Annotating Deeply Embedded Languages
Robbert van der HelmEmbedded languages
- Language written inside of another language
- That other language is called the host language
- May be domain specific
Different kinds of embeddings
- Shallow embeddings
- Deep embeddings
Advantages
- Integrates with the host language
- No separate parsing step
Disadvantages
- No separate parsing step
- Deep embeddings lack context information
Objectives
- Recover context in deeply embedded programs
- Annotate the embedded program with that information
- Find other uses for the annotation system
Background
Implicit Parameters
Explicit parameters
- Works great in simple cases
- Adds boilerplate passing arguments around when calling lots of other functions
Reader monad
- Avoids explicitly passing the argument around
- Boilerplate moved from passing the argument around to accessing the argument
Implicit parameters
- Parameter is implicitly passed around
- All the benefits of the reader monad with almost no boilerplate
Background
Call stacks
- GHC Call Stacks
- RTS Execution Stacks
GHC Call Stacks
RTS Execution Stacks
- Runtime backtraces
- Does not require code changes like HasCallStack
- Sadly, not usable in its current state
Background
A deeply embedded language
The idea
- The language describes an abstract syntax
- The abstract syntax is represented by a tree structure
- Smart constructors construct this tree
Abstract syntax
Smart constructors
- Construct the AST
- Forms the user-facing language
Can be implemented in terms of
- Regular free functions
- Existing type classes (e.g. Num)
- Pattern synonyms
Annotations
Goals
- Annotations store metadata for an AST node
- Should be easily extensible
- Adding them shouldn't change the user-facing language
Storing annotations
- Multiple appraoches possible
- The Trees that Grow paper explores this in more detail
data Ann = Ann { ... }
data Exp a where
Const :: Ann -> a -> Exp a
Var :: Ann -> Ident t -> Exp t
Pair :: Ann -> Exp a -> Exp b -> Exp (a, b)
...
Annotating ASTs
Annotating AST subtrees
Rewriting in-place Bottom-to-top modification order
Deferred modification
Top-to-bottom modification order
Doesn't rewrite every term
Using annotations
- Recover source locations, annotate the AST with it
- Manually influence the compiler's optimizer
Source mapping
- Main goal of this thesis
- Map parts of the AST back to the original source code
- Useful for diagnnostics, profiling, debugging
Three scenarios
| Regular free functions | GHC Call Stacks |
| Existing type classes | RTS Execution Stacks |
| Pattern synonyms | GHC Call Stacks plus some trickery |
Source mapping
GHC Call Stacks
HasCallStack woes
Implicit parameters to the rescue
- Defined in a separate module
- OpaqueType's constructor is not exported
- sourceMap is the only way to satisfy SourceMapped
main :: IO ()
main = foo
foo :: IO ()
foo = bar -- Compilation error: Unbound implicit parameter
foo' :: IO ()
foo' = sourceMap bar -- Runtime error: No HasCallStack
foo'' :: HasCallStack => IO ()
foo'' = sourceMap bar -- Works!
bar :: SourceMapped => IO ()
bar = print callStack
Now to combine everything
mkAnn :: SourceMapped => Ann
mkAnn = Ann { locations = capture ?callStack, ... }
where
capture = ...
constant :: HasCallStack => a -> Exp a
constant = sourceMap $ Const mkAnn
Source mapping
GHC Call Stacks part two: Pattern Synonyms
Important bits
- Pattern synonyms can be simple aliases
- Or have explicit expression (construction) and pattern (destructure) parts
- Or somewhere inbetween
- They desugar to function calls
Source mapping
RTS exeuction stacks
The idea
- Capture runtime execution stack trace
- Filter out everything but the smart constructor call
- Convert to GHC Call Stacks
- Use sourceMap as normal
The problem
- Too much noise
- Contains holes
- Obscure
Source mapping
Explicit context information
The problem
- Source mapping information may be missing
- Or the captured function names may be too vague
Recall the subtree annotations from earlier.
factorial :: (Num a, Ord a, Typeable a) => Exp a -> Exp a
factorial n = context "factorial" $
letfn (\factorial' n' -> cond (n' <= 1)
1
(n' * factorial' (n' - 1)))
(\factorial' -> factorial' n)
Optimization flags
The idea
- Superoptimization is slow
- Compilers lack domain knowledge
- Have a way to influence the compiler's decisions
- Information can be stored as annotations
May be applied to
- A single expression
- An entire subtree or subprogram
- An entire compilation unit
Applicable optimizations
- Forcing inlining
- Loop unrolling
- Unsafe floating point optimizations (-ffast-math)
- Target architecture configuration
- And many more...
