[meta] Check residenial variables
m_01_6_check_resid
Ross Gayler
2021-04-02
Last updated: 2021-04-03
Checks: 6 1
Knit directory:
fa_sim_cal/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes.
To know which version of the R Markdown file created these
results, you’ll want to first commit it to the Git repo. If
you’re still working on the analysis, you can ignore this
warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and
build the HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20201104) was run prior to running the code in the R Markdown file.
Setting a seed ensures that any results that rely on randomness, e.g.
subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 9b4272d. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the
analysis have been committed to Git prior to generating the results (you can
use wflow_publish or wflow_git_commit). workflowr only
checks the R Markdown file, but you know if there are other scripts or data
files that it depends on. Below is the status of the Git repository when the
results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: .tresorit/
Ignored: _targets/
Ignored: data/VR_20051125.txt.xz
Ignored: data/VR_Snapshot_20081104.txt.xz
Ignored: output/blk_char.fst
Ignored: output/ent_blk.fst
Ignored: output/ent_cln.fst
Ignored: output/ent_raw.fst
Ignored: renv/library/
Ignored: renv/local/
Ignored: renv/staging/
Unstaged changes:
Modified: analysis/index.Rmd
Modified: analysis/m_01_5_check_admin.Rmd
Modified: analysis/m_01_6_check_resid.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made
to the R Markdown (analysis/m_01_6_check_resid.Rmd) and HTML (docs/m_01_6_check_resid.html)
files. If you’ve configured a remote Git repository (see
?wflow_git_remote), click on the hyperlinks in the table below to
view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 9b4272d | Ross Gayler | 2021-04-02 | WIP |
| html | 9b4272d | Ross Gayler | 2021-04-02 | WIP |
# NOTE this notebook can be run manually or automatically by {targets}
# So load the packages required by this notebook here
# rather than relying on _targets.R to load them.
# Set up the project environment, because {workflowr} knits each Rmd file
# in a new R session, and doesn't execute the project .Rprofile
library(targets) # access data from the targets cache
library(tictoc) # capture execution time
library(here) # construct file paths relative to project root
library(fs) # file system operations
library(vroom) # fast reading of delimited text files
library(tibble) # enhanced data frames
library(stringr) # string matching
library(skimr) # compact summary of each variable
library(lubridate) # date parsing
Attaching package: 'lubridate'The following objects are masked from 'package:base':
date, intersect, setdiff, unionlibrary(forcats) # manipulation of factors
library(ggplot2) # graphics
library(tidyr) # data tidying
# start the execution time clock
tictoc::tic("Computation time (excl. render)")
# Get the path to the raw entity data file
# This is a target managed by {targets}
f_entity_raw_tsv <- tar_read(c_raw_entity_data_file)1 Introduction
The aim of this set of meta notebooks is to work out how to read the raw
entity data. and get it sufficiently neatened so that we can construct
standardised names and modelling features without needing any further
neatening. To be clear, the target (c_raw_entity_data) corresponding
to the objective of this set of notebooks is the neatened raw data,
before constructing any modelling features.
This notebook documents the checking of the “residential” variables for any issues that need fixing. These are the residential address and the phone number (which is tied to the address if the telephone is a land-line). The subsequent notebooks in this set will checking the other variables for any issues that need fixing.
Regardless of whether there are any issues that need to be fixed, the analyses here may inform our use of these variables in later analyses.
We have no intention of using the residence variables as predictors for entity resolution. However, they may be of use for manually checking the results of entity resolution. Consequently, the checking done here is minimal.
Define the residential variables:
unit_num- Residential address unit numberhouse_num- Residential address street numberhalf_code- Residential address street number half codestreet_dir- Residential address street direction (N,S,E,W,NE,SW, etc.)street_name- Residential address street namestreet_type_cd- Residential address street type (RD, ST, DR, BLVD, etc.)street_sufx_cd- Residential address street suffix (BUS, EXT, and directional)res_city_desc- Residential address city namestate_cd- Residential address state codezip_code- Residential address zip codearea_cd- Area code for phone numberphone_num- Telephone number
vars_resid <- c(
"unit_num", "house_num",
"half_code", "street_dir", "street_name", "street_type_cd", "street_sufx_cd",
"res_city_desc", "state_cd", "zip_code",
"area_cd", "phone_num"
)2 Read entity data
Read the raw entity data file using the previously defined functions
raw_entity_data_read(), raw_entity_data_excl_status(),
raw_entity_data_excl_test(), raw_entity_data_drop_novar(),
raw_entity_data_parse_dates(), and raw_entity_data_drop_cancel_dt().
# Show the data file name
fs::path_file(f_entity_raw_tsv)[1] "VR_20051125.txt.xz"d <- raw_entity_data_read(f_entity_raw_tsv) %>%
raw_entity_data_excl_status() %>%
raw_entity_data_excl_test() %>%
raw_entity_data_drop_novar() %>%
raw_entity_data_parse_dates() %>%
raw_entity_data_drop_cancel_dt()
dim(d)[1] 4099699 243 Dwelling
unit_num- Residential address unit numberhouse_num- Residential address street numberhalf_code- Residential address street number half code
d %>%
dplyr::select(unit_num, house_num, half_code) %>%
skimr::skim()| Name | Piped data |
| Number of rows | 4099699 |
| Number of columns | 3 |
| _______________________ | |
| Column type frequency: | |
| character | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| unit_num | 3755239 | 0.08 | 1 | 7 | 0 | 16116 | 0 |
| house_num | 0 | 1.00 | 1 | 6 | 0 | 27534 | 0 |
| half_code | 4088996 | 0.00 | 1 | 1 | 0 | 41 | 0 |
We are mostly interested in how much these fields are used, so concentrate on complete_rate.
