H3K27me3 and TE overlap
Renee Matthews
2026-01-23
Last updated: 2026-01-23
Checks: 7 0
Knit directory: DXR_continue/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20250701) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version e8e2585. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/Bed_exports/
Ignored: data/Cormotif_data/
Ignored: data/DER_data/
Ignored: data/Other_paper_data/
Ignored: data/RDS_files/
Ignored: data/TE_annotation/
Ignored: data/alignment_summary.txt
Ignored: data/all_peak_final_dataframe.txt
Ignored: data/cell_line_info_.tsv
Ignored: data/full_summary_QC_metrics.txt
Ignored: data/motif_lists/
Ignored: data/number_frag_peaks_summary.txt
Untracked files:
Untracked: H3K27ac_all_regions_test.bed
Untracked: H3K27ac_consensus_clusters_test.bed
Untracked: analysis/GREAT_H3K27ac.Rmd
Untracked: analysis/H3K27ac_ChromHMM_FC.Rmd
Untracked: analysis/H3K27ac_cisRE.Rmd
Untracked: analysis/Top2a_Top2b_expression.Rmd
Untracked: analysis/chromHMM.Rmd
Untracked: analysis/maps_and_plots.Rmd
Untracked: analysis/proteomics.Rmd
Untracked: other_analysis/
Unstaged changes:
Modified: analysis/H3K27_TE_overlap_extend.Rmd
Modified: analysis/H3K27ac_RNA_integration.Rmd
Modified: analysis/H3K27ac_TF_motifs.Rmd
Modified: analysis/final_analysis.Rmd
Modified: analysis/repeatmasker_data.Rmd
Modified: analysis/summit_files_processing.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/H3K27me3_TE_overlap.Rmd)
and HTML (docs/H3K27me3_TE_overlap.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | e8e2585 | reneeisnowhere | 2026-01-23 | image update |
library(tidyverse)
library(GenomicRanges)
library(plyranges)
library(genomation)
library(readr)
library(rtracklayer)
library(stringr)
library(ggrepel)
library(DT)First steps: breakdown repeatmasker into groups and pull out the ones by each class I am interested in.
repeatmasker <- read_delim("data/Other_paper_data/repeatmasker_20250911.txt",
delim = "\t", escape_double = FALSE,
trim_ws = TRUE)
colnames(repeatmasker) [1] "#bin" "swScore" "milliDiv" "milliDel" "milliIns" "genoName"
[7] "genoStart" "genoEnd" "genoLeft" "strand" "repName" "repClass"
[13] "repFamily" "repStart" "repEnd" "repLeft" "id" repeatmasker_clean <- repeatmasker %>% mutate(
strand = ifelse(strand == "C", "-", "+")
) %>%
mutate(
start = genoStart + 1,
end = genoEnd)%>%
mutate(repFamily= str_remove(repFamily, "\\?$"))
rpt_split <- split(repeatmasker_clean, repeatmasker_clean$repClass)
rpt_split_gr_list <- lapply(rpt_split, function(df) {
GRanges(
seqnames = df$genoName,
ranges = IRanges(start = df$start, end = df$end),
strand = df$strand,
repName = df$repName,
repClass = df$repClass,
repFamily = df$repFamily,
swScore = df$swScore,
milliDiv = df$milliDiv,
id = df$id
)
})SINE_gr <- rpt_split_gr_list$SINE
