Comparing predictdb & Munro: predictdb eQTL + sQTL + Munro rsQTL + apaQTL VS all 8 weights
XSun
2024-09-09
Last updated: 2024-09-10
Checks: 6 1
Knit directory: multigroup_ctwas_analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has unstaged changes. To know which version of
the R Markdown file created these results, you’ll want to first commit
it to the Git repo. If you’re still working on the analysis, you can
ignore this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20231112) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 253c078. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: results/
Unstaged changes:
Modified: analysis/multi_group_compare_predictdb_munro_4weights_8weights.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/multi_group_compare_predictdb_munro_4weights_8weights.Rmd)
and HTML
(docs/multi_group_compare_predictdb_munro_4weights_8weights.html)
files. If you’ve configured a remote Git repository (see
?wflow_git_remote), click on the hyperlinks in the table
below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 253c078 | XSun | 2024-09-10 | update |
| html | 253c078 | XSun | 2024-09-10 | update |
| Rmd | d45c3aa | XSun | 2024-09-09 | update |
| html | d45c3aa | XSun | 2024-09-09 | update |
| Rmd | a581199 | XSun | 2024-09-09 | update |
| html | a581199 | XSun | 2024-09-09 | update |
Settings
6 modalities from Munro
- Weight processing:
PredictDB:
all the PredictDB are converted from FUSION weights
- drop_strand_ambig = TRUE,
- scale_by_ld_variance = F (FUSION converted weights)
- load_predictdb_LD = F,
- Parameter estimation and fine-mapping
- niter_prefit = 5,
- niter = 30(default),
- L: determined by uniform susie,
- group_prior_var_structure = “shared_type”,
- maxSNP = 20000,
- min_nonSNP_PIP = 0.5,
weights from predictdb
- Weight processing:
PredictDB (eqtl, sqtl)
- drop_strand_ambig = TRUE,
- scale_by_ld_variance = T
- load_predictdb_LD = F,
- Parameter estimation and fine-mapping
- group_prior_var_structure = “shared_type”,
- filter_L = TRUE,
- filter_nonSNP_PIP = FALSE,
- min_nonSNP_PIP = 0.5,
- min_abs_corr = 0.1,
mem: 100g 5cores
Results
Four weights
predictdb eQTL + sQTL + Munro rsQTL + apaQTL
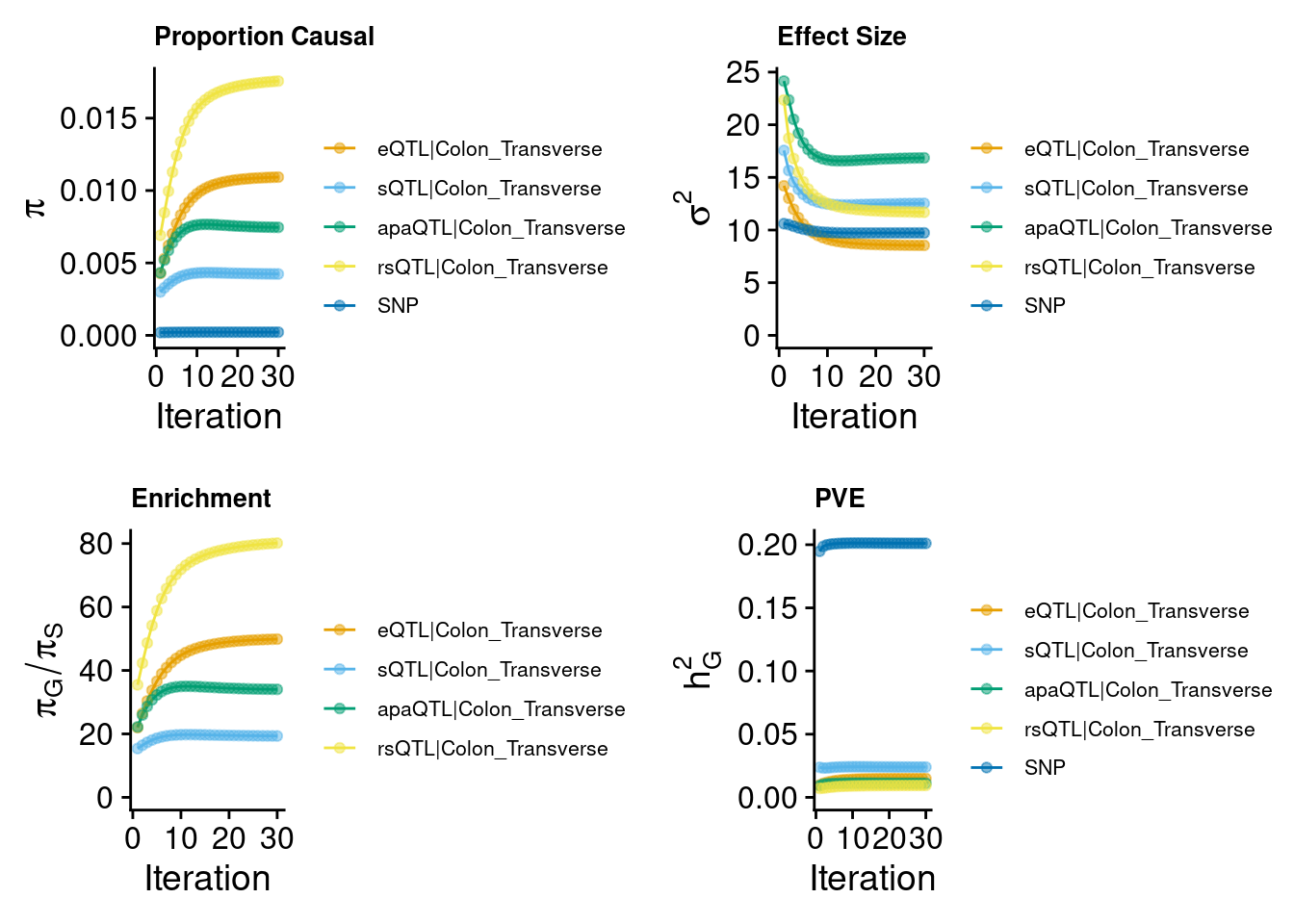
| Version | Author | Date |
|---|---|---|
| a581199 | XSun | 2024-09-09 |
2024-09-10 10:30:54 INFO::Annotating ctwas finemapping result ...
2024-09-10 10:31:04 INFO::add gene_name and gene_type
