Sequence data quality control
Maeva Techer
2022-11-07
Last updated: 2022-11-07
Checks: 7 0
Knit directory:
locust-phase-transition-RNAseq/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20221025) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version e6f6c2e. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: analysis/.DS_Store
Ignored: data/.DS_Store
Ignored: data/americana/.DS_Store
Ignored: data/americana/STAR_counts_4thcol/.DS_Store
Ignored: data/cancellata/.DS_Store
Ignored: data/cancellata/STAR_counts_4thcol/.DS_Store
Ignored: data/cubense/.DS_Store
Ignored: data/cubense/STAR_counts_4thcol/.DS_Store
Ignored: data/gregaria/.DS_Store
Ignored: data/gregaria/STAR_counts_4thcol/.DS_Store
Ignored: data/gregaria/list/.DS_Store
Ignored: data/metadata/.DS_Store
Ignored: data/nitens/.DS_Store
Ignored: data/nitens/STAR_counts_4thcol/.DS_Store
Ignored: data/piceifrons/.DS_Store
Ignored: data/piceifrons/.Rhistory
Ignored: data/piceifrons/DEseq2_SPICE_HEAD 2/
Ignored: data/piceifrons/DEseq2_SPICE_HEAD/.DS_Store
Ignored: data/piceifrons/STAR_counts_4thcol/.DS_Store
Ignored: data/piceifrons/edgeR_SPICE_HEAD/.DS_Store
Ignored: data/piceifrons/list/.DS_Store
Unstaged changes:
Modified: data/piceifrons/DEseq2_SPICE_HEAD/SPICE_HEAD_report.html
Modified: data/piceifrons/edgeR_SPICE_HEAD/SPICE_HEAD_report.html
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/seqdata-qc.Rmd) and HTML
(docs/seqdata-qc.html) files. If you’ve configured a remote
Git repository (see ?wflow_git_remote), click on the
hyperlinks in the table below to view the files as they were in that
past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| html | fdea907 | MaevaTecher | 2022-11-06 | Build site. |
| html | f47f4dd | MaevaTecher | 2022-11-06 | Build site. |
| Rmd | b5a3c0f | MaevaTecher | 2022-11-06 | workflowr::wflow_publish("analysis/seqdata-qc.Rmd") |
| html | 74a9a83 | MaevaTecher | 2022-11-06 | Build site. |
| Rmd | bb5af6b | MaevaTecher | 2022-11-06 | workflowr::wflow_publish("analysis/seqdata-qc.Rmd") |
| html | 1fa8b99 | MaevaTecher | 2022-11-01 | Build site. |
| html | 40deb86 | MaevaTecher | 2022-11-01 | Build site. |
| html | 83b00b8 | MaevaTecher | 2022-11-01 | Build site. |
| html | 05f27e6 | MaevaTecher | 2022-11-01 | Build site. |
| html | ec83778 | MaevaTecher | 2022-11-01 | Build site. |
| html | 834088c | MaevaTecher | 2022-10-31 | Build site. |
| html | 8481823 | MaevaTecher | 2022-10-31 | Build site. |
| html | ea70380 | MaevaTecher | 2022-10-31 | Build site. |
| Rmd | de64b6b | MaevaTecher | 2022-10-31 | wflow_publish(c("analysis/_site.yml", "analysis/map-refseq.Rmd", |
| html | 8b34f19 | MaevaTecher | 2022-10-30 | Build site. |
| html | bd04bb5 | MaevaTecher | 2022-10-30 | Build site. |
| html | 61f4b75 | MaevaTecher | 2022-10-30 | Build site. |
| Rmd | f65c630 | MaevaTecher | 2022-10-30 | wflow_publish(c("analysis/_site.yml", "analysis/gene-quant.Rmd", |
Load R libraries (install first from CRAN or Bioconductor)
library("knitr")
library("rmdformats")
library("tidyverse")
library("DT") # for making interactive search table
library("plotly") # for interactive plots
library("ggthemes") # for theme_calc
library("reshape2")
## Global options
options(max.print="10000")
knitr::opts_chunk$set(
echo = TRUE,
message = FALSE,
warning = FALSE,
cache = FALSE,
comment = FALSE,
prompt = FALSE,
tidy = TRUE
)
opts_knit$set(width=75)Control the quality of fastq files
From the point we have the renamed, and paired-end / single-end read
for the species of interest (one folder), we are ready to run our
Snakemake pipeline on it. If not provided beforehand by TxGen, we need
to check the quality of the sequences downloaded or generated using
FASTQC.