LINE_gr <- rpt_split_gr_list$LINE
LTR_gr <- rpt_split_gr_list$LTR
SVA_gr <- rpt_split_gr_list$Retroposon
DNA_gr <- rpt_split_gr_list$DNAH3K27me3_summit_gr <- readRDS("data/RDS_files/H3K27me3_complete_summit_gr.RDS")
peakAnnoList_H3K27me3 <- readRDS("data/motif_lists/H3K27me3_annotated_peaks.RDS")
H3K27me3_lookup <- imap_dfr(peakAnnoList_H3K27me3[1:3], ~
tibble(Peakid = .x@anno$Peakid, cluster = .y)
)
##assigning Peakid as name of summit region
mcols(H3K27me3_summit_gr)$name <- mcols(H3K27me3_summit_gr)$Peakid
comparisons <- tibble(
cluster2 = c("Set_2"),
cluster1 = c("Set_1")
)# Generic pairwise Fisher test
test_pair_TE_generic <- function(df_long, te_name, cluster1, cluster2) {
sub_df <- df_long %>%
filter(TE_type == te_name) %>%
complete(
cluster = c(cluster1, cluster2),
status = c("TE", "not_TE"),
fill = list(count = 0))
# enforce fixed order
status_levels <- c("TE", "not_TE")
# assume "status" column has TE vs wnot_TE automatically
statuses <- unique(sub_df$status)
if(length(statuses) != 2) {
# ensure we have exactly two categories, fill missing with 0
sub_df <- sub_df %>%
complete(cluster, status, fill = list(count = 0))
statuses <- unique(sub_df$status)
}
# extract counts for cluster1
c1_counts <- sub_df %>%
filter(cluster == cluster1) %>%
arrange(factor(status, levels = status_levels)) %>% # ensure same order
pull(count)
# extract counts for cluster2
c2_counts <- sub_df %>%
filter(cluster == cluster2) %>%
arrange(factor(status, levels = status_levels)) %>%
pull(count)
# build 2x2 matrix
mat <- matrix(
c(c2_counts, c1_counts),
nrow = 2,
byrow = TRUE,
dimnames = list(
cluster = c(cluster2, cluster1),
category = status_levels
)
)
ft <- tryCatch(
fisher.test(mat, workspace = 2e8),
error = function(e) fisher.test(mat, simulate.p.value = TRUE, B = 1e5)
)
tibble(
TE_type = te_name,
comparison = paste(cluster2, "vs", cluster1),
odds_ratio = ft$estimate,
lower_CI = ft$conf.int[1],
upper_CI = ft$conf.int[2],
p_value = ft$p.value
)
}SINE
Overlapping SINE family with summits to get a count
sine_hits <- findOverlaps(H3K27me3_summit_gr, SINE_gr, ignore.strand = TRUE)
SINE_overlap_df <- tibble(
summit_id = queryHits(sine_hits),
cluster = mcols(H3K27me3_summit_gr)$cluster[queryHits(sine_hits)],
TE_type = mcols(SINE_gr)$repFamily[subjectHits(sine_hits)])
SINE_counts <- SINE_overlap_df %>%
count(cluster, TE_type, name = "count") %>%
mutate(status = "TE")
total_SINE_summits <- tibble(
cluster = mcols(H3K27me3_summit_gr)$cluster
) %>% count(cluster, name = "total")
not_SINE_counts <- SINE_counts %>%
left_join(total_SINE_summits, by = "cluster") %>%
mutate(count = total - count,
status = "not_TE") %>%
select(cluster, TE_type, status, count)
SINE_df_long <- bind_rows(SINE_counts %>%
dplyr::select(cluster, TE_type, status, count),
