Evaluation of fastTopics DE analysis methods in simulations—case of more than 2 topics
Peter Carbonetto
Last updated: 2022-01-12
Checks: 7 0
Knit directory: single-cell-topics/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(1) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 14459bc. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: data/droplet.RData
Ignored: data/pbmc_68k.RData
Ignored: data/pbmc_purified.RData
Ignored: data/pulseseq.RData
Ignored: output/droplet/diff-count-droplet.RData
Ignored: output/droplet/fits-droplet.RData
Ignored: output/droplet/rds/
Ignored: output/pbmc-68k/fits-pbmc-68k.RData
Ignored: output/pbmc-68k/rds/
Ignored: output/pbmc-purified/fits-pbmc-purified.RData
Ignored: output/pbmc-purified/rds/
Ignored: output/pulseseq/diff-count-pulseseq.RData
Ignored: output/pulseseq/fits-pulseseq.RData
Ignored: output/pulseseq/rds/
Ignored: output/sims/
Untracked files:
Untracked: analysis/de_analysis_detailed_look_cache/
Untracked: analysis/de_analysis_detailed_look_more_cache/
Untracked: plots/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/de_analysis_six_topics.Rmd) and HTML (docs/de_analysis_six_topics.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 14459bc | Peter Carbonetto | 2022-01-12 | workflowr::wflow_publish(“de_analysis_six_topics.Rmd”) |
| html | 4ddceb7 | Peter Carbonetto | 2022-01-12 | Added the MCMC scatterplots and ranking histograms to the |
| Rmd | c636d97 | Peter Carbonetto | 2022-01-12 | workflowr::wflow_publish(“de_analysis_six_topics.Rmd”) |
| html | b1da836 | Peter Carbonetto | 2022-01-05 | Added MCMC scatterplots to de_analysis_two_topics analysis. |
| Rmd | 5aac256 | Peter Carbonetto | 2022-01-05 | workflowr::wflow_publish(“de_analysis_two_topics.Rmd”, verbose = TRUE) |
