Corrmotif overlap
Last updated: 2025-03-04
Checks: 6 1
Knit directory: CX5461_Project/
This reproducible R Markdown analysis was created with workflowr (version 1.7.1). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of
the R Markdown file created these results, you’ll want to first commit
it to the Git repo. If you’re still working on the analysis, you can
ignore this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20250129) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 2e1090a. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .RData
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: data/Corr_Conc/
Unstaged changes:
Modified: analysis/Corrmotif_overlap.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/Corrmotif_overlap.Rmd) and
HTML (docs/Corrmotif_overlap.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 63ae929 | sayanpaul01 | 2025-03-04 | Commit |
| html | 63ae929 | sayanpaul01 | 2025-03-04 | Commit |
📌 Overlap of GO functions between Corrmotif all and corrmotif Conc.
library(UpSetR)
library(dplyr)
library(tools)
library(biomaRt)
# Set the folder path
folder_path <- "data/all_GO"
# Get a list of all CSV files in the folder
csv_files <- list.files(folder_path, pattern = "\\.csv$", full.names = TRUE)
# Loop through each file and assign it as a variable in the global environment
for (file in csv_files) {
# Generate a valid R variable name from the file name (remove extension and replace spaces)
file_name <- tools::file_path_sans_ext(basename(file))
file_name <- gsub(" ", "_", file_name) # Replace spaces with underscores
file_name <- make.names(file_name) # Ensure the name is valid in R
# Assign the CSV file as a variable in the environment
assign(file_name, read.csv(file, stringsAsFactors = FALSE))
}
# Define datasets (lists of Entrez Gene IDs)
sets <- list(
"Non response all" = prob_all_1$ID,
"CX_DOX shared late response all" = prob_all_2$ID,
"Dox specific response all" = prob_all_3$ID,
"Late high dose DOX specific response all" = prob_all_4$ID,
"Non response (0.1)" = prob_1_0.1$ID,
"DOX only mid-late (0.1)" = prob_2_0.1$ID,
"CX_DOX mid-late (0.1)" = prob_3_0.1$ID,
"Non response (0.5)" = prob_1_0.5$ID,
"DOX only early-mid (0.5)" = prob_2_0.5$ID,
"DOX only mid-late (0.5)" = prob_3_0.5$ID,
"CX only mid-late (0.5)" = prob_4_0.5$ID,
"CX_DOX mid-late (0.5)" = prob_5_0.5$ID
)
# Create a binary matrix for UpSet plot
all_genes <- unique(unlist(sets)) # Get all unique Entrez Gene IDs
binary_matrix <- data.frame(Gene_ID = all_genes) # Initialize DataFrame
