Prepare temperature data and vertically align to climatology
David Stappard & Jens Daniel Müller
15 November, 2023
Last updated: 2023-11-15
Checks: 7 0
Knit directory: bgc_argo_r_argodata/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20211008) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 3eba518. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: output/
Unstaged changes:
Modified: code/start_background_job.R
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown
(analysis/temp_align_climatology.Rmd) and HTML
(docs/temp_align_climatology.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 3eba518 | ds2n19 | 2023-11-15 | Introduction of vertical alignment and cluster analysis to github website. |
Task
This markdown file reads previously created temperature climatology file and uses that as the definition of the depth levels that the Argo temperature data should be aligned to. As the climatology is based on pressure it is first aligned to standard depths. Previously created BGC data (bgc_data.rds) and metadata (bgc_metadata.rds) are loaded from the BGC preprocessed folder.
Base data qc flags are checked to ensure that the float position, pressure measurements and temperature measurements are good. Pressure is used to derive the depth of each measurement. The temperature profile is checked to ensure that significant gaps (specified by the opt_gap_limit, opt_gap_min_depth and opt_gap_max_depth) do not exist. Profiles are assigned a profile_range field that identifies the depth 1 = 600 m, 2 = 1200 m and 3 = 1500 m.
The float temperature profiles are then aligned using the spline function to match the depth levels of the climatology resulting in data frame bgc_data_temp_interpolated_clean. An anomaly file is then created from the vertically aligned profiles and climatology.
Set directories
location of pre-prepared data
Set options
Define options that are used to determine profiles that we will us in the ongoing analysis
# Options
# opt_profile_depth_range
# The profile must have at least one temperature reading at a depth <= opt_profile_depth_range[1, ]
# The profile must have at least one temperature reading at a depth >= opt_profile_depth_range[2, ].
# In addition if the profile depth does not exceed the min(opt_profile_depth_range[2, ]) (i.e. 600) it will be removed.
profile_range <- c(1, 2, 3)
min_depth <- c(5.0, 5.0, 5.0)
max_depth <- c(600, 1200, 1500)
opt_profile_depth_range <- data.frame(profile_range, min_depth, max_depth)
# opt_gap...
# The profile should not have a gap greater that opt_gap_limit within the range defined by opt_gap_min_depth and opt_gap_max_depth
opt_gap_limit <- c(28, 55, 110)
opt_gap_min_depth <- c(0, 400, 1000)
opt_gap_max_depth <- c(400, 1000, 1500)
# opt_measure_label, opt_xlim and opt_xbreaks are associated with formatting
opt_measure_label <- "temperature anomaly (°C)"
opt_xlim <- c(-4.5, 4.5)
opt_xbreaks <- c(-4, -2, 0, 2, 4)
# opt_n_prof_sel
# The selection criteria that is used against n_prof, here set to 1
# Description of n_prof usage is provided at https://argo.ucsd.edu/data/data-faq/version-3-profile-files/ the next two lines are from that page.
# The main Argo CTD profile is stored in N_PROF=1. All other parameters (including biogeochemical parameters) that are measured
# with the same vertical sampling scheme and at the same location and time as the main Argo CTD profile are also stored in N_PROF=1.
opt_n_prof_sel = 1
# opt_exclude_shallower
# This option will exclude depths from the climatology and subsequent vertically aligned data that are shallower than opt_exclude_shallower.
# e.g. set to 4.5 to ensure that the top depth of 0.0 m is excluded
# Set to 0.0 to ensure no depths are excluded.
opt_exclude_shallower <- 4.5
# opt_shallow_check_perc and opt_shallow_check_diff
# A check is made to ensure that the pH of the shallowest depth in the profile after vertical alignment is within a limit of the
# pH of the shallowest depth in the profile before vertical alignment
# a opt_shallow_check values of 0.01 results in those with greater than a 1% difference will be reported. Set to 0.0 if percentage check is not required.
# a opt_shallow_report_diff that is non-zero and positive will check that absolute difference. Set to 0.0 if absolute difference check is not required.
