Leucegene Normals
Last updated: 2021-05-28
Checks: 7 0
Knit directory: MINTIE-paper-analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200415) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version ed3d2b6. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/cache/
Ignored: data/.DS_Store
Ignored: data/RCH_B-ALL/
Ignored: data/leucegene/.DS_Store
Ignored: data/leucegene/KMT2A-PTD_results/.DS_Store
Ignored: data/leucegene/normals_ncontrols_test_results/.DS_Store
Ignored: data/leucegene/normals_ncontrols_test_results/ncon0/.DS_Store
Ignored: data/leucegene/normals_ncontrols_test_results/ncon1/.DS_Store
Ignored: data/leucegene/salmon_out/
Ignored: data/leucegene/sample_info/KMT2A-PTD_8-2.fa.xls
Ignored: data/leucegene/validation_results/.DS_Store
Ignored: data/simu/.DS_Store
Ignored: data/simu/results/.DS_Store
Ignored: data/simu/results/MINTIE/.DS_Store
Ignored: data/simu/results/MINTIE/varying_dispersion/.DS_Store
Ignored: output/Leucegene_gene_counts.tsv
Ignored: packrat/lib-R/
Ignored: packrat/lib-ext/
Ignored: packrat/lib/
Untracked files:
Untracked: data/leucegene/validation_results/TAP/
Unstaged changes:
Modified: .Rprofile
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/Leucegene_Normals.Rmd) and HTML (docs/Leucegene_Normals.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | ed3d2b6 | Marek Cmero | 2021-05-28 | Figures tweaks and reordering. |
| html | 4206f12 | Marek Cmero | 2021-04-30 | Build site. |
| Rmd | dde9f5b | Marek Cmero | 2021-04-30 | wflow_publish(files = list.files(pattern = "*Rmd")) |
| Rmd | 9595530 | Marek Cmero | 2021-04-30 | Updated analyses |
| html | 41431cc | Marek Cmero | 2020-07-07 | Build site. |
| html | 4b8113e | Marek Cmero | 2020-07-03 | Build site. |
| html | e9e4917 | Marek Cmero | 2020-06-24 | Build site. |
| Rmd | 9434bfe | Marek Cmero | 2020-06-24 | Updated results with latest MINTIE run. Fixed bug with KMT2A PTD checking in different controls. Added leucegene |
| html | b5825d3 | Marek Cmero | 2020-06-11 | Build site. |
| Rmd | c2c1c58 | Marek Cmero | 2020-06-11 | Fixed several tables to reflect paper more closely |
| html | 0b21347 | Marek Cmero | 2020-06-11 | Build site. |
| Rmd | fa6bf0c | Marek Cmero | 2020-06-11 | Updated with new results; improved tables |
| html | fa6bf0c | Marek Cmero | 2020-06-11 | Updated with new results; improved tables |
| html | 3702862 | Marek Cmero | 2020-05-18 | Removed MLM samples from final B-ALL results |
| html | a166ab8 | Marek Cmero | 2020-05-08 | Build site. |
| html | a600688 | Marek Cmero | 2020-05-07 | Build site. |
| html | 1c40e33 | Marek Cmero | 2020-05-07 | Build site. |
| Rmd | bbc278a | Marek Cmero | 2020-05-07 | Refactoring |
| html | 87b4e62 | Marek Cmero | 2020-05-07 | Build site. |
| Rmd | af503f2 | Marek Cmero | 2020-05-07 | Refactoring |
| html | 5c045b5 | Marek Cmero | 2020-05-07 | Build site. |
| html | 90c7fd9 | Marek Cmero | 2020-05-06 | Build site. |
| Rmd | ff4b1dc | Marek Cmero | 2020-05-06 | Leucegene results |
| html | 358aa53 | Marek Cmero | 2020-05-04 | Build site. |
| Rmd | 453d754 | Marek Cmero | 2020-05-04 | Added controls comparison in normals analysis. Added variant class collation function. Added variant summary for |
| html | 4a5d6ae | Marek Cmero | 2020-05-01 | Build site. |
| Rmd | 9556ebb | Marek Cmero | 2020-05-01 | Added leucegene normals analysis. Added expressed genes analysis to leucegene gene expression analysis. |
# util
library(data.table)
library(dplyr)
library(here)
library(stringr)
# plotting/tables
library(ggplot2)
library(gt)options(stringsAsFactors = FALSE)source(here("code/leucegene_helper.R"))Leucegene Normals
Here we generate the results presented in the MINTIE paper, of the method run on a set of non-cancer samples obtained from Leucegene.