Case study
Accelerate
Accelerate
- Deeply embedded data-parallel array language
- Multiple backends (CPU, GPU, others...)
- Looks similar to regular Haskell array programs
- Much faster than regular Haskell array programs
What makes Accelerate interesting
Multiple expression types
- Parallel collective array operations
- Scalar expressions
Multiple AST types
- Higher-order abstract syntax with 'inline' terms
- First-order abstract syntax with let-bindings
- Multiple variations on the latter
- Backend-specific representations
Multiple backends
- Interpreter
- LLVM backend with multiple targets:
- Highly vectorized CPU backend
- NVIDIA GPU backend through CUDA/PTX
- Open ended, possible to implement other backends without changing Accelerate itself
(relevant parts of)
the compilation pipeline
- Sharing recovery
- Simplification
- Array fusion
- Code generation
Compiling Accelerate
Sharing recovery
- Finds shared parts of the AST based on stable names
- Moves those parts to let-bindings
- New: Applies subtree annotations from
top to bottom
- Finds shared parts of the AST based on stable names
- Moves those parts to let-bindings
- New: Applies subtree annotations from
top to bottom
- Implicit parameters keep track of the current subtree annotation state
- These subtree annotations are merged with every produced AST node
Compiling Accelerate
Simplification
- Rewrite rules for common simplifications
- Constant propagation
- New: Annotations may need to be merged
- Rewrite rules for common simplifications
- Constant propagation
- New: Annotations may need to be merged
- Multiple AST nodes may be merged into one
- Annotations are joined
- New annotation contains the union of the call stack sets
- Actual merging of call stacks still happens only when they are used
Compiling Accelerate
Array fusion