2024-09-10 10:31:08 INFO::split PIPs for traits mapped to multiple genes
2024-09-10 10:31:08 INFO::use gene mid positions
2024-09-10 10:31:08 INFO::add SNP positionsEight weights
predictdb eQTL + sQTL + Munro 6 modalities
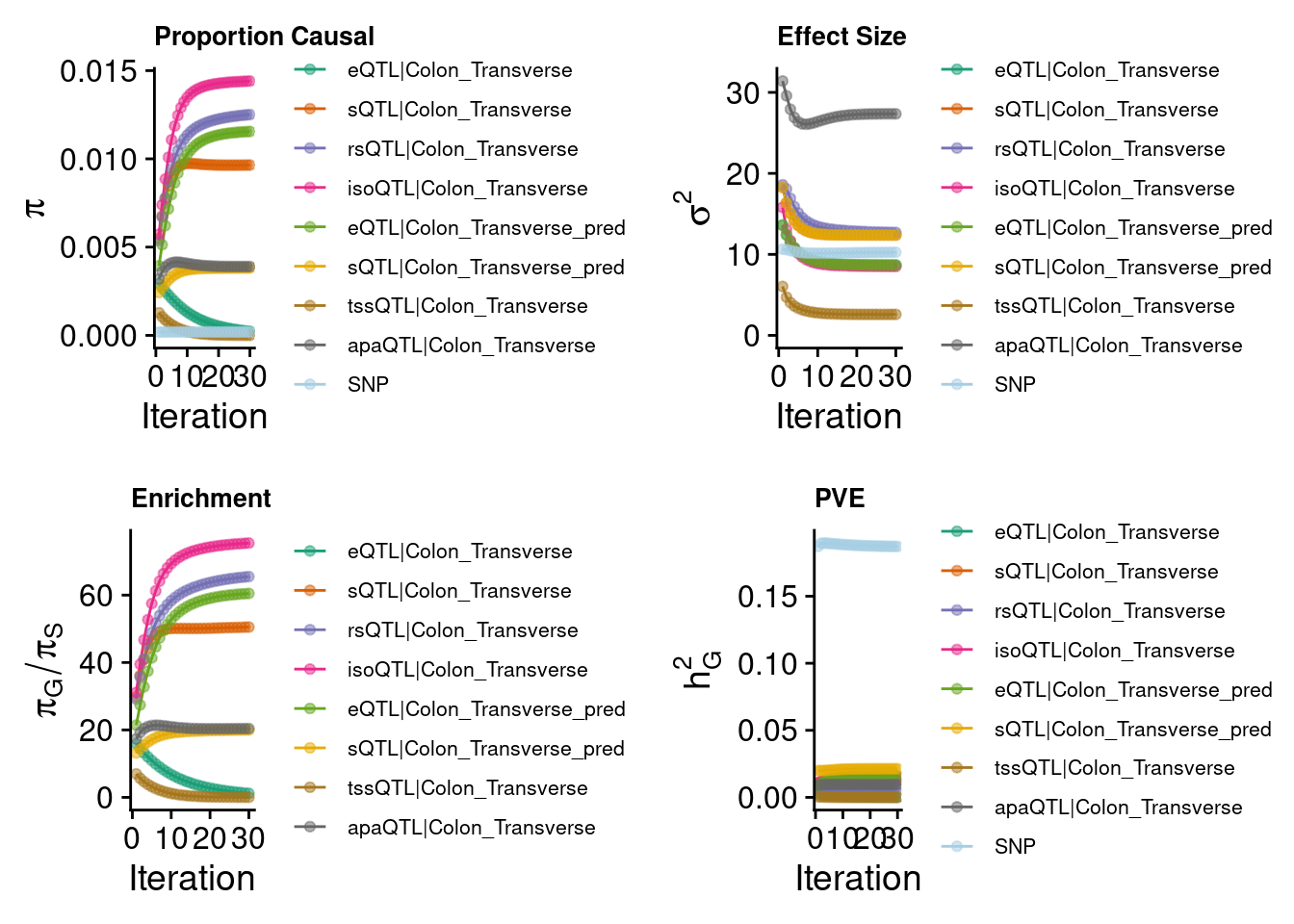
| Version | Author | Date |
|---|---|---|
| a581199 | XSun | 2024-09-09 |
2024-09-10 10:31:30 INFO::Annotating ctwas finemapping result ...
2024-09-10 10:31:34 INFO::add gene_name and gene_typeWarning in left_join(., gene_annot, by = "gene_id", multiple = "all"): Detected an unexpected many-to-many relationship between `x` and `y`.
i Row 185 of `x` matches multiple rows in `y`.
i Row 3411 of `y` matches multiple rows in `x`.
i If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.2024-09-10 10:31:34 INFO::split PIPs for traits mapped to multiple genes
2024-09-10 10:31:35 INFO::use gene mid positions
2024-09-10 10:31:35 INFO::add SNP positionsComparing results from 2 settings
[1] "all genes discovered by 4 weights setting were overlapped with 8 weights setting"Unique genes reported by 8 weights setting
We notice TNFRSF6B PIP was from predictdb sQTL, it should be discovered in the 4 weights setting.
