BMI - Brain Nucleus accumbens basal ganglia
sheng Qian
2021-2-6
Last updated: 2022-02-21
Checks: 6 1
Knit directory: cTWAS_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20211220) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Using absolute paths to the files within your workflowr project makes it difficult for you and others to run your code on a different machine. Change the absolute path(s) below to the suggested relative path(s) to make your code more reproducible.
| absolute | relative |
|---|---|
| /project2/xinhe/shengqian/cTWAS/cTWAS_analysis/data/ | data |
| /project2/xinhe/shengqian/cTWAS/cTWAS_analysis/code/ctwas_config.R | code/ctwas_config.R |
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version bbf6737. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .ipynb_checkpoints/
Untracked files:
Untracked: Rplot.png
Untracked: analysis/Glucose_Adipose_Subcutaneous.Rmd
Untracked: analysis/Glucose_Adipose_Visceral_Omentum.Rmd
Untracked: analysis/Splicing_Test.Rmd
Untracked: code/.ipynb_checkpoints/
Untracked: code/AF_out/
Untracked: code/BMI_S_out/
Untracked: code/BMI_out/
Untracked: code/Glucose_out/
Untracked: code/LDL_S_out/
Untracked: code/T2D_out/
Untracked: code/ctwas_config.R
Untracked: code/mapping.R
Untracked: code/out/
Untracked: code/run_AF_analysis.sbatch
Untracked: code/run_AF_analysis.sh
Untracked: code/run_AF_ctwas_rss_LDR.R
Untracked: code/run_BMI_analysis.sbatch
Untracked: code/run_BMI_analysis.sh
Untracked: code/run_BMI_analysis_S.sbatch
Untracked: code/run_BMI_analysis_S.sh
Untracked: code/run_BMI_ctwas_rss_LDR.R
Untracked: code/run_BMI_ctwas_rss_LDR_S.R
Untracked: code/run_Glucose_analysis.sbatch
Untracked: code/run_Glucose_analysis.sh
Untracked: code/run_Glucose_ctwas_rss_LDR.R
Untracked: code/run_LDL_analysis_S.sbatch
Untracked: code/run_LDL_analysis_S.sh
