Exploratory analysis of Cnr1 in mouse Onecut3-GABAergic and dopaminergic hypothalamic neurons during development
Evgenii Tretiakov
2023-05-29
Last updated: 2023-05-29
Checks: 6 1
Knit directory: PeVN-dopaminergic-Cnr1/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
The R Markdown file has staged changes. To know which version of the
R Markdown file created these results, you’ll want to first commit it to
the Git repo. If you’re still working on the analysis, you can ignore
this warning. When you’re finished, you can run
wflow_publish to commit the R Markdown file and build the
HTML.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20230529) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 66a65ae. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: analysis/figure/
Ignored: output/tables/
Staged changes:
Modified: analysis/_site.yml
New: analysis/eda.Rmd
New: code/functions.R
New: code/genes.R
New: data/.gitattributes
New: data/colours_wtree.tsv
New: data/oc3_fin.h5seurat
New: data/oldCCA_nae_srt.rds
New: data/rar2020.srt.cont.oc2or3.raw.h5seurat
New: data/samples.tsv
New: output/figures/stat-corr-plt_oc3-rna-data-Onecut3-Cnr1_.pdf
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
There are no past versions. Publish this analysis with
wflow_publish() to start tracking its development.
# Load tidyverse infrastructure packages
library(here)
library(tidyverse)
library(magrittr)
library(zeallot)
library(future)
# Load packages for scRNA-seq analysis and visualisation
library(sctransform)
library(Seurat)
library(SeuratWrappers)
library(SeuratDisk)
library(scCustomize)
library(UpSetR)
library(patchwork)
library(RColorBrewer)
library(Nebulosa)src_dir <- here("code")
data_dir <- here("data")
output_dir <- here("output")
plots_dir <- here(output_dir, "figures")
tables_dir <- here(output_dir, "tables")source(here(src_dir, "functions.R"))
source(here(src_dir, "genes.R"))reseed <- 42
set.seed(seed = reseed)# available cores
n_cores <- available_cores(prop2use = .5)
# Parameters for parallel execution
plan("multicore", workers = n_cores)
options(
future.globals.maxSize = Inf,
future.rng.onMisuse = "ignore"
)
plan()multicore:
- args: function (..., workers = 16, envir = parent.frame())
- tweaked: TRUE
- call: plan("multicore", workers = n_cores)Read data
rar2020_ages_all <- c("E15", "E17", "P00", "P02", "P10", "P23")
rar2020_ages_postnat <- c("P02", "P10", "P23")
samples_df <- read_tsv(here("data/samples.tsv"))
colours_wtree <- setNames(
read_lines(here(data_dir, "colours_wtree.tsv")),
1:45
)
rar2020_srt_pub <-
readr::read_rds(file.path(data_dir, "oldCCA_nae_srt.rds"))
rar2020_srt_pub %<>% UpdateSeuratObject()
colnames(rar2020_srt_pub@reductions$umap@cell.embeddings) <-
c("UMAP_1", "UMAP_2")
rar2020_srt_pub$orig.ident <-
rar2020_srt_pub %>%
colnames() %>%
str_split(pattern = ":", simplify = TRUE) %>%
.[, 1] %>%
plyr::mapvalues(
x = .,
from = samples_df$fullname,
to = samples_df$sample
)
rar2020_srt_pub$age <-
plyr::mapvalues(
x = rar2020_srt_pub$orig.ident,
from = samples_df$sample,
to = samples_df$age
)
Idents(rar2020_srt_pub) <- "wtree"
neurons <-
subset(rar2020_srt_pub, idents = c("18", "32"))
neurons <-
