pCO2 product synopsis
Jens Daniel Müller
20 March, 2024
Last updated: 2024-03-20
Checks: 7 0
Knit directory:
heatwave_co2_flux_2023/analysis/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20240307) was run prior to running
the code in the R Markdown file. Setting a seed ensures that any results
that rely on randomness, e.g. subsampling or permutations, are
reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version 46f7ed5. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for
the analysis have been committed to Git prior to generating the results
(you can use wflow_publish or
wflow_git_commit). workflowr only checks the R Markdown
file, but you know if there are other scripts or data files that it
depends on. Below is the status of the Git repository when the results
were generated:
Ignored files:
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/figure/
Untracked files:
Untracked: analysis/child/
Untracked: code/Workflowr_project_managment.R
Untracked: figure/
Unstaged changes:
Modified: analysis/_site.yml
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were
made to the R Markdown (analysis/pco2_product_synopsis.Rmd)
and HTML (docs/pco2_product_synopsis.html) files. If you’ve
configured a remote Git repository (see ?wflow_git_remote),
click on the hyperlinks in the table below to view the files as they
were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | 46f7ed5 | jens-daniel-mueller | 2024-03-20 | Synopsis pco2 products added |
center <- -160
boundary <- center + 180
target_crs <- paste0("+proj=robin +over +lon_0=", center)
# target_crs <- paste0("+proj=eqearth +over +lon_0=", center)
# target_crs <- paste0("+proj=eqearth +lon_0=", center)
# target_crs <- paste0("+proj=igh_o +lon_0=", center)
worldmap <- ne_countries(scale = 'small',
type = 'map_units',
returnclass = 'sf')
worldmap <- worldmap %>% st_break_antimeridian(lon_0 = center)
worldmap_trans <- st_transform(worldmap, crs = target_crs)
# ggplot() +
# geom_sf(data = worldmap_trans)
coastline <- ne_coastline(scale = 'small', returnclass = "sf")
coastline <- st_break_antimeridian(coastline, lon_0 = 200)
coastline_trans <- st_transform(coastline, crs = target_crs)
# ggplot() +
# geom_sf(data = worldmap_trans, fill = "grey", col="grey") +
# geom_sf(data = coastline_trans)
bbox <- st_bbox(c(xmin = -180, xmax = 180, ymax = 65, ymin = -78), crs = st_crs(4326))
bbox <- st_as_sfc(bbox)
bbox_trans <- st_break_antimeridian(bbox, lon_0 = center)
bbox_graticules <- st_graticule(
x = bbox_trans,
crs = st_crs(bbox_trans),
datum = st_crs(bbox_trans),
lon = c(20, 20.001),
lat = c(-78,65),
ndiscr = 1e3,
margin = 0.001
)
bbox_graticules_trans <- st_transform(bbox_graticules, crs = target_crs)
rm(worldmap, coastline, bbox, bbox_trans)
# ggplot() +
# geom_sf(data = worldmap_trans, fill = "grey", col="grey") +
# geom_sf(data = coastline_trans) +
# geom_sf(data = bbox_graticules_trans)
lat_lim <- ext(bbox_graticules_trans)[c(3,4)]*1.002
lon_lim <- ext(bbox_graticules_trans)[c(1,2)]*1.005
# ggplot() +
# geom_sf(data = worldmap_trans, fill = "grey90", col = "grey90") +
# geom_sf(data = coastline_trans) +
# geom_sf(data = bbox_graticules_trans, linewidth = 1) +
# coord_sf(crs = target_crs,
# ylim = lat_lim,
# xlim = lon_lim,
# expand = FALSE) +
# theme(
# panel.border = element_blank(),
# axis.text = element_blank(),
# axis.ticks = element_blank()
# )
latitude_graticules <- st_graticule(
x = bbox_graticules,
crs = st_crs(bbox_graticules),
datum = st_crs(bbox_graticules),
lon = c(20, 20.001),
lat = c(-60,-30,0,30,60),
ndiscr = 1e3,
margin = 0.001
)
latitude_graticules_trans <- st_transform(latitude_graticules, crs = target_crs)
latitude_labels <- data.frame(lat_label = c("60°N","30°N","Eq.","30°S","60°S"),
lat = c(60,30,0,-30,-60)-4, lon = c(35)-c(0,2,4,2,0))
latitude_labels <- st_as_sf(x = latitude_labels,
coords = c("lon", "lat"),
crs = "+proj=longlat")
latitude_labels_trans <- st_transform(latitude_labels, crs = target_crs)
# ggplot() +
# geom_sf(data = worldmap_trans, fill = "grey", col = "grey") +
# geom_sf(data = coastline_trans) +
# geom_sf(data = bbox_graticules_trans) +
# geom_sf(data = latitude_graticules_trans,
# col = "grey60",
# linewidth = 0.2) +
# geom_sf_text(data = latitude_labels_trans,
# aes(label = lat_label),
# size = 3,
# col = "grey60")Read data
files <- list.files("../data",
pattern = "_anomaly_map_annual.csv",
full.names = TRUE)
pco2_product_coarse_annual_regression <-
read_csv(files,
id = "product")
pco2_product_coarse_annual_regression <-
pco2_product_coarse_annual_regression %>%
mutate(product = str_extract(product, "OceanSODA|SOM_FFN"))files <- list.files("../data",
pattern = "_anomaly_map_monthly.csv",
full.names = TRUE)
pco2_product_coarse_monthly_regression <-
read_csv(files,
id = "product")
pco2_product_coarse_monthly_regression <-
pco2_product_coarse_monthly_regression %>%
mutate(product = str_extract(product, "OceanSODA|SOM_FFN"))files <- list.files("../data",
pattern = "_anomaly_hovmoeller_monthly.csv",
full.names = TRUE)
pco2_product_hovmoeller_monthly_regression <-
read_csv(files,
id = "product")
pco2_product_hovmoeller_monthly_regression <-
pco2_product_hovmoeller_monthly_regression %>%
mutate(product = str_extract(product, "OceanSODA|SOM_FFN"))files <- list.files("../data",
pattern = "_biome_annual_detrended.csv",
full.names = TRUE)
pco2_product_annual_detrended <-
read_csv(files,
id = "product")
pco2_product_annual_detrended <-
pco2_product_annual_detrended %>%
mutate(product = str_extract(product, "OceanSODA|SOM_FFN"))map <-
read_rds("../data/map.rds")
key_biomes <-
read_rds("../data/key_biomes.rds")Define labels and breaks
name_core <- c("fgco2", "sol", "spco2", "kw", "fgco2_int", "fgco2_hov")labels_breaks <- function(i_name) {
if (i_name == "dco2") {
i_legend_title <- "ΔpCO<sub>2</sub><br>(µatm)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "dfco2") {
i_legend_title <- "ΔfCO<sub>2</sub><br>(µatm)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "atm_co2") {
i_legend_title <- "pCO<sub>2,atm</sub><br>(µatm)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "sol") {
i_legend_title <- "CO<sub>2</sub> solubility<br>(mol m<sup>-3</sup> µatm<sup>-1</sup>)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "kw") {
i_legend_title <- "K<sub>w</sub><br>(m yr<sup>-1</sup>)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "spco2") {
i_legend_title <- "pCO<sub>2,ocean</sub><br>(µatm)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "sfco2") {
i_legend_title <- "fCO<sub>2,ocean</sub><br>(µatm)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "fgco2") {
i_legend_title <- "FCO<sub>2</sub><br>(mol m<sup>-2</sup> yr<sup>-1</sup>)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "fgco2_hov") {
i_legend_title <- "FCO<sub>2</sub><br>(PgC deg<sup>-1</sup> yr<sup>-1</sup>)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "fgco2_int") {
i_legend_title <- "FCO<sub>2</sub><br>(PgC yr<sup>-1</sup>)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "temperature") {
i_legend_title <- "SST<br>(°C)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "salinity") {
i_legend_title <- "SSS"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "chl") {
i_legend_title <- "Chl-a<br>(mg m<sup>-3</sup>)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "mld") {
i_legend_title <- "MLD<br>(m)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
if (i_name == "press") {
i_legend_title <- "pressure<sub>atm</sub><br>(unit?)"