Untracked: code/run_LDL_ctwas_rss_LDR_S.R
Untracked: code/run_T2D_analysis.sbatch
Untracked: code/run_T2D_analysis.sh
Untracked: code/run_T2D_ctwas_rss_LDR.R
Untracked: data/.ipynb_checkpoints/
Untracked: data/AF/
Untracked: data/BMI/
Untracked: data/BMI_S/
Untracked: data/Glucose/
Untracked: data/LDL_S/
Untracked: data/T2D/
Untracked: data/TEST/
Untracked: data/UKBB/
Untracked: data/UKBB_SNPs_Info.text
Untracked: data/gene_OMIM.txt
Untracked: data/gene_pip_0.8.txt
Untracked: data/mashr_Heart_Atrial_Appendage.db
Untracked: data/mashr_sqtl/
Untracked: data/summary_known_genes_annotations.xlsx
Untracked: data/untitled.txt
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/BMI_Brain_Nucleus_accumbens_basal_ganglia.Rmd) and HTML (docs/BMI_Brain_Nucleus_accumbens_basal_ganglia.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | bbf6737 | sq-96 | 2022-02-21 | update |
| html | 91f38fa | sq-96 | 2022-02-13 | Build site. |
| Rmd | eb13ecf | sq-96 | 2022-02-13 | update |
| html | e6bc169 | sq-96 | 2022-02-13 | Build site. |
| Rmd | 87fee8b | sq-96 | 2022-02-13 | update |
Weight QC
#number of imputed weights
nrow(qclist_all)[1] 11487#number of imputed weights by chromosome
table(qclist_all$chr)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
1134 801 689 451 561 646 551 431 414 460 695 611 220 384 375 529
17 18 19 20 21 22
672 184 903 357 131 288 #number of imputed weights without missing variants
sum(qclist_all$nmiss==0)[1] 9066#proportion of imputed weights without missing variants
mean(qclist_all$nmiss==0)[1] 0.7892Check convergence of parameters
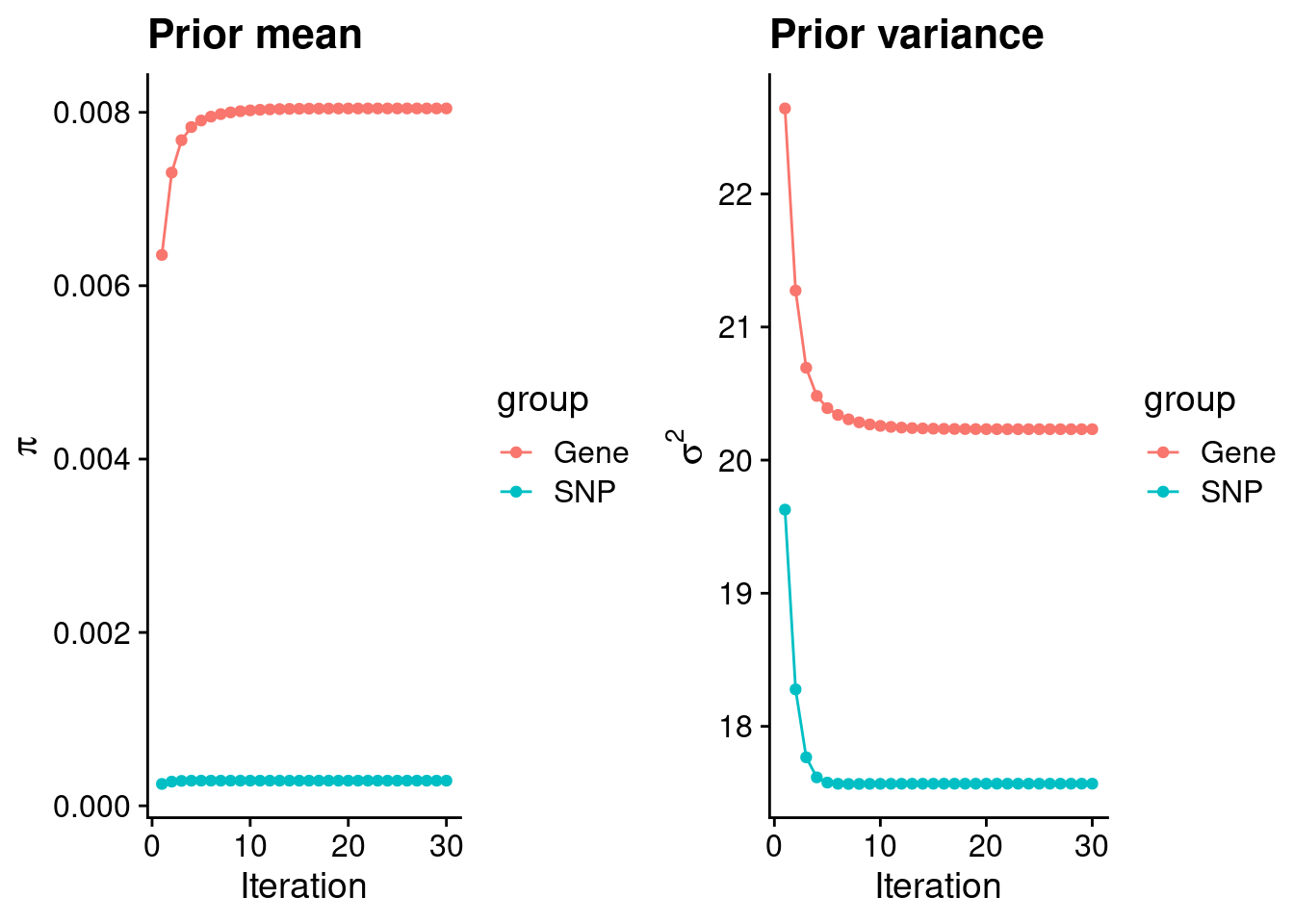
| Version | Author | Date |
|---|---|---|
| e6bc169 | sq-96 | 2022-02-13 |
#estimated group prior
estimated_group_prior <- group_prior_rec[,ncol(group_prior_rec)]
names(estimated_group_prior) <- c("gene", "snp")
