Characterise Simulation Data (Multiple Targets)
Ross Gayler
2021-08-07
Last updated: 2021-08-11
Checks: 7 0
Knit directory:
VSA_altitude_hold/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210617) was run prior to running the code in the R Markdown file.
Setting a seed ensures that any results that rely on randomness, e.g.
subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 9fabf0e. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the
analysis have been committed to Git prior to generating the results (you can
use wflow_publish or wflow_git_commit). workflowr only
checks the R Markdown file, but you know if there are other scripts or data
files that it depends on. Below is the status of the Git repository when the
results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: renv/library/
Ignored: renv/local/
Ignored: renv/staging/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made
to the R Markdown (analysis/characterise_multiple_target_data.Rmd) and HTML (docs/characterise_multiple_target_data.html)
files. If you’ve configured a remote Git repository (see
?wflow_git_remote), click on the hyperlinks in the table below to
view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 9fabf0e | Ross Gayler | 2021-08-11 | WIP |
| html | 9fabf0e | Ross Gayler | 2021-08-11 | WIP |
| Rmd | c8a9adc | Ross Gayler | 2021-08-09 | WIP |
| html | c8a9adc | Ross Gayler | 2021-08-09 | WIP |
| Rmd | 3e2622c | Ross Gayler | 2021-08-08 | WIP |
| html | 3e2622c | Ross Gayler | 2021-08-08 | WIP |
| html | 5d9cef3 | Ross Gayler | 2021-08-08 | WIP |
| Rmd | a62e0b9 | Ross Gayler | 2021-08-07 | WIP |
| html | a62e0b9 | Ross Gayler | 2021-08-07 | WIP |
This notebook characterises data generated by the simulation of the classically implemented altitude hold controller. We need to understand the properties of the signals in order to design VSA implementations of them. This set of simulation data files has multiple target altitudes within each simulation. The duration of each simulation has been doubled to 10 seconds.
This notebook is essentially a copy of the single target notebook with the minimal changes necessitated by having multiple targets.
The values to be characterised are all the real scalars corresponding to the nodes in the data flow diagram for Design 01.
1 Data
The data is generated from runs of the classically implemented simulation.
The data files are stored in the
data/multiple_targetdirectory.The data is supplied as CSV files, each file corresponding to a different run of the simulation.
Each run of the simulation corresponds to a set of target altitudes, parameters, and program details.
The name of each data file contains the values of the starting conditions, parameters, and program details.
The only starting condition that varies between runs is the initial altitude. The multicopter is released at the starting height and the multicopter must command the motors to attain the first target altitude.
In this set of data files the target altitude parameter (\(k_{tgt}\)) varies (piecewise constant) over the duration of each simulation.
The target altitude changes at time steps 335 and 668. (There are three target altitudes over the course of each simulation.)
The other parameters are tuning constants (\(k_p\), \(k_i\), and \(k_{windup}\)) for the PID controller and are constant across runs of the simulation.
The program details that vary between simulation files in the single target data set are constant across all files in the multiple target data set.
The \(uclip\) program detail indicates whether the motor demand value (\(u\)) has been clipped to the the range \([0, 1]\) prior to export. The clipped value is what is used to command the motors. However, the unclipped value is more useful for comparing to the mathematically reconstructed value of the other nodes.
- The \(uclip\) program detail can be interpreted as indicating whether the clipped or unclipped value has been exported. \(uclip = TRUE\) corresponds to exporting the value of the \(u\) node of the data flow diagram for Design 01. \(uclip = FALSE\) corresponds to exporting the value of the node \(i7\).
- \(uclip = FALSE\) for all files in the multiple target data set.
The \(dz0\) program detail indicates whether the vertical velocity (\(dz\)) is zero on the first recorded time step.
- The simulation is based on OpenAI Gym which has a “convention of having the reset() function call the step() function, which updates the state and returns the new state, reward, and a flag for whether the game is over”. This was used to intialise the simulations (\(dz0 = FALSE\)), with the result that the state update was run as part of the initialisation. This isn’t particularly significant except that the starting state of the simulation is not quite what you might expect.
- \(dz0 = TRUE\) for all files in the multiple target data set.
Each row of the data file corresponds to a point in time and successive rows correspond to successive points in time. (This is a discrete time simulation with fixed time steps of 10ms.)
Each file contains 1,000 time steps of 10ms (i.e. 10s total).
Each column of the data file corresponds to a node of the data flow diagram.
Only a subset of the nodes are supplied (\(z\), \(dz\), \(e\), \(ei\), and \(u\) - the nodes in rectangular boxes in the DFD supplied by Simon Levy) and the values of the other nodes can be reconstructed mathematically.
The values supplied from the input files are recorded to three decimal places, so there is scope for approximation error due to the limited precision.
Where a node value is supplied from the input file and that node also has upstream nodes in the DFD the supplied and calculated values should be equal and can be compared.
- For nodes like this, in this notebook I will use the imported value rather than the calculatedt value as the input for downstream nodes in order to avoid propagating approximation errors.
1.1 Read data
Read the data from the simulations and mathematically reconstruct the values of the nodes not included in the input files.
# function to clip value to a range
clip <- function(
x, # numeric
x_min, # numeric[1] - minimum output value
x_max # numeric[1] - maximum output value
) # value # numeric - x constrained to the range [x_min, x_max]
{
x %>% pmax(x_min) %>% pmin(x_max)
}
# function to extract a numeric parameter value from the file name
get_param_num <- function(
file, # character - vector of file names
regexp # character[1] - regular expression for "param=value"
# use a capture group to get the value part
) # value # numeric - vector of parameter values
{
file %>% str_match(regexp) %>%
subset(select = 2) %>% as.numeric()
}
# function to extract a sequence of numeric parameter values from the file name
get_param_num_seq <- function(
file, # character - vector of file names
regexp # character[1] - regular expression for "param=value"
# use a capture group to get the value part
) # value # character - character representation of a sequence, e.g. "(1,2,3)"
{
file %>% str_match(regexp) %>%
subset(select = 2) %>%
str_replace_all(c("^" = "(", "_" = ",", "$" = ")")) # reformat as sequence
}
# function to extract a logical parameter value from the file name
get_param_log <- function(
file, # character - vector of file names
regexp # character[1] - regular expression for "param=value"
# use a capture group to get the value part
# value *must* be T or F
) # value # logical - vector of logical parameter values
{
file %>% str_match(regexp) %>%
subset(select = 2) %>% as.character() %>% "=="("T")
}
# read the data
d_wide <- fs::dir_ls(path = here::here("data", "multiple_target"), regexp = "/targets=.*\\.csv$") %>% # get file paths
vroom::vroom(id = "file") %>% # read files
dplyr::rename(k_tgt = target) %>% # rename for consistency with single target data
dplyr::mutate( # add extra columns
file = file %>% fs::path_ext_remove() %>% fs::path_file(), # get file name
# get parameters
targets = file %>% get_param_num_seq("targets=([._0-9]+)_start="), # hacky
k_start = file %>% get_param_num("start=([.0-9]+)"),
sim_id = paste(targets, k_start), # short ID for each simulation
k_p = file %>% get_param_num("kp=([.0-9]+)"),
k_i = file %>% get_param_num("Ki=([.0-9]+)"),
# k_tgt = file %>% get_param_num("k_tgt=([.0-9]+)"), # no longer needed
k_windup = file %>% get_param_num("k_windup=([.0-9]+)"),
uclip = FALSE, # constant across all files
dz0 = TRUE, # constant across all files
# Deal with the fact that the interpretation of the imported u value
# depends on the uclip parameter
u_import = u, # keep a copy of the imported value to one side
u = dplyr::if_else(uclip, # make u the "correct" value
u_import,
clip(u_import, 0, 1)
),
# reconstruct the missing nodes
i1 = k_tgt - z,
i2 = i1 - dz,
i3 = e * k_p,
i9 = lag(ei, n = 1, default = 0), # initialised to zero
i4 = e + i9,
i5 = i4 %>% clip(-k_windup, k_windup),
i6 = ei * k_i,
i7 = i3 + i6,
i8 = i7 %>% clip(0, 1)
) %>%
# add time variable per file
dplyr::group_by(file) %>%
dplyr::mutate(t = 1:n()) %>%
dplyr::ungroup()Rows: 6000 Columns: 8── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
dbl (7): time, target, z, dz, e, ei, u
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.dplyr::glimpse(d_wide)Rows: 6,000
Columns: 27
$ file <chr> "targets=1_3_5_start=3_kp=0.20_Ki=3.00_k_windup=0.20", "targe…
$ time <dbl> 0.00, 0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0…
$ k_tgt <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ z <dbl> 3.000, 3.000, 3.003, 3.005, 3.006, 3.006, 3.005, 3.002, 2.999…
$ dz <dbl> 0.000, 0.286, 0.188, 0.090, -0.008, -0.106, -0.204, -0.302, -…
$ e <dbl> -2.000, -2.286, -2.191, -2.095, -1.998, -1.899, -1.800, -1.70…
$ ei <dbl> -0.200, -0.200, -0.200, -0.200, -0.200, -0.200, -0.200, -0.20…
$ u <dbl> 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000, 0.000…
$ targets <chr> "(1,3,5)", "(1,3,5)", "(1,3,5)", "(1,3,5)", "(1,3,5)", "(1,3,…
$ k_start <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
$ sim_id <chr> "(1,3,5) 3", "(1,3,5) 3", "(1,3,5) 3", "(1,3,5) 3", "(1,3,5) …
$ k_p <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0…
$ k_i <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
$ k_windup <dbl> 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0…
$ uclip <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALSE…
$ dz0 <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, T…
$ u_import <dbl> -1.000, -1.057, -1.038, -1.019, -1.000, -0.980, -0.960, -0.94…
$ i1 <dbl> -2.000, -2.000, -2.003, -2.005, -2.006, -2.006, -2.005, -2.00…
$ i2 <dbl> -2.000, -2.286, -2.191, -2.095, -1.998, -1.900, -1.801, -1.70…
$ i3 <dbl> -0.4000, -0.4572, -0.4382, -0.4190, -0.3996, -0.3798, -0.3600…
$ i9 <dbl> 0.000, -0.200, -0.200, -0.200, -0.200, -0.200, -0.200, -0.200…
$ i4 <dbl> -2.000, -2.486, -2.391, -2.295, -2.198, -2.099, -2.000, -1.90…
$ i5 <dbl> -0.200, -0.200, -0.200, -0.200, -0.200, -0.200, -0.200, -0.20…
$ i6 <dbl> -0.600, -0.600, -0.600, -0.600, -0.600, -0.600, -0.600, -0.60…
$ i7 <dbl> -1.0000, -1.0572, -1.0382, -1.0190, -0.9996, -0.9798, -0.9600…
$ i8 <dbl> 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.000…
$ t <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18…1.2 Check data
Check the data for consistency.
1.2.1 Initial values
The different starting conditions correspond to the multicopter being dropped/released at different altitudes.
Time \(t = 1\) should correspond to the moment of release. At that time the altitude should be exactly the starting altitude and the vertical velocity (\(dz\)) should be exactly zero (when \(dz0 = TRUE\), which is the case for all the simulations in this data set).
Treating propagation through the DFD as instantaneous, we can calculate the values of the internal nodes as a function of the imposed initial values of the imported nodes. The internal nodes are generally functions of the values at the same time. However, the nodes involved in the calculation of the integrated errors (\(ei\)) are functions of the integrated error at the previous time step. This means that there is a dependency on the initial value of \(ei\) (which is initialised to zero in the simulation code)
Check the initial node values imported from the simulations.
d_wide %>%
dplyr::filter(t == 1) %>% # get initial time step
dplyr::arrange(k_start, dz0, uclip) %>%
dplyr::select(file, k_start, z, k_tgt, dz0, dz, e, ei, u) %>%
DT::datatable(rownames = FALSE)As expected, the initial altitude (\(z\)) is equal to (\(k_{start}\)) for all simulations.
As expected, The initial vertical velocities (\(dz\)) are zero because \(dz0 = TRUE\).
As expected, the error \(e\) and integrated error \(ei\) are nonzero at the first time step because the starting altitudes are not equal to the target altitude and because of the instantaneous propagation of values through the DFD. The correctness of the values will be checked in the next section.
As expected, the motor command \(u\) is nonzero when the starting altitude is below the target (because the multicopter has to climb to the target) and zero when the starting altitude is above the target (because the multicopter has to fall to the target). The correctness of the values will be checked in the next section.
1.2.2 Check calculated values
Where possible, compare the calculated values with the values imported from the simulator. The calculated nodes which can be checked against the imported reference values are: e, ei, u.
The analyses below involve calculating the distributions of values over the available time steps. This is a slightly odd interpretation of distribution in that the available time steps do not constitute a sample from some stationary distribution. Rather, the values should be interpreted as roughly representative of the multicopter’s response to a perturbation.
1.2.2.1 e = i2
\(e\) and \(i2\) should be identical (up to approximation error).
d_wide %>%
dplyr::group_by(file) %>%
dplyr::summarise(
min = min(e - i2) %>% round(3),
p01 = quantile(e - i2, probs = 0.01) %>% round(3), #1st percentile
p50 = median(e - i2) %>% round(3),
p99 = quantile(e - i2, probs = 0.99) %>% round(3), # 99th percentile
max = max(e - i2) %>% round(3)
) %>%
DT::datatable(rownames = FALSE, caption = "*** e - i2 ***")- The imported and reconstructed values agree except for approximation error due to the low precision of the numbers in the files.
1.2.2.2 ei = i5
\(ei\) and \(i5\) should be identical (up to approximation error).
d_wide %>%
dplyr::group_by(file) %>%
dplyr::summarise(
min = min(ei - i5) %>% round(3),
p01 = quantile(ei - i5, probs = 0.01) %>% round(3), #1st percentile
p50 = median(ei - i5) %>% round(3),
p99 = quantile(ei - i5, probs = 0.99) %>% round(3), # 99th percentile
max = max(ei - i5) %>% round(3)
) %>%
DT::datatable(rownames = FALSE, caption = "*** ei - i5 ***")- The imported and reconstructed values agree except for approximation error due to the low precision of the numbers in the files.
1.2.2.3 u = i7
When \(uclip = FALSE\), \(u\) and \(i7\) should be identical (up to approximation error). \(uclip = FALSE\) for all the files in this data set.
d_wide %>%
dplyr::group_by(file) %>%
dplyr::summarise(
min = min(u_import - i7) %>% round(3),
p01 = quantile(u_import - i7, probs = 0.01) %>% round(3), #1st percentile
p50 = median(u_import - i7) %>% round(3),
p99 = quantile(u_import - i7, probs = 0.99) %>% round(3), # 99th percentile
max = max(u_import - i7) %>% round(3)
) %>%
DT::datatable(rownames = FALSE, caption = "*** u_import - i7 ***")The imported and reconstructed values agree except for approximation error due to the low precision of the numbers in the files.
- I am prepared to believe that the larger approximation error in this case is due to the accumulation of errors over the longer path through the DFD.
Look at the rows where the largest approximation errors occur.
d_wide %>%
dplyr::filter(abs(u_import - i7) >= 0.002) %>%
dplyr::arrange(file, u_import - i7) %>%
dplyr::select(file, t, u_import, i7, i3, i6, ei) %>%
DT::datatable(rownames = FALSE)- The larger approximation errors only occur when \(u\) is in the middle of its range. Approximation errors can’t occur at the extremes because of clipping.
1.2.3 Check \(z\) and \(dz\)
The altitude (\(z\)) and vertical velocity (\(dz\)) are input values from the simulation data files. The simulation calculates the altitude by integrating the velocity with respect to time.
In most PID controllers, the derivative is calculated internally. In our project the velocity is supplied as an input to the PID controller because it is readily available.
The altitude (\(z\)) is scaled in metres and the vertical velocity (\(dz\)) is scaled in metres per second. Check that these supplied values are consistent by calculating the velocity from altitude at successive time steps.
The altitude is imported to three decimal places precision, so the rounding of successive values might generate an approximation error of the difference up to magnitude 0.001 (rounding error of 0.0005 on each value). The time difference between successive steps is 10ms, so the magnitude of the approximation error in metres per second could be up to \(0.001 / 0.010 = 0.1\).
d <- d_wide %>%
dplyr::group_by(file) %>%
dplyr::arrange(t, by_group = TRUE) %>%
dplyr::mutate(
dz_est = (z - lag(z, n = 1, default = NA)) / 0.010, # time step is 0.010 sec
d2z_est = (dz - lag(dz, n = 1, default = NA)) / 0.010, # acceleration
dz_diff = dz - dz_est # difference between input and estimated values
) %>%
dplyr::ungroup()
# velocity_error ~ velocity
d %>% ggplot() +
geom_hline(yintercept = c(-0.1, 0, 0.1)) +
geom_point(aes(x = dz, y = dz_diff, colour = as_factor(file)))Warning: Removed 6 rows containing missing values (geom_point).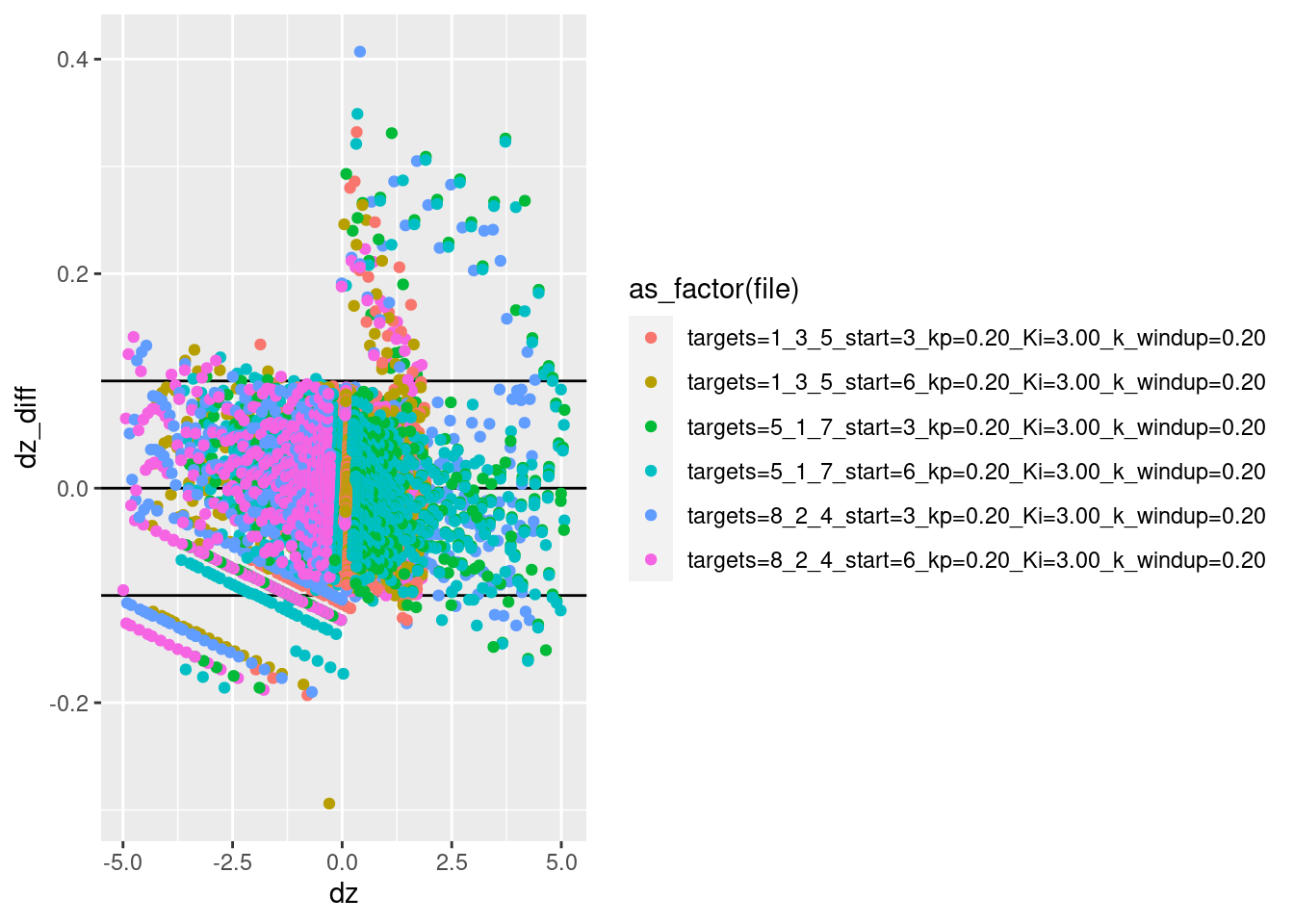
Most of the estimated velocities are within the calculated range of approximation error.
There are a modest number of points between the calculated errors bound and three times the error bound.
There are a few points with error more than three times the error bound.
The estimated velocity is likely to have larger estimation errors when the acceleration is high, because the velocity is changing more rapidly. Take a look at velocity estimation error as a function of acceleration.
