Log2022
Last updated: 2022-04-14
Checks: 7 0
Knit directory: GradLog/
This reproducible R Markdown analysis was created with workflowr (version 1.7.0). The Checks tab describes the reproducibility checks that were applied when the results were created. The Past versions tab lists the development history.
Great! Since the R Markdown file has been committed to the Git repository, you know the exact version of the code that produced these results.
Great job! The global environment was empty. Objects defined in the global environment can affect the analysis in your R Markdown file in unknown ways. For reproduciblity it’s best to always run the code in an empty environment.
The command set.seed(20201014) was run prior to running the code in the R Markdown file. Setting a seed ensures that any results that rely on randomness, e.g. subsampling or permutations, are reproducible.
Great job! Recording the operating system, R version, and package versions is critical for reproducibility.
Nice! There were no cached chunks for this analysis, so you can be confident that you successfully produced the results during this run.
Great job! Using relative paths to the files within your workflowr project makes it easier to run your code on other machines.
Great! You are using Git for version control. Tracking code development and connecting the code version to the results is critical for reproducibility.
The results in this page were generated with repository version fae1f4e. See the Past versions tab to see a history of the changes made to the R Markdown and HTML files.
Note that you need to be careful to ensure that all relevant files for the analysis have been committed to Git prior to generating the results (you can use wflow_publish or wflow_git_commit). workflowr only checks the R Markdown file, but you know if there are other scripts or data files that it depends on. Below is the status of the Git repository when the results were generated:
Ignored files:
Ignored: .DS_Store
Ignored: .Rhistory
Ignored: .Rproj.user/
Ignored: analysis/.DS_Store
Ignored: analysis/test_log.Rmd
Ignored: code/.DS_Store
Ignored: data/.DS_Store
Ignored: output/.DS_Store
Note that any generated files, e.g. HTML, png, CSS, etc., are not included in this status report because it is ok for generated content to have uncommitted changes.