estimated_group_prior["snp"] <- estimated_group_prior["snp"]*thin #adjust parameter to account for thin argument
print(estimated_group_prior) gene snp
0.0080450 0.0002899 #estimated group prior variance
estimated_group_prior_var <- group_prior_var_rec[,ncol(group_prior_var_rec)]
names(estimated_group_prior_var) <- c("gene", "snp")
print(estimated_group_prior_var) gene snp
20.23 17.57 #report sample size
print(sample_size)[1] 336107#report group size
group_size <- c(nrow(ctwas_gene_res), n_snps)
print(group_size)[1] 11487 7535010#estimated group PVE
estimated_group_pve <- estimated_group_prior_var*estimated_group_prior*group_size/sample_size #check PVE calculation
names(estimated_group_pve) <- c("gene", "snp")
print(estimated_group_pve) gene snp
0.005563 0.114195 #compare sum(PIP*mu2/sample_size) with above PVE calculation
c(sum(ctwas_gene_res$PVE),sum(ctwas_snp_res$PVE))[1] 0.05016 17.88795Genes with highest PIPs
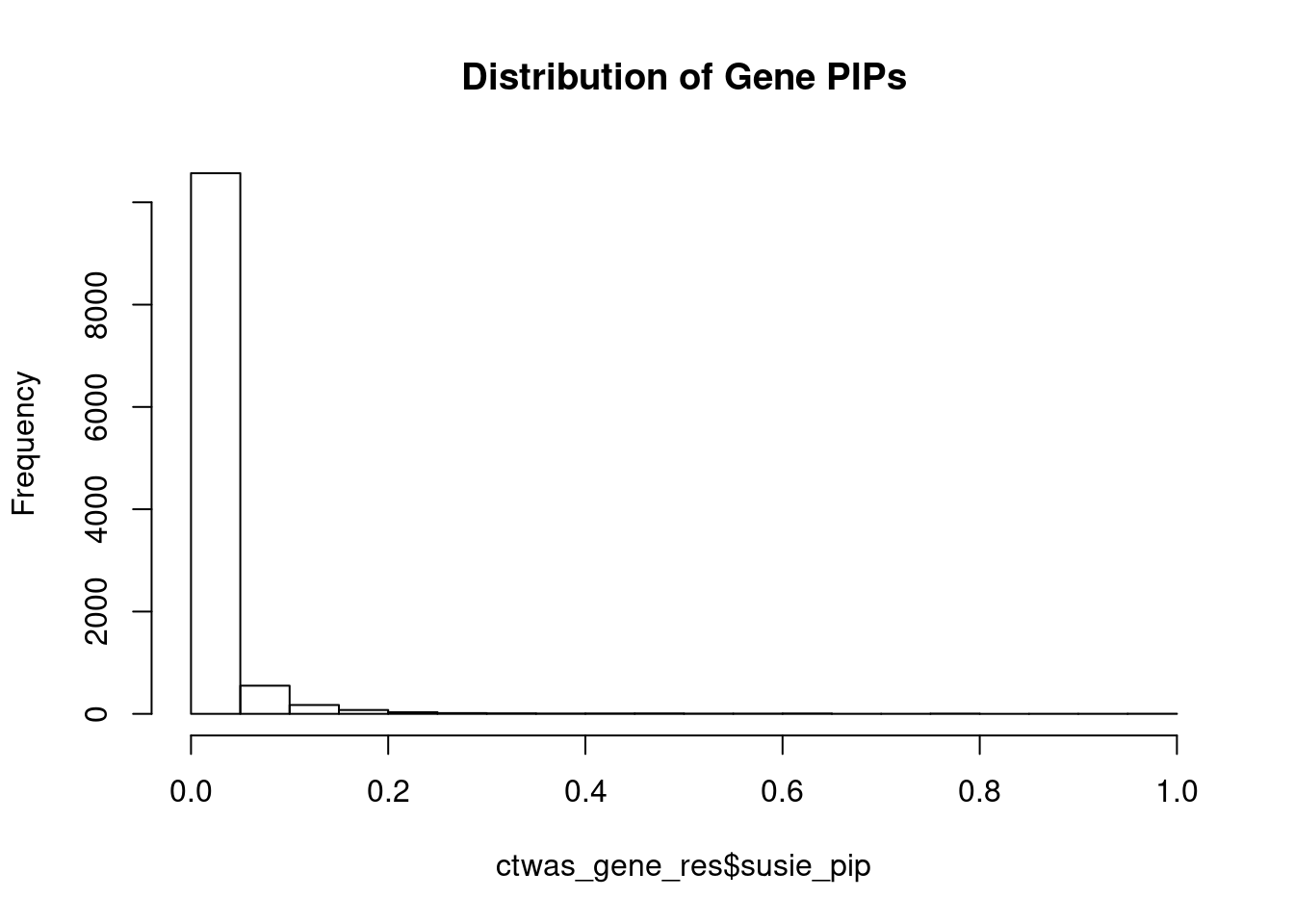
genename region_tag susie_pip mu2 PVE z num_eqtl
8160 SMAD3 15_31 1.0000 8015.87 2.385e-02 -2.853 2
9866 TMIE 3_33 0.9990 35.00 1.040e-04 -7.092 2
3378 CCND2 12_4 0.9649 28.86 8.286e-05 -5.120 1
9479 NIM1K 5_28 0.9385 3262.53 9.110e-03 5.551 2
7777 ZNF12 7_9 0.9364 27.18 7.571e-05 5.127 2
13756 NOL12 22_15 0.8990 61.45 1.644e-04 -4.511 2
7320 TAL1 1_29 0.7874 49.34 1.156e-04 -6.866 1
1678 NINL 20_19 0.7831 32.88 7.659e-05 -5.600 2
12851 CYP2A6 19_28 0.7800 21.54 4.999e-05 -3.990 1
13574 RP11-108M9.6 1_12 0.7772 28.35 6.556e-05 -4.915 1
7010 NBL1 1_13 0.7556 34.04 7.653e-05 -5.638 1
4404 TUBG1 17_25 0.7230 30.27 6.512e-05 -5.660 1
13759 RP11-823E8.3 12_54 0.7000 103.66 2.159e-04 -6.438 1
4137 PODXL 7_80 0.6950 26.19 5.416e-05 4.018 1
9422 SOX11 2_4 0.6665 26.53 5.261e-05 4.517 1
7829 YWHAZ 8_69 0.6476 22.78 4.389e-05 4.235 1
5519 CDH13 16_46 0.6397 23.81 4.533e-05 -4.826 1
1132 RRN3 16_15 0.6239 22.14 4.110e-05 4.374 1