# velocity_error ~ acceleration
d %>% ggplot() +
geom_hline(yintercept = c(-0.1, 0, 0.1)) +
geom_smooth(aes(x = d2z_est, y = dz_diff)) +
geom_point(aes(x = d2z_est, y = dz_diff, colour = as_factor(file)))`geom_smooth()` using method = 'gam' and formula 'y ~ s(x, bs = "cs")'Warning: Removed 6 rows containing non-finite values (stat_smooth).Warning: Removed 6 rows containing missing values (geom_point).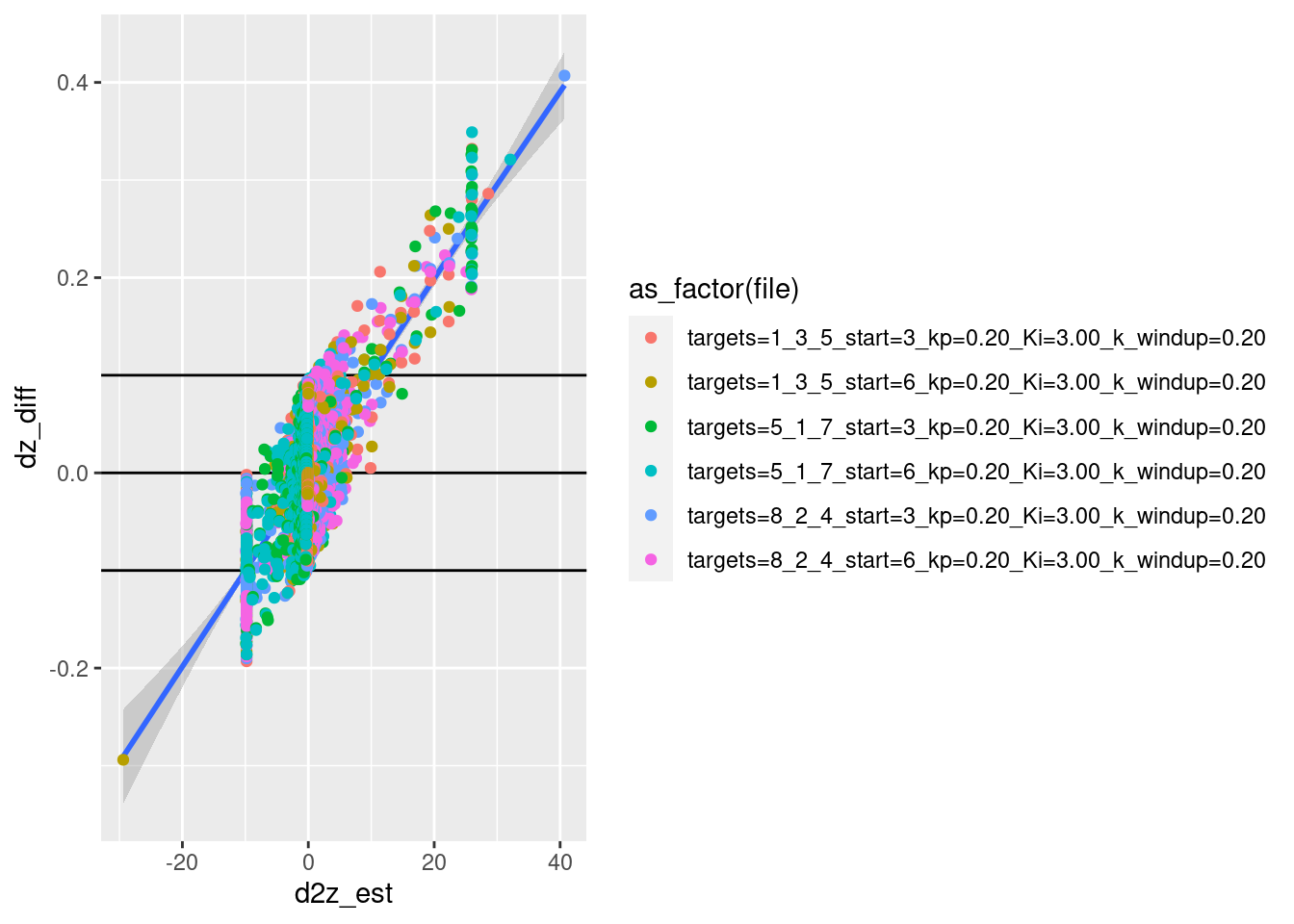
- The estimation error is pretty much explained by the acceleration.
I am happy that the input altitude and velocity are correctly related.
2 Plots
Plot the relationships between the major nodes. This is not necessarily of immediate use in deciding the design fo VSA components, but gives a feel for the dynamics of the system.
2.1 Time explicit
Show the values of the major nodes as a function of time.
2.1.1 Altitude versus time:
p <- d_wide %>%
dplyr::mutate(
d2z = (dz - lag(dz, n = 1, default = NA)) / 0.010 # get vertical acceleration
) %>%
ggplot(aes(x = t, group = file, colour = sim_id))
p +
geom_hline(yintercept = c(1,2,3,5,7,8), alpha = 0.2) + #targets
geom_path(aes(y = z))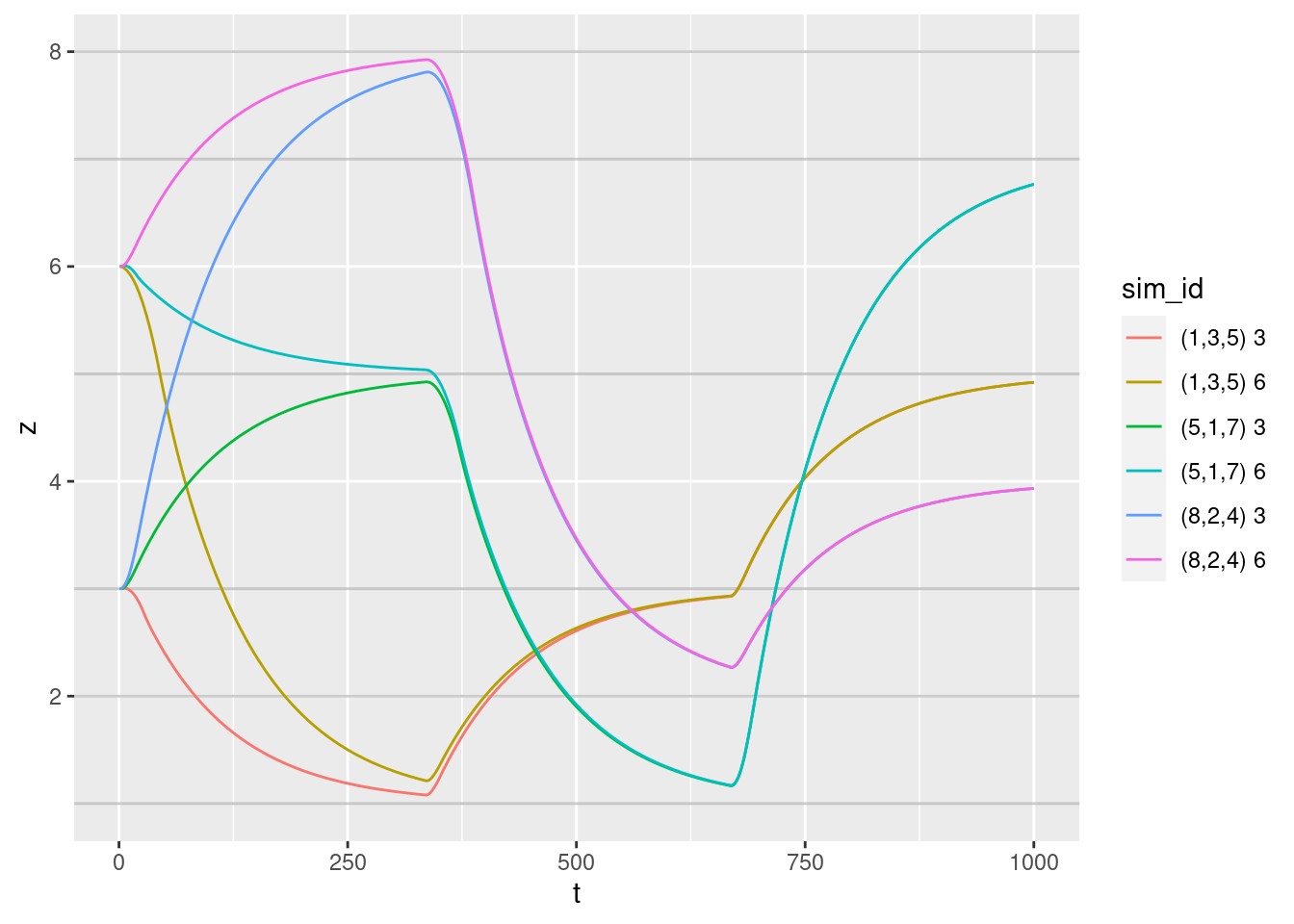
Altitude versus time:
- Looks clean and reasonable.
- For the larger changes in target altitude the multicopter has not quite reached the target altitude by the time the target altitude changes.
2.1.2 Velocity versus time:
p + geom_path(aes(y = dz))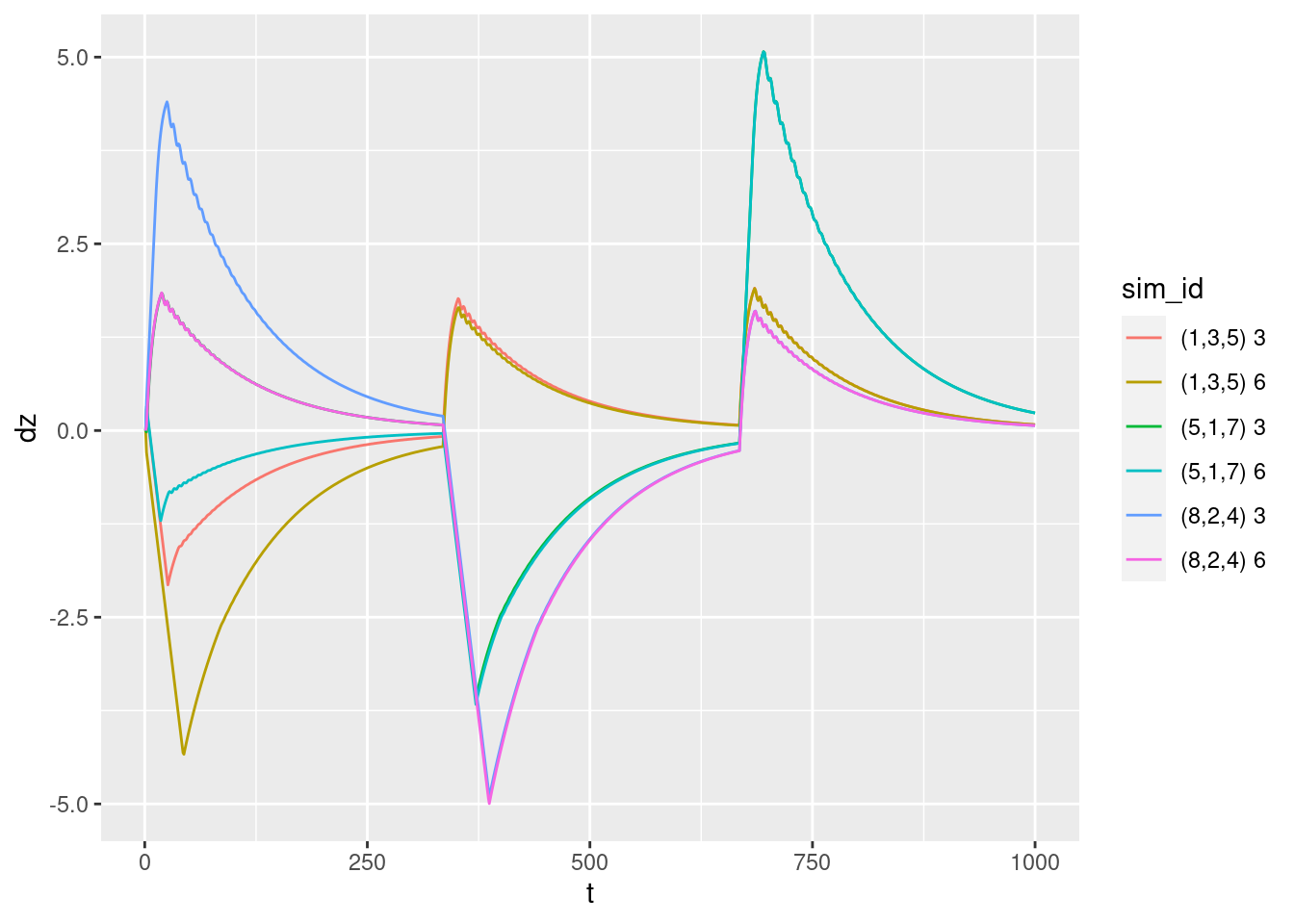
Velocity versus time:
- Looks reasonable, but …
- The sharp peaks in all curves indicate that the controller is initially heading for the target altitude as fast as possible, then suddenly switches into a mode where it tapers off the effort.
- The oscillations visible in most of the curves are only visible in the mode where the effort tapers off. I suspect they mean that the tuning of the PID controller could be improved.
Zoom in on some of the oscillations to see how the frequency of the oscillations compares with the sampling rate.
d_wide %>%
dplyr::mutate(
d2z = (dz - lag(dz, n = 1, default = NA)) / 0.010 # get vertical acceleration
) %>%
ggplot(aes(x = t, group = file, colour = sim_id)) +
geom_path(aes(y = dz)) +
geom_point(aes(y = dz)) +
coord_cartesian(xlim = c(683, 703), ylim = c(1.25, 2.0))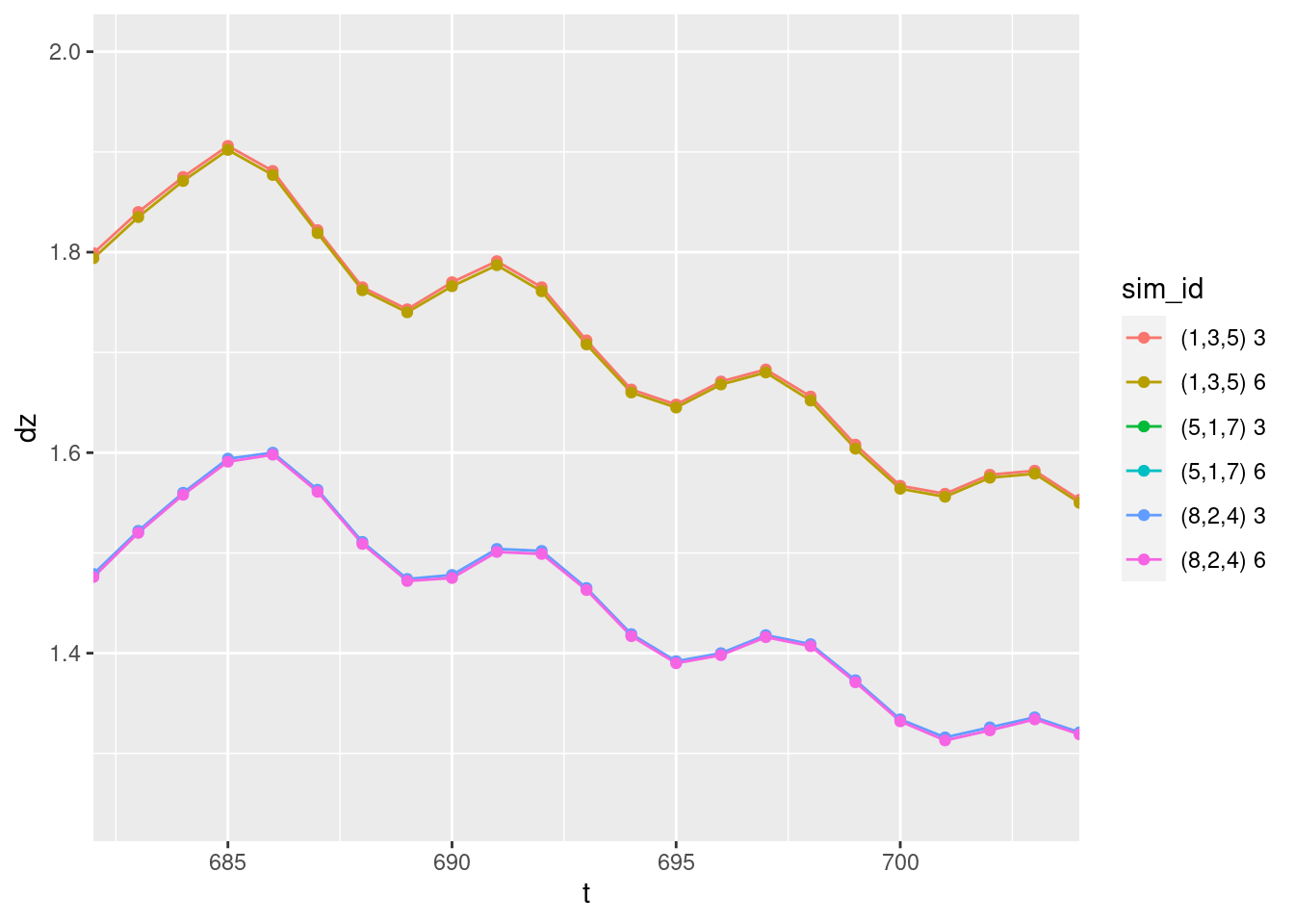
- The cycle length of the oscillation is ~6 time steps - so quite rapid, but 1/3 the maximum frequency that could be observed.
2.1.3 Acceleration versus time
The acceleration is estimated from successive differences in velocity. This is inaccurate for the first two time steps, so the estimated acceleration is set to missing for the first two time steps.
Note that the acceleration should be directly related to the motor power command.
p + geom_path(aes(y = d2z))Warning: Removed 1 row(s) containing missing values (geom_path).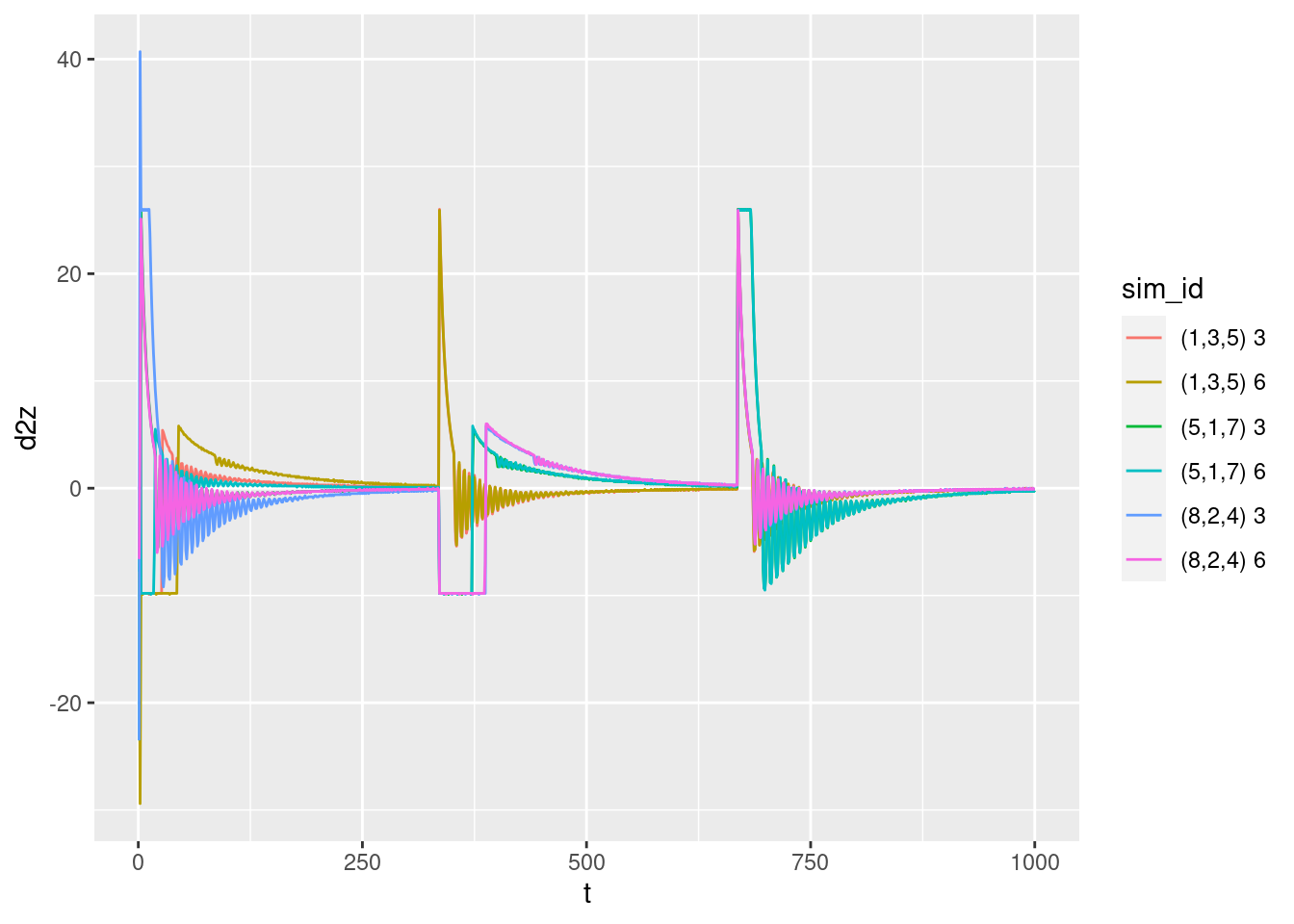
Acceleration versus time:
- The large initial acceleration spikes in the first few time steps look like they might be artifacts of the estimation of the acceleration (analogous to the estimation errors of the velocity).
Zoom in on the initial steps after each target altitude is set.
