Data base
Jens Daniel Müller
21 October, 2019
Last updated: 2019-10-21
Checks: 6 1
Knit directory: BloomSail/
This reproducible R Markdown analysis was created with workflowr (version 1.4.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20191021) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Using absolute paths to the files within your workflowr project makes it difficult for you and others to run your code on a different machine. Change the absolute path(s) below to the suggested relative path(s) to make your code more reproducible.
| absolute | relative |
|---|---|
| C:/Mueller_Jens_Data/Research/Projects/BloomSail/data/TinaV/Sensor/Profiles_Transects | data/TinaV/Sensor/Profiles_Transects |
| C:/Mueller_Jens_Data/Research/Projects/BloomSail/ | . |
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility. The version displayed above was the version of the Git repository at the time these results were generated.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: data/TinaV/
Ignored: data/_merged_data_files/
Ignored: data/_summarized_data_files/
Ignored: docs/figure/
Unstaged changes:
Modified: code/Workflowr_project_managment.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the R Markdown and HTML files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view them.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 4131b9c | jens-daniel-mueller | 2019-10-21 | finisehd read CTD and HydroC, created merging Rmd |
| html | a059c41 | jens-daniel-mueller | 2019-10-21 | Build site. |
| Rmd | eff54ce | jens-daniel-mueller | 2019-10-21 | Added CTD read-in |
| html | 32ec4f7 | jens-daniel-mueller | 2019-10-21 | Build site. |
| Rmd | b2d2bbb | jens-daniel-mueller | 2019-10-21 | Structured data base and response time Rmd |
| html | bafa88f | jens-daniel-mueller | 2019-10-21 | Build site. |
| html | 076a36b | jens-daniel-mueller | 2019-10-21 | Build site. |
| Rmd | 3e8a32e | jens-daniel-mueller | 2019-10-21 | Structured data base and response time Rmd |
| html | b2d0164 | jens-daniel-mueller | 2019-10-21 | Build site. |
| Rmd | 53ae361 | jens-daniel-mueller | 2019-10-21 | Added data base and response time Rmd |
library(tidyverse)
library(data.table)
library(lubridate)CTD Sensor data
Regular profiles and transects
CTD Sensor data including recordings from auxillary pH, O2, Chla and pCO2 data were read-in. Measurement frequency was 15 sec. pCO2 data were also internally recorded on the Contros HydroC instrument with higher temporal resolution and will later be replaced.
setwd("C:/Mueller_Jens_Data/Research/Projects/BloomSail/data/TinaV/Sensor/Profiles_Transects")