subset(neurons, subset = Slc17a6 == 0)
onecut3 <-
subset(neurons,
subset = Onecut3 > 0 | Th > 0 | Ddc > 0 | Slc6a3 > 0
)
onecut3 <-
Store_Palette_Seurat(
seurat_object = onecut3,
palette = rev(brewer.pal(n = 11, name = "Spectral")),
palette_name = "div_Colour_Pal"
)Thus we subset the dataset to the neurons of interest from cluster 18, which are GABAergic and dopaminergic neurons expressing Onecut3 transcription factor. We also explicitly exclude Slc17a6-expressing neurons, which are glutamatergic neurons just in case to reduce noise. As the control group we use dopaminergic TIDA-neurons from the arcuate nucleus.
Derive and filter matrix of neurons of interest
mtx_oc3 <-
onecut3 %>%
GetAssayData("data", "RNA") %>%
as.data.frame() %>%
t()
rownames(mtx_oc3) <- colnames(onecut3)
# Filter features
filt_low_genes <-
colSums(mtx_oc3) %>%
.[. > quantile(., 0.4)] %>%
names()
mtx_oc3 %<>% .[, filt_low_genes]
min_filt_vector <-
mtx_oc3 %>%
as_tibble() %>%
select(all_of(filt_low_genes)) %>%
summarise(across(.fns = ~ quantile(.x, .1))) %>%
as.list() %>%
map(as.double) %>%
simplify() %>%
.[colnames(mtx_oc3)]
# Prepare table of intersection sets analysis
content_mtx_oc3 <-
(mtx_oc3 > min_filt_vector) %>%
as_tibble() %>%
mutate_all(as.numeric)Plot UMAPs density
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Onecut3"),
custom_palette = onecut3@misc$div_Colour_Pal
)
Plot_Density_Custom(
seurat_object = onecut3,
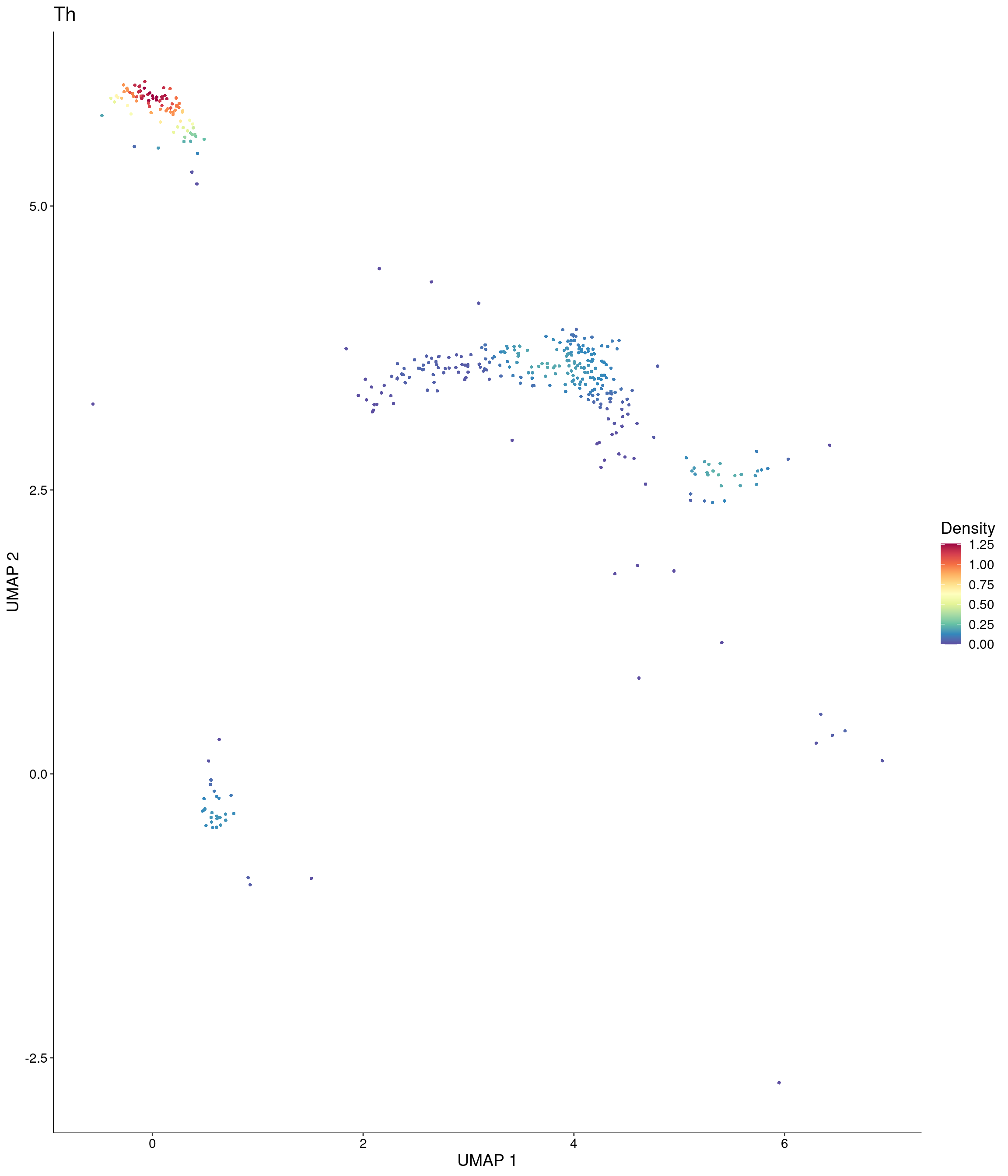
features = c("Th"),
custom_palette = onecut3@misc$div_Colour_Pal
)
Plot_Density_Custom(
seurat_object = onecut3,
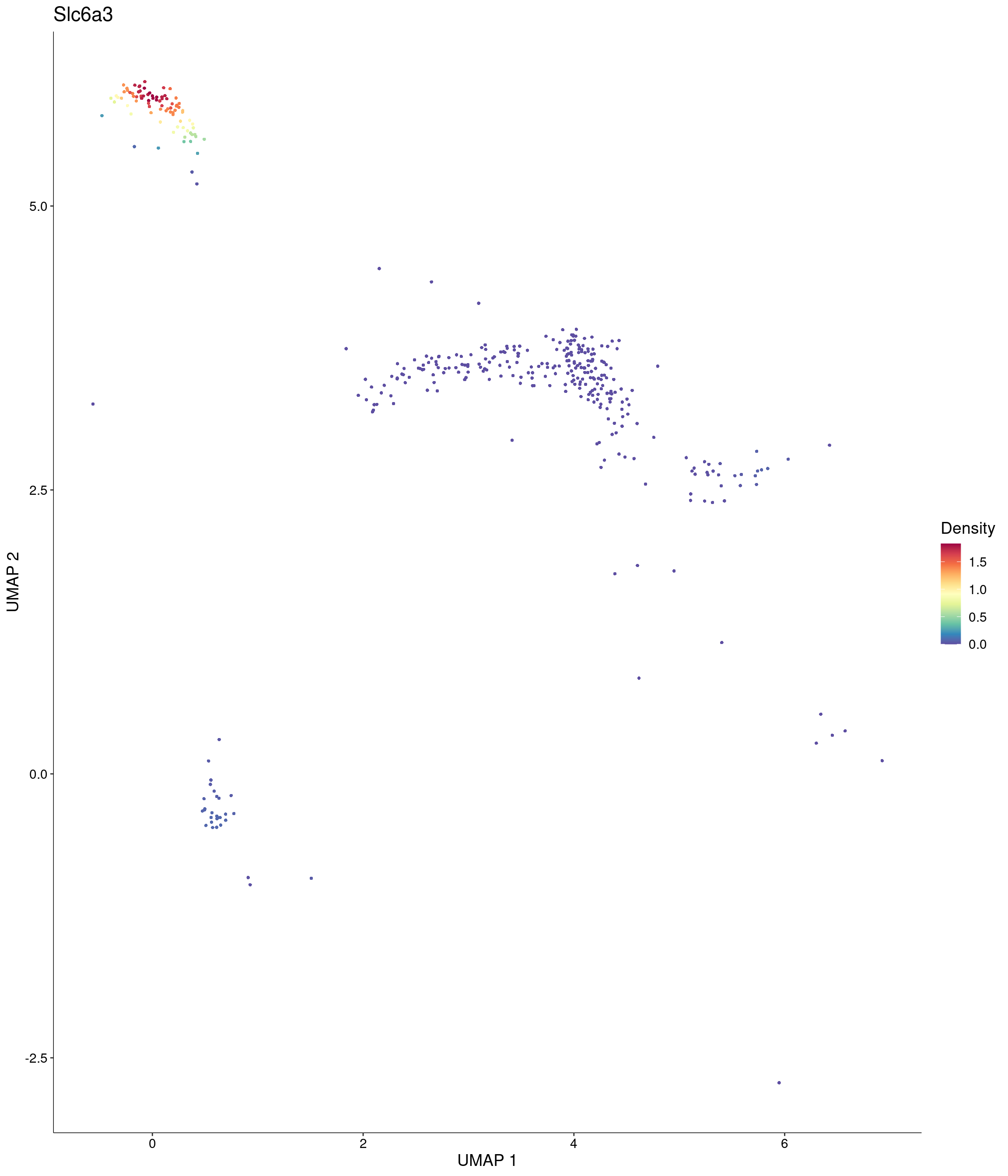
features = c("Slc6a3"),
custom_palette = onecut3@misc$div_Colour_Pal
)
Plot_Density_Custom(
seurat_object = onecut3,
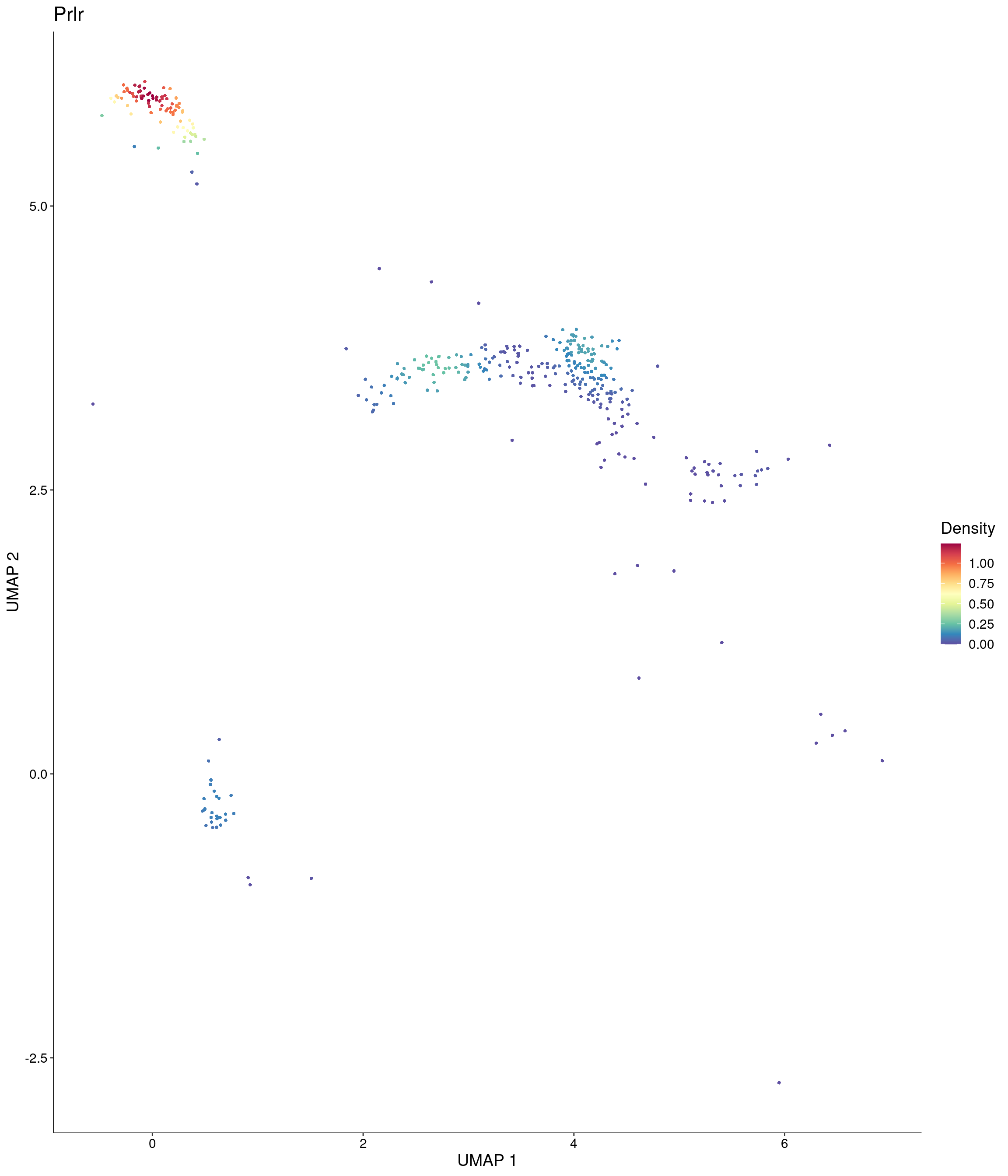
features = c("Prlr"),
custom_palette = onecut3@misc$div_Colour_Pal
)
Plot_Density_Custom(
seurat_object = onecut3,
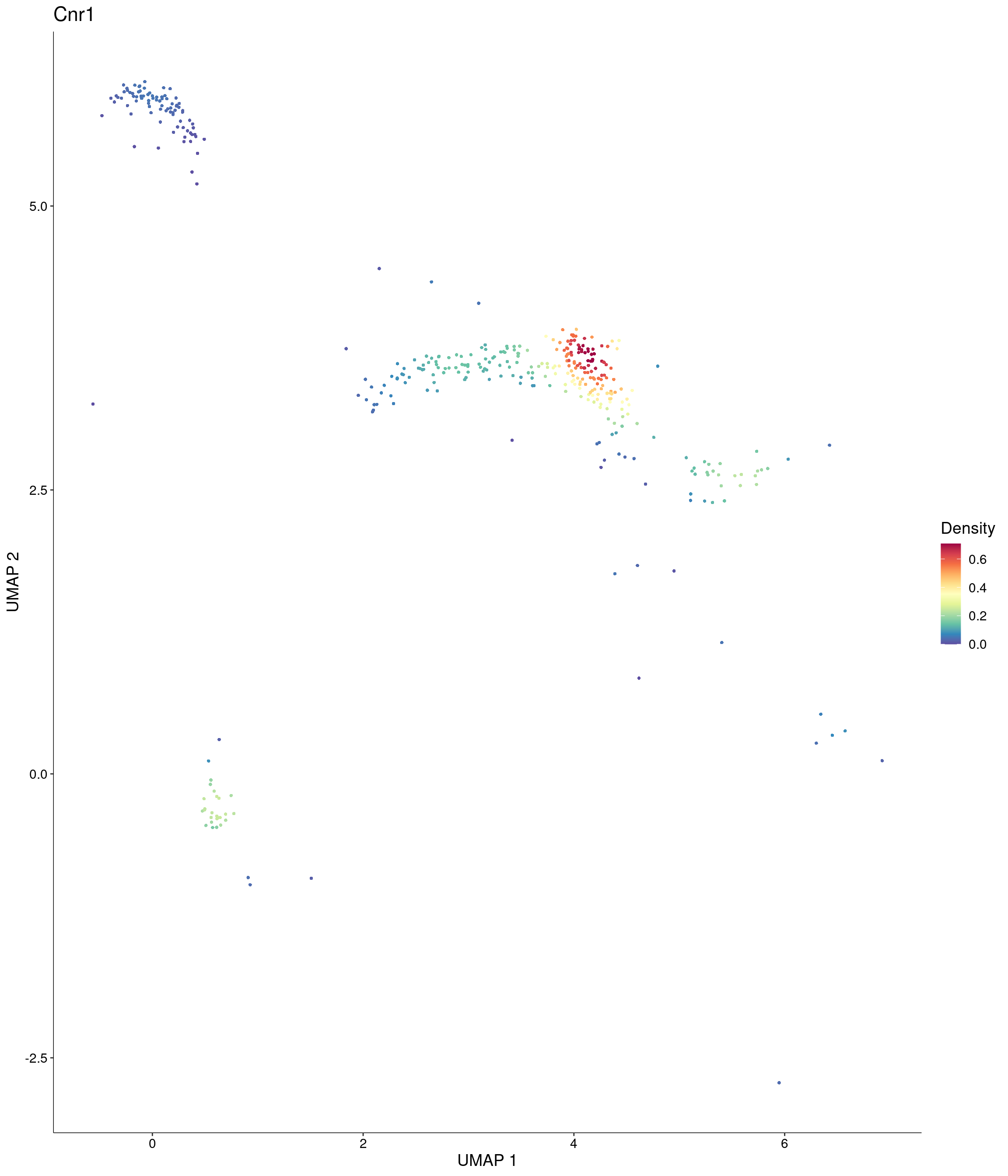
features = c("Cnr1"),
custom_palette = onecut3@misc$div_Colour_Pal
)
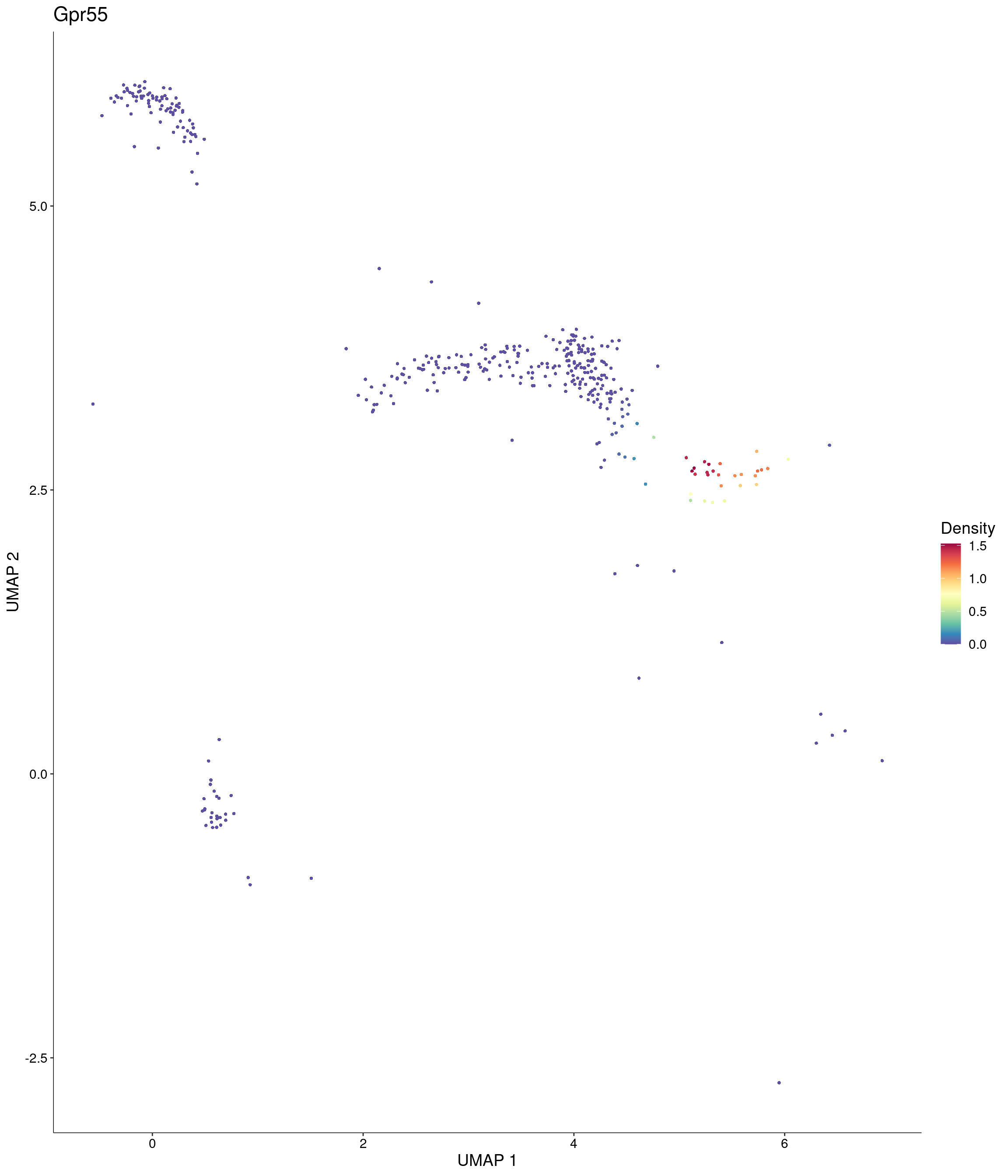
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Gpr55"),
custom_palette = onecut3@misc$div_Colour_Pal
)
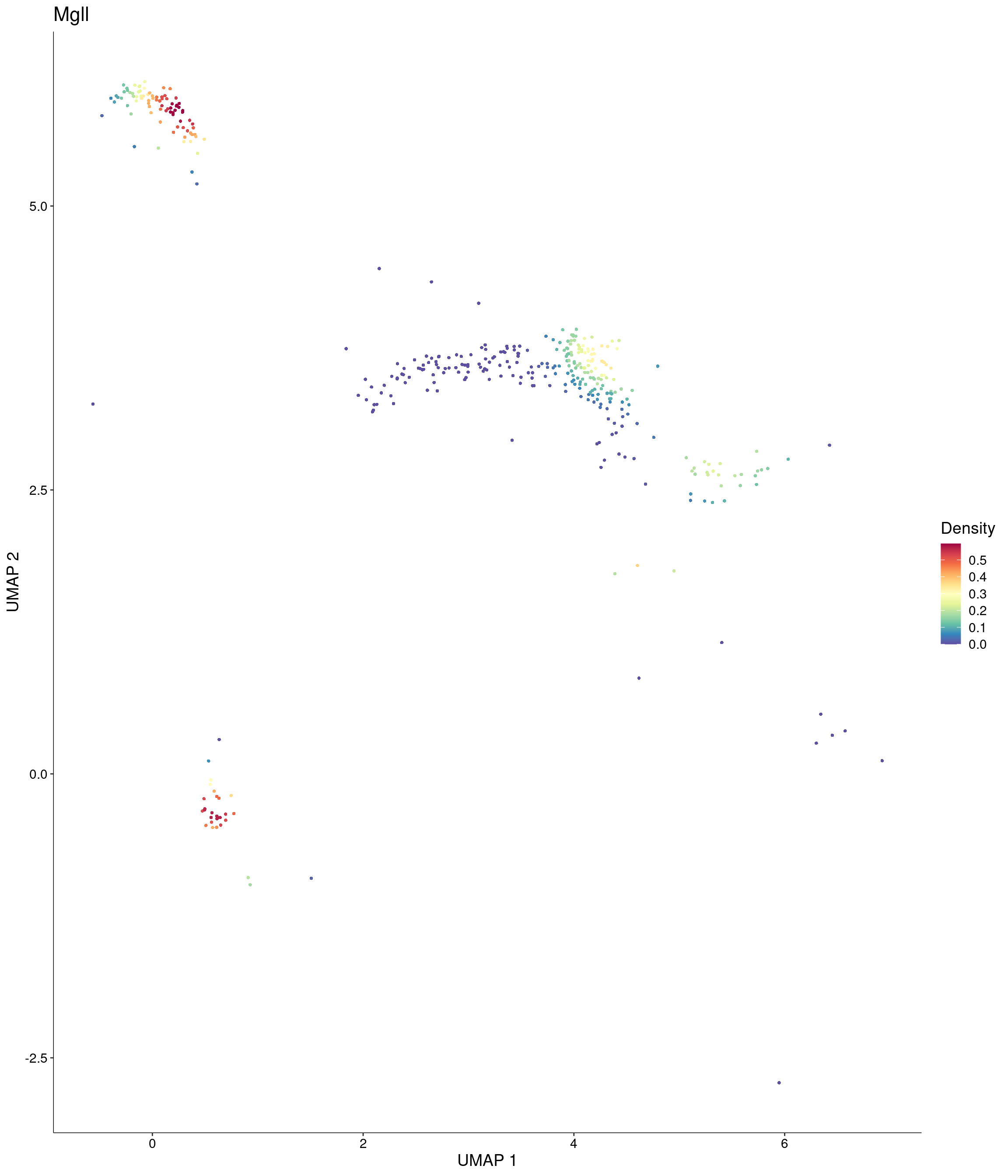
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Mgll"),
custom_palette = onecut3@misc$div_Colour_Pal
)
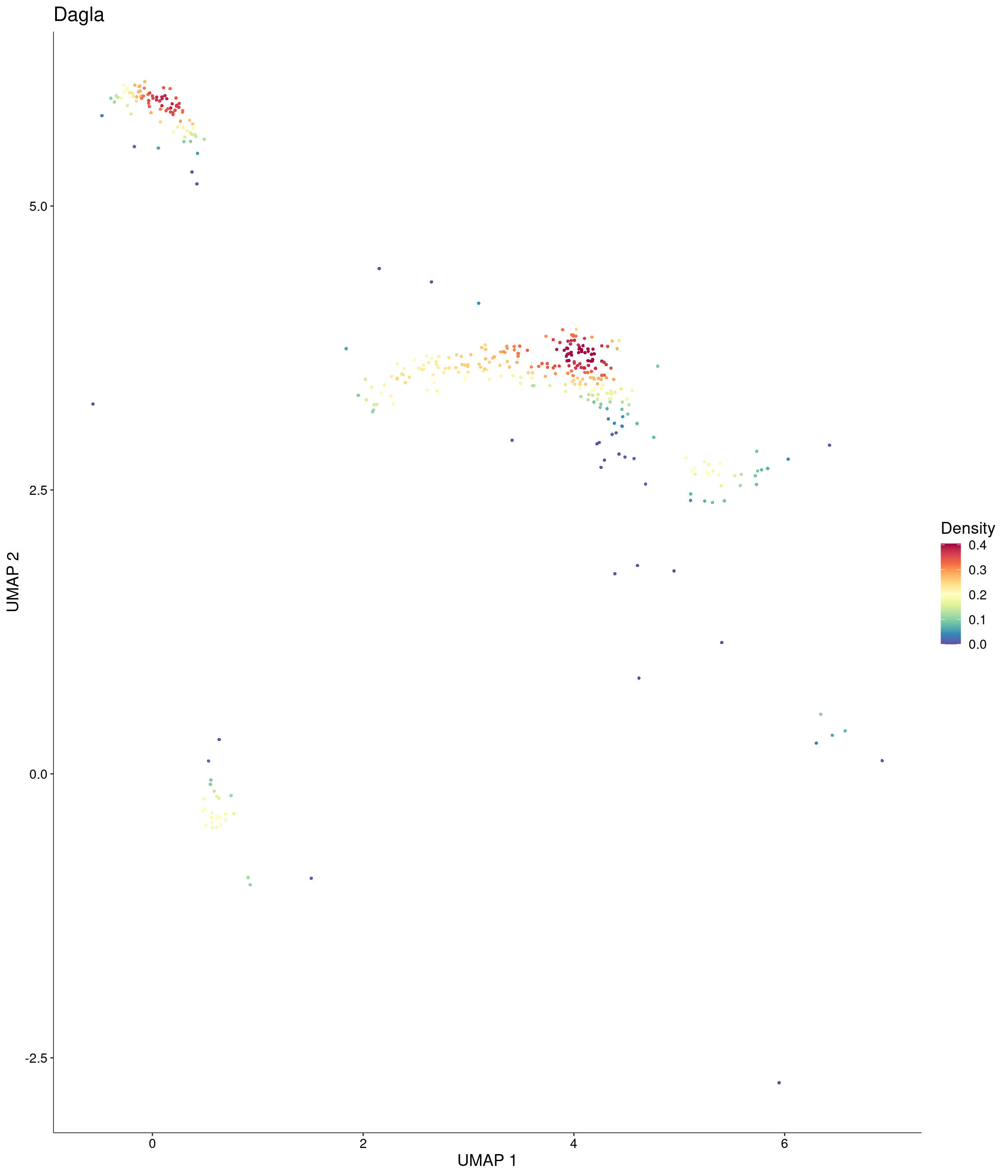
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Dagla"),
custom_palette = onecut3@misc$div_Colour_Pal
)
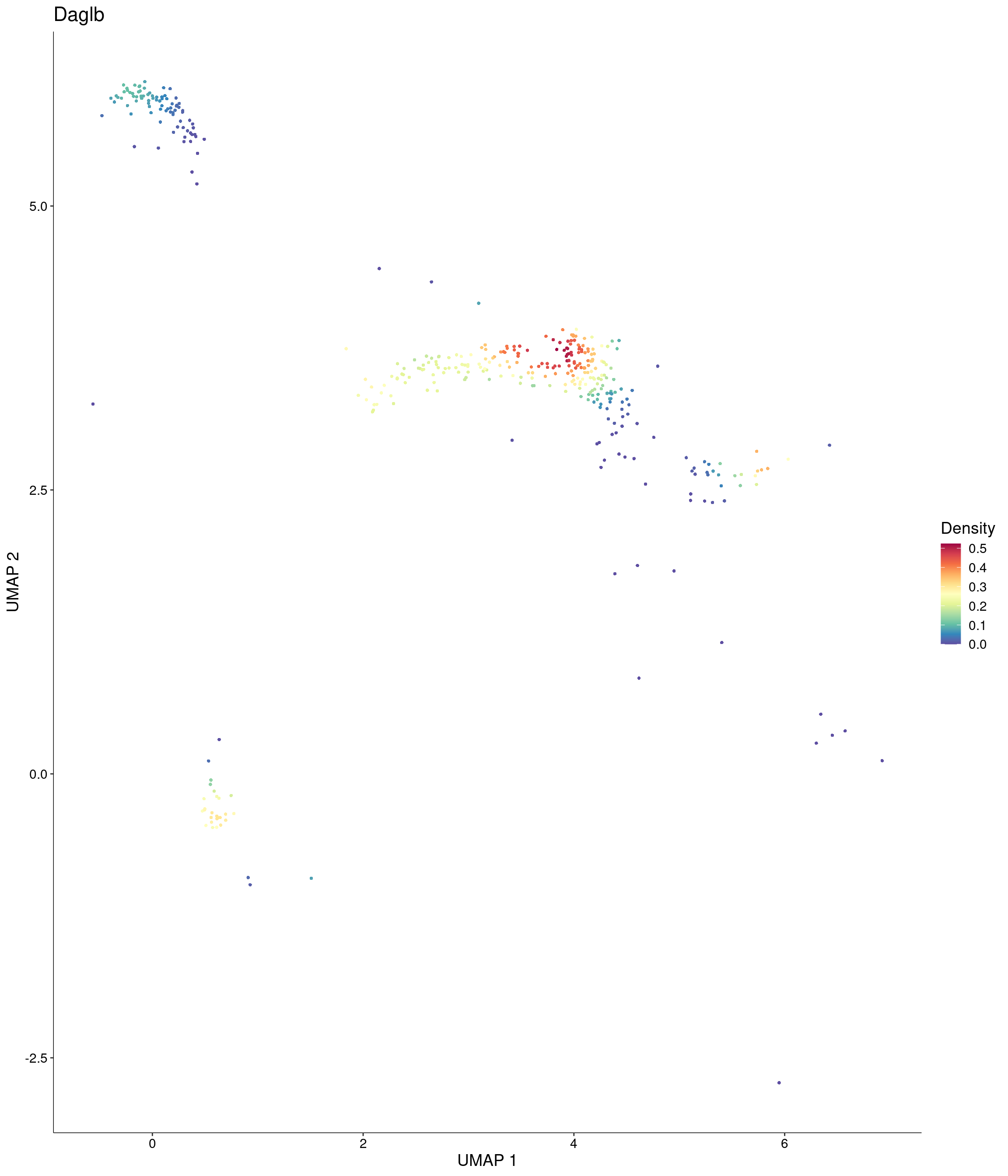
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Daglb"),
custom_palette = onecut3@misc$div_Colour_Pal
)
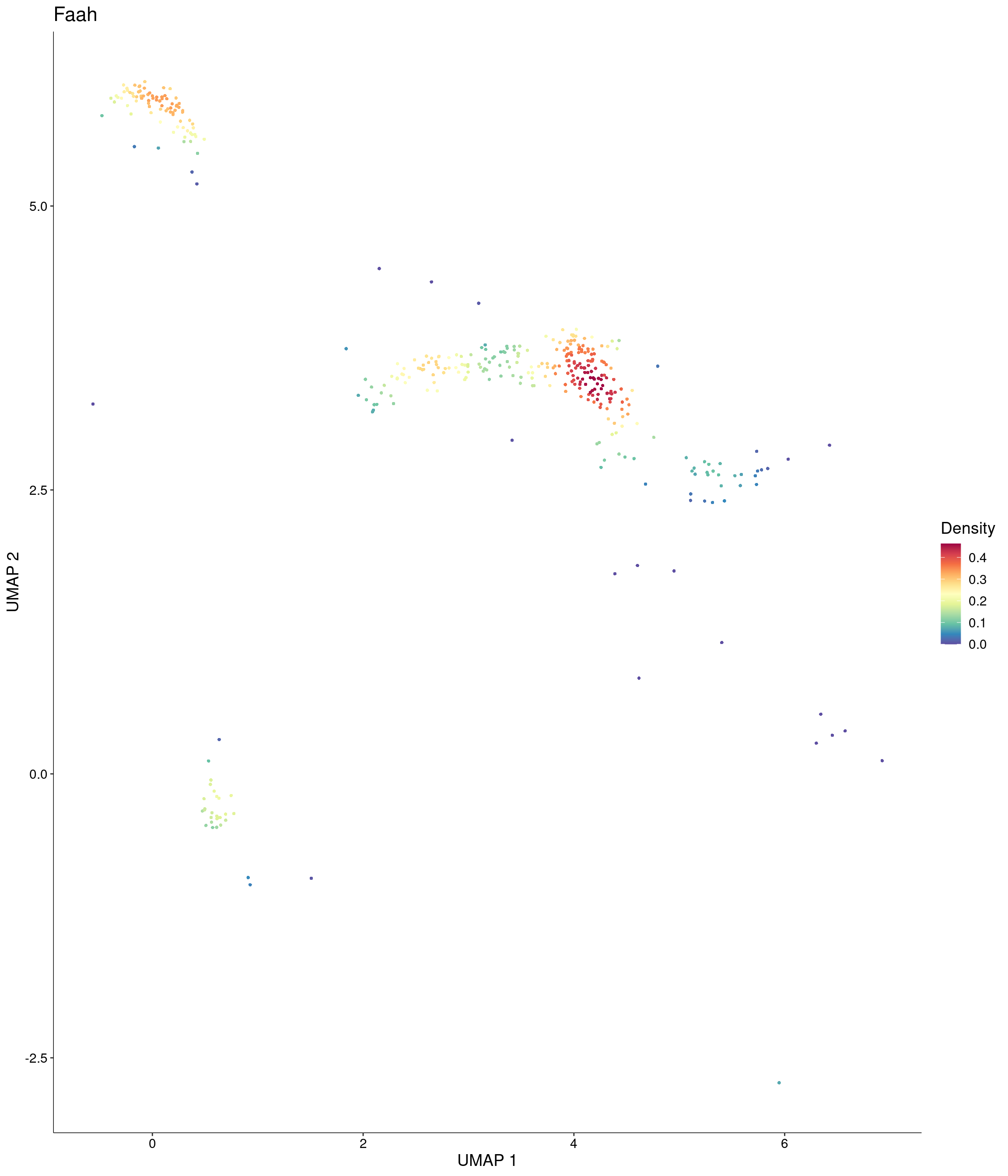
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Faah"),
custom_palette = onecut3@misc$div_Colour_Pal
)
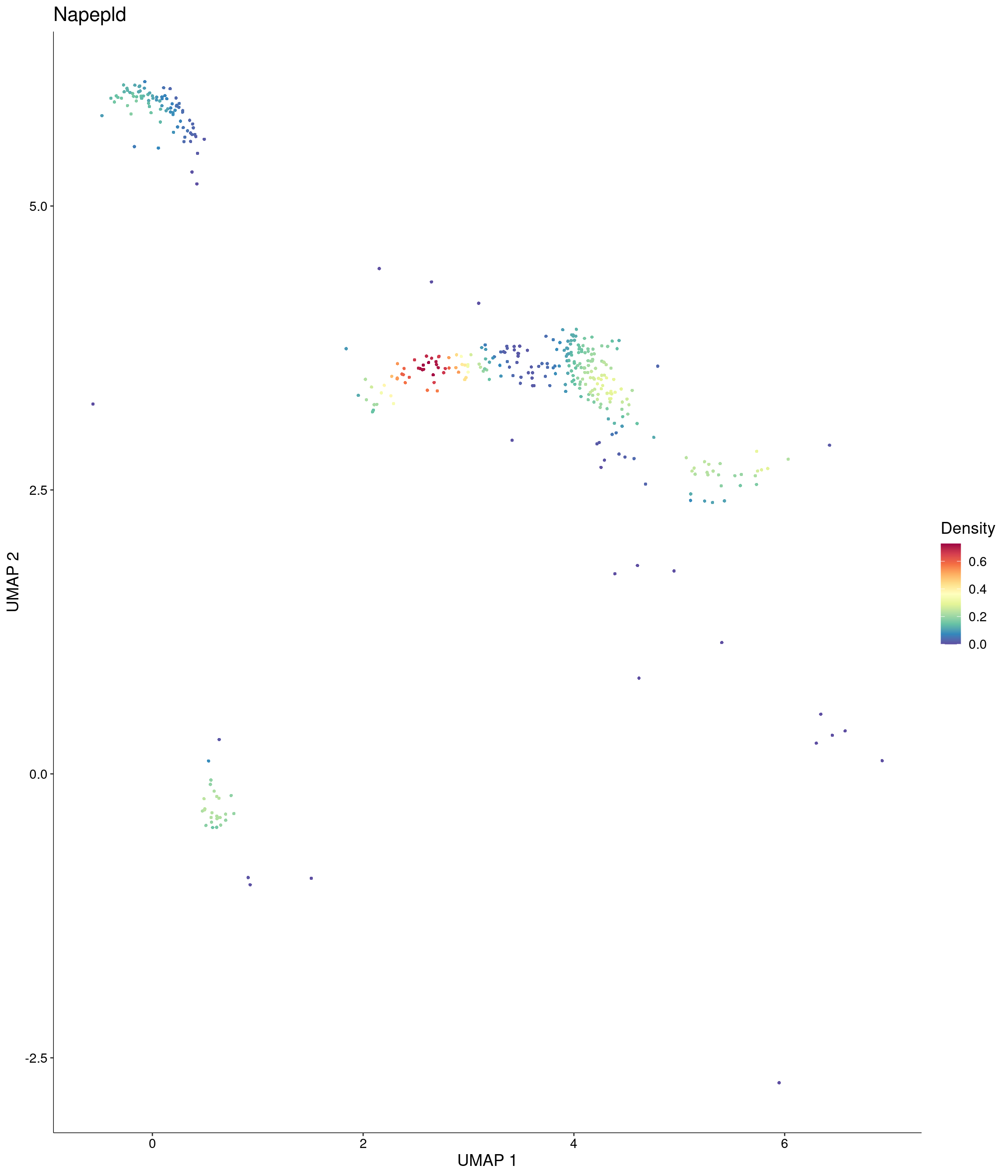
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Napepld"),
custom_palette = onecut3@misc$div_Colour_Pal
)
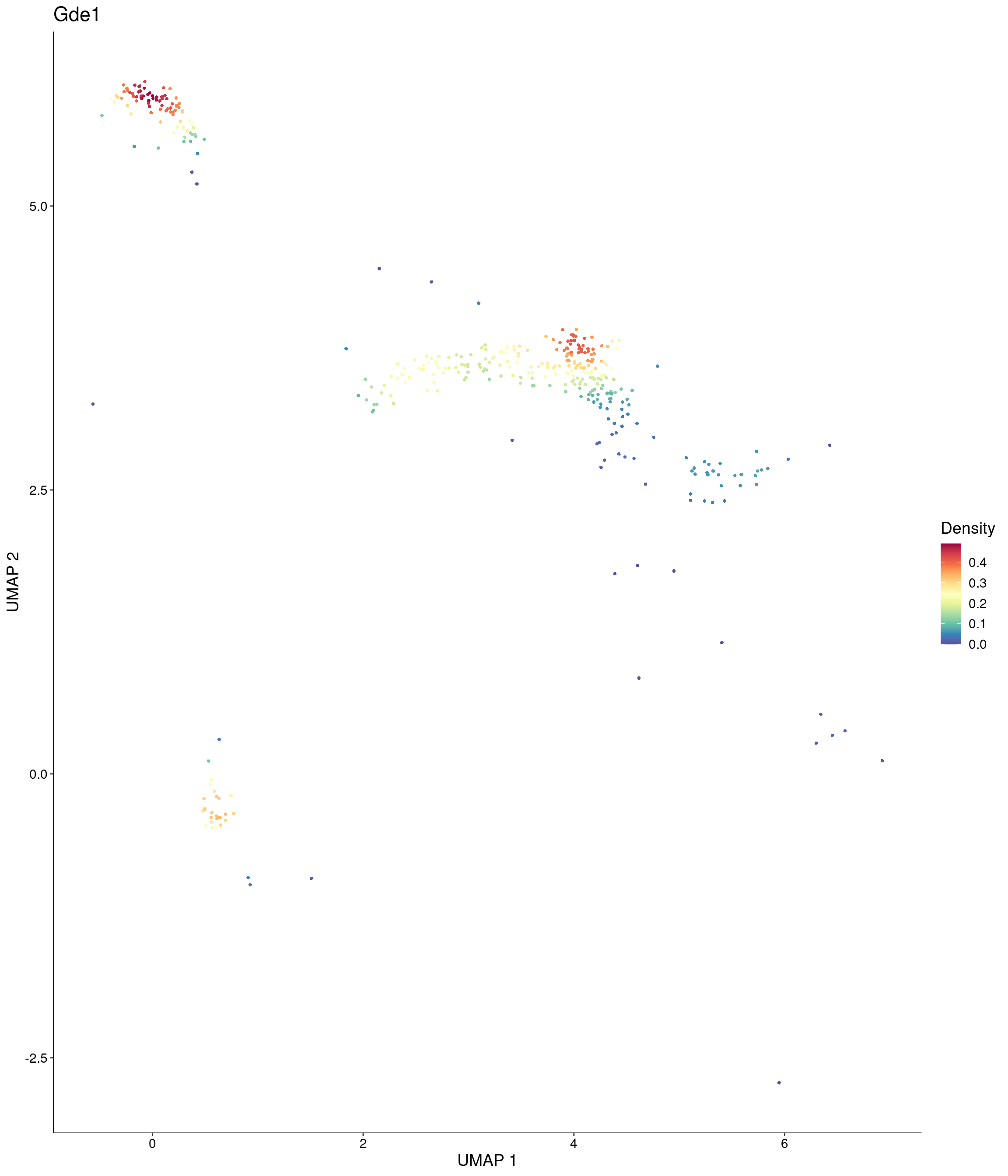
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Gde1"),
custom_palette = onecut3@misc$div_Colour_Pal
)
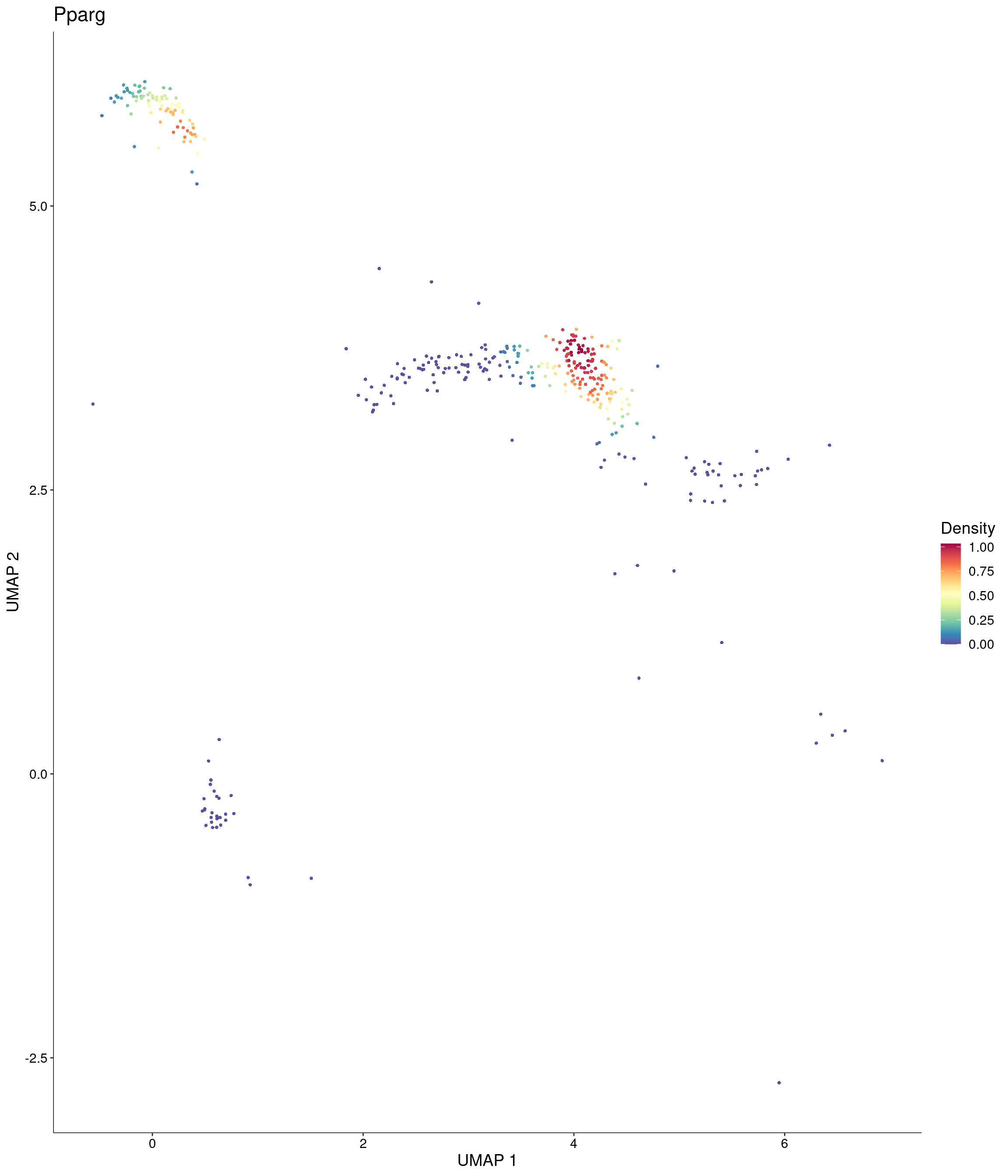
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Pparg"),
custom_palette = onecut3@misc$div_Colour_Pal
)
