BGC-Argo pH Data
Pasqualina Vonlanthen & Jens Daniel Müller
11 November, 2021
Last updated: 2021-11-11
Checks: 7 0
Knit directory: bgc_argo_r_argodata/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20211008) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version fb668ef. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: output/
Untracked files:
Untracked: code/creating_dataframe.R
Untracked: code/creating_map.R
Untracked: code/pH_data_timeseries.R
Unstaged changes:
Modified: analysis/_site.yml
Modified: code/Workflowr_project_managment.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/ph_data.Rmd) and HTML (docs/ph_data.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | f7807db | pasqualina-vonlanthendinenna | 2021-11-11 | added oxygen data page |
| html | 6276d6c | pasqualina-vonlanthendinenna | 2021-11-11 | Build site. |
| Rmd | 8baed53 | pasqualina-vonlanthendinenna | 2021-11-11 | added pH data page |
Task
Explore BGC-Argo pH data through timeseries and monthly climatological maps
path_argo <- '/nfs/kryo/work/updata/bgc_argo_r_argodata'
path_emlr_utilities <- "/nfs/kryo/work/jenmueller/emlr_cant/utilities/files/"Load pH data
Load in delayed-mode adjusted pH values from the BGC-Argo synthetic profile files
# set cache directory
argo_set_cache_dir(cache_dir = path_argo)
# periodically update the cached files
argo_update_global(max_global_cache_age = Inf)
argo_update_data(max_data_cache_age = Inf)
# load synthetic Argo files containing delayed-mode data between 2013 and now
bgc_subset <- argo_global_synthetic_prof() %>%
argo_filter_data_mode(data_mode = 'delayed') %>% # load in delayed-mode data
argo_filter_date(date_min = '2013-01-01',
date_max = Sys.time())Loading argo_global_synthetic_prof()# read in the pH data (with corresponding CTD data)
ph_data <- argo_prof_levels(
path = bgc_subset,
vars =
c(
'PRES_ADJUSTED',
'PRES_ADJUSTED_QC',
'PRES_ADJUSTED_ERROR',
'PSAL_ADJUSTED',
'PSAL_ADJUSTED_QC',
'PSAL_ADJUSTED_ERROR',
'TEMP_ADJUSTED',
'TEMP_ADJUSTED_QC',
'TEMP_ADJUSTED_ERROR',
'PH_IN_SITU_TOTAL_ADJUSTED',
'PH_IN_SITU_TOTAL_ADJUSTED_QC',
'PH_IN_SITU_TOTAL_ADJUSTED_ERROR'
),
quiet = TRUE
)
# read in corresponding metadata
ph_metadata <- argo_prof_prof(path = bgc_subset)Extracting from 138081 files# merge the data and metadata
ph_merge <-
full_join(ph_data, ph_metadata)Joining, by = c("file", "n_prof")# harmonize lat and lon variables and remove columns with no data
ph_merge <- ph_merge %>%
rename(lon = longitude,
lat = latitude) %>%
mutate(lon = if_else(lon < 20, lon + 360, lon)) %>%
mutate(
lat = cut(lat, seq(-90, 90, 2), seq(-89.5, 89.5, 2)),
lat = as.numeric(as.character(lat)),
lon = cut(lon, seq(20, 380, 2), seq(20.5, 379.5, 2)), # change to 2x2º grid
lon = as.numeric(as.character(lon))
) %>%
select(
-c(profile_doxy_qc:profile_cdom_qc),
-c(profile_cndc_qc:profile_up_radiance555_qc)
) # remove columns which don't contain data Southern Ocean surface pH
The focus here is on surface pH (in the top 10 m of the watercolumn), in the region south of 30ºS
# select only best pH data (with QC flag 1) below 30ºS, for the top 10 m of the watercolumn
ph_surface <- ph_merge %>%
mutate(depth = swDepth(pres_adjusted, latitude = lat), .before = pres_adjusted) %>%
filter(ph_in_situ_total_adjusted_qc == '1', # keep only 'good' data
lat <= -30, # keep only data at or south of 30ºS
depth <= 10) %>% # keep only data above or at 10 m depth
mutate(
year = year(date), # separate the year and month from the date column
month = month(date), .after = n_prof
)
# check the correct latitudes, QC flags, and depth levels have been filtered
# max(ph_surface$lat)
# min(ph_surface$lat)
# table(ph_surface$ph_in_situ_total_adjusted_qc)
# max(ph_surface$depth)Monthly climatological map
Create a climatological monthly map of surface pH, in a 2x2º longitude/latitude grid, for the region south of 30ºS (monthly pH averaged over April 2014-August 2021)
# average pH values in the top 10 m for each month in each 2 x 2º longitude/latitude grid
ph_mean <- ph_surface %>%
group_by(lat, lon, month) %>%
summarise(ph_ave_month = mean(ph_in_situ_total_adjusted))`summarise()` has grouped output by 'lat', 'lon'. You can override using the `.groups` argument.# read in the map from updata
map <-
read_rds(paste(path_emlr_utilities,
"map_landmask_WOA18.rds",
sep = ""))
# map a monthly climatology of pH (April 2014 - August 2021)
map +
geom_tile(data = ph_mean,
aes(lon, lat, fill = ph_ave_month)) +
lims(y = c(-85, -25)) +
scale_fill_gradientn(colors = oceColorsJet(n = ph_mean$ph_ave_month)) +
labs(x = 'lon',
y = 'lat',
fill = 'pH',
title = 'Monthly average pH values (Apr 2014 - Aug 2021)') +
facet_wrap(~month)Warning in seq.int(0, 1, length.out = n): first element used of 'length.out'
argumentWarning: Raster pixels are placed at uneven vertical intervals and will be
shifted. Consider using geom_tile() instead.Warning: Removed 153708 rows containing missing values (geom_raster).