12949 RP11-566J3.2 14_52 0.6215 34.21 6.326e-05 -5.489 1
2821 SENP6 6_52 0.6091 25.38 4.600e-05 -4.618 2Genes with largest effect sizes
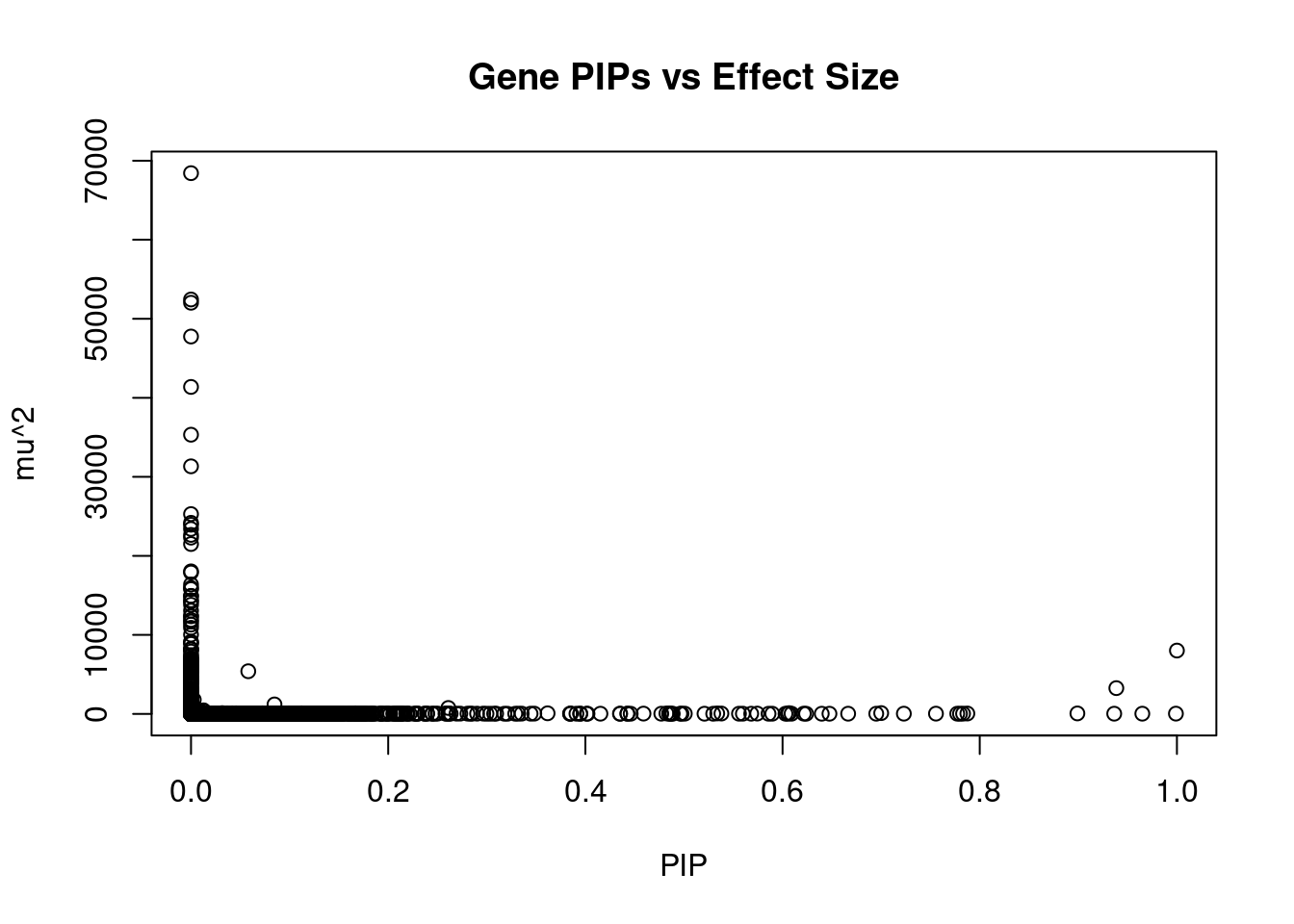
genename region_tag susie_pip mu2 PVE z num_eqtl
10604 SLC38A3 3_35 0.000e+00 68426 0.00e+00 6.726 1
7846 CCDC171 9_13 0.000e+00 52441 0.00e+00 7.973 2
7671 CAMKV 3_35 0.000e+00 52028 0.00e+00 -9.574 2
2153 PIK3R2 19_14 0.000e+00 47755 0.00e+00 -7.140 1
36 RBM6 3_35 0.000e+00 41376 0.00e+00 12.536 1
7673 MST1R 3_35 0.000e+00 35329 0.00e+00 -12.623 2
9620 STX19 3_59 0.000e+00 31329 0.00e+00 -5.060 1
5542 NOB1 16_37 0.000e+00 25285 0.00e+00 2.763 1
10375 GSAP 7_49 0.000e+00 24183 0.00e+00 5.120 3
5442 MFAP1 15_16 4.269e-12 23938 3.04e-13 4.303 1
7668 RNF123 3_35 0.000e+00 23403 0.00e+00 -10.957 1
5264 TMOD3 15_21 0.000e+00 22653 0.00e+00 -4.222 1
5446 LYSMD2 15_21 0.000e+00 22305 0.00e+00 -4.403 1
1353 WDR76 15_16 0.000e+00 21498 0.00e+00 4.809 2
901 MCM6 2_80 0.000e+00 18038 0.00e+00 -3.886 1
2155 PDE4C 19_14 0.000e+00 17891 0.00e+00 6.668 1
5158 TUBGCP4 15_16 0.000e+00 16376 0.00e+00 3.555 2
1434 MAST3 19_14 0.000e+00 15939 0.00e+00 -2.208 1
9613 NSUN3 3_59 0.000e+00 15792 0.00e+00 4.755 1
8457 LCMT2 15_16 0.000e+00 14935 0.00e+00 -2.861 1Genes with highest PVE
genename region_tag susie_pip mu2 PVE z num_eqtl
8160 SMAD3 15_31 1.00000 8015.87 2.385e-02 -2.853 2
9479 NIM1K 5_28 0.93854 3262.53 9.110e-03 5.551 2
13498 CTC-498M16.4 5_52 0.05807 5398.40 9.328e-04 7.883 1
10849 TTC30B 2_107 0.26101 752.00 5.840e-04 -3.137 1
7062 ADPGK 15_34 0.08467 1200.49 3.024e-04 5.925 3
13759 RP11-823E8.3 12_54 0.70005 103.66 2.159e-04 -6.438 1
10660 SKOR1 15_31 0.60658 97.96 1.768e-04 -9.880 2
13756 NOL12 22_15 0.89905 61.45 1.644e-04 -4.511 2
7320 TAL1 1_29 0.78744 49.34 1.156e-04 -6.866 1
9866 TMIE 3_33 0.99898 35.00 1.040e-04 -7.092 2