[1] "Locus plot -- 4 weights setting"2024-09-10 10:31:42 INFO::focal gene: TNFRSF6B
2024-09-10 10:31:42 INFO::focal id: ENSG00000243509.4|expression_Colon_Transverse
2024-09-10 10:31:42 INFO::plot locus range: chr20 63558727,64328976
2024-09-10 10:31:42 INFO::TNFRSF6B Colon_Transverse eQTL QTLs
2024-09-10 10:31:42 INFO::QTL positions: 63662692,63697127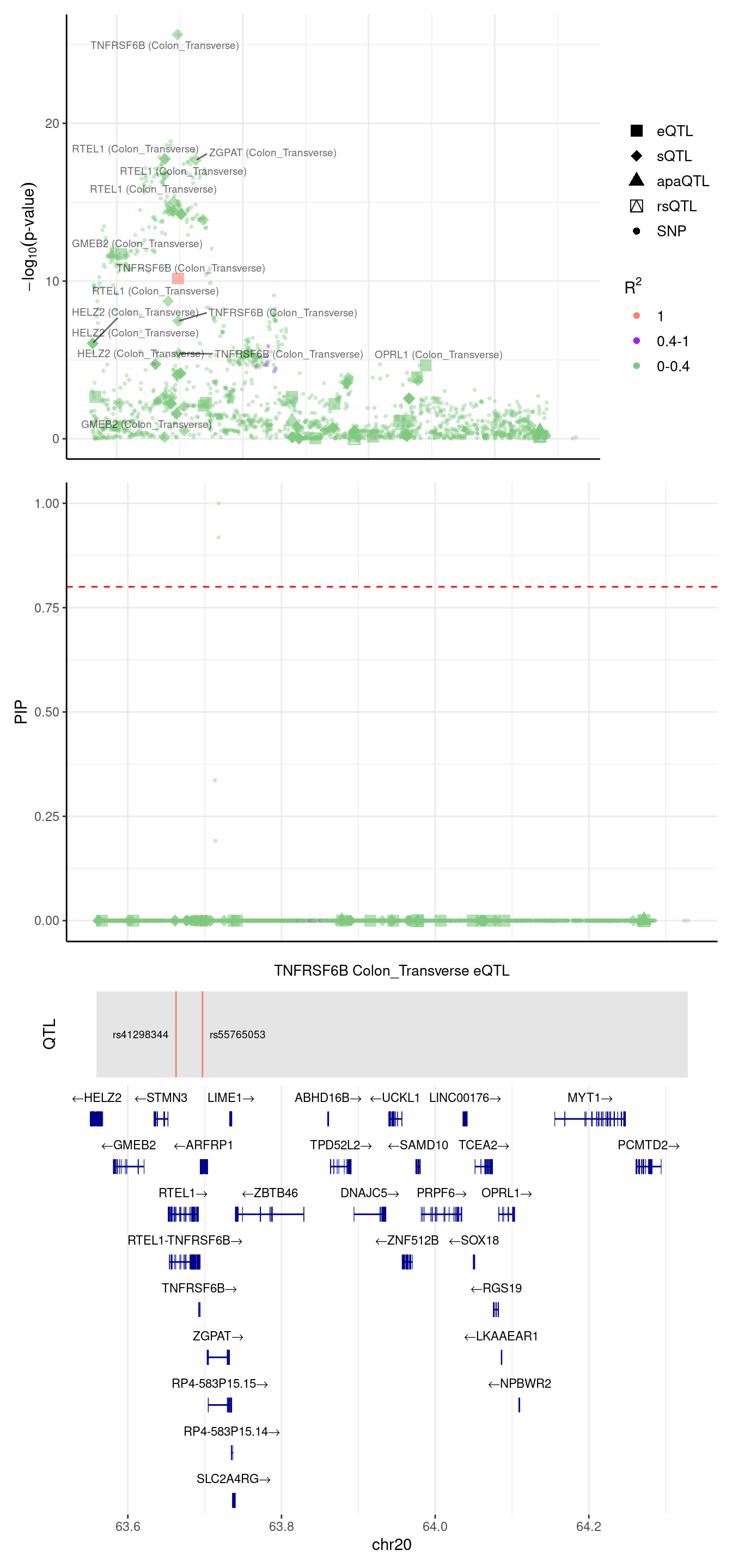
| Version | Author | Date |
|---|---|---|
| d45c3aa | XSun | 2024-09-09 |
[1] "Locus plot -- 8 weights setting"2024-09-10 10:31:46 INFO::focal gene: TNFRSF6B
2024-09-10 10:31:46 INFO::focal id: intron_20_63695854_63696760|splicing_Colon_Transverse
2024-09-10 10:31:46 INFO::plot locus range: chr20 63558727,64328976
2024-09-10 10:31:46 INFO::TNFRSF6B Colon_Transverse_pred sQTL_pred QTLs
2024-09-10 10:31:46 INFO::QTL positions: 63697746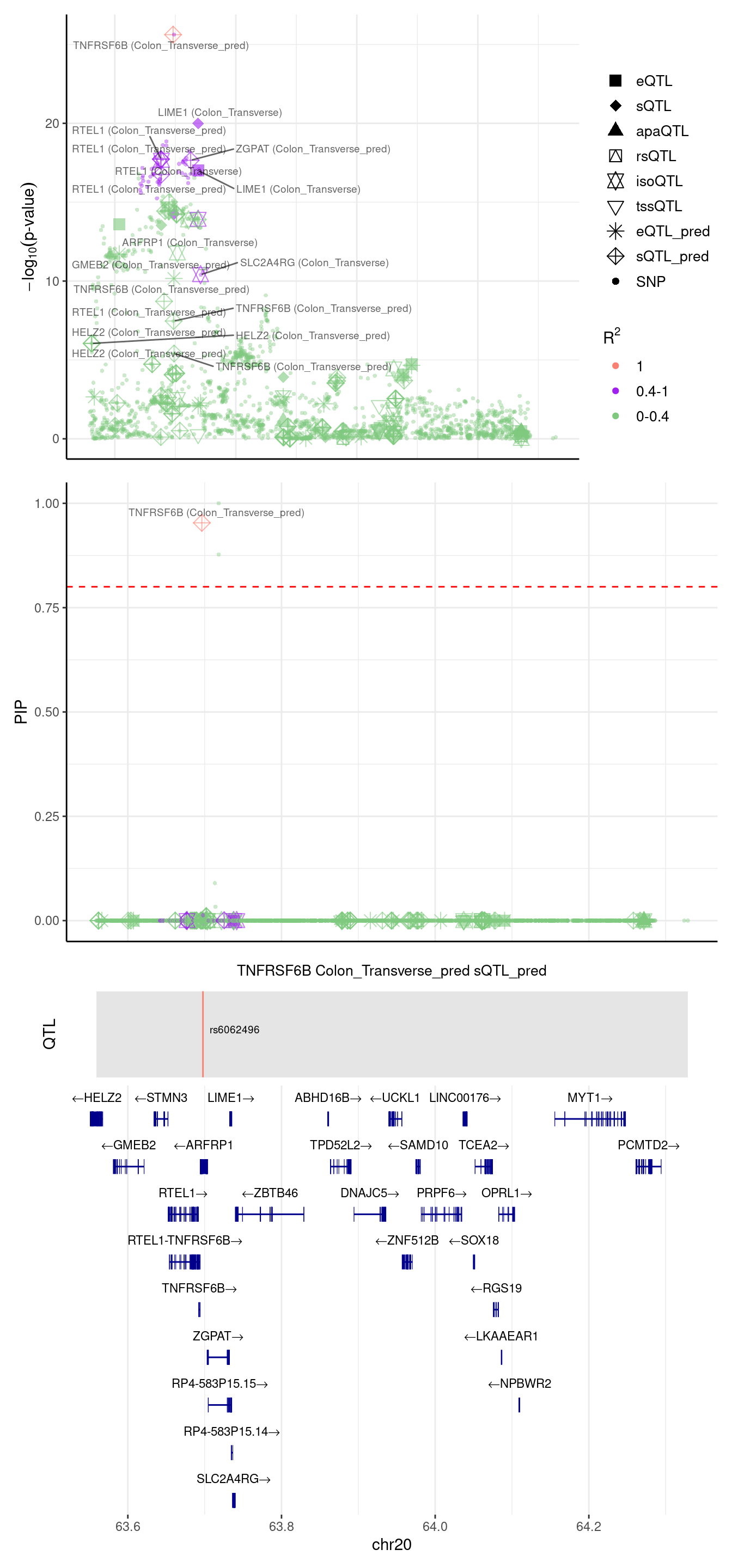
| Version | Author | Date |
|---|---|---|
| d45c3aa | XSun | 2024-09-09 |
[1] "weights for "
[1] "ENSG00000243509:chr20:63695854:63696760:clu_44474_+|splicing_Colon_Transverse"
weight
rs6011040 -0.0211776
rs8957 -0.0255221
[1] "weights for "
[1] "ENSG00000243509.4|expression_Colon_Transverse"
weight
rs41298344 -0.1634486
rs55765053 0.0848684
[1] "weights for "
[1] "intron_20_63697191_63697328|splicing_Colon_Transverse"
weight
rs55765053 0.2576402
[1] "weights for "
[1] "intron_20_63697522_63698280|splicing_Colon_Transverse"
