Home
Last updated: 2020-07-06
Checks: 2 0
Knit directory: duplex_sequencing_screen/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version e4a901d. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Untracked files:
Untracked: analysis/bcrabl_hill_ic50s.csv
Untracked: analysis/column_definitions_for_twinstrand_data_06062020.csv
Untracked: analysis/dose_response_curve_fitting_with_errorbars.Rmd
Untracked: analysis/dosing_normalization_standard_deviations.pdf
Untracked: analysis/multinomial_sims.Rmd
Untracked: analysis/pooled_growth_fig_corrected_070320.pdf
Untracked: analysis/r1r2_1in3000.pdf
Untracked: analysis/r1r2_1in5000.pdf
Untracked: analysis/r1r3_1in3000.pdf
Untracked: analysis/simple_data_generation.Rmd
Untracked: analysis/twinstrand_growthrates_simple.csv
Untracked: analysis/twinstrand_maf_merge_simple.csv
Untracked: analysis/wildtype_growthrates_sequenced.csv
Untracked: code/microvariation.normalizer.R
Untracked: data/Combined_data_frame_IC_Mutprob_abundance.csv
Untracked: data/IC50HeatMap.csv
Untracked: data/Twinstrand/
Untracked: data/gfpenrichmentdata.csv
Untracked: data/heatmap_concat_data.csv
Untracked: figures_archive/
Untracked: output/archive/
Untracked: output/bmes_abstract_51220.pdf
Untracked: output/clinicalabundancepredictions_BMES_abstract_51320.pdf
Untracked: output/clinicalabundancepredictions_BMES_abstract_52020.pdf
Untracked: output/enrichment_simulations_3mutants_52020.pdf
Untracked: output/grant_fig.pdf
Untracked: output/grant_fig_v2.pdf
Untracked: output/grant_fig_v2updated.pdf
Untracked: output/ic50data_all_conc.csv
Untracked: output/ic50data_all_confidence_intervals_individual_logistic_fits.csv
Untracked: output/ic50data_all_confidence_intervals_raw_data.csv
Untracked: output/twinstrand_microvariations_normalized.csv
Untracked: shinyapp/
Unstaged changes:
Modified: analysis/4_7_20_update.Rmd
