nmf_simple_examples
Matthew Stephens
2020-10-09
Last updated: 2020-10-13
Checks: 7 0
Knit directory: misc/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(1) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 3304a12. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.RData
Ignored: analysis/.Rhistory
Ignored: analysis/ALStruct_cache/
Ignored: data/.Rhistory
Ignored: data/pbmc/
Untracked files:
Untracked: .dropbox
Untracked: Icon
Untracked: analysis/GHstan.Rmd
Untracked: analysis/GTEX-cogaps.Rmd
Untracked: analysis/PACS.Rmd
Untracked: analysis/Rplot.png
Untracked: analysis/SPCAvRP.rmd
Untracked: analysis/admm_02.Rmd
Untracked: analysis/admm_03.Rmd
Untracked: analysis/compare-transformed-models.Rmd
Untracked: analysis/cormotif.Rmd
Untracked: analysis/cp_ash.Rmd
Untracked: analysis/eQTL.perm.rand.pdf
Untracked: analysis/eb_prepilot.Rmd
Untracked: analysis/eb_var.Rmd
Untracked: analysis/ebpmf1.Rmd
Untracked: analysis/flash_test_tree.Rmd
Untracked: analysis/flash_tree.Rmd
Untracked: analysis/ieQTL.perm.rand.pdf
Untracked: analysis/lasso_em_03.Rmd
Untracked: analysis/m6amash.Rmd
Untracked: analysis/mash_bhat_z.Rmd
Untracked: analysis/mash_ieqtl_permutations.Rmd
Untracked: analysis/mixsqp.Rmd
Untracked: analysis/mr.ash_lasso_init.Rmd
Untracked: analysis/mr.mash.test.Rmd
Untracked: analysis/mr_ash_modular.Rmd
Untracked: analysis/mr_ash_parameterization.Rmd
Untracked: analysis/mr_ash_pen.Rmd
Untracked: analysis/mr_ash_ridge.Rmd
Untracked: analysis/nejm.Rmd
Untracked: analysis/normal_conditional_on_r2.Rmd
Untracked: analysis/normalize.Rmd
Untracked: analysis/pbmc.Rmd
Untracked: analysis/poisson_transform.Rmd
Untracked: analysis/pseudodata.Rmd
Untracked: analysis/qrnotes.txt
Untracked: analysis/ridge_iterative_02.Rmd
Untracked: analysis/ridge_iterative_splitting.Rmd
Untracked: analysis/samps/
Untracked: analysis/sc_bimodal.Rmd
Untracked: analysis/shrinkage_comparisons_changepoints.Rmd
Untracked: analysis/susie_en.Rmd
Untracked: analysis/susie_z_investigate.Rmd
Untracked: analysis/svd-timing.Rmd
Untracked: analysis/temp.RDS
Untracked: analysis/temp.Rmd
Untracked: analysis/test-figure/
Untracked: analysis/test.Rmd
Untracked: analysis/test.Rpres
Untracked: analysis/test.md
Untracked: analysis/test_qr.R
Untracked: analysis/test_sparse.Rmd
Untracked: analysis/z.txt
Untracked: code/multivariate_testfuncs.R
Untracked: code/rqb.hacked.R
Untracked: data/4matthew/
Untracked: data/4matthew2/
Untracked: data/E-MTAB-2805.processed.1/
Untracked: data/ENSG00000156738.Sim_Y2.RDS