opt_shallow_check_perc <- 0.05
opt_shallow_report_perc <- 'profile where shallow check exceeds percentage criteria: '
opt_shallow_check_diff <- 0.5
opt_shallow_report_diff <- 'profile where shallow check exceeds absolute difference criteria: 'read climatology
read temperature climatology and prepare to a set range of depths
# climatology values (clim_temp (°C)) available for lat, lon, month and pressure
boa_temp_clim <- read_rds(file = paste0(path_argo_preprocessed, '/boa_temp_clim.rds'))
#What is the max depth we are interested in
opt_profile_max_depth <- max(opt_profile_depth_range$max_depth)
# existing pressure levels become the target depths that we align to
pressure_range <- unique(boa_temp_clim[c("pres")])
target_depth_levels <- pressure_range %>% filter (pres <= opt_profile_max_depth) %>% mutate(target_depth = pres) %>% select(target_depth)
# select variable of interest and prepare target_depth field
boa_temp_clim_clean <- boa_temp_clim %>%
select(
lat,
lon,
month,
depth,
clim_temp
) %>%
mutate(
target_depth = depth, .after = depth
)
# Exclude 0.0 m depth from the climatology and target_depth_levels
target_depth_levels <- target_depth_levels %>% filter(target_depth > opt_exclude_shallower)
boa_temp_clim_clean <- boa_temp_clim_clean %>% filter(depth > opt_exclude_shallower)
# create all possible combinations of location and month climatologies and depth levels for interpolation
target_depth_grid <-
expand_grid(target_depth_levels,
boa_temp_clim_clean %>% distinct(lat, lon, month))
# extend climatology depth vectors with target depths
boa_temp_clim_extended <-
full_join(boa_temp_clim_clean, target_depth_grid) %>%
arrange(lat, lon, month, target_depth)
# filter where target depths outside range of climatology depths
# depth is slightly lower than pressure so 1.02 factor is used to ensure bottom value is not lost.
boa_temp_clim_extended <-
boa_temp_clim_extended %>%
group_by(lat, lon, month) %>%
filter(
target_depth <= max(depth, na.rm = TRUE)*1.02,
target_depth >= min(depth, na.rm = TRUE)
) %>%
ungroup()
# predict spline interpolation on adjusted depth grid for climatology loaction and month
boa_temp_clim_interpolated <-
boa_temp_clim_extended %>%
group_by(lat, lon, month) %>%
mutate(clim_temp_spline = spline(target_depth, clim_temp,
method = "natural",
xout = target_depth)$y) %>%
ungroup()
# subset interpolated values on traget depth grid
boa_temp_clim_interpolated_clean <-
inner_join(target_depth_levels, boa_temp_clim_interpolated)
# select columns and rename to initial names
boa_temp_clim_interpolated_clean <-
boa_temp_clim_interpolated_clean %>%
select(lat, lon, month,
depth = target_depth,
clim_temp = clim_temp_spline)
# clean up working tables
rm(boa_temp_clim_clean, boa_temp_clim_extended, boa_temp_clim_interpolated)read temp data
read temperature profile and carry out basic checks, good data.
# base data and associated metadata
bgc_data <- read_rds(file = paste0(path_argo_preprocessed, '/bgc_data.rds'))
bgc_metadata <- read_rds(file = paste0(path_argo_preprocessed, '/bgc_metadata.rds'))
# Select relevant field from metadata ready to join to bgc_data
bgc_metadata_select <- bgc_metadata %>%
filter (position_qc == 1) %>%
select(file_id,
date,
lat,
lon) %>%
mutate(year = year(date),
month = month(date),
.after = date)
# we only want pressure and temperature data
# conditions
# n_prof == 1
# pres_adjusted_qc %in% c(1, 8) - pressure data marked as good
# temp_adjusted_qc %in% c(1, 8) - temperature data marked as good
# !is.na(pres_adjusted) - pressure value must be present
# !is.na(temp_adjusted) - temperature value must be present
bgc_data_temp <- bgc_data %>%
filter(
pres_adjusted_qc %in% c(1, 8) &
temp_adjusted_qc %in% c(1, 8) &
n_prof == opt_n_prof_sel &
!is.na(pres_adjusted) &
!is.na(temp_adjusted)
) %>%
select(file_id,
pres_adjusted,
temp_adjusted)
# join with metadata information and calculate depth field
bgc_data_temp <-
inner_join(bgc_metadata_select %>% select(file_id, lat),
bgc_data_temp) %>%
mutate(depth = gsw_z_from_p(pres_adjusted, latitude = lat) * -1.0,
.before = pres_adjusted) %>%
select(-c(lat, pres_adjusted))
# ensure we have a depth, and temp_adjusted for all rows in bgc_data_temp
bgc_data_temp <- bgc_data_temp %>%
filter(!is.na(depth) & !is.na(temp_adjusted))
# clean up working tables
rm(bgc_data, bgc_metadata)
gc() used (Mb) gc trigger (Mb) max used (Mb)
Ncells 1351538 72.2 4162172 222.3 5202714 277.9
Vcells 581532719 4436.8 4853790924 37031.5 6033520929 46032.2Profile limits
Apply the rules that are determined by options set in set_options. Profile must cover a set range and not contain gaps.
