GLODAPv2_2020
Jens Daniel Müller
17 July, 2020
Last updated: 2020-07-17
Checks: 7 0
Knit directory: Cant_eMLR/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200707) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 4685ad7. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rproj.user/
Ignored: data/GLODAPv2_2016b_MappedClimatologies/
Ignored: data/GLODAPv2_2020/
Ignored: data/World_Ocean_Atlas_2018/
Ignored: data/pCO2_atmosphere/
Ignored: dump/
Ignored: output/plots/
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/read_GLODAPv2_2020.Rmd) and HTML (docs/read_GLODAPv2_2020.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 4685ad7 | jens-daniel-mueller | 2020-07-17 | 150m depth limit implemented |
| html | 56c3ed9 | jens-daniel-mueller | 2020-07-14 | Build site. |
| Rmd | aed89af | jens-daniel-mueller | 2020-07-14 | added Rmd for MappedClimatologies |
| html | 74d4abd | jens-daniel-mueller | 2020-07-14 | Build site. |
| html | 1c511ce | jens-daniel-mueller | 2020-07-14 | Build site. |
| Rmd | e03016e | jens-daniel-mueller | 2020-07-14 | split read in per data set |
library(tidyverse)
library(lubridate)
library(patchwork)1 Read master file
- Data source:
GLODAPv2.2020_Merged_Master_File.csvfrom glodap.info
GLODAP <- read_csv(here::here("data/GLODAPv2_2020/Merged_data_product",
"GLODAPv2.2020_Merged_Master_File.csv"),
na = "-9999",
col_types = cols(.default = col_double()))