Modified: analysis/E255K_alphas_figure.Rmd
Modified: analysis/clinical_abundance_predictions.Rmd
Modified: analysis/dose_response_curve_fitting.Rmd
Modified: analysis/nonlinear_growth_analysis.Rmd
Modified: analysis/spikeins_depthofcoverages.Rmd
Modified: analysis/twinstrand_spikeins_data_generation.Rmd
Deleted: data/README.md
Modified: output/twinstrand_maf_merge.csv
Modified: output/twinstrand_simple_melt_merge.csv
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/index.Rmd) and HTML (docs/index.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | e4a901d | haiderinam | 2020-07-06 | wflow_publish(“analysis/index.Rmd”) |
| html | 231d21d | haiderinam | 2020-06-07 | Build site. |
| html | 8f50f99 | haiderinam | 2020-06-07 | Build site. |
| Rmd | 5da3af0 | haiderinam | 2020-06-07 | wflow_publish(“analysis/index.Rmd”) |
| html | 75ddcb1 | haiderinam | 2020-06-02 | Build site. |
| Rmd | a173683 | haiderinam | 2020-06-02 | wflow_publish(“analysis/index.Rmd”) |
| html | bd2dec5 | haiderinam | 2020-06-02 | Build site. |
| Rmd | 1bb5940 | haiderinam | 2020-06-02 | wflow_publish(“analysis/index.Rmd”) |
| html | c43acef | haiderinam | 2020-06-02 | Build site. |
| Rmd | d5c9f64 | haiderinam | 2020-06-02 | wflow_publish(“analysis/index.Rmd”) |
| html | eaca616 | haiderinam | 2020-04-20 | Build site. |
| Rmd | 2bba93e | haiderinam | 2020-04-20 | wflow_publish("analysis/*.Rmd") |
| html | 05e3df6 | haiderinam | 2020-04-07 | Build site. |
| html | 1c86f69 | haiderinam | 2020-04-07 | Build site. |
| Rmd | e731909 | haiderinam | 2020-04-07 | wflow_publish(“analysis/index.Rmd”) |
| html | 4516a7f | haiderinam | 2020-04-06 | Build site. |
| Rmd | 3a57291 | haiderinam | 2020-04-06 | wflow_publish(files = “analysis/index.Rmd”) |
| html | c2930d5 | haiderinam | 2020-04-03 | Build site. |
| Rmd | 52f6884 | haiderinam | 2020-04-03 | wflow_publish("analysis/*.Rmd") |
