Cluster annotation
Katharina Hembach
5/29/2020
Last updated: 2020-06-12
Checks: 7 0
Knit directory: neural_scRNAseq/
This reproducible R Markdown analysis was created with workflowr (version 1.6.2). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20200522) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version a8f31cd. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: ._.DS_Store
Ignored: .__workflowr.yml
Ignored: ._neural_scRNAseq.Rproj
Ignored: analysis/.DS_Store
Ignored: analysis/.Rhistory
Ignored: analysis/._.DS_Store
Ignored: analysis/._01-preprocessing.Rmd
Ignored: analysis/._01-preprocessing.html
Ignored: analysis/._02.1-SampleQC.Rmd
Ignored: analysis/._04-clustering.Rmd
Ignored: analysis/._04-clustering.knit.md
Ignored: analysis/._05-annotation.Rmd
Ignored: analysis/.__site.yml
Ignored: analysis/01-preprocessing_cache/
Ignored: analysis/02-1-SampleQC_cache/
Ignored: analysis/02-quality_control_cache/
Ignored: analysis/02.1-SampleQC_cache/
Ignored: analysis/03-filtering_cache/
Ignored: analysis/04-clustering_cache/
Ignored: analysis/figure/
Ignored: analysis/sample5_QC_cache/
Ignored: data/.DS_Store
Ignored: data/._.DS_Store
Ignored: data/._.smbdeleteAAA17ed8b4b
Ignored: data/._metadata.csv
Ignored: data/data_sushi/
Ignored: data/filtered_feature_matrices/
Ignored: output/.DS_Store
Ignored: output/._.DS_Store
Ignored: output/figures/
Ignored: output/sce_01_preprocessing.rds
Ignored: output/sce_02_quality_control.rds
Ignored: output/sce_03_filtering.rds
Ignored: output/sce_preprocessing.rds
Ignored: output/so_04_clustering.rds
Untracked files:
Untracked: Rplots.pdf
Untracked: analysis/sample5_QC.Rmd
Untracked: scripts/
Unstaged changes:
Modified: analysis/_site.yml
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/05-annotation.Rmd) and HTML (docs/05-annotation.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | a8f31cd | khembach | 2020-06-12 | analyze known marker genes |
| html | f116d0f | khembach | 2020-06-10 | Build site. |
| Rmd | b6767a6 | khembach | 2020-06-10 | wflow_publish(“analysis/05-annotation.Rmd”, verbose = TRUE) |
| html | 419ac73 | khembach | 2020-06-09 | Build site. |
| html | a4d0e04 | khembach | 2020-05-29 | Build site. |
| Rmd | 97d5a52 | khembach | 2020-05-29 | cluster analysis |
Load packages
library(ComplexHeatmap)
library(cowplot)
library(ggplot2)
library(dplyr)
library(muscat)
library(purrr)
library(RColorBrewer)
library(viridis)
library(scran)
library(Seurat)
library(SingleCellExperiment)
library(stringr)
library(RCurl)Load data & convert to SCE
so <- readRDS(file.path("output", "so_04_clustering.rds"))
sce <- as.SingleCellExperiment(so, assay = "RNA")
colData(sce) <- as.data.frame(colData(sce)) %>%
mutate_if(is.character, as.factor) %>%
DataFrame(row.names = colnames(sce))Nb. of clusters by resolution
cluster_cols <- grep("res.[0-9]", colnames(colData(sce)), value = TRUE)
sapply(colData(sce)[cluster_cols], nlevels)integrated_snn_res.0.1 integrated_snn_res.0.2 integrated_snn_res.0.4
8 12 17
integrated_snn_res.0.8 integrated_snn_res.1 integrated_snn_res.1.2
24 29 31
integrated_snn_res.2
39 Cluster-sample counts
# set cluster IDs to resolution 0.4 clustering
so <- SetIdent(so, value = "integrated_snn_res.0.4")
so@meta.data$cluster_id <- Idents(so)
sce$cluster_id <- Idents(so)
(n_cells <- table(sce$cluster_id, sce$sample_id))
1NSC 2NSC 3NC52 4NC52 5NC96 6NC96
0 4850 5041 186 98 308 82
1 0 0 1552 1279 492 627
2 1037 1011 337 288 563 391
3 12 10 572 383 1806 372
4 1351 1221 69 56 76 16
5 0 0 1017 847 380 415
6 2 9 628 620 528 774
7 253 236 577 606 376 369
8 0 0 1007 867 250 285
9 0 0 924 764 327 379
10 688 716 130 121 188 119
11 3 3 582 524 211 248
12 0 0 365 281 186 235
13 0 0 339 247 141 174
14 1 1 205 260 210 194
15 51 70 148 153 64 89
16 83 90 49 44 83 24Relative cluster-abundances
fqs <- prop.table(n_cells, margin = 2)
mat <- as.matrix(unclass(fqs))
Heatmap(mat,
col = rev(brewer.pal(11, "RdGy")[-6]),
name = "Frequency",
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
row_title = "cluster_id",
column_title = "sample_id",
column_title_side = "bottom",
rect_gp = gpar(col = "white"),
cell_fun = function(i, j, x, y, width, height, fill)
grid.text(round(mat[j, i] * 100, 2), x = x, y = y,
gp = gpar(col = "white", fontsize = 8)))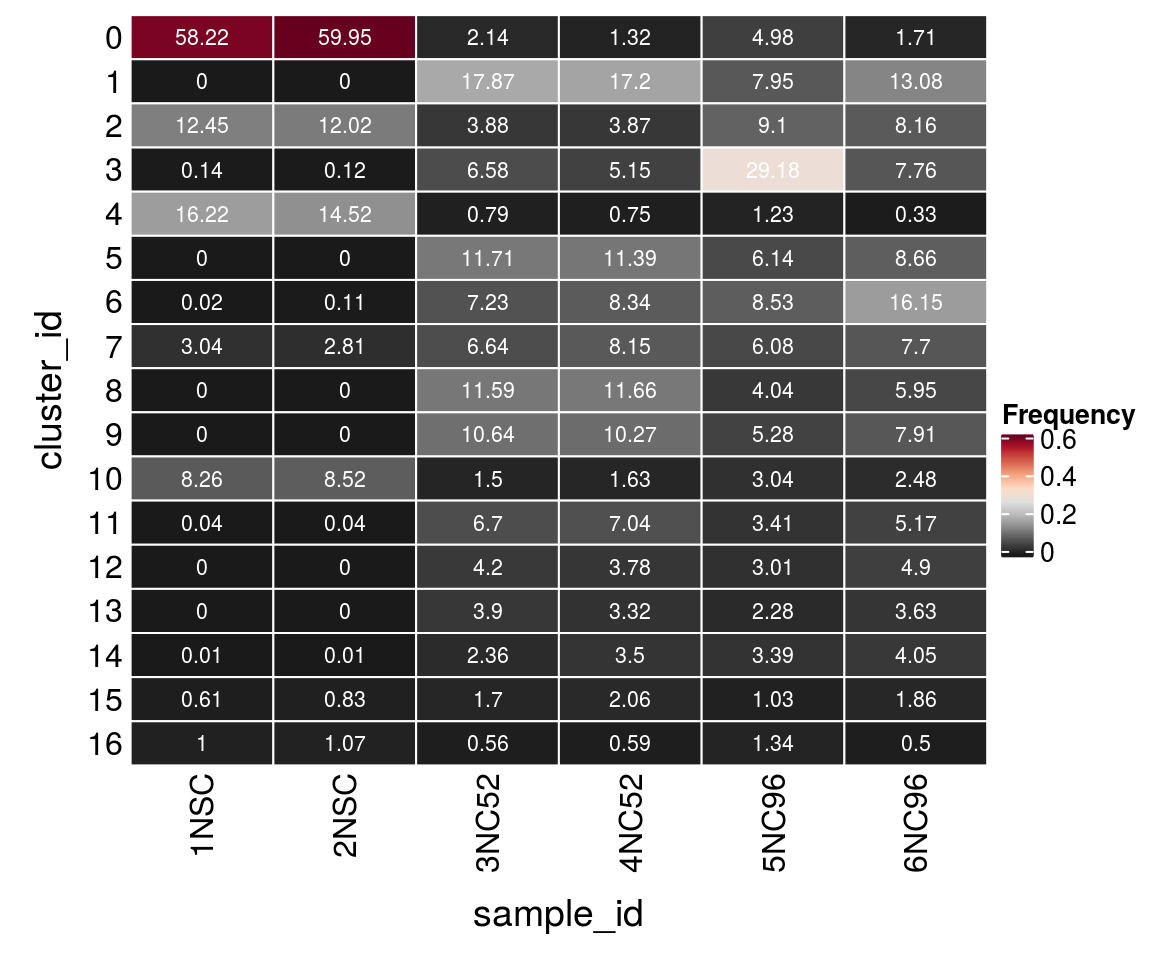
Cell cycle
We assign each cell a cell cycle scores and visualize them in the DR plots. We use known G2/M and S phase markers that come with the Seurat package. The markers are anticorrelated and cells that to not express the markers should be in G1 phase.