# Determine profile min and max depths
bgc_profile_limits <- bgc_data_temp %>%
group_by(file_id) %>%
summarise(
min_depth = min(depth),
max_depth = max(depth),
) %>%
ungroup()
# --------------------------------------------------------------------------------------
# What is the distribution of min depths
out <- bgc_profile_limits %>%
filter(min_depth > 0 & min_depth < 10) %>%
mutate(min_bin = cut(min_depth, breaks = c(seq(0, 10, by = 0.5))))
out <- out %>%
group_by(min_bin) %>%
summarise(count_profiles = n())
out %>%
ggplot(aes(min_bin)) +
geom_bar(aes(weight = count_profiles)) +
scale_fill_viridis_d() +
labs(title = "temperature profiles minimum depth",
x = "min depth (m)",
y = "profile count")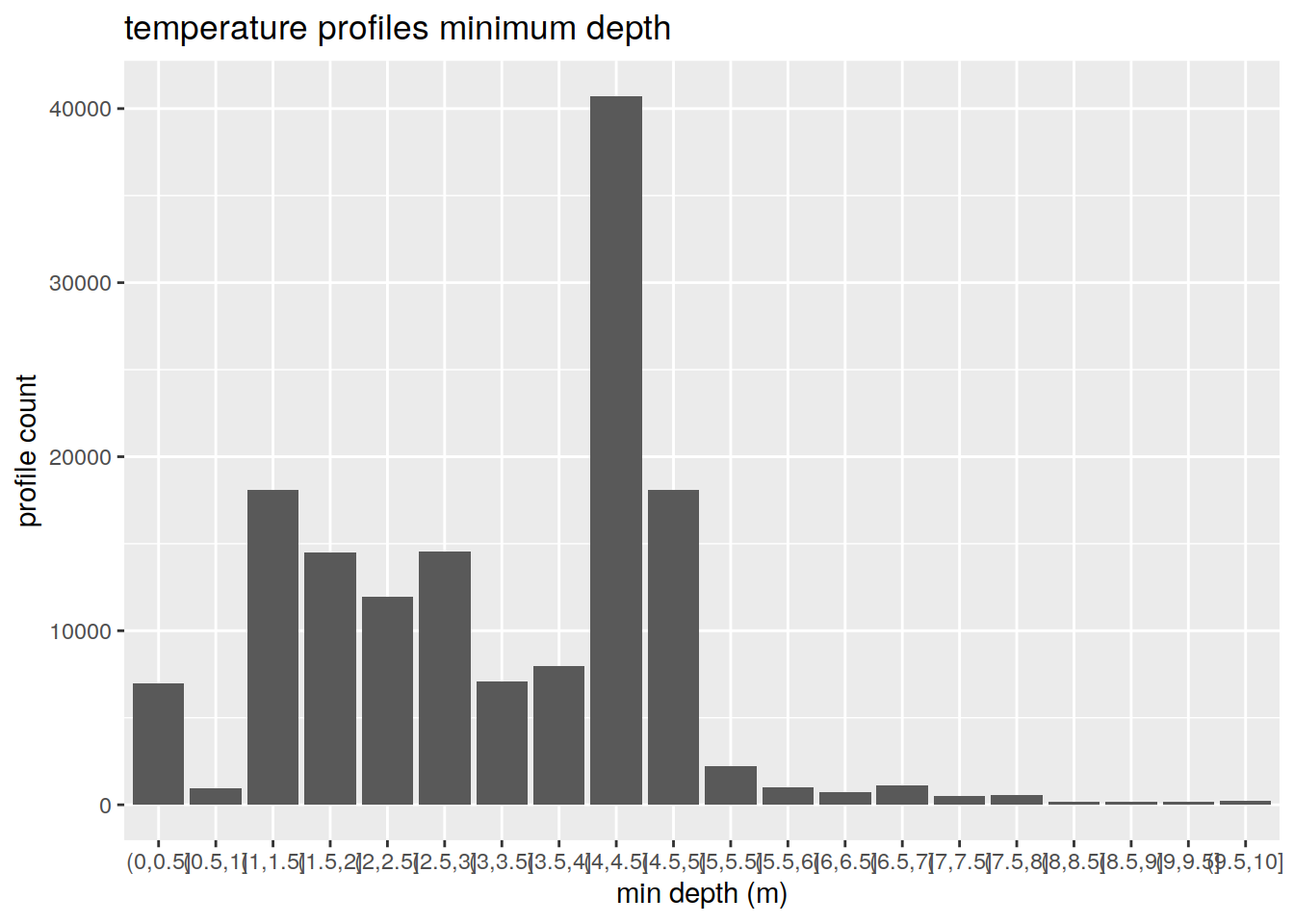
rm(out)
# --------------------------------------------------------------------------------------
# The profile much match at least one of teh range criteria
force_min <- min(opt_profile_depth_range$min_depth)
force_max <- min(opt_profile_depth_range$max_depth)
# Apply profile min and max restrictions
bgc_apply_limits <- bgc_profile_limits %>%
filter(
min_depth <= force_min &
max_depth >= force_max
)
# Ensure working data set only contains profiles that have confrormed to the range test
bgc_data_temp <- right_join(bgc_data_temp,
bgc_apply_limits %>% select(file_id))