# i_breaks <- c(-Inf, seq(0, 80, 10), Inf)
# i_contour_level <- 50
# i_contour_level_abs <- 2200
}
all_labels_breaks <- lst(i_legend_title,
# i_breaks,
# i_contour_level,
# i_contour_level_abs
)
return(all_labels_breaks)
}
# labels_breaks("fgco2")
x_axis_labels <-
c(
"dco2" = labels_breaks("dco2")$i_legend_title,
"dfco2" = labels_breaks("dfco2")$i_legend_title,
"atm_co2" = labels_breaks("atm_co2")$i_legend_title,
"sol" = labels_breaks("sol")$i_legend_title,
"kw" = labels_breaks("kw")$i_legend_title,
"spco2" = labels_breaks("spco2")$i_legend_title,
"sfco2" = labels_breaks("sfco2")$i_legend_title,
"fgco2_hov" = labels_breaks("fgco2_hov")$i_legend_title,
"fgco2_int" = labels_breaks("fgco2_int")$i_legend_title,
"temperature" = labels_breaks("temperature")$i_legend_title,
"salinity" = labels_breaks("salinity")$i_legend_title,
"chl" = labels_breaks("chl")$i_legend_title,
"mld" = labels_breaks("mld")$i_legend_title,
"press" = labels_breaks("press")$i_legend_title
)Maps
The following maps show the absolute state of each variable in 2023 as provided through the pCO2 product, the change in that variable from 1990 to 2023, as well es the anomalies in 2023. Changes and anomalies are determined based on the predicted value of a linear regression model fit to the data from 1990 to 2022.
