Nuclear fraction and nascent transcription
Briana Mittleman
5/15/2019
Last updated: 2019-06-13
Checks: 6 0
Knit directory: apaQTL/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.3.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20190411) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/.DS_Store
Ignored: output/.DS_Store
Untracked files:
Untracked: .Rprofile
Untracked: ._.DS_Store
Untracked: .gitignore
Untracked: _workflowr.yml
Untracked: analysis/._PASdescriptiveplots.Rmd
Untracked: analysis/._cuttoffPercUsage.Rmd
Untracked: analysis/QTLexampleplots.Rmd
Untracked: analysis/cuttoffPercUsage.Rmd
Untracked: analysis/eQTLoverlap.Rmd
Untracked: analysis/oldstuffNotNeeded.Rmd
Untracked: apaQTL.Rproj
Untracked: code/.NascentRNAdtPlotFirstintronicPAS.sh.swp
Untracked: code/._ApaQTL_nominalNonnorm.sh
Untracked: code/._BothFracDTPlotGeneRegions_normalized.sh
Untracked: code/._FC_NucintornUpandDown.sh
Untracked: code/._FC_UTR.sh
Untracked: code/._FC_intornUpandDownsteamPAS.sh
Untracked: code/._FC_newPeaks_olddata.sh
Untracked: code/._HMMpermuteTotal.py
Untracked: code/._HmmPermute.py
Untracked: code/._LC_samplegroups.py
Untracked: code/._NascentRNAdtPlot.sh
Untracked: code/._NascentRNAdtPlot3UTRPAS.sh
Untracked: code/._NascentRNAdtPlotExcludeFirstintronicPAS.sh
Untracked: code/._NascentRNAdtPlotNucPAS.sh
Untracked: code/._NascentRNAdtPlotTotPAS.sh
Untracked: code/._NascentRNAdtPlotintronicPAS.sh
Untracked: code/._NascnetRNAdtPlotPAS.sh
Untracked: code/._NetSeq_fourthintronDT.sh
Untracked: code/._QTL2bed.py
Untracked: code/._QTL2bed_withstrand.py
Untracked: code/._SnakefilePAS
Untracked: code/._SnakefilefiltPAS
Untracked: code/._TESplots100bp.sh
Untracked: code/._TESplots150bp.sh
Untracked: code/._TESplots200bp.sh
Untracked: code/._Untitled
Untracked: code/._ZipandTabPheno.sh
Untracked: code/._aAPAqtl_nominal39ind.sh
Untracked: code/._apaQTLCorrectPvalMakeQQ.R
Untracked: code/._apaQTL_Nominal.sh
Untracked: code/._apaQTL_permuted.sh
Untracked: code/._assignNucIntonpeak2intronlocs.sh
Untracked: code/._assignTotIntronpeak2intronlocs.sh
Untracked: code/._bam2BW_5primemost.sh
Untracked: code/._bed2saf.py
Untracked: code/._bothFracDTplot1stintron.sh
Untracked: code/._bothFracDTplot4thintron.sh
Untracked: code/._bothFrac_FC.sh
Untracked: code/._callPeaksYL.py
Untracked: code/._chooseAnno2SAF.py
Untracked: code/._chooseSignalSite
Untracked: code/._chooseSignalSite.py
Untracked: code/._cluster.json
Untracked: code/._clusterPAS.json
Untracked: code/._clusterfiltPAS.json
Untracked: code/._codingdms2bed.py
Untracked: code/._config.yaml
Untracked: code/._config2.yaml
Untracked: code/._configOLD.yaml
Untracked: code/._convertNominal2SNPLOC.py
Untracked: code/._convertNumeric.py
Untracked: code/._correctNomeqtl.R
Untracked: code/._dag.pdf
Untracked: code/._eQTLgenestestedapa.py
Untracked: code/._encodeRNADTplots.sh
Untracked: code/._extractGenotypes.py
Untracked: code/._extractseqfromqtlfastq.py
Untracked: code/._fc2leafphen.py
Untracked: code/._filter5perc.R
Untracked: code/._filter5percPheno.py
Untracked: code/._filterpeaks.py
Untracked: code/._finalPASbed2SAF.py
Untracked: code/._fix4su304corr.py
Untracked: code/._fix4su604corr.py
Untracked: code/._fix4sukalisto.py
Untracked: code/._fixExandUnexeQTL
Untracked: code/._fixExandUnexeQTL.py
Untracked: code/._fixFChead.py
Untracked: code/._fixFChead_bothfrac.py
Untracked: code/._fixH3k12ac.py
Untracked: code/._fixRNAhead4corr.py
Untracked: code/._fixRNAkalisto.py
Untracked: code/._fixgroupedtranscript.py
Untracked: code/._fixhead_netseqfc.py
Untracked: code/._getAPAfromanyeQTL.py
Untracked: code/._getApapval4eqtl.py
Untracked: code/._getApapval4eqtl_unexp.py
Untracked: code/._getDownstreamIntronNuclear.py
Untracked: code/._getIntronDownstreamPAS.py
Untracked: code/._getIntronUpstreamPAS.py
Untracked: code/._getQTLalleles.py
Untracked: code/._getQTLfastq.sh
Untracked: code/._getUpstreamIntronNuclear.py
Untracked: code/._grouptranscripts.py
Untracked: code/._keep5perMAF.py
Untracked: code/._keepSNP_vcf.sh
Untracked: code/._make5percPeakbed.py
Untracked: code/._makeFileID.py
Untracked: code/._makePheno.py
Untracked: code/._makeSAFbothfrac5perc.py
Untracked: code/._makeSNP2rsidfile.py
Untracked: code/._makeeQTLempirical_unexp.py
Untracked: code/._makeeQTLempiricaldist.py
Untracked: code/._makegencondeTSSfile.py
Untracked: code/._mergeAllBam.sh
Untracked: code/._mergeBW_norm.sh
Untracked: code/._mergeBamNascent.sh
Untracked: code/._mergeByFracBam.sh
Untracked: code/._mergePeaks.sh
Untracked: code/._mnase1stintron.sh
Untracked: code/._mnaseDT_fourthintron.sh
Untracked: code/._namePeaks.py
Untracked: code/._netseqDTplot1stIntron.sh
Untracked: code/._netseqFC.sh
Untracked: code/._peak2PAS.py
Untracked: code/._peakFC.sh
Untracked: code/._pheno2countonly.R
Untracked: code/._processYRIgen.py
Untracked: code/._qtlRegionseq.sh
Untracked: code/._qtlsPvalOppFrac.py
Untracked: code/._quantassign2parsedpeak.py
Untracked: code/._removeXfromHmm.py
Untracked: code/._removeloc_pheno.py
Untracked: code/._runCorrectNomEqtl.sh
Untracked: code/._runHMMpermuteAPAqtls.sh
Untracked: code/._runHMMpermuteeQTLS.sh
Untracked: code/._runMakeEmpiricaleQTL_unexp.sh
Untracked: code/._runMakeeQTLempirical.sh
Untracked: code/._run_getApaPval4eqtl.sh
Untracked: code/._run_getapafromeQTL.py
Untracked: code/._run_getapafromeQTL.sh
Untracked: code/._run_getapapval4eqtl_unexp.sh
Untracked: code/._run_leafcutterDiffIso.sh
Untracked: code/._run_sepUsagephen.sh
Untracked: code/._run_sepgenobychrom.sh
Untracked: code/._selectNominalPvalues.py
Untracked: code/._sepUsagePhen.py
Untracked: code/._sepgenobychrom.py
Untracked: code/._snakemakePAS.batch
Untracked: code/._snakemakefiltPAS.batch
Untracked: code/._submit-snakemakePAS.sh
Untracked: code/._submit-snakemakefiltPAS.sh
Untracked: code/._subsetApanoteGene.py
Untracked: code/._subsetUnexplainedeQTLs.py
Untracked: code/._subset_diffisopheno.py
Untracked: code/._subsetpermAPAwithGenelist.py
Untracked: code/._subtrachfiveprimeUTR.sh
Untracked: code/._subtractExons.sh
Untracked: code/._subtractfiveprimeUTR.sh
Untracked: code/._tabixSNPS.sh
Untracked: code/._utrdms2saf.py
Untracked: code/.snakemake/
Untracked: code/APAqtl_nominal.err
Untracked: code/APAqtl_nominal.out
Untracked: code/APAqtl_nominal_39.err
Untracked: code/APAqtl_nominal_39.out
Untracked: code/APAqtl_nominal_nonNorm.err
Untracked: code/APAqtl_nominal_nonNorm.out
Untracked: code/APAqtl_permuted.err
Untracked: code/APAqtl_permuted.out
Untracked: code/ApaQTL_nominalNonnorm.sh
Untracked: code/BothFracDTPlot1stintron.err
Untracked: code/BothFracDTPlot1stintron.out
Untracked: code/BothFracDTPlot4stintron.err
Untracked: code/BothFracDTPlot4stintron.out
Untracked: code/BothFracDTPlotGeneRegions.err
Untracked: code/BothFracDTPlotGeneRegions.out
Untracked: code/BothFracDTPlotGeneRegions_norm.err
Untracked: code/BothFracDTPlotGeneRegions_norm.out
Untracked: code/BothFracDTPlotGeneRegions_normalized.sh
Untracked: code/DistPAS2Sig.py
Untracked: code/EncodeRNADTPlotGeneRegions.err
Untracked: code/EncodeRNADTPlotGeneRegions.out
Untracked: code/FC_NucintornUpandDown.sh
Untracked: code/FC_NucintronPASupandDown.err
Untracked: code/FC_NucintronPASupandDown.out
Untracked: code/FC_UTR.err
Untracked: code/FC_UTR.out
Untracked: code/FC_UTR.sh
Untracked: code/FC_intornUpandDownsteamPAS.sh
Untracked: code/FC_intronPASupandDown.err
Untracked: code/FC_intronPASupandDown.out
Untracked: code/FC_newPAS_olddata.err
Untracked: code/FC_newPAS_olddata.out
Untracked: code/FC_newPeaks_olddata.sh
Untracked: code/HMMpermuteTotal.py
Untracked: code/HmmPermute.p
Untracked: code/HmmPermute.py
Untracked: code/LC_samplegroups.py
Untracked: code/NascentDTPlotGeneRegions.err
Untracked: code/NascentDTPlotGeneRegions.out
Untracked: code/NascentDTPlotPAS.err
Untracked: code/NascentDTPlotPAS.out
Untracked: code/NascentDTPlotPAS_3utr.err
Untracked: code/NascentDTPlotPAS_3utr.out
Untracked: code/NascentDTPlotPAS_firstintron.err
Untracked: code/NascentDTPlotPAS_firstintron.out
Untracked: code/NascentDTPlotPAS_intron.err