weight
rs74748720 -0.01402964
[1] "weights for "
[1] "intron_20_63695854_63696760|splicing_Colon_Transverse"
weight
rs6062496 -0.0549018The LD for the high pip SNPs in 4 weights setting and the sQTLs in 8 weights setting. The SNPs in row1 and row2 (column1 and column2) are the high pip SNPs in 4 weights setting.
We notice that, the 2 high pip SNPs are in LD themselves. And they are in LD with rs6011040 and rs8957, the sQTL for ENSG00000243509:chr20:63695854:63696760:clu_44474_+|splicing_Colon_Transverse, whose susie pip = 7.516698e-11 in 8 weights setting.
| RS_number | rs6089961 | rs202143810 | rs41298344 | rs55765053 | rs6062496 | rs74748720 | rs6011040 | rs8957 |
|---|---|---|---|---|---|---|---|---|
| rs6089961 | 1.0 | 0.963 | 0.164 | 0.021 | 0.364 | 0.009 | 0.592 | 0.447 |
| rs202143810 | 0.963 | 1.0 | 0.152 | 0.02 | 0.35 | 0.008 | 0.569 | 0.445 |
| rs41298344 | 0.164 | 0.152 | 1.0 | 0.004 | 0.071 | 0.002 | 0.103 | 0.128 |
| rs55765053 | 0.021 | 0.02 | 0.004 | 1.0 | 0.055 | 0.003 | 0.034 | 0.028 |
| rs6062496 | 0.364 | 0.35 | 0.071 | 0.055 | 1.0 | 0.023 | 0.611 | 0.486 |
| rs74748720 | 0.009 | 0.008 | 0.002 | 0.003 | 0.023 | 1.0 | 0.014 | 0.012 |
| rs6011040 | 0.592 | 0.569 | 0.103 | 0.034 | 0.611 | 0.014 | 1.0 | 0.791 |
| rs8957 | 0.447 | 0.445 | 0.128 | 0.028 | 0.486 | 0.012 | 0.791 | 1.0 |
However, the earlier 2 SNPs still have high pip