# load MINTIE results from leucegene normals
normals_results_dir <- here("data/leucegene/normals_results")
normals_results <- list.files(normals_results_dir, full.names = TRUE) %>%
lapply(., read.delim) %>%
rbindlist(fill = TRUE) %>%
filter(logFC > 5)
# load cell type info and add to results
celltype <- read.delim(here("data/leucegene/sample_info/celltypes_info.tsv"))
normals_results <- inner_join(normals_results, celltype,
by = c("sample" = "SRX_ID"))Variant Summary
Summary results for variants called by MINTIE on Leucegene normals.
normals_results %>%
group_by(sample) %>%
summarise(variants = length(unique(variant_id))) %>%
summarise(min = min(variants),
median = median(variants),
max = max(variants)) %>%
gt() %>%
tab_header(
title = md("**Variants called by sample summary**")
) %>%
tab_options(
table.font.size = 12
) %>%
cols_label(
min = md("**Min**"),
median = md("**Median**"),
max = md("**Max**")
)| Variants called by sample summary | ||
|---|---|---|
| Min | Median | Max |
| 61 | 122 | 1397 |
collate_vartypes(normals_results) %>%
group_by(class) %>%
summarise(variants = length(unique(variant_id))) %>%
mutate(fraction = variants / sum(variants)) %>%
gt() %>%
fmt_number(columns = vars(fraction), decimals = 3) %>%
tab_header(
title = md("**Variants called summary by class**")
) %>%
tab_options(
table.font.size = 12
) %>%
cols_label(
variants = md("**Variants**"),
fraction = md("**Fraction**")