We compute cell cycle phase using the 2000 anchor genes of the integrated data.
# A list of cell cycle markers, from Tirosh et al, 2015
cc_file <- getURL("https://raw.githubusercontent.com/hbc/tinyatlas/master/cell_cycle/Homo_sapiens.csv")
cc_genes <- read.csv(text = cc_file)
# match the marker genes to the features
m <- match(cc_genes$geneID[cc_genes$phase == "S"],
str_split(rownames(GetAssayData(so)),
pattern = "\\.", simplify = TRUE)[,1])
s_genes <- rownames(GetAssayData(so))[m]
(s_genes <- s_genes[!is.na(s_genes)]) [1] "ENSG00000051180.RAD51" "ENSG00000092853.CLSPN"
[3] "ENSG00000093009.CDC45" "ENSG00000094804.CDC6"
[5] "ENSG00000111247.RAD51AP1" "ENSG00000112312.GMNN"
[7] "ENSG00000119969.HELLS" "ENSG00000131153.GINS2"
[9] "ENSG00000132646.PCNA" "ENSG00000143476.DTL"
[11] "ENSG00000151725.CENPU" "ENSG00000156802.ATAD2"
[13] "ENSG00000162607.USP1" "ENSG00000171848.RRM2"
[15] "ENSG00000176890.TYMS" m <- match(cc_genes$geneID[cc_genes$phase == "G2/M"],
str_split(rownames(GetAssayData(so)),
pattern = "\\.", simplify = TRUE)[,1])
g2m_genes <- rownames(GetAssayData(so))[m]
(g2m_genes <- g2m_genes[!is.na(g2m_genes)]) [1] "ENSG00000010292.NCAPD2" "ENSG00000011426.ANLN" "ENSG00000013810.TACC3"
[4] "ENSG00000072571.HMMR" "ENSG00000075218.GTSE1" "ENSG00000080986.NDC80"
[7] "ENSG00000087586.AURKA" "ENSG00000088325.TPX2" "ENSG00000089685.BIRC5"
[10] "ENSG00000111665.CDCA3" "ENSG00000112742.TTK" "ENSG00000113810.SMC4"
[13] "ENSG00000114346.ECT2" "ENSG00000115163.CENPA" "ENSG00000117399.CDC20"
[16] "ENSG00000117650.NEK2" "ENSG00000117724.CENPF" "ENSG00000123485.HJURP"
[19] "ENSG00000123975.CKS2" "ENSG00000126787.DLGAP5" "ENSG00000129195.PIMREG"
[22] "ENSG00000131747.TOP2A" "ENSG00000134222.PSRC1" "ENSG00000134690.CDCA8"
[25] "ENSG00000136108.CKAP2" "ENSG00000137804.NUSAP1" "ENSG00000137807.KIF23"
[28] "ENSG00000138160.KIF11" "ENSG00000138182.KIF20B" "ENSG00000138778.CENPE"
[31] "ENSG00000139354.GAS2L3" "ENSG00000142945.KIF2C" "ENSG00000143228.NUF2"
[34] "ENSG00000143401.ANP32E" "ENSG00000148773.MKI67" "ENSG00000157456.CCNB2"
[37] "ENSG00000158402.CDC25C" "ENSG00000164104.HMGB2" "ENSG00000169607.CKAP2L"
[40] "ENSG00000169679.BUB1" "ENSG00000170312.CDK1" "ENSG00000173207.CKS1B"
[43] "ENSG00000175063.UBE2C" "ENSG00000178999.AURKB" "ENSG00000184661.CDCA2"
[46] "ENSG00000188229.TUBB4B" "ENSG00000189159.JPT1" so <- CellCycleScoring(so, s.features = s_genes, g2m.features = g2m_genes,
set.ident = TRUE)DR colored by cluster ID
cs <- sample(colnames(so), 5e3)
.plot_dr <- function(so, dr, id)
DimPlot(so, cells = cs, group.by = id, reduction = dr, pt.size = 0.4) +
guides(col = guide_legend(nrow = 11,
override.aes = list(size = 3, alpha = 1))) +
theme_void() + theme(aspect.ratio = 1)
ids <- c("cluster_id", "group_id", "sample_id", "Phase")
for (id in ids) {
cat("## ", id, "\n")
p1 <- .plot_dr(so, "tsne", id)
lgd <- get_legend(p1)
p1 <- p1 + theme(legend.position = "none")
p2 <- .plot_dr(so, "umap", id) + theme(legend.position = "none")
ps <- plot_grid(plotlist = list(p1, p2), nrow = 1)
p <- plot_grid(ps, lgd, nrow = 1, rel_widths = c(1, 0.2))
print(p)
cat("\n\n")
}cluster_id

group_id

sample_id


Find markers using scran
We identify candidate marker genes for each cluster that enable a separation of that group from all other groups.
scran_markers <- findMarkers(sce,
groups = sce$cluster_id, block = sce$sample_id,
direction = "up", lfc = 2, full.stats = TRUE)Heatmap of mean marker-exprs. by cluster
We aggregate the cells to pseudobulks and plot the average expression of the condidate marker genes in each of the clusters.
