Clase 1: Comandos Basicos
Miguel Tripp
2021-04-12
Last updated: 2021-04-18
Checks: 7 0
Knit directory: 2021/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20210412) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 02e6728. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/procesados/
Untracked files:
Untracked: Bioestadistica2021.Rproj
Untracked: Curso_Bioestadistica_MTripp_cuatriII.docx
Untracked: Curso_Bioestadistica_MTripp_cuatriII.pdf
Untracked: data/crudos/
Unstaged changes:
Deleted: 2021.Rproj
Modified: README.md
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/Clase1_Basicos.Rmd) and HTML (docs/Clase1_Basicos.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | 02e6728 | Miguel Tripp | 2021-04-18 | Build site. |
| Rmd | 8c50c39 | Miguel Tripp | 2021-04-18 | Publish the initial files for myproject |
1 Uso como calculadora en la linea de comandos
operaciones basicas:
1 + 2 #suma[1] 34 - 3 #resta[1] 15 * 5 #multiplicación[1] 254 / 2 #división[1] 24 ^ 2 #Exponente[1] 164 ** 2 #Exponente[1] 16!! ¿por qué hay un [1] en cada resultado?
El resultado es un vector, aunque solo consista en un elemento. Por lo tanto, R indica que este el primer [1] elemento de un vector
Operadores en R:
| Operador | significado |
|---|---|
| * | Multiplicación |
| - | Resta |
| + | Suma |
| ^ | Elevar a potencia |
| / | División |
| < | Menor que |
| > | Mayor que |
| <= | Menor o igual que |
| >= | Mayor o igual que |
| == | Exactamente igual |
| != | Distinto |
2 Uso de objetos
Para crear un nuevo objeto se puede usar “=” o “<-”. Este nuevo objeto, se almacenará en la memoria y se puede usar para otras operaciones.
x <- 2 #asignar a la variable x el valor de 2
x
y = 3 #asignar a la variable y el valor de 3
y
#resultado de la suma x + y
x + y
z <- x + y#asiganr el resultado de x + y a la variable z
z
#uso de c para incluir mas de un elemento
numeros <- c(1,2,3,4,5)
numeros
variables <- c(x,y,z)
variables
variables_mas <- variables + 1
variables_mas
variables_expo <- variables ^2
2 ^ variables -> expo_variables
variables_numero <- variables * numeros
#¿que pasara aqui?Las variables no solo puede contener números, sino caracteres, listas o incluso graficas
caracter <- "siete"
caracter[1] "siete"mix <- c(1,2,"tres")
mix[1] "1" "2" "tres"¿cual serial el resultado de multiplicar la variable mix x 3?
¿Cuales de estas formas de definir una variables es incorrecta?
mi.variable <-mi_variable <-mi variable <-mi-variable <-
3 Tipos y estructura de datos (Classes)
R tiene los siguientes tipos de datos basicos:
logical:valores lógicos, pueden ser TRUE o FALSEnumeric:numeros realescharacter:caracteres (letras y/o númoeros). Delimitados por ""interger:valores enterosNA:dato no disponibleNaN:no es un número (not a number)
Las estructuras de datos son:
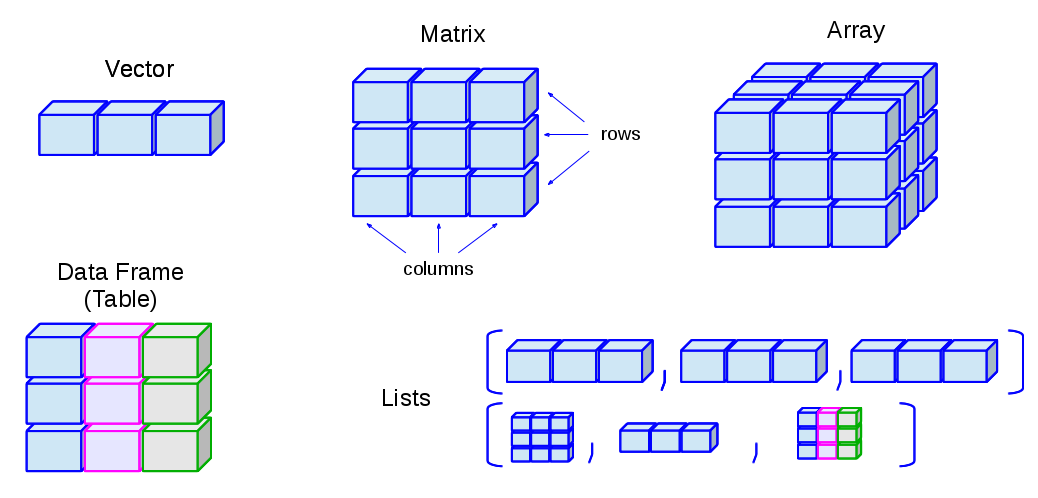
fuente: http://venus.ifca.unican.es/Rintro/_images/dataStructuresNew.png
Si no sabes que tipo de dato contiene una variable, se puede sar la funcions class()
class(numeros) [1] "numeric"class(caracter) [1] "character"class(numeros)[1] "numeric"class(mix)[1] "character"R utiliza funciones para realizar operaciones, por ejemplo class(). Para utilizar una función deben especificarse determiandos argumentos, los cuales se escriben dentro del parentesis.