- Combines operations that produce arrays with other operations
- Unless the produced array is used multiple times
- Avoids expensive memory operations and multiple sequential loops
- New: Forcing inlining may allow for more fusion
- New: Handling of conflicting annotations
Compiling Accelerate
Code generation
- Fused array operations are compiled into kernels
- Scalar expressions are embedded in those kernels
- The backend may also evaluate terms directly
- New: The compiler can access annotation
data
- For the current expression
- Using implicit parameters
LLVM backend changes
- Profiler instrumentation
- Debug symbols
- Optimizations
Frame profiling
- Intended for profiling frames in video games
- Can also be used for profiling other repetitive tasks
Accelerate's LLVM backend already supports the Tracy frame profiler
The problem
- Indecipherable kernel names
- Difficult to tell kernels apparent in non-trival programs
The solution
- Source locations!
- The implicit parameters already carry the required information
Optimizations
- Forcing inlining
- Loop unrolling
- Unsafe floating point optimizations (-ffast-math)
- CUDA kernel register limits
Results
Two examples
- Fixing a compensated summation implementation
- Profiling and optimizing a hydrodynamics simulation
Compensated summation
Adds (many) floating point numbers while compensating for floating point rounding errors
According to programming languages
With single-precision IEEE-754 floating point numbers. \[\begin{aligned} 1.0 + 2.0^{100} + 1.0 - 2.0^{100} & = 0.0 \\ 1.0 + 2.0^{100} - 2.0^{100} + 1.0 & = 1.0 \\ \end{aligned}\]The problem
- The algorithms require additions and subtractions in a specific order
- Accelerate uses unsafe floating point optimizations that reorder operations
The workaround
- Directly import the non-ffast-math versions of the addition and subtraction intrinsics
