Motif analysis using topic modeling results for Cusanovich et al (2018) scATAC-seq data
Kaixuan Luo
Last updated: 2021-01-19
Checks: 7 0
Knit directory: scATACseq-topics/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it's best to always run the code in an empty environment.
The command set.seed(20200729) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version f51b56e. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: analysis/diff_count_Buenrostro2018_chomVAR_scPeaks.Rmd
Untracked: analysis/gene_analysis_Cusanovich2018.Rmd
Untracked: analysis/process_data_Buenrostro2018_Chen2019.Rmd
Untracked: analysis/single_cell_rnaseq_demo.Rmd
Untracked: output/Cusanovich2018/
Untracked: output/clustering-Cusanovich2018.rds
Untracked: output/gsea_topic_1_Cusanovich2018-k=13-TSS-sum.html
Untracked: output/gsea_topic_1_Cusanovich2018-k=13-TSS-sum.png
Untracked: output/gsea_topic_1_Cusanovich2018-k=13-TSS-sum_files/
Untracked: output/gsea_topic_1_Cusanovich2018-k=13-genebody-sum.html
Untracked: output/gsea_topic_1_Cusanovich2018-k=13-genebody-sum.png
Untracked: output/gsea_topic_1_Cusanovich2018-k=13-genebody-sum_files/
Untracked: output/volcano_topic_1_Cusanovich2018-k=13-TSS-sum.html
Untracked: output/volcano_topic_1_Cusanovich2018-k=13-TSS-sum.png
Untracked: output/volcano_topic_1_Cusanovich2018-k=13-TSS-sum_files/
Untracked: output/volcano_topic_1_Cusanovich2018-k=13-genebody-sum.html
Untracked: output/volcano_topic_1_Cusanovich2018-k=13-genebody-sum.png
Untracked: output/volcano_topic_1_Cusanovich2018-k=13-genebody-sum_files/
Untracked: scripts/fit_all_models_Buenrostro_2018_chromVar_scPeaks_filtered.sbatch
Unstaged changes:
Modified: analysis/cisTopic_Buenrostro2018_chomVAR_scPeaks.Rmd
Modified: analysis/motif_gene_analysis_Cusanovich2018.Rmd
Modified: analysis/plots_Lareau2019_bonemarrow.Rmd
Modified: code/motif_analysis.R
Modified: code/plots.R
Modified: scripts/fit_all_models_Buenrostro_2018.sbatch