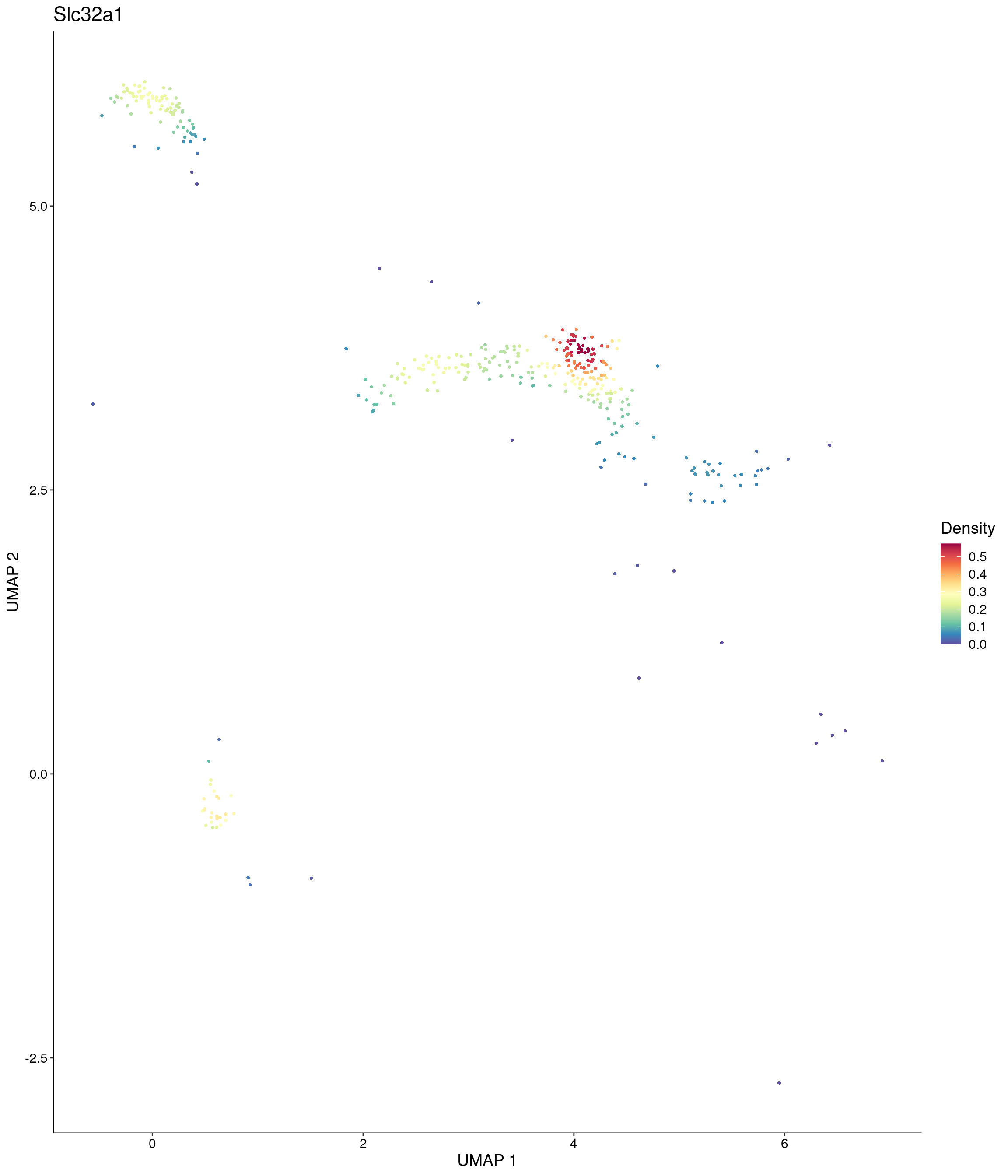
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Slc32a1"),
custom_palette = onecut3@misc$div_Colour_Pal
)
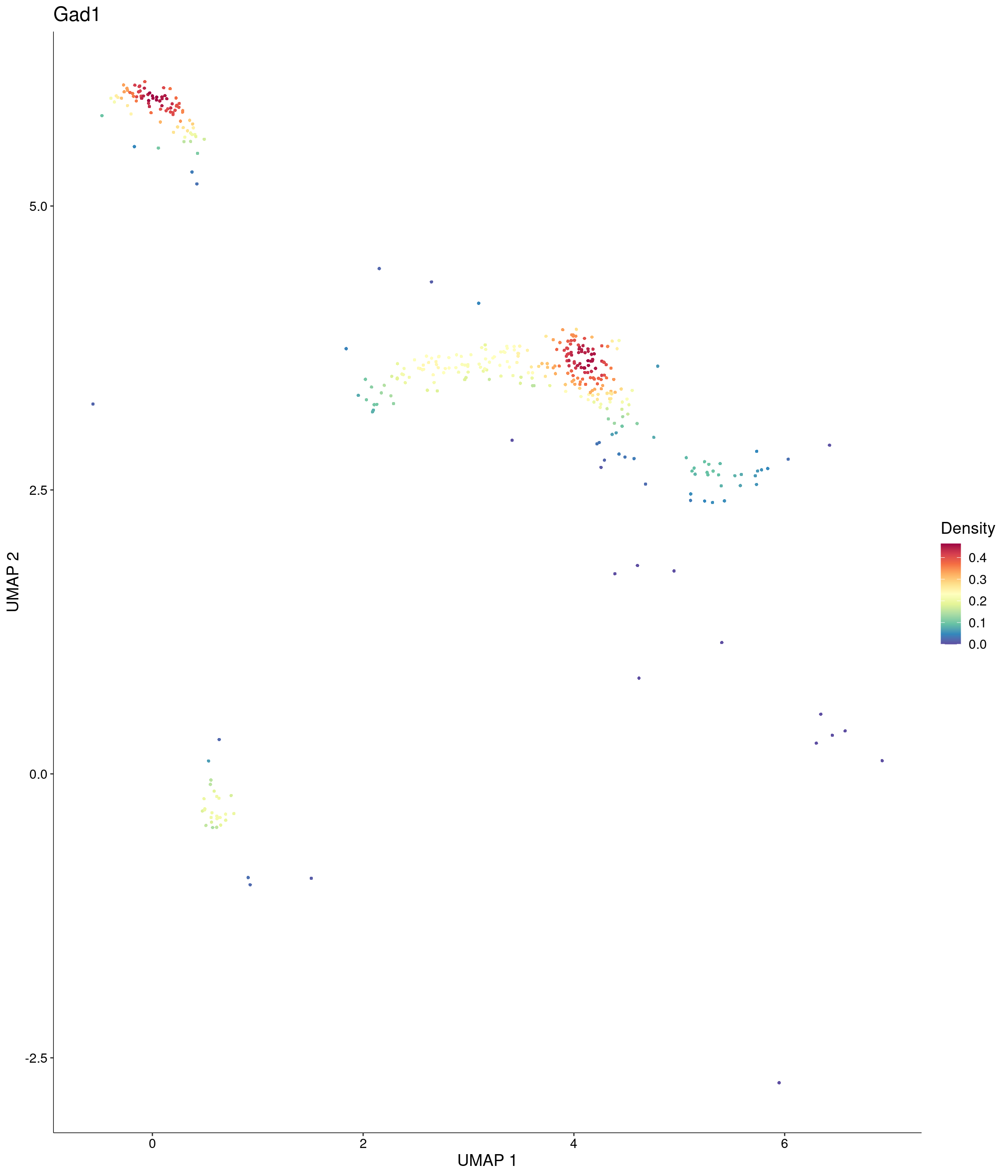
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Gad1"),
custom_palette = onecut3@misc$div_Colour_Pal
)
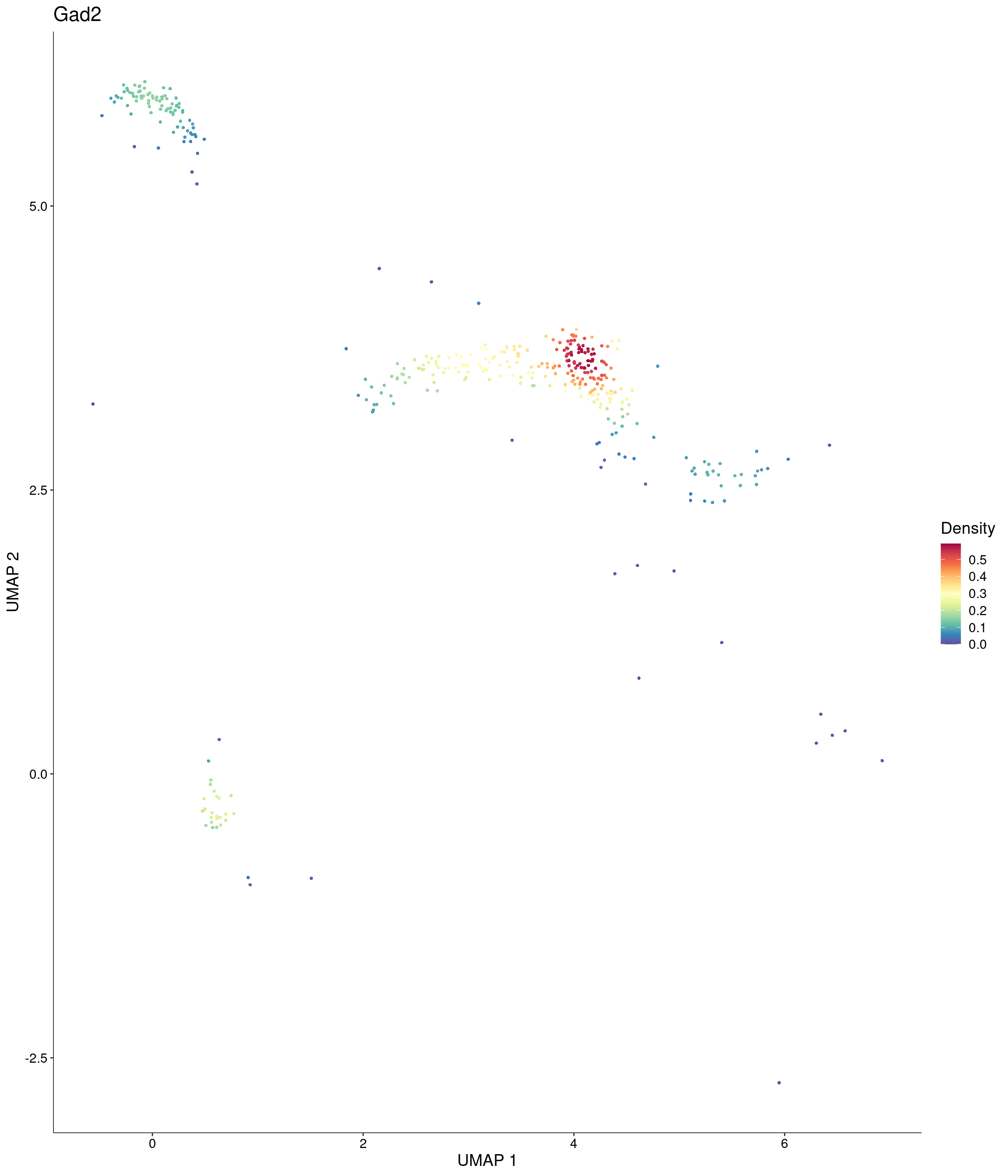
Plot_Density_Custom(
seurat_object = onecut3,
features = c("Gad2"),
custom_palette = onecut3@misc$div_Colour_Pal
)
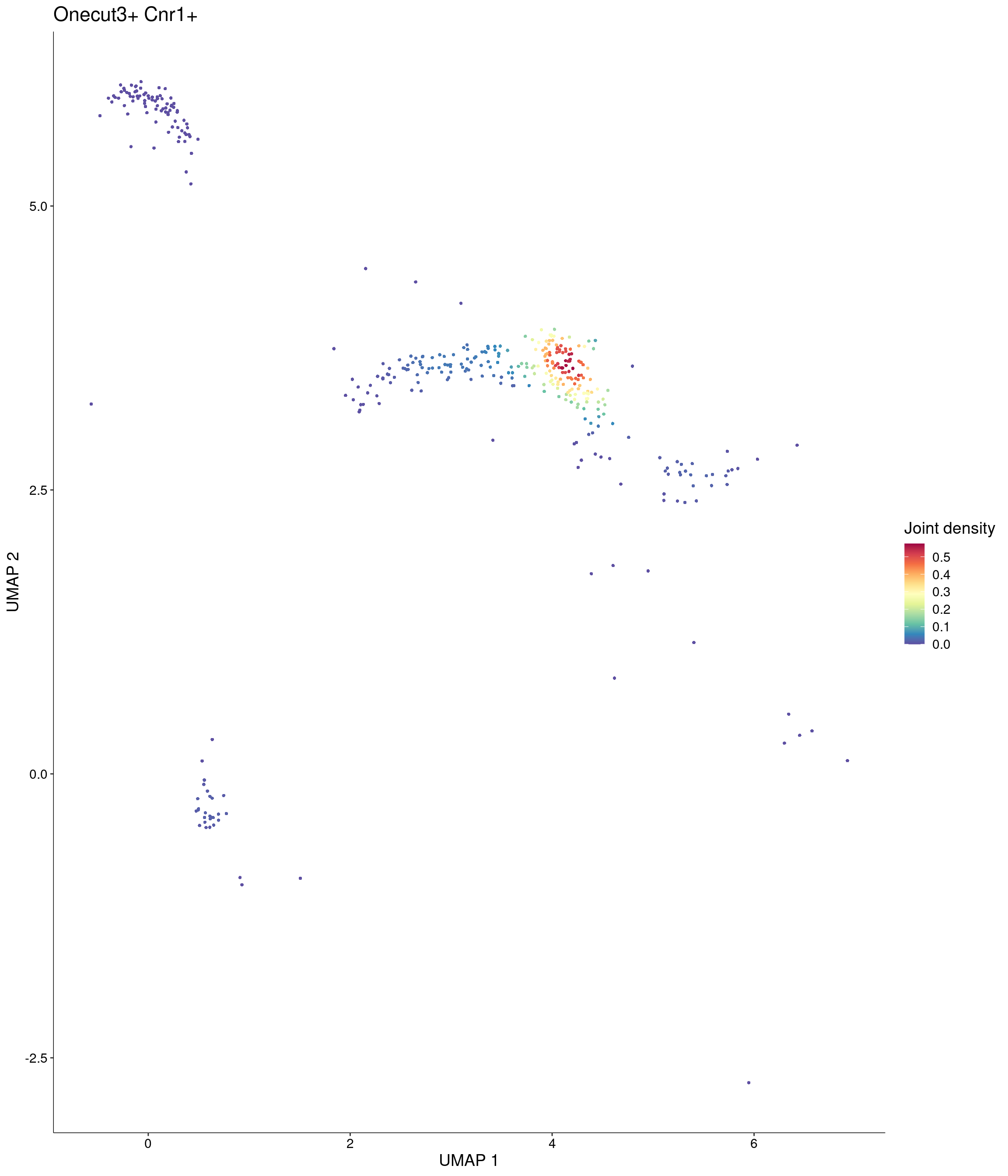
Joint density UMAP’s plots
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Onecut3", "Cnr1"),
custom_palette = onecut3@misc$div_Colour_Pal
)
Plot_Density_Joint_Only(
seurat_object = onecut3,
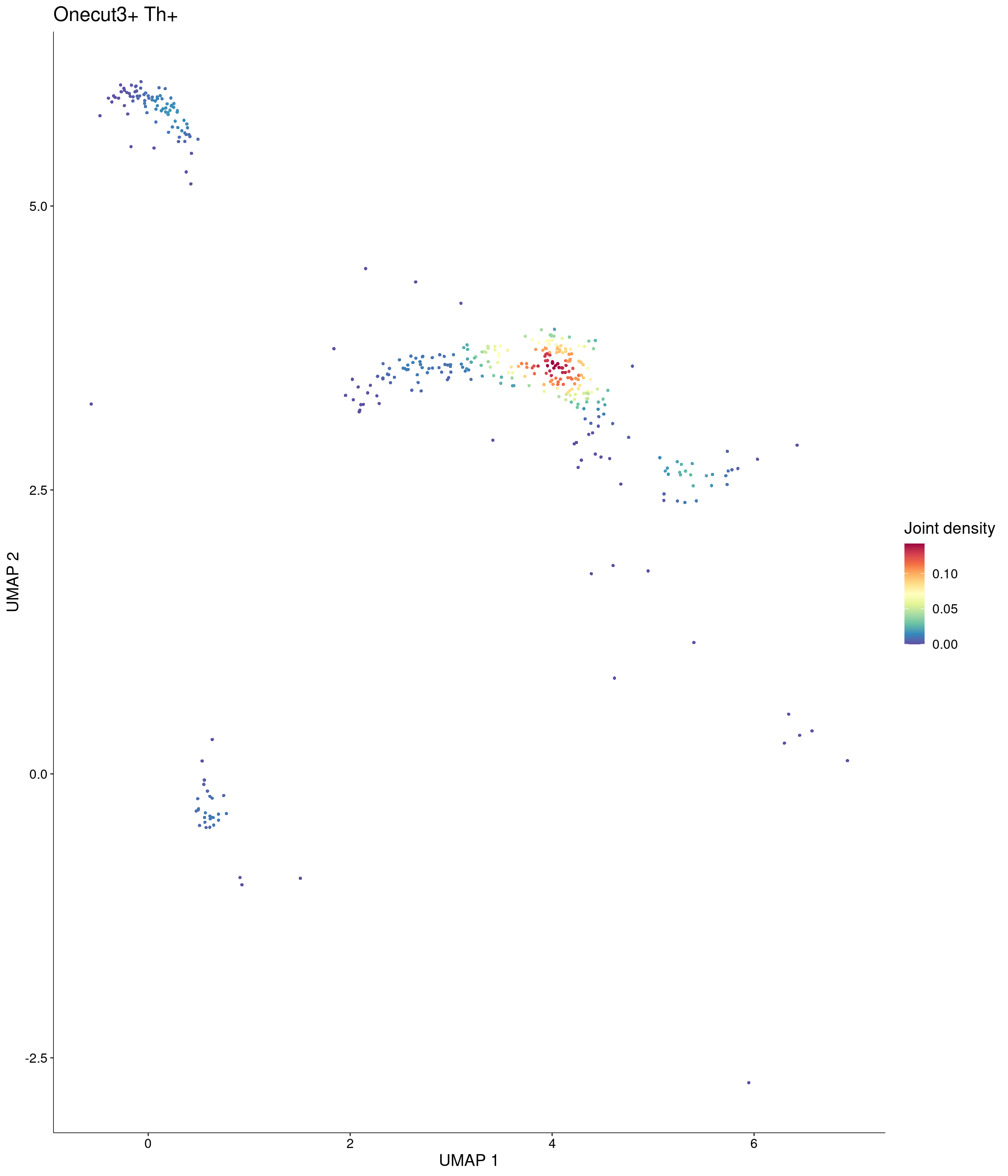
features = c("Onecut3", "Th"),
custom_palette = onecut3@misc$div_Colour_Pal
)
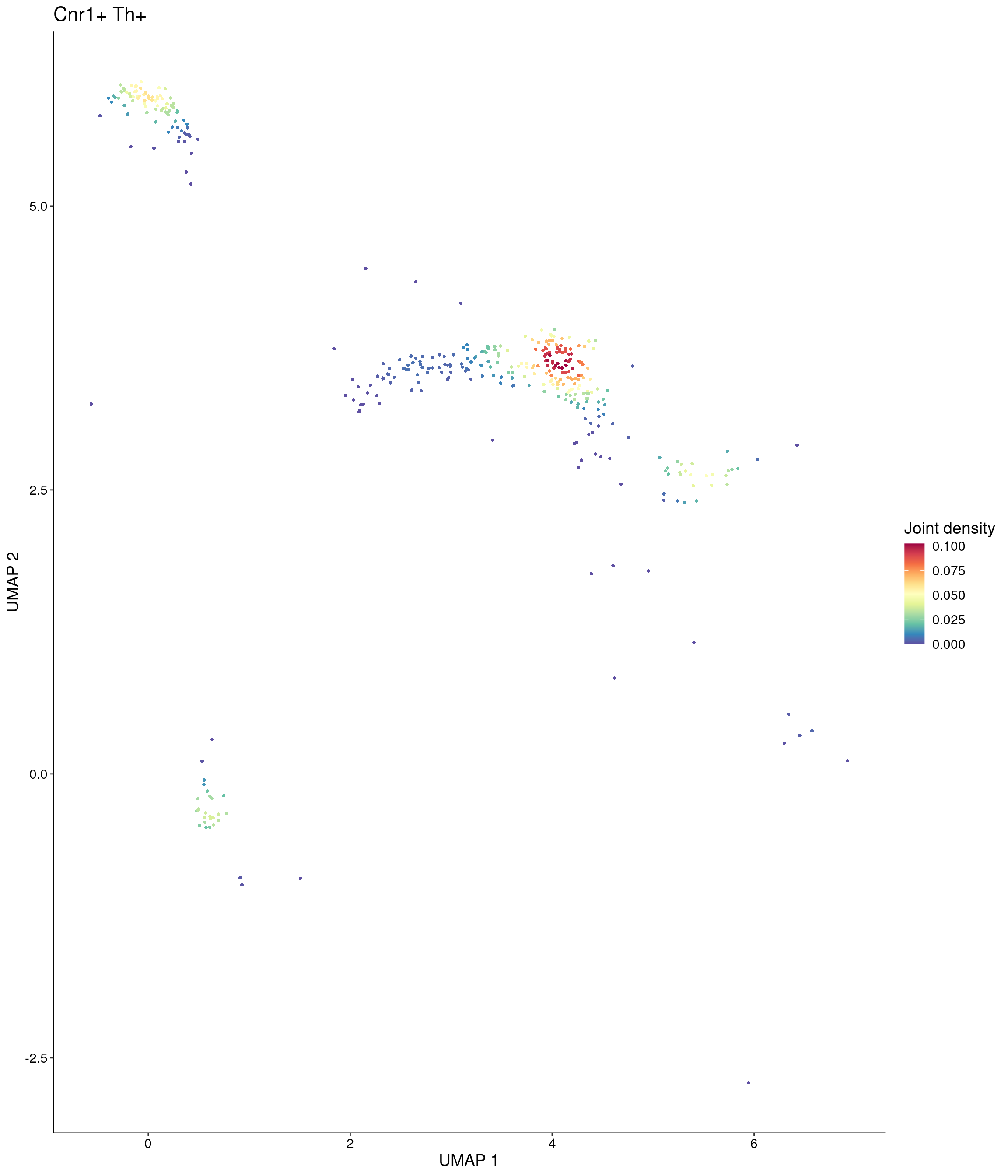
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Cnr1", "Th"),
custom_palette = onecut3@misc$div_Colour_Pal
)
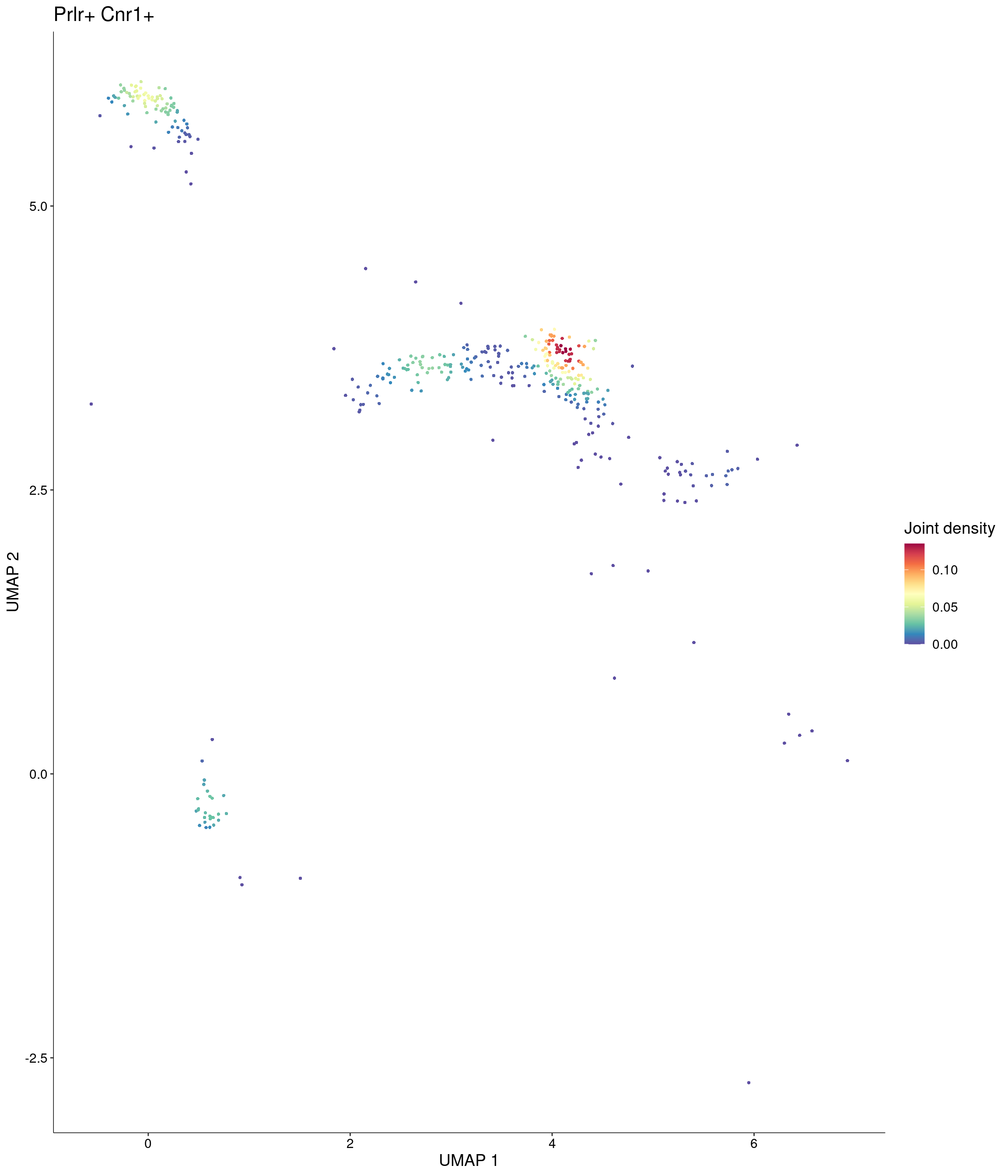
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Prlr", "Cnr1"),
custom_palette = onecut3@misc$div_Colour_Pal
)
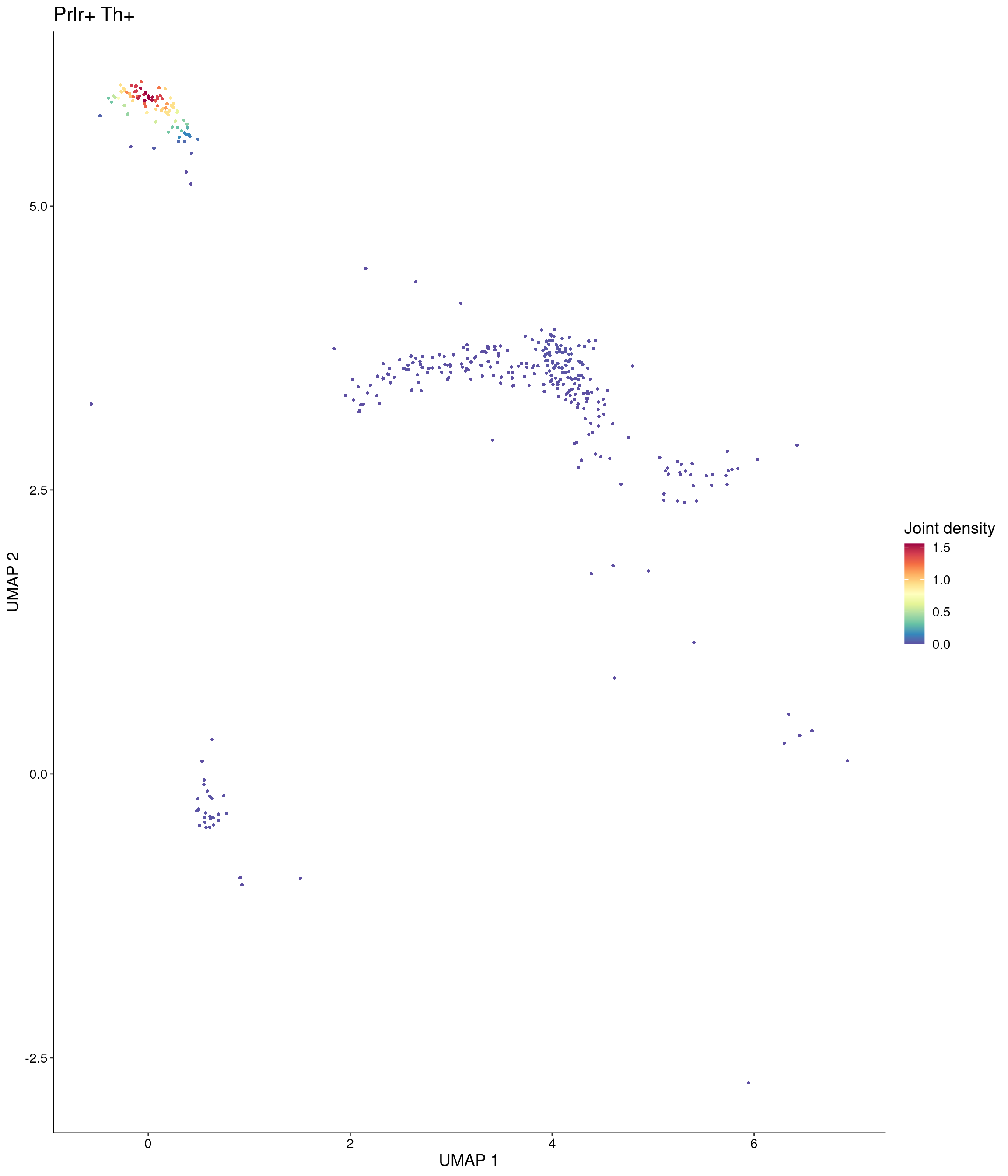
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Prlr", "Th"),
custom_palette = onecut3@misc$div_Colour_Pal
)
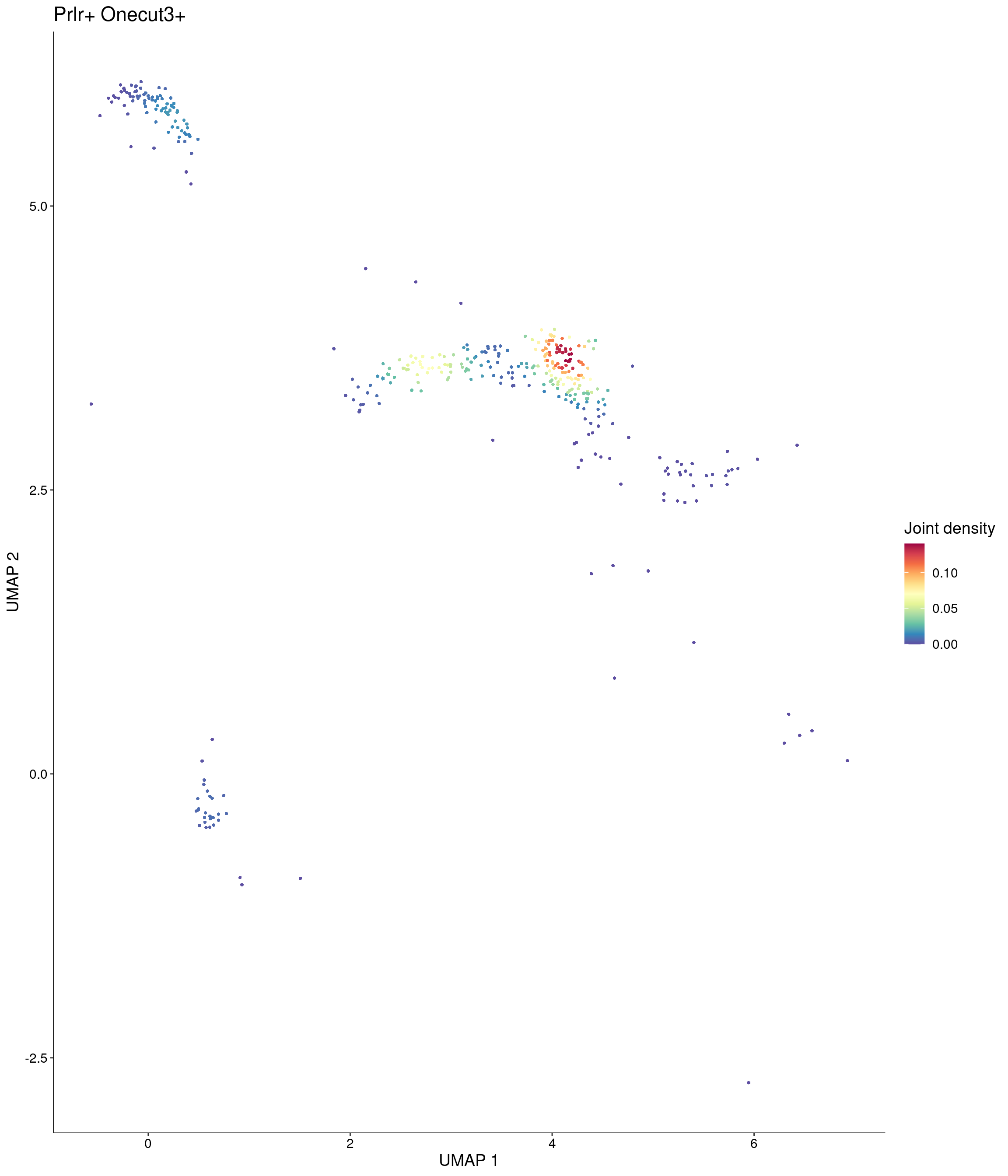
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Prlr", "Onecut3"),
custom_palette = onecut3@misc$div_Colour_Pal
)
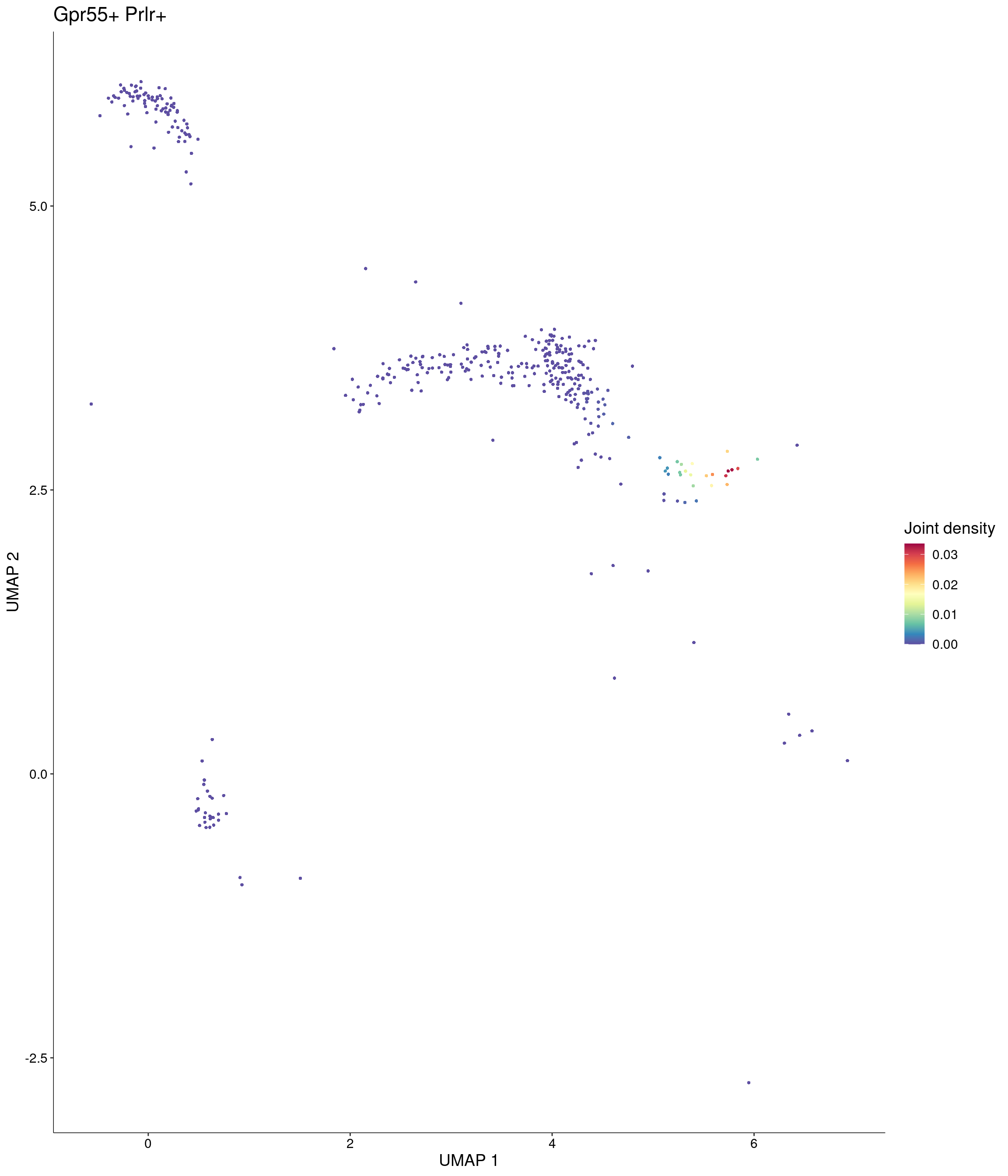
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Gpr55", "Prlr"),
custom_palette = onecut3@misc$div_Colour_Pal
)
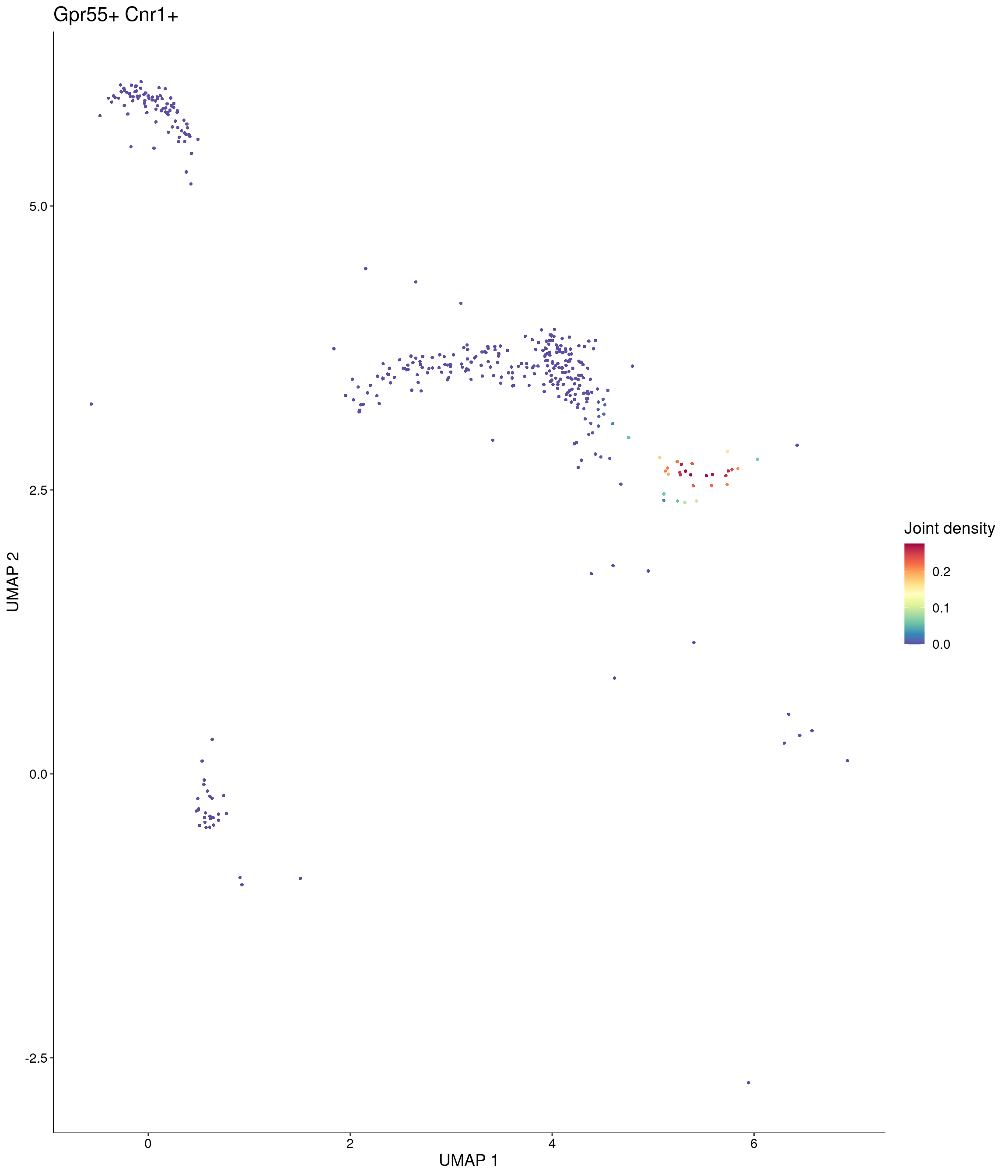
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Gpr55", "Cnr1"),
custom_palette = onecut3@misc$div_Colour_Pal
)
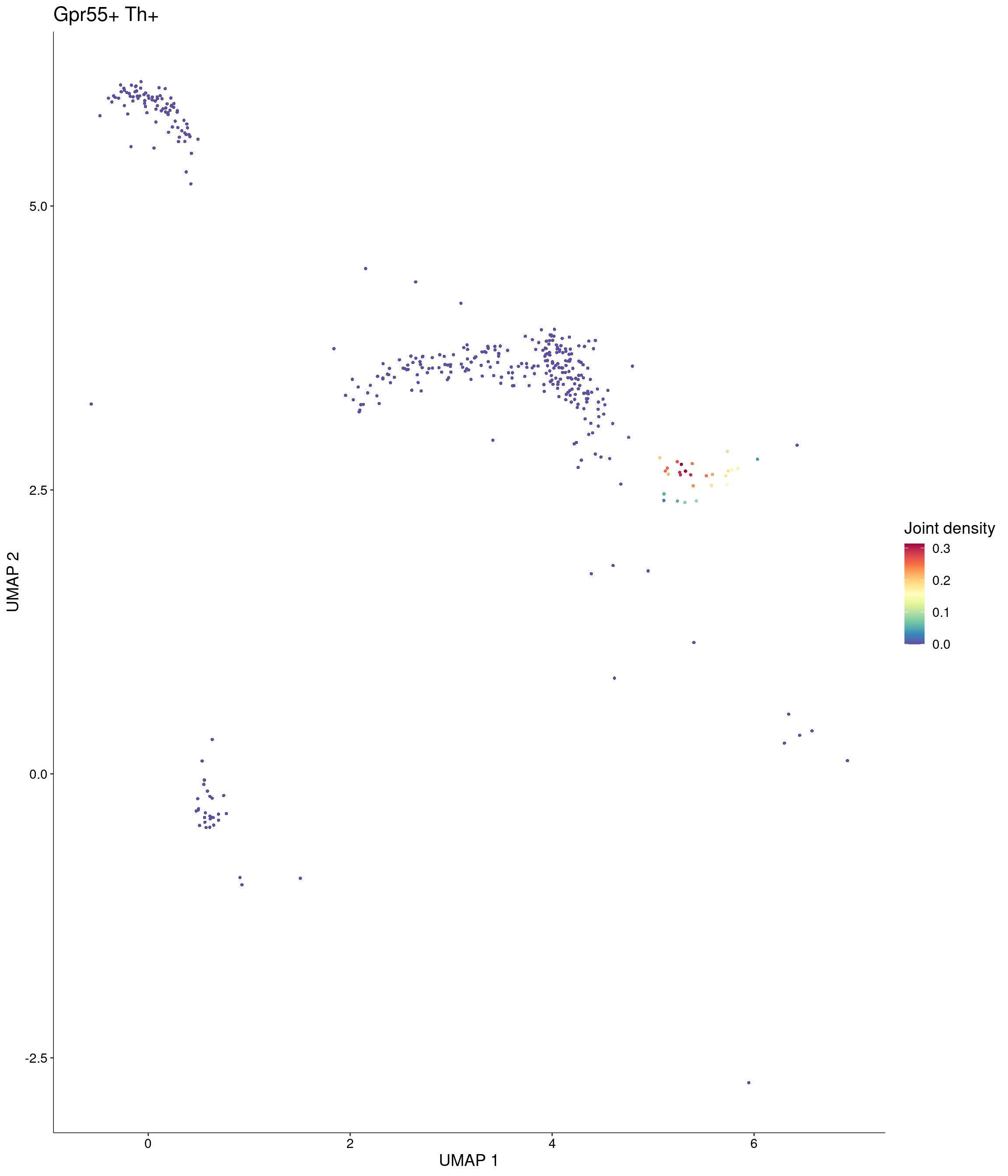
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Gpr55", "Th"),
custom_palette = onecut3@misc$div_Colour_Pal
)
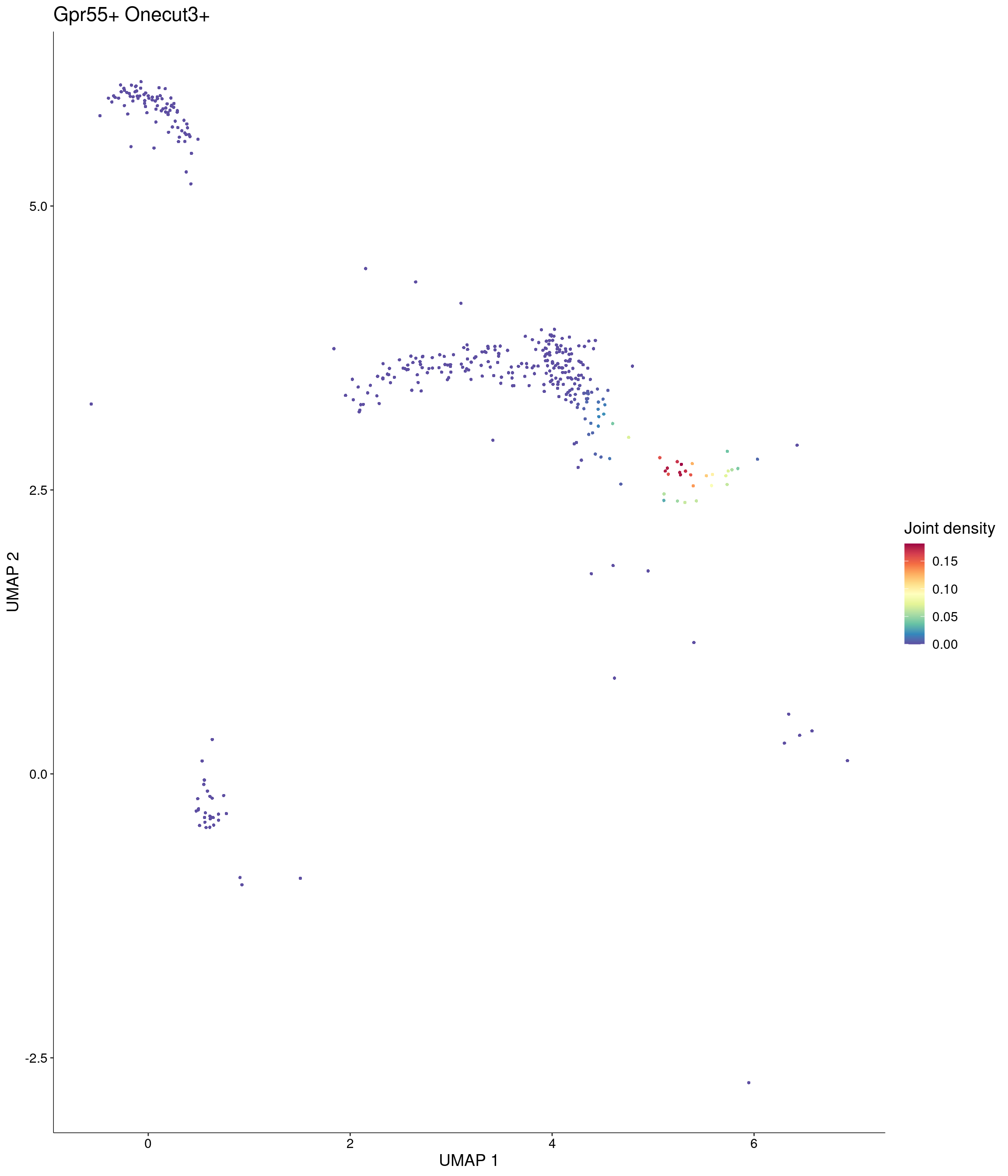
Plot_Density_Joint_Only(
seurat_object = onecut3,
features = c("Gpr55", "Onecut3"),
custom_palette = onecut3@misc$div_Colour_Pal
)
Correlation analysis visualisation between different genes
p_corrs <- list(
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
x = Onecut3,
y = Cnr1,
xfill = "#ffc400",
yfill = "#e22ee2"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
x = Slc32a1,
y = Onecut3,
xfill = "#0000da",
yfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
x = Gpr55,
y = Onecut3,
xfill = "#006eff",
yfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
x = Slc32a1,
y = Cnr1,
xfill = "#0000da",
yfill = "#e22ee2"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
x = Gpr55,
y = Cnr1,
xfill = "#006eff",
yfill = "#e22ee2"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
x = Slc32a1,
y = Gpr55,
xfill = "#0000da",
yfill = "#006eff"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Slc32a1,
x = Onecut3,
yfill = "#0000da",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Gpr55,
x = Onecut3,
yfill = "#006eff",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Th,
x = Onecut3,
yfill = "#ff0000",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Gad1,
x = Onecut3,