)| Variants called summary by class | ||
|---|---|---|
| class | Variants | Fraction |
| Fusion | 93 | 0.016 |
| Novel splice variant | 3180 | 0.562 |
| Transcribed structural variant | 1069 | 0.189 |
| Unknown | 1318 | 0.233 |
Variant Genes
MINTIE paper Figure 4B showing the number of variant genes called across the Leucegene normal samples.
results_summary <- get_results_summary(mutate(normals_results, group_var = cell_type),
group_var_name = "cell_type")
results_summary %>%
summarise(min = min(V1),
median = median(V1),
max = max(V1),
total = sum(V1)) %>%
gt() %>%
tab_header(
title = md("**Variant genes called by sample summary**")
) %>%
tab_options(
table.font.size = 12
) %>%
cols_label(
min = md("**Min**"),
median = md("**Median**"),
max = md("**Max**"),
total = md("**Total**")
)| Variant genes called by sample summary | |||
|---|---|---|---|
| Min | Median | Max | Total |
| 64 | 117 | 465 | 3482 |
ggplot(results_summary, aes(cell_type, V1, group=sample)) +
geom_bar(position = position_dodge2(width = 0.9, preserve = "single"), stat = "identity") +
theme_bw() +
xlab("") +
ylab("Genes with variants")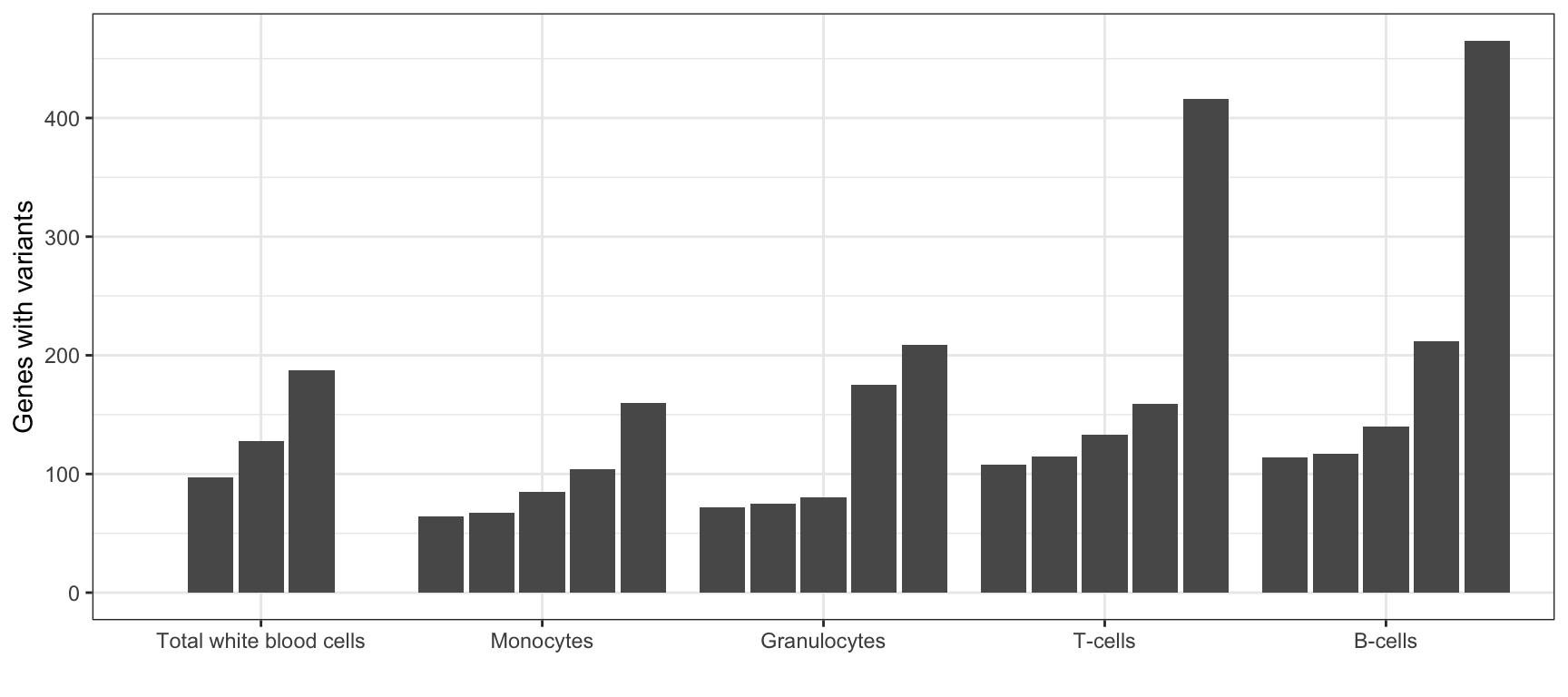
Library Size and Variant Number Correlation
Perform correlation calculation on the library size and number of variant genes found per sample.
Leucegene Gene Expression notebook must be run before this chunk to generate the expression counts matrix.
