SCZ - Brain Amygdala
sheng Qian
2021-2-6
Last updated: 2022-03-03
Checks: 5 2
Knit directory: cTWAS_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of the R Markdown file created these results, you’ll want to first commit it to the Git repo. If you’re still working on the analysis, you can ignore this warning. When you’re finished, you can run wflow_publish to commit the R Markdown file and build the HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20211220) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Using absolute paths to the files within your workflowr project makes it difficult for you and others to run your code on a different machine. Change the absolute path(s) below to the suggested relative path(s) to make your code more reproducible.
| absolute | relative |
|---|---|
| /project2/xinhe/shengqian/cTWAS/cTWAS_analysis/data/ | data |
| /project2/xinhe/shengqian/cTWAS/cTWAS_analysis/code/ctwas_config.R | code/ctwas_config.R |
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 0ed6e7b. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .ipynb_checkpoints/
Ignored: data/AF/
Untracked files:
Untracked: Rplot.png
Untracked: analysis/.ipynb_checkpoints/
Untracked: code/.ipynb_checkpoints/
Untracked: code/AF_out/
Untracked: code/Autism_out/
Untracked: code/BMI_S_out/
Untracked: code/BMI_out/
Untracked: code/Glucose_out/
Untracked: code/LDL_S_out/
Untracked: code/SCZ_S_out/
Untracked: code/SCZ_out/
Untracked: code/T2D_out/
Untracked: code/ctwas_config.R
Untracked: code/mapping.R
Untracked: code/out/
Untracked: code/run_AF_analysis.sbatch
Untracked: code/run_AF_analysis.sh
Untracked: code/run_AF_ctwas_rss_LDR.R
Untracked: code/run_Autism_analysis.sbatch
Untracked: code/run_Autism_analysis.sh
Untracked: code/run_Autism_ctwas_rss_LDR.R
Untracked: code/run_BMI_analysis.sbatch
Untracked: code/run_BMI_analysis.sh
Untracked: code/run_BMI_analysis_S.sbatch
Untracked: code/run_BMI_analysis_S.sh
Untracked: code/run_BMI_ctwas_rss_LDR.R
Untracked: code/run_BMI_ctwas_rss_LDR_S.R
Untracked: code/run_Glucose_analysis.sbatch
Untracked: code/run_Glucose_analysis.sh
Untracked: code/run_Glucose_ctwas_rss_LDR.R
Untracked: code/run_LDL_analysis_S.sbatch
Untracked: code/run_LDL_analysis_S.sh
Untracked: code/run_LDL_ctwas_rss_LDR_S.R
Untracked: code/run_SCZ_analysis.sbatch
Untracked: code/run_SCZ_analysis.sh
Untracked: code/run_SCZ_analysis_S.sbatch
Untracked: code/run_SCZ_analysis_S.sh
Untracked: code/run_SCZ_ctwas_rss_LDR.R
Untracked: code/run_SCZ_ctwas_rss_LDR_S.R
Untracked: code/run_T2D_analysis.sbatch
Untracked: code/run_T2D_analysis.sh
Untracked: code/run_T2D_ctwas_rss_LDR.R
Untracked: code/wflow_build.R
Untracked: code/wflow_build.sbatch
Untracked: data/.ipynb_checkpoints/
Untracked: data/Autism/