# 1st target
d_wide %>%
dplyr::mutate(
d2z = (dz - lag(dz, n = 1, default = NA)) / 0.010 # get vertical acceleration
) %>%
ggplot(aes(x = t, group = file, colour = sim_id)) +
geom_path(aes(y = d2z)) +
geom_point(aes(y = d2z)) +
coord_cartesian(xlim = c(1, 20))Warning: Removed 1 row(s) containing missing values (geom_path).Warning: Removed 1 rows containing missing values (geom_point).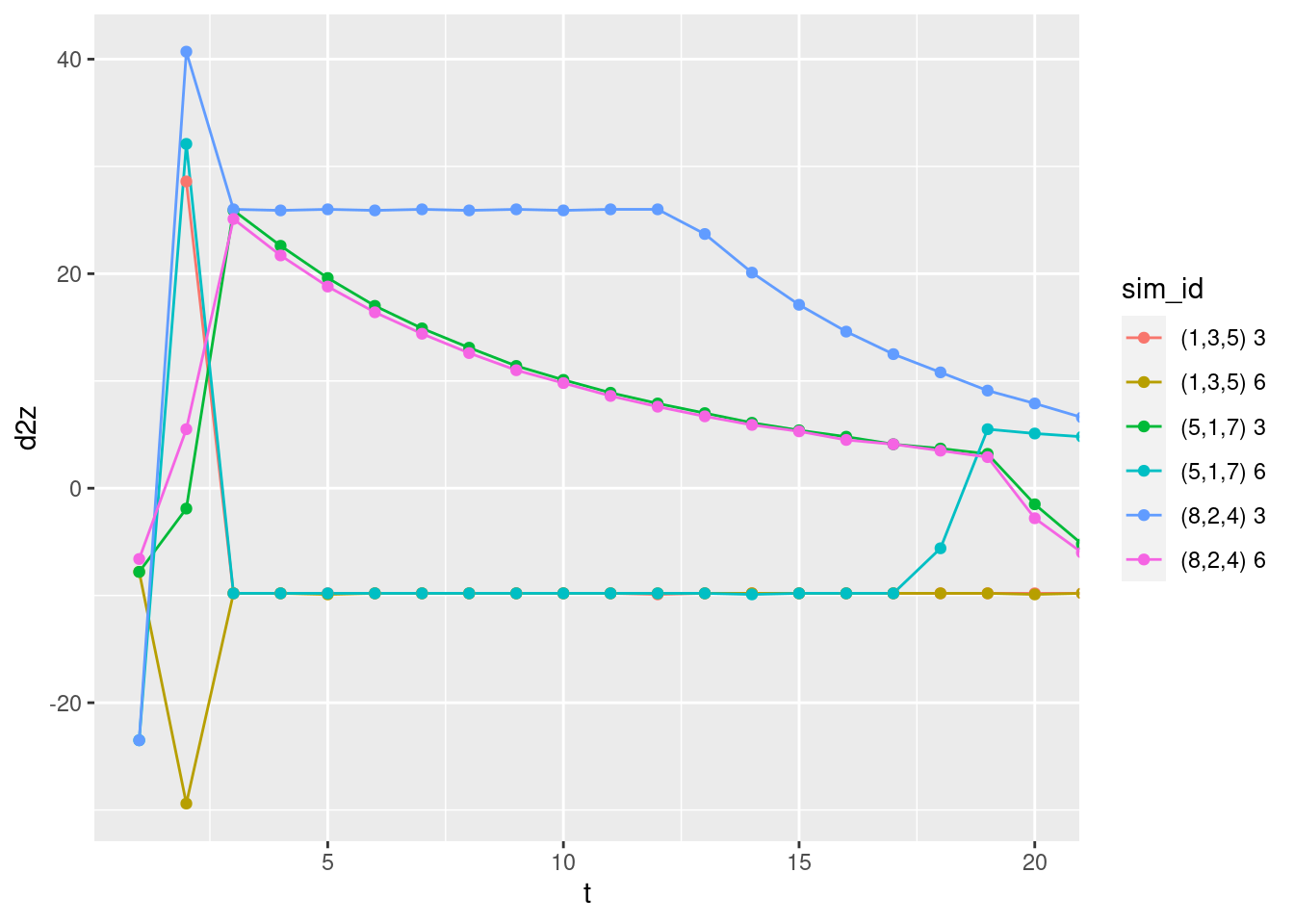
# 2ndt target
d_wide %>%
dplyr::mutate(
d2z = (dz - lag(dz, n = 1, default = NA)) / 0.010 # get vertical acceleration
) %>%
ggplot(aes(x = t, group = file, colour = sim_id)) +
geom_path(aes(y = d2z)) +
geom_point(aes(y = d2z)) +
coord_cartesian(xlim = c(333, 353))Warning: Removed 1 row(s) containing missing values (geom_path).
Warning: Removed 1 rows containing missing values (geom_point).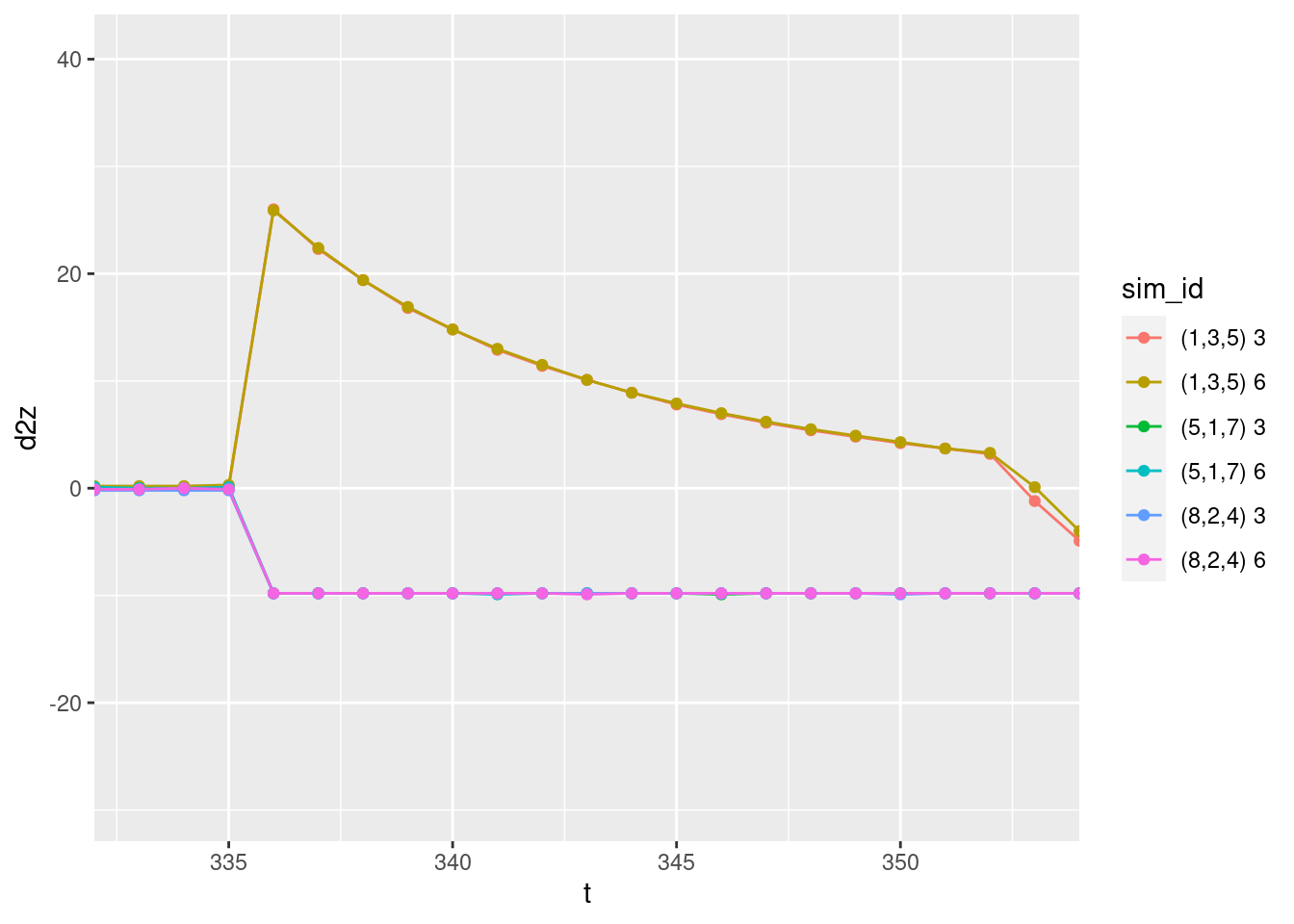
# 3rd target
d_wide %>%
dplyr::mutate(
d2z = (dz - lag(dz, n = 1, default = NA)) / 0.010 # get vertical acceleration
) %>%
ggplot(aes(x = t, group = file, colour = sim_id)) +
geom_path(aes(y = d2z)) +
geom_point(aes(y = d2z)) +
coord_cartesian(xlim = c(666, 686))Warning: Removed 1 row(s) containing missing values (geom_path).
Warning: Removed 1 rows containing missing values (geom_point).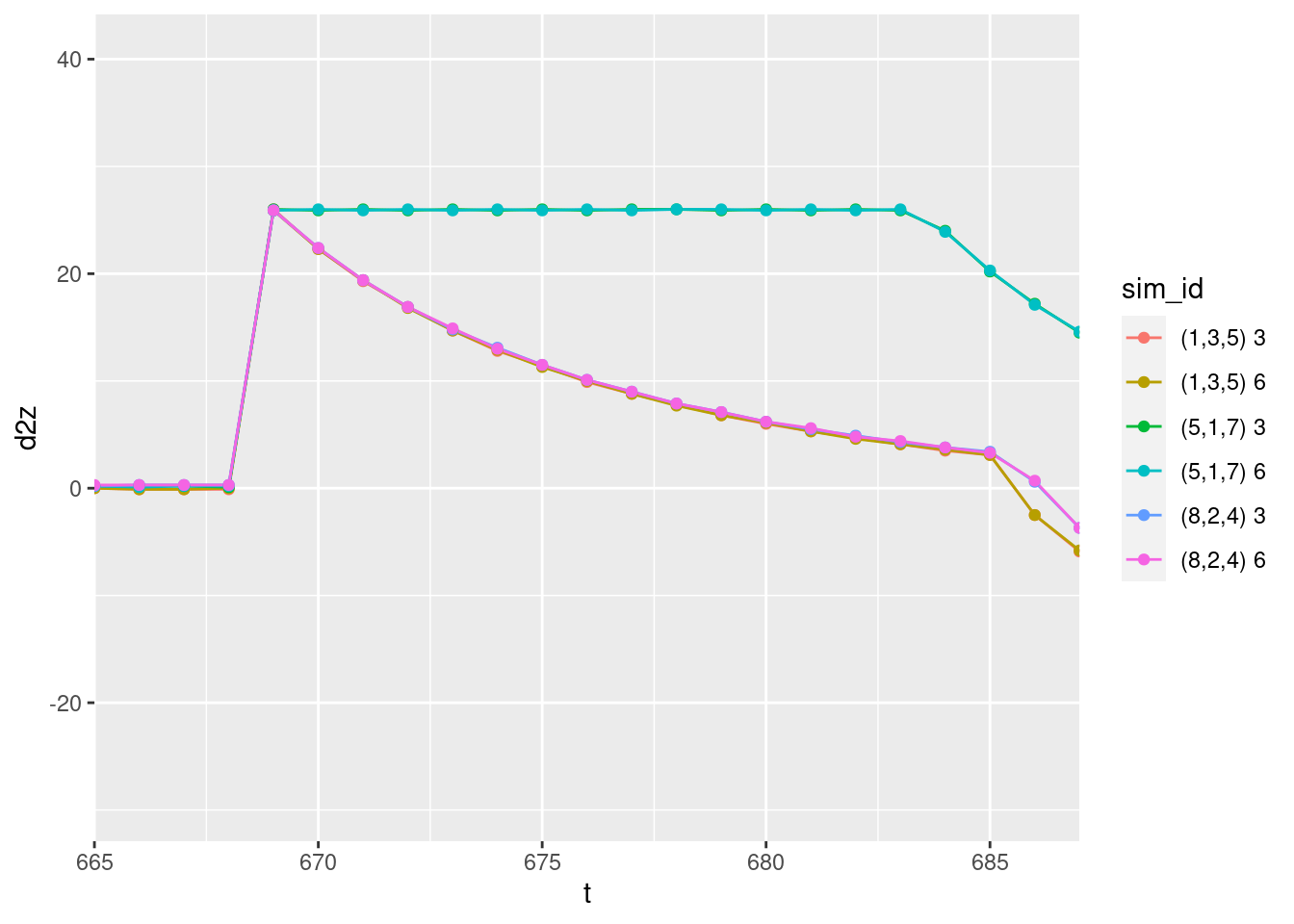
The positive and negative acceleration should be maximum and constant when the motor command is 1 or 0 respectively. This corresponds to the flat initial segments of the curves for the first target.
- The curves for starting altitude above the target have an initial acceleration of approximately \(-10 ms^{-2}\) which is near enough to gravitational acceleration of \(-9.8 ms^{-2}\), considering it is being read off a graph. For the simulations with starting altitude above the target the multicopter initially drops with the motors turned off, so we would expect the initial acceleration to match gravitational acceleration.
- The curves for starting altitude below the target have an initial acceleration of approximately \(+26 ms^{-2}\). In these cases the multicopter initially runs the motors at maximum power.
- The magnitude of the upward acceleration at maximum power relative to the downward acceleration when the motors are off implies that the maximum thrust is ~3.6 times the weight of the multicopter. This seems reasonable.
The acceleration curves look reasonable from time \(t = 3\) onwards.
There are no issues with the estimated acceleration when the the target altitude changes in the middle of the simulation.
I conclude that the estimated acceleration is not trustworthy for \(t < 3\).
Re-plot the acceleration curve making the estimated acceleration missing when \(t < 3\).
p <- d_wide %>%
dplyr::mutate(
d2z = (dz - lag(dz, n = 1, default = NA)) / 0.010, # get vertical acceleration
d2z = if_else(t >= 3, d2z, NA_real_)
) %>%
ggplot(aes(x = t, group = file, colour = sim_id))
p + geom_path(aes(y = d2z))Warning: Removed 12 row(s) containing missing values (geom_path).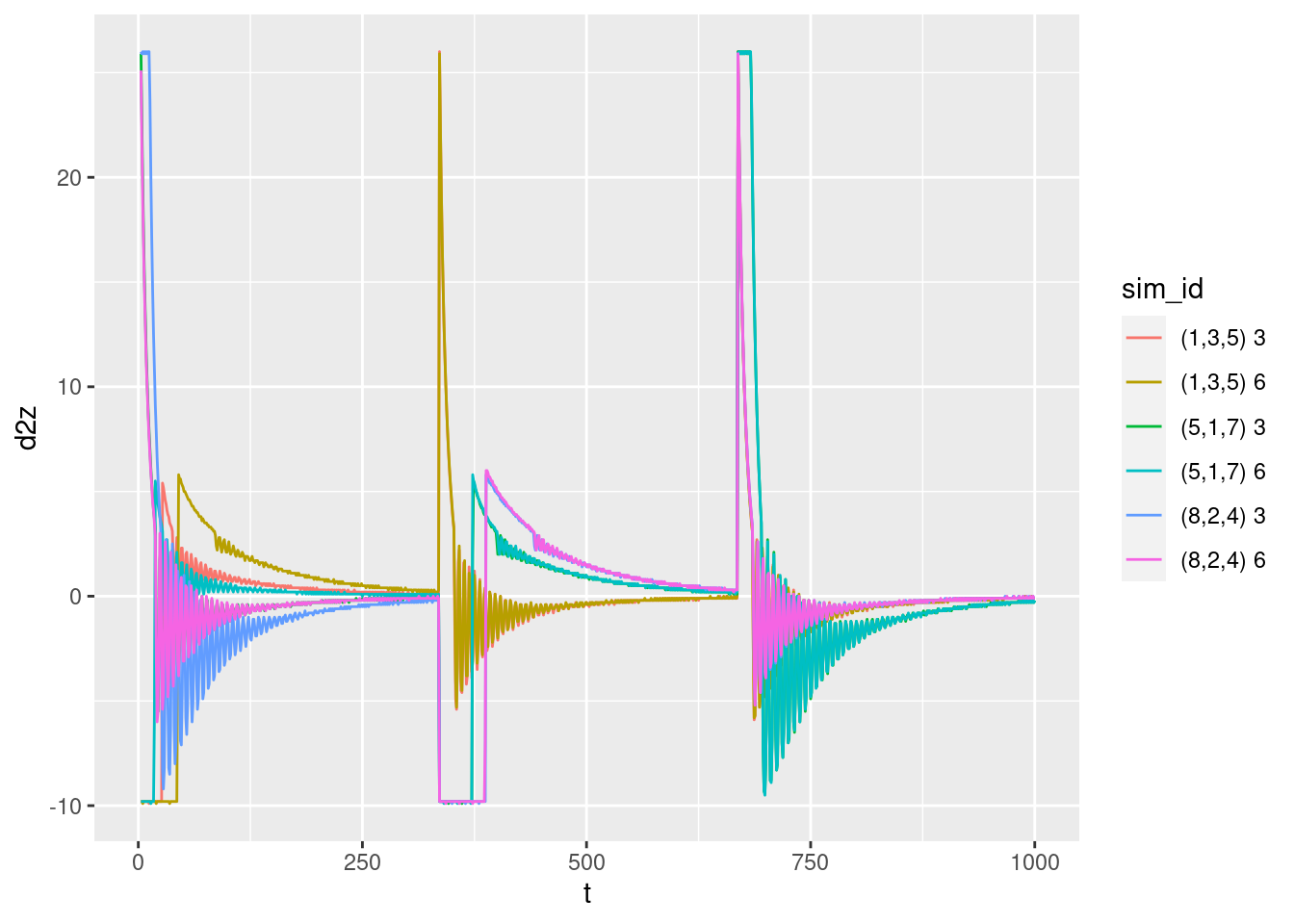
- The oscillations are much more visible.
- It is clear that the oscillations “switch on” at a time that varies by starting height and target. We’ll see later that the oscillation turns on when the integrated error term (\(ei\)) is not being clipped.
- The oscillations in acceleration imply oscillations in the motor power level.
2.1.4 Error versus time
p + geom_path(aes(y = e))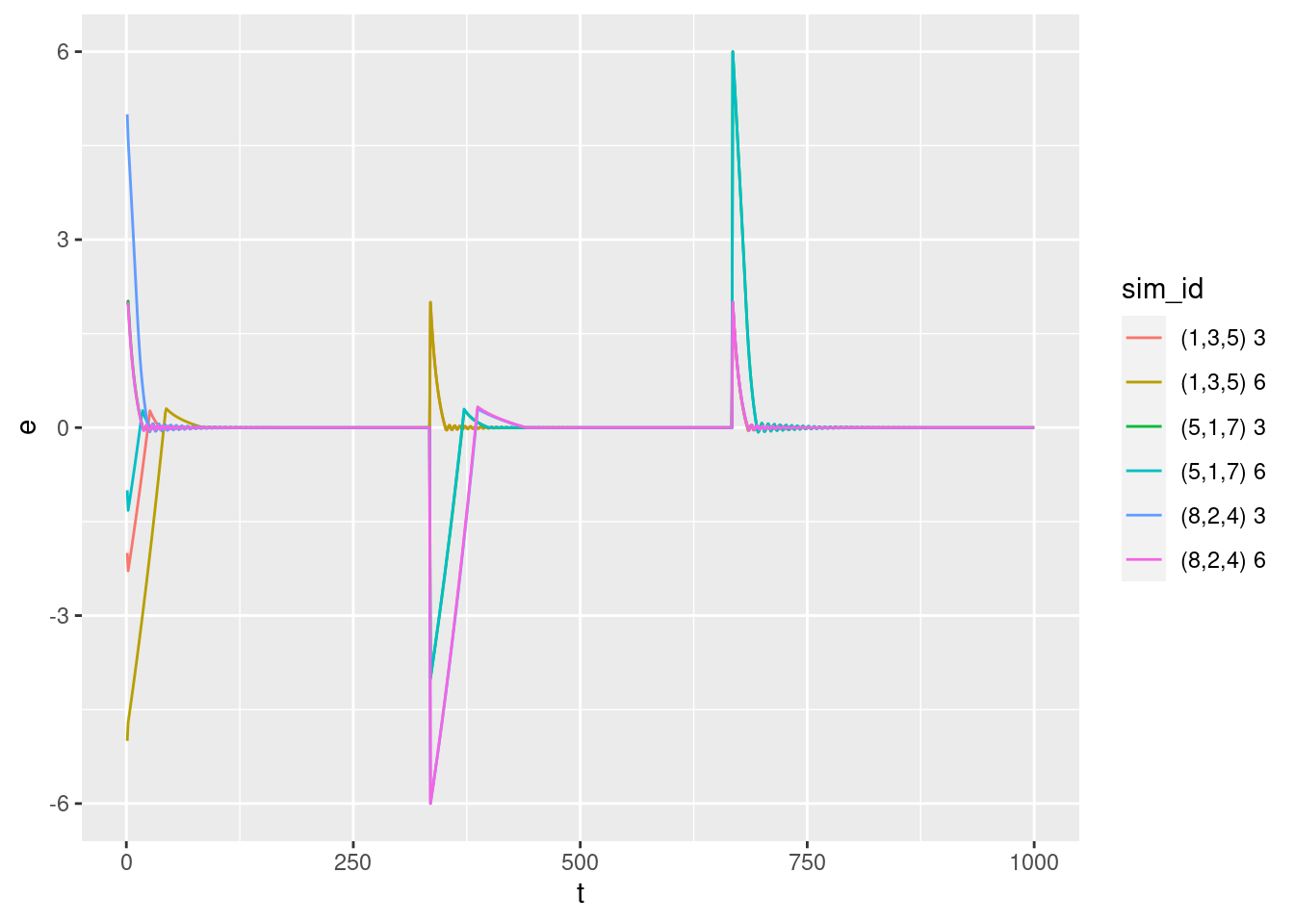
Error versus time:
- The error terms approach zero very rapidly. They are at approximately zero long before the multicopter reaches target height. This is because the error term includes a velocity component, so the error should be interpreted as the predicted error in altitude one second in the future, assuming that the current velocity is maintained for that period.
- Each curve appears to rapidly approach zero then oscillate around zero.
- Curves for flights which start above their target altitude (i.e. have negative error) appear to have a significant overshoot, whereas there does not appear to be obvious overshoot for flights which start below their target altitudes.
- Each curve appears to eventually settle to zero.
