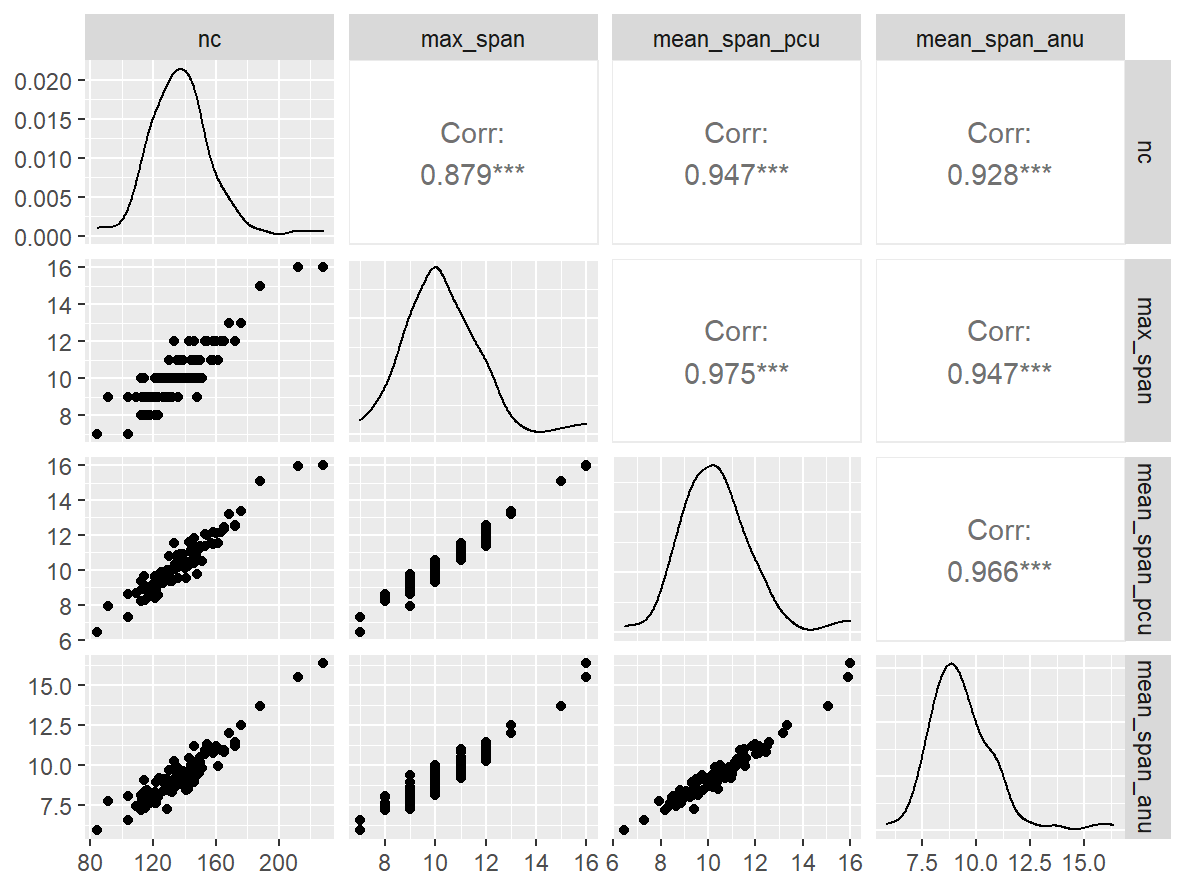
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)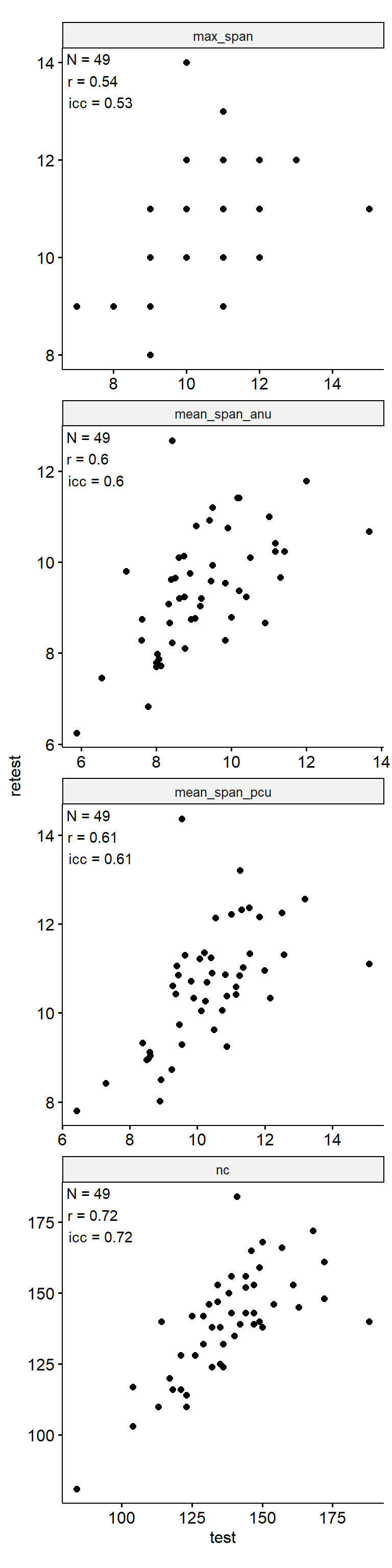
图形推理
data <- indices |>
filter(
game_name_abbr == "NVR",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: NVR
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()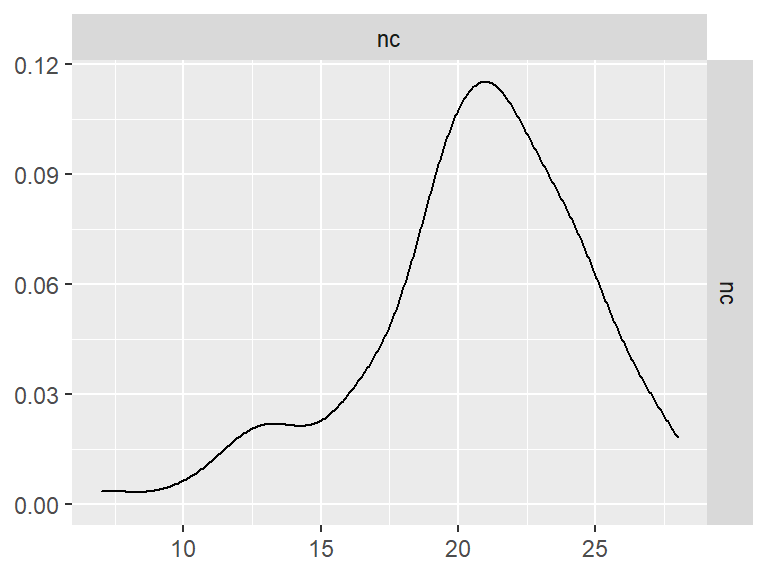
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)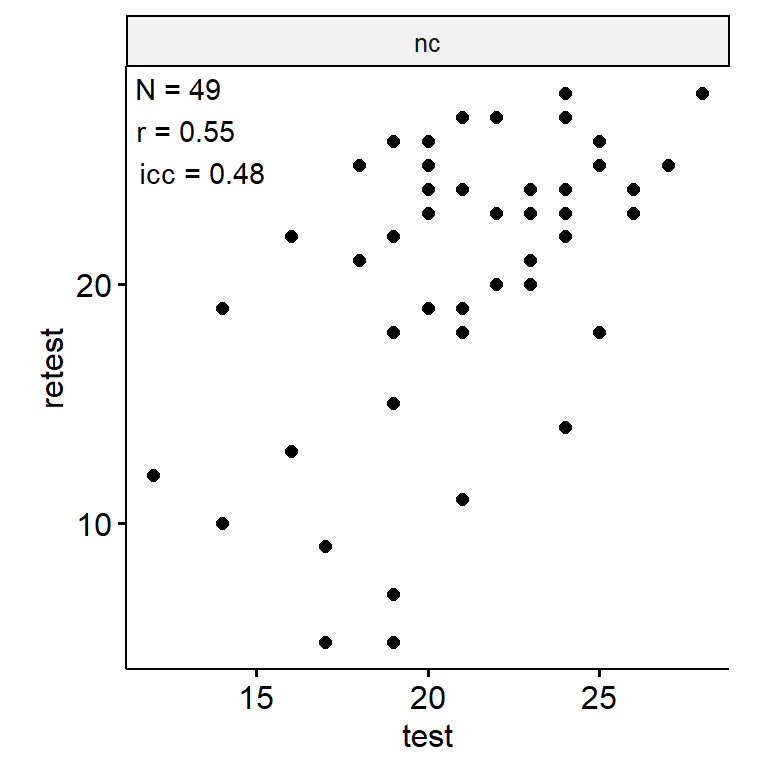
数字推理
data <- indices |>
filter(
game_name_abbr == "DR",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: DR
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()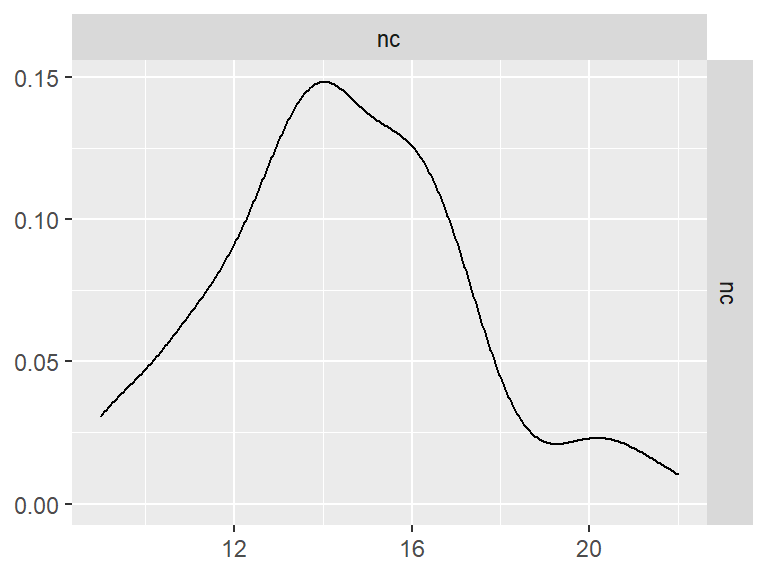
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)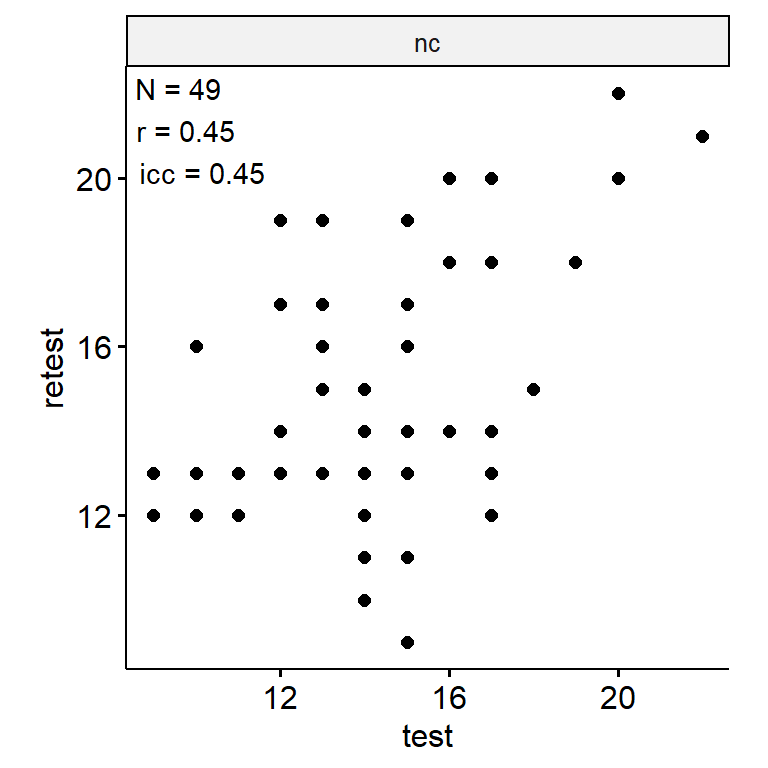
文字推理
data <- indices |>
filter(
game_name_abbr == "VR",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: VR
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()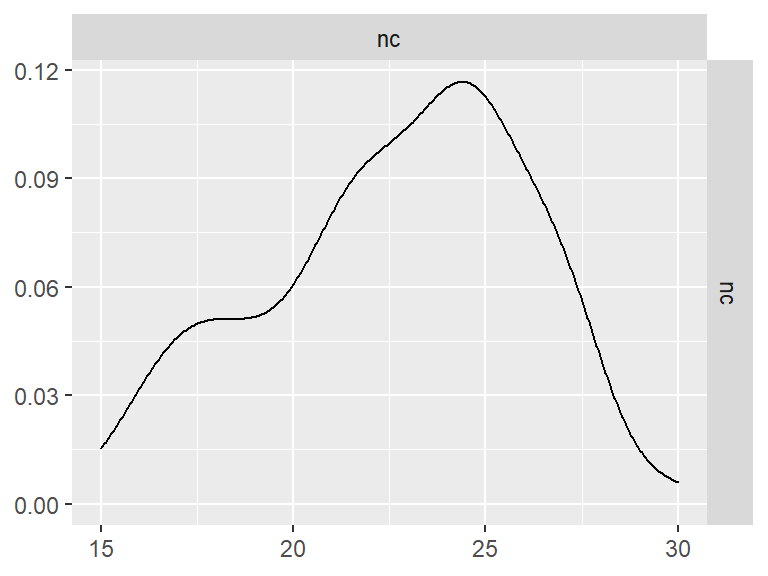
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)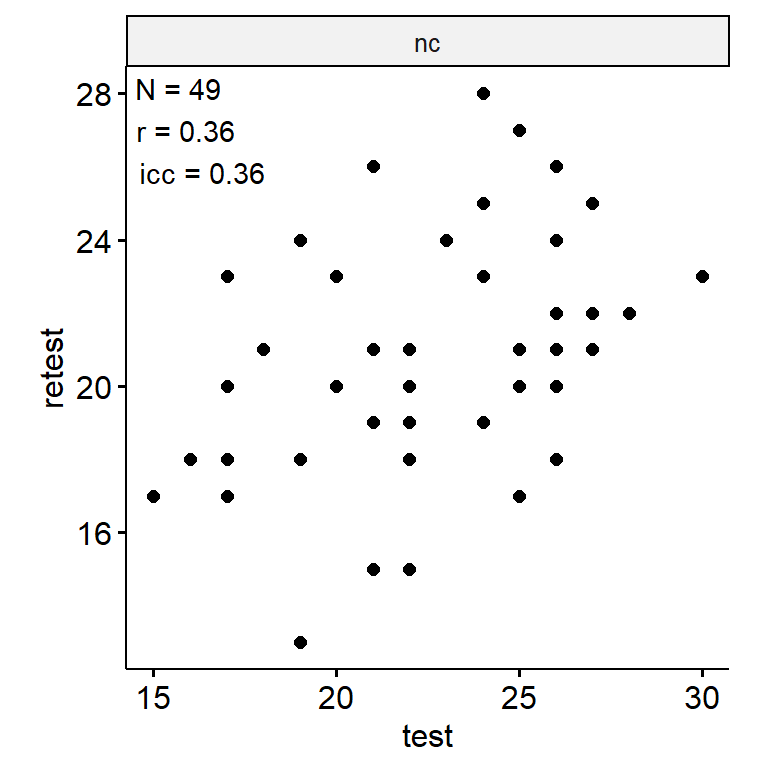
三维心理旋转测试
data <- indices |>
filter(
game_name_abbr == "MR3D",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: MR3D