# load counts data, calculate library sizes and add to results summary
counts <- fread(here("output/Leucegene_gene_counts.tsv"))
libsizes <- apply(counts, 2, sum) %>% data.frame()
colnames(libsizes) <- "libsize"
libsizes$sample <- factor(rownames(libsizes),
levels = results_summary$sample)
results_summary <- left_join(results_summary, libsizes, by ="sample", "sample")
lib_var_cor <- cor(results_summary$libsize, results_summary$V1, method = "spearman")
print(paste("Spearman correlation between library size and variant genes called:", lib_var_cor))[1] "Spearman correlation between library size and variant genes called: 0.210474308300395"ggplot(results_summary, aes(libsize, V1, colour = cell_type)) +
geom_point() +
theme_bw() +
ylab("Genes with variants")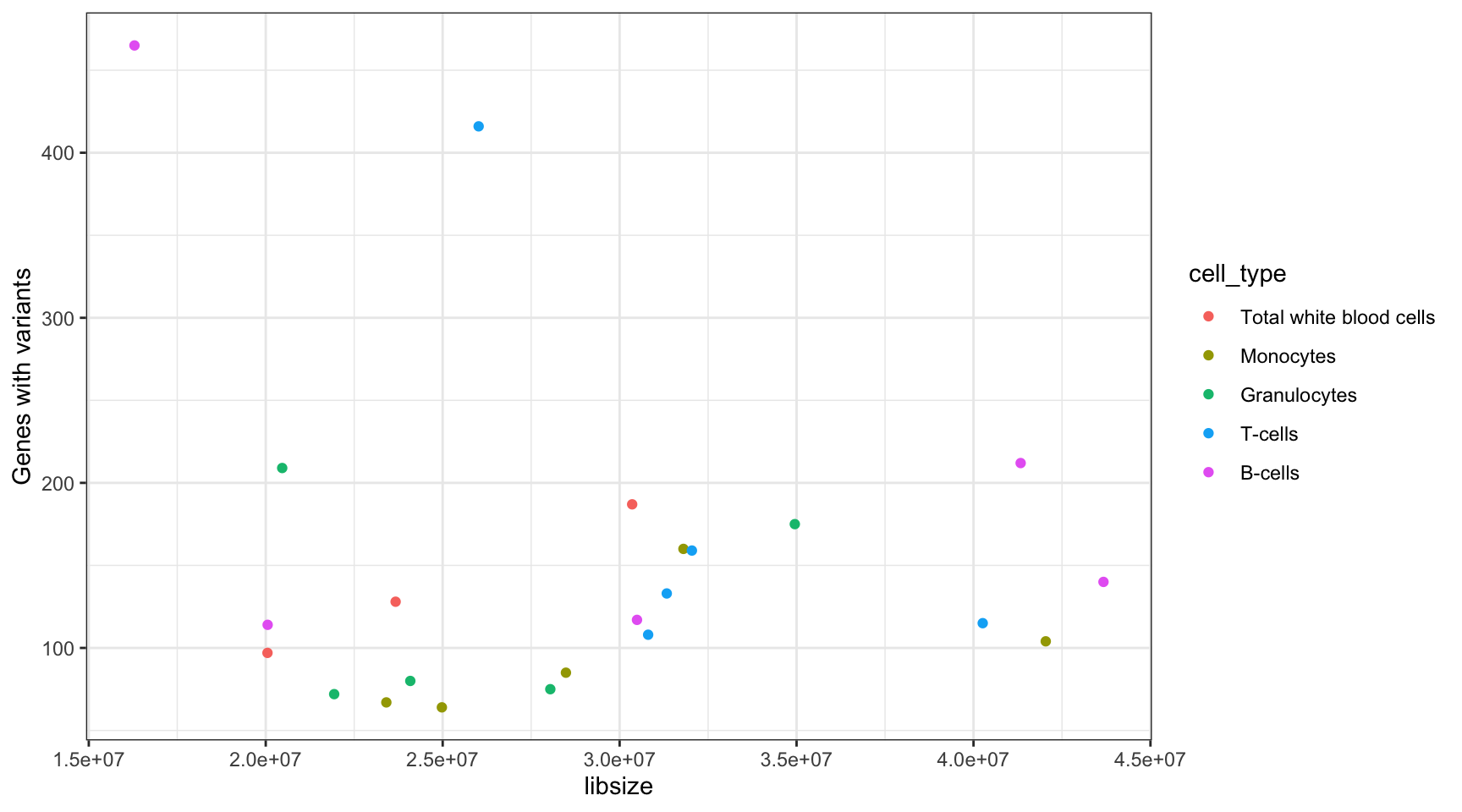
Protein Coding Genes
Proportion of protein coding genes observed in the MINTIE results.