# relevant columns
GLODAP <- GLODAP %>%
select(cruise:talkqc)
GLODAP <- GLODAP %>%
mutate(date = ymd(paste(year, month, day))) %>%
#decade = as.factor(floor(year / 10) * 10)) %>%
relocate(date)
GLODAP <- GLODAP %>%
select(-c(month:minute,
maxsampdepth, pressure,
theta, sigma0:gamma,
nitrate:nitritef))2 Clean data
Only samples with all relevant parameters determined were selected. The following subsetting parameters were defined:
flag_f <- 2
flag_qc <- 1
min_depth <- 150
flag_f[1] 2flag_qc[1] 1min_depth[1] 150- calculate summary statistics during cleaning process
GLODAP_stats <- GLODAP %>%
summarise(total = n())
GLODAP <- GLODAP %>%
filter(!is.na(tco2))
GLODAP <- GLODAP %>%
filter(tco2f == flag_f) %>%
select(-tco2f)
GLODAP <- GLODAP %>%
filter(tco2qc == flag_qc) %>%
select(-tco2qc)
GLODAP_stats_temp <- GLODAP %>%
summarise(tco2 = n())
GLODAP_stats <- cbind(GLODAP_stats, GLODAP_stats_temp)
rm(GLODAP_stats_temp)
##
GLODAP <- GLODAP %>%
filter(!is.na(talk))
GLODAP <- GLODAP %>%
filter(talkf == flag_f) %>%
select(-talkf)
GLODAP <- GLODAP %>%
filter(talkqc == flag_qc) %>%
select(-talkqc)
##
GLODAP <- GLODAP %>%
filter(!is.na(phosphate))
GLODAP <- GLODAP %>%
filter(phosphatef == flag_f) %>%
select(-phosphatef)
GLODAP <- GLODAP %>%
filter(phosphateqc == flag_qc) %>%
select(-phosphateqc)
GLODAP_stats_temp <- GLODAP %>%
summarise(C_star_variables = n())
GLODAP_stats <- cbind(GLODAP_stats, GLODAP_stats_temp)