13962 DHRS11 17_22 0.53374 61.96 9.840e-05 -8.128 1
8419 ATXN2L 16_23 0.36167 77.23 8.310e-05 -10.702 1
3378 CCND2 12_4 0.96490 28.86 8.286e-05 -5.120 1
5575 C18orf8 18_12 0.48219 57.71 8.279e-05 7.477 2
1678 NINL 20_19 0.78308 32.88 7.659e-05 -5.600 2
7010 NBL1 1_13 0.75559 34.04 7.653e-05 -5.638 1
7777 ZNF12 7_9 0.93640 27.18 7.571e-05 5.127 2
5380 SUOX 12_35 0.53799 47.10 7.539e-05 -5.191 1
385 PHLPP2 16_38 0.57431 41.84 7.149e-05 4.619 1
13574 RP11-108M9.6 1_12 0.77719 28.35 6.556e-05 -4.915 1Genes with largest z scores
genename region_tag susie_pip mu2 PVE z num_eqtl
7673 MST1R 3_35 0.000e+00 35329.04 0.000e+00 -12.623 2
36 RBM6 3_35 0.000e+00 41375.93 0.000e+00 12.536 1
7668 RNF123 3_35 0.000e+00 23402.76 0.000e+00 -10.957 1
8554 INO80E 16_24 3.166e-02 99.46 9.370e-06 10.886 2
8419 ATXN2L 16_23 3.617e-01 77.23 8.310e-05 -10.702 1
10629 CLN3 16_23 4.170e-02 75.23 9.334e-06 10.363 2
10875 C6orf106 6_28 2.561e-05 120.41 9.173e-09 -10.264 1
12178 NPIPB7 16_23 3.663e-02 74.39 8.107e-06 10.038 1
8218 ZNF668 16_24 1.121e-01 77.19 2.575e-05 10.000 1
10660 SKOR1 15_31 6.066e-01 97.96 1.768e-04 -9.880 2
9435 NFATC2IP 16_23 4.577e-02 75.98 1.035e-05 -9.863 1
4330 ZC3H4 19_33 5.248e-03 98.99 1.546e-06 9.849 1
1906 KAT8 16_24 1.702e-02 72.07 3.650e-06 -9.785 1
1905 BCKDK 16_24 1.243e-02 68.65 2.539e-06 9.638 1
11636 NDUFS3 11_29 1.310e-02 84.89 3.309e-06 -9.629 2
7671 CAMKV 3_35 0.000e+00 52028.02 0.000e+00 -9.574 2
8924 C1QTNF4 11_29 1.137e-02 83.82 2.836e-06 9.564 1
11640 LAT 16_23 7.245e-02 77.05 1.661e-05 -9.553 1
10852 FAM180B 11_29 1.083e-02 82.28 2.652e-06 -9.490 1
2550 MTCH2 11_29 1.053e-02 81.11 2.540e-06 -9.432 1Comparing z scores and PIPs
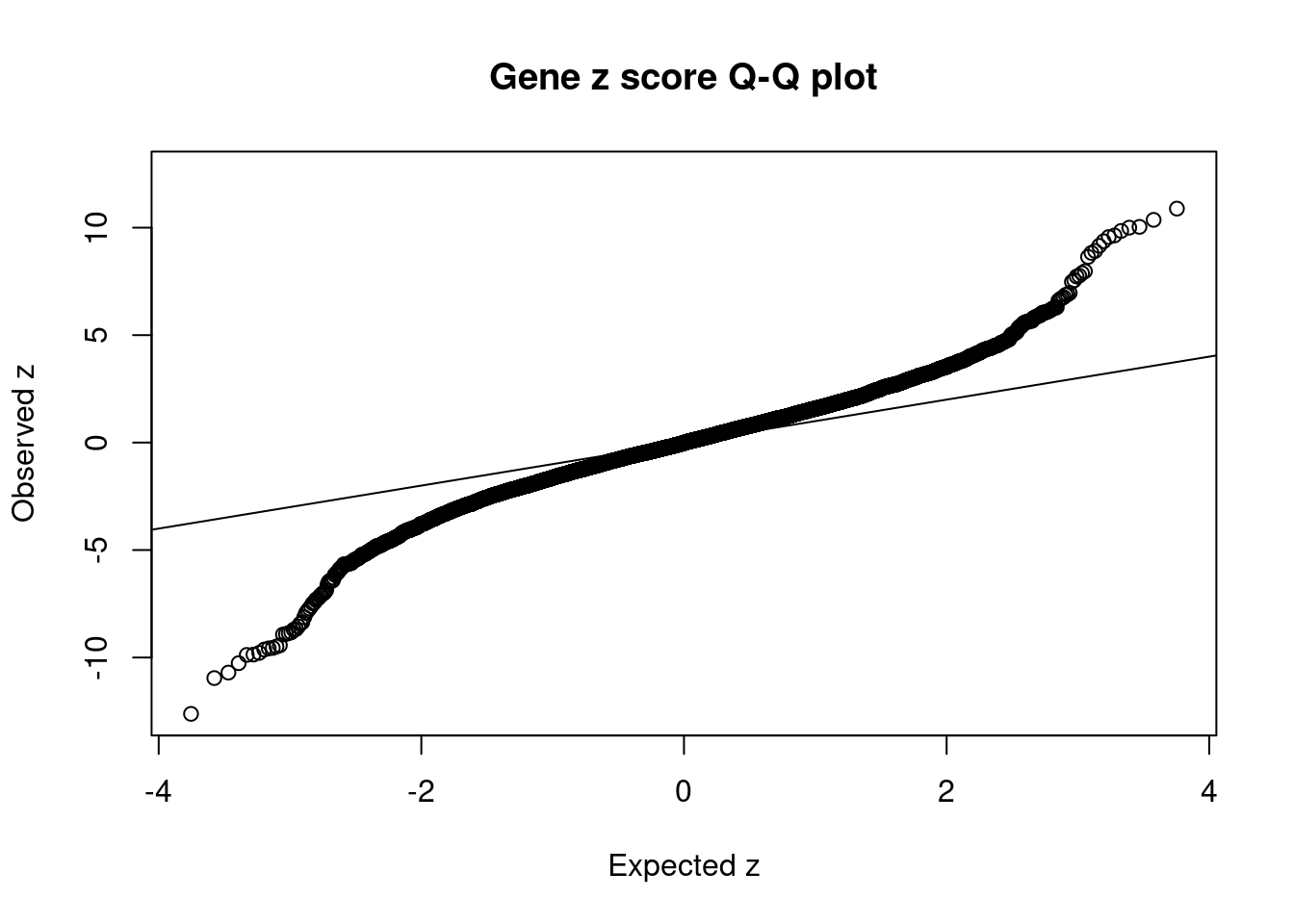
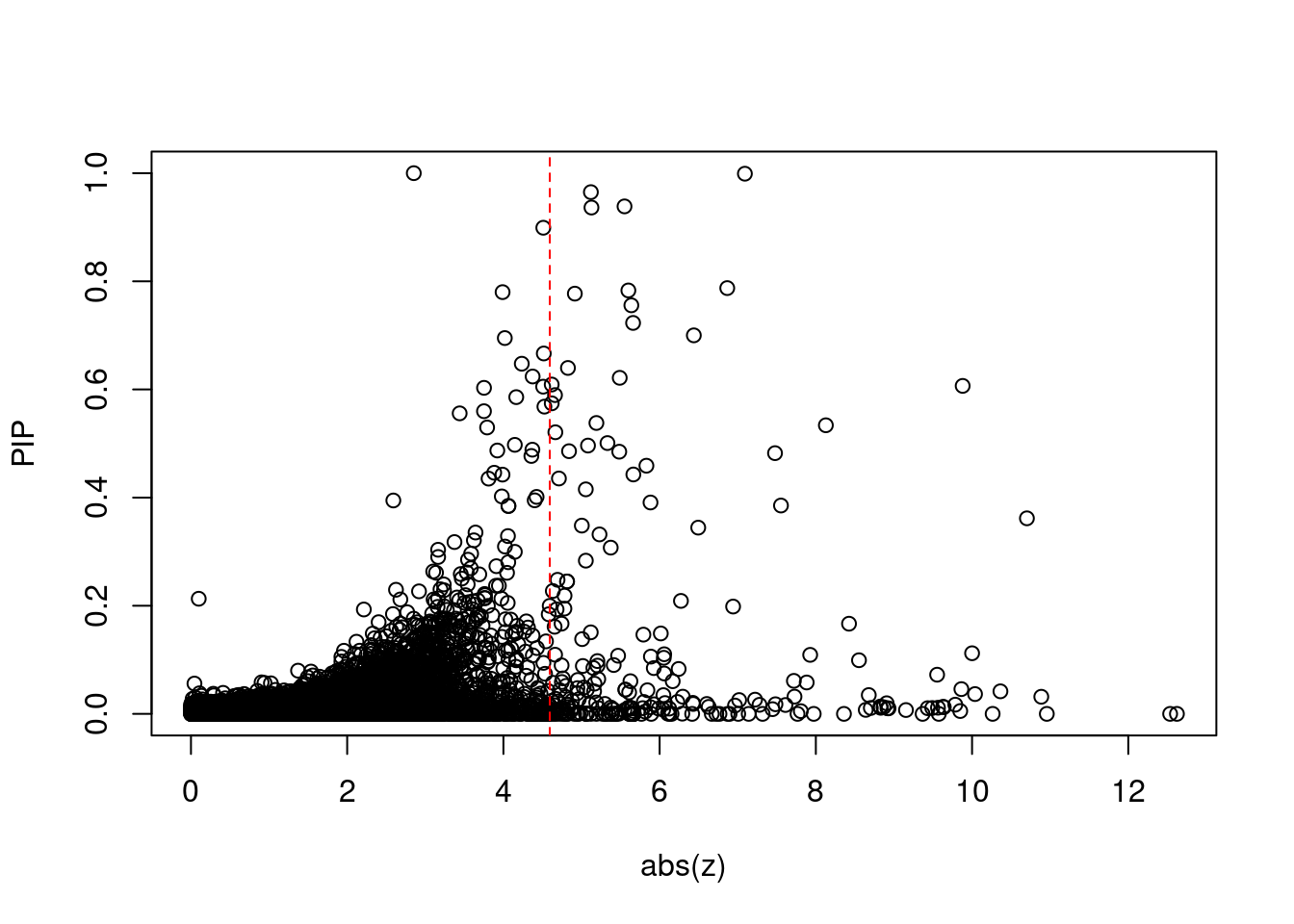
[1] 0.02002 genename region_tag susie_pip mu2 PVE z num_eqtl
7673 MST1R 3_35 0.000e+00 35329.04 0.000e+00 -12.623 2