Untracked: data/GDS5363_full.soft.gz
Untracked: data/GSE41265_allGenesTPM.txt
Untracked: data/Muscle_Skeletal.ACTN3.pm1Mb.RDS
Untracked: data/Thyroid.FMO2.pm1Mb.RDS
Untracked: data/bmass.HaemgenRBC2016.MAF01.Vs2.MergedDataSources.200kRanSubset.ChrBPMAFMarkerZScores.vs1.txt.gz
Untracked: data/bmass.HaemgenRBC2016.Vs2.NewSNPs.ZScores.hclust.vs1.txt
Untracked: data/bmass.HaemgenRBC2016.Vs2.PreviousSNPs.ZScores.hclust.vs1.txt
Untracked: data/eb_prepilot/
Untracked: data/finemap_data/fmo2.sim/b.txt
Untracked: data/finemap_data/fmo2.sim/dap_out.txt
Untracked: data/finemap_data/fmo2.sim/dap_out2.txt
Untracked: data/finemap_data/fmo2.sim/dap_out2_snp.txt
Untracked: data/finemap_data/fmo2.sim/dap_out_snp.txt
Untracked: data/finemap_data/fmo2.sim/data
Untracked: data/finemap_data/fmo2.sim/fmo2.sim.config
Untracked: data/finemap_data/fmo2.sim/fmo2.sim.k
Untracked: data/finemap_data/fmo2.sim/fmo2.sim.k4.config
Untracked: data/finemap_data/fmo2.sim/fmo2.sim.k4.snp
Untracked: data/finemap_data/fmo2.sim/fmo2.sim.ld
Untracked: data/finemap_data/fmo2.sim/fmo2.sim.snp
Untracked: data/finemap_data/fmo2.sim/fmo2.sim.z
Untracked: data/finemap_data/fmo2.sim/pos.txt
Untracked: data/logm.csv
Untracked: data/m.cd.RDS
Untracked: data/m.cdu.old.RDS
Untracked: data/m.new.cd.RDS
Untracked: data/m.old.cd.RDS
Untracked: data/mainbib.bib.old
Untracked: data/mat.csv
Untracked: data/mat.txt
Untracked: data/mat_new.csv
Untracked: data/matrix_lik.rds
Untracked: data/paintor_data/
Untracked: data/temp.txt
Untracked: data/y.txt
Untracked: data/y_f.txt
Untracked: data/zscore_jointLCLs_m6AQTLs_susie_eQTLpruned.rds
Untracked: data/zscore_jointLCLs_random.rds
Untracked: explore_udi.R
Untracked: output/fit.k10.rds
Untracked: output/fit.varbvs.RDS
Untracked: output/glmnet.fit.RDS
Untracked: output/test.bv.txt
Untracked: output/test.gamma.txt
Untracked: output/test.hyp.txt
Untracked: output/test.log.txt
Untracked: output/test.param.txt
Untracked: output/test2.bv.txt
Untracked: output/test2.gamma.txt
Untracked: output/test2.hyp.txt
Untracked: output/test2.log.txt
Untracked: output/test2.param.txt
Untracked: output/test3.bv.txt
Untracked: output/test3.gamma.txt
Untracked: output/test3.hyp.txt
Untracked: output/test3.log.txt
Untracked: output/test3.param.txt
Untracked: output/test4.bv.txt
Untracked: output/test4.gamma.txt
Untracked: output/test4.hyp.txt
Untracked: output/test4.log.txt
Untracked: output/test4.param.txt
Untracked: output/test5.bv.txt
Untracked: output/test5.gamma.txt
Untracked: output/test5.hyp.txt