# Add profile type field and set all to 1.
# All profile that meet the minimum requirements are profile_range = 1
bgc_data_temp <- bgc_data_temp %>%
mutate(profile_range = 1)
for (i in 2:nrow(opt_profile_depth_range)) {
#i = 3
range_min <- opt_profile_depth_range[i,'min_depth']
range_max <- opt_profile_depth_range[i,'max_depth']
# Apply profile min and max restrictions
bgc_apply_limits <- bgc_profile_limits %>%
filter(min_depth <= range_min &
max_depth >= range_max) %>%
select(file_id) %>%
mutate (profile_range = i)
# Update profile range to i for these profiles
# bgc_data_temp <- full_join(bgc_data_temp, bgc_apply_limits) %>%
# filter(!is.na(min_depth))
bgc_data_temp <-
bgc_data_temp %>% rows_update(bgc_apply_limits, by = "file_id")
}
# Find the gaps within the profiles
profile_gaps <- full_join(bgc_data_temp,
opt_profile_depth_range) %>%
filter(depth >= min_depth &
depth <= max_depth) %>%
select(file_id,
depth) %>%
arrange(file_id, depth) %>%
group_by(file_id) %>%
mutate(gap = depth - lag(depth, default = 0)) %>%
ungroup()
# Ensure we do not have gaps in the profile that invalidate it
for (i_gap in opt_gap_limit) {
# The limits to be applied in that pass of for loop
# i_gap <- opt_gap_limit[3]
i_gap_min = opt_gap_min_depth[which(opt_gap_limit == i_gap)]
i_gap_max = opt_gap_max_depth[which(opt_gap_limit == i_gap)]
# Which gaps are greater than i_gap
profile_gaps_remove <- profile_gaps %>%
filter(gap > i_gap) %>%
filter(depth >= i_gap_min & depth <= i_gap_max) %>%
distinct(file_id) %>%
pull()
# Remonve gap-containing profiles from working data set
bgc_data_temp <- bgc_data_temp %>%
filter(!file_id %in% profile_gaps_remove)
}
# clean up working tables
rm(bgc_profile_limits, profile_gaps, profile_gaps_remove, bgc_apply_limits)
gc() used (Mb) gc trigger (Mb) max used (Mb)
Ncells 1497477 80.0 4162172 222.3 5202714 277.9
Vcells 660480418 5039.1 3883032740 29625.2 6033520929 46032.2# For each profile what is the temp at the shallowest depth of the profile, this is used in a comparison after vertical alignment
shallow_temp_raw <- right_join(
bgc_data_temp,
bgc_data_temp %>%
group_by(file_id) %>%
summarise(depth = min(depth)) %>%
ungroup()
) %>%
select (file_id, temp_shallow_raw = temp_adjusted)Vertical align temp
We have a set of temperature profiles that match our criteria we now need to align that data set to match the depth that are in target_depth_levels, this will match the range of climatology values in boa_temp_clim_interpolated_clean
# create unique combinations of file_id and profile ranges
profile_range_file_id <-
bgc_data_temp %>%
distinct(file_id, profile_range)
# select variable of interest and prepare target_depth field
bgc_data_temp_clean <- bgc_data_temp %>%
select(-profile_range) %>%
mutate(target_depth = depth, .after = depth)
rm(bgc_data_temp)
gc() used (Mb) gc trigger (Mb) max used (Mb)
Ncells 1486314 79.4 4162172 222.3 5202714 277.9
Vcells 565022774 4310.8 3106426192 23700.2 6033520929 46032.2# create all possible combinations of location, month and depth levels for interpolation
target_depth_grid <-
expand_grid(
target_depth_levels,
profile_range_file_id
)
# Constrain target_depth_grid to profile depth range
target_depth_grid <-
left_join(target_depth_grid, opt_profile_depth_range) %>%
filter(target_depth <= max_depth)
target_depth_grid <- target_depth_grid %>%
select(target_depth,
file_id)
# extend temp depth vectors with target depths
bgc_data_temp_extended <-
full_join(bgc_data_temp_clean, target_depth_grid) %>%
arrange(file_id, target_depth)
rm(bgc_data_temp_clean)
gc() used (Mb) gc trigger (Mb) max used (Mb)
Ncells 1486509 79.4 4162172 222.3 5202714 277.9
Vcells 608413397 4641.9 2485140954 18960.2 6033520929 46032.2# predict spline interpolation on adjusted depth grid for temp location and month
bgc_data_temp_interpolated <-
bgc_data_temp_extended %>%
group_by(file_id) %>%
mutate(temp_spline = spline(target_depth, temp_adjusted,
method = "natural",
xout = target_depth)$y) %>%
ungroup()
rm(bgc_data_temp_extended)
gc() used (Mb) gc trigger (Mb) max used (Mb)
Ncells 1486550 79.4 4162172 222.3 5202714 277.9
