class: center, middle, inverse, title-slide # Working with text in R ### Ella Kaye ### October 5th, 2019 --- class: center, inverse background-image: url("edX_digital_humanities.png") background-position: center background-size: contain --- class: center, inverse background-image: url("Washington-and-Jefferson.jpg") background-position: center background-size: contain --- # Command line **Research question**: lengths of sentences in presidential speeches over the course of a presidency: terse and to the point at the beginning, long windered towards the end? Do they stay the same? - Take word counts of each sentence and calculate the average word count per sentence per speech. - Want table with year, month and sentence length recorded for each presidential speech. --- # [https://voyant-tools.org](https://voyant-tools.org) 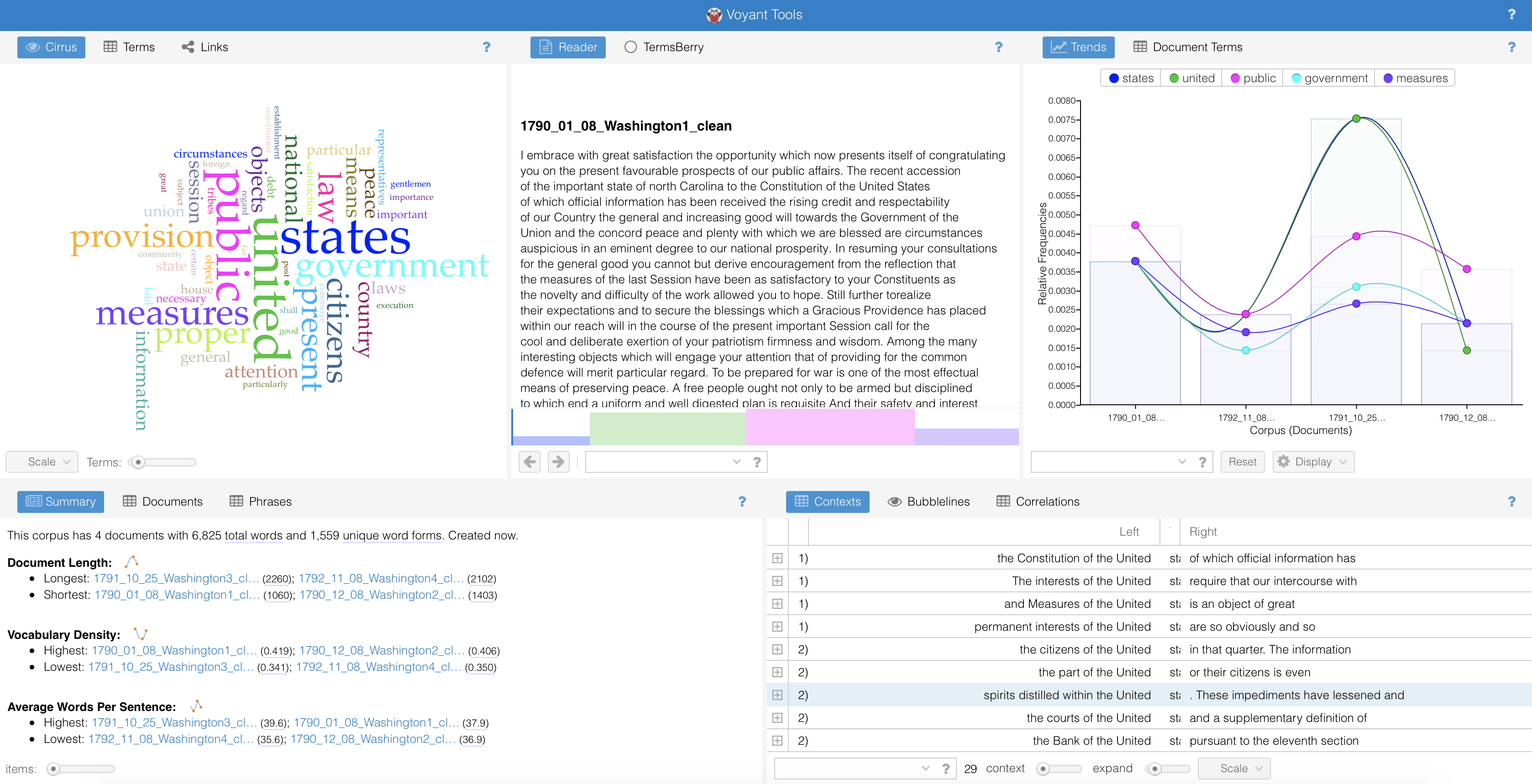 --- # Libraries ```r library(tidyverse) # especially `stringr` library(RVerbalExpressions) library(tidytext) library(wordcloud) library(tidygraph) library(ggraph) ``` --- # Inputting the text ```r text <- read_file("1790_01_08_Washington1.txt") ``` -- (show this) --- # Regular expressions A sequence of characters that defines a search pattern. --  --- # `RVerbalExpressions` [https://github.com/VerbalExpressions/RVerbalExpressions](https://github.com/VerbalExpressions/RVerbalExpressions) ```r span_rx <- rx() %>% rx_find("<") %>% rx_anything_but(">") %>% rx_find(">") span_rx ``` ``` ## [1] "(<)([^>]*)(>)" ``` -- ## Other Regular Expressions resources in R - [rex](https://github.com/kevinushey/rex) - [RegExplain](https://github.com/gadenbuie/regexplain) --- # Cleaning the text ```r text_clean <- text %>% str_remove_all(span_rx) %>% # remove html tags str_remove_all("\\\\xe2\\\\x80\\\\x94") %>% # remove unicode str_replace_all(" ", " ") %>% # replace html space with space str_squish() %>% # remove excess white space str_replace_all("-", " ") %>% # remove hyphens (pros and cons) str_remove_all("[^[:alnum:][:space:].]") %>% # remove punctuation except "." str_remove("This work is in the.*") # remove final sentence write_file(text_clean, "1790_01_08_Washington1_clean.txt") ``` -- ## `stringr` resources - [`stringr` package site](https://stringr.tidyverse.org) - [cheatsheet](https://resources.rstudio.com/rstudio-cheatsheets/stringr-cheat-sheet) - [Strings chapter in R for Data Science](https://r4ds.had.co.nz/strings.html) --- # Tidy Text - The tidy text format is a table with one-token-per-row. - A token is a meaningful unit of text, such as a word, that we are interested in using for analysis - Tokenization is the process of splitting text into tokens. When text is stored in this way, we can manipulate and plot it with other tidy tools, such as `dplyr`, `tidyr` and `ggplot2`. -- The tidy text approach was developed by [Julia Silge](https://juliasilge.com) and [David Robinson](http://varianceexplained.org). The main reference is the book [Text Mining with R: A tidy approach](https://www.tidytextmining.com). Tools for this approach are provided in the [`tidytext`](https://juliasilge.github.io/tidytext/) package. --- # Tokenizing the Washington speech ```r text_df <- tibble(speech = text_clean) %>% unnest_tokens(sentence, speech, token = "sentences") text_df ``` ``` ## # A tibble: 28 x 1 ## sentence ## <chr> ## 1 i embrace with great satisfaction the opportunity which now presents it… ## 2 the recent accession of the important state of north carolina to the co… ## 3 in resuming your consultations for the general good you cannot but deri… ## 4 still further to realize their expectations and to secure the blessings… ## 5 among the many interesting objects which will engage your attention tha… ## 6 to be prepared for war is one of the most effectual means of preserving… ## 7 a free people ought not only to be armed but disciplined to which end a… ## 8 the proper establishment of the troops which may be deemed indispensibl… ## 9 in the arrangements which may be made respecting it it will be of impor… ## 10 there was reason to hope that the pacific measures adopted with regard … ## # … with 18 more rows ``` --- # Get sentence lengths ```r text_df %>% mutate(sentence_length = str_count(sentence, boundary("word"))) %>% summarise(mean_sentence_length = mean(sentence_length)) ``` ``` ## # A tibble: 1 x 1 ## mean_sentence_length ## <dbl> ## 1 38.2 ``` --- # Working with multiple text files ```r washington_speeches <- tibble(speech_name = c("1790_01_08_Washington1.txt", "1790_12_08_Washington2.txt", "1791_10_25_Washington3.txt", "1792_11_08_Washington4.txt")) washington_speeches_df <- washington_speeches %>% mutate(speech = map_chr(speech_name, ~read_file(.x))) %>% mutate(speech = str_remove_all(speech, "<[^>]*>")) %>% # remove html tags mutate(speech = str_remove_all(speech, "\\\\xe2\\\\x80\\\\x94")) %>% mutate(speech = str_remove_all(speech, " ")) %>% # replace spaces mutate(speech = str_squish(speech)) %>% # remove excess white space mutate(speech = str_replace_all(speech, "-", " ")) %>% # remove hyphens mutate(speech = str_remove_all(speech, "[^[:alnum:][:space:].]")) %>% mutate(speech = str_remove(speech, "This work is in the.