not_SINE_counts) %>%
filter(!is.na(cluster))
SINE_results <- comparisons %>%
mutate(results = map2(cluster2, cluster1, function(c2, c1) {
SINE_df_long %>%
distinct(TE_type) %>%
pull() %>%
map_dfr(function(te) {
test_pair_TE_generic(
SINE_df_long,
te_name = te,
cluster1 = c1,
cluster2 = c2
)
})
})
) %>%
unnest(results) %>%
mutate(FDR = p.adjust(p_value, method = "BH"))datatable(SINE_counts,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE))# ---- Prepare the table ----
SINE_counts_display <- SINE_results %>%
# 1. Split comparison
separate(comparison, into = c("cluster2", "cluster1"), sep = " vs ", remove = FALSE) %>%
# 2. Add log2 odds ratio
mutate(log2OR = log2(odds_ratio)) %>%
# 3. Add enrichment/depletion direction
mutate(direction = case_when(
odds_ratio > 1 ~ "enriched",
odds_ratio < 1 ~ "depleted",
TRUE ~ "neutral"
)) %>%
# 4. Flag significant
mutate(significant = FDR < 0.05) %>%
# Optional: arrange for readability
arrange(cluster2, direction, desc(log2OR))
# ---- Create interactive datatable ----
datatable(
SINE_counts_display,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE
)
) %>%
# Conditional coloring by direction
formatStyle(
'direction',
target = 'row',
backgroundColor = styleEqual(
c('enriched', 'depleted'),
c('#FFDD99', '#99CCFF') # enriched = light orange, depleted = light blue
)
) %>%
# Bold significant rows
formatStyle(
'significant',
fontWeight = styleEqual(TRUE, 'bold')
) %>%
# Round numeric columns for readability
formatRound(columns = c('odds_ratio','log2OR','FDR'), digits = 2)ggplot(SINE_results, aes(x = (odds_ratio), y = -log10(FDR),label = TE_type)) +
geom_point(aes(color = odds_ratio > 1), size = 3) +
# geom_text_repel(data = subset(SVA_results, FDR < 0.05)) +
geom_text_repel(size=3, max.overlaps = Inf)+
geom_hline(yintercept = -log10(0.05), linetype = "dashed") +
labs(
x = "(Odds Ratio)",
y = "-log10(FDR)",
title = "SINE family enrichment at ROI summits\nH3K27me3"
) +
theme_classic() +
facet_wrap(~comparison)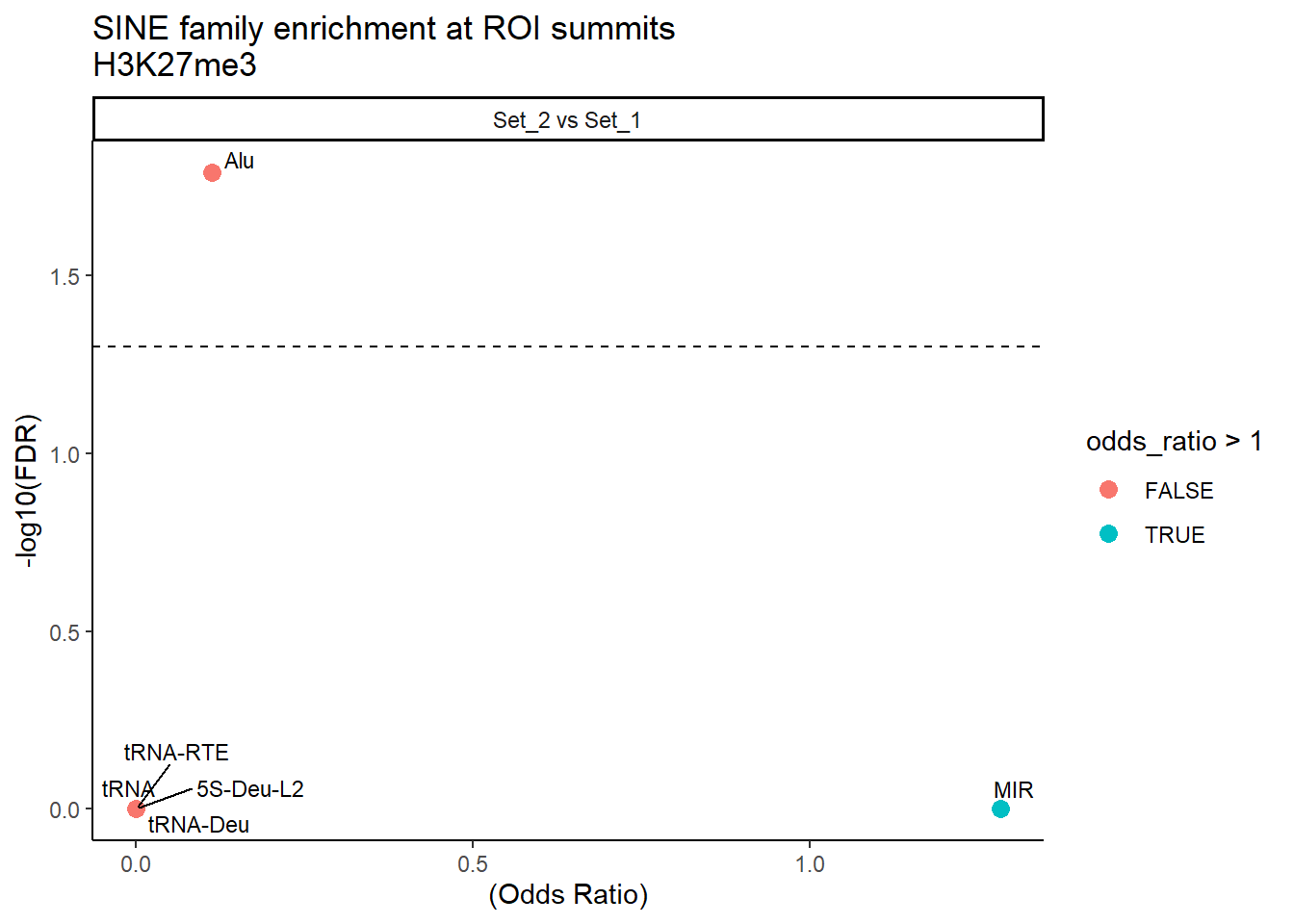
LINE
Overlapping LINE family with summits to get a count
LINE_hits <- findOverlaps(H3K27me3_summit_gr, LINE_gr, ignore.strand = TRUE)
LINE_overlap_df <- tibble(
summit_id = queryHits(LINE_hits),
cluster = mcols(H3K27me3_summit_gr)$cluster[queryHits(LINE_hits)],
TE_type = mcols(LINE_gr)$repFamily[subjectHits(LINE_hits)])
LINE_counts <- LINE_overlap_df %>%
count(cluster, TE_type, name = "count") %>%
mutate(status = "TE")
total_LINE_summits <- tibble(
cluster = mcols(H3K27me3_summit_gr)$cluster
) %>% count(cluster, name = "total")
not_LINE_counts <- LINE_counts %>%
left_join(total_LINE_summits, by = "cluster") %>%
mutate(count = total - count,
status = "not_TE") %>%
select(cluster, TE_type, status, count)
LINE_df_long <- bind_rows(LINE_counts %>%