Untracked: data/BMI/
Untracked: data/BMI_S/
Untracked: data/Glucose/
Untracked: data/LDL_S/
Untracked: data/SCZ/
Untracked: data/SCZ_S/
Untracked: data/T2D/
Untracked: data/TEST/
Untracked: data/UKBB/
Untracked: data/UKBB_SNPs_Info.text
Untracked: data/gene_OMIM.txt
Untracked: data/gene_pip_0.8.txt
Untracked: data/mashr_Heart_Atrial_Appendage.db
Untracked: data/mashr_sqtl/
Untracked: data/summary_known_genes_annotations.xlsx
Untracked: data/untitled.txt
Unstaged changes:
Modified: analysis/SCZ_Brain_Amygdala.Rmd
Modified: analysis/SCZ_Brain_Amygdala_S.Rmd
Modified: analysis/SCZ_Brain_Anterior_cingulate_cortex_BA24.Rmd
Modified: analysis/SCZ_Brain_Anterior_cingulate_cortex_BA24_S.Rmd
Modified: analysis/SCZ_Brain_Caudate_basal_ganglia.Rmd
Modified: analysis/SCZ_Brain_Cerebellar_Hemisphere.Rmd
Modified: analysis/SCZ_Brain_Cerebellum.Rmd
Modified: analysis/SCZ_Brain_Cortex.Rmd
Modified: analysis/SCZ_Brain_Cortex_S.Rmd
Modified: analysis/SCZ_Brain_Frontal_Cortex_BA9.Rmd
Modified: analysis/SCZ_Brain_Frontal_Cortex_BA9_S.Rmd
Modified: analysis/SCZ_Brain_Hippocampus.Rmd
Modified: analysis/SCZ_Brain_Hypothalamus.Rmd
Modified: analysis/SCZ_Brain_Nucleus_accumbens_basal_ganglia.Rmd
Modified: analysis/SCZ_Brain_Putamen_basal_ganglia_S.Rmd
Modified: analysis/SCZ_Brain_Spinal_cord_cervical_c-1.Rmd
Modified: analysis/SCZ_Brain_Substantia_nigra.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/SCZ_Brain_Amygdala.Rmd) and HTML (docs/SCZ_Brain_Amygdala.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 75a1466 | sq-96 | 2022-02-27 | Build site. |
| Rmd | 1c69dd2 | sq-96 | 2022-02-27 | update |
| html | ff6403a | sq-96 | 2022-02-27 | Build site. |
| Rmd | 3dd5b4c | sq-96 | 2022-02-27 | update |
Weight QC
#number of imputed weights
nrow(qclist_all)[1] 10292#number of imputed weights by chromosome
table(qclist_all$chr)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
1005 740 588 392 518 542 481 374 407 397 632 597 222 335 340 460
17 18 19 20 21 22
598 163 797 309 120 275 #number of imputed weights without missing variants
sum(qclist_all$nmiss==0)[1] 8408#proportion of imputed weights without missing variants
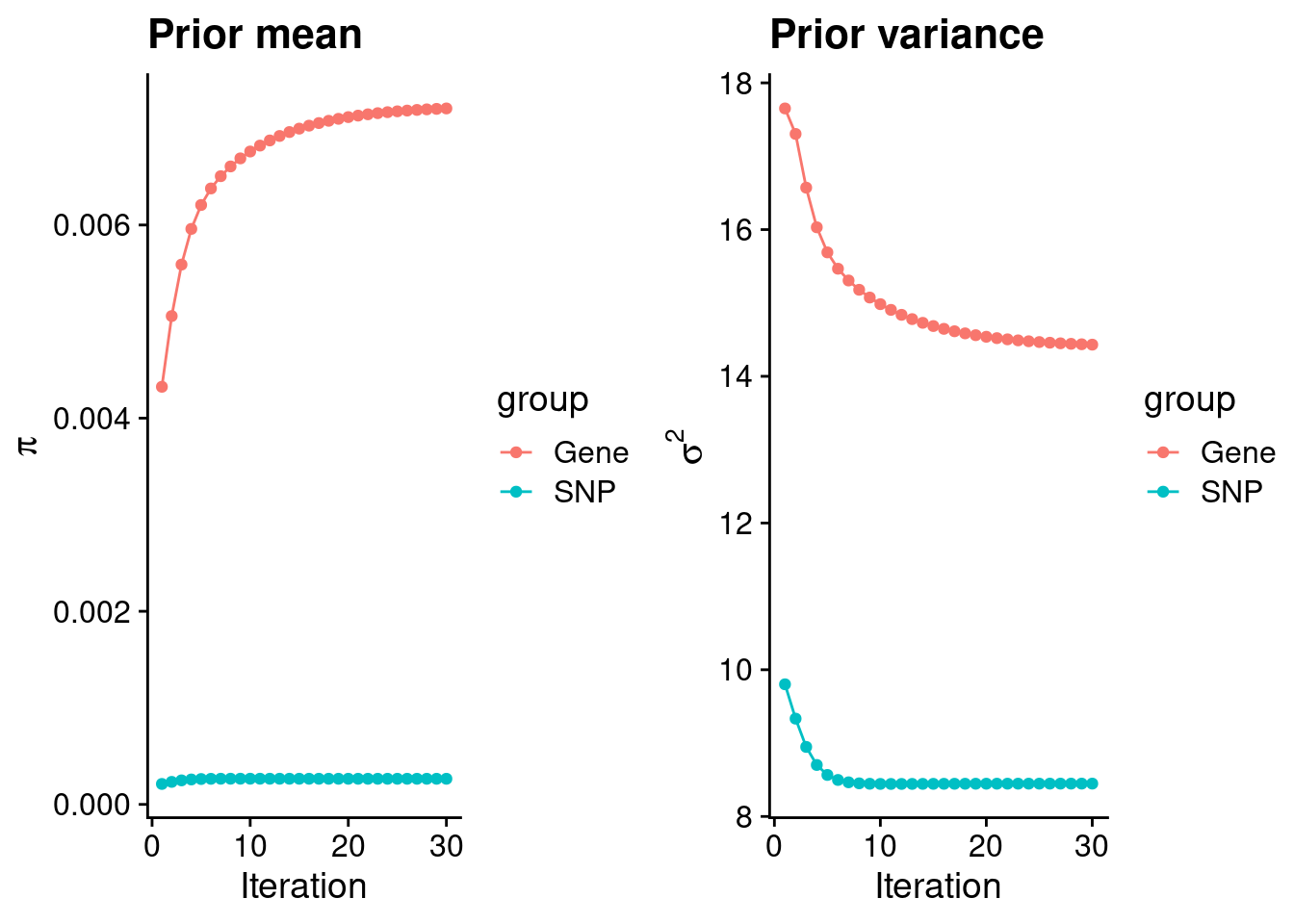
mean(qclist_all$nmiss==0)[1] 0.8169Check convergence of parameters
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
#estimated group prior
estimated_group_prior <- group_prior_rec[,ncol(group_prior_rec)]
names(estimated_group_prior) <- c("gene", "snp")
estimated_group_prior["snp"] <- estimated_group_prior["snp"]*thin #adjust parameter to account for thin argument
print(estimated_group_prior) gene snp
0.0072071 0.0002653 #estimated group prior variance
estimated_group_prior_var <- group_prior_var_rec[,ncol(group_prior_var_rec)]
names(estimated_group_prior_var) <- c("gene", "snp")