| html | 6af2cdc | haiderinam | 2020-04-03 | Build site. |
| Rmd | 5cda9d3 | haiderinam | 2020-04-03 | wflow_publish("analysis/*.Rmd") |
| html | 0b9b87b | haiderinam | 2020-04-02 | Build site. |
| Rmd | fc5b9c0 | haiderinam | 2020-04-02 | wflow_publish("analysis/*.Rmd") |
| html | 2bce927 | haiderinam | 2020-04-02 | Build site. |
| html | 4ed9b35 | haiderinam | 2020-04-02 | Build site. |
| Rmd | e31836a | haiderinam | 2020-04-02 | wflow_publish("analysis/*.Rmd") |
| html | 99181d5 | haiderinam | 2020-04-02 | Build site. |
| Rmd | 17c01d4 | haiderinam | 2020-04-02 | wflow_publish(“analysis/index.Rmd”) |
| html | 1e2f469 | haiderinam | 2020-04-02 | Build site. |
| html | e11eec5 | haiderinam | 2020-04-02 | Build site. |
| Rmd | 0053f96 | haiderinam | 2020-04-02 | wflow_publish("analysis/*.Rmd") |
| html | b1cbbfa | haiderinam | 2020-04-02 | Build site. |
| Rmd | 703346a | haiderinam | 2020-04-02 | Start workflowr project. |