Modified: scripts/fit_cisTopic_Buenrostro_2018_chromVAR_scPeaks.sh
Modified: scripts/postfit_Buenrostro2018.sh
Modified: scripts/postfit_Cusanovich2018.sh
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/motif_analysis_Cusanovich2018.Rmd) and HTML (docs/motif_analysis_Cusanovich2018.html) files. If you've configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | f51b56e | kevinlkx | 2021-01-19 | added colors to scatterplots for motif enrichment and gene scores |
| html | 14eac34 | kevinlkx | 2021-01-19 | Build site. |
| Rmd | 5f18411 | kevinlkx | 2021-01-19 | Plot motif enrichment and correlate with gene scores |
Here we perform TF motif analysis for the Cusanovich et al (2018) scATAC-seq result inferred from the multinomial topic model with \(k = 13\).
Load packages and some functions used in this analysis
library(Matrix)
library(fastTopics)
library(dplyr)
library(tidyr)
library(ggplot2)
library(ggrepel)
library(cowplot)
library(plotly)
library(htmlwidgets)
library(DT)
library(reshape2)
source("code/plots.R")Load data and topic model results
Load the data and the \(k = 13\) Poisson NMF fit results.
data.dir <- "/project2/mstephens/kevinluo/scATACseq-topics/data/Cusanovich_2018/processed_data/"
load(file.path(data.dir, "Cusanovich_2018.RData"))
rm(counts)fit.dir <- "/project2/mstephens/kevinluo/scATACseq-topics/output/Cusanovich_2018"
fit <- readRDS(file.path(fit.dir, "/fit-Cusanovich2018-scd-ex-k=13.rds"))$fit
fit_multinom <- poisson2multinom(fit)Visualize by Structure plot grouped by tissues
set.seed(10)
colors_topics <- c("#a6cee3","#1f78b4","#b2df8a","#33a02c","#fb9a99","#e31a1c",
"#fdbf6f","#ff7f00","#cab2d6","#6a3d9a","#ffff99","#b15928",
"gray")
rows <- sample(nrow(fit$L),4000)
samples$tissue <- as.factor(samples$tissue)
p.structure <- structure_plot(select(fit_multinom,loadings = rows),
grouping = samples[rows, "tissue"],n = Inf,gap = 40,