Vcells 710273027 5419.0 1988112764 15168.1 6033520929 46032.2# subset interpolated values on target depth range
bgc_data_temp_interpolated_clean <-
inner_join(target_depth_levels, bgc_data_temp_interpolated)
rm(bgc_data_temp_interpolated)
gc() used (Mb) gc trigger (Mb) max used (Mb)
Ncells 1486594 79.4 4162172 222.3 5202714 277.9
Vcells 279120340 2129.6 1590490212 12134.5 6033520929 46032.2# select columns and rename to initial names
bgc_data_temp_interpolated_clean <-
bgc_data_temp_interpolated_clean %>%
select(file_id,
depth = target_depth,
temp = temp_spline)
# merge with profile range
bgc_data_temp_interpolated_clean <-
full_join(bgc_data_temp_interpolated_clean,
profile_range_file_id)
# merge with meta data
bgc_data_temp_interpolated_clean <-
left_join(bgc_data_temp_interpolated_clean,
bgc_metadata_select)
# For each profile what is the temp at the shallowest depth of the profile after vertical alignment
shallow_temp_va <- right_join(
bgc_data_temp_interpolated_clean,
bgc_data_temp_interpolated_clean %>%
group_by(file_id) %>%
summarise(depth = min(depth)) %>%
ungroup()
) %>%
select (file_id, temp_shallow_va = temp)Check shallow
A check is made that the shallowest temp value after the vertical alignment is within a specified percentage of the shallowest temp value before the vertical alignment
# Combined dataframe with shallow value pre and post vertical alignment
shallow_temp_check <-
full_join(shallow_temp_raw, shallow_temp_va)
# Determine those profile that are outside of percentage criteria.
if (opt_shallow_check_perc > 0.0){
shallow_check_report <- shallow_temp_check %>%
filter (abs((temp_shallow_raw - temp_shallow_va) / temp_shallow_raw) > opt_shallow_check_perc)
# Write issues to console
if (nrow(shallow_check_report) > 0) {
print (opt_shallow_report_perc)
shallow_check_report %>% rmarkdown::paged_table()
}
}
# Determine those profile that are outside of absolute difference criteria.
if (opt_shallow_check_diff > 0.0){
shallow_check_report <- shallow_temp_check %>%
filter (abs(temp_shallow_raw - temp_shallow_va) > opt_shallow_check_diff)
# Write issues to console
if (nrow(shallow_check_report) > 0) {
print (opt_shallow_report_diff)
shallow_check_report %>% rmarkdown::paged_table()
}
}
# remove working files
rm(shallow_temp_check, shallow_temp_raw, shallow_temp_va, shallow_check_report)
gc()Create anomaly profiles
Create anomaly profiles as observed - climatology
# Create bgc_temp_anomaly, but only where we have an climatology temperature
bgc_temp_anomaly <-
inner_join(bgc_data_temp_interpolated_clean, boa_temp_clim_interpolated_clean)
# Calculate the anomaly temperature
bgc_temp_anomaly <- bgc_temp_anomaly %>%
mutate(
anomaly = temp - clim_temp
)
# -----------------------------------------------------------------------------
# Climatology check
# -----------------------------------------------------------------------------
# It is possible even though we have observational measures to full depth the climatology may not matach all depth.
# These profiles will be removed from both temp_bgc_va and temp_anomaly_va
# Anomaly max depth
bgc_temp_anomaly_depth_check <- bgc_temp_anomaly %>%
group_by(file_id,
profile_range) %>%
summarise(min_pdepth = min(depth),
max_pdepth = max(depth)) %>%
ungroup()
# Add the required min depth and max depth
bgc_temp_anomaly_depth_check <- left_join(bgc_temp_anomaly_depth_check, opt_profile_depth_range)
# This profiles do not match the depth required by the profile_range
# min_depth_check <- min(target_depth_grid$target_depth)
# Please double check if the criterion should be
# each profile is checked against the min depth specified in min_depth
# max depth specified in max_depth.
remove_profiles <- bgc_temp_anomaly_depth_check %>%
filter((max_pdepth < max_depth) | (min_pdepth > min_depth)) %>%
distinct(file_id)
# remove from both bgc_data_temp_interpolated_clean and bgc_temp_anomaly
bgc_data_temp_interpolated_clean <-
anti_join(bgc_data_temp_interpolated_clean, remove_profiles)
bgc_temp_anomaly <- anti_join(bgc_temp_anomaly, remove_profiles)Write files
Write the climatology that maps onto depth levels, interpolated temperature profiles that map onto depth levels and resulting anomaly files.