Duplex Sequencing Spike-Ins
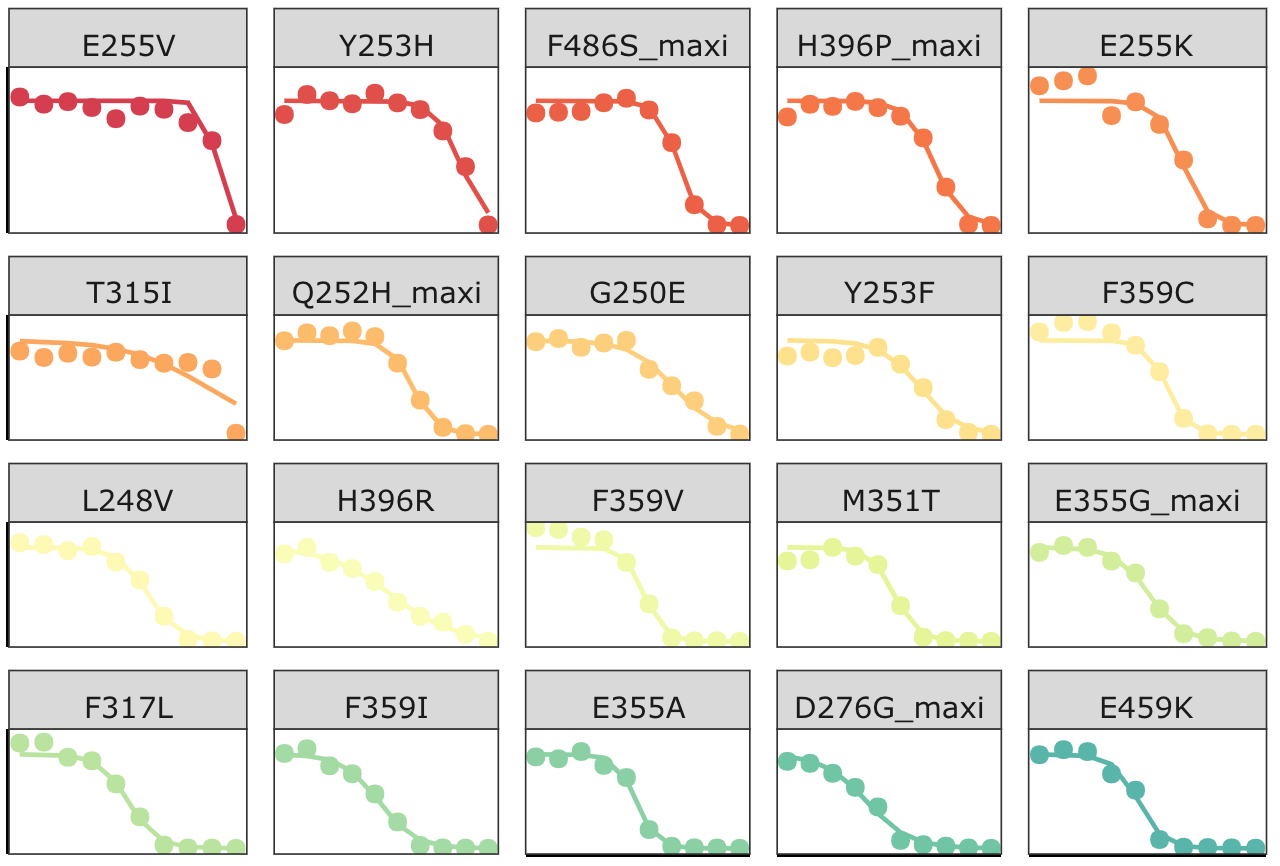
###Click here for the script that reads BCRABL dose response data, and fits it to a 4-parameter dose response curve.
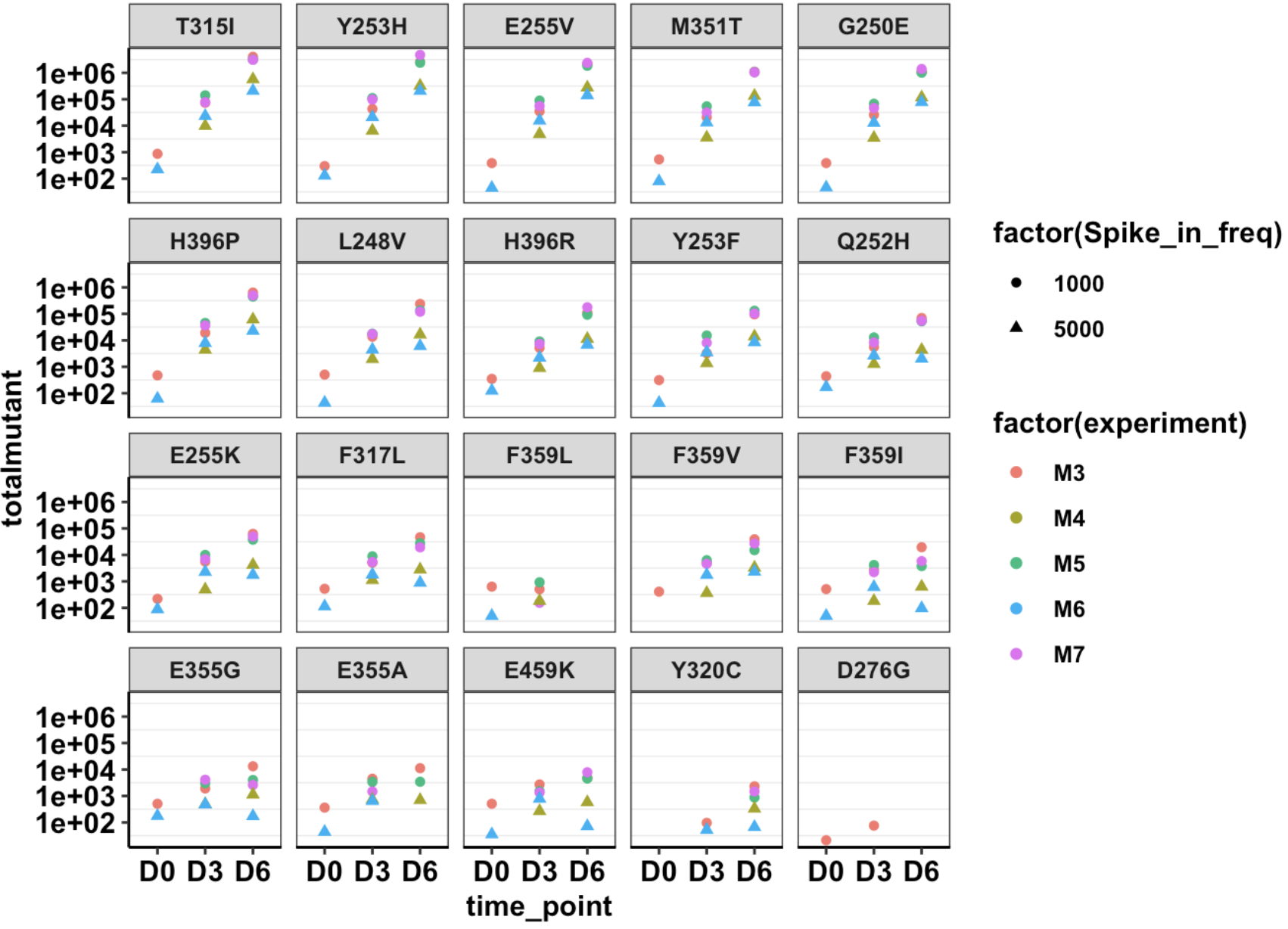
###Click here for the script that reads mutation annotation data and generates dataframes with annotated variants and the correct cell counts
###Click here for initial growth rate plots
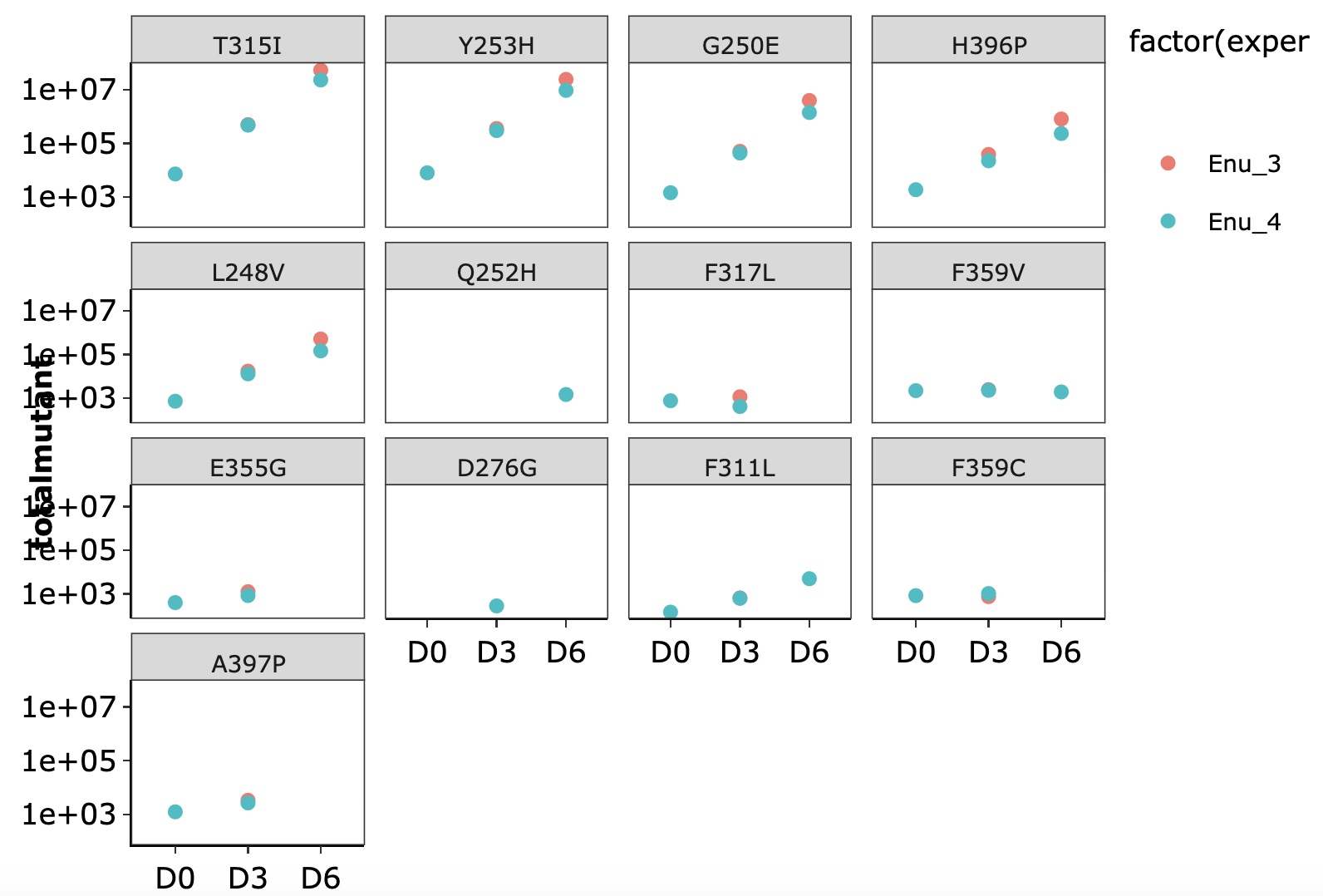
###Click here for growth rate plots for ENU mutants
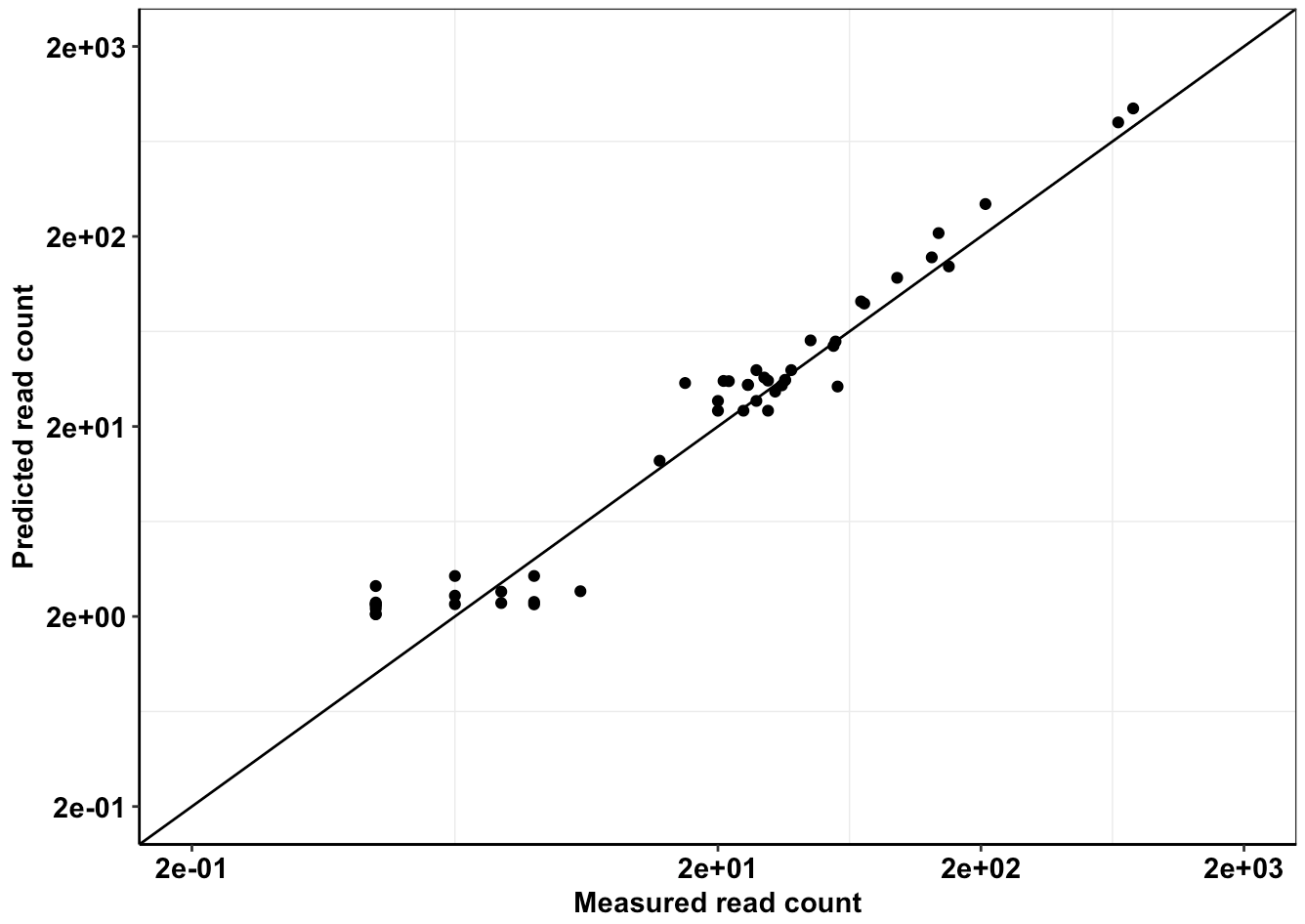
###Click here for analysis looking at whether we achieved our desired depth of coverages
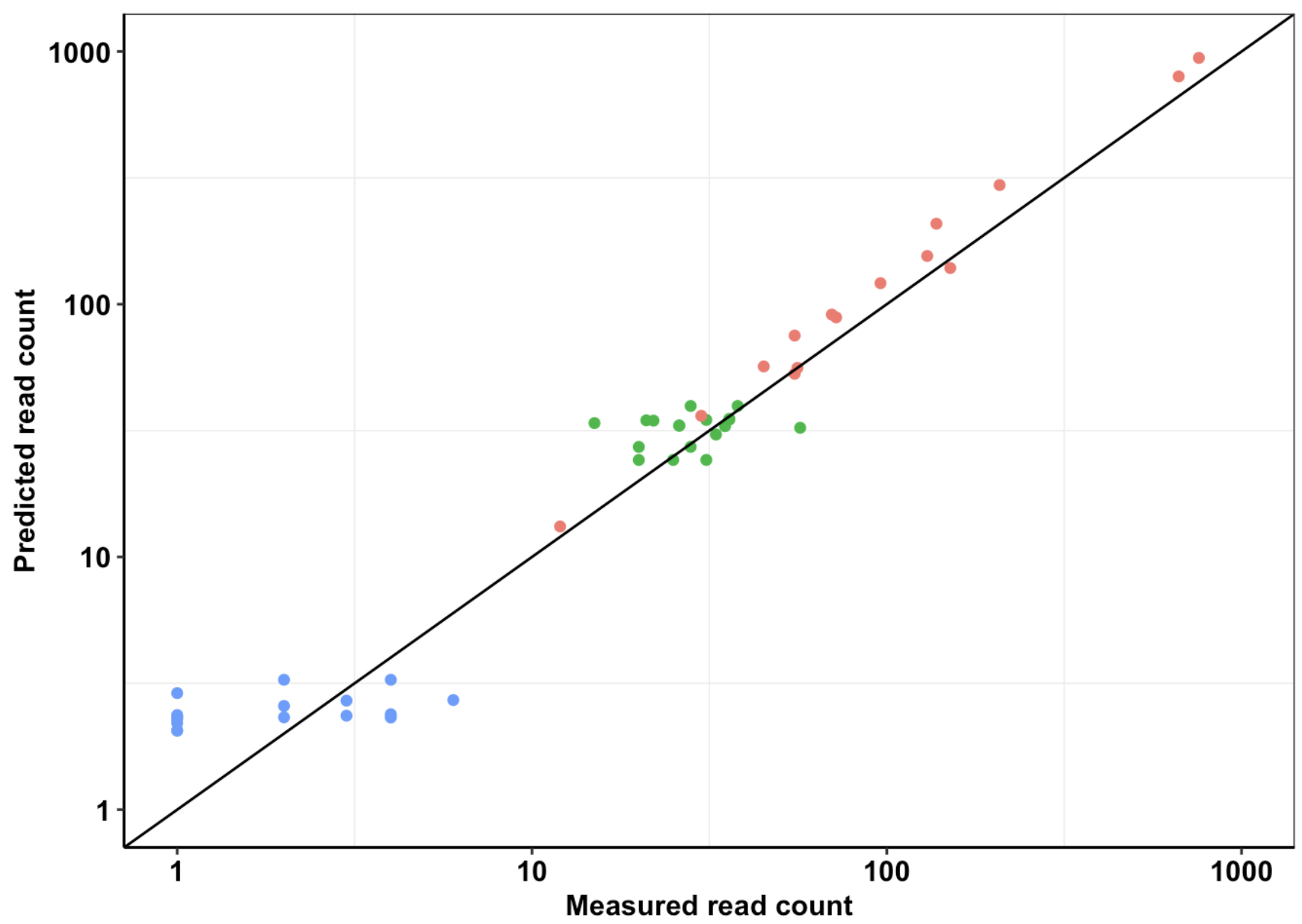
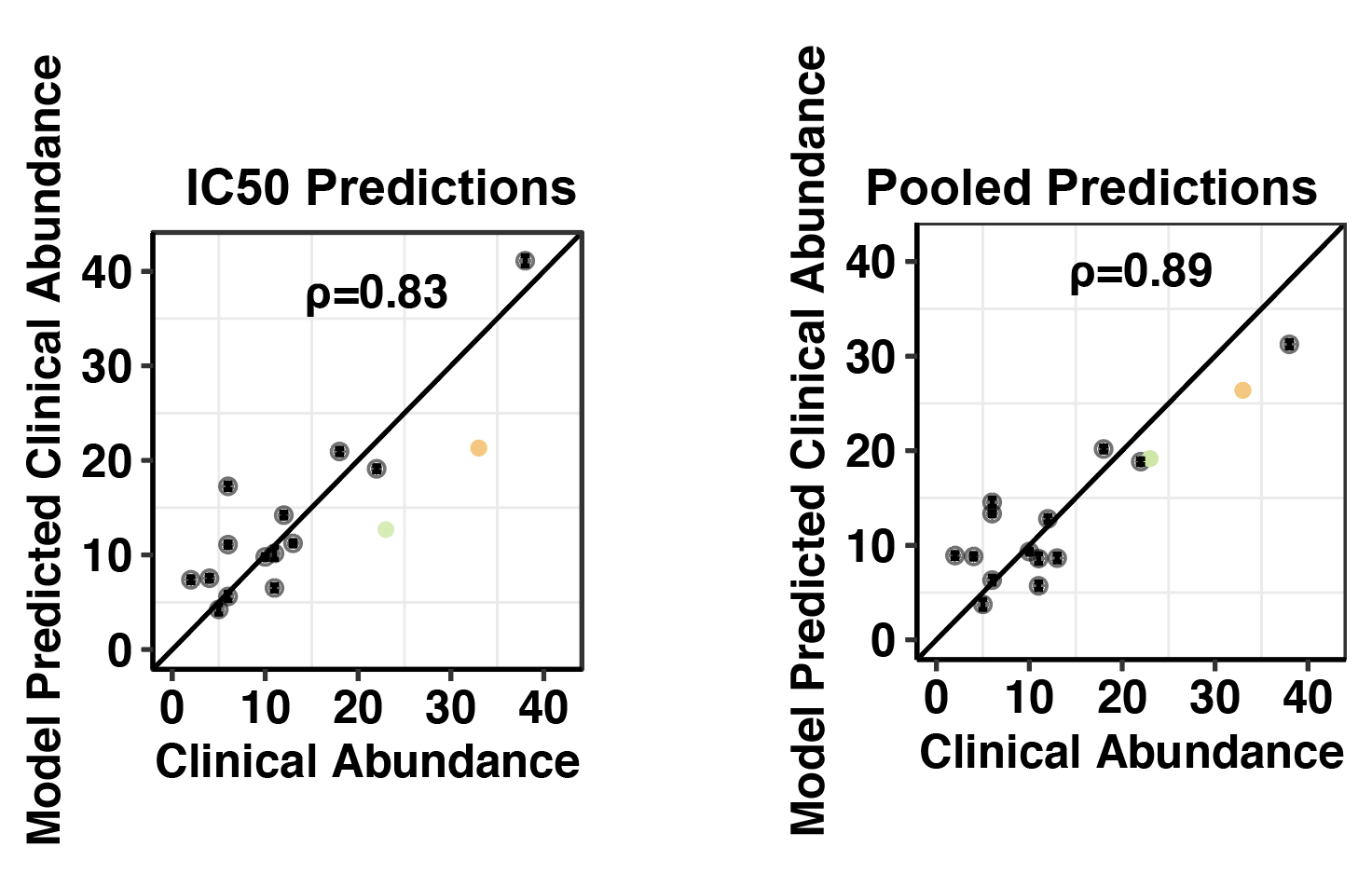
###Click here for analysis looking at how well our data predicts BCRABL clinical abundance compared to conventional IC50s
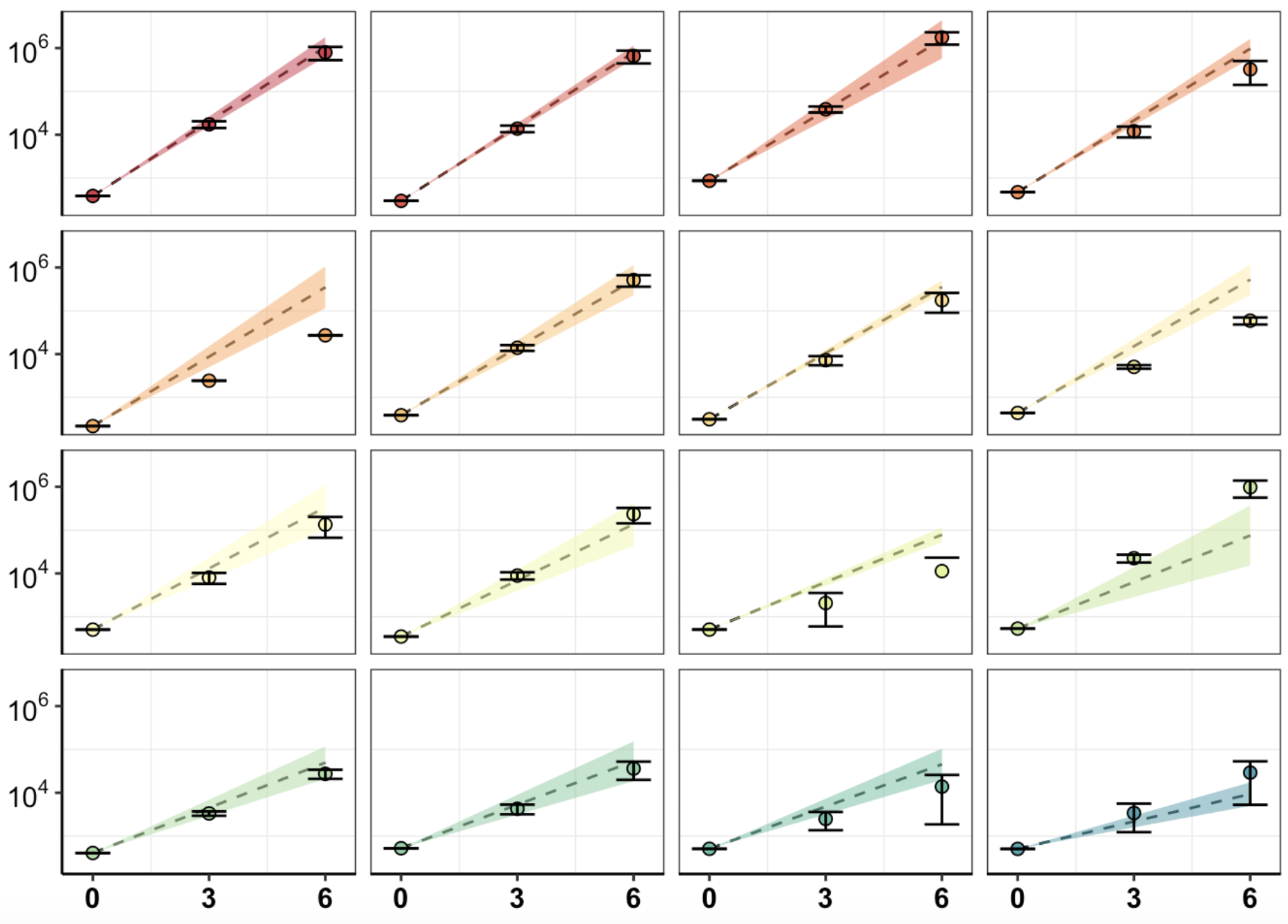