| Version | Author | Date |
|---|---|---|
| 6276d6c | pasqualina-vonlanthendinenna | 2021-11-11 |
Monthly timeseries
Plot timeseries of monthly pH values, averaged over the whole region south of 30ºS
# plot a timeseries of monthly values over the whole southern ocean south of 30ºS
ph_month <- ph_surface %>%
group_by(year, month) %>%
summarise(ph_ave = mean(ph_in_situ_total_adjusted))`summarise()` has grouped output by 'year'. You can override using the `.groups` argument.# timeseries of monthly pH values over 2014-2021 (separate panels for each month)
ph_month %>%
ggplot(aes(x = year, y = ph_ave)) +
facet_wrap(~month) +
geom_line() +
geom_point() +
labs(x = 'year',
y = 'pH in situ (total scale)',
title = 'monthly mean pH (Apr 2014-Aug 2021, south of 30ºS)')
#all months on one plot in different colors (not very nice plot)
# ph_month %>%
# ggplot(aes(x = year, y = ph_ave, group = month, col = as.character(month))) +
# geom_line() +
# geom_point() +
# labs(x = 'year', y = 'pH in situ (total scale)', title = 'monthly mean pH (Apr 2014-Aug 2021)')Plot the monthly average pH, per year (from Jan 2015 - Dec 2020), over the whole region south of 30ºS
# timeseries of monthly pH values for each year (separate years on the same plot)
ph_month %>%
filter(year != 2014,
year != 2021) %>% # remove the two years that are missing data (keep only data for full years)
ggplot(aes(x = month, y = ph_ave, group = year, col = as.character(year)))+
geom_line()+
geom_point()+
scale_x_continuous(breaks = seq(1, 12, 1))+
labs(x = 'month',
y = 'pH in situ (total scale)',
title = 'monthly mean pH (Jan 2015-Dec 2020, south of 30ºS)',
col = 'year')
| Version | Author | Date |
|---|---|---|
| 6276d6c | pasqualina-vonlanthendinenna | 2021-11-11 |
# calculate a yearly average ph (one ph value per year, for the whole domain)
ph_year <- ph_surface %>%
group_by(year) %>%
summarise(ph_ave = mean(ph_in_situ_total_adjusted))
# plot a timeseries of the yearly average pH value (one value per year)
ph_year %>%
ggplot(aes(x = year, y = ph_ave))+
lims(y = c(8.03, 8.06))+
geom_line()+
geom_point()+
labs(x = 'year',
y = 'pH in situ (total scale)',
title = 'yearly mean pH (Apr 2014-Aug 2021, south of 30ºS)')Northwest Pacific surface pH
Focus on surface pH in the northwest Pacific Ocean (10ºN - 70ºN, -190ºE - -140ºE)
# select only best oxygen data (with QC flag 1) between 10 and 70ºN, and 190 and 140ºW, for the top 10 m of the watercolumn
ph_nwpacific <- ph_merge %>%
mutate(depth = swDepth(pres_adjusted, latitude = lat), .before = pres_adjusted) %>%
filter(ph_in_situ_total_adjusted_qc == '1', # keep only 'good' data
between(lat, 10, 70),
between(lon, 190, 240), # keep only data at or south of 30ºS
depth <= 10) %>% # keep only data above or at 10 m depth
mutate(
year = year(date), # separate the year and month from the date column
month = month(date), .after = n_prof
)
# longitudes larger than -180ºE are lon-380Monthly climatological map
Create a map of climatological monthly surface pH values, in the north-west Pacific ocean (10ºN - 70ºN, -190ºE, -140ºE), for
# average oxygen values in the top 10 m for each month in each 2 x 2º longitude/latitude grid
ph_mean_nwpacific <- ph_nwpacific %>%
group_by(lat, lon, month) %>%
summarise(ph_ave_month = mean(ph_in_situ_total_adjusted))`summarise()` has grouped output by 'lat', 'lon'. You can override using the `.groups` argument.# map a monthly climatology of surface oxygen (Jan 2013 - August 2021)
map +
geom_tile(data = ph_mean_nwpacific,
aes(lon, lat, fill = ph_ave_month)) +
lims(y = c(5, 60),
x = c(180, 250)) +
scale_fill_gradientn(colors = oceColorsJet(n = ph_mean_nwpacific$ph_ave_month)) +
labs(x = 'lon',
y = 'lat',
fill = 'pH',
title = 'Monthly average pH (Jan 2013-Aug 2021)') +
theme(legend.position = 'right')+
facet_wrap(~month)Warning in seq.int(0, 1, length.out = n): first element used of 'length.out'
argumentWarning: Removed 219516 rows containing missing values (geom_raster).