Results can be view by opening the *.html files in web browser.
However as we analyzed a large number of files, it is easier to
inspect them using the multiqc report that summarize
everything into one single file.
module load GCC/9.3.0 OpenMPI/4.0.3 MultiQC/1.9-Python-3.8.2
multiqc --title 'TYPE THE TITLE YOU WANT' -v /PATHTODIRECTORY[WRITE ABOUT MULTIQC]
Trim and adapter removal
After checking the initial sequence quality, we can determine any
parameters change for Trimmomatic.
########################################
# Snakefile rule
########################################
rule trim_adapt:
input:
read1 = OUTdir + "/reads/{locust}_1.fastq.gz",
read2 = OUTdir + "/reads/{locust}_2.fastq.gz",
adaptfile = OUTdir + "/list/TruSeqNextera_PE.fa"
output:
trimmedread1 = OUTdir + "/trimming/{locust}_trim1P_1.fastq.gz",
badread1 = OUTdir + "/trimming/{locust}_trim1U_1.fastq.gz",
trimmedread2 = OUTdir + "/trimming/{locust}_trim2P_2.fastq.gz",
badread2 = OUTdir + "/trimming/{locust}_trim2U_2.fastq.gz",
shell:
"""
module load Trimmomatic/0.39-Java-11
java -jar $EBROOTTRIMMOMATIC/trimmomatic-0.39.jar PE -threads 2 -phred33 {input.read1} {input.read2} {output.trimmedread1} {output.badread1} {output.trimmedread2} {output.badread2} ILLUMINACLIP:{input.adaptfile}:2:30:10 LEADING:30 TRAILING:30 SLIDINGWINDOW:4:15 MINLEN:36
"""
########################################
# Parameters in the cluster.json file
########################################
"trim_adapt":
{
"cpus-per-task" : 2,
"partition" : "medium",
"ntasks": 2,
"mem" : "1G",
"time": "0-04:00:00"
},
Trim quality control
We always QC after trimming to ensure fine-tuning that the sequences clipping and filtering were not unnecessarily harsh. Given the number of sequences we work with, we do not need to go through each file immediately for time purposes. Instead, sample randomly across species, rearing conditions, and tissues to see that the process worked well.
########################################
# Snakefile rule
########################################