- Use the FFI to call those in place of the regular operators
The solution
- Implement the algorithms like any ordinary Accelerate program
- Wrap the implementation in withoutFastMath
LULESH
- Stripped down hydrodynamics simulation
- Details are not important
- Complex enough to benefit from the new tools
The idea
- Use the new profiling tools to find hotspots
- Use the new optimization flags on those hot loops
- Hopefully, make it run faster
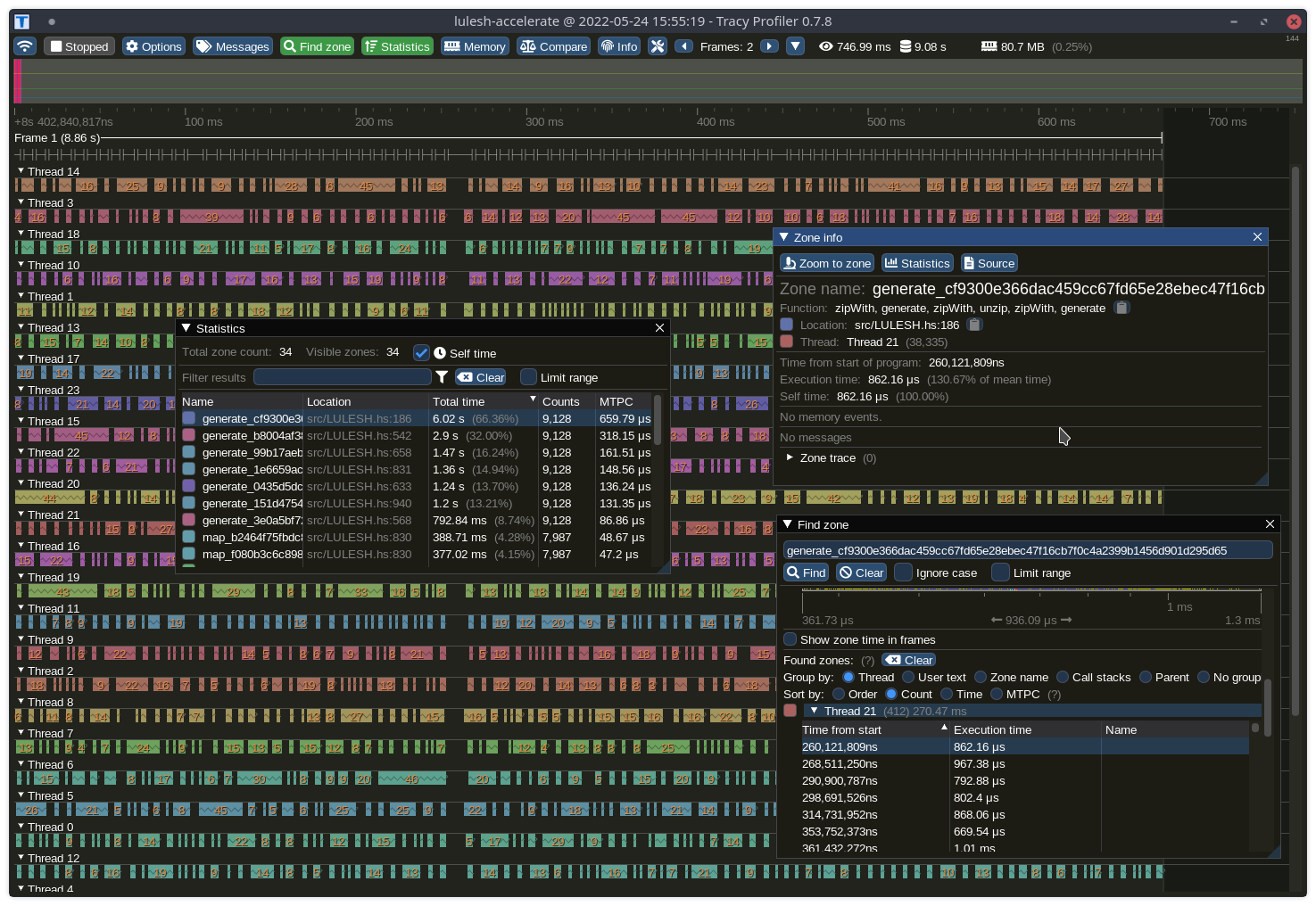
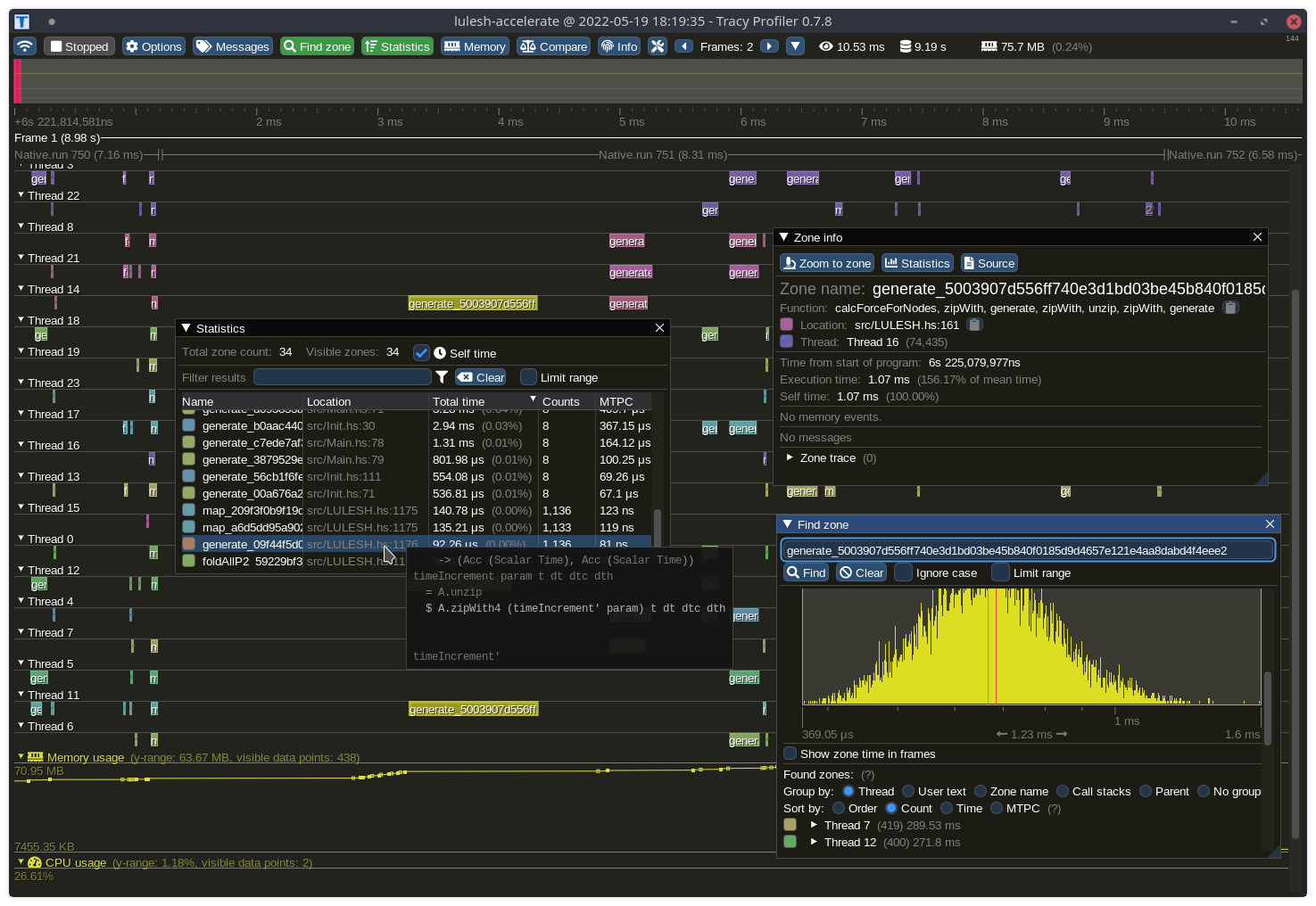
One kernel ran for 66% of the time
Which makes it a good candidate for experimenting with loop unrolling...
...and the average runtime on the CPU backend with a 12-core 24-thread Ryzen 9 5900x went up from an 8.65 seconds average to a 9.60 second average after unrolling eight times.
What happeend?
According to a one minute run under Cachegrind:
- 14 times higher L1 instruction cache miss rate
- 7 times higher LL instruction cache miss rate
- The first 33% of the runtime was shared
On the other hand
Under the GPU backend with an RTX 2080 SUPER the program became (statistically) significantly faster:
- Average runtimes decreased from 3.13 seconds to 3.07 seconds with standard deviations of 0.04 seconds in both cases
- Only an 1.8% speedup
- Still free performance
Summary
- The new annotation-based tools enable new profiling-driving optimizing workflows
- These optimizations are highly dependent on the situation
But more importantly, the annotation system serves as a foundation for new areas of exploration.
Future work
- Expression-level debugging and profiling
- Granular loop optimizations for fused, multidimensional, and sequential loops
- Compiler diagnostics for deeply embedded languages
- Portable compiled programs embedded in compiled host binaries