Untracked: code/NascentDTPlotPAS_intron.out
Untracked: code/NascentDTPlotPAS_nuc.err
Untracked: code/NascentDTPlotPAS_nuc.out
Untracked: code/NascentDTPlotPAS_tot.err
Untracked: code/NascentDTPlotPAS_tot.out
Untracked: code/NascentRNAdtPlot.sh
Untracked: code/NascentRNAdtPlot3UTRPAS.sh
Untracked: code/NascentRNAdtPlotExcludeFirstintronicPAS.sh
Untracked: code/NascentRNAdtPlotFirstintronicPAS.sh
Untracked: code/NascentRNAdtPlotNucPAS.sh
Untracked: code/NascentRNAdtPlotTotPAS.sh
Untracked: code/NascentRNAdtPlotintronicPAS.sh
Untracked: code/NascnetRNAdtPlotPAS.sh
Untracked: code/NetSeq_fourthintronDT.sh
Untracked: code/QTL2bed.py
Untracked: code/QTL2bed_withstrand.py
Untracked: code/README.md
Untracked: code/Rplots.pdf
Untracked: code/TESplots100bp.err
Untracked: code/TESplots100bp.out
Untracked: code/TESplots100bp.sh
Untracked: code/TESplots150bp.err
Untracked: code/TESplots150bp.out
Untracked: code/TESplots150bp.sh
Untracked: code/TESplots200bp.err
Untracked: code/TESplots200bp.out
Untracked: code/TESplots200bp.sh
Untracked: code/Untitled
Untracked: code/Upstream100Bases_general.py
Untracked: code/ZipandTabPheno.sh
Untracked: code/aAPAqtl_nominal39ind.sh
Untracked: code/apaQTLCorrectPvalMakeQQ_4pc.R
Untracked: code/apaQTL_Nominal_4pc.sh
Untracked: code/apaQTL_permuted.4pc.sh
Untracked: code/apafacetboxplots.R
Untracked: code/apaqtlfacetboxplots.R
Untracked: code/assignNucIntonpeak2intronlocs.sh
Untracked: code/assignPeak2Intronicregion.err
Untracked: code/assignPeak2Intronicregion.out
Untracked: code/assignTotIntronpeak2intronlocs.sh
Untracked: code/assigntotPeak2Intronicregion.err
Untracked: code/assigntotPeak2Intronicregion.out
Untracked: code/bam2BW_5primemost.sh
Untracked: code/bam2bw.err
Untracked: code/bam2bw.out
Untracked: code/bam2bw_5primemost.err
Untracked: code/bam2bw_5primemost.out
Untracked: code/bothFracDTplot1stintron.sh
Untracked: code/bothFracDTplot4thintron.sh
Untracked: code/bothFrac_FC.err
Untracked: code/bothFrac_FC.out
Untracked: code/bothFrac_FC.sh
Untracked: code/codingdms2bed.py
Untracked: code/convertNominal2SNPLOC.py
Untracked: code/correctNomeqtl.R
Untracked: code/dag.pdf
Untracked: code/dagPAS.pdf
Untracked: code/dagfiltPAS.pdf
Untracked: code/eQTLgenestestedapa.py
Untracked: code/encodeRNADTplots.sh
Untracked: code/extractGenotypes.py
Untracked: code/extractseqfromqtlfastq.py
Untracked: code/fc2leafphen.py
Untracked: code/finalPASbed2SAF.py
Untracked: code/findbuginpeaks.R
Untracked: code/fix4su304corr.py
Untracked: code/fix4su604corr.py
Untracked: code/fix4sukalisto.py
Untracked: code/fixExandUnexeQTL
Untracked: code/fixExandUnexeQTL.py
Untracked: code/fixFChead_bothfrac.py
Untracked: code/fixFChead_summary.py
Untracked: code/fixH3k12ac.py
Untracked: code/fixRNAhead4corr.py
Untracked: code/fixRNAkalisto.py
Untracked: code/fixgroupedtranscript.py
Untracked: code/fixhead_netseqfc.py
Untracked: code/genotypesYRI.gen.proc.keep.vcf.log
Untracked: code/genotypesYRI.gen.proc.keep.vcf.recode.vcf
Untracked: code/get100upPAS.py
Untracked: code/getAPAfromanyeQTL.py
Untracked: code/getApapval4eqtl.py
Untracked: code/getApapval4eqtl_unexp.py
Untracked: code/getDownstreamIntronNuclear.py
Untracked: code/getIntronDownstreamPAS.py
Untracked: code/getIntronUpstreamPAS.py
Untracked: code/getQTLalleles.py
Untracked: code/getQTLfastq.sh
Untracked: code/getSeq100up.sh
Untracked: code/getUpstreamIntronNuclear.py
Untracked: code/getseq100up.err
Untracked: code/getseq100up.out
Untracked: code/grouptranscripts.err
Untracked: code/grouptranscripts.out
Untracked: code/grouptranscripts.py
Untracked: code/keep5perMAF.py
Untracked: code/keepSNP_vcf.sh
Untracked: code/log/
Untracked: code/makeSAFbothfrac5perc.py
Untracked: code/makeSNP2rsidfile.py
Untracked: code/makeeQTLempirical_unexp.py
Untracked: code/makeeQTLempiricaldist.py
Untracked: code/makegencondeTSSfile.py
Untracked: code/mergeBW_norm.sh
Untracked: code/mergeBWnorm.err
Untracked: code/mergeBWnorm.out
Untracked: code/mergeBamNacent.err
Untracked: code/mergeBamNacent.out
Untracked: code/mergeBamNascent.sh
Untracked: code/mnase1stintron.sh
Untracked: code/mnaseDTPlot1stintron.err
Untracked: code/mnaseDTPlot1stintron.out
Untracked: code/mnaseDTPlot4thintron.err
Untracked: code/mnaseDTPlot4thintron.out
Untracked: code/mnaseDT_fourthintron.sh
Untracked: code/netDTPlot4thintron.out
Untracked: code/netseqDTplot1stIntron.sh
Untracked: code/netseqFC.err
Untracked: code/netseqFC.out
Untracked: code/netseqFC.sh
Untracked: code/neyDTPlot4thintron.err
Untracked: code/processYRIgen.py
Untracked: code/qtlFacetBoxplots.err
Untracked: code/qtlFacetBoxplots.out
Untracked: code/qtlRegionseq.sh
Untracked: code/qtlsPvalOppFrac.py
Untracked: code/removeXfromHmm.py
Untracked: code/removeloc_pheno.py
Untracked: code/runCorrectNomEqtl.sh
Untracked: code/runCorrectNomeqtl.err
Untracked: code/runCorrectNomeqtl.out
Untracked: code/runHMMpermute.err
Untracked: code/runHMMpermute.out
Untracked: code/runHMMpermuteAPAqtls.sh
Untracked: code/runHMMpermuteeQTLS.sh
Untracked: code/runHMMpermuteeQTLs.err
Untracked: code/runHMMpermuteeQTLs.out
Untracked: code/runMakeEmpiricaleQTL_unexp.sh
Untracked: code/runMakeEmpiricaleQTLs.err
Untracked: code/runMakeEmpiricaleQTLs.out
Untracked: code/runMakeEmpiricaleQTLsunex.err
Untracked: code/runMakeEmpiricaleQTLsunex.out
Untracked: code/runMakeeQTLempirical.sh
Untracked: code/run_DistPAS2Sig.err
Untracked: code/run_DistPAS2Sig.out
Untracked: code/run_distPAS2Sig.sh
Untracked: code/run_getAPAfromanyeQTL.err
Untracked: code/run_getAPAfromanyeQTL.out
Untracked: code/run_getApaPval4eQTLs.err
Untracked: code/run_getApaPval4eQTLs.out
Untracked: code/run_getApaPval4eQTLsunexplained.err
Untracked: code/run_getApaPval4eQTLsunexplained.out
Untracked: code/run_getApaPval4eqtl.sh
Untracked: code/run_getapafromeQTL.sh
Untracked: code/run_getapapval4eqtl_unexp.sh
Untracked: code/run_leafcutterDiffIso.sh
Untracked: code/run_leafcutter_ds.err
Untracked: code/run_leafcutter_ds.out
Untracked: code/run_qtlFacetBoxplots.sh
Untracked: code/run_sepUsagephen.sh
Untracked: code/run_sepgenobychrom.err
Untracked: code/run_sepgenobychrom.out
Untracked: code/run_sepgenobychrom.sh
Untracked: code/run_sepusage.err
Untracked: code/run_sepusage.out
Untracked: code/selectNominalPvalues.py
Untracked: code/sepUsagePhen.py
Untracked: code/sepgenobychrom.py
Untracked: code/seqQTLfastq.err
Untracked: code/seqQTLfastq.out
Untracked: code/seqQTLregion.err
Untracked: code/seqQTLregion.out
Untracked: code/snakePASlog.out
Untracked: code/snakefiltPASlog.out
Untracked: code/subsetApanoteGene.py
Untracked: code/subsetUnexplainedeQTLs.py
Untracked: code/subset_diffisopheno.py
Untracked: code/subsetpermAPAwithGenelist.py
Untracked: code/subtract5UTR.err
Untracked: code/subtract5UTR.out
Untracked: code/subtractExons.err
Untracked: code/subtractExons.out
Untracked: code/subtractExons.sh
Untracked: code/subtractfiveprimeUTR.sh
Untracked: code/tabixSNPS.sh
Untracked: code/tabixSNPs.err
Untracked: code/tabixSNPs.out
Untracked: code/transcriptdm2bed.py
Untracked: code/utrdms2saf.py
Untracked: code/vcf_keepsnps.err
Untracked: code/vcf_keepsnps.out
Untracked: code/zipandtabPhen.err
Untracked: code/zipandtabPhen.out
Untracked: data/._.DS_Store
Untracked: data/ApaByEgene/
Untracked: data/CompareOldandNew/
Untracked: data/DTmatrix/
Untracked: data/DiffIso/
Untracked: data/EncodeRNA/
Untracked: data/ExampleQTLPlots/
Untracked: data/GeuvadisRNA/
Untracked: data/HMMqtls/
Untracked: data/Li_eQTLs/
Untracked: data/NascentRNA/
Untracked: data/PAS/
Untracked: data/QTLGenotypes/
Untracked: data/QTLoverlap/
Untracked: data/QTLoverlap_nonNorm/
Untracked: data/README.md
Untracked: data/RNAseq/
Untracked: data/Reads2UTR/
Untracked: data/SignalSiteFiles/
Untracked: data/ThirtyNineIndQtl_nominal/
Untracked: data/apaQTLNominal/
Untracked: data/apaQTLNominal_4pc/
Untracked: data/apaQTLPermuted/
Untracked: data/apaQTLPermuted_4pc/
Untracked: data/apaQTLs/
Untracked: data/assignedPeaks/
Untracked: data/bam/
Untracked: data/bam_clean/
Untracked: data/bam_waspfilt/