yfill = "#a50202",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Gad2,
x = Onecut3,
yfill = "#4002a5",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Onecut2,
x = Onecut3,
yfill = "#6402a5",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Prlr,
x = Onecut3,
yfill = "#2502a5",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Ddc,
x = Onecut3,
yfill = "#4002a5",
xfill = "#ffc400"
),
ggstatsplot::ggscatterstats(
as.data.frame(mtx_oc3),
y = Slc6a3,
x = Onecut3,
yfill = "#2502a5",
xfill = "#ffc400"
)
)
n_corrs <- list(
"oc3-rna-data-Onecut3-Cnr1",
"oc3-rna-data-Slc32a1-Onecut3",
"oc3-rna-data-Gpr55-Onecut3",
"oc3-rna-data-Slc32a1-Cnr1",
"oc3-rna-data-Gpr55-Cnr1",
"oc3-rna-data-Slc32a1-Gpr55",
"oc3-rna-data-Onecut3-Slc32a1",
"oc3-rna-data-Onecut3-Gpr55",
"oc3-rna-data-Onecut3-Th",
"oc3-rna-data-Onecut3-Gad1",
"oc3-rna-data-Onecut3-Gad2",
"oc3-rna-data-Onecut3-Onecut2",
"oc3-rna-data-Onecut3-Prlr",
"oc3-rna-data-Onecut3-Ddc",
"oc3-rna-data-Onecut3-Slc6a3"
)
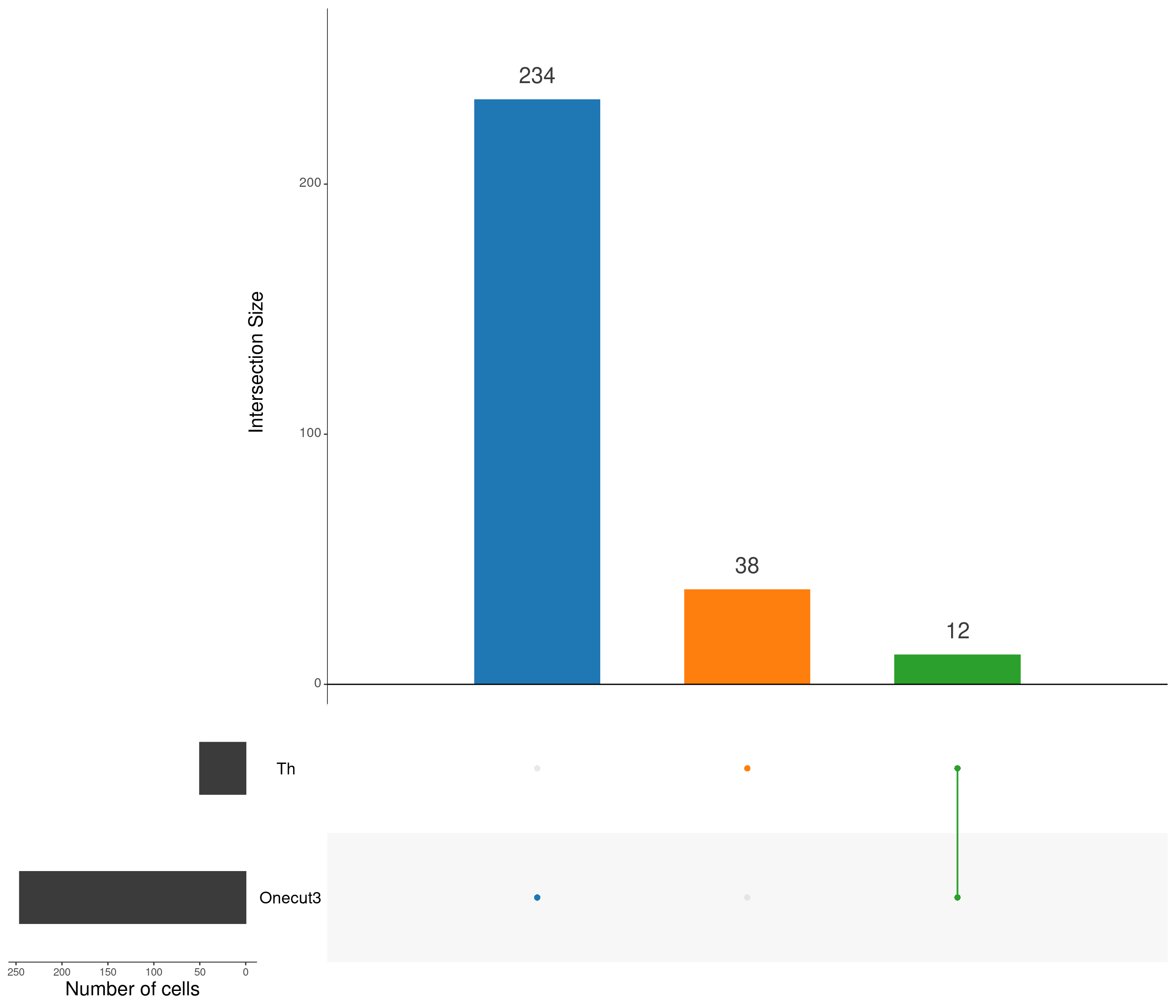
walk2(n_corrs, p_corrs, save_my_plot, type = "stat-corr-plt")Visualise intersections sets that we are going to use (highlighted)
upset(
as.data.frame(content_mtx_oc3),
order.by = "freq",
sets.x.label = "Number of cells",
text.scale = c(2, 1.6, 2, 1.3, 2, 3),
nsets = 15,
sets = c("Th", "Onecut3"),
queries = list(
list(
query = intersects,
params = list("Onecut3"),
active = T
),
list(
query = intersects,
params = list("Th"),
active = T
),
list(
query = intersects,
params = list("Th", "Onecut3"),
active = T
)
),
nintersects = 60,
empty.intersections = "on"
)
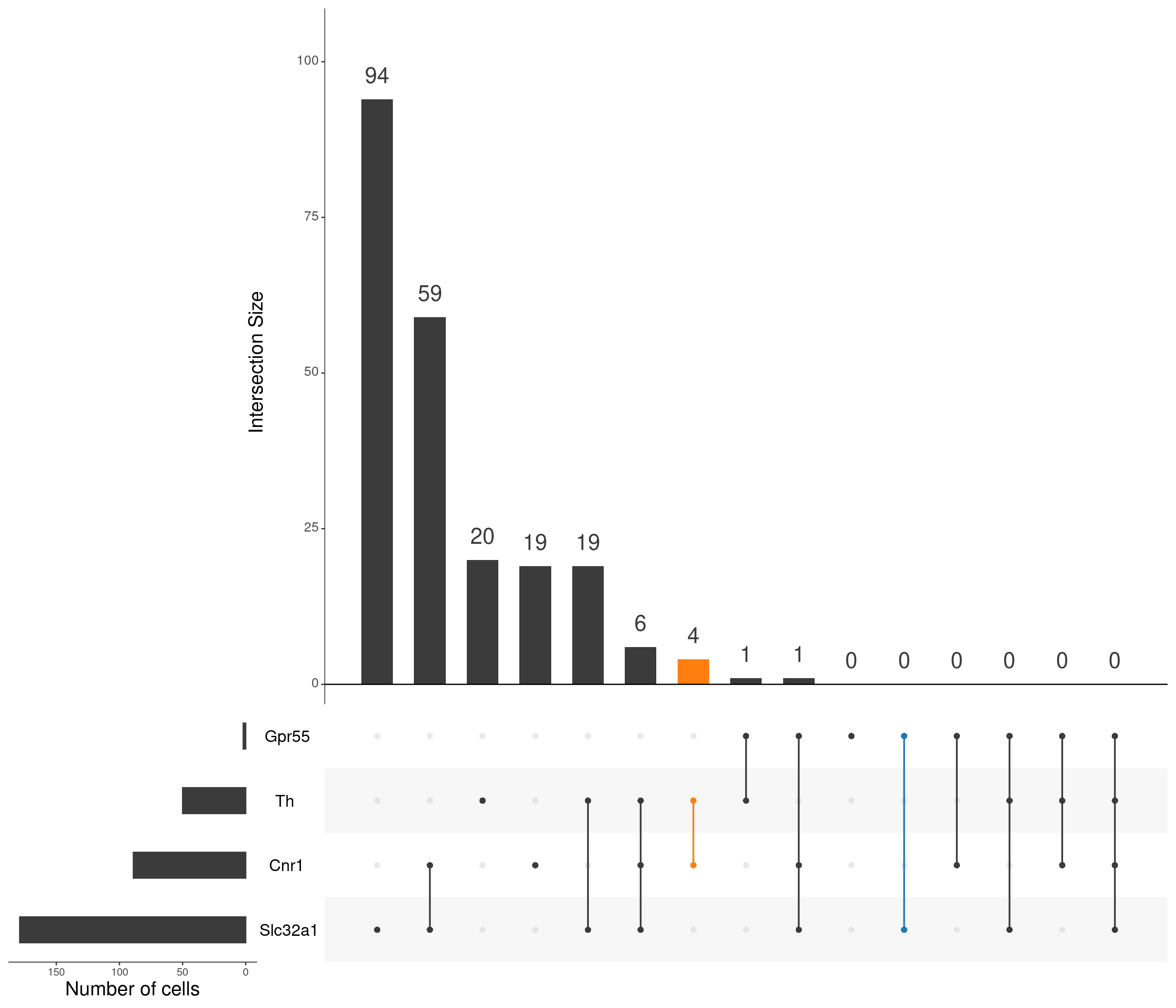
upset(
as.data.frame(content_mtx_oc3),
order.by = "freq",
sets.x.label = "Number of cells",
text.scale = c(2, 1.6, 2, 1.3, 2, 3),
nsets = 15,
sets = c("Gpr55", "Cnr1", "Slc32a1", "Th"),
queries = list(
list(
query = intersects,
params = list("Gpr55", "Slc32a1"),
active = T
),
list(
query = intersects,
params = list("Cnr1", "Th"),
active = T
)
),
nintersects = 60,
empty.intersections = "on"
)
Regroup factor by stages for more balanced groups
onecut3$age %>% forcats::fct_count()onecut3$stage <-
onecut3$age %>%
forcats::fct_collapse(
`Embrionic day 15` = "E15",
`Embrionic day 17` = "E17",
Neonatal = c("P00", "P02"),
Postnatal = c("P10", "P23")
)
onecut3$stage %>% forcats::fct_count()Make subset of stable neurons
onecut3$gaba_status <-
content_mtx_oc3 %>%
select(Gad1, Gad2, Slc32a1) %>%
mutate(gaba = if_all(.fns = ~ .x > 0)) %>%
.$gaba
onecut3$gaba_occurs <-
content_mtx_oc3 %>%
select(Gad1, Gad2, Slc32a1) %>%
mutate(gaba = if_any(.fns = ~ .x > 0)) %>%
.$gaba
onecut3$th_status <-
content_mtx_oc3 %>%
select(Th, Ddc, Slc6a3) %>%
mutate(dopamin = if_any(.fns = ~ .x > 0)) %>%
.$dopamin
oc3_fin <- onecut3Check contingency tables for neurotransmitter signature
oc3_fin@meta.data %>%
janitor::tabyl(th_status, gaba_status)By age
oc3_fin@meta.data %>%
janitor::tabyl(age, th_status)By stage
oc3_fin@meta.data %>%
janitor::tabyl(stage, th_status)Make splits of neurons by neurotransmitter signature
oc3_fin$status <- oc3_fin$th_status %>%
if_else(true = "dopaminergic",
false = "GABAergic"
)
Idents(oc3_fin) <- "status"
SaveH5Seurat(
object = oc3_fin,
filename = here(data_dir, "oc3_fin"),