dplyr::select(cluster, TE_type, status, count),
not_LINE_counts) %>%
filter(!is.na(cluster))
LINE_results <- comparisons %>%
mutate(results = map2(cluster2, cluster1, function(c2, c1) {
LINE_df_long %>%
distinct(TE_type) %>%
pull() %>%
map_dfr(function(te) {
test_pair_TE_generic(
LINE_df_long,
te_name = te,
cluster1 = c1,
cluster2 = c2
)
})
})
) %>%
unnest(results) %>%
mutate(FDR = p.adjust(p_value, method = "BH"))datatable(LINE_counts,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE))total_LINE_summits# A tibble: 3 × 2
cluster total
<chr> <int>
1 Set_1 148911
2 Set_2 235
3 all_H3K27me3_regions 150464# ---- Prepare the table ----
LINE_counts_display <- LINE_results %>%
# 1. Split comparison
separate(comparison, into = c("cluster2", "cluster1"), sep = " vs ", remove = FALSE) %>%
# 2. Add log2 odds ratio
mutate(log2OR = log2(odds_ratio)) %>%
# 3. Add enrichment/depletion direction
mutate(direction = case_when(
odds_ratio > 1 ~ "enriched",
odds_ratio < 1 ~ "depleted",
TRUE ~ "neutral"
)) %>%
# 4. Flag significant
mutate(significant = FDR < 0.05) %>%
# Optional: arrange for readability
arrange(cluster2, direction, desc(log2OR))
# ---- Create interactive datatable ----
datatable(
LINE_counts_display,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE
)
) %>%
# Conditional coloring by direction
formatStyle(
'direction',
target = 'row',
backgroundColor = styleEqual(
c('enriched', 'depleted'),
c('#FFDD99', '#99CCFF') # enriched = light orange, depleted = light blue
)
) %>%
# Bold significant rows
formatStyle(
'significant',
fontWeight = styleEqual(TRUE, 'bold')
) %>%
# Round numeric columns for readability
formatRound(columns = c('odds_ratio','log2OR','FDR'), digits = 2)ggplot(LINE_results, aes(x = (odds_ratio), y = -log10(FDR),label = TE_type)) +
geom_point(aes(color = odds_ratio > 1), size = 3) +
# geom_text_repel(data = subset(SVA_results, FDR < 0.05)) +
geom_text_repel(size=3, max.overlaps = Inf)+
geom_hline(yintercept = -log10(0.05), linetype = "dashed") +
labs(
x = "(Odds Ratio)",
y = "-log10(FDR)",
title = "LINE family enrichment at ROI summits\nH3K27me3"
) +
theme_classic()+
facet_wrap(~comparison)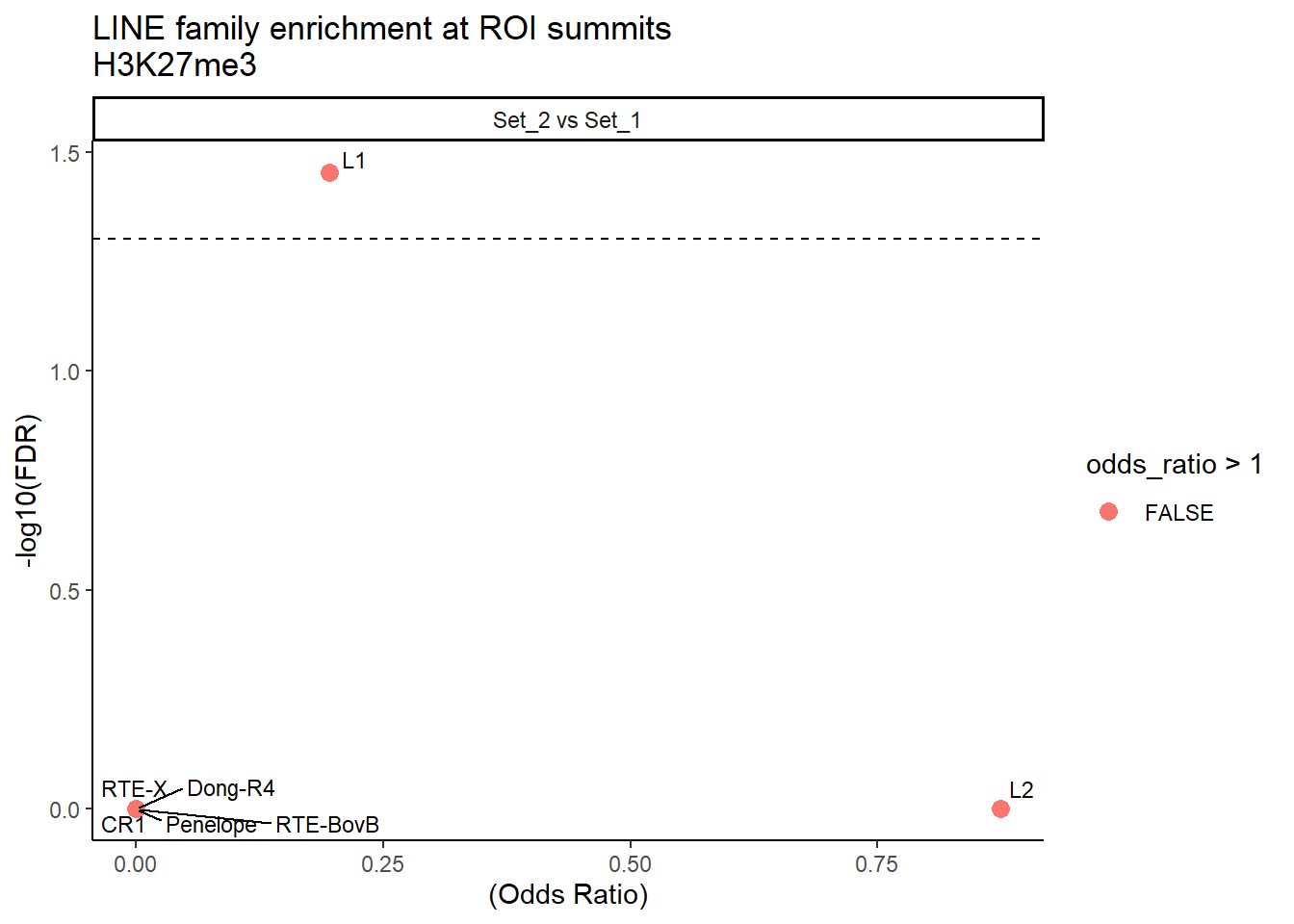
LTR
Overlapping LTR family summits to get a count
LTR_hits <- findOverlaps(H3K27me3_summit_gr, LTR_gr, ignore.strand = TRUE)
LTR_overlap_df <- tibble(
summit_id = queryHits(LTR_hits),
cluster = mcols(H3K27me3_summit_gr)$cluster[queryHits(LTR_hits)],
TE_type = mcols(LTR_gr)$repFamily[subjectHits(LTR_hits)])
LTR_counts <- LTR_overlap_df %>%
count(cluster, TE_type, name = "count") %>%
mutate(status = "TE")
total_LTR_summits <- tibble(
cluster = mcols(H3K27me3_summit_gr)$cluster
) %>% count(cluster, name = "total")
not_LTR_counts <- LTR_counts %>%
left_join(total_LTR_summits, by = "cluster") %>%