gs <- lapply(scran_markers, function(u) rownames(u)[u$Top == 1])
## candidate cluster markers
lapply(gs, function(x) str_split(x, pattern = "\\.", simplify = TRUE)[,2])$`0`
[1] "SAMD11" "NEFL" "VIM" "CKB" "TTYH1"
$`1`
[1] "SAMD11" "STMN2" "CRABP1" "ZFHX3" "HOXB8" "MT-CO2"
$`2`
[1] "S100A10" "S100A11" "CLU" "VIM" "TAGLN" "CKB" "TPM1"
$`3`
[1] "SAMD11" "STMN2" "SNCG" "RTN1" "HOXB5" "ONECUT2" "PCP4"
[8] "MT-CO2"
$`4`
[1] "HMGB2" "VIM" "CKB" "TOP2A"
$`5`
[1] "STMN2" "RTN1" "MEIS2" "HOXB9" "PCP4" "MT-ND3"
$`6`
[1] "C1orf61" "SPP1" "FABP5" "VIM" "HOXB9" "TTYH1" "MT-ND4"
$`7`
[1] "CLU" "LY6H" "VIM" "TAGLN" "DLK1" "CKB" "METRN"
$`8`
[1] "SAMD11" "TAC1" "STMN2" "ZFHX3" "HOXB8" "LAMP5" "MT-CO2"
$`9`
[1] "SAMD11" "FOXP1" "STMN2" "PCP4"
$`10`
[1] "SAMD11" "VGF" "EIF4EBP1" "ANXA1" "VIM" "CKB" "FTL"
$`11`
[1] "ENC1" "STMN2" "NFIB" "HOXB8" "HOXB9" "MT-RNR2"
$`12`
[1] "TAC1" "STMN2"
$`13`
[1] "STMN2" "SNCG" "MPPED2" "PCP4"
$`14`
[1] "STMN2" "DDIT3"
$`15`
[1] "C1orf61" "HES6" "SOX2" "VIM" "CKB"
$`16`
[1] "S100A11" "COL3A1" "COL1A1" sub <- sce[unique(unlist(gs)), ]
pbs <- aggregateData(sub, assay = "logcounts", by = "cluster_id", fun = "mean")
mat <- t(muscat:::.scale(assay(pbs)))
## remove the Ensembl ID from the gene names
colnames(mat) <- str_split(colnames(mat), pattern = "\\.", simplify = TRUE)[,2]
Heatmap(mat,
name = "scaled avg.\nexpression",
col = viridis(10),
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
row_title = "cluster_id",
rect_gp = gpar(col = "white"))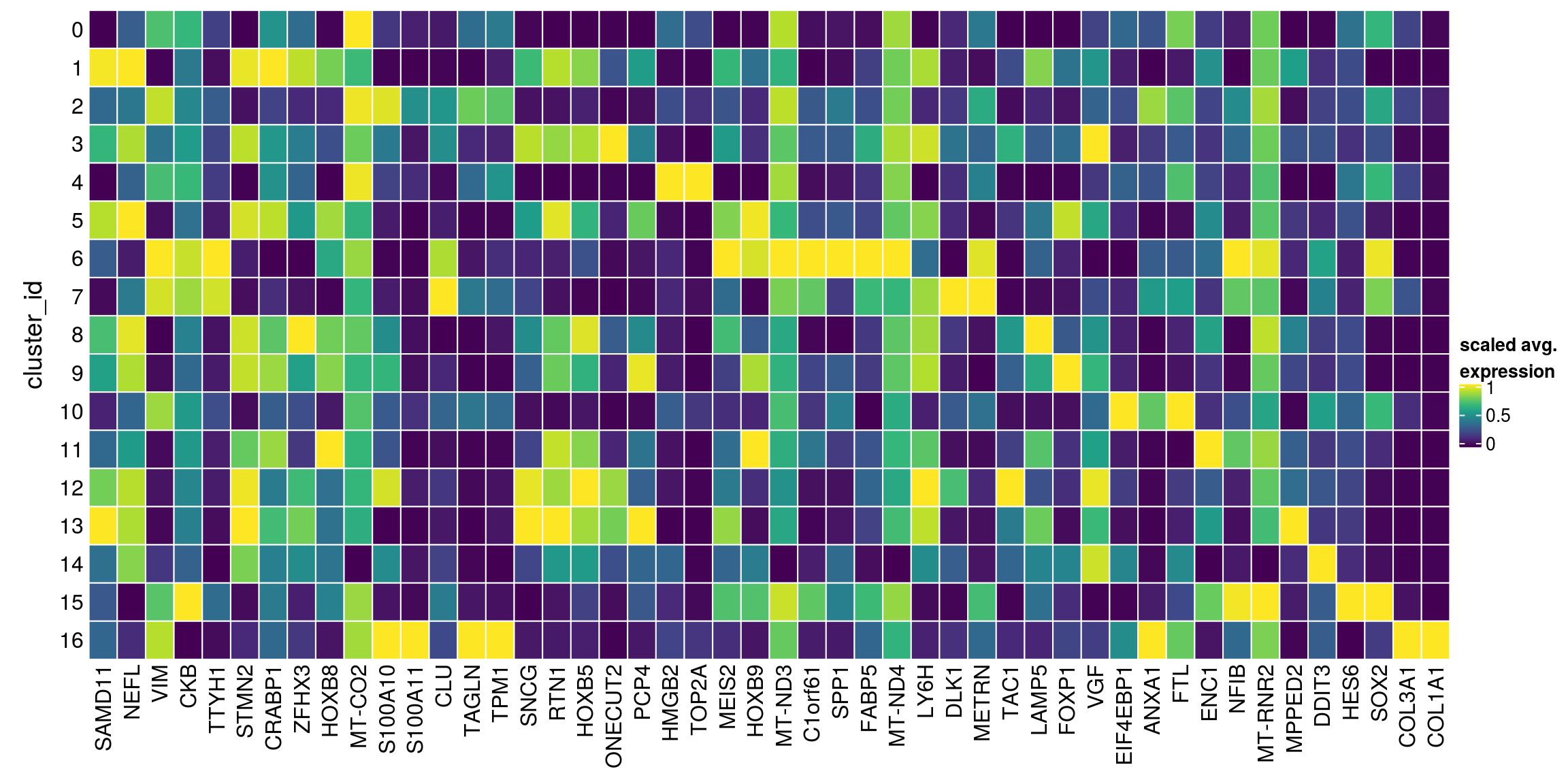
| Version | Author | Date |
|---|---|---|
| f116d0f | khembach | 2020-06-10 |