print(estimated_group_prior_var) gene snp
14.431 8.448 #report sample size
print(sample_size)[1] 82315#report group size
group_size <- c(nrow(ctwas_gene_res), n_snps)
print(group_size)[1] 10292 7573890#estimated group PVE
estimated_group_pve <- estimated_group_prior_var*estimated_group_prior*group_size/sample_size #check PVE calculation
names(estimated_group_pve) <- c("gene", "snp")
print(estimated_group_pve) gene snp
0.0130 0.2062 #compare sum(PIP*mu2/sample_size) with above PVE calculation
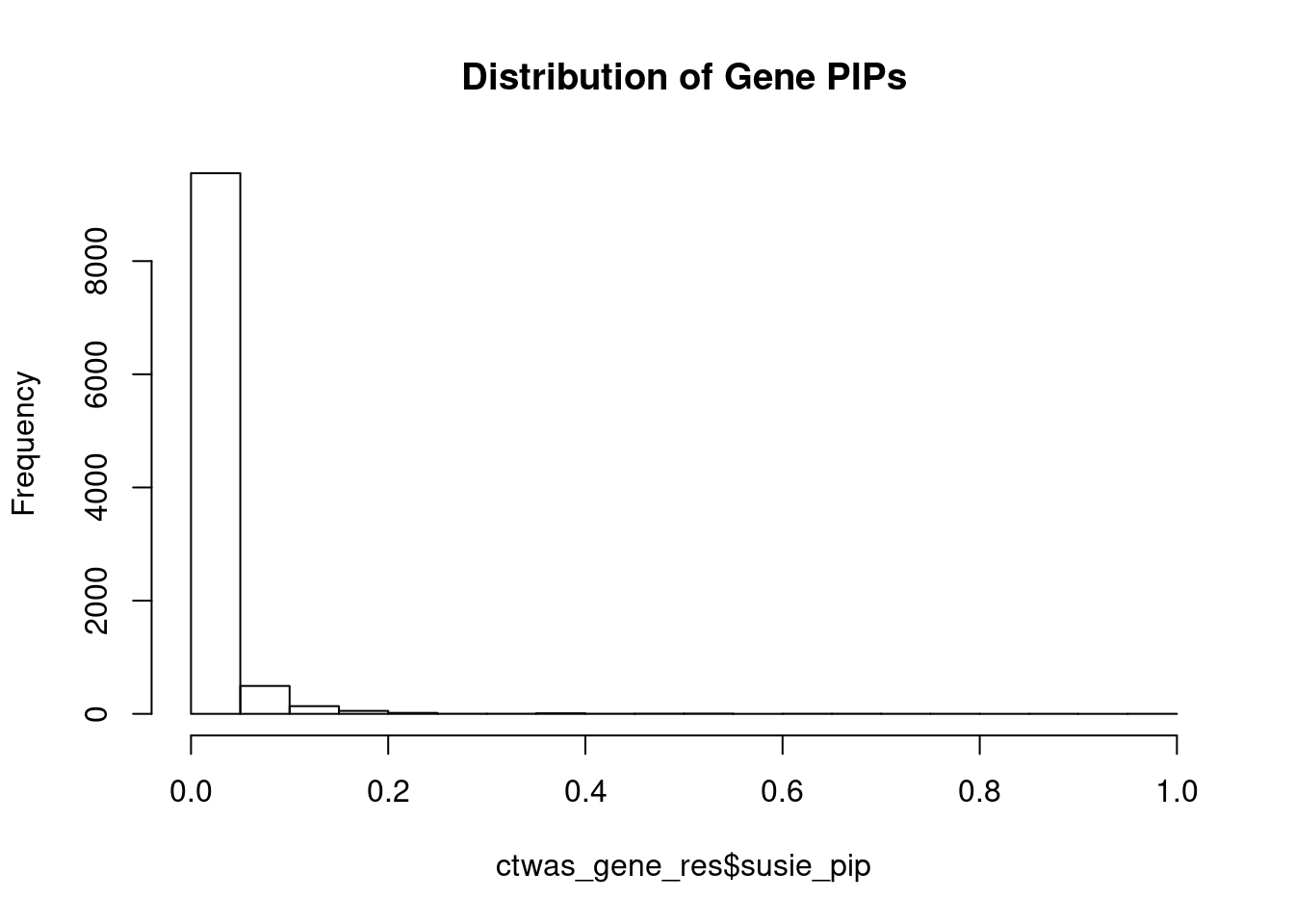
c(sum(ctwas_gene_res$PVE),sum(ctwas_snp_res$PVE))[1] 0.04663 1.55649Genes with highest PIPs
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
genename region_tag susie_pip mu2 PVE z num_eqtl
10169 ZNF823 19_10 0.9717 30.47 0.0003597 5.455 1
11179 HIST1H2BN 6_21 0.8621 100.93 0.0010571 10.773 1
11222 AC012074.2 2_15 0.8529 23.33 0.0002418 4.648 2
2362 B3GAT1 11_84 0.7950 23.70 0.0002289 -4.459 2
242 VSIG2 11_77 0.7863 26.81 0.0002560 -3.818 1
5997 TMEM56 1_58 0.7396 21.89 0.0001967 -3.918 1
3251 CYSTM1 5_83 0.7299 23.06 0.0002045 -4.025 1
10971 LINC00390 13_17 0.6968 22.04 0.0001866 -4.220 1
5798 ARFGAP2 11_29 0.6909 25.35 0.0002128 4.740 1
5920 PLBD2 12_68 0.6614 22.50 0.0001808 3.986 1
3172 HSDL2 9_57 0.6477 25.20 0.0001983 -4.322 1
10503 ZFP57 6_23 0.6316 73.92 0.0005672 7.267 1
10520 TCTN1 12_67 0.6306 24.15 0.0001850 4.840 1
5344 RIT1 1_76 0.5471 23.38 0.0001554 -3.496 1
377 CTNNA1 5_82 0.5417 25.60 0.0001685 5.064 1
9014 FAM83H 8_94 0.5412 24.57 0.0001616 4.317 2
677 PPP2R5B 11_36 0.5310 25.56 0.0001649 -4.623 1
11888 RP11-220I1.5 9_28 0.5132 23.80 0.0001484 -4.450 1
9316 ACOT1 14_34 0.4857 28.81 0.0001700 3.967 2
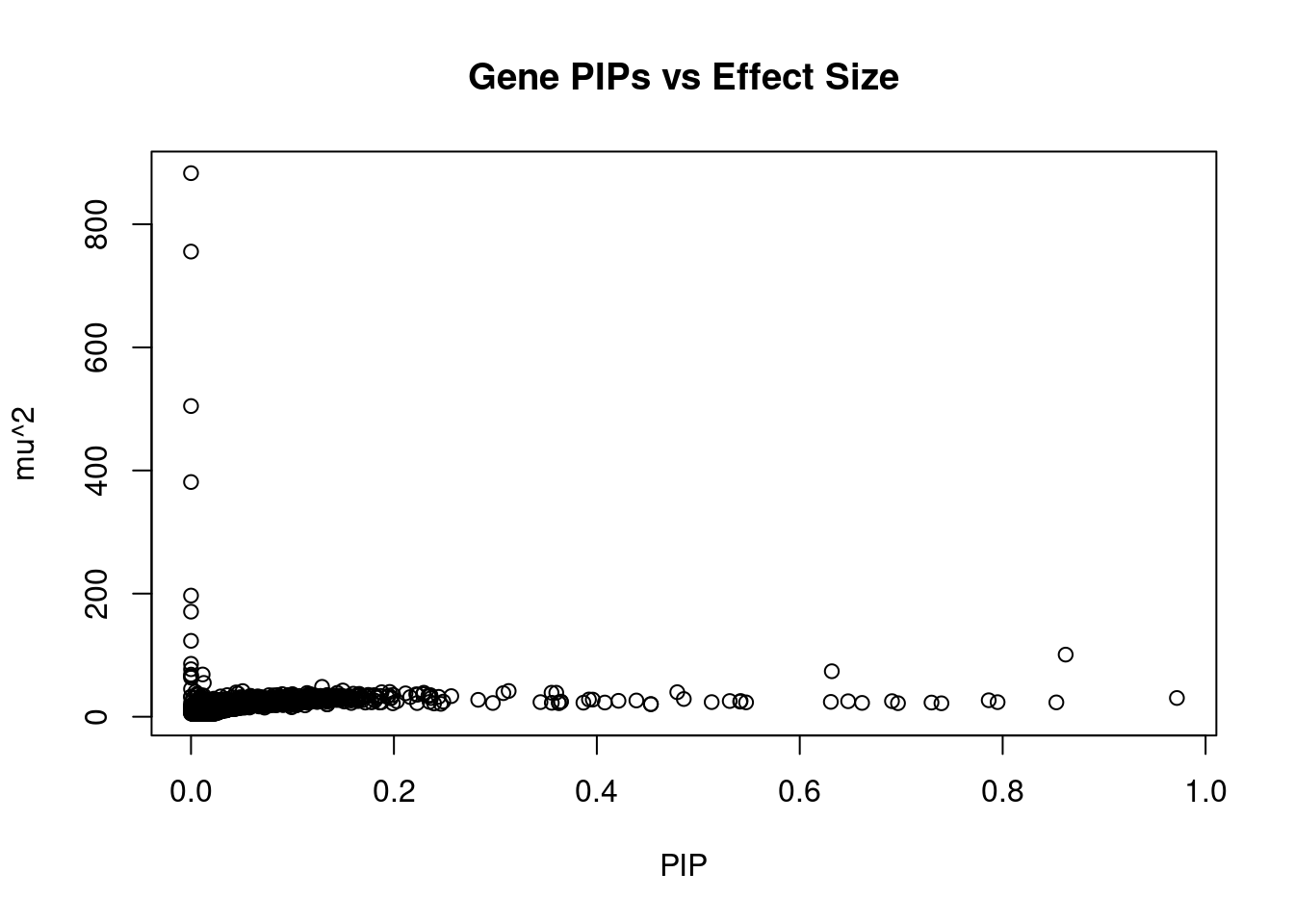
2406 MDK 11_28 0.4793 39.90 0.0002323 -6.357 1Genes with largest effect sizes
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
genename region_tag susie_pip mu2 PVE z num_eqtl
8899 HLA-DQB1 6_26 5.651e-14 882.98 6.062e-16 4.2352 1
9980 HLA-DQA1 6_26 7.838e-14 755.62 7.195e-16 4.0876 1
9870 HLA-DRB1 6_26 8.471e-14 504.68 5.194e-16 4.3158 1
10465 MSH5 6_26 8.843e-13 381.27 4.096e-15 8.8122 1
9057 ACBD4 17_27 0.000e+00 196.81 0.000e+00 1.1059 1
10458 SLC44A4 6_26 5.934e-12 170.69 1.230e-14 6.2502 1
9377 FMNL1 17_27 0.000e+00 123.32 0.000e+00 -0.6638 1
11179 HIST1H2BN 6_21 8.621e-01 100.93 1.057e-03 10.7729 1
10706 CLIC1 6_26 2.934e-13 86.02 3.066e-16 0.4634 1
1218 PUS7 7_65 0.000e+00 77.22 0.000e+00 -3.2022 1
10503 ZFP57 6_23 6.316e-01 73.92 5.672e-04 7.2673 1
9573 BTN3A2 6_20 1.147e-02 68.67 9.569e-06 9.0494 3
2240 GOSR2 17_27 0.000e+00 68.45 0.000e+00 -2.5096 1
4578 NMT1 17_27 0.000e+00 66.09 0.000e+00 2.2782 1
8918 RPRML 17_27 0.000e+00 63.52 0.000e+00 1.5727 1
8984 HIST1H2BC 6_20 1.263e-02 55.02 8.443e-06 -8.0277 1