All these variables are character variables, so min and max refer to the minimum and maximum lengths of the values as character strings.
The number of unique values, n_unique, is also of interest.
unit_num- 8% filled
- There are some awfully long unit numbers
- There are an awful lot of unique unit numbers
house_num- 100% filled
- There are some awfully long house numbers
- There are an awful lot of unique house numbers
half_code0.3% filled- All exactly 1 character long
- There are more unique values than I would expect for a one character string
3.1 unit_num
unit_num- Residential address unit number
Look at some examples grouped by length
d %>%
dplyr::select(unit_num) %>%
dplyr::filter(!is.na(unit_num)) %>%
dplyr::mutate(length = stringr::str_length(unit_num)) %>%
dplyr::group_by(length) %>%
dplyr::count(unit_num) %>% # count occurrences of each unique value
dplyr::slice_max(order_by = n, n = 5) %>%
knitr::kable()| length | unit_num | n |
|---|---|---|
| 1 | A | 28214 |
| 1 | B | 26535 |
| 1 | C | 14240 |
| 1 | D | 12452 |
| 1 | E | 7956 |
| 2 | 10 | 2090 |
| 2 | 11 | 1878 |
| 2 | 12 | 1844 |
| 2 | 14 | 1390 |
| 2 | 13 | 1378 |
| 3 | 102 | 2579 |
| 3 | 101 | 2499 |
| 3 | 103 | 2296 |
| 3 | 201 | 2205 |
| 3 | 104 | 2201 |
| 4 | APTB | 194 |
| 4 | APTA | 185 |
| 4 | APTC | 106 |
| 4 | APT2 | 73 |
| 4 | APT4 | 73 |
| 5 | APT-A | 813 |
| 5 | APT-B | 680 |
| 5 | APT-C | 165 |
| 5 | APT-D | 119 |
| 5 | APT-1 | 109 |
| 6 | APT-1B | 30 |
| 6 | APT-2B | 24 |
| 6 | APT-1A | 22 |
| 6 | APT-4A | 20 |
| 6 | APT-4B | 19 |
| 7 | APT 205 | 6 |
| 7 | APT-204 | 6 |
| 7 | CONOVER | 6 |
| 7 | APT-106 | 5 |
| 7 | APT-203 | 5 |
| 7 | APT-302 | 5 |
- Longer values are due to inclusion of text, e.g. “APT-106”
3.2 house_num
house_num- Residential address street number
Look at some examples grouped by length
d %>%
dplyr::select(house_num) %>%
dplyr::filter(!is.na(house_num)) %>%
dplyr::mutate(length = stringr::str_length(house_num)) %>%
dplyr::group_by(length) %>%
dplyr::count(house_num) %>% # count occurrences of each unique value
dplyr::slice_max(order_by = n, n = 5) %>%
knitr::kable()| length | house_num | n |
|---|---|---|
| 1 | 0 | 36335 |
| 1 | 1 | 8601 |
| 1 | 5 | 5488 |
| 1 | 6 | 5356 |
| 1 | 4 | 5143 |
| 2 | 10 | 5649 |
| 2 | 15 | 5332 |
| 2 | 11 | 4730 |
| 2 | 20 | 4243 |
| 2 | 12 | 4115 |
| 3 | 105 | 18195 |
| 3 | 104 | 17159 |
| 3 | 100 | 15605 |
| 3 | 102 | 15147 |
| 3 | 103 | 15070 |
| 4 | 1000 | 3826 |
| 4 | 1200 | 3674 |
| 4 | 1005 | 3238 |
| 4 | 1001 | 3158 |
| 4 | 1801 | 3064 |
| 5 | 10400 | 238 |
| 5 | 10000 | 230 |
| 5 | 30005 | 229 |
| 5 | 10001 | 188 |
| 5 | 10301 | 183 |
| 6 | 100000 | 9 |
| 6 | 100001 | 1 |
| 6 | 102099 | 1 |
| 6 | 103580 | 1 |
| 6 | 601708 | 1 |
- I am mildly surprised by house number “0”. I wouldn’t be surprised if someone was using that as a misiing value flag.
- Large numbers are plausible, because these are not uncommon in the USA.
- Very large numbers are somewhat suspect.