rm(GLODAP_stats_temp)
##
GLODAP <- GLODAP %>%
filter(!is.na(temperature))
##
GLODAP <- GLODAP %>%
filter(!is.na(salinity))
GLODAP <- GLODAP %>%
filter(salinityf == flag_f) %>%
select(-salinityf)
GLODAP <- GLODAP %>%
filter(salinityqc == flag_qc) %>%
select(-salinityqc)
##
GLODAP <- GLODAP %>%
filter(!is.na(silicate))
GLODAP <- GLODAP %>%
filter(silicatef == flag_f) %>%
select(-silicatef)
GLODAP <- GLODAP %>%
filter(silicateqc == flag_qc) %>%
select(-silicateqc)
##
GLODAP <- GLODAP %>%
filter(!is.na(oxygen))
GLODAP <- GLODAP %>%
filter(oxygenf == flag_f) %>%
select(-oxygenf)
GLODAP <- GLODAP %>%
filter(oxygenqc == flag_qc) %>%
select(-oxygenqc)
##
GLODAP <- GLODAP %>%
filter(!is.na(aou))
GLODAP <- GLODAP %>%
filter(aouf == flag_f) %>%
select(-aouf)
GLODAP_stats_temp <- GLODAP %>%
summarise(eMLR_variables = n())
GLODAP_stats <- cbind(GLODAP_stats, GLODAP_stats_temp)
rm(GLODAP_stats_temp)
##
GLODAP <- GLODAP %>%
filter(depth >= min_depth)
GLODAP_stats_temp <- GLODAP %>%
summarise(eMLR_variables_150 = n())
GLODAP_stats <- cbind(GLODAP_stats, GLODAP_stats_temp)
rm(GLODAP_stats_temp)
GLODAP_stats_long <- GLODAP_stats %>%
pivot_longer(1:length(GLODAP_stats), names_to = "parameter", values_to = "n")
GLODAP_stats_long %>% write_csv(here::here("data/GLODAPv2_2020/_summarized_data_files",
"GLODAPv2.2020_stats.csv"))
rm(GLODAP_stats_long, GLODAP_stats)3 Assign reference eras