# Write files
bgc_data_temp_interpolated_clean %>%
write_rds(file = paste0(path_argo_preprocessed, "/temp_bgc_va.rds"))
boa_temp_clim_interpolated_clean %>%
write_rds(file = paste0(path_argo_preprocessed, "/temp_clim_va.rds"))
bgc_temp_anomaly %>%
write_rds(file = paste0(path_argo_preprocessed, "/temp_anomaly_va.rds"))
# Rename so that names match if just reading existing files
temp_bgc_va <- bgc_data_temp_interpolated_clean
temp_clim_va <- boa_temp_clim_interpolated_clean
temp_anomaly_va <- bgc_temp_anomaly
#rm(bgc_data_temp_interpolated_clean, boa_temp_clim_interpolated_clean, bgc_temp_anomaly)read files
Read files that were previously created ready for analysis
# read files
temp_bgc_va <- read_rds(file = paste0(path_argo_preprocessed, "/temp_bgc_va.rds"))
temp_clim_va <- read_rds(file = paste0(path_argo_preprocessed, "/temp_clim_va.rds"))
temp_anomaly_va <- read_rds(file = paste0(path_argo_preprocessed, "/temp_anomaly_va.rds"))Analysis
Temperature anomaly
Details of mean anomaly over analysis period
max_depth_1 <- opt_profile_depth_range[1, "max_depth"]
max_depth_2 <- opt_profile_depth_range[2, "max_depth"]
max_depth_3 <- opt_profile_depth_range[3, "max_depth"]
# Profiles to 600m
anomaly_overall_mean_1 <- temp_anomaly_va %>%
filter(profile_range %in% c(1, 2, 3) & depth <= max_depth_1) %>%
group_by(depth) %>%
summarise(temp_count = n(),
temp_anomaly_mean = mean(anomaly, na.rm = TRUE),
temp_anomaly_sd = sd(anomaly, na.rm = TRUE))
anomaly_year_mean_1 <- temp_anomaly_va %>%
filter(profile_range %in% c(1, 2, 3) & depth <= max_depth_1) %>%
group_by(year, depth) %>%
summarise(temp_count = n(),
temp_anomaly_mean = mean(anomaly, na.rm = TRUE),
temp_anomaly_sd = sd(anomaly, na.rm = TRUE))
# Profiles to 1200m
anomaly_overall_mean_2 <- temp_anomaly_va %>%
filter(profile_range %in% c(2, 3) & depth <= max_depth_2) %>%
group_by(depth) %>%
summarise(temp_count = n(),
temp_anomaly_mean = mean(anomaly, na.rm = TRUE),
temp_anomaly_sd = sd(anomaly, na.rm = TRUE))
anomaly_year_mean_2 <- temp_anomaly_va %>%
filter(profile_range %in% c(2, 3) & depth <= max_depth_2) %>%
group_by(year, depth) %>%
summarise(temp_count = n(),
temp_anomaly_mean = mean(anomaly, na.rm = TRUE),
temp_anomaly_sd = sd(anomaly, na.rm = TRUE))
# Profiles to 1500m
anomaly_overall_mean_3 <- temp_anomaly_va %>%
filter(profile_range %in% c(3) & depth <= max_depth_3) %>%
group_by(depth) %>%
summarise(temp_count = n(),
temp_anomaly_mean = mean(anomaly, na.rm = TRUE),
temp_anomaly_sd = sd(anomaly, na.rm = TRUE))
anomaly_year_mean_3 <- temp_anomaly_va %>%
filter(profile_range %in% c(3) & depth <= max_depth_3) %>%
group_by(year, depth) %>%