*")) %>% mutate(speech_name = str_remove(speech_name, "[:digit:]\\.txt")) ``` --- # Split into sentences... ```r washington_speeches_df %>% unnest_tokens(sentence, speech, token = "sentences") ``` ``` ## # A tibble: 183 x 2 ## speech_name sentence ## <chr> <chr> ## 1 1790_01_08_Washing… i embrace with great satisfaction the opportunity w… ## 2 1790_01_08_Washing… the recent accession of the important state of nort… ## 3 1790_01_08_Washing… in resuming your consultations for the general good… ## 4 1790_01_08_Washing… still further torealize their expectations and to s… ## 5 1790_01_08_Washing… among the many interesting objects which will engag… ## 6 1790_01_08_Washing… to be prepared for war is one of the most effectual… ## 7 1790_01_08_Washing… a free people ought not only to be armed but discip… ## 8 1790_01_08_Washing… the proper establishment of the troops which may be… ## 9 1790_01_08_Washing… in the arrangements which may be made respecting it… ## 10 1790_01_08_Washing… there was reason to hope that the pacific measures … ## # … with 173 more rows ``` --- # ...and get average sentence length ```r washington_speeches_summary <- washington_speeches_df %>% unnest_tokens(sentence, speech, token = "sentences") %>% mutate(sentence_length = str_count(sentence, boundary("word"))) %>% group_by(speech_name) %>% summarise(mean_sentence_length = mean(sentence_length)) %>% separate(speech_name, sep = "_", into = c("Year", "Month", "Day", "President")) washington_speeches_summary ``` ``` ## # A tibble: 4 x 5 ## Year Month Day President mean_sentence_length ## <chr> <chr> <chr> <chr> <dbl> ## 1 1790 01 08 Washington 38.1 ## 2 1790 12 08 Washington 36.0 ## 3 1791 10 25 Washington 39.7 ## 4 1792 11 08 Washington 35.6 ``` ``` ## # A tibble: 4 x 5 ## Year Month Day President mean_sentence_length ## <chr> <chr> <chr> <chr> <dbl> ## 1 1801 12 08 Jefferson 37.2 ## 2 1802 12 15 Jefferson 36.7 ## 3 1803 10 17 Jefferson 49.3 ## 4 1804 11 08 Jefferson 44.7 ``` --- # Word counts ```r washington_by_word <- washington_speeches_df %>% unnest_tokens(word, speech, token = "words") ``` -- ```r washington_by_word %>% count(word, sort = TRUE) ``` ``` ## # A tibble: 1,560 x 2 ## word n ## <chr> <int> ## 1 the 650 ## 2 of 445 ## 3 to 280 ## 4 and 214 ## 5 in 135 ## 6 a 115 ## 7 which 109 ## 8 be 101 ## 9 that 89 ## 10 for 76 ## # … with 1,550 more rows ``` --- # Stop words ```r data(stop_words) # contained in `tidytext` washington_words <- washington_by_word %>% anti_join(stop_words, by = "word") washington_count <- washington_words %>% count(word, sort = TRUE) washington_count ``` ``` ## # A tibble: 1,285 x 2 ## word n ## <chr> <int> ## 1 united 28 ## 2 public 25 ## 3 citizens 17 ## 4 government 17 ## 5 measures 17 ## 6 provision 17 ## 7 proper 16 ## 8 law 15 ## 9 national 13 ## 10 country 12 ## # … with 1,275 more rows ``` --- class: inverse, center, middle  --- # What's missing? -- ```r stop_words %>% filter(word == "states") ``` ``` ## # A tibble: 1 x 2 ## word lexicon ## <chr> <chr> ## 1 states onix ``` --- # Try again... ```r stop_words_modified <- stop_words %>% filter(word != "states") washington_words <- washington_by_word %>% anti_join(stop_words_modified, by = "word") washington_count <- washington_words %>% count(word, sort = TRUE) washington_count ``` ``` ## # A tibble: 1,286 x 2 ## word n ## <chr> <int> ## 1 states 29 ## 2 united 28 ## 3 public 25 ## 4 citizens 17 ## 5 government 17 ## 6 measures 17 ## 7 provision 17 ## 8 proper 16 ## 9 law 15 ## 10 national 13 ## # … with 1,276 more rows ``` --- # Visualising as bar chart .pull-left[ ```r washington_count %>% filter(n > 9) %>% mutate(word = reorder(word, n)) %>% ggplot(aes(word, n)) + geom_col() + xlab(NULL) + coord_flip() ``` ] .pull-right[ <!-- --> ] --- # Visualising as wordcloud ```r set.seed(2) wordcloud(words = washington_count$word, freq = washington_count$n, min.freq = 9, rot.per = 0.35, colors = brewer.pal(8, "YlGnBu")) ``` <!-- --> --- # Bigrams ```r washington_bigrams <- washington_speeches_df %>% unnest_tokens(bigram, speech, token = "ngrams", n = 2) washington_bigrams ``` ``` ## # A tibble: 6,830 x 2 ## speech_name bigram ## <chr> <chr> ## 1 1790_01_08_Washington i embrace ## 2 1790_01_08_Washington embrace with ## 3 1790_01_08_Washington with great ## 4 1790_01_08_Washington great satisfaction ## 5 1790_01_08_Washington satisfaction the ## 6 1790_01_08_Washington the opportunity ## 7 1790_01_08_Washington opportunity which ## 8 1790_01_08_Washington which now ## 9 1790_01_08_Washington now presents ## 10 1790_01_08_Washington presents itself ## # … with 6,820 more rows ``` --- # Separate out and remove stop words ```r washington_bigrams <- washington_bigrams %>% separate(bigram, c("word1", "word2"), sep = " ") %>% filter(!word1 %in% stop_words_modified$word) %>% filter(!word2 %in% stop_words_modified$word) ``` ```r washington_bigram_counts <- washington_bigrams %>% count(word1, word2, sort = TRUE) washington_bigram_counts ``` ``` ## # A tibble: 483 x 3 ## word1 word2 n ## <chr> <chr> <int> ## 1 united states 27 ## 2 fellow citizens 6 ## 3 post office 5 ## 4 post roads 4 ## 5 public debt 4 ## 6 national prosperity 3 ## 7 3000000 florins 2 ## 8 adequate provision 2 ## 9 current service 2 ## 10 due attention 2 ## # … with 473 more rows ``` --- # Create a graph ```r washington_bigram_graph <- washington_bigram_counts %>% filter(n > 1) %>% as_tbl_graph() ``` --- ```r washington_bigram_graph ``` ``` ## # A tbl_graph: 38 nodes and 23 edges ## # ## # A rooted forest with 15 trees ## # ## # Node Data: 38 x 1 (active) ## name ## <chr> ## 1 united ## 2 fellow ## 3 post ## 4 public ## 5 national ## 6 3000000 ## # … with 32 more rows ## # ## # Edge Data: 23 x 3 ## from to n ## <int> <int> <int> ## 1 1 17 27 ## 2 2 18 6 ## 3 3 19 5 ## # … with 20 more rows ``` --- # Plot the graph ```r set.seed(1) ggraph(washington_bigram_graph, layout = "fr") + geom_edge_link() + geom_node_point() + geom_node_text(aes(label = name), vjust = 1, hjust = 1, repel = TRUE) ``` --- <!