These are the previous versions of the repository in which changes were made to the R Markdown (analysis/Log2022.Rmd) and HTML (docs/Log2022.html) files. If you’ve configured a remote Git repository (see ?wflow_git_remote), click on the hyperlinks in the table below to view the files as they were in that past version.
| File | Version | Author | Date | Message |
|---|---|---|---|---|
| Rmd | fae1f4e | liliw-w | 2022-04-14 | adjust fig position |
| html | 3395a26 | liliw-w | 2022-04-14 | Build site. |
| Rmd | d0a08e6 | liliw-w | 2022-04-14 | adjust fig position |
| html | 8b9071e | liliw-w | 2022-04-14 | Build site. |
| Rmd | 424015b | liliw-w | 2022-04-14 | add new week |
| html | 72025bf | liliw-w | 2022-02-04 | Build site. |
| Rmd | 089c609 | liliw-w | 2022-02-04 | new week |
| html | 1274e24 | llw | 2022-01-19 | Build site. |
| Rmd | 9976af6 | llw | 2022-01-19 | new week |
| html | bd69a21 | llw | 2022-01-13 | Build site. |
| Rmd | 28d0a2b | llw | 2022-01-13 | new week |
| html | ec0a2af | llw | 2022-01-04 | Build site. |
| Rmd | 9e5c2e0 | llw | 2022-01-04 | new week |
| html | 97b4ca1 | llw | 2022-01-03 | Build site. |
| html | 4c90bd8 | llw | 2022-01-03 | Build site. |
| Rmd | 6dc3f9c | llw | 2022-01-03 | add a new year |
Apr 13
1. Run PCO on eQTLGen
Why?
To see if new signals in eQTLGen with much larger sample size.
To see the replcation of DGN signals in eQTLGen.
How to run PCO on eQTLGen z’s?
Determine modules - 166 DGN modules.
Sum stat of each SNP on genes in the module.
Problem
\(\Sigma\): no raw expression data for estimating \(\Sigma\).
eQTLGen sum stats from meta analysis, didn’t remove mappability reads.
Solution
Use eQTLGen NULL z’s to estimate \(\Sigma\). By definition.
Remove genes in module that are cross-map with cis-genes of the SNP of interest (SNP-wise PCO).
Observation
signals claimed by Bonferroni correction, i.e. \(0.05/166/9918\)
p-values distribution
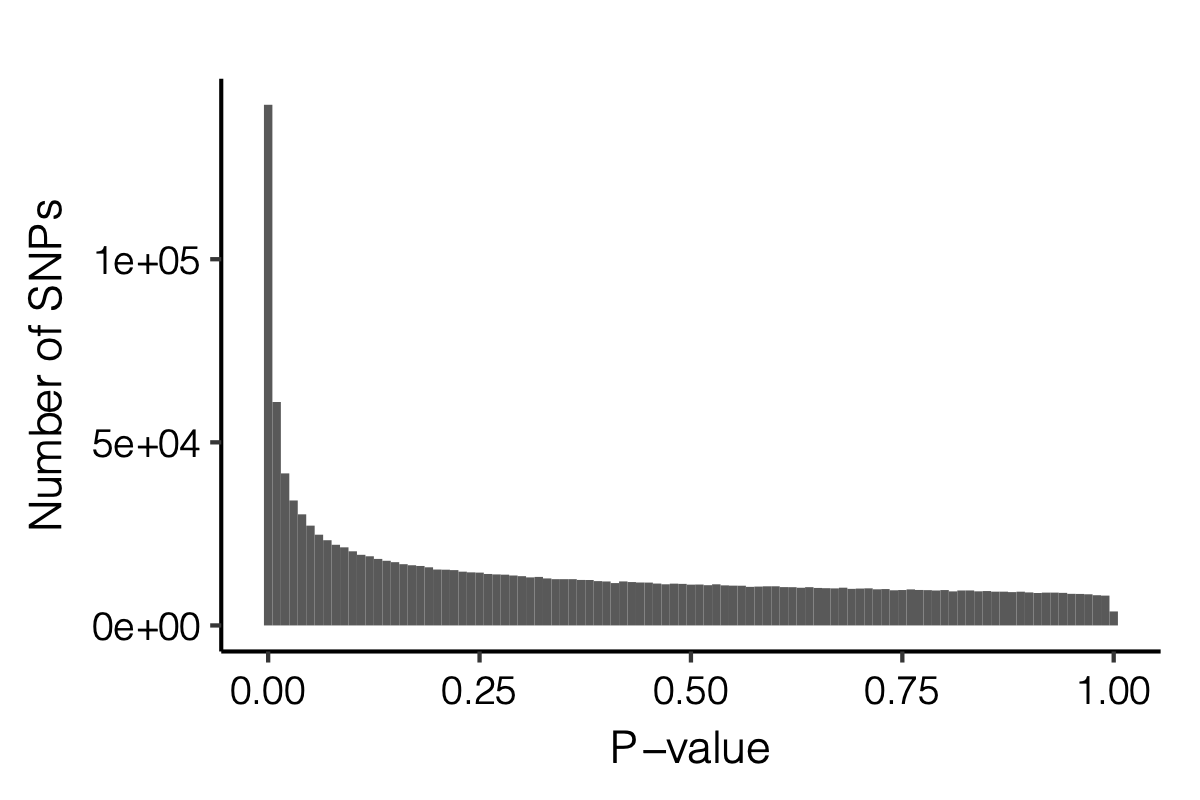
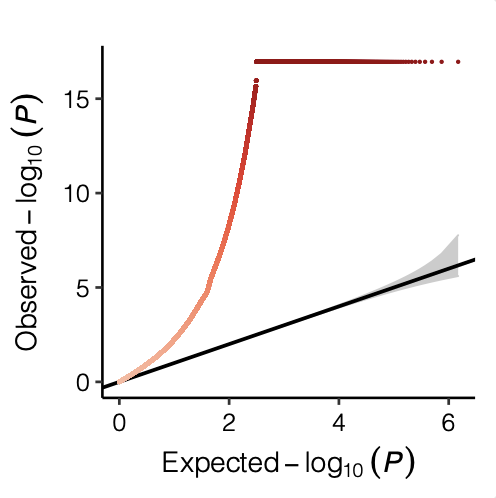
| Version | Author | Date |
|---|---|---|
| ec19552 | liliw-w | 2022-04-14 |
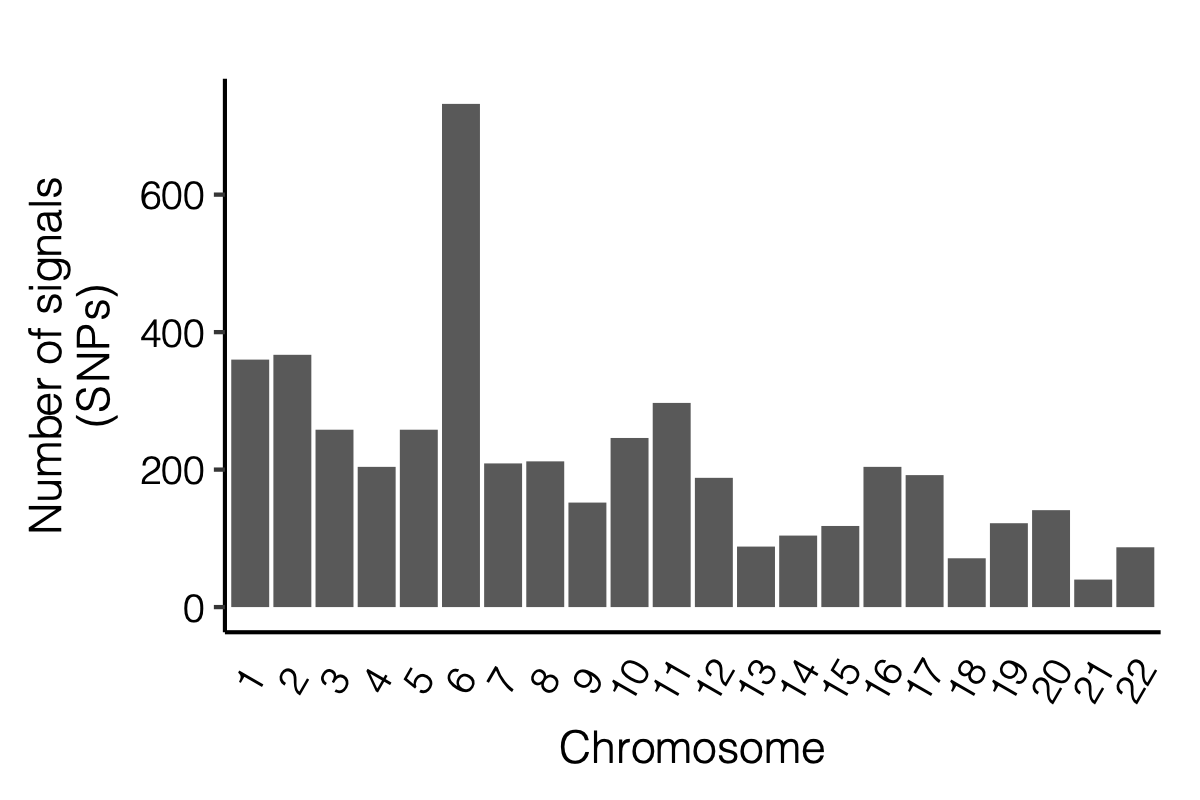
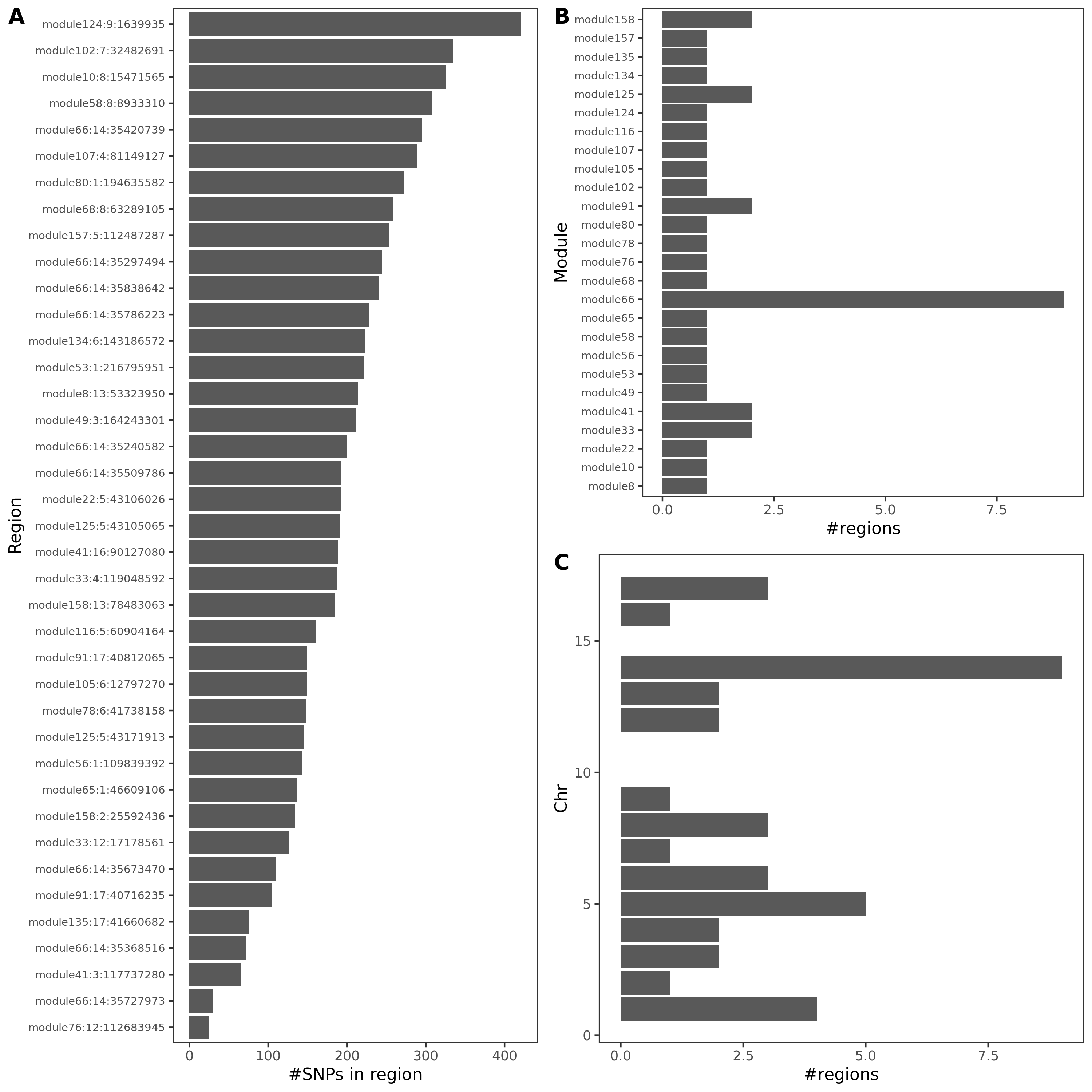
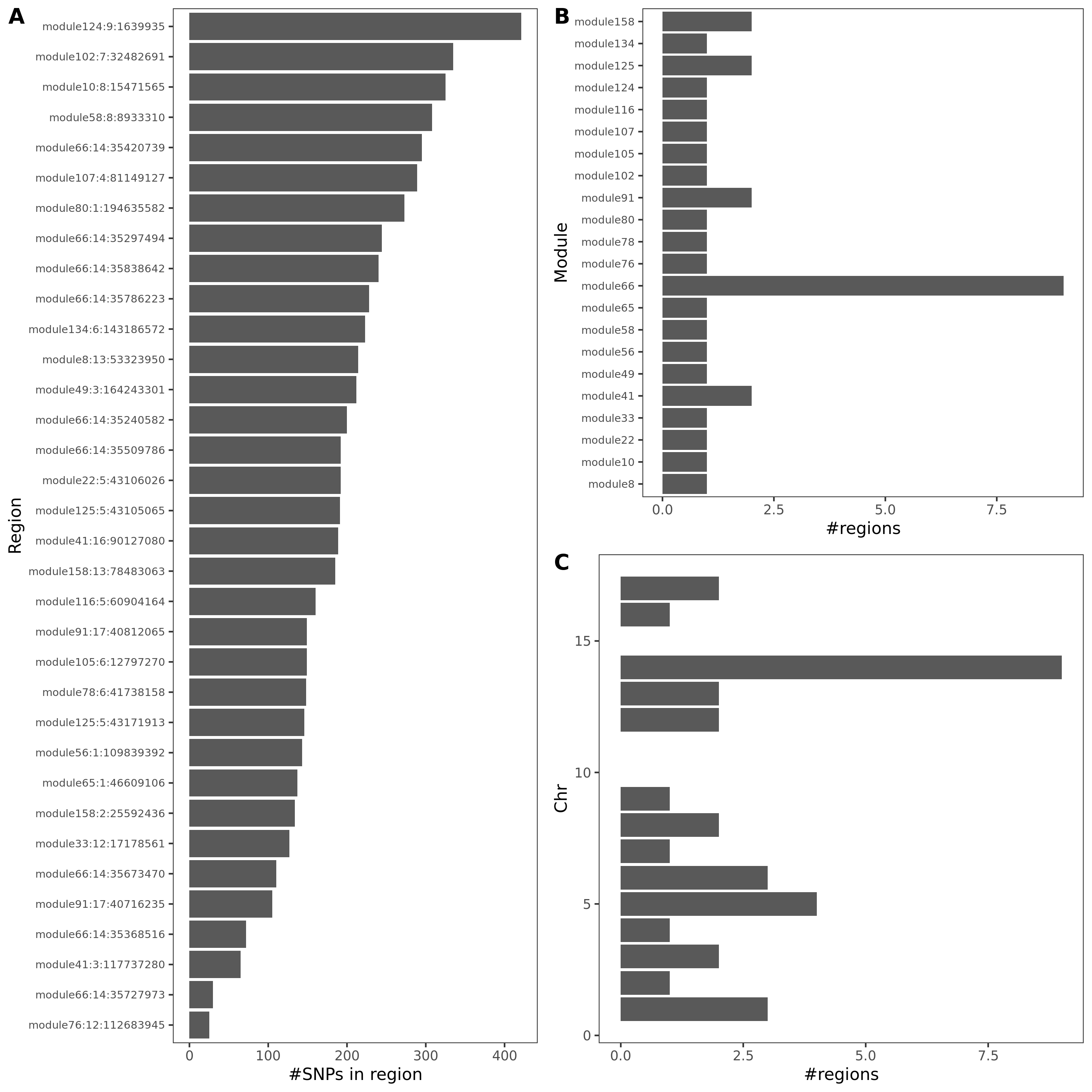
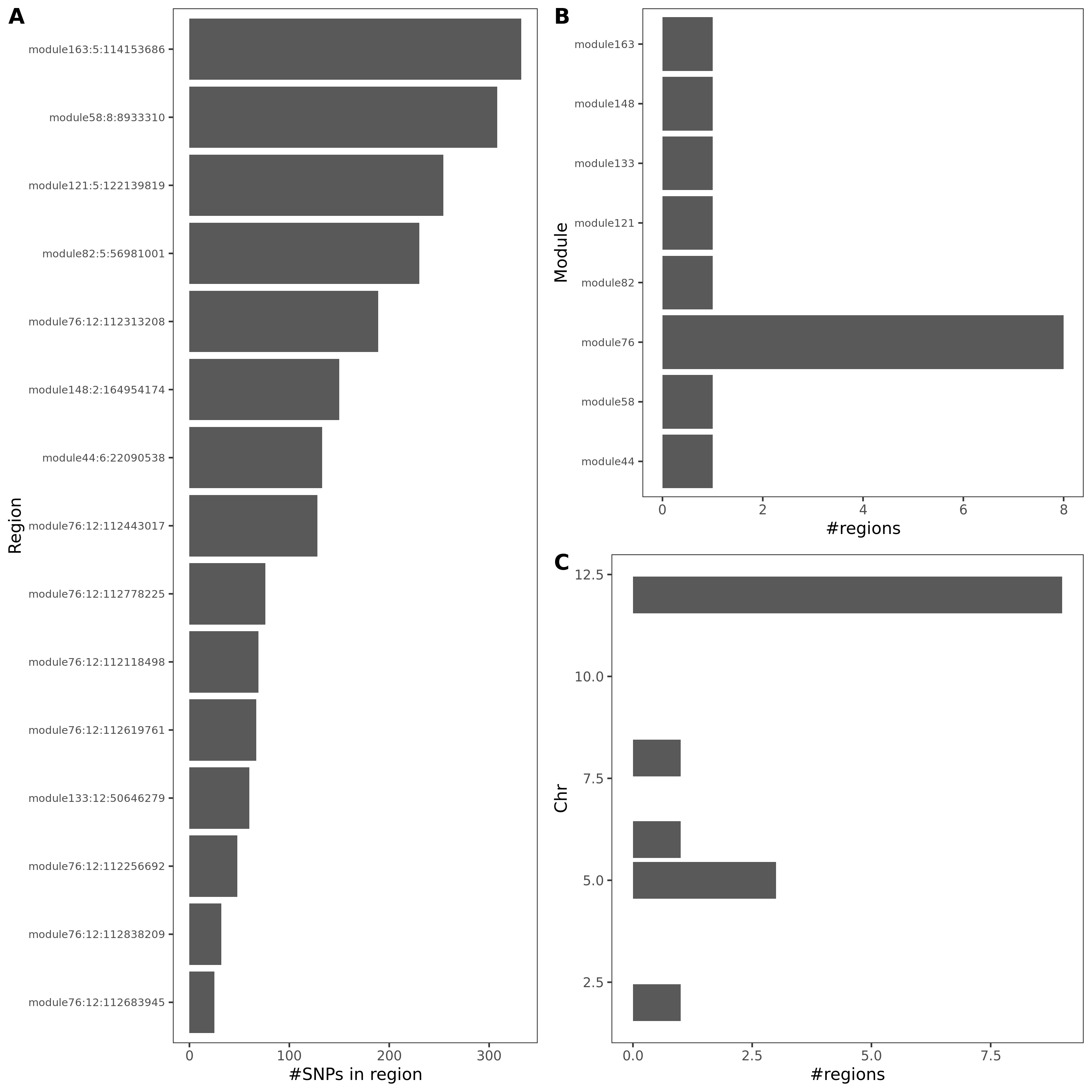
- Signals distribution for each (module, chr), module, and chr.