3.3 half_code
half_code- Residential address street number half code
d %>%
dplyr::select(half_code) %>%
dplyr::filter(!is.na(half_code)) %>%
dplyr::count(half_code) %>% # count occurrences of each unique value
dplyr::arrange(desc(n)) %>%
# knitr::kable() # strange multibyte character kills kable()
print(n = Inf)# A tibble: 41 x 2
half_code n
<chr> <int>
1 "A" 3313
2 "B" 2725
3 "\xbd" 1730
4 "C" 948
5 "D" 569
6 "E" 273
7 "F" 214
8 "H" 174
9 "G" 154
10 "J" 78
11 "K" 58
12 "L" 48
13 "M" 48
14 "1" 44
15 "S" 38
16 "I" 36
17 "2" 35
18 "N" 33
19 "+" 32
20 "W" 24
21 "P" 21
22 "R" 13
23 "T" 13
24 "4" 10
25 "/" 8
26 "Q" 7
27 "5" 6
28 "6" 6
29 "O" 6
30 "V" 6
31 "`" 5
32 "3" 5
33 "7" 5
34 "8" 4
35 "X" 4
36 "U" 3
37 "\xab" 3
38 "-" 1
39 "0" 1
40 "9" 1
41 "Y" 1half_codeappears to indicate where there are multiple dwellings on one street-numbered block. Typical values would be A, B, …- Punctuation and non-printing characters are not plausible
4 Street
street_dir- Residential address street direction (N,S,E,W,NE,SW, etc.)street_name- Residential address street namestreet_type_cd- Residential address street type (RD, ST, DR, BLVD, etc.)street_sufx_cd- Residential address street suffix (BUS, EXT, and directional)
Take a quick look at the summaries.
d %>%
dplyr::select(starts_with("street_")) %>%
skimr::skim()| Name | Piped data |
| Number of rows | 4099699 |
| Number of columns | 4 |
| _______________________ | |
| Column type frequency: | |
| character | 4 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| street_dir | 3812561 | 0.07 | 1 | 2 | 0 | 8 | 0 |
| street_name | 7 | 1.00 | 1 | 30 | 0 | 83244 | 0 |
| street_type_cd | 154594 | 0.96 | 2 | 4 | 0 | 119 | 0 |
| street_sufx_cd | 3941004 | 0.04 | 1 | 3 | 0 | 11 | 0 |
We are mostly interested in how much these fields are used, so concentrate on complete_rate.
All these variables are character variables, so min and max refer to the minimum and maximum lengths of the values as character strings.
The number of unique values, n_unique, is also of interest.
street_dir- 7% filled
- 1 or 2 characters long
- 8 unique values
street_name- ~100% filled (7 missing)
- Some very short names
- Wide range of lengths
- Many unique values
street_type_cd- 96% filled
- 2 to 4 characters long
- 119 unique values
street_sufx_cd- 4% filled
- 1 to 3 characters long
- 11 unique values
4.1 street_dir
street_dir- Residential address street direction (N,S,E,W,NE,SW, etc.)
Look at the distribution of values.
d %>%
dplyr::count(street_dir) %>%
dplyr::arrange(desc(n)) %>%
knitr::kable()| street_dir | n |
|---|---|
| NA | 3812561 |
| N | 72784 |
| E | 71244 |
| W | 69476 |
| S | 68612 |
| NE | 2161 |
| SE | 1221 |
| NW | 911 |
| SW | 729 |
- They are literally just compass directions.
4.2 street_name
street_name- Residential address street name
Seven records are missing street name. Look at them.
d %>%
dplyr::filter(is.na(street_name)) %>%
dplyr::select(unit_num, house_num, half_code, starts_with("street_"), res_city_desc:zip_code) %>%
knitr::kable()| unit_num | house_num | half_code | street_dir | street_name | street_type_cd | street_sufx_cd | res_city_desc | state_cd | zip_code |
|---|---|---|---|---|---|---|---|---|---|
| NA | 0 | NA | NA | NA | NA | NA | STONY POINT | NC | 28678 |
| NA | 0 | NA | NA | NA | NA | NA | NA | NA | NA |
| NA | 0 | NA | NA | NA | NA | NA | NA | NA | NA |
| NA | 0 | NA | NA | NA | NA | NA | NA | NA | NA |
| NA | 0 | NA | NA | NA | NA | NA | NA | NA | NA |
| NA | 0 | NA | NA | NA | NA | NA | NA | NA | NA |
| NA | 0 | NA | NA | NA | NA | NA | BELMONT | NC | 28012 |
- Seven records have no residential address. Are these homeless people or data entry errors?
Look at some other information for the same records.
d %>%
dplyr::filter(is.na(street_name)) %>%
dplyr::select(last_name, first_name, sex, age, birth_place, phone_num, registr_dt) %>%
knitr::kable()| last_name | first_name | sex | age | birth_place | phone_num | registr_dt |
|---|---|---|---|---|---|---|
| MECIMORE | BETTIE | FEMALE | 0 | NA | NA | 1968-02-25 |
| BOYCE | LAWRENCE | UNK | 0 | NA | NA | 1900-01-01 |
| BUNCH | QUEEN | UNK | 0 | NA | NA | 1900-01-01 |
| SAWYER | THOMAS | UNK | 0 | NA | NA | 1900-01-01 |
| SIMPSON | RICHARD | UNK | 0 | NA | NA | 1900-01-01 |
| VAUGHAN | DARRELL | UNK | 0 | NA | NA | 1900-01-01 |
| ROGERS | MILDRED | FEMALE | 65 | NC | NA | 1980-10-04 |
- Lots of missing values for these people.