# load CHESS gene reference containing gene types
chess_genes <- get_chess_genes(gzfile(here("data/ref/chess2.2.genes.gz")))
# join gene info with results and summarise by gene type
results_by_gene <- get_results_by_gene(normals_results)
gene_count <- left_join(results_by_gene, chess_genes, by = "gene") %>%
group_by(Gene_Type) %>%
summarise(n_genes = length(unique(gene))) %>%
data.table()
n_protein_coding <- gene_count[gene_count$Gene_Type == "protein_coding", "n_genes"]
n_var_genes <- sum(gene_count$n_genes)
paste("proportion of protein coding genes =",
(n_protein_coding / n_var_genes) %>% round(4),
paste0("(", n_protein_coding, "/", n_var_genes, ")")) %>%
print()[1] "proportion of protein coding genes = 0.8333 (1969/2363)"Controls Comparison
MINTIE Supplementary Figure 4 showing variant genes called in Leucegene Total White Blood Cell samples with different cell types as control groups.
# get TWBC results
controls_comp <- normals_results[normals_results$cell_type == "Total white blood cells",]
controls_comp$controls <- "twbc"
controls_comp$cell_type <- NULL
# load comparisons against all other controls
controls_test_dir <- here("data/leucegene/normals_controls_test_results")
controls_comp <- load_controls_comparison(controls_test_dir) %>%
rbind(controls_comp, ., fill = TRUE)
results_summary <- get_results_summary(mutate(controls_comp,
group_var = controls),
group_var_name = "controls")
results_summary %>%
group_by(controls) %>%
summarise(tcount = sum(V1)) %>%
gt() %>%
tab_header(
title = md("**Total variant genes called using different controls**")
) %>%
tab_options(
table.font.size = 12
) %>%
cols_label(
controls = md("**Controls**"),