Maps are first presented as annual means, and than as monthly means. Note that the 2023 predictions for the monthly maps are done individually for each month, such the mean seasonal anomaly from the annual mean is removed.
Note: The increase the computational speed, I regridded all maps to 5X5° grid.
Annual means
2023 anomaly
pco2_product_coarse_annual_regression %>%
filter(name %in% name_core) %>%
group_split(name) %>%
# head(4) %>%
map(
~ map +
geom_tile(data = .x,
aes(lon, lat, fill = resid)) +
labs(title = "2023 anomaly") +
scale_fill_divergent(name = labels_breaks(.x %>% distinct(name))) +
theme(legend.title = element_markdown()) +
facet_wrap( ~ product, ncol = 1)
)[[1]]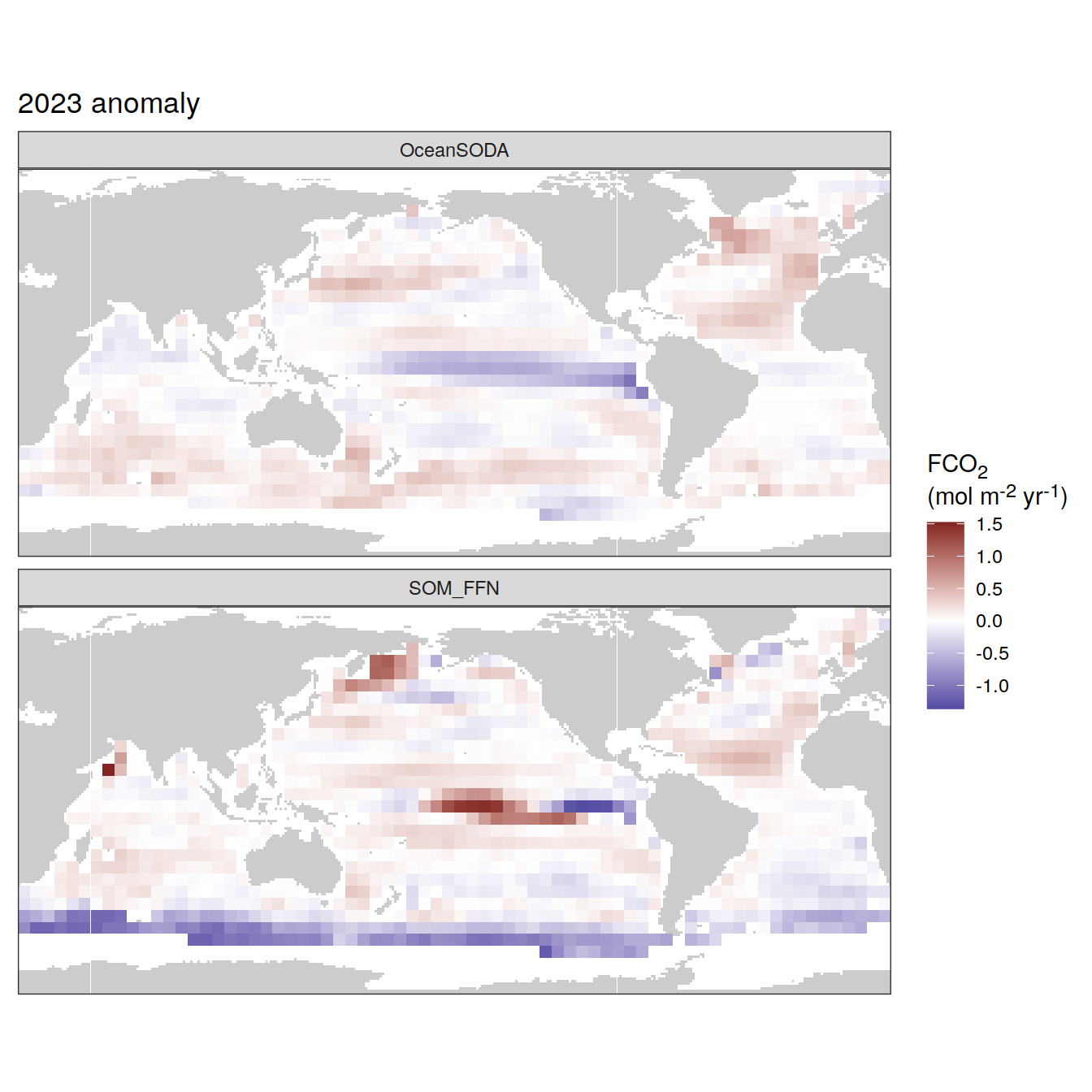
[[2]]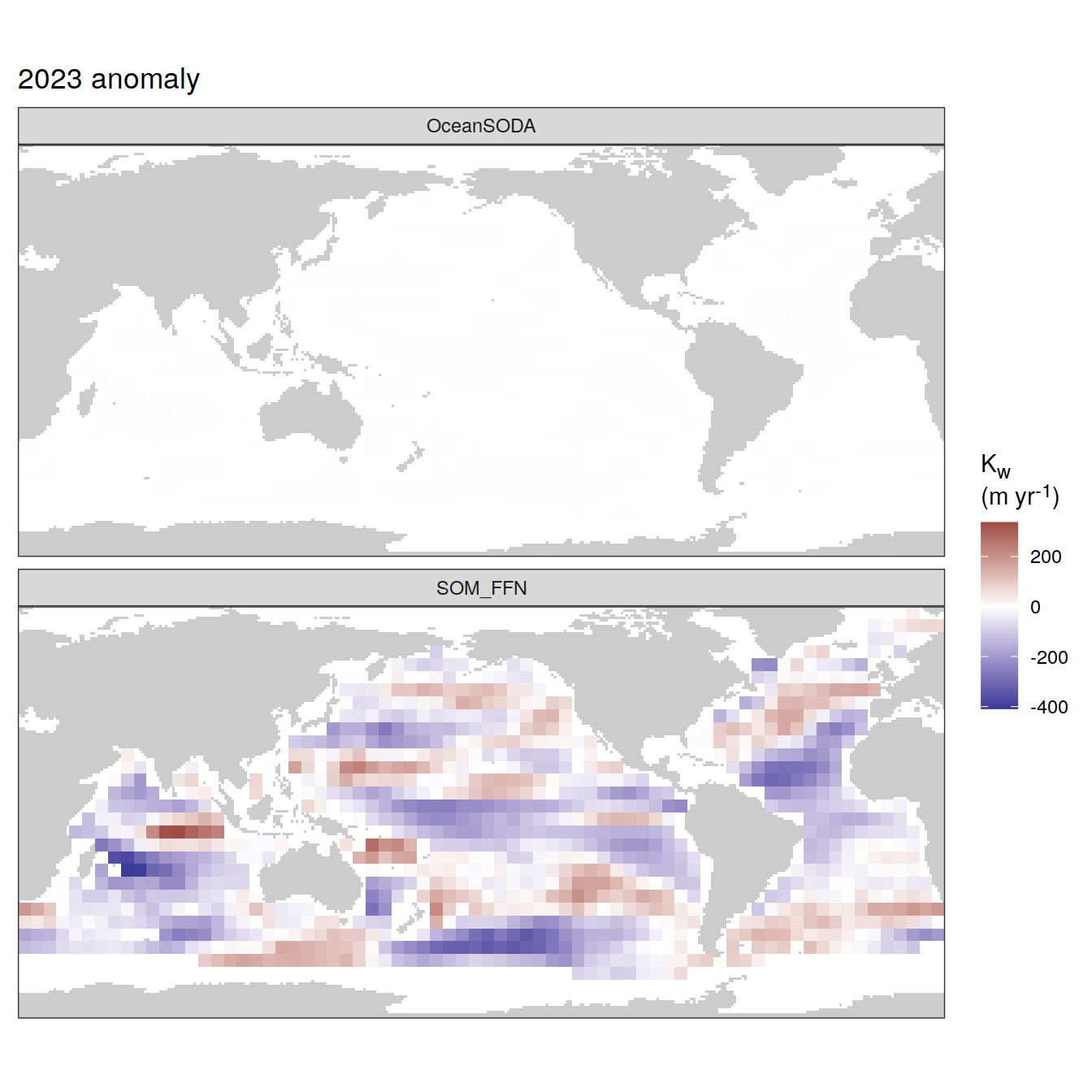
[[3]]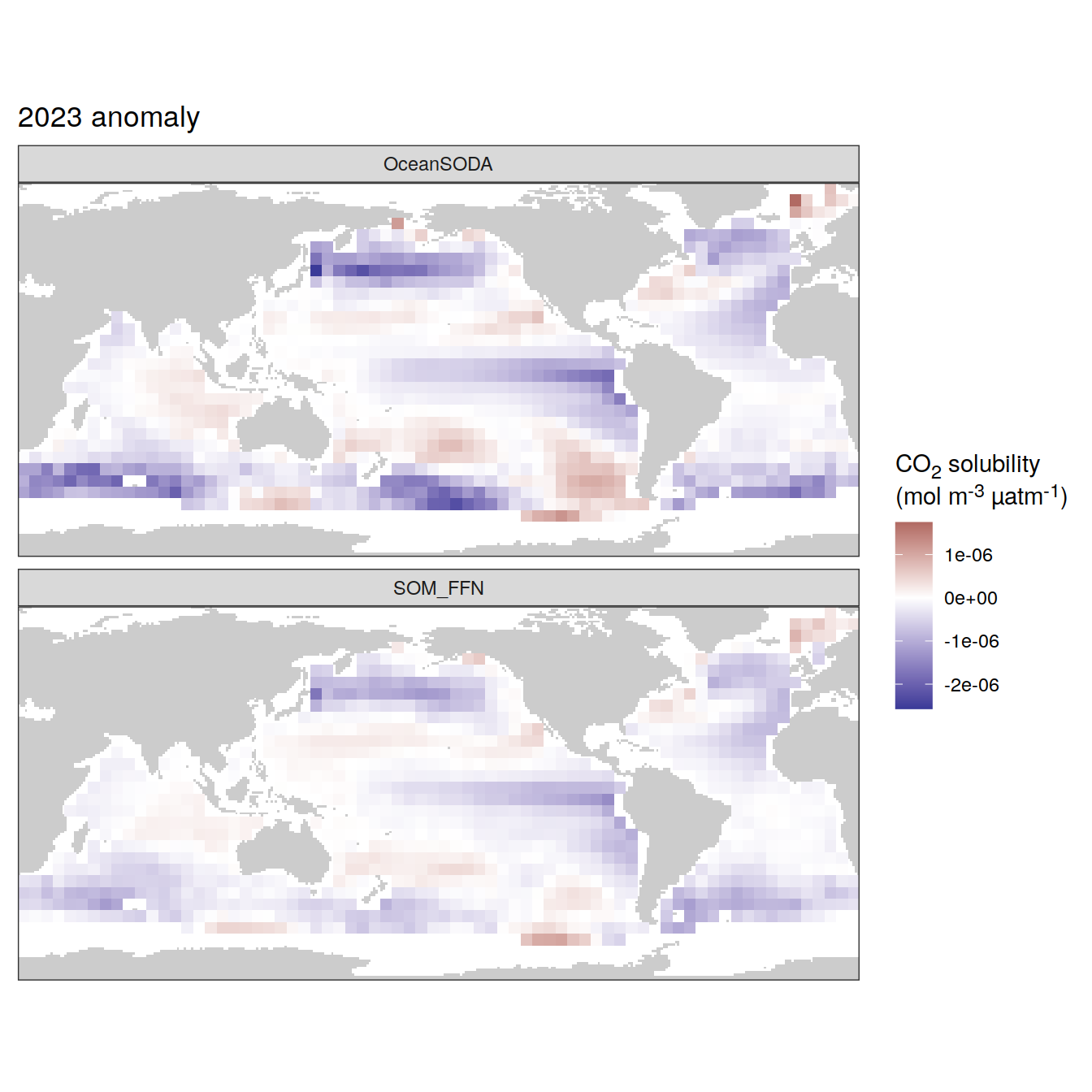
[[4]]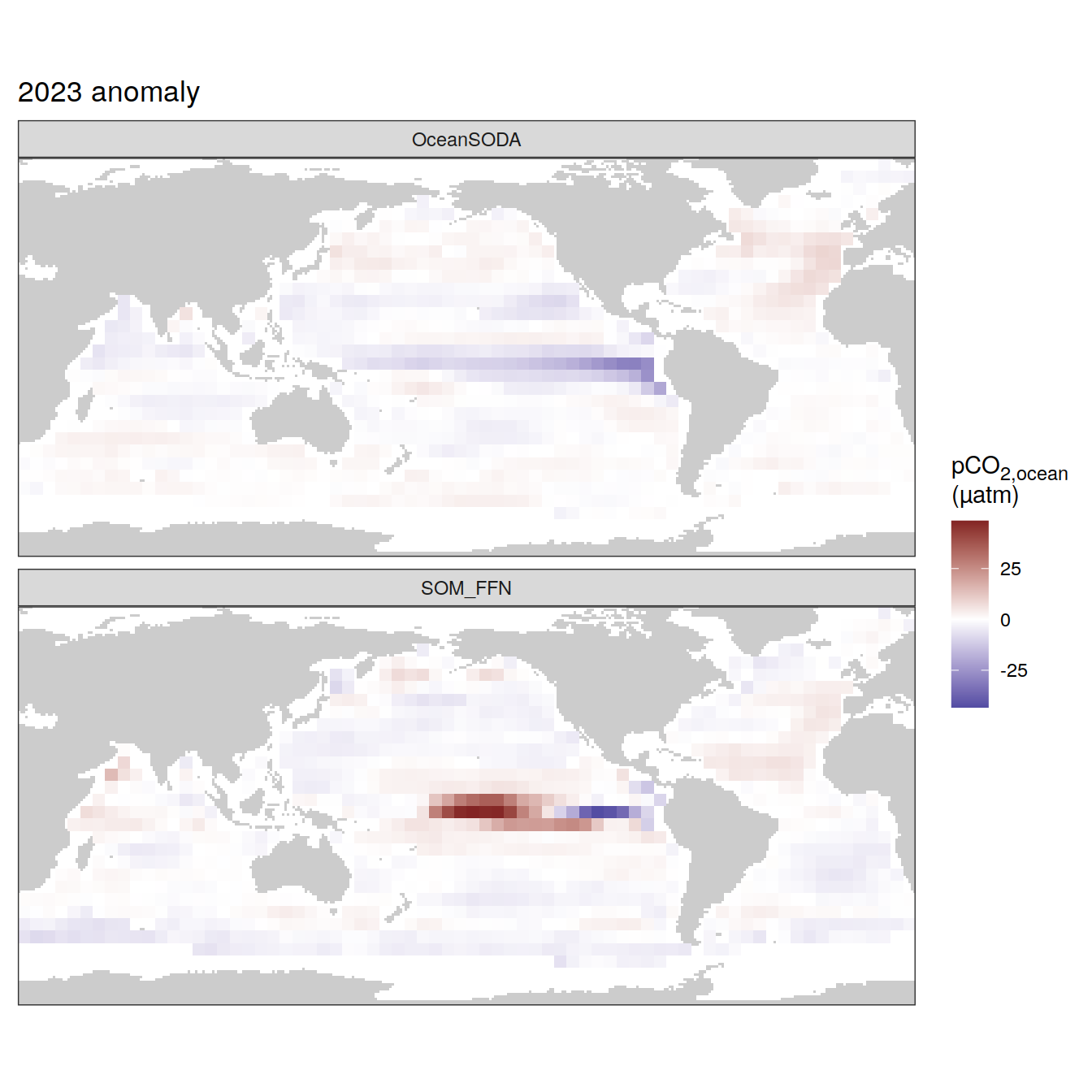
Monthly means
2023 anomaly
pco2_product_coarse_monthly_regression %>%
filter(name %in% name_core) %>%
group_split(name) %>%
head(1) %>%
map(
~ map +
geom_tile(data = .x,
aes(lon, lat, fill = resid)) +
labs(title = "2023 anomaly") +
scale_fill_divergent(name = labels_breaks(.x %>% distinct(name))) +
theme(legend.title = element_markdown()) +
facet_grid(month ~ product)
)[[1]]
Hovmoeller plots
The following Hovmoeller plots show the value of each variable as provided through the pCO2 product, as well as the anomalies from the prediction of a linear/quadratic fit to the data from 1990 to 2022.