###Click here for method to obtain confidence intervals on growth rates from IC50 measurements. Plotted alongside observed growth rate data, these confidence intervals show how well our pooled data matches predictions based off of IC50s. (Needs updates in methodology)
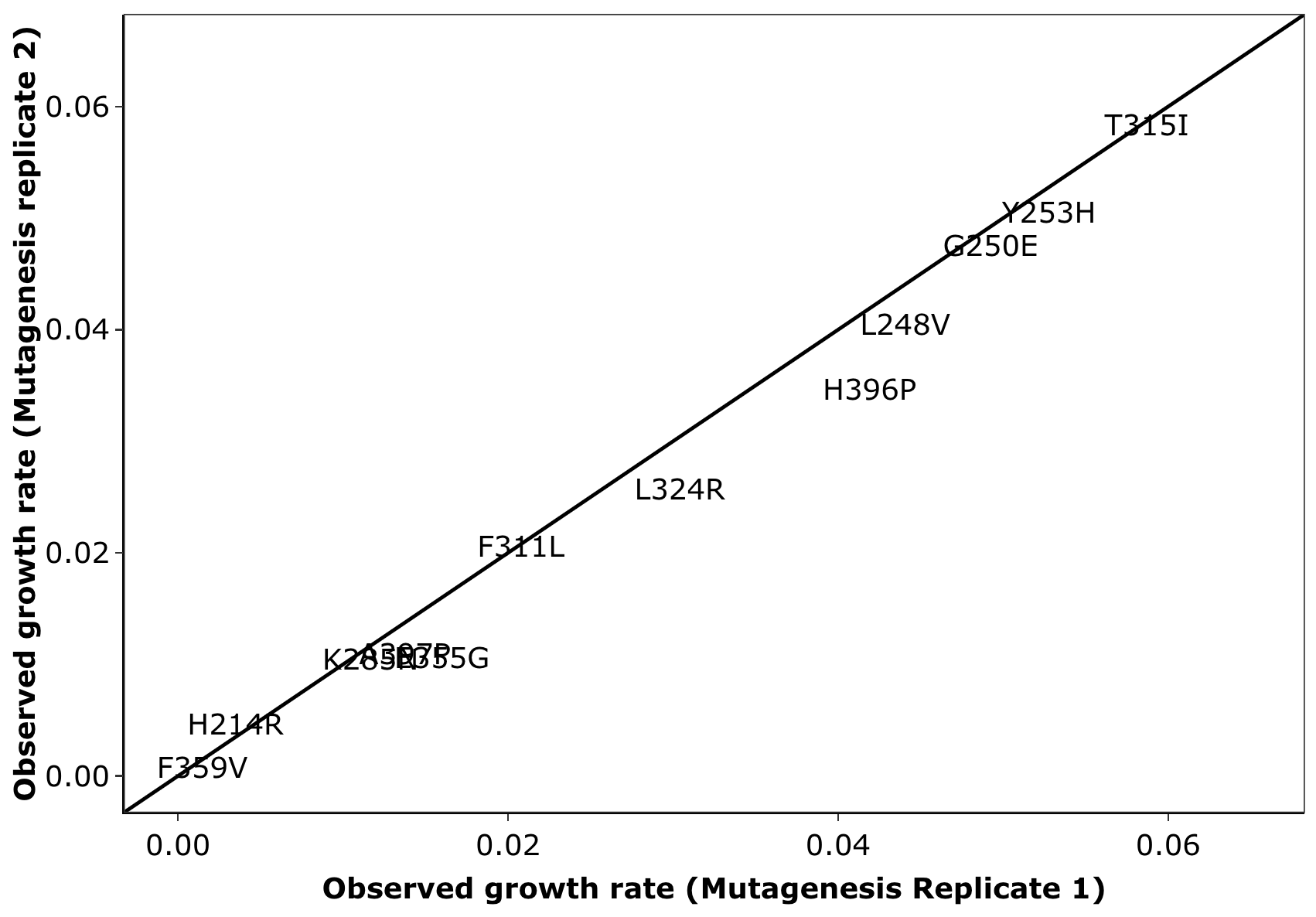
###Click here for analyses of replicate to replicate agreement between the spike in replicates. Also includes this analysis for the mutagenesis replicates. Also includes the agreement in observed vs predicted depth of coverages for all sequencing pools. Note: this analysis does not include dosage corrections that improves replicate to replicate heterogeneity.
###Click here to see analysis of predictions based on Enrich2 vs Shendure vs our method
###Click here for our dosing normalization strategy
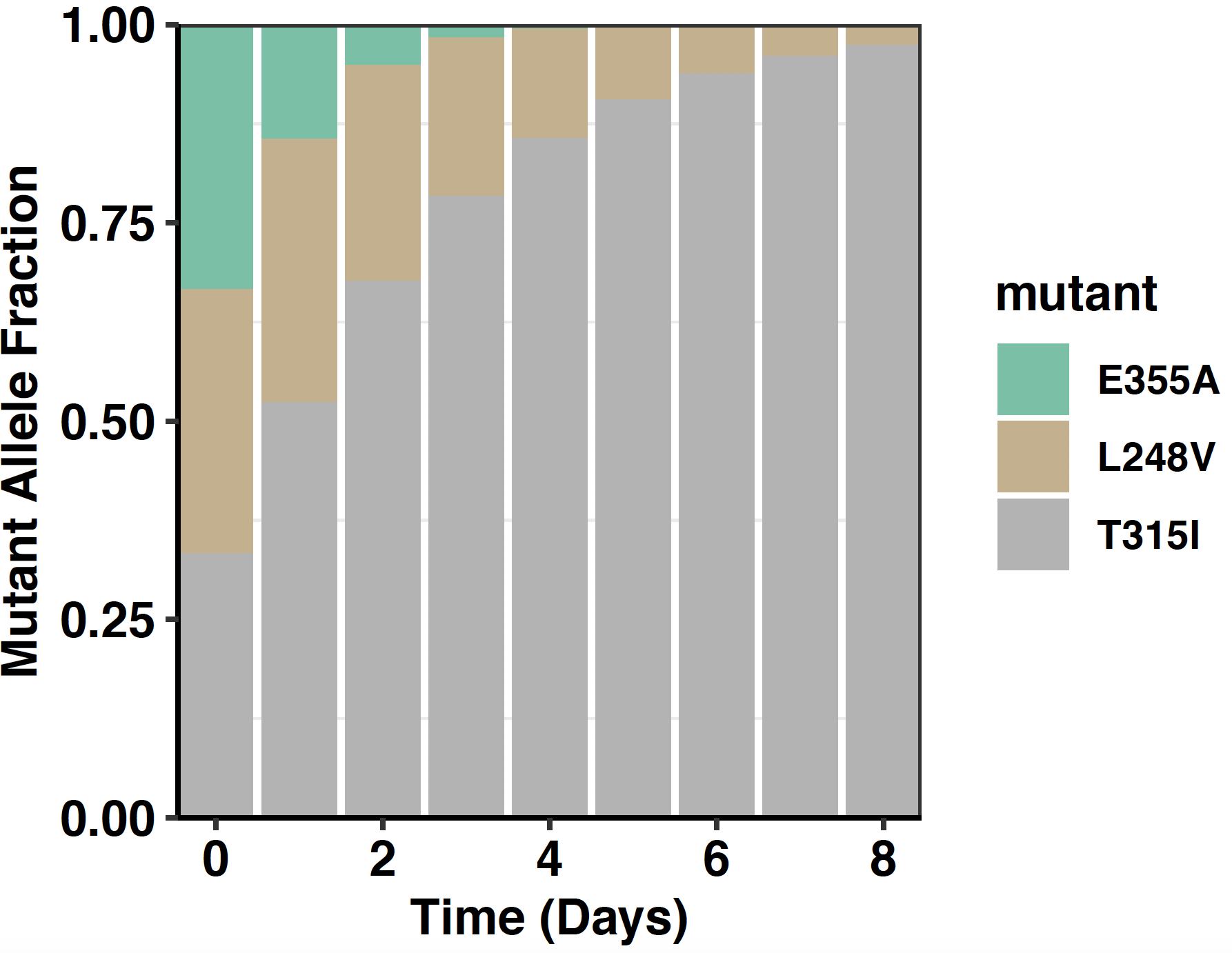
###Click here for simulations showing enrichment and depletion events in a 3 mutant pool.
