probability
wiesehahn
2020-08-31
Last updated: 2020-09-02
Checks: 7 0
Knit directory: baumarten/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200723) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 1197f9e. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.Rhistory
Ignored: data/sen2/
Untracked files:
Untracked: data/reference/train_test/train_test.rds
Unstaged changes:
Modified: code/workflow_project_setup.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/probability.Rmd) and HTML (docs/probability.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 1197f9e | wiesehahn | 2020-09-02 | Publish all files for myproject |
Probabilities
Probability distribution
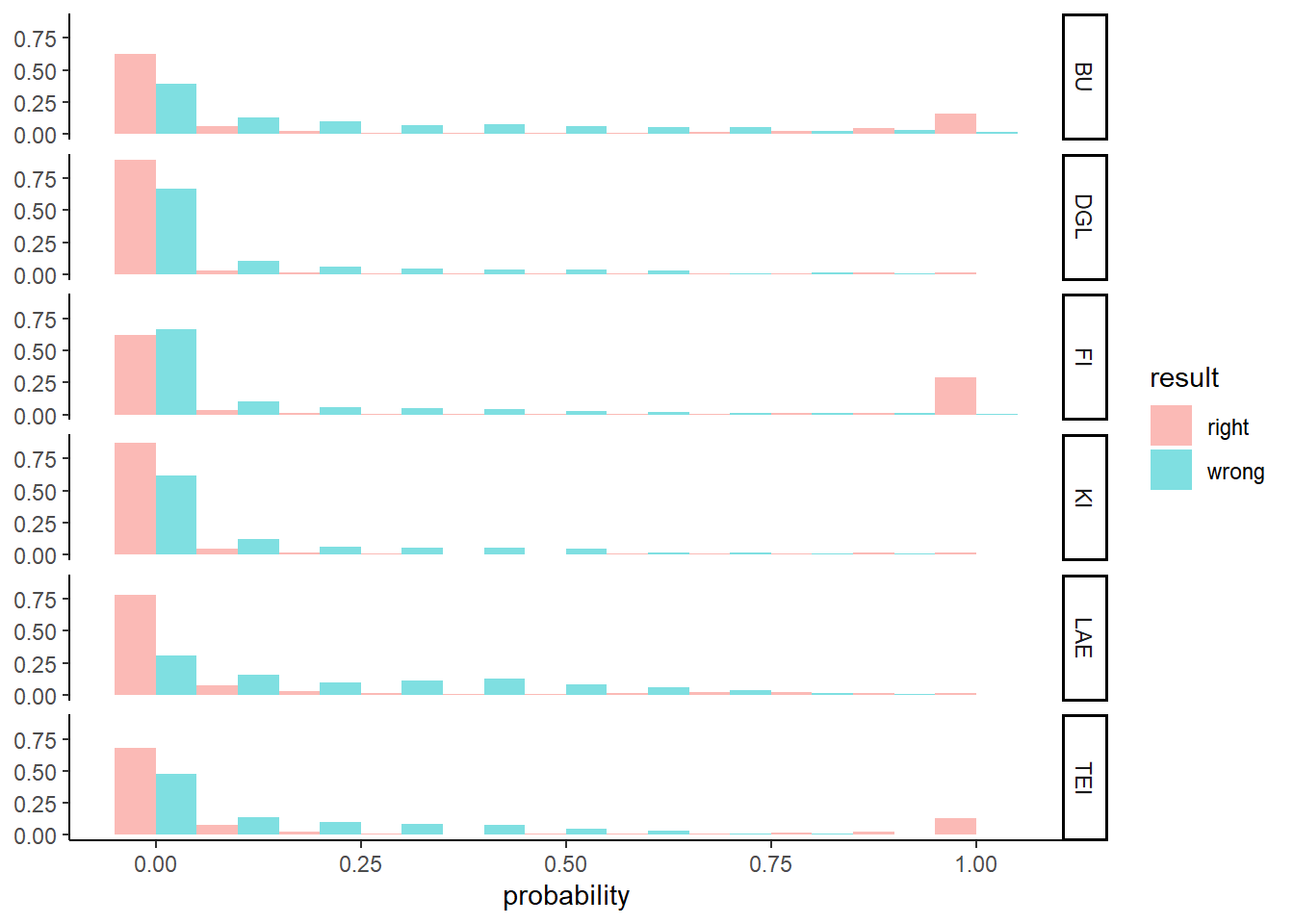
Relative probability distributions for correctly und uncorrectly classified forest stands by tree species
Reduced number of classes
What happens to prediction probabilities if the number of predicted tree species is reduced?
To test this I trained the model on just four species (beech, spruce, pine, oak)
6-Class-Accuracy
The effect on validation accuracy, including all 6 tree species is tested.
Error Matrix| Baumart | BU | DGL | FI | KI | LAE | TEI |
|---|---|---|---|---|---|---|
| BU | 2308 | 2 | 8 | 4 | 356 | 148 |
| DGL | 0 | 0 | 0 | 0 | 0 | 0 |
| FI | 0 | 394 | 2786 | 22 | 55 | 1 |
| KI | 16 | 97 | 49 | 538 | 307 | 2 |
| LAE | 0 | 0 | 0 | 0 | 0 | 0 |
| TEI | 83 | 35 | 5 | 4 | 251 | 1673 |
We can see, that Douglas fir is mainly classified as Spruce, while Larch is classified as either Beech, Pine or Oak!
