Speech AI
Examples
toni.heittola@tuni.fi
Introduction¶
Applications covered:
- Speech separation
- Speech enhancement
- Language identification
- Speech recognition
- Text to speech
- Voice activity detection
Key tools used:¶
speechbrain– PyTorch powered speech toolkit, https://speechbrain.github.io/espnet– end-to-end speech processing toolkit, https://github.com/espnet/espnet
Pretrained models are mostly downloaded from Hugging Face
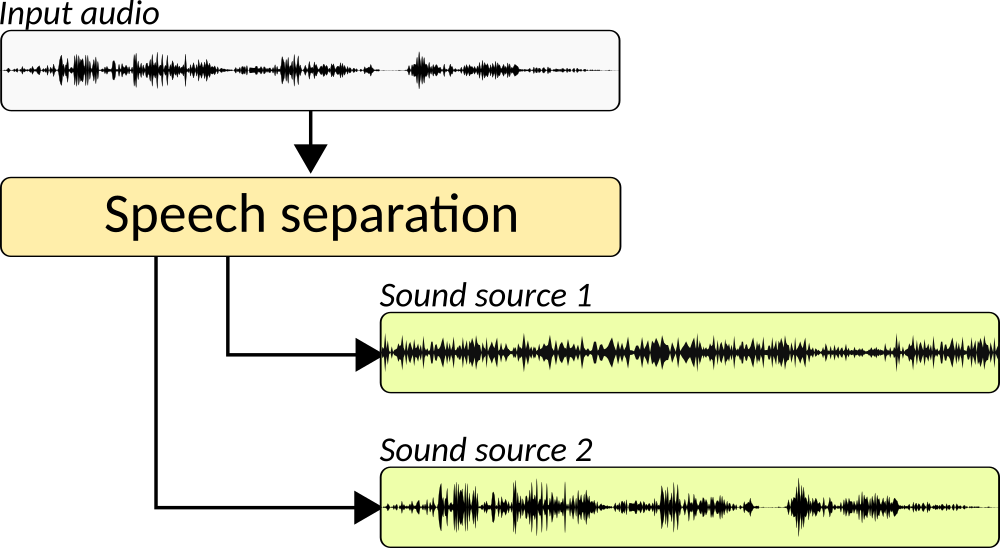
SepFormer¶
Transformer-based neural network for speech separation
- State-of-the-art speech separation system published 2021
- Uses transformers that replace RNNs with a multi-scale pipeline composed of transformers that learn both short and long-term dependencies
- Model composed of multi-head attention and feed-forward layers
- Trained with WSJ0-2mix dataset with mixtures of two overlapping speakers
- Designed for single-channel audio with an 8kHz sampling rate
C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi and J. Zhong, "Attention Is All You Need In Speech Separation," ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021, pp. 21-25. PDF
Usage¶
We will use SepformerSeparation class from the SpeechBrain library with pretrained model (speechbrain/sepformer-wsj02mix) from Hugging Face (https://huggingface.co/speechbrain/sepformer-wsj02mix).
# Import
from speechbrain.pretrained import SepformerSeparation
# Create and download pretrained model
speech_separator = SepformerSeparation.from_hparams(
source='speechbrain/sepformer-wsj02mix', # Model name
savedir='pretrained_models/sepformer-wsj02mix',
run_opts={'device':'cuda'} # Use GPU
)
# Apply model to example audio
estimated_sources = speech_separator.separate_file(
path='speechbrain/sepformer-wsj02mix/test_mixture.wav'
)
Example¶
Signal with two males speaking different languages (English and French) at the same time

Estimate sound sources¶
# Estimate source from the mixure signal
estimated_sources = speech_separator.separate_batch(
torch.from_numpy(mixture.data).float()[None,:]
)
# Create audio containers for source1 and source2
source1 = AudioContainer(
data=tensor_to_numpy(estimated_sources[:, :, 0]),
fs=8000
)
source2 = AudioContainer(
data=tensor_to_numpy(estimated_sources[:, :, 1]),
fs=8000
)
Source 1¶

Source 2¶


SepFormer for Speech Enhancement¶
Transformer-based neural network for speech separation
- Speech separation system can be used for speech enhancement too
- Trained with WHAMR! dataset
- Augmented version of WHAM! dataset with synthetic reverberated sources
- WHAM! is a noise augmented version of the WSJ0-2mix dataset
- Dataset contains overlapping speech with varying gains and environmental noises recorded in various urban environments
- Dataset contains 28000 samples, and in total 81 hours of audio
- Designed for single-channel audio with an 8kHz sampling rate
C. Subakan, M. Ravanelli, S. Cornell, M. Bronzi and J. Zhong, "Attention Is All You Need In Speech Separation," ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2021, pp. 21-25. PDF
Usage¶
We will use again SepformerSeparation class from the SpeechBrain library with pretrained model (speechbrain/sepformer-whamr-enhancement) from Hugging Face (https://huggingface.co/speechbrain/sepformer-whamr-enhancement).
from speechbrain.pretrained import SepformerSeparation
speech_enhancer = SepformerSeparation.from_hparams(
source='speechbrain/sepformer-whamr-enhancement',
savedir='pretrained_models/sepformer-whamr-enhancement'
)
est_sources = speech_enhancer.separate_file(
path='speechbrain/sepformer-whamr-enhancement/example_whamr.wav'
)
Example with two source in noisy environment¶
Mixture signal with two males speaking different languages (English and French) at the same time in a metro station.