Known marker genes
## source file with list of known marker genes
source(file.path("data", "known_cell_type_markers.R"))
fs <- lapply(fs, sapply, function(g)
grep(pattern = paste0("\\.", g, "$"), rownames(sce), value = TRUE)
)
fs <- lapply(fs, function(x) unlist(x[lengths(x) !=0]) )
gs <- gsub(".*\\.", "", unlist(fs))
ns <- vapply(fs, length, numeric(1))
ks <- rep.int(names(fs), ns)
labs <- lapply(fs, function(x) gsub(".*\\.", "",x))Heatmap of mean marker-exprs. by cluster
# split cells by cluster
cs_by_k <- split(colnames(sce), sce$cluster_id)
# compute cluster-marker means
ms_by_cluster <- lapply(fs, function(gs) {
cat(gs)
vapply(cs_by_k, function(i)
Matrix::rowMeans(logcounts(sce)[gs, i, drop = FALSE]),
numeric(length(gs)))}
)ENSG00000132688.NES ENSG00000181449.SOX2 ENSG00000175745.NR2F1 ENSG00000170558.CDH2 ENSG00000170561.IRX2 ENSG00000182968.SOX1 ENSG00000007372.PAX6 ENSG00000184486.POU3F2 ENSG00000135903.PAX3 ENSG00000026025.VIM ENSG00000104067.TJP1ENSG00000105825.TFPI2 ENSG00000175063.UBE2C ENSG00000110092.CCND1 ENSG00000129757.CDKN1C ENSG00000108106.UBE2S ENSG00000164611.PTTG1 ENSG00000134057.CCNB1 ENSG00000187840.EIF4EBP1 ENSG00000135069.PSAT1 ENSG00000070669.ASNS ENSG00000168003.SLC3A2 ENSG00000092621.PHGDH ENSG00000166803.PCLAF ENSG00000171848.RRM2ENSG00000258947.TUBB3 ENSG00000111674.ENO2 ENSG00000078018.MAP2 ENSG00000077279.DCX ENSG00000102003.SYP ENSG00000104435.STMN2 ENSG00000167281.RBFOX3 ENSG00000149294.NCAM1 ENSG00000104722.NEFM ENSG00000277586.NEFL ENSG00000273706.LHX1 ENSG00000186868.MAPT ENSG00000132639.SNAP25 ENSG00000117632.STMN1 ENSG00000172020.GAP43 ENSG00000179915.NRXN1 