Hovmoeller plots are first presented as annual means, and than as monthly means. Note that the predictions for the monthly Hovmoeller plots are done individually for each month, such the mean seasonal anomaly from the annual mean is removed.
Monthly means
Anomalies
pco2_product_hovmoeller_monthly_regression %>%
filter(name %in% name_core) %>%
group_split(name) %>%
# head(1) %>%
map(
~ ggplot(data = .x,
aes(decimal, lat, fill = resid)) +
geom_raster() +
scale_fill_divergent(name = labels_breaks(.x %>% distinct(name))) +
theme(legend.title = element_markdown()) +
coord_cartesian(expand = 0) +
labs(title = "Monthly mean anomalies",
y = "Latitude") +
theme(axis.title.x = element_blank()) +
facet_wrap( ~ product, ncol = 1)
)[[1]]
[[2]]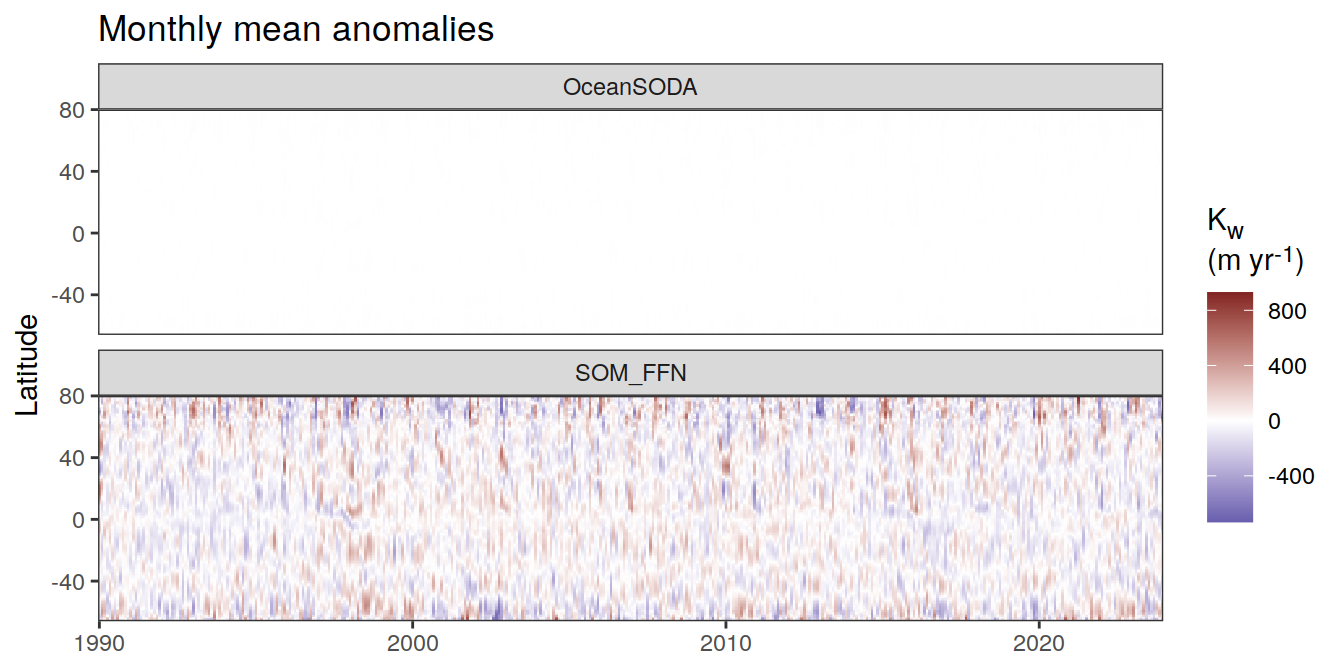
[[3]]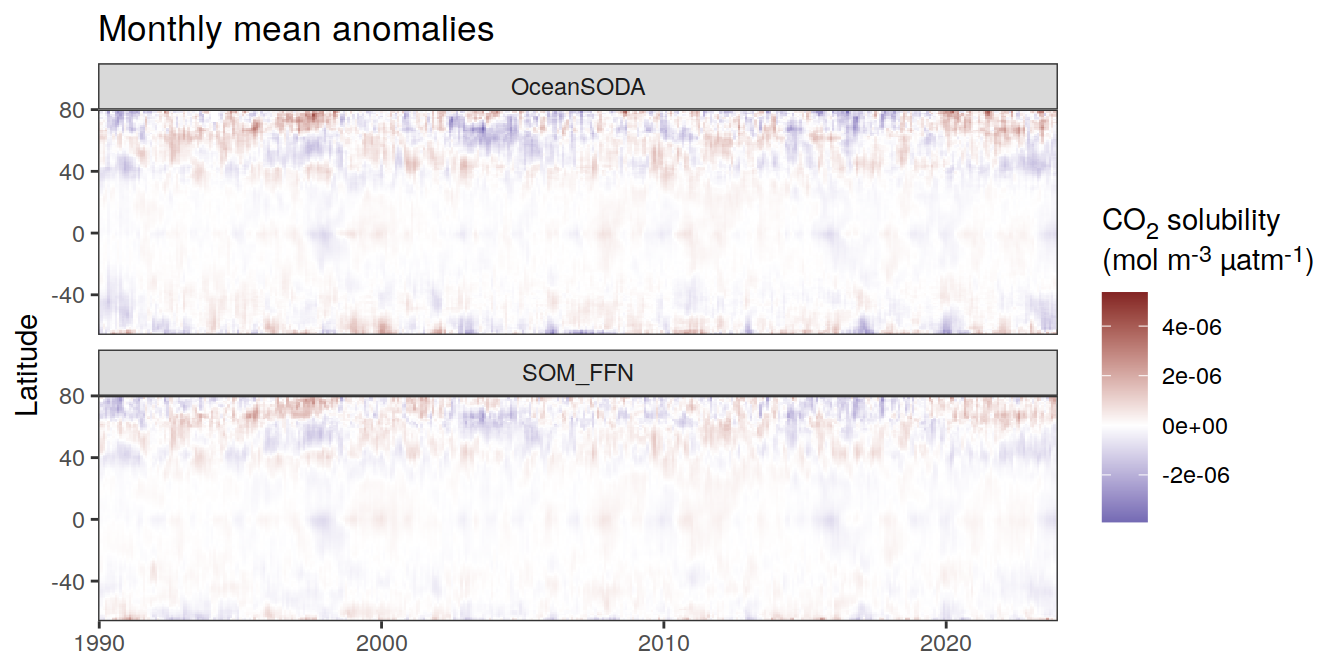
[[4]]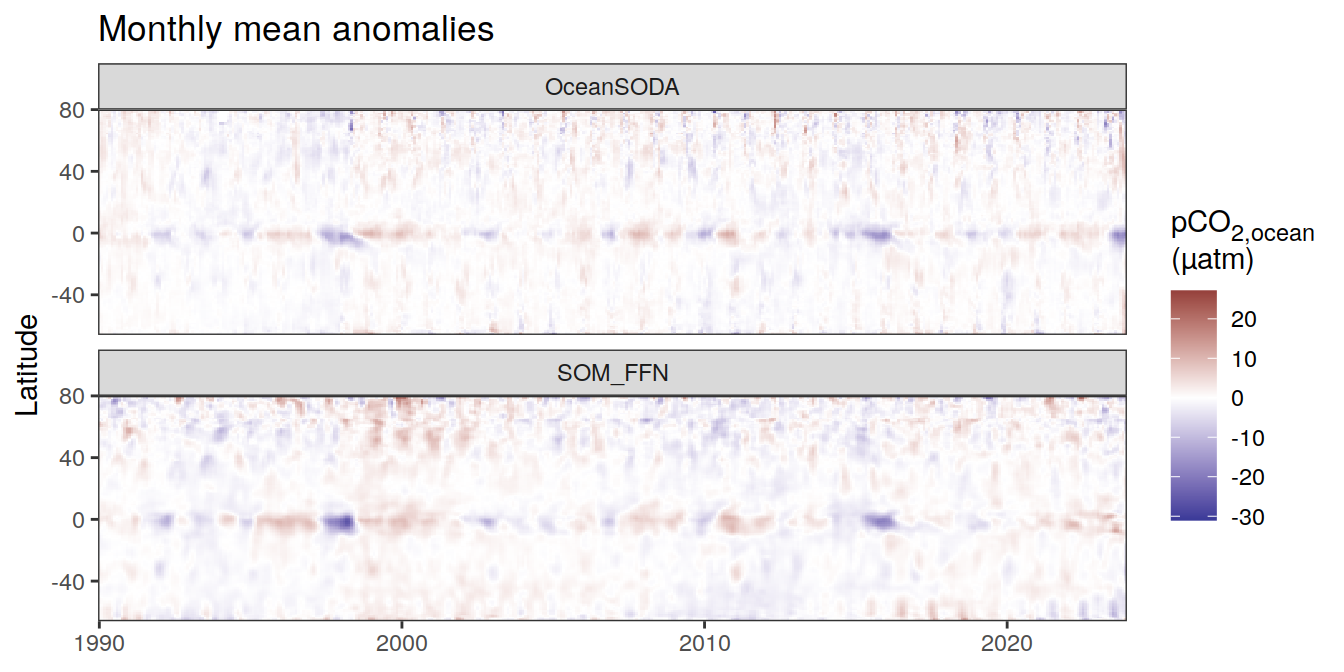
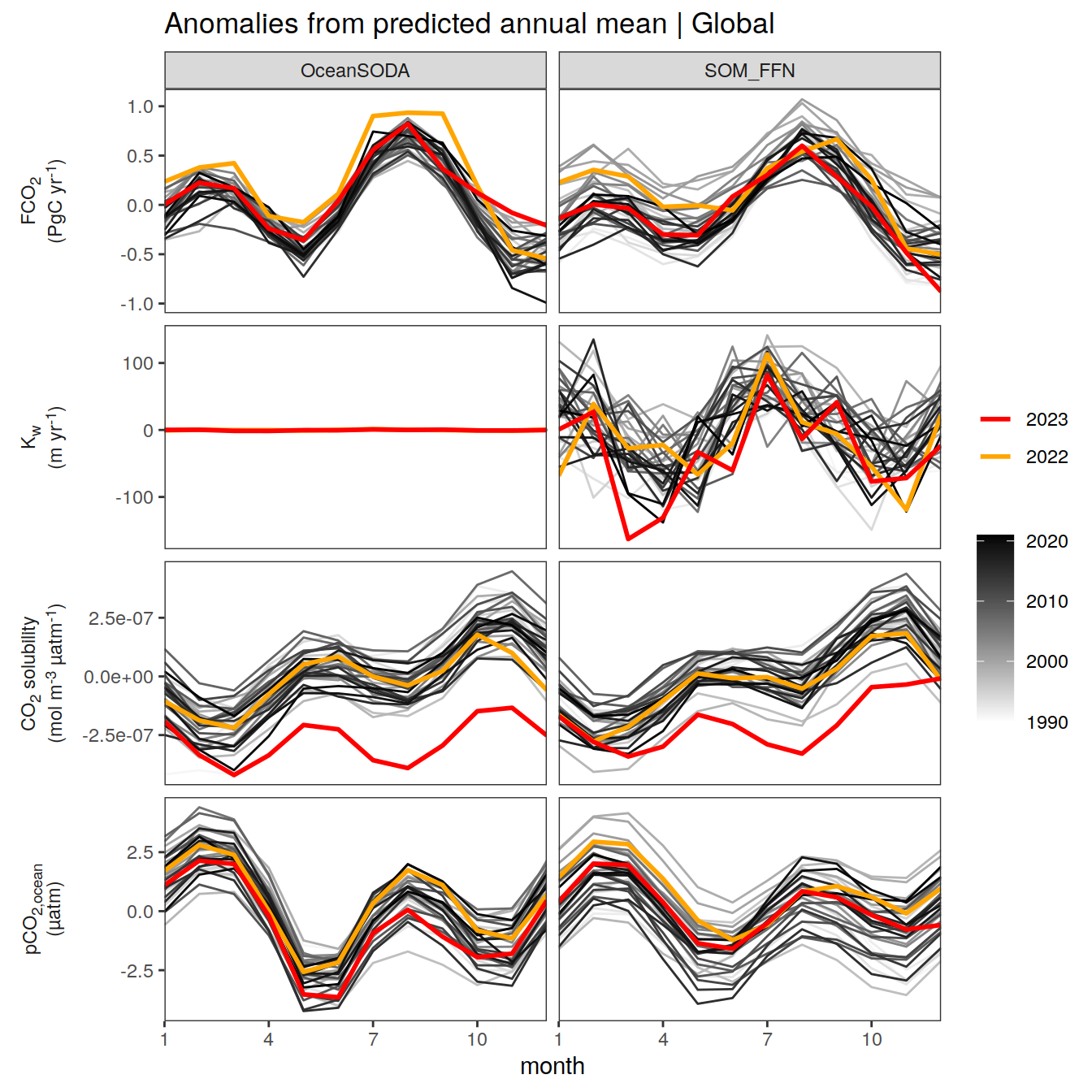
Regional means and integrals