Respective Accuracy| Accuracy | Kappa | AccuracyLower | AccuracyUpper |
|---|---|---|---|
| 0.7988845 | 0.7340012 | 0.7905195 | 0.8070587 |
4-Class-Accuracy
The effect on validation accuracy, including only the classes on which the model was trained.
Error Matrix| Baumart | BU | DGL | FI | KI | LAE | TEI |
|---|---|---|---|---|---|---|
| BU | 2308 | 0 | 8 | 4 | 0 | 148 |
| DGL | 0 | 0 | 0 | 0 | 0 | 0 |
| FI | 0 | 0 | 2786 | 22 | 0 | 1 |
| KI | 16 | 0 | 49 | 538 | 0 | 2 |
| LAE | 0 | 0 | 0 | 0 | 0 | 0 |
| TEI | 83 | 0 | 5 | 4 | 0 | 1673 |
| Accuracy | Kappa | AccuracyLower | AccuracyUpper |
|---|---|---|---|
| 0.9552766 | 0.936171 | 0.9504019 | 0.9598003 |
Boxplots
Correct probabilities
propabilities of predicted tree species which were classified correct
Reducing the number of predicted tree species results in higher model certainties for all species.
Uncorrect probabilties
propabilities of predicted tree species which were classified uncorrect (e.g. predicted probability of beech which is in fact oak)
Quite unsurprisingly the (false) probabilities of uncorrectly classified forest stands rise with reduced number of species if we are considering all reference data, including Larch and Douglas fir. These stands are classified as one of the other four species and hence are uncorrect by default.
propabilities of reference tree species which were classified uncorrect (e.g. probability of oak which was predicted as beech)
Probabilities for the (true) reference species, which were classified uncorrectly as another species increased slighty with reduced number of predicted species. This is mainly due to the fact that probabilities are split among four instead of six species.
R version 4.0.2 (2020-06-22)
Platform: i386-w64-mingw32/i386 (32-bit)
Running under: Windows 10 x64 (build 18362)
Matrix products: default
locale:
[1] LC_COLLATE=German_Germany.1252 LC_CTYPE=German_Germany.1252
[3] LC_MONETARY=German_Germany.1252 LC_NUMERIC=C
[5] LC_TIME=German_Germany.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ranger_0.12.1 caret_6.0-86 lattice_0.20-41 recipes_0.1.13
[5] dplyr_1.0.0 here_0.1 plotly_4.9.2.1 ggplot2_3.3.2
[9] readr_1.3.1 kableExtra_1.1.0 viridis_0.5.1 viridisLite_0.3.0
[13] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] httr_1.4.2 tidyr_1.1.0 jsonlite_1.7.0
[4] splines_4.0.2 foreach_1.5.0 prodlim_2019.11.13
[7] highr_0.8 stats4_4.0.2 yaml_2.2.1
[10] ipred_0.9-9 pillar_1.4.6 backports_1.1.7
[13] glue_1.4.1 pROC_1.16.2 digest_0.6.25
[16] RColorBrewer_1.1-2 promises_1.1.1 rvest_0.3.6
[19] colorspace_1.4-1 htmltools_0.5.0 httpuv_1.5.4
[22] Matrix_1.2-18 plyr_1.8.6 timeDate_3043.102
[25] pkgconfig_2.0.3 purrr_0.3.4 scales_1.1.1
[28] webshot_0.5.2 whisker_0.4 later_1.1.0.1
[31] gower_0.2.2 lava_1.6.7 git2r_0.27.1
[34] tibble_3.0.3 farver_2.0.3 generics_0.0.2
[37] ellipsis_0.3.1 withr_2.2.0 nnet_7.3-14
[40] lazyeval_0.2.2 survival_3.2-3 magrittr_1.5
[43] crayon_1.3.4 evaluate_0.14 fs_1.4.2
[46] nlme_3.1-148 MASS_7.3-51.6 xml2_1.3.2
[49] class_7.3-17 tools_4.0.2 data.table_1.12.8
[52] hms_0.5.3 lifecycle_0.2.0 stringr_1.4.0
[55] munsell_0.5.0 e1071_1.7-3 compiler_4.0.2
[58] rlang_0.4.7 grid_4.0.2 iterators_1.0.12
[61] rstudioapi_0.11 htmlwidgets_1.5.1 crosstalk_1.1.0.1
[64] labeling_0.3 rmarkdown_2.3 ModelMetrics_1.2.2.2
[67] gtable_0.3.0 codetools_0.2-16 reshape2_1.4.4
[70] R6_2.4.1 gridExtra_2.3 lubridate_1.7.9
[73] knitr_1.29 rprojroot_1.3-2 stringi_1.4.6
[76] Rcpp_1.0.5 vctrs_0.3.2 rpart_4.1-15
[79] tidyselect_1.1.0 xfun_0.15