ENSG00000129355.CDKN2DENSG00000131095.GFAP ENSG00000026508.CD44 ENSG00000171885.AQP4 ENSG00000160307.S100BENSG00000026025.VIM ENSG00000181449.SOX2 ENSG00000167614.TTYH1 ENSG00000125462.C1orf61 ENSG00000117519.CNN3 ENSG00000185650.ZFP36L1 ENSG00000171476.HOPX ENSG00000152583.SPARCL1 ENSG00000147588.PMP2 ENSG00000185201.IFITM2 ENSG00000142089.IFITM3 ENSG00000163132.MSX1 ENSG00000182718.ANXA2 ENSG00000108821.COL1A1 ENSG00000139329.LUM ENSG00000163359.COL6A3 ENSG00000011465.DCNENSG00000106278.PTPRZ1 ENSG00000112531.QKI ENSG00000046653.GPM6B ENSG00000137558.PI15 ENSG00000185650.ZFP36L1 ENSG00000148053.NTRK2ENSG00000184221.OLIG1 ENSG00000134853.PDGFRAENSG00000136750.GAD2 ENSG00000128683.GAD1 ENSG00000101438.SLC32A1 ENSG00000157103.SLC6A1 ENSG00000075891.PAX2 ENSG00000172137.CALB2 ENSG00000157005.SSTENSG00000165970.SLC6A5 ENSG00000101438.SLC32A1ENSG00000091664.SLC17A6 ENSG00000176884.GRIN1 ENSG00000115419.GLS ENSG00000273079.GRIN2B ENSG00000183454.GRIN2AENSG00000132437.DDC ENSG00000136531.SCN2A ENSG00000180176.TH ENSG00000147434.CHRNA6 ENSG00000136944.LMX1B ENSG00000157542.KCNJ6ENSG00000135116.HRK ENSG00000116717.GADD45A ENSG00000175197.DDIT3 ENSG00000105327.BBC3# prep. for plotting & scale b/w 0 and 1
mat <- do.call("rbind", ms_by_cluster)
mat <- muscat:::.scale(mat)
rownames(mat) <- gs
cols <- muscat:::.cluster_colors[seq_along(fs)]
cols <- setNames(cols, names(fs))
row_anno <- rowAnnotation(
df = data.frame(label = factor(ks, levels = names(fs))),
col = list(label = cols), gp = gpar(col = "white"))
Heatmap(mat,
name = "scaled avg.\nexpression",
col = viridis(10),
cluster_rows = FALSE,