sessionInfo()R version 4.2.0 (2022-04-22)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: CentOS Linux 7 (Core)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.3.13-el7-x86_64/lib/libopenblas_haswellp-r0.3.13.so
locale:
[1] C
attached base packages:
[1] stats4 stats graphics grDevices utils datasets methods
[8] base
other attached packages:
[1] EnsDb.Hsapiens.v86_2.99.0 ensembldb_2.20.2
[3] AnnotationFilter_1.20.0 GenomicFeatures_1.48.3
[5] AnnotationDbi_1.58.0 Biobase_2.56.0
[7] GenomicRanges_1.48.0 GenomeInfoDb_1.39.9
[9] IRanges_2.30.0 S4Vectors_0.34.0
[11] BiocGenerics_0.42.0 forcats_0.5.1
[13] stringr_1.5.1 dplyr_1.1.4
[15] purrr_1.0.2 readr_2.1.2
[17] tidyr_1.3.0 tibble_3.2.1
[19] ggplot2_3.5.1 tidyverse_1.3.1
[21] data.table_1.14.2 logging_0.10-108
[23] ctwas_0.4.11
loaded via a namespace (and not attached):
[1] colorspace_2.0-3 rjson_0.2.21
[3] ellipsis_0.3.2 rprojroot_2.0.3
[5] XVector_0.36.0 locuszoomr_0.2.1
[7] fs_1.5.2 rstudioapi_0.13
[9] farver_2.1.0 DT_0.22
[11] ggrepel_0.9.1 bit64_4.0.5
[13] lubridate_1.8.0 fansi_1.0.3
[15] xml2_1.3.3 codetools_0.2-18
[17] cachem_1.0.6 knitr_1.39
[19] jsonlite_1.8.0 workflowr_1.7.0
[21] Rsamtools_2.12.0 broom_0.8.0
[23] dbplyr_2.1.1 png_0.1-7
[25] compiler_4.2.0 httr_1.4.3
[27] backports_1.4.1 assertthat_0.2.1
[29] Matrix_1.5-3 fastmap_1.1.0
[31] lazyeval_0.2.2 cli_3.6.1
[33] later_1.3.0 htmltools_0.5.2
[35] prettyunits_1.1.1 tools_4.2.0