Some street names are very short. Look at the distribution of length of street name.
summary(stringr::str_length(d$street_name)) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
1.00 6.00 8.00 8.78 11.00 30.00 7 d %>%
ggplot() +
geom_histogram(aes(x = stringr::str_length(street_name) %>% replace_na(0)), binwidth = 1) +
scale_y_sqrt()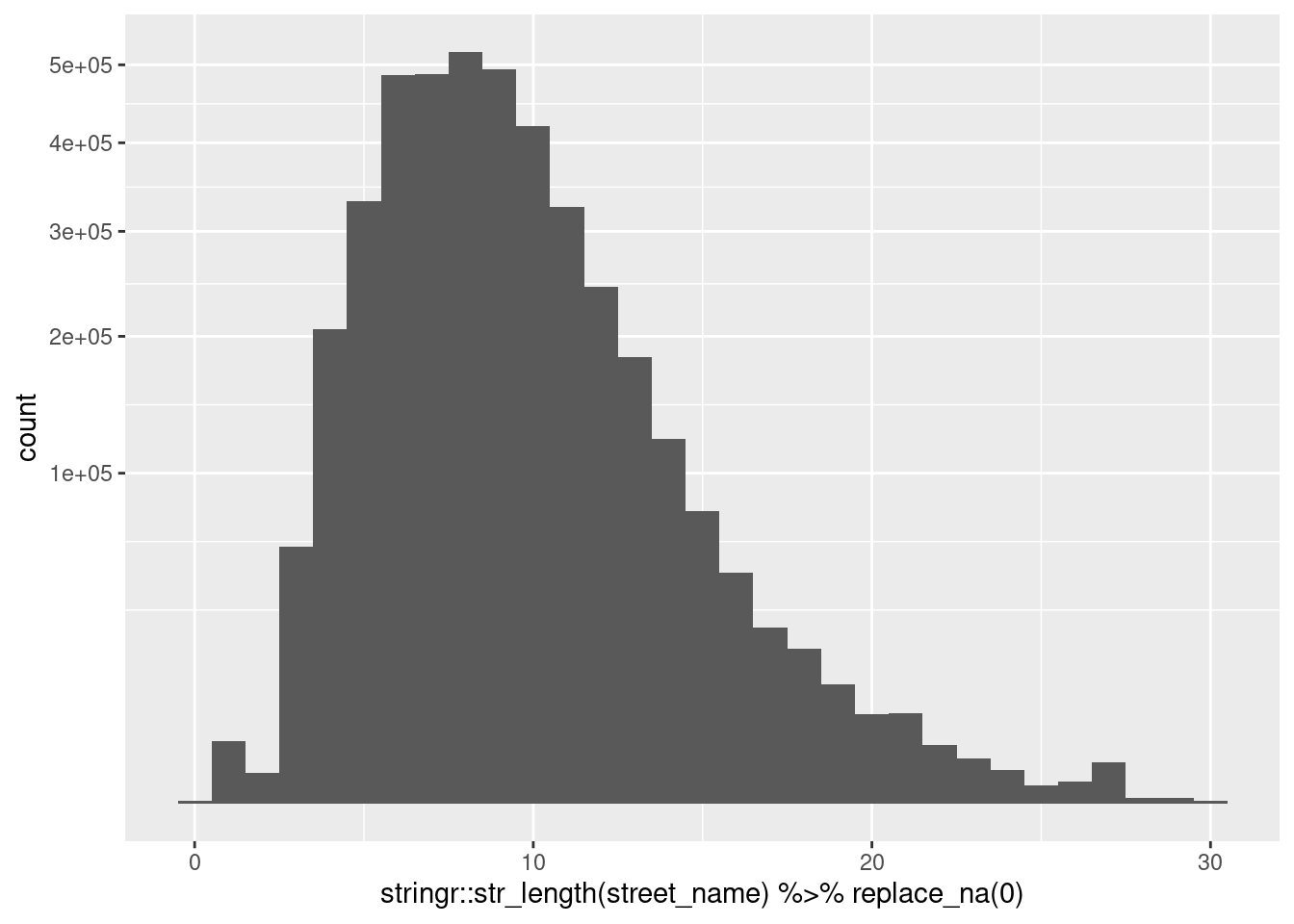
Look at examples of short street names.