cluster_columns = FALSE,
row_names_side = "left",
column_title = "cluster_id",
column_title_side = "bottom",
rect_gp = gpar(col = "white"),
left_annotation = row_anno)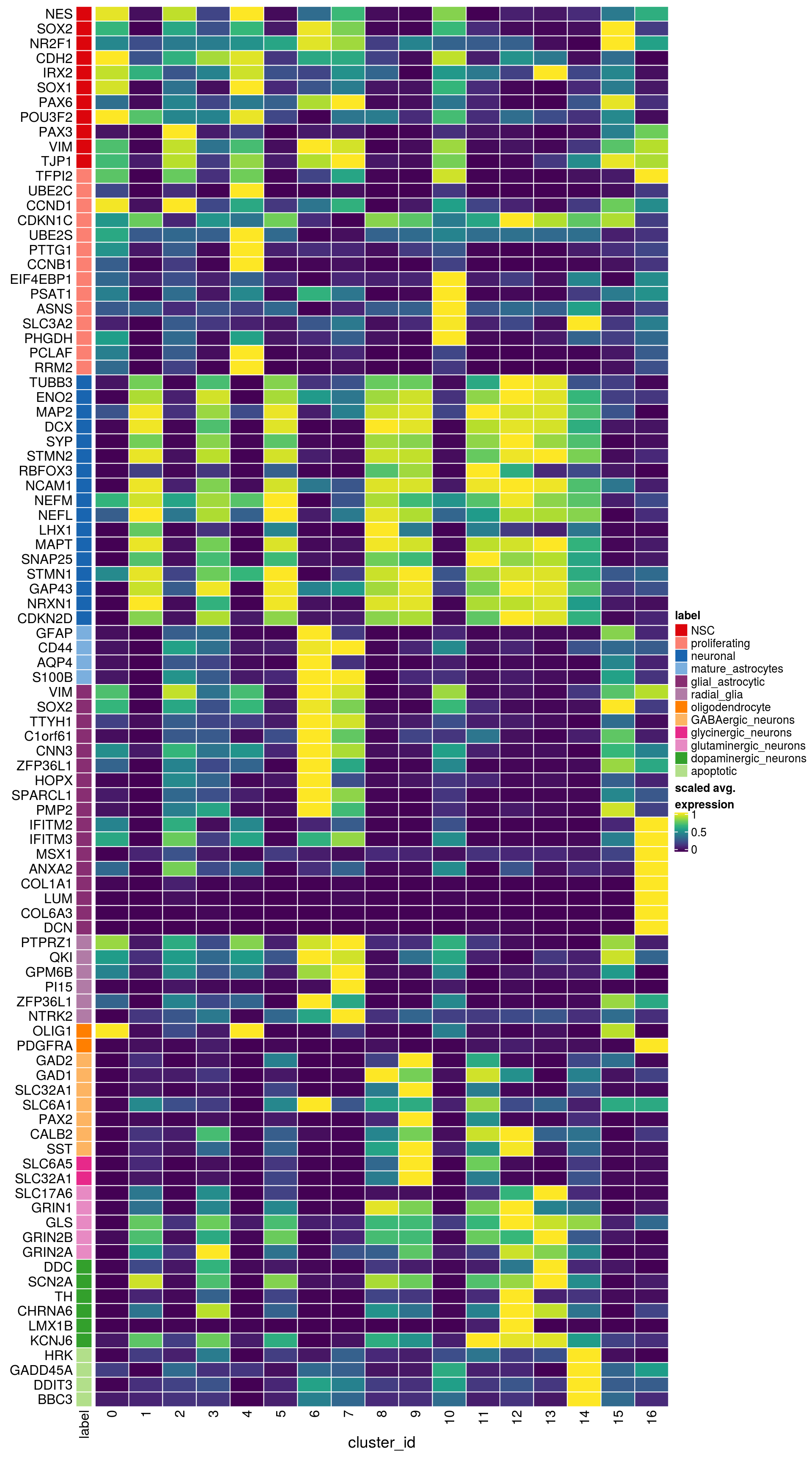
DR colored by marker expression
# downsample to 5000 cells
cs <- sample(colnames(sce), 5e3)
sub <- subset(so, cells = cs)
# UMAPs colored by marker-expression
for (m in seq_along(fs)) {
cat("## ", names(fs)[m], "\n")
ps <- lapply(seq_along(fs[[m]]), function(i) {
if (!fs[[m]][i] %in% rownames(so)) return(NULL)
FeaturePlot(sub, features = fs[[m]][i], reduction = "umap", pt.size = 0.4) +
theme(aspect.ratio = 1, legend.position = "none") +
ggtitle(labs[[m]][i]) + theme_void() + theme(aspect.ratio = 1)
})
# arrange plots in grid
ps <- ps[!vapply(ps, is.null, logical(1))]
p <- plot_grid(plotlist = ps, ncol = 4, label_size = 10)
print(p)
cat("\n\n")
}## NSC 
## proliferating 
## neuronal 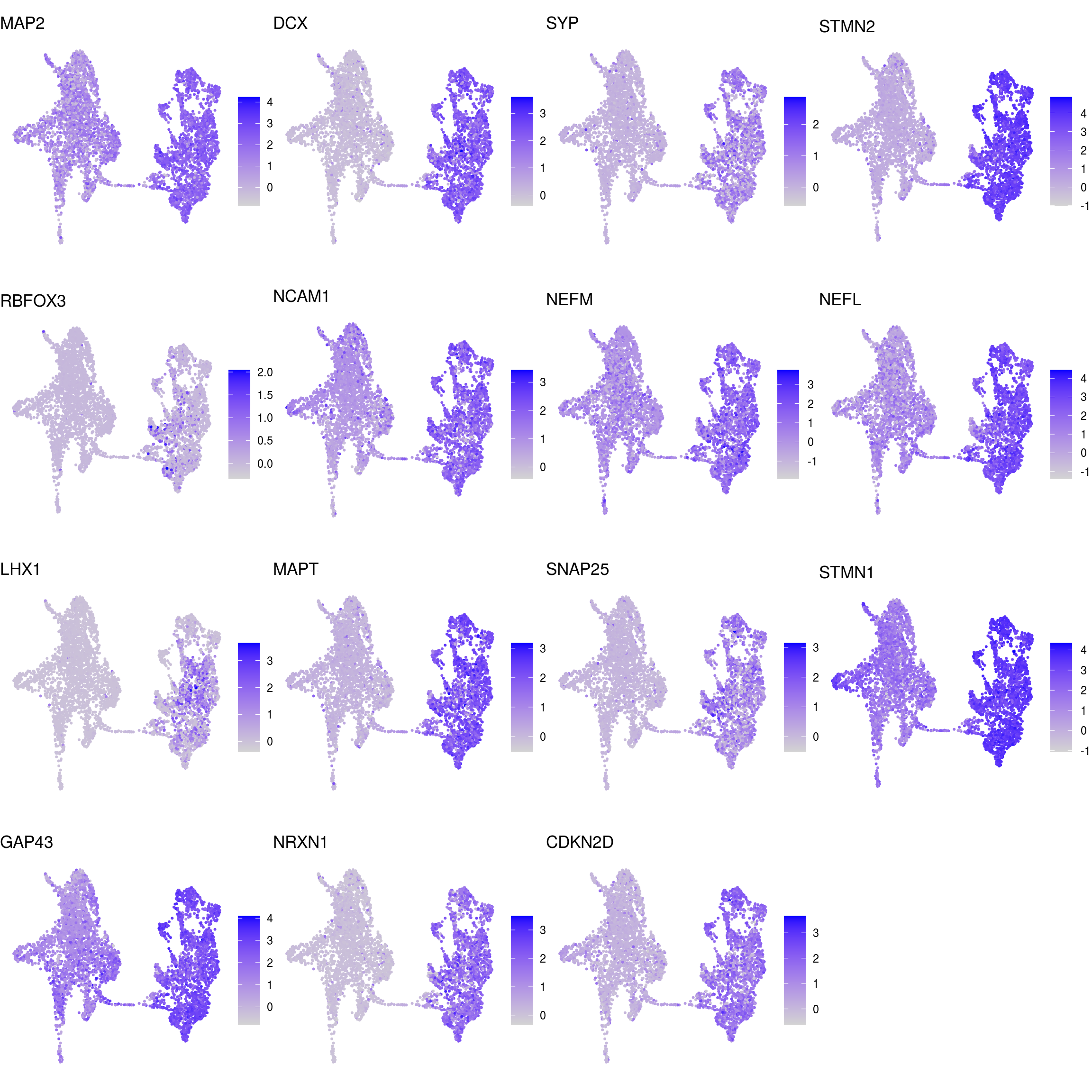
## mature_astrocytes 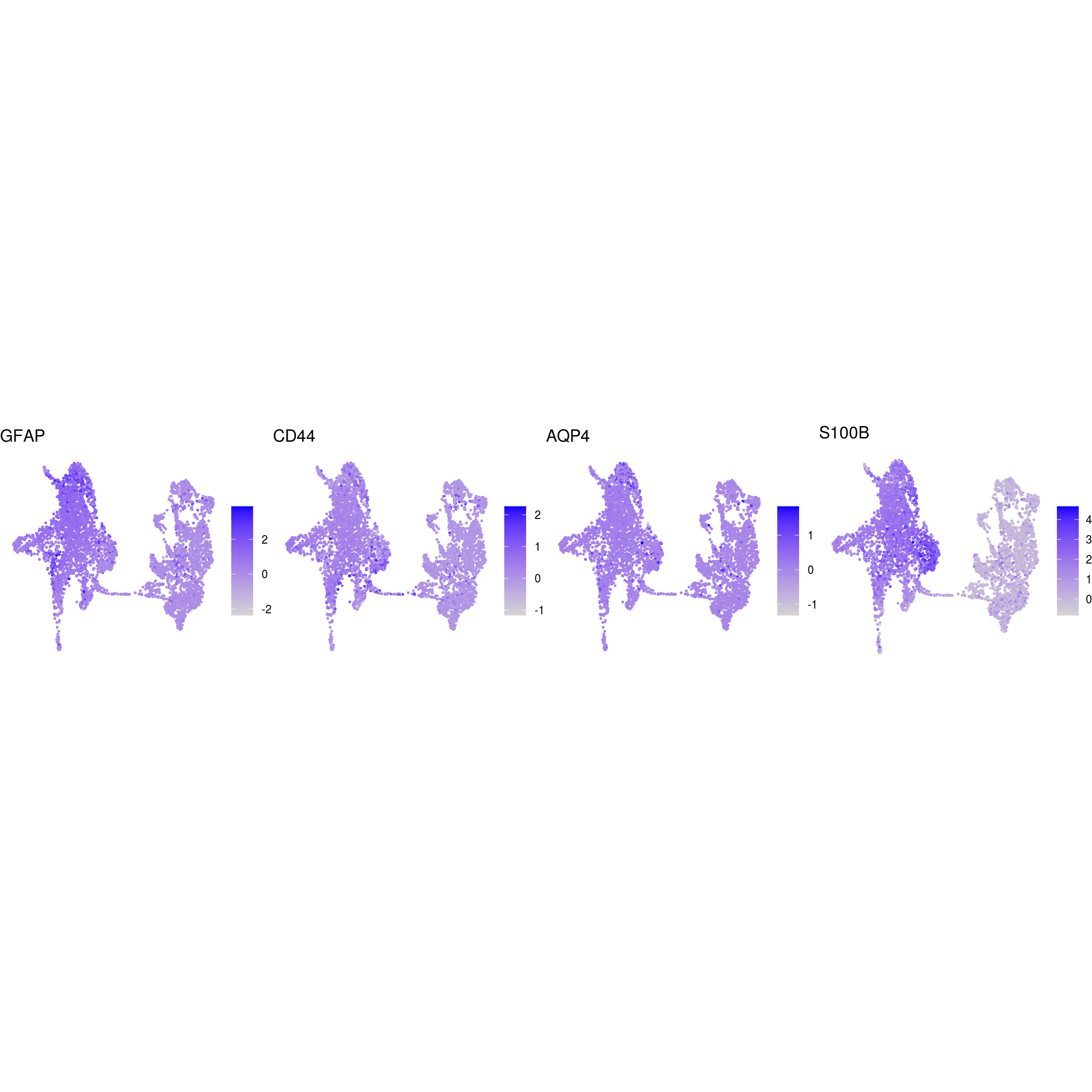
## glial_astrocytic 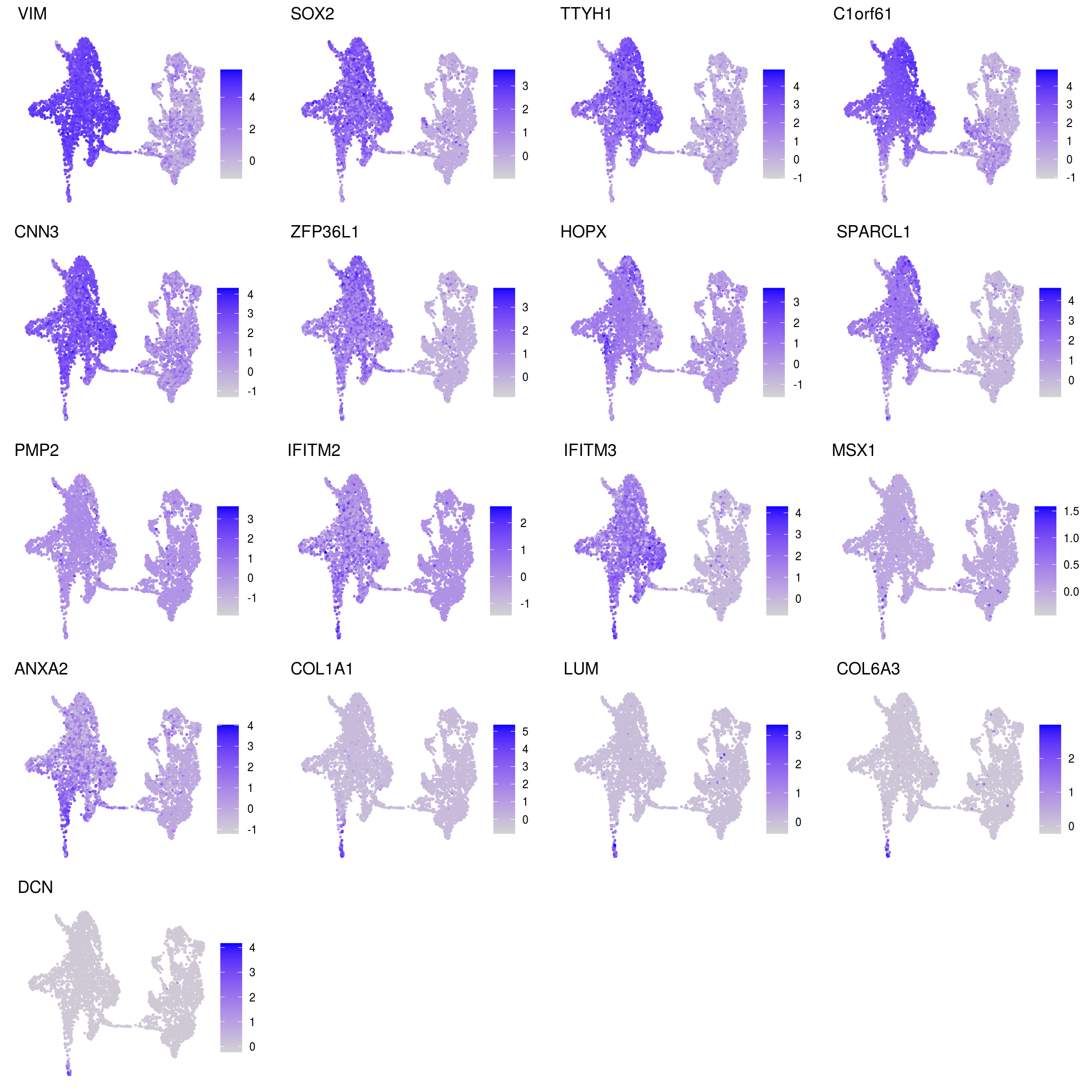
## radial_glia 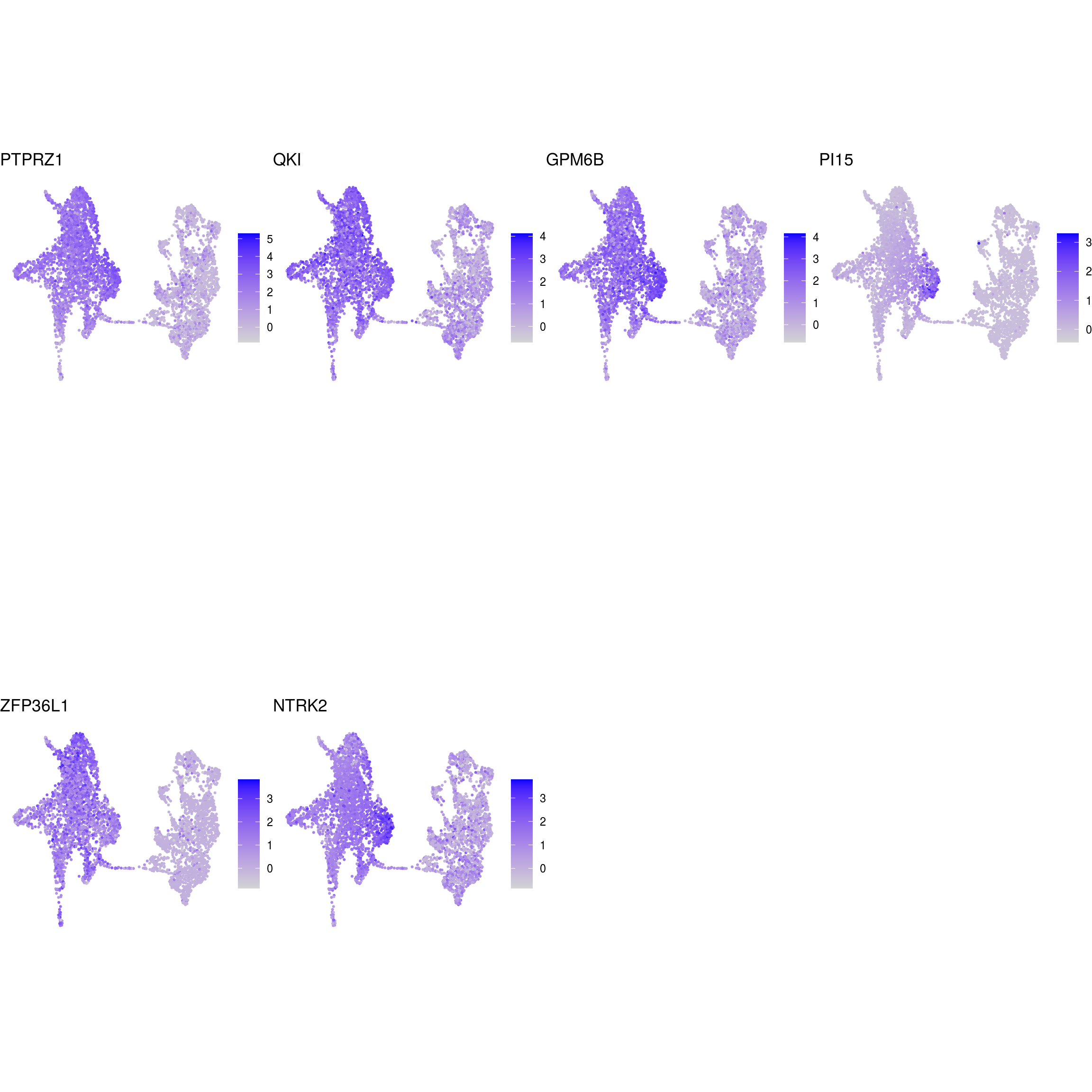
## oligodendrocyte 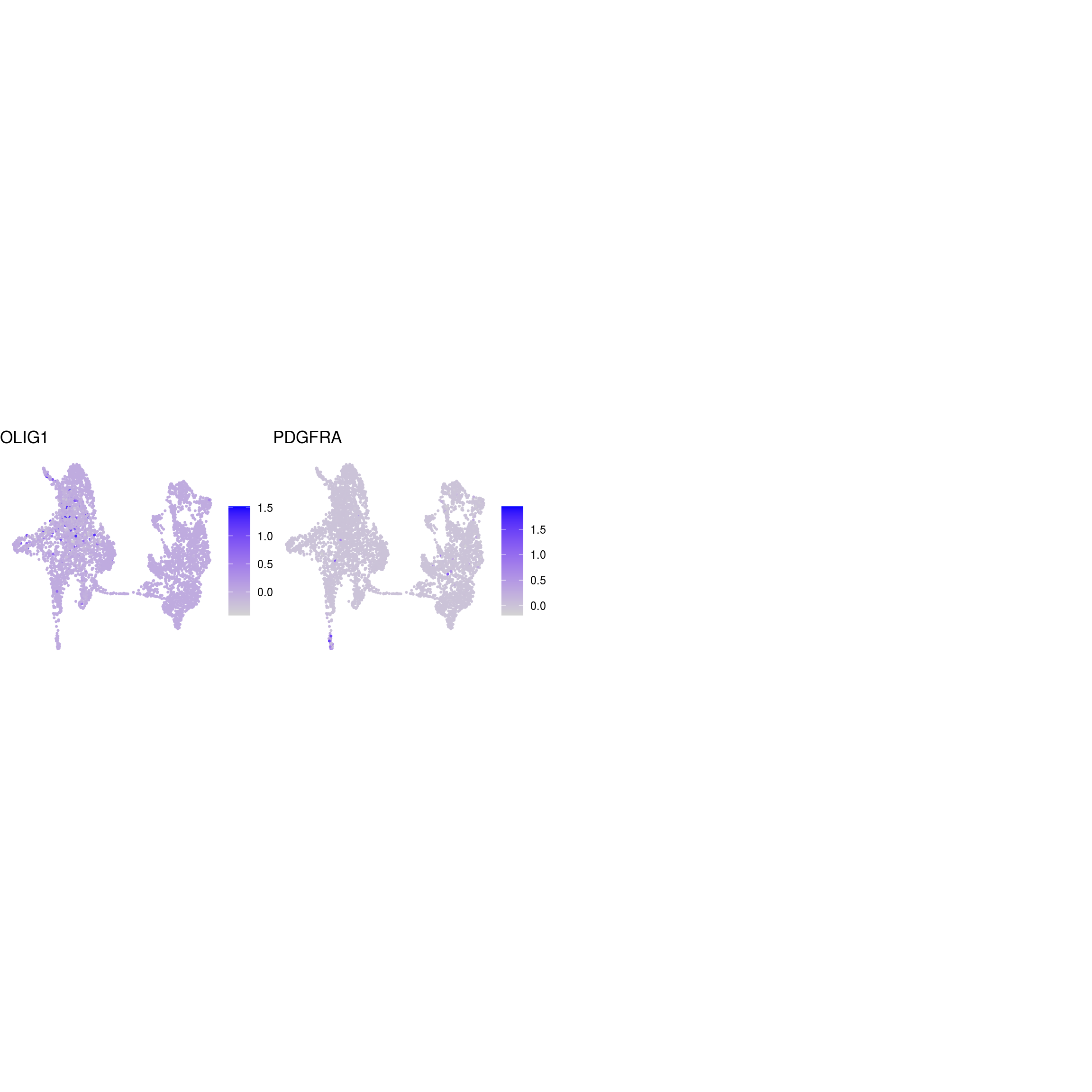
## GABAergic_neurons 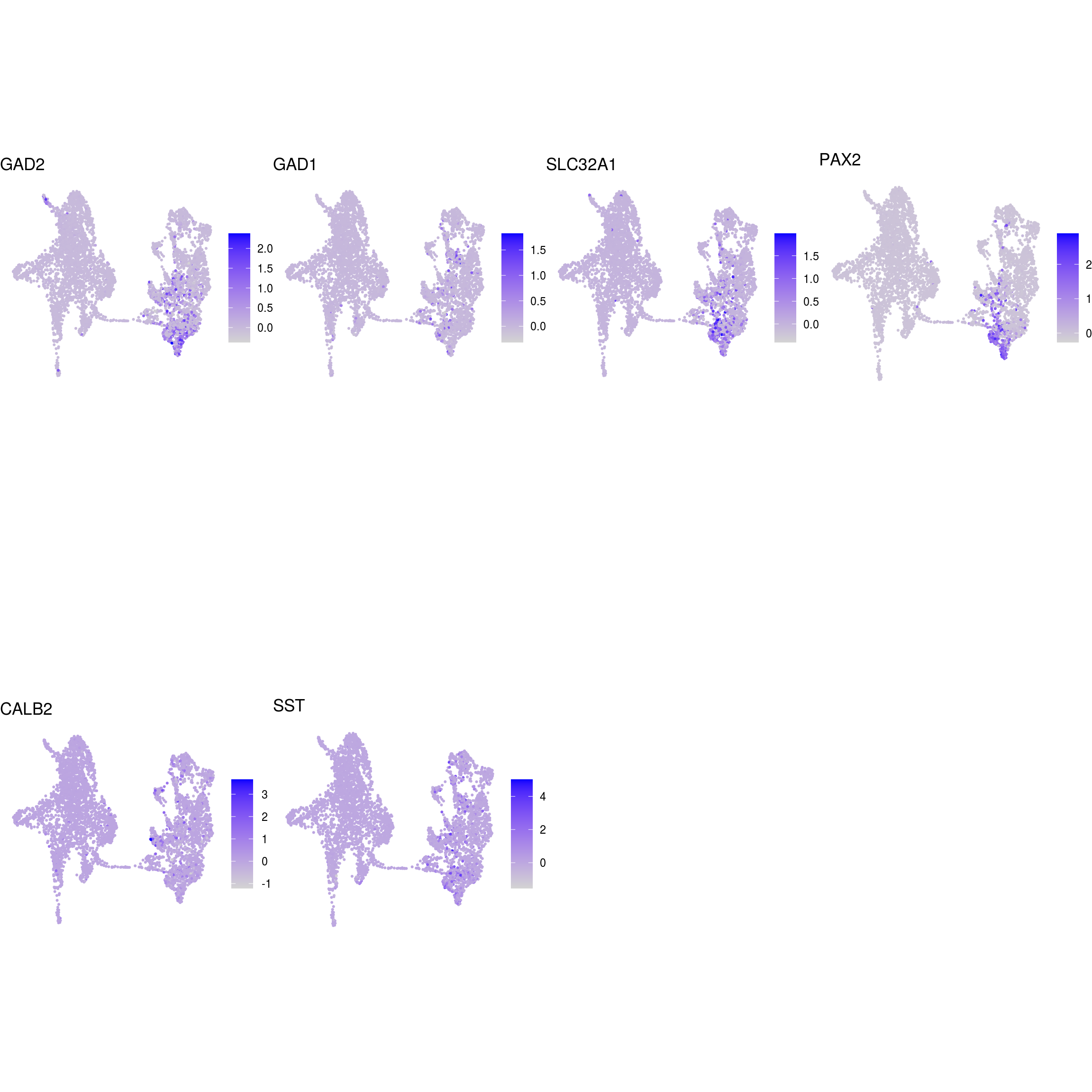
## glycinergic_neurons 
## glutaminergic_neurons 
## dopaminergic_neurons 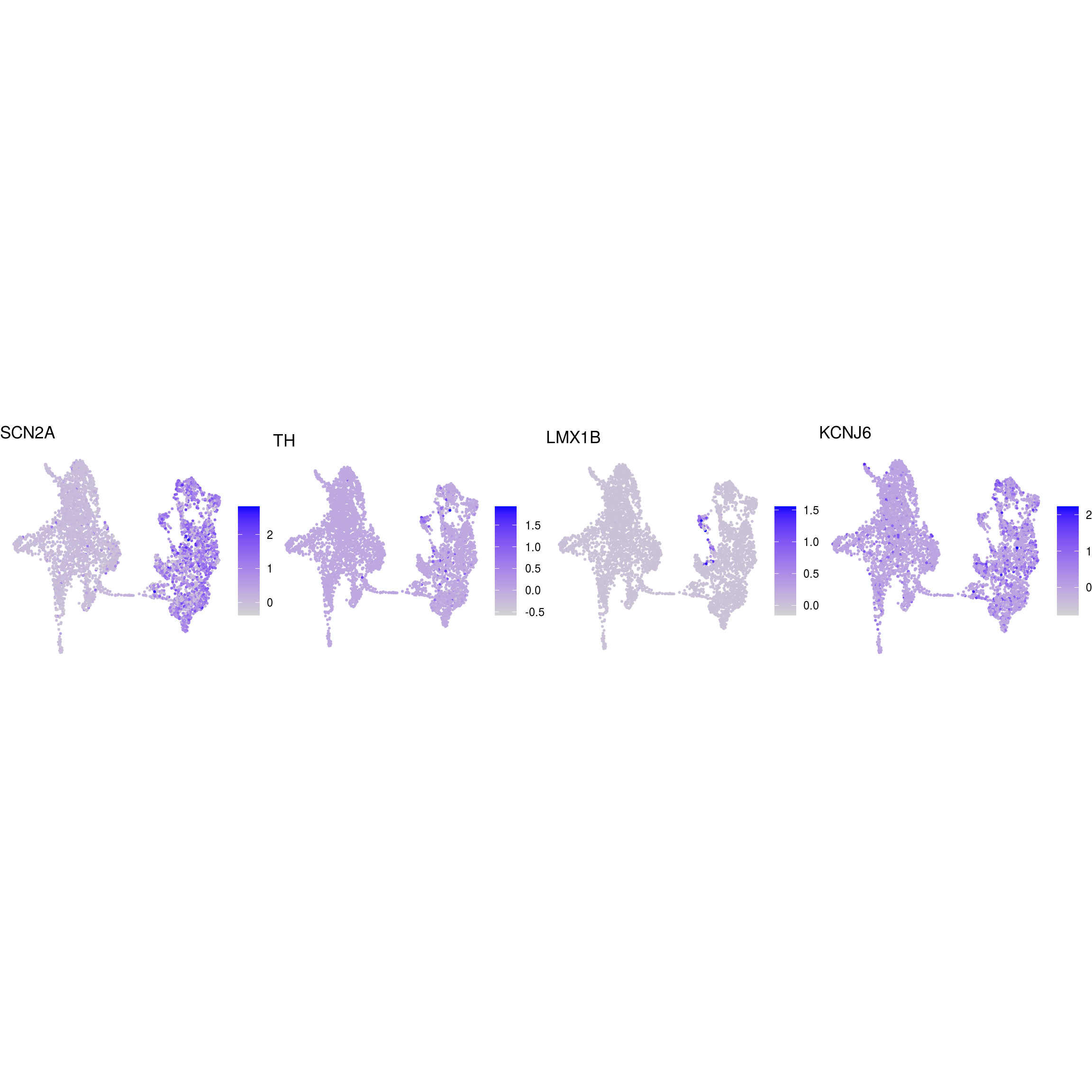
## apoptotic 
Cluster annotation
Based on the plots we annotated the clusters: …
sessionInfo()R version 4.0.0 (2020-04-24)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 16.04.6 LTS
Matrix products: default
BLAS: /usr/local/R/R-4.0.0/lib/libRblas.so