Untracked: data/bed_10up/
Untracked: data/bed_clean/
Untracked: data/bed_clean_sort/
Untracked: data/bed_waspfilter/
Untracked: data/bedsort_waspfilter/
Untracked: data/bothFrac_FC/
Untracked: data/bw_norm/
Untracked: data/eQTLs/
Untracked: data/exampleQTLs/
Untracked: data/fastq/
Untracked: data/filterPeaks/
Untracked: data/fourSU/
Untracked: data/h3k27ac/
Untracked: data/highdiffsiggenes.txt
Untracked: data/inclusivePeaks/
Untracked: data/inclusivePeaks_FC/
Untracked: data/intronRNAratio/
Untracked: data/intron_analysis/
Untracked: data/mergedBG/
Untracked: data/mergedBW_byfrac/
Untracked: data/mergedBW_norm/
Untracked: data/mergedBam/
Untracked: data/mergedbyFracBam/
Untracked: data/motifdistrupt/
Untracked: data/netseq/
Untracked: data/nonNorm_pheno/
Untracked: data/nuc_10up/
Untracked: data/nuc_10upclean/
Untracked: data/overlapeQTL_try2/
Untracked: data/overlapeQTLs/
Untracked: data/peakCoverage/
Untracked: data/peaks_5perc/
Untracked: data/phenotype/
Untracked: data/phenotype_5perc/
Untracked: data/sigDiffGenes.txt
Untracked: data/sort/
Untracked: data/sort_clean/
Untracked: data/sort_waspfilter/
Untracked: nohup.out
Untracked: output/._.DS_Store
Untracked: output/._meanCorrelationPhenotypes.svg
Untracked: output/dtPlots/
Untracked: output/fastqc/
Untracked: output/meanCorrelationPhenotypes.svg
Unstaged changes:
Modified: analysis/Readdistagainstfeatures.Rmd
Modified: analysis/index.Rmd
Modified: analysis/nucintronicanalysis.Rmd
Modified: analysis/overlapapaqtlsandeqtls.Rmd
Modified: code/BothFracDTPlotGeneRegions.sh
Modified: code/Snakefile
Deleted: code/Upstream10Bases_general.py
Modified: code/apaQTLCorrectPvalMakeQQ.R
Modified: code/apaQTL_Nominal.sh
Modified: code/apaQTL_permuted.sh
Modified: code/apaQTLsnake.err
Modified: code/bam2bw.sh
Modified: code/bed2saf.py
Modified: code/cluster.json
Modified: code/clusterfiltPAS.json
Modified: code/config.yaml
Modified: code/environment.yaml
Modified: code/makePheno.py
Deleted: code/test.txt
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 5ea9c06 | brimittleman | 2019-06-13 | fix bug |
| html | 7aeba54 | brimittleman | 2019-05-17 | Build site. |
| Rmd | 78b53a1 | brimittleman | 2019-05-17 | add full apa by loc |
| html | a295d27 | brimittleman | 2019-05-16 | Build site. |
| Rmd | 75f4567 | brimittleman | 2019-05-16 | add total intron/all |
| html | 460e1fb | brimittleman | 2019-05-16 | Build site. |
| Rmd | 1df3fe1 | brimittleman | 2019-05-16 | seperate fractions by locations |
| html | 81a3e16 | brimittleman | 2019-05-15 | Build site. |
| Rmd | f484dcd | brimittleman | 2019-05-15 | add nascent transcription plot |
library(reshape2)
library(workflowr)This is workflowr version 1.3.0
Run ?workflowr for help getting startedlibrary(tidyverse)── Attaching packages ─────────────────────────────────────────────────────────────── tidyverse 1.2.1 ──✔ ggplot2 3.1.1 ✔ purrr 0.3.2
✔ tibble 2.1.1 ✔ dplyr 0.8.0.1
✔ tidyr 0.8.3 ✔ stringr 1.3.1
✔ readr 1.3.1 ✔ forcats 0.3.0 ── Conflicts ────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()library(viridis)Loading required package: viridisLiteGene name switch file:
geneNames=read.table("../../genome_anotation_data/ensemble_to_genename.txt", sep="\t", col.names = c('gene_id', 'GeneName', 'source' ),stringsAsFactors = F)Create transcription phenotype
4su data
FourSU=read.table(file = "../data/fourSU//tr_decay_table_norm.txt", header=T, stringsAsFactors = F) %>% dplyr::select(gene_id,contains("4su_30"))
FourSU_geneNames=FourSU %>% inner_join(geneNames, by="gene_id") %>% dplyr::select(GeneName, contains("4su_30"))
FourgeneNames_long=melt(FourSU_geneNames,id.vars = "GeneName", value.name = "FourSU", variable.name = "FourSU_ind") %>% separate(FourSU_ind, into=c("type","time", "1400", "MAf", "Individual"), sep="_") %>% dplyr::select(GeneName, Individual, FourSU)
FourSU_geneMean=FourgeneNames_long %>% group_by(GeneName) %>%summarise(Mean_4su=mean(FourSU))rna seq
RNA=read.table(file = "../data/fourSU/tr_decay_table_norm.txt", header=T, stringsAsFactors = F) %>% dplyr::select(gene_id,contains("RNAseq_14000"))
RNA_geneNames=RNA %>% inner_join(geneNames, by="gene_id") %>% dplyr::select(GeneName, contains("RNA"))
RNAgeneNames_long=melt(RNA_geneNames,id.vars = "GeneName", value.name = "RNA", variable.name = "RNA_ind") %>% separate(RNA_ind, into=c("type", "1400", "MAf", "Individual"), sep="_") %>% dplyr::select(GeneName, Individual, RNA)
RNA_geneMean=RNAgeneNames_long %>% group_by(GeneName) %>%summarise(Mean_RNA=mean(RNA))Make transcription phenotype
Transcription=FourSU_geneMean %>% inner_join(RNA_geneMean, by="GeneName") %>% mutate(Transcription=Mean_4su/(Mean_4su + Mean_RNA)) %>% dplyr::select(GeneName, Transcription) %>% dplyr::rename("gene"=GeneName)
Transcription2=FourSU_geneMean %>% inner_join(RNA_geneMean, by="GeneName") %>% mutate(Transcription=Mean_4su/Mean_RNA) %>% dplyr::select(GeneName, Transcription) %>% dplyr::rename("gene"=GeneName)APA phenotype
5 perc apa
peaknumlist=read.table("../data/peaks_5perc/APApeak_Peaks_GeneLocAnno.5perc.bed", stringsAsFactors = F, header=F, col.names = c("chr", "start","end", "id", "score", "strand")) %>% separate(id, into=c("peaknum", "geneid"), sep=":") %>% mutate(peakid=paste("peak", peaknum,sep=""))Restrict to genes with large diff between file:
sig_genes=read.table(file="../data/highdiffsiggenes.txt",col.names = "gene",stringsAsFactors = F)Nuclear apa
NucAPA=read.table("../data/peakCoverage/APAPeaks.ALLChrom.Filtered.Named.GeneLocAnnoPARSED.Nuclear.Quant.Fixed.fc", stringsAsFactors = F, header = T) %>% dplyr::select(-Chr, -Start, -End, -Strand, -Length) %>% separate(Geneid, into=c("peakid","chrom", "start", "end", "strand", "geneID"),sep=":") %>% semi_join(peaknumlist, by="peakid") %>% separate(geneID, into=c("gene", "loc"), sep="_") %>% dplyr::select(-chrom , -start, -end, -strand, -loc) %>% semi_join(sig_genes, by="gene")
NucApaMelt=melt(NucAPA, id.vars =c( "peakid", "gene"), value.name="count", variable.name="Ind") %>% separate(Ind, into=c('Individual', 'fraction') ,sep="_")%>% dplyr::select(peakid, gene, Individual, count)
NucAPA_bygene= NucApaMelt %>% group_by(gene,Individual) %>% summarise(NuclearSum=sum(count))total apa
TotAPA=read.table("../data/peakCoverage/APAPeaks.ALLChrom.Filtered.Named.GeneLocAnnoPARSED.Total.Quant.Fixed.fc", stringsAsFactors = F, header = T) %>% dplyr::select(-Chr, -Start, -End, -Strand, -Length) %>% separate(Geneid, into=c("peakid","chrom", "start", "end", "strand", "geneID"),sep=":") %>% semi_join(peaknumlist, by="peakid") %>% separate(geneID, into=c("gene", "loc"), sep="_") %>% dplyr::select(-chrom , -start, -end, -strand, -loc) %>% semi_join(sig_genes, by="gene")
TotApaMelt=melt(TotAPA, id.vars =c( "peakid", "gene"), value.name="count", variable.name="Ind") %>% separate(Ind, into=c('Individual', 'fraction') ,sep="_")%>% dplyr::select(peakid, gene, Individual, count)
TotAPA_bygene= TotApaMelt %>% group_by(gene,Individual) %>% summarise(TotalSum=sum(count))Sum together:
ApaBothFrac=TotAPA_bygene %>% inner_join(NucAPA_bygene, by=c("gene", "Individual"))
ApaBothFrac_melt=melt(ApaBothFrac, id.vars=c("gene", "Individual"),value.name="APA_val" ) %>% mutate(fraction=ifelse(variable=="TotalSum", "total", "nuclear"), line=paste("NA", substring(Individual, 2), sep="")) %>% dplyr::select(gene, fraction, line, APA_val)Normalize with meta data info:
metadata=read.table("../data/MetaDataSequencing.txt", header = T,stringsAsFactors = F) %>% dplyr::select(line, fraction, Mapped_noMP)
metadata$line= as.character(metadata$line)
ApaBothFracStand=ApaBothFrac_melt %>% full_join(metadata, by=c("line", "fraction")) %>% mutate(StandApa=APA_val/Mapped_noMP)
ApaBothFracStand_geneMean=ApaBothFracStand %>% group_by(fraction, gene) %>% summarise(meanAPA=mean(StandApa, na.rm=T))
ApaBothFracStand_geneMean_spread= spread(ApaBothFracStand_geneMean,fraction,meanAPA ) %>% mutate(APAVal=nuclear/(total+ nuclear)) Join data and plot
Density function:
get_density <- function(x, y, ...) {
dens <- MASS::kde2d(x, y, ...)