Untracked: output/test5.log.txt
Untracked: output/test5.param.txt
Unstaged changes:
Modified: analysis/ash_delta_operator.Rmd
Modified: analysis/ash_pois_bcell.Rmd
Modified: analysis/lasso_em.Rmd
Modified: analysis/minque.Rmd
Modified: analysis/mr_missing_data.Rmd
Modified: analysis/ridge_admm.Rmd
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/nmf_simple_examples.Rmd) and HTML (docs/nmf_simple_examples.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 3304a12 | Matthew Stephens | 2020-10-13 | workflowr::wflow_publish(“nmf_simple_examples.Rmd”) |
| html | 40bc193 | Matthew Stephens | 2020-10-13 | Build site. |
| Rmd | 051454d | Matthew Stephens | 2020-10-13 | workflowr::wflow_publish(“nmf_simple_examples.Rmd”) |
| html | ef937bb | Matthew Stephens | 2020-10-09 | Build site. |
| Rmd | 170c0bc | Matthew Stephens | 2020-10-09 | workflowr::wflow_publish(“nmf_simple_examples.Rmd”) |
library(NNLM)
library("flashier")
library("magrittr")Introduction
I wanted to try some simple non-negative covariance examples, to assess challenges of getting convergence.
Simple 3-factor case
I set up a covariance matrix with 3 factors (columns of L). I add some very small noise.
set.seed(123)
L= matrix(0,nrow=100,ncol=3)
L[1:50,1] = 1
L[51:100,2] = 1
L[26:75,3] = 1
S = L %*% t(L) + rnorm(100*100,0,0.01)
image(S)
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
SVD
Start with svd: you can see the PCs kind of pick up the three factors, although not exactly of course (SVD is not non-negative….) So this should be a relatively easy case.
S.svd = svd(S)
par(mfcol=c(1,3))
plot(S.svd$u[,1],main='first eigenvector')
plot(S.svd$u[,2],main='second eigenvector')
plot(S.svd$u[,3],main='third eigenvector')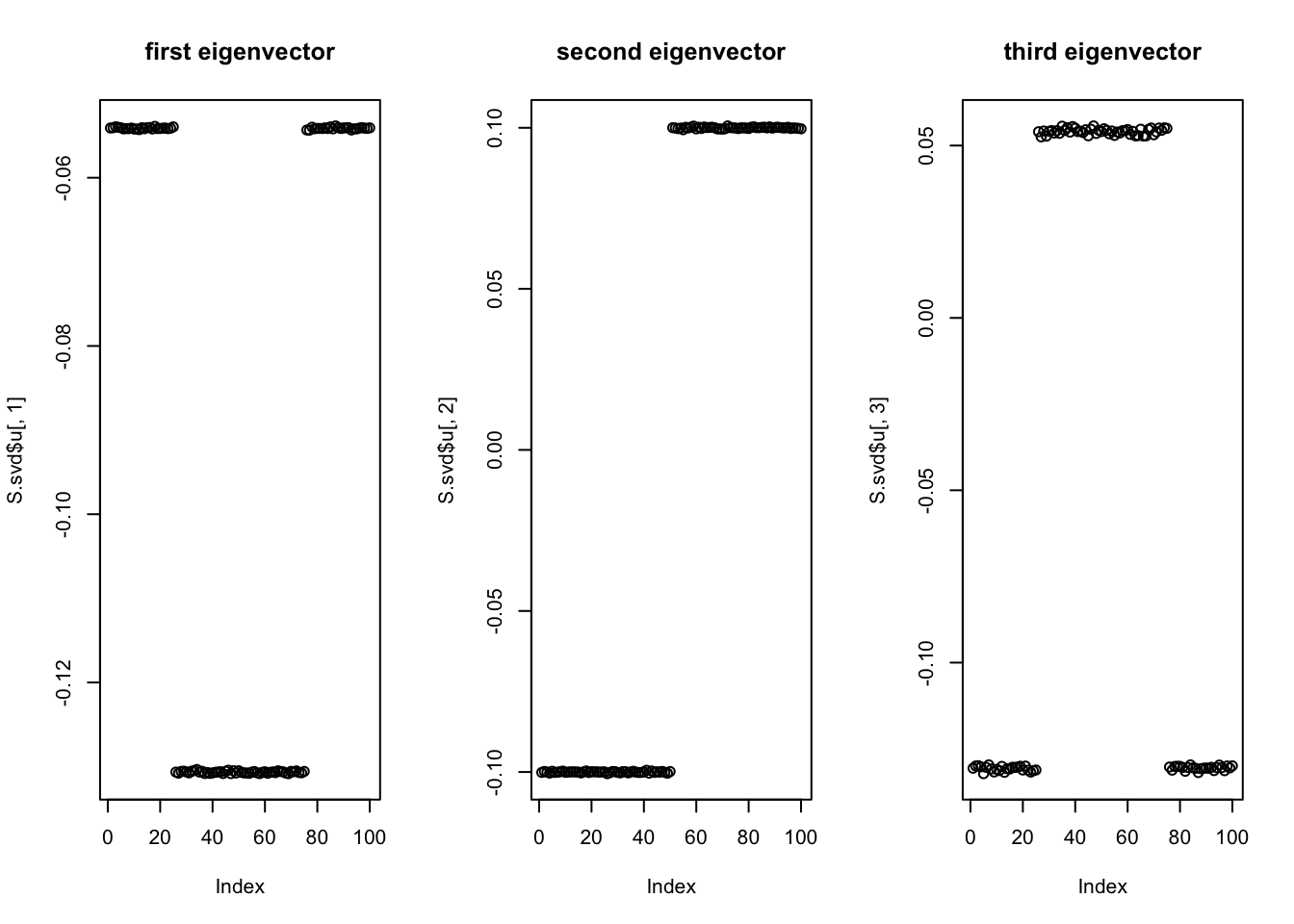
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
NMF
Try non-negative matrix factorization. It works well here.
S.nnmf = nnmf(S,k=3)
par(mfcol=c(1,3))
plot(S.nnmf$W[,1])
plot(S.nnmf$W[,2])
plot(S.nnmf$W[,3])
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
Harder 9-factor case
Negligible noise
Now I do 9 non-negative factors, each having 20 positive entries (out of 100).
K=9
set.seed(1)
L2 = matrix(0,nrow=100,ncol=K)
for(i in 1:K){L2[sample(1:100,20),i]=1}
S2 = L2 %*% t(L2) +rnorm(100*100,0,0.01)
image(S2)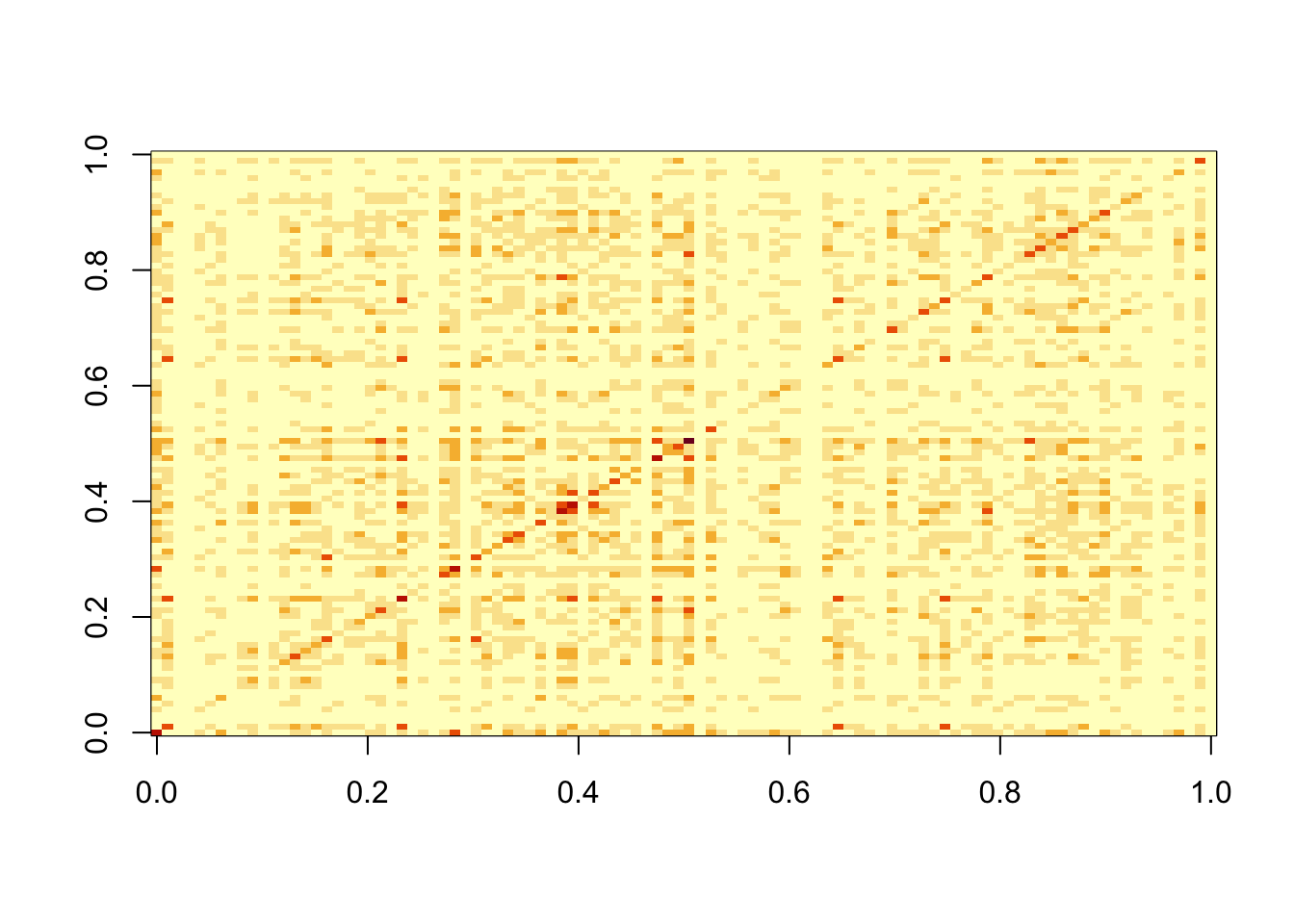
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
SVD
Do svd. We see the rank 10 structure clearly, but the actual factors are clearly now all mixed up among the PCs.