LAPACK: /usr/local/R/R-4.0.0/lib/libRlapack.so
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_US.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
attached base packages:
[1] parallel stats4 grid stats graphics grDevices utils
[8] datasets methods base
other attached packages:
[1] RCurl_1.98-1.2 stringr_1.4.0
[3] Seurat_3.1.5 scran_1.16.0
[5] SingleCellExperiment_1.10.1 SummarizedExperiment_1.18.1
[7] DelayedArray_0.14.0 matrixStats_0.56.0
[9] Biobase_2.48.0 GenomicRanges_1.40.0
[11] GenomeInfoDb_1.24.0 IRanges_2.22.2
[13] S4Vectors_0.26.1 BiocGenerics_0.34.0
[15] viridis_0.5.1 viridisLite_0.3.0
[17] RColorBrewer_1.1-2 purrr_0.3.4
[19] muscat_1.2.0 dplyr_0.8.5
[21] ggplot2_3.3.0 cowplot_1.0.0
[23] ComplexHeatmap_2.4.2 workflowr_1.6.2
loaded via a namespace (and not attached):
[1] backports_1.1.7 circlize_0.4.9
[3] blme_1.0-4 igraph_1.2.5
[5] plyr_1.8.6 lazyeval_0.2.2
[7] TMB_1.7.16 splines_4.0.0
[9] BiocParallel_1.22.0 listenv_0.8.0
[11] scater_1.16.0 digest_0.6.25
[13] foreach_1.5.0 htmltools_0.4.0
[15] gdata_2.18.0 lmerTest_3.1-2
[17] magrittr_1.5 memoise_1.1.0
[19] cluster_2.1.0 doParallel_1.0.15
[21] ROCR_1.0-11 limma_3.44.1
[23] globals_0.12.5 annotate_1.66.0
[25] prettyunits_1.1.1 colorspace_1.4-1
[27] rappdirs_0.3.1 ggrepel_0.8.2
[29] blob_1.2.1 xfun_0.14
[31] jsonlite_1.6.1 crayon_1.3.4
[33] genefilter_1.70.0 lme4_1.1-23
[35] zoo_1.8-8 ape_5.3
[37] survival_3.1-12 iterators_1.0.12
[39] glue_1.4.1 gtable_0.3.0
[41] zlibbioc_1.34.0 XVector_0.28.0
[43] leiden_0.3.3 GetoptLong_0.1.8
[45] BiocSingular_1.4.0 future.apply_1.5.0
[47] shape_1.4.4 scales_1.1.1