tcount = md("**Variant genes**")
)| Total variant genes called using different controls | |
|---|---|
| Controls | Variant genes |
| twbc | 412 |
| mono | 715 |
| gran | 763 |
| tc | 1564 |
| bc | 1630 |
ggplot(results_summary, aes(sample, V1, fill=controls)) +
geom_bar(position=position_dodge2(width=0.9, preserve="single"), stat="identity") +
theme_bw() +
xlab("") +
ylab("Genes with variants") +
scale_fill_brewer(palette = "RdYlBu",
labels = c("mono" = "Monocytes",
"twbc" = "Total white blood cells",
"gran" = "Granulocytes",
"tc" = "T-Cells",
"bc" = "B-Cells"))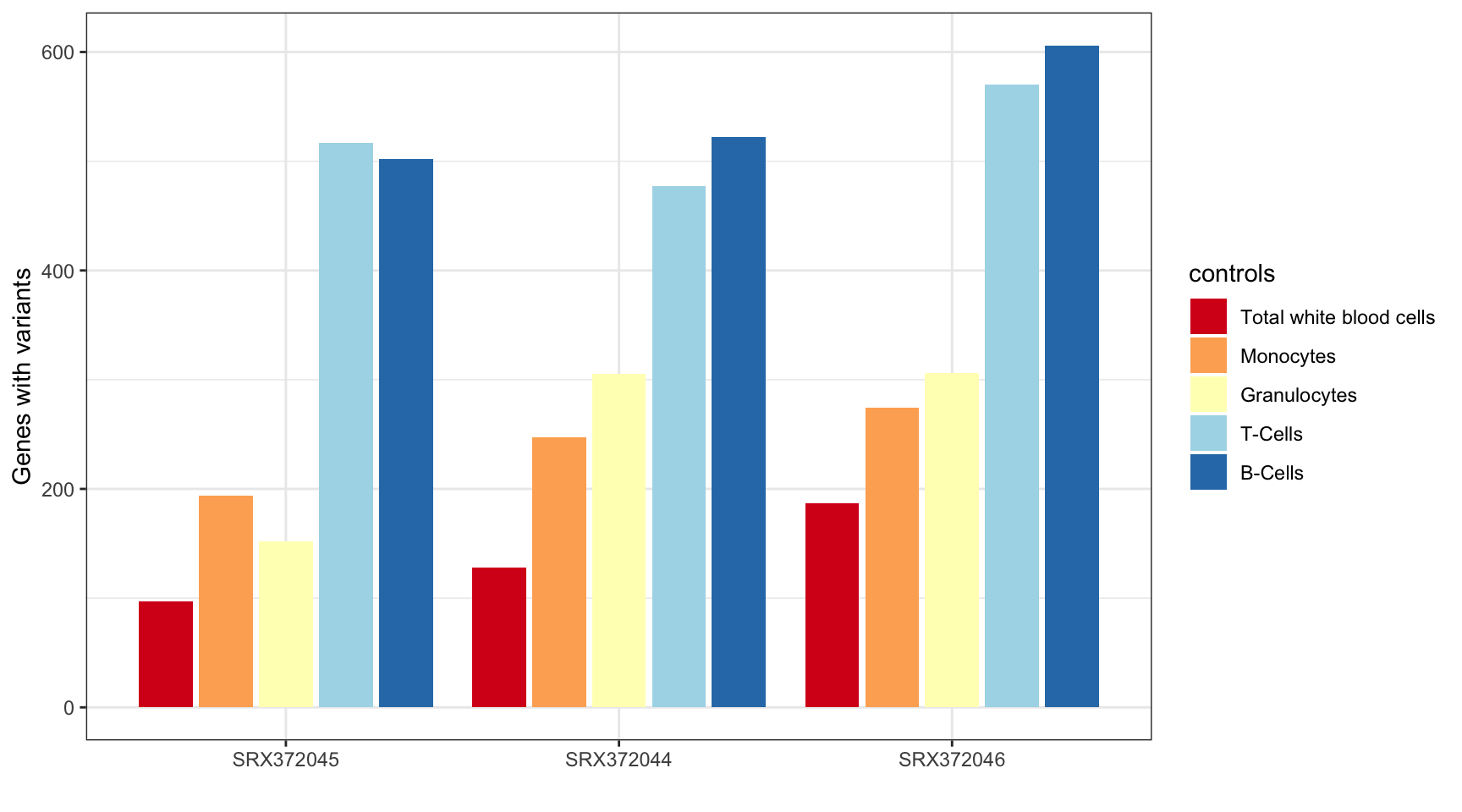
1..N controls experiments
MINTIE Figure 4C showing range of variant genes called in granulocytes with different combinations of 1..N controls. The table output also includes numbers for the runs where 0 controls were used.
# load in data
ncon_dirs <- here("data/leucegene/normals_ncontrols_test_results/")
ncon_results <- data.frame()
for (ncon_dir in list.dirs(ncon_dirs, recursive = FALSE)) {
run <- str_split(ncon_dir, "ncon")[[1]] %>%
tail(1)
ncon <- str_split(run, "r") %>% unlist() %>% head(1) %>% as.numeric()
results <- list.files(ncon_dir, pattern = "*results.tsv.gz", full.names = TRUE) %>%
lapply(., read.delim) %>%
rbindlist() %>%
get_results_by_gene() %>%
mutate(n_controls = ncon, run = run)
ncon_results <- rbindlist(list(ncon_results, results), fill = TRUE)
}
ncon_results <- ncon_results[logFC > 5 | is.na(logFC),]
# prepare results summary
results_summary <- get_results_summary(mutate(ncon_results,
group_var = run),
group_var_name = "run")
results_summary$n_controls <- results_summary$run %>%
as.character() %>%