overwrite = TRUE,
verbose = TRUE
)
## Split on basis of neurotrans and test for difference
oc3_fin_neurotrans <- SplitObject(oc3_fin, split.by = "status")
## Split on basis of age and test for difference
oc3_fin_ages <- SplitObject(oc3_fin, split.by = "age")DotPlots grouped by age
Expression of GABA receptors in GABAergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$GABAergic,
features = gabar,
group.by = "age",
cols = c("#adffff", "#0084ff"),
col.min = -1, col.max = 1
) + RotatedAxis()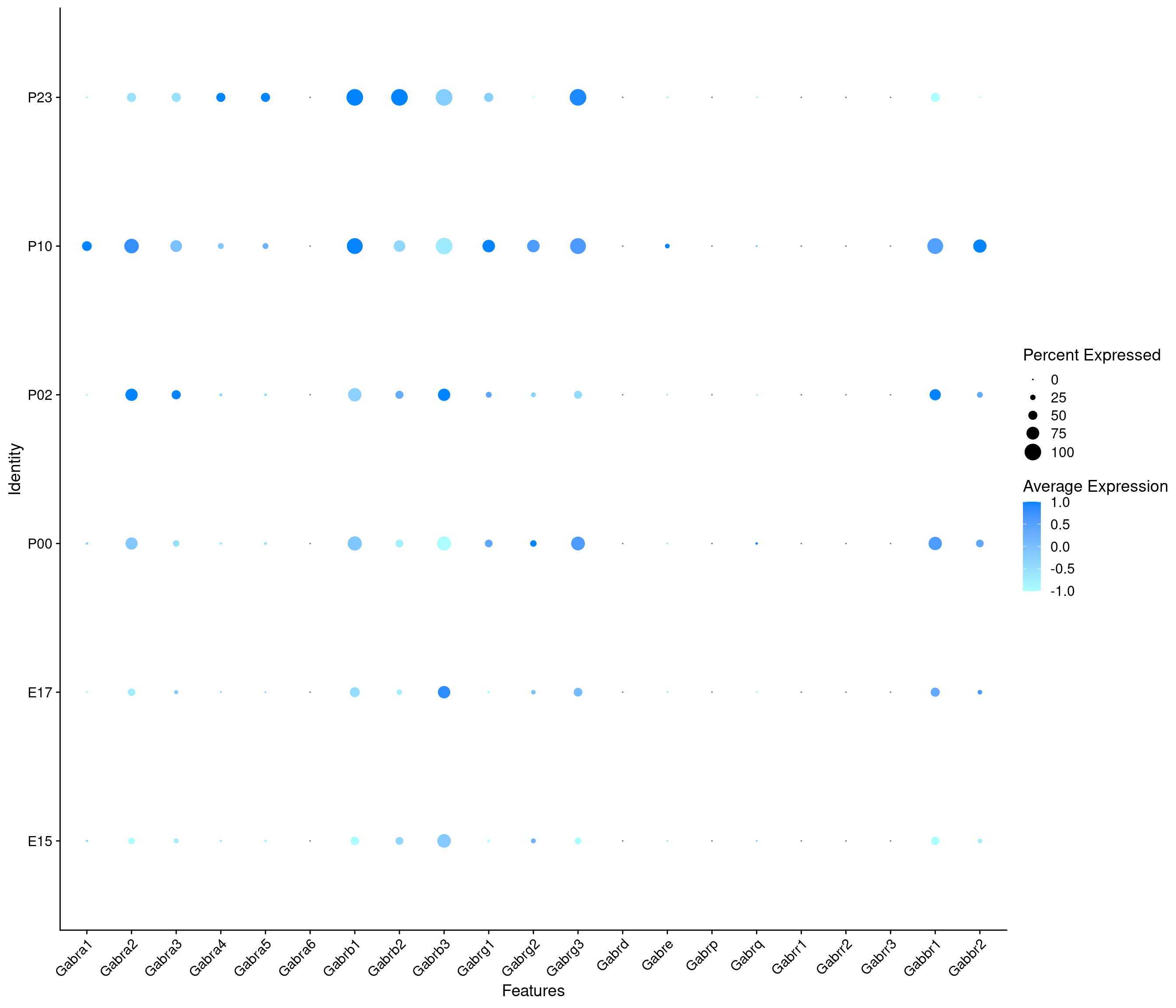
Expression of GABA receptors in dopaminergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$dopaminergic,
features = gabar,
group.by = "age",
cols = c("#ffc2c2", "#ff3c00"),
col.min = -1, col.max = 1
) + RotatedAxis()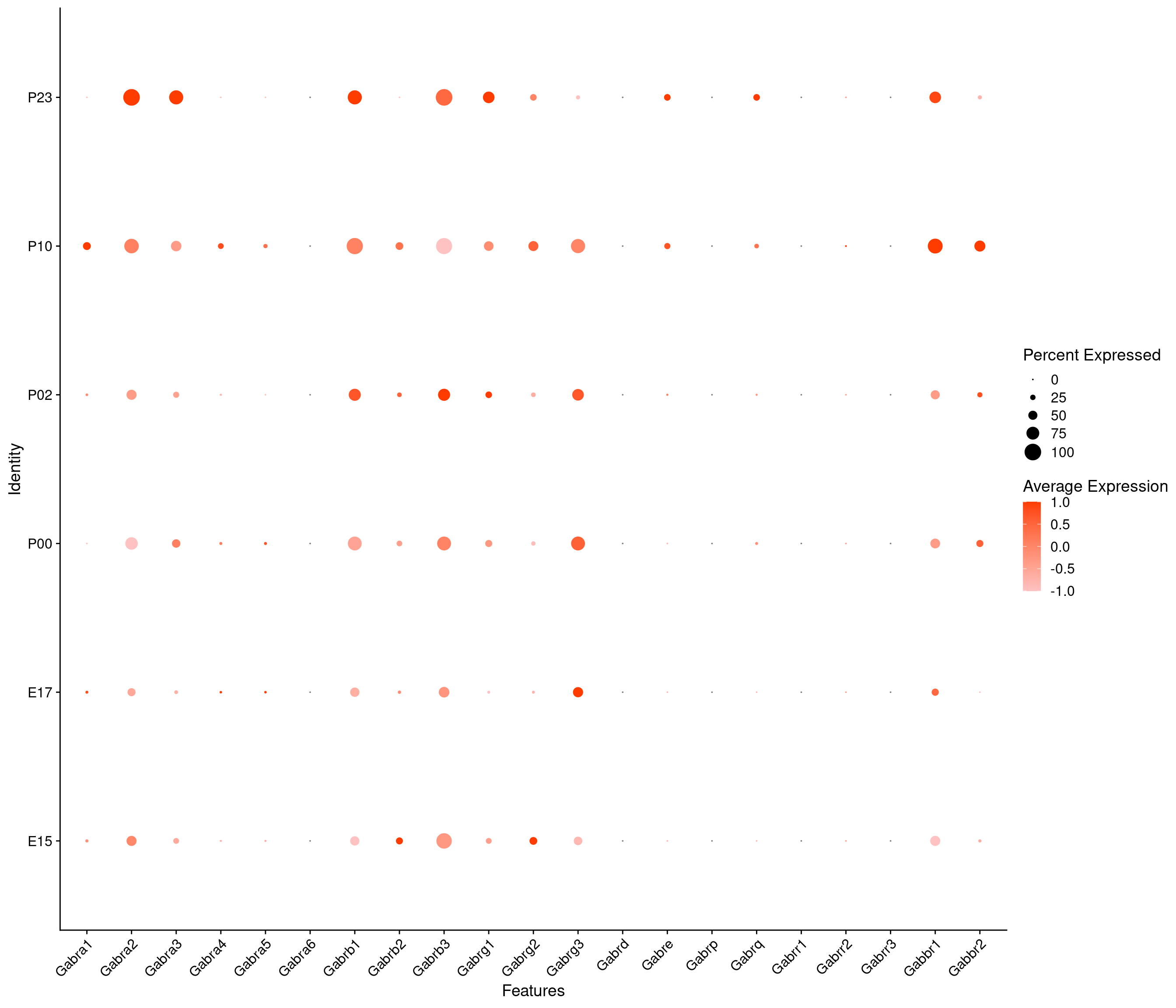
Expression of glutamate receptors in GABAergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$GABAergic,
features = glutr,
group.by = "age",
cols = c("#adffff", "#0084ff"),
col.min = -1, col.max = 1
) + RotatedAxis()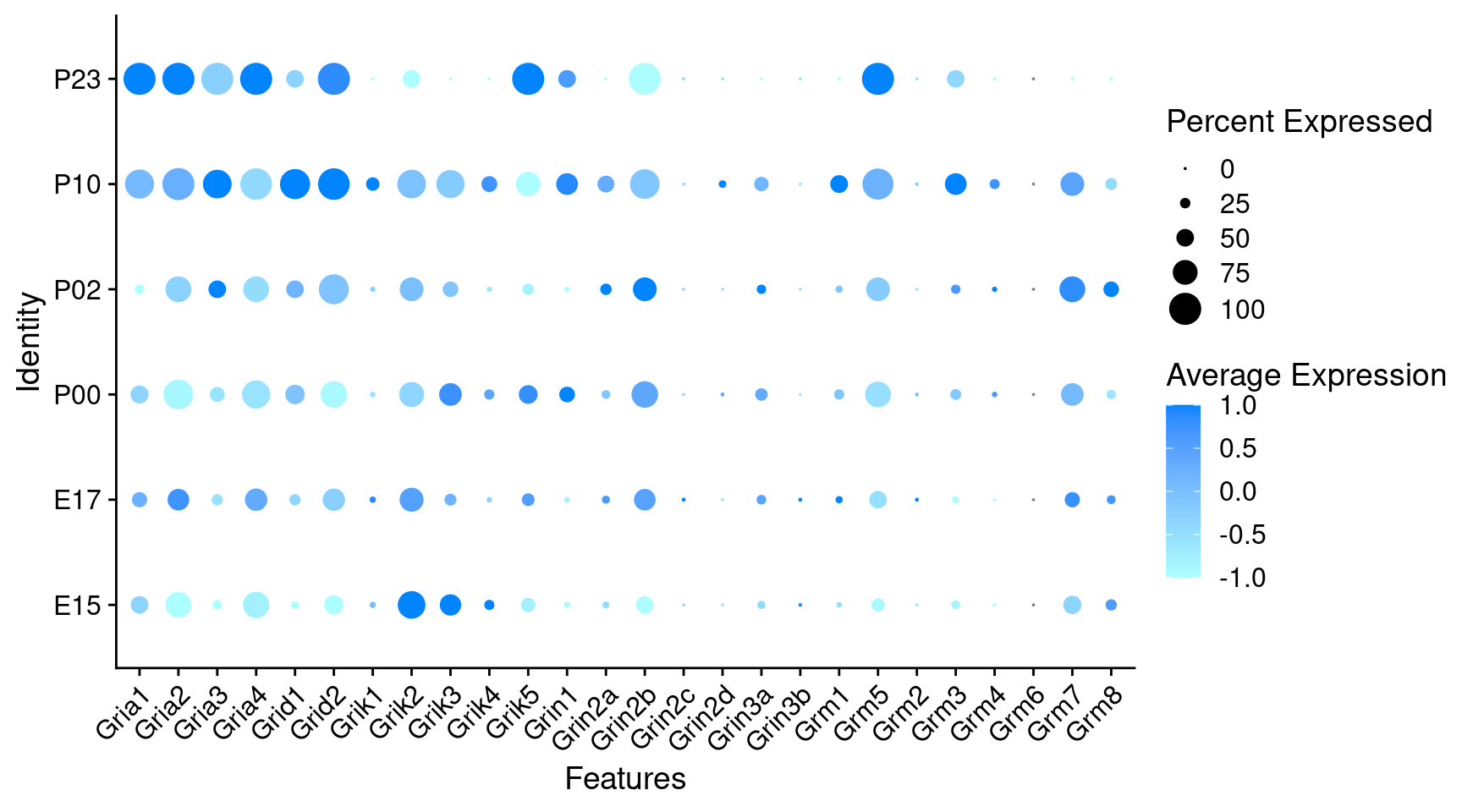
Expression of glutamate receptors in dopaminergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$dopaminergic,
features = glutr,
group.by = "age",
cols = c("#ffc2c2", "#ff3c00"),
col.min = -1, col.max = 1
) + RotatedAxis()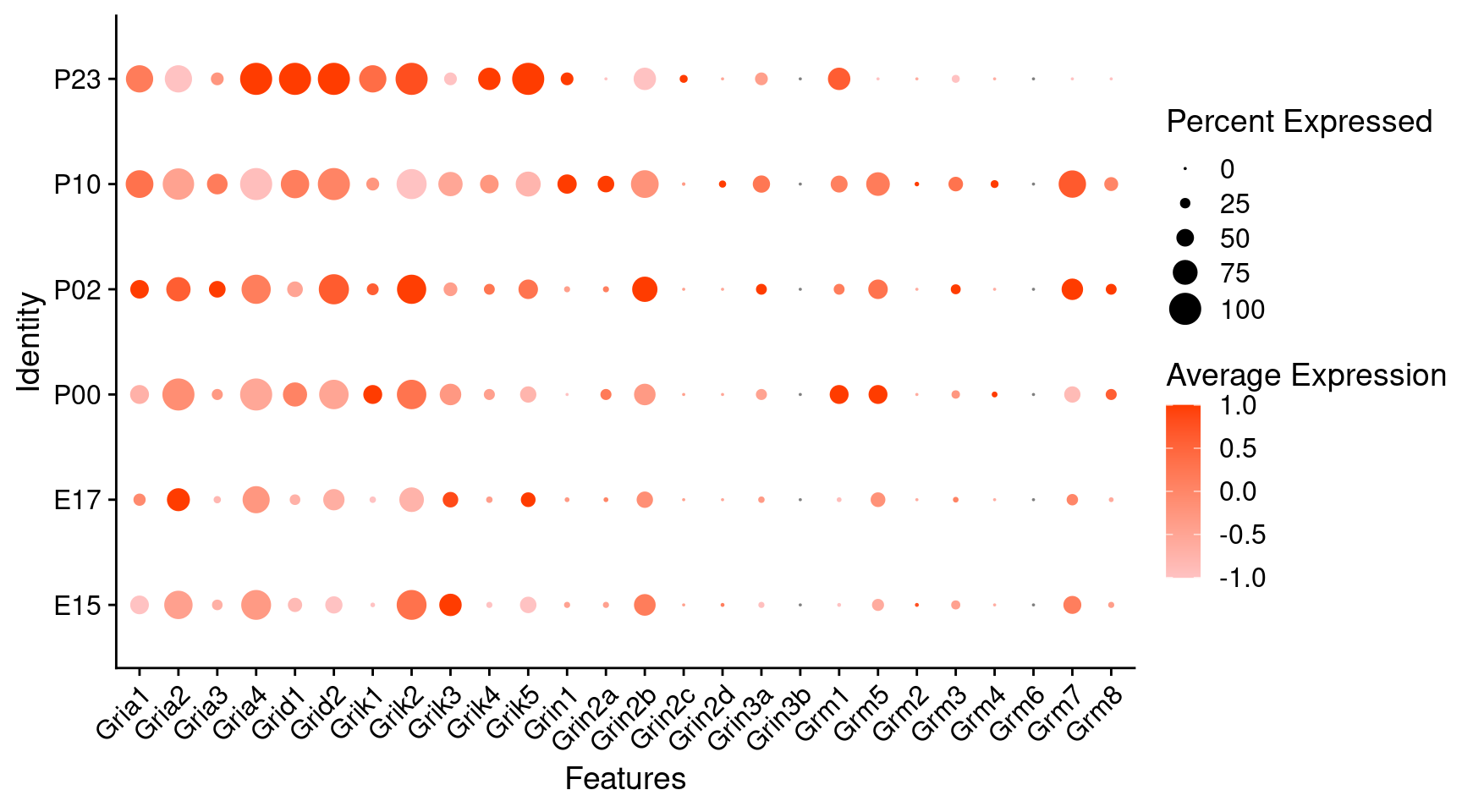
DotPlots grouped by stage
Expression of GABA receptors in GABAergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$GABAergic,
features = gabar,
group.by = "stage",
cols = c("#adffff", "#0084ff"),
col.min = -1, col.max = 1
) + RotatedAxis()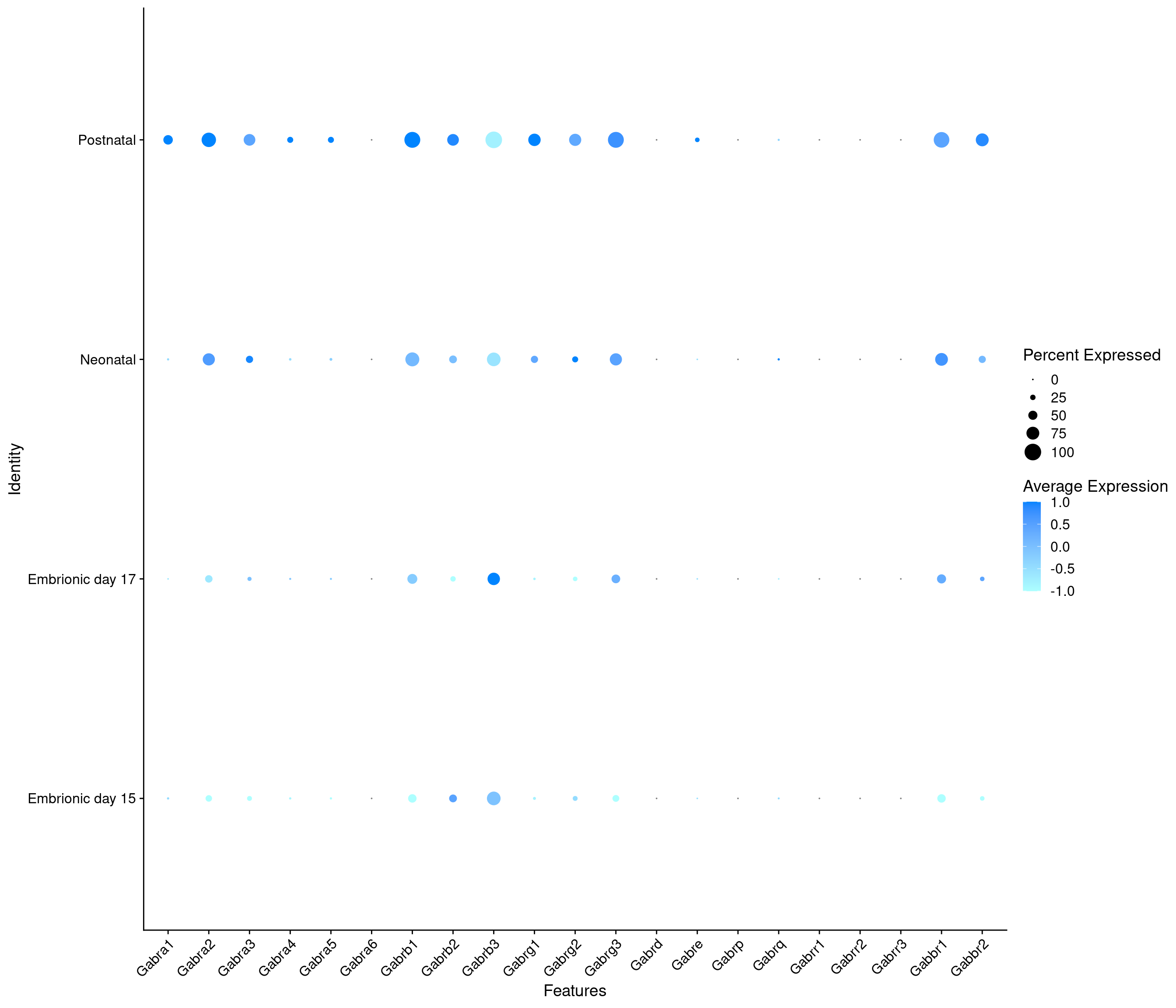
Expression of GABA receptors in dopaminergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$dopaminergic,
features = gabar,
group.by = "stage",
cols = c("#ffc2c2", "#ff3c00"),
col.min = -1, col.max = 1
) + RotatedAxis()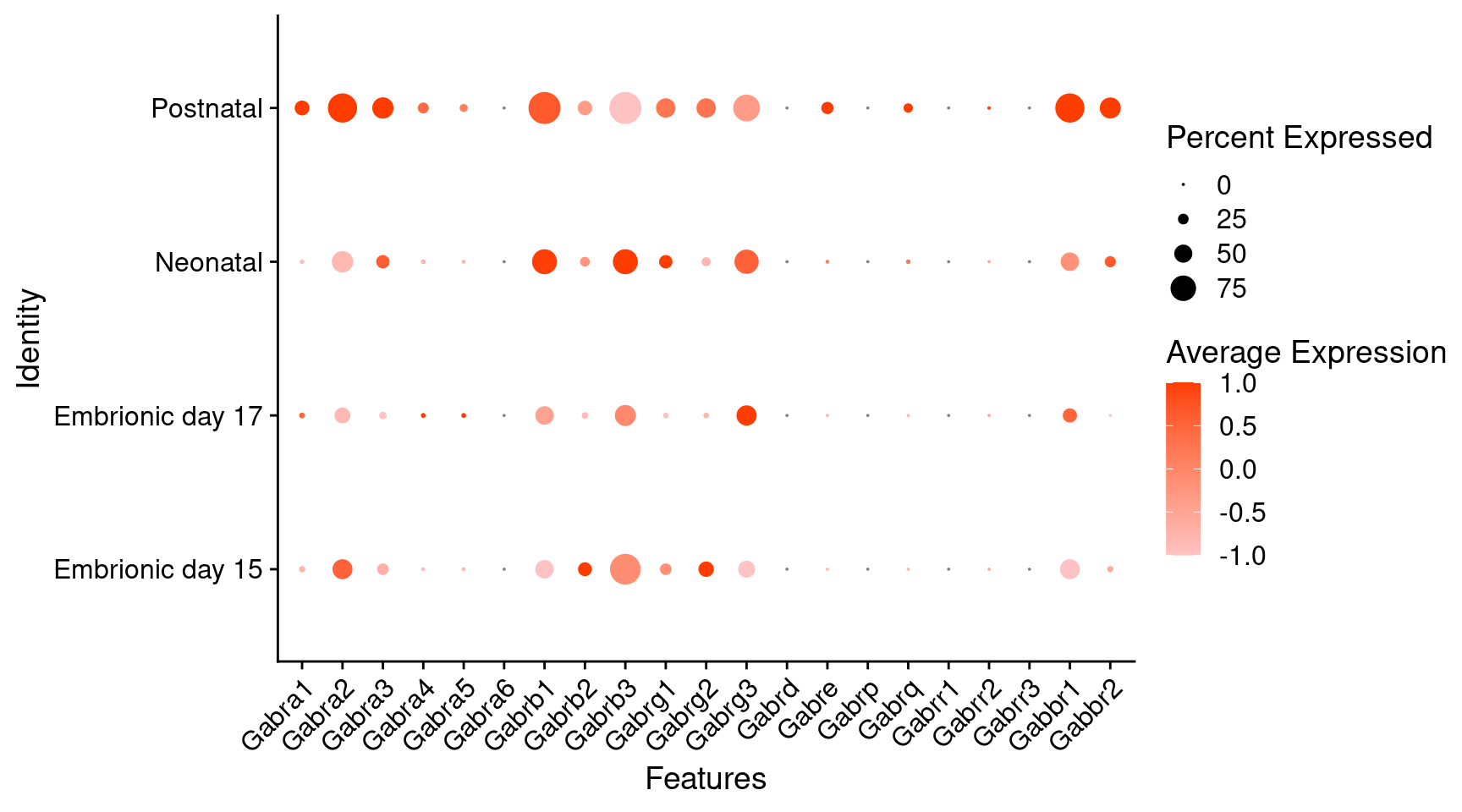
Expression of glutamate receptors in GABAergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$GABAergic,
features = glutr,
group.by = "stage",
cols = c("#adffff", "#0084ff"),
col.min = -1, col.max = 1
) + RotatedAxis()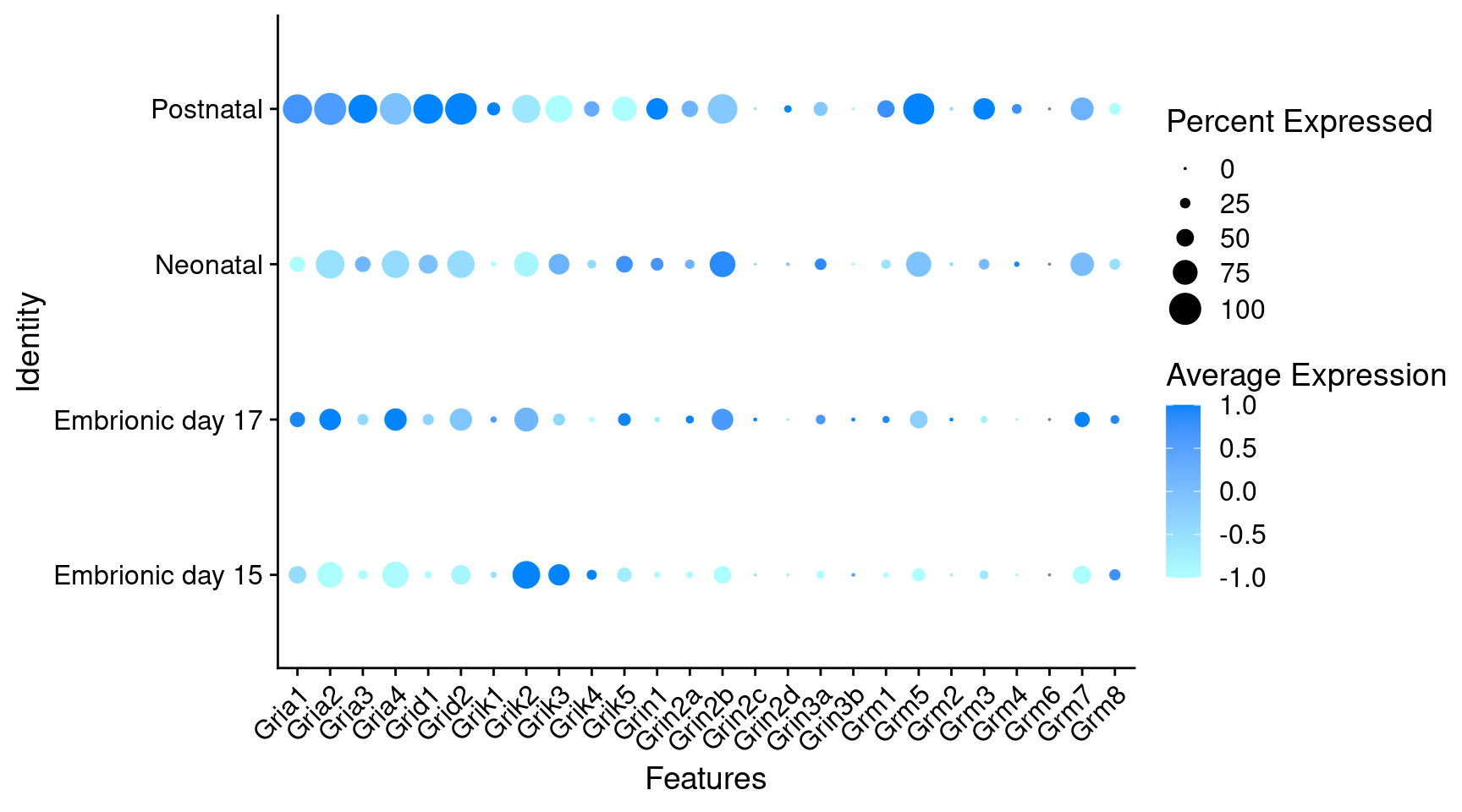
Expression of glutamate receptors in dopaminergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$dopaminergic,
features = glutr,
group.by = "stage",
cols = c("#ffc2c2", "#ff3c00"),
col.min = -1, col.max = 1
) + RotatedAxis()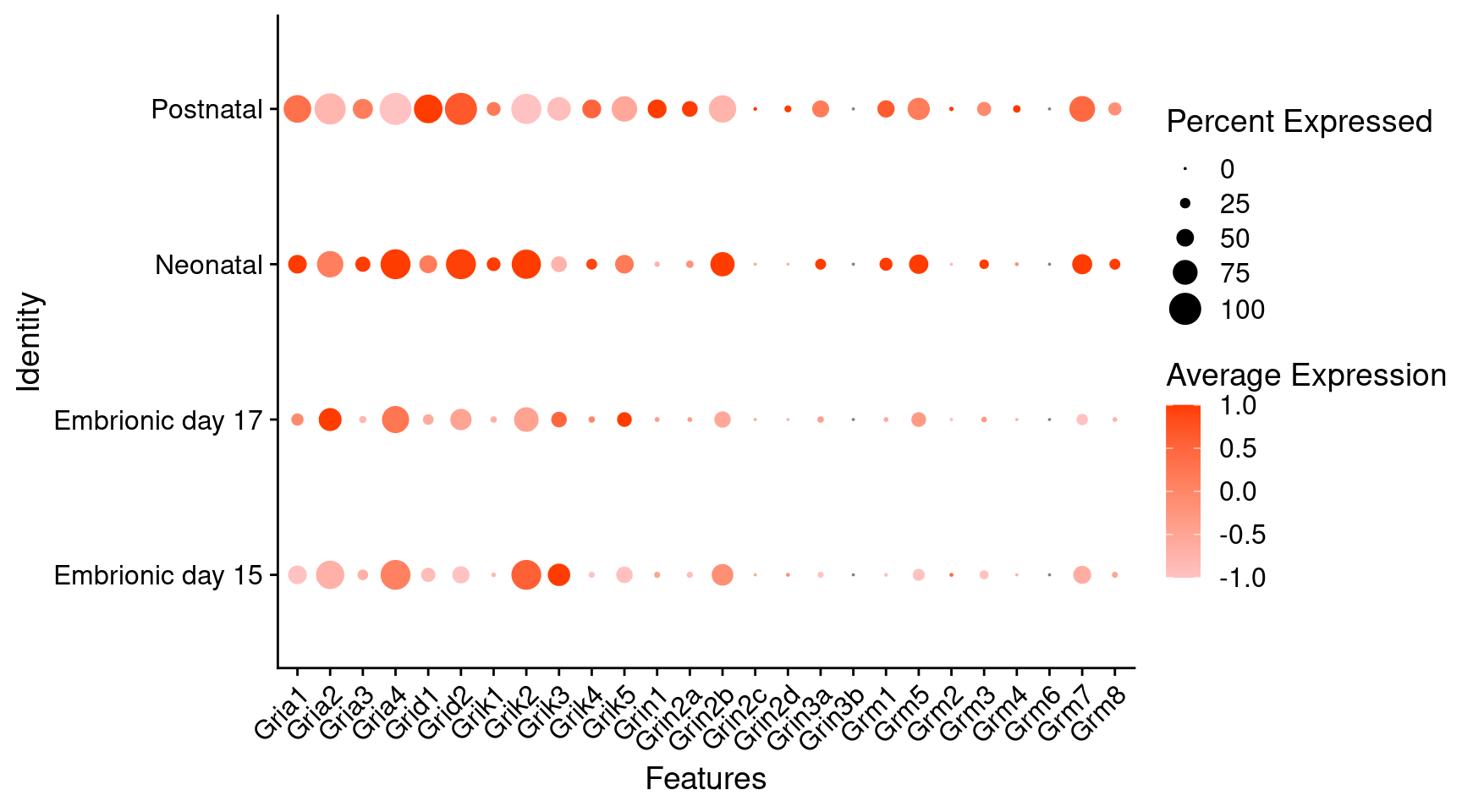
Expression of neuromodulators receptors in GABAergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$GABAergic,
features = npr,
group.by = "stage",
cols = c("#adffff", "#0084ff"),
col.min = -1, col.max = 1
) + RotatedAxis()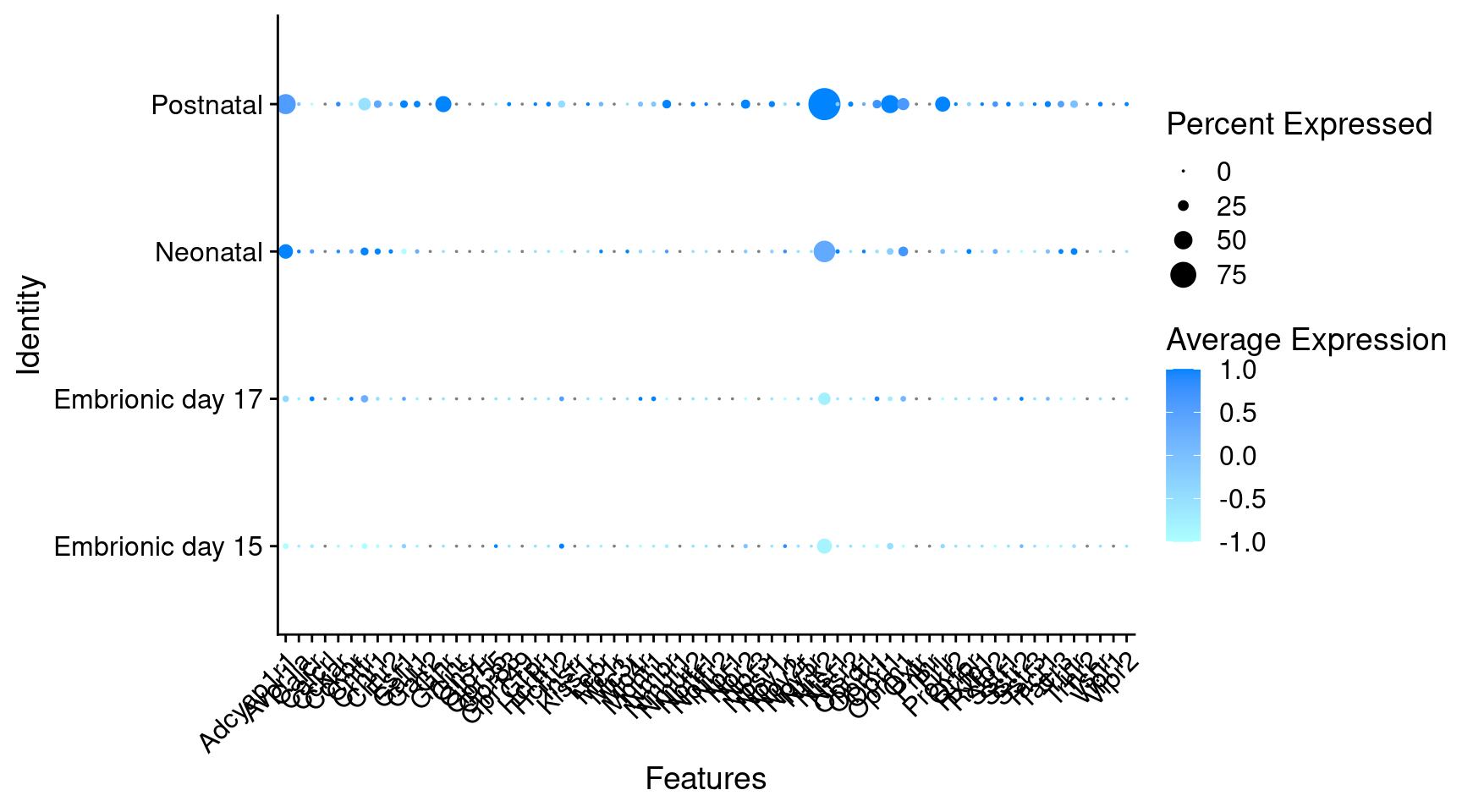
Expression of neuromodulators receptors in dopaminergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$dopaminergic,
features = npr,
group.by = "stage",
cols = c("#ffc2c2", "#ff3c00"),
col.min = -1, col.max = 1
) + RotatedAxis()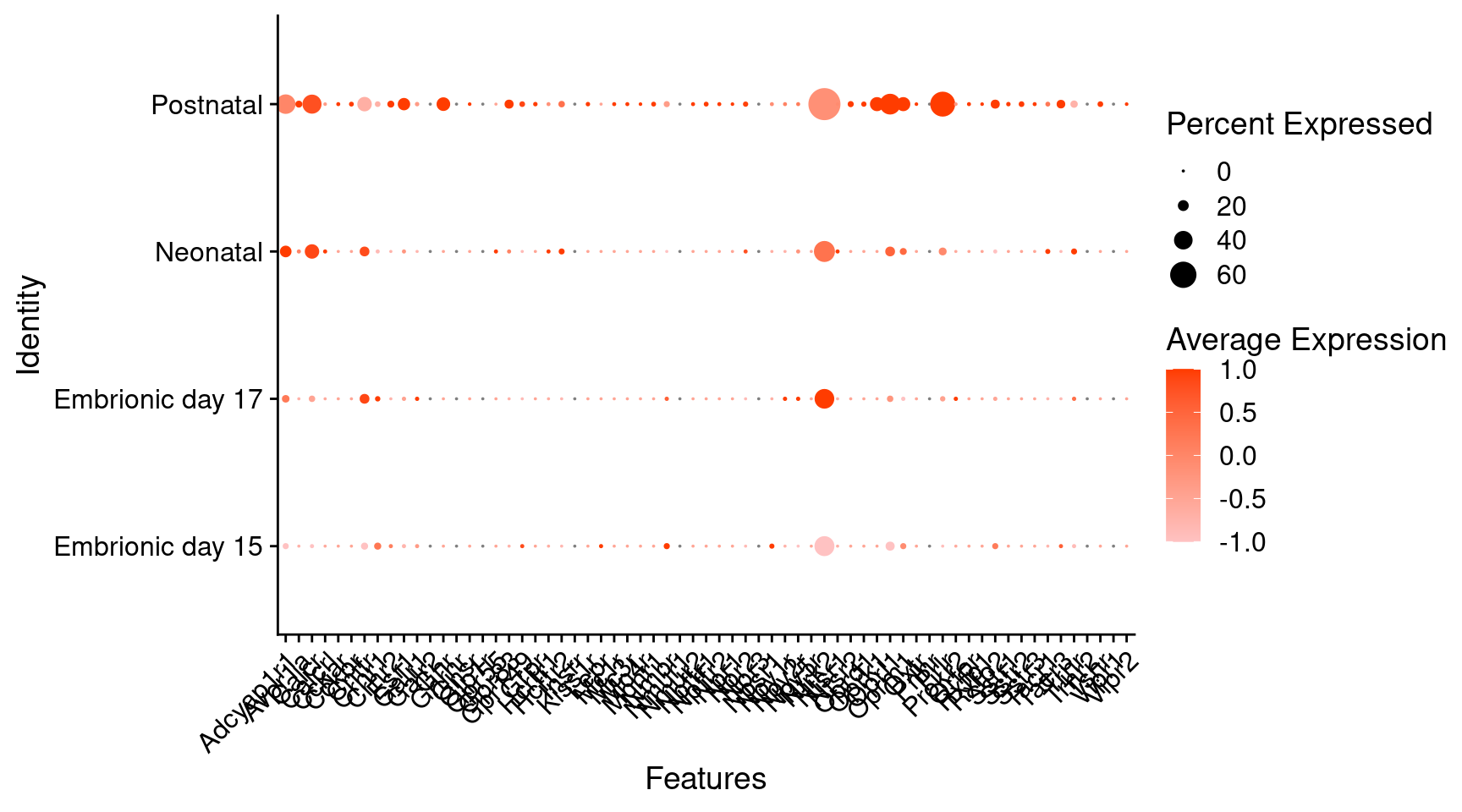
Expression of endocannabinoids relevant genes in GABAergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$GABAergic,
features = cnbn,
group.by = "stage",
cols = c("#adffff", "#0084ff"),
col.min = -1, col.max = 1