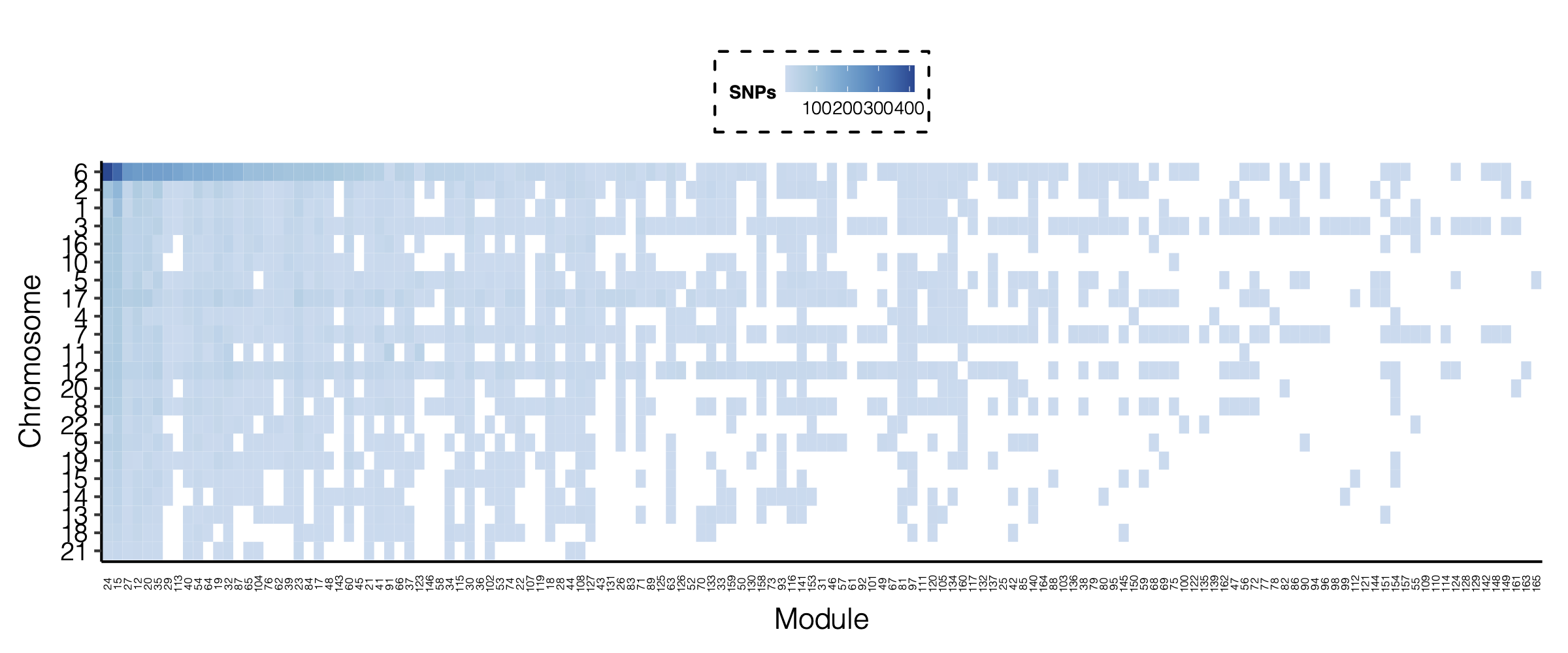
Figure: Signal distribution for pair of (module, chr).
| Version | Author | Date |
|---|---|---|
| ec19552 | liliw-w | 2022-04-14 |
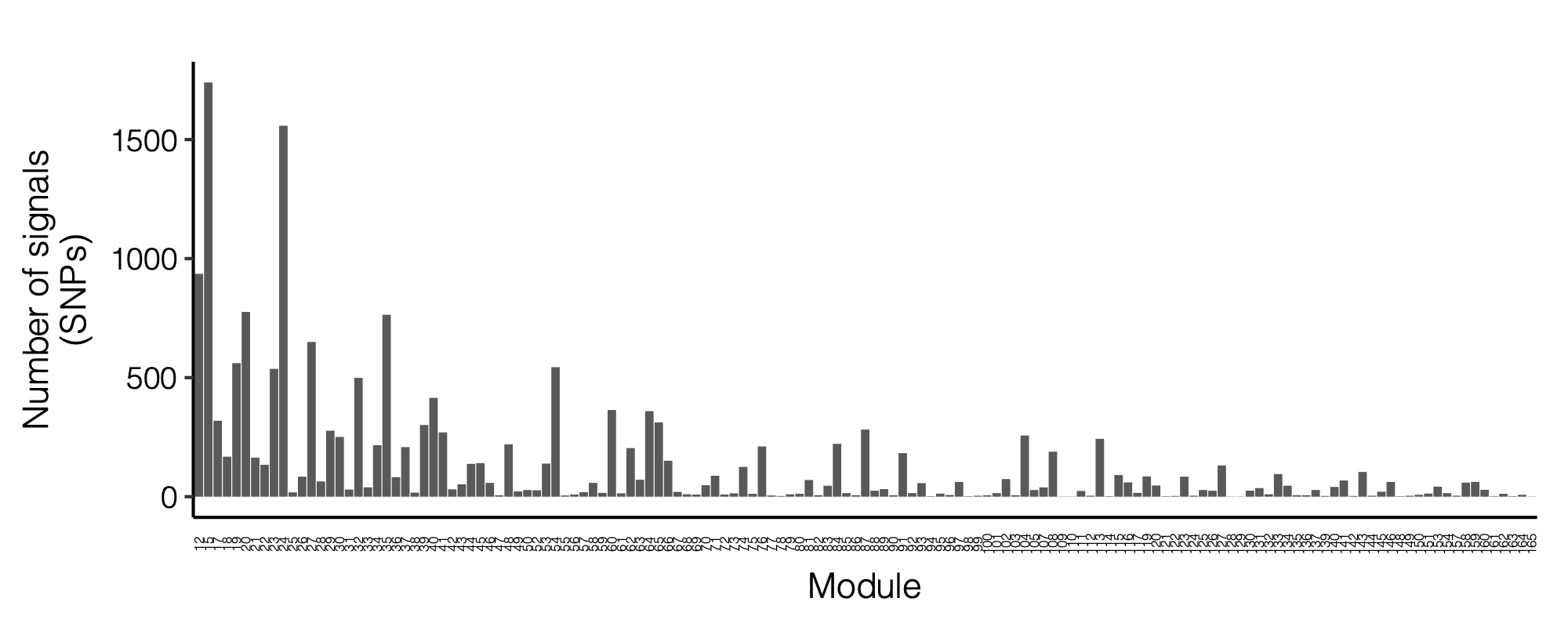
| Version | Author | Date |
|---|---|---|
| ec19552 | liliw-w | 2022-04-14 |
2. Simulation - Are eQTLGen PCO signals of large modules inflated?
Problem
We see from the above figure the trend, which is larges modules have more signals. There can be two possible reasons,
Those are true signals, as larger modules with more genes could have more trans-eQTLd.
Those are inflated signals (false positives).
I looked into the second reason
Why is it possible? Because at the very beginning, we first used the correlation matrix of gene samples from DGN to estiamte \(\Sigma\) and use it as \(\hat\Sigma\) for eQTLGen. And we observed all 9918 SNPs are significant, and SNPs’ p-values for each module are almost all 0. That seemed unreasonable.
And we found that may be because of the use of inaccurate \(\hat\Sigma\). So we decided to use \(\hat\Sigma\) from \(cor(Z^{NULL})\) of eQTLGen’s own null sum stat.
We learned that inaccurate \(\hat\Sigma\) could inflate signals.
And using \(cor(Z^{NULL})\) can also lead to inaccurate \(\hat\Sigma\) is because for a module of \(K\) genes, we need to estimate a \(K \times K\) matrix, using \(Z^{NULL}\) of dimension \(m \times K\) with \(m\) NULL SNPs of these genes from eQTLGen.
This can be problematic for large modules with large \(K\), because
There are fewer SNPs with null sum stat for all \(K\) genes in the module, i.e. smaller \(m\).
If \(m\) is not larger enough than \(K\), \(\hat\Sigma\) by \(cor(Z^{NULL})\) is inaccurate.
There can be lots of extremely small p-values. Inflate PCO signals.
Observation
We did observe a decreasing number of null SNPs for larger modules.
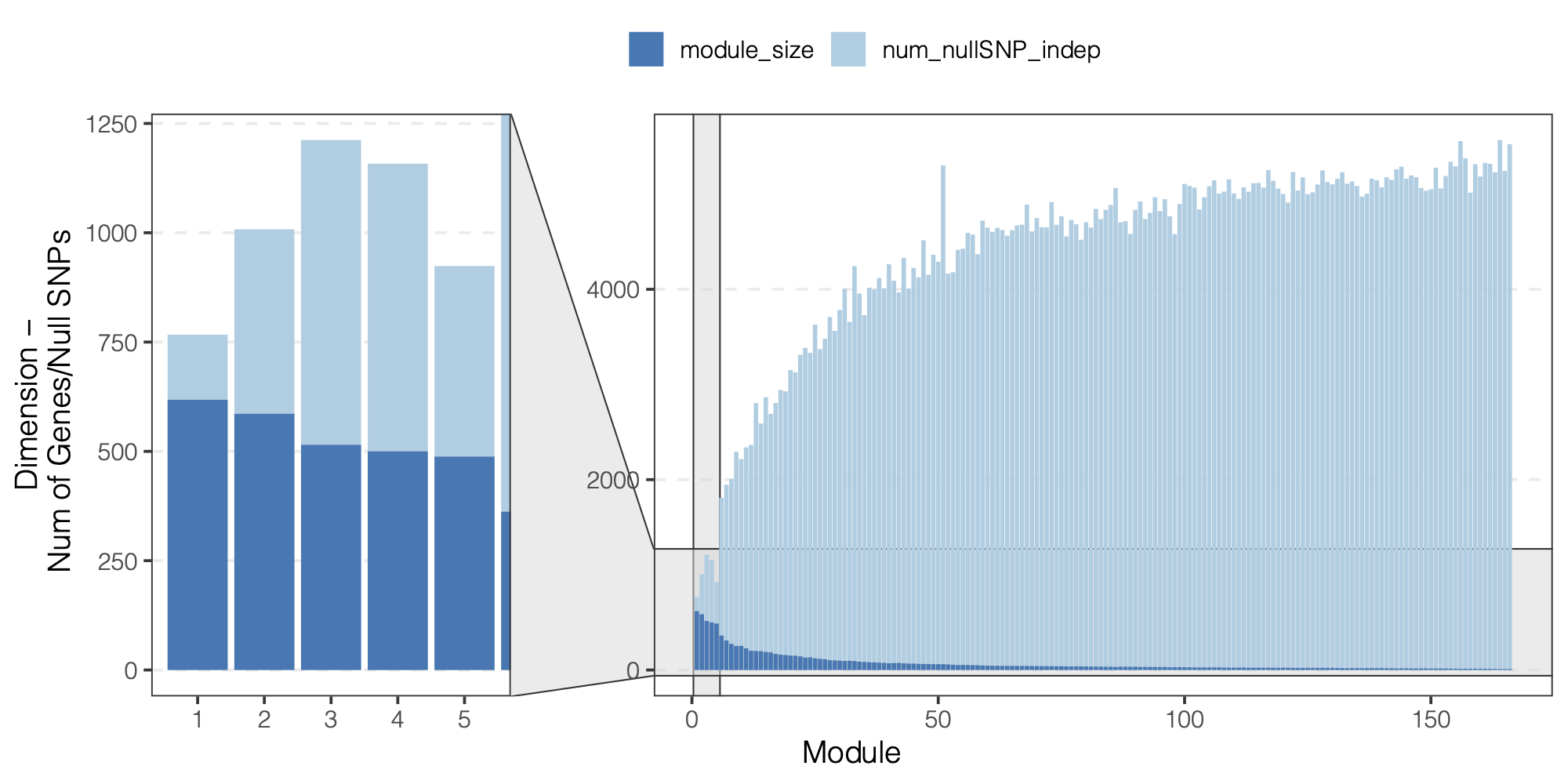
Figure: We did observe a decreasing number of null SNPs for larger modules.
| Version | Author | Date |
|---|---|---|
| ec19552 | liliw-w | 2022-04-14 |
Does \(\hat\Sigma\) by \(cor(Z^{NULL})\) lead to inflated PCO signals?
We want to check if \(\hat\Sigma\) by \(cor(Z^{NULL})\) really lead to extremely small pvalues and inflated PCO signals.
How to check?
We use simulations. Specifically,
- Choose a real module from DGN.
- Generate sum stat (Z) of NULL SNPs from the real \(\Sigma\).
- Use these NULL SNPs to estimate a \(\hat\Sigma\).
- Run PCO on another set of NULL SNPs using the true \(\Sigma\) and \(\hat\Sigma\) by \(cor(Z^{NULL})\).
- Compare their p-values.
The p-values using true \(\Sigma\) should represent the true case. By comparing p-values using \(\hat\Sigma\) to it, we should be able to see if \(P_{\hat\Sigma}\) have extreme values.
Simulation setting
I looked at multiple modules with various module size, including module 1-11, 15, 20, 30, 40, 50, 60, 70, 90, 100, 150, 166.
I looked at various \(m/K\) ratios for estimating \(\hat\Sigma\), including 1, 5, 10, 50, 100, 150.