files <- list.files(pattern = "[.]cnv$")
#file <- files[1]
for (file in files){
start.date <- data.table(read.delim(file, sep="#", nrows = 160))[[78,1]]
start.date <- substr(start.date, 15, 34)
start.date <- mdy_hms(start.date, tz="UTC")
tempo <- read.delim(file, sep="", skip = 160, header = FALSE)
tempo <- data.table(tempo[,c(2,3,4,5,6,7,9,11,13)])
names(tempo) <- c("date", "Dep.S", "Tem.S", "Sal.S", "V_pH", "pH", "Chl", "O2", "pCO2")
tempo$start.date <- start.date
tempo$date <- tempo$date + tempo$start.date
tempo$transect.ID <- substr(file, 1, 6)
tempo$type <- substr(file, 8,8)
tempo$label <- substr(file, 8,10)
tempo$cast <- "up"
tempo[date < mean(tempo[Dep.S == max(tempo$Dep.S)]$date)]$cast <- "down"
if (exists("dataset")){
dataset <- rbind(dataset, tempo)
}
if (!exists("dataset")){
dataset <- tempo
}
rm(start.date)
rm(tempo)
}
CTD <- dataset
rm(dataset, file, files)
#### plots to check succesful read-in and data-quality ####
#### removal of errornous recordings ####
#### Profiling data
# Temperature
# CTD %>%
# filter(type == "P") %>%
# ggplot(aes(Tem.S, Dep.S, col=label, linetype = cast))+
# geom_line()+
# scale_y_reverse()+
# geom_vline(xintercept = c(10, 20))+
# facet_wrap(~transect.ID)
CTD[transect.ID == "180723" & label == "P07" & Dep.S < 2 & cast == "up"]$Tem.S <- NA
# Salinity
# CTD %>%
# filter(type == "P") %>%
# ggplot(aes(Sal.S, Dep.S, col=label, linetype = cast))+
# geom_path()+
# scale_y_reverse()+
# facet_wrap(~transect.ID)
CTD[Sal.S < 6]$Sal.S <- NA
# pH
# CTD %>%
# filter(type == "P") %>%
# ggplot(aes(pH, Dep.S, col=label, linetype=cast))+
# geom_path()+
# scale_y_reverse()+
# facet_wrap(~transect.ID)
#
# CTD %>%
# filter(type == "P") %>%
# ggplot(aes(V_pH, Dep.S, col=label, linetype=cast))+
# geom_path()+
# scale_y_reverse()+
# facet_wrap(~transect.ID)
CTD[pH < 7.5]$V_pH <- NA
CTD[pH < 7.5]$pH <- NA
CTD[transect.ID == "180709" & label == "P03" & Dep.S < 5 & cast == "down"]$pH <- NA
CTD[transect.ID == "180709" & label == "P05" & Dep.S < 10 & cast == "down"]$pH <- NA
CTD[transect.ID == "180718" & label == "P10" & Dep.S < 3 & cast == "down"]$pH <- NA
CTD[transect.ID == "180815" & label == "P03" & Dep.S < 2 & cast == "down"]$pH <- NA
CTD[transect.ID == "180820" & label == "P11" & Dep.S < 15 & cast == "down"]$pH <- NA
CTD[transect.ID == "180709" & label == "P03" & Dep.S < 5 & cast == "down"]$V_pH <- NA
CTD[transect.ID == "180709" & label == "P05" & Dep.S < 10 & cast == "down"]$V_pH <- NA
CTD[transect.ID == "180718" & label == "P10" & Dep.S < 3 & cast == "down"]$V_pH <- NA