perplexity = 50,topics = 1:13,colors = colors_topics,
num_threads = 4,verbose = FALSE)
print(p.structure)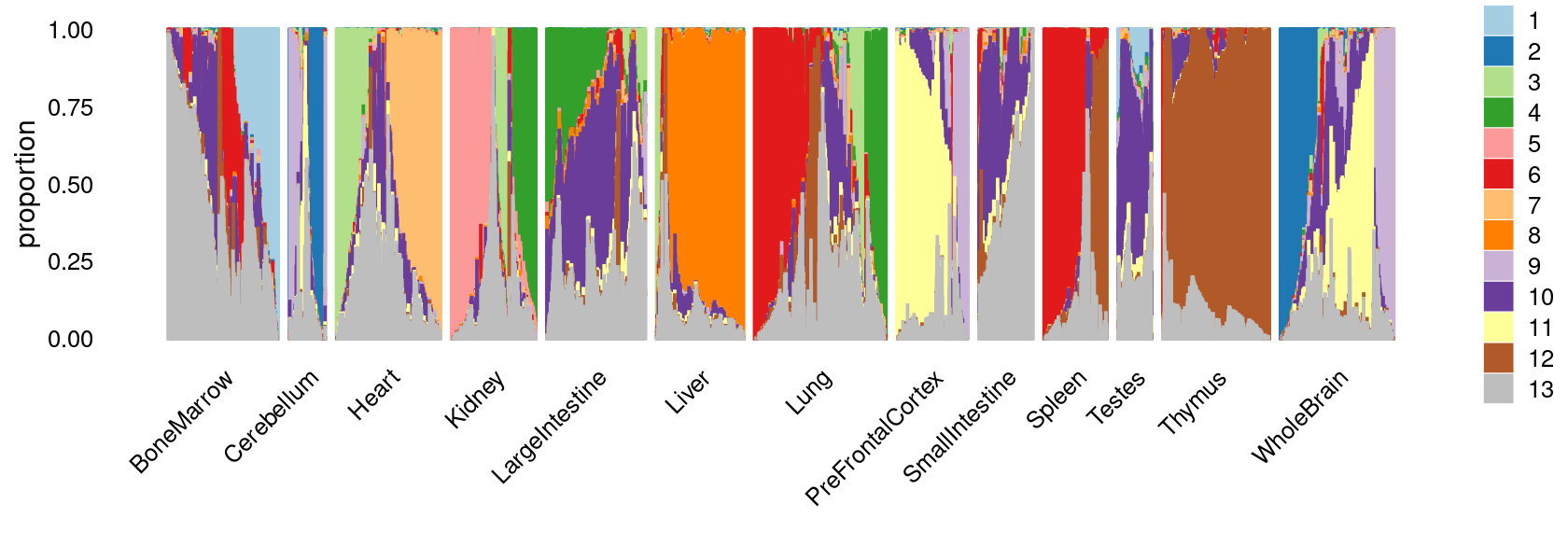
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
Differential accessbility analysis of the ATAC-seq regions for the topics
Load results from differential accessbility analysis for the topics
out.dir <- "/project2/mstephens/kevinluo/scATACseq-topics/output/Cusanovich_2018"
cat(sprintf("Load results from %s \n", out.dir))# Load results from /project2/mstephens/kevinluo/scATACseq-topics/output/Cusanovich_2018diff_count_topics <- readRDS(file.path(out.dir, "/diffcount-Cusanovich2018-13topics.rds"))Distribution of z-scores
zscore_topics <- melt(diff_count_topics$Z)
colnames(zscore_topics) <- c("region", "topic", "zscore")
levels(zscore_topics$topic) <- colnames(diff_count_topics$Z)
z.quantile.99 <- apply(abs(diff_count_topics$Z), 2, quantile, 0.99)
cat("z-score 99% quantile: \n")
print(z.quantile.99)
p.hist.zscores <- ggplot(zscore_topics, aes(x=zscore)) +
geom_histogram(binwidth=1, color="black", fill="white") +
coord_cartesian(xlim = c(-10, 30)) + theme_cowplot(font_size = 10) +
facet_wrap(~ topic, ncol=4)
print(p.hist.zscores)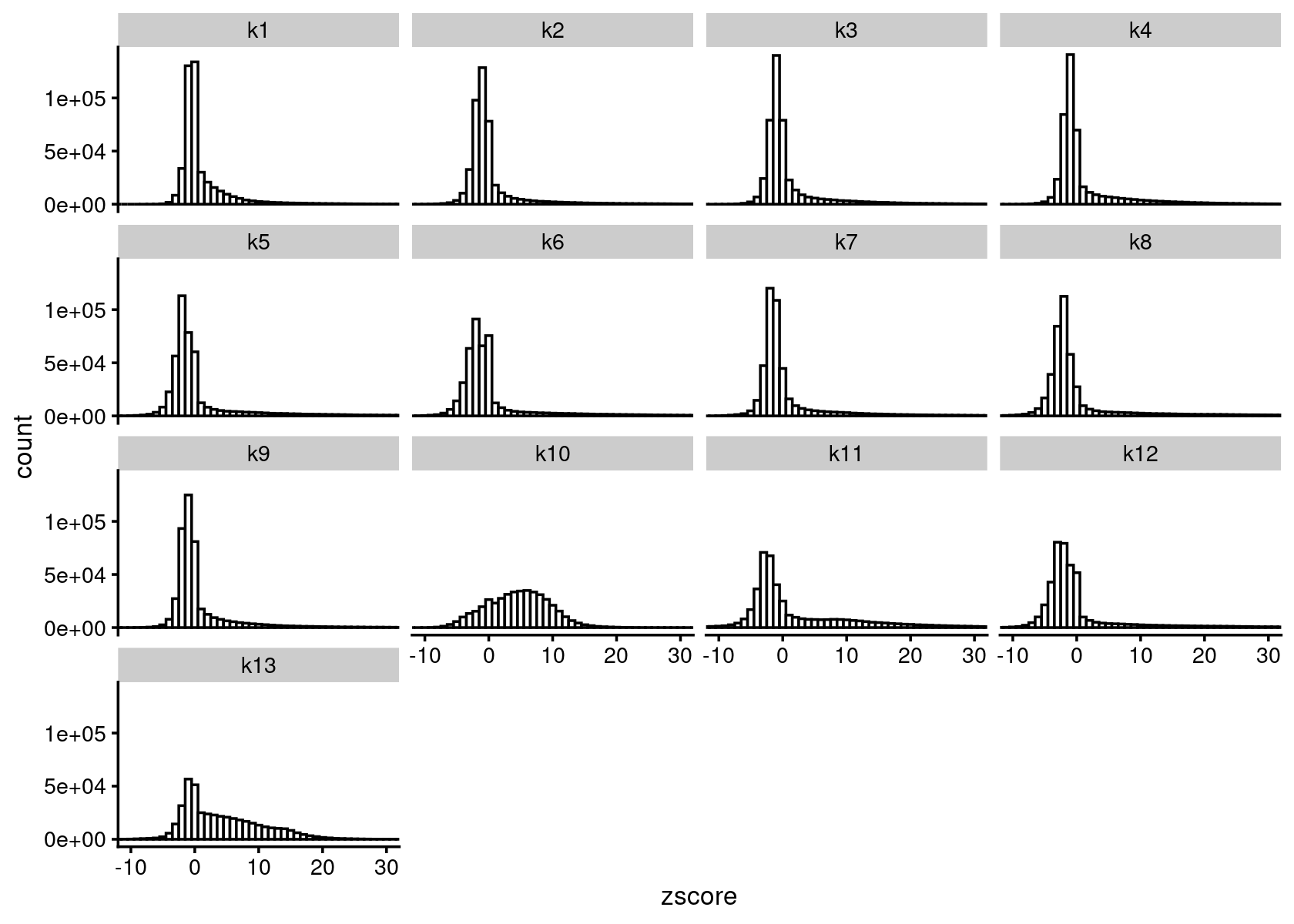
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
# z-score 99% quantile:
# k1 k2 k3 k4 k5 k6 k7 k8
# 21.42992 31.48751 25.46082 25.97670 34.64418 37.09098 32.07250 39.65746
# k9 k10 k11 k12 k13
# 25.93102 15.88394 34.29782 39.80147 20.71928Volcano plot of the regions for topic 1
volcano_plot(diff_count_topics,k = 1,label_above_quantile = Inf,
subsample_below_quantile = 0.7, subsample_rate = 0.1)# 161397 out of 436206 data points will be included in plot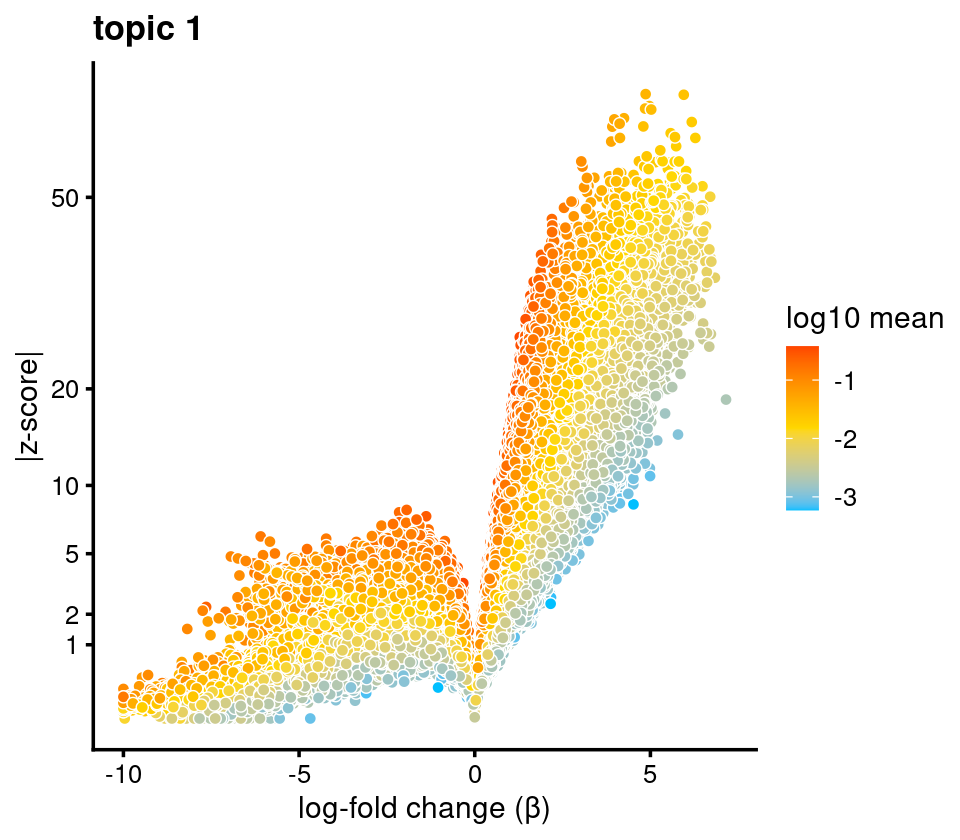
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
Motif enrichment analysis using HOMER
- Details about HOMER motif analysis:
- Motif enrichment result using regions with z-score above 99% quantile.