mutate(count = total - count,
status = "not_TE") %>%
select(cluster, TE_type, status, count)
LTR_df_long <- bind_rows(LTR_counts %>%
dplyr::select(cluster, TE_type, status, count),
not_LTR_counts) %>%
filter(!is.na(cluster))
LTR_results <- comparisons %>%
mutate(results = map2(cluster2, cluster1, function(c2, c1) {
LTR_df_long %>%
distinct(TE_type) %>%
pull() %>%
map_dfr(function(te) {
test_pair_TE_generic(
LTR_df_long,
te_name = te,
cluster1 = c1,
cluster2 = c2
)
})
})
) %>%
unnest(results) %>%
mutate(FDR = p.adjust(p_value, method = "BH"))datatable(LTR_counts,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE))total_LTR_summits# A tibble: 3 × 2
cluster total
<chr> <int>
1 Set_1 148911
2 Set_2 235
3 all_H3K27me3_regions 150464# ---- Prepare the table ----
LTR_counts_display <- LTR_results %>%
# 1. Split comparison
separate(comparison, into = c("cluster2", "cluster1"), sep = " vs ", remove = FALSE) %>%
# 2. Add log2 odds ratio
mutate(log2OR = log2(odds_ratio)) %>%
# 3. Add enrichment/depletion direction
mutate(direction = case_when(
odds_ratio > 1 ~ "enriched",
odds_ratio < 1 ~ "depleted",
TRUE ~ "neutral"
)) %>%
# 4. Flag significant
mutate(significant = FDR < 0.05) %>%
# Optional: arrange for readability
arrange(cluster2, direction, desc(log2OR))
# ---- Create interactive datatable ----
datatable(
LTR_counts_display,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE
)
) %>%
# Conditional coloring by direction
formatStyle(
'direction',
target = 'row',
backgroundColor = styleEqual(
c('enriched', 'depleted'),
c('#FFDD99', '#99CCFF') # enriched = light orange, depleted = light blue
)
) %>%
# Bold significant rows
formatStyle(
'significant',
fontWeight = styleEqual(TRUE, 'bold')
) %>%
# Round numeric columns for readability
formatRound(columns = c('odds_ratio','log2OR','FDR'), digits = 2)ggplot(LTR_results, aes(x = (odds_ratio), y = -log10(FDR),label = TE_type)) +
geom_point(aes(color = odds_ratio > 1), size = 3) +
# geom_text_repel(data = subset(SVA_results, FDR < 0.05)) +
geom_text_repel(size=3, max.overlaps = Inf)+
geom_hline(yintercept = -log10(0.05), linetype = "dashed") +
labs(
x = "(Odds Ratio)",
y = "-log10(FDR)",
title = "LTR family enrichment at ROI summits\nH3K27me3"
) +
theme_classic()+
facet_wrap(~comparison)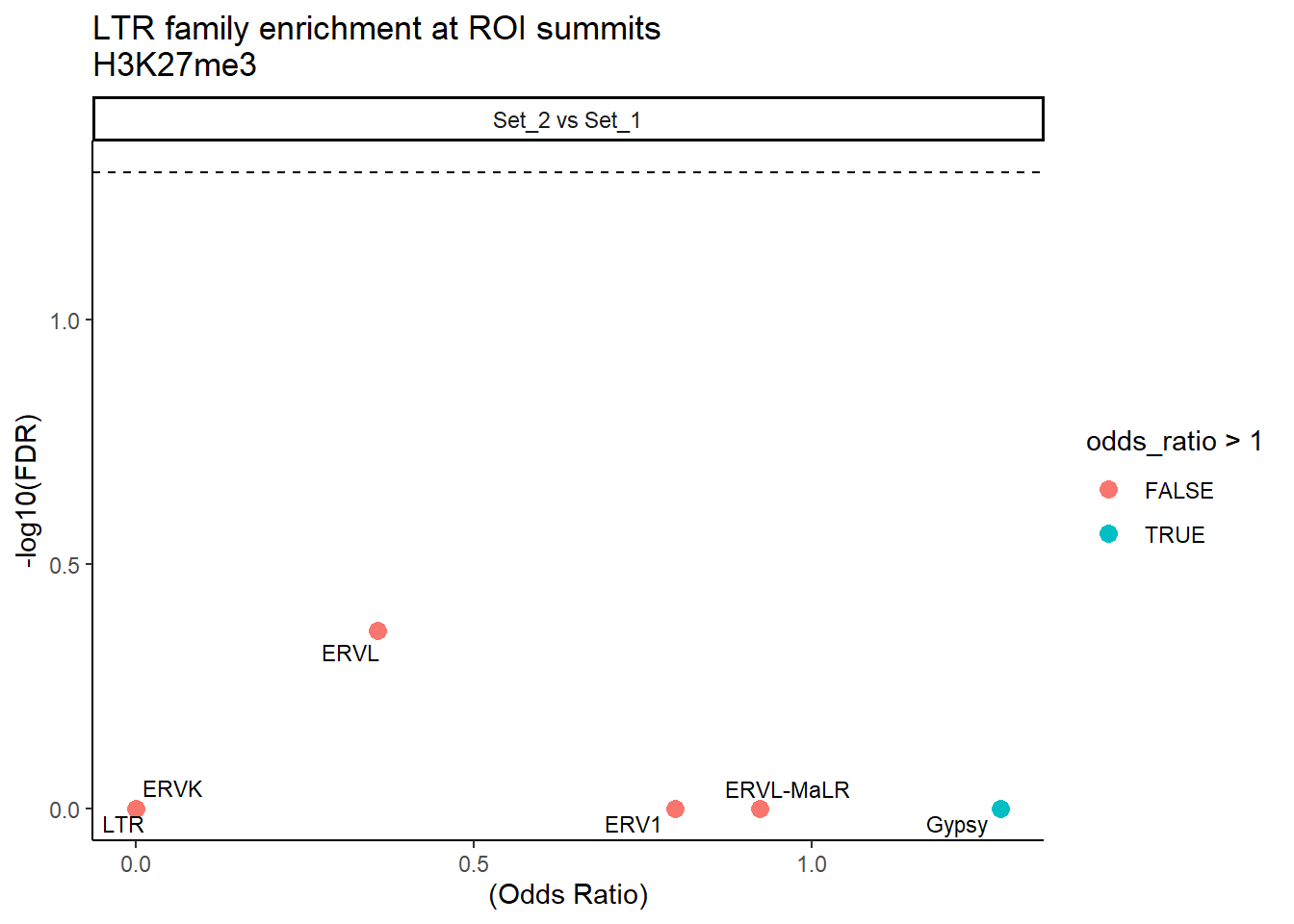 ### SVA
### SVA
Overlapping SVA family with summits to get a count
SVA_hits <- findOverlaps(H3K27me3_summit_gr, SVA_gr, ignore.strand = TRUE)
SVA_overlap_df <- tibble(
summit_id = queryHits(SVA_hits),
cluster = mcols(H3K27me3_summit_gr)$cluster[queryHits(SVA_hits)],
TE_type = mcols(SVA_gr)$repName[subjectHits(SVA_hits)])
SVA_counts <- SVA_overlap_df %>%
count(cluster, TE_type, name = "count") %>%
mutate(status = "TE")
total_SVA_summits <- tibble(