#Quality control step after trimming: checked for adapter content in particular and quality scores
rule trim_fastqc:
input:
read1 = OUTdir + "/trimming/{locust}_trim1P_1.fastq.gz",
read2 = OUTdir + "/trimming/{locust}_trim2P_2.fastq.gz",
output:
htmlqc1 = OUTdir + "/trimming/{locust}_trim1P_1_fastqc.html",
htmlqc2 = OUTdir + "/trimming/{locust}_trim2P_2_fastqc.html",
shell:
"""
module load FastQC/0.11.9-Java-11
fastqc {input.read1}
fastqc {input.read2}
"""
########################################
# Parameters in the cluster.json file
########################################
"trim_fastqc":
{
"cpus-per-task" : 2,
"partition" : "medium",
"ntasks": 1,
"mem" : "500M",
"time": "0-03:00:00"
},
EXAMPLE OF READS QUALITY BEFORE TRIMMING
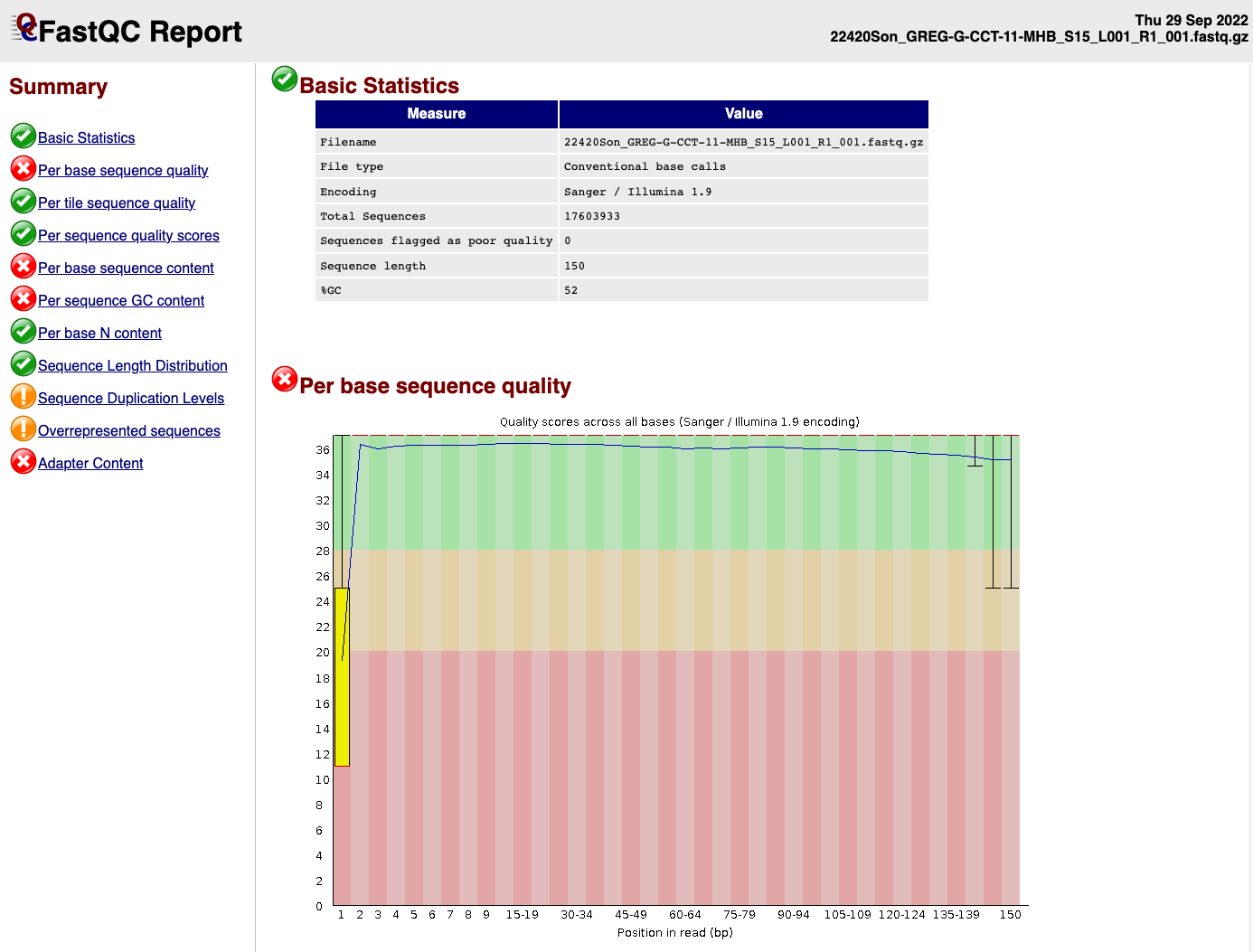
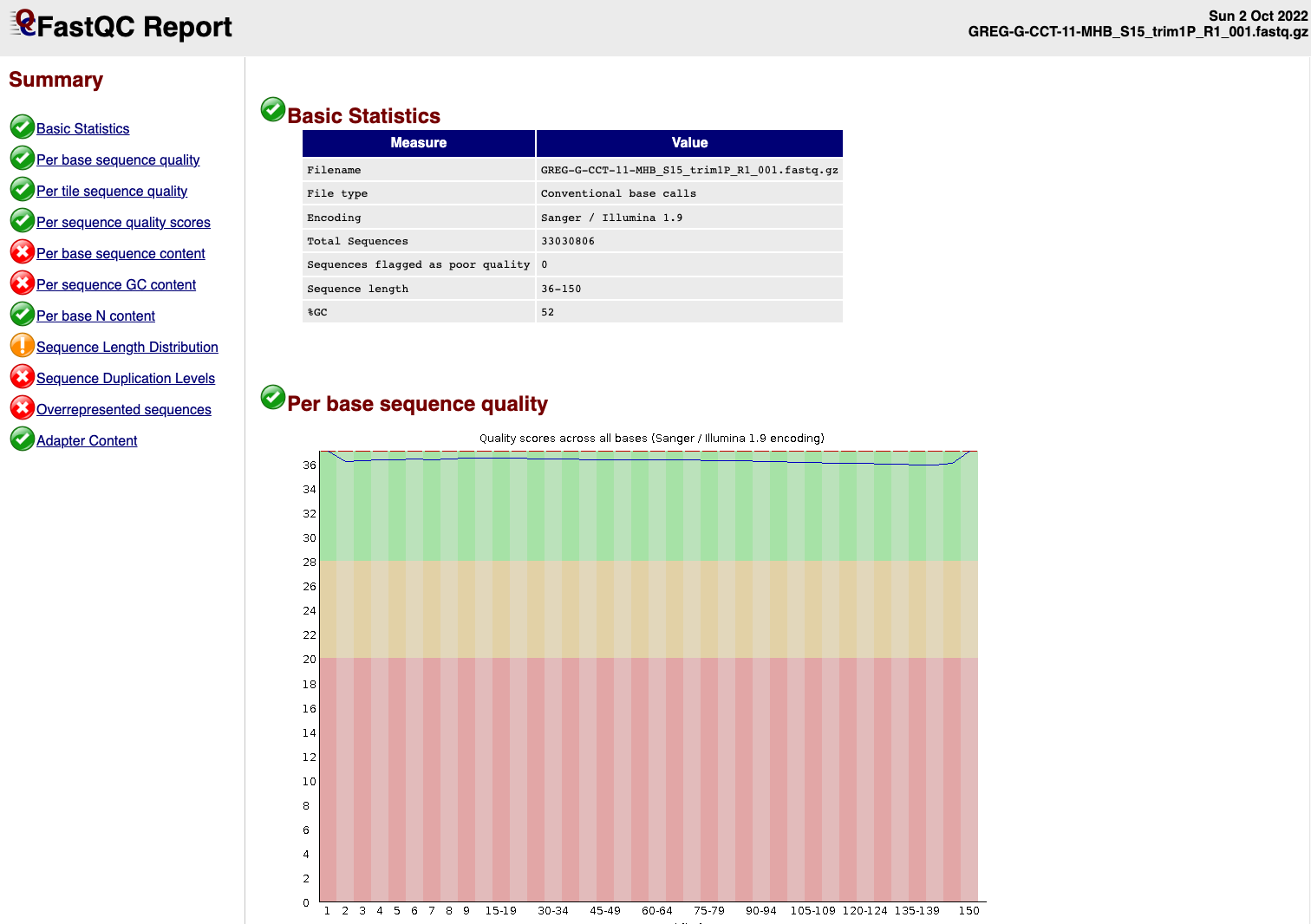
EXAMPLE OF READS QUALITY AFTER TRIMMING
We can see that the sequence length has changed and that the 5’ and 3’
end positions with lower quality have been removed.