[37] gtable_0.3.0 glue_1.6.2
[39] GenomeInfoDbData_1.2.8 rappdirs_0.3.3
[41] Rcpp_1.0.12 cellranger_1.1.0
[43] jquerylib_0.1.4 vctrs_0.6.5
[45] Biostrings_2.64.0 rtracklayer_1.56.0
[47] crosstalk_1.2.0 xfun_0.41
[49] rvest_1.0.2 lifecycle_1.0.4
[51] irlba_2.3.5 restfulr_0.0.14
[53] XML_3.99-0.14 zlibbioc_1.42.0
[55] zoo_1.8-10 scales_1.3.0
[57] gggrid_0.2-0 hms_1.1.1
[59] promises_1.2.0.1 MatrixGenerics_1.8.0
[61] ProtGenerics_1.28.0 parallel_4.2.0
[63] SummarizedExperiment_1.26.1 LDlinkR_1.2.3
[65] yaml_2.3.5 curl_4.3.2
[67] memoise_2.0.1 sass_0.4.1
[69] biomaRt_2.54.1 stringi_1.7.6
[71] RSQLite_2.3.1 highr_0.9
[73] BiocIO_1.6.0 filelock_1.0.2
[75] BiocParallel_1.30.3 rlang_1.1.2
[77] pkgconfig_2.0.3 matrixStats_0.62.0
[79] bitops_1.0-7 evaluate_0.15
[81] lattice_0.20-45 labeling_0.4.2
[83] GenomicAlignments_1.32.0 htmlwidgets_1.5.4
[85] cowplot_1.1.1 bit_4.0.4
[87] tidyselect_1.2.0 magrittr_2.0.3
[89] R6_2.5.1 generics_0.1.2
[91] DelayedArray_0.22.0 DBI_1.2.2
[93] withr_2.5.0 haven_2.5.0
[95] pgenlibr_0.3.3 pillar_1.9.0
[97] whisker_0.4 KEGGREST_1.36.3
[99] RCurl_1.98-1.7 mixsqp_0.3-43
[101] modelr_0.1.8 crayon_1.5.1
[103] utf8_1.2.2 BiocFileCache_2.4.0
[105] plotly_4.10.0 tzdb_0.4.0
[107] rmarkdown_2.25 progress_1.2.2
[109] readxl_1.4.0 grid_4.2.0
[111] blob_1.2.3 git2r_0.30.1
[113] reprex_2.0.1 digest_0.6.29
[115] httpuv_1.6.5 munsell_0.5.0
[117] viridisLite_0.4.0 bslib_0.3.1