36 RBM6 3_35 0.000e+00 41375.93 0.000e+00 12.536 1
7668 RNF123 3_35 0.000e+00 23402.76 0.000e+00 -10.957 1
8554 INO80E 16_24 3.166e-02 99.46 9.370e-06 10.886 2
8419 ATXN2L 16_23 3.617e-01 77.23 8.310e-05 -10.702 1
10629 CLN3 16_23 4.170e-02 75.23 9.334e-06 10.363 2
10875 C6orf106 6_28 2.561e-05 120.41 9.173e-09 -10.264 1
12178 NPIPB7 16_23 3.663e-02 74.39 8.107e-06 10.038 1
8218 ZNF668 16_24 1.121e-01 77.19 2.575e-05 10.000 1
10660 SKOR1 15_31 6.066e-01 97.96 1.768e-04 -9.880 2
9435 NFATC2IP 16_23 4.577e-02 75.98 1.035e-05 -9.863 1
4330 ZC3H4 19_33 5.248e-03 98.99 1.546e-06 9.849 1
1906 KAT8 16_24 1.702e-02 72.07 3.650e-06 -9.785 1
1905 BCKDK 16_24 1.243e-02 68.65 2.539e-06 9.638 1
11636 NDUFS3 11_29 1.310e-02 84.89 3.309e-06 -9.629 2
7671 CAMKV 3_35 0.000e+00 52028.02 0.000e+00 -9.574 2
8924 C1QTNF4 11_29 1.137e-02 83.82 2.836e-06 9.564 1
11640 LAT 16_23 7.245e-02 77.05 1.661e-05 -9.553 1
10852 FAM180B 11_29 1.083e-02 82.28 2.652e-06 -9.490 1
2550 MTCH2 11_29 1.053e-02 81.11 2.540e-06 -9.432 1GO enrichment analysis for genes with PIP>0.5
#number of genes for gene set enrichment
length(genes)[1] 34Uploading data to Enrichr... Done.
Querying GO_Biological_Process_2021... Done.
Querying GO_Cellular_Component_2021... Done.
Querying GO_Molecular_Function_2021... Done.
Parsing results... Done.
[1] "GO_Biological_Process_2021"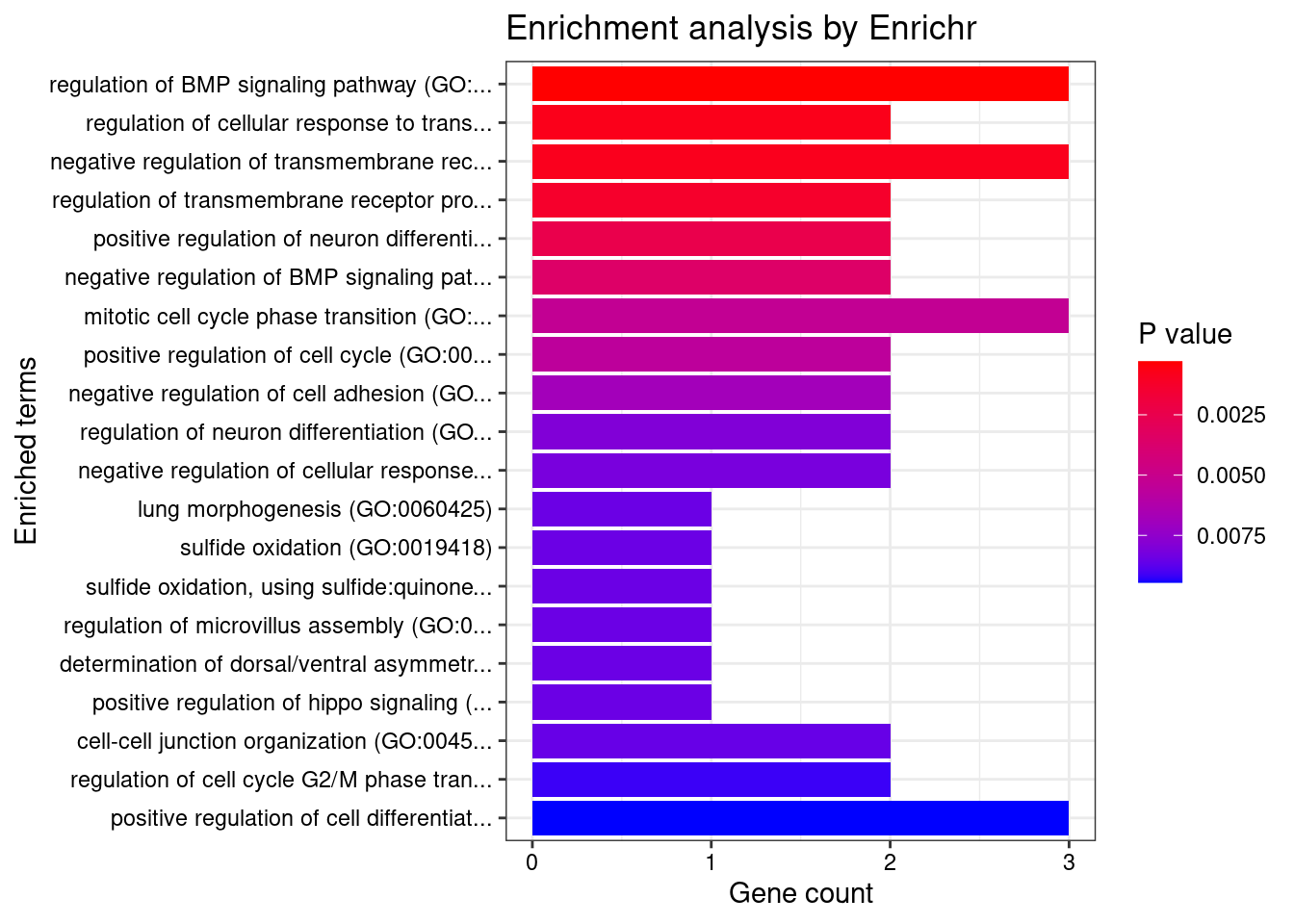
[1] Term Overlap Adjusted.P.value Genes
<0 rows> (or 0-length row.names)
[1] "GO_Cellular_Component_2021"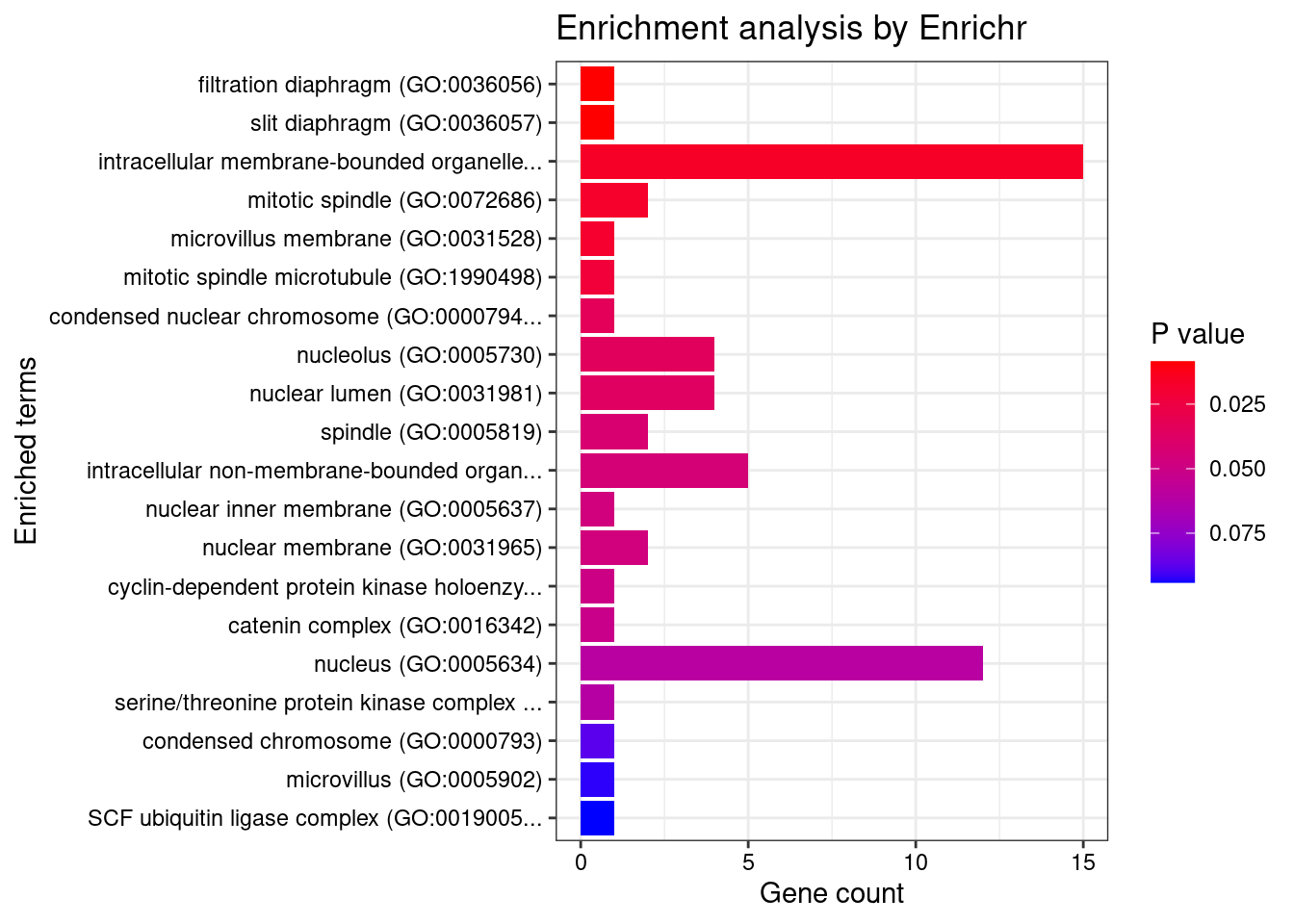
[1] Term Overlap Adjusted.P.value Genes
<0 rows> (or 0-length row.names)
[1] "GO_Molecular_Function_2021"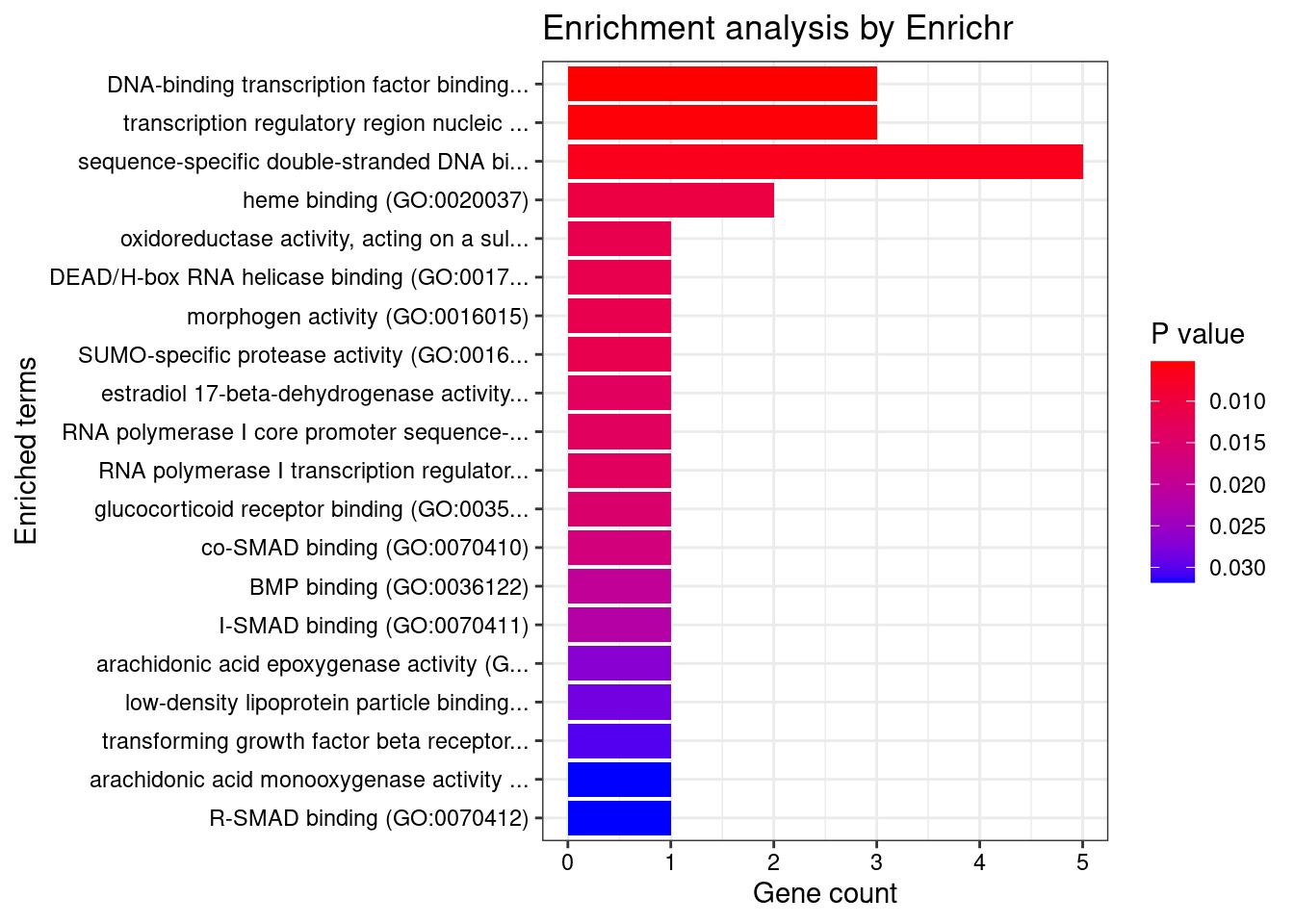
[1] Term Overlap Adjusted.P.value Genes
<0 rows> (or 0-length row.names)DisGeNET enrichment analysis for genes with PIP>0.5
Description FDR Ratio BgRatio
49 Lung Neoplasms 0.02168 4/17 265/9703