Samples were assigned to following eras:
JGOFS/WOCE 1981 - 1999
GO-SHIP 2000 - 2012
new_era 2013 - now
GLODAP <- GLODAP %>%
filter(year >= 1981) %>%
mutate(era = "JGOFS/WOCE",
era = if_else(year >= 2000, "GO-SHIP", era),
era = if_else(year >= 2013, "new_era", era))GLODAP %>% write_csv(here::here("data/GLODAPv2_2020/_summarized_data_files",
"GLODAPv2.2020_clean.csv"))4 Overview plots
Open clean data file.
GLODAP <- read_csv(here::here("data/GLODAPv2_2020/_summarized_data_files",
"GLODAPv2.2020_clean.csv"))4.1 Assign spatial grid
For the following plots, observations were gridded spatially to 5°x5° intervals.
GLODAP <- GLODAP %>%
mutate(lat_grid = cut(latitude, seq(-90, 90, 5), seq(-87.5, 87.5, 5)),
lat_grid = as.numeric(as.character(lat_grid)),
lon_grid = cut(longitude, seq(-180, 180, 5), seq(-177.5, 177.5, 5)),
lon_grid = as.numeric(as.character(lon_grid))) %>%
arrange(date)4.2 Cleaning stats
GLODAP_stats_long <- read_csv(here::here("data/GLODAPv2_2020/_summarized_data_files",
"GLODAPv2.2020_stats.csv"))
GLODAP_stats_long <- GLODAP_stats_long %>%
mutate(parameter = fct_reorder(parameter, n))
GLODAP_stats_long %>%
ggplot(aes(parameter, n/1000))+
geom_col()+
coord_flip()+
labs(y="n (1000)")+
theme(axis.title.y = element_blank())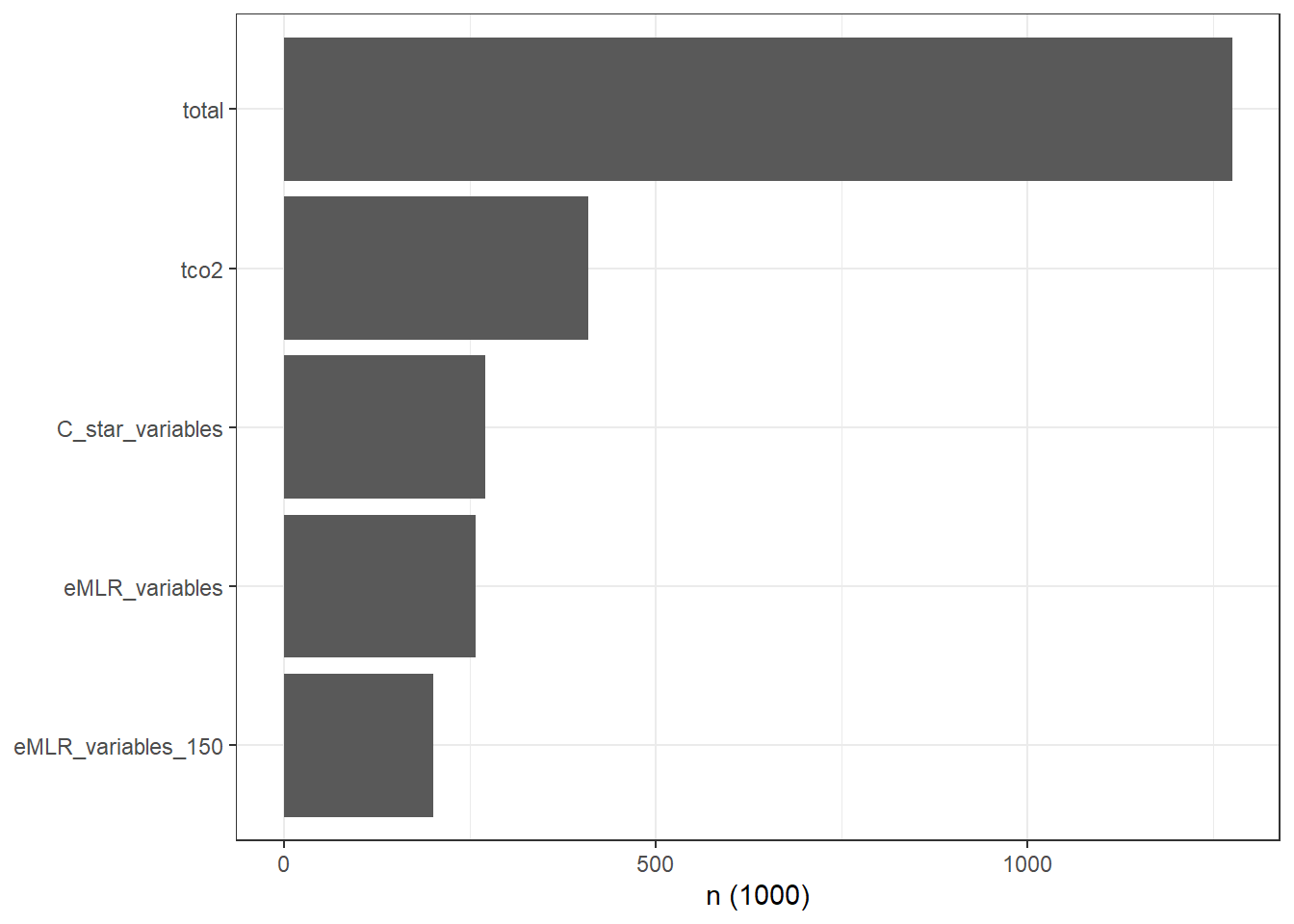
rm(GLODAP_stats_long)4.3 Histogram latitudes
GLODAP_histogram_lat <- GLODAP %>%
group_by(era, lat_grid) %>%
tally() %>%