437 MPHOSPH9 12_75 1.291e-01 48.60 7.624e-05 7.1580 1
4868 PRDM5 4_78 0.000e+00 45.06 0.000e+00 0.3272 2
6704 LEMD2 6_28 1.496e-01 42.65 7.752e-05 4.2792 2
12183 RP11-247A12.7 9_66 3.131e-01 41.87 1.593e-04 4.3022 1Genes with highest PVE
genename region_tag susie_pip mu2 PVE z num_eqtl
11179 HIST1H2BN 6_21 0.8621 100.93 0.0010571 10.773 1
10503 ZFP57 6_23 0.6316 73.92 0.0005672 7.267 1
10169 ZNF823 19_10 0.9717 30.47 0.0003597 5.455 1
242 VSIG2 11_77 0.7863 26.81 0.0002560 -3.818 1
11222 AC012074.2 2_15 0.8529 23.33 0.0002418 4.648 2
2406 MDK 11_28 0.4793 39.90 0.0002323 -6.357 1
2362 B3GAT1 11_84 0.7950 23.70 0.0002289 -4.459 2
5798 ARFGAP2 11_29 0.6909 25.35 0.0002128 4.740 1
3251 CYSTM1 5_83 0.7299 23.06 0.0002045 -4.025 1
3172 HSDL2 9_57 0.6477 25.20 0.0001983 -4.322 1
5997 TMEM56 1_58 0.7396 21.89 0.0001967 -3.918 1
10971 LINC00390 13_17 0.6968 22.04 0.0001866 -4.220 1
10520 TCTN1 12_67 0.6306 24.15 0.0001850 4.840 1
5920 PLBD2 12_68 0.6614 22.50 0.0001808 3.986 1
413 ARID1B 6_102 0.3600 39.03 0.0001707 3.907 1
9316 ACOT1 14_34 0.4857 28.81 0.0001700 3.967 2
5866 TAOK2 16_24 0.3554 39.04 0.0001685 6.189 1
377 CTNNA1 5_82 0.5417 25.60 0.0001685 5.064 1
677 PPP2R5B 11_36 0.5310 25.56 0.0001649 -4.623 1
9014 FAM83H 8_94 0.5412 24.57 0.0001616 4.317 2Genes with largest z scores
genename region_tag susie_pip mu2 PVE z num_eqtl
11179 HIST1H2BN 6_21 8.621e-01 100.93 1.057e-03 10.773 1
9573 BTN3A2 6_20 1.147e-02 68.67 9.569e-06 9.049 3
10465 MSH5 6_26 8.843e-13 381.27 4.096e-15 8.812 1
8984 HIST1H2BC 6_20 1.263e-02 55.02 8.443e-06 -8.028 1
5778 CNNM2 10_66 1.144e-01 38.59 5.363e-05 -7.691 1
10503 ZFP57 6_23 6.316e-01 73.92 5.672e-04 7.267 1
437 MPHOSPH9 12_75 1.291e-01 48.60 7.624e-05 7.158 1
5903 ABCB9 12_75 4.331e-03 40.53 2.133e-06 6.404 1
2406 MDK 11_28 4.793e-01 39.90 2.323e-04 -6.357 1
11226 ZSCAN31 6_22 9.442e-03 28.74 3.296e-06 -6.270 2
10458 SLC44A4 6_26 5.934e-12 170.69 1.230e-14 6.250 1
9777 DPYD 1_60 6.071e-03 37.20 2.744e-06 -6.222 1
5866 TAOK2 16_24 3.554e-01 39.04 1.685e-04 6.189 1
8969 HARBI1 11_28 1.658e-01 37.21 7.496e-05 6.169 1
10617 DNAJC19 3_111 2.294e-01 39.04 1.088e-04 6.158 1
2590 TRIM38 6_20 9.834e-03 30.60 3.656e-06 5.841 2
10231 ZKSCAN8 6_22 6.487e-03 37.40 2.948e-06 5.829 1
3264 SNX19 11_81 4.623e-02 37.69 2.117e-05 5.761 3
7375 CKB 14_54 9.933e-03 29.53 3.563e-06 -5.704 1
9987 ZSCAN16 6_22 7.220e-03 35.90 3.149e-06 5.677 1Comparing z scores and PIPs
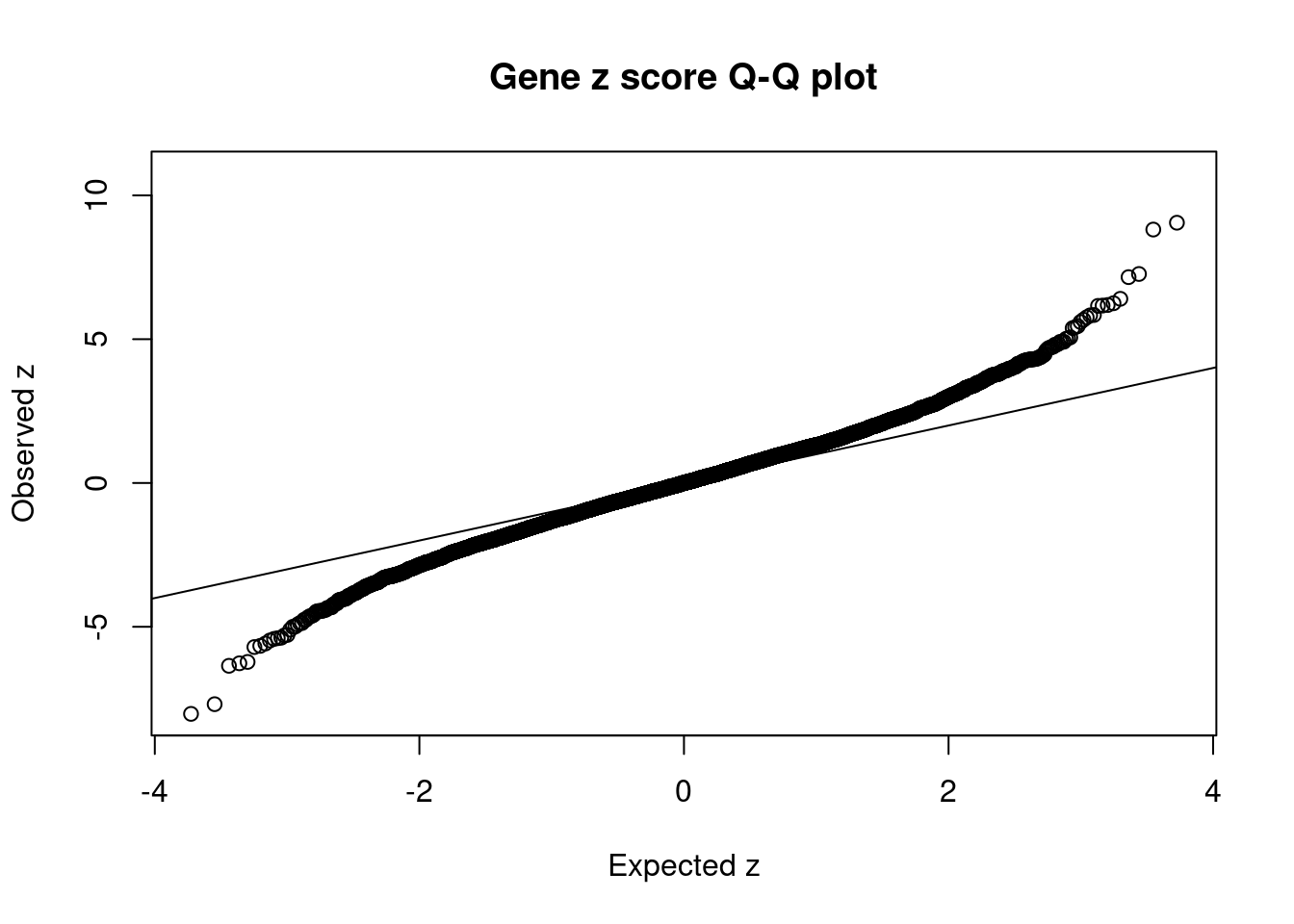
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
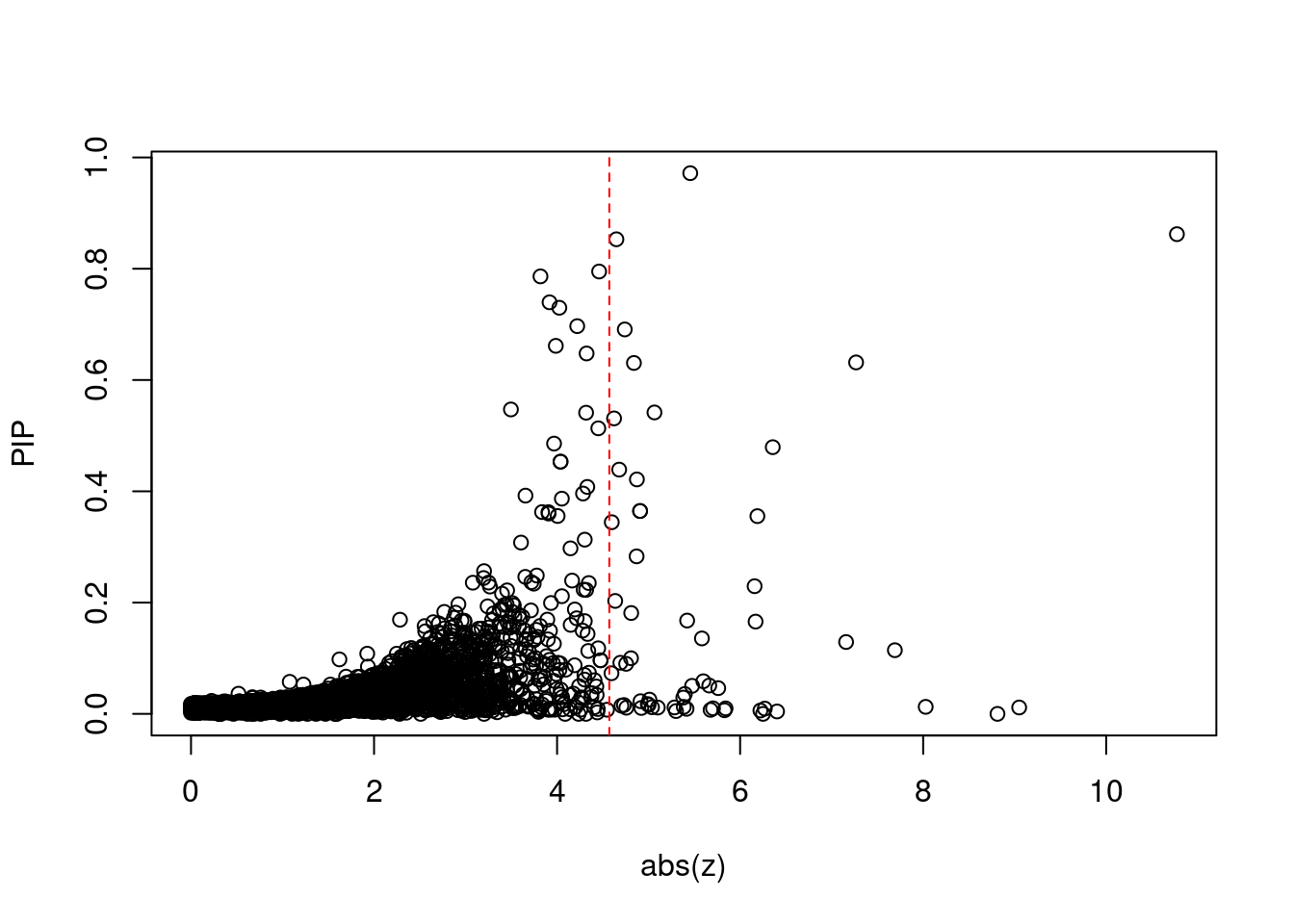
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
[1] 0.005733GO enrichment analysis for genes with PIP>0.5
#number of genes for gene set enrichment
length(genes)[1] 18Uploading data to Enrichr... Done.