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()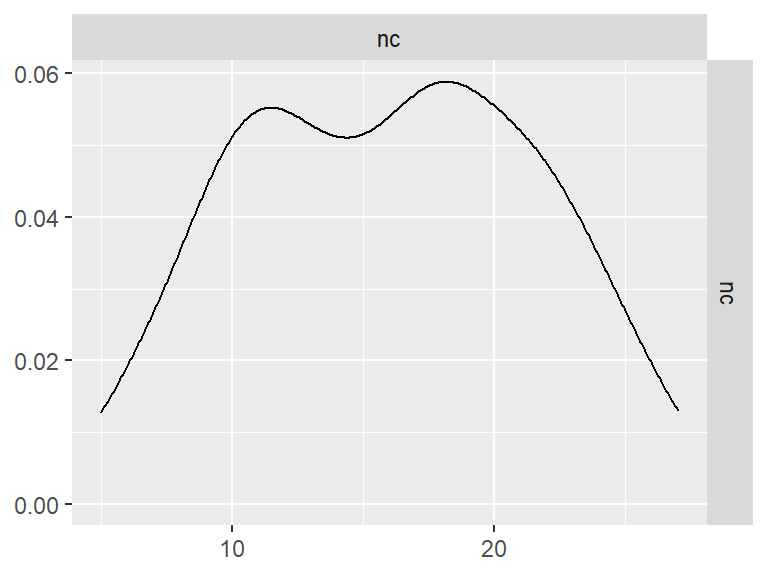
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)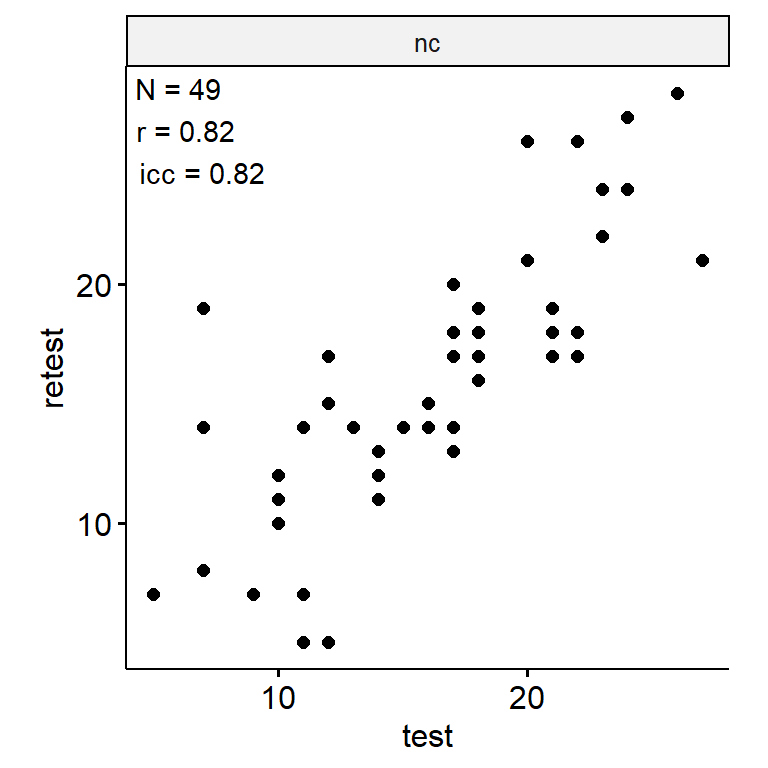
时长分辨
data <- indices |>
filter(
game_name_abbr == "DD",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: DD
- Sample Size: 99
- Index Names:
- threshold
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)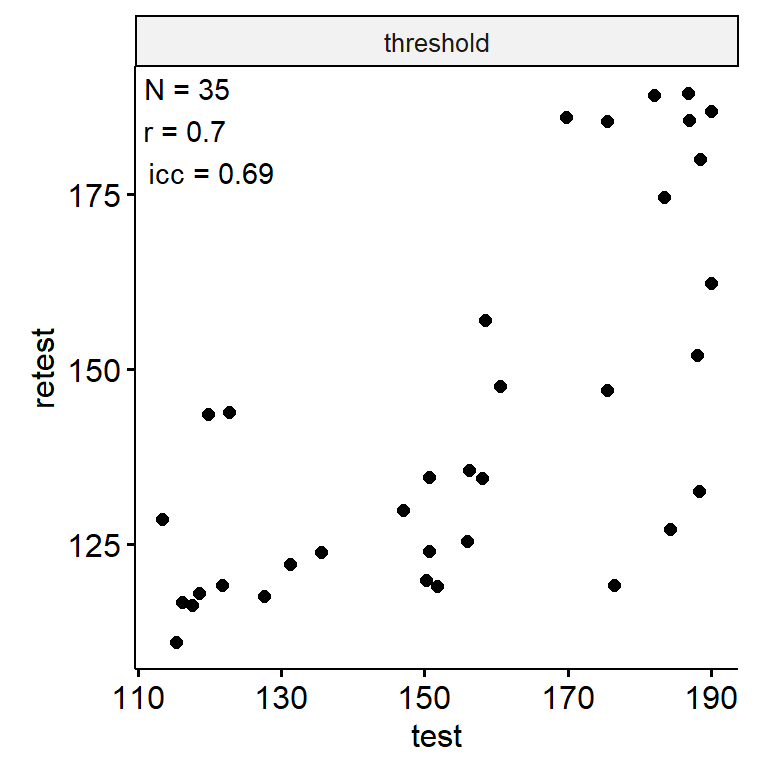
时间顺序判断
data <- indices |>
filter(
game_name_abbr == "TOJ",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: TOJ
- Sample Size: 99
- Index Names:
- threshold
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()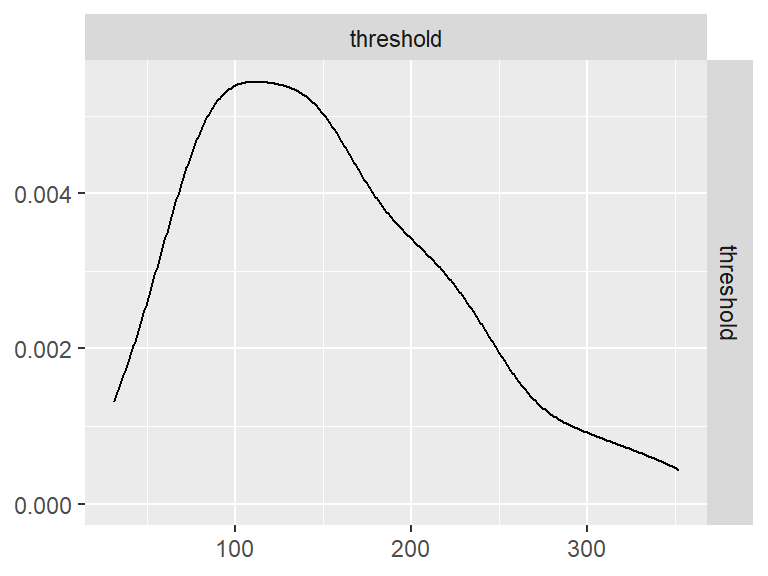
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)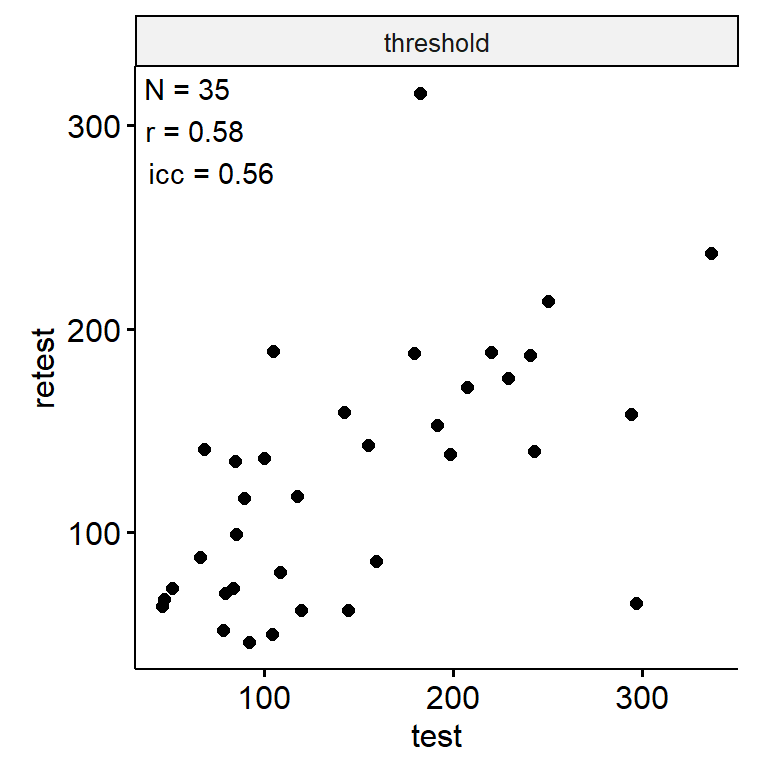
节奏感知
data <- indices |>
filter(
game_name_abbr == "RP",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: RP
- Sample Size: 99
- Index Names:
- threshold
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)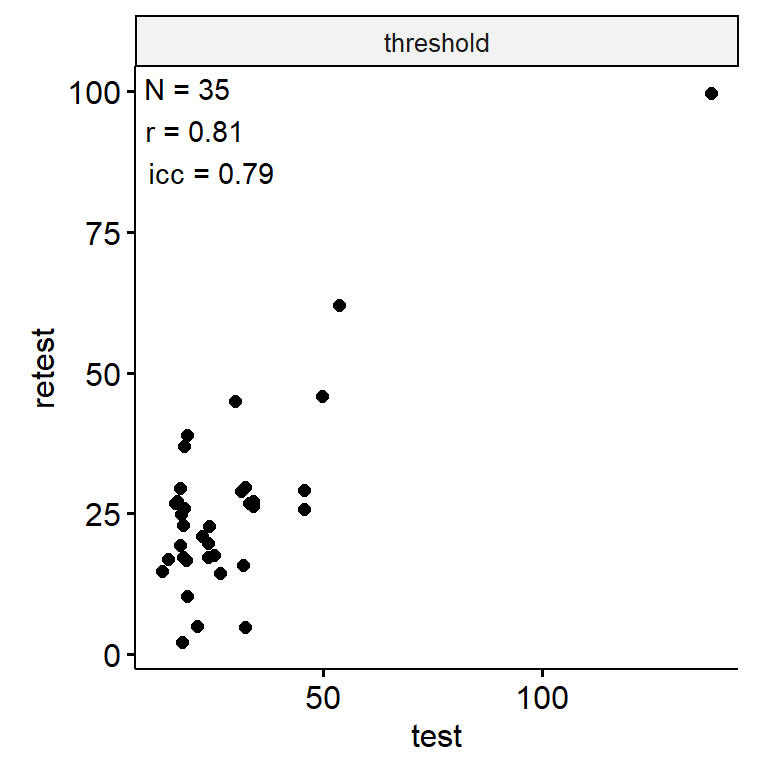
专注大师_中级
data <- indices |>
filter(