Separate sound sources¶
noisy_estimated_sources = speech_separator.separate_batch(
torch.from_numpy(noisy_mixture.data).float()[None,:]
)
Source 1¶
Source 2¶
Enhanced source 1¶
estimated_source = speech_enhancer.separate_batch(
torch.from_numpy(noisy_source1.data).float()[None,:]
)

Enhanced source 2¶
estimated_source = speech_enhancer.separate_batch(
torch.from_numpy(noisy_source2.data).float()[None,:]
)

Language identification¶
The task that automatically identifies the language of a given spoken utterance

ECAPA-TDNN Spoken Language Identification¶
- ECAPA-TDNN architecture
- Based on X-vector architecture using Time Delay Neural Network (TDNN) enhanced with statistics pooling layer, additional skip connections to propagate and aggregate channels, and channel attention
- Used also for speech recognition and speaker verification
- Model trained with VoxLingua107
- Dataset consists of short speech segments automatically extracted from YouTube videos and labeled according to the language of the video title and description
- Data for 107 languages, ~62 hours per language, 6628 hours in total
- Designed for single-channel audio with a 16kHz sampling rate
Desplanques, B., Thienpondt, J., Demuynck, K., ECAPA-TDNN: Emphasized Channel Attention, Propagation and Aggregation in TDNN Based Speaker Verification. Proc. Interspeech 2020, pp. 3830-3834. PDF
Usage¶
We will use EncoderClassifier class from the SpeechBrain library with pretrained model (speechbrain/lang-id-voxlingua107-ecapa) from Hugging Face (https://huggingface.co/speechbrain/lang-id-voxlingua107-ecapa)
# Import
from speechbrain.pretrained import EncoderClassifier
# Create and download pretrained model
language_id = EncoderClassifier.from_hparams(
source="speechbrain/lang-id-voxlingua107-ecapa",
savedir='pretrained_models/lang-id-voxlingua107-ecapa',
run_opts={"device":"cuda"}
)
# Identify language
signal = language_id.load_audio("https://omniglot.com/soundfiles/udhr/udhr_fi.mp3")
lang = language_id.classify_batch(signal)[-1][0]
Identified language: Finnish
Example¶
Let's estimate languages for the sound sources separated earlier in the speech separation section.
# Identify languages for both sources
prediction1 = language_id.classify_batch(
wavs=torch.from_numpy(source1.data).float()
)
prediction2 = language_id.classify_batch(
wavs=torch.from_numpy(source2.data).float()
)
Identified language for source 1: French Identified language for source 2: English