cluster = mcols(H3K27me3_summit_gr)$cluster
) %>% count(cluster, name = "total")
not_SVA_counts <- SVA_counts %>%
left_join(total_SVA_summits, by = "cluster") %>%
mutate(count = total - count,
status = "not_TE") %>%
select(cluster, TE_type, status, count)
SVA_df_long <- bind_rows(SVA_counts %>%
dplyr::select(cluster, TE_type, status, count),
not_SVA_counts) %>%
filter(!is.na(cluster))
SVA_results <- comparisons %>%
mutate(results = map2(cluster2, cluster1, function(c2, c1) {
SVA_df_long %>%
distinct(TE_type) %>%
pull() %>%
map_dfr(function(te) {
test_pair_TE_generic(
SVA_df_long,
te_name = te,
cluster1 = c1,
cluster2 = c2
)
})
})
) %>%
unnest(results) %>%
mutate(FDR = p.adjust(p_value, method = "BH"))datatable(SVA_counts,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE))total_SVA_summits# A tibble: 3 × 2
cluster total
<chr> <int>
1 Set_1 148911
2 Set_2 235
3 all_H3K27me3_regions 150464# ---- Prepare the table ----
SVA_counts_display <- SVA_results %>%
# 1. Split comparison
separate(comparison, into = c("cluster2", "cluster1"), sep = " vs ", remove = FALSE) %>%
# 2. Add log2 odds ratio
mutate(log2OR = log2(odds_ratio)) %>%
# 3. Add enrichment/depletion direction
mutate(direction = case_when(
odds_ratio > 1 ~ "enriched",
odds_ratio < 1 ~ "depleted",
TRUE ~ "neutral"
)) %>%
# 4. Flag significant
mutate(significant = FDR < 0.05) %>%
# Optional: arrange for readability
arrange(cluster2, direction, desc(log2OR))
# ---- Create interactive datatable ----
datatable(
SVA_counts_display,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE
)
) %>%
# Conditional coloring by direction
formatStyle(
'direction',
target = 'row',
backgroundColor = styleEqual(
c('enriched', 'depleted'),
c('#FFDD99', '#99CCFF') # enriched = light orange, depleted = light blue
)
) %>%
# Bold significant rows
formatStyle(
'significant',
fontWeight = styleEqual(TRUE, 'bold')
) %>%
# Round numeric columns for readability
formatRound(columns = c('odds_ratio','log2OR','FDR'), digits = 2)ggplot(SVA_results, aes(x = (odds_ratio), y = -log10(FDR),label = TE_type)) +
geom_point(aes(color = odds_ratio > 1), size = 3) +
# geom_text_repel(data = subset(SVA_results, FDR < 0.05)) +
geom_text_repel(size=3, max.overlaps = Inf)+
geom_hline(yintercept = -log10(0.05), linetype = "dashed") +
labs(
x = "(Odds Ratio)",
y = "-log10(FDR)",
title = "SVA family enrichment at ROI summits\nH3K27me3"
) +
theme_classic()+
facet_wrap(~comparison)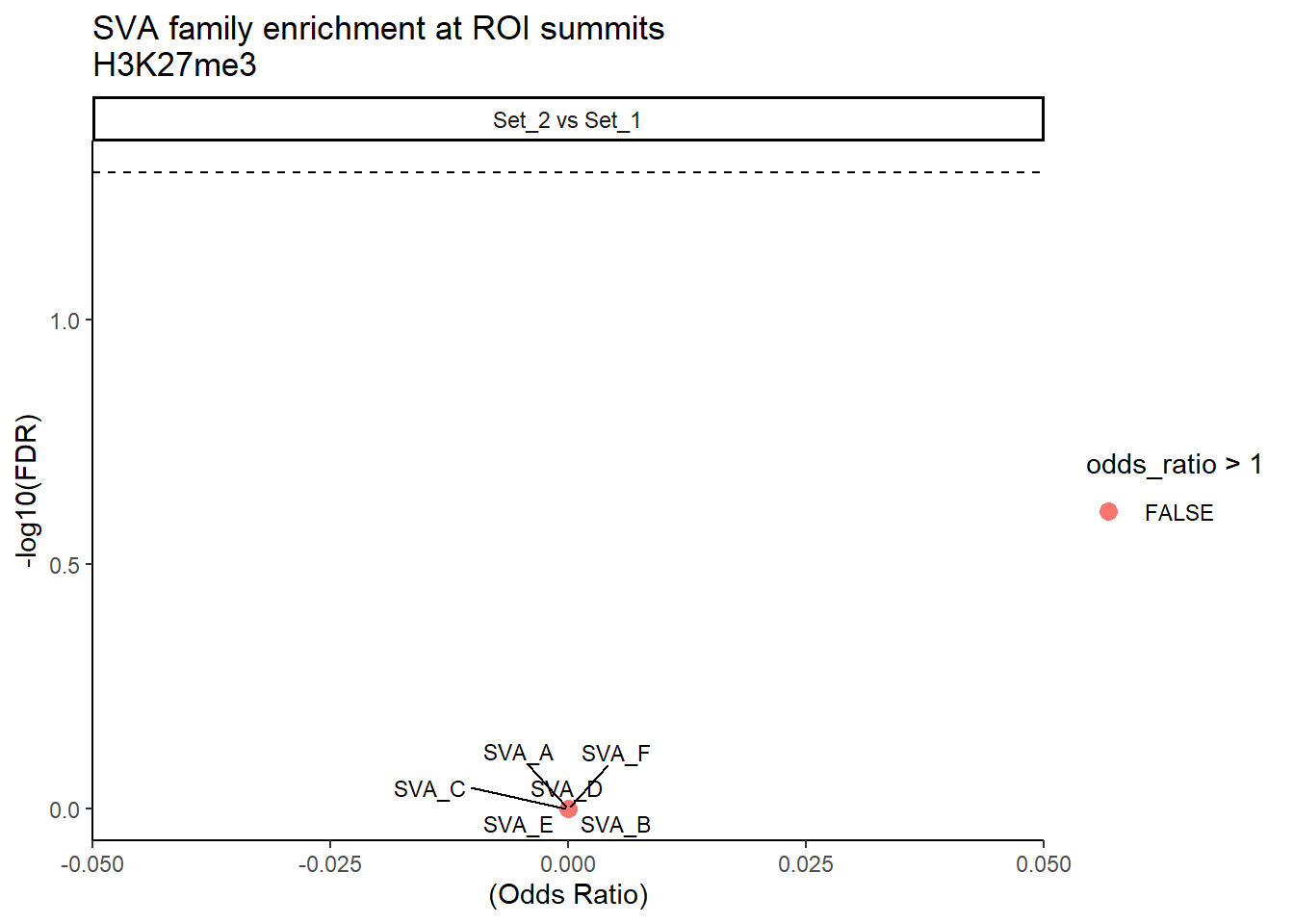 ### DNA
### DNA
Overlapping DNA family with summits to get a count
DNA_hits <- findOverlaps(H3K27me3_summit_gr, DNA_gr, ignore.strand = TRUE)
DNA_overlap_df <- tibble(
summit_id = queryHits(DNA_hits),
cluster = mcols(H3K27me3_summit_gr)$cluster[queryHits(DNA_hits)],