S2.svd = svd(S2)
plot(S2.svd$d[1:30],main="eigenvalues")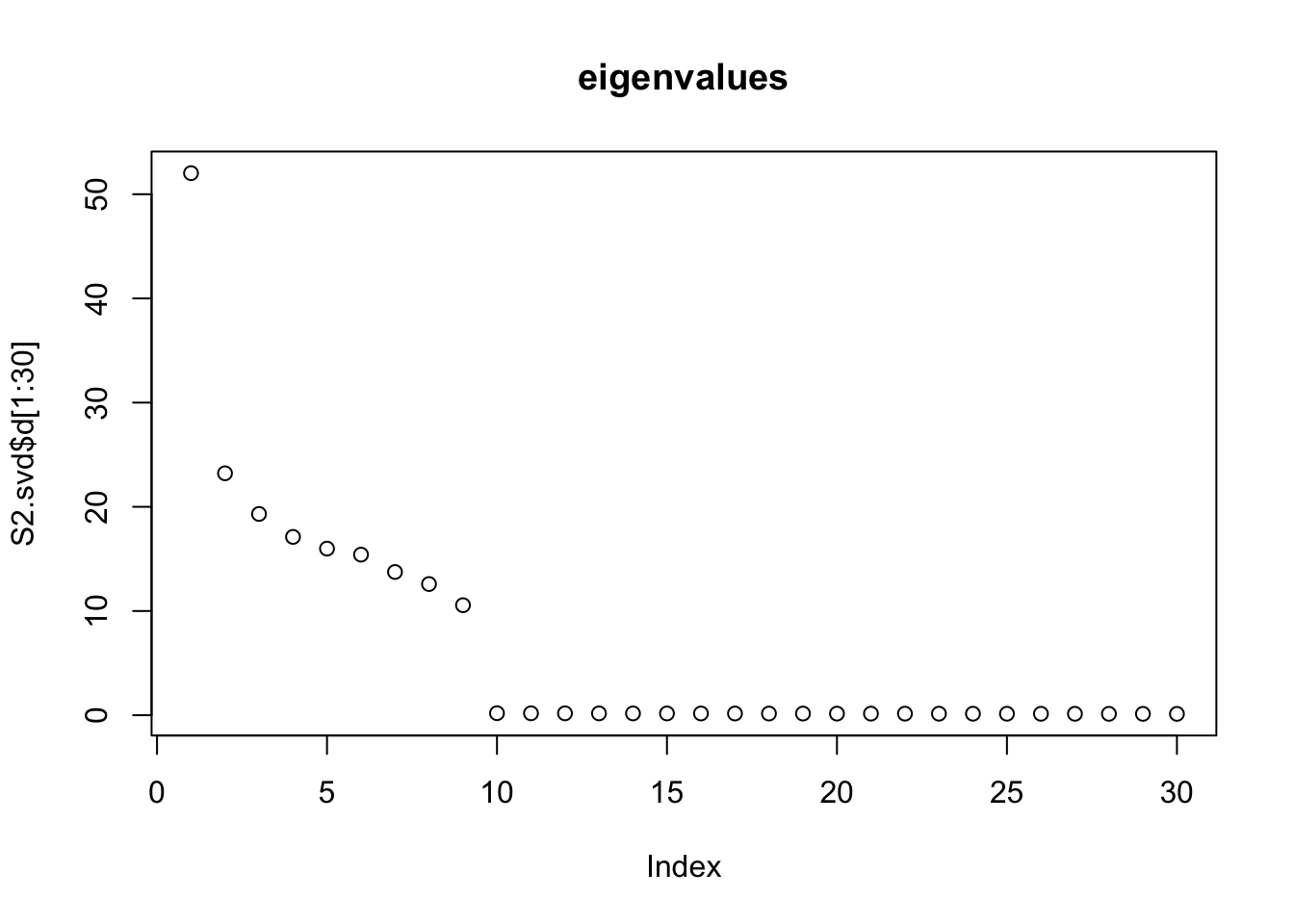
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
par(mfcol=c(1,3))
plot(S2.svd$u[,1],main='first eigenvector')
plot(S2.svd$u[,2],main='second eigenvector')
plot(S2.svd$u[,3],main='third eigenvector')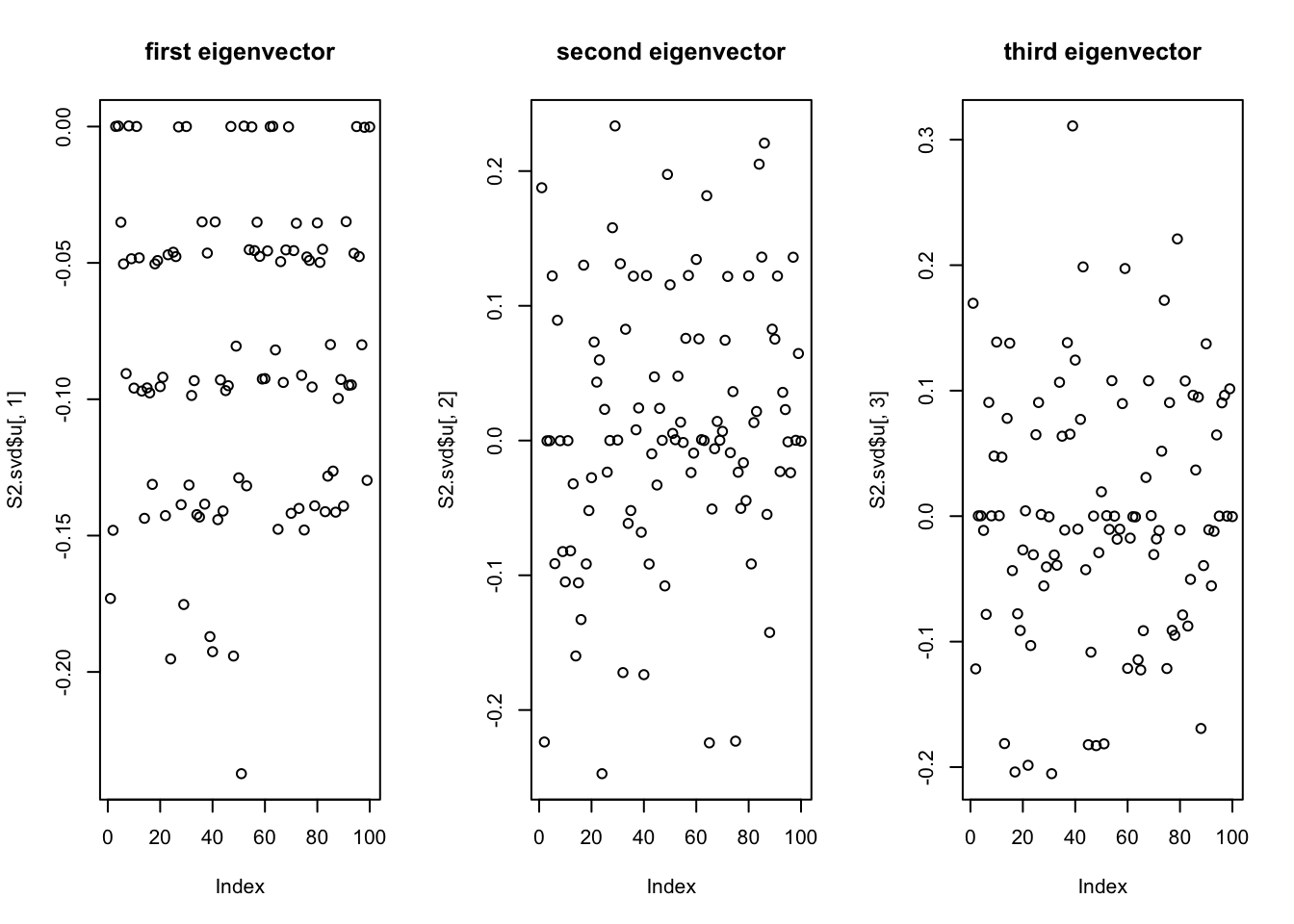
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
NMF
NMF – slightly suprisingly to me it looks great! (I did give it the right K)
S2.nnmf = nnmf(S2,k=K)
# for each column of W find the best matching column in L
get_bestmatch = function(L,W){
LW.c = (cor(L,W)) # finds correlation between columns of L and W
bestmatch = rep(0, ncol(W))
for(i in 1:ncol(W)){
bestmatch[i] = which.max(LW.c[,i])
}
return(bestmatch)
}
bm = get_bestmatch(L2,S2.nnmf$W)
par(mfcol=c(3,3),mai=rep(0.25,4))
for(i in 1:K){
plot(L2[,bm[i]],S2.nnmf$W[,i], main="True L vs Estimate")
}
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
Higher noise (NMF)
Try adding some noise and running NMF. Now the results are (as expected) less clean.
S2n = S2+rnorm(100*100,0,1)
S2n.nnmf = nnmf(S2n,k=K)
bm = get_bestmatch(L2,S2n.nnmf$W)
par(mfcol=c(3,3),mai=rep(0.25,4))
for(i in 1:K){
plot(L2[,bm[i]],S2n.nnmf$W[,i], main="True L vs Estimate")
}
| Version | Author | Date |
|---|---|---|
| ef937bb | Matthew Stephens | 2020-10-09 |
Here I see if I can improve performance by using EB shrinkage methods. (Could also try penalties?). In this one I just use a non-negative prior (not 0-1).