Zoom in on the heads of the curves to see if they really oscillate around zero.
p +
geom_hline(yintercept = 0) +
geom_path(aes(y = e)) +
geom_point(aes(y = e)) +
coord_cartesian(xlim = c(10, 100), ylim = c(-0.2, 0.4))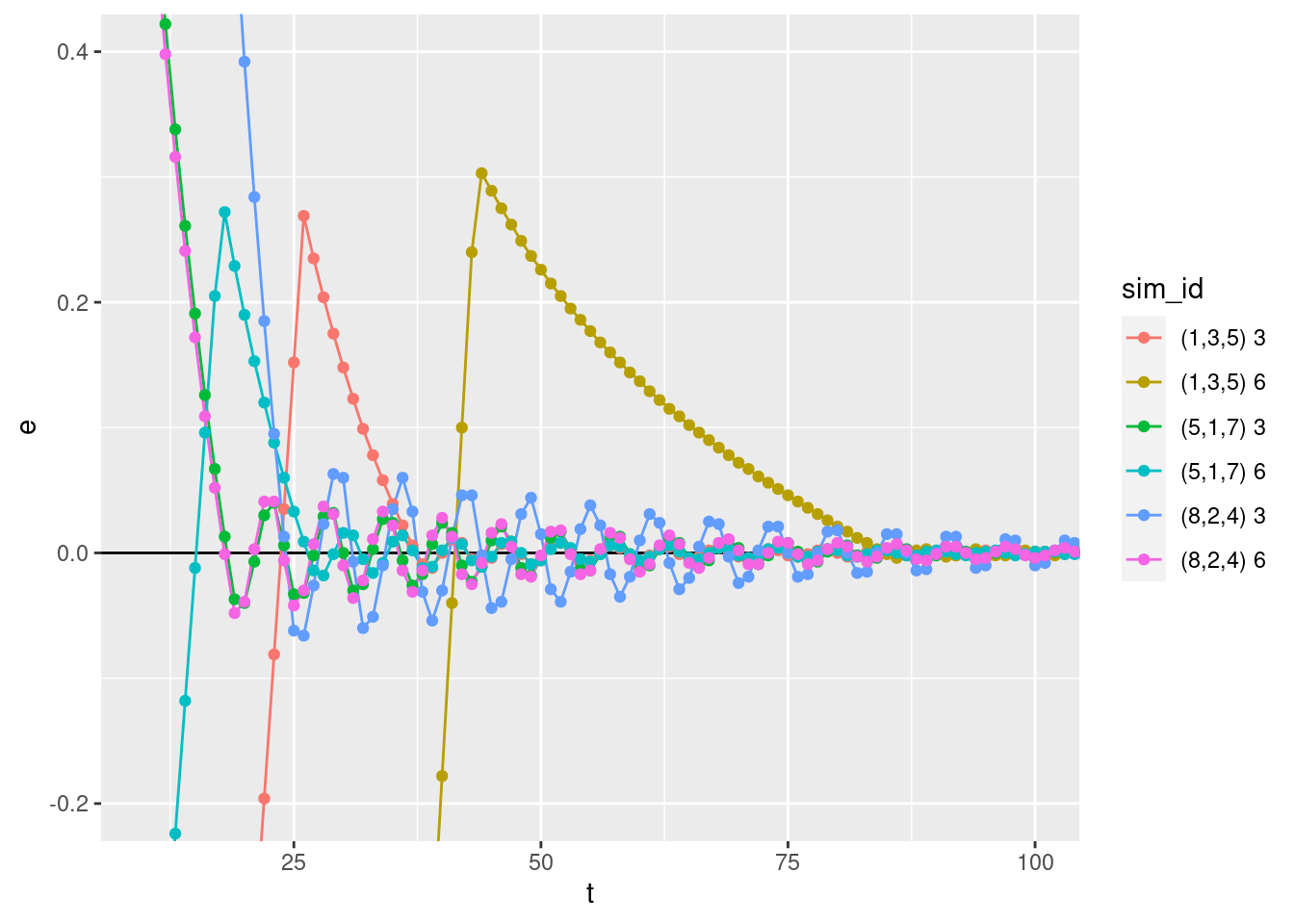
- The error curves oscillate around zero.
Zoom in on the tails of the curves to see how close the error term approaches zero.
p +
geom_hline(yintercept = 0) +
geom_path(aes(y = e)) +
geom_point(aes(y = e)) +
coord_cartesian(xlim = c(100, 250), ylim = c(-0.003, 0.003))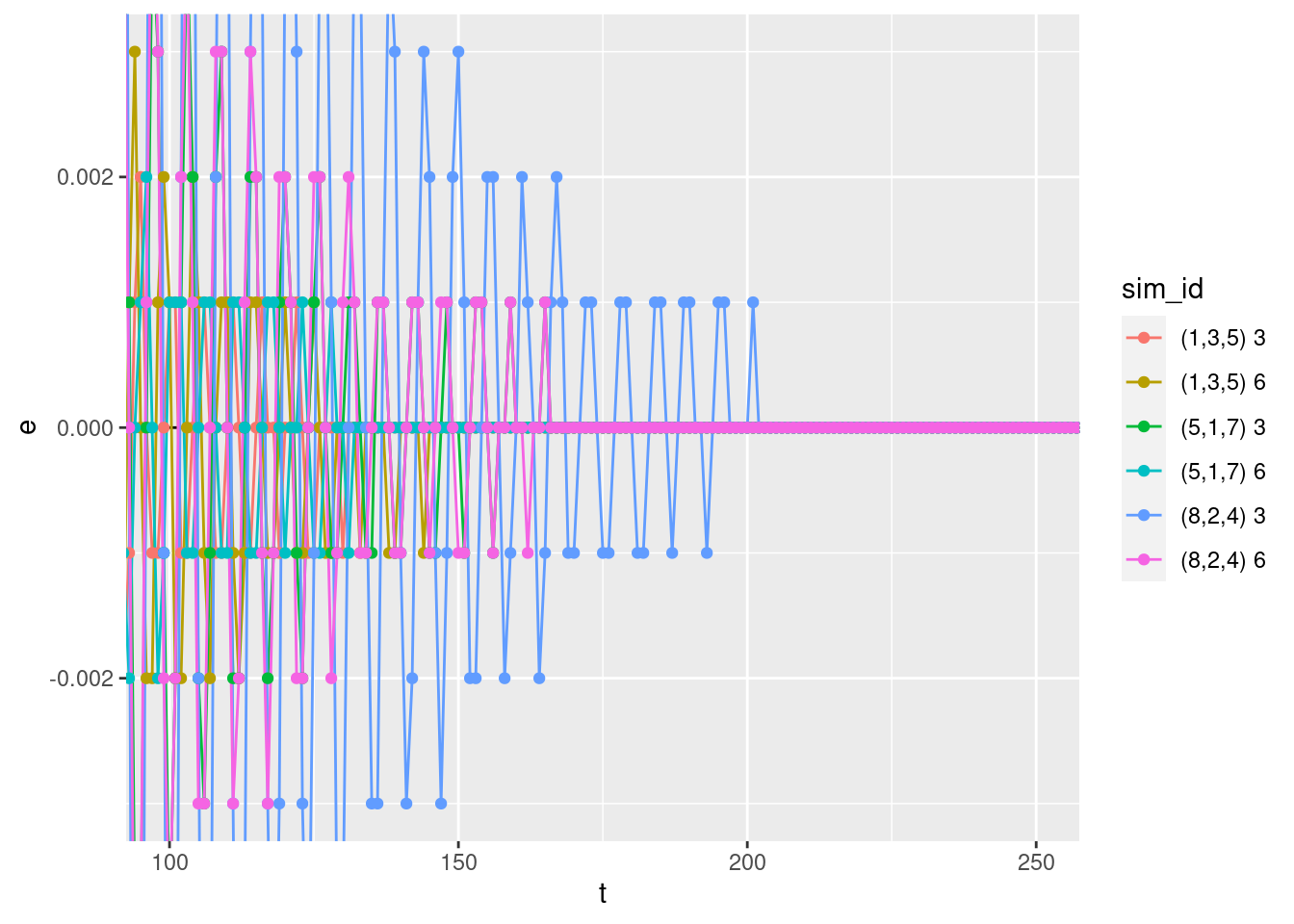
- The error term gets very close to zero. All the curves have reached zero to within the 3 decimal place precision of the import files.
2.1.5 Integrated error versus time
p +
geom_hline(yintercept = 0.174, alpha = 0.2) +
geom_path(aes(y = ei))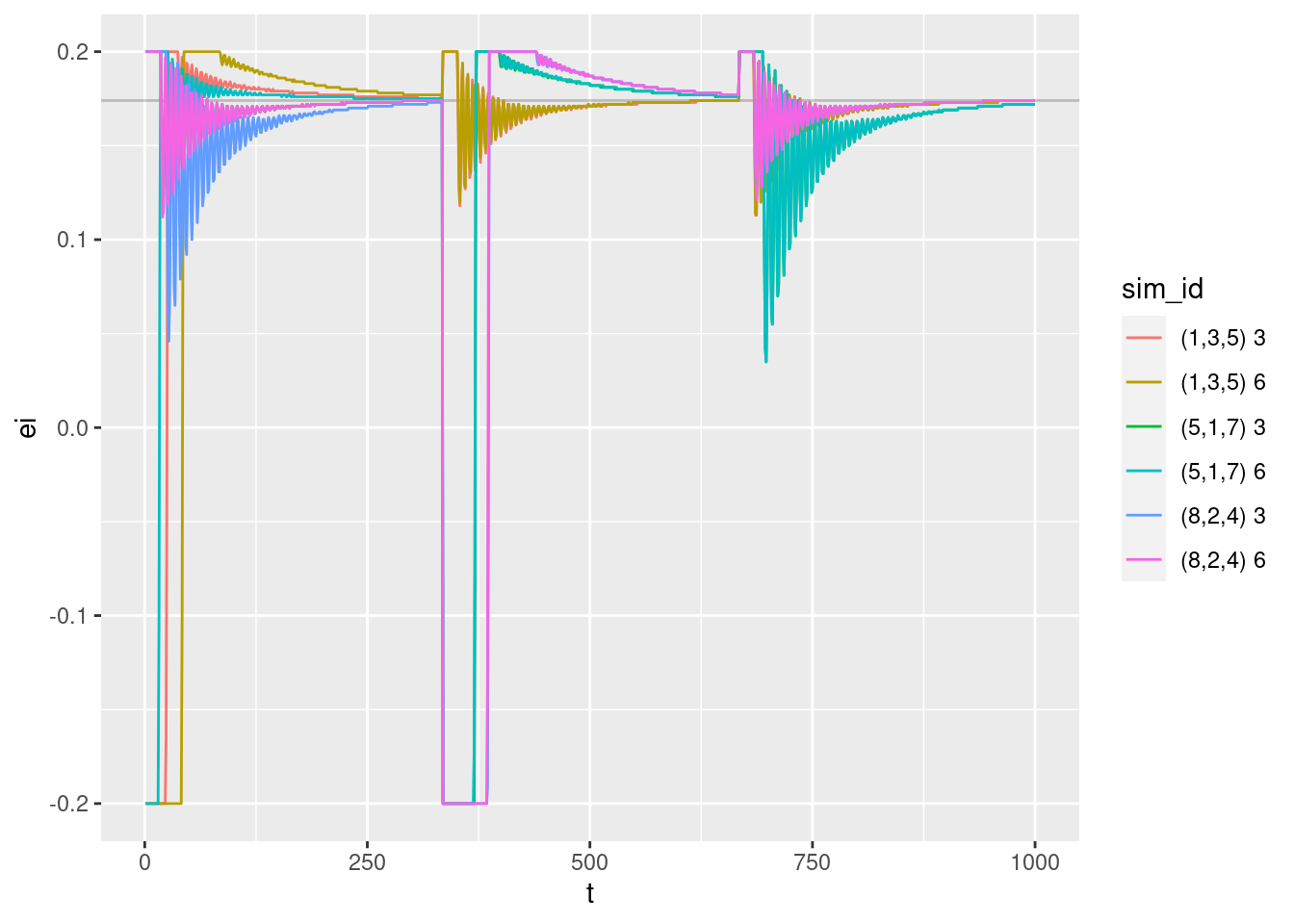
Integrated error versus time:
- The values are bounded between the clipping limits.
- Some early values jump between the negative and positive clipping limits very rapidly.
- Once the curves move into the unclipped value range they oscillate.
- All the curves converge to a value of approximately 0.174. Presumably, this corresponds to the motor power level required for the multicopter to have zero vertical velocity (hover).
2.1.6 Motor command versus time
p +
geom_hline(yintercept = 0.524, alpha = 0.2) +
geom_path(aes(y = u))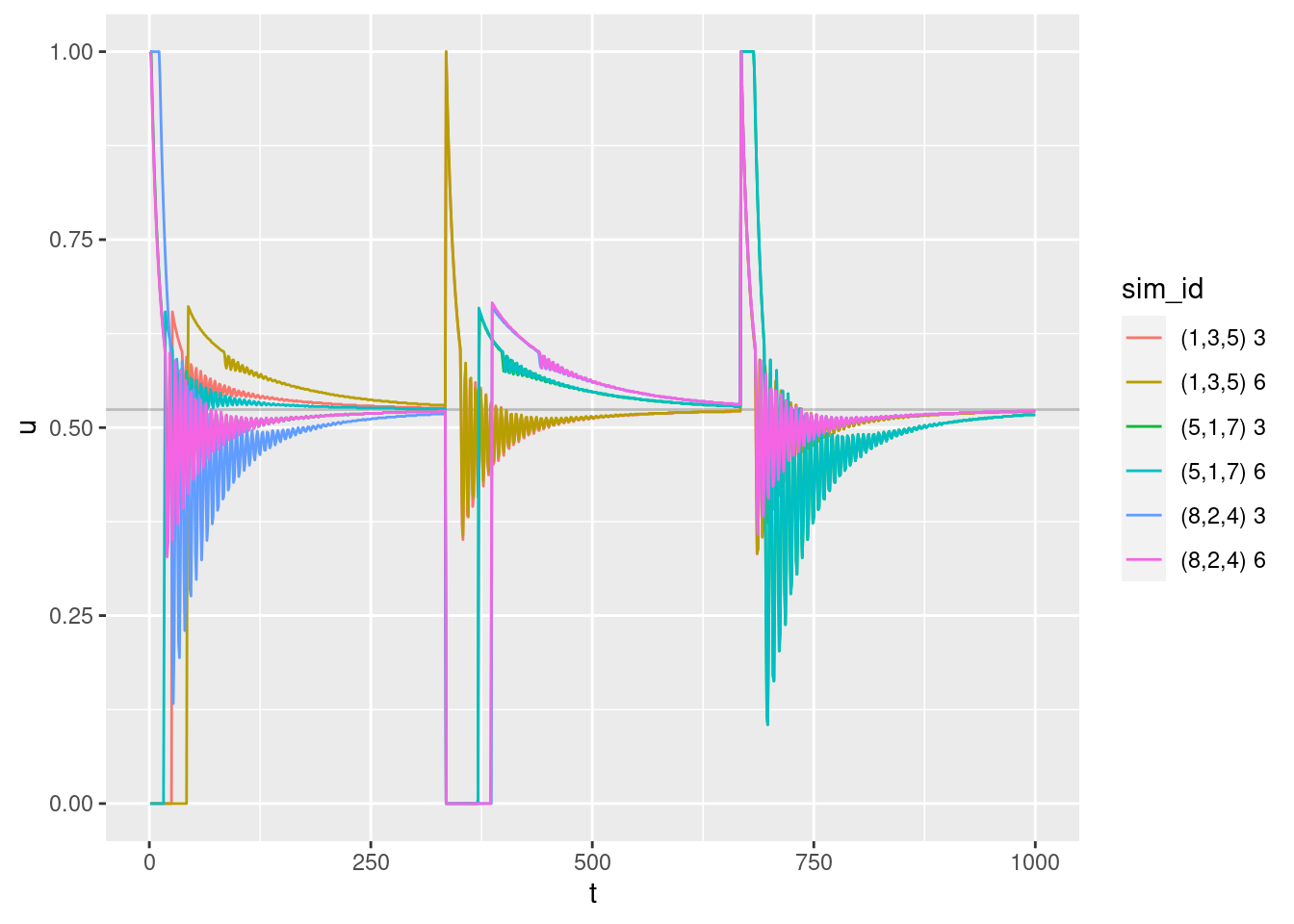
Motor command versus time:
- Curves for flights starting below the target altitude have maximum initial motor command.
- Curves for flights starting above the target altitude have minimum initial motor command.
- All curves show oscillatory behaviour after the initial period of extreme command.
- The oscillation does not always start immediately after the motor command becomes intermediate.
- All curves converge to a value of 0.524. Presumably, this corresponds to the motor power level required for the multicopter to have zero vertical velocity (hover).
2.2 Time implicit
Show the values of the major nodes (\(z\), \(dz\), \(e\), \(ei\), and \(u\), augmented with estimated acceleration: \(d2z\)) as a function of each other (pair plots) with time implicit. There is little commentary on these graphs - just enjoy the pretty pictures.
The acceleration is estimated from successive differences in velocity. This is inaccurate for the first two time steps, so the estimated acceleration is set to missing for the first two time steps.
Place an arrow head on each curve to indicate the direction of time. Because the curves tend to converge on the same location I have placed the arrow head at the beginning of each curve (i.e. when the target altitude is set/changed). The arrow head points in the direction of increasing time.
WARNING - The scales vary between facets.
p <- d_wide %>%
dplyr::group_by(file, k_tgt) %>%
dplyr::arrange(t) %>%
dplyr::mutate(
d2z = (dz - lag(dz, n = 1, default = NA)) / 0.010, # get vertical acceleration
d2z = if_else(t >= 3, d2z, NA_real_) # not accurate for first two steps
) %>%
ggplot(aes(group = file, colour = sim_id)) +
facet_wrap(vars(k_tgt), nrow = 2, scales = "free", labeller = label_both)
a <- grid::arrow(ends = "first", angle = 150, # 150 = 30 reversed
length = unit(0.3, "cm"), type = "closed")
###
p +
geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = z, y = dz), arrow = a, alpha = 0.2) +
geom_point(aes(x = z, y = dz), size = 0.1)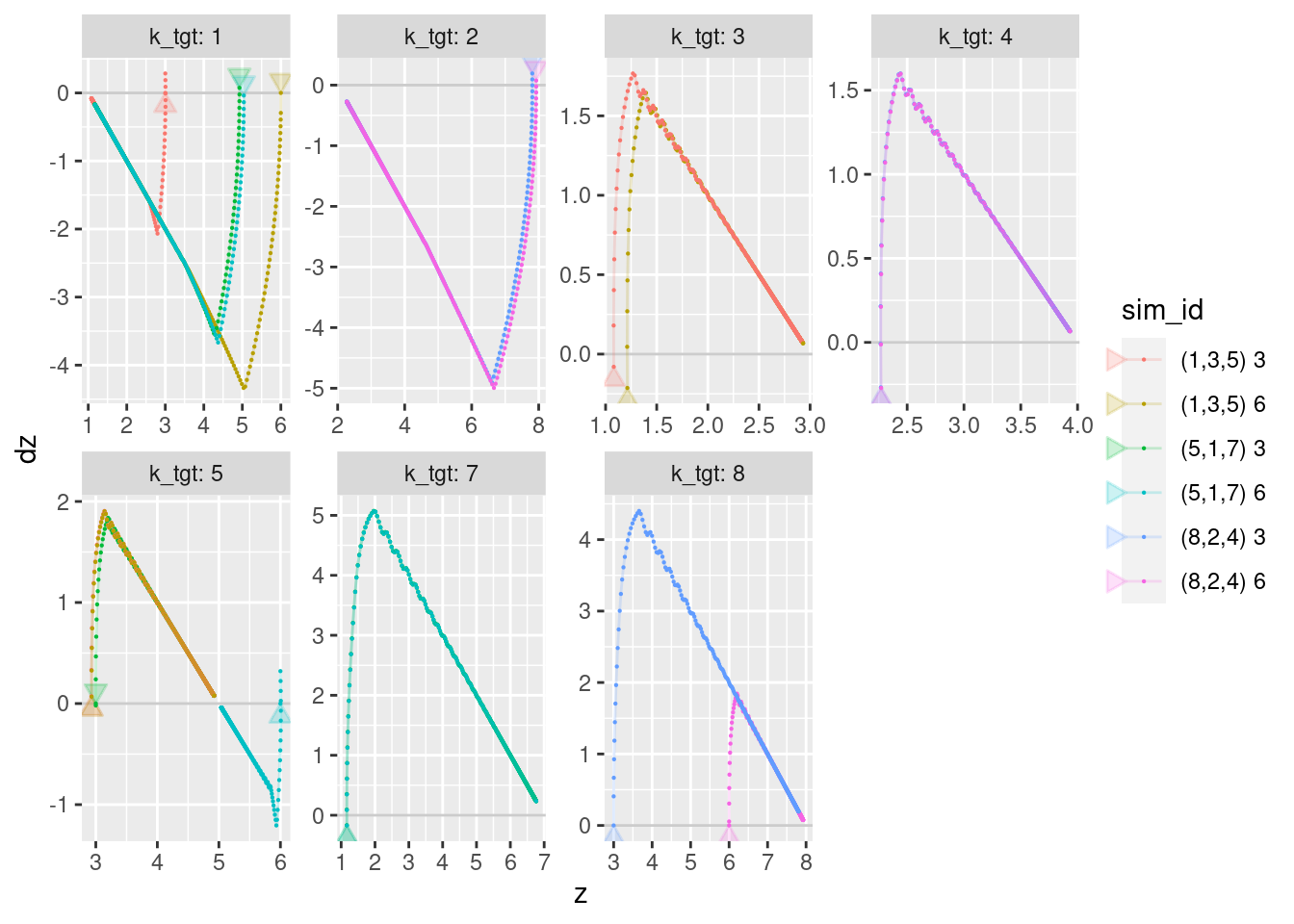
- It’s interesting that each curve always has a terminal segment where the velocity and altitude error are multiplicatively related so that the velocity reduces linearly with the distance to the target altitude so that the altitude error and the velocity reach zero simultaneously.