d %>%
dplyr::filter(stringr::str_length(street_name) == 1) %>%
dplyr::select(starts_with("street_"), res_city_desc) %>%
dplyr::slice_sample(n = 20) %>%
knitr::kable()| street_dir | street_name | street_type_cd | street_sufx_cd | res_city_desc |
|---|---|---|---|---|
| W | F | ST | NA | ERWIN |
| NA | F | AVE | SE | HICKORY |
| W | A | ST | NA | KANNAPOLIS |
| W | B | ST | NA | KANNAPOLIS |
| NA | A | ST | NA | GOLDSBORO |
| E | E | ST | NA | BUTNER |
| NA | A | ST | NA | CAMP LEJEUNE |
| NA | B | ST | NA | NEW BERN |
| NA | E | AVE | SE | HICKORY |
| NA | J | ST | NA | NORTH WILKESBORO |
| E | E | ST | NA | BUTNER |
| E | J | ST | NA | ERWIN |
| NA | E | NA | NA | ELLERBE |
| NA | B | AVE | SE | HICKORY |
| NA | A | ST | NA | CAMP LEJEUNE |
| NA | A | ST | NA | CAMP LEJEUNE |
| NA | E | ST | NA | NORTH WILKESBORO |
| NA | A | ST | NA | CAMP LEJEUNE |
| NA | A | ST | NA | CAMP LEJEUNE |
| E | D | ST | NA | ERWIN |
d %>%
dplyr::filter(stringr::str_length(street_name) == 2) %>%
dplyr::select(starts_with("street_"), res_city_desc) %>%
dplyr::slice_sample(n = 20) %>%
knitr::kable()| street_dir | street_name | street_type_cd | street_sufx_cd | res_city_desc |
|---|---|---|---|---|
| NA | 19 | HWY | NA | MARS HILL |
| W | ST | ST | NA | ROANOKE RAPIDS |
| NA | 19 | HWY | NA | MARS HILL |
| NA | JB | LN | NA | BATTLEBORO |
| NA | WR | LN | NA | CLAREMONT |
| NA | 23 | HWY | NA | MARS HILL |
| NA | DJ | DR | NA | STATESVILLE |
| NA | KY | FLDS | NA | WEAVERVILLE |
| NA | 23 | HWY | NA | MARS HILL |
| NA | 19 | HWY | NA | MARS HILL |
| NA | RH | RD | NA | HICKORY |
| NA | WJ | RD | NA | WAYNESVILLE |
| NA | CC | DR | NA | MORGANTON |
| NA | 19 | HWY | NA | MARS HILL |
| NA | DJ | DR | NA | STATESVILLE |
| N | ST | NA | NA | ASHEVILLE |
| NA | 63 | HWY | NA | LEICESTER |
| NA | JD | DR | NA | LOCUST |
| NA | VI | LN | NA | CLAYTON |
| NA | JD | CT | NA | CHAPEL HILL |
I checked some of these examples against a map.
- Some streets have names like A, B, C, …
- “JC Road” is a valid street name
Look at examples of long street names.
d %>%
dplyr::filter(stringr::str_length(street_name) >= 28) %>%
dplyr::select(starts_with("street_"), res_city_desc) %>%
dplyr::distinct(.keep_all = TRUE) %>%
dplyr::arrange(street_name) %>%
knitr::kable()| street_dir | street_name | street_type_cd | street_sufx_cd | res_city_desc |
|---|---|---|---|---|
| NA | BROOKFIELD RETIREMENT CENTER | NA | NA | LILLINGTON |
| NA | CROSS MEMORIAL BAPTIST CHURCH | LOOP | NA | MARION |
| NA | KINGSDALE MANOR NURSING CENTER | NA | NA | LUMBERTON |
| NA | LOMBARDY VILLAGE MOBILE HOME | PARK | NA | LUMBERTON |
| NA | LOMBARDY VILLAGE MOBILE HOME | PARK | NA | SHANNON |
| NA | LOMBARDY VILLAGE MOBILE HOME | PARK | NA | REX |
| NA | NC HWY 197N NEAR COVY ROCK CHU | NA | NA | BURNSVILLE |
| NA | OLD TAMMANY-OINE ROOKER DAIRY | RD | NA | NORLINA |
| NA | SWEPSONVILLE-METHODIST CHURCH | RD | NA | GRAHAM |
| NA | WHEELING VILLAGE TRAILER PARK | NA | NA | WINSTON SALEM |
| NA | WILDLIFE RECREATION AREA ACC | RD | NA | LEXINGTON |
| NA | WISE-FIVE FORKS- ROBERSON FERR | NA | NA | MACON |
Long street names are multi-word phrases
- Some appear to have been truncated
4.3 street_type_cd
street_type_cd- Residential address street type (RD, ST, DR, BLVD, etc.)
table(d$street_type_cd, useNA = "ifany")
ALY ANX ARC AVE BCH BLF BLVD BND BR BRG
266 23 7 207808 1 47 27022 250 166 7
BRK BTM BYP CIR CLB CMN CMNS COR COVE CRES
56 1 1205 99489 18 28 20 44 3 534
CRK CRSE CRST CSWY CT CTR CV DL DM DORM
141 8 12 22 249682 15 2527 4 1 1756
DR EST ESTS EXPY EXT FALL FLDS FLS FLT FLTS
926884 457 203 18 4931 2 64 19 8 4
FRD FRK FRST FT FWY GDN GDNS GLN GRN GRV
9 13 22 1 4 6 110 61 6 94
HBR HL HLS HOLW HTS HVN HWY IS JCT KNL
38 513 261 200 1684 24 44189 19 6 162
KNLS LAND LDG LK LKS LN LNDG LOOP MDW MDWS
51 2 6 51 16 347932 371 9505 2 37
MEWS MHP MNR MTN ORCH OVAL PARK PASS PATH PKWY
102 2 222 78 7 2 2013 171 1035 6665
PL PLZ PNES PSGE PT RAMP rd RD RDG ROW
82253 211 21 21 2263 1 1 1287597 2124 333
RST RTE RUN SHR SHRS SMT SPG SPGS SPUR SQ
2 2731 5219 3 33 11 6 32 58 1169
ST STA TER TPKE TRAK TRCE TRL TRLR VIA VIS
512983 9 7959 13 10 1319 44565 26 2 60
VL VLG VLY VW WALK WAY WYND XING XRDS <NA>
1 991 67 217 581 51625 328 652 163 154594 4.4 street_sufx_cd
street_sufx_cd- Residential address street suffix (BUS, EXT, and directional)
table(d$street_sufx_cd, useNA = "ifany")
BUS E EXT I N NE NW S SE SW
169 13021 1481 1 17869 24755 29472 18870 13095 26587
W <NA>
13375 3941004 5 Locality
res_city_desc Residential address city name
state_cd Residential address state code
zip_code Residential address zip code
d %>%
dplyr::select(res_city_desc : zip_code) %>%
skimr::skim()| Name | Piped data |
| Number of rows | 4099699 |
| Number of columns | 3 |
| _______________________ | |
| Column type frequency: | |
| character | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| res_city_desc | 19 | 1 | 3 | 20 | 0 | 783 | 0 |
| state_cd | 18 | 1 | 2 | 2 | 0 | 5 | 0 |
| zip_code | 21 | 1 | 5 | 9 | 0 | 902 | 0 |
res_city_desc~100% filled (19 missing)state_cd~100% filled (19 missing)zip_code~100% filled (19 missing)
Look at the addresses with any missing locality variable.