ix <- findInterval(x, dens$x)
iy <- findInterval(y, dens$y)
ii <- cbind(ix, iy)
return(dens$z[ii])
}
set.seed(1)
dat <- data.frame(
x = c(
rnorm(1e4, mean = 0, sd = 0.1),
rnorm(1e3, mean = 0, sd = 0.1)
),
y = c(
rnorm(1e4, mean = 0, sd = 0.1),
rnorm(1e3, mean = 0.1, sd = 0.2)
)
)Joing apa and transcription
APAandTranscrption= Transcription %>% inner_join(ApaBothFracStand_geneMean_spread, by="gene")
APAandTranscrption$density <- get_density(APAandTranscrption$APAVal, APAandTranscrption$Transcription, n = 100)
summary(lm(data=APAandTranscrption, APAVal~Transcription))
Call:
lm(formula = APAVal ~ Transcription, data = APAandTranscrption)
Residuals:
Min 1Q Median 3Q Max
-0.33795 -0.08278 0.00284 0.08772 0.30261
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.46672 0.01894 24.641 < 2e-16 ***
Transcription 0.16317 0.03465 4.709 2.88e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1153 on 917 degrees of freedom
Multiple R-squared: 0.02361, Adjusted R-squared: 0.02254
F-statistic: 22.17 on 1 and 917 DF, p-value: 2.877e-06Plot:
ggplot(APAandTranscrption, aes(x=Transcription, y=APAVal))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="4su/4su+RNA", y="Nuclear/Nuclear+Total", title="Relationship between APA fraction and transcription") + scale_color_viridis()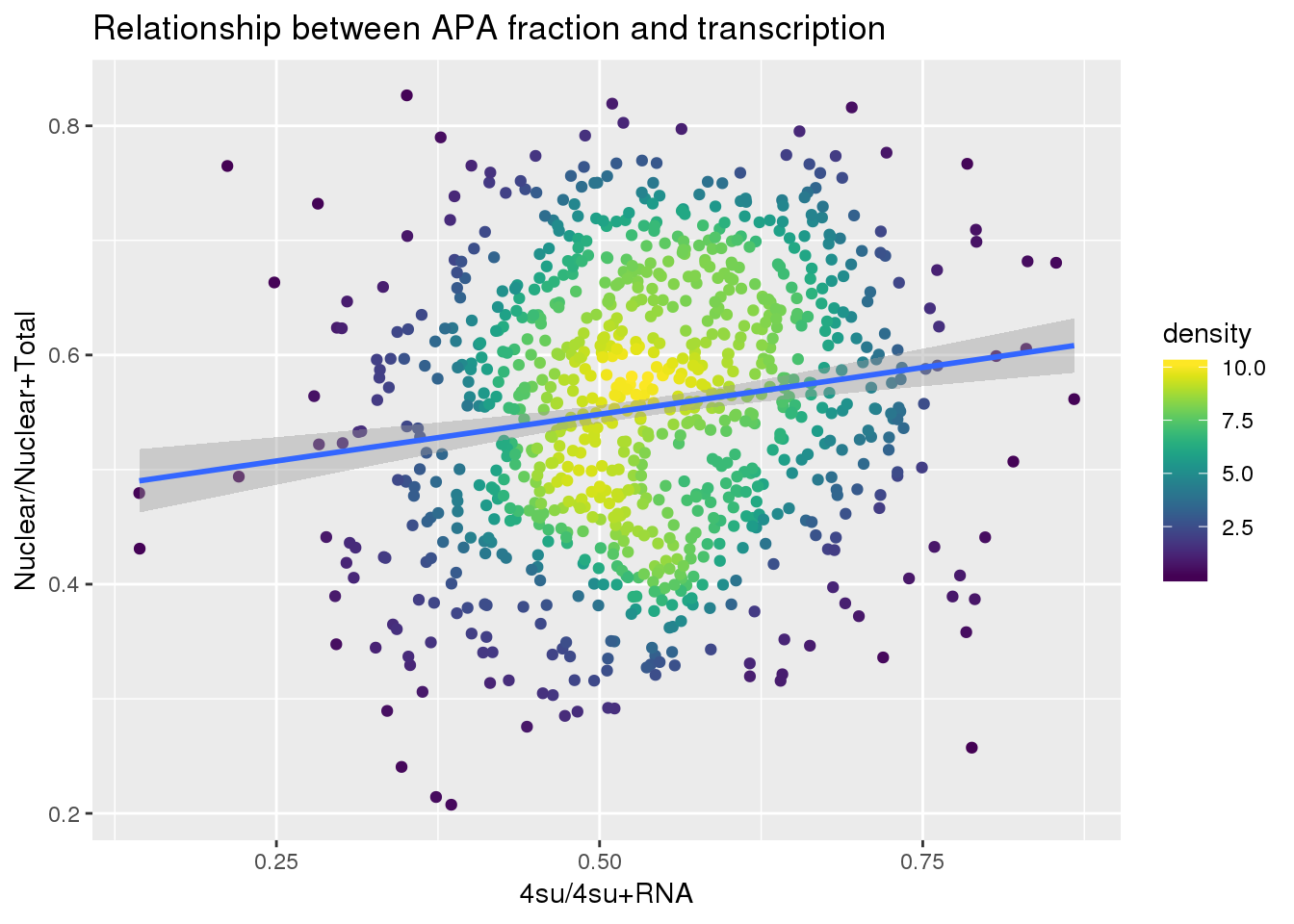
Split Nuclear by intronic
Nuclear intronic:
I will have to change the gene names for the 3’ info:
NucAPAIntron=read.table("../data/peakCoverage/APAPeaks.ALLChrom.Filtered.Named.GeneLocAnnoPARSED.Nuclear.Quant.Fixed.fc", stringsAsFactors = F, header = T) %>% dplyr::select(-Chr, -Start, -End, -Strand, -Length) %>% separate(Geneid, into=c("peakid","chrom", "start", "end", "strand", "geneID"),sep=":") %>% semi_join(peaknumlist, by="peakid") %>% separate(geneID, into=c("gene", "loc"), sep="_") %>% filter(loc=="intron")%>% dplyr::select(-chrom , -start, -end, -strand, -loc)
NucApaIntronMelt=melt(NucAPAIntron, id.vars =c( "peakid", "gene"), value.name="count", variable.name="Ind") %>% separate(Ind, into=c('Individual', 'fraction') ,sep="_")%>% dplyr::select(peakid, gene, Individual, count)
NucAPAIntron_bygene= NucApaIntronMelt %>% group_by(gene,Individual) %>% summarise(NuclearIntronSum=sum(count))Total UTR
TotUTRAPA=read.table("../data/peakCoverage/APAPeaks.ALLChrom.Filtered.Named.GeneLocAnnoPARSED.Total.Quant.Fixed.fc", stringsAsFactors = F, header = T) %>% dplyr::select(-Chr, -Start, -End, -Strand, -Length) %>% separate(Geneid, into=c("peakid","chrom", "start", "end", "strand", "geneID"),sep=":") %>% semi_join(peaknumlist, by="peakid") %>% separate(geneID, into=c("gene", "loc"), sep="_") %>%filter(loc=="utr3") %>% dplyr::select(-chrom , -start, -end, -strand, -loc)
TotApaUTRMelt=melt(TotUTRAPA, id.vars =c( "peakid", "gene"), value.name="count", variable.name="Ind") %>% separate(Ind, into=c('Individual', 'fraction') ,sep="_")%>% dplyr::select(peakid, gene, Individual, count)
TotAPAUTR_bygene= TotApaUTRMelt %>% group_by(gene,Individual) %>% summarise(TotalUTRSum=sum(count))ApaBothFracLoc=TotAPAUTR_bygene %>% inner_join(NucAPAIntron_bygene, by=c("gene", "Individual"))
ApaBothFracLoc_melt=melt(ApaBothFracLoc, id.vars=c("gene", "Individual"),value.name="APA_val" ) %>% mutate(fraction=ifelse(variable=="TotalUTRSum", "total", "nuclear"), line=paste("NA", substring(Individual, 2), sep="")) %>% dplyr::select(gene, fraction, line, APA_val)
ApaBothFracLocStand=ApaBothFracLoc_melt %>% full_join(metadata, by=c("line", "fraction")) %>% mutate(StandApa=APA_val/Mapped_noMP)
ApaBothFracLocStand_geneMean=ApaBothFracLocStand %>% group_by(fraction, gene) %>% summarise(meanAPA=mean(StandApa, na.rm=T))
ApaBothFracLocStand_geneMean_spread= spread(ApaBothFracLocStand_geneMean,fraction,meanAPA ) %>% mutate(APAValLoc=nuclear/(total+nuclear))
ApaBothFracLocStand_geneMean_spread2= spread(ApaBothFracLocStand_geneMean,fraction,meanAPA ) %>% mutate(APAValLoc=nuclear/total) Join this with the transcription info:
APAlocationandTranscrption= Transcription %>% inner_join(ApaBothFracLocStand_geneMean_spread, by="gene")
APAlocationandTranscrption$density <- get_density(APAlocationandTranscrption$APAValLoc, APAlocationandTranscrption$Transcription, n = 100)ggplot(APAlocationandTranscrption, aes(x=Transcription, y=APAValLoc))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="4su/4su+RNA", y="NuclearIntron/TotalUTR + IntronNuclear", title="Relationship between APA fraction and transcription") + scale_color_viridis()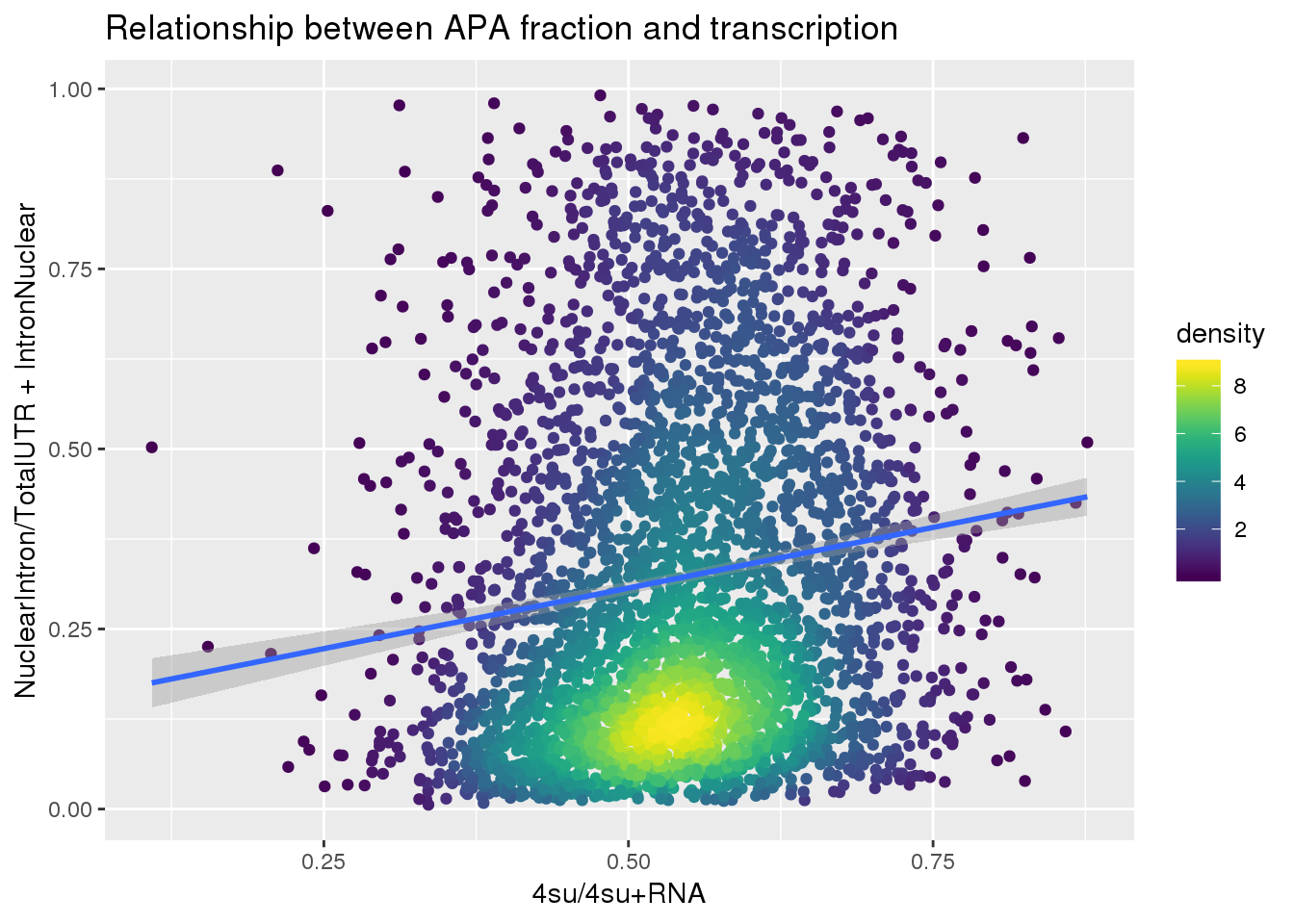
summary(lm(data=APAlocationandTranscrption, APAValLoc~Transcription))
Call:
lm(formula = APAValLoc ~ Transcription, data = APAlocationandTranscrption)
Residuals:
Min 1Q Median 3Q Max
-0.37748 -0.19928 -0.06962 0.15961 0.73348
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.13859 0.02161 6.414 1.6e-10 ***
Transcription 0.33661 0.03889 8.656 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2425 on 3618 degrees of freedom
Multiple R-squared: 0.02029, Adjusted R-squared: 0.02002
F-statistic: 74.93 on 1 and 3618 DF, p-value: < 2.2e-16Just the ratio:
APAlocationandTranscrption2= Transcription2 %>% inner_join(ApaBothFracLocStand_geneMean_spread2, by="gene")
APAlocationandTranscrption2$density <- get_density(APAlocationandTranscrption2$APAValLoc, APAlocationandTranscrption2$Transcription, n = 100)
summary(lm(data=APAlocationandTranscrption2, log10(APAValLoc)~log10(Transcription)))
Call:
lm(formula = log10(APAValLoc) ~ log10(Transcription), data = APAlocationandTranscrption2)
Residuals:
Min 1Q Median 3Q Max
-1.59020 -0.44292 -0.04325 0.39823 2.53804
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.47676 0.01104 -43.202 <2e-16 ***
log10(Transcription) 0.51566 0.05285 9.756 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.608 on 3618 degrees of freedom
Multiple R-squared: 0.02563, Adjusted R-squared: 0.02536
F-statistic: 95.18 on 1 and 3618 DF, p-value: < 2.2e-16ggplot(APAlocationandTranscrption2, aes(x=log10(Transcription), y=log10(APAValLoc)))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="log10(4su/RNA)", y="log10(NuclearIntron/TotalUTR)", title="Relationship between APA fraction and transcription") + scale_color_viridis()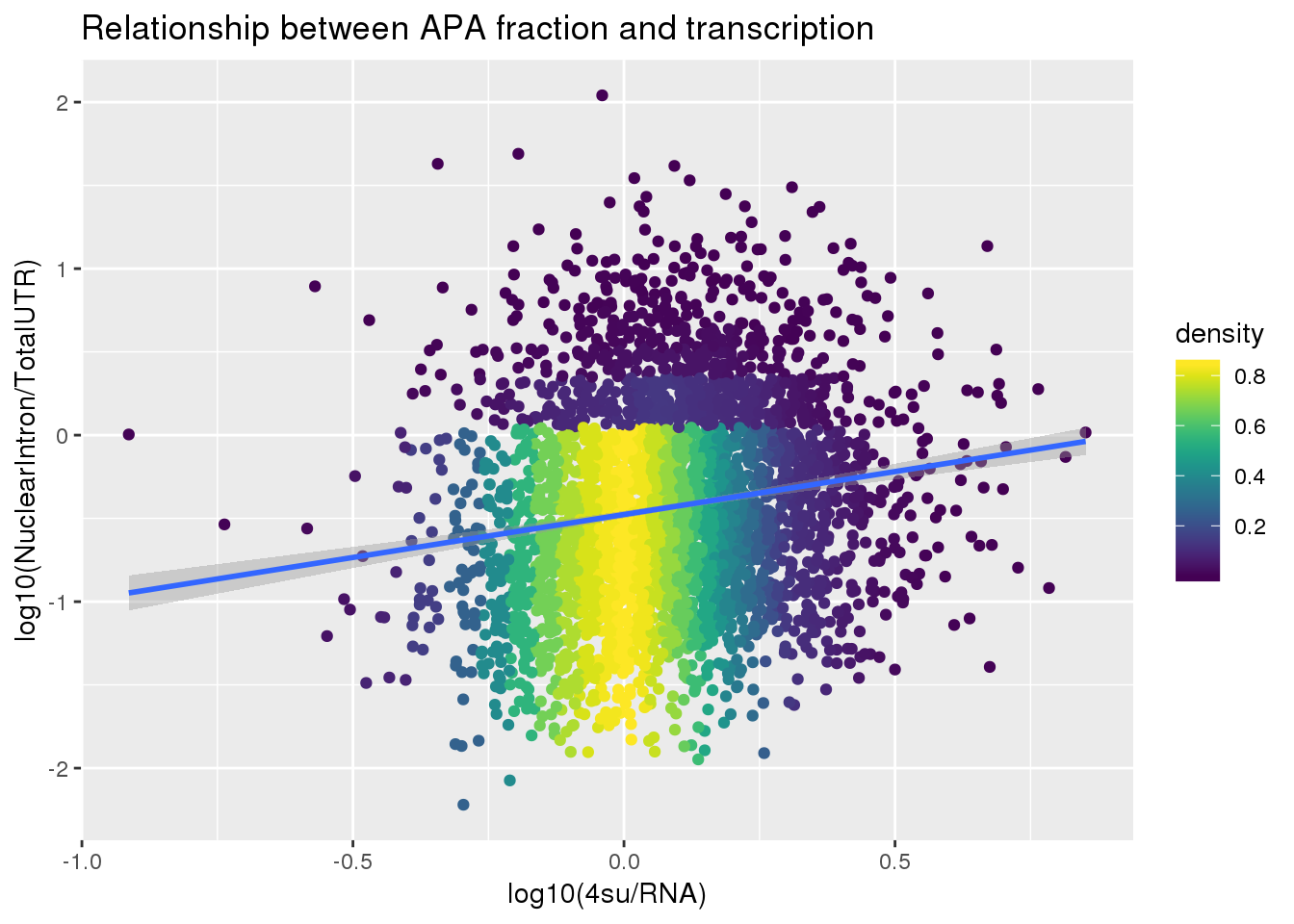
Compare nuclear and total UTR
NucAPAUTR=read.table("../data/peakCoverage/APAPeaks.ALLChrom.Filtered.Named.GeneLocAnnoPARSED.Nuclear.Quant.Fixed.fc", stringsAsFactors = F, header = T) %>% dplyr::select(-Chr, -Start, -End, -Strand, -Length) %>% separate(Geneid, into=c("peakid","chrom", "start", "end", "strand", "geneID"),sep=":") %>% semi_join(peaknumlist, by="peakid") %>% separate(geneID, into=c("gene", "loc"), sep="_") %>% filter(loc=="utr3")%>% dplyr::select(-chrom , -start, -end, -strand, -loc)
NucAPAUTRMelt=melt(NucAPAUTR, id.vars =c( "peakid", "gene"), value.name="count", variable.name="Ind") %>% separate(Ind, into=c('Individual', 'fraction') ,sep="_")%>% dplyr::select(peakid, gene, Individual, count)
NucAPAUTR_bygene= NucAPAUTRMelt %>% group_by(gene,Individual) %>% summarise(NuclearUTRSum=sum(count))ApaBothFracUTR=TotAPAUTR_bygene %>% inner_join(NucAPAUTR_bygene, by=c("gene", "Individual"))
ApaBothFracUTR_melt=melt(ApaBothFracUTR, id.vars=c("gene", "Individual"),value.name="APA_val" ) %>% mutate(fraction=ifelse(variable=="TotalUTRSum", "total", "nuclear"), line=paste("NA", substring(Individual, 2), sep="")) %>% dplyr::select(gene, fraction, line, APA_val)
ApaBothFracUTRStand=ApaBothFracUTR_melt %>% full_join(metadata, by=c("line", "fraction")) %>% mutate(StandApa=APA_val/Mapped_noMP)
ApaBothFracUTRStand_geneMean=ApaBothFracUTRStand %>% group_by(fraction, gene) %>% summarise(meanAPA=mean(StandApa, na.rm=T))
ApaBothFracUTRStand_geneMean_spread= spread(ApaBothFracUTRStand_geneMean,fraction,meanAPA ) %>% mutate(APAValLoc=nuclear/total)