game_name_abbr == "CalcSpdMed",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: CalcSpdMed
- Sample Size: 94
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)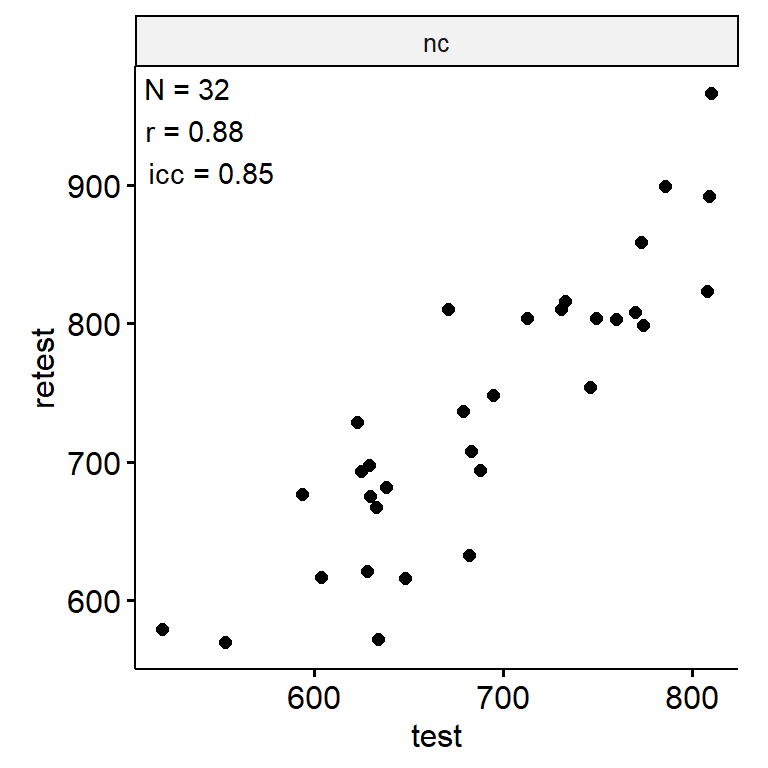
眼耳并用
data <- indices |>
filter(
game_name_abbr == "Dual2back",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: Dual2back
- Sample Size: 99
- Index Names:
- pc_aud
- pc_both
- pc_vis
- mrt_aud
- mrt_both
- mrt_vis
- dprime_aud
- dprime_both
- dprime_vis
- c_aud
- c_both
- c_vis
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
变戏法
data <- indices |>
filter(
game_name_abbr == "AntiSac",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: AntiSac
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)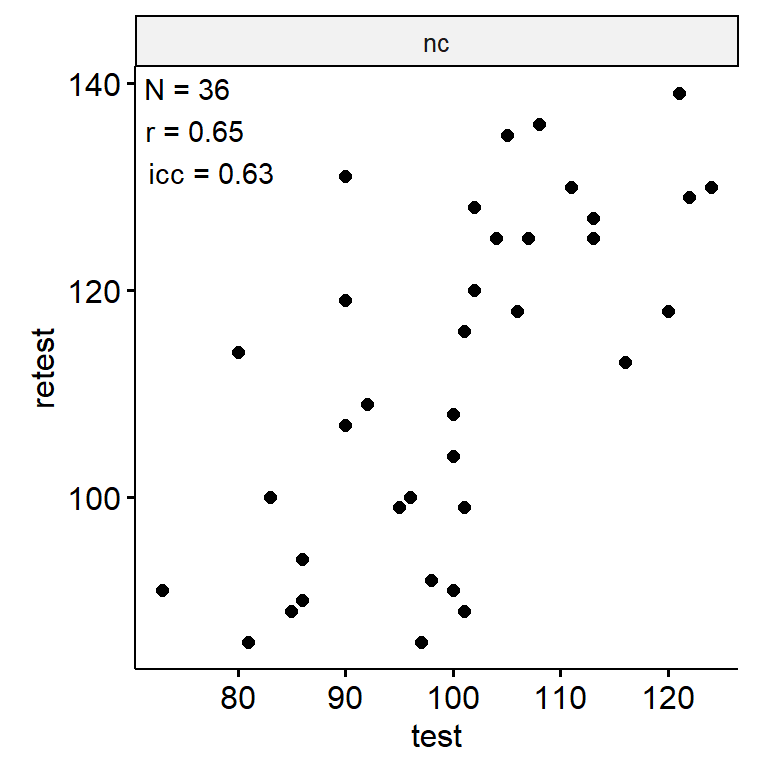
舒尔特方格(中级)
data <- indices |>
filter(
game_name_abbr == "SchulteMed",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: SchulteMed
- Sample Size: 99
- Index Names:
- nc_cor
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)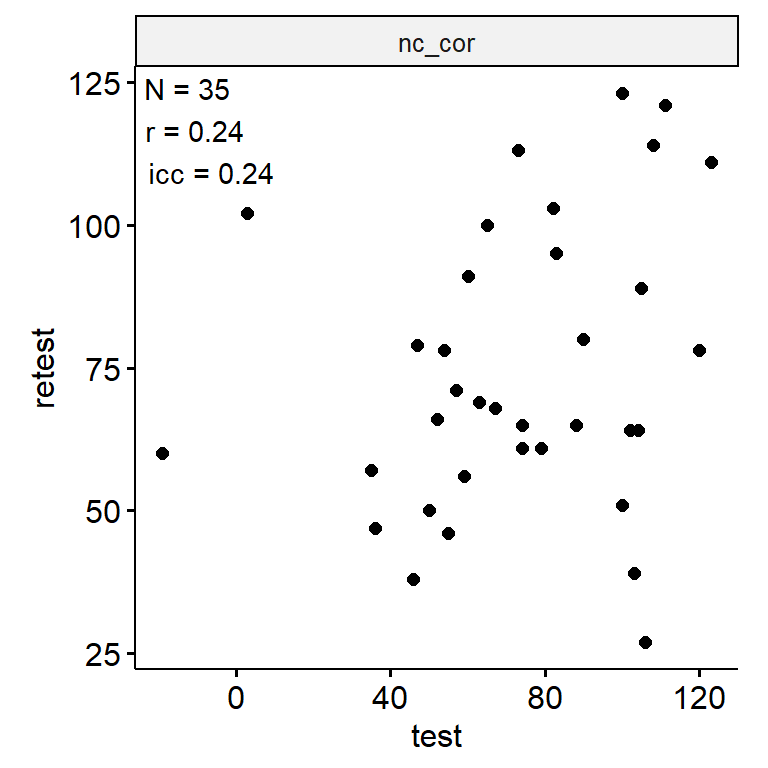
欢乐餐厅
data <- indices |>
filter(
game_name_abbr == "AscMem",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: AscMem