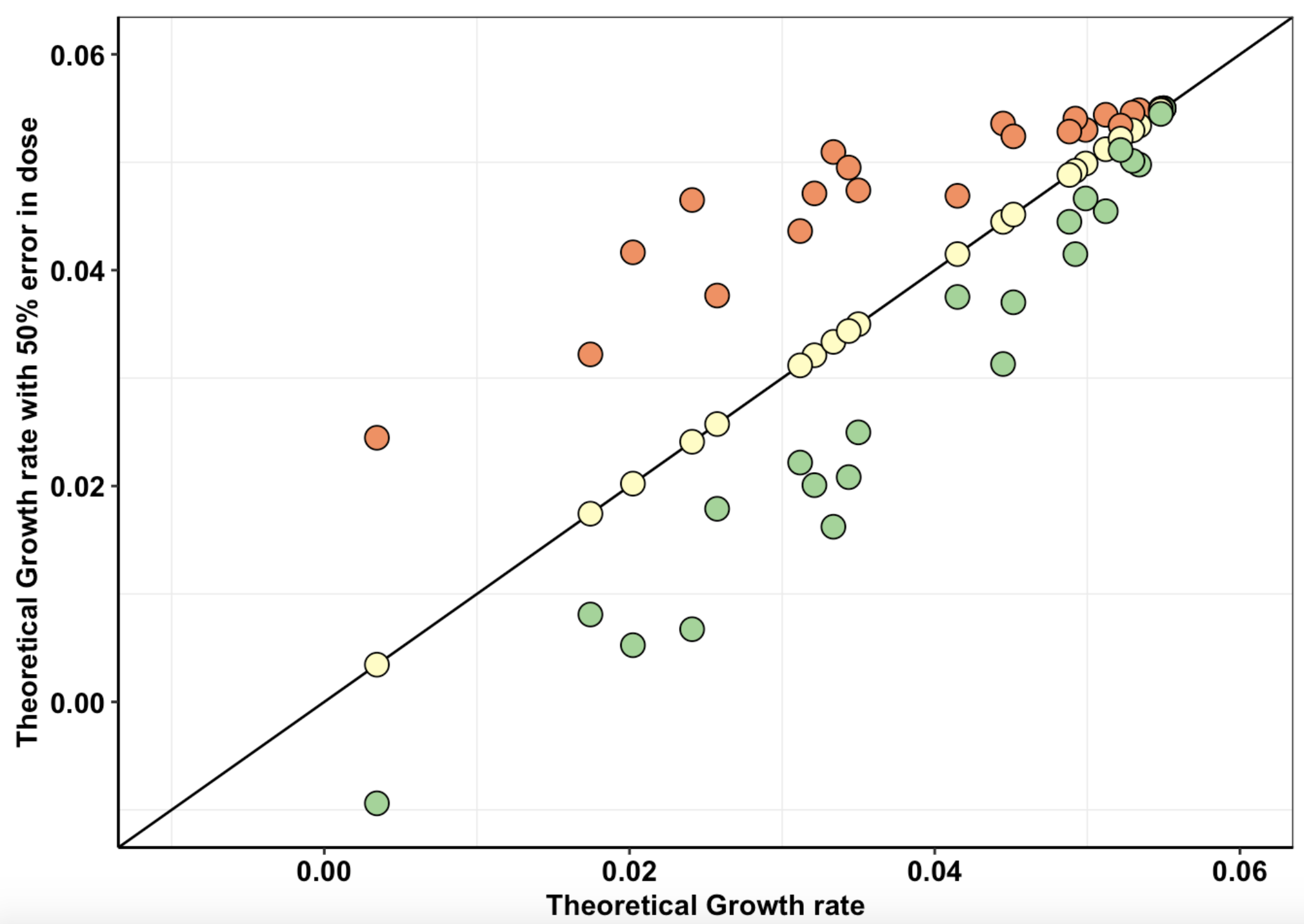
###Click here showing the conformity between the growth rates in the presence of drug measured at a low MAF via FACs, sequencing, and via IC50 studies for a single mutant.

Click here to be redirected to the github page that contains all the data and analysis rmd files.
What is in each directory:
- Data: contains data downloaded prior to analyses.
- Output: contains data that the code makes
- Analysis: contains your Rmarkdown files with the code.
- Docs: contain the html output from the Rmd files in the analysis directory.
- Code: contains .R files that are functions that the Rmd files in the analysis folder use.