Querying GO_Biological_Process_2021... Done.
Querying GO_Cellular_Component_2021... Done.
Querying GO_Molecular_Function_2021... Done.
Parsing results... Done.
[1] "GO_Biological_Process_2021"
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
[1] Term Overlap Adjusted.P.value Genes
<0 rows> (or 0-length row.names)
[1] "GO_Cellular_Component_2021"
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
[1] Term Overlap Adjusted.P.value Genes
<0 rows> (or 0-length row.names)
[1] "GO_Molecular_Function_2021"
| Version | Author | Date |
|---|---|---|
| ff6403a | sq-96 | 2022-02-27 |
[1] Term Overlap Adjusted.P.value Genes
<0 rows> (or 0-length row.names)DisGeNET enrichment analysis for genes with PIP>0.5
Description FDR Ratio BgRatio
45 JOUBERT SYNDROME 13 0.02597 1/9 1/9703
50 NOONAN SYNDROME 8 0.02597 1/9 1/9703
36 Macular Dystrophy, Butterfly-Shaped Pigmentary, 2 0.03114 1/9 3/9703
38 Patterned dystrophy of retinal pigment epithelium 0.03114 1/9 3/9703
54 Butterfly-shaped pigmentary macular dystrophy 0.03114 1/9 3/9703
22 Amelogenesis Imperfecta, Type III 0.03459 1/9 4/9703
35 Diabetes Mellitus, Transient Neonatal, 1 0.03704 1/9 5/9703
1 Amelogenesis Imperfecta 0.06312 1/9 12/9703
2 Hereditary Nonpolyposis Colorectal Neoplasms 0.06312 1/9 26/9703
3 Diabetes Mellitus 0.06312 1/9 32/9703WebGestalt enrichment analysis for genes with PIP>0.5
Loading the functional categories...
Loading the ID list...
Loading the reference list...
Performing the enrichment analysis...Warning in oraEnrichment(interestGeneList, referenceGeneList, geneSet, minNum =
minNum, : No significant gene set is identified based on FDR 0.05!NULL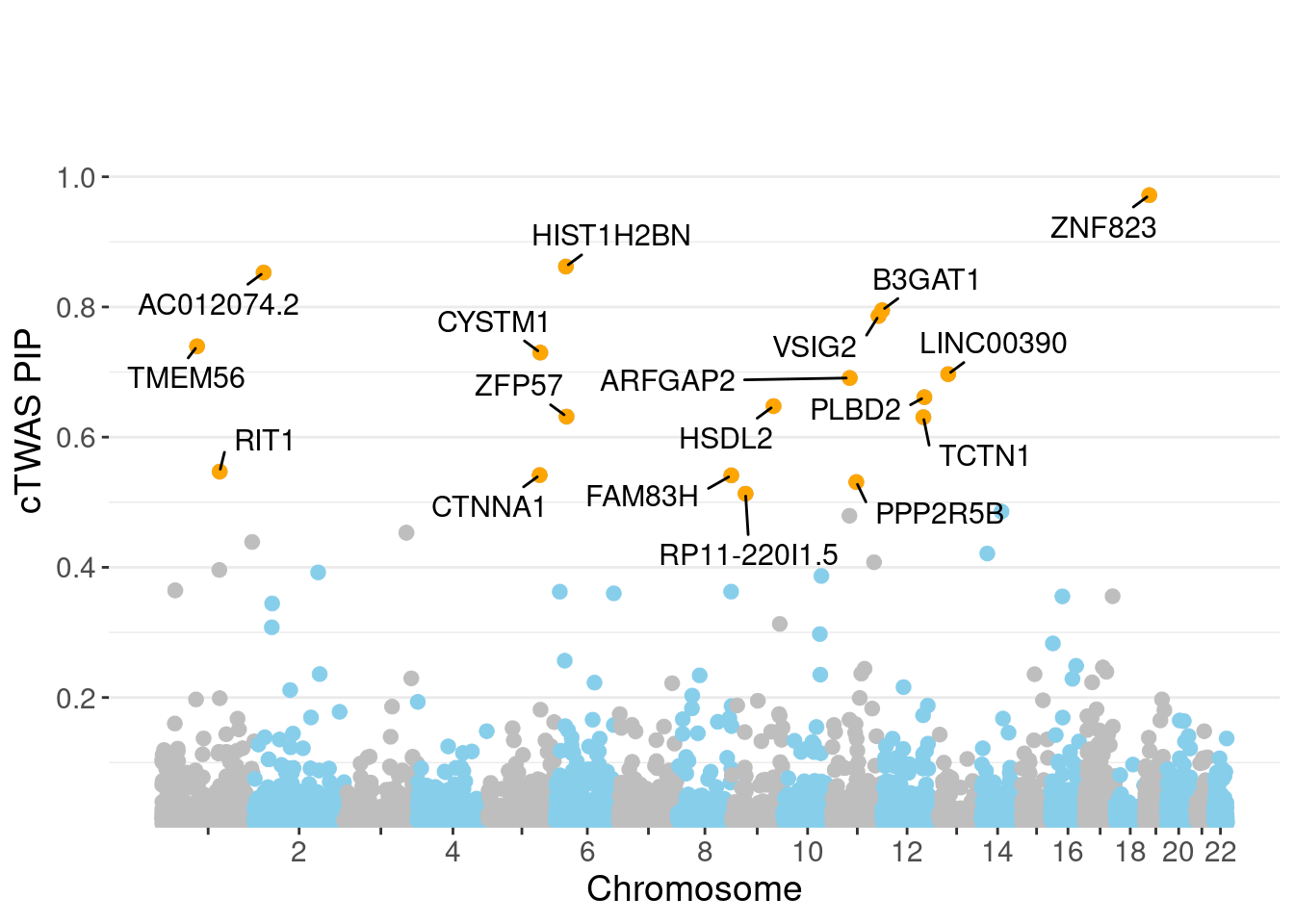
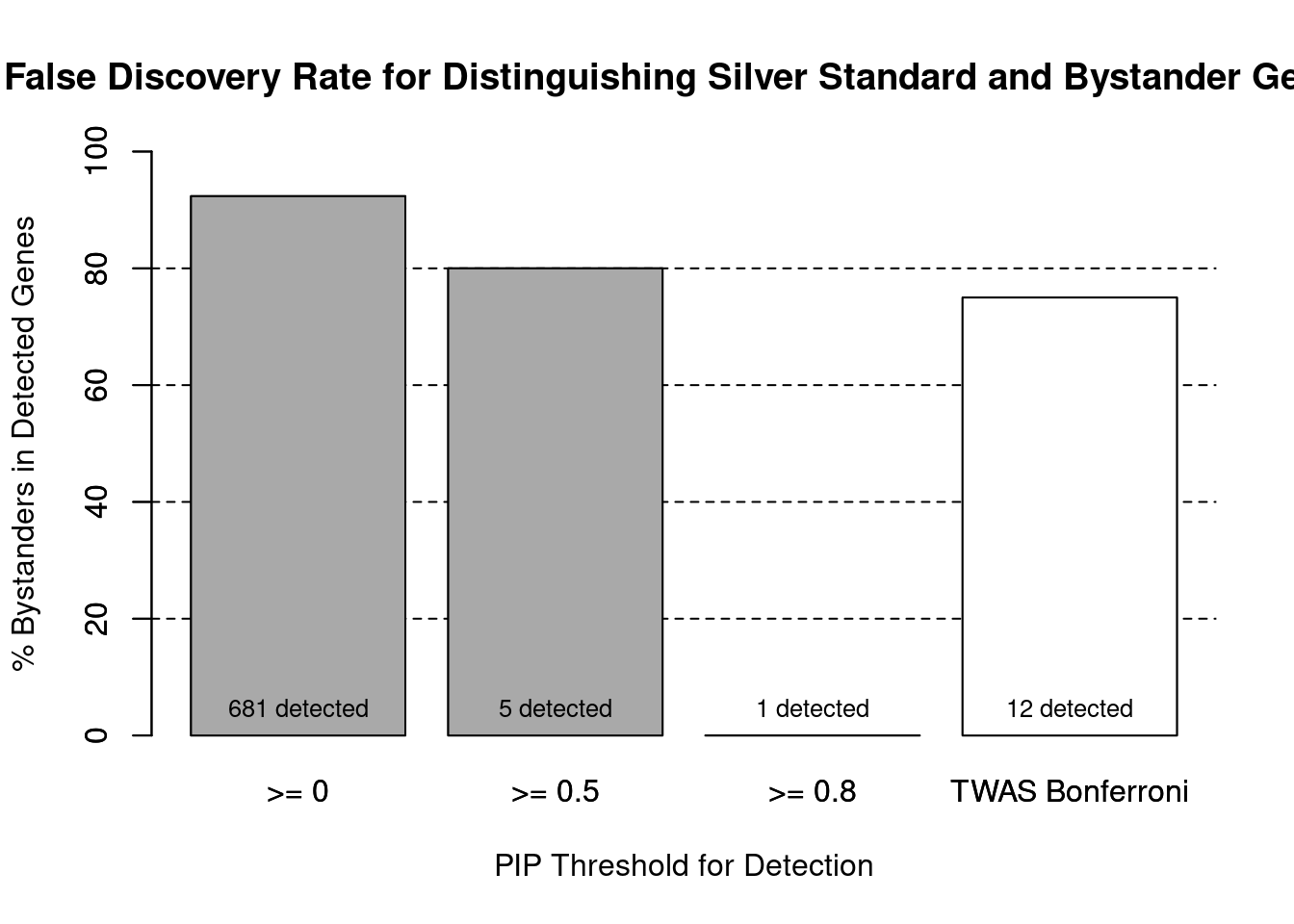
Sensitivity, specificity and precision for silver standard genes
#number of genes in known annotations
print(length(known_annotations))[1] 130#number of genes in known annotations with imputed expression
print(sum(known_annotations %in% ctwas_gene_res$genename))[1] 52#significance threshold for TWAS
print(sig_thresh)[1] 4.571#number of ctwas genes