CTD[transect.ID == "180815" & label == "P03" & Dep.S < 2 & cast == "down"]$V_pH <- NA
CTD[transect.ID == "180820" & label == "P11" & Dep.S < 15 & cast == "down"]$V_pH <- NA
# pCO2
# CTD %>%
# filter(type == "P") %>%
# ggplot(aes(pCO2, Dep.S, col=label, linetype = cast))+
# geom_path()+
# scale_y_reverse()+
# facet_wrap(~transect.ID)
CTD[transect.ID == "180616"]$pCO2 <- NA
# O2
# CTD %>%
# filter(type == "P") %>%
# ggplot(aes(O2, Dep.S, col=label, linetype = cast))+
# geom_path()+
# scale_y_reverse()+
# facet_wrap(~transect.ID)
# Chlorophyll
# CTD %>%
# filter(type == "P") %>%
# ggplot(aes(Chl, Dep.S, col=label, linetype = cast))+
# geom_path()+
# scale_y_reverse()+
# facet_wrap(~transect.ID)
CTD[Chl > 100]$Chl <- NA
#### Surface transect data
# CTD %>%
# filter(type == "T") %>%
# ggplot(aes(date, Dep.S, col=label))+
# geom_point()+
# scale_y_reverse()+
# facet_wrap(~transect.ID, scales = "free_x")
#
# CTD %>%
# filter(type == "T") %>%
# ggplot(aes(date, Tem.S, col=label))+
# geom_point()+
# facet_wrap(~transect.ID, scales = "free_x")
#
# CTD %>%
# filter(type == "T") %>%
# ggplot(aes(date, Sal.S, col=label))+
# geom_point()+
# facet_wrap(~transect.ID, scales = "free_x")
#
# CTD %>%
# filter(type == "T") %>%
# ggplot(aes(date, pCO2, col=label))+
# geom_point()+
# facet_wrap(~transect.ID, scales = "free_x")
#
# CTD %>%
# filter(type == "T") %>%
# ggplot(aes(date, pH, col=label))+
# geom_point()+
# facet_wrap(~transect.ID, scales = "free_x")
#
# CTD %>%
# filter(type == "T") %>%
# ggplot(aes(date, Chl, col=label))+
# geom_point()+
# facet_wrap(~transect.ID, scales = "free_x")
CTD[type == "T" & Chl > 10]$Chl <- NA
# CTD %>%
# filter(type == "T") %>%
# ggplot(aes(date, O2, col=label))+
# geom_point()+
# facet_wrap(~transect.ID, scales = "free_x")
CTD <-
CTD %>%
select(date_time=date,
ID=transect.ID,
type,
station=label,
cast,
dep=Dep.S,
sal=Sal.S,
tem=Tem.S,
pCO2,pH,V_pH,O2,Chl)
CTD <- CTD %>%
filter(station %in% c("P01", "P02", "P03", "P04", "P05", "P06", "P07", "P08",
"P09", "P10", "P11", "P12", "P13"))
setwd("C:/Mueller_Jens_Data/Research/Projects/BloomSail/")
CTD %>%
write_csv(here::here("data/_summarized_data_files", "Tina_V_Sensor_Profiles_Transects.csv"))CTD %>%
arrange(date_time) %>%
filter(type == "P") %>%
ggplot(aes(tem, dep, col=station, linetype = cast))+
geom_path()+
scale_y_reverse()+
labs(x="Temperature (°C)", y="Depth (m)")+
facet_wrap(~ID, labeller = label_both)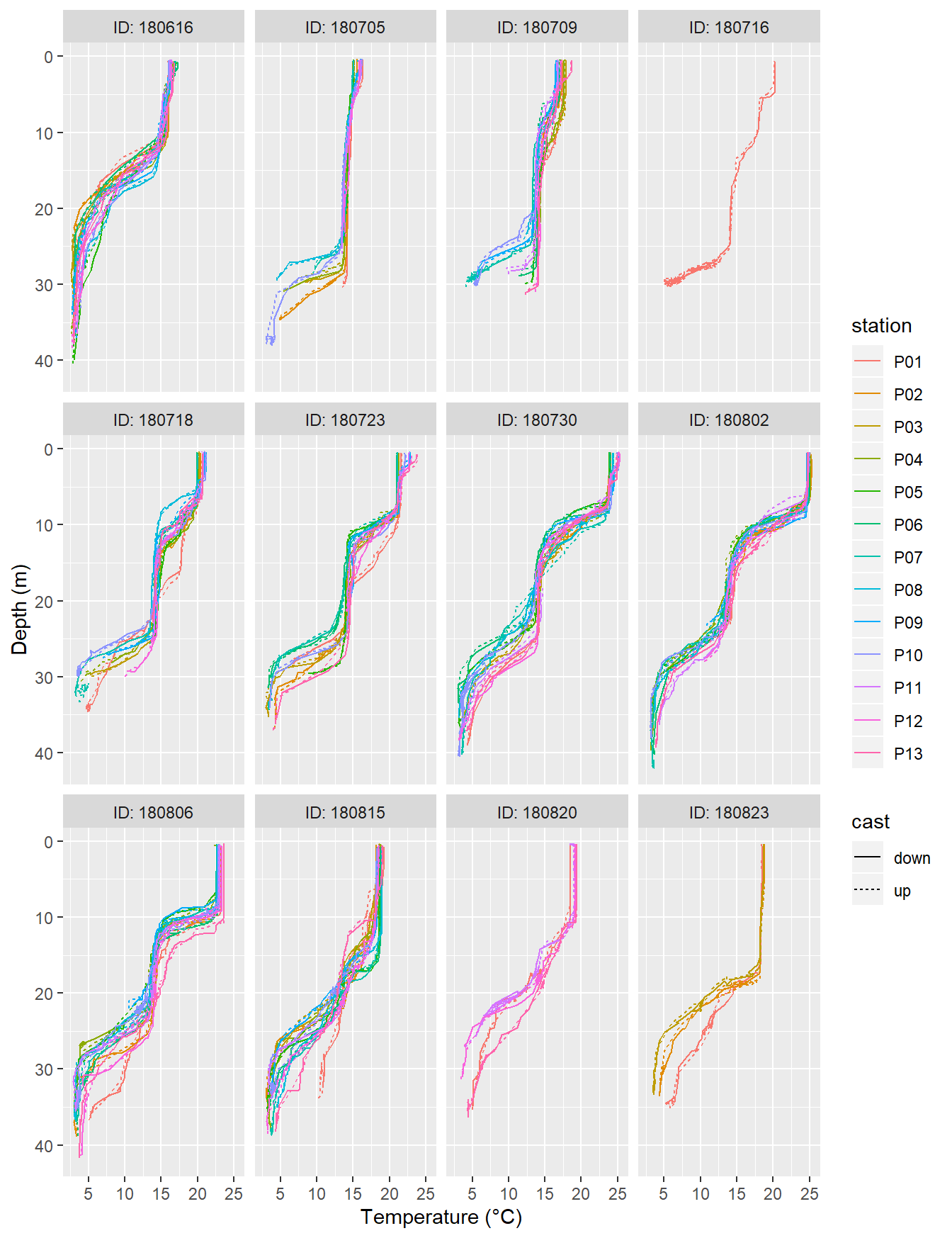
Temperature profiles recorded on regular stations P01-P13. ID refers to the starting date of each cruise.