61 Opisthorchiasis 0.02168 1/17 1/9703
65 Prostatic Neoplasms 0.02168 6/17 616/9703
66 Pulmonary Emphysema 0.02168 2/17 17/9703
110 Malignant neoplasm of lung 0.02168 4/17 266/9703
115 Sulfite oxidase deficiency 0.02168 1/17 1/9703
117 Opisthorchis felineus Infection 0.02168 1/17 1/9703
118 Opisthorchis viverrini Infection 0.02168 1/17 1/9703
122 Malignant neoplasm of prostate 0.02168 6/17 616/9703
156 DEAFNESS, AUTOSOMAL RECESSIVE 6 0.02168 1/17 1/9703WebGestalt enrichment analysis for genes with PIP>0.5
Loading the functional categories...
Loading the ID list...
Loading the reference list...
Performing the enrichment analysis...Warning in oraEnrichment(interestGeneList, referenceGeneList, geneSet, minNum =
minNum, : No significant gene set is identified based on FDR 0.05!NULLPIP Manhattan Plot
Warning: ggrepel: 7 unlabeled data points (too many overlaps). Consider
increasing max.overlaps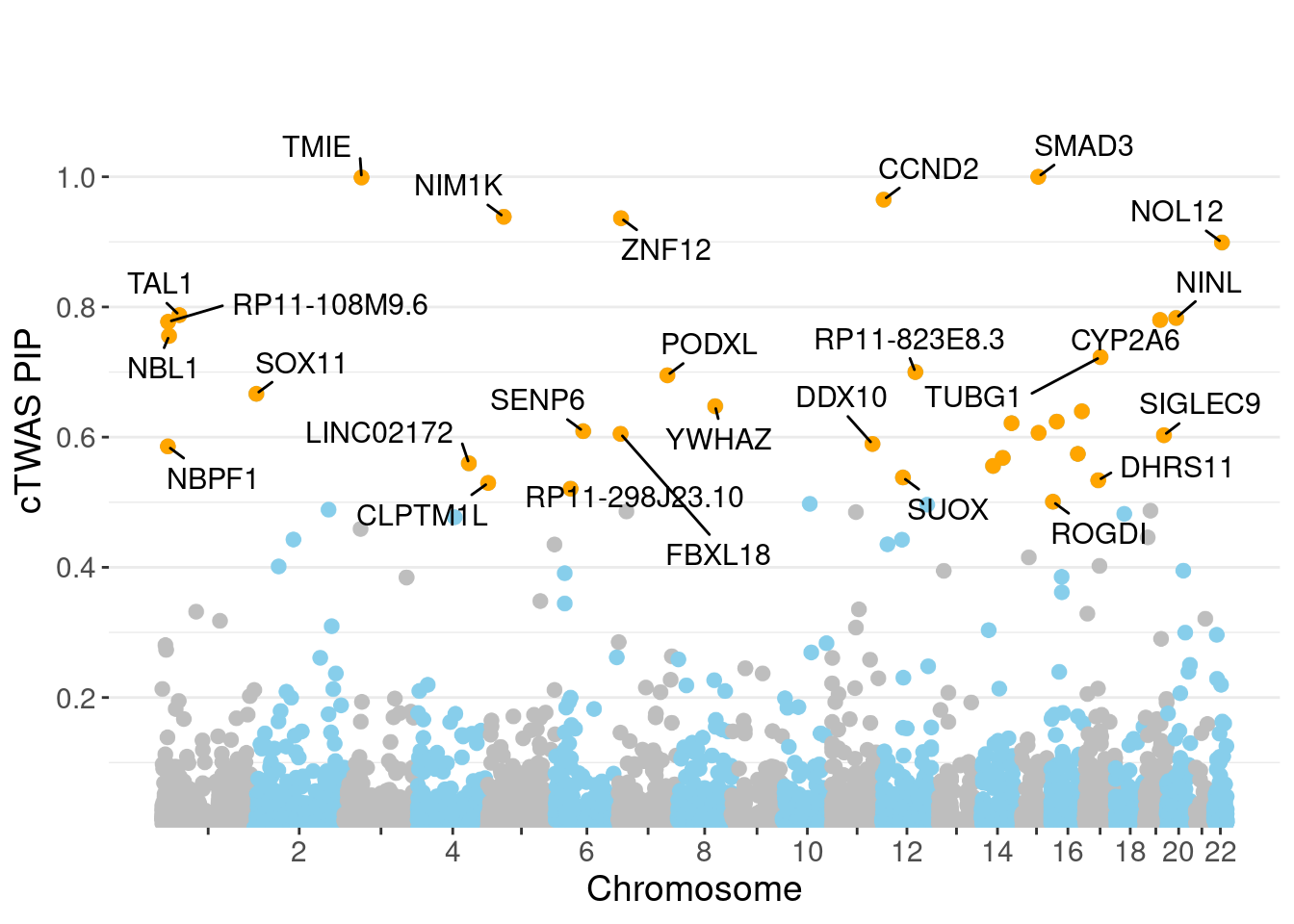
Sensitivity, specificity and precision for silver standard genes
#number of genes in known annotations
print(length(known_annotations))[1] 41#number of genes in known annotations with imputed expression
print(sum(known_annotations %in% ctwas_gene_res$genename))[1] 24#significance threshold for TWAS
print(sig_thresh)[1] 4.594#number of ctwas genes
length(ctwas_genes)[1] 6#number of TWAS genes
length(twas_genes)[1] 230#show novel genes (ctwas genes with not in TWAS genes)
ctwas_gene_res[ctwas_gene_res$genename %in% novel_genes,report_cols] genename region_tag susie_pip mu2 PVE z num_eqtl
8160 SMAD3 15_31 1.000 8015.87 0.0238492 -2.853 2
13756 NOL12 22_15 0.899 61.45 0.0001644 -4.511 2#sensitivity / recall
print(sensitivity) ctwas TWAS
0.00000 0.04878 #specificity
print(specificity) ctwas TWAS
0.9995 0.9801 #precision / PPV
print(precision) ctwas TWAS
0.000000 0.008696 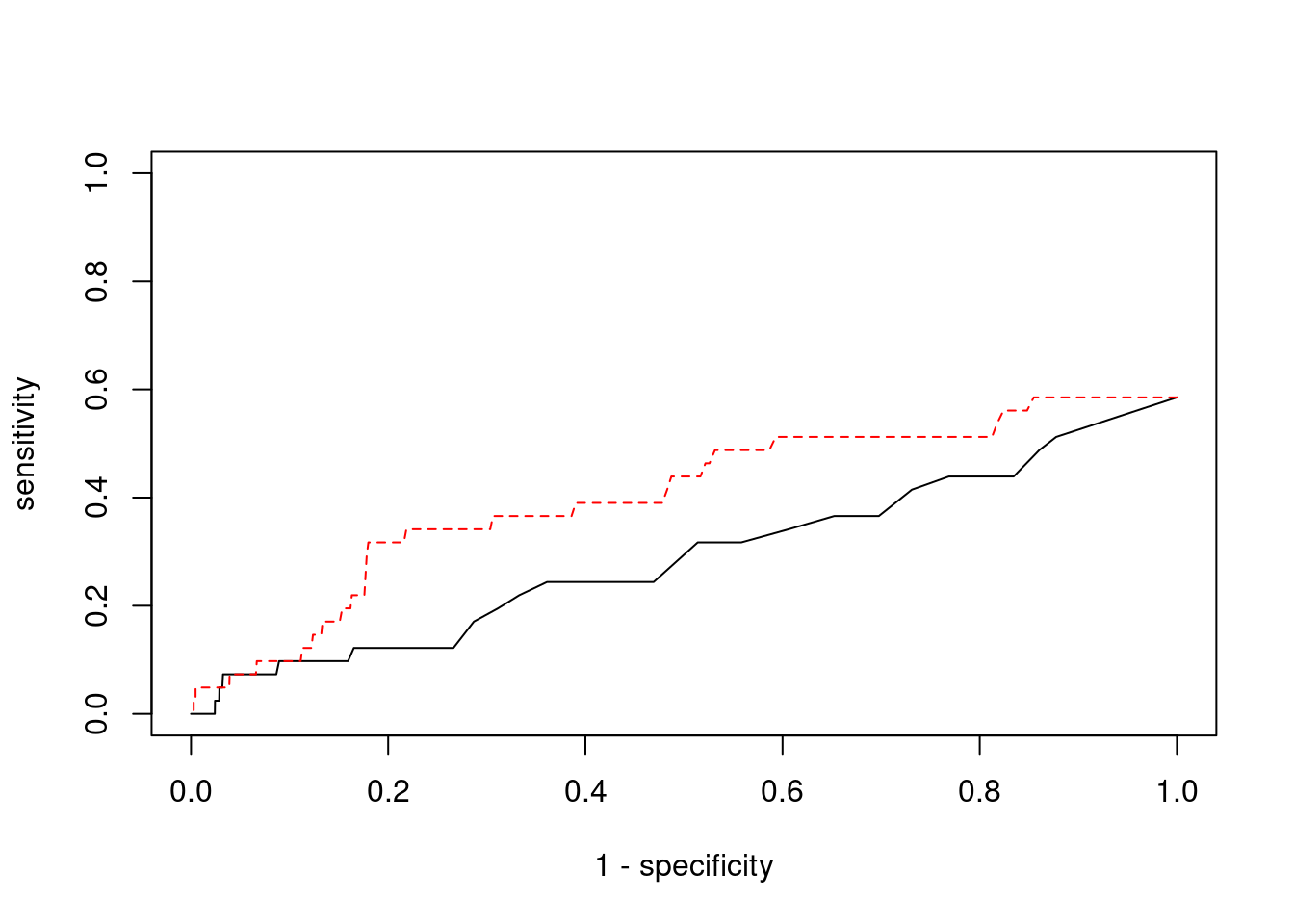