The following plots show biome- or global- averaged/integrated values of each variable as provided through the pCO2 product, as well as the anomalies from the prediction of a linear/quadratic fit to the data from 1990 to 2022.
Anomalies are first presented relative to the predicted annual mean of each year, hence preserving the seasonality. Furthermore, anomalies are presented relative to the predicted monthly mean values, such that the mean seasonality is removed.
Anomalies
Annual mean trends
pco2_product_annual_detrended %>%
filter(biome %in% "Global",
name %in% name_core) %>%
ggplot(aes(month, resid, group = as.factor(year))) +
geom_path(data = . %>% filter(year < 2022),
aes(col = year)) +
scale_color_grayC() +
new_scale_color() +
geom_path(data = . %>% filter(year >= 2022),
aes(col = as.factor(year)),
linewidth = 1) +
scale_color_manual(values = c("orange", "red"),
guide = guide_legend(reverse = TRUE,
order = 1)) +
scale_x_continuous(breaks = seq(1, 12, 3), expand = c(0, 0)) +
labs(title = "Anomalies from predicted annual mean | Global") +
facet_grid(name ~ product,
scales = "free_y",
labeller = labeller(name = x_axis_labels),
switch = "y"
) +
theme(
strip.text.y.left = element_markdown(),
strip.placement = "outside",
strip.background.y = element_blank(),
axis.title.y = element_blank(),
legend.title = element_blank()
)
pco2_product_annual_detrended %>%
filter(biome %in% key_biomes,
name %in% name_core) %>%
group_split(biome) %>%
# head(1) %>%
map(
~ ggplot(data = .x,
aes(month, resid, group = as.factor(year))) +
geom_path(data = . %>% filter(year < 2022),
aes(col = year)) +
scale_color_grayC() +
new_scale_color() +
geom_path(
data = . %>% filter(year >= 2022),
aes(col = as.factor(year)),
linewidth = 1
) +
scale_color_manual(
values = c("orange", "red"),
guide = guide_legend(reverse = TRUE,
order = 1)
) +
scale_x_continuous(breaks = seq(1, 12, 3), expand = c(0, 0)) +
labs(title = paste("Anomalies from predicted annual mean |", .x$biome)) +
facet_grid(
name ~ product,
scales = "free_y",