CTD %>%
arrange(date_time) %>%
filter(type == "P") %>%
ggplot(aes(pCO2, dep, col=station, linetype = cast))+
geom_path()+
scale_y_reverse()+
labs(x=expression(pCO[2]~(µatm)), y="Depth (m)")+
facet_wrap(~ID, labeller = label_both)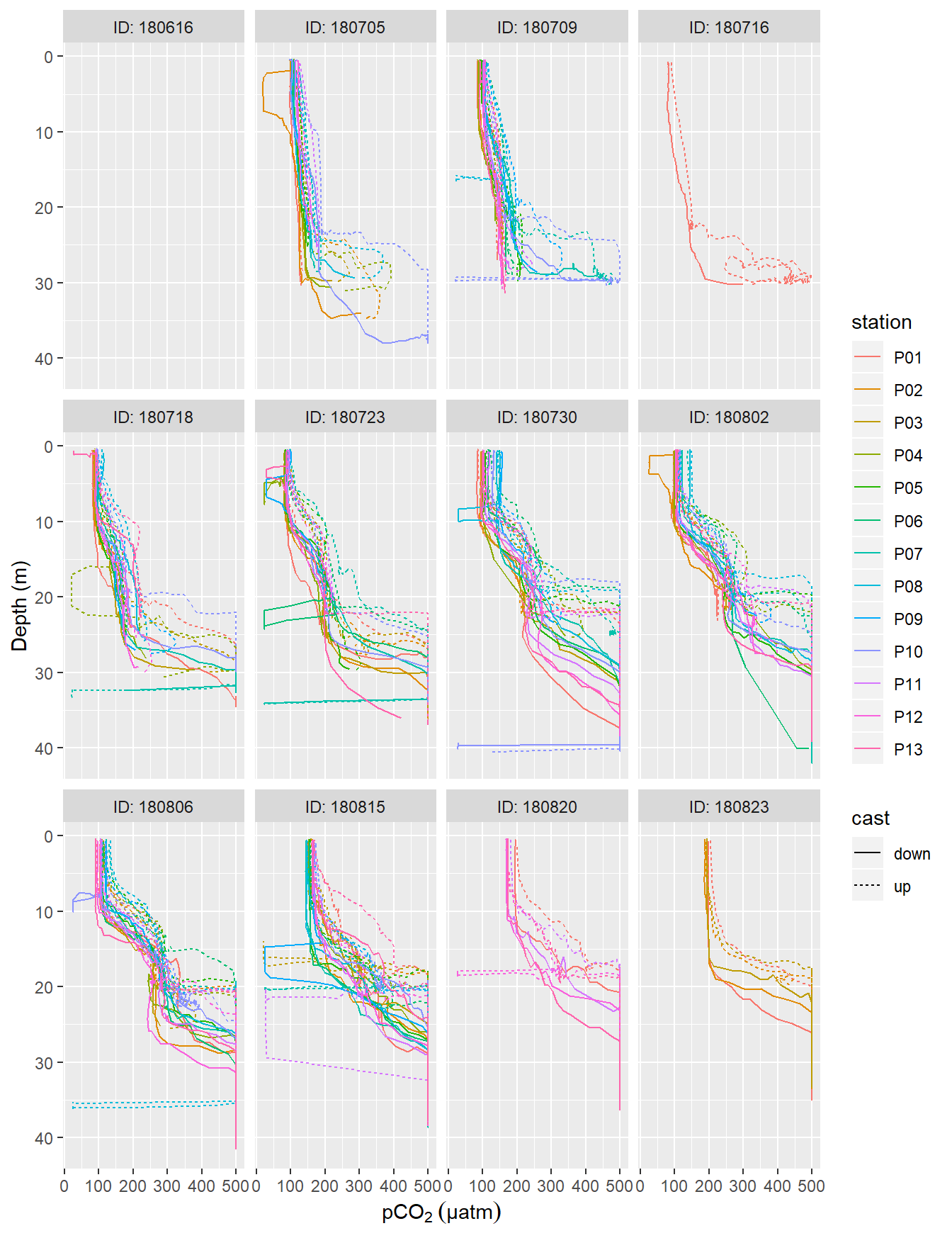
pCO2 profiles (analog output from HydroC) recorded on regular stations P01-P13. ID refers to the starting date of each cruise. Please note that pCO2 measurement range is restricted to 100-500 µatm here due to the settings of the analog voltage output of the sensor.