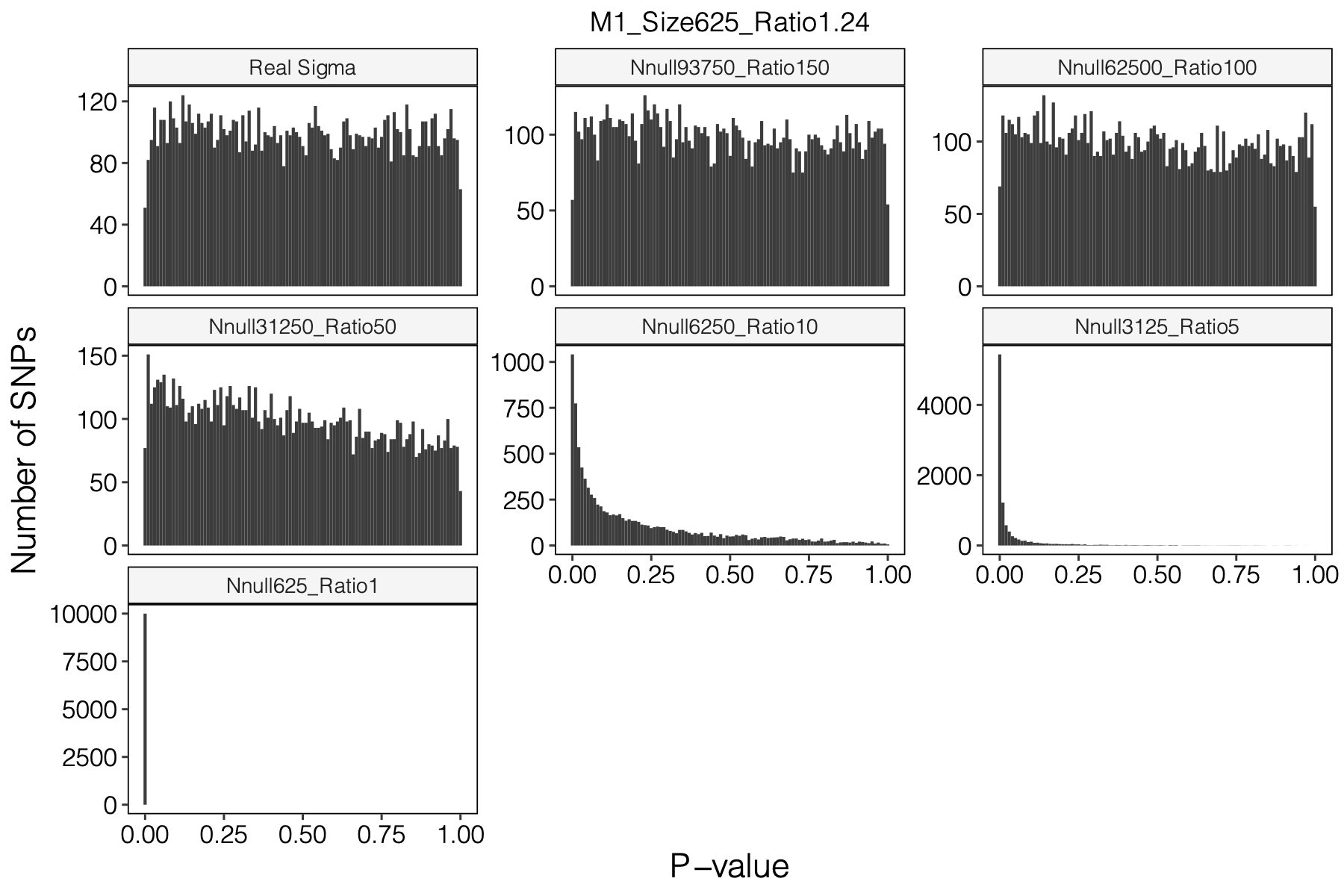
Figure: Histogram of p-values using various Sigma’s.
| Version | Author | Date |
|---|---|---|
| ec19552 | liliw-w | 2022-04-14 |
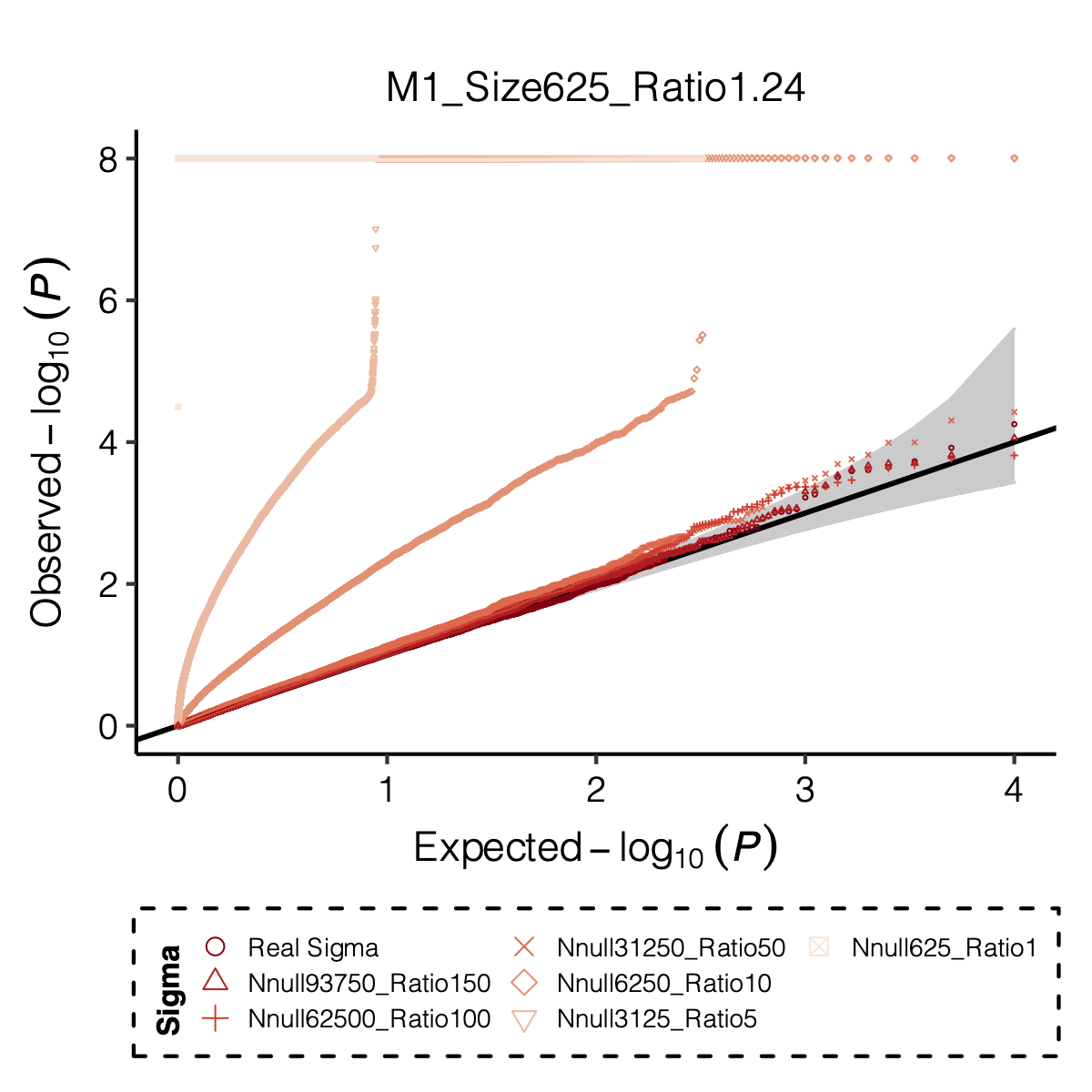
Figure: QQ-plot of p-values using various Sigma’s.
| Version | Author | Date |
|---|---|---|
| ec19552 | liliw-w | 2022-04-14 |
Observation
P-values looked similar to the true case when ratio \(>50\).
The ratio has smaller inflation effects on smaller modules, e.g. p-values of module 166 using \(\Sigma\) of ratio 20 are closer to that of module 1 using \(\Sigma\) of same ratio.
In eQTLGen analysis, ??? modules have \(m/K\) ratio \(>50\).
3. In DGN, larger module, more signals?
We wonder if this trend also exists in DGN data.
\(\hat\Sigma\): module size v.s. sample size
4. Remaining questions
- Inaccurate \(\hat\Sigma\) leads to false negatives? in DGN?
Mar 30
- eQTLGen analysis
Mar 25
- Signal SNPs genomic location annotation
torus: GTEx
snpEff
Mar 02
1. About “replication of signals in eQTLGen”
In the abstract of The Biology of Genome conference, you added something as
The trans-eQTLs are highly replicable, and all were replicated in the eQTLGen.
At first, I thought you were referring to the replication of the identified trans-eQTLs in eQTLGen. But I didn’t remember we had this observation. So I wondered where this impression came from.
I think maybe because previous section. I looked at what are those lead-SNPs of the colocalized regions (dark green regions). Specifically, are those dark green signals eQTLGen signals (cis- or trans- signals)?
I observed that, out of 74 unique lead SNPs of colocalized regions for all blood-related traits, 65 are included in eQTLGen SNPs. And 63 are eQTLGen cis- or trans- signals.
2. preious eQTGen signals using trans-PCO
| Sigma | #modules | PCO_lambda_thre | #signals |
|---|---|---|---|
| DGN | less | 1.0 | ~367 |
| DGN | less | 0.1 | 9918 |
| DGN | more | 1.0 | ~460 |
| DGN | more | 0.1 | 9905 |
| nullz | more | 0.1 | NA |
At first, we used \(\text{PCO}_{\lambda<1}\) and observed hundreds of eQTLGen SNPs that are significant trans-eQTL signals.
We decided to choose \(\text{PCO}_{\lambda<0.1}\) over \(\text{PCO}_{\lambda<1}\).
Then we observed almost all 9918 eQTLGen SNPs are trans-eQTL signals. We doubted some signals are false positives.
Replication_of_eQTLGen_results_in_trans-PCO_of_eQTLGen_summary_stats
Why_there_are_so_many_eQTLGen_signals
- We thought false positives occurred because we used \(\Sigma\) of DGN for estimating \(\hat{\Sigma}\) of eQTLGen. So we tried using null zscores from eQTLGen to build sigma. We observed a significant drop of pvalues.
Feb 16
1. Simulation
Re-run simulation using \(\Sigma\) from the updated 166 modules of DGN_no_filter_on_mappability.
QQ plot of null distribution.
Figures are stored on server.
Power plot.
{kind=link}
{kind=link}
Jan 26
1. Update coloc figures with less stringent pvalue threshold
Previously, we defined the green regions with module-QTL \(p<1e-8\). This threshold is not premutation based. I looked at the permutation-based p threshold, and it is \(\approx 3e-8\). We’d like to use a less stringent threshold, so I chose \(p<1e-7\) to define the green regions.
In total, we considered three (four) types of coloc. Coloc with (1) 29 blood related traits from ukbb, (2) 11 immune traits, (3) 27 more traits from ukbb. (The 4-th type is coloc with cis genes.)
I updated the figures and tables.