labeller = labeller(name = x_axis_labels),
switch = "y"
) +
theme(strip.text.y.left = element_markdown(),
strip.placement = "outside",
strip.background.y = element_blank(),
axis.title = element_blank(),
legend.title = element_blank()
)
)[[1]]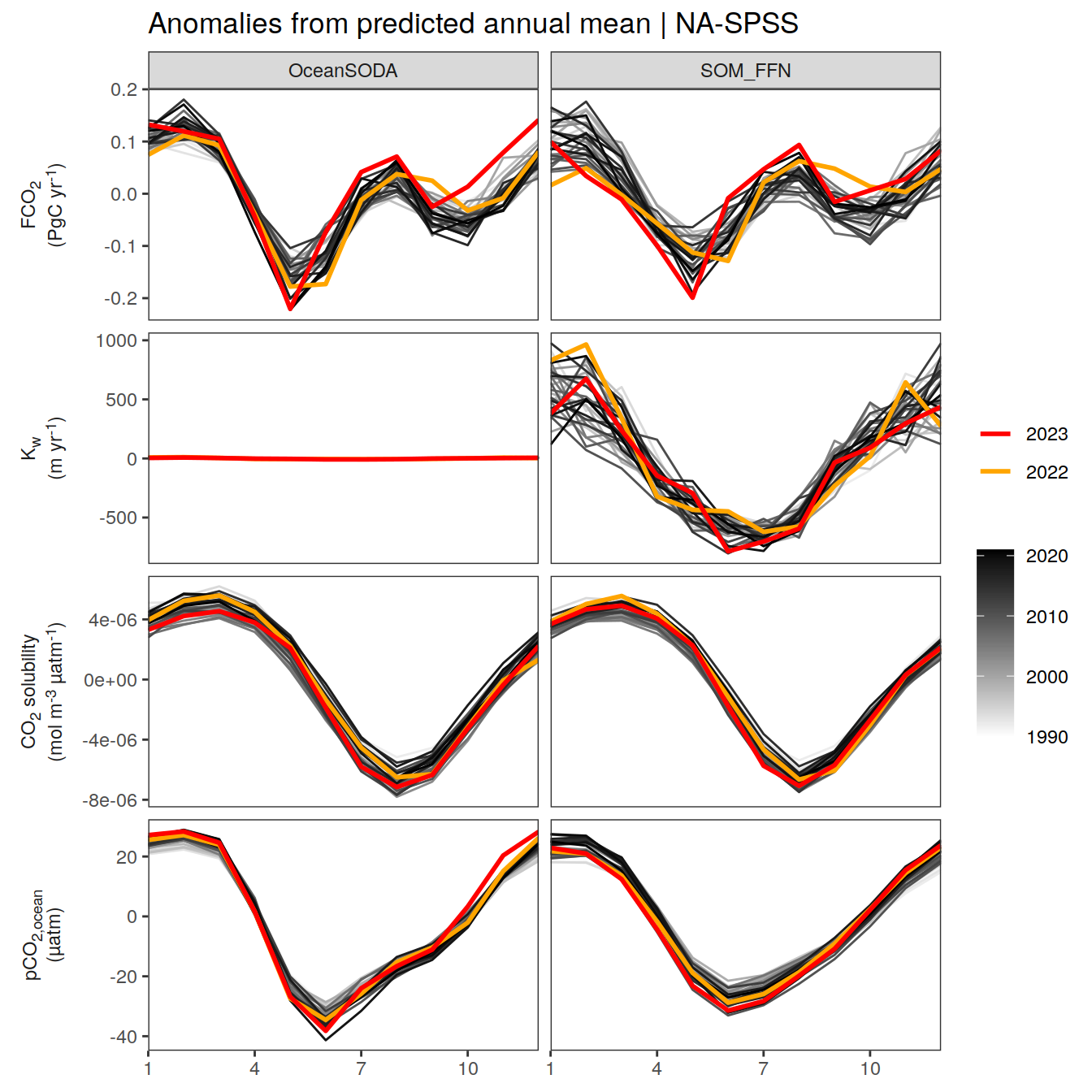
[[2]]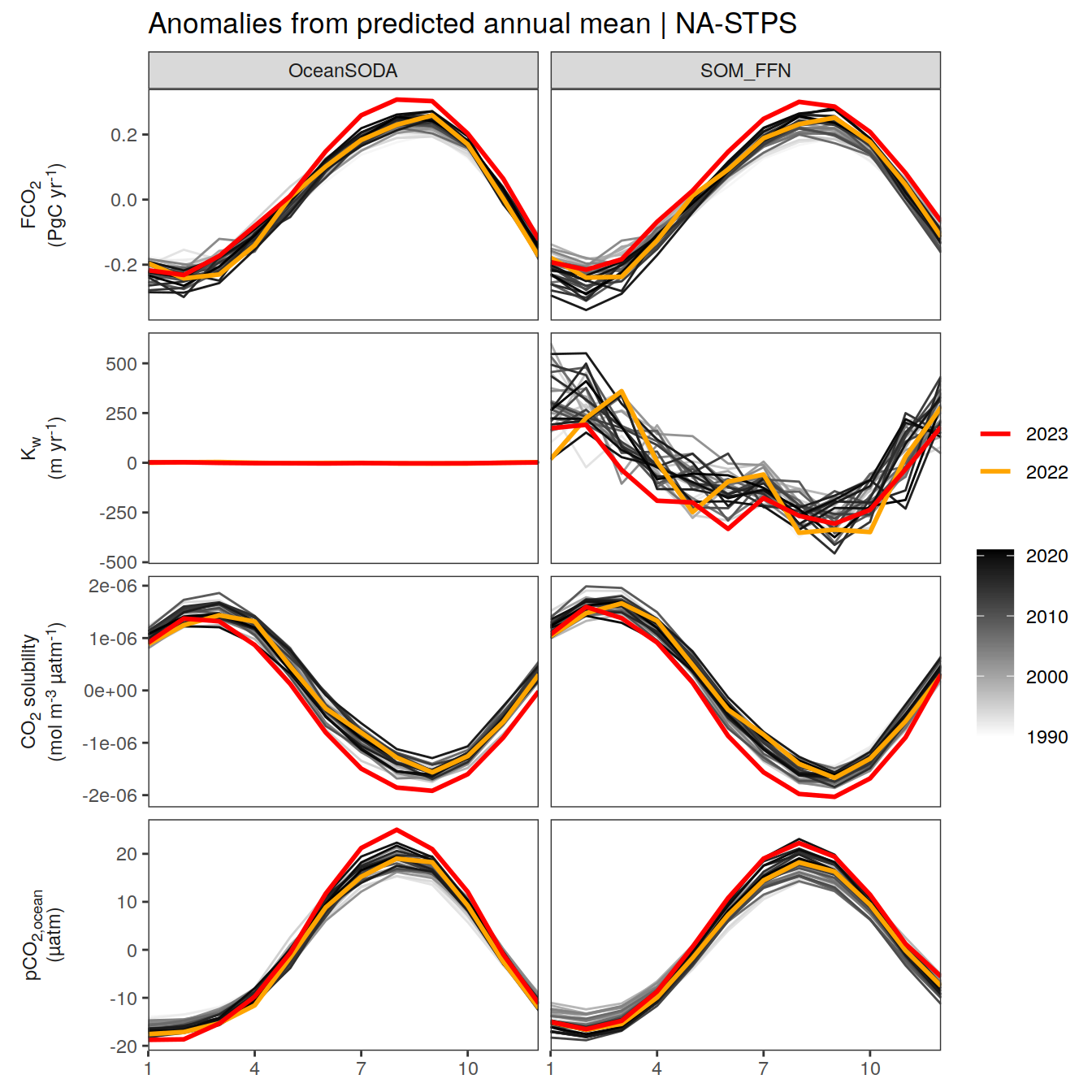
[[3]]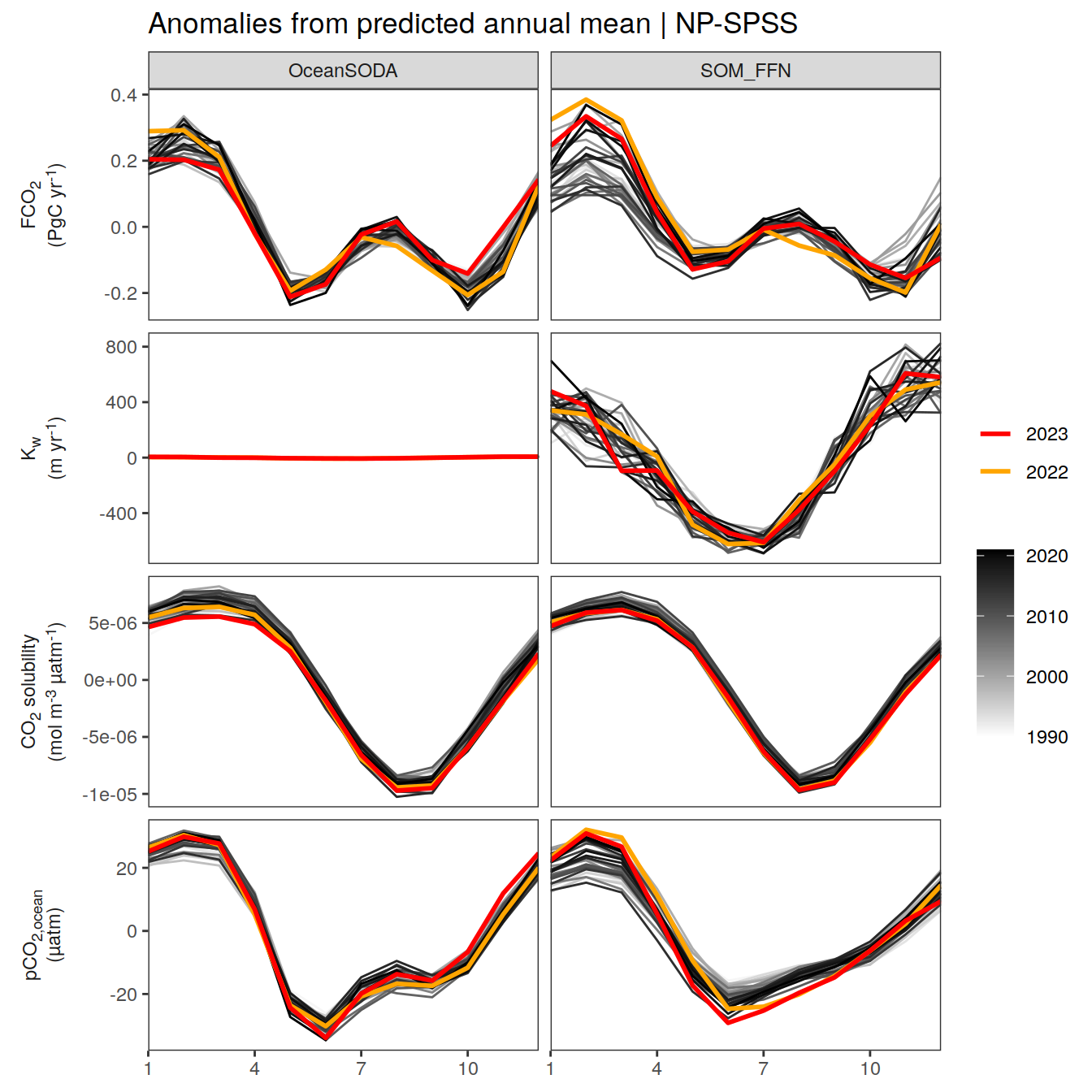
[[4]]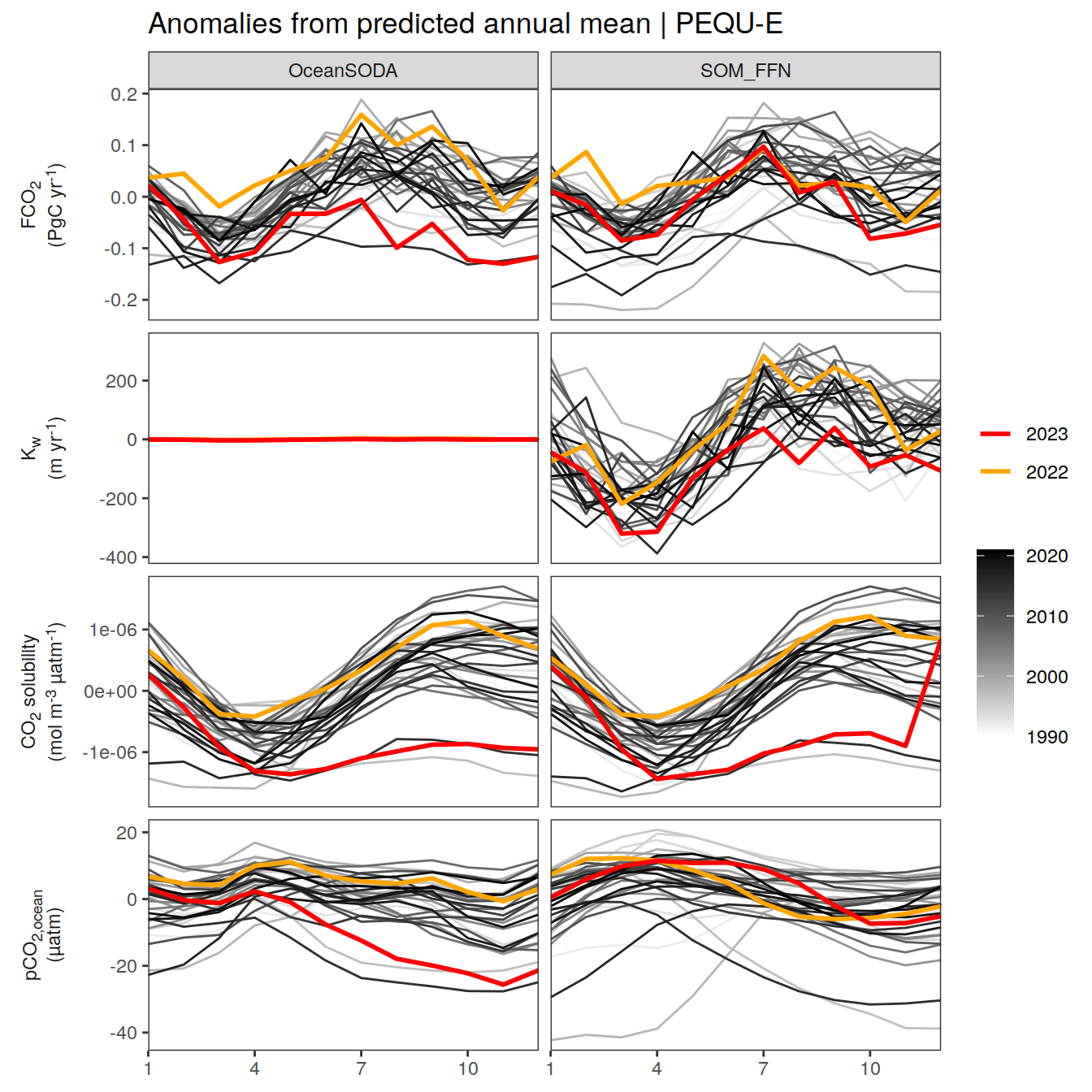
[[5]]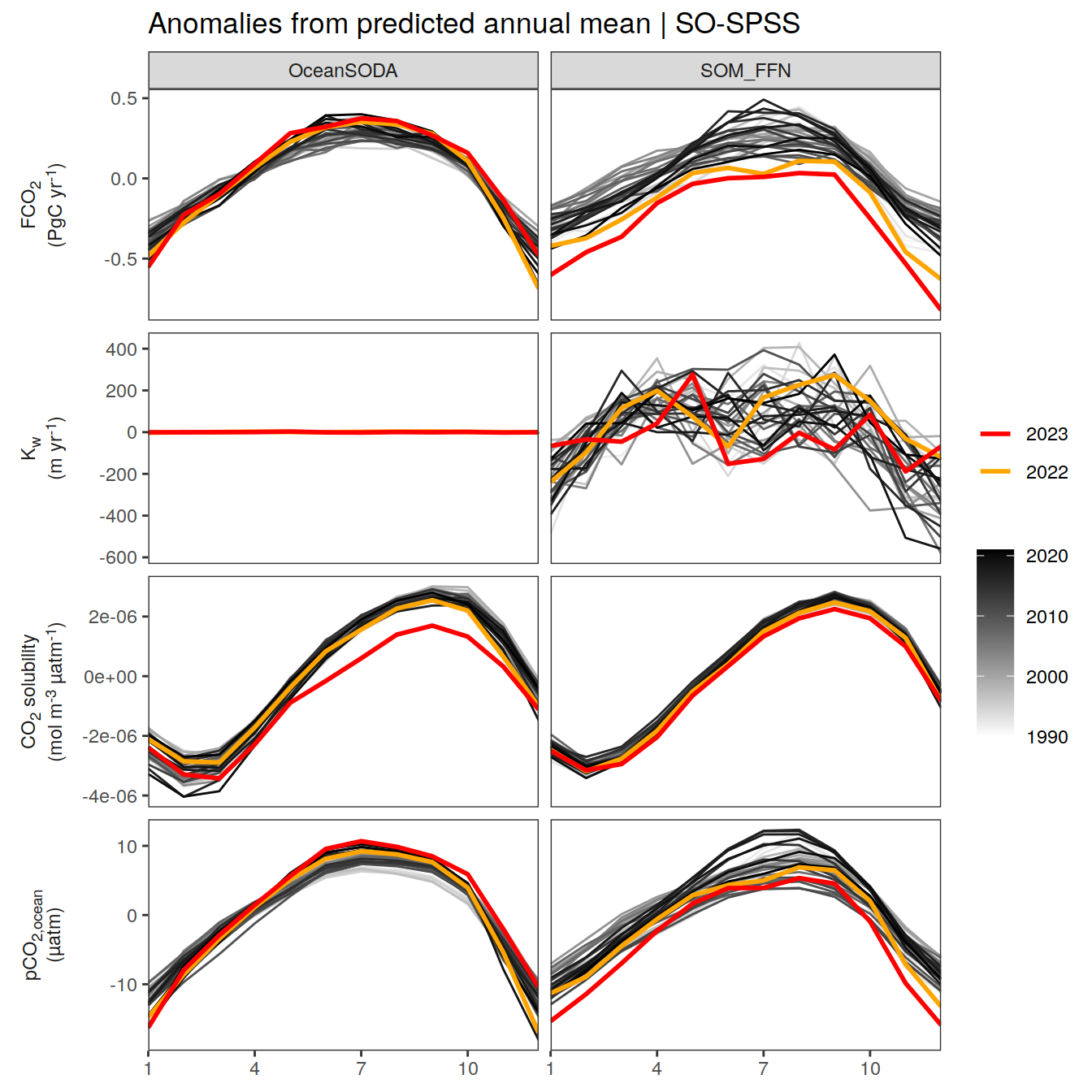
Flux anomaly correlation
The following plots aim to unravel the correlation between biome- or globally- integrated monthly flux anomalies and the corresponding anomalies of the means/integrals of each other variable.
Anomalies are first presented are first presented in absolute units. Due to the different flux magnitudes, we need to plot the globally and biome-integrated fluxes separately. Secondly, we normalize the anomalies to the monthly spread (expressed as standard deviation) of the anomalies from 1990 to 2022.