ungroup()
GLODAP_histogram_lat %>%
ggplot(aes(lat_grid, n, fill=era))+
geom_col()+
scale_x_continuous(breaks = seq(-87.5,90,10))+
scale_fill_viridis_d()+
coord_flip(expand = 0)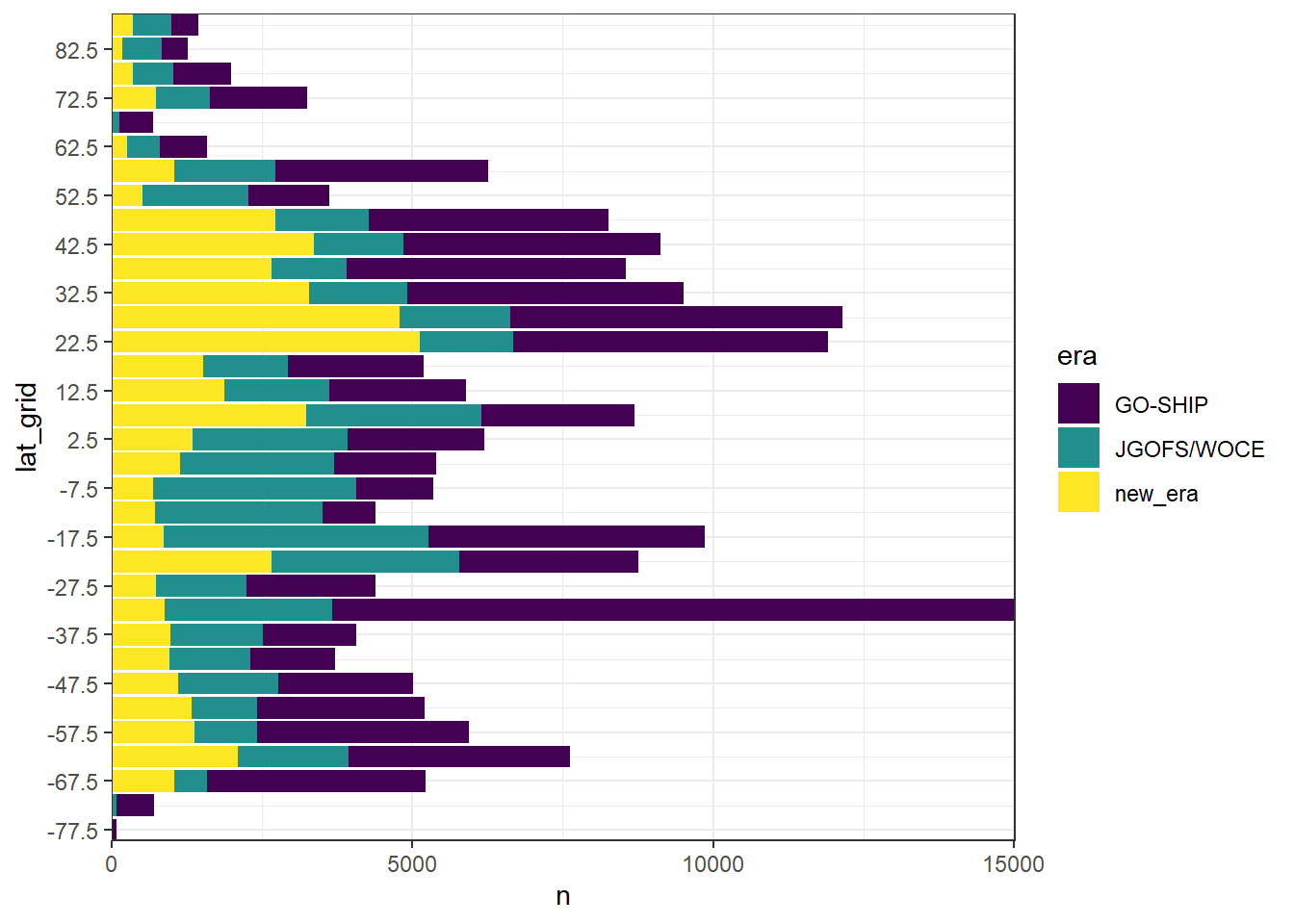
rm(GLODAP_histogram_lat)4.4 Histogram year
GLODAP_histogram_year <- GLODAP %>%
group_by(era, year) %>%
tally() %>%
ungroup()
era_median_year <- GLODAP %>%
group_by(era) %>%
summarise(t_ref = median(year)) %>%
ungroup()
GLODAP_histogram_year %>%
ggplot(aes(year, n, fill=era))+
geom_col()+
geom_vline(data = era_median_year, aes(xintercept = t_ref))+
coord_cartesian(expand = 0)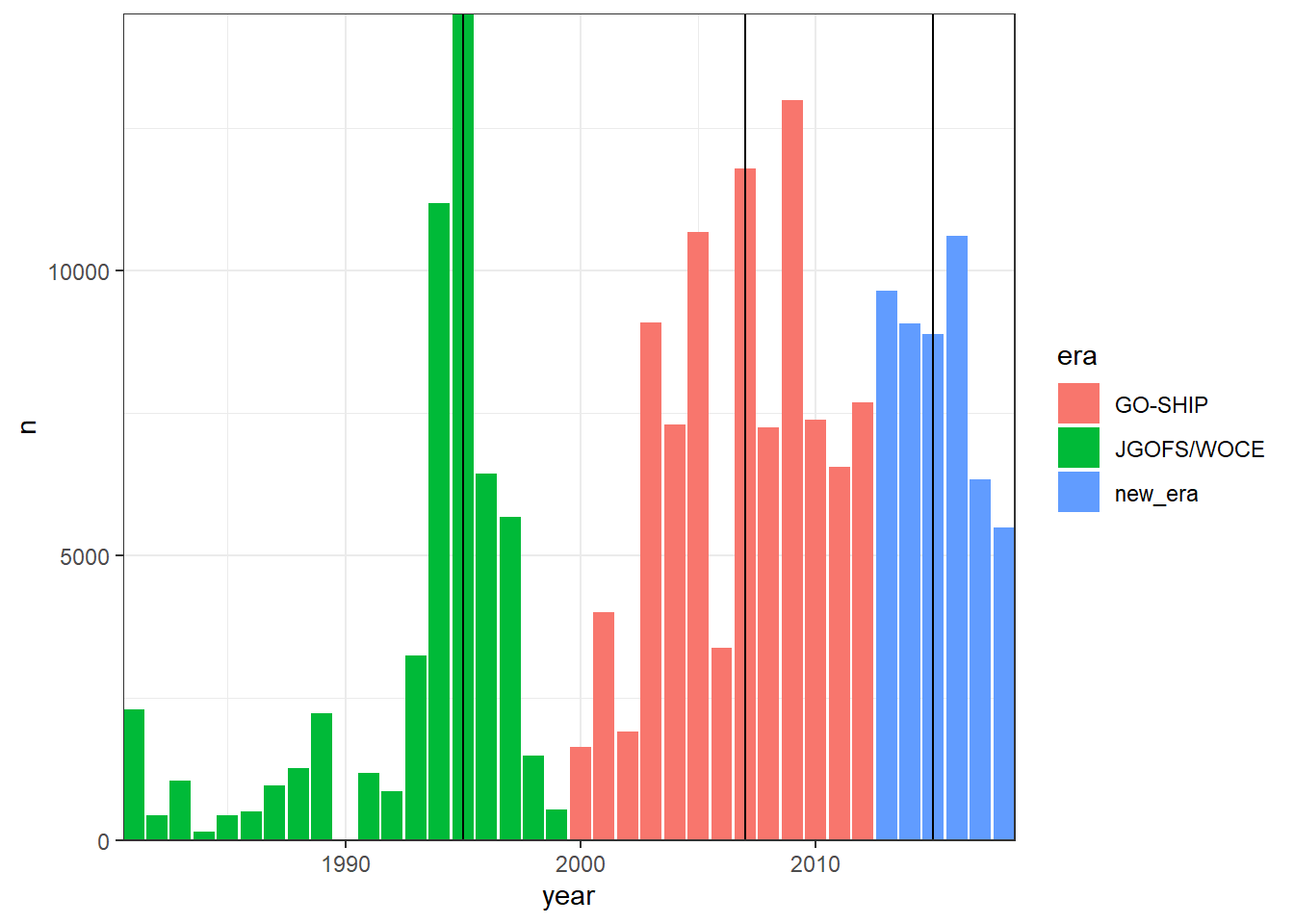
rm(GLODAP_histogram_year,
era_median_year)4.5 Hovmoeller (lat vs year)
GLODAP_hovmoeller_year <- GLODAP %>%
group_by(year, lat_grid) %>%
tally() %>%
ungroup()
GLODAP_hovmoeller_year %>%
ggplot(aes(year, lat_grid, fill=log10(n)))+
geom_tile()+
geom_vline(xintercept = c(1999.5, 2012.5))+
scale_fill_viridis_c(option = "magma", direction = -1)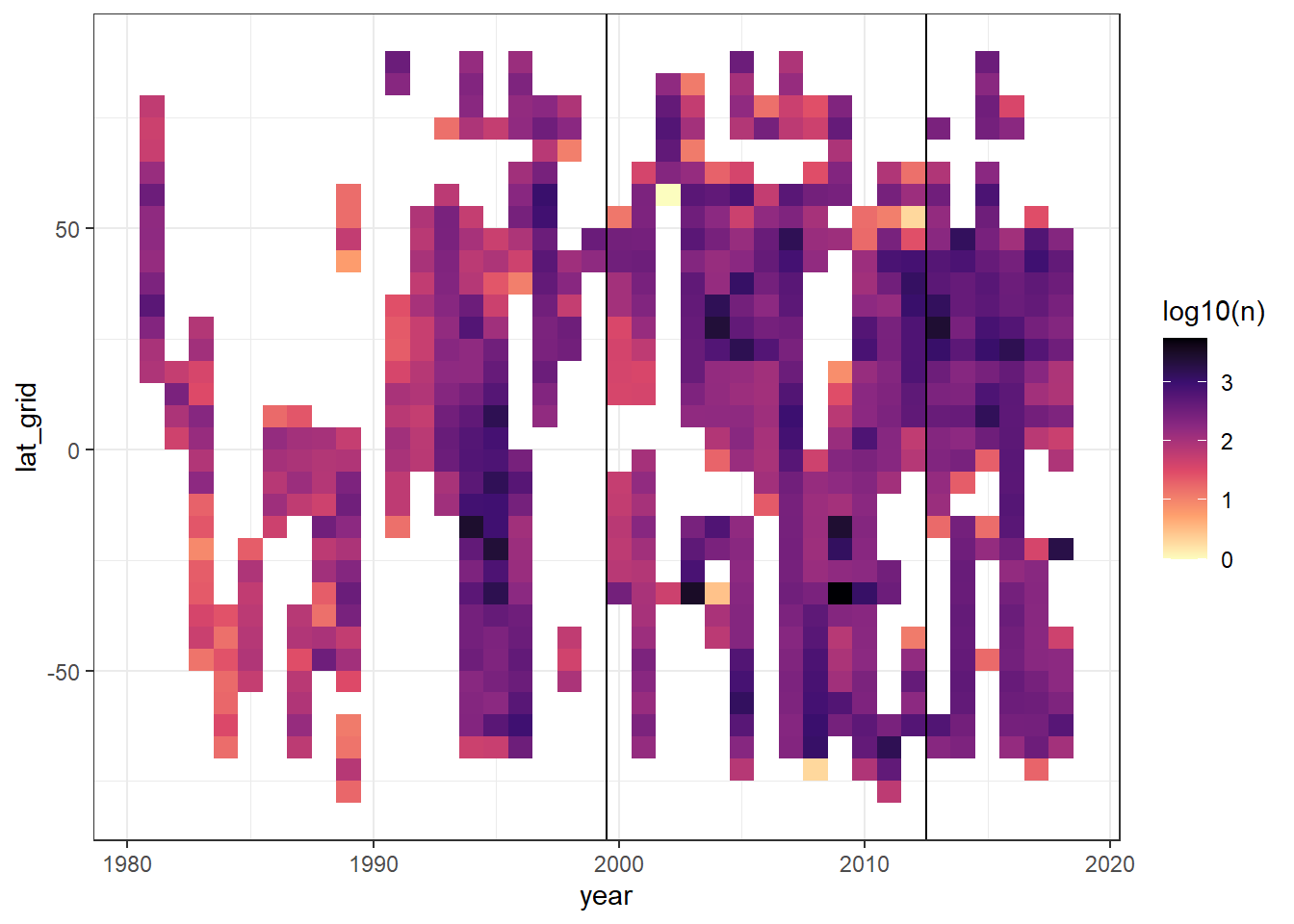
rm(GLODAP_hovmoeller_year)4.6 Maps by era
mapWorld <- borders("world", colour="gray60", fill="gray60")
GLODAP_map_era <- GLODAP %>%
group_by(era, lat_grid, lon_grid) %>%
tally() %>%
ungroup()
GLODAP_map_era <- GLODAP_map_era %>%
mutate(era = factor(era, c("JGOFS/WOCE", "GO-SHIP", "new_era")))
GLODAP_map_era %>%
ggplot(aes(lon_grid, lat_grid, fill=log10(n)))+
mapWorld+
geom_raster()+