summarise(temp_count = n(),
temp_anomaly_mean = mean(anomaly, na.rm = TRUE),
temp_anomaly_sd = sd(anomaly, na.rm = TRUE))
# All years anomaly
anomaly_overall_mean_1 %>%
ggplot()+
geom_path(aes(x = temp_anomaly_mean,
y = depth))+
geom_ribbon(aes(xmax = temp_anomaly_mean + temp_anomaly_sd,
xmin = temp_anomaly_mean - temp_anomaly_sd,
y = depth),
alpha = 0.2)+
geom_vline(xintercept = 0)+
scale_y_reverse() +
coord_cartesian(xlim = opt_xlim) +
scale_x_continuous(breaks = opt_xbreaks) +
labs(
title = paste0('Overall mean anomaly profiles to ', max_depth_1, 'm'),
x = opt_measure_label,
y = 'depth (m)'
)
anomaly_overall_mean_2 %>%
ggplot()+
geom_path(aes(x = temp_anomaly_mean,
y = depth))+
geom_ribbon(aes(xmax = temp_anomaly_mean + temp_anomaly_sd,
xmin = temp_anomaly_mean - temp_anomaly_sd,
y = depth),
alpha = 0.2)+
geom_vline(xintercept = 0)+
scale_y_reverse() +
coord_cartesian(xlim = opt_xlim) +
scale_x_continuous(breaks = opt_xbreaks) +
labs(
title = paste0('Overall mean anomaly profiles to ', max_depth_2, 'm'),
x = opt_measure_label,
y = 'depth (m)'
)
anomaly_overall_mean_3 %>%
ggplot()+
geom_path(aes(x = temp_anomaly_mean,
y = depth))+
geom_ribbon(aes(xmax = temp_anomaly_mean + temp_anomaly_sd,
xmin = temp_anomaly_mean - temp_anomaly_sd,
y = depth),
alpha = 0.2)+
geom_vline(xintercept = 0)+
scale_y_reverse() +
coord_cartesian(xlim = opt_xlim) +
scale_x_continuous(breaks = opt_xbreaks) +
labs(
title = paste0('Overall mean anomaly profiles to ', max_depth_3, 'm'),
x = opt_measure_label,
y = 'depth (m)'
)
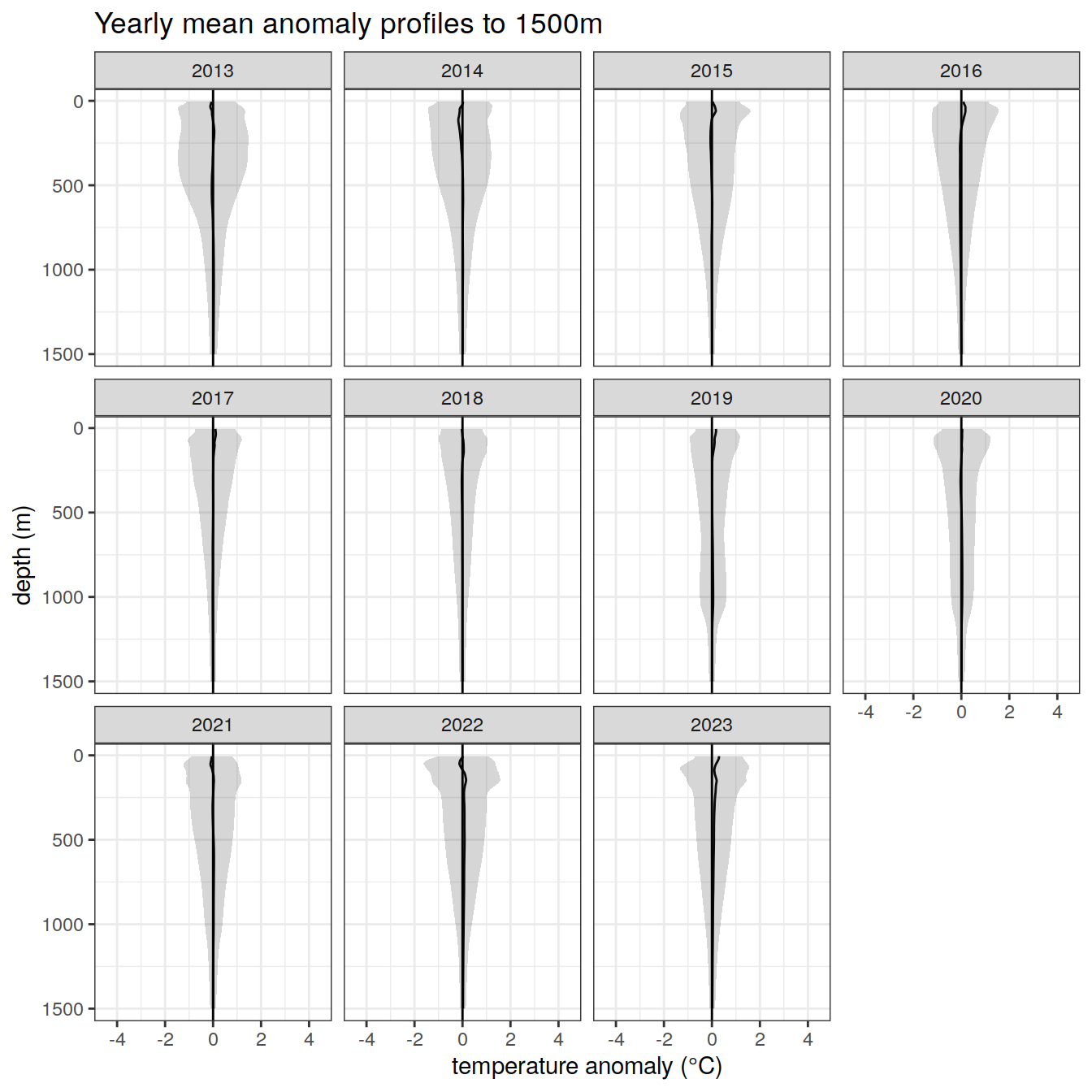
# yearly anomaly
anomaly_year_mean_1 %>%
ggplot()+
geom_path(aes(x = temp_anomaly_mean,
y = depth))+
geom_ribbon(aes(xmax = temp_anomaly_mean + temp_anomaly_sd,
xmin = temp_anomaly_mean - temp_anomaly_sd,
y = depth),
alpha = 0.2)+
geom_vline(xintercept = 0)+
scale_y_reverse() +
facet_wrap(~year)+
coord_cartesian(xlim = opt_xlim) +
scale_x_continuous(breaks = opt_xbreaks) +
labs(
title = paste0('Yearly mean anomaly profiles to ', max_depth_1, 'm'),
x = opt_measure_label,
y = 'depth (m)'
)
anomaly_year_mean_2 %>%
ggplot()+
geom_path(aes(x = temp_anomaly_mean,
y = depth))+
geom_ribbon(aes(xmax = temp_anomaly_mean + temp_anomaly_sd,
xmin = temp_anomaly_mean - temp_anomaly_sd,
y = depth),
alpha = 0.2)+
geom_vline(xintercept = 0)+
scale_y_reverse() +
facet_wrap(~year)+
coord_cartesian(xlim = opt_xlim) +
scale_x_continuous(breaks = opt_xbreaks) +
labs(
title = paste0('Yearly mean anomaly profiles to ', max_depth_2, 'm'),
x = opt_measure_label,
y = 'depth (m)'
)
anomaly_year_mean_3 %>%
ggplot()+
geom_path(aes(x = temp_anomaly_mean,
y = depth))+