d %>%
dplyr::filter(is.na(res_city_desc) | is.na(state_cd) | is.na(zip_code)) %>%
dplyr::select(house_num : zip_code) %>%
dplyr::distinct(.keep_all = TRUE) %>%
dplyr::arrange(state_cd, res_city_desc, zip_code) %>%
knitr::kable()| house_num | half_code | street_dir | street_name | street_type_cd | street_sufx_cd | unit_num | res_city_desc | state_cd | zip_code |
|---|---|---|---|---|---|---|---|---|---|
| 5189 | NA | NA | COVE | RD | NA | NA | MARION | NC | NA |
| 5030 | NA | NA | COVE | RD | NA | NA | MARION | NC | NA |
| 0 | NA | NA | H & N MOBILE HOME | PARK | NA | NA | NA | NC | NA |
| 0 | NA | NA | UNKNOWN | NA | NA | NA | NA | NC | NA |
| 1407 | NA | NA | OVERLOOK | DR | NA | NA | LENOIR | NA | 28645 |
| 0 | NA | NA | CONFIDENTIAL | NA | NA | NA | NA | NA | NA |
| 0 | NA | NA | NA | NA | NA | NA | NA | NA | NA |
- Some appear to be good addresses, apart from a missing zip code
- One appears to be a good address, apart from a missing state code
- Some are CONFIDENTIAL addresses, with all details missing
- Some appear to be completely missing the address (homeless persons?)
5.1 state_cd
state_cd Residential address state code
table(d$state_cd, useNA = "ifany")
GA NC SC TN VA <NA>
13 4099631 1 29 7 18 Residential state codes are almost entirely Georgia
- There are a small number in neighbouring states (non-resident voters?)
5.2 zip_code
zip_code Residential address zip code
The zip codes are not all the same length. Look at the distribution of length of zip code
table(stringr::str_length(d$zip_code), useNA = "ifany")
5 9 <NA>
4099667 11 21 Look at the 9-digit zip codes.
d %>%
dplyr::filter(stringr::str_length(zip_code) == 9) %>%
dplyr::select(street_name : zip_code) %>%
dplyr::arrange(zip_code) %>%
knitr::kable()| street_name | street_type_cd | street_sufx_cd | unit_num | res_city_desc | state_cd | zip_code |
|---|---|---|---|---|---|---|
| ECHO | LN | NA | NA | SANFORD | NC | 273308492 |
| UNKNOWN | NA | NA | NA | LILLINGTON | NC | 275468949 |
| LINCOLN MCKAY | DR | NA | NA | LILLINGTON | NC | 275469001 |
| SMITH | ST | NA | NA | ALBEMARLE | NC | 280014351 |
| INDIAN MOUND | RD | NA | NA | ALBEMARLE | NC | 280019245 |
| POND | ST | NA | NA | ALBEMARLE | NC | 280019766 |
| NC 731 HWY | NA | NA | B | NORWOOD | NC | 281289420 |
| FRIENDLY MCLEOD | LN | NA | NA | DUNN | NC | 283349250 |
| BEAVER DAM | RD | NA | NA | ERWIN | NC | 283399790 |
| WIRE | RD | NA | NA | LINDEN | NC | 283569413 |
| WALKER | RD | NA | NA | LINDEN | NC | 283569416 |
- 5-digit and 9-digit zip codes are valid# Timing {.unnumbered}
6 Telephone
area_cd- Area code for phone numberphone_num- Telephone number
d %>%
dplyr::select(area_cd, phone_num) %>%
skimr::skim()| Name | Piped data |
| Number of rows | 4099699 |
| Number of columns | 2 |
| _______________________ | |
| Column type frequency: | |
| character | 2 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| area_cd | 2628117 | 0.36 | 1 | 3 | 0 | 507 | 0 |
| phone_num | 2540990 | 0.38 | 1 | 7 | 0 | 1072592 | 0 |
Look at the relationship between missing area code and missing phone number.
table(area_miss = is.na(d$area_cd), phone_miss = is.na(d$phone_num)) phone_miss
area_miss FALSE TRUE
FALSE 1449568 22014
TRUE 109141 2518976- Area code and phone number are generally missing together, but …
- Area code is frequently missing even when phone number is present.