p +
geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = z, y = d2z), arrow = a, alpha = 0.2) +
geom_point(aes(x = z, y = d2z), size = 0.1)Warning: Removed 12 row(s) containing missing values (geom_path).Warning: Removed 24 rows containing missing values (geom_point).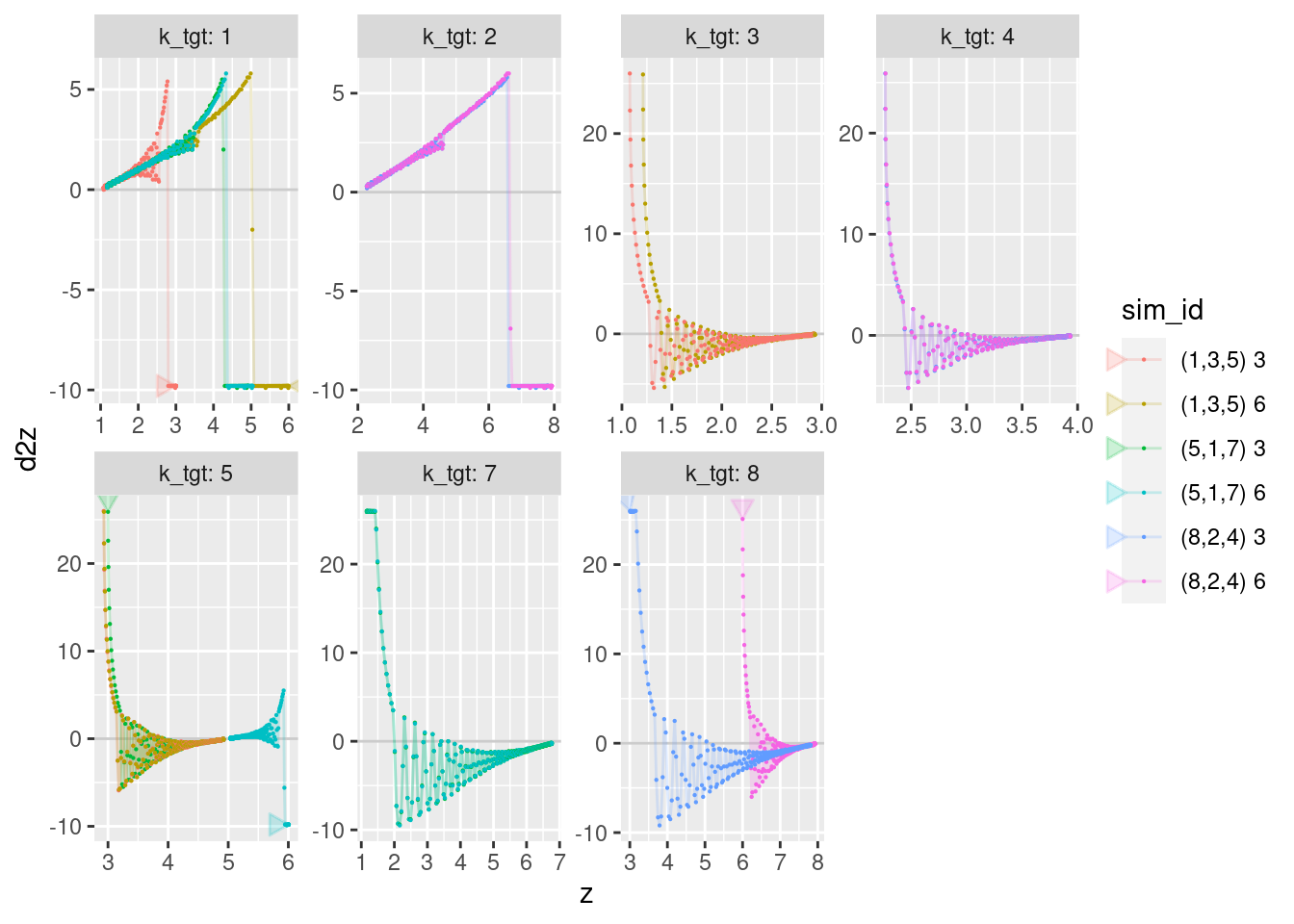
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = z, y = e), arrow = a, alpha = 0.2) +
geom_point(aes(x = z, y = e), size = 0.1)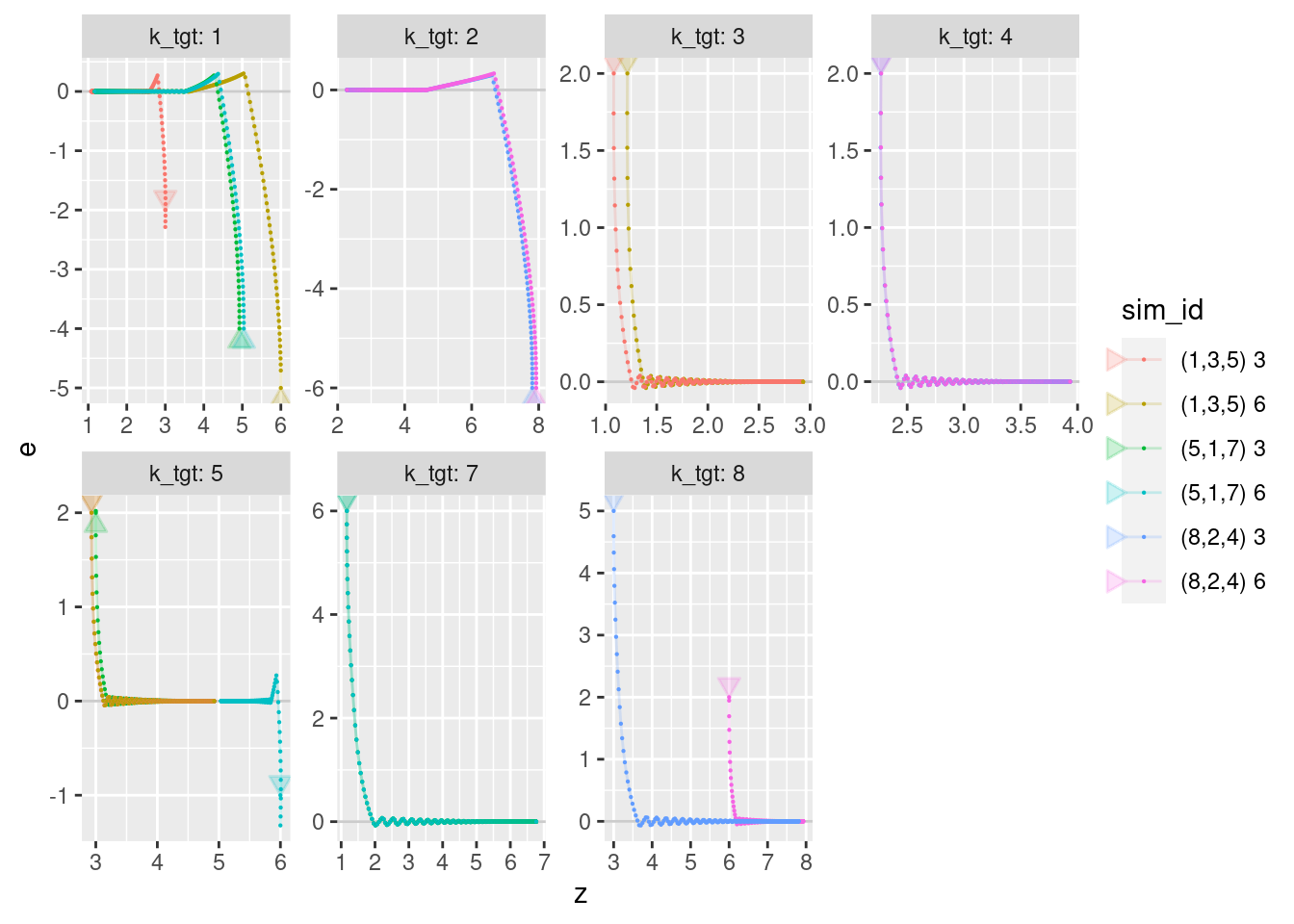
- The error (\(e\)) is approximately zero for quite a long terminal period of each flight.
- Remember that the error (\(e\)) is the sum of an altitude term and a velocity term, so it is effectively the predicted altitude error one second in the future (assuming constant velocity).
p +
geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = z, y = ei), arrow = a, alpha = 0.2) +
geom_point(aes(x = z, y = ei), size = 0.1)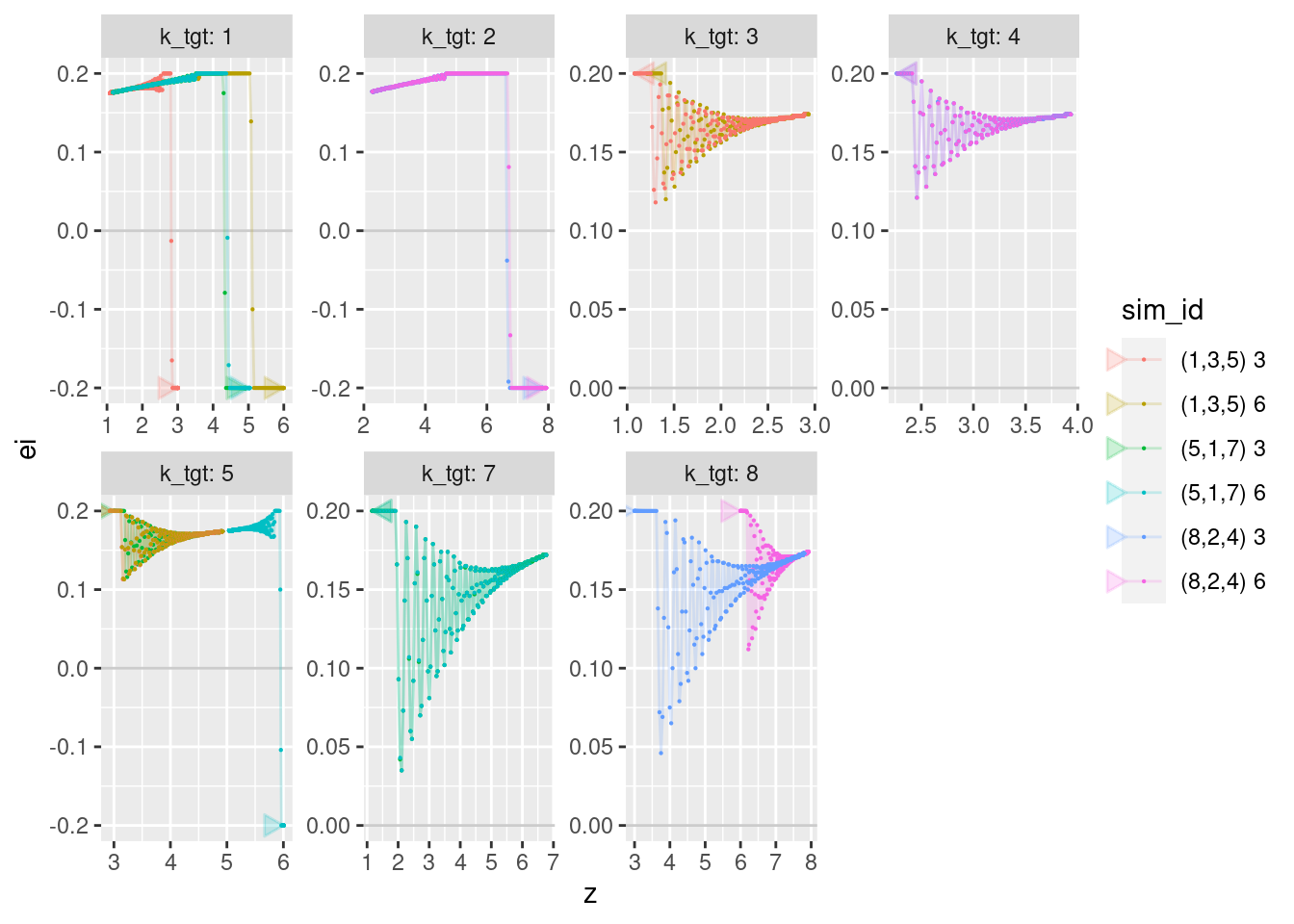
- Integrated error (\(ei\)) is close to effectively being a binary value.
p +
geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = z, y = u), arrow = a, alpha = 0.2) +
geom_point(aes(x = z, y = u), size = 0.1)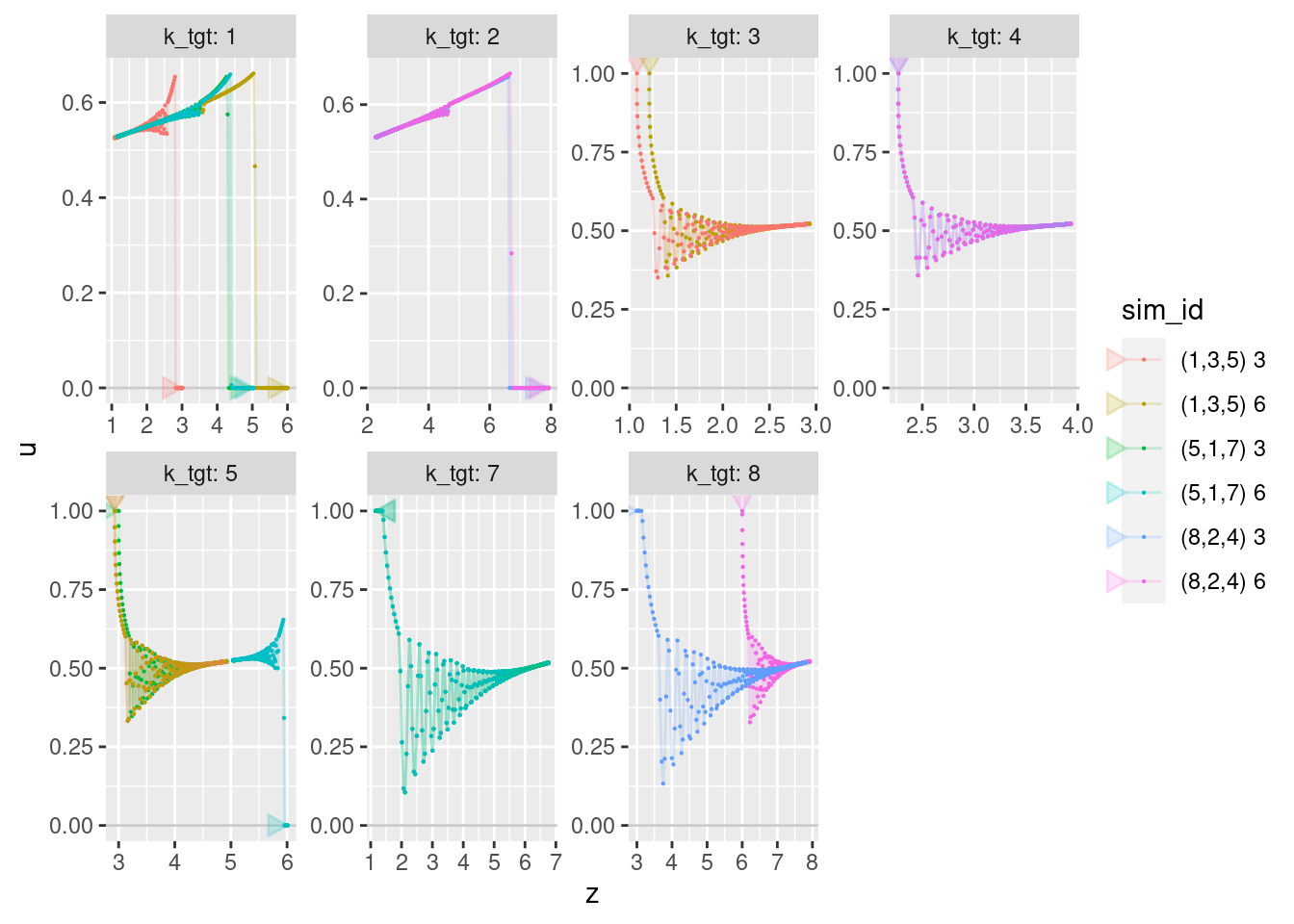
- Motor command (\(u\)) converges on the level required to hover.
p +
geom_vline(xintercept = 0, alpha = 0.2) + geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = dz, y = d2z), arrow = a, alpha = 0.2) +
geom_point(aes(x = dz, y = d2z), size = 0.1)Warning: Removed 12 row(s) containing missing values (geom_path).Warning: Removed 24 rows containing missing values (geom_point).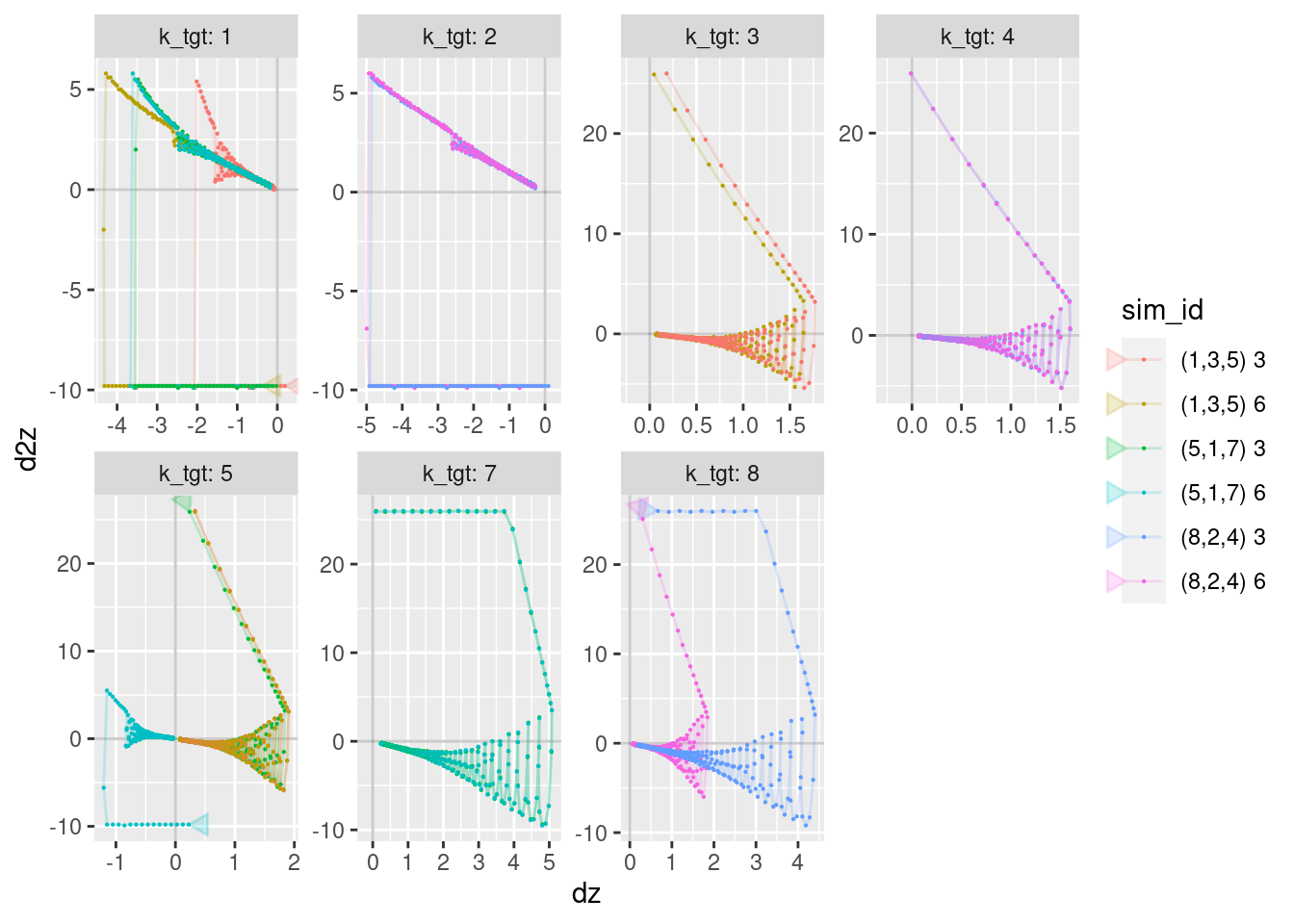
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_vline(xintercept = 0, alpha = 0.2) + geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = dz, y = e), arrow = a, alpha = 0.2) +
geom_point(aes(x = dz, y = e), size = 0.1)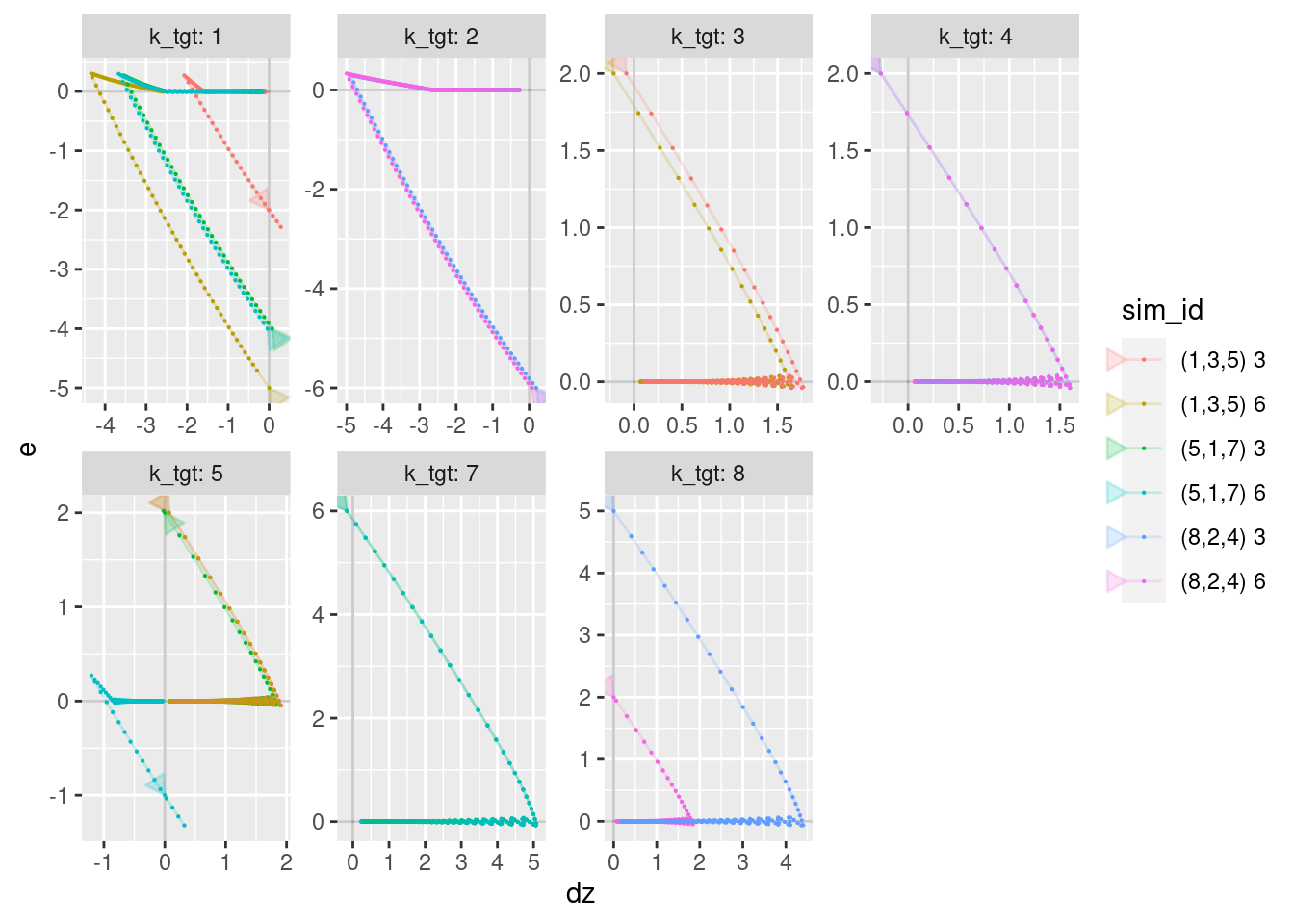
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
- The magnitude of the velocity (\(dz\)) increases as the combined error term (\(e\)) approaches zero, then the magnitude of the velocity decreases gradually to zero as the combined error term stays at zero.