ApaBothFracUTRStand_geneMean_spread2= spread(ApaBothFracUTRStand_geneMean,fraction,meanAPA ) %>% mutate(APAValLoc=nuclear/(total+nuclear))THis is nuclear vs total only looking at teh UTR:
APAUTRandTranscrption= Transcription %>% inner_join(ApaBothFracUTRStand_geneMean_spread, by="gene")
APAUTRandTranscrption$density <- get_density(APAUTRandTranscrption$APAValLoc, APAUTRandTranscrption$Transcription, n = 100)
summary(lm(data=APAUTRandTranscrption, log10(APAValLoc)~log10(Transcription)))
Call:
lm(formula = log10(APAValLoc) ~ log10(Transcription), data = APAUTRandTranscrption)
Residuals:
Min 1Q Median 3Q Max
-0.69129 -0.18916 -0.00344 0.19699 0.90698
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.153728 0.008935 17.20 <2e-16 ***
log10(Transcription) 0.481833 0.029049 16.59 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2526 on 7709 degrees of freedom
Multiple R-squared: 0.03446, Adjusted R-squared: 0.03433
F-statistic: 275.1 on 1 and 7709 DF, p-value: < 2.2e-16ggplot(APAUTRandTranscrption, aes(x=Transcription, y=APAValLoc))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="4su/RNA", y="NuclearUTR/TotalUTR", title="Relationship between APA fraction and transcription") + scale_color_viridis()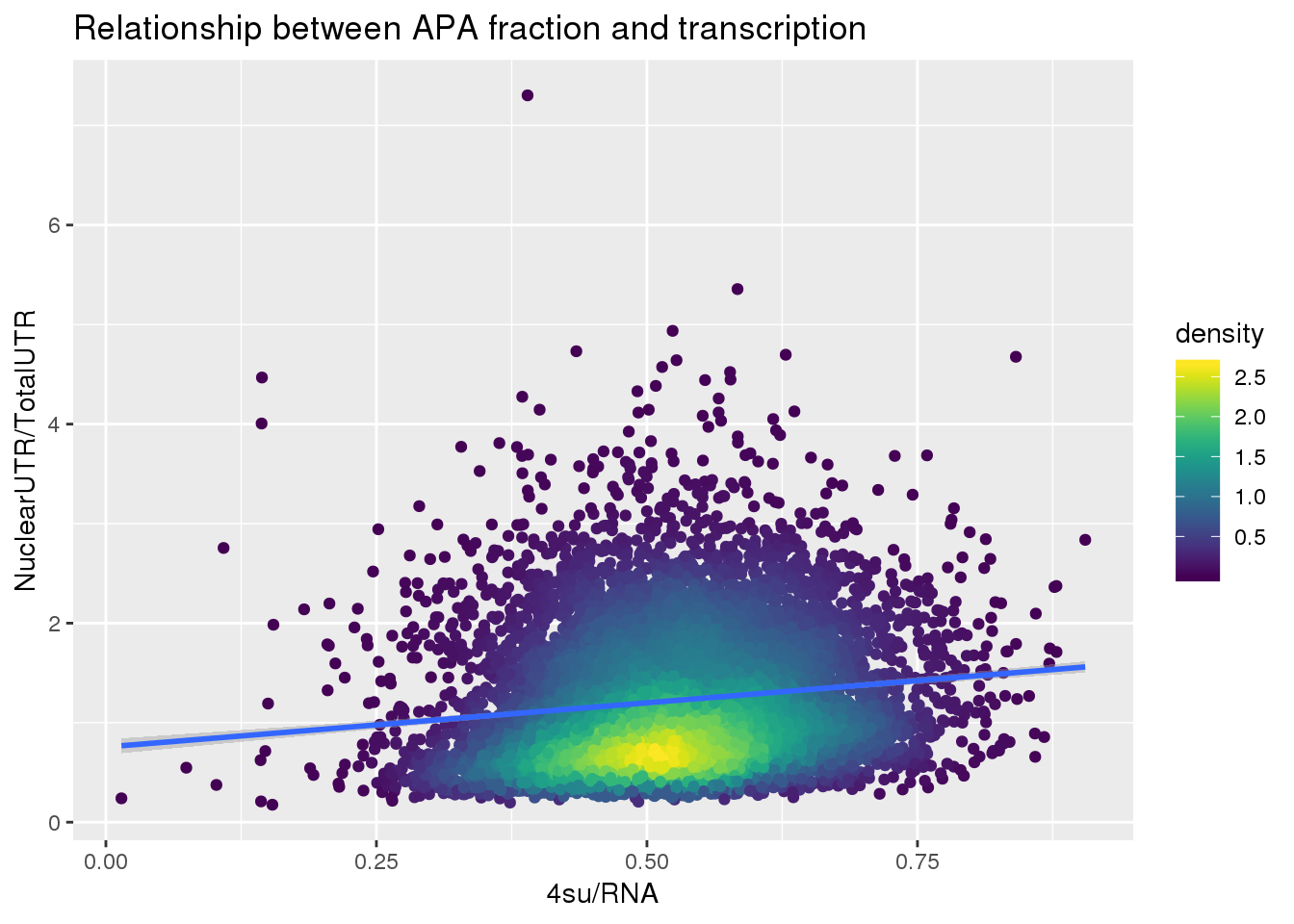
| Version | Author | Date |
|---|---|---|
| 460e1fb | brimittleman | 2019-05-16 |
APAUTRandTranscrption2= Transcription %>% inner_join(ApaBothFracUTRStand_geneMean_spread2, by="gene")
APAUTRandTranscrption2$density <- get_density(APAUTRandTranscrption2$APAValLoc, APAUTRandTranscrption2$Transcription, n = 100)
summary(lm(data=APAUTRandTranscrption2, log10(APAValLoc)~log10(Transcription)))
Call:
lm(formula = log10(APAValLoc) ~ log10(Transcription), data = APAUTRandTranscrption2)
Residuals:
Min 1Q Median 3Q Max
-0.45003 -0.08569 0.01581 0.10162 0.37243
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.234761 0.004493 -52.25 <2e-16 ***
log10(Transcription) 0.268002 0.014607 18.35 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.127 on 7709 degrees of freedom
Multiple R-squared: 0.04184, Adjusted R-squared: 0.04171
F-statistic: 336.6 on 1 and 7709 DF, p-value: < 2.2e-16ggplot(APAUTRandTranscrption2, aes(x=Transcription, y=APAValLoc))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="4su/RNA+4su", y="NuclearUTR/TotalUTR+NuclearUTR", title="Relationship between APA fraction and transcription") + scale_color_viridis()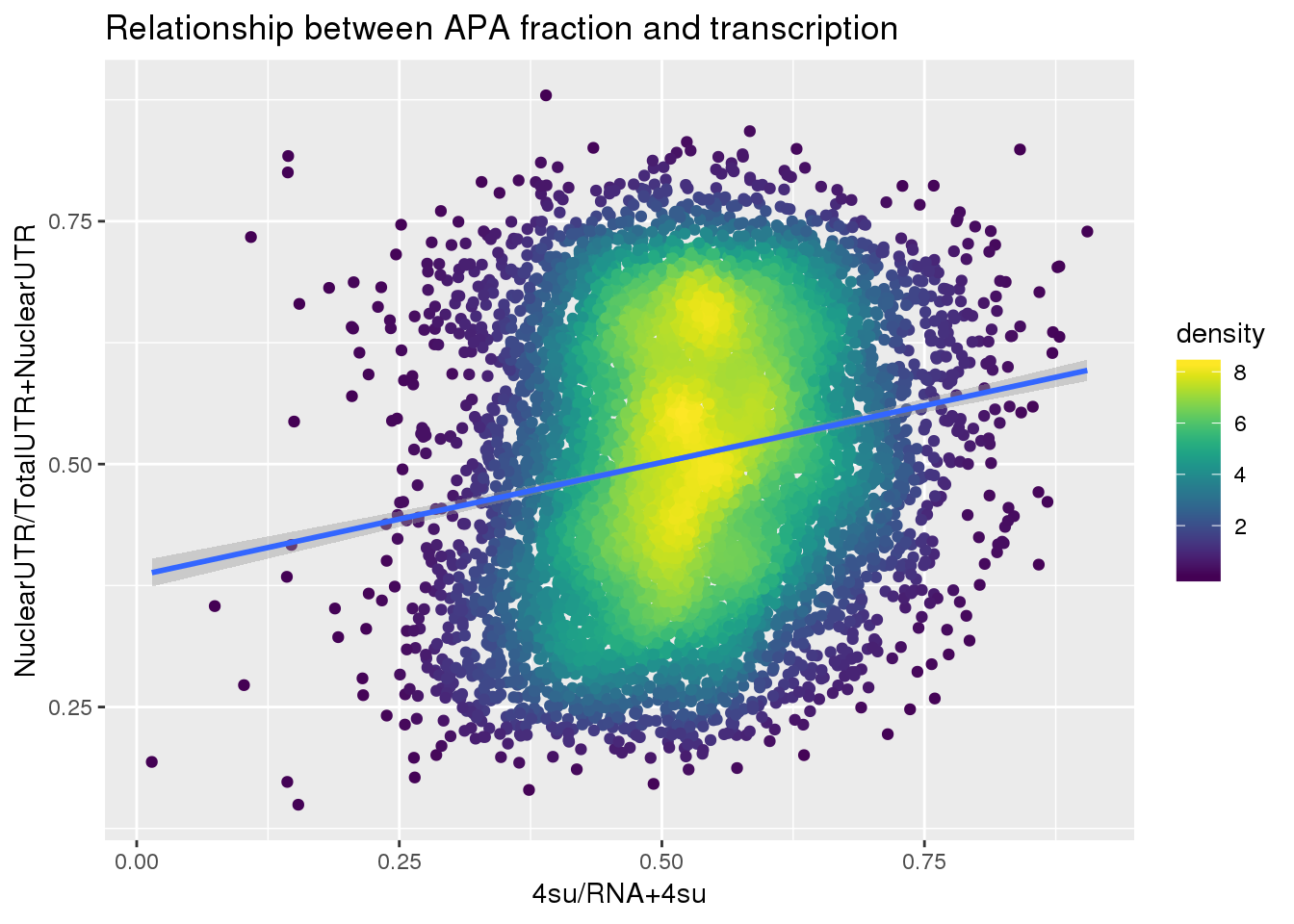
Intron Nuclear over all nuclear
Nuclear intron= NucAPAIntron_bygene
all nuclear =NucAPA_bygene
Create this pheno:
ApaNuclear_byloc=NucAPAIntron_bygene %>% inner_join(NucAPA_bygene, by=c("gene", "Individual")) %>% mutate(IntronOverAll=NuclearIntronSum/NuclearSum) %>% mutate(fraction="nuclear",line=paste("NA", substring(Individual, 2), sep="")) %>% dplyr::select(gene, fraction, line, IntronOverAll) %>% group_by(gene) %>% filter(IntronOverAll!=0) %>% summarise(MeanIntronoverAll=mean(IntronOverAll)) %>% dplyr::rename("GeneName"=gene)Join with RNA
nuclearandRNA=ApaNuclear_byloc %>% inner_join(RNA_geneMean, by="GeneName")
nuclearandRNA$density <- get_density(nuclearandRNA$MeanIntronoverAll, nuclearandRNA$Mean_RNA, n = 100)Plot:
ggplot(nuclearandRNA, aes(x=log10(Mean_RNA), y=MeanIntronoverAll))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="log10(RNA)", y="NuclearIntron/NuclearAll", title="Relationship between APA fraction and transcription") + scale_color_viridis()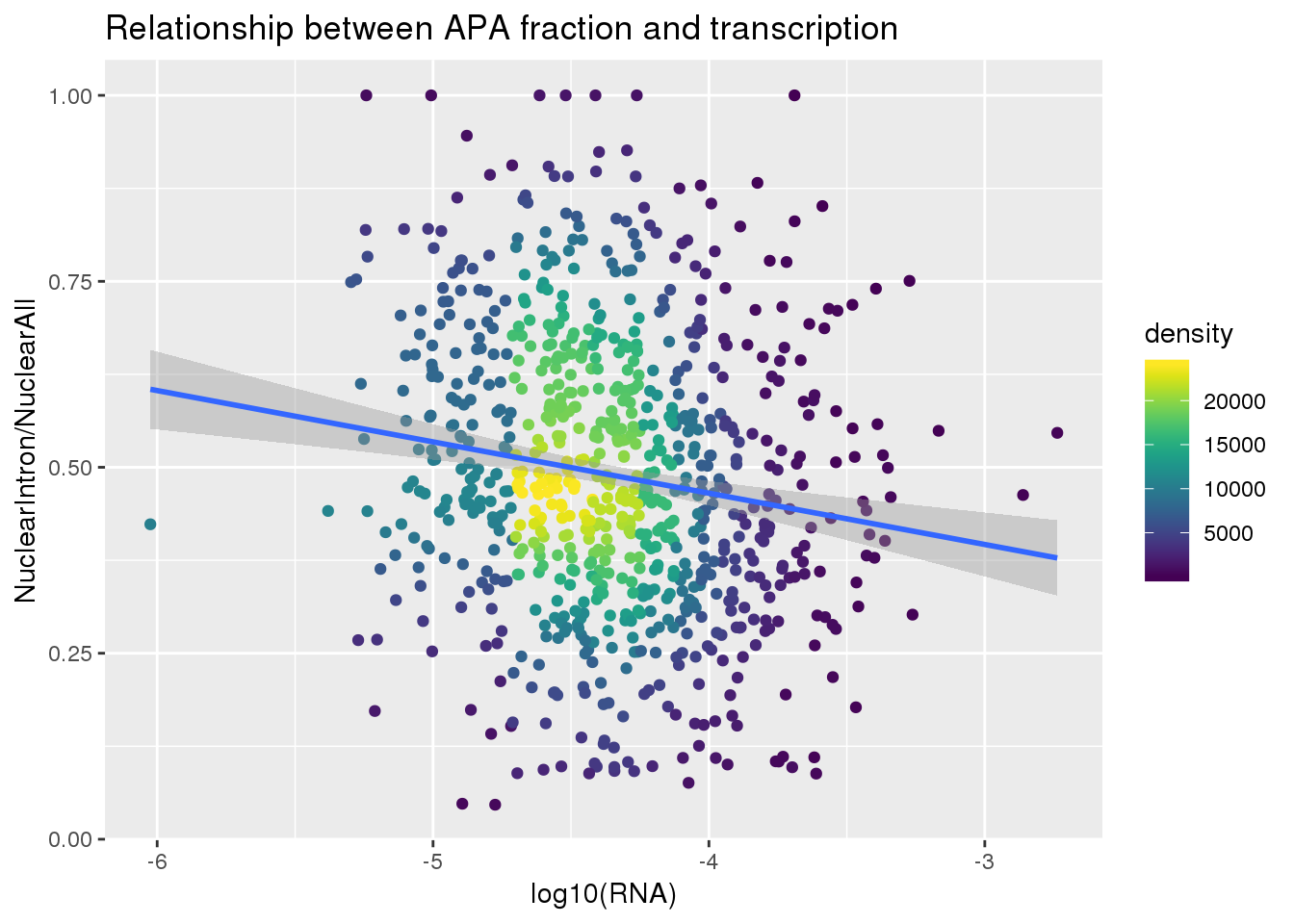
summary(lm(data=nuclearandRNA, MeanIntronoverAll~log10(Mean_RNA)))
Call:
lm(formula = MeanIntronoverAll ~ log10(Mean_RNA), data = nuclearandRNA)
Residuals:
Min 1Q Median 3Q Max
-0.47913 -0.12703 -0.01765 0.12618 0.55620
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.18933 0.06799 2.784 0.00549 **
log10(Mean_RNA) -0.06897 0.01559 -4.425 1.1e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1865 on 811 degrees of freedom