- Phone number is less frequently missing when area code is present.
6.1 area_cd
Look at some area code examples grouped by length, where there is a phone number.
d %>%
dplyr::filter(!is.na(phone_num)) %>%
dplyr::mutate(length = stringr::str_length(area_cd) %>% replace_na(0)) %>%
dplyr::group_by(length) %>%
dplyr::count(area_cd) %>% # count occurrences of each unique value
dplyr::slice_max(order_by = n, n = 10) %>%
knitr::kable()| length | area_cd | n |
|---|---|---|
| 0 | NA | 109141 |
| 2 | 70 | 1 |
| 2 | 91 | 1 |
| 3 | 828 | 356621 |
| 3 | 910 | 345033 |
| 3 | 252 | 216848 |
| 3 | 704 | 208035 |
| 3 | 919 | 170862 |
| 3 | 336 | 131018 |
| 3 | 999 | 4824 |
| 3 | 980 | 1386 |
| 3 | 000 | 1291 |
| 3 | 757 | 967 |
- Many records with phone numbers are missing area code.
- Area codes less than 3 characters long are probably typos.
- Area code “000” is probably missing.
6.2 phone_num
Look at some phone number examples grouped by length, where there is a phone number.
d %>%
dplyr::filter(!is.na(phone_num)) %>%
dplyr::mutate(length = stringr::str_length(phone_num) %>% replace_na(0)) %>%
dplyr::group_by(length) %>%
dplyr::count(phone_num) %>% # count occurrences of each unique value
dplyr::slice_max(order_by = n, n = 5) %>%
knitr::kable()| length | phone_num | n |
|---|---|---|
| 1 | - | 14 |
| 1 | 0 | 1 |
| 1 | 6 | 1 |
| 1 | 9 | 1 |
| 3 | 299 | 1 |
| 3 | 368 | 1 |
| 3 | 372 | 1 |
| 3 | 562 | 1 |
| 3 | 565 | 1 |
| 3 | 566 | 1 |
| 3 | 759 | 1 |
| 3 | 890 | 1 |
| 4 | -221 | 1 |
| 4 | -644 | 1 |
| 4 | -691 | 1 |
| 4 | -700 | 1 |
| 4 | -708 | 1 |
| 4 | -791 | 1 |
| 4 | 0204 | 1 |
| 4 | 0425 | 1 |
| 4 | 1159 | 1 |
| 4 | 1338 | 1 |
| 4 | 1403 | 1 |
| 4 | 1722 | 1 |
| 4 | 1920 | 1 |
| 4 | 2303 | 1 |
| 4 | 2320 | 1 |
| 4 | 2391 | 1 |
| 4 | 2403 | 1 |
| 4 | 2600 | 1 |
| 4 | 2669 | 1 |
| 4 | 2715 | 1 |
| 4 | 2903 | 1 |
| 4 | 3125 | 1 |
| 4 | 3210 | 1 |
| 4 | 3544 | 1 |
| 4 | 3566 | 1 |
| 4 | 3999 | 1 |
| 4 | 5043 | 1 |
| 4 | 5258 | 1 |
| 4 | 6767 | 1 |
| 4 | 7426 | 1 |
| 4 | 8427 | 1 |
| 4 | 8464 | 1 |
| 4 | 8605 | 1 |
| 4 | 9025 | 1 |
| 4 | 9051 | 1 |
| 4 | 9267 | 1 |
| 5 | 11959 | 1 |
| 5 | 26108 | 1 |
| 5 | 61974 | 1 |
| 5 | 89054 | 1 |
| 6 | 089909 | 1 |
| 6 | 324171 | 1 |
| 6 | 335788 | 1 |
| 6 | 335940 | 1 |
| 6 | 349803 | 1 |
| 6 | 350459 | 1 |
| 6 | 361343 | 1 |
| 6 | 364187 | 1 |
| 6 | 364312 | 1 |
| 6 | 365057 | 1 |
| 6 | 371519 | 1 |
| 6 | 372540 | 1 |
| 6 | 377424 | 1 |
| 6 | 377796 | 1 |
| 6 | 386322 | 1 |
| 6 | 389126 | 1 |
| 6 | 392571 | 1 |
| 6 | 395119 | 1 |
| 6 | 395133 | 1 |
| 6 | 395962 | 1 |
| 6 | 399380 | 1 |
| 6 | 403745 | 1 |
| 6 | 408799 | 1 |
| 6 | 410554 | 1 |
| 6 | 423477 | 1 |
| 6 | 430667 | 1 |
| 6 | 441457 | 1 |
| 6 | 449817 | 1 |
| 6 | 472126 | 1 |
| 6 | 488522 | 1 |
| 6 | 493921 | 1 |
| 6 | 494124 | 1 |
| 6 | 498136 | 1 |
| 6 | 506603 | 1 |
| 6 | 521678 | 1 |
| 6 | 524344 | 1 |
| 6 | 530816 | 1 |
| 6 | 531786 | 1 |
| 6 | 531997 | 1 |
| 6 | 532735 | 1 |
| 6 | 535094 | 1 |
| 6 | 535999 | 1 |
| 6 | 536717 | 1 |
| 6 | 541864 | 1 |
| 6 | 543132 | 1 |
| 6 | 545005 | 1 |