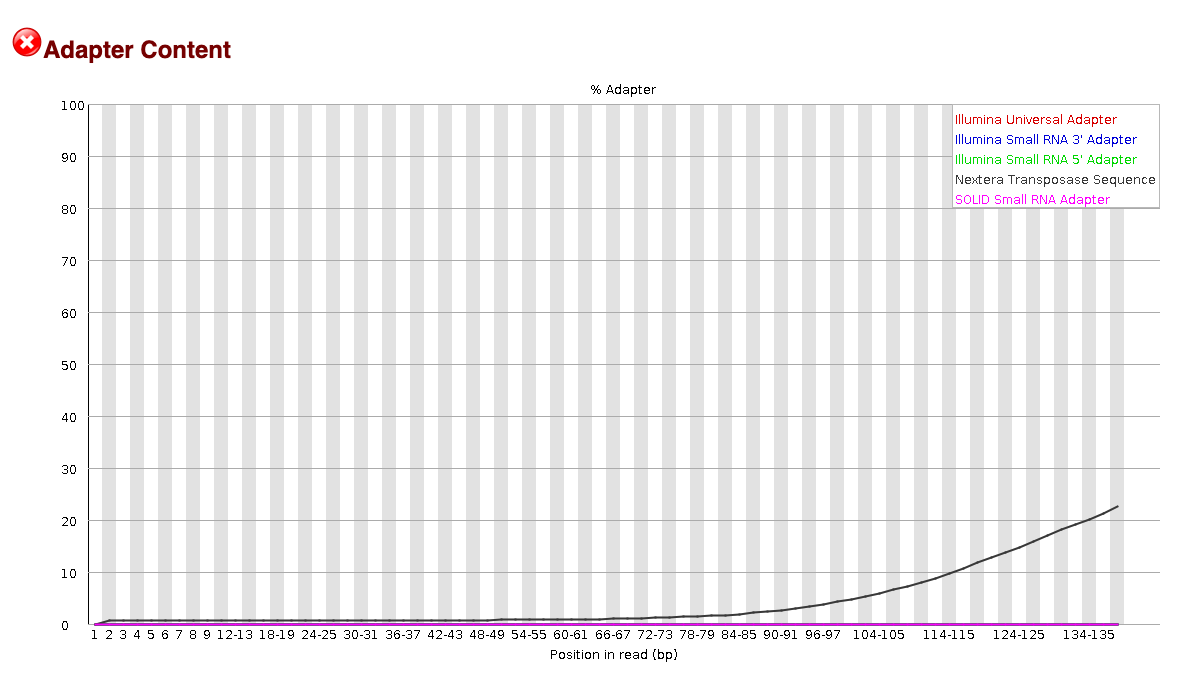
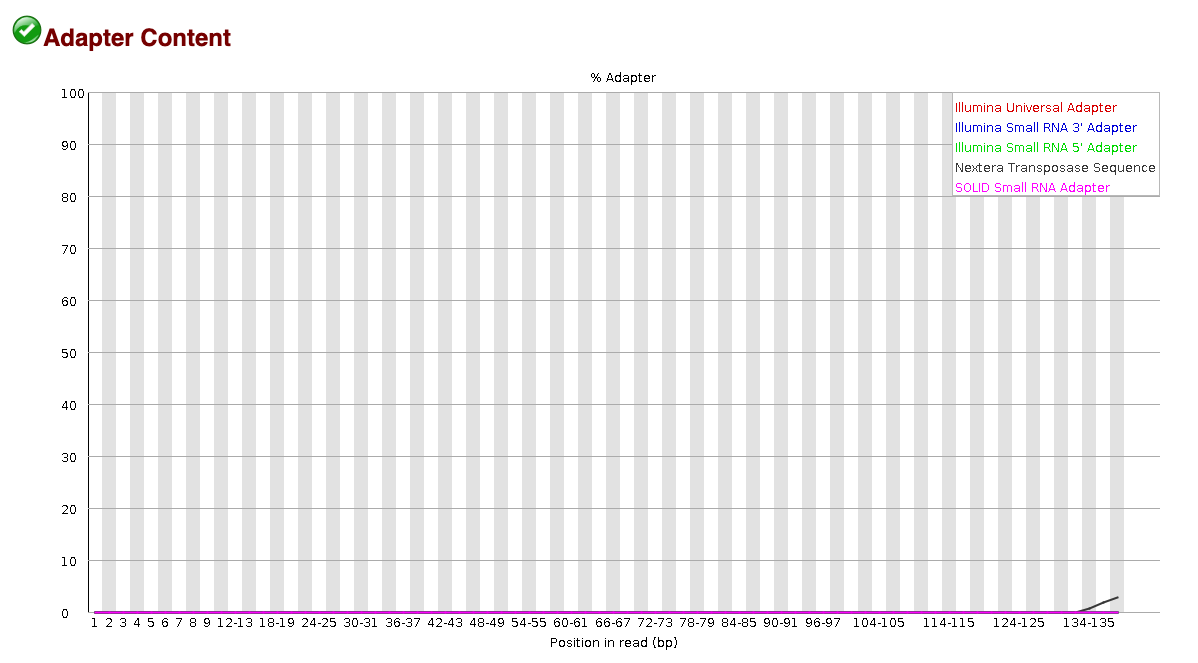
EXAMPLE OF READS QUALITY AFTER TRIMMING
We can see that most detected adapter sequences have been adequately removed after trimming.