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)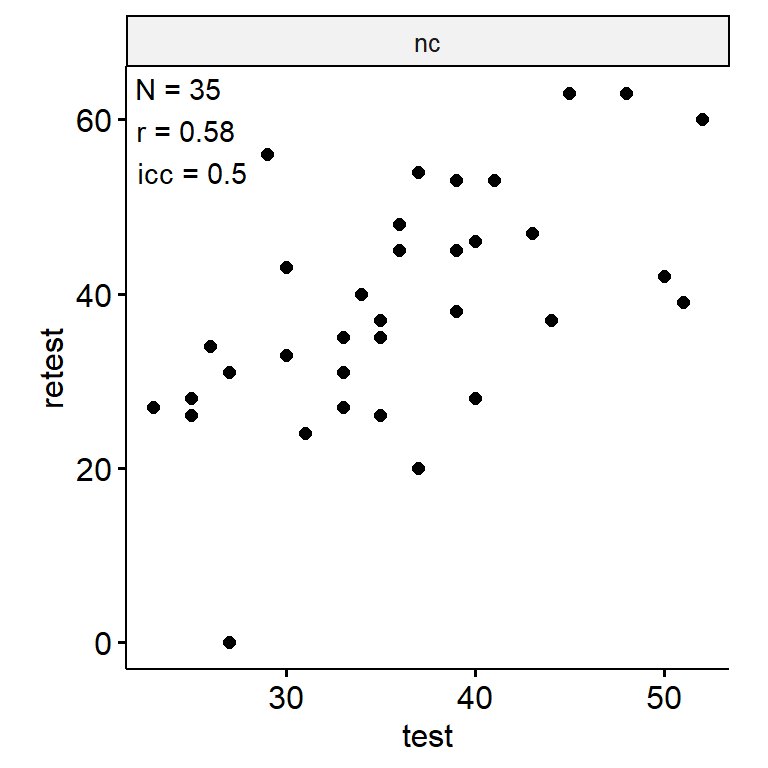
登陆月球(中级)
data <- indices |>
filter(
game_name_abbr == "NLEMed",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: NLEMed
- Sample Size: 99
- Index Names:
- mean_abs_err
- mean_log_err
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)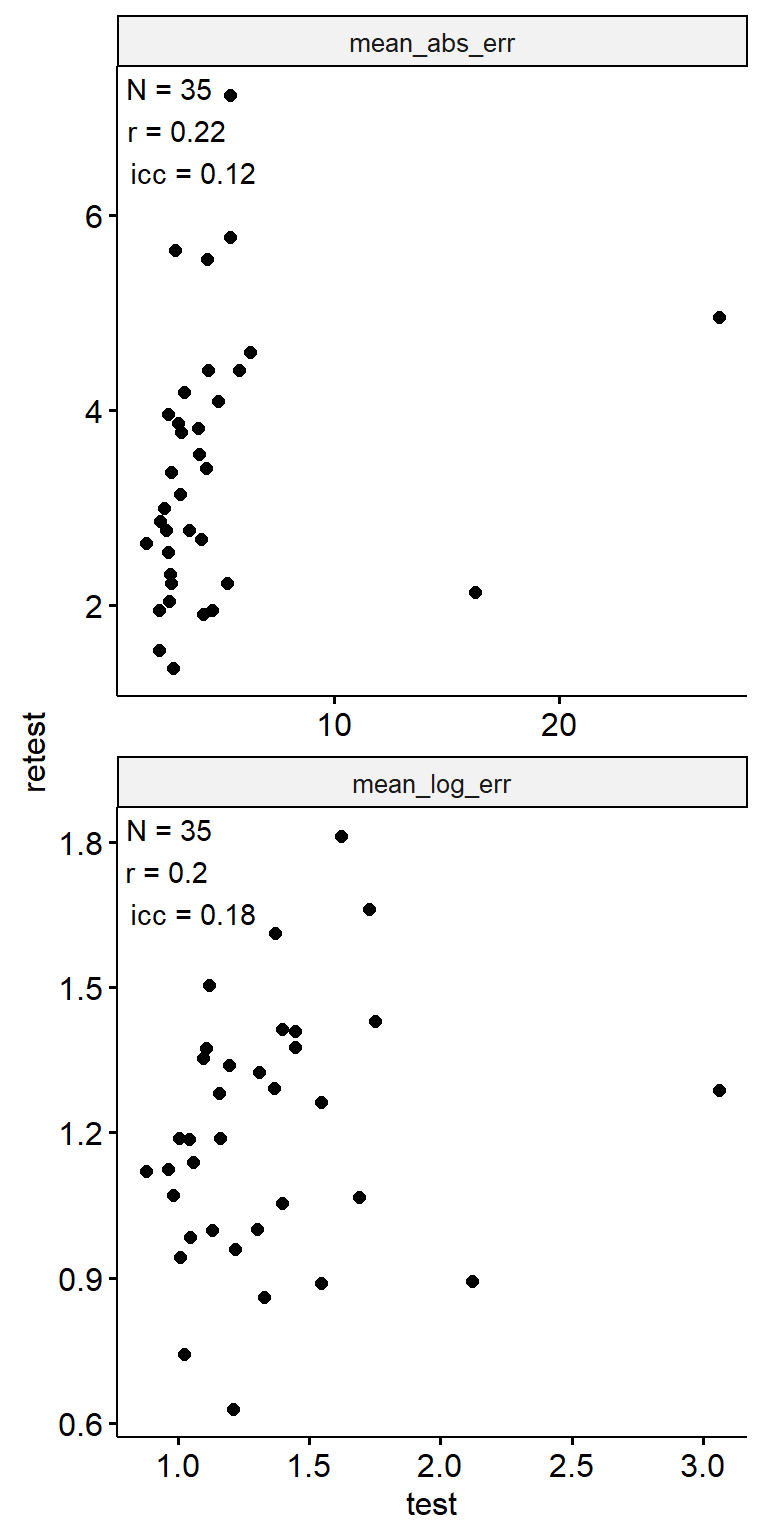
速算师(中级)
data <- indices |>
filter(
game_name_abbr == "CalcMed",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: CalcMed
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()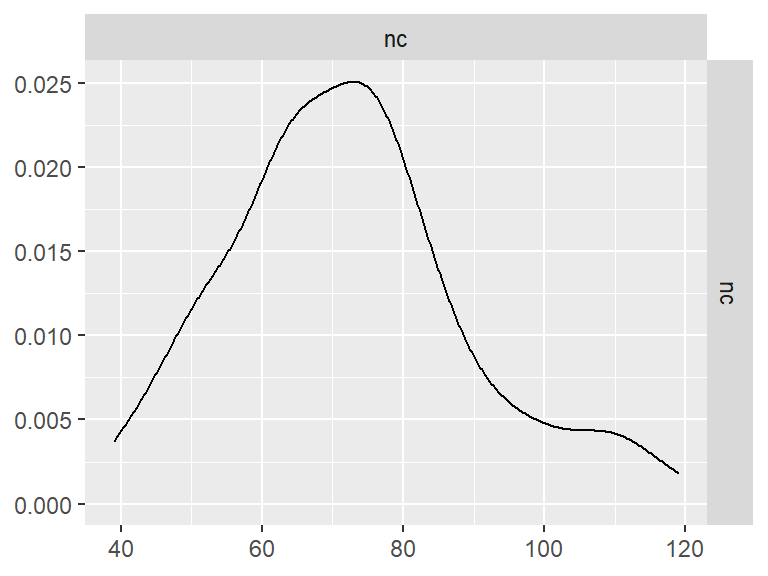
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)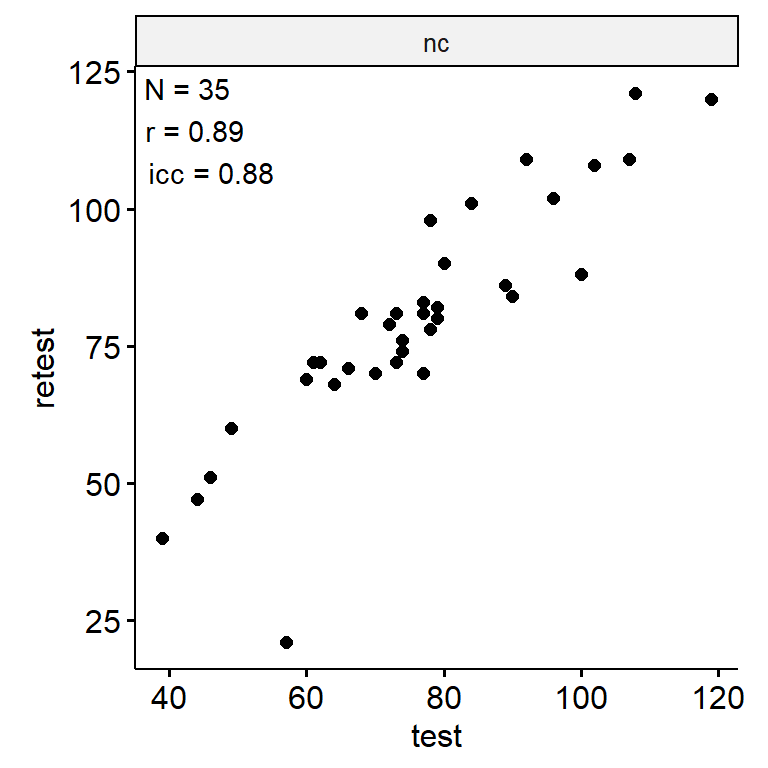
图形折叠
data <- indices |>
filter(
game_name_abbr == "FR",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: FR
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()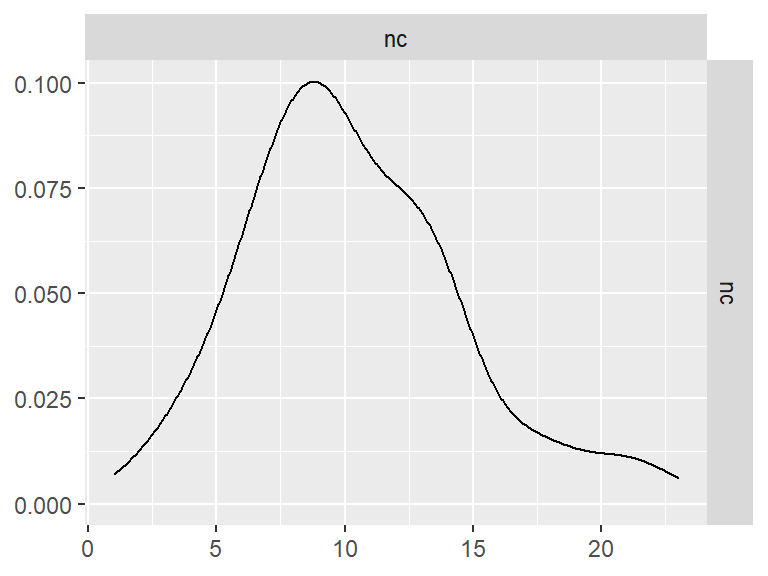
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
远距离联想
data <- indices |>
filter(
game_name_abbr == "RAT",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: RAT
- Sample Size: 99
- Index Names:
- nc
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()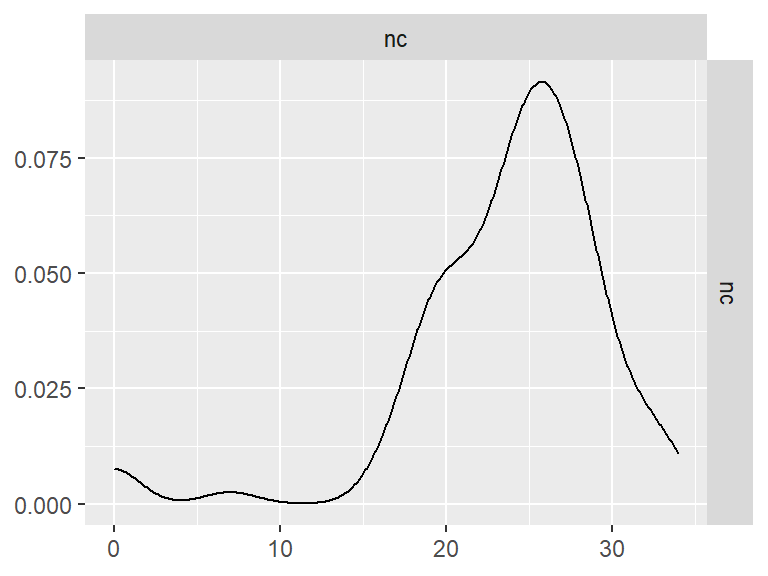
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)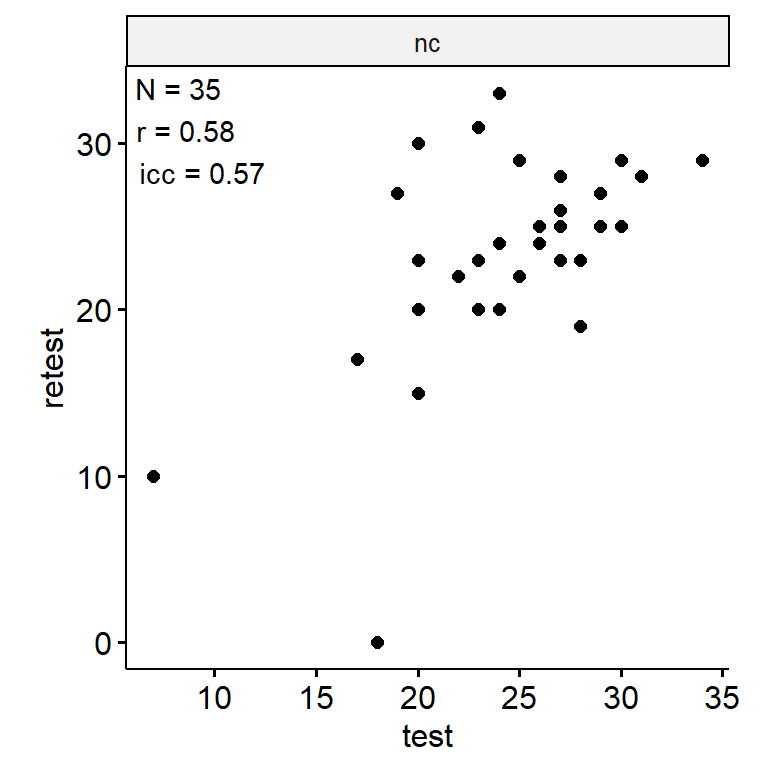
幸运小球
data <- indices |>
filter(
game_name_abbr == "OCSpan",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: OCSpan
- Sample Size: 99
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()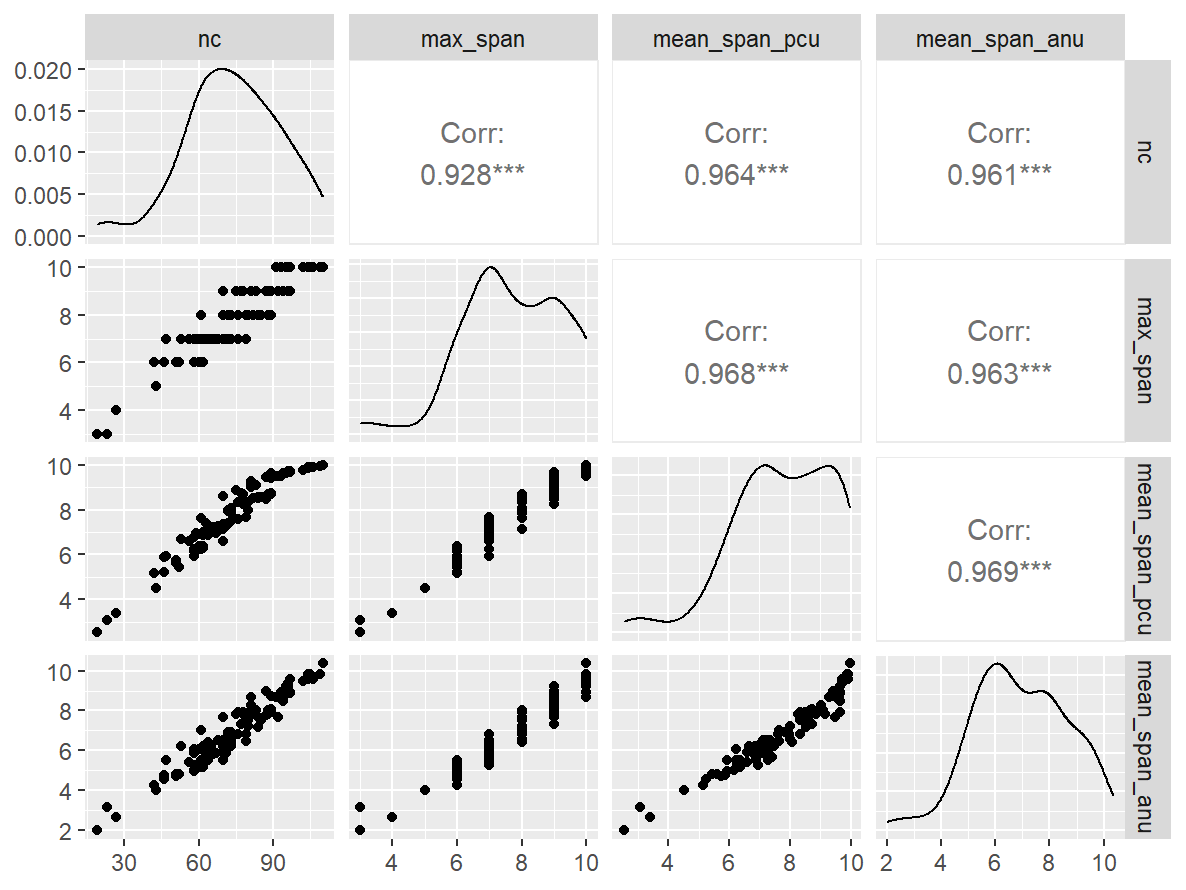
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)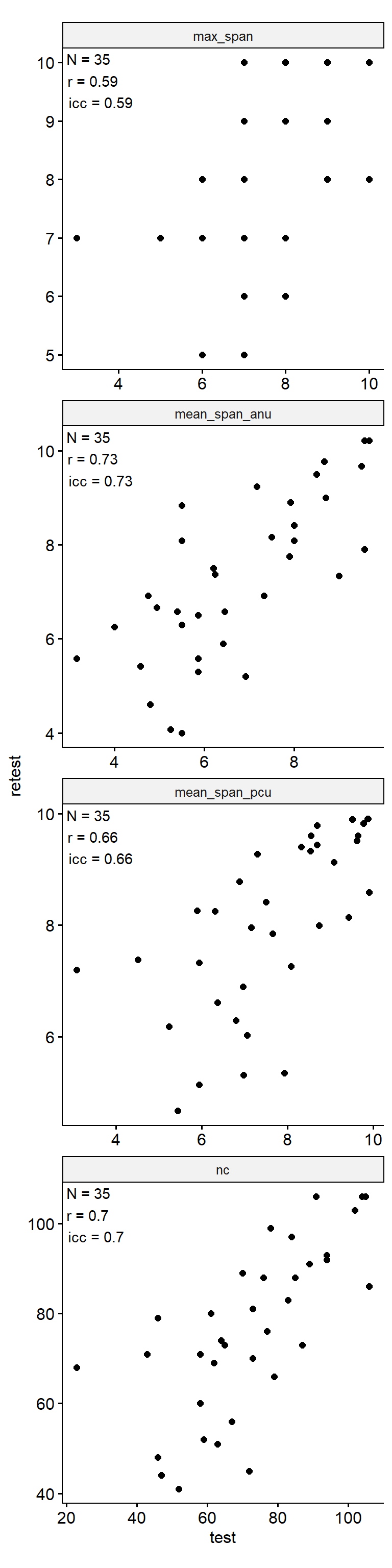
打靶场
data <- indices |>
filter(
game_name_abbr == "RSpan",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: RSpan
- Sample Size: 99
- Index Names:
- nc
- max_span
- mean_span_pcu
- mean_span_anu
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()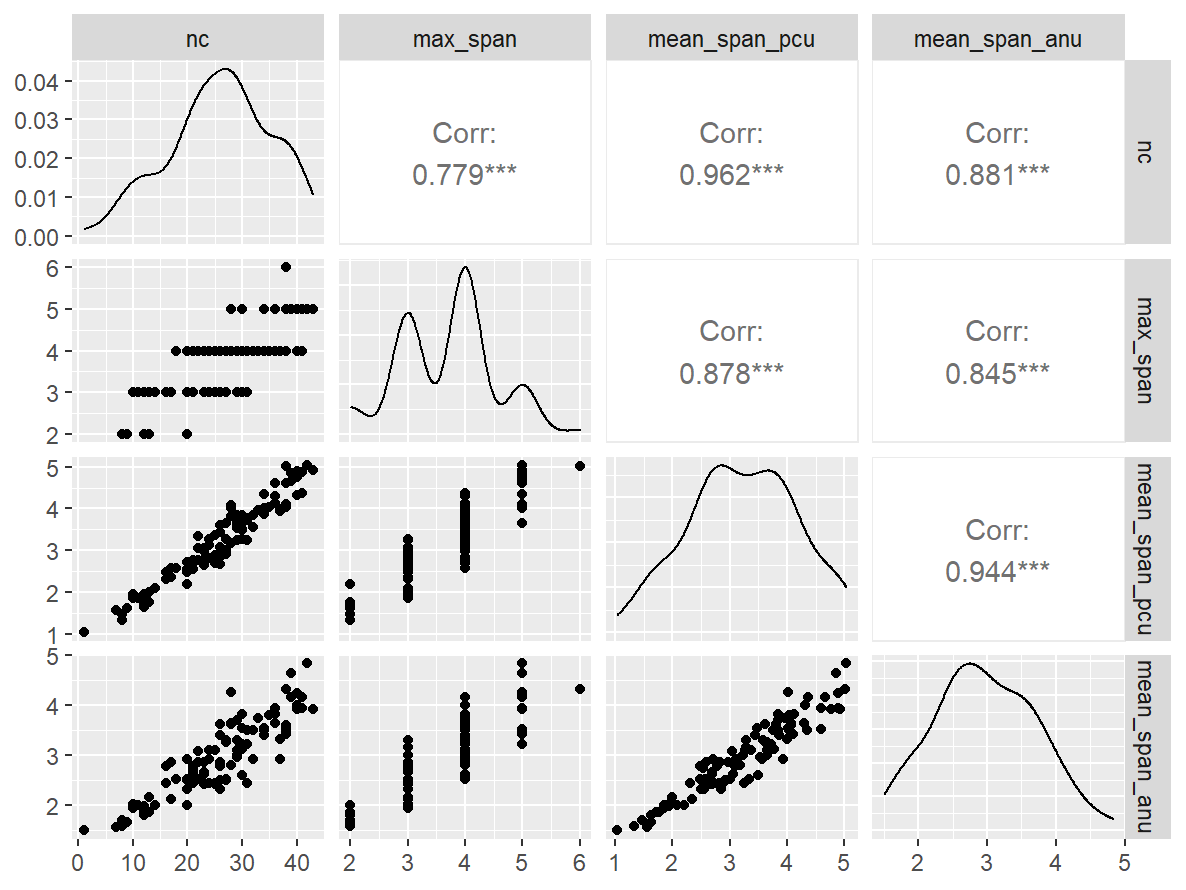
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)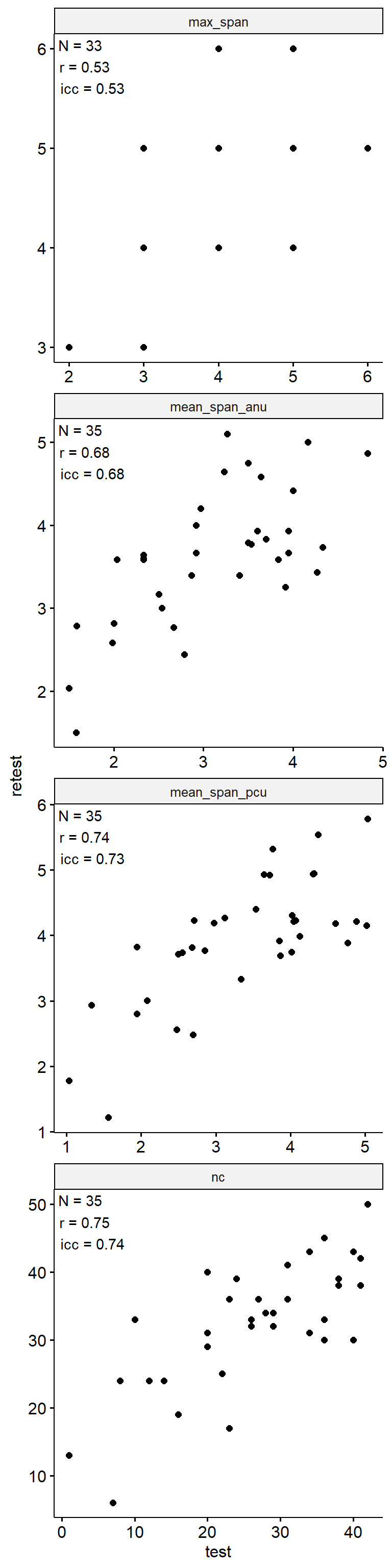
雪花收藏家
data <- indices |>
filter(
game_name_abbr == "DirectSrc",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: DirectSrc
- Sample Size: 99
- Index Names:
- nc_cor