S2n.f <- flash.init(S2n) %>% flash.init.factors(list(S2n.nnmf$W,t(S2n.nnmf$H)),prior.family = prior.nonnegative()) %>% flash.backfit()Backfitting 9 factors (tolerance: 1.49e-04)...
Difference between iterations is within 1.0e+01...
Difference between iterations is within 1.0e+00...
Difference between iterations is within 1.0e-01...
Difference between iterations is within 1.0e-02...
Difference between iterations is within 1.0e-03...
Wrapping up...
Done.par(mfcol=c(3,3),mai=rep(0.25,4))
for(i in 1:K){
plot(L2[,bm[i]],S2n.f$loadings.pm[[1]][,i], main="True L vs Estimate")
}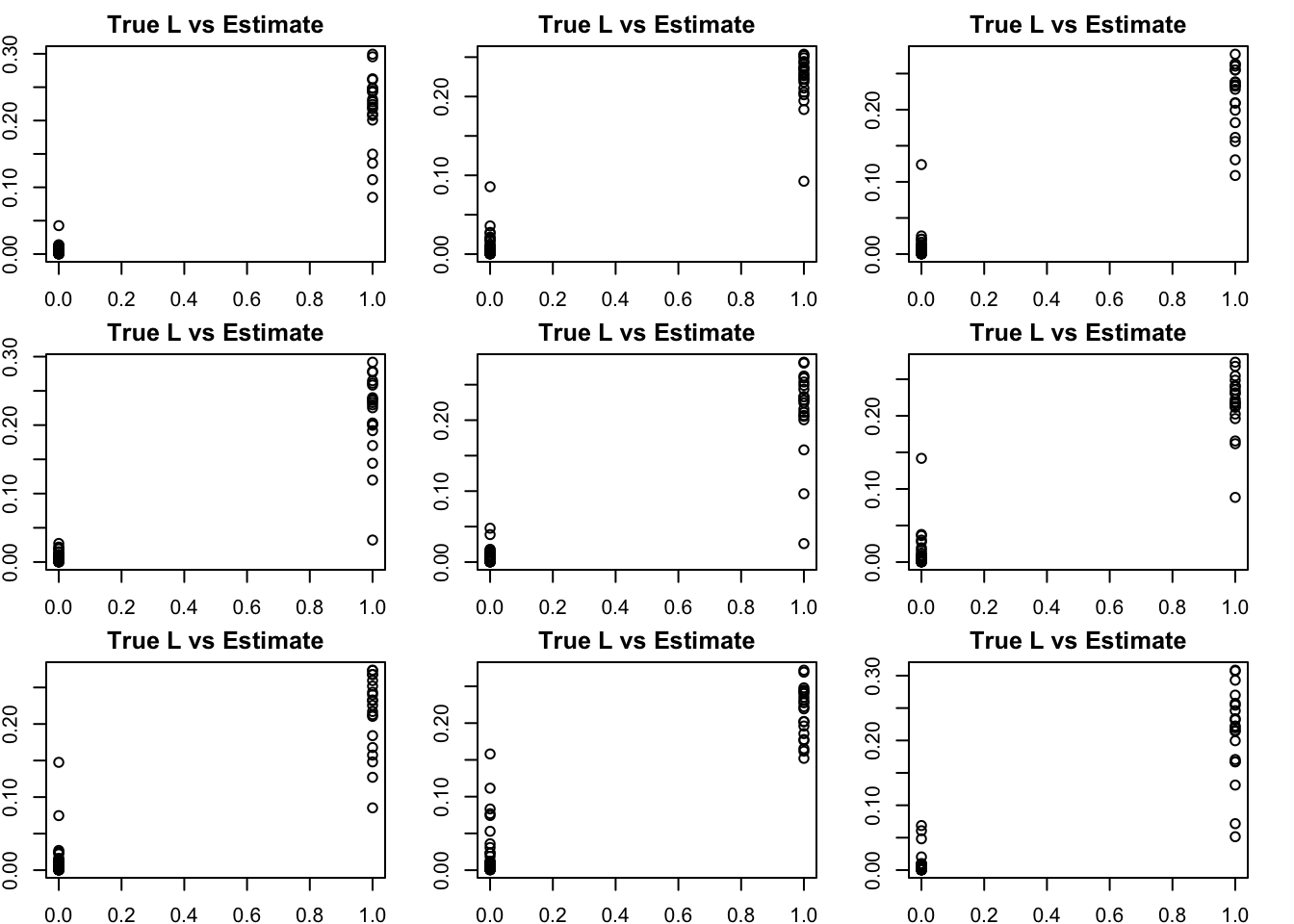
Although the plots do not look so different, the EB shrinkage ddoes consistently improves the correlations between the true values and the estimates:
cors = matrix(nrow=K, ncol=2)
colnames(cors) = c("flash","nnmf")
for(i in 1:K){
cors[i,] = (c(cor(L2[,bm[i]],S2n.f$loadings.pm[[1]][,i]), cor(L2[,bm[i]],S2n.nnmf$W[,i])))
}
print(cors,digits=2) flash nnmf
[1,] 0.96 0.91
[2,] 0.95 0.92
[3,] 0.95 0.90
[4,] 0.98 0.94
[5,] 0.95 0.90
[6,] 0.95 0.89
[7,] 0.96 0.92
[8,] 0.96 0.93
[9,] 0.93 0.88Tree-like case
We have found some challenges with tree-like case, so we try that here. This simulates a symmetric 4-tip tree (6 branches total), with a factor for each branch.