| 6 | 545998 | 1 |
| 6 | 547501 | 1 |
| 6 | 554825 | 1 |
| 6 | 560520 | 1 |
| 6 | 567509 | 1 |
| 6 | 568308 | 1 |
| 6 | 571214 | 1 |
| 6 | 573901 | 1 |
| 6 | 577150 | 1 |
| 6 | 578847 | 1 |
| 6 | 579409 | 1 |
| 6 | 595516 | 1 |
| 6 | 596268 | 1 |
| 6 | 598402 | 1 |
| 6 | 605611 | 1 |
| 6 | 605649 | 1 |
| 6 | 608580 | 1 |
| 6 | 623217 | 1 |
| 6 | 634122 | 1 |
| 6 | 650513 | 1 |
| 6 | 655147 | 1 |
| 6 | 656139 | 1 |
| 6 | 658887 | 1 |
| 6 | 662158 | 1 |
| 6 | 668993 | 1 |
| 6 | 676470 | 1 |
| 6 | 700151 | 1 |
| 6 | 700621 | 1 |
| 6 | 712151 | 1 |
| 6 | 725243 | 1 |
| 6 | 734699 | 1 |
| 6 | 751124 | 1 |
| 6 | 766051 | 1 |
| 6 | 777560 | 1 |
| 6 | 779083 | 1 |
| 6 | 779584 | 1 |
| 6 | 798202 | 1 |
| 6 | 822070 | 1 |
| 6 | 833505 | 1 |
| 6 | 846453 | 1 |
| 6 | 867858 | 1 |
| 6 | 889351 | 1 |
| 6 | 890165 | 1 |
| 6 | 908597 | 1 |
| 6 | 911157 | 1 |
| 6 | 921499 | 1 |
| 6 | 923671 | 1 |
| 6 | 924976 | 1 |
| 6 | 940721 | 1 |
| 6 | 947427 | 1 |
| 6 | 947566 | 1 |
| 6 | 954748 | 1 |
| 6 | 978071 | 1 |
| 6 | 992648 | 1 |
| 6 | 996229 | 1 |
| 7 | 0000000 | 9671 |
| 7 | 9999999 | 6282 |
| 7 | 5244446 | 182 |
| 7 | 4975411 | 108 |
| 7 | 2987911 | 94 |
- Phone numbers less than 7 characters long are probably typos.
- Phone numbers “0000000” and “9999999” is probably missing.
Timing
Computation time (excl. render): 390.703 sec elapsed
sessionInfo()R version 4.0.3 (2020-10-10)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 20.10
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.9.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.9.0
locale:
[1] LC_CTYPE=en_AU.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_AU.UTF-8 LC_COLLATE=en_AU.UTF-8
[5] LC_MONETARY=en_AU.UTF-8 LC_MESSAGES=en_AU.UTF-8
[7] LC_PAPER=en_AU.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_AU.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices datasets utils methods base
other attached packages:
[1] tidyr_1.1.3 ggplot2_3.3.3 forcats_0.5.1 lubridate_1.7.10
[5] skimr_2.1.3 stringr_1.4.0 tibble_3.1.0 vroom_1.4.0
[9] fs_1.5.0 tictoc_1.0 here_1.0.1 workflowr_1.6.2
[13] targets_0.3.1
loaded via a namespace (and not attached):
[1] Rcpp_1.0.6 ps_1.6.0 assertthat_0.2.1 rprojroot_2.0.2
[5] digest_0.6.27 utf8_1.2.1 R6_2.5.0 repr_1.1.3
[9] evaluate_0.14 highr_0.8 pillar_1.5.1 rlang_0.4.10
[13] rstudioapi_0.13 data.table_1.14.0 whisker_0.4 callr_3.6.0
[17] jquerylib_0.1.3 rmarkdown_2.7 labeling_0.4.2 igraph_1.2.6
[21] bit_4.0.4 munsell_0.5.0 compiler_4.0.3 httpuv_1.5.5
[25] xfun_0.22 pkgconfig_2.0.3 base64enc_0.1-3 htmltools_0.5.1.1
[29] tidyselect_1.1.0 bookdown_0.21 codetools_0.2-18 fansi_0.4.2
[33] crayon_1.4.1 dplyr_1.0.5 withr_2.4.1 later_1.1.0.1
[37] grid_4.0.3 jsonlite_1.7.2 gtable_0.3.0 lifecycle_1.0.0
[41] DBI_1.1.1 git2r_0.28.0 magrittr_2.0.1 scales_1.1.1
[45] cli_2.3.1 stringi_1.5.3 farver_2.1.0 renv_0.13.2
[49] promises_1.2.0.1 bslib_0.2.4 ellipsis_0.3.1 vctrs_0.3.7
[53] generics_0.1.0 tools_4.0.3 bit64_4.0.5 glue_1.4.2
[57] purrr_0.3.4 parallel_4.0.3 processx_3.5.0 yaml_2.2.1
[61] colorspace_2.0-0 knitr_1.31 sass_0.3.1