scale_fill_viridis_c(option = "magma", direction = -1)+
scale_x_continuous(breaks = seq(-180, 180, 30))+
scale_y_continuous(breaks = seq(-90, 90, 30))+
coord_quickmap(expand = FALSE)+
facet_wrap(~era, ncol=1)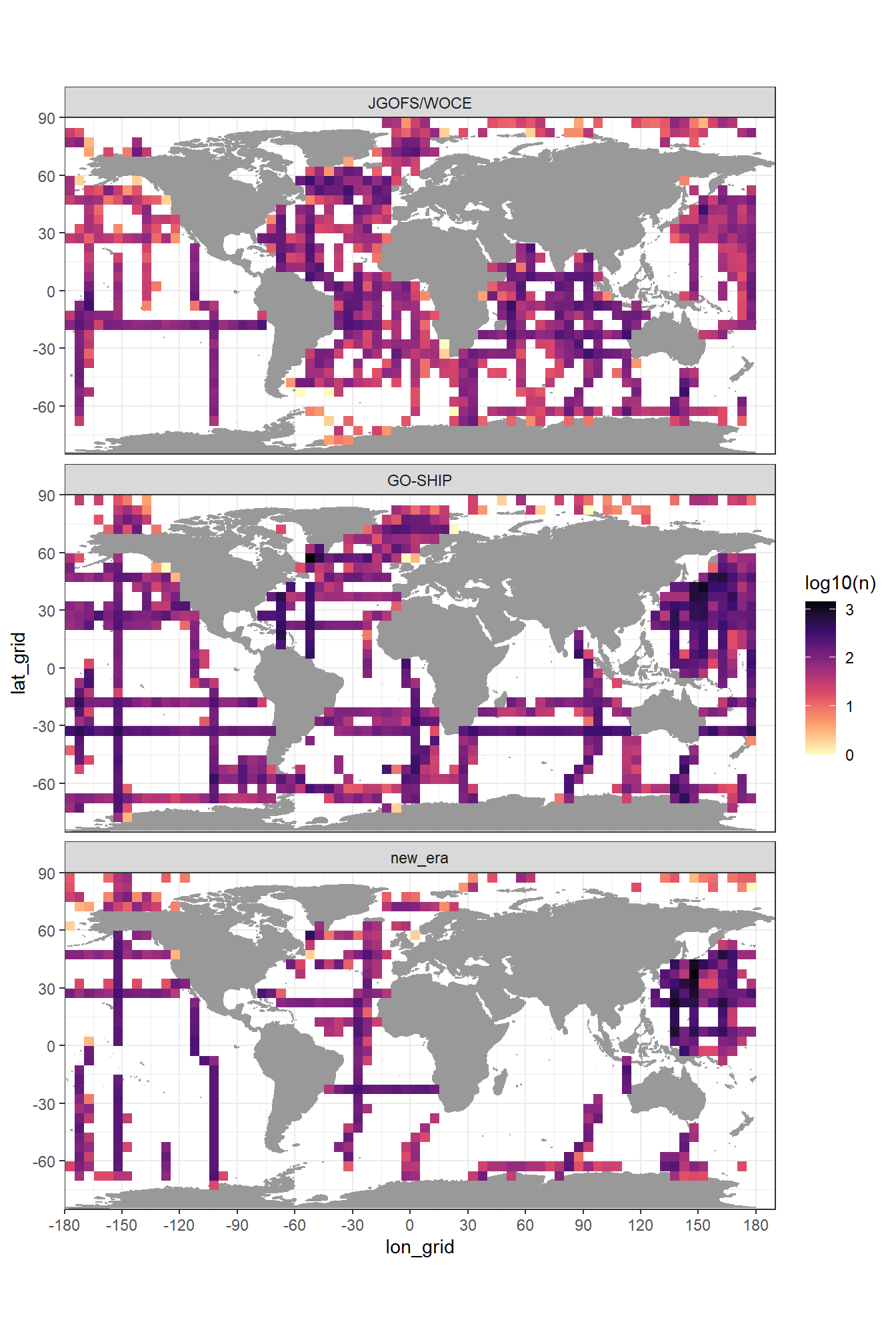
rm(GLODAP_map_era,
mapWorld)5 Individual cruise sections
cruises <- GLODAP %>%
group_by(cruise) %>%
summarise(date_mean = mean(date, na.rm = TRUE),
n = n()) %>%
ungroup() %>%
arrange(date_mean)
GLODAP <- full_join(GLODAP, cruises)
mapWorld <- borders("world", colour="gray60", fill="gray60")
n <- 0
for (i_cruise in unique(cruises$cruise)) {
#i_cruise <- unique(cruises$cruise)[1]
n <- n+1
print(n)
GLODAP_cruise <- GLODAP %>%
filter(cruise == i_cruise) %>%
arrange(date)
cruises_cruise <- cruises %>%
filter(cruise == i_cruise)
map <- GLODAP_cruise %>%
ggplot(aes(longitude, latitude))+
mapWorld+
geom_point(aes(col=date))+
geom_path()+
coord_quickmap(expand = FALSE)+
scale_color_viridis_c(trans = "date")+
labs(title = paste("Mean date:", cruises_cruise$date_mean,
"| cruise:", cruises_cruise$cruise,
"| n(samples):", cruises_cruise$n))
lon_section <- GLODAP_cruise %>%
ggplot(aes(longitude, depth))+
scale_y_reverse()+
scale_color_viridis_c()
lon_tco2 <- lon_section+
geom_point(aes(col=tco2))
lon_talk <- lon_section+
geom_point(aes(col=talk))
lon_phosphate <- lon_section+
geom_point(aes(col=phosphate))
lat_section <- GLODAP_cruise %>%
ggplot(aes(latitude, depth))+