- figures
29 blood related traits from ukbb; earlier result with 1e-8 thre
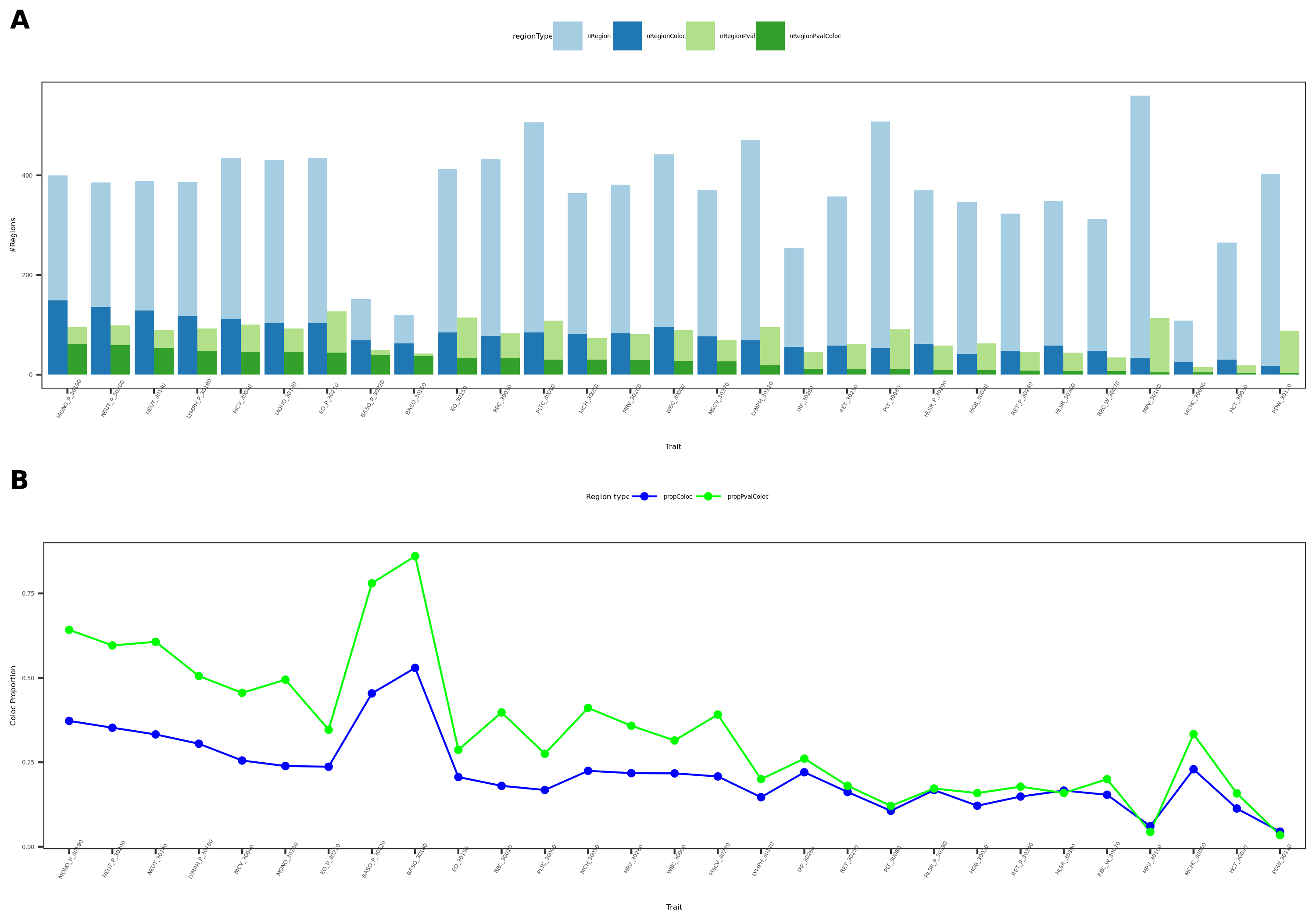{kind=link}
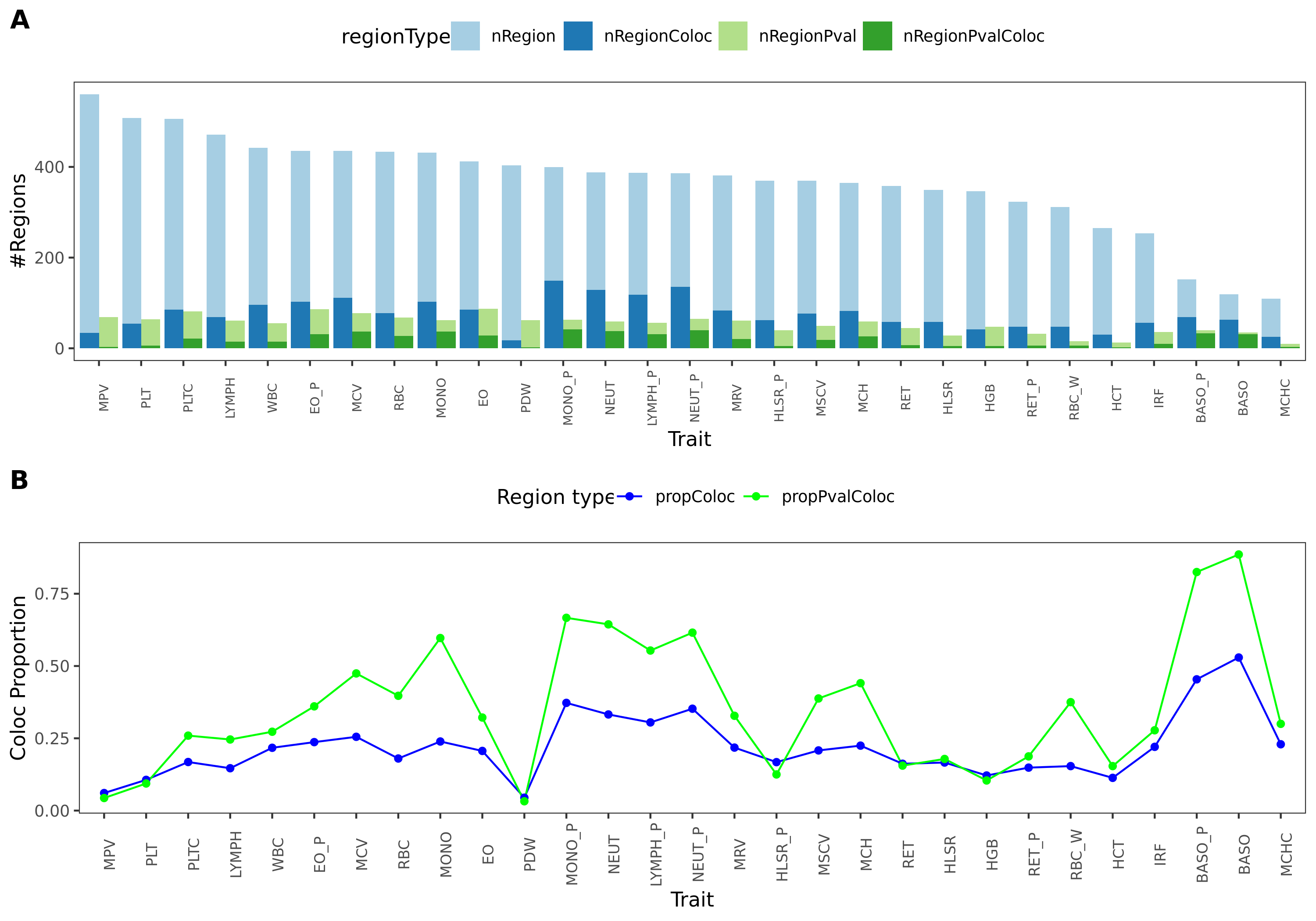{kind=link}
11 immune traits; earlier result with 1e-8 thre
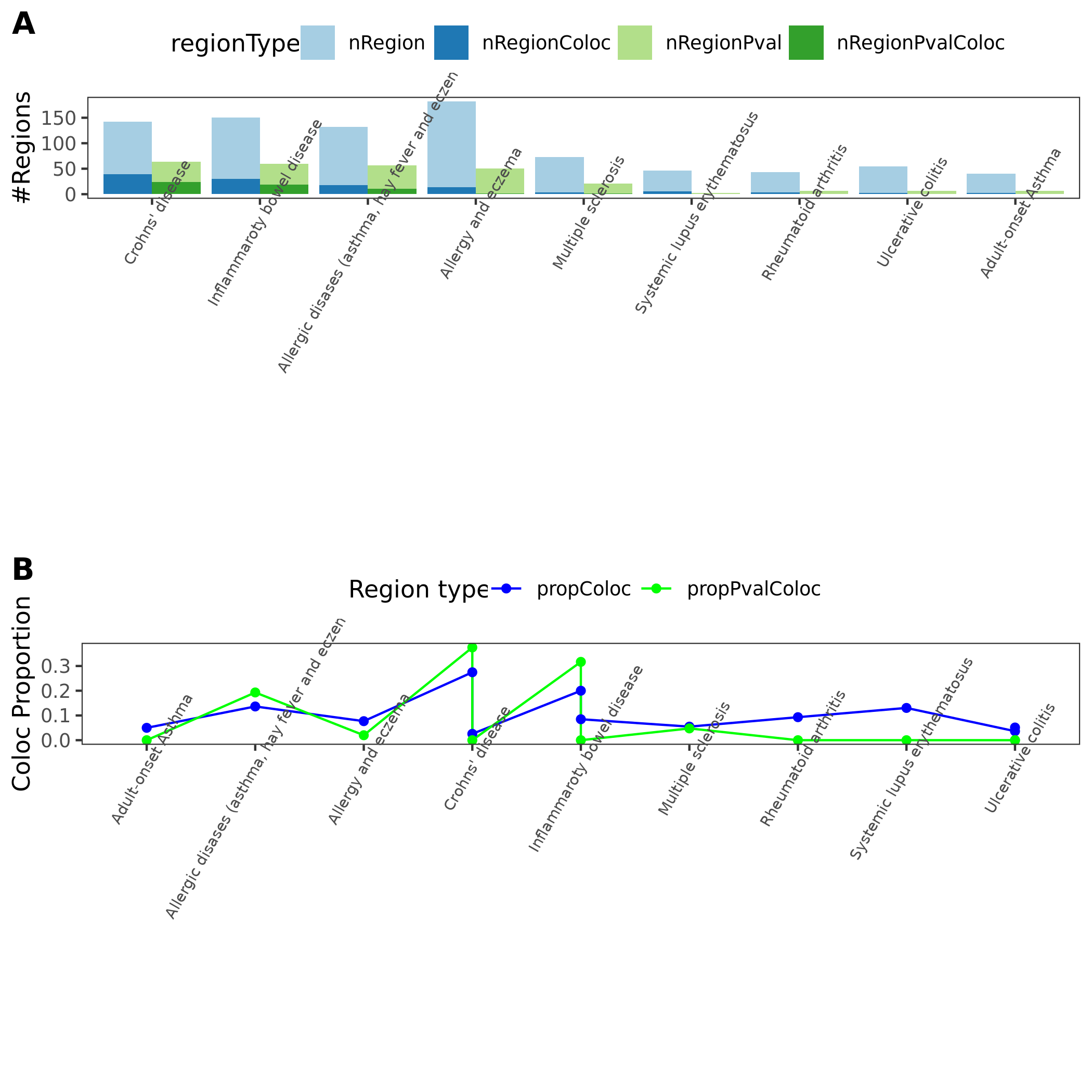{kind=link}
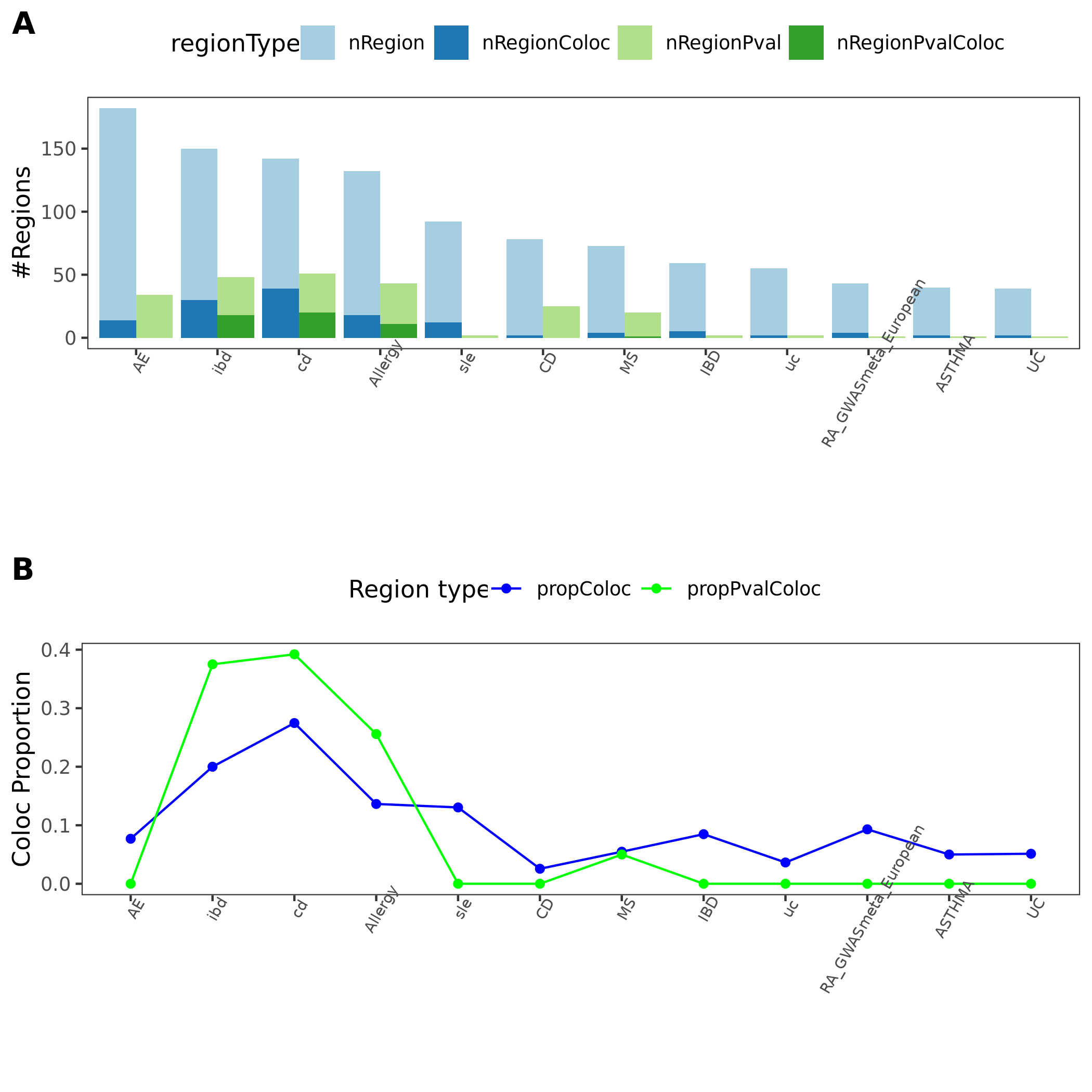{kind=link}
27 more traits from ukbb; earlier result with 1e-8 thre
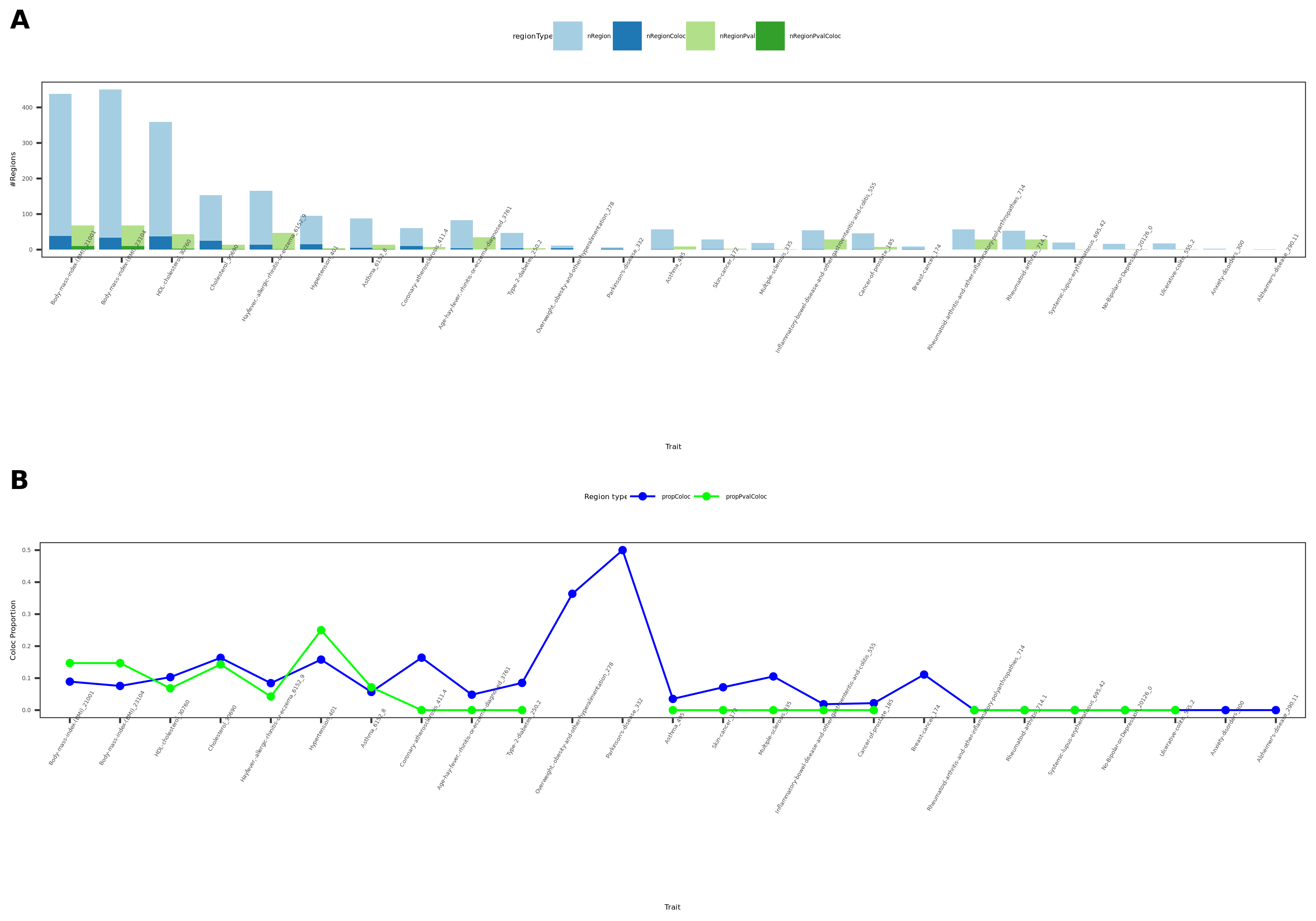{kind=link}
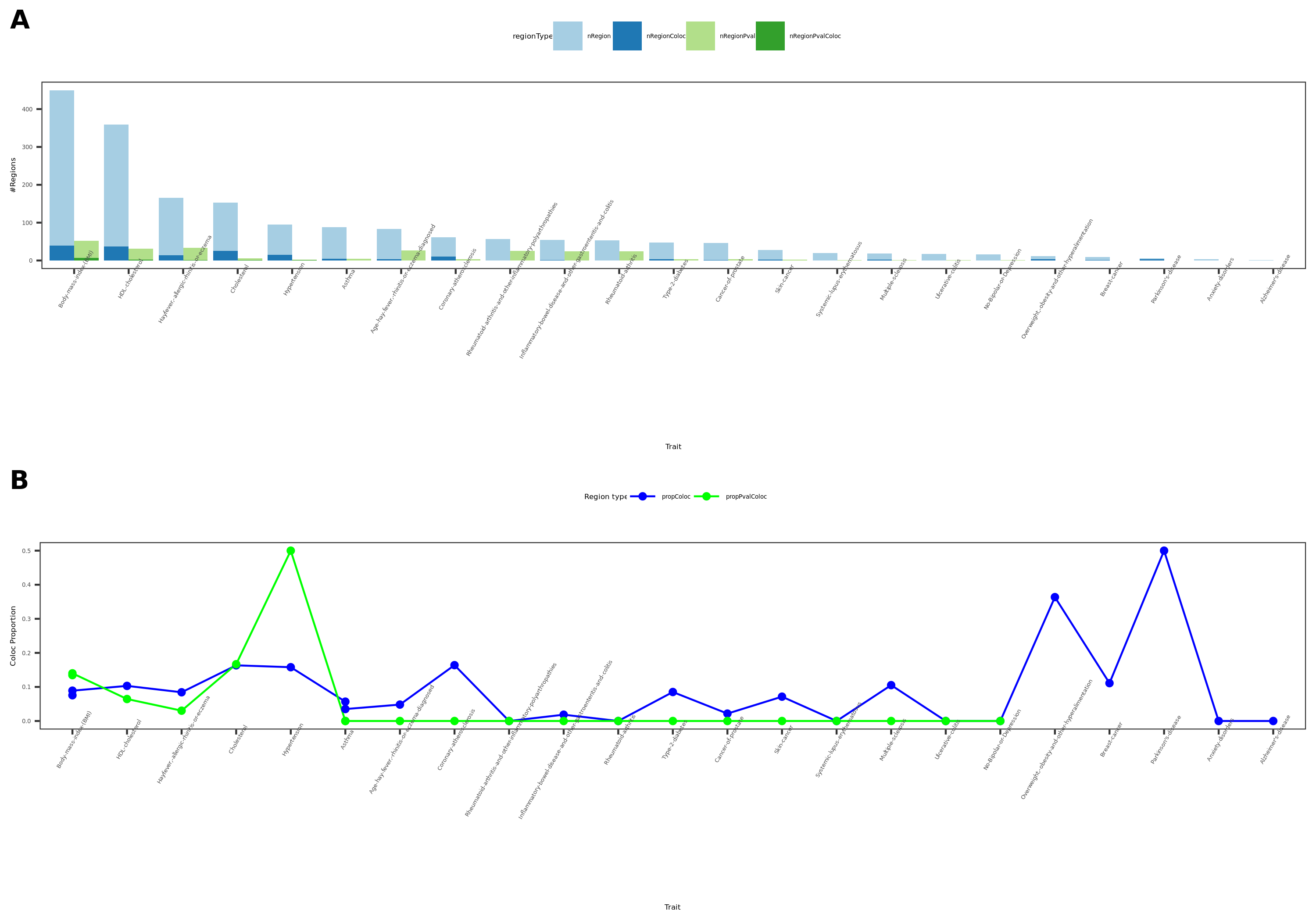{kind=link}
- tables with detailed numerical results
2. Other types of modules coloc with traits
Jan 19
1. Comprehensive analysis of coloc regions of trait MS
Add MS’s result to previous coloc analysis (dark green coloc regions)
See earlier section.
dark blue coloc regions
There are 4 dark blue coloc regions, i.e. coloc regions with module-QTL lead pvalue < 1e-5.
| Region | nSNPs | Pval | PP4 |
|---|---|---|---|
| module121:19:10423815 | 140 | 1.5e-06 | 0.98 |
| module108:7:50308811 | 122 | 1.6e-06 | 0.98 |
| module50:7:149331042 | 265 | 2.0e-06 | 0.94 |
| module44:7:50308527 | 69 | 0.0e+00 | 0.89 |
In earlier section, the region “module108:7:50308811” coloc with MS is included in these dark blue regions.
2. More traits, from UKBB
Extracted traits
- How?
I extracted specific traits from ukbb traits manifest file, based on:
Traits from eQTLGen traits
Traits from Mu et al paper
Powerful (and interesting) ukbb GWASs
Sorted by case number of EUR
n_cases_EUR.
- What traits?
26 ukbb GWASs in total, including height, BMI, Cholesterol, Hypertension, Asthma, Type 2 diabetes etc.
Exclude height, as not GWASed for EUR.
Use height sum stat from another meta analysis instead. It also has another BMI sum stat.
Meta analyze inds from GIANT and ukbb.
Meta-analysis of genome-wide association studies for height and body mass index in ~700,000 individuals of European ancestry.
Thus, as a result, 27 GWASs. 22 unique traits.