TE_type = mcols(DNA_gr)$repFamily[subjectHits(DNA_hits)])
DNA_counts <- DNA_overlap_df %>%
count(cluster, TE_type, name = "count") %>%
mutate(status = "TE")
total_DNA_summits <- tibble(
cluster = mcols(H3K27me3_summit_gr)$cluster
) %>% count(cluster, name = "total")
not_DNA_counts <- DNA_counts %>%
left_join(total_DNA_summits, by = "cluster") %>%
mutate(count = total - count,
status = "not_TE") %>%
select(cluster, TE_type, status, count)
DNA_df_long <- bind_rows(DNA_counts %>%
dplyr::select(cluster, TE_type, status, count),
not_DNA_counts) %>%
filter(!is.na(cluster))
DNA_results <- comparisons %>%
mutate(results = map2(cluster2, cluster1, function(c2, c1) {
DNA_df_long %>%
distinct(TE_type) %>%
pull() %>%
map_dfr(function(te) {
test_pair_TE_generic(
DNA_df_long,
te_name = te,
cluster1 = c1,
cluster2 = c2
)
})
})
) %>%
unnest(results) %>%
mutate(FDR = p.adjust(p_value, method = "BH"))datatable(DNA_counts,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE))total_DNA_summits# A tibble: 3 × 2
cluster total
<chr> <int>
1 Set_1 148911
2 Set_2 235
3 all_H3K27me3_regions 150464# ---- Prepare the table ----
DNA_counts_display <- DNA_results %>%
# 1. Split comparison
separate(comparison, into = c("cluster2", "cluster1"), sep = " vs ", remove = FALSE) %>%
# 2. Add log2 odds ratio
mutate(log2OR = log2(odds_ratio)) %>%
# 3. Add enrichment/depletion direction
mutate(direction = case_when(
odds_ratio > 1 ~ "enriched",
odds_ratio < 1 ~ "depleted",
TRUE ~ "neutral"
)) %>%
# 4. Flag significant
mutate(significant = FDR < 0.05) %>%
# Optional: arrange for readability
arrange(cluster2, direction, desc(log2OR))
# ---- Create interactive datatable ----
datatable(
DNA_counts_display,
rownames = FALSE,
filter = 'top', # add filter/search boxes
options = list(
pageLength = 10,
autoWidth = TRUE,
scrollX = TRUE
)
) %>%
# Conditional coloring by direction
formatStyle(
'direction',
target = 'row',
backgroundColor = styleEqual(
c('enriched', 'depleted'),
c('#FFDD99', '#99CCFF') # enriched = light orange, depleted = light blue
)
) %>%
# Bold significant rows
formatStyle(
'significant',
fontWeight = styleEqual(TRUE, 'bold')
) %>%
# Round numeric columns for readability
formatRound(columns = c('odds_ratio','log2OR','FDR'), digits = 2)ggplot(DNA_results, aes(x = (odds_ratio), y = -log10(FDR),label = TE_type)) +
geom_point(aes(color = odds_ratio > 1), size = 3) +
# geom_text_repel(data = subset(SVA_results, FDR < 0.05)) +
geom_text_repel(size=3, max.overlaps = Inf)+
geom_hline(yintercept = -log10(0.05), linetype = "dashed") +
labs(
x = "(Odds Ratio)",
y = "-log10(FDR)",
title = "DNA family enrichment at ROI summits\nH3K27me3"
) +
theme_classic()+
facet_wrap(~comparison)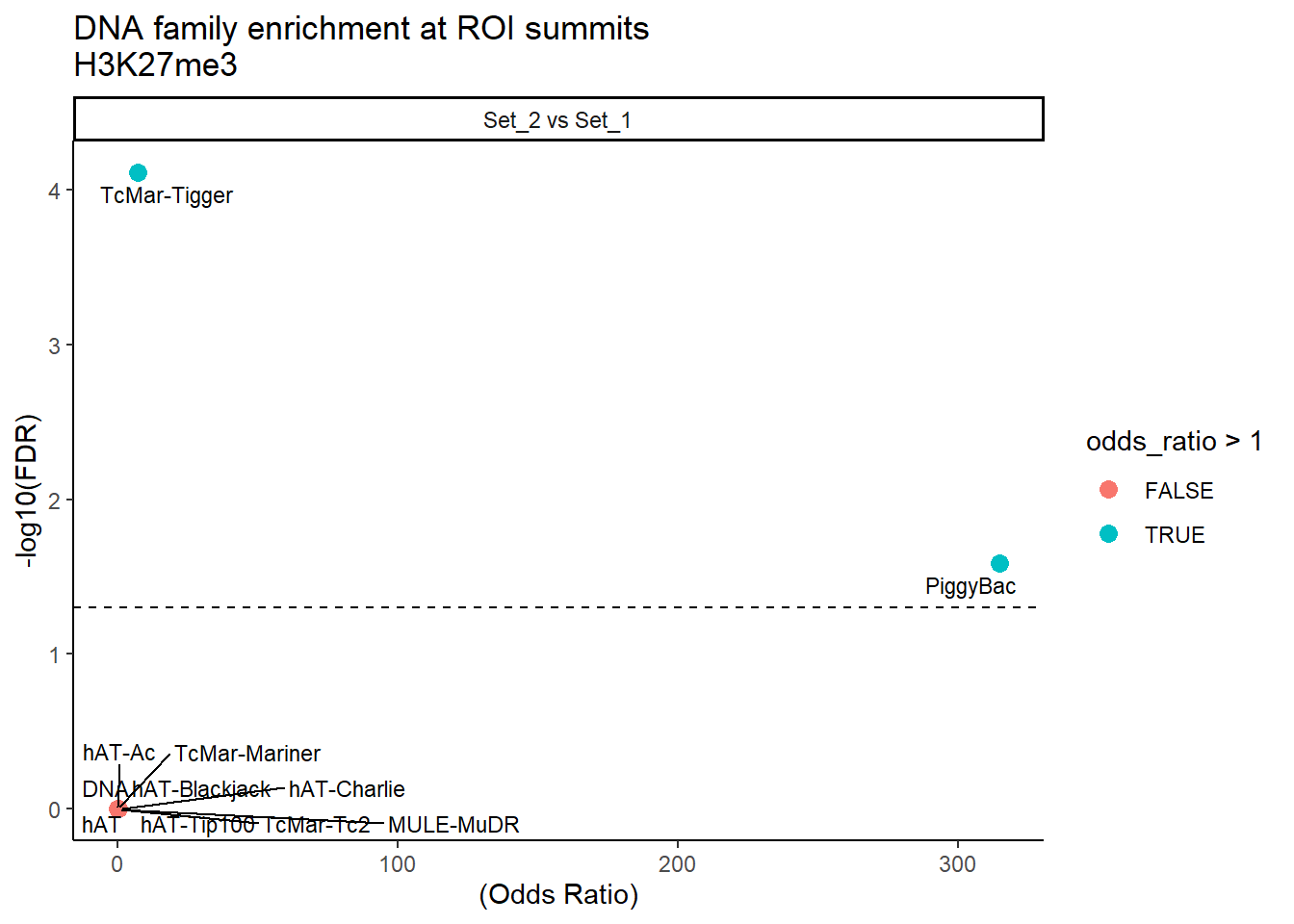
peakAnnoList_H3K27me3 <- readRDS("data/motif_lists/H3K27me3_annotated_peaks.RDS")