Here we evaluate performance of the grade-of-membership DE methods in simulations, focussing on the case of \(K = 6\) topics. A smaller simulation with \(K = 6\) topics was first performed here, and based on this initial simulation we have conducted a larger set of simulations using the run_sims.R script. Here we summarize the results of this larger set of simulations.
Load the packages needed for this analysis, and some additional functions used to compile the results and generate the plots.
library(Matrix)
library(fastTopics)
library(ggplot2)
library(cowplot)
source("../code/de_analysis_functions.R")Load the results of the simulations.
load("../output/sims/sims-k=6.RData")Before comparing the methods, we first assess accuracy of the Monte Carlo computations by comparing the estimates from two independent MCMC runs.
res["session.info"] <- NULL
pdat <- data.frame(lfc1 = combine_sim_res(res,function (x) c(x$de1$postmean)),
lfc2 = combine_sim_res(res,function (x) c(x$de2$postmean)),
z1 = combine_sim_res(res,function (x) c(x$de1$z)),
z2 = combine_sim_res(res,function (x) c(x$de2$z)))
i <- which(abs(pdat$z1) <= 1 & abs(pdat$z2) <= 1)
j <- which(abs(pdat$z1) > 1 | abs(pdat$z2) > 1)
i <- sample(i,1e5)
pdat <- pdat[c(i,j),]
p1 <- ggplot(pdat,aes(x = lfc1,y = lfc2)) +
geom_point(color = "dodgerblue",shape = 4,size = 0.75) +
geom_abline(intercept = 0,slope = 1,linetype = "dotted") +
labs(x = "first posterior mean",y = "second posterior mean") +
theme_cowplot(font_size = 12)
p2 <- ggplot(pdat,aes(x = z1,y = z2)) +
geom_point(color = "dodgerblue",shape = 4,size = 0.75) +
geom_abline(intercept = 0,slope = 1,linetype = "dotted") +
labs(x = "first z-score estimate",y = "second z-score estimate") +
xlim(-22,102) +
ylim(-22,102) +
theme_cowplot(font_size = 12)
plot_grid(p1,p2)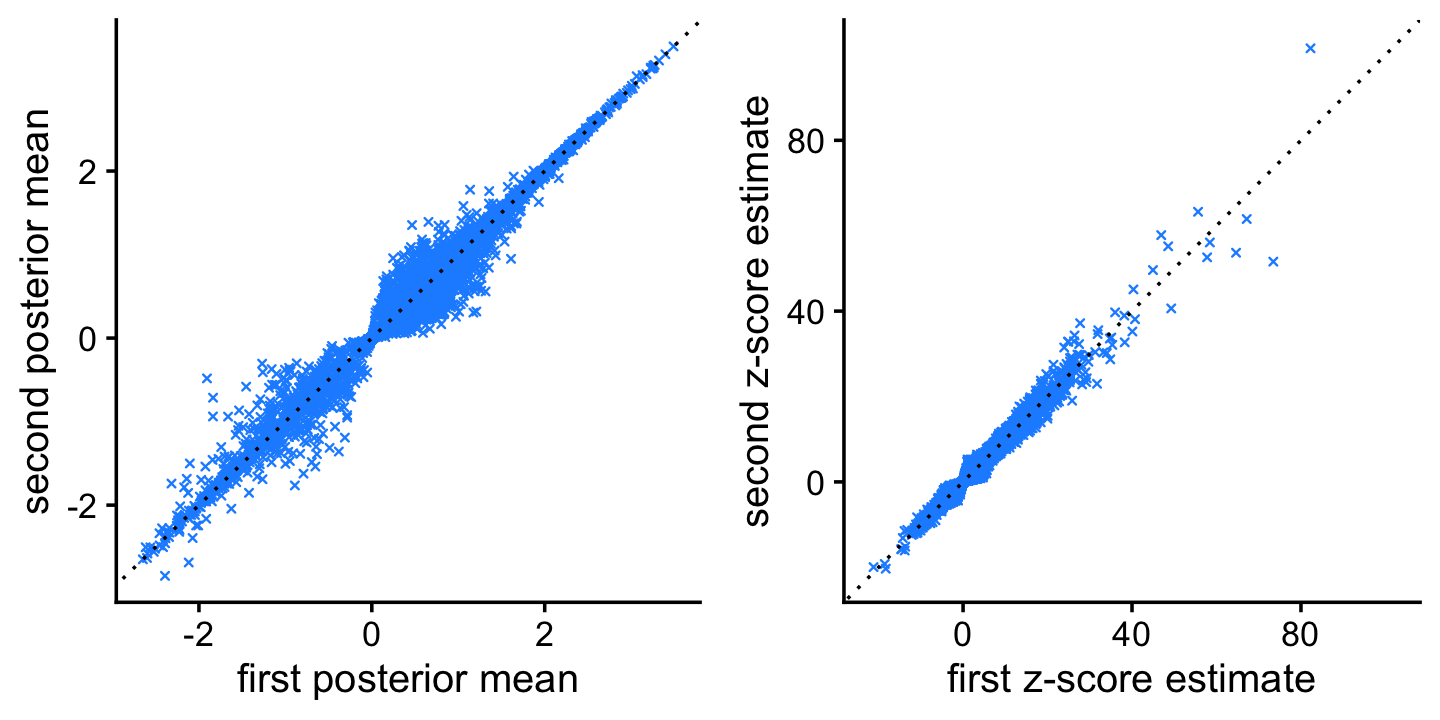
| Version | Author | Date |
|---|---|---|
| 4ddceb7 | Peter Carbonetto | 2022-01-12 |
We see from these scatterplots that the estimates of the posterior mean LFCs and z-scores generated by the two MCMC runs are very similar.