length(ctwas_genes)[1] 3#number of TWAS genes
length(twas_genes)[1] 59#show novel genes (ctwas genes with not in TWAS genes)
ctwas_gene_res[ctwas_gene_res$genename %in% novel_genes,report_cols][1] genename region_tag susie_pip mu2 PVE z num_eqtl
<0 rows> (or 0-length row.names)#sensitivity / recall
print(sensitivity) ctwas TWAS
0.007692 0.023077 #specificity
print(specificity) ctwas TWAS
0.9998 0.9945 #precision / PPV
print(precision) ctwas TWAS
0.33333 0.05085 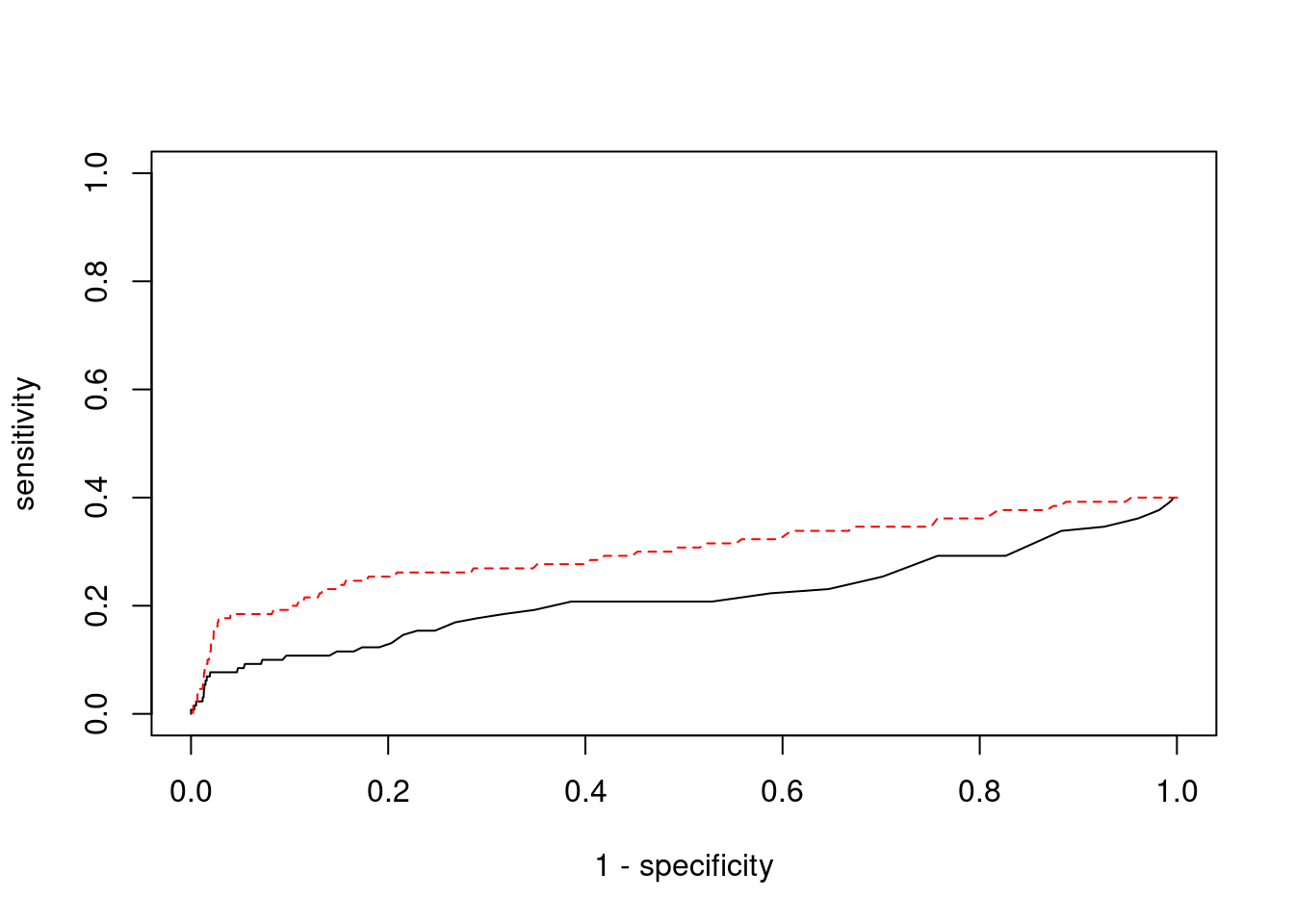
cTWAS is more precise than TWAS in distinguishing silver standard and bystander genes
#number of genes in known annotations (with imputed expression)
print(length(known_annotations))[1] 52#number of bystander genes (with imputed expression)
print(length(unrelated_genes))[1] 628#subset results to genes in known annotations or bystanders
ctwas_gene_res_subset <- ctwas_gene_res[ctwas_gene_res$genename %in% c(known_annotations, unrelated_genes),]
#assign ctwas and TWAS genes
ctwas_genes <- ctwas_gene_res_subset$genename[ctwas_gene_res_subset$susie_pip>0.8]
twas_genes <- ctwas_gene_res_subset$genename[abs(ctwas_gene_res_subset$z)>sig_thresh]
#significance threshold for TWAS
print(sig_thresh)[1] 4.571#number of ctwas genes (in known annotations or bystanders)
length(ctwas_genes)[1] 1#number of TWAS genes (in known annotations or bystanders)
length(twas_genes)[1] 12#sensitivity / recall
sensitivity ctwas TWAS
0.01923 0.05769 #specificity / (1 - False Positive Rate)
specificity ctwas TWAS
1.0000 0.9857 #precision / PPV / (1 - False Discovery Rate)
precisionctwas TWAS
1.00 0.25 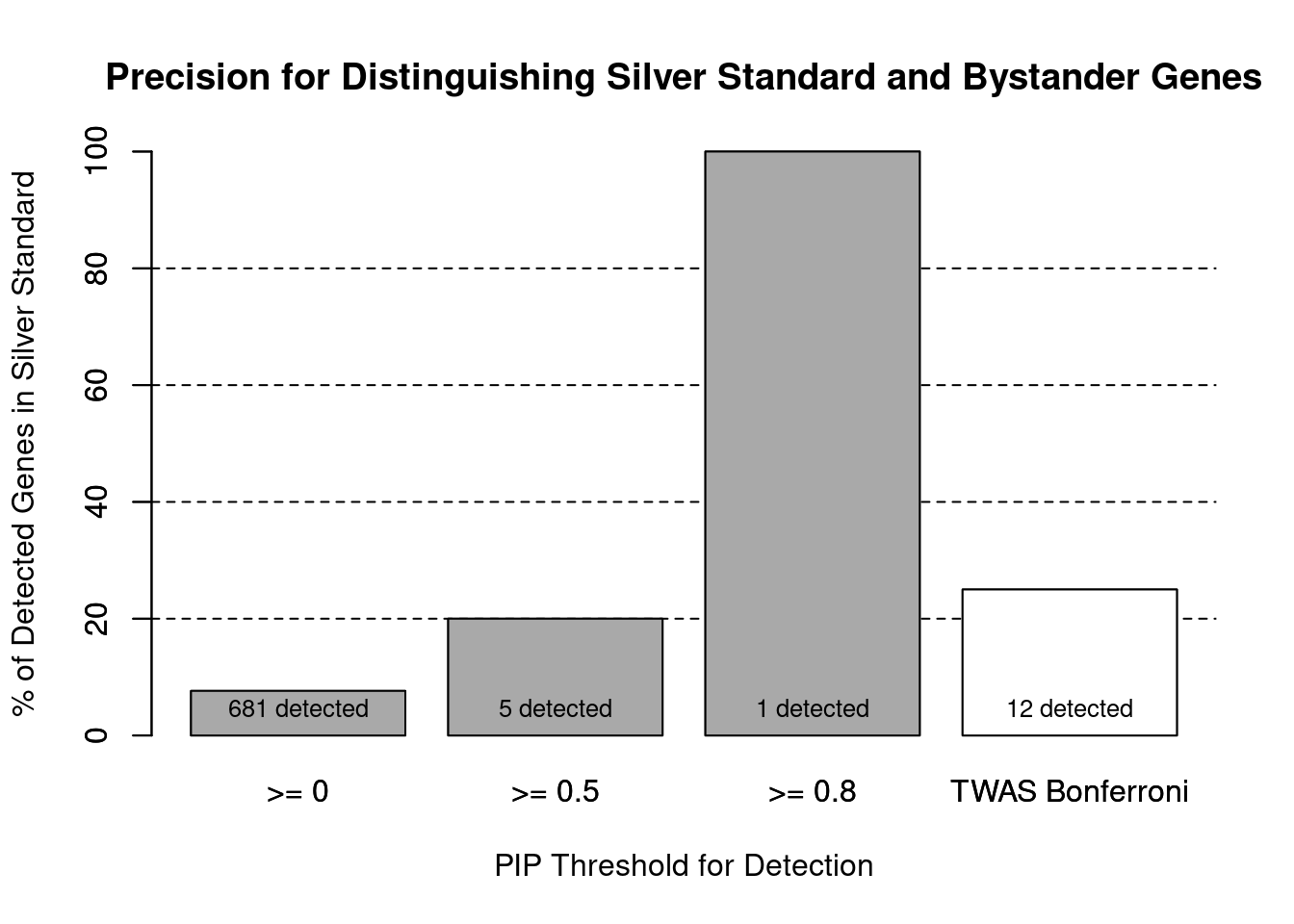
pip_range <- (0:1000)/1000
sensitivity <- rep(NA, length(pip_range))
specificity <- rep(NA, length(pip_range))
for (index in 1:length(pip_range)){
pip <- pip_range[index]
ctwas_genes <- ctwas_gene_res_subset$genename[ctwas_gene_res_subset$susie_pip>=pip]
sensitivity[index] <- sum(ctwas_genes %in% known_annotations)/length(known_annotations)
specificity[index] <- sum(!(unrelated_genes %in% ctwas_genes))/length(unrelated_genes)