Monthly timeseries
Timeseries of monthly mean pH, averaged over the whole NW-Pacific region (10ºN - 70ºN, -190ºE - -140ºE), in the upper 10 m of the watercolumn.
# plot a timeseries of monthly values over the whole southern ocean south of 30ºS
ph_month_nwpacific <- ph_nwpacific %>%
group_by(year, month) %>%
summarise(ph_ave = mean(ph_in_situ_total_adjusted))`summarise()` has grouped output by 'year'. You can override using the `.groups` argument.# timeseries of monthly pH values over 2014-2021 (separate panels for each month)
ph_month_nwpacific %>%
ggplot(aes(x = year, y = ph_ave)) +
facet_wrap(~month) +
scale_x_continuous(breaks = seq(2013, 2021, 2)) +
geom_line() +
geom_point() +
labs(x = 'year',
y = 'pH in situ (total scale)',
title = 'monthly mean pH (Jan 2013-Aug 2021, NW Pacific)')
Monthly average pH, per year, over the NW Pacific region
# timeseries of monthly pH values for each year (separate years on the same plot)
ph_month_nwpacific %>%
filter(year != 2016,
year != 2021) %>% # remove the two years that are missing data (keep only data for full years)
ggplot(aes(x = month, y = ph_ave, group = year, col = as.character(year)))+
geom_line()+
geom_point()+
scale_x_continuous(breaks = seq(1, 12, 1))+
labs(x = 'month',
y = 'pH in situ (total scale)',
title = 'monthly mean pH (Jan 2013-Dec 2020, NW Pacific)',
col = 'year')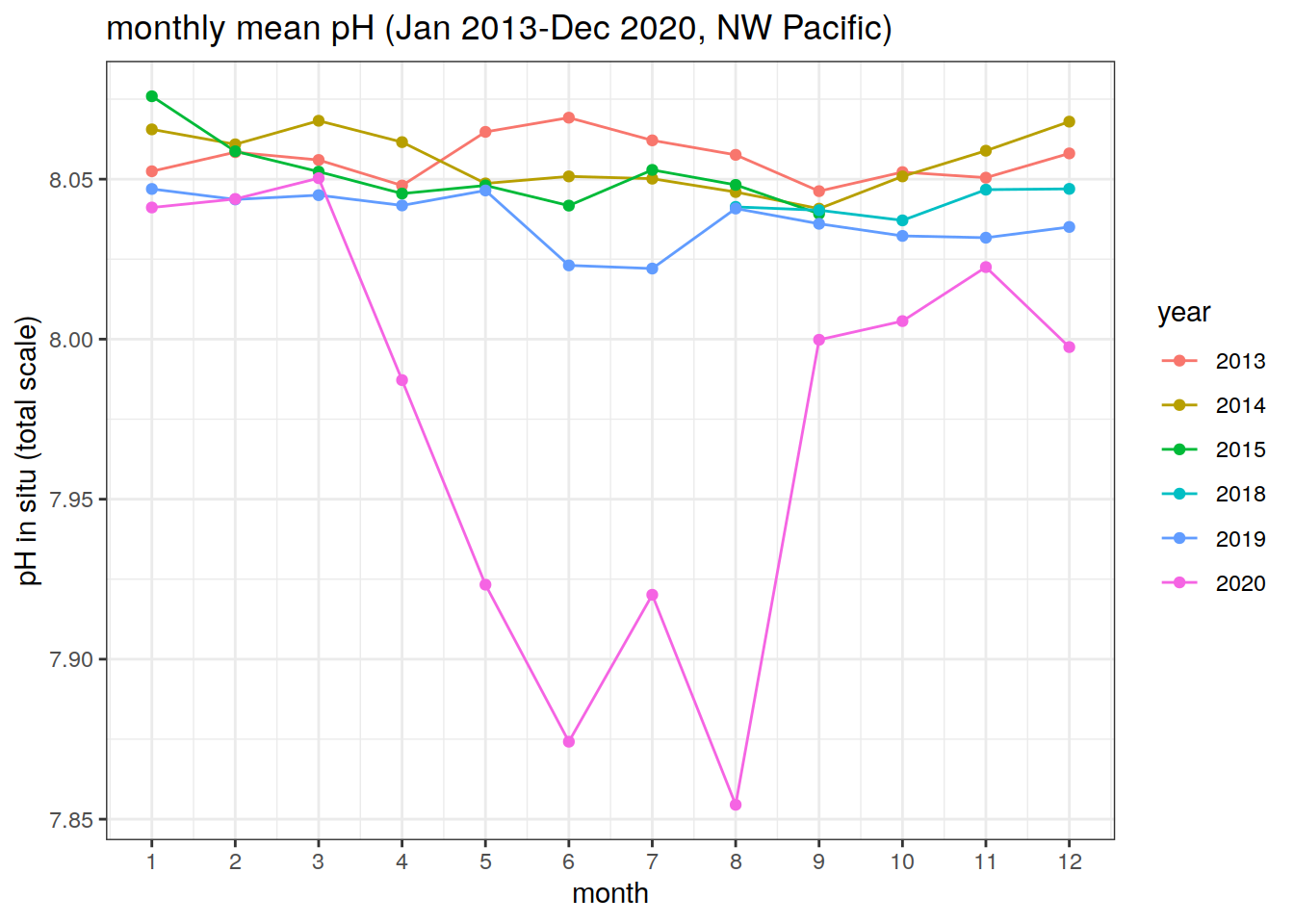
sessionInfo()R version 4.0.3 (2020-10-10)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: openSUSE Leap 15.2
Matrix products: default