-- --> --- # Improve the graph ```r set.seed(1) a <- grid::arrow(type = "closed", length = unit(.1, "inches")) ggraph(washington_bigram_graph, layout = "fr") + geom_edge_link(aes(edge_alpha = n), show.legend = FALSE, arrow = a, end_cap = circle(.07, 'inches')) + geom_node_point(color = "lightblue", size = 5) + geom_node_text(aes(label = name), vjust = 1, hjust = 1, repel = TRUE) + theme_void() ``` --- <!-- --> --- ## Compare word frequencies in two sets of texts ```r frequency <- bind_rows(washington_words, jefferson_words) %>% mutate(speech_name = str_extract_all(speech_name, "Washington|Jefferson", simplify = TRUE)) %>% rename(president = speech_name) %>% count(president, word) %>% group_by(president) %>% mutate(proportion = n/sum(n)) %>% select(-n) %>% spread(president, proportion) ``` -- ```r set.seed(1) sample_n(frequency, 6) ``` ``` ## # A tibble: 6 x 3 ## word Jefferson Washington ## <chr> <dbl> <dbl> ## 1 dependent 0.000562 0.000397 ## 2 exonerate NA 0.000397 ## 3 mark 0.000281 NA ## 4 surrounded 0.000281 NA ## 5 congratulating NA 0.000397 ## 6 suggested NA 0.000794 ``` --- # Plot ```r ggplot(frequency, aes(x = Washington, y = Jefferson, color = abs(Washington - Jefferson))) + geom_abline(color = "gray40", lty = 2) + geom_jitter(alpha = 0.1, size = 2.5, width = 0.3, height = 0.3) + geom_text(aes(label = word), check_overlap = TRUE, vjust = 1.5) + scale_x_log10(labels = scales::percent_format()) + scale_y_log10(labels = scales::percent_format()) + scale_color_gradient(limits = c(0, 0.001), low = "darkslategray4", high = "gray75") + theme(legend.position="none") ``` --- ``` ## Warning: Removed 1771 rows containing missing values (geom_point). ``` ``` ## Warning: Removed 1771 rows containing missing values (geom_text). ``` <!-- --> --- # Some other resources - [readtext.quanteda.io](https://readtext.quanteda.io) - import and handling for plain and formatted text files - [pdftools](https://docs.ropensci.org/pdftools/) - extracting text and metadata from pdf files in R - [tesseract](https://cran.r-project.org/web/packages/tesseract/vignettes/intro.html) - optical character recognition in R - [quantedo.io](http://quanteda.io) - managing and analyzing texts; apply natural language processing to texts [@rivaquiroga](https://twitter.com/rivaquiroga) (via [@WeAreRLadies](https://twitter.com/WeAreRLadies)) --- class: center, middle, inverse ## Please ask me questions! ## I'd love to hear from you: [E.Kaye.1@warwick.ac.uk](mailto:E.Kaye.1@warwick.ac.uk) [@ellamkaye](https://twitter.com/ellamkaye) [ellakaye.rbind.io](https://ellakaye.rbind.io) [github.com/EllaKaye](https://github.com/ellakaye)