scale_y_reverse()+
scale_color_viridis_c()
lat_tco2 <- lat_section+
geom_point(aes(col=tco2))
lat_talk <- lat_section+
geom_point(aes(col=talk))
lat_phosphate <- lat_section+
geom_point(aes(col=phosphate))
map /
((lat_tco2 / lat_talk / lat_phosphate) |
(lon_tco2 / lon_talk / lon_phosphate))
ggsave(here::here("output/plots/data/all_cruises_clean",
paste("GLODAP_cruise_date",
cruises_cruise$date_mean,
"n",
cruises_cruise$n,
"cruise",
cruises_cruise$cruise,
".png",
sep = "_")),
width = 9, height = 9)
rm(map,
lon_section, lat_section,
lat_tco2, lat_talk, lat_phosphate, lon_tco2, lon_talk, lon_phosphate,
GLODAP_cruise, cruises_cruise)
}
# library("rnaturalearth")
# library("rnaturalearthdata")
# library("sf")
#
# world <- ne_countries(scale = "small", returnclass = "sf")
# class(world)
#
# GLODAP_map <- GLODAP %>%
# group_by(lat_grid, lon_grid) %>%
# tally() %>%
# ungroup()
#
# ggplot() +
# geom_raster(data = GLODAP_map, aes(lon_grid, lat_grid))+
# geom_sf(data = world)+
# coord_sf(crs = "+proj=robin +lat_0=0 +lon_0=0 +x0=0 +y0=0")
# https://gist.github.com/clauswilke/783e1a8ee3233775c9c3b8bfe531e28a
# https://twitter.com/clauswilke/status/1066024436208406529
# https://www.r-spatial.org/r/2018/10/25/ggplot2-sf.html6 Open tasks
- remove marginal seas and data north of 65°N
- move A16 cruises from new_era to GO-SHIP era
7 Questions
- exclude coastal area in general?