out_dir <- "data/Bed_exports/H3K27me3_sets"
set_list <- names(peakAnnoList_H3K27me3)
for (group_name in set_list) {
cs <- peakAnnoList_H3K27me3[[group_name]]
gr <- cs@anno
# Set BED name column
mcols(gr)$name <- mcols(gr)$Peakid
# Optional: if you want a score column
if(!"score" %in% colnames(mcols(gr))) {
mcols(gr)$score <- 0
}
# Export to BED
bed_file <- file.path(out_dir, paste0(group_name, "_H3K27me3.bed"))
# Export
export(gr, bed_file, format = "BED")
cat("Exported:", bed_file, "\n")
}
sessionInfo()R version 4.4.2 (2024-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 11 x64 (build 26200)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] grid stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] DT_0.33 ggrepel_0.9.6 rtracklayer_1.66.0
[4] genomation_1.38.0 plyranges_1.26.0 GenomicRanges_1.58.0
[7] GenomeInfoDb_1.42.3 IRanges_2.40.1 S4Vectors_0.44.0
[10] BiocGenerics_0.52.0 lubridate_1.9.4 forcats_1.0.0
[13] stringr_1.5.1 dplyr_1.1.4 purrr_1.1.0
[16] readr_2.1.5 tidyr_1.3.1 tibble_3.3.0
[19] ggplot2_3.5.2 tidyverse_2.0.0 workflowr_1.7.1
loaded via a namespace (and not attached):
[1] bitops_1.0-9 rlang_1.1.6
[3] magrittr_2.0.3 git2r_0.36.2
[5] gridBase_0.4-7 matrixStats_1.5.0
[7] compiler_4.4.2 getPass_0.2-4
[9] callr_3.7.6 vctrs_0.6.5
[11] reshape2_1.4.4 pkgconfig_2.0.3
[13] crayon_1.5.3 fastmap_1.2.0
[15] XVector_0.46.0 labeling_0.4.3
[17] utf8_1.2.6 Rsamtools_2.22.0
[19] promises_1.3.3 rmarkdown_2.29
[21] tzdb_0.5.0 UCSC.utils_1.2.0
[23] ps_1.9.1 bit_4.6.0
[25] xfun_0.52 zlibbioc_1.52.0
[27] cachem_1.1.0 jsonlite_2.0.0
[29] later_1.4.2 DelayedArray_0.32.0
[31] BiocParallel_1.40.2 parallel_4.4.2
[33] R6_2.6.1 bslib_0.9.0
[35] stringi_1.8.7 RColorBrewer_1.1-3
[37] jquerylib_0.1.4 Rcpp_1.1.0
[39] SummarizedExperiment_1.36.0 knitr_1.50
[41] httpuv_1.6.16 Matrix_1.7-3
[43] timechange_0.3.0 tidyselect_1.2.1
[45] rstudioapi_0.17.1 dichromat_2.0-0.1
[47] abind_1.4-8 yaml_2.3.10
[49] seqPattern_1.38.0 codetools_0.2-20
[51] curl_7.0.0 processx_3.8.6
[53] lattice_0.22-7 plyr_1.8.9
[55] Biobase_2.66.0 withr_3.0.2
[57] evaluate_1.0.5 Biostrings_2.74.1
[59] pillar_1.11.0 MatrixGenerics_1.18.1
[61] whisker_0.4.1 KernSmooth_2.23-26
[63] generics_0.1.4 vroom_1.6.5
[65] rprojroot_2.1.1 RCurl_1.98-1.17
[67] hms_1.1.3 scales_1.4.0
[69] glue_1.8.0 tools_4.4.2
[71] BiocIO_1.16.0 data.table_1.17.8
[73] BSgenome_1.74.0 GenomicAlignments_1.42.0
[75] fs_1.6.6 XML_3.99-0.18
[77] impute_1.80.0 plotrix_3.8-4
[79] crosstalk_1.2.2 colorspace_2.1-1
[81] GenomeInfoDbData_1.2.13 restfulr_0.0.16
[83] cli_3.6.5 S4Arrays_1.6.0
[85] gtable_0.3.6 sass_0.4.10
[87] digest_0.6.37 SparseArray_1.6.2
[89] htmlwidgets_1.6.4 rjson_0.2.23
[91] farver_2.1.2 htmltools_0.5.8.1
[93] lifecycle_1.0.4 httr_1.4.7
[95] bit64_4.6.0-1