- Visualize the sample sizes of selected traits
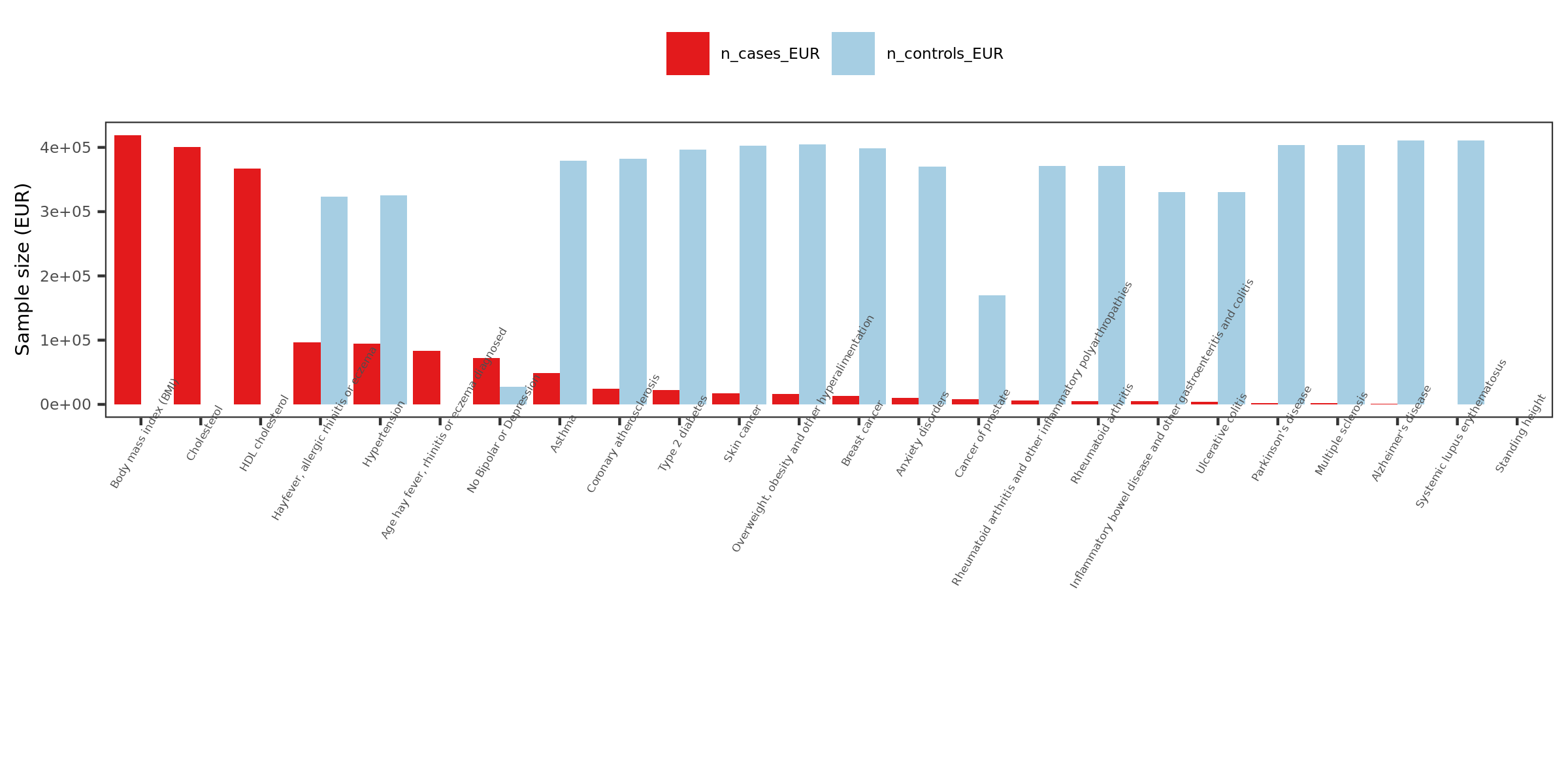
| Version | Author | Date |
|---|---|---|
| 1b40fde | llw | 2022-01-19 |
coloc results {More-traits-from-UKBB}
- Visualize
See figure.

| Version | Author | Date |
|---|---|---|
| 1b40fde | llw | 2022-01-19 |
For detailed numbers, see file.
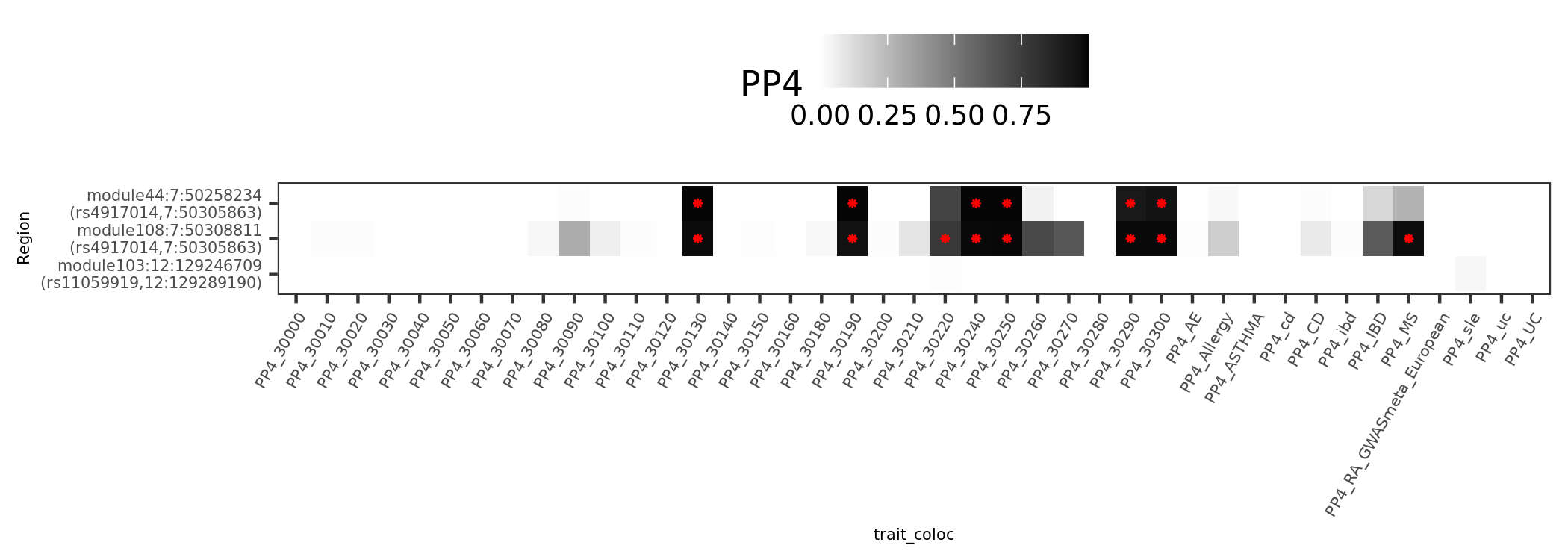
- In-depth visualization for selected traits (dark blue regions)
{kind=link}
{kind=link}
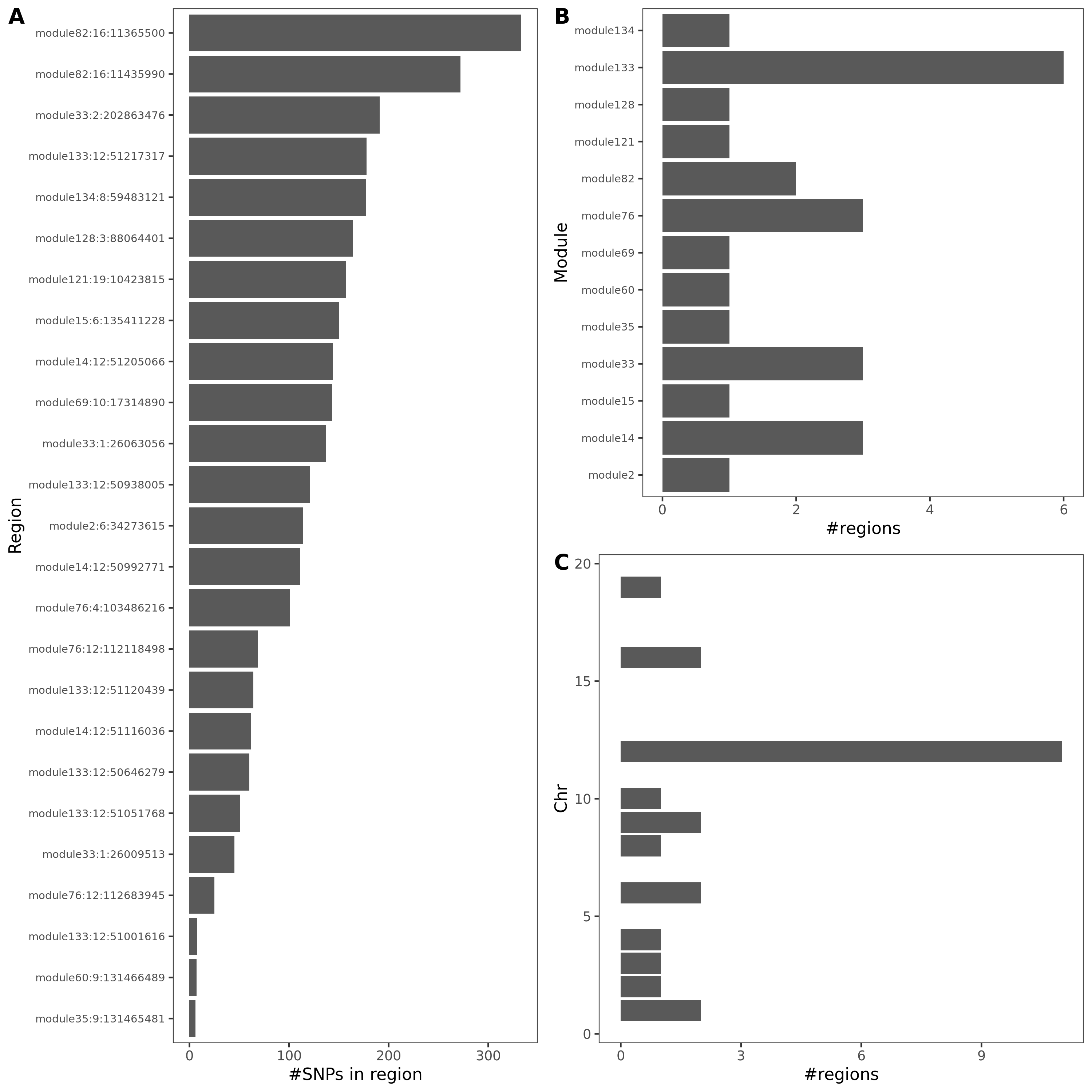{kind=link}
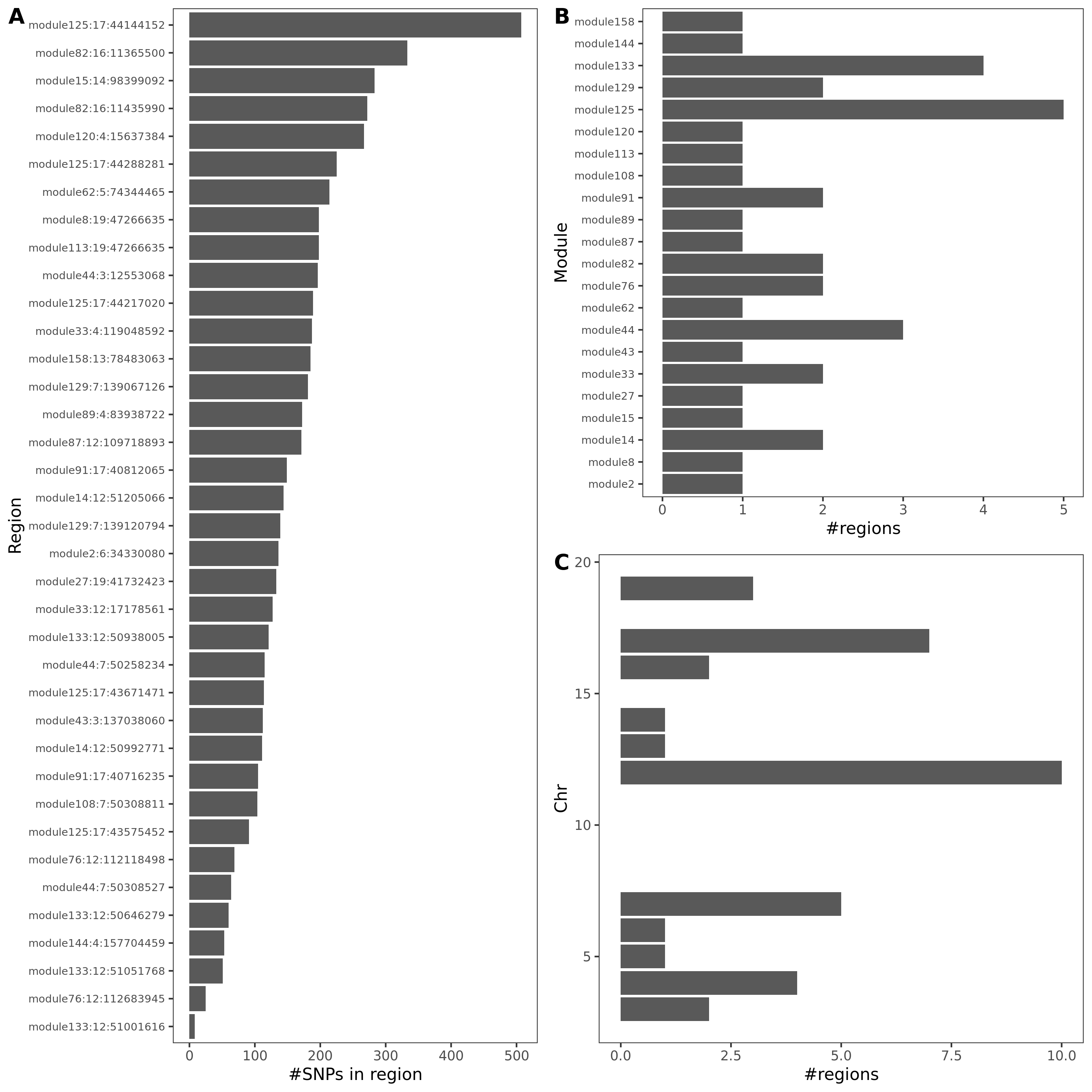{kind=link}
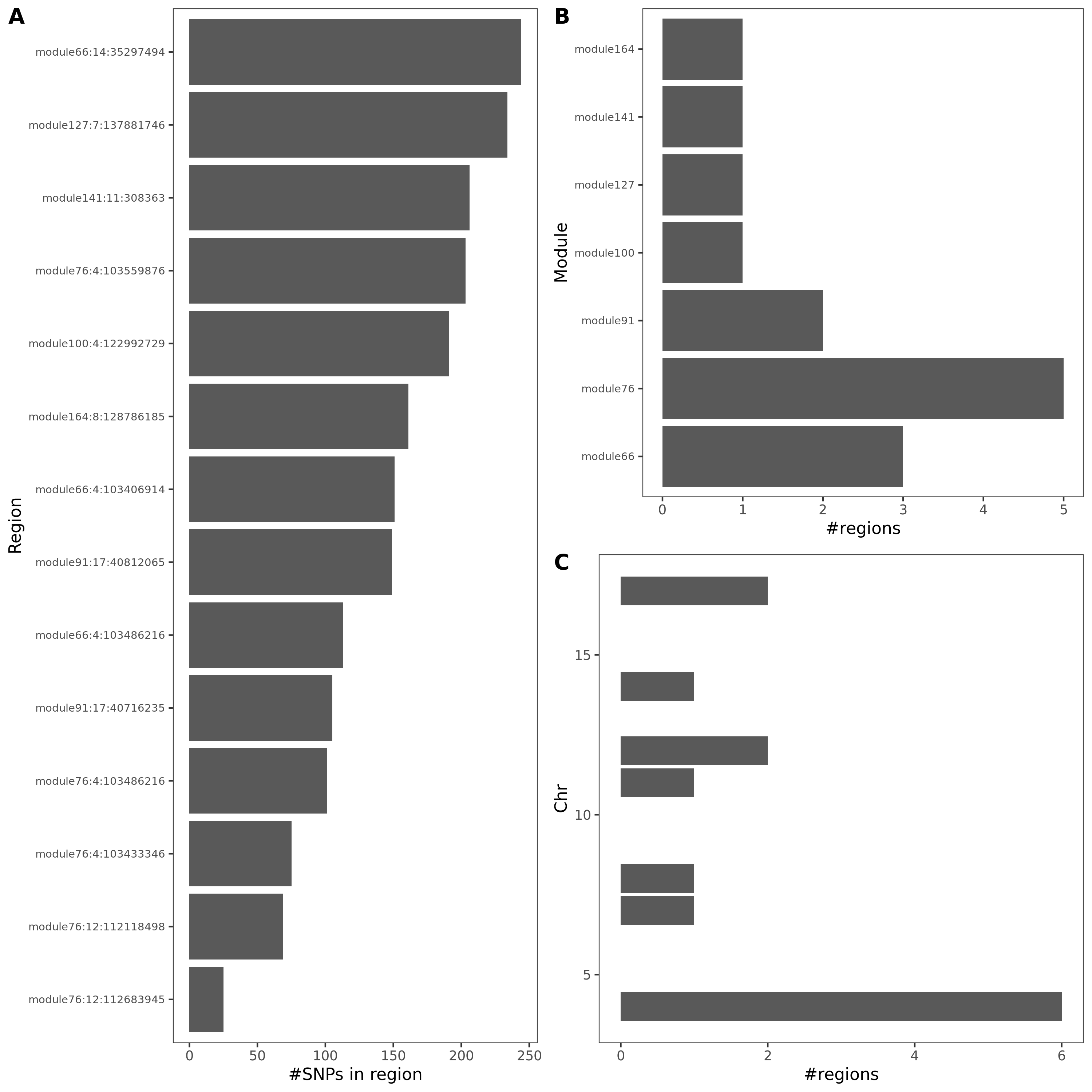{kind=link}
{kind=link}
Jan 12
1. Make a story out of the trans- signals
More concrete examples
- Trait, gene, trans- signal
SLE signals in Fig. 5.
reflecting the involvement of interferon signaling in SLE pathophysiology
| Version | Author | Date |
|---|---|---|
| 664d0d7 | llw | 2022-01-13 |
- additional examples of trans-eQTL variants associated with traits
ZNF131 locus, age of menarche
Supplementary Figure 11A, rs1532331
FADS1/FADS2 locus, lipid levels
Supplementary Figure 11B, rs174574
IFIH1 locus, inflammatory bowel disease and SLE
Supplementary Figure 11C, rs1990760
GSDMB locus, asthma
Supplementary Figure 11D, rs7216389
CLOCK locus, height
Supplementary Figure 11E, rs1311351834
eQTSs genes GO enrichment
eQTSs genes associated with HDL
Jan 05
1. trans-eQTL and complex disease in eQTLGen, Võsa, Franke et al
Question: are there any trans-eQTLs that are GWAS hits?
Observations from the paper:
Meta-analysis using up to 31,684 blood samples from 37 eQTLGen Consortium cohorts.
For trans, they focused on 10,317 trait-associated SNPs.
The paper linked trans-eQTLs with traits in two ways to find the potential driver genes for traits.
- trans-eQTL analysis
One-third of trait-associated variants have distal effects.
Identified 59,786 trans-eQTL, representing 3,853 SNPs (37% of tested GWAS SNPs) and 6,298 genes (32% of tested genes).
The largest previous trans-eQTL meta-analysis in blood (N = 5,311) identified trans-eQTL for 8% of tested SNPs.
Identify genes that are coordinately affected by multiple independent trait-associated SNPs.
Identified 47 GWAS traits for which at least four independent variants affected the same gene in trans (Supplementary Tables 10). Examples genes affected by at least three SLE-associated genetic variants.
But, Individual trans-eQTL effects too weak to detect. Another way to look for the potential driver genes for traits and the “core” genes:
- eQTSs (associations between PGSs and gene expression, Fig. 6a, 6b)
Individual trait-associated SNPs are combined into a PGS that is associated with gene expression.
when the PGS for a trait correlates with the expression of a gene, trans-eQTL effects of individual risk variants converge on that gene, and it can be prioritized as a putative driver of the disease.