}
plot(1-specificity, sensitivity, type="l", xlim=c(0,1), ylim=c(0,1), main="", xlab="1 - Specificity", ylab="Sensitivity")
title(expression("ROC Curve for cTWAS (black) and TWAS (" * phantom("red") * ")"))
title(expression(phantom("ROC Curve for cTWAS (black) and TWAS (") * "red" * phantom(")")), col.main="red")
sig_thresh_range <- seq(from=0, to=max(abs(ctwas_gene_res_subset$z)), length.out=length(pip_range))
for (index in 1:length(sig_thresh_range)){
sig_thresh_plot <- sig_thresh_range[index]
twas_genes <- ctwas_gene_res_subset$genename[abs(ctwas_gene_res_subset$z)>=sig_thresh_plot]
sensitivity[index] <- sum(twas_genes %in% known_annotations)/length(known_annotations)
specificity[index] <- sum(!(unrelated_genes %in% twas_genes))/length(unrelated_genes)
}
lines(1-specificity, sensitivity, xlim=c(0,1), ylim=c(0,1), col="red", lty=1)
abline(a=0,b=1,lty=3)
#add previously computed points from the analysis
ctwas_genes <- ctwas_gene_res_subset$genename[ctwas_gene_res_subset$susie_pip>0.8]
twas_genes <- ctwas_gene_res_subset$genename[abs(ctwas_gene_res_subset$z)>sig_thresh]
points(1-specificity_plot["ctwas"], sensitivity_plot["ctwas"], pch=21, bg="black")
points(1-specificity_plot["TWAS"], sensitivity_plot["TWAS"], pch=21, bg="red")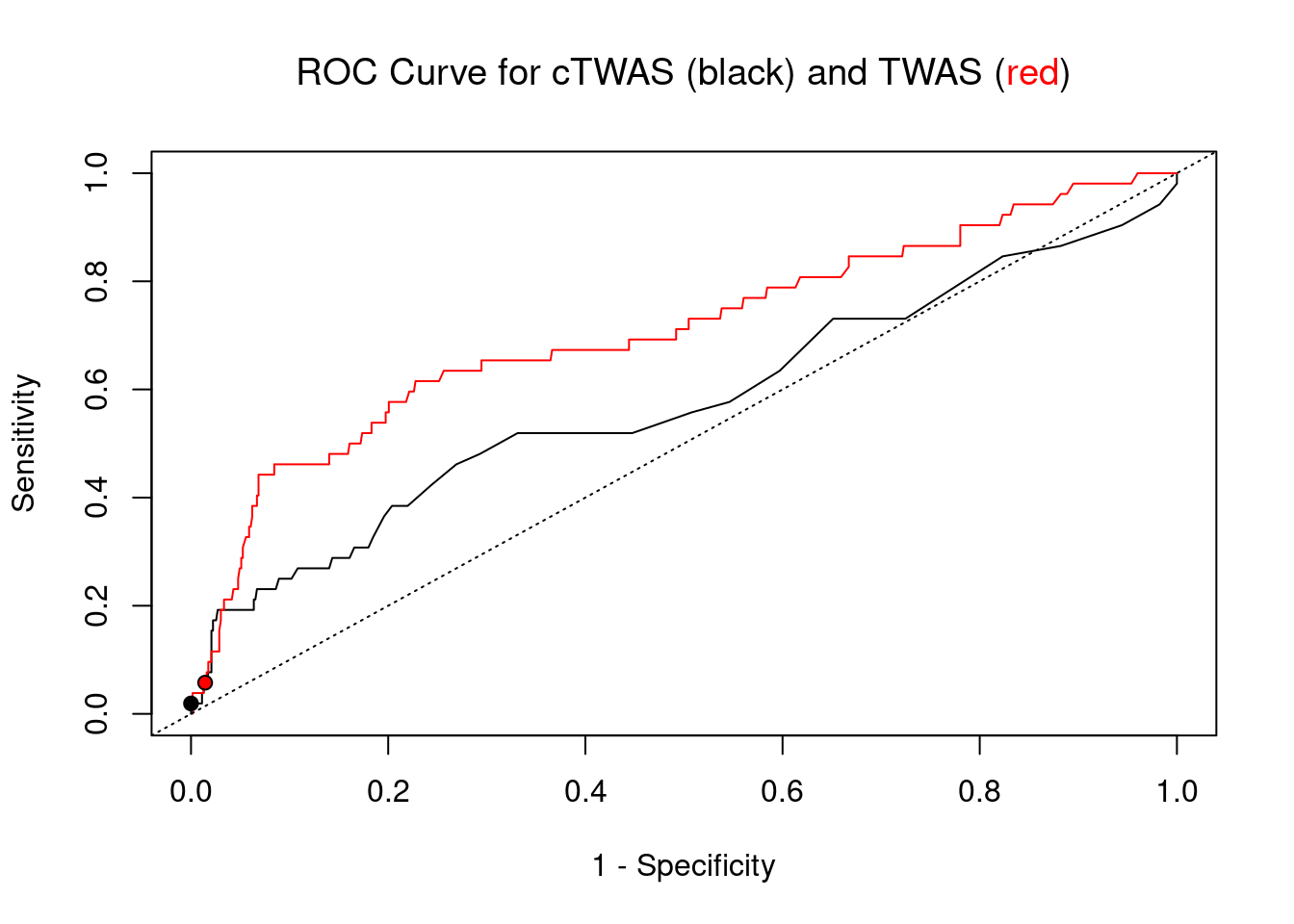
Undetected silver standard genes have low TWAS z-scores or stronger signal from nearby variants
#table of outcomes for silver standard genes
-sort(-table(silver_standard_case))silver_standard_case
Not Imputed Insignificant z-score Nearby SNP(s)
78 49 2
Detected (PIP > 0.8)
1 #show inconclusive genes
silver_standard_case[silver_standard_case=="Inconclusive"]named character(0)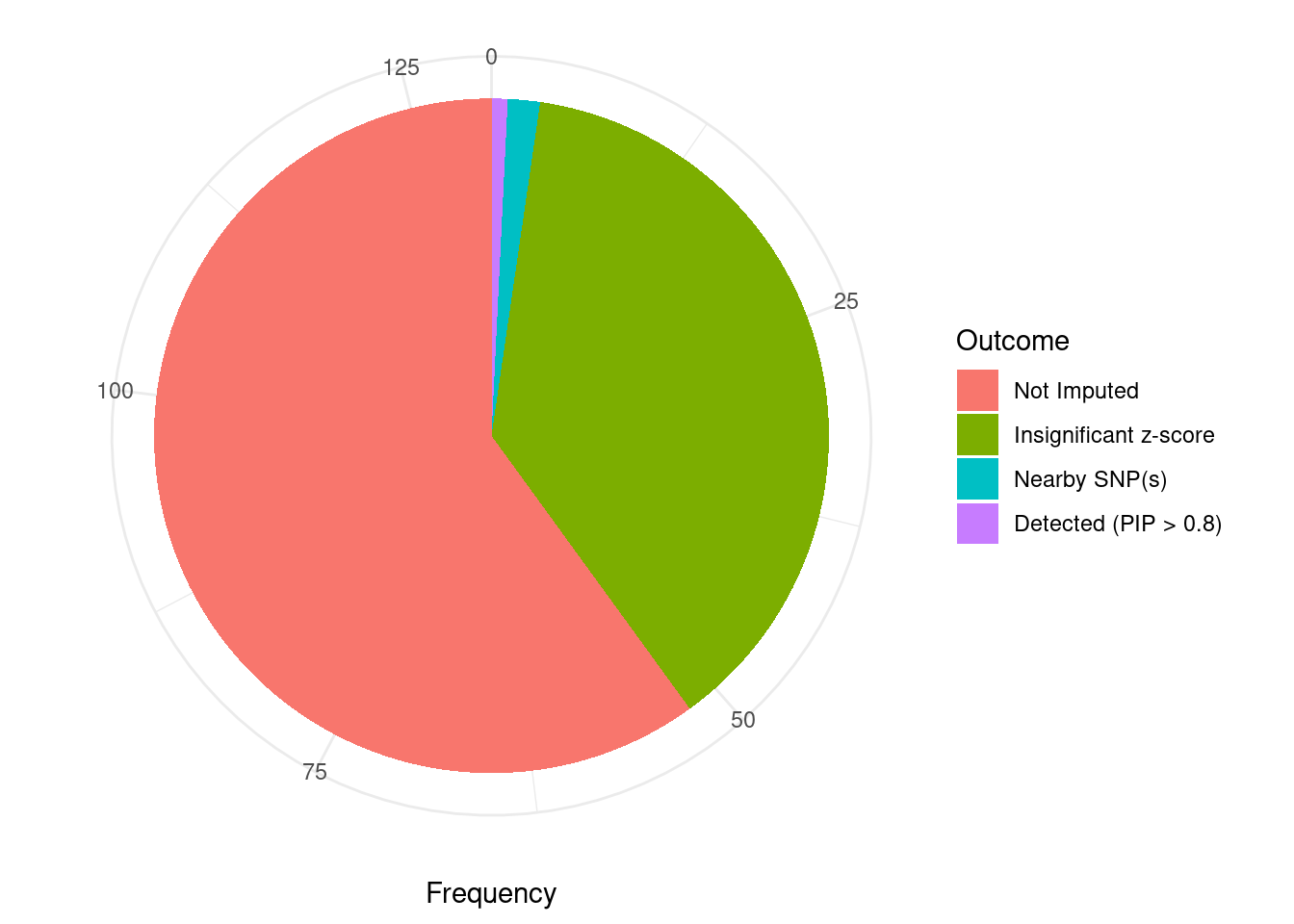
sessionInfo()R version 3.6.1 (2019-07-05)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.4 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.2.19-el7-x86_64/lib/libopenblas_haswellp-r0.2.19.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel stats4 stats graphics grDevices utils datasets