Multiple R-squared: 0.02357, Adjusted R-squared: 0.02237
F-statistic: 19.58 on 1 and 811 DF, p-value: 1.098e-05Same plot with transcription phenotype on bottom:
ApaNuclear_byloc_rename=ApaNuclear_byloc %>% dplyr::rename("gene"=GeneName)
nuclearandtranscription=ApaNuclear_byloc_rename %>% inner_join(Transcription, by="gene")
nuclearandtranscription$density <- get_density(nuclearandtranscription$MeanIntronoverAll, nuclearandtranscription$Transcription, n = 100)
ggplot(nuclearandtranscription, aes(x=Transcription, y=MeanIntronoverAll))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="4su/4su+RNA", y="NuclearIntron/NuclearAll", title="Relationship between APA fraction and transcription") + scale_color_viridis()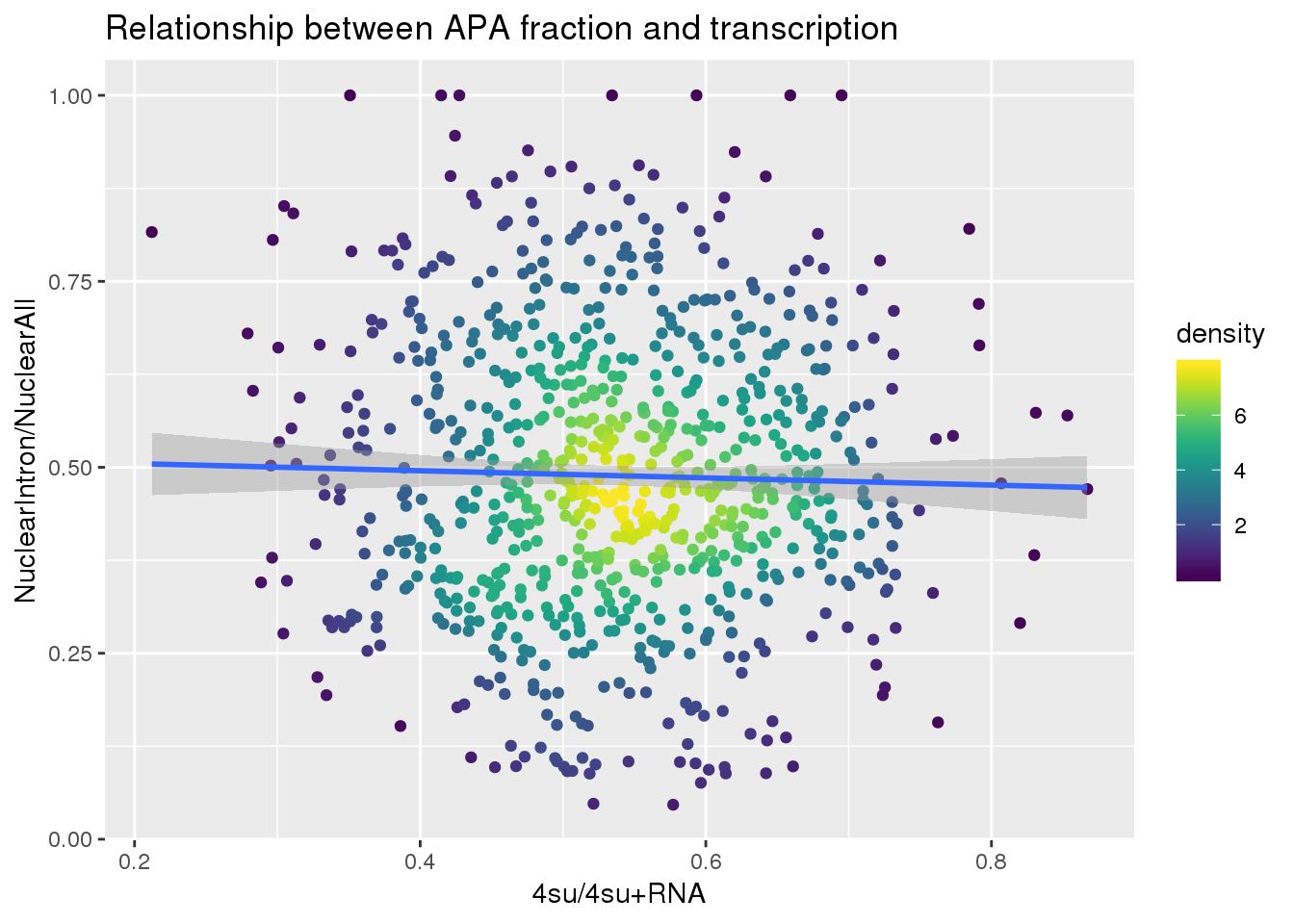
summary(lm(data=nuclearandtranscription, MeanIntronoverAll~Transcription))
Call:
lm(formula = MeanIntronoverAll ~ Transcription, data = nuclearandtranscription)
Residuals:
Min 1Q Median 3Q Max
-0.44181 -0.13029 -0.01467 0.12672 0.51883
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.51462 0.03432 14.994 <2e-16 ***
Transcription -0.04813 0.06269 -0.768 0.443
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1887 on 811 degrees of freedom
Multiple R-squared: 0.0007261, Adjusted R-squared: -0.000506
F-statistic: 0.5893 on 1 and 811 DF, p-value: 0.4429Intron Total over all Total
First I need to get the total intronic:
TotAPAIntron=read.table("../data/peakCoverage/APAPeaks.ALLChrom.Filtered.Named.GeneLocAnnoPARSED.Total.Quant.Fixed.fc", stringsAsFactors = F, header = T) %>% dplyr::select(-Chr, -Start, -End, -Strand, -Length) %>% separate(Geneid, into=c("peakid","chrom", "start", "end", "strand", "geneID"),sep=":") %>% semi_join(peaknumlist, by="peakid") %>% separate(geneID, into=c("gene", "loc"), sep="_") %>%filter(loc=="intron") %>% dplyr::select(-chrom , -start, -end, -strand, -loc)
TotAPAIntronMelt=melt(TotAPAIntron, id.vars =c( "peakid", "gene"), value.name="count", variable.name="Ind") %>% separate(Ind, into=c('Individual', 'fraction') ,sep="_")%>% dplyr::select(peakid, gene, Individual, count)
TotAPAIntron_bygene= TotAPAIntronMelt %>% group_by(gene,Individual) %>% summarise(TotalIntronSum=sum(count))ApaTotal_byloc=TotAPAIntron_bygene %>% inner_join(TotAPA_bygene, by=c("gene", "Individual")) %>% mutate(IntronOverAll=TotalIntronSum/TotalSum) %>% mutate(fraction="total",line=paste("NA", substring(Individual, 2), sep="")) %>% dplyr::select(gene, fraction, line, IntronOverAll) %>% group_by(gene) %>% filter(IntronOverAll!=0) %>% summarise(MeanIntronoverAll=mean(IntronOverAll)) %>% dplyr::rename("GeneName"=gene)Join with RNA
totalandRNA=ApaTotal_byloc %>% inner_join(RNA_geneMean, by="GeneName")
totalandRNA$density <- get_density(totalandRNA$MeanIntronoverAll, totalandRNA$Mean_RNA, n = 100)Plot:
ggplot(totalandRNA, aes(x=log10(Mean_RNA), y=MeanIntronoverAll))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="log10(RNA)", y="TotalIntron/TotalAll", title="Relationship between APA fraction and transcription") + scale_color_viridis()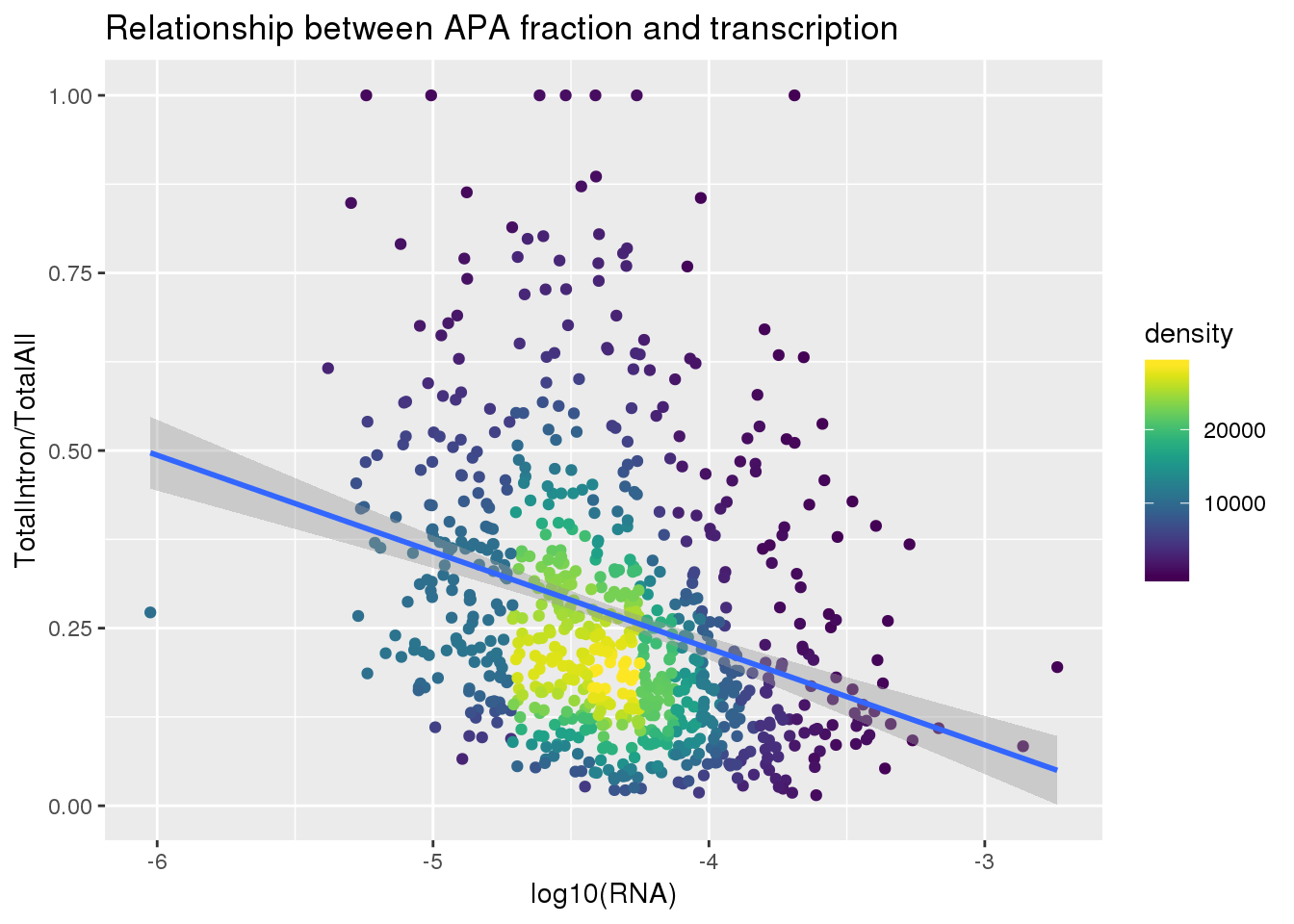
summary(lm(data=totalandRNA, MeanIntronoverAll~log10(Mean_RNA)))
Call:
lm(formula = MeanIntronoverAll ~ log10(Mean_RNA), data = totalandRNA)
Residuals:
Min 1Q Median 3Q Max
-0.27714 -0.12468 -0.04078 0.06442 0.82065
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.32230 0.06483 -4.972 8.1e-07 ***
log10(Mean_RNA) -0.13596 0.01486 -9.149 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1779 on 811 degrees of freedom
Multiple R-squared: 0.09355, Adjusted R-squared: 0.09243
F-statistic: 83.7 on 1 and 811 DF, p-value: < 2.2e-16Same plot with transcription phenotype on bottom:
ApaTotal_byloc_rename=ApaTotal_byloc %>% dplyr::rename("gene"=GeneName)
totalandtranscription=ApaTotal_byloc_rename %>% inner_join(Transcription, by="gene")