set.seed(1)
L3 = matrix(0,nrow=100,ncol=6)
L3[1:50,1] = 1 #top split L
L3[51:100,2] = 1 # top split R
L3[1:25,3] = 1
L3[26:50,4] = 1
L3[51:75,5] = 1
L3[76:100,6] = 1
S3 = L3 %*% t(L3) +rnorm(100*100,0,0.01)
image(S3)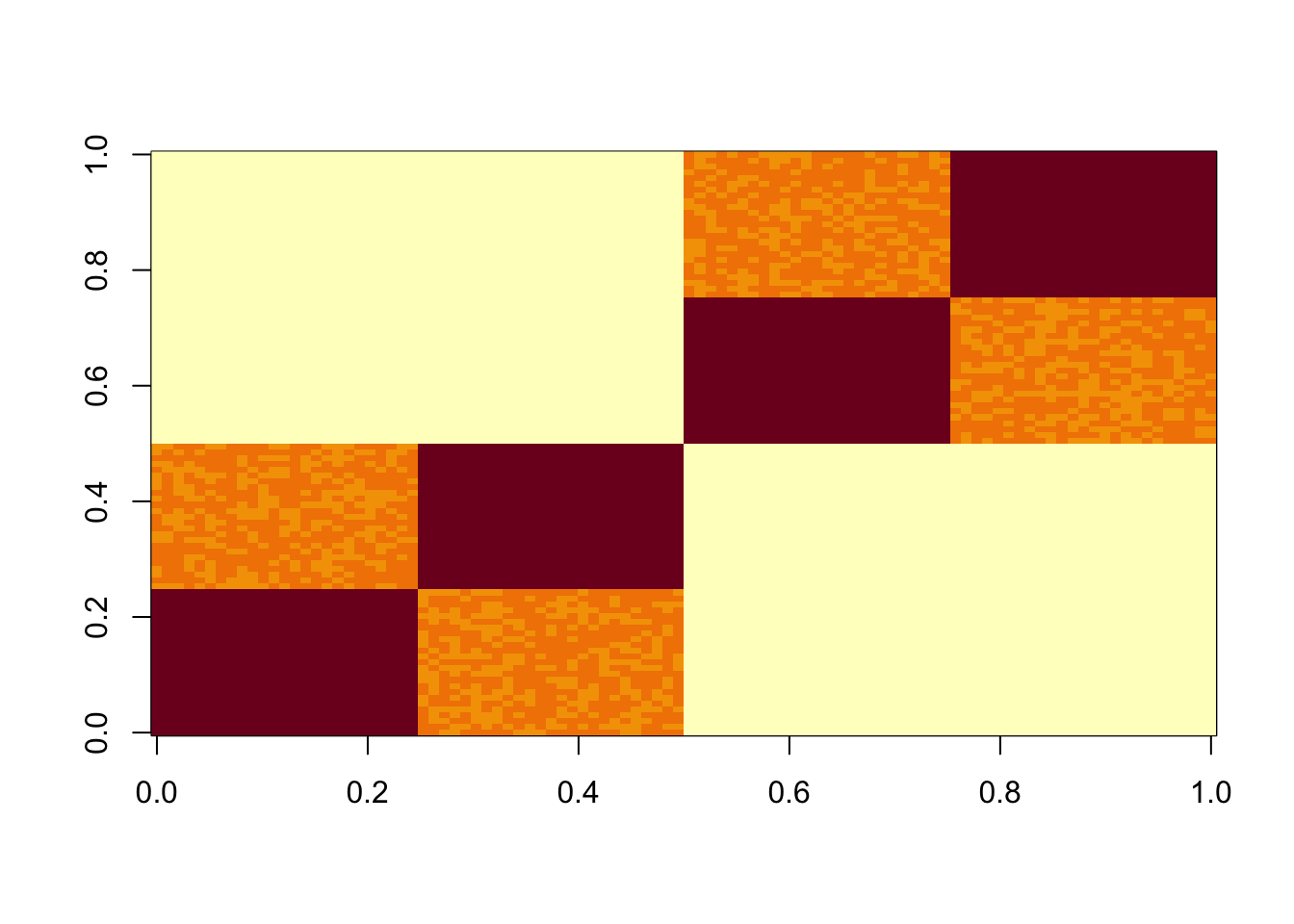
| Version | Author | Date |
|---|---|---|
| 40bc193 | Matthew Stephens | 2020-10-13 |
The results confirm that finding the representation that we want (in which each factor represents a branch) is not achieved by off-the-shelf methods. This is essentially because many factors (in the branch represenation) are linearly dependent with one another.