pCO2 data
HydroC pCO2 data were provided by KM Contros after applying a drift correction to the raw data, which was based on pre- and post-deployment calibration results.
# Read Contros corrected data file
HC <-
read_csv2(here::here("Data/TinaV/Sensor/HydroC-pCO2/corrected_Contros",
"parameter&pCO2s(method 43).txt"),
col_names = c("date_time", "Zero", "Flush", "p_NDIR",
"p_in", "T_control", "T_gas", "%rH_gas",
"Signal_raw", "Signal_ref", "T_sensor",
"pCO2", "Runtime", "nr.ave")) %>%
mutate(Flush = as.factor(as.character(Flush)),
Zero = as.factor(as.character(Zero))) %>%
select(date_time, Zero, Flush, pCO2)Individual deployments (periods of observations with less than 30 sec between recordings) were identified and relevant deployment periods were subsetted.
# Deployments: Identification
HC <- HC %>%
mutate(date_time = dmy_hms(date_time),
deployment = cumsum(c(TRUE,diff(date_time)>=30)))
# Deployments: Plots ------------------------------------------------------
# for (i in unique(HC$deployment)) {
#
# HC %>%
# filter(deployment == i) %>%
# ggplot(aes(date_time, pCO2_corr, col=as.factor(Zero)))+
# geom_line()
#
# ggsave(here::here("/Plots/TinaV/Sensor/HydroC_diagnostics/Deployments",
# paste(i,"_deployment_HydroC_timeseries.jpg", sep="")),
# width = 15, height = 4)
#
# }
#
# HC %>%
# ggplot(aes(date_time, pCO2_corr, col=as.factor(deployment)))+
# geom_line()
#
# ggsave(here::here("/Plots/TinaV/Sensor/HydroC_diagnostics/Deployments",
# "all_deployment_HydroC_timeseries.jpg"),
# width = 40, height = 4)
# Deployments: Subset relevant periods ------------------------------------
# Subset deployment 29 for high resolution response time determination
# HC %>%
# filter(deployment == 29) %>%
# write_csv(here::here("Data/_summarized_data_files",
# "Tina_V_Sensor_HydroC_RT-experiment_29.csv"))
HC <- HC %>%
filter(deployment %in% c(2,6,9,14,17,21,23,27,29,31,33,34,35,37))Individual zeroings were labeled with a counter and a period of 10 min after the zeroing was labelled as Flush period (overriding the internal Flush flag). A flag mixing was introduced, flagging the initial 20 sec of each Flush period as “mixing” and the rest as “equilibration”.