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()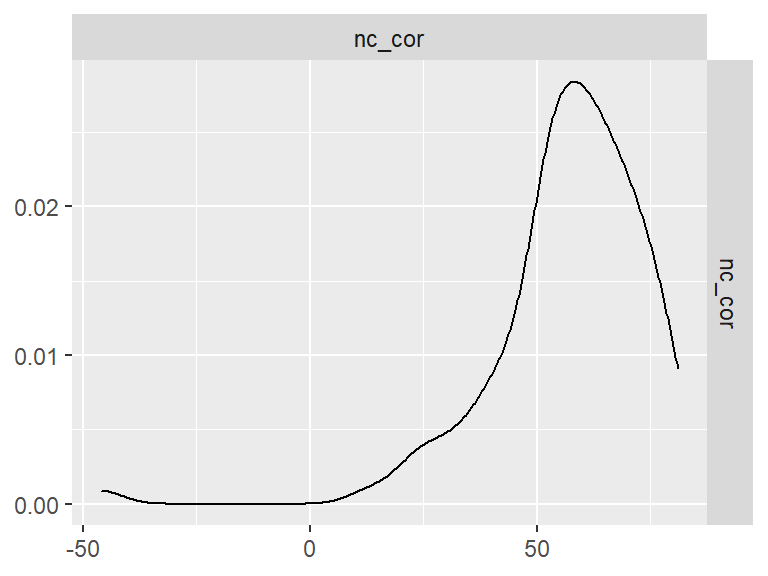
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)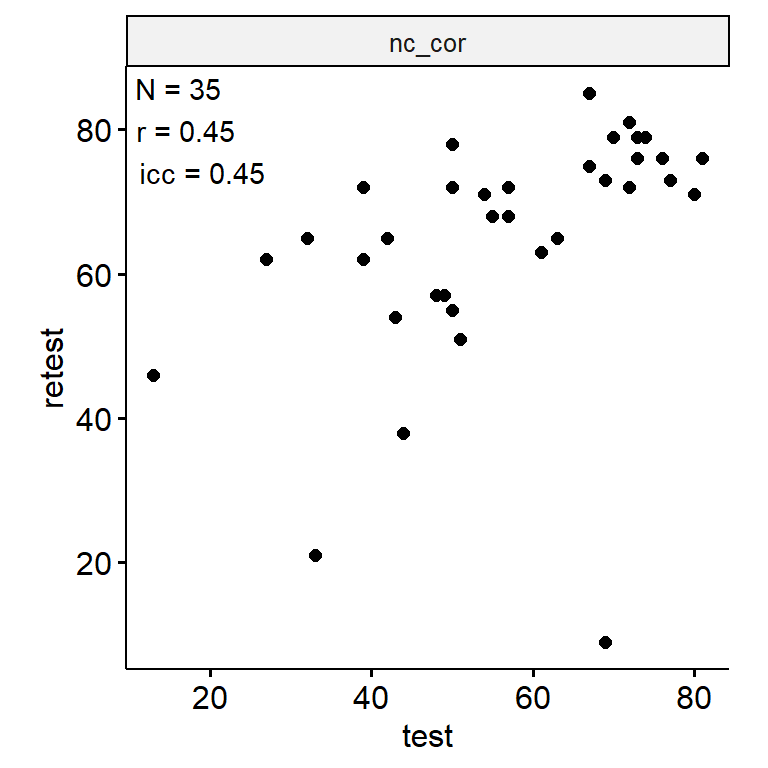
我是大厨
data <- indices |>
filter(
game_name_abbr == "MSynWin",
across(contains("test"), ~ !is.infinite(.x)),
!(is.na(test) & is.na(retest))
)
n_indices <- n_distinct(data$index_name)Basic Information
- Abbreviation: MSynWin
- Sample Size: 99
- Index Names:
- score_total
- score_aud
- score_mem
- score_vis
Pairwise Correlation of indices
data |>
pivot_wider(
id_cols = user_id,
names_from = index_name,
values_from = test
) |>
select(-user_id) |>
GGally::ggpairs()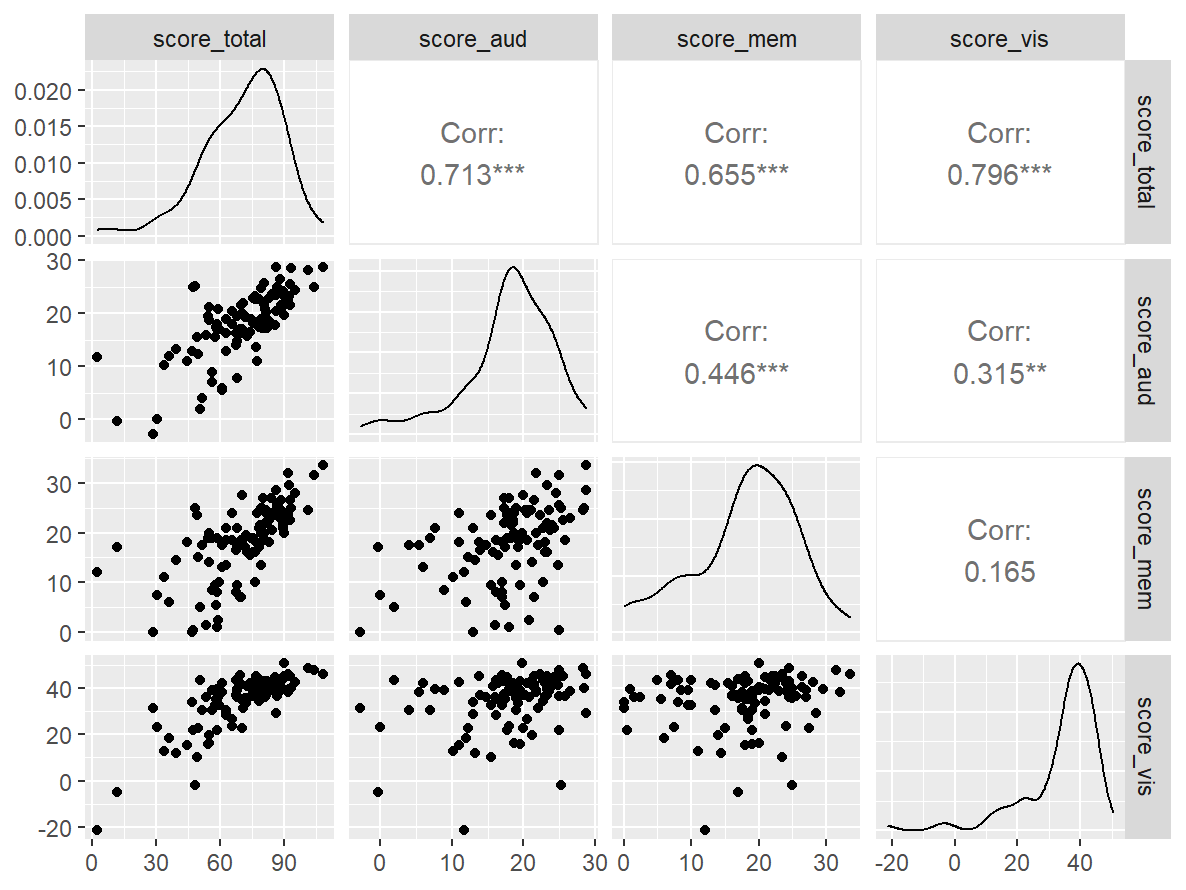
Test-Retest
data_test_retest <- drop_na(data)
reliability <- data_test_retest |>
group_by(index_name) |>
group_modify(
~ tibble(
n = nrow(.x),
icc = .x |>
select(contains("test")) |>
psych::ICC() |>
pluck("results", "ICC", 3),
r = cor(.x$test, .x$retest)
)
) |>
ungroup()
data_test_retest |>
ggpubr::ggscatter("test", "retest") +
geom_text(
data = reliability,
aes(
x = -Inf, y = Inf,
label = str_glue("N = {n}\nr = {round(r, 2)}\nicc = {round(icc, 2)}")
),
hjust = -0.1, vjust = 1.1