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.4 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.2.19-el7-x86_64/lib/libopenblas_haswellp-r0.2.19.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] readxl_1.3.1 forcats_0.5.1 stringr_1.4.0 dplyr_1.0.7
[5] purrr_0.3.4 readr_2.1.1 tidyr_1.1.4 tidyverse_1.3.1
[9] tibble_3.1.6 WebGestaltR_0.4.4 disgenet2r_0.99.2 enrichR_3.0
[13] cowplot_1.0.0 ggplot2_3.3.5 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] fs_1.5.2 lubridate_1.8.0 bit64_4.0.5 doParallel_1.0.16
[5] httr_1.4.2 rprojroot_2.0.2 tools_3.6.1 backports_1.4.1
[9] doRNG_1.8.2 utf8_1.2.2 R6_2.5.1 vipor_0.4.5
[13] DBI_1.1.1 colorspace_2.0-2 withr_2.4.3 ggrastr_1.0.1
[17] tidyselect_1.1.1 bit_4.0.4 curl_4.3.2 compiler_3.6.1
[21] git2r_0.26.1 cli_3.1.0 rvest_1.0.2 Cairo_1.5-12.2
[25] xml2_1.3.3 labeling_0.4.2 scales_1.1.1 apcluster_1.4.8
[29] digest_0.6.29 rmarkdown_2.11 svglite_1.2.2 pkgconfig_2.0.3
[33] htmltools_0.5.2 dbplyr_2.1.1 fastmap_1.1.0 highr_0.9
[37] rlang_0.4.12 rstudioapi_0.13 RSQLite_2.2.8 jquerylib_0.1.4
[41] farver_2.1.0 generics_0.1.1 jsonlite_1.7.2 vroom_1.5.7
[45] magrittr_2.0.1 Matrix_1.2-18 ggbeeswarm_0.6.0 Rcpp_1.0.7
[49] munsell_0.5.0 fansi_0.5.0 gdtools_0.1.9 lifecycle_1.0.1
[53] stringi_1.7.6 whisker_0.3-2 yaml_2.2.1 plyr_1.8.6
[57] grid_3.6.1 blob_1.2.2 ggrepel_0.9.1 parallel_3.6.1
[61] promises_1.0.1 crayon_1.4.2 lattice_0.20-38 haven_2.4.3
[65] hms_1.1.1 knitr_1.36 pillar_1.6.4 igraph_1.2.10
[69] rjson_0.2.20 rngtools_1.5.2 reshape2_1.4.4 codetools_0.2-16
[73] reprex_2.0.1 glue_1.5.1 evaluate_0.14 data.table_1.14.2
[77] modelr_0.1.8 vctrs_0.3.8 tzdb_0.2.0 httpuv_1.5.1
[81] foreach_1.5.1 cellranger_1.1.0 gtable_0.3.0 assertthat_0.2.1
[85] cachem_1.0.6 xfun_0.29 broom_0.7.10 later_0.8.0
[89] iterators_1.0.13 beeswarm_0.2.3 memoise_2.0.1 ellipsis_0.3.2