p +
geom_vline(xintercept = 0, alpha = 0.2) + geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = dz, y = ei), arrow = a, alpha = 0.2) +
geom_point(aes(x = dz, y = ei), size = 0.1)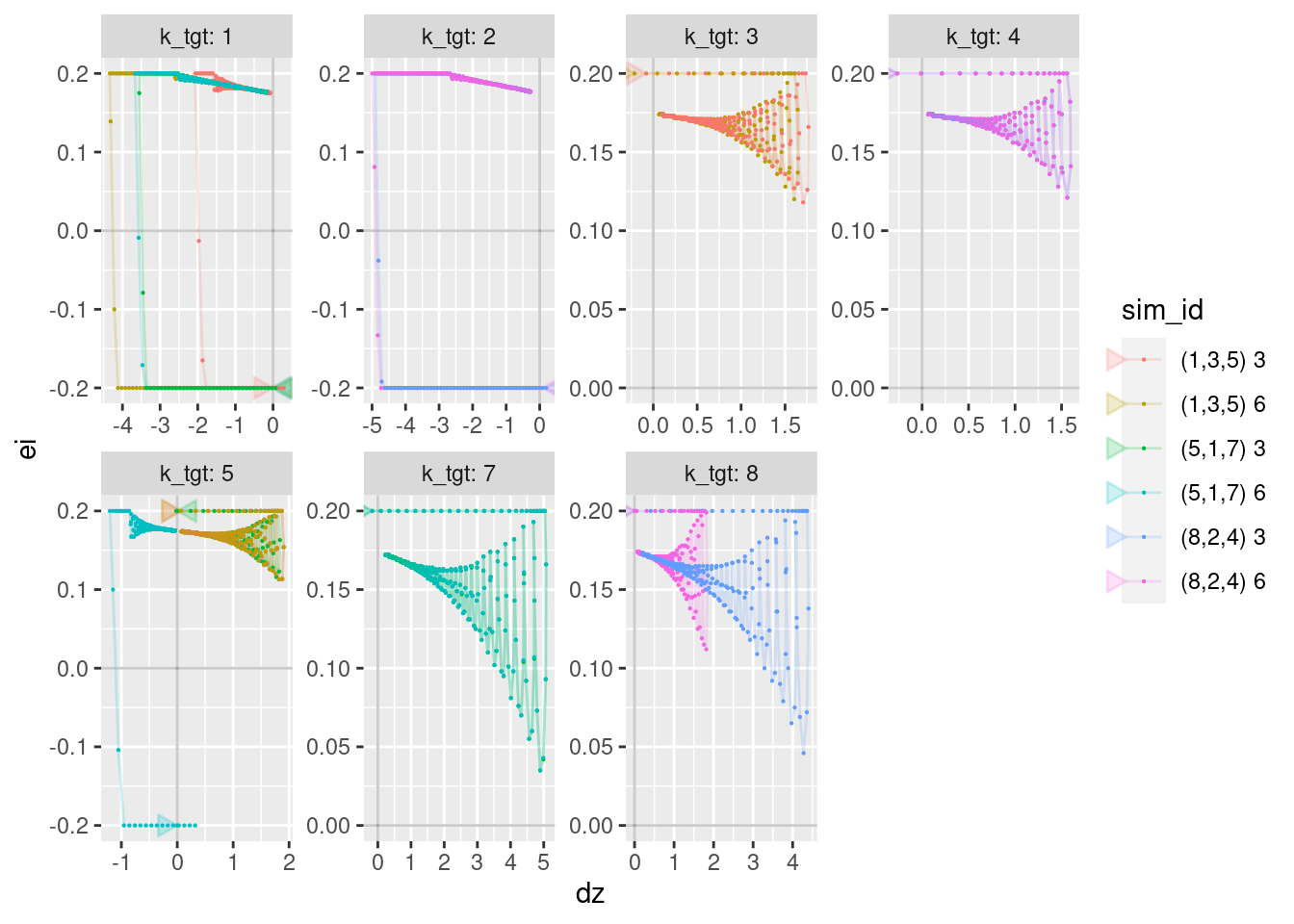
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = dz, y = u), arrow = a, alpha = 0.2) +
geom_point(aes(x = dz, y = u), size = 0.1)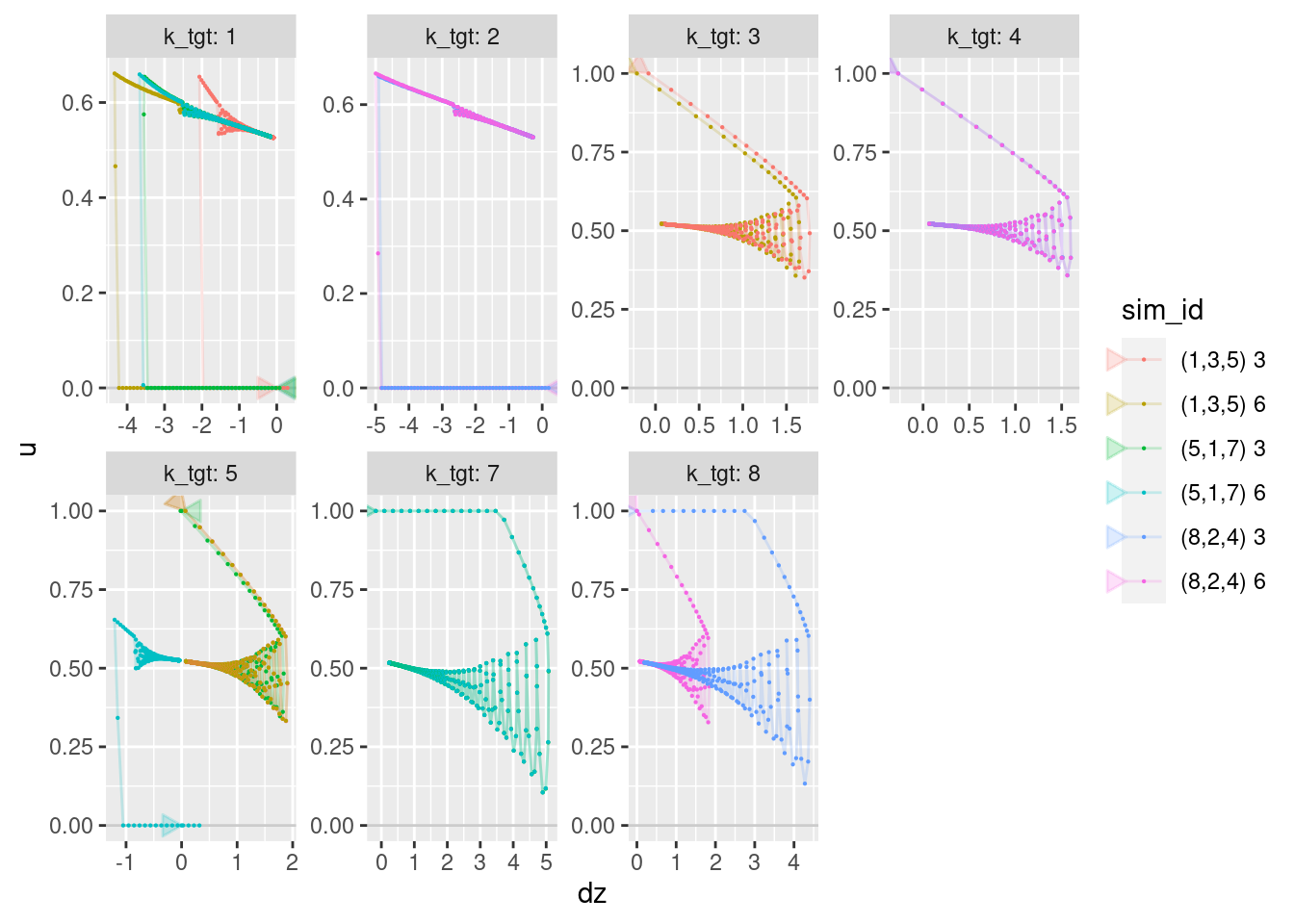
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_vline(xintercept = 0, alpha = 0.2) + geom_hline(yintercept = 0, alpha = 0.2) +
geom_path(aes(x = d2z, y = e), arrow = a, alpha = 0.2) +
geom_point(aes(x = d2z, y = e), size = 0.1)Warning: Removed 12 row(s) containing missing values (geom_path).Warning: Removed 24 rows containing missing values (geom_point).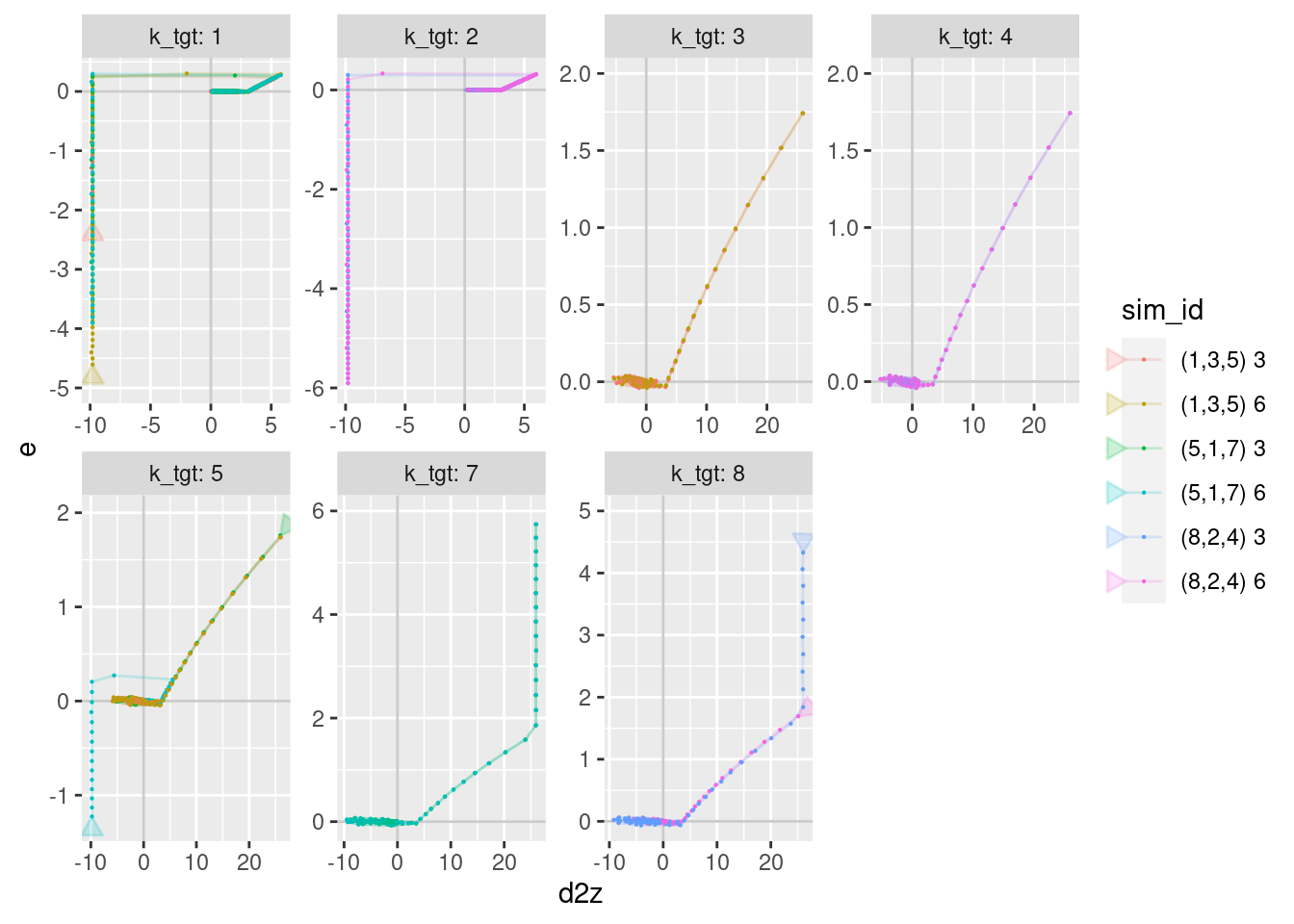
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_vline(xintercept = 0, alpha = 0.2) +
geom_path(aes(x = d2z, y = ei), arrow = a, alpha = 0.2) +
geom_point(aes(x = d2z, y = ei), size = 0.1)Warning: Removed 12 row(s) containing missing values (geom_path).Warning: Removed 24 rows containing missing values (geom_point).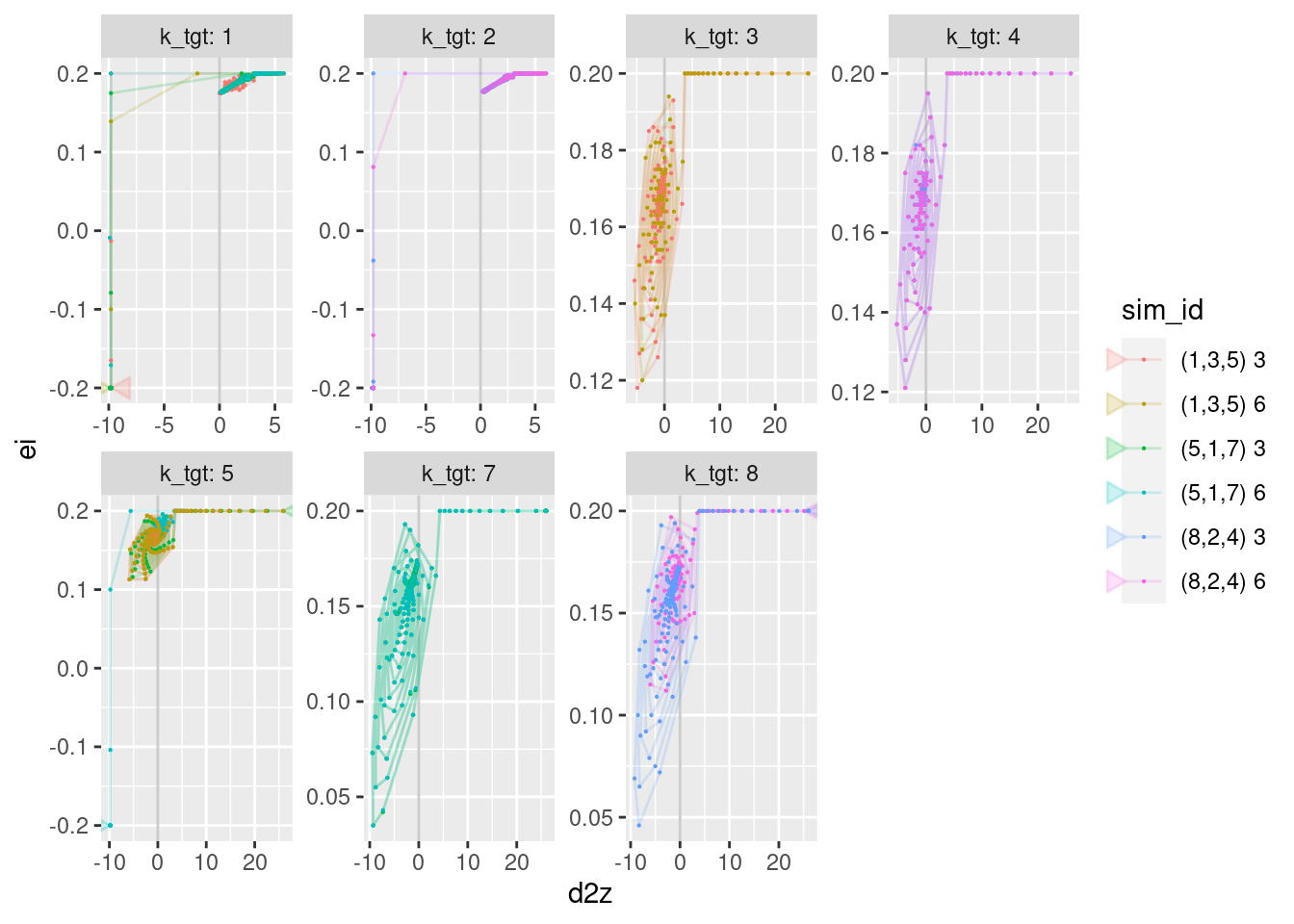
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_vline(xintercept = 0, alpha = 0.2) +
geom_path(aes(x = d2z, y = u), arrow = a, alpha = 0.2) +
geom_point(aes(x = d2z, y = u), size = 0.1)Warning: Removed 12 row(s) containing missing values (geom_path).Warning: Removed 24 rows containing missing values (geom_point).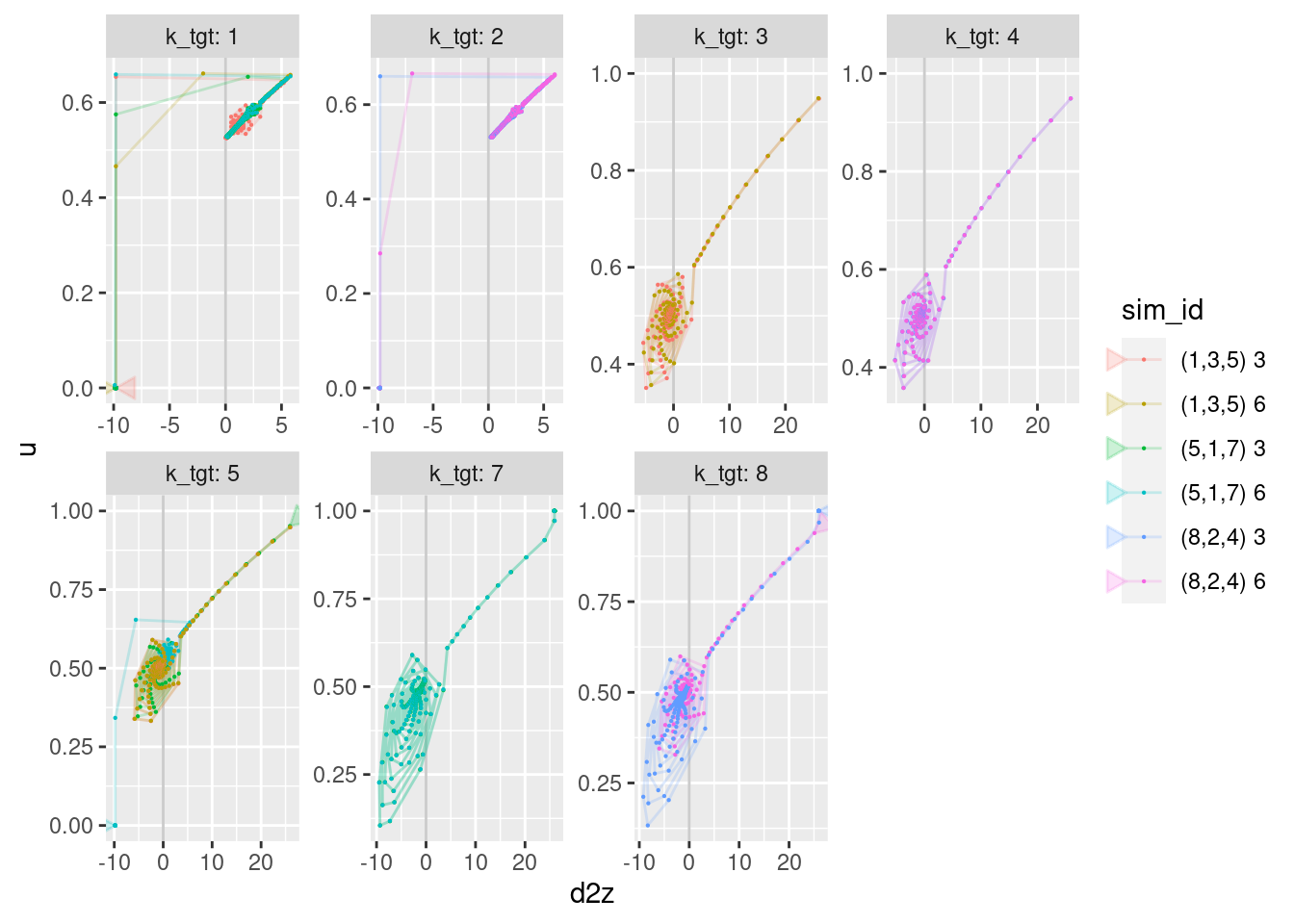
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_vline(xintercept = 0, alpha = 0.2) +
geom_path(aes(x = d2z, y = u), arrow = a, alpha = 0.2) +
geom_point(aes(x = d2z, y = u), size = 0.1)Warning: Removed 12 row(s) containing missing values (geom_path).Warning: Removed 24 rows containing missing values (geom_point).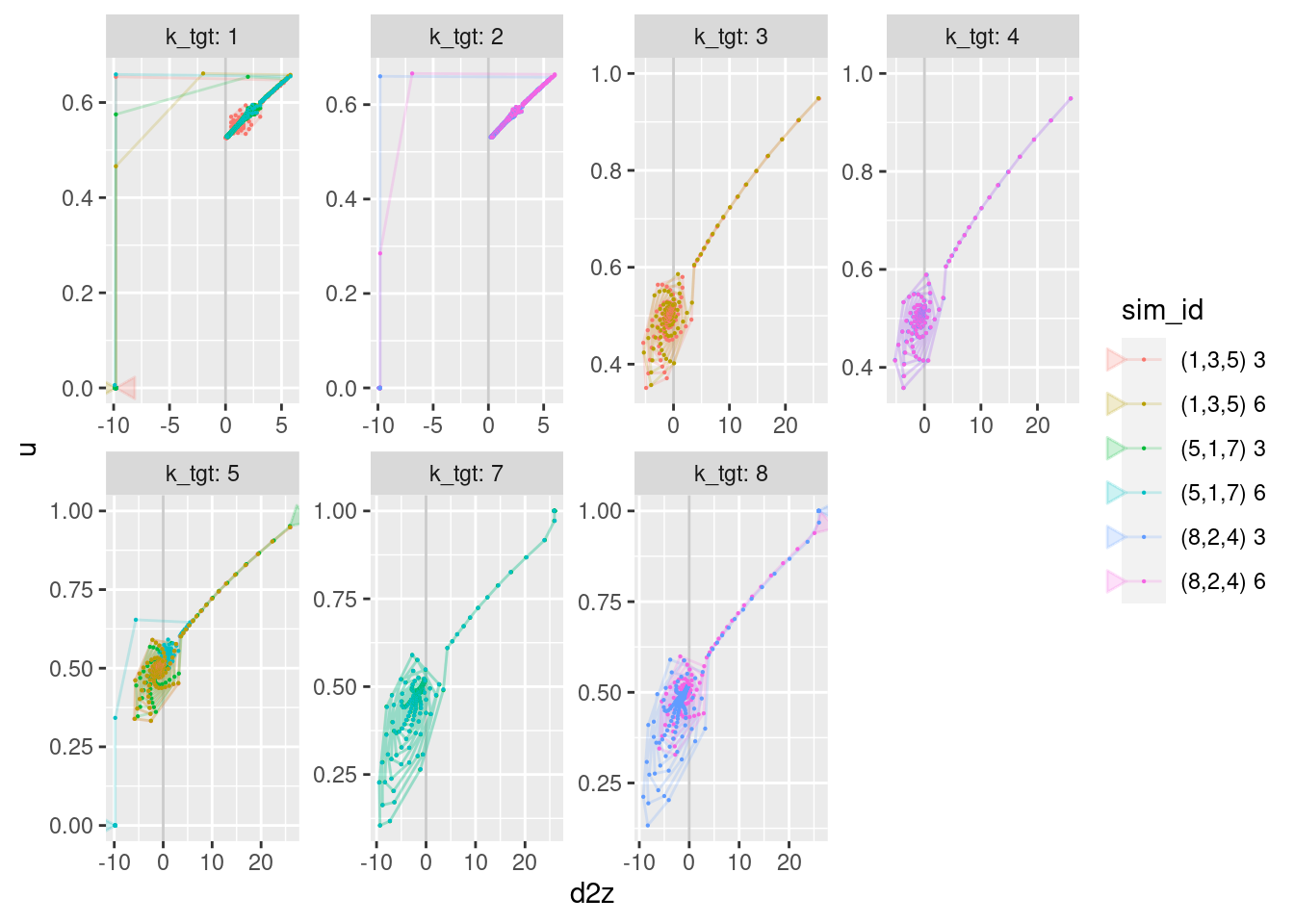
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_vline(xintercept = 0, alpha = 0.2) +
geom_path(aes(x = e, y = ei), arrow = a, alpha = 0.2) +
geom_point(aes(x = e, y = ei), size = 0.1)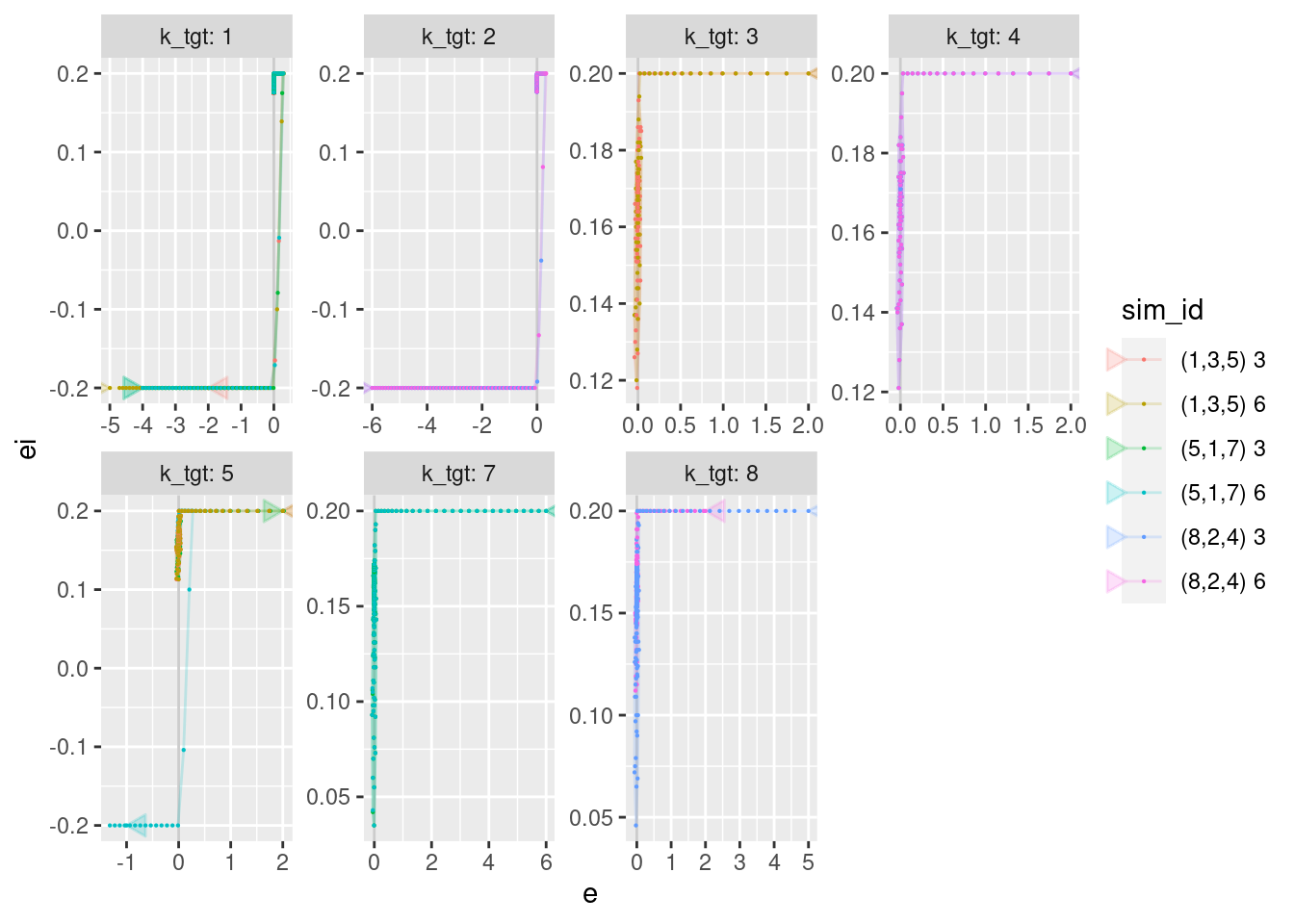
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_vline(xintercept = 0, alpha = 0.2) +
geom_path(aes(x = e, y = u), arrow = a, alpha = 0.2) +
geom_point(aes(x = e, y = u), size = 0.1)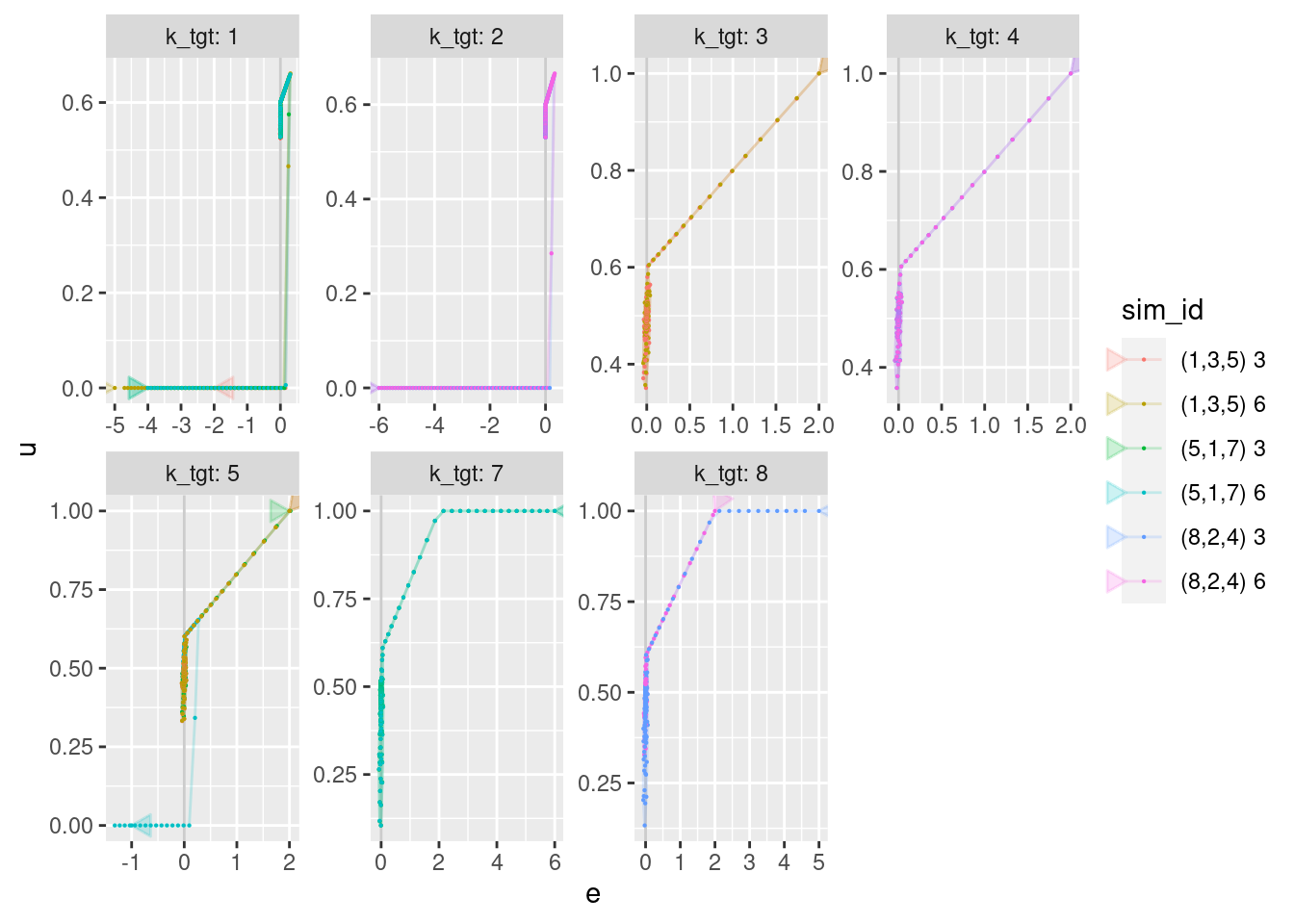