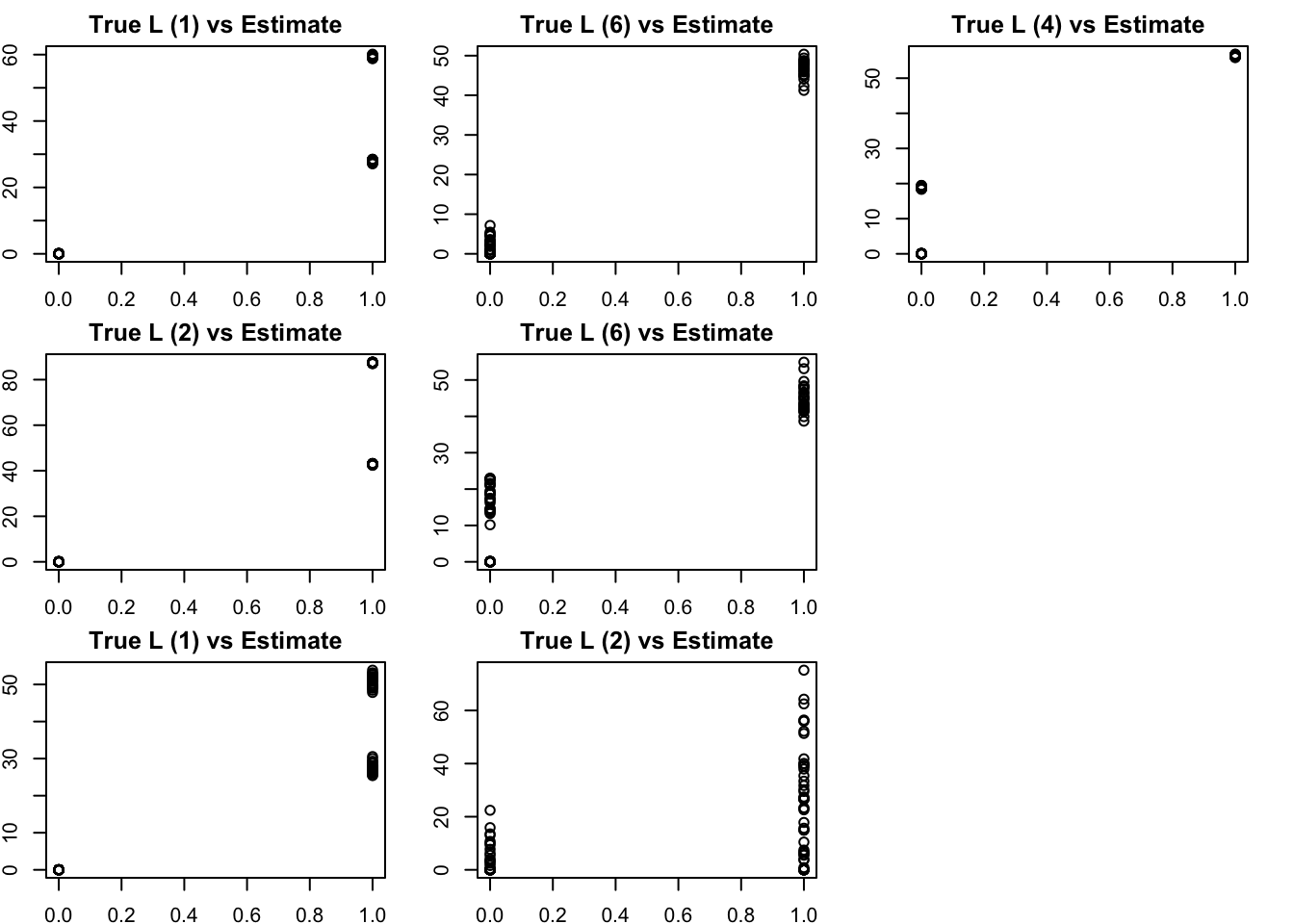
Here, many of the estimated factors from NMF correlate most with the top split (factor 1 or 2) and have partial memberships that capture some of the lower splits.
S3.nnmf = nnmf(S3,k=7)
bm = get_bestmatch(L3,S3.nnmf$W)
par(mfcol=c(3,3),mai=rep(0.25,4))
for(i in 1:7){
plot(L3[,bm[i]],S3.nnmf$W[,i], main=paste0("True L (",bm[i], ") vs Estimate"))
}
| Version | Author | Date |
|---|---|---|
| 40bc193 | Matthew Stephens | 2020-10-13 |
sessionInfo()R version 3.6.0 (2019-04-26)
Platform: x86_64-apple-darwin15.6.0 (64-bit)
Running under: macOS Mojave 10.14.6
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] magrittr_1.5 flashier_0.2.7 NNLM_0.4.4
loaded via a namespace (and not attached):
[1] Rcpp_1.0.5 pillar_1.4.6 compiler_3.6.0 later_1.1.0.1
[5] git2r_0.27.1 workflowr_1.6.2 tools_3.6.0 digest_0.6.25
[9] evaluate_0.14 lifecycle_0.2.0 tibble_3.0.3 lattice_0.20-41
[13] pkgconfig_2.0.3 rlang_0.4.7 Matrix_1.2-18 rstudioapi_0.11
[17] parallel_3.6.0 yaml_2.2.1 ebnm_0.1-24 xfun_0.16
[21] invgamma_1.1 stringr_1.4.0 knitr_1.29 fs_1.4.2
[25] vctrs_0.3.4 rprojroot_1.3-2 grid_3.6.0 glue_1.4.2
[29] R6_2.4.1 rmarkdown_2.3 mixsqp_0.3-43 irlba_2.3.3
[33] ashr_2.2-51 whisker_0.4 backports_1.1.10 promises_1.1.1
[37] ellipsis_0.3.1 htmltools_0.5.0 httpuv_1.5.4 stringi_1.4.6
[41] truncnorm_1.0-8 SQUAREM_2020.3 crayon_1.3.4