[8] methods base
other attached packages:
[1] GenomicRanges_1.36.1 GenomeInfoDb_1.20.0 IRanges_2.18.1
[4] S4Vectors_0.22.1 BiocGenerics_0.30.0 biomaRt_2.40.1
[7] readxl_1.3.1 forcats_0.5.1 stringr_1.4.0
[10] dplyr_1.0.7 purrr_0.3.4 readr_2.1.1
[13] tidyr_1.1.4 tidyverse_1.3.1 tibble_3.1.6
[16] WebGestaltR_0.4.4 disgenet2r_0.99.2 enrichR_3.0
[19] cowplot_1.0.0 ggplot2_3.3.5 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] ggbeeswarm_0.6.0 colorspace_2.0-2 rjson_0.2.20
[4] ellipsis_0.3.2 rprojroot_2.0.2 XVector_0.24.0
[7] fs_1.5.2 rstudioapi_0.13 farver_2.1.0
[10] ggrepel_0.9.1 bit64_4.0.5 AnnotationDbi_1.46.0
[13] fansi_1.0.2 lubridate_1.8.0 xml2_1.3.3
[16] codetools_0.2-16 doParallel_1.0.17 cachem_1.0.6
[19] knitr_1.36 jsonlite_1.7.2 apcluster_1.4.8
[22] Cairo_1.5-12.2 broom_0.7.10 dbplyr_2.1.1
[25] compiler_3.6.1 httr_1.4.2 backports_1.4.1
[28] assertthat_0.2.1 Matrix_1.2-18 fastmap_1.1.0
[31] cli_3.1.0 later_0.8.0 prettyunits_1.1.1
[34] htmltools_0.5.2 tools_3.6.1 igraph_1.2.10
[37] GenomeInfoDbData_1.2.1 gtable_0.3.0 glue_1.6.2
[40] reshape2_1.4.4 doRNG_1.8.2 Rcpp_1.0.8
[43] Biobase_2.44.0 cellranger_1.1.0 jquerylib_0.1.4
[46] vctrs_0.3.8 svglite_1.2.2 iterators_1.0.14
[49] xfun_0.29 ps_1.6.0 rvest_1.0.2
[52] lifecycle_1.0.1 rngtools_1.5.2 XML_3.99-0.3
[55] zlibbioc_1.30.0 getPass_0.2-2 scales_1.1.1
[58] vroom_1.5.7 hms_1.1.1 promises_1.0.1
[61] yaml_2.2.1 curl_4.3.2 memoise_2.0.1
[64] ggrastr_1.0.1 gdtools_0.1.9 stringi_1.7.6
[67] RSQLite_2.2.8 highr_0.9 foreach_1.5.2
[70] rlang_1.0.1 pkgconfig_2.0.3 bitops_1.0-7
[73] evaluate_0.14 lattice_0.20-38 labeling_0.4.2
[76] bit_4.0.4 processx_3.5.2 tidyselect_1.1.1
[79] plyr_1.8.6 magrittr_2.0.2 R6_2.5.1
[82] generics_0.1.1 DBI_1.1.2 pillar_1.6.4
[85] haven_2.4.3 whisker_0.3-2 withr_2.4.3
[88] RCurl_1.98-1.5 modelr_0.1.8 crayon_1.5.0
[91] utf8_1.2.2 tzdb_0.2.0 rmarkdown_2.11
[94] progress_1.2.2 grid_3.6.1 data.table_1.14.2
[97] blob_1.2.2 callr_3.7.0 git2r_0.26.1
[100] reprex_2.0.1 digest_0.6.29 httpuv_1.5.1
[103] munsell_0.5.0 beeswarm_0.2.3 vipor_0.4.5