# Convert gene lists into a presence/absence matrix (1 = present, 0 = absent)
for (set_name in names(sets)) {
binary_matrix[[set_name]] <- as.integer(all_genes %in% sets[[set_name]])
}
# Remove Gene_ID column as UpSetR only needs the binary matrix
binary_matrix <- binary_matrix[, -1]
upset(binary_matrix,
sets = names(sets),
order.by = "freq",
sets.bar.color = "#56B4E9", # Blue bars for set sizes
mainbar.y.label = "Number of Shared Functions",
sets.x.label = "GO terms per set",
text.scale = 1.2,
nintersects = 30)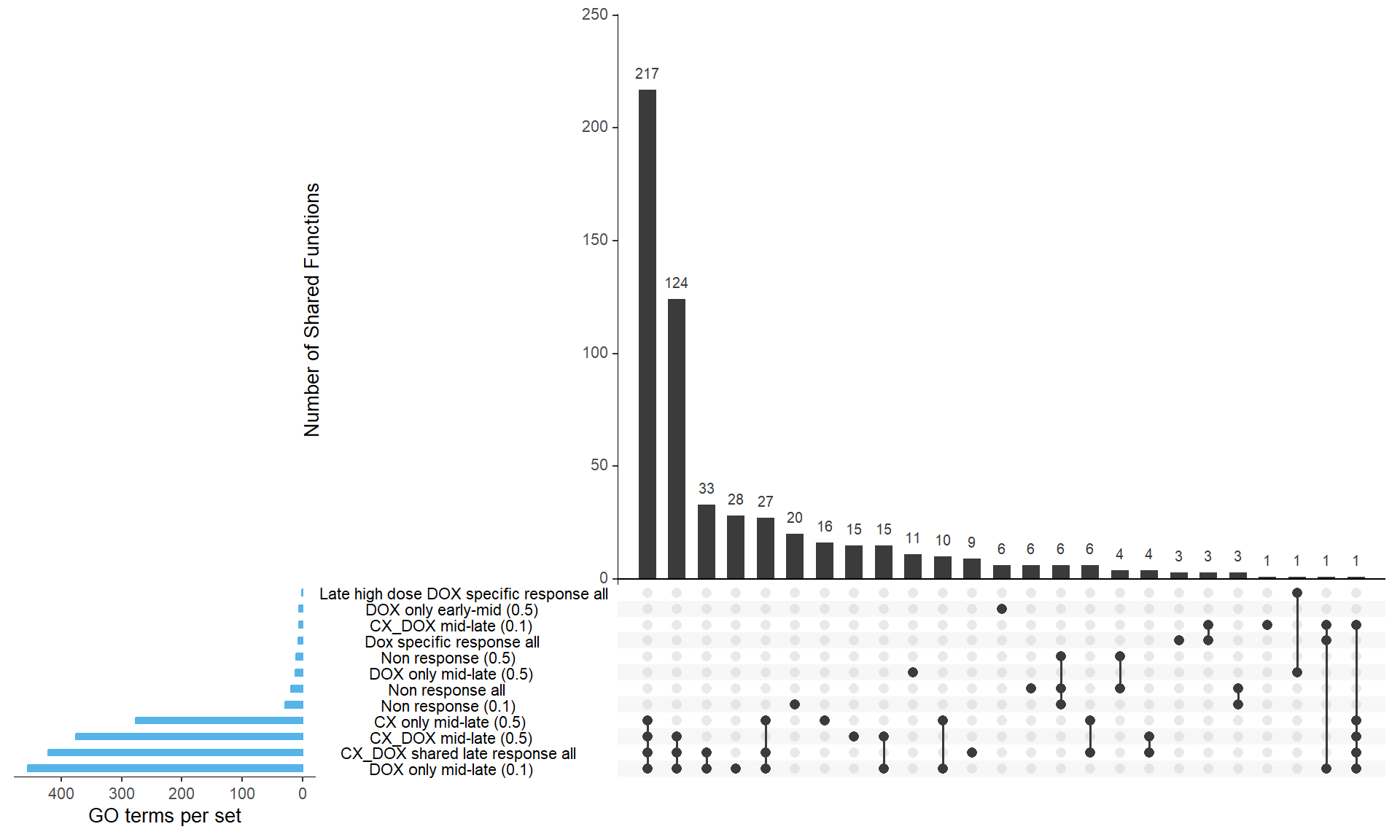
| Version | Author | Date |
|---|---|---|
| 63ae929 | sayanpaul01 | 2025-03-04 |
📌 Identify Unique GO Terms for Each Response Group
# Create a list to store unique GO terms per category
unique_go_terms <- list()
# Loop through each set to find unique GO terms
for (set_name in names(sets)) {
# Get the GO terms for the current set
current_go_terms <- sets[[set_name]]
# Find GO terms that appear **only** in this set and not in others
unique_terms <- current_go_terms[!(current_go_terms %in% unlist(sets[names(sets) != set_name]))]
# Store in the list if there are any unique terms
if (length(unique_terms) > 0) {
unique_go_terms[[set_name]] <- unique_terms
}
}
# Display unique GO terms for each category
unique_go_terms$`Non response all`
[1] "GO:0071339" "GO:1990204" "GO:0101031" "GO:0070469" "GO:0070971"
[6] "GO:0044665"
$`CX_DOX shared late response all`
[1] "GO:0009132" "GO:0097421" "GO:0140719" "GO:0140299" "GO:0035064"
[6] "GO:0140034" "GO:1990498" "GO:0005682" "GO:0030532"
$`Dox specific response all`
[1] "GO:0045177" "GO:0016323" "GO:0009925"
$`Non response (0.1)`
[1] "GO:0034470" "GO:0042254" "GO:0022613" "GO:0140053" "GO:0006413"
[6] "GO:0006364" "GO:0032543" "GO:0048193" "GO:0033108" "GO:0016072"
[11] "GO:0008135" "GO:0090079" "GO:0030684" "GO:0005759" "GO:0098800"
[16] "GO:0098803" "GO:0010494" "GO:0000313" "GO:0005761" "GO:0035770"
$`DOX only mid-late (0.1)`
[1] "GO:0009162" "GO:0009130" "GO:0006999" "GO:0006221" "GO:0007096"
[6] "GO:0045859" "GO:0006978" "GO:0009129" "GO:0046785" "GO:0002562"
[11] "GO:0016444" "GO:0042772" "GO:0010458" "GO:0071900" "GO:0051292"
[16] "GO:0006289" "GO:0008584" "GO:0008406" "GO:0046546" "GO:0045739"
[21] "GO:0045137" "GO:0043549" "GO:0009124" "GO:0048144" "GO:0008301"
[26] "GO:0017056" "GO:0000803" "GO:0043240"
$`CX_DOX mid-late (0.1)`
[1] "GO:0005402"
$`DOX only early-mid (0.5)`
[1] "GO:0140297" "GO:0061629" "GO:0090575" "GO:0005667" "GO:0097550"
[6] "GO:0005669"