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
p +
geom_path(aes(x = ei, y = u), arrow = a, alpha = 0.2) +
geom_point(aes(x = ei, y = u), size = 0.1)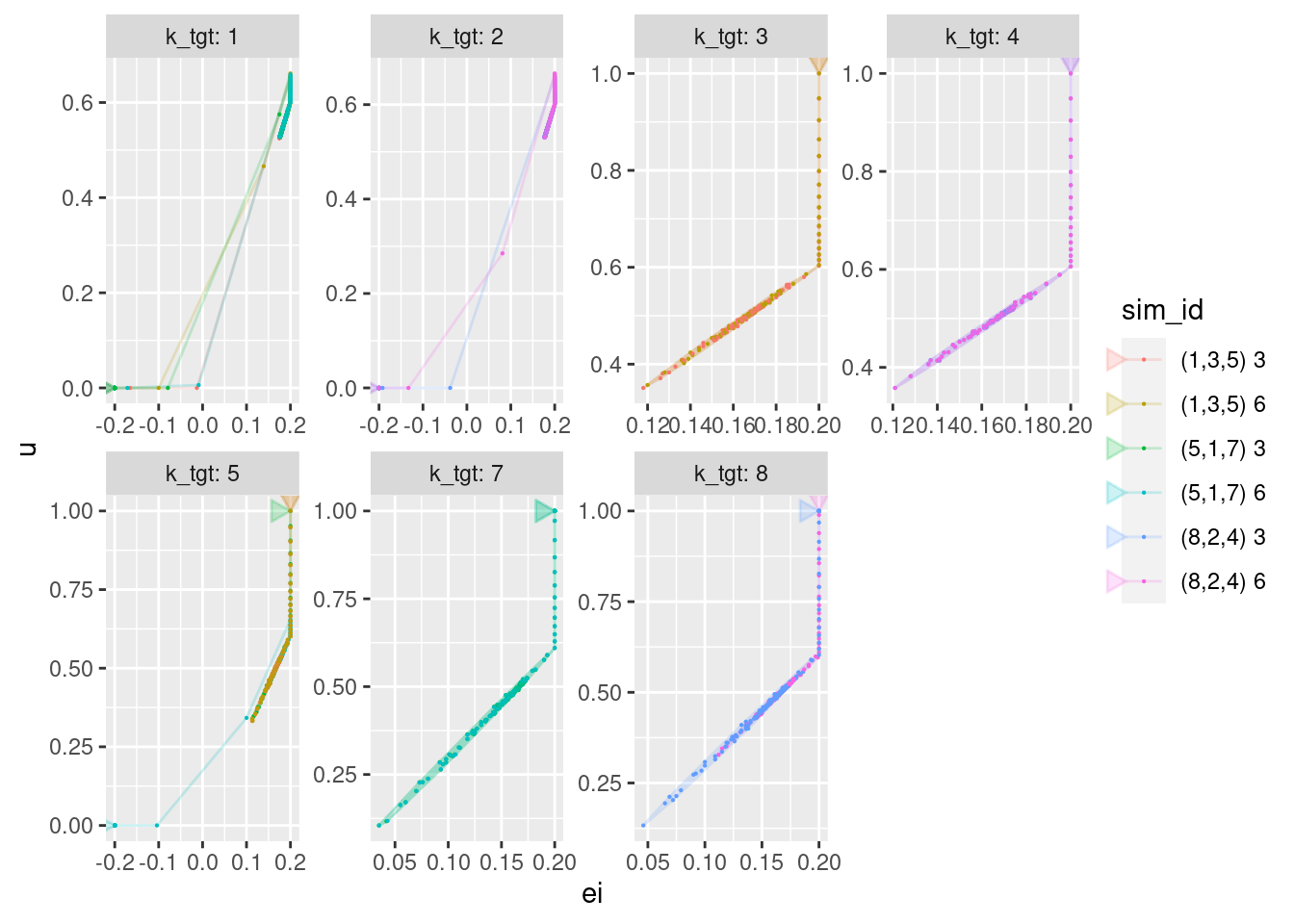
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
3 Distributions
Look at the distributions of the values of all the nodes of the data flow diagram.
Note that these distributions are calculated over all the input files pooled.
Also note that the concept of a distribution is somewhat suspect when applied to an arbitrary selection of nonstationary signals.
3.1 Summary dsitributions
Display a quick summary of the distributions of values of all the nodes (except the parameter nodes) and those internal nodes which are identical to imported nodes (\(i2 := e\), \(i5 := ei\), and \(i8 := u\)).
The observed minimum (\(p0\)) and maximum (\(p100\)) will inform the value ranges of the corresponding VSA representations.
d_wide %>%
dplyr::select(z:u, i1, i3, i4, i6, i7) %>%
skimr::skim()| Name | Piped data |
| Number of rows | 6000 |
| Number of columns | 10 |
| _______________________ | |
| Column type frequency: | |
| numeric | 10 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| z | 0 | 1 | 3.98 | 1.85 | 1.08 | 2.55 | 3.81 | 5.09 | 7.93 | ▇▇▇▃▃ |
| dz | 0 | 1 | 0.07 | 1.39 | -5.00 | -0.45 | 0.16 | 0.68 | 5.07 | ▁▂▇▂▁ |
| e | 0 | 1 | -0.05 | 0.71 | -6.00 | 0.00 | 0.00 | 0.00 | 6.00 | ▁▁▇▁▁ |
| ei | 0 | 1 | 0.16 | 0.08 | -0.20 | 0.17 | 0.17 | 0.18 | 0.20 | ▁▁▁▁▇ |
| u | 0 | 1 | 0.51 | 0.13 | 0.00 | 0.51 | 0.52 | 0.54 | 1.00 | ▁▁▇▁▁ |
| i1 | 0 | 1 | 0.02 | 1.68 | -5.93 | -0.48 | 0.17 | 0.71 | 5.84 | ▁▁▇▂▁ |
| i3 | 0 | 1 | -0.01 | 0.14 | -1.20 | 0.00 | 0.00 | 0.00 | 1.20 | ▁▁▇▁▁ |
| i4 | 0 | 1 | 0.11 | 0.77 | -6.10 | 0.17 | 0.17 | 0.18 | 6.18 | ▁▁▇▁▁ |
| i6 | 0 | 1 | 0.47 | 0.23 | -0.60 | 0.51 | 0.52 | 0.54 | 0.60 | ▁▁▁▁▇ |
| i7 | 0 | 1 | 0.46 | 0.35 | -1.80 | 0.51 | 0.52 | 0.54 | 1.80 | ▁▁▁▇▁ |
3.2 Detailed distributions
Look at the detailed distribution of all the nodes (except the parameter nodes) and those internal nodes which are identical to imported nodes (\(i2 := e\), \(i5 := ei\), and \(i8 := u\)).
The distributions will give some idea about how much different regions of the value ranges are used.
Use a logarithmic scale for the counts to bring out the detail in the low density areas.