Compile Homer results across topics
homer.dir <- paste0(out.dir, "/motifanalysis-Cusanovich2018-k=13-quantile/HOMER")
cat(sprintf("Directory of motif analysis result: %s \n", homer.dir))
homer_res_topics <- readRDS(file.path(homer.dir, "/homer_knownResults.rds"))
selected_regions <- readRDS(file.path(homer.dir, "/selected_regions.rds"))
# Compile Homer results (pvalue and ranking) across topics
motif_res <- compile_homer_motif_res(homer_res_topics)
saveRDS(motif_res, paste0(homer.dir, "/homer_motif_enrichment_results.rds"))
cat("compiled homer motif results are saved in", paste0(homer.dir, "/homer_motif_enrichment_results.rds"))
motif_table <- data.frame(motif = gsub("/.*", "", rownames(motif_res$mlog10P)),
motif_res$mlog10P)
DT::datatable(motif_table, rownames = F, caption = "Motif enrichment (-log10P)")# Directory of motif analysis result: /project2/mstephens/kevinluo/scATACseq-topics/output/Cusanovich_2018/motifanalysis-Cusanovich2018-k=13-quantile/HOMER
# compiled homer motif results are saved in /project2/mstephens/kevinluo/scATACseq-topics/output/Cusanovich_2018/motifanalysis-Cusanovich2018-k=13-quantile/HOMER/homer_motif_enrichment_results.rdsTop 10 motifs
cat("Number of regions selected for each topic: \n")
print(mapply(nrow, selected_regions[1:(length(selected_regions)-1)]))
colnames_homer <- c("motif_name", "consensus", "P", "log10P", "Padj", "num_target", "percent_target", "num_bg", "percent_bg")
top_motifs <- data.frame(matrix(nrow=10, ncol = length(homer_res_topics)))
colnames(top_motifs) <- names(homer_res_topics)
for (k in 1:length(homer_res_topics)){
homer_res <- homer_res_topics[[k]]
colnames(homer_res) <- colnames_homer
homer_res <- homer_res %>% separate(motif_name, c("motif", "origin", "database"), "/")
top_motifs[,k] <- head(homer_res$motif, 10)
}