[49] DBI_1.1.0 edgeR_3.30.0
[51] Rcpp_1.0.4.6 xtable_1.8-4
[53] progress_1.2.2 clue_0.3-57
[55] reticulate_1.16 dqrng_0.2.1
[57] bit_1.1-15.2 rsvd_1.0.3
[59] tsne_0.1-3 htmlwidgets_1.5.1
[61] httr_1.4.1 gplots_3.0.3
[63] ellipsis_0.3.1 ica_1.0-2
[65] farver_2.0.3 pkgconfig_2.0.3
[67] XML_3.99-0.3 uwot_0.1.8
[69] locfit_1.5-9.4 labeling_0.3
[71] tidyselect_1.1.0 rlang_0.4.6
[73] reshape2_1.4.4 later_1.0.0
[75] AnnotationDbi_1.50.0 munsell_0.5.0
[77] tools_4.0.0 RSQLite_2.2.0
[79] ggridges_0.5.2 evaluate_0.14
[81] yaml_2.2.1 knitr_1.28
[83] bit64_0.9-7 fs_1.4.1
[85] fitdistrplus_1.1-1 caTools_1.18.0
[87] RANN_2.6.1 pbapply_1.4-2
[89] future_1.17.0 nlme_3.1-148
[91] whisker_0.4 pbkrtest_0.4-8.6
[93] compiler_4.0.0 plotly_4.9.2.1
[95] beeswarm_0.2.3 png_0.1-7
[97] variancePartition_1.18.0 tibble_3.0.1
[99] statmod_1.4.34 geneplotter_1.66.0
[101] stringi_1.4.6 lattice_0.20-41
[103] Matrix_1.2-18 nloptr_1.2.2.1
[105] vctrs_0.3.0 pillar_1.4.4
[107] lifecycle_0.2.0 lmtest_0.9-37
[109] GlobalOptions_0.1.1 RcppAnnoy_0.0.16
[111] BiocNeighbors_1.6.0 data.table_1.12.8
[113] bitops_1.0-6 irlba_2.3.3
[115] patchwork_1.0.0 httpuv_1.5.2
[117] colorRamps_2.3 R6_2.4.1
[119] promises_1.1.0 KernSmooth_2.23-17
[121] gridExtra_2.3 vipor_0.4.5
[123] codetools_0.2-16 boot_1.3-25
[125] MASS_7.3-51.6 gtools_3.8.2
[127] assertthat_0.2.1 DESeq2_1.28.1
[129] rprojroot_1.3-2 rjson_0.2.20
[131] withr_2.2.0 sctransform_0.2.1
[133] GenomeInfoDbData_1.2.3 hms_0.5.3
[135] tidyr_1.1.0 glmmTMB_1.0.1
[137] minqa_1.2.4 rmarkdown_2.1
[139] DelayedMatrixStats_1.10.0 Rtsne_0.15
[141] git2r_0.27.1 numDeriv_2016.8-1.1
[143] ggbeeswarm_0.6.0