Check for sequencing data contamination
Contamination is likely bound to happen during experiments, tissue acquisition, RNA extraction and library preparation. One can hope to reduces as much as possible its impact on the final sequencing data which can affect the mapping rate success.
Screen for microbial contamination
We decided to screen for microbes sequences present in the trimmed
paired end reads fastq.gz files using the tool Kaiju.
Kaiju translates metatranscriptomics sequencing reads into
six possible reading frames and searches for maximum exact matches of
amino acid sequences in a given annotation protein database.
We used the most extensive microbial database nr_euk
which encompass the subset of NCBI BLAST nr database containing all
proteins belonging to Archaea, Bacteria, Viruses, Fungi and microbial
Eukaryotes.
## Downloading the 2022-03-10 database from Kaiju webserver
wget https://kaiju.binf.ku.dk/database/kaiju_db_nr_euk_2022-03-10.tgzTo run Kaiju we used the following
Snakemake rule:
########################################
# Snakefile rule
########################################
rule kaiju:
input:
read1 = OUTdir + "/trimming/{locust}_trim1P_1.fastq.gz",
read2 = OUTdir + "/trimming/{locust}_trim2P_2.fastq.gz",
database = KAIJUdir + "/kaiju_db_nr_euk.fmi",
taxonid = KAIJUdir + "/nodes.dmp",
taxonnames = KAIJUdir + "/names.dmp",
output:
report = OUTdir + "/kaiju/{locust}_kaiju.out",
classification = OUTdir + "/kaiju/{locust}_kaiju.tsv",
shell:
"""
ml GCC/8.3.0 OpenMPI/3.1.4 Kaiju/1.7.3-Python-3.7.4
kaiju -z 12 -v -a greedy -f {input.database} -t {input.taxonid} -i {input.read1} -j {input.read2} -o {output.report}
kaiju2table -v -t {input.taxonid} -n {input.taxonnames} -r phylum -o {output.classification} {output.report}
"""
########################################
# Parameters in the cluster.json file
########################################
"kaiju":
{
"cpus-per-task" : 6,
"partition" : "medium",
"ntasks": 2,
"mem" : "200G",
"time": "0-12:00:00"
},
The ouput produced here allows us to see the percentage of reads that map to unclassified (likely our locust host here) and the percentage of microbial contamination ranked in a phylum level.
Visualize the metatranscriptomics result
Kaiju output can be exported to be view in a interactive
and hierarchical multi-layered pie-charts using Krona. The
results are generated by a .html page. We followed the Kaiju tutorial
on the Github page:
########################################
# Snakefile rule
########################################
rule krona:
input:
kaijuout = OUTdir + "/kaiju/{locust}_kaiju.out",
taxonid = KAIJUdir + "/nodes.dmp",
taxonnames = KAIJUdir + "/names.dmp",
output:
conversion = OUTdir + "/kaiju/{locust}_krona.out",
webreport = OUTdir + "/kaiju/{locust}_krona.html",
shell:
"""
ml GCCcore/8.2.0 KronaTools/2.7.1
kaiju2krona -t {input.taxonid} -n {input.taxonnames} -i {input.kaijuout} -o {output.conversion}
ktImportText -o {output.webreport} {output.conversion}
"""
########################################
# Parameters in the cluster.json file
########################################
"krona":
{
"cpus-per-task" : 2,
"partition" : "short",
"ntasks": 1,
"mem" : "500M",
"time": "0-0:10:00"
},Filter for rRNA?