DT::datatable(data.frame(rank = 1:10, top_motifs), rownames = F, caption = "Top 10 motifs enriched in each topic.")# Number of regions selected for each topic:
# k1 k2 k3 k4 k5 k6 k7 k8 k9 k10 k11 k12 k13
# 4363 4363 4363 4363 4363 4363 4363 4363 4363 4363 4363 4363 4363Heatmap of motif enrichment across topics
Clustering motifs by hierarchical clustering (motifs with similar enrichment across topics are plotted together)
create_motif_enrichment_heatmap(motif_res, cluster_motifs = TRUE, cluster_topics = FALSE, filter_motifs = TRUE, min_enrichment = 50,
max_enrichment = 100, method_cluster = "average", font.size.motifs = 4, font.size.topics = 9)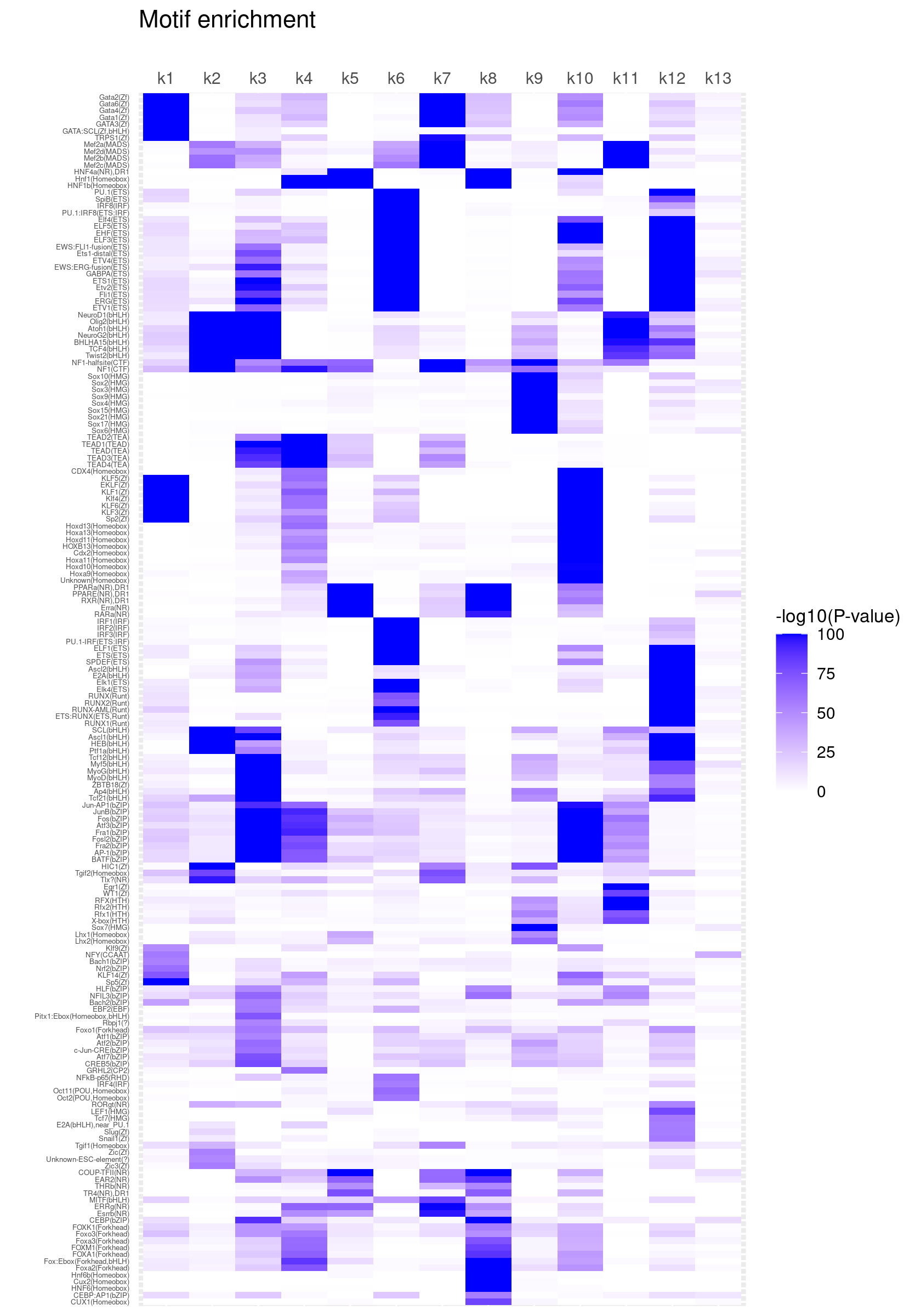
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
# 180 out of 439 motifs included the heatmapCluster both motifs and topics by hierarchical clustering
create_motif_enrichment_heatmap(motif_res, cluster_motifs = TRUE, cluster_topics = TRUE, filter_motifs = TRUE, min_enrichment = 50,
max_enrichment = 100, method_cluster = "average", font.size.motifs = 4, font.size.topics = 9)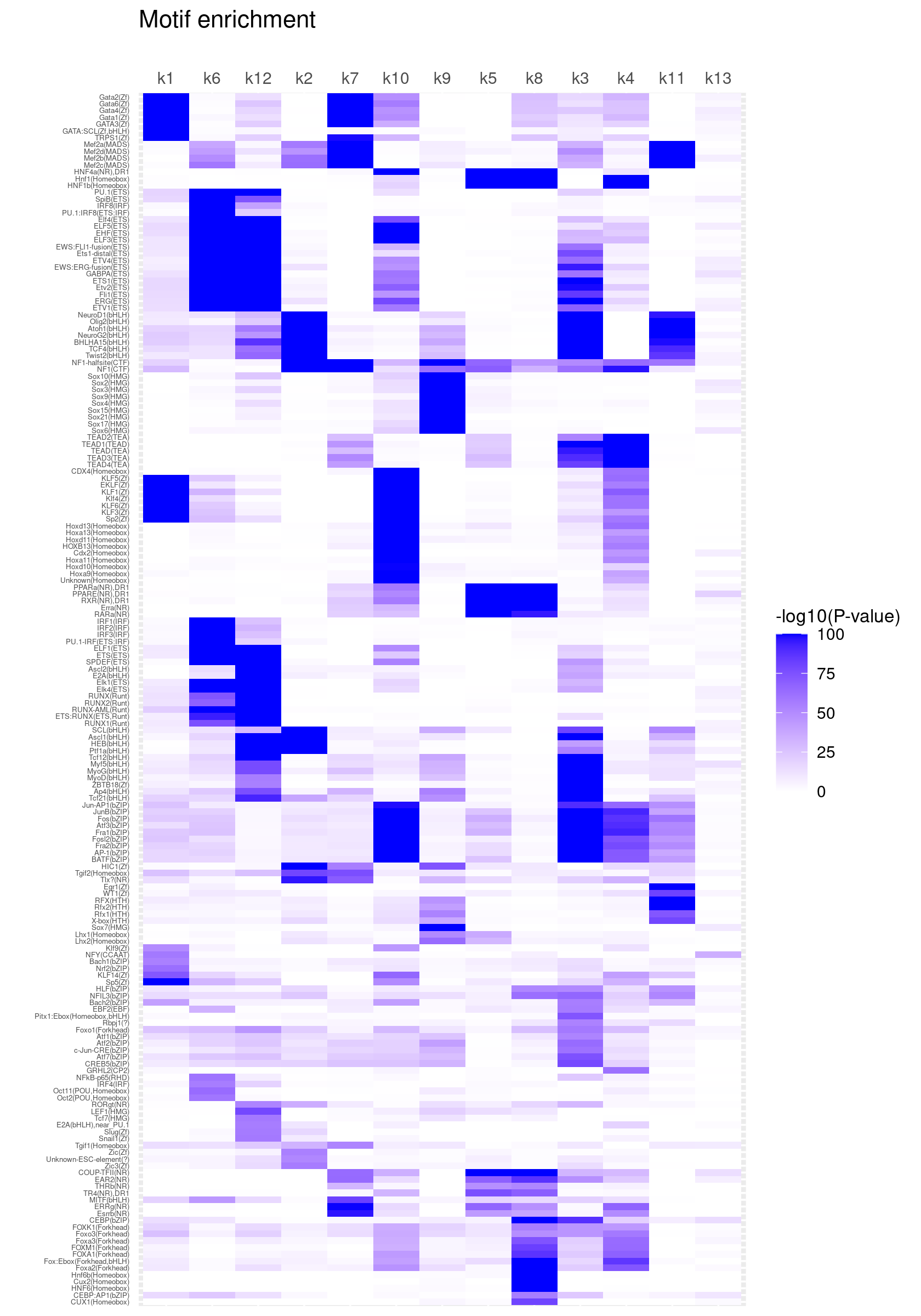
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
# 180 out of 439 motifs included the heatmapScatterplots of motif enrichment
Plot enrichment (-log10 p-value) and ranking of the motifs
plots <- vector("list", ncol(motif_res$mlog10P))
names(plots) <- colnames(motif_res$mlog10P)
for( i in 1:length(plots)){
plots[[i]] <- create_motif_enrichment_ranking_plot(motif_res, k = i,
max.overlaps = 15, subsample = FALSE)
}
# do.call(plot_grid,plots)Plot motif enrichment (-log10 p-value) and ranking in topic 1
print(plots[[1]])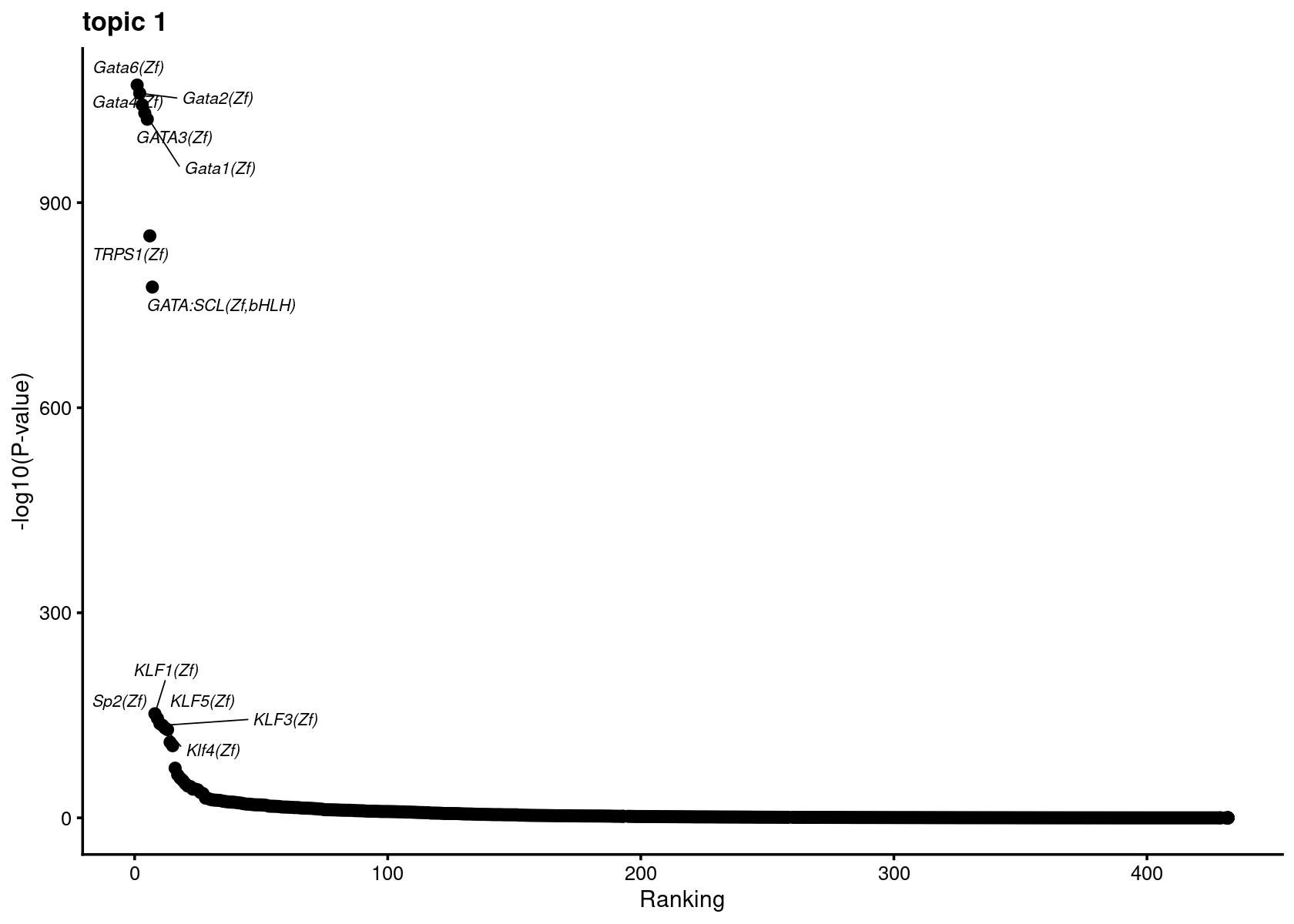
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
Plot motif enrichment (-log10 p-value) in each topic vs other topics
plots <- vector("list", ncol(motif_res$mlog10P))
names(plots) <- colnames(motif_res$mlog10P)