Also, divide the ranges into quintiles to give an idea of where range boundaries might be if we used a low resolution representation (effectively dividing each value range into “high negative”, “medium negative”, “neutral”, “medium positive”, “high positive”). This is relevant to the question of value resolution. The quintile boundaries are displayed as red lines.
d_node <- d_wide %>%
dplyr::select(z:u, i1, i3, i4, i6, i7) %>%
tidyr::pivot_longer(cols = everything(), names_to = "node", values_to = "value")
d_quintile <- d_node %>%
dplyr::group_by(node) %>%
dplyr::summarise(
p01 = quantile(value, probs = 0.01, names = FALSE),
p02 = quantile(value, probs = 0.02, names = FALSE),
p05 = quantile(value, probs = 0.05, names = FALSE),
p20 = quantile(value, probs = 0.2, names = FALSE),
p40 = quantile(value, probs = 0.4, names = FALSE),
p60 = quantile(value, probs = 0.6, names = FALSE),
p80 = quantile(value, probs = 0.8, names = FALSE),
p95 = quantile(value, probs = 0.95, names = FALSE),
p98 = quantile(value, probs = 0.98, names = FALSE),
p99 = quantile(value, probs = 0.99, names = FALSE)
)
d_node %>%
ggplot(aes(x = value)) +
facet_wrap(facets = vars(node), ncol = 2, scales = "free") +
geom_histogram(bins = 50) +
scale_y_log10() +
geom_vline(data = d_quintile, aes(xintercept = p01), colour = "orange", linetype = "dotted") +
geom_vline(data = d_quintile, aes(xintercept = p02), colour = "orange", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p05), colour = "orange", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p20), colour = "red", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p40), colour = "red", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p60), colour = "red", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p80), colour = "red", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p95), colour = "orange", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p98), colour = "orange", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p99), colour = "orange", linetype = "dotted")Warning: Transformation introduced infinite values in continuous y-axisWarning: Removed 44 rows containing missing values (geom_bar).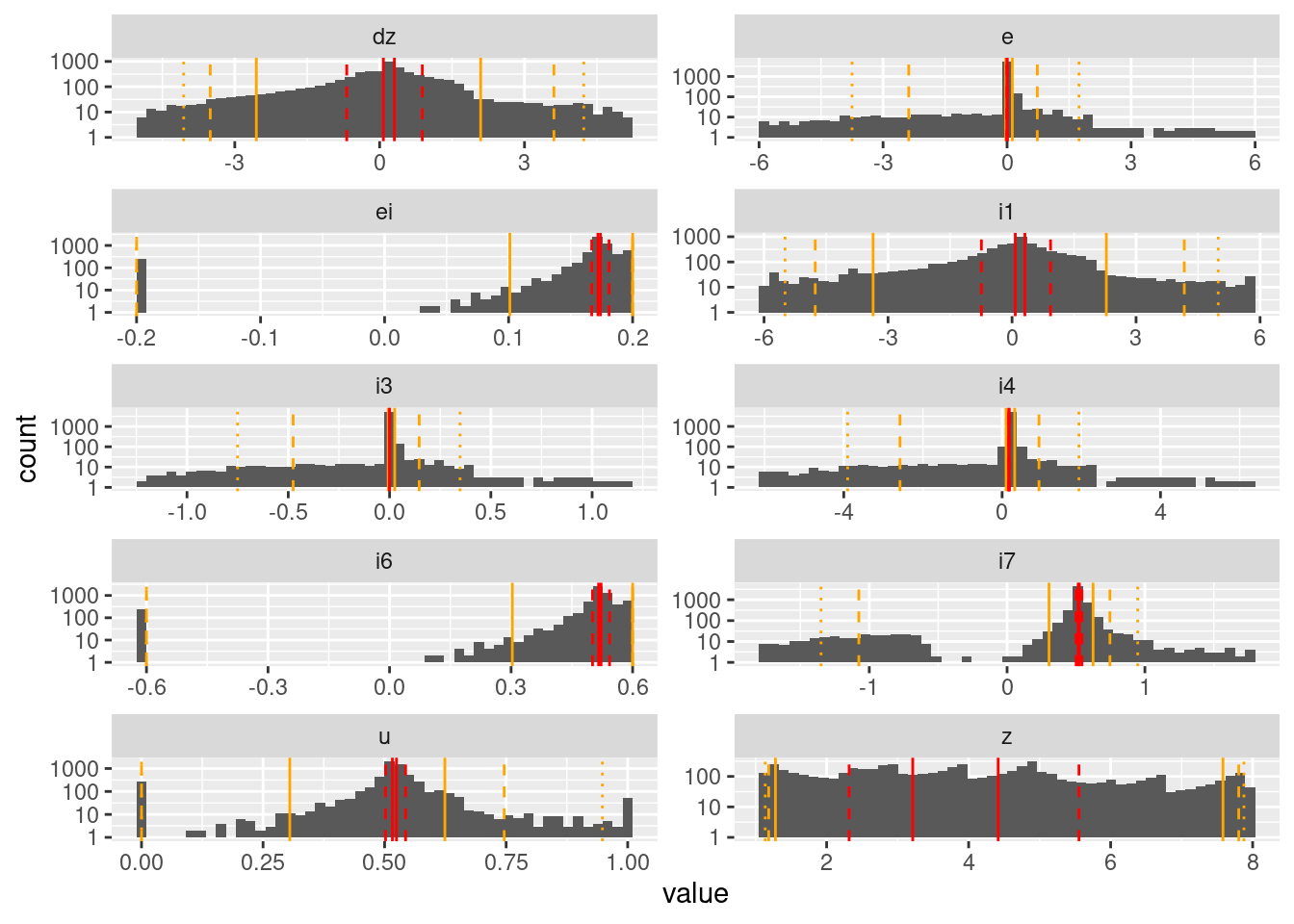
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
Values which are driven to variable targets (\(z\)) are multimodal with a mode corresponding to each target.
Values which are driven to a fixed target (\(dz\), \(e\), \(i1\), \(i3\), \(i4\)) have unimodal distributions.
- \(i4\) is part of the calculation of integrated error, so I would have expected it to be bimodal,but it’s calculation is dominated by \(e\) (identical to \(i2\)), so has a unimodal distribution.
Values driven by the integrated error (\(ei\), \(i6\), \(i7\), \(u\)) have bimodal or trimodal distributions.
- \(ei\), \(i6\), and \(u\) are all effectively clipped distributions with the effect that what would otherwise have been long tails are pulled in to the clipping limits and form modes there.
- \(i7\) is unconstrained and therefore does not have modes at the extremes. It is bimodal.
- The values of motor command (\(u\)) have a trimodal distribution (full on, full off, hovering).
The quintiles are very closely clustered around the principal mode of each distribution. This indicates that a quintile-based resolution would not be very useful.
- This suggests that an encoding would either need to be based on the values rather than quantiles, or quantiles would have to be defined with respect to when the system dynamics is doing something interesting.
4 Value resolution
VSA representations, like any physical implementation have limited value resolution. In this section I would like to find the value resolution that is required by the PID controller in order to work satisfactorily. I won’t be doing that because that is probably more effort than is justified at this stage. A proper answer to that question would probably involve something like injecting noise into the value at each node to see how PID performance decreases as noise is increased.
Instead, I will try to get some feel for the effective value resolution in the classically implemented PID controller. I will do this by looking at the distribution of the differences between successive values. The intuition behind this is that the differences between successive values represent the increments in which the state of the dynamic system evolves.
This analysis will not provide any conclusive answers. Rather, it will provide some context for later thinking about the VSA designs.
I expect that the initial VSA designs will be thoroughly over-resourced, so that they have far more value resolution than is required for implementation of the PID controller.
Look at the distributions of absolute differences of successive values at each node.
Exclude observations where the successive difference is zero, because eventually all node values will converge to a steady state which is uninteresting and can be arbitrarily prolonged.
# function to calculate the absolute successive difference
abs_diff <- function(
x # numeric - vector of values at successive time steps
) # value # numeric - vector of absolute values of first differences
{
(x - dplyr::lag(x)) %>% abs()
}
d_node <- d_wide %>%
dplyr::select(file, t, z:u, i1, i3, i4, i6, i7) %>%
dplyr::arrange(file, t) %>% # guarantee correct order for successive differences
dplyr::group_by(file) %>%
dplyr::mutate(
across(z:i7, abs_diff)
) %>%
dplyr::ungroup() %>%
dplyr::select(-file, -t) %>%
tidyr::pivot_longer(cols = everything(), names_to = "node", values_to = "value") %>%
dplyr::filter(!is.na(value) & value > 0) # exclude rows with zero change
# calculate quantiles for each node
d_quintile <- d_node %>%
dplyr::group_by(node) %>%
dplyr::summarise(
p01 = quantile(value, probs = 0.01, names = FALSE),
p02 = quantile(value, probs = 0.02, names = FALSE),
p05 = quantile(value, probs = 0.05, names = FALSE),
p20 = quantile(value, probs = 0.2, names = FALSE),
p40 = quantile(value, probs = 0.4, names = FALSE),
p60 = quantile(value, probs = 0.6, names = FALSE),
p80 = quantile(value, probs = 0.8, names = FALSE),
p95 = quantile(value, probs = 0.95, names = FALSE),
p98 = quantile(value, probs = 0.98, names = FALSE),
p99 = quantile(value, probs = 0.99, names = FALSE)
)
d_node %>%
ggplot(aes(x = value)) +
facet_wrap(facets = vars(node), ncol = 2, scales = "free") +
geom_histogram(bins = 50) +
scale_x_log10() +
scale_y_log10() +
geom_vline(data = d_quintile, aes(xintercept = p01), colour = "orange", linetype = "dotted") +
geom_vline(data = d_quintile, aes(xintercept = p02), colour = "orange", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p05), colour = "orange", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p20), colour = "red", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p40), colour = "red", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p60), colour = "red", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p80), colour = "red", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p95), colour = "orange", linetype = "solid") +
geom_vline(data = d_quintile, aes(xintercept = p98), colour = "orange", linetype = "dashed") +
geom_vline(data = d_quintile, aes(xintercept = p99), colour = "orange", linetype = "dotted")Warning: Transformation introduced infinite values in continuous y-axisWarning: Removed 181 rows containing missing values (geom_bar).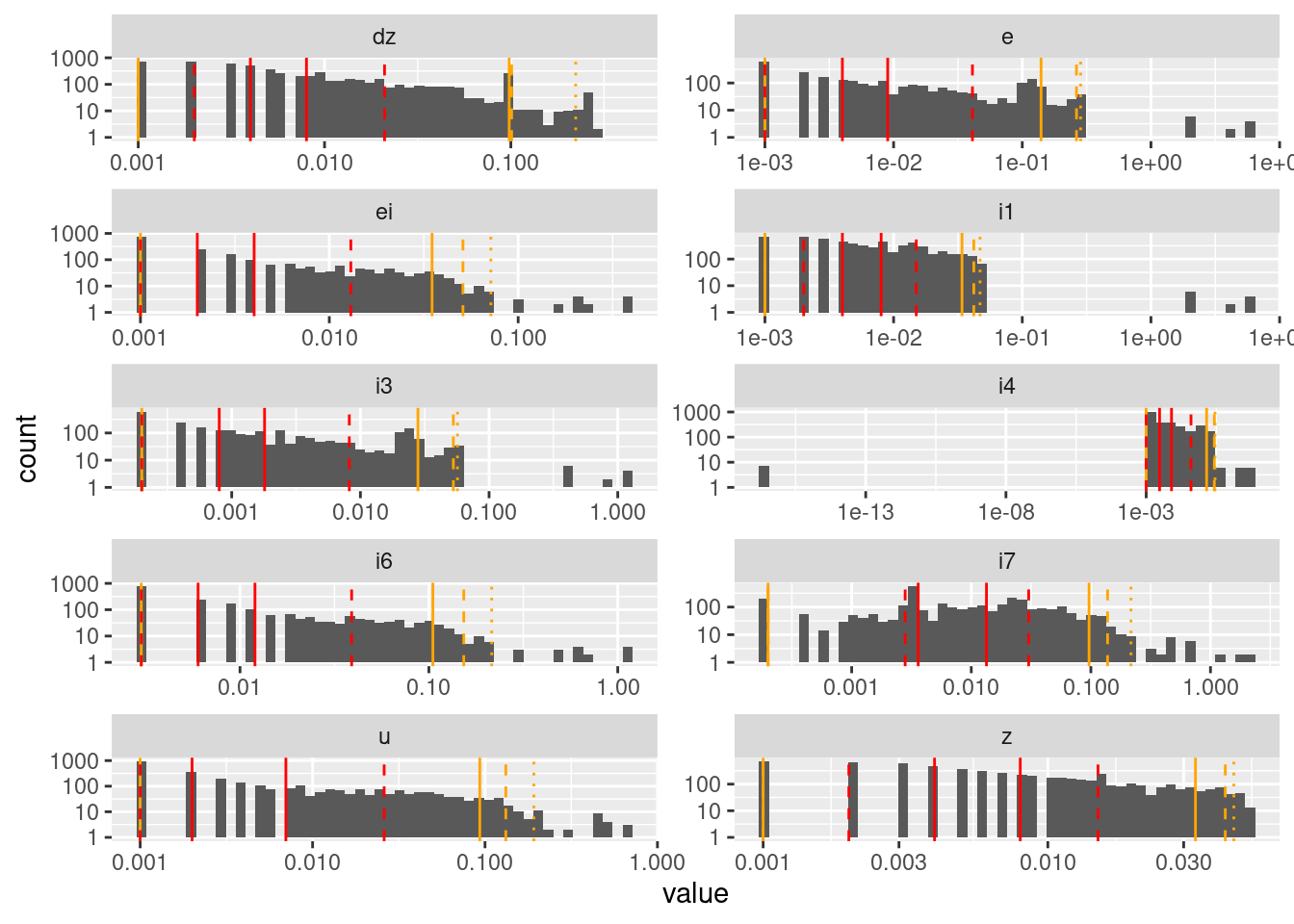
| Version | Author | Date |
|---|---|---|
| cc65206 | Ross Gayler | 2021-08-09 |
The pattern of separated bars is due to the values being quantised to three decimal places.
Successive differences are very heavily concentrated near zero for all nodes.
Some nodes (\(dz\), \(e\), \(i3\), \(i4\)) have a secondary mode that is clearly nonzero.
Node \(i7\) has a possibly bimodal distribution.
I don’t know that I would draw any conclusions from that analysis, other than that most values evolve in small increments, and when the increments are large it is probably in the initial stages of detecting and reacting to a large mismatch to the target.
5 Temporal resolution
Temporal resolution is possibly even more problematic than value resolution.
I will look at the power spectra of the values. The data being analysed here is generated by the classically implemented simulation. So the frequencies with relatively higher power will be interpreted as important to the dynamics of the classically implemented PID controller.
Looking at the earlier plots of values as a function of time, I would expect the low frequencies to be prominent as many of the curves show a slow and smooth approach to a target value.
However, there will be some high frequency components corresponding to the sudden turning on or off of the motors.
I also expect to see some frequency component corresponding to the observed oscillatory behaviour. However, this might not be essential to the dynamics of the PID as I suspect the oscillation is an undesired behaviour that could be removed by tuning.
I will look at the power spectrum for each node for an episode of settling (i.e. the period from when a target altitude is set until the target altitude changes or the simulation finishes). This averages over the simulation files and episodes. This is a slightly odd set to be averaging over because the responses to the different episodes probably don’t constitute a stationary signal, but I am going to take the episodes as being representative of the system’s behaviour.
Some nodes are redundant (they have identical spectra to other nodes) because they are linear transforms of the other nodes. The redundant nodes have been removed from the plots.
- \(i1\) (= \(z\) minus constant)
- \(i3\) (= \(e\) times constant)
- \(i6\) (= \(ei\) times constant)
The ordering of the node plots corresponds to ordering of the nodes along the data flow diagram from altitude (\(z\)) to motor command (\(u\)).
The spectra are displayed as functions of period rather than frequency because this makes them a little easier to relate to the dynamics observed in the graphs of node value as a function of time.
Both the period and power axes are displayed on logarithmic scales.
# function to spectral analyse one time series as a frame
spec_an <- function(
d # data frame - contains a "value" column
) # value # spectrum object - result of spectral analysis of d
{
spec_obj <- d %>%
dplyr::pull(value) %>% # get the time series of values
scale() %>% # centre and standardise the time series
spectrum(
method = "pgram", detrend = TRUE, plot = FALSE
) # return a spectrum object
tibble(freq = spec_obj[["freq"]], spec = spec_obj[["spec"]])
}
d_wide %>%
dplyr::select(sim_id, k_tgt, t, z, dz, e, i4, ei, i7, u) %>% # only keep non-redundant nodes
dplyr::arrange(sim_id, t) %>% # guarantee correct time order
dplyr::group_by(sim_id, k_tgt) %>% # group by episode (i.e. sim_id x k_tgt)
dplyr::slice_head(n = 333) %>% # make all episodes same duration
dplyr::ungroup() %>%
tidyr::pivot_longer(cols = z:u, names_to = "node", values_to = "value") %>%
tidyr::nest(node_series = c(t, value)) %>% # analysis per episode x node
dplyr::mutate(
spectrum = node_series %>% map(spec_an), # calculate the spectra
node = node %>% forcats::fct_relevel(
c("z", "dz", "e", "i4", "ei", "i7", "u")
) # reorder levels of node for display
) %>%
dplyr::select(-node_series) %>% # drop time series
tidyr::unnest(cols = spectrum) %>%
dplyr::group_by(node, freq) %>% # average over sim_id x k_tgt
dplyr::summarise(spec = mean(spec), .groups = "drop") %>%
ggplot() +
geom_vline(xintercept = 6, alpha = 0.2) +
geom_path(aes(x = 1/freq, y = spec)) +
geom_point(aes(x = 1/freq, y = spec), size = 0.5) +
scale_x_log10() + scale_y_log10() +
xlab("Period (time steps)") + ylab("Power") +
facet_wrap(vars(node), ncol = 4)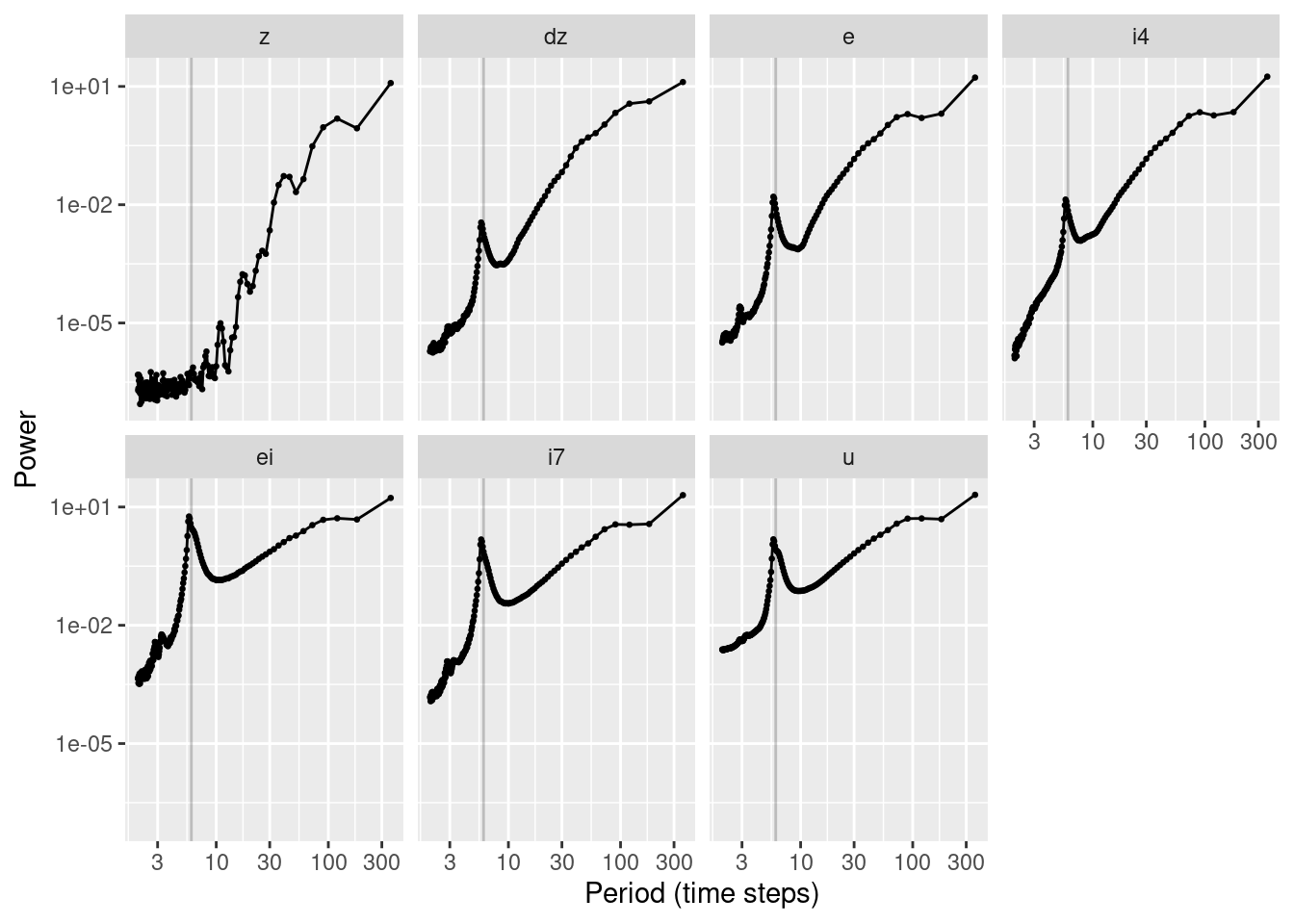
As expected, the power is highest at high periods (low frequencies), indicating that the strongest tendency is for the signals to evolve slowly and smoothly.
As we progress across nodes from altitude (\(z\)) to motor command (\(u\)) the relative contribution of shorter periods (higher frequencies) increases.
- This suggests that the nodes can be thought of as constituting a series fo filters that emphasise higher frequency components that will eventually be the motor commands.
For all nodes except altitude (\(z\)) there is a clear peak in power at a period of ~6 time steps. This corresponds to the oscillation that was observed in the earlier plots of the node values as functions of time.
If I am going to draw any tentative conclusions from this it is that:
- Most of the action in the system happens relatively slowly, but …
- Things get faster as you get closer to the motor command.
sessionInfo()R version 4.1.0 (2021-05-18)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 21.04
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=en_AU.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_AU.UTF-8 LC_COLLATE=en_AU.UTF-8
[5] LC_MONETARY=en_AU.UTF-8 LC_MESSAGES=en_AU.UTF-8
[7] LC_PAPER=en_AU.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_AU.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices datasets utils methods base
other attached packages:
[1] Matrix_1.3-4 DiagrammeR_1.0.6.1 purrr_0.3.4 tidyr_1.1.3
[5] ggplot2_3.3.5 forcats_0.5.1 skimr_2.1.3 stringr_1.4.0
[9] DT_0.18 dplyr_1.0.7 vroom_1.5.4 here_1.0.1
[13] fs_1.5.0
loaded via a namespace (and not attached):
[1] Rcpp_1.0.7 lattice_0.20-44 visNetwork_2.0.9 rprojroot_2.0.2
[5] digest_0.6.27 utf8_1.2.2 R6_2.5.0 repr_1.1.3
[9] evaluate_0.14 highr_0.9 pillar_1.6.2 rlang_0.4.11
[13] rstudioapi_0.13 whisker_0.4 rmarkdown_2.10 splines_4.1.0
[17] labeling_0.4.2 htmlwidgets_1.5.3 bit_4.0.4 munsell_0.5.0
[21] compiler_4.1.0 httpuv_1.6.1 xfun_0.25 pkgconfig_2.0.3
[25] base64enc_0.1-3 mgcv_1.8-36 htmltools_0.5.1.1 tidyselect_1.1.1
[29] tibble_3.1.3 bookdown_0.22 workflowr_1.6.2 fansi_0.5.0
[33] crayon_1.4.1 tzdb_0.1.2 withr_2.4.2 later_1.2.0
[37] grid_4.1.0 nlme_3.1-152 jsonlite_1.7.2 gtable_0.3.0
[41] lifecycle_1.0.0 git2r_0.28.0 magrittr_2.0.1 scales_1.1.1
[45] cli_3.0.1 stringi_1.7.3 farver_2.1.0 renv_0.14.0
[49] promises_1.2.0.1 ellipsis_0.3.2 generics_0.1.0 vctrs_0.3.8
[53] RColorBrewer_1.1-2 tools_4.1.0 bit64_4.0.5 glue_1.4.2
[57] crosstalk_1.1.1 parallel_4.1.0 yaml_2.2.1 colorspace_2.0-2
[61] knitr_1.33