Encoder-Decoder based Speech Recognition¶
- Encoder-Decoder architecture, a common architecture for sequence modeling
- Encoder - sequence of speech is converted into a hidden representation
- Pretrained wav2vec 2.0 embeddings combined with two DNN layers that are finetuned on the training dataset
- Decoder - consumes the hidden representation and predicts the output
- Encoder - sequence of speech is converted into a hidden representation
- Model trained with CommonVoice dataset
- Multi-language dataset created with volunteer contributors
- For English there are 81085 speakers, in a total of 2953 hours of audio, annotations are 75% human validated
- Designed for single-channel audio with a 16kHz sampling rate
S. Watanabe, T. Hori, S. Kim, J. R. Hershey, and T. Hayashi, Hybrid CTC/Attention Architecture for End-to-End Speech Recognition, in IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 8, pp. 1240-1253, Dec. 2017. PDF
Usage¶
We will use EncoderASR or EncoderDecoderASR classes from the SpeechBrain library with pretrained model (speechbrain/asr-wav2vec2-commonvoice-LANG) from Hugging Face (https://huggingface.co/speechbrain/asr-wav2vec2-commonvoice-en)
# Import
from speechbrain.pretrained import EncoderDecoderASR
# Create and download pretrained model
ASR = EncoderDecoderASR.from_hparams(
source='speechbrain/asr-wav2vec2-commonvoice-en',
savedir='pretrained_models/asr-wav2vec2-commonvoice-en',
run_opts={'device':'cuda'} # for GPU
)
# Apply speech recognition
text = ASR.transcribe_file('speechbrain/asr-wav2vec2-commonvoice-en/example.wav')
Recognized speech: THE BIRCH CANOE SLID ON SMOOTH PLANKS
Example¶
Let's estimate the content for both speech signals separated earlier in the speech separation section.
from speechbrain.pretrained import EncoderASR, EncoderDecoderASR
# Create models with languages (English and French)
asr_models = {
'fr': EncoderASR.from_hparams(
source='speechbrain/asr-wav2vec2-commonvoice-fr',
savedir='pretrained_models/asr-wav2vec2-commonvoice-fr',
run_opts={"device":"cuda"} # for GPU
),
'en': EncoderDecoderASR.from_hparams(
source='speechbrain/asr-wav2vec2-commonvoice-en',
savedir='pretrained_models/asr-wav2vec2-commonvoice-en',
run_opts={"device":"cuda"} # for GPU
),
}
Apply speech recognition¶
pred_str1, pred_tokens1 = asr_models[lang1].transcribe_batch(
wavs=torch.from_numpy(source1.resample(16000).data).float().unsqueeze(0),
wav_lens=torch.tensor([1.0])
)
text1 = pred_str1[0]
Recognized content for source 1 [fr]: TOUS LES ÊTRES HUMAINS NAISSENT LIBRES ET ÉGAUX EN DIGNITÉ ET EN DROIT ILS SONT DOUÉS DE RAISONS ET DE CONSCIENCE ET DOIVENT AGIR LES UNS ENVERS LES AUTRES DANS UN ESPRIT DE FRATERNITÉ
pred_str2, pred_tokens2 = asr_models[lang2].transcribe_batch(
wavs=torch.from_numpy(source2.resample(16000).data).float().unsqueeze(0),
wav_lens=torch.tensor([1.0])
)
text2 = pred_str2[0]
Recognized content for source 2 [en]: ALL HUMAN BEINGS ON FREE AND EQUAL IN DIGNITY AND RIGHT THEY ARE ENDOWED WITH REASON AND CONSCIENCE AND SHOULD ACT TOWARDS ONE ANOTHER IN A SPIRIT OF BROTHERHOOD

Tacotron¶
An end-to-end speech synthesis system by Google
- One of the first successful deep learning-based text-to-mel spectrogram models
- Model:
- Encoder-decoder architecture with attention
- Input: character sequence
- Output: mel spectrogram (50ms frame length and 12.5ms frame hop)
- Model trained with LJ Speech dataset
- Speech dataset consisting of 13100 short audio clips of a single speaker reading passages from 7 non-fiction books
- In total 24 hours of audio
Wang, Yuxuan, R. J. Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J. Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Z. Chen, Samy Bengio, Quoc V. Le, Yannis Agiomyrgiannakis, Robert A. J. Clark and Rif A. Saurous. Tacotron: Towards End-to-End Speech Synthesis, INTERSPEECH (2017) PDF
Example¶
We will use Text2Speech class from the espnet2 library with pretrained model to convert recognized content of speech from sound source 2 into audio.
from espnet_model_zoo.downloader import ModelDownloader
from espnet2.bin.tts_inference import Text2Speech
d = ModelDownloader('pretrained_models') # Data downloader
# Create and download pretrained model
text2speech = Text2Speech(
**d.download_and_unpack(
'kan-bayashi/ljspeech_tts_train_vits_raw_phn_tacotron_g2p_en_no_space_train.total_count.ave'
), device="cuda"
)
# Apply model to text
speech = text2speech(text2)["wav"]
ALL HUMAN BEINGS ON FREE AND EQUAL IN DIGNITY AND RIGHT THEY ARE ENDOWED WITH REASON AND CONSCIENCE AND SHOULD ACT TOWARDS ONE ANOTHER IN A SPIRIT OF BROTHERHOOD

CRNN Voice activity detection¶
- CRNN architecture
- Two CNN blocks, two bidirectional LSTM blocks, and a fully-connected layer
- Model trained with LibriParty dataset
- Dataset consists of ~5min long recordings created by mixing speech samples from LibriSpeech dataset with background sounds (environmental sounds)
- 250 recordings, 20 hours in total
- Designed for single-channel audio with a 16kHz sampling rate
- System outputs posteriors probabilities with a value close to one for speech frames and close to zero for non-speech segments. A threshold is applied on top of the posteriors to detect candidate speech boundaries.
Usage¶
We will use VAD class from the SpeechBrain library with pretrained model (speechbrain/vad-crdnn-libriparty) from Hugging Face (https://huggingface.co/speechbrain/vad-crdnn-libriparty).
# Import
from speechbrain.pretrained import VAD
# Create and download pretrained model
VAD = VAD.from_hparams(
source='speechbrain/vad-crdnn-libriparty', # Model name
savedir='pretrained_models/vad-crdnn-libriparty'
)
# Detect segments with speech, segment boudaries in seconds
speech_segments = VAD.get_speech_segments(
audio_file='speechbrain/vad-crdnn-libriparty/example_vad.wav'
)
Start Stop ----- ---- 14.3s 17.3s 18.1s 21.6s 28.6s 36.9s
Example¶
Let's run voice activity detection on a long speech signal with environmental sounds in the background.