str_split(., pattern = "r") %>%
lapply(., head, n=1) %>% unlist() %>% as.numeric()
rs <- results_summary %>%
group_by(sample, n_controls) %>%
summarise(mean=round(mean(V1, na.rm=TRUE)),
min=min(V1, na.rm=TRUE),
max=max(V1, na.rm=TRUE)) %>%
data.frame()
rs %>%
gt() %>%
tab_header(
title = md("**Total variant genes called using different numbers of controls**")
) %>%
tab_options(
table.font.size = 12
) %>%
cols_label(
n_controls = md("**Controls**"),
mean = md("**Mean**"),
min = md("**Min**"),
max = md("**Max**")
)| Total variant genes called using different numbers of controls | ||||
|---|---|---|---|---|
| sample | Controls | Mean | Min | Max |
| SRX372056 | 0 | 4129 | 4129 | 4129 |
| SRX372056 | 1 | 186 | 155 | 220 |
| SRX372056 | 2 | 140 | 132 | 155 |
| SRX372056 | 3 | 100 | 99 | 102 |
| SRX372056 | 4 | 80 | 80 | 80 |
| SRX372054 | 0 | 5079 | 5079 | 5079 |
| SRX372054 | 1 | 214 | 200 | 229 |
| SRX372054 | 2 | 123 | 113 | 139 |
| SRX372054 | 3 | 100 | 96 | 103 |
| SRX372054 | 4 | 75 | 75 | 75 |
| SRX372053 | 0 | 4570 | 4570 | 4570 |
| SRX372053 | 1 | 292 | 168 | 346 |
| SRX372053 | 2 | 227 | 102 | 295 |
| SRX372053 | 3 | 190 | 88 | 291 |
| SRX372053 | 4 | 72 | 72 | 72 |
| SRX372055 | 0 | 6063 | 6063 | 6063 |
| SRX372055 | 1 | 431 | 368 | 469 |
| SRX372055 | 2 | 249 | 226 | 266 |
| SRX372055 | 3 | 218 | 212 | 225 |
| SRX372055 | 4 | 175 | 175 | 175 |
| SRX372052 | 0 | 4543 | 4543 | 4543 |
| SRX372052 | 1 | 789 | 148 | 1051 |
| SRX372052 | 2 | 750 | 170 | 1040 |
| SRX372052 | 3 | 598 | 185 | 1011 |
| SRX372052 | 4 | 209 | 209 | 209 |
rs$n_controls <- as.factor(rs$n_controls)
ggplot(rs[rs$n_controls!=0,], aes(sample, mean, fill=n_controls)) +