) + RotatedAxis()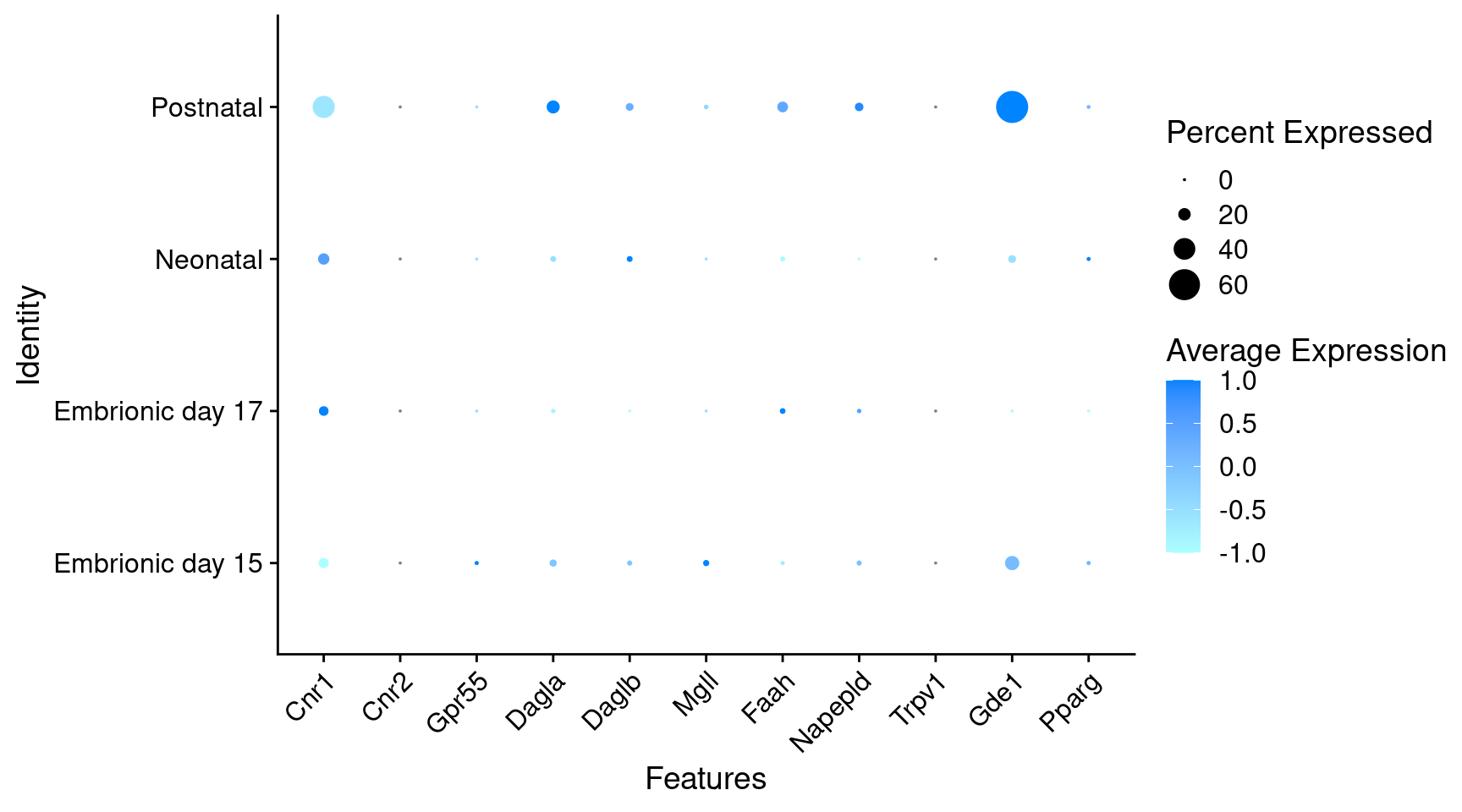
Expression of endocannabinoids relevant genes in dopaminergic Onecut3 positive cells
DotPlot(
object = oc3_fin_neurotrans$dopaminergic,
features = cnbn,
group.by = "stage",
cols = c("#ffc2c2", "#ff3c00"),
col.min = -1, col.max = 1
) + RotatedAxis()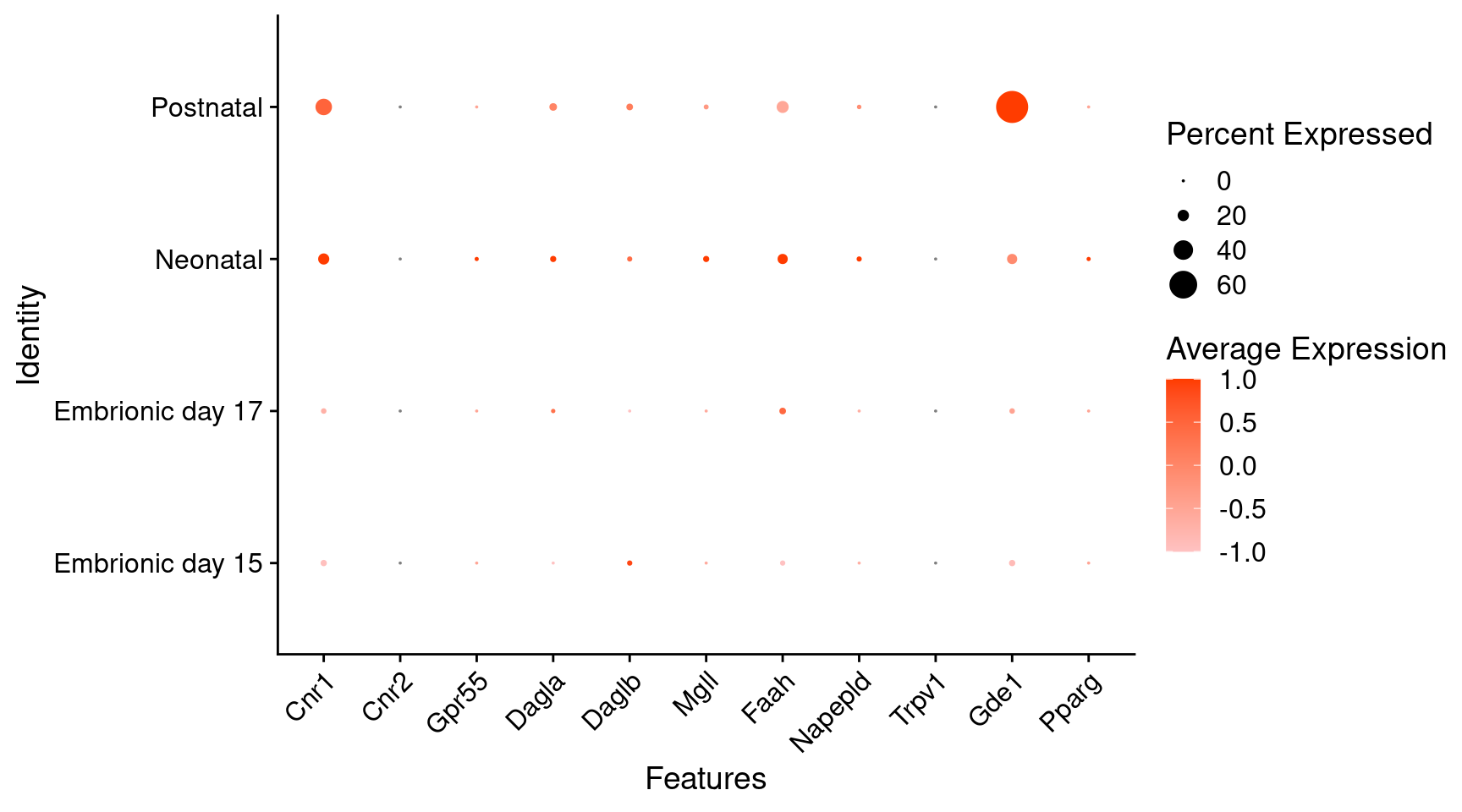
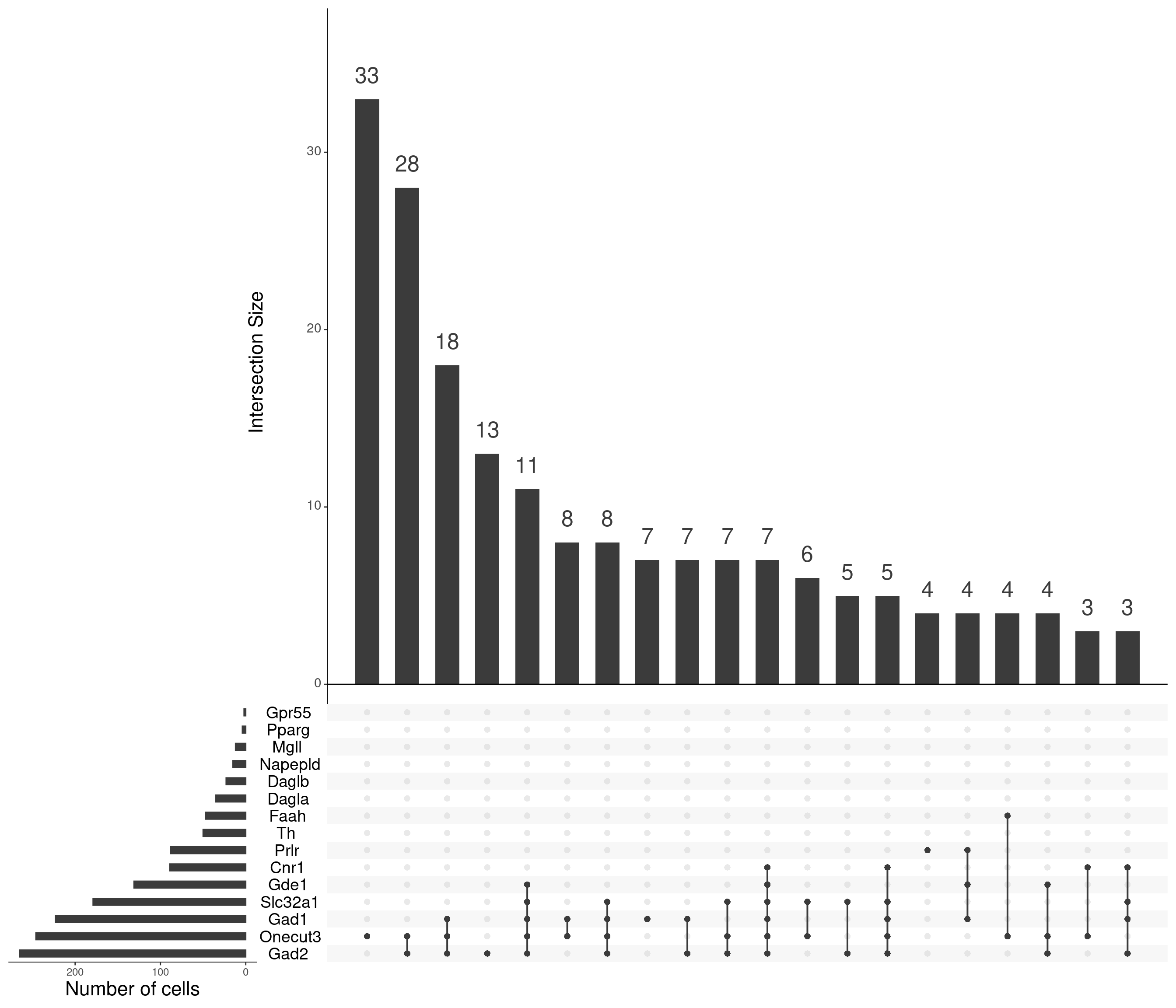
Overrepresentation analysis
Idents(oc3_fin) <- "status"
sbs_mtx_oc <-
oc3_fin %>%
GetAssayData("data", "RNA") %>%
as.data.frame() %>%
t()
rownames(sbs_mtx_oc) <- colnames(oc3_fin)
# Filter features
filt_low_genes2 <-
colSums(sbs_mtx_oc) %>%
.[. > quantile(., 0.4)] %>%
names()
sbs_mtx_oc %<>% .[, filt_low_genes2]
min_filt_vector2 <-
sbs_mtx_oc %>%
as_tibble() %>%
select(all_of(filt_low_genes2)) %>%
summarise(across(.fns = ~ quantile(.x, .005))) %>%
as.list() %>%
map(as.double) %>%
simplify() %>%
.[filt_low_genes2]
# Prepare table of intersection sets analysis
content_sbs_mtx_oc <-
(sbs_mtx_oc > min_filt_vector2) %>%
as_tibble() %>%
mutate_all(as.numeric)upset(
as.data.frame(content_sbs_mtx_oc),
order.by = "freq",
sets.x.label = "Number of cells",
text.scale = c(2, 1.6, 2, 1.3, 2, 3),
nsets = 15,
sets = c(
"Gad1", "Gad2", "Slc32a1",
"Th", "Onecut3",
cnbn, "Prlr"
) %>%
.[. %in% colnames(content_sbs_mtx_oc)],
nintersects = 20,
empty.intersections = NULL
)
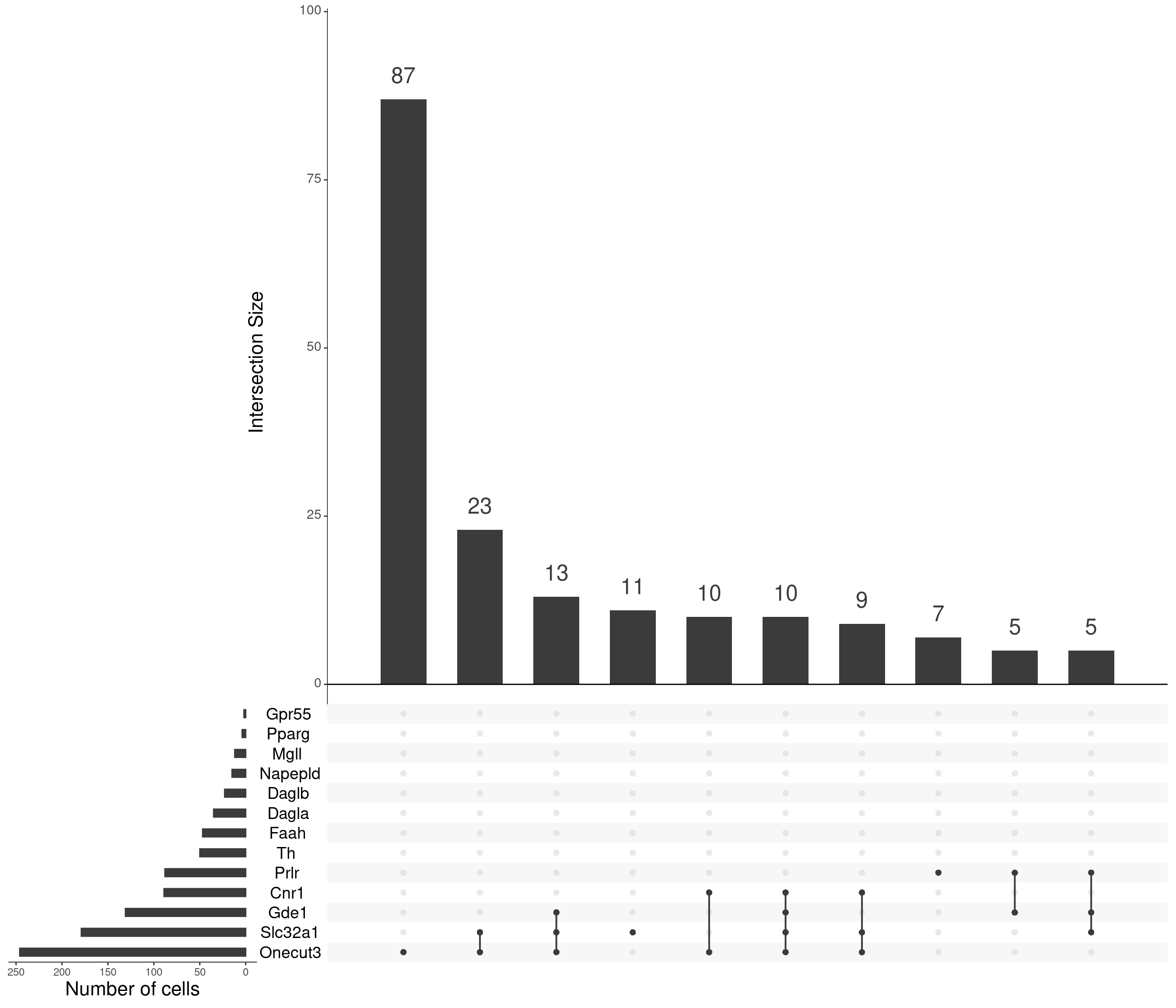
upset(
as.data.frame(content_sbs_mtx_oc),
order.by = "freq",
sets.x.label = "Number of cells",
text.scale = c(2, 1.6, 2, 1.3, 2, 3),
nsets = 15,
sets = c(cnbn, "Prlr", "Slc32a1", "Th", "Onecut3") %>%
.[. %in% colnames(content_sbs_mtx_oc)],
nintersects = 10,
empty.intersections = NULL
)
sbs_mtx_oc_full <- content_sbs_mtx_oc |>
select(any_of(c(
neurotrans, cnbn, "Prlr", "Cnr1", "Gpr55", "Onecut3"
))) |>
dplyr::bind_cols(oc3_fin@meta.data)
sbs_mtx_oc_full |> glimpse()Rows: 401
Columns: 43
$ Slc17a8 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ Slc1a1 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,…
$ Slc1a2 <dbl> 0, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0,…
$ Slc1a6 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ Gad1 <dbl> 1, 1, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1,…
$ Slc32a1 <dbl> 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0,…
$ Slc6a1 <dbl> 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 0, 1, 0,…
$ Cnr1 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,…
$ Gpr55 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ Dagla <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,…
$ Daglb <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ Mgll <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ Faah <dbl> 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 1,…
$ Napepld <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ Gde1 <dbl> 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 1, 0, 1, 1,…
$ Pparg <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ Prlr <dbl> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…
$ Onecut3 <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
$ nGene <int> 3034, 2551, 2029, 1415, 1513, 1079, 3160, 3072, 2778,…
$ nUMI <dbl> 6868, 5316, 3696, 2667, 2490, 1789, 8247, 8544, 6478,…