totalandtranscription$density <- get_density(totalandtranscription$MeanIntronoverAll, totalandtranscription$Transcription, n = 100)
ggplot(totalandtranscription, aes(x=Transcription, y=MeanIntronoverAll))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="4su/4su+RNA", y="TotalIntron/TotalAll", title="Relationship between APA fraction and transcription") + scale_color_viridis()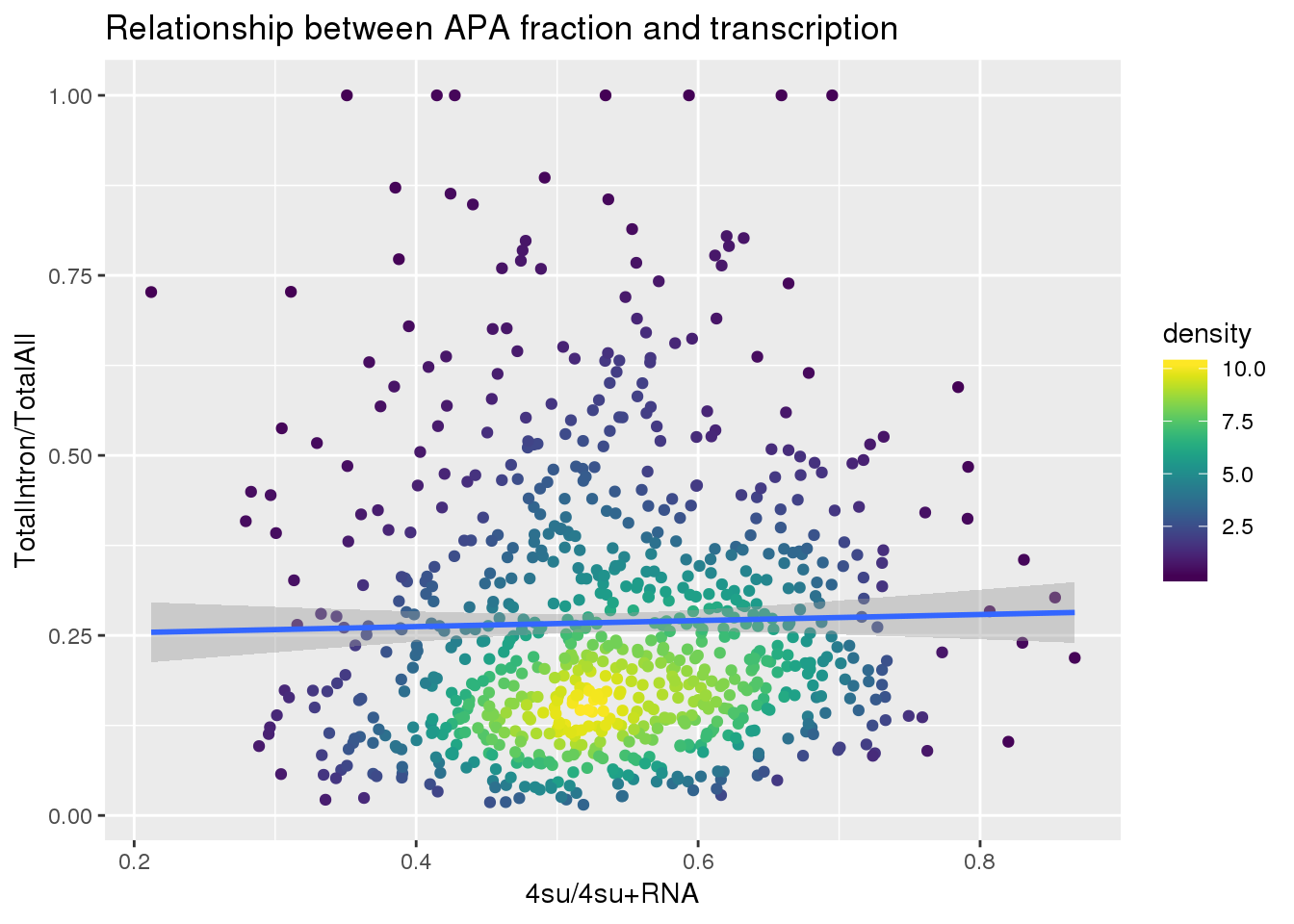
| Version | Author | Date |
|---|---|---|
| 7aeba54 | brimittleman | 2019-05-17 |
summary(lm(data=totalandtranscription, MeanIntronoverAll~Transcription))
Call:
lm(formula = MeanIntronoverAll ~ Transcription, data = totalandtranscription)
Residuals:
Min 1Q Median 3Q Max
-0.25236 -0.13687 -0.04965 0.08509 0.73980
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.24548 0.03396 7.227 1.14e-12 ***
Transcription 0.04196 0.06204 0.676 0.499
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1868 on 811 degrees of freedom
Multiple R-squared: 0.0005638, Adjusted R-squared: -0.0006685
F-statistic: 0.4575 on 1 and 811 DF, p-value: 0.499Put it all together:
(Nuclear intronic/nuclear all)/(total intronic/total all) vs 4su/(4su+RNA)
Nucintron v nuc all:
ApaNuclear_byloc_rename
ApaTotal_byloc_rename
Transcription
fullapa=ApaNuclear_byloc_rename %>% dplyr::rename("NuclearIntronoverall"=MeanIntronoverAll)%>% inner_join(ApaTotal_byloc_rename, by="gene") %>% mutate(fullAPA=NuclearIntronoverall/MeanIntronoverAll) %>% dplyr::select(gene,fullAPA)
#join with transcription
BothlocPhenoandtranscription=fullapa %>% inner_join(Transcription, by="gene")
BothlocPhenoandtranscription$density <- get_density(BothlocPhenoandtranscription$fullAPA, BothlocPhenoandtranscription$Transcription, n = 100)
ggplot(BothlocPhenoandtranscription, aes(x=Transcription, y=fullAPA))+ geom_point(aes(color=density)) + geom_smooth(method = "lm") + labs(x="4su/4su+RNA", y="log10(NuclearIntron/Nuclearall)/(TotalIntron/TotalAll)", title="Relationship between APA fraction and transcription") + scale_color_viridis()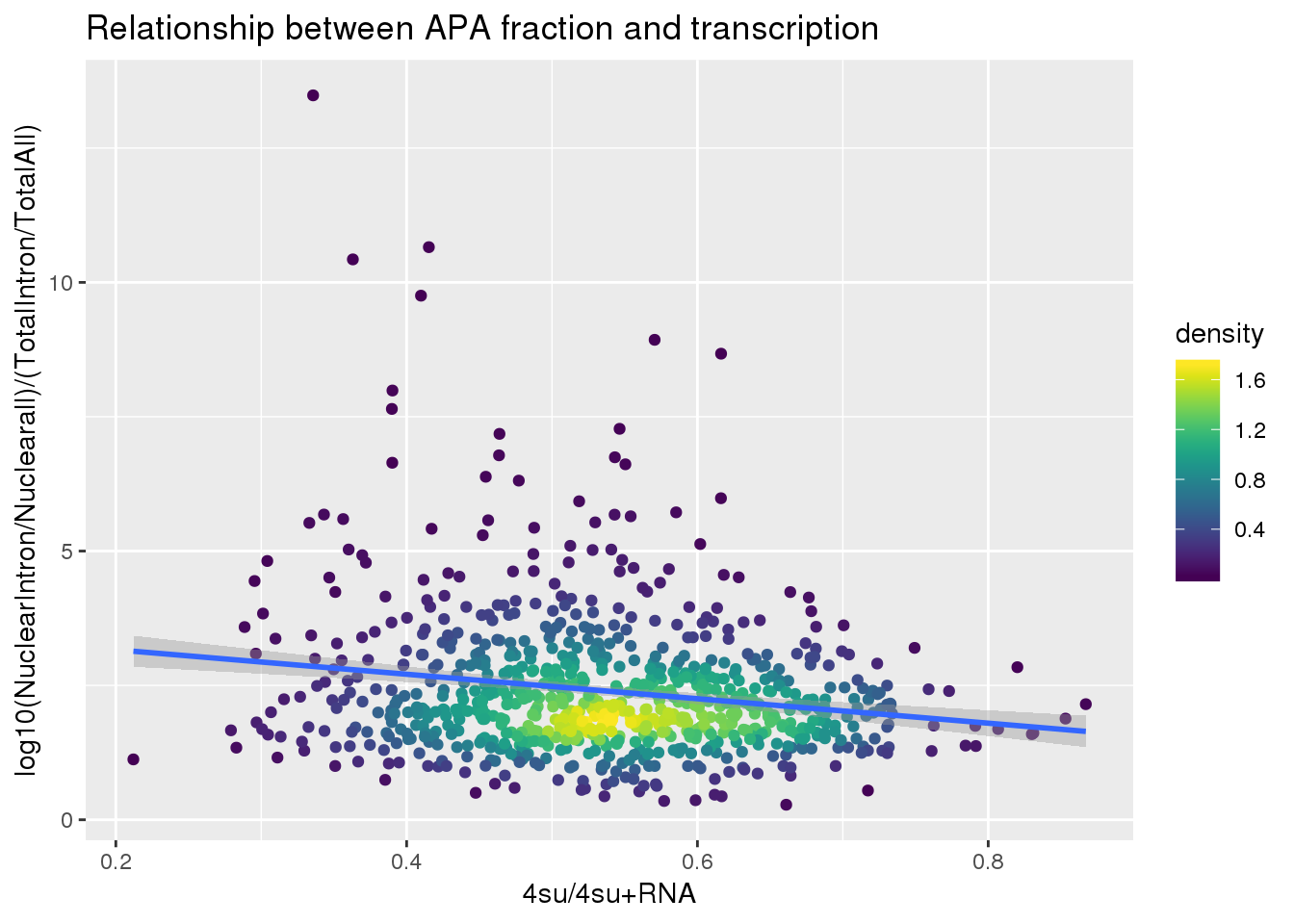
summary(lm(data=BothlocPhenoandtranscription, log10(fullAPA)~Transcription))
Call:
lm(formula = log10(fullAPA) ~ Transcription, data = BothlocPhenoandtranscription)
Residuals:
Min 1Q Median 3Q Max
-0.84376 -0.12135 -0.00255 0.12460 0.74230
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.48793 0.03819 12.777 < 2e-16 ***
Transcription -0.29941 0.06975 -4.292 1.98e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.21 on 811 degrees of freedom
Multiple R-squared: 0.02221, Adjusted R-squared: 0.02101
F-statistic: 18.42 on 1 and 811 DF, p-value: 1.981e-05
sessionInfo()R version 3.5.1 (2018-07-02)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Scientific Linux 7.4 (Nitrogen)
Matrix products: default
BLAS/LAPACK: /software/openblas-0.2.19-el7-x86_64/lib/libopenblas_haswellp-r0.2.19.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] viridis_0.5.1 viridisLite_0.3.0 forcats_0.3.0
[4] stringr_1.3.1 dplyr_0.8.0.1 purrr_0.3.2
[7] readr_1.3.1 tidyr_0.8.3 tibble_2.1.1
[10] ggplot2_3.1.1 tidyverse_1.2.1 workflowr_1.3.0
[13] reshape2_1.4.3
loaded via a namespace (and not attached):
[1] tidyselect_0.2.5 haven_1.1.2 lattice_0.20-38 colorspace_1.3-2
[5] generics_0.0.2 htmltools_0.3.6 yaml_2.2.0 rlang_0.3.1
[9] pillar_1.3.1 glue_1.3.0 withr_2.1.2 modelr_0.1.2
[13] readxl_1.1.0 plyr_1.8.4 munsell_0.5.0 gtable_0.2.0
[17] cellranger_1.1.0 rvest_0.3.2 evaluate_0.12 labeling_0.3
[21] knitr_1.20 broom_0.5.1 Rcpp_1.0.0 scales_1.0.0
[25] backports_1.1.2 jsonlite_1.6 fs_1.2.6 gridExtra_2.3
[29] hms_0.4.2 digest_0.6.18 stringi_1.2.4 grid_3.5.1
[33] rprojroot_1.3-2 cli_1.0.1 tools_3.5.1 magrittr_1.5
[37] lazyeval_0.2.1 crayon_1.3.4 whisker_0.3-2 pkgconfig_2.0.2
[41] MASS_7.3-51.1 xml2_1.2.0 lubridate_1.7.4 assertthat_0.2.0
[45] rmarkdown_1.10 httr_1.3.1 rstudioapi_0.10 R6_2.3.0
[49] nlme_3.1-137 git2r_0.25.2 compiler_3.5.1