Monthly anomalies
Absolute
pco2_product_monthly_detrended_anomaly <-
pco2_product_monthly_detrended %>%
select(year, month, biome, name, resid) %>%
pivot_wider(names_from = name,
values_from = resid)
pco2_product_monthly_detrended_anomaly %>%
filter(biome == "Global") %>%
pivot_longer(-c(year, month, biome, fgco2_int)) %>%
ggplot(aes(value, fgco2_int)) +
geom_hline(yintercept = 0) +
geom_point(data = . %>% filter(year <= 2022),
aes(fill = year),
shape = 21) +
scale_fill_grayC(name = "") +
new_scale_fill() +
geom_path(data = . %>% filter(year > 2022),
aes(col = as.factor(month), group = 1)) +
geom_point(data = . %>% filter(year > 2022),
aes(fill = as.factor(month)),
shape = 21,
size = 3) +
scale_color_scico_d(palette = "buda",
guide = guide_legend(reverse = TRUE,
order = 1),
name = "Month\nof 2023") +
scale_fill_scico_d(palette = "buda",
guide = guide_legend(reverse = TRUE,
order = 1),
name = "Month\nof 2023") +
labs(title = "Globally integrated fluxes",
y = labels_breaks("fgco2_int")$i_legend_title) +
facet_wrap(
~ name,
scales = "free_x",
labeller = labeller(name = x_axis_labels),
strip.position = "bottom",
ncol = 2
) +
theme(
strip.text.x.bottom = element_markdown(),
strip.placement = "outside",
strip.background.x = element_blank(),
axis.title.y = element_markdown(),
axis.title.x = element_blank()
)pco2_product_monthly_detrended_anomaly %>%
filter(biome != "Global") %>%
pivot_longer(-c(year, month, biome, fgco2_int)) %>%
group_split(name) %>%
# head(1) %>%
map(
~ ggplot(data = .x,
aes(value, fgco2_int)) +
geom_hline(yintercept = 0) +
geom_point(
data = . %>% filter(year <= 2022),
aes(fill = year),
shape = 21
) +
scale_fill_grayC(name = "") +
new_scale_fill() +
geom_path(data = . %>% filter(year > 2022),
aes(col = as.factor(month), group = 1)) +
geom_point(
data = . %>% filter(year > 2022),
aes(fill = as.factor(month)),
shape = 21,
size = 3
) +
scale_color_scico_d(
palette = "buda",
guide = guide_legend(reverse = TRUE,
order = 1),
name = "Month\nof 2023"
) +
scale_fill_scico_d(
palette = "buda",
guide = guide_legend(reverse = TRUE,
order = 1),
name = "Month\nof 2023"
) +
facet_wrap( ~ biome, ncol = 3, scales = "free_x") +
labs(
title = "Biome integrated fluxes",
y = labels_breaks("fgco2_int")$i_legend_title,
x = labels_breaks(.x %>% distinct(name))$i_legend_title
) +
theme(axis.title.x = element_markdown(),
axis.title.y = element_markdown())
)Relative to spread
pco2_product_monthly_detrended_anomaly_spread <-
pco2_product_monthly_detrended_anomaly %>%
pivot_longer(-c(month, biome, year)) %>%
filter(year < 2023) %>%
group_by(month, biome, name) %>%
summarise(spread = sd(value)) %>%
ungroup()
pco2_product_monthly_detrended_anomaly_relative <-
full_join(
pco2_product_monthly_detrended_anomaly_spread,
pco2_product_monthly_detrended_anomaly %>%
pivot_longer(-c(month, biome, year))
)
pco2_product_monthly_detrended_anomaly_relative <-
pco2_product_monthly_detrended_anomaly_relative %>%
mutate(value = value / spread) %>%
select(-spread) %>%
pivot_wider() %>%
pivot_longer(-c(month, biome, year, fgco2_int))
pco2_product_monthly_detrended_anomaly_relative %>%
group_split(name) %>%
# head(1) %>%
map(
~ ggplot(data = .x,
aes(value, fgco2_int)) +
geom_vline(xintercept = 0) +
geom_hline(yintercept = 0) +
geom_point(
data = . %>% filter(year <= 2022),
aes(fill = year),
shape = 21
) +
scale_fill_grayC() +
new_scale_fill() +
geom_path(data = . %>% filter(year > 2022),
aes(col = as.factor(month), group = 1)) +
geom_point(
data = . %>% filter(year > 2022),
aes(fill = as.factor(month)),
shape = 21,
size = 3
) +
scale_color_scico_d(
palette = "buda",
guide = guide_legend(reverse = TRUE,
order = 1),
name = "Month\nof 2023"
) +
scale_fill_scico_d(
palette = "buda",
guide = guide_legend(reverse = TRUE,
order = 1),
name = "Month\nof 2023"
) +
facet_wrap( ~ biome, ncol = 3) +
coord_fixed() +
labs(
title = "Biome integrated fluxes normalized to spread",
y = str_split_i(labels_breaks("fgco2_int")$i_legend_title, "<br>", i = 1),
x = str_split_i(labels_breaks(.x %>% distinct(name))$i_legend_title, "<br>", i = 1)
) +
theme(axis.title.x = element_markdown(),
axis.title.y = element_markdown())
)
sessionInfo()R version 4.2.2 (2022-10-31)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: openSUSE Leap 15.5
Matrix products: default
BLAS: /usr/local/R-4.2.2/lib64/R/lib/libRblas.so
LAPACK: /usr/local/R-4.2.2/lib64/R/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] ggtext_0.1.2 khroma_1.9.0 ggnewscale_0.4.8
[4] terra_1.7-65 sf_1.0-9 rnaturalearth_0.1.0
[7] geomtextpath_0.1.1 colorspace_2.0-3 marelac_2.1.10
[10] shape_1.4.6 ggforce_0.4.1 metR_0.13.0
[13] scico_1.3.1 patchwork_1.1.2 collapse_1.8.9
[16] forcats_0.5.2 stringr_1.5.0 dplyr_1.1.3
[19] purrr_1.0.2 readr_2.1.3 tidyr_1.3.0
[22] tibble_3.2.1 ggplot2_3.4.4 tidyverse_1.3.2
loaded via a namespace (and not attached):
[1] googledrive_2.0.0 ellipsis_0.3.2 class_7.3-20
[4] rprojroot_2.0.3 markdown_1.4 fs_1.5.2
[7] gridtext_0.1.5 rstudioapi_0.15.0 proxy_0.4-27
[10] farver_2.1.1 bit64_4.0.5 fansi_1.0.3
[13] lubridate_1.9.0 xml2_1.3.3 codetools_0.2-18
[16] cachem_1.0.6 knitr_1.41 polyclip_1.10-4
[19] jsonlite_1.8.3 workflowr_1.7.0 gsw_1.1-1
[22] broom_1.0.5 dbplyr_2.2.1 compiler_4.2.2
[25] httr_1.4.4 backports_1.4.1 assertthat_0.2.1
[28] fastmap_1.1.0 gargle_1.2.1 cli_3.6.1
[31] later_1.3.0 tweenr_2.0.2 htmltools_0.5.3
[34] tools_4.2.2 gtable_0.3.1 glue_1.6.2
[37] rnaturalearthdata_0.1.0 Rcpp_1.0.11 cellranger_1.1.0
[40] jquerylib_0.1.4 vctrs_0.6.4 xfun_0.35
[43] rvest_1.0.3 timechange_0.1.1 lifecycle_1.0.3
[46] googlesheets4_1.0.1 oce_1.7-10 MASS_7.3-58.1
[49] scales_1.2.1 vroom_1.6.0 hms_1.1.2
[52] promises_1.2.0.1 parallel_4.2.2 yaml_2.3.6
[55] memoise_2.0.1 sass_0.4.4 stringi_1.7.8
[58] highr_0.9 e1071_1.7-12 checkmate_2.1.0
[61] commonmark_1.8.1 rlang_1.1.1 pkgconfig_2.0.3
[64] systemfonts_1.0.4 evaluate_0.18 lattice_0.20-45
[67] SolveSAPHE_2.1.0 labeling_0.4.2 bit_4.0.5
[70] tidyselect_1.2.0 seacarb_3.3.1 magrittr_2.0.3
[73] R6_2.5.1 generics_0.1.3 DBI_1.1.3
[76] pillar_1.9.0 haven_2.5.1 whisker_0.4
[79] withr_2.5.0 units_0.8-0 sp_1.5-1
[82] modelr_0.1.10 crayon_1.5.2 KernSmooth_2.23-20
[85] utf8_1.2.2 tzdb_0.3.0 rmarkdown_2.18
[88] grid_4.2.2 readxl_1.4.1 data.table_1.14.6
[91] git2r_0.30.1 reprex_2.0.2 digest_0.6.30
[94] classInt_0.4-8 httpuv_1.6.6 textshaping_0.3.6
[97] munsell_0.5.0 bslib_0.4.1