Por ejemplo, en la función round(), la ayuda nos dice que debemos especificar round(x, digits = 0) donde x es el objecto (número o vector) y digits es el número de decimales.
3.1 Trabajando con vectores
Ejercicio:
Supon que tienes un cultivo de abulones y tienes que revisarlo todos los dias y contar los organismos muertos. Despues de una semana tienes el siguiente resultado:
- lunes: 4
- martes: 6
- miercoles: 0
- jueves: 10
- viernes: 12
- sabado: 8
- domingo: 4
1: crea un vector con los valores diarios 2: nombre cada valor con el dia de la semana usando la funcion names()
mortalidad <- c(4,6,0,10,12,8,4)
mortalidad[1] 4 6 0 10 12 8 4names(mortalidad) <- c("Lunes", "Martes", "Miercoles", "Jueves", "Viernes", "Sabado", "Domingo")
mortalidad Lunes Martes Miercoles Jueves Viernes Sabado Domingo
4 6 0 10 12 8 4 #nombrar la mortalidad con la funcion namesOperaciones basicas con vectores
| Función | significado |
|---|---|
| min() | Minimo |
| max() | Máximo |
| length() | longitud |
| range() | intervalo de valores |
| sort() | Ordena de menor a mayor |
| unique() | Valores unicos |
| mean() | Promedio |
| sum() | suma |
| which() | proporciona los indices TRUE |
Ejercicio: Contesta lo siguiente:
- ¿cual fue el valor minimo y el maximo?
- ¿cuantos abulones murieron esa semana?
4 Indices
Una tarea común al trabajar con vectores de datos es el de aislar uno o varios valores que cumplen con algún criterio.
Mostrar el primer valor del vector
mortalidad[1]Lunes
4 Mostrar todos los valores excepto el segundo
mortalidad[-2] Lunes Miercoles Jueves Viernes Sabado Domingo
4 0 10 12 8 4 Se puede obtener multiples series de elementos al mismo tiempo usando c()
mortalidad[c(1,2:4)] Lunes Martes Miercoles Jueves
4 6 0 10 o si por el contrario queremos eliminar estos elementos se usa c(-)
mortalidad[-c(1,2:4)]Viernes Sabado Domingo
12 8 4 Obtener los dias en donde la mortalidad fue mayor a 5
mortalidad > 5 Lunes Martes Miercoles Jueves Viernes Sabado Domingo
FALSE TRUE FALSE TRUE TRUE TRUE FALSE #Mostrar solo los dias donde la mortalidad fue > 5
mortalidad[mortalidad > 5] Martes Jueves Viernes Sabado
6 10 12 8 #Mediante una variable
mor_5 <- mortalidad > 5
mortalidad[mor_5] Martes Jueves Viernes Sabado
6 10 12 8 Ejercicio
Identificar:
- ¿En que dia se observó la menor mortalidad?
- ¿Que dias tuvieron una mortalidad igual a 12?
- ¿Que dias tuvieron una mortalidad menor al promedio?