1,263 traits in total. 18,210 eQTSs representing 689 unique traits (55% of tested traits) and 2,568 genes (13% of tested genes).
Of these genes, 719 (28%) were not identified in the trans-eQTL analysis.
Therefore, all 3,853 trans-eQTLs eQTLGen identified are GWAS hits.
Question: if so, can we replicate them?
Among 10,317 trait-associated SNPs, 9,056 (~89%) are included in DGN SNPs. Among 3,853 eQTLGen trans- eQTLs, 27 (~0.7%) are replicated in DGN signals (1,863, \(p<1e-8\)).
In the paper, another trans- study was mentioned,
The largest previous trans-eQTL meta-analysis in blood (N = 5,311) identified trans-eQTL for 8% of tested SNPs.
2. gene SENP7
the cross mappability of SENP7 and the genes in the trans modules
As noted in earlier section, we observed,
- SENP7 is the neasrest gene of the lead SNPs of coloc regions.
- Gene ZNF90P1 is located within SENP7.
- Modules 25, 51, 153, 156 have coloc regions with immune traits and consist of many zinc finger genes.
Therefore, we wanted to know,
- Does gene ZNF90P1 have expression data?
I looked at the expression matrix of 13634 genes. ZNF90P1 doesn’t have expression data in this matrix.
- What is the cross mappability between SENP7 and the zinc finger genes in the modules?
See files for the cross mappability for module 25, module 51, module 153, module 156.
The columns include: “score” for cross mappability score, “score_map1” for mappability score of gene1, “score_map2” for mappability score of gene2.
- For the genes in the trans modules,
See a previous file here.
highlighting SENP7 as a trans-meQTL
https://www-nature-com.proxy.uchicago.edu/articles/s41588-021-00969-x Another paper highlighting SENP7 as a trans-meQTL.
3. pQTL resource
R version 4.1.2 (2021-11-01)
Platform: x86_64-apple-darwin17.0 (64-bit)
Running under: macOS Big Sur 10.16
Matrix products: default
BLAS: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRblas.0.dylib
LAPACK: /Library/Frameworks/R.framework/Versions/4.1/Resources/lib/libRlapack.dylib
locale:
[1] en_US.UTF-8/en_US.UTF-8/en_US.UTF-8/C/en_US.UTF-8/en_US.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] workflowr_1.7.0
loaded via a namespace (and not attached):
[1] Rcpp_1.0.8 highr_0.9 compiler_4.1.2 pillar_1.7.0
[5] later_1.3.0 git2r_0.29.0 jquerylib_0.1.4 tools_4.1.2
[9] getPass_0.2-2 digest_0.6.29 evaluate_0.14 tibble_3.1.6
[13] lifecycle_1.0.1 pkgconfig_2.0.3 rlang_1.0.0 cli_3.1.1
[17] rstudioapi_0.13 yaml_2.2.2 xfun_0.29 fastmap_1.1.0
[21] httr_1.4.2 stringr_1.4.0 knitr_1.37 fs_1.5.2
[25] vctrs_0.3.8 rprojroot_2.0.2 glue_1.6.1 R6_2.5.1
[29] processx_3.5.2 fansi_1.0.2 rmarkdown_2.11 callr_3.7.0
[33] magrittr_2.0.2 whisker_0.4 ps_1.6.0 promises_1.2.0.1
[37] htmltools_0.5.2 ellipsis_0.3.2 httpuv_1.6.5 utf8_1.2.2
[41] stringi_1.7.6 crayon_1.4.2