$ orig.ident <chr> "FC2P23", "FC2P23", "FC2P23", "FC2P23", "FC2P23", "FC…
$ res.0.2 <chr> "5", "5", "5", "5", "5", "5", "5", "5", "5", "5", "5"…
$ res.0.4 <chr> "26", "26", "26", "26", "26", "26", "26", "26", "26",…
$ res.0.8 <chr> "31", "31", "31", "31", "31", "31", "31", "31", "31",…
$ res.1.2 <chr> "36", "36", "36", "36", "36", "36", "36", "36", "36",…
$ res.2 <chr> "37", "37", "37", "37", "37", "37", "37", "37", "37",…
$ tree.ident <int> 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 22, 2…
$ pro_Inter <chr> "17", "17", "17", "17", "17", "17", "17", "17", "17",…
$ pro_Enter <chr> "17", "17", "17", "17", "17", "17", "17", "17", "17",…
$ tree_final <fct> 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 12, 1…
$ subtree <fct> 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 19, 1…
$ prim_walktrap <fct> 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 28, 2…
$ umi_per_gene <dbl> 2.263678, 2.083889, 1.821587, 1.884806, 1.645737, 1.6…
$ log_umi_per_gene <dbl> 0.3548147, 0.3188745, 0.2604499, 0.2752666, 0.2163604…
$ nCount_RNA <dbl> 6868, 5316, 3696, 2667, 2490, 1789, 8247, 8544, 6478,…
$ nFeature_RNA <int> 3034, 2551, 2029, 1415, 1513, 1079, 3160, 3072, 2778,…
$ wtree <fct> 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 32, 3…
$ age <chr> "P23", "P23", "P23", "P23", "P23", "P23", "P10", "P10…
$ stage <fct> Postnatal, Postnatal, Postnatal, Postnatal, Postnatal…
$ gaba_status <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, FALSE…
$ gaba_occurs <lgl> TRUE, TRUE, FALSE, FALSE, TRUE, TRUE, TRUE, TRUE, TRU…
$ th_status <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE,…
$ status <chr> "dopaminergic", "dopaminergic", "dopaminergic", "dopa…sbs_mtx_oc_full$modulator <-
sbs_mtx_oc_full %>%
select(Cnr1, Gpr55) %>%
mutate(modulator = if_any(.fns = ~ .x > 0)) %>%
.$modulator
sbs_mtx_oc_full$oc3 <-
(sbs_mtx_oc_full$Onecut3 > 0)
library(ggstatsplot)
# for reproducibility
set.seed(123)
# plot
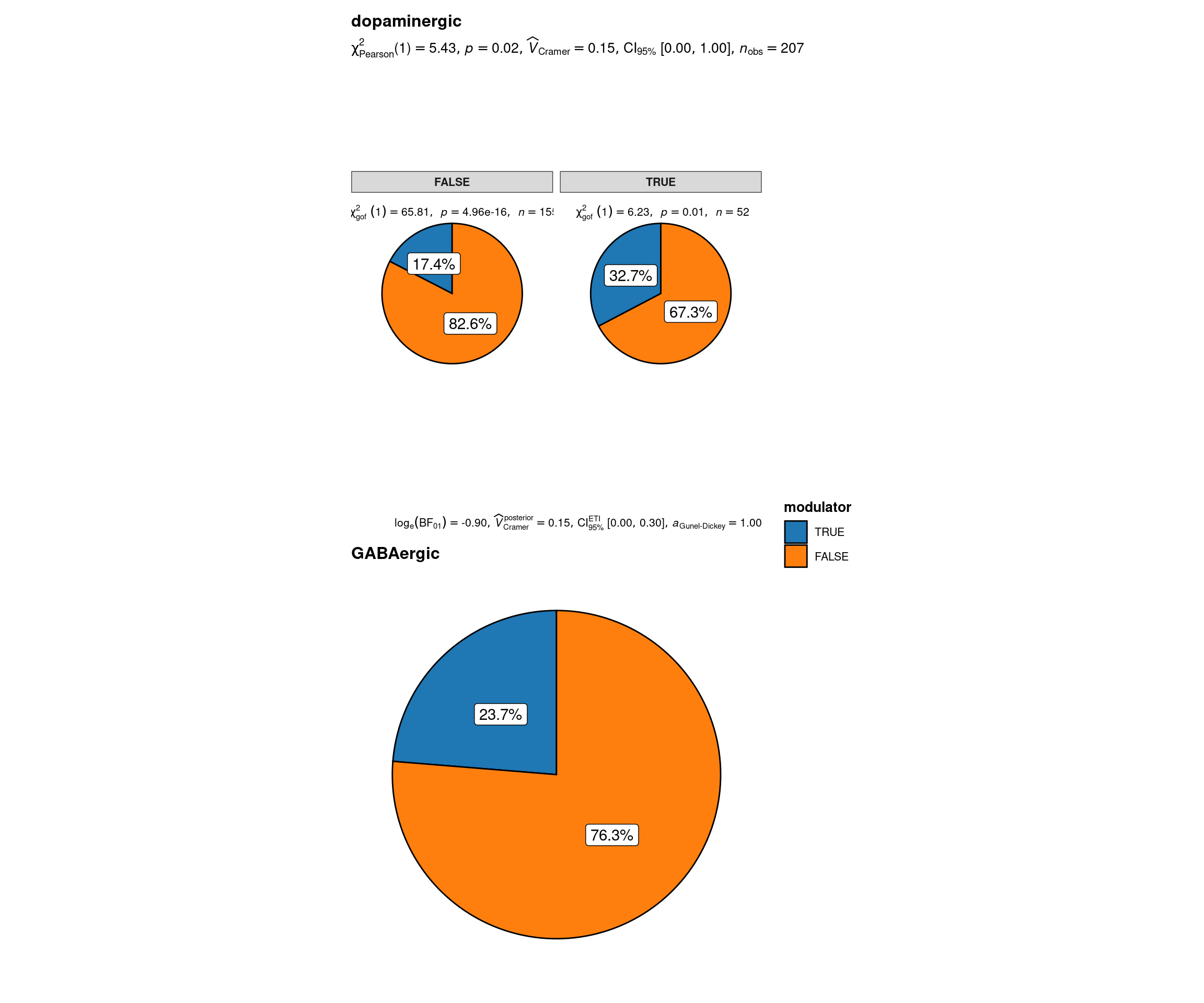
grouped_ggpiestats(
# arguments relevant for `ggpiestats()`
data = sbs_mtx_oc_full,
x = modulator,
y = oc3,
grouping.var = status,
perc.k = 1,
package = "ggsci",
palette = "category10_d3",
# arguments relevant for `combine_plots()`
title.text = "Neuromodulator specification of onecut-driven hypothalamic neuronal lineages by Onecut3 and main neurotransmitter expression",
caption.text = "Asterisks denote results from proportion tests; \n***: p < 0.001, ns: non-significant",
plotgrid.args = list(nrow = 2)
)
sessionInfo()R version 4.3.0 (2023-04-21)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 22.04.2 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
time zone: Etc/UTC
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggstatsplot_0.11.1.9000 Nebulosa_1.10.0 RColorBrewer_1.1-3
[4] patchwork_1.1.2.9000 UpSetR_1.4.0 scCustomize_1.1.1
[7] SeuratDisk_0.0.0.9020 SeuratWrappers_0.3.1 SeuratObject_4.1.3
[10] Seurat_4.3.0 sctransform_0.3.5 future_1.32.0
[13] zeallot_0.1.0 magrittr_2.0.3 lubridate_1.9.2
[16] forcats_1.0.0 stringr_1.5.0 dplyr_1.1.2
[19] purrr_1.0.1 readr_2.1.4 tidyr_1.3.0
[22] tibble_3.2.1 ggplot2_3.4.2 tidyverse_2.0.0.9000
[25] here_1.0.1 workflowr_1.7.0