# Zeroing ID labelling ----------------------------------------------------
HC <- HC %>%
group_by(Zero) %>%
mutate(Zero_ID = as.factor(cumsum(c(TRUE,diff(date_time)>=30)))) %>%
ungroup()
# Flush: Identification ---------------------------------------------------
HC <- HC %>%
mutate(Flush = 0) %>%
group_by(Zero, Zero_ID) %>%
mutate(start = min(date_time),
duration = date_time - start,
Flush = if_else(Zero == 0 & duration < 600, "1", "0")) %>%
ungroup()
# Flush: Identify equilibration and internal gas mixing periods ----------
HC <- HC %>%
mutate(mixing = if_else(duration < 20, "mixing", "equilibration"))
# Flush <- HC %>%
# filter(Flush == 1, duration <=300)
# Flush: Plot individual periods ------------------------------------------
# for (i in unique(Flush$Zero_ID)) {
#
# Flush %>%
# filter(Zero_ID == i) %>%
# ggplot(aes(duration, pCO2, col=mixing))+
# geom_point() +
# scale_color_brewer(palette = "Set1")
#
# ggsave(here::here("/Plots/TinaV/Sensor/HydroC_diagnostics/Flush",
# paste(i,"_Zero_ID_HydroC_Flush.jpg", sep="")),
# width = 10, height = 4)
#
# }
#
# for (i in unique(HC$Zero_ID)) {
#
# HC %>%
# filter(Flush == 1, Zero_ID == i) %>%
# ggplot(aes(duration, pCO2, col=mixing))+
# geom_point() +
# scale_color_brewer(palette = "Set1")
#
# ggsave(here::here("/Plots/TinaV/Sensor/HydroC_diagnostics/Flush",
# paste(i,"_Zero_ID_HydroC_HC.jpg", sep="")),
# width = 10, height = 4)
#
# }
# Clean data: Plot deployments --------------------------------------------
# for (i in unique(HC$deployment)) {
#
# HC %>%
# filter(Zero ==0, Flush == 0, deployment == i) %>%
# ggplot(aes(date_time, pCO2_corr, col=Zero_ID))+
# geom_line()
#
# ggsave(here::here("/Plots/TinaV/Sensor/HydroC_diagnostics/Deployments_clean", paste(i,"_deployment_only_HydroC_timeseries.jpg", sep="")),
# width = 15, height = 4)
#
# }
# Write summarized data files ----------------------------------------------
HC %>%
write_csv(here::here("Data/_summarized_data_files",
"Tina_V_HydroC.csv"))
# Flush %>%
# write_csv(here::here("Data/_summarized_data_files",
# "Tina_V_HydroC_Flush.csv"))Tasks / open questions
include data around Ostergarnsholm island and crossing large vessels
Include information about HydroC calibration results and raw data correction by Contros
Check results from field response time experiment (high zeroing frequency)
sessionInfo()R version 3.5.0 (2018-04-23)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 17763)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252
[2] LC_CTYPE=English_United States.1252
[3] LC_MONETARY=English_United States.1252
[4] LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] lubridate_1.7.4 data.table_1.12.2 forcats_0.4.0
[4] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2
[7] readr_1.3.1 tidyr_1.0.0 tibble_2.1.3
[10] ggplot2_3.2.1 tidyverse_1.2.1
loaded via a namespace (and not attached):
[1] tidyselect_0.2.5 xfun_0.9 haven_2.1.1 lattice_0.20-35
[5] colorspace_1.3-2 vctrs_0.2.0 generics_0.0.2 htmltools_0.3.6
[9] yaml_2.2.0 rlang_0.4.0 pillar_1.3.1 glue_1.3.1
[13] withr_2.1.2 modelr_0.1.5 readxl_1.3.1 lifecycle_0.1.0
[17] plyr_1.8.4 munsell_0.5.0 gtable_0.2.0 workflowr_1.4.0
[21] cellranger_1.1.0 rvest_0.3.4 evaluate_0.14 labeling_0.3
[25] knitr_1.25 highr_0.7 broom_0.5.2 Rcpp_1.0.1
[29] backports_1.1.2 scales_0.5.0 jsonlite_1.6 fs_1.3.1
[33] hms_0.5.1 digest_0.6.18 stringi_1.1.7 grid_3.5.0
[37] rprojroot_1.3-2 here_0.1 cli_1.1.0 tools_3.5.0
[41] magrittr_1.5 lazyeval_0.2.1 crayon_1.3.4 whisker_0.3-2
[45] pkgconfig_2.0.2 zeallot_0.1.0 xml2_1.2.2 assertthat_0.2.0
[49] rmarkdown_1.15 httr_1.4.1 rstudioapi_0.10 R6_2.2.2
[53] nlme_3.1-137 git2r_0.23.0 compiler_3.5.0