geom_bar(position=position_dodge2(width=0.9, preserve="single"), stat="identity") +
geom_errorbar(aes(ymin=min, ymax=max, group=n_controls), width=.2,
position=position_dodge(.9)) +
theme_bw() +
xlab("") +
ylab("Mean genes with variants") +
scale_fill_brewer(palette = "Dark2") +
theme(legend.position = "bottom")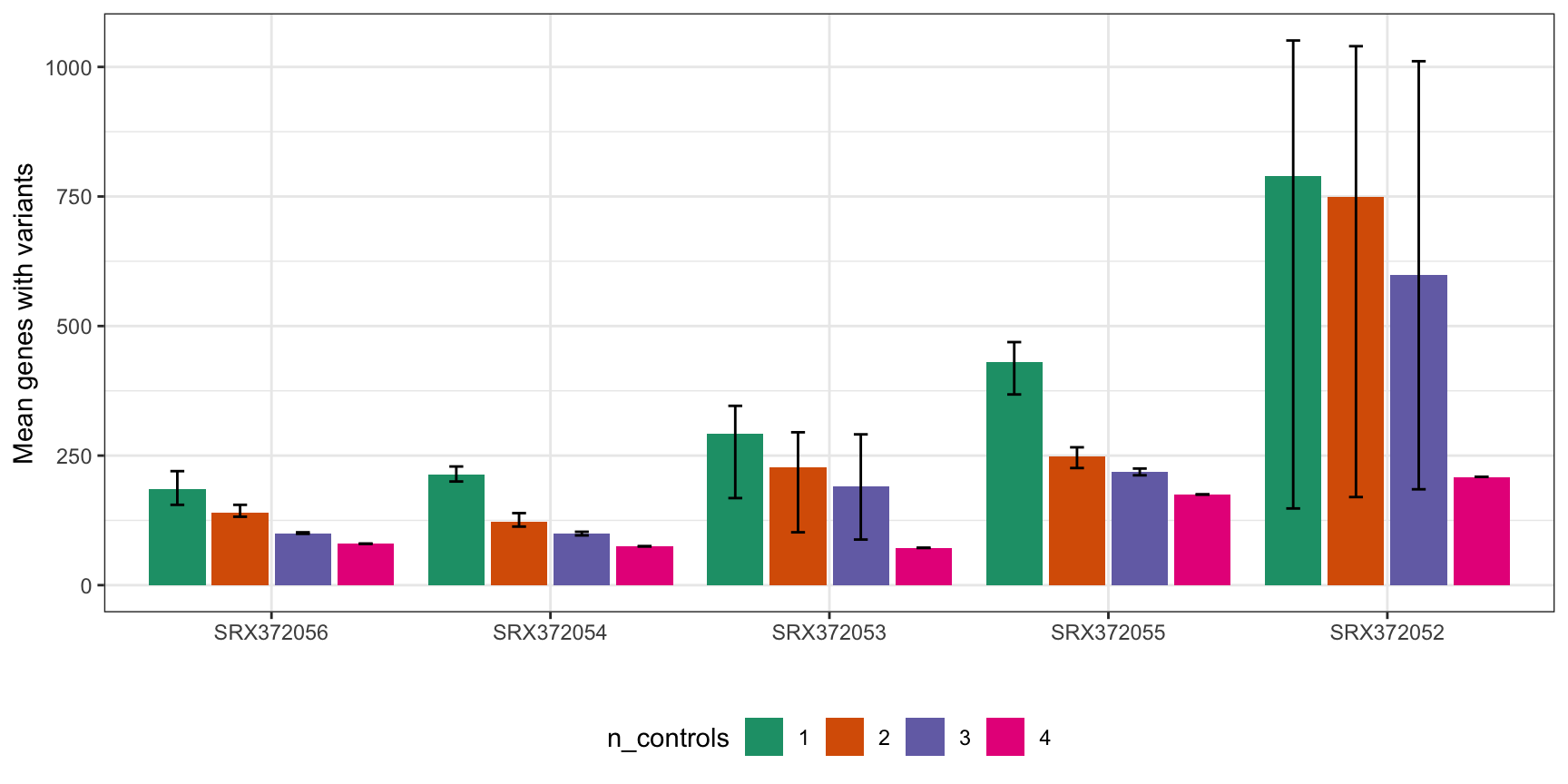
| Version | Author | Date |
|---|---|---|
| 4206f12 | Marek Cmero | 2021-04-30 |
sessionInfo()R version 4.0.3 (2020-10-10)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Catalina 10.15.7
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRblas.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.0/Resources/lib/libRlapack.dylib
locale:
[1] en_AU.UTF-8/en_AU.UTF-8/en_AU.UTF-8/C/en_AU.UTF-8/en_AU.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] gt_0.2.2 ggplot2_3.3.3 stringr_1.4.0 here_1.0.1
[5] dplyr_1.0.4 data.table_1.13.6 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] Rcpp_1.0.6 RColorBrewer_1.1-2 highr_0.8 pillar_1.4.7
[5] compiler_4.0.3 later_1.1.0.1 git2r_0.28.0 tools_4.0.3
[9] digest_0.6.27 checkmate_2.0.0 gtable_0.3.0 evaluate_0.14
[13] lifecycle_1.0.0 tibble_3.0.6 pkgconfig_2.0.3 rlang_0.4.10
[17] DBI_1.1.1 commonmark_1.7 yaml_2.2.1 xfun_0.21
[21] withr_2.4.1 knitr_1.31 sass_0.3.1 generics_0.1.0
[25] fs_1.5.0 vctrs_0.3.6 rprojroot_2.0.2 grid_4.0.3
[29] tidyselect_1.1.0 glue_1.4.2 R6_2.5.0 rmarkdown_2.6
[33] farver_2.0.3 purrr_0.3.4 magrittr_2.0.1 whisker_0.4
[37] backports_1.2.1 scales_1.1.1 promises_1.2.0.1 ellipsis_0.3.1
[41] htmltools_0.5.1.1 assertthat_0.2.1 colorspace_2.0-0 httpuv_1.5.5
[45] labeling_0.4.2 stringi_1.5.3 munsell_0.5.0 crayon_1.4.1