[SHOULD WE USE SORTMERNA]
sessionInfo()FALSE R version 4.2.1 (2022-06-23)
FALSE Platform: x86_64-apple-darwin17.0 (64-bit)
FALSE Running under: macOS Big Sur ... 10.16
FALSE
FALSE Matrix products: default
FALSE BLAS: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRblas.0.dylib
FALSE LAPACK: /Library/Frameworks/R.framework/Versions/4.2/Resources/lib/libRlapack.dylib
FALSE
FALSE locale:
FALSE [1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
FALSE
FALSE attached base packages:
FALSE [1] stats graphics grDevices utils datasets methods base
FALSE
FALSE other attached packages:
FALSE [1] reshape2_1.4.4 ggthemes_4.2.4 plotly_4.10.0 DT_0.26
FALSE [5] forcats_0.5.2 stringr_1.4.1 dplyr_1.0.10 purrr_0.3.5
FALSE [9] readr_2.1.3 tidyr_1.2.1 tibble_3.1.8 ggplot2_3.3.6
FALSE [13] tidyverse_1.3.2 rmdformats_1.0.4 knitr_1.40
FALSE
FALSE loaded via a namespace (and not attached):
FALSE [1] httr_1.4.4 sass_0.4.2 jsonlite_1.8.3
FALSE [4] viridisLite_0.4.1 modelr_0.1.9 bslib_0.4.0
FALSE [7] assertthat_0.2.1 googlesheets4_1.0.1 cellranger_1.1.0
FALSE [10] yaml_2.3.6 pillar_1.8.1 backports_1.4.1
FALSE [13] glue_1.6.2 digest_0.6.30 promises_1.2.0.1
FALSE [16] rvest_1.0.3 colorspace_2.0-3 htmltools_0.5.3
FALSE [19] httpuv_1.6.6 plyr_1.8.7 pkgconfig_2.0.3
FALSE [22] broom_1.0.1 haven_2.5.1 bookdown_0.29
FALSE [25] scales_1.2.1 whisker_0.4 later_1.3.0
FALSE [28] tzdb_0.3.0 git2r_0.30.1 googledrive_2.0.0
FALSE [31] generics_0.1.3 ellipsis_0.3.2 cachem_1.0.6
FALSE [34] withr_2.5.0 lazyeval_0.2.2 cli_3.4.1
FALSE [37] magrittr_2.0.3 crayon_1.5.2 readxl_1.4.1
FALSE [40] evaluate_0.17 fs_1.5.2 fansi_1.0.3
FALSE [43] xml2_1.3.3 tools_4.2.1 data.table_1.14.4
FALSE [46] hms_1.1.2 formatR_1.12 gargle_1.2.1
FALSE [49] lifecycle_1.0.3 munsell_0.5.0 reprex_2.0.2
FALSE [52] compiler_4.2.1 jquerylib_0.1.4 rlang_1.0.6
FALSE [55] grid_4.2.1 rstudioapi_0.14 htmlwidgets_1.5.4
FALSE [58] rmarkdown_2.17 gtable_0.3.1 DBI_1.1.3
FALSE [61] R6_2.5.1 lubridate_1.8.0 fastmap_1.1.0
FALSE [64] utf8_1.2.2 workflowr_1.7.0 rprojroot_2.0.3
FALSE [67] stringi_1.7.8 Rcpp_1.0.9 vctrs_0.5.0
FALSE [70] dbplyr_2.2.1 tidyselect_1.2.0 xfun_0.34