sessionInfo()R version 3.6.3 (2020-02-29)
Platform: i386-w64-mingw32/i386 (32-bit)
Running under: Windows 10 x64 (build 18363)
Matrix products: default
locale:
[1] LC_COLLATE=English_Germany.1252 LC_CTYPE=English_Germany.1252
[3] LC_MONETARY=English_Germany.1252 LC_NUMERIC=C
[5] LC_TIME=English_Germany.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] patchwork_1.0.1 lubridate_1.7.9 forcats_0.5.0 stringr_1.4.0
[5] dplyr_1.0.0 purrr_0.3.4 readr_1.3.1 tidyr_1.1.0
[9] tibble_3.0.3 ggplot2_3.3.2 tidyverse_1.3.0 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] jsonlite_1.7.0 rstudioapi_0.11 generics_0.0.2 magrittr_1.5
[5] farver_2.0.3 gtable_0.3.0 rmarkdown_2.3 vctrs_0.3.1
[9] fs_1.4.2 hms_0.5.3 xml2_1.3.2 pillar_1.4.6
[13] htmltools_0.5.0 haven_2.3.1 later_1.1.0.1 broom_0.7.0
[17] cellranger_1.1.0 tidyselect_1.1.0 knitr_1.29 git2r_0.27.1
[21] whisker_0.4 lifecycle_0.2.0 pkgconfig_2.0.3 R6_2.4.1
[25] digest_0.6.25 xfun_0.15 colorspace_1.4-1 rprojroot_1.3-2
[29] stringi_1.4.6 yaml_2.2.1 evaluate_0.14 labeling_0.3
[33] fansi_0.4.1 httr_1.4.1 compiler_3.6.3 here_0.1
[37] cli_2.0.2 withr_2.2.0 backports_1.1.5 munsell_0.5.0
[41] DBI_1.1.0 modelr_0.1.8 Rcpp_1.0.5 readxl_1.3.1
[45] maps_3.3.0 dbplyr_1.4.4 ellipsis_0.3.1 assertthat_0.2.1
[49] blob_1.2.1 tools_3.6.3 reprex_0.3.0 viridisLite_0.3.0
[53] httpuv_1.5.4 scales_1.1.1 crayon_1.3.4 glue_1.4.1
[57] rlang_0.4.7 rvest_0.3.5 promises_1.1.1 grid_3.6.3