for( i in 1:length(homer_res_topics)){
plots[[i]] <- create_motif_enrichment_plot(motif_res, k = i,
max.overlaps = 15, subsample = TRUE)
}
# do.call(plot_grid,plots)Plot motif enrichment (-log10 p-value) in topic 1 vs other topics
print(plots[[1]])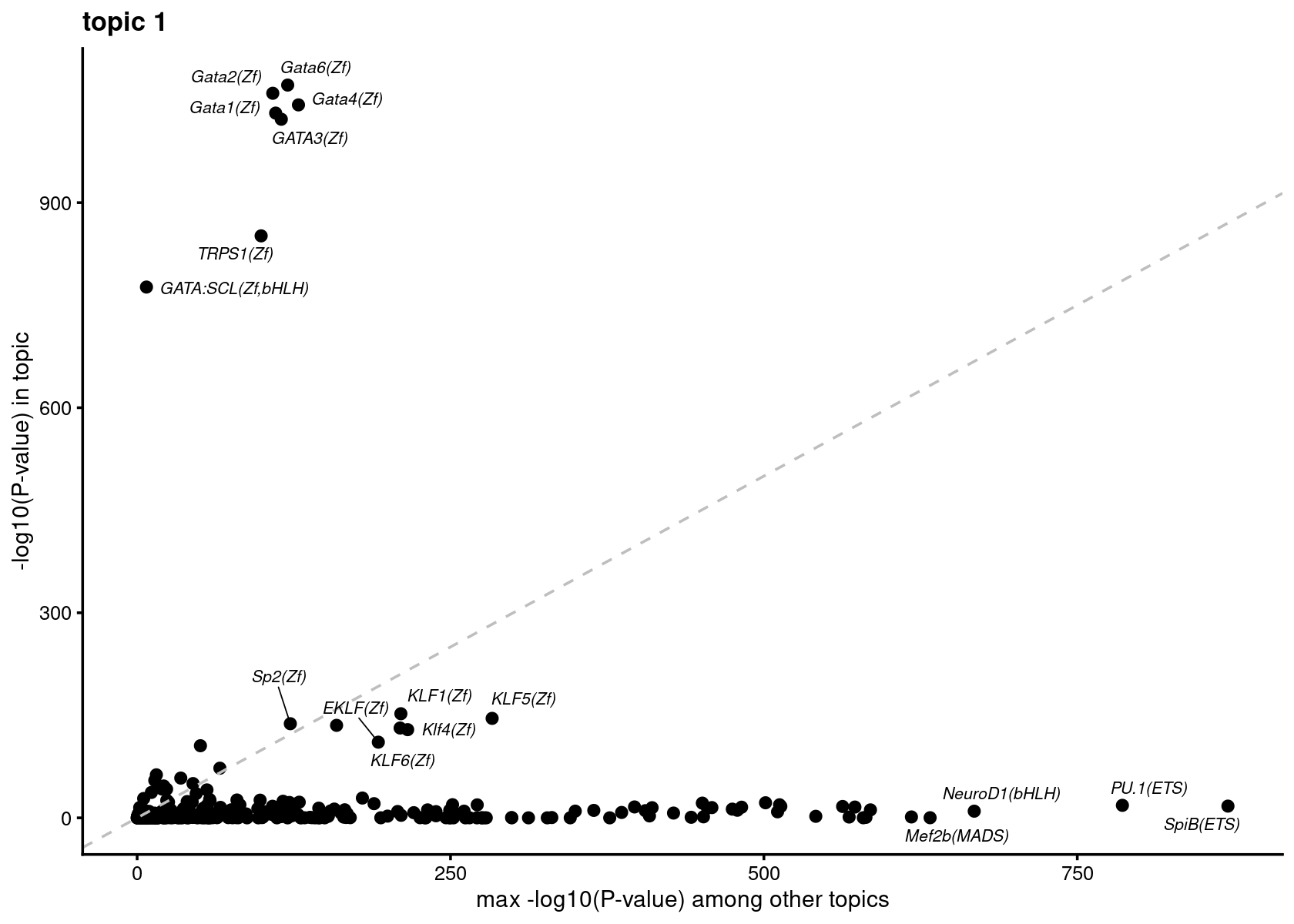
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
Motif enrichment vs gene score
Load pre-computed gene scores
gene.dir <- paste0(out.dir, "/geneanalysis-Cusanovich2018-k=13-TSS-sum")
cat(sprintf("Directory of gene analysis result: %s \n", gene.dir))
genescore_res <- readRDS(file.path(gene.dir, "genescore_result_topics.rds"))
genes <- genescore_res$genes
gene_scores <- genescore_res$Z
rownames(gene_scores) <- genes$SYMBOL
gene_logFC <- genescore_res$beta
rownames(gene_logFC) <- genes$SYMBOL# Directory of gene analysis result: /project2/mstephens/kevinluo/scATACseq-topics/output/Cusanovich_2018/geneanalysis-Cusanovich2018-k=13-TSS-sumGet TF genes
motif_names <- gsub("\\s*\\(.*", "", motif_res$motifs$motif)
gene_names <- genes$SYMBOL
TF_genes <- intersect(toupper(motif_names), toupper(gene_names))
cat(sprintf("%s TF genes mapped between motif names and gene symbol. \n", length(TF_genes)))# 250 TF genes mapped between motif names and gene symbol.Compute correlation between motif enrichment and gene score:
Plot motif enrichment (-log10 p-value) and correlation to gene scores for topic 1
motif_gene_mapping <- create_motif_enrichment_cor_plot(motif_res$mlog10P, gene_scores, motif_names, gene_names, TF_genes, k = 1,
cor.method = "pearson", max.overlaps = 15)# Warning: ggrepel: 230 unlabeled data points (too many overlaps). Consider
# increasing max.overlaps
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
motif_gene_mapping <- motif_gene_mapping[with(motif_gene_mapping, order(motif.mlog10P1*cor, decreasing = T)),]