geom_ribbon(aes(xmax = temp_anomaly_mean + temp_anomaly_sd,
xmin = temp_anomaly_mean - temp_anomaly_sd,
y = depth),
alpha = 0.2)+
geom_vline(xintercept = 0)+
scale_y_reverse() +
facet_wrap(~year)+
coord_cartesian(xlim = opt_xlim) +
scale_x_continuous(breaks = opt_xbreaks) +
labs(
title = paste0('Yearly mean anomaly profiles to ', max_depth_3, 'm'),
x = opt_measure_label,
y = 'depth (m)'
)
#rm(anomaly_overall_mean)Profile counts
Details of the number of profiles and to which depths over the analysis period
temp_histogram <- temp_bgc_va %>%
group_by(year, profile_range = as.character(profile_range)) %>%
summarise(num_profiles = n_distinct(file_id)) %>%
ungroup()
temp_histogram %>%
ggplot() +
geom_bar(
aes(
x = year,
y = num_profiles,
fill = profile_range,
group = profile_range
),
position = "stack",
stat = "identity"
) +
scale_fill_viridis_d() +
labs(title = "temperature profiles per year and profile range",
x = "year",
y = "profile count",
fill = "profile range")
sessionInfo()R version 4.2.2 (2022-10-31)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: openSUSE Leap 15.4
Matrix products: default
BLAS: /usr/local/R-4.2.2/lib64/R/lib/libRblas.so
LAPACK: /usr/local/R-4.2.2/lib64/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggforce_0.4.1 gsw_1.1-1 gridExtra_2.3 lubridate_1.9.0
[5] timechange_0.1.1 argodata_0.1.0 forcats_0.5.2 stringr_1.5.0
[9] dplyr_1.1.3 purrr_1.0.2 readr_2.1.3 tidyr_1.3.0
[13] tibble_3.2.1 ggplot2_3.4.4 tidyverse_1.3.2
loaded via a namespace (and not attached):
[1] httr_1.4.4 sass_0.4.4 viridisLite_0.4.1
[4] jsonlite_1.8.3 modelr_0.1.10 bslib_0.4.1
[7] assertthat_0.2.1 highr_0.9 googlesheets4_1.0.1
[10] cellranger_1.1.0 yaml_2.3.6 pillar_1.9.0
[13] backports_1.4.1 glue_1.6.2 digest_0.6.30
[16] promises_1.2.0.1 polyclip_1.10-4 rvest_1.0.3
[19] colorspace_2.0-3 htmltools_0.5.3 httpuv_1.6.6
[22] pkgconfig_2.0.3 broom_1.0.5 haven_2.5.1
[25] scales_1.2.1 tweenr_2.0.2 whisker_0.4
[28] later_1.3.0 tzdb_0.3.0 git2r_0.30.1
[31] googledrive_2.0.0 generics_0.1.3 farver_2.1.1
[34] ellipsis_0.3.2 cachem_1.0.6 withr_2.5.0
[37] cli_3.6.1 magrittr_2.0.3 crayon_1.5.2
[40] readxl_1.4.1 evaluate_0.18 fs_1.5.2
[43] fansi_1.0.3 MASS_7.3-58.1 xml2_1.3.3
[46] tools_4.2.2 hms_1.1.2 gargle_1.2.1
[49] lifecycle_1.0.3 munsell_0.5.0 reprex_2.0.2
[52] compiler_4.2.2 jquerylib_0.1.4 RNetCDF_2.6-1
[55] rlang_1.1.1 grid_4.2.2 rstudioapi_0.15.0
[58] labeling_0.4.2 rmarkdown_2.18 gtable_0.3.1
[61] DBI_1.1.3 R6_2.5.1 knitr_1.41
[64] fastmap_1.1.0 utf8_1.2.2 workflowr_1.7.0
[67] rprojroot_2.0.3 stringi_1.7.8 Rcpp_1.0.10
[70] vctrs_0.6.4 dbplyr_2.2.1 tidyselect_1.2.0
[73] xfun_0.35