$`DOX only mid-late (0.5)`
[1] "GO:0007186" "GO:0048738" "GO:0014706" "GO:0099084" "GO:0099173"
[6] "GO:0045598" "GO:0046486" "GO:0003013" "GO:0045444" "GO:0046620"
[11] "GO:0016236"
$`CX only mid-late (0.5)`
[1] "GO:0048599" "GO:0090305" "GO:0009994" "GO:2000243" "GO:0018105"
[6] "GO:0018209" "GO:0035561" "GO:0090657" "GO:0048477" "GO:0071732"
[11] "GO:0006264" "GO:0000722" "GO:0071731" "GO:1902170" "GO:0004518"
[16] "GO:0019205"
$`CX_DOX mid-late (0.5)`
[1] "GO:0048146" "GO:0030865" "GO:0051493" "GO:0051782" "GO:0090399"
[6] "GO:2000279" "GO:0030010" "GO:1901875" "GO:0032147" "GO:0031398"
[11] "GO:0007163" "GO:0051972" "GO:0000235" "GO:0005818" "GO:0101019"
sessionInfo()R version 4.3.0 (2023-04-21 ucrt)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 11 x64 (build 22631)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.utf8
[2] LC_CTYPE=English_United States.utf8
[3] LC_MONETARY=English_United States.utf8
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.utf8
time zone: America/Chicago
tzcode source: internal
attached base packages:
[1] tools stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] biomaRt_2.58.2 dplyr_1.1.4 UpSetR_1.4.0
loaded via a namespace (and not attached):
[1] KEGGREST_1.42.0 gtable_0.3.6 xfun_0.50
[4] bslib_0.8.0 ggplot2_3.5.1 Biobase_2.62.0
[7] vctrs_0.6.5 bitops_1.0-7 generics_0.1.3
[10] curl_6.0.1 stats4_4.3.0 tibble_3.2.1
[13] AnnotationDbi_1.64.1 RSQLite_2.3.3 blob_1.2.4
[16] pkgconfig_2.0.3 dbplyr_2.5.0 S4Vectors_0.40.1
[19] lifecycle_1.0.4 GenomeInfoDbData_1.2.11 farver_2.1.2
[22] compiler_4.3.0 stringr_1.5.1 git2r_0.35.0
[25] progress_1.2.3 Biostrings_2.70.1 munsell_0.5.1
[28] httpuv_1.6.15 GenomeInfoDb_1.38.8 htmltools_0.5.8.1
[31] sass_0.4.9 RCurl_1.98-1.13 yaml_2.3.10
[34] later_1.3.2 pillar_1.10.1 crayon_1.5.3
[37] jquerylib_0.1.4 whisker_0.4.1 cachem_1.0.8
[40] tidyselect_1.2.1 digest_0.6.34 stringi_1.8.3
[43] labeling_0.4.3 rprojroot_2.0.4 fastmap_1.1.1
[46] grid_4.3.0 colorspace_2.1-0 cli_3.6.1
[49] magrittr_2.0.3 XML_3.99-0.17 withr_3.0.2
[52] rappdirs_0.3.3 filelock_1.0.3 prettyunits_1.2.0
[55] scales_1.3.0 promises_1.3.0 bit64_4.0.5
[58] rmarkdown_2.29 XVector_0.42.0 httr_1.4.7
[61] bit_4.0.5 gridExtra_2.3 workflowr_1.7.1
[64] hms_1.1.3 png_0.1-8 memoise_2.0.1
[67] evaluate_1.0.3 knitr_1.49 IRanges_2.36.0
[70] BiocFileCache_2.10.2 rlang_1.1.3 Rcpp_1.0.12
[73] glue_1.7.0 DBI_1.2.3 xml2_1.3.6
[76] BiocGenerics_0.48.1 rstudioapi_0.17.1 jsonlite_1.8.9
[79] R6_2.5.1 plyr_1.8.9 fs_1.6.3
[82] zlibbioc_1.48.0