) +
facet_wrap(~ index_name, ncol = 1, scales = "free") +
theme(aspect.ratio = 1)
sessionInfo()R version 4.1.2 (2021-11-01)
Platform: i386-w64-mingw32/i386 (32-bit)
Running under: Windows 10 x64 (build 22000)
Matrix products: default
locale:
[1] LC_COLLATE=Chinese (Simplified)_China.936
[2] LC_CTYPE=Chinese (Simplified)_China.936
[3] LC_MONETARY=Chinese (Simplified)_China.936
[4] LC_NUMERIC=C
[5] LC_TIME=Chinese (Simplified)_China.936
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] targets_0.10.0 forcats_0.5.1 stringr_1.4.0 dplyr_1.0.7
[5] purrr_0.3.4 readr_2.1.1 tidyr_1.1.4.9000 tibble_3.1.6
[9] ggplot2_3.3.5 tidyverse_1.3.1 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] minqa_1.2.4 colorspace_2.0-2 ggsignif_0.6.3
[4] ellipsis_0.3.2 rprojroot_2.0.2 fs_1.5.2
[7] rstudioapi_0.13 ggpubr_0.4.0 farver_2.1.0
[10] bit64_4.0.5 fansi_1.0.0 lubridate_1.8.0
[13] xml2_1.3.3 codetools_0.2-18 splines_4.1.2
[16] mnormt_2.0.2 knitr_1.37 jsonlite_1.7.2
[19] nloptr_1.2.2.3 broom_0.7.11 dbplyr_2.1.1
[22] compiler_4.1.2 httr_1.4.2 backports_1.4.1
[25] assertthat_0.2.1 Matrix_1.4-0 fastmap_1.1.0