loaded via a namespace (and not attached):
[1] fs_1.6.2 matrixStats_0.63.0
[3] spatstat.sparse_3.0-1 bitops_1.0-7
[5] httr_1.4.5 insight_0.19.1
[7] tools_4.3.0 utf8_1.2.3
[9] R6_2.5.1 statsExpressions_1.5.0
[11] mgcv_1.8-42 lazyeval_0.2.2
[13] uwot_0.1.14 withr_2.5.0
[15] sp_1.6-0 gridExtra_2.3
[17] progressr_0.13.0 textshaping_0.3.6
[19] cli_3.6.1 Biobase_2.60.0
[21] spatstat.explore_3.1-0 sandwich_3.0-2
[23] prismatic_1.1.1 labeling_0.4.2
[25] sass_0.4.5 mvtnorm_1.1-3
[27] spatstat.data_3.0-1 ggridges_0.5.4
[29] pbapply_1.7-0 systemfonts_1.0.4
[31] R.utils_2.12.2 parallelly_1.35.0
[33] rstudioapi_0.14 generics_0.1.3
[35] shape_1.4.6 ica_1.0-3
[37] spatstat.random_3.1-4 vroom_1.6.1
[39] Matrix_1.5-4 ggbeeswarm_0.7.1.9000
[41] fansi_1.0.4 S4Vectors_0.38.0
[43] abind_1.4-5 R.methodsS3_1.8.2
[45] lifecycle_1.0.3 whisker_0.4.1
[47] multcomp_1.4-23 yaml_2.3.7
[49] snakecase_0.11.0 SummarizedExperiment_1.30.0
[51] Rtsne_0.16 paletteer_1.5.0
[53] grid_4.3.0 promises_1.2.0.1
[55] crayon_1.5.2 miniUI_0.1.1.1
[57] lattice_0.21-8 cowplot_1.1.1
[59] pillar_1.9.0 knitr_1.42
[61] GenomicRanges_1.52.0 estimability_1.4.1
[63] future.apply_1.10.0 codetools_0.2-19
[65] leiden_0.4.3 glue_1.6.2
[67] getPass_0.2-2 data.table_1.14.8
[69] remotes_2.4.2 vctrs_0.6.2
[71] png_0.1-8 gtable_0.3.3
[73] rematch2_2.1.2 datawizard_0.7.1
[75] cachem_1.0.7 ks_1.14.0
[77] xfun_0.39 mime_0.12
[79] correlation_0.8.4 ggside_0.2.2
[81] pracma_2.4.2 coda_0.19-4
[83] survival_3.5-5 SingleCellExperiment_1.22.0
[85] ellipsis_0.3.2 fitdistrplus_1.1-11
[87] TH.data_1.1-2 ROCR_1.0-11
[89] nlme_3.1-162 bit64_4.0.5
[91] RcppAnnoy_0.0.20 GenomeInfoDb_1.36.0
[93] rprojroot_2.0.3 bslib_0.4.2
[95] irlba_2.3.5.1 vipor_0.4.5
[97] KernSmooth_2.23-20 colorspace_2.1-0
[99] BiocGenerics_0.46.0 ggrastr_1.0.1
[101] tidyselect_1.2.0 processx_3.8.1
[103] emmeans_1.8.5 bit_4.0.5
[105] compiler_4.3.0 git2r_0.32.0
[107] hdf5r_1.3.8 DelayedArray_0.25.0
[109] plotly_4.10.1 bayestestR_0.13.1
[111] scales_1.2.1 lmtest_0.9-40
[113] callr_3.7.3 digest_0.6.31
[115] goftest_1.2-3 spatstat.utils_3.0-2
[117] rmarkdown_2.21 XVector_0.40.0
[119] htmltools_0.5.5 pkgconfig_2.0.3
[121] MatrixGenerics_1.12.0 highr_0.10
[123] fastmap_1.1.1 rlang_1.1.0
[125] GlobalOptions_0.1.2 htmlwidgets_1.6.2
[127] shiny_1.7.4 farver_2.1.1
[129] jquerylib_0.1.4 zoo_1.8-12
[131] jsonlite_1.8.4 mclust_6.0.0
[133] R.oo_1.25.0 RCurl_1.98-1.12
[135] GenomeInfoDbData_1.2.10 parameters_0.21.0
[137] munsell_0.5.0 Rcpp_1.0.10
[139] reticulate_1.28-9000 stringi_1.7.12
[141] zlibbioc_1.46.0 MASS_7.3-59
[143] plyr_1.8.8 parallel_4.3.0
[145] listenv_0.9.0 ggrepel_0.9.3
[147] deldir_1.0-6 splines_4.3.0
[149] tensor_1.5 hms_1.1.3
[151] circlize_0.4.15 ps_1.7.5
[153] igraph_1.4.2 spatstat.geom_3.1-0
[155] effectsize_0.8.3 reshape2_1.4.4
[157] stats4_4.3.0 evaluate_0.20
[159] BiocManager_1.30.20 ggprism_1.0.4
[161] tzdb_0.3.0 httpuv_1.6.9
[163] MatrixModels_0.5-1 BayesFactor_0.9.12-4.4
[165] RANN_2.6.1 polyclip_1.10-4
[167] scattermore_0.8 rsvd_1.0.5
[169] janitor_2.2.0.9000 xtable_1.8-4
[171] later_1.3.0 ragg_1.2.5
[173] viridisLite_0.4.1 beeswarm_0.4.0
[175] IRanges_2.34.0 cluster_2.1.4
[177] timechange_0.2.0 globals_0.16.2