BLAS: /usr/local/R-4.0.3/lib64/R/lib/libRblas.so
LAPACK: /usr/local/R-4.0.3/lib64/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] oce_1.4-0 testthat_3.0.4 sf_1.0-2
[4] gsw_1.0-6 lubridate_1.7.9 argodata_0.0.0.9000
[7] forcats_0.5.0 stringr_1.4.0 dplyr_1.0.5
[10] purrr_0.3.4 readr_1.4.0 tidyr_1.1.3
[13] tibble_3.1.3 ggplot2_3.3.5 tidyverse_1.3.0
[16] workflowr_1.6.2
loaded via a namespace (and not attached):
[1] fs_1.5.0 bit64_4.0.5 progress_1.2.2 httr_1.4.2
[5] rprojroot_2.0.2 tools_4.0.3 backports_1.1.10 bslib_0.2.5.1
[9] utf8_1.2.2 R6_2.5.1 KernSmooth_2.23-17 DBI_1.1.1
[13] colorspace_2.0-2 withr_2.4.2 tidyselect_1.1.0 prettyunits_1.1.1
[17] bit_4.0.4 compiler_4.0.3 git2r_0.27.1 cli_3.0.1
[21] rvest_0.3.6 RNetCDF_2.4-2 xml2_1.3.2 labeling_0.4.2
[25] sass_0.4.0 scales_1.1.1 classInt_0.4-3 proxy_0.4-26
[29] digest_0.6.27 rmarkdown_2.10 pkgconfig_2.0.3 htmltools_0.5.1.1
[33] dbplyr_1.4.4 highr_0.8 rlang_0.4.11 readxl_1.3.1
[37] rstudioapi_0.13 jquerylib_0.1.4 generics_0.1.0 farver_2.1.0
[41] jsonlite_1.7.2 vroom_1.5.5 magrittr_2.0.1 Rcpp_1.0.7
[45] munsell_0.5.0 fansi_0.5.0 lifecycle_1.0.0 stringi_1.5.3
[49] whisker_0.4 yaml_2.2.1 grid_4.0.3 blob_1.2.1
[53] parallel_4.0.3 promises_1.2.0.1 crayon_1.4.1 haven_2.3.1
[57] hms_0.5.3 knitr_1.33 pillar_1.6.2 reprex_0.3.0
[61] glue_1.4.2 evaluate_0.14 modelr_0.1.8 vctrs_0.3.8
[65] tzdb_0.1.2 httpuv_1.6.2 cellranger_1.1.0 gtable_0.3.0
[69] assertthat_0.2.1 xfun_0.25 broom_0.7.9 e1071_1.7-8
[73] later_1.3.0 class_7.3-17 units_0.7-2 ellipsis_0.3.2