cat("Top motifs by motif enrichment (-log10 p-value) and correlation to gene scores: \n")
rownames(motif_gene_mapping) <- 1:nrow(motif_gene_mapping)
print(head(motif_gene_mapping, 10))# Top motifs by motif enrichment (-log10 p-value) and correlation to gene scores:
# gene motif motif.mlog10P1 motif.mlog10P0 cor cor.pval
# 1 Gata2 Gata2(Zf) 1060.00 108.20 0.62996339 2.101795e-02
# 2 Gata1 Gata1(Zf) 1031.00 110.50 0.56449139 4.445294e-02
# 3 Klf1 KLF1(Zf) 152.30 210.40 0.56294117 4.517048e-02
# 4 Klf5 KLF5(Zf) 145.50 283.20 0.38552159 1.932744e-01
# 5 Sp2 Sp2(Zf) 137.70 122.20 0.39882226 1.770453e-01
# 6 Gata4 Gata4(Zf) 1043.00 128.70 0.05110547 8.683118e-01
# 7 Bach1 Bach1(bZIP) 54.72 14.08 0.37361028 2.085752e-01
# 8 Klf14 KLF14(Zf) 72.62 66.01 0.25921375 3.924431e-01
# 9 Spib SpiB(ETS) 17.16 870.20 0.99145723 4.403225e-11
# 10 Tcf21 Tcf21(bHLH) 18.96 271.30 0.89029474 4.525020e-05Plot motif enrichment (-log10 p-value) and gene scores for GATA genes
colors_topics <- c("#a6cee3","#1f78b4","#b2df8a","#33a02c","#fb9a99","#e31a1c",
"#fdbf6f","#ff7f00","#cab2d6","#6a3d9a","#ffff99","#b15928",
"gray")
GATA_genes <- grep("GATA", TF_genes, ignore.case=T, value=T)
plots <- create_motif_gene_scatterplot(motif_matrix = motif_res$mlog10P,
gene_matrix = gene_scores,
motif_names, gene_names,
selected_genes = GATA_genes,
colors = colors_topics,
max.overlaps = 10)
do.call(plot_grid,plots)# Warning: ggrepel: 8 unlabeled data points (too many overlaps). Consider
# increasing max.overlaps# Warning: ggrepel: 10 unlabeled data points (too many overlaps). Consider
# increasing max.overlaps# Warning: ggrepel: 8 unlabeled data points (too many overlaps). Consider
# increasing max.overlaps
| Version | Author | Date |
|---|---|---|
| 14eac34 | kevinlkx | 2021-01-19 |
sessionInfo()# R version 3.6.1 (2019-07-05)