4.1 Enistar y borrar objectos
Las funciones ls()y objects()hacen lo mismo: enlistan los objetos que hemos definido en la sesión.
ls() [1] "caracter" "expo_variables" "mix" "mor_5"
[5] "mortalidad" "numeros" "variables" "variables_expo"
[9] "variables_mas" "variables_numero" "x" "y"
[13] "z" Y si queremos borrar objectos, se usa la funcion rm() Si quieremos borrrar todos los objectos del ambiente, se ejecuta rm(list=ls()).
5 Trabajando con tablas
Ahora supongamos que tienes que revisar tus estanques por otra semana. Sin embargo, el jueves de la tercera semana no pudiste ir, por lo que no tienes valores para ese dia. Estos son los resultados.
- lunes: 16
- martes: 12
- miercoles: 8
- jueves: no hay dato
- viernes: 14
- sabado: 4
- domingo: 10
Ejercicio: Construye un vector para la semana 2 con el nombre semana2.
De que forma podriamos nombrar cada dia de la semana en semana2?
6 Crear una tabla con data.frame
dia_sem <- c("Lunes", "Martes", "Miercoles", "Jueves", "Viernes", "Sabado", "Domingo")
tabla <- data.frame(dia = dia_sem, semana1 = mortalidad, semana2 = semana2)
tabla # los dias de la semana aparecen doble dia semana1 semana2
Lunes Lunes 4 16
Martes Martes 6 12
Miercoles Miercoles 0 8
Jueves Jueves 10 NA
Viernes Viernes 12 14
Sabado Sabado 8 4
Domingo Domingo 4 10tabla <- data.frame(row.names = dia_sem, semana1 = mortalidad, semana2 = semana2)
tabla semana1 semana2
Lunes 4 16
Martes 6 12
Miercoles 0 8
Jueves 10 NA
Viernes 12 14
Sabado 8 4
Domingo 4 10¿Que tipo de dato es el objecto tabla?
Ejercicio: Para cada semana, busca el valor minimo, maximo y promedio. Con estos valores crea un vector para cada semana y nombralos Semana1_sum y Semana2_sum.
Para esto es posible seguir dos aproximaciones:
- usando indices:
tabla[filas , columnas] - con el operado
$:tabla$columna
max(tabla$semana1)[1] 12min(tabla[,2])[1] NAmean(tabla$semana2, na.rm = TRUE)[1] 10.666676.1 Estructura de una tabla
#muestra las primeras n filas de la tabla
head(tabla) semana1 semana2
Lunes 4 16
Martes 6 12
Miercoles 0 8
Jueves 10 NA
Viernes 12 14
Sabado 8 4#muestra el numero de filas
nrow(tabla)[1] 7#muestra el numero de columnas
ncol(tabla)[1] 2#muestra el nombre de las columnas
colnames(tabla)[1] "semana1" "semana2"#muestra el nombre de las filsa
rownames(tabla)[1] "Lunes" "Martes" "Miercoles" "Jueves" "Viernes" "Sabado"
[7] "Domingo" otras operaciones utiles para data.frames:
colSums ()
rowSums ()
colMeans()
rowMeans()
Ejercicio: En el objetvo tabla, crea una columan con el promedio de organismos muertos por dia
Ejercicio: Te diste cuenta que esta nueva columna no te sirve. ¿como la eliminas?
pista: Puedes usar indices o NULL
sessionInfo()R version 4.0.5 (2021-03-31)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19041)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252
[2] LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.5 whisker_0.4 knitr_1.30 magrittr_2.0.1
[5] R6_2.5.0 rlang_0.4.10 fansi_0.4.1 stringr_1.4.0
[9] tools_4.0.5 xfun_0.20 utf8_1.1.4 git2r_0.27.1
[13] htmltools_0.5.0 ellipsis_0.3.1 rprojroot_2.0.2 yaml_2.2.1
[17] digest_0.6.27 tibble_3.0.4 lifecycle_1.0.0 crayon_1.4.1
[21] later_1.1.0.1 vctrs_0.3.6 promises_1.1.1 fs_1.5.0
[25] glue_1.4.2 evaluate_0.14 rmarkdown_2.6 stringi_1.5.3
[29] compiler_4.0.5 pillar_1.6.0 httpuv_1.5.4 pkgconfig_2.0.3