[28] cli_3.1.0 later_1.3.0 htmltools_0.5.2
[31] tools_4.1.2 igraph_1.2.11 gtable_0.3.0
[34] glue_1.6.0 Rcpp_1.0.7 carData_3.0-5
[37] cellranger_1.1.0 jquerylib_0.1.4 vctrs_0.3.8
[40] nlme_3.1-153 psych_2.1.9 xfun_0.29
[43] ps_1.6.0 lme4_1.1-27.1 rvest_1.0.2
[46] lifecycle_1.0.1 rstatix_0.7.0 getPass_0.2-2
[49] MASS_7.3-54 scales_1.1.1 vroom_1.5.7
[52] hms_1.1.1 promises_1.2.0.1 parallel_4.1.2
[55] RColorBrewer_1.1-2 qs_0.25.2 yaml_2.2.1
[58] sass_0.4.0 reshape_0.8.8 stringi_1.7.6
[61] highr_0.9 boot_1.3-28 rlang_0.99.0.9001
[64] pkgconfig_2.0.3 evaluate_0.14 lattice_0.20-45
[67] labeling_0.4.2 bit_4.0.4 processx_3.5.2
[70] tidyselect_1.1.1 here_1.0.1 GGally_2.1.2
[73] plyr_1.8.6 magrittr_2.0.1 R6_2.5.1
[76] generics_0.1.1 base64url_1.4 DBI_1.1.2
[79] pillar_1.6.4 haven_2.4.3 whisker_0.4
[82] withr_2.4.3 abind_1.4-5 modelr_0.1.8
[85] crayon_1.4.2 car_3.0-12 utf8_1.2.2
[88] tmvnsim_1.0-2 RApiSerialize_0.1.0 tzdb_0.2.0
[91] rmarkdown_2.11 grid_4.1.2 readxl_1.3.1
[94] data.table_1.14.2 callr_3.7.0 git2r_0.29.0
[97] reprex_2.0.1 digest_0.6.29 httpuv_1.6.5
[100] RcppParallel_5.1.5 munsell_0.5.0 stringfish_0.15.5
[103] bslib_0.3.1