# Platform: x86_64-pc-linux-gnu (64-bit)
# Running under: Scientific Linux 7.4 (Nitrogen)
#
# Matrix products: default
# BLAS/LAPACK: /software/openblas-0.2.19-el7-x86_64/lib/libopenblas_haswellp-r0.2.19.so
#
# locale:
# [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
# [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
# [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
# [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
# [9] LC_ADDRESS=C LC_TELEPHONE=C
# [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#
# attached base packages:
# [1] stats graphics grDevices utils datasets methods base
#
# other attached packages:
# [1] reshape2_1.4.3 DT_0.16 htmlwidgets_1.5.3 plotly_4.9.2.1
# [5] cowplot_1.1.0 ggrepel_0.9.0 ggplot2_3.3.2 tidyr_1.1.2
# [9] dplyr_1.0.2 fastTopics_0.4-6 Matrix_1.2-18 workflowr_1.6.2
#
# loaded via a namespace (and not attached):
# [1] Rcpp_1.0.5 lattice_0.20-41 prettyunits_1.1.1 rprojroot_2.0.2
# [5] digest_0.6.27 plyr_1.8.6 R6_2.5.0 MatrixModels_0.4-1
# [9] evaluate_0.14 coda_0.19-4 httr_1.4.2 pillar_1.4.7
# [13] rlang_0.4.9 progress_1.2.2 lazyeval_0.2.2 data.table_1.13.4
# [17] irlba_2.3.3 SparseM_1.78 whisker_0.4 rmarkdown_2.6
# [21] labeling_0.4.2 Rtsne_0.15 stringr_1.4.0 munsell_0.5.0
# [25] compiler_3.6.1 httpuv_1.5.4 xfun_0.19 pkgconfig_2.0.3
# [29] mcmc_0.9-7 htmltools_0.5.0 tidyselect_1.1.0 tibble_3.0.4
# [33] quadprog_1.5-8 matrixStats_0.57.0 viridisLite_0.3.0 withr_2.3.0
# [37] crayon_1.3.4 conquer_1.0.2 later_1.1.0.1 MASS_7.3-53
# [41] grid_3.6.1 jsonlite_1.7.2 gtable_0.3.0 lifecycle_0.2.0
# [45] git2r_0.27.1 magrittr_2.0.1 scales_1.1.1 RcppParallel_5.0.2
# [49] stringi_1.5.3 farver_2.0.3 fs_1.3.1 promises_1.1.1
# [53] ellipsis_0.3.1 generics_0.1.0 vctrs_0.3.6 tools_3.6.1
# [57] glue_1.4.2 purrr_0.3.4 crosstalk_1.1.0.1 hms_0.5.3
# [61] yaml_2.2.1 colorspace_2.0-0 knitr_1.30 quantreg_5.75
# [65] MCMCpack_1.4-9