Next we consider the K-L divergence measure used in Dey, Hsiao & Stephens (2017) to rank genes, and compare its ranking to a ranking based on p-values (without using adaptive shrinkage) or s-values (after applying adaptive shrinkage). Since the K-L divergence is not a signed ranking, we restrict this comparison only to LFCs that are estimated to be positive.
get_nonneg_lfcs <- function (de)
which(de$est > -1e-8)
nonzero_lfc <- combine_sim_res(res,
function (x) {
n <- nrow(x$dat$F)
k <- ncol(x$dat$F)
out <- matrix(FALSE,n,k)
for (i in 1:n) {
y <- x$dat$F[i,]
if (max(y) - min(y) > 1e-8) {
j <- which.max((y - mean(y))^2)
out[i,j] <- TRUE
}
}
return(out[get_nonneg_lfcs(x$de1)])
})
noshrink <-
combine_sim_res(res,function (x) x$de0$lpval[get_nonneg_lfcs(x$de1)])
shrink <-
combine_sim_res(res,function(x)x$de1$svalue[get_nonneg_lfcs(x$de1)])
lfsr <- combine_sim_res(res,function(x)x$de1$lfsr[get_nonneg_lfcs(x$de1)])
lkl <- combine_sim_res(res,function (x)
fastTopics:::min_kl_poisson(x$fit$F)[get_nonneg_lfcs(x$de1)])
pdat <- data.frame(nonzero_lfc = factor(nonzero_lfc),
noshrink = 10^(-noshrink),
shrink = shrink,
lfsr = lfsr,
lkl = log10(lkl + 1e-8))
p1 <- ggplot(pdat,aes(x = lkl,color = nonzero_lfc,fill = nonzero_lfc)) +
geom_histogram(bins = 64,show.legend = FALSE) +
scale_color_manual(values = c("darkorange","darkblue")) +
scale_fill_manual(values = c("darkorange","darkblue")) +
coord_cartesian(ylim = c(0,2.5e4)) +
labs(x = "log10 K-L divergence",y = "genes",title = "K-L divergence") +
theme_cowplot(font_size = 12)
p2 <- ggplot(pdat,aes(x = noshrink,color = nonzero_lfc,fill = nonzero_lfc)) +
geom_histogram(bins = 64,show.legend = FALSE) +
scale_color_manual(values = c("darkorange","darkblue")) +
scale_fill_manual(values = c("darkorange","darkblue")) +
coord_cartesian(ylim = c(0,2.5e4)) +
labs(x = "p-value",y = "genes",title = "without shrinkage") +
theme_cowplot(font_size = 12)
p3 <- ggplot(pdat,aes(x = shrink,color = nonzero_lfc,fill = nonzero_lfc)) +
geom_histogram(bins = 64,show.legend = FALSE) +
scale_color_manual(values = c("darkorange","darkblue")) +
scale_fill_manual(values = c("darkorange","darkblue")) +
coord_cartesian(ylim = c(0,2.5e4)) +
labs(x = "s-value",y = "genes",title = "with shrinkage") +
theme_cowplot(font_size = 12)
plot_grid(p1,p2,p3,nrow = 1,ncol = 3)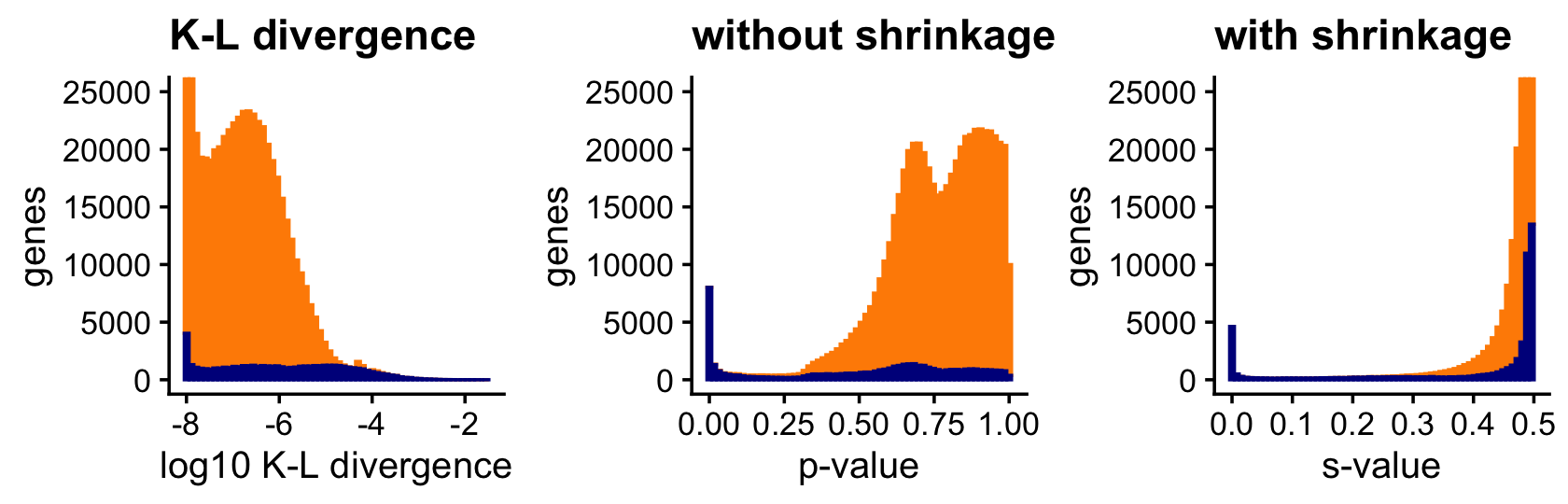
| Version | Author | Date |
|---|---|---|
| 4ddceb7 | Peter Carbonetto | 2022-01-12 |
Having compared the overall distributions of the gene-wise rankings, we now compare performance of these rankings by plotting power vs. FDR. Again, we restrict this comparison only to positive LFCs.
v1 <- create_fdr_vs_power_curve(-pdat$lkl,nonzero_lfc,length.out = 400)
v2 <- create_fdr_vs_power_curve(pdat$noshrink,nonzero_lfc,length.out = 400)
v3 <- create_fdr_vs_power_curve(pdat$lfsr,nonzero_lfc,length.out = 400)
dat <- rbind(cbind(v1,method = "kl"),
cbind(v2,method = "noshrink"),
cbind(v3,method = "shrink"))
p <- ggplot(dat,aes(x = fdr,y = power,color = method)) +
geom_line(size = 0.65,orientation = "y") +
scale_color_manual(values = c("royalblue","limegreen","orange")) +
theme_cowplot()
print(p)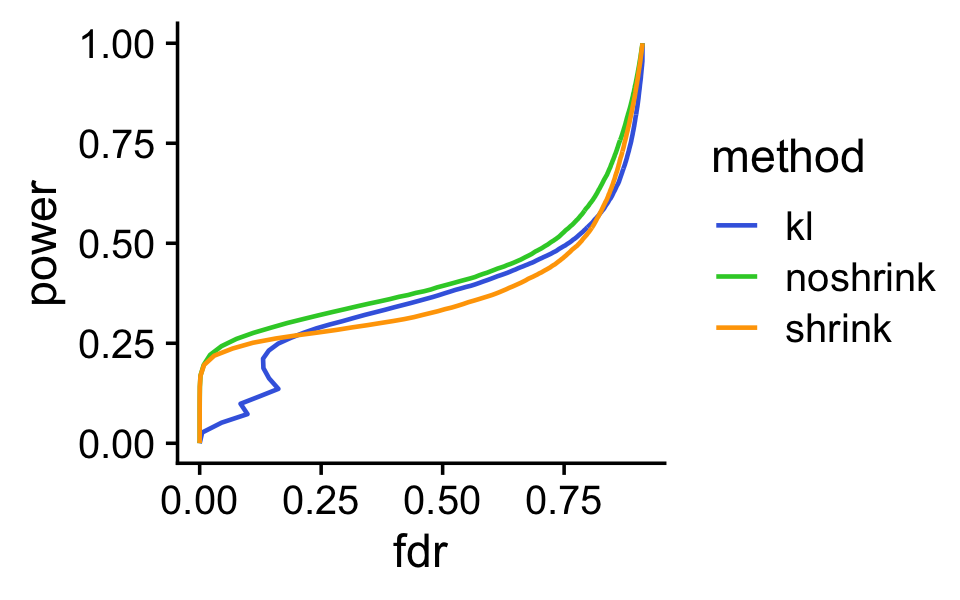
sessionInfo()
# R version 3.6.2 (2019-12-12)
# Platform: x86_64-apple-darwin15.6.0 (64-bit)
# Running under: macOS Catalina 10.15.7
#
# Matrix products: default
# BLAS: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRblas.0.dylib
# LAPACK: /Library/Frameworks/R.framework/Versions/3.6/Resources/lib/libRlapack.dylib
#
# locale:
# [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
#
# attached base packages:
# [1] stats graphics grDevices utils datasets methods base
#
# other attached packages:
# [1] cowplot_1.0.0 ggplot2_3.3.5 fastTopics_0.6-96 Matrix_1.2-18
#
# loaded via a namespace (and not attached):
# [1] httr_1.4.2 tidyr_1.1.3 jsonlite_1.7.2 viridisLite_0.3.0
# [5] RcppParallel_4.4.2 assertthat_0.2.1 highr_0.8 mixsqp_0.3-46
# [9] yaml_2.2.0 progress_1.2.2 ggrepel_0.9.1 pillar_1.6.2
# [13] backports_1.1.5 lattice_0.20-38 quantreg_5.54 glue_1.4.2
# [17] quadprog_1.5-8 digest_0.6.23 promises_1.1.0 colorspace_1.4-1
# [21] htmltools_0.4.0 httpuv_1.5.2 pkgconfig_2.0.3 invgamma_1.1
# [25] SparseM_1.78 purrr_0.3.4 scales_1.1.0 whisker_0.4
# [29] later_1.0.0 Rtsne_0.15 MatrixModels_0.4-1 git2r_0.26.1
# [33] tibble_3.1.3 farver_2.0.1 generics_0.0.2 ellipsis_0.3.2
# [37] withr_2.4.2 ashr_2.2-51 pbapply_1.5-1 lazyeval_0.2.2
# [41] magrittr_2.0.1 crayon_1.4.1 mcmc_0.9-6 evaluate_0.14
# [45] fs_1.3.1 fansi_0.4.0 MASS_7.3-51.4 truncnorm_1.0-8
# [49] tools_3.6.2 data.table_1.12.8 prettyunits_1.1.1 hms_1.1.0
# [53] lifecycle_1.0.0 stringr_1.4.0 MCMCpack_1.4-5 plotly_4.9.2
# [57] munsell_0.5.0 irlba_2.3.3 compiler_3.6.2 systemfonts_1.0.2
# [61] rlang_0.4.11 grid_3.6.2 htmlwidgets_1.5.1 labeling_0.3
# [65] rmarkdown_2.3 gtable_0.3.0 DBI_1.1.0 R6_2.4.1
# [69] knitr_1.37 dplyr_1.0.7 uwot_0.1.10 utf8_1.1.4
# [73] workflowr_1.7.0 rprojroot_1.3-2 ragg_0.3.1 stringi_1.4.3
# [77] parallel_3.6.2 SQUAREM_2017.10-1 Rcpp_1.0.7 vctrs_0.3.8
# [81